2601.03192_MemRL: Self-Evolving Agents via Runtime Reinforcement Learning on Episodic Memory¶
引用:
组织:
总结¶
关键图片¶
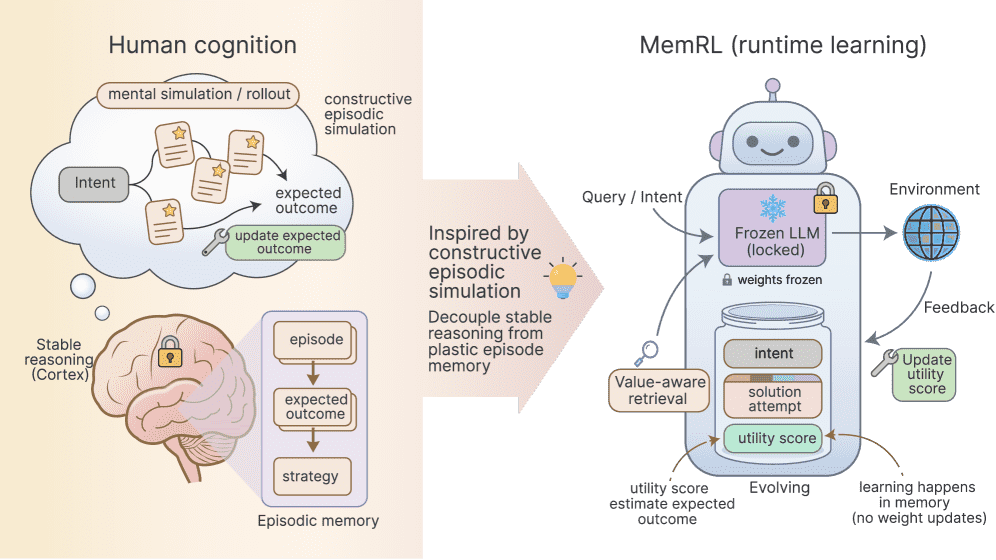
Figure 1:The conceptual framework of MemRL.
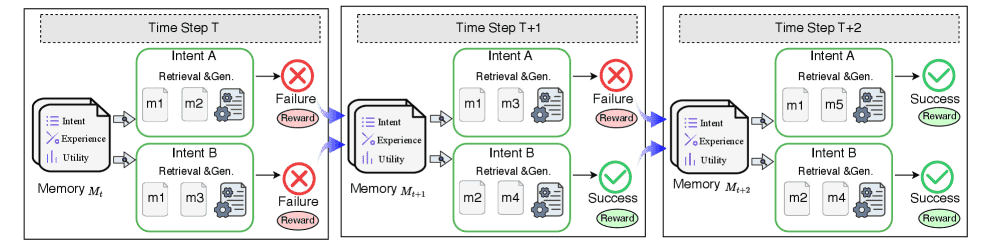
Figure 2: An illustrative example of memory-augmented decision making under a Markov Decision Process.
图2分析
在时间步 (t) 时,智能体从一个初始记忆集合 \(\mathcal{M}_t\) 开始。
在时间步 (t+1) 时,一个意图(Intent A)会检索相关的历史经验,但最初导致生成失败。相比之下,另一个意图(Intent B)成功完成任务,并将其对应的经验加入到记忆中。
在时间步 (t+2) 时,Intent A 再次进行检索,这次它能够获取到由 Intent B 新存入的成功经验,从而成功完成任务。
这个例子表明:记忆检索机制可以在不同意图之间实现知识复用,并通过共享经验隐式地支持系统的自我进化。
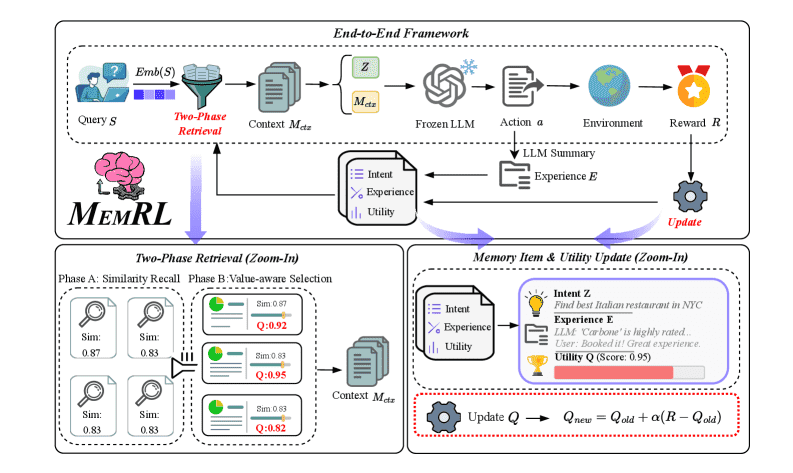
Figure 3:Overview of MemRL. The end-to-end learning loop(Top)
图3分析
端到端学习循环(上):
给定一个查询(s),智能体从记忆(M)中检索上下文 (m_ctx),基于该上下文生成输出(y),并根据奖励(R)更新记忆的价值(Q)。
两阶段检索(左下):
首先通过相似度召回候选记忆,然后基于学习到的 Q 值进行重排序(re-ranking)。
效用更新(右下):
通过环境奖励更新价值(Q),从而将“功能性效用”与“语义相似性”区分开来。
1. 文献背景、研究目的与问题概述¶
1.1 背景¶
人类智能的核心特征之一是能够通过从过往经验中学习来掌握新技能,即“自进化”能力。然而,当前的AI智能体在模仿这种能力时面临两难困境:
微调: 虽然能将经验内化到模型权重中,但计算成本高昂,且容易导致“灾难性遗忘”,即在学习新知识时忘记了旧知识。
检索增强生成(RAG): 虽然不需要修改权重,但现有的RAG方法主要依赖被动的语义匹配(即“内容相似”),往往检索到的是语义相近但实际效用低(即“没用”或“错误”)的噪声信息。
1.2 研究目的¶
作者旨在解决**“稳定性-可塑性困境”**。即,如何在不破坏预训练模型(保持稳定性)的前提下,让智能体在部署后能够通过与环境的交互持续进化(保持可塑性)。
1.3 核心问题¶
如何让智能体在运行时区分“高价值策略”与“语义噪声”,从而实现无需权重更新的自我进化?
2. 研究方法、关键数据与主要发现¶
2.1 核心方法:MemRL¶
MemRL 提出了一种非参数化的强化学习框架。它将大语言模型(LLM)的推理能力与外部记忆解耦,通过强化学习优化记忆的检索策略,而不是优化模型权重。
关键机制:¶
三元组记忆结构: 将记忆存储为
(Intent, Experience, Utility)三元组。Intent (意图): 任务的查询向量。
Experience (经验): 过去的成功轨迹或解决方案。
Utility (效用/Q值): 该经验在解决类似意图时的预期回报(由RL学习得出)。
