2508.09874_Memory Decoder: A Pretrained, Plug-and-Play Memory for Large Language Models¶
引用: 1(2025-09-04)
组织:
1 LUMIA Lab, Shanghai Jiao Tong University, Shanghai, China
2 Shanghai AI Laboratory, Shanghai, China
3 Department of Electronic Engineering, Tsinghua University, Beijing, China
总结¶
总结
Memory Decoder的本质是训练一个小的Transformer模型
这个模型可以模仿kNN检索器产生的整个概率分布 p_kNN
类似 kNN-LM ,只不过用这个小模型代替kNN的 k/v 键值对获取 p_kNN
背景
两种特定领域适应(Domain Adaptation)的主流方法
Domain Adaptive Pre-Training (DAPT)
缺点:计算成本高,效率低且可能引发“灾难性遗忘”
Retrieval-Augmented Generation (RAG)
在推理阶段需要进行多次kNN搜索,计算和存储开销大,影响效率
【定义】领域自适应(Domain Adaptation)
给定一个预训练模型和一个领域语料,目标是优化模型在目标领域的下一个词预测分布
【定义】k最近邻语言模型(k Nearest Neighbor Language Models)
kNN-LM 是一种非参数化(non-parametric)的领域自适应方法,无需修改预训练模型的参数
Memory Decoder
一种即插即用的预训练记忆组件,能够在不修改原始模型参数的前提下,实现高效的领域适应
采用一个小型的 Transformer Decoder,学习模拟外部非参数检索器的行为。
第一个提出了一种用紧凑的参数模型取代传统非参数检索器的方法
Memory Decoder (MemDec) 是一个预先训练好的、小巧的“插件”模型。
它的目的是让大型语言模型(LLM)能够快速、高效地适应某个特定领域(如生物医学、法律),而无需进行耗时的微调或维护庞大的外部数据库。
它是一种有损压缩。MemDec用模型容量(参数数量)换取效率,必然会损失一些原始数据库中的信息。
两大组件:
预训练
MemDec的学习目标不是记忆训练数据中的具体答案 y_i,而是去模仿kNN检索器产生的整个概率分布 p_kNN。
本质:一个高效的“概率分布模拟器”
一旦训练完成,这个函数就被固化在了模型的参数中。
在进行推理时,你不需要再访问原始数据库,只需要对输入 x_i 做一次前向传播,这个“模拟器”就会直接输出一个近似于kNN搜索得到的概率分布。
推理
并行处理:给同一个输入上下文 x,分别输入到原来的大语言模型 (M_PLM) 和MemDec (M_Mem) 中。
插值融合:将两个模型输出的概率分布按比例混合(Eq. 7)。
对比
kNN搜索:每次遇到问题都重新现场计算一遍 1 + 2 + 3 + … + 1000(计算开销大)。
MemDec:通过学习,直接记住了公式 n(n+1)/2(这里是 1000*1001/2 = 500500)。
它存储的是“公式”(决策逻辑),而不是“计算结果”(具体知识)。
需要时直接套用公式,速度极快。
Abstract¶
近年来,大型语言模型(LLMs) 在通用语言任务中表现出色,但在特定领域适应方面仍存在挑战。目前的方法如领域自适应预训练(DAPT)需要参数量庞大的微调训练,并且容易导致灾难性遗忘问题。另一方面,基于检索增强生成(RAG)的方法虽然不修改模型参数,但在推理阶段依赖代价较高的最近邻检索,导致推理延迟增加且输入上下文变长。
为了解决这些问题,本文提出了Memory Decoder,一种即插即用的预训练记忆组件,能够在不修改原始模型参数的前提下,实现高效的领域适应。Memory Decoder 采用一个小型的 Transformer Decoder,学习模拟外部非参数检索器的行为。一旦训练完成,该组件可以无缝集成到任何使用相同分词器的预训练语言模型中,无需针对具体模型进行修改。
重点内容:
Memory Decoder 的优势:
无需修改原始模型参数;
无需昂贵的外部检索,提升推理效率;
可适配多种模型规模;
可即插即用地增强模型性能。
实验结果:
Memory Decoder 被成功用于适配多个 Qwen 和 Llama 模型到医疗、金融、法律三个专业领域。
显著降低困惑度(perplexity),平均减少 6.17 分。
核心贡献:
提出一种全新的基于预训练记忆的领域适应范式;
该记忆架构可跨多个模型进行共享与集成,提升一致性能表现。
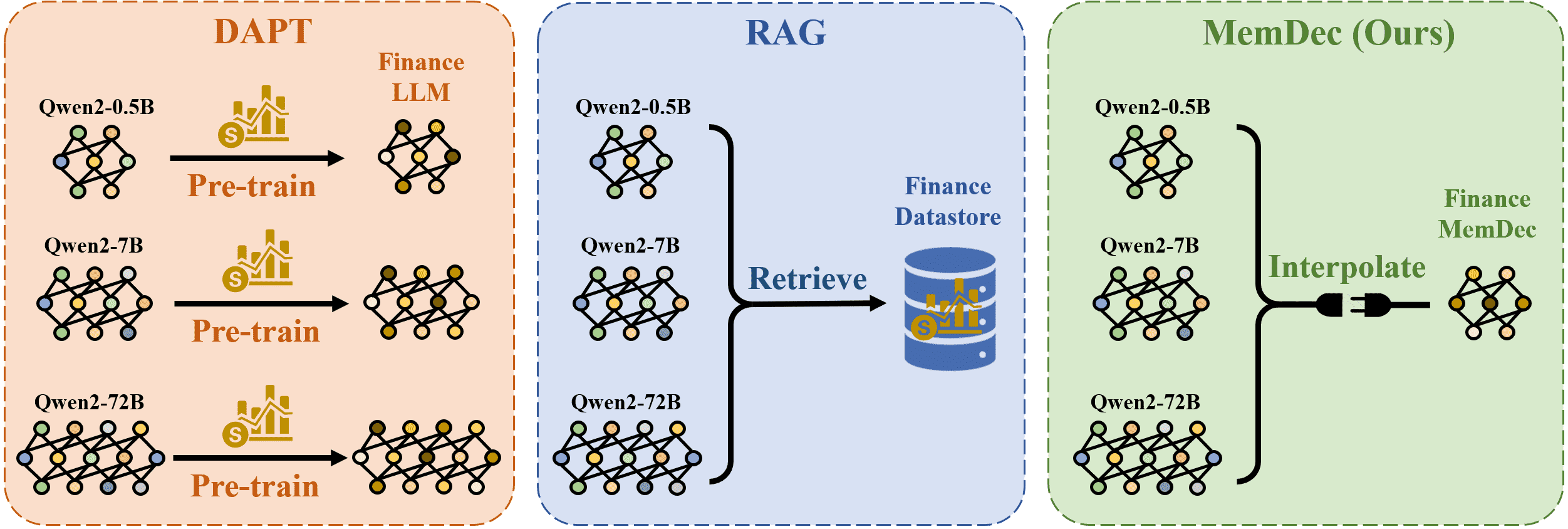
Figure 1:Comparison of domain adaptation approaches. DAPT (left) requires separate pre-training for each model size, modifying original parameters. RAG (middle) maintains model parameters but requires expensive retrieval from external datastores during inference. Memory Decoder (right) offers a plug-and-play solution where a single pretrained memory component can be interpolated with models of different sizes, avoiding both parameter modification and retrieval overhead.
