2307.06281_MMBench: Is Your Multi-modal Model an All-around Player?¶
引用: 1259(2025-07-26)
组织
1Shanghai AI Laboratory
2Nanyang Technological University
3The Chinese University of Hong Kong
4National University of Singapore
5Zhejiang University
总结¶
简介
背景:
缺乏一个统一、全面的评估体系来检验VLM模型是否真正具备“全方面”能力
评估大尺度视觉-语言模型(VLMs)多模态能力的双语(中英)基准测试
客观基准测试
CircularEval 评估策略
数据集
3217 个精心挑选的多项选择题
涵盖 20 个细粒度能力维度(L-3),每个维度有约 125 题
能力维度
一级(L-1)能力为“感知”和“推理”
二级(L-2)能力有六个子类(参见 A.1)
粗粒度感知(Coarse Perception)
图像风格、场景、情感、质量、主题的判断
示例包括识别图像是否为照片、绘画、CT图像等
细粒度感知(单实例)(Fine-grained Perception - single-instance)
对图像中的单个对象进行位置、属性、名人识别、OCR(文本/公式/表格识别)等任务
细粒度感知(跨实例)(Fine-grained Perception - cross-instance)
识别图像中多个对象之间的空间关系、属性比较、人类行为(如动作、人与物/人与人互动)
属性推理(Attribute Reasoning)
推理物体的物理属性(如挥发性)、功能(如扫帚的功能)、身份(如通过着装判断职业)
关系推理(Relation Reasoning)
社会关系(如父子关系)、物理关系(如3D空间关系)、自然关系(如共生、捕食)等
逻辑推理(Logic Reasoning)
理解结构化图像-文本内容(如图表分析)、预测未来事件(如天气变化、情绪变化)
三级(L-3)能力则细分为 20 个具体的子类
数据集
MMBench
MMBench-CN
数据集划分为开发集(dev)和测试集(test)
比例为 4:6。开发集提供所有答案
测试集仅发布数据样本,答案需提交至评估服务器获取结果
数据收集
多个来源手动收集(参见 A.2)
20% 来自已有的公开数据集(如 COCO、CLEVR、ScienceQA 等)
80% 来自互联网(Internet),问题是作者自行构造的
质量控制策略
文本独立试题过滤:使用先进语言模型(如 GPT-4、Gemini-Pro)判断问题是否仅依赖文本即可回答,若可以则剔除
错误样本检测:使用先进的 VLM 模型对所有问题进行测试,若多个模型都无法正确作答,则进行人工检查并剔除
CircularEval评估策略
核心思想
对同一道多选题,将选项进行循环移位(即打乱顺序),反复测试VLM多次(次数等于选项数量)
只有在所有测试中都正确预测答案,才算作该问题通过。
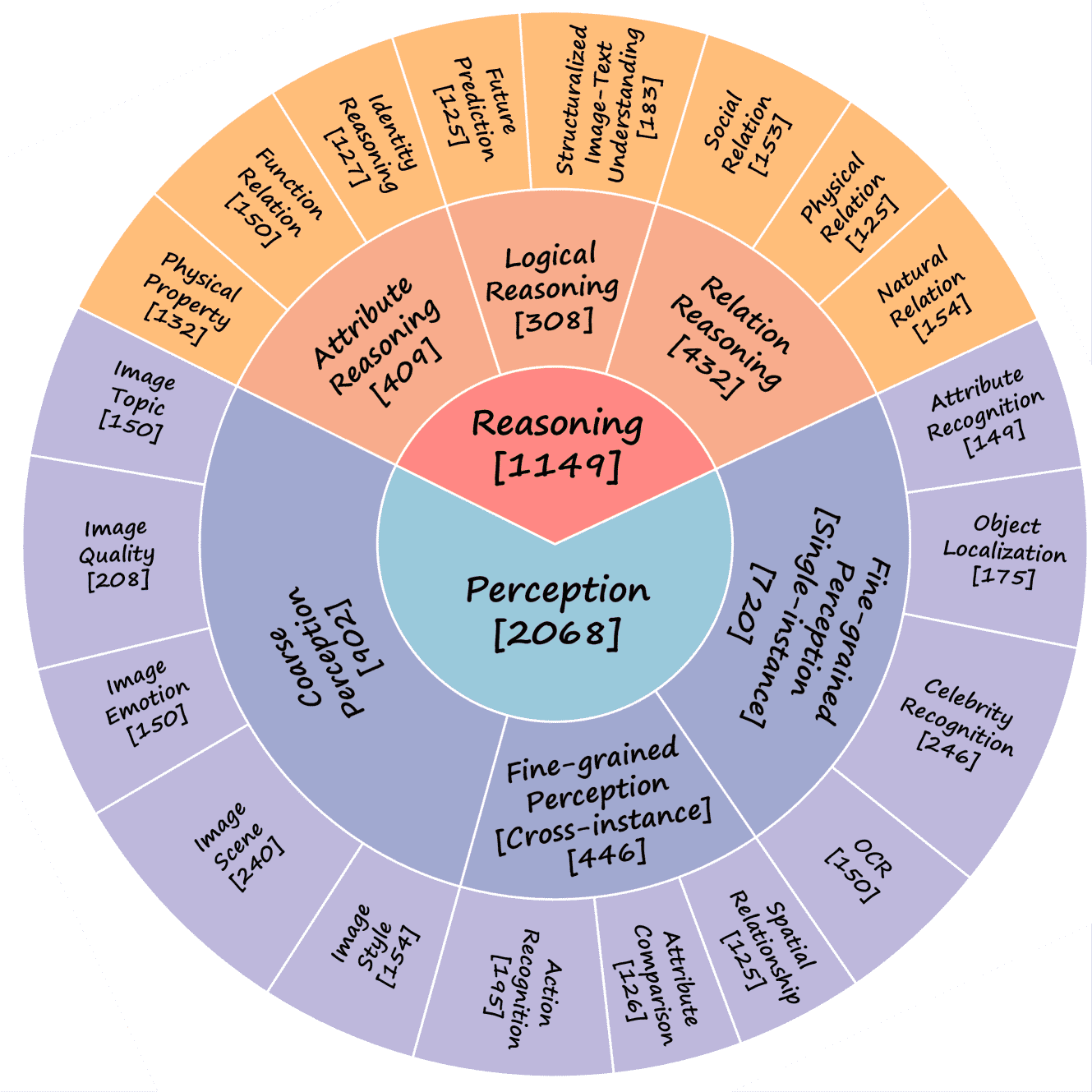
MMBench 中的能力维度
Abstract¶
这段内容主要介绍了 MMBench —— 一个用于评估大尺度视觉-语言模型(VLMs)多模态能力的双语基准测试。文章指出,尽管当前的 VLMs 在多模态感知和推理方面取得了显著进展,但如何有效评估这些模型仍是一个重大挑战。现有的评估方法存在局限性:定量基准如 VQAv2 或 COCO Caption 虽然提供了性能指标,但缺乏细粒度的能力评估;而主观评估如 OwlEval 虽全面但依赖人力,难以扩展且可能存在偏差。