两阶段检索:
阶段A (语义召回): 基于相似度筛选出候选记忆集合(过滤掉完全不相关的)。
阶段B (价值选择): 结合语义相似度和学习到的Q值(效用)对候选记忆进行重排序。公式为:\(Score = (1-\lambda) \cdot Sim + \lambda \cdot Q\)。这使得检索从“被动匹配”转变为“主动决策”。
非参数化RL更新: 在运行时,根据环境反馈(奖励 \(r\))直接更新记忆库中的Q值。采用蒙特卡洛风格的更新规则: $\(Q_{new} \leftarrow Q_{old} + \alpha (r - Q_{old})\)$ 这种方法无需反向传播,计算开销极小,但能让智能体“记住”哪些策略是真正有效的。
2.2 实验设置¶
基准测试: HLE (多学科推理), BigCodeBench (代码生成), ALFWorld (具身导航), Lifelong Agent Bench (OS/DB交互)。
对比基线: No Memory, Pass@k, RAG, Self-RAG, Mem0, MemP。
评价指标: 成功率 (SR), 累积成功率 (CSR)。
2.3 主要发现与结论¶
性能优越: MemRL 在所有基准测试中均显著优于基线,特别是在探索密集型环境(如 ALFWorld 和 OS 任务)中,累积成功率 (CSR) 比最强基线 提升了约 3.8% - 6.2%。
抗遗忘能力: 实验表明,MemRL 的遗忘率极低(0.041),远低于基于启发式方法的 MemP (0.051)。Q值机制能有效过滤导致性能下降的噪声记忆。
可迁移性: 经过训练的记忆库可以直接迁移到不同的模型(如从 Gemini-pro 迁移到 GPT 或 Qwen),且能显著提升弱模型的性能,证明了其捕获的是通用的解题模式而非模型特定的特征。
3. 新颖概念通俗解释¶
3.1 非参数化强化学习¶
通俗解释: 传统的AI学习(如ChatGPT的训练)就像是**“改写教科书”**(修改神经网络权重),这很慢且一旦改错就很难恢复。
MemRL的做法: 就像是**“做笔记”**。MemRL 不修改大脑(模型权重),而是在笔记本(外部记忆)上做标记。如果某个笔记帮你解决了问题,你就在旁边打个五角星(提高Q值);如果没用,就打个叉。下次遇到类似问题,优先翻看五角星多的笔记。这种学习方式不伤脑子(不破坏模型),且速度极快。
3.2 两阶段检索¶
通俗解释: 这就好比你去图书馆找书。
阶段A (语义召回): 图书管理员先根据书名(语义相似性)把所有相关的书都抱过来,可能有10本。
阶段B (价值选择): 你不看这10本书的内容,而是看书皮上你之前贴的“推荐指数”(Q值)。你只挑那几本以前真的帮到过你的书,哪怕它们的名字看起来没那么像。这避免了被“标题党”(语义相似但内容无用)误导。
3.3 稳定性-可塑性困境¶
通俗解释: 这是一个经典的神经科学难题。
可塑性: 像小孩子一样,学东西快,但容易忘事(不稳定)。
稳定性: 像老人一样,经验丰富,很难忘记旧知识,但也很难学会新东西。
MemRL的解法: 把“稳定的推理能力”留给冻结的大模型,把“可塑的学习能力”交给外部的记忆库。这样既保留了老人的智慧(不遗忘),又有了小孩子的学习能力(通过记忆进化)。
4. 优缺点评价与后续研究方向¶
4.1 优点¶
无需微调: 完美避开了微调带来的高昂算力成本和灾难性遗忘风险,非常适合实际部署。
理论支撑: 论文不仅提供了算法,还通过数学证明(EMA收敛性、广义EM算法)论证了Q值更新的稳定性和收敛性,这在Agent领域的论文中较为少见。