图 1 解释: 图中比较了三种领域适应方法:
左侧 DAPT:为每个模型规模分别预训练,修改原始参数;
中间 RAG:保持模型参数不变,但需要外部数据库检索;
右侧 Memory Decoder:提供即插即用的解决方案,仅需预训练一个记忆组件即可用于多种模型规模,避免参数修改和检索开销。
附加信息: 论文作者承诺在论文被接受后发布代码和检查点(checkpoints),有助于后续研究和应用。
1 Introduction¶
背景介绍¶
近年来,大语言模型(Large Language Models, LLMs)在自然语言处理任务中表现出卓越的能力。这些模型通过在大规模通用文本语料上预训练,显著提升了语言理解和生成的效果。然而,尽管LLMs在通用任务上表现出色,它们在特定领域(如生物医学、金融、法律)中的应用仍然面临挑战。在这些领域中,准确和可靠的表现依赖于领域专业知识和术语,而通用模型往往缺乏这种能力。
现有方法及其局限性¶
目前,LLMs的领域适应主要依赖两种主流方法:
Domain Adaptive Pre-Training (DAPT)
通过在特定领域的语料上继续预训练模型,可以提升其在该领域的表现。
缺点:计算成本高,尤其是对于参数量巨大的模型;需要为每个模型单独训练,效率低;且可能引发“灾难性遗忘”,即在适应新领域的同时,模型可能丢失原有通用能力。
Retrieval-Augmented Generation (RAG)
在生成过程中引入外部检索,通过查找相关知识来增强输出。
优点:不需要重新训练模型,保留原始参数。
缺点:在推理阶段需要进行多次kNN搜索,计算和存储开销大,影响效率。
现有方法的矛盾与挑战¶
DAPT和RAG分别面临训练成本高和推理效率低的问题,两者之间存在一个根本性的权衡:
DAPT虽然适应效果好,但无法高效地跨多个模型部署;
RAG虽然灵活,但推理阶段效率较低,难以满足实际部署需求。
因此,亟需一种既能高效适应领域,又不会显著增加推理成本的方法。
本文提出的方法:Memory Decoder(MemDec)¶
为了解决上述问题,作者提出了Memory Decoder(MemDec),这是一种预训练的、即插即用的领域适配器。其核心思想是:
不修改原模型参数,通过一个小型的Transformer 解码器来模拟非参数检索器(如kNN-LM)的行为;
通过预训练使其输出分布与非参数检索器一致,从而达到类似RAG的效果,但无需实际检索;
MemDec可以在不重新训练原模型的前提下,与任何使用相同tokenizer的LLM无缝集成。
方法的创新点¶
即插即用性(Plug-and-Play):MemDec在训练完成后,可直接接入不同模型,无需模型特定的适配或训练;
计算效率高:与RAG相比,没有额外的检索开销,推理效率更高;
适应性强:只需训练一个MemDec,即可跨多个模型使用,节省资源。
实验与结果¶
作者在三个专业领域(生物医学、金融、法律)及多个模型架构上验证了MemDec的有效性。以金融领域为例(如图2所示),仅使用0.5B参数的MemDec,就能显著提升Qwen2.5系列7个不同模型的性能。这验证了MemDec的通用性和高效性,有效结合了非参数方法的优势,同时避免了其计算开销。
贡献总结¶
本文的主要贡献包括:
提出Memory Decoder(MemDec),一种无需修改原模型参数即可实现高效领域适配的即插即用预训练模块;
提出首个用紧凑参数模型替代传统非参数检索器的方法,在不使用昂贵检索操作的前提下,实现性能提升;
证明MemDec具有良好的泛化能力,一个MemDec可跨多个使用相同tokenizer的模型进行部署。
如上所示,引言部分清晰地指出了现有方法的不足,并提出了MemDec这一创新解决方案,为LLMs的高效领域适配提供了新思路。
2 Background¶
2.1 问题定义(Problem Formulation)¶
核心目标:领域自适应(Domain Adaptation)旨在提升预训练语言模型(PLM)在特定领域文本上的表现。
形式化定义:给定一个预训练模型 \(\mathcal{M}_{\text{PLM}}\)(参数为 \(\theta\))和一个领域语料 \(\mathcal{D}_{\text{domain}}\),目标是优化模型在目标领域的下一个词预测分布 \(p_{\text{PLM}}(y_t|x;\theta)\)。
\(x = (x_1, x_2, \dots, x_{t-1})\) 是上下文序列;
\(y_t\) 是目标词;
优化目标是使模型输出更符合目标领域的语言模式。
2.2 最近邻语言模型(Nearest Neighbor Language Models)¶
定义与方法:kNN-LM 是一种无参数(non-parametric)的领域自适应方法,无需修改预训练模型的参数。
1. 构建键值存储(Key-Value Datastore)¶
从领域语料中提取特征对 \((\phi(x_i), y_i)\),构建数据存储 \((K,V)\): $\( (K,V) = \{(\phi(x_i), y_i) \mid (x_i, y_i) \in \mathcal{D}_{\text{domain}}\} \)$
其中 \(\phi(\cdot)\) 表示从预训练模型中提取隐藏表示。
2. 推理阶段(Inference)¶
对于输入 \(x\),计算其隐藏表示 \(k_t = \phi(x)\);
从存储中检索出 \(k\) 个最近邻邻居;
构建基于距离的预测分布: $\( p_{\text{kNN}}(y_t|x) \propto \sum_{(k_i,v_i)\in\mathcal{N}(k_t,k)} \mathbb{1}_{y_t = v_i} \exp(-d(k_t,k_i)/\tau) \)$
其中 \(d\) 为距离函数,\(\tau\) 为温度参数。
3. 最终预测(Final Prediction)¶
将 kNN 分布与预训练模型分布进行插值,得到最终预测: $\( p_{\text{kNN-PLM}}(y_t|x) = \lambda \cdot p_{\text{kNN}}(y_t|x) + (1-\lambda) \cdot p_{\text{PLM}}(y_t|x) \)$
\(\lambda\) 为插值系数。
优点与缺点¶
优点:无需修改模型结构,可有效提升模型在特定领域的表现;
缺点:
存储开销大:例如,Wikitext-103 的 kNN 数据库(使用 GPT2-small)就需要接近 500GB;
推理效率低:需要进行复杂检索和计算。
引出 Memory Decoder 的动机¶
由于 kNN-LM 等方法在推理阶段存在显著的计算和存储负担,作者提出 Memory Decoder,它是一个紧凑的参数化模型,通过预训练来模拟检索行为,从而:
无需维护大规模数据库;
推理过程高效;
实现与 kNN-LM 类似的领域增强效果。
3 Memory Decoder¶
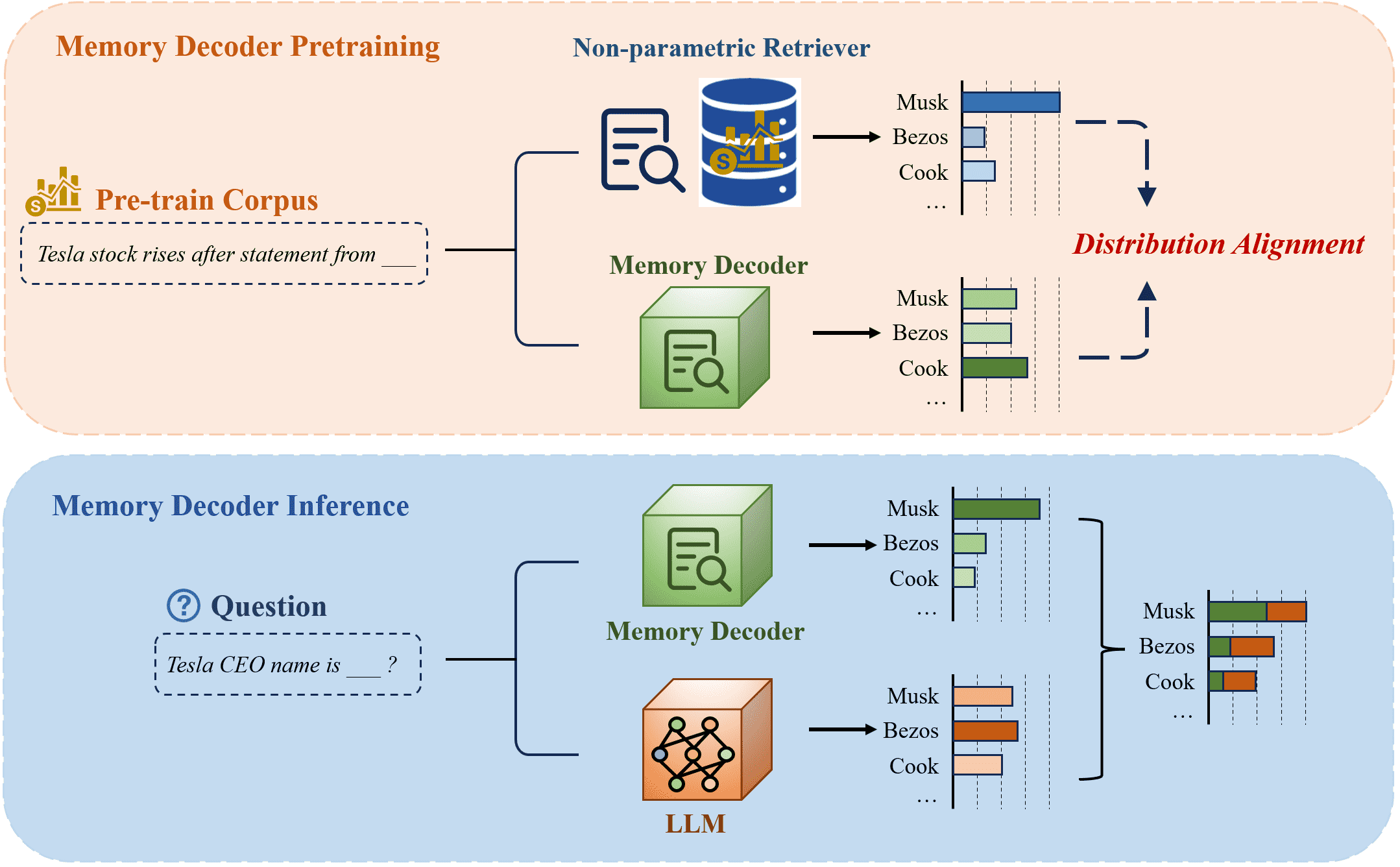
Figure 3:Overview of Memory Decoder architecture. Upper§ 3.1: During pre-training, Memory Decoder learns to align its output distributions with those generated by non-parametric retrievers through distribution alignment loss. Lower§ 3.2: During inference, Memory Decoder processes input in parallel with the base LLM, and their distributions are interpolated to produce domain-enhanced predictions without retrieval overhead.