针对这些问题,作者提出了 MMBench,其核心特点包括:
高质量的数据构建:通过精心设计的质量控制机制,MMBench 在问题数量和评估能力的多样性方面超越了现有基准。
CircularEval 评估策略:引入了一种严格的评估方法,并结合大语言模型将自由形式的模型输出转换为预定义选项,从而更准确地评估缺乏良好指令遵循能力的模型。
双语支持:提供中英文版本的多项选择题,使得在双语环境下对 VLMs 的表现进行公平比较成为可能。
综上,MMBench 是一个系统设计的客观基准,旨在提供对视觉-语言模型的全面、稳健评估,有助于研究社区更好地评估模型性能,并推动该领域的发展。MMBench 的评估代码已集成到 VLMEvalKit 工具中,并在 2024 年 4 月发布了改进版本 v1.1。
1 Introduction¶
该章节主要介绍了多模态视觉语言模型(Large Vision-Language Models, LVLMs)的评估背景、现有方法的不足,以及作者提出的新评估基准 MMBench。以下是该章节的总结:
一、背景与动机¶
LLMs 的进展:大型语言模型(如 GPT-4)在推理能力上取得了显著进展,甚至在某些方面超越了人类。
LVLMs 的兴起:受 LLMs 启发,视觉语言模型(如 GPT-4v、Gemini-Pro-V、LLaVA)在图像识别和推理方面表现优异。
评估方法的挑战:
早期研究的不足:偏重定性展示,缺乏定量实验,难以横向比较不同模型性能。
现有评估方法的局限性:
使用公共数据集(如 VQAv2、COCO Caption)进行定量评估,但存在“假阴性”问题和缺乏细节分析。
依赖人类主观评估(如 OwlEval、LVLM-eHub),虽然更全面,但存在成本高、可重复性差、样本量小等问题。
二、MMBench 的提出¶
为克服现有评估方法的局限,作者提出了 MMBench,这是一个系统性构建、用于全面评估大视觉语言模型能力的客观基准。
1. 数据集设计¶
内容:包含 3217 个精心挑选的多项选择题。
覆盖能力维度:涵盖 20 个细粒度能力维度,如物体定位、社交推理等。
平衡分布:每个维度有约 125 题,保证评估的全面性和公平性。
2. 评估策略¶
GPT-4 辅助选择匹配:
部分模型无法直接输出选项标签(如 A、B、C),因此采用 GPT-4 将模型输出与选项进行匹配,减少“假阴性”问题。
GPT-4 与人类评估的一致性高达 91.5%,显示出其匹配能力的可靠性和鲁棒性。
CircularEval 策略:
提出一种新的循环评估策略,以提升评估过程的稳定性和准确性(详见第 4.3 节)。
3. 评估与分析¶
模型数量:对 21 个知名视觉语言模型(涵盖多种架构和规模)在 MMBench 上进行了全面评估。
结果价值:
提供模型在各项能力维度上的性能排名,便于横向比较。
为模型优化和未来研究方向提供有价值的反馈。
三、主要贡献¶
系统化构建数据集:精心挑选覆盖 20 个维度技能的 3217 道题,全面评估 VLM 能力。
鲁棒评估策略:引入 GPT-4 辅助匹配和 CircularEval 循环评估策略,提升评估稳定性与准确性。
模型评估与洞察:对多个主流 VLM 进行综合评估,提供性能排名与改进建议,促进社区研究。
总结¶
该章节系统地梳理了当前视觉语言模型评估的现状与挑战,提出了一种新的、全面且鲁棒的评估基准 MMBench。通过结合 GPT-4 辅助匹配与创新评估策略,MMBench 为模型能力的公平、细致评估提供了新思路,具有较强的实用性和参考价值。