即插即用: 记忆库具有跨模型迁移能力,这意味着可以用强模型训练记忆,然后赋能给便宜的弱模型使用。
4.2 缺点与局限性¶
长轨迹的方差问题: 目前的更新是单步的,在长周期的复杂任务中,奖励信号可能带有高方差噪声,导致Q值估计不准。
归因模糊: 当一次检索引用了多条记忆时,如果任务成功,很难精确判断是哪一条记忆起了关键作用(信用分配问题)。
依赖任务相似度: 实验分析显示,如果任务之间的语义相似度很低(如HLE数据集),MemRL的效果会退化,接近于单纯的“死记硬背”而非策略泛化。
4.3 后续研究方向¶
多步更新与记忆巩固: 研究更复杂的更新机制(如多步TD误差)和定期的记忆压缩/去重,以提高长周期任务的稳定性。
精确的信用分配: 引入类似 Shapley Value 的方法,在多条记忆被同时检索时,更公平地分配奖励。
多智能体记忆共享: 探索多个Agent如何共享和同步记忆库,实现“群体智能”的进化。
安全性: 研究如何防止恶意数据污染记忆库(即“记忆投毒”),以及如何快速从错误记忆中恢复。
“阶段B”是如何“桥接”并最终筛选出最优记忆¶
核心公式回顾¶
阶段B的决策依据是这个综合评分公式:
这个公式是连接两个阶段的“桥梁”。让我们拆解一下:
\( s \):当前的任务/意图。
\( z_i, e_i \):记忆库中的一个候选记忆,由“意图”和“经验”组成。
\( \widehat{sim} \):归一化后的语义相似度(这是阶段A的结果,表示“相关性”)。
\( \widehat{Q_i} \):归一化后的效用值(这是通过强化学习学到的,表示“有用性”)。
\( \lambda \):一个平衡因子(通常设为0.5),决定更看重“相关性”还是“有用性”。
“桥接”过程详解:从阶段A到阶段B¶
假设我们在做一道OS操作题,任务 \( s \) 是“修改配置文件/etc/ssh/sshd_config,将端口改为2222”。
第一步:阶段A的召回(语义过滤)¶
阶段A通过语义相似度 \( sim \) 从庞大的记忆库中初步筛选出一个候选集 \( \mathcal{C}(s) \)。这一步会筛掉大量完全不相关的内容。
假设候选集 \( \mathcal{C}(s) \) 里现在有三个候选记忆:
记忆A(成功经验):意图是“修改SSH端口号”,经验是具体的sed命令,Q值很高(0.9)。
记忆B(失败经验,但战略价值高):意图是“修改SSH端口号”,经验是“我尝试用sed直接替换,但发现配置文件中该行被注释了,导致修改失败。教训是必须先取消注释再修改。”,Q值中等(0.6)。
记忆C(干扰噪音):意图是“修改配置文件权限”,经验是chmod 777。它与当前任务“修改端口”在语义上有一定相似度(都涉及配置文件),但在实际操作中毫无用处,Q值很低(0.1)。
第二步:阶段B的加权评分与排序(价值精炼)¶
现在,阶段B登场。它会对候选集 \( \mathcal{C}(s) \) 中的这三个记忆,分别计算一个综合得分。
我们假设这些值经过归一化(\( \widehat{sim} \) 和 \( \widehat{Q_i} \))后,范围都在[0,1]之间。同时,我们设 \( \lambda = 0.5 \),即相关性和有用性各占一半权重。
记忆 |
归一化相似度 \( \widehat{sim} \) |
归一化Q值 \( \widehat{Q_i} \) |
综合得分 \( \text{score} = 0.5 * \widehat{sim} + 0.5 * \widehat{Q_i} \) |
|---|---|---|---|