本节提出了一种名为 Memory Decoder (MemDec) 的可插拔预训练记忆模块,用于大型语言模型的高效领域自适应。该方法旨在通过预训练捕捉领域知识并在推理过程中进行快速部署,从而减少传统检索增强方法中的计算开销。
核心思想¶
MemDec 的设计包含两个主要部分:
预训练阶段(Section 3.1):通过非参数检索器的分布对 MemDec 进行训练,使其能够模仿这些检索器的输出。
推理阶段(Section 3.2):通过插值的方式将 MemDec 与任意兼容的语言模型结合,实现高效且灵活的领域自适应。
如图 3 所示,MemDec 在预训练阶段学习非参数检索分布(上部分),在推理阶段与语言模型结合使用(下部分),避免了传统方法中维护数据存储和进行最近邻搜索的计算开销。
3.1 Pre-training¶
MemDec 的预训练目标是使其输出的概率分布尽可能接近非参数检索器在相同上下文中生成的分布。这一步骤有效地将大型键值数据存储中的领域知识编码进了 MemDec 的参数中。
数据构建¶
为实现这一目标,作者构建了训练样本对 \((x_i, p_{\text{kNN}}(\cdot|x_i))\),其中 \(x_i\) 是输入上下文,\(p_{\text{kNN}}(\cdot|x_i)\) 是通过 kNN 检索得到的概率分布。构建步骤如下:
使用领域语料构建键值存储 \((K,V)\),其中键是从预训练模型中提取的隐藏表示。
对每个上下文 \(x_i\),进行 kNN 检索,排除掉自身的重复项以避免干扰。
计算非参数分布 \(p_{\text{kNN}}(\cdot|x_i)\),并缓存用于训练。
预训练目标¶
不同于传统的单标签语言建模目标,kNN 分布提供了更丰富的监督信号,反映了上下文中可能的多种输出。为了优化 MemDec,作者提出了一种混合损失函数(Hybrid Objective),包括两个部分:
分布对齐损失(KL Divergence): $\( \mathcal{L}_{\text{KL}}(x_i) = \text{KL}(p_{\text{kNN}}(\cdot|x_i) \parallel p_{\text{Mem}}(\cdot|x_i)) \)$ 该损失用于最小化 MemDec 输出与 kNN 分布之间的差异。
语言建模损失(LM Loss): $\( \mathcal{L}_{\text{LM}}(x_i) = -\log p_{\text{Mem}}(y_i|x_i) \)$ 用于防止 MemDec 完全脱离原始语料的分布。
最终的损失函数为两者的加权组合,由超参数 \(\beta\) 控制: $\( \mathcal{L}(x_i) = \beta \cdot \mathcal{L}_{\text{KL}}(x_i) + (1 - \beta) \cdot \mathcal{L}_{\text{LM}}(x_i) \)$
重点: KL 散度和 LM 损失的联合使用是 MemDec 预训练的关键,确保模型既贴近检索分布,又保持语言建模能力。相关失败尝试及分析见附录 H。
3.2 Inference¶
预训练完成后,MemDec 可以作为可插拔组件与任何兼容的语言模型结合,通过概率插值来增强领域适应能力。
推理过程¶
在推理阶段,MemDec 和预训练语言模型(PLM)并行处理同一上下文,输出分布进行插值: $\( p_{\text{Mem-PLM}}(y_t|x) = \alpha \cdot p_{\text{Mem}}(y_t|x) + (1 - \alpha) \cdot p_{\text{PLM}}(y_t|x) \)\( 其中参数 \)\alpha \in [0,1]$ 控制MemDec对最终输出的影响权重。
效率优势¶
与传统的检索增强方法(如 RAG、kNN-LM)相比,MemDec 的优势在于:
无需维护数据存储或执行最近邻搜索,只需一次前向传播。
推理效率显著提高:MemDec 相比基线模型仅增加 1.28 倍的推理延迟,远优于 In-Context RAG(1.51 倍)和 kNN-LM(2.17 倍)。
随着处理 token 增多,效率优势更明显。
在大规模数据存储下(如 5 亿数据条目)表现更佳,因为 MemDec 与语言模型之间的通信开销被长推理时间摊薄,而 kNN 检索的延迟随存储规模线性增长。
重点: MemDec 的推理效率优势和其模型无关性,使其非常适合需要高性能与高效率兼顾的生产环境。
总结¶
本节提出了一种高效的、可插拔的领域自适应方法——Memory Decoder。通过预训练对齐非参数检索分布,并在推理阶段通过插值与语言模型结合,MemDec 实现了:
捕获领域知识;
避免传统检索方法的计算开销;
推理效率显著优于现有方法。
该方法在实际部署中具有重要价值,尤其适用于需要快速适应新领域且对响应速度有高要求的场景。
4 Experimental Setup¶
Overview(概览)¶
本节通过表格和实验设置对比了多种领域自适应方法在不同规模的 GPT-2 模型上的表现。核心指标是 语言模型的困惑度(perplexity, PPL),越低表示模型在特定领域上的语言建模能力越强。
表1总结:
表中列出了 GPT-2 四种模型规模(small、medium、large、xl)在非参数方法(In-Context RAG, kNN-LM)和参数方法(DAPT, LoRA, Memory Decoder)下的 PPL。
Memory Decoder 在所有规模下都表现良好,尤其是在 GPT-2 medium(345M 参数) 模型上,Memory Decoder(124M 参数)的 PPL 比 DAPT 更低,证明其在不改变原模型参数的前提下,能有效捕捉领域知识。
非参数方法(如 RAG)表现一般,说明其在语言建模任务上可能不如参数方法高效。
关键发现:
Memory Decoder 是一个轻量、即插即用的模块,可在多种模型上提升领域适应性。
与 DAPT 相比,Memory Decoder 不需要完全重新训练整个模型,节省了计算资源。
实验设置(Evaluation Settings)¶
论文在六个互补的实验设置中对 Memory Decoder 进行了评估,以验证其适应性与泛化能力:
语言建模(WikiText-103)
评估 Memory Decoder 在不同规模 GPT-2 模型上的语言建模能力(即语言建模性能)。下游任务(Downstream Tasks)
验证 Memory Decoder 在领域自适应过程中是否保留了模型的通用能力(如情感分析、文本蕴含等)。跨模型自适应(Cross-Model Adaptation)
展示 Memory Decoder 能够提升 Qwen 模型的性能,涵盖从 0.5B 到 72B 参数的多个模型规模。跨词典自适应(Cross-Vocabulary Adaptation)
检验 Memory Decoder 在不同 tokenizer 家族之间迁移的效率,说明其词汇兼容性强。知识密集型问答(Knowledge-Intensive QA)
验证 Memory Decoder 在推理能力(如逻辑推理和事实记忆)上的表现,弥补了传统检索方法在推理方面的不足。领域特定下游任务(Domain-Specific Downstream Tasks)