3 The construction of MMBench¶
这段内容主要介绍了 MMBench 基准测试的构建过程及其特点,主要包括以下几个方面:
MMBench 的三大特点:
多样化能力评估:MMBench 采用来自不同来源的图像和问题,评估模型在多层次能力分类体系下的多样化理解能力。
严格的质量控制:在样本筛选过程中引入严格的质量控制机制,确保测试样本的正确性和有效性。
双语支持:MMBench 是一个支持中英文的多模态基准,便于在中英文环境下对视觉语言模型(VLM)进行公平比较。
能力分类体系:
MMBench 的能力体系分为三个层次:一级(L-1)能力为“感知”和“推理”,二级(L-2)能力有六个子类,三级(L-3)能力则细分为 20 个具体的子类。
该能力体系模拟了人类在感知和推理方面的认知过程,为模型评估提供了系统化框架。
数据收集与质量控制:
问题收集方式:每个 L-3 能力对应多个选择题,问题由志愿者从多个来源手动收集,包括公开数据集和网络资源。
质量控制策略:
文本独立试题过滤:使用先进语言模型(如 GPT-4、Gemini-Pro)判断问题是否仅依赖文本即可回答,若可以则剔除。
错误样本检测:使用先进的 VLM 模型对所有问题进行测试,若多个模型都无法正确作答,则进行人工检查并剔除。
MMBench-CN 的构建:将 MMBench 翻译为中文版本,以支持中英文环境下模型的公平评估。
数据统计与划分:
MMBench 共包含 3,217 个样本,覆盖 20 个 L-3 能力,每个能力类别的样本数量尽量保持均衡(至少 125 个)。
数据集划分为开发集(dev)和测试集(test),比例为 4:6。开发集提供所有答案,测试集仅发布数据样本,答案需提交至评估服务器获取结果。
总结:MMBench 是一个结构清晰、质量严格、支持中英文的多模态理解基准,通过层次化能力分类和严格的数据筛选机制,为评估视觉语言模型的综合能力提供了全面而公平的平台。
4 Evaluation Strategy¶
本章节介绍了MMBench中用于评估视觉语言模型(VLM)的新策略,重点包括两个核心部分:LLM参与的选择提取(LLM-involved Choice Extraction)和CircularEval评估策略。
一、LLM参与的选择提取(LLM-involved Choice Extraction)¶
在评估过程中,许多VLM在面对多选题时,输出形式不规范,常常以自然语言形式给出回答,而非明确的选项标签(如“A”、“B”)。这给自动评估带来了挑战。
为了解决这一问题,作者设计了一个两步评估策略:
第一步:启发式匹配(Heuristic Matching)
尝试从VLM输出中提取选项标签(如A、B、C、D)。
如果成功,直接使用该标签作为预测结果。
第二步:LLM辅助提取
如果启发式匹配失败,则使用最先进的LLM(如GPT-4)帮助提取预测选项。
提供问题、选项和VLM的原始输出给LLM,要求其将预测内容对齐到最接近的选项标签。
若LLM认为模型的预测与所有选项都显著不同,则返回伪选项“Z”。
实验表明,LLM在绝大多数情况下都能正确匹配预测结果。
实验结果:¶
不同VLM的“指令遵循能力”差异较大,部分开源模型(如MiniGPT4、VisualGLM)匹配成功率较低。
引入LLM作为选择提取器后,这些模型的最终准确率显著提升。例如,VisualGLM的匹配成功率从64.8%提升到88.1%。
LLM的对齐能力也很强,GPT-4与人类判断的对齐率达到91.5%,远高于其他模型。
因此,在后续评估中使用GPT-4-0125作为默认的选项提取器。