记忆A |
0.9 (非常相关) |
0.9 (高效用) |
0.50.9 + 0.50.9 = 0.9 |
记忆B |
0.9 (非常相关) |
0.6 (中等效用) |
0.50.9 + 0.50.6 = 0.75 |
记忆C |
0.7 (有点相关) |
0.1 (低效用) |
0.50.7 + 0.50.1 = 0.4 |
现在,阶段B会根据这个综合得分对三个记忆进行重新排序。排序结果是:A (0.9) > B (0.75) > C (0.4)。
第三步:最终选择¶
最后,阶段B会从排序后的列表中选择 \( k_2 \) 个(通常比\( k_1 \)小)最高分的记忆作为最终的上下文 \( \mathcal{M}_{ctx} \)。
在这个例子里,如果设置 \( k_2 = 2 \),那么最终被选中的将是记忆A(高分成功经验)和记忆B(高分战略失败经验)。
结论:阶段B是如何“桥接”的?¶
阶段B的“桥接”体现在它用一个加权公式,同时考量了两个阶段的成果:
它“携带”了阶段A的成果:公式中的 \( \widehat{sim} \) 直接来自阶段A。这意味着,一个完全不相干的记忆(语义相似度为0)在阶段B的初始分就是0,无论其Q值多高,它都没有资格被选中。相关性是门槛。
它“升华”了阶段A的成果:光有“相关性”是不够的。通过引入 \( \widehat{Q_i} \),阶段B有能力对阶段A召回的记忆进行价值重估。
在纯RAG中,记忆C(干扰噪音)可能会因为0.7的相似度而被误选。
但在MemRL中,它的低Q值(0.1)拉低了综合得分,使其被排除在外。
更重要的是,记忆B(高价值失败经验)得以保留。它的高相似度保证了它不跑题,它的中等Q值说明了它的战略指导意义。这在纯RAG中很难被选到。
所以,阶段B的本质是:在阶段A划定的“相关候选圈”内,用强化学习学到的“效用”作为一把精准的尺子,进行第二次、更精细的筛选。 它确保最终送入LLM的,不仅是与当前任务“看起来像”的经验,更是历史上被证明“能导向成功”或“提供关键教训”的高价值经验。这就是它解决“语义相似但实际无用”问题的根本机制。
Q值的计算与更新机制¶
Q值的计算是MemRL的核心,它不是一次性算出来的,而是在与环境交互的过程中不断学习和更新的。让我详细拆解这个过程。
一、Q值的本质¶
Q值本质上是一个期望效用值,代表“如果在当前意图下使用某个经验,预期能获得多少回报”。
初始值:当新经验被写入记忆时,其Q值初始化为一个默认值(论文中设为0.0)
动态更新:每次使用该经验后,根据获得的奖励(成功/失败),Q值会进行更新
二、Q值的更新公式(核心)¶
论文使用的是蒙特卡洛风格的指数移动平均更新规则:
公式中的变量:¶
变量 |
含义 |
取值范围/说明 |
|---|---|---|
\( Q_{old} \) |
更新前的Q值 |
历史累积的经验效用 |
\( r \) |
当前获得的奖励 |
成功通常为1.0,失败为0.0 |
\( \alpha \) |
学习率 |
论文中设为0.3,控制新经验的影响程度 |
\( Q_{new} \) |
更新后的Q值 |
新的效用估计 |
三、具体计算示例¶
让我们通过一个例子来理解这个更新过程。
假设有一个记忆,其当前Q值 \( Q_{old} = 0.6 \),学习率 \( \alpha = 0.3 \)。
场景1:这次使用成功了,奖励 \( r = 1.0 \)¶
结果:Q值从0.6上升到0.72,因为这次成功表明该经验比之前认为的更有价值。
场景2:这次使用失败了,奖励 \( r = 0.0 \)¶