在 13 个真实世界基准任务上验证 Memory Decoder 在领域自适应后仍保留了 in-context learning 能力。
结论:Memory Decoder 是一种通用、高效、可插拔的模块,适用于多种模型架构和任务场景。
数据集(Datasets)¶
语言建模任务:使用 Wikitext-103,包含超过 1 亿个 Wikipedia 语料。
通用任务评估:包括情感分析(如 SST2、MR、CR、RT)、文本蕴含(如 HYP、CB、RTE)、文本分类(如 AGN、Yahoo)等 9 个 NLP 任务。
领域特定任务:使用三个专业领域语料库:
医疗领域:MIMIC-III,包含超过 46,000 份临床记录。
金融领域:2024 年 4 月至 2025 年 2 月的股票新闻。
法律领域:Asylex 文档,包含 59,112 份加拿大难民裁决文件。
对比方法(Baselines)¶
In-Context RAG:基于 BM25 检索器的上下文增强方法,每 4 个 token 检索 32 个查询 token。
kNN-LM:使用近邻语言模型,采用插值参数 λ=0.25,温度参数 τ=1(小模型)或 τ=13(大模型)。
LoRA:对查询、键、值和 MLP 层进行低秩适配,参数量与 Memory Decoder 相当。
DAPT:完整重训练所有模型参数以适应领域数据。
训练细节(Training Details)¶
硬件环境:8×A800 80GB GPU。
语言建模与下游任务训练:
使用 GPT2-xl 构建 Key-Value 数据库和非参数分布。
在 GPT2-small 上继续训练,学习率设为 1e-3。
跨模型自适应:
使用 Qwen2.5-1.5B 构建数据库,在 Qwen2.5-0.5B 上训练,学习率设为 1e-4。
跨词典自适应:
使用 Llama3.2-1B 构建数据库,并重新初始化嵌入层和语言模型头。
训练预算:所有实验的计算量等价于训练一个 7B 参数模型 1 轮。
关键超参数 β:设置为 0.5,用于平衡原始模型与新模块的输出。
评估指标(Evaluation Metrics)¶
语言建模、跨模型、跨词典实验:使用 滑动窗口困惑度(sliding window perplexity),设定上下文长度为 1024,仅评分后 512 个 token。
下游任务:使用 领域条件下的 PMI 评分规则(domain-conditional PMI scoring rule),并根据任务在验证集上调整插值参数 α。
更多细节:见附录 A,其中详细描述了各任务的 α 调参过程。
总结¶
本节详细介绍了实验设置,包括对比方法、数据集、训练细节和评估指标。通过全面的实验验证,Memory Decoder 被证明是一个 高效、通用、即插即用的领域自适应模块,适用于不同模型架构、任务类型和领域需求。
5 Results¶
5.1 Language Modeling on Wikitext-103(Wikitext-103上的语言建模)¶
本节展示了 Memory Decoder 在 GPT2 模型家族上的出色表现。其核心结论如下:
Memory Decoder 仅使用 124M 参数,即可显著提升 GPT2 各版本(包括 small、medium、large)的语言建模性能,体现了其 plug-and-play(即插即用) 特性。
对于 小模型,Memory Decoder 表现优于所有适应方法,特别是比 DAPT 高出 15.1%。
对于 大模型,尽管 DAPT 有参数更新的优势,但 Memory Decoder 仍 保持竞争力,并优于其他参数高效方法。
结论:Memory Decoder 能够有效捕捉非参数检索的优点,同时避免了计算开销,是一个高效的增强方案。
5.2 Downstream Performance(下游任务性能)¶
本节通过多个 NLP 任务(如情感分析、文本蕴含、文本分类)评估 Memory Decoder 的泛化能力,结果如下:
Memory Decoder 在 零样本(zero-shot) 设置下,平均得分最高,优于基线模型、kNN-LM 和 LoRA。
DAPT 在部分任务上(如 HYP 和 Yahoo)出现严重遗忘,性能下降接近一半。
Memory Decoder 在 文本蕴含类任务(如 CB 和 RTE) 上表现尤为突出。
核心优势:通过保留原始模型参数,Memory Decoder 实现了 领域适应,同时 不牺牲通用语言能力。
5.3 Cross-Model Adaptation(跨模型适应)¶
本节验证了 Memory Decoder 在 不同规模和架构的模型之间 的通用性:
一个 0.5B 参数的 Memory Decoder 能够提升 Qwen2 和 Qwen2.5 家族中从 0.5B 到 72B 参数的多个模型。
对于 小模型(如 Qwen2-0.5B),Memory Decoder 显著提升性能,达到 SOTA。
对 大模型(如 Qwen2-72B),Memory Decoder 也带来了实质性改进。
最重要的是,1B 的 Memory Decoder 增强模型性能超过 72B 的原始模型,参数效率高达 140倍。
结论:Memory Decoder 可作为 共享 tokenizer 的多模型通用组件,实现高效的跨模型领域适应。
5.4 Cross-Vocabulary Adaptation(跨词表适应)¶
本节评估了 Memory Decoder 在 不同词表(如 Llama)上 的迁移能力:
通过 仅重新初始化嵌入层和语言模型头,Qwen2.5 上训练的 Memory Decoder 成功迁移到 Llama 模型家族,且训练预算仅为 10%。
Memory Decoder 在 生物、金融等领域 表现出显著性能提升,优于 LoRA。
在 法律文本 上稍弱,仍有提升空间。
结论:Memory Decoder 不仅适用于单一模型家族,还能 高效迁移至不同词表的模型,扩展了其实际应用范围。
5.5 Knowledge-Intensive Reasoning Tasks(知识密集型推理任务)¶
本节测试 Memory Decoder 在 需要复杂推理的问答任务(如 NQ 和 HotpotQA)中的表现:
kNN-LM 在这些任务中 提升有限甚至退化。
Memory Decoder 实现了 显著提升,例如在 NQ 任务上提升 4.37%,在 HotpotQA 上提升 2.58%。
关键原因:Memory Decoder 不依赖显式检索,而是通过训练 “内部化检索” 模式,从而 保留了组合推理能力。
优势:解决了传统检索方法在多跳问题上的局限性,平衡了知识获取与推理能力。
总结¶
Memory Decoder 作为一项 预训练、即插即用的记忆增强组件,在多个维度上展示了其强大能力:
在 语言建模 和 下游任务 中优于现有方法,尤其在零样本设置下;
实现了 跨模型、跨词表 的高效迁移;
在 知识密集型任务 中表现出色,克服了传统检索方法的局限;
具备 参数高效 和 无需修改原始模型参数 的优势。
这些结果验证了 Memory Decoder 的 通用性、可扩展性与实用性,为 LLM 的领域适应提供了一种新的、高效解决方案。
6 Analysis¶
6.1 Case Study: Bridging Parametric and Non-Parametric Methods(案例研究:连接参数化与非参数化方法)¶
本节通过具体案例,展示了 Memory Decoder 在结合参数化方法和非参数化方法中的优势。
表格数据对比:
长尾知识(Long-tail Knowledge):对于“Jacobi”和“1906”等罕见事实信息,Memory Decoder 显著优于基础语言模型(Base LM)(如 68.94% vs. 0.12%,98.65% vs. 1.57%),表明其能够有效捕捉非参数方法的记忆能力。
语义连贯性(Semantic Coherence):对于“on”和“C”等逻辑连接词,Memory Decoder 的表现更接近基础模型,而不是低概率的 kNN 方法,表明其在语言连贯性方面具有优势。
核心结论:
Memory Decoder 成功融合了非参数方法的记忆能力和参数方法的泛化能力,能够在处理长尾知识的同时保持语言流畅性。这种“两全其美”的效果,使其在多种任务中表现优异。
6.2 Sensitivity Analysis of Interpolation Parameter(插值参数敏感性分析)¶
本节分析了 Memory Decoder 中插值参数 α 的敏感性。
表格数据:
α 在 0.40 到 0.80 范围内,平均困惑度(PPL)变化幅度小于 2.5%,最佳点为 α = 0.6。
即便在 α 的极值(0.4 和 0.8)下,性能下降幅度也很小(最大 2.4%)。
核心结论:
Memory Decoder 对超参数选择具有较强的鲁棒性,实际部署中不需要繁琐的调参过程,具有良好的可部署性。
6.3 Impact of Memory Decoder Size(Memory Decoder 尺寸影响)¶
本节评估了不同大小的 Memory Decoder 对性能的影响。
表格数据:
即使是最小的 Memory Decoder(117M 参数),在 GPT-2 中的表现也优于全参数微调(DAPT)。
随着 Memory Decoder 规模的增大,性能持续提升,其中 774M 参数的版本表现最佳。
核心结论:
Memory Decoder 提供了一种比全模型微调更高效的替代方案。用户可根据计算资源选择合适的规模,同时保留原有模型的能力。
6.4 Ablation on Pre-training Objective(预训练目标的消融实验)¶
本节通过消融实验验证 Memory Decoder 预训练目标的有效性。
表格数据:
Memory Decoder 混合训练目标(KL + CE)在生物医学领域优于单一目标(仅 KL 或仅 CE)。
与 DAPT 相比,仅使用交叉熵(CE)的插值方法效果更差,进一步验证了 Memory Decoder 的训练目标设计更优。
核心结论:
Memory Decoder 的预训练目标融合了非参数分布知识和语料结构信息,使其能够捕捉更丰富的语言模式。混合目标的设计是其性能提升的关键因素。
总结¶
本章通过多个角度验证了 Memory Decoder 的有效性:
功能优势:融合了非参数方法的记忆能力和参数方法的泛化能力。
性能优势:在处理长尾知识和保持语义连贯性方面表现突出。
鲁棒性:对超参数 α 的选择具有高度鲁棒性,适合实际部署。
可扩展性:不同规模的 Memory Decoder 均可取得良好效果,适合不同计算资源需求。
训练设计优势:混合训练目标(KL + CE)优于单目标设计,提升了模型对语言模式的捕捉能力。
这些特性共同支撑了 Memory Decoder 在多种任务中的优越表现。
8 Conclusion¶
在本论文中,我们提出了 Memory Decoder,这是一种用于大语言模型领域适应的新颖即插即用方法。通过预训练一个小型的Transformer解码器来模拟非参数检索器的行为,Memory Decoder能够在不修改模型参数的情况下,将任何兼容的语言模型适配到特定领域。我们在多个模型家族和专业领域进行了全面实验,结果表明,Memory Decoder在性能上持续优于参数化适应方法和传统的检索增强方法。
核心创新:通用性与高效性¶
Memory Decoder 的关键创新点在于其通用性与高效性。一个预训练好的 Memory Decoder 可以无缝增强任何使用相同分词器的模型,而且通过少量额外训练,还可以适配不同分词器和架构的模型。这一能力使得我们能够在不同模型家族之间高效地进行领域适应,显著减少开发定制化模型所需的资源。
我们的实验结果还表明,Memory Decoder 在保留检索增强方法性能优势的同时,保持了基础模型的通用能力,避免了参数微调方法中常见的“灾难性遗忘”问题。
重新定义领域适应范式¶
Memory Decoder 提出了一种新的领域适应范式,其核心在于将领域知识与模型架构解耦。通过预训练的“记忆”组件,我们的方法提供了一个模块化、高效且易于使用的框架,用于提升语言模型在专业领域的表现。这种方法不仅提高了模型适应的灵活性,也为未来语言模型的领域定制提供了新的思路。
9 Limitations¶
本节总结了 Memory Decoder 方法在领域自适应方面的局限性。
首先,预训练阶段 需要通过在键值数据存储中搜索,以获取 kNN 分布作为训练信号,这一过程会引入额外的计算开销。尽管这种开销只在每个领域中发生一次,并且可以通过所有适应后的模型来分摊成本,但它仍然是整个训练流程中的一个瓶颈。
其次,跨分词器的自适应 虽然比从头开始训练所需的训练量小得多,但仍需要进行一些参数更新,以对齐嵌入空间。因此,这种方法无法实现完全意义上的零样本跨架构迁移(true zero-shot cross-architecture transfer)。
重点内容总结:
预训练阶段搜索 kNN 分布带来计算开销,成为性能瓶颈。
跨分词器自适应仍需参数调整,无法实现真正的零样本跨架构迁移。
Appendix A Interpolation hyperparameter \(\alpha\) of all tasks¶
A.1 在 Wikitext-103 上的语言建模¶
在 Wikitext-103 任务上的语言建模中(见第5.1节),我们使用了不同的 GPT-2 模型大小,并为每种模型选择了一个对应的 α 值,如下表所示:
模型 |
α 值 |
|---|---|
GPT-2-small |
0.80 |
GPT-2-medium |
0.60 |
GPT-2-large |
0.55 |
GPT-2-xl |
0.55 |
表 10:GPT-2 模型在 Wikitext-103 上的插值超参数 α
观察到一个趋势:模型越大,所使用的 α 值越小。这一趋势符合直觉——更强的基模型对记忆组件的依赖程度更小。整体上,α 值主要集中在 0.6 左右,这表明 α=0.6 是一个稳健的默认选择。
A.2 下游任务表现¶
在第 5.2 节所涉及的下游任务中,我们为每个任务找到了最优的 α 值,如下表所示:
任务 |
α 值 |
|---|---|
SST-2 |
0.30 |
MR |
0.30 |
CR |
0.05 |
RT |
0.20 |
HYP |
0.20 |
CB |
0.30 |
RTE |
0.60 |
AGN |
0.20 |
Yahoo |
0.20 |
表 11:下游任务的最优插值超参数 α
从整体趋势来看,多数任务的 α 值集中在 0.3 左右,这与 Shi 等人 (2022) 的研究结果一致。这说明在语言建模和任务适配中,α=0.3 是一个较为通用的值。
A.3 跨模型和跨词汇的适应¶
在针对特定领域的语言建模任务中(见第 5.3 和 5.4 节),我们通过在验证集上搜索 {0.4, 0.6, 0.8, 0.9} 的 α 值进行调优。结果发现,α=0.6 在大多数情况下表现最佳。这表明在跨模型和跨词汇领域适应中,α=0.6 是一个较为稳健的设置。
Appendix B Analysis of DAPT Performance on Downstream Tasks¶
背景¶