二、CircularEval评估策略¶
为了提高评估的鲁棒性和公平性,作者提出了CircularEval策略。
核心思想:¶
对同一道多选题,将选项进行循环移位(即打乱顺序),反复测试VLM多次(次数等于选项数量)。
只有在所有测试中都正确预测答案,才算作该问题通过。
比如,如果一个问题有4个选项,则需对4种选项顺序排列分别进行测试,VLM必须都正确回答才算成功。
优势:¶
提升鲁棒性:防止模型依赖选项顺序,减少随机猜测的影响(如4选1时随机猜对概率为25%)。
减少评估偏差:防止某些VLM偏好特定选项的问题。
控制成本:一旦某次测试失败,就不再继续测试其他排列,实际成本低于理论最大值。
实验效果:¶
CircularEval能够更有效地展示不同VLM之间的性能差异。
通过该策略,模型的稳定性表现更真实,评估结果更具说服力。
总结¶
本章提出了一套系统性的评估策略,包括:
使用LLM辅助提取VLM的预测结果,以应对自由文本输出的问题;
引入CircularEval策略,通过多次测试和选项循环,提升评估的鲁棒性和公平性。
这些策略共同保证了MMBench评估体系的可靠性和有效性,尤其适用于评估不同指令遵循能力的VLM,为后续模型比较提供了坚实基础。
5 Evaluation Results¶
本文第5章“Evaluation Results”主要围绕 MMBench 数据集对多种视觉语言模型(VLMs)进行评估,涵盖了三类模型:仅文本模型、开源 VLMs 和专有 VLMs。通过采用 CircularEval(多轮推理、一致性为前提)与 VanillaEval(单次推理)两种评估方法,对模型在不同任务和语言环境下的性能进行了系统分析。以下是对各部分的总结:
5.1 实验设置(Experimental Setup)¶
模型分类:
仅文本模型:如 GPT-4。
开源 VLMs:包括 OpenFlamingo、MiniGPT4、InstructBLIP、LLaVA、IDEFICS、CogVLM、Qwen-VL、Yi-VL、mPLUG-Owl、InternLM-XComposer 和 MiniCPM-V 等。
专有 VLMs:如 Qwen-VL-Plus/Max、Gemini-Pro-V 和 GPT-4v。
评估设置:
所有模型在 MMBench 上均使用 zero-shot 设置(即不进行额外训练)进行推理。
使用统一提示(prompt)和“gpt-4-0125”作为选择提取器。
评估工具为 VLMEvalKit。
附录中提供了模型架构、参数规模和更多设置下的额外结果。
5.2 主要结果(Main Results)¶
CircularEval vs VanillaEval 对比(见表2):
在 CircularEval 设置中,大多数 VLM 的精度显著下降,说明其推理一致性较差。
例如,LLaVA-v1.5-13B 在 VanillaEval 下比 7B 版本高出 2.1%,但在 CircularEval 下差距扩大至 4.7%。
OpenFlamingo v2 在 CircularEval 下几乎失效(从 36.7% 降至 2.6%)。
甚至专有模型(如 GPT-4v、Qwen-VL-Max)也会在 CircularEval 下下降约 10%。
因此,研究者将 CircularEval 作为默认评估标准,以更严格地衡量模型性能。
MMBench 测试集整体表现(见表3):
InternLM-XComposer2 在开源模型中表现最佳,超越了大多数专有模型。
LLaVA 系列(如 LLaVA-InternLM2-20B)和 Yi-VL 系列也表现出色,仅次于 GPT-4v 和 Qwen-VL-Max。