结果:Q值从0.6下降到0.42,因为这次失败表明该经验可能没那么可靠。
四、为什么这样设计?¶
1. 指数移动平均的收敛性¶
这个公式的本质是对历史奖励进行带遗忘的加权平均。将公式展开可以得到:
这意味着:
旧的奖励以指数速度衰减
新的奖励权重更高
最终Q值会收敛到真实平均奖励
2. 为何不用更复杂的TD更新?¶
论文中提到,他们使用蒙特卡洛风格的单步更新(而非多步TD更新)来平衡复杂度与性能。这是因为:
每个任务在论文的设置中可以被视为一个独立的片段(episode)
单步更新足以让Q值收敛到期望奖励
实现更简单,计算开销更小
五、完整的工作流程¶
让我们用一个完整的例子串联起来:
graph TD
A[新经验写入记忆] -->|Q_init = 0.0| B[记忆库]
B --> C[阶段A/B: 检索到该记忆]
C --> D[LLM使用该经验生成答案]
D --> E{执行结果}
E -->|成功 r=1.0| F[Q = 0.0 + 0.3*(1.0-0.0)=0.3]
E -->|失败 r=0.0| G[Q = 0.0 + 0.3*(0.0-0.0)=0.0]
F --> H[记忆库更新Q值]
G --> H
H --> I[下次使用该记忆]
I --> J[Q值继续迭代更新]
具体数值演算示例:¶
使用次数 |
结果 |
奖励r |
更新前Q |
更新后Q |
解释 |
|---|---|---|---|---|---|
第1次 |
成功 |
1.0 |
0.00 |
0.30 |
第一次成功,Q从0升至0.3 |
第2次 |
成功 |
1.0 |
0.30 |
0.51 |
连续成功,Q升至0.51 |
第3次 |
失败 |
0.0 |
0.51 |
0.36 |
一次失败,Q回落到0.36 |
第4次 |
成功 |
1.0 |
0.36 |
0.55 |
再次成功,Q恢复上升 |
第5次 |
成功 |
1.0 |
0.55 |
0.68 |
稳定成功,Q向1.0收敛 |
六、关键细节补充¶
1. 奖励的来源¶
奖励 \( r \) 来自环境反馈,不同类型的任务有不同的奖励定义:
任务类型 |
奖励定义 |
|---|---|
代码生成(BigCodeBench) |
代码能否通过测试用例(通过=1,不通过=0) |
操作系统交互 |
命令执行是否成功,是否达成目标 |
ALFWorld导航 |
是否完成指定的多步骤任务 |
HLE多学科推理 |
答案是否正确 |
2. 学习率α的选择¶
论文中将学习率设为0.3。这个选择体现了平衡:
太小的α(如0.01):收敛慢,需要很多次交互才能反映真实效用
太大的α(如0.9):过于敏感,单次成败会导致Q值剧烈波动
0.3是一个合理的折中值,既能快速适应环境变化,又不会过度反应。
3. 同时更新多个记忆¶
当一个任务引用了多个记忆时,这些被引用的记忆全部会根据同一个奖励r进行更新。这是当前方法的局限之一(论文在“局限性”部分提到了信用分配问题),但实验证明在大多数情况下依然有效。
总结¶
Q值的计算不是一个公式,而是一个持续的学习过程:
初始化:新记忆Q=0.0(或可配置的默认值)
使用时:检索到的记忆参与生成
反馈后:根据成功/失败,通过 \( Q_{new} = Q_{old} + \alpha(r - Q_{old}) \) 更新
持续迭代:每次使用都会更新,Q值逐渐收敛到该经验的真实效用
这种设计的妙处在于:它让记忆自己“学会了”自己的价值,而不是靠人工标注。成功的记忆Q值会升高,低效的记忆Q值会降低,干扰性的噪音记忆即使被误召也会因为低奖励而被迅速淘汰。