已有研究表明,领域自适应预训练(DAPT)可能会对模型的提示能力产生负面影响(Cheng 等人,2023)。本研究的实验表明,这种影响在使用领域条件化 PMI(DCPMI)评分进行评估时尤为明显,尤其是在标签词与预训练领域词汇重叠的任务中。
表格总结(Table 12)¶
模型 |
Yahoo (LM) |
Yahoo (DCPMI) |
HYP (LM) |
HYP (DCPMI) |
平均 |
|---|---|---|---|---|---|
GPT-2-small |
0.466 |
0.495 |
0.639 |
0.638 |
0.559 |
+DAPT |
0.429 |
0.244 |
0.608 |
0.361 |
0.410 |
Δ\Delta |
-0.037 |
-0.251 |
-0.031 |
-0.277 |
-0.149 |
GPT-2-xl |
0.520 |
0.499 |
0.628 |
0.609 |
0.564 |
+DAPT |
0.490 |
0.491 |
0.624 |
0.618 |
0.556 |
Δ\Delta |
-0.030 |
-0.008 |
-0.004 |
+0.009 |
-0.008 |
重点内容:
GPT-2-small 在 DAPT 后,DCPMI 评分显著下降(下降约 25%),而 LM 评分下降幅度较小。
GPT-2-xl 在 DAPT 后 DCPMI 评分变化不大,甚至在某些任务中略有提升,说明大模型对这种评估偏差具有更强的鲁棒性。
结论:在使用 DCPMI 评分时,DAPT 在小模型上表现出明显性能下降,而在大模型上表现更稳定。
原因分析¶
本文采用了模糊词化方法(fuzzy verbalizers),如 Shi 等人(2022)所述。
Yahoo 和 AGN 任务中的标签词(如“politics”、“technology”)在训练数据(如 WikiText-103)中频繁出现。
DAPT 提高了这些词在目标领域的概率,导致 DCPMI 评分的分母增大,从而使得 PMI 值下降明显。
总结¶
小模型在 DAPT 后 DCPMI 评分下降明显,是由于评估方法与领域适应之间的交互效应,而非方法本身的根本性缺陷。
大模型(如 GPT-2-xl)在 DAPT 后的 DCPMI 评分变化较小,表现出更高的鲁棒性。
启示:在使用基于提示(prompt-based)的评估方法时,需注意领域适应与评估指标之间的潜在冲突,这对评估结果的解读至关重要。
Appendix C Knowledge-Intensive Reasoning Task Corpus Composition¶
在第5.5节中提到的知识密集型推理实验中,作者构建了一个大规模异构语料库,方法参考了 Geng 等人(2024)。该语料库通过整合多样化的文本来源,提供了广泛的事实性知识覆盖和不同的写作风格,从而更好地支持模型在知识密集型任务中的表现。完整的语料库已公开在 HuggingFace 平台,地址为:https://huggingface.co/datasets/wentingzhao/knn-prompt-datastore。
语料库组成(Table 13)¶
该异构语料库由多个数据集组成,具体如下:
语料库名称 |
体积 |
|---|---|
WikiText-103 |
181MB |
Amazon Reviews |
89MB |
CC-NEWS |
457MB |
IMDB |
45MB |
总计 |
722MB |
重点说明:
WikiText-103:来源于维基百科的文本数据,提供了广泛的事实性知识,是语料库中体积最大的部分。
Amazon Reviews 和 IMDB:包含用户评论和影评,提供多样的写作风格和主观性内容。
CC-NEWS:来源于新闻网站的文本,涵盖大量实时和广泛领域的信息,是语料库中第二大组成部分。
总容量 722MB:表明该语料库在规模上适中,便于处理和训练,同时保证了内容的多样性和丰富性。
总结:
本附录介绍了用于训练 Memory Decoder 在知识密集型任务中的异构语料库。该语料库通过组合多种文本来源,确保了模型可以接触广泛的事实知识和多样的写作风格,从而提升其推理能力。语料库已公开,便于其他研究者复现和扩展相关工作。
Appendix D Domain-Specific Downstream Tasks¶
为了全面评估 Memory Decoder 在保持上下文学习能力的同时实现领域适应的能力,作者在生物医学、金融和法律三个领域中的 13 个真实任务 上进行了广泛的实验。实验设置沿用了 Cheng 等人(2023)的领域语料库和评估框架。这些基准任务测试了模型在 zero-shot(零样本) 和 few-shot(少量样本) 的表现,旨在严格评估领域适应是否保留了模型的提示能力(prompting abilities),这是传统 DAPT(Domain Adapted Pre-training) 方法的已知薄弱点(Cheng et al., 2023)。
D.1 生物医学领域任务¶
ChemProt |
MQP |
PubmedQA |
RCT |
USMLE |
平均 |
|
|---|---|---|---|---|---|---|
(13-shot) |
(4-shot) |
(0-shot) |
(10-shot) |
(0-shot) |
||
Qwen2.5-7B |
24.40 |
83.44 |
63.70 |
70.10 |
36.92 |
55.71 |
+ DAPT |
17.59 |
76.22 |
65.70 |
21.00 |
34.64 |
43.03 |
+ MemDec (0.5B) |
24.40 |
84.09 |
64.40 |
74.06 |
36.84 |
56.76 |
表 14:生物医学领域特定任务的表现。
Memory Decoder 在保持上下文学习能力的同时提高了领域性能。
特别值得注意的是 RCT 任务,DAPT 表现严重下降(从 70.10 降到 21.00),而 Memory Decoder 不仅没有下降,反而提升了 74.06。
这表明传统 DAPT 方法在领域适应时会对模型的原始能力造成显著损害。
D.2 金融领域任务¶
FiQA_SA |
FPB |
Headline |
NER |
ConvFinQA |
平均 |
|
|---|---|---|---|---|---|---|
(5-shot) |
(5-shot) |
(5-shot) |
(20-shot) |
(0-shot) |
||
Qwen2.5-7B |
80.46 |
70.96 |
87.08 |
68.92 |
60.53 |
73.59 |
+ DAPT |
75.59 |
66.39 |
86.03 |
69.32 |
58.52 |
71.17 |
+ MemDec (0.5B) |
81.34 |
71.25 |
87.95 |
69.21 |
63.69 |
74.68 |
表 15:金融领域特定任务的表现。
Memory Decoder 在所有任务上都实现了稳定的性能提升,而 DAPT 在多数任务上性能下降。
这表明 Memory Decoder 不仅适应了金融领域的知识,还没有损害模型的通用能力。
D.3 法律领域任务¶
SCOTUS (micro) |
SCOTUS (macro) |
CaseHOLD (micro) |
CaseHOLD (macro) |
UNFAIR-ToS |
平均 |
|
|---|---|---|---|---|---|---|
(0-shot) |
(0-shot) |
(0-shot) |
(0-shot) |
(4-shot) |
||