MiniCPM-V 在小参数规模(≤3B)下也能达到 60% 以上的 Top-1 准确率。
MiniGPT、IDEFICS、VisualGLM 和 InstructBLIP 等模型表现较差,OpenFlamingo v2 接近随机水平。
LLM 的作用显著:LLM 的性能直接影响 VLM 的整体能力,例如 LLaVA 在换用更强的 LLM 后,其推理任务性能大幅提升。
中英文表现差异(MMBench-CN):
大部分模型在中国语料上的表现低于英文,但 InternLM-XComposer2 表现稳定,下降幅度小于 1%。
差异可能源于训练数据中中英文语料的不平衡。
排名靠前的模型在双语环境下总体表现突出,EN-CN 差异小。
5.3 细粒度分析(Fine-grained Analysis)¶
专有 VLMs 的内容审查机制:
GPT-4v、Gemini-Pro-V 和 Qwen-VL-Max 在 CircularEval 中拒绝回答部分问题,尤其是关于名人识别的问题。
内容审查对评估精度有一定影响(最多约 2.4%),但影响较小。
专有 VLMs vs 开源 VLMs 的差距:
专有模型在以下两类任务上有显著优势:
结构化图文理解:如表格、代码、图表和布局。
需要外部知识的任务:如名人识别、物理属性推理。
开源模型在其他感知和推理任务上可能更具优势。
MMBench 中的困难案例:
所有 VLM 在以下任务上表现不佳:
低级视觉特征识别:如亮度、对比度、图像锐度等。
结构化视觉输入理解:如表格、图表(即使是简单示例)。
对象间空间关系理解:2D 或 3D 空间中的物体关系推理。
总结¶
本章通过 CircularEval 与 VanillaEval 的对比,揭示了当前 VLMs 在多轮推理一致性方面的不足。实验表明,模型性能受 LLM 能力影响显著,专有模型在结构化视觉理解与外部知识任务上更具优势,但开源模型在小参数下也表现出潜力。MMBench-CN 的分析进一步指出中英文数据不平衡的问题,以及某些模型在双语支持上的优势。通过细粒度分析,研究者识别出 VLMs 的主要短板,为未来模型优化提供了方向。
6 Conclusion¶
本章总结了研究的主要内容和贡献。作者提出了MMBench,这是一个包含3000多个多选题、涵盖20项能力维度的多模态评估基准,用于对视觉语言模型(VLM)进行客观评估。为了获得更稳健和可靠的评估结果,作者引入了一种名为CircularEval的新评估策略,该策略比传统的单次评估更严格,同时保持了较低的成本。针对部分VLM指令跟随能力有限的问题,作者还结合大语言模型(LLM)从模型预测中提取选项,以提升评估准确性。最后,作者在MMBench上对20多种主流VLM进行了全面评估,涵盖了不同的模型架构和参数规模,并得出了对未来模型改进有价值的见解。
Appendix A More Details about the Data¶
这篇附录主要详细介绍了 MMBench 数据集的构成细节,主要包括两个部分:
A.1 各叶能力(Leaf Abilities)的定义与示例¶
MMBench 评估模型多模态能力的维度被细分为六个主要能力类别(每个能力下包含若干子能力),并为每个子能力提供了定义和可视化示例:
粗粒度感知(Coarse Perception)
图像风格、场景、情感、质量、主题的判断。
示例包括识别图像是否为照片、绘画、CT图像等。
细粒度感知(单实例)(Fine-grained Perception - single-instance)
对图像中的单个对象进行位置、属性、名人识别、OCR(文本/公式/表格识别)等任务。
细粒度感知(跨实例)(Fine-grained Perception - cross-instance)
识别图像中多个对象之间的空间关系、属性比较、人类行为(如动作、人与物/人与人互动)。
属性推理(Attribute Reasoning)
推理物体的物理属性(如挥发性)、功能(如扫帚的功能)、身份(如通过着装判断职业)。
关系推理(Relation Reasoning)
社会关系(如父子关系)、物理关系(如3D空间关系)、自然关系(如共生、捕食)等。
逻辑推理(Logic Reasoning)
理解结构化图像-文本内容(如图表分析)、预测未来事件(如天气变化、情绪变化)。
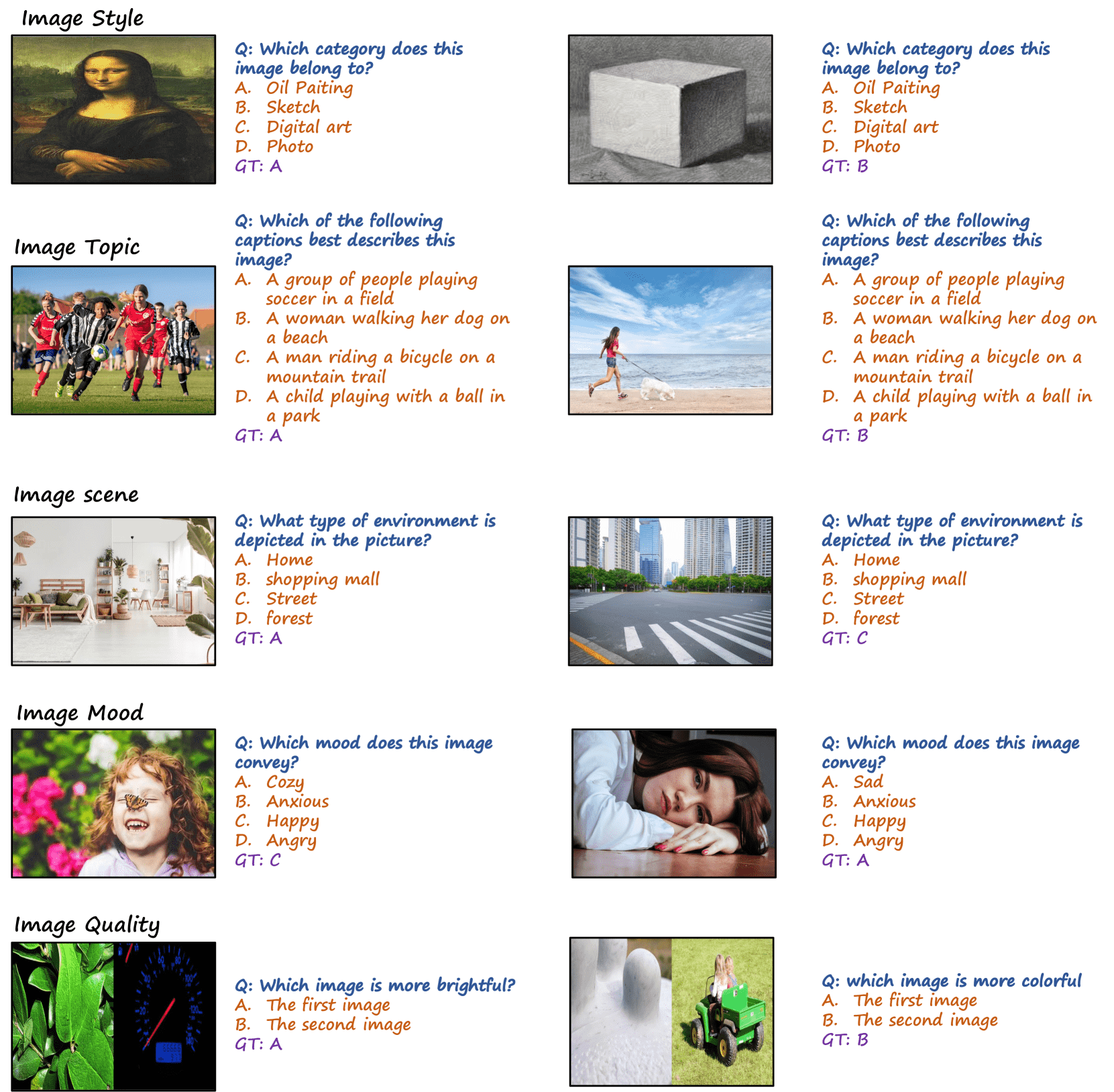
Figure 11: Coarse Perception

Figure 12: Fine-grained Perception (single-instance)

Figure 13:Fine-grained Perception (cross-instance)

Figure 14:Attribute Reasoning

Figure 15:Relation Reasoning

Figure 16:Logic Reasoning
A.2 MMBench 的数据来源¶
MMBench 的数据主要来自两个渠道:
80% 来自互联网(Internet),问题是作者自行构造的。
20% 来自已有的公开数据集(如 COCO、CLEVR、ScienceQA 等),部分问题和答案是定制的或从数据集中选取的。
附录提供了详细的来源统计表格,列出了每个数据集的使用数量和占比(共 3200 多条数据)。
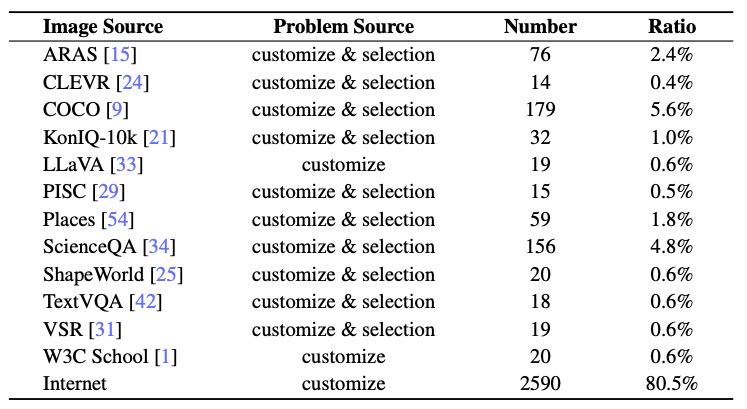
Table 5: The source of (Q, C, I, A) in MMBench . Customize means all of question, choices and answer are constructed by us. Customize & selection implies that these components are either constructed by us or selected from the original dataset.
说明
Q: Question
C: Choices
I: Image
A: Answer
总结¶
本附录系统性地展示了 MMBench 数据集的构建过程和评估维度,通过对每种能力的详细定义和视觉化样本的呈现,帮助读者理解该数据集评估模型的能力范围,并说明了数据来源的构成比例。
Appendix B More Details on MMBench Construction¶
本节主要介绍了MMBench数据集构建过程中所采用的质量控制方法,以及中译中任务(MMBench-CN)的翻译提示(prompt)设计。
核心内容总结如下:¶
“纯文本”问题过滤
为了排除可通过纯文本输入正确回答的问题,作者使用了三个先进的大语言模型(GPT-4、Gemini-Pro、Qwen-Max)进行推理测试。如果超过两个模型能正确回答该问题,则该问题会被人工审核并可能被移除。图17(a)展示了被过滤掉的不合格问题示例。“错误”问题过滤
在初步研究中,作者发现部分数据样本存在问题,如题目或选项模糊、选项重复、答案错误等。为此,他们使用了多个视觉语言模型(VLM)进行推理,如果所有VLM都无法正确回答一个问题,则该问题会被人工检查。图17(b)展示了被过滤的错误问题示例。质量控制方法的通用性