Qwen2.5-7B |
26.66 |
17.90 |
35.92 |
35.93 |
87.05 |
40.69 |
+ DAPT |
28.33 |
16.82 |
35.70 |
35.69 |
87.18 |
40.74 |
+ MemDec (0.5B) |
31.66 |
21.05 |
37.58 |
37.59 |
87.05 |
42.99 |
表 16:法律领域特定任务的表现。
Memory Decoder 在基于案例的推理任务(如 CaseHOLD)中表现突出,同时在合同分析(UNFAIR-ToS)中也保持了强性能。
与 DAPT 相比,Memory Decoder 在零样本和少量样本设置下表现更稳定且更好。
D.4 分析¶
Memory Decoder 的关键优势在于:
提升领域性能:在生物医学、金融和法律三个领域中都显著提升了任务表现;
保留上下文学习能力:在 zero-shot 和 few-shot 任务中,Memory Decoder 表现优于 DAPT,而 DAPT 在一些任务中性能甚至大幅下降;
避免模型能力退化:DAPT 通过修改原始模型来适应领域,而 Memory Decoder 是通过扩展而非修改原始模型,从而保留了模型原有的通用能力;
实际部署价值:在真实场景中,模型需要同时处理领域知识和通用推理任务,Memory Decoder 提供了重要的平衡能力。
总结:Memory Decoder 是一种更有效、更安全的领域适应方法,能够增强模型的领域表现,同时避免传统 DAPT 方法带来的能力退化问题。
Appendix E Comparison with DAPT Model Interpolation¶
核心观点:¶
本节比较了 Memory Decoder 与另一种自然的基线方法——通过领域自适应预训练(DAPT)模型进行 logit 插值的效果。结果显示,Memory Decoder 在多个指标和模型规模下均优于 DAPT 模型插值,验证了其训练目标(结合分布对齐和语言建模)的有效性。
1. 比较方法简介¶
DAPT 模型插值:
使用小型模型进行领域自适应预训练,然后将其预测结果与基础 LLM 的输出进行插值。
依赖传统的语言建模目标,而非 Memory Decoder 的分布对齐训练方法。
Memory Decoder:
在推理时进行插值,但训练过程中结合了分布对齐与语言建模的混合目标。
通过学习数据存储中的非参数分布,捕捉更丰富的领域知识。
2. 实验结果(表17)¶
Base Model |
Baseline PPL |
+ DAPT (Small) |
+ MemDec (Small) |
|---|---|---|---|
GPT2-small |
24.89 |
15.95 |
13.36 (+2.59) |
GPT2-medium |
18.29 |
14.26 |
12.25 (+2.01) |
GPT2-large |
15.80 |
13.13 |
11.53 (+1.60) |
GPT2-xl |
14.39 |
12.30 |
10.93 (+1.37) |
Average |
18.34 |
13.91 |
12.01 (+1.90) |
结论:
Memory Decoder 在所有 GPT-2 模型变体上都优于 DAPT 插值,平均提升 1.90 perplexity。
对较小的模型(如 GPT2-small)效果更显著,说明 Memory Decoder 在资源有限的情况下更具优势。
3. 性能差异的原因分析¶
DAPT 的局限性:
仅通过最大化领域语料的似然来训练模型。
无法捕捉更复杂的延续模式和领域知识。
Memory Decoder 的优势:
在训练过程中同时学习语言建模和分布对齐,从非参数数据存储中学习分布模式。
能更好捕捉领域知识的延续性,从而提升推理质量。
与消融实验的对比:
CE-only 基线(等同于 DAPT)大幅落后于 Memory Decoder 的完整方法(见 6.4 节)。
4. 模型规模下的表现一致性¶
无论模型大小,Memory Decoder 的优势都保持一致。
即使在最大模型(GPT2-xl)上,DAPT 已经带来了显著提升,但 Memory Decoder 仍能进一步提升 1.37 perplexity。
表明其优势不是模型规模或结构的产物,而是训练方法本身的优势。
总结要点:¶
Memory Decoder 的混合训练目标(分布对齐 + 语言建模)比传统 DAPT 更有效。
在多个模型规模下持续表现优异,尤其在小模型中效果显著。
其优势源于对领域知识分布的更好建模和检索能力。
实验验证了 Memory Decoder 训练方法的通用性和有效性。
Appendix F In-Context Learning Performance Analysis¶
总体目标¶
Memory Decoder 被设计为一种补充现有自适应方法的方式,尤其是上下文学习(In-Context Learning, ICL)。虽然文章主要比较的是领域自适应预训练的效果,但为了验证 Memory Decoder 是否保留并增强模型利用上下文示例的能力(这是传统领域自适应方法常导致性能下降的关键点),作者进行了专门的性能分析。
实验设置¶
基准任务:CaseHOLD 法律推理任务。
评估方式:在不同上下文示例数量(0-shot, 4-shot, 8-shot, 16-shot)下进行测试。
模型对比:
基础模型:Qwen2.5-7B。
带 Memory Decoder 的模型:+ MemDec (0.5B)。
实验结果总结(表格 18)¶
情况 |
0-shot |
4-shot |
8-shot |
16-shot |
最佳性能 |
|---|---|---|---|---|---|
Qwen2.5-7B |
35.92 |
36.34 |
36.34 |
36.09 |
36.34 |
+ MemDec |
37.58 |
37.95 |
38.29 |
37.53 |
38.29 |
重点结论¶
Zero-shot 优势显著
Memory Decoder 在没有示例的情况下(0-shot)表现(37.58)已经超过了基础模型的最佳 few-shot 性能(36.34),说明它有效编码了领域知识,无需多个示例即可达到良好效果。上下文示例仍能带来提升
Memory Decoder 在加入上下文示例后性能进一步提升(从 0-shot 37.58 到 8-shot 38.29),说明其保留了从示例中学习的能力,并且与编码的领域知识是正交互补的。性能提升稳定
在所有测试的 shot 数量下(0, 4, 8, 16),Memory Decoder 相比基础模型都有稳定提升(提升幅度 1.43 到 1.95),表明其与上下文学习机制相容而非干扰。最佳 shot 数相同,长上下文略有下降
两种模型的最佳性能都出现在 8-shot,16-shot 略有下降,可能是由于上下文长度增加带来的噪声。但 Memory Decoder 的下降曲线与基础模型一致,说明其未在长上下文场景中引入额外脆弱性。
总体结论¶
Memory Decoder 保留并增强了上下文学习能力,这与传统领域自适应方法(如 DAPT)形成鲜明对比,后者通常会削弱模型对上下文示例的利用能力。
这一特性使 Memory Decoder 特别适用于真实应用场景,尤其在需要处理领域特定任务与通用推理任务、且示例数量可能变化的场景中。
与传统方法的对比¶
DAPT(Domain-Adaptive Pretraining):虽然在领域任务上可能有效,但通常会损害模型的上下文学习能力。
Memory Decoder:不仅提供强领域自适应能力,同时不牺牲上下文学习能力,因此更具实用价值。