作者指出,所采用的质量控制方法具有通用性,不仅适用于MMBench,也可以用于其他多模态评估基准(如MME、SEEDBench)。图18展示了该方法在其他基准中检测出的低质量样本。MMBench-CN的翻译
为了将MMBench的英文题目翻译成中文,作者设计了一个翻译提示(prompt),并使用GPT-4生成翻译结果,之后进行人工审核以确保准确性。附录中给出了具体的翻译提示模板和示例(图19),包括输入输出的JSON格式要求,以及需要保留不翻译的专有名词、符号等内容的说明。
总结:¶
本节详细介绍了MMBench数据集构建过程中的质量控制机制,包括如何过滤“纯文本”和“错误”问题,并强调了该方法在多模态评估中的通用性。此外,还提供了中译中的翻译策略和提示模板,以确保翻译的准确性和一致性。
Appendix C More Details on LLM-based Choice Extraction¶
本章节主要讨论了基于LLM(大语言模型)的选择题答案提取方法及其应用效果,以下是其内容总结:
一、启发式匹配的失败案例¶
图20 展示了GPT-4v在精确匹配(Exact Matching)中的失败案例。
失败原因包括:
VLM(视觉语言模型)拒绝回答或无法回答问题;
回答的表达方式与标准选项不同,但含义相近;
回答中包含多个选项标签(如A、B、C等),导致匹配困难。
二、基于LLM的选择提取提示(Prompt)¶
图21 给出了用于选择提取的提示模板,包含示例以帮助LLM更好地理解任务。
提示内容包括:
提供问题、选项和LLM的原始回答;
要求LLM仅根据字面意思进行匹配,不依赖外部知识;
如果没有合适选项,输出“Z”;
输出应为单一的大写字母(A/B/C/D 或 Z);
中文版提示用于MMBench-CN的中文任务。
三、不同选择提取器的性能评估¶
在表6中,比较了使用不同LLM作为选择提取器时,VLM在MMBench-dev数据集上的表现。
评估使用的LLM包括:
GPT-4(0125版本)
GPT-3.5-Turbo(0613 和 0125版本)
InternLM2-7B
观察结果:
使用不同提取器对评估结果影响不大;
VisualGLM的性能波动最大(约1.4%);
高性能VLM(如GPT-4v、Gemini-Pro-V)的性能差异不超过0.3%。
四、LLM语义匹配的有效性验证¶
在表7中,比较了精确匹配(Exact Matching)和基于LLM的语义匹配(LLM-based Matching)在多个VQA任务(GQA、OK-VQA、Text-VQA)上的表现。
使用GPT-3.5-Turbo评估VLM预测与标准答案的相似度(1-5分,5分为完全正确)。
核心发现:
LLM匹配方法能够识别出精确匹配无法识别的近似正确答案;
例如,MiniGPT-4在表8中给出的答案虽然与标准答案略有不同,但被LLM判定为完全正确(得分为5);
LLM的匹配趋势与精确匹配结果一致,但更具包容性和判断力。
五、总结¶
LLM作为语义匹配工具在多模态任务中具有广泛的应用潜力;
相较于传统的精确匹配,LLM可以更好地处理近义、表达形式不同的答案;
不同提取器对最终结果影响较小,但LLM提供了更灵活、准确的匹配方式;
该方法已在多个基准任务中验证有效,适合用于提升VLM评估的鲁棒性和公平性。
Appendix D Evaluation Settings and Results¶
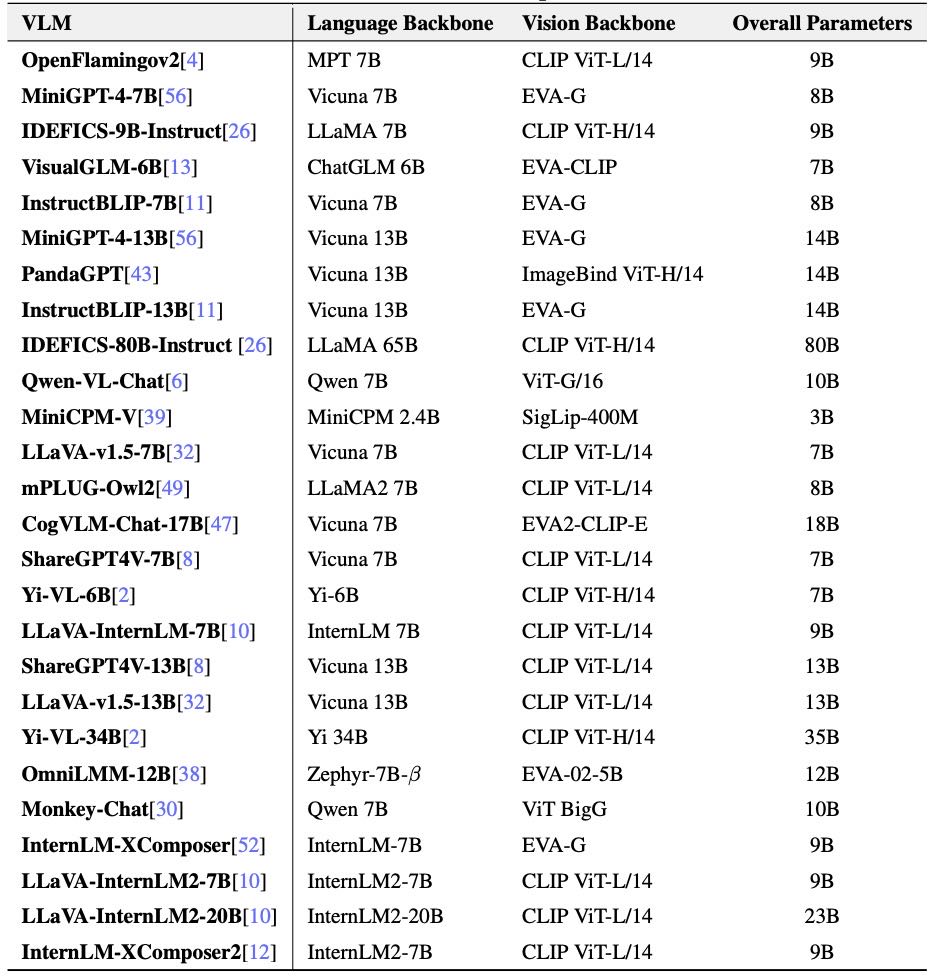
Table 9: Details of the evaluated Open-Source VLMs.
该章节内容总结如下:
本附录详细介绍了论文中对MMBench和MMBench-CN的评估设置及结果,补充了主文中未展示的模型细节和更多评估数据。
评估设置:
默认采用**零样本(zero-shot)**评估方式,未特别说明的情况下,所有结果均基于此设置。
也尝试了**少样本(few-shot)和链式推理(chain-of-thought)**评估,但效果不理想。
提供了用于零样本推理的提示模板,包括问题、选项和选择答案的指令。
模型设置:
表格中列出了参与评估的开源多模态模型(VLM)的详细配置,包括:
语言模型主干(Language Backbone)
视觉模型主干(Vision Backbone)
总参数量(Overall Parameters)
涉及的模型参数范围从3B到80B不等,语言和视觉模型的组合多样,涵盖了MPT、Vicuna、LLaMA、ChatGLM、InternLM等多个主流模型。
总结:本节为模型在MMBench上的评估提供了完整的背景资料和配置信息,有助于理解不同模型在多模态任务中的表现及其架构特点。
D.3 More Results¶
在本节中,作者对不同视觉语言模型(VLMs)在 MMBench 和 MMBench-CN 两个基准测试任务中的性能进行了更详细的分析。主要考察了30个VLM模型,包括开源模型和专有模型,并在 L-2 abilities(中级能力)上进行了评估。
总体表现总结:¶
模型总体表现差异显著:从结果可以看出,不同模型在整体(Overall)指标上的表现差异很大。例如,InternLM-XComposer2 是表现最好的模型之一,在 MMBench-dev、MMBench-test、MMBench-CN-dev 和 MMBench-CN-test 上的总体得分分别为 79.1%、78.1%、77.2% 和 77.1%,而某些开源模型如 OpenFlamingo v2 的得分则远低于平均水平(MMBench-dev 为 2.6%)。
开源模型与专有模型对比:部分开源模型(如 LLaVA-InternLM2-20B、InternLM-XComposer2)的性能接近甚至超过专有模型(如 GPT-4v、Qwen-VL-Max)。
参数规模与模型性能的关系:通常情况下,模型参数规模越大,表现越好,例如 13B 或 20B 参数的模型 通常比 7B 参数模型 表现更优。但并非所有大模型都优于小模型,例如 MiniGPT4-13B 的性能略优于 MiniGPT4-7B,但并非所有模型都遵循这一趋势。
不同能力指标的表现差异:
CP(Conceptual Proficiency):多数模型在该指标上的表现较好,例如 InternLM-XComposer2 在 MMBench-dev 的 CP 得分为 83.4%。
FP-S(Fine-grained Perception - Single) 与 FP-C(Fine-grained Perception - Complex):模型在 FP-C 上表现通常低于 FP-S,说明复杂细粒度感知任务更具挑战性。
AR(Abstraction Reasoning):多数模型在该指标上的表现较好,部分模型如 InternLM-XComposer2 在 MMBench-dev 上达到了 83.7% 的高分。
LR(Language Reasoning):该指标表现差异较大,部分模型如 GPT-4v 在 MMBench-dev 上得分为 67.7%,而一些其他模型得分较低。
RR(Reasoning and Response):表现总体较好,InternLM-XComposer2 达到了 74.4%。
MMBench 与 MMBench-CN 的差异:在中文任务(MMBench-CN)上,部分模型(如 CogVLM-Chat-17B、LLaVA-v1.5-7B)表现优于英文任务,说明这些模型在中文语义理解和推理方面进行了优化。
使用内部数据训练的影响:部分模型(如 Qwen-VL-Chat、Yi-VL-6B)在性能上有显著提升,标签中标注为 “*”,表明它们在训练中使用了内部数据。
重要发现:¶
InternLM-XComposer2 和 LLaVA-InternLM2-20B 是综合表现最好的模型。
GPT-4v 和 Qwen-VL-Max 作为专有模型,在多个指标上表现优异。
开源模型在部分任务上可以达到或接近专有模型的性能。
模型在中文任务上表现差异较大,某些模型(如 LLaVA-InternLM2-20B)在 MMBench-CN 上表现优于英文任务。
总结:¶
本节提供了多维度的模型评估结果,涵盖了多个视觉语言模型在不同任务和指标上的表现。通过这些结果,可以更清晰地了解不同模型的优劣势,并为模型选择提供依据。