Appendix G Characteristics of kk-NN Distributions¶
G.1 Extreme Sparsity and Concentration(极端稀疏与集中)¶
重点内容:
kk-NN 分布与标准语言模型(LM)输出有着本质区别。标准 LM 模型的概率分布通常是平滑的,并具有长尾特征,而 kk-NN 分布则表现出极端稀疏性。例如,在 50,257 维的词汇空间中,kk-NN 分布通常只对 2–3 个词赋予非零概率,表现出明显的集中性。
原因主要有两点:
硬性选择机制: kk-NN 只选择最近的 k 个邻居,排除了低概率候选词。
高维空间效应(维度灾难): 例如 GPT-2-Large 的嵌入维度为 1280,高维空间中距离的放大效应使得最近邻占据主导地位。
图示说明:
图 5 展示了 kk-NN、标准 LM 和 Memory Decoder 的概率分布对比,可见 kk-NN 分布非常稀疏,概率质量高度集中。
G.2 Scale-Dependent Behavior(规模相关行为)¶
重点内容:
模型的规模对 kk-NN 分布的质量有显著影响。更大的模型会生成更稀疏、更集中的 kk-NN 分布。例如:
GPT-2-Small(117M)生成的分布与 LM 输出差异较小(top-1 概率约 50%)。
GPT-2-Large(1.5B)生成的分布 top-1 概率达到 93.48%,比基线高出 67%。
图示说明:
图 6 显示了在相同检索参数(k=1024)下,模型规模越大,kk-NN 分布越稀疏。
表 19 总结:
不同模型规模下训练的 Memory Decoder 的困惑度(PPL)表现。模型越大,PPL 越低,说明检索效果越好。
原因主要有两点:
维度集中效应更强: 更大的模型嵌入空间更高维,强化了最近邻的主导地位。
更好的上下文表示能力: 大模型能更准确地区分多义词,语义表示更清晰,从而提升检索的准确性与一致性。
G.3 Domain Adaptation Effects(领域适应效果)¶
重点内容:
经过领域微调的模型生成的 kk-NN 分布更清晰、更尖锐。领域适应通过形成更专业的嵌入簇,减少了簇内差异并增加了簇间距离,从而提升了检索的决定性。
效果验证:
使用微调后模型的 kk-NN 分布训练的 Memory Decoder 持续表现出更低的困惑度,验证了领域适应后的表示能提供更优质的检索目标。
总结:
领域适应不仅优化了语义表示,也直接影响了 kk-NN 分布的质量,使其更适用于实际任务中的检索和生成场景。
Appendix H Alternative Loss Functions for Imitating kk-NN Distributions¶
本附录探讨了在模仿 kk-NN 分布任务中,除了成功的 KL 散度方法之外,其他几种替代性损失函数的尝试与比较。主要结论为:KL 散度(结合交叉熵正则化)是唯一在性能和稀疏性上都表现良好的方法,其他方法均未达到理想效果。
H.1 Failed Approaches(失败的方法)¶
作者系统验证了多种替代损失函数,但它们在模仿 kk-NN 分布时表现不佳,具体如下:
H.1.1 Focal Loss(焦点损失)¶
公式:
$\(
\mathcal{L}_{\text{Focal}} = -\sum_{i}\left[\alpha(1-p_{\theta}(i))^{\gamma}p_{\text{kNN}}(i)\log p_{\theta}(i)+(1-\alpha)p_{\theta}(i)^{\gamma}(1-p_{\text{kNN}}(i))\log(1-p_{\theta}(i))\right]
\)$
参数:α = 0.5,γ = 2
特点:通过梯度重缩放解决类别不平衡问题,理论上能关注难分类的稀疏区域。
问题:虽然设计初衷合理,但在实践中未能实现足够好的分布集中性,效果不佳。
H.1.2 Jensen-Shannon Divergence(JS 散度)¶
公式:
$\(
\text{JSD}(P\parallel Q) = \frac{1}{2}D_{\text{KL}}(P\parallel M) + \frac{1}{2}D_{\text{KL}}(Q\parallel M),\quad M=\frac{1}{2}(P+Q)
\)$
特点:是对称的 KL 散度的替代方案,避免了方向性偏差。
问题:对于极度稀疏的目标分布(kk-NN 分布)并没有优势,效果不如 KL 散度。
H.1.3 Bi-directional Logits Difference (BiLD)(双向对数差异)¶
公式:
$\(
\mathcal{L}_{\text{BiLD}} = D_{\text{KL}}[p_{\text{led}}^{\text{kNN}}\|p_{\text{cor}}^{\theta}] + D_{\text{KL}}[p_{\text{cor}}^{\text{kNN}}\|p_{\text{led}}^{\theta}]
\)$
特点:关注 top-k 对数之间的相对排名,适合顺序比绝对概率更重要的分布。
问题:尽管理论合理,但在实践中始终不如标准 KL 散度表现好。
H.1.4 Explicit Sparsity Penalty(显式稀疏惩罚)¶
公式:
$\(
\mathcal{L}_{\text{sparse}} = \mathcal{L}_{\text{KL}} + \alpha\sum_{i}\mathbb{I}_{\{p_{\text{kNN}}(i)=0\}}\cdot p_{\theta}(i),\quad \alpha=0.01
\)$
特点:对零概率区域中非零预测进行显式惩罚,试图提升输出的稀疏性。
问题:训练不稳定,且未显著提升输出的稀疏性,效果不理想。
H.2 Why KL Divergence Succeeds(为什么 KL 散度成功)¶
KL 散度结合交叉熵正则化之所以在 kk-NN 分布模仿任务中表现优异,主要基于其数学性质与任务目标的高度契合:
1. 不对称惩罚结构¶
KL 散度的公式为:
$\(
D_{\text{KL}}(P||Q) = \sum_{i} P(i) \log \frac{P(i)}{Q(i)}
\)$
其中,它对“预测分布在目标为0的位置分配概率”的情况施加高惩罚,而对“目标有概率但预测没有”的情况则惩罚较小。这种不对称性自然促使模型输出稀疏分布,与 kk-NN 的稀疏特性高度匹配。
2. 模式捕获行为(Mode-seeking behavior)¶
KL 散度(尤其是前向 KL)具有“模式捕获”特性,即倾向于捕捉目标分布中的少数高概率模式,而不是覆盖整个分布。这与 kk-NN 分布中通常只有2-3个主导模式的特性非常契合,而对称损失(如 JSD)或“模式覆盖”损失则不符合该需求。
3. 信息论最优性¶
KL 散度直接最小化两个分布之间的编码长度差异。对于表示“检索感知不确定性”的 kk-NN 分布来说,KL 散度能够保留其信息结构,包括高置信度的峰值和候选项的排序。
4. 正则化的作用¶
交叉熵正则化组件确保模型输出在语言上合理,防止模型退化到语义无效的极端稀疏状态。与 KL 散度的稀疏性驱动相结合,使得模型在稀疏性和语义合理性之间取得了良好平衡。
总结¶
KL 散度结合交叉熵正则化是模仿 kk-NN 分布的最佳选择,因其数学性质与任务目标高度一致。
其他损失函数如 Focal Loss、JSD、BiLD 和显式稀疏惩罚虽然各有理论优势,但在实践中均未达到理想效果。
KL 散度的不对称惩罚、模式捕获、信息论最优性和正则化机制共同促成了其在该任务中的优异表现。