2312.17653_❇️LARP: Language-Agent Role Play for Open-World Games¶
引用: 20(2025-08-08)
组织: 1MiAO
LARP: Language Agent for Role-Playing
引用链接
memory 定义与运作机制: https://zhuanlan.zhihu.com/p/21982477056
总结¶
记忆分类
长期记忆(Long-term Memory):存储容量大,用于存储重要记忆。
陈述性记忆(Declarative Memory)
语义记忆(Semantic Memory):关于世界的一般知识,如游戏规则和世界观,分为外部数据库存储和符号语言存储。
情景记忆(Episodic Memory):个体经历的特定事件,如与其他玩家或代理的互动,采用向量数据库存储,并引入衰减参数模拟记忆遗忘
程序性记忆(Procedural Memory)
自动化的技能,如游泳、骑车等
以API形式在系统中表示,分为公共API和个人API,后者可通过学习扩展
工作记忆(Working Memory):容量有限的临时缓存,用于支持复杂认知任务和交互任务。
用于支持复杂认知任务和交互任务
是短期记忆的实现形式(本文把短期记忆和工作记忆看做是同一种记忆)
对于人类来说,在短期记忆中保留项目的平均容量约为 7±2,保留时间大约为 20 到 30 秒
记忆处理(Memory Processing):核心模块,负责记忆的编码、存储与回忆。
决策模块(Decision Making):根据检索到的信息生成后续行为或对话。
Abstract¶
摘要部分简要说明了语言代理(language agents)在特定设定和短时间内展示出强大的问题解决能力。然而,面对日益复杂的开放世界模拟环境,当前代理在适应性和长期记忆保持方面存在不足。因此,研究团队提出了一个名为 LARP(Language Agent for Role-Playing) 的语言代理框架,以弥合语言代理与开放世界游戏之间的差距。
LARP 框架包含以下几个核心模块:
认知架构:包括记忆处理和决策辅助系统,这是框架的核心部分,强调代理需要具备长期记忆和灵活决策的能力,以适应复杂的环境。
环境交互模块:该模块拥有一个反馈驱动的可学习动作空间,使代理能够通过与环境的互动不断优化自身行为。这是实现适应性和智能交互的关键。
后处理方法:用于增强代理在不同个性设定下的行为一致性,促进多种个性角色的对齐,从而提升整体交互体验。
LARP 框架通过为代理预设独特的背景与个性,增强了用户与代理之间的互动质量,从而提升开放世界游戏的沉浸感和游戏体验。此外,该研究还强调了语言模型在娱乐、教育和各类模拟场景中的多样应用。
最后,项目页面已发布在:https://miao-ai-lab.github.io/LARP/,读者可进一步了解和访问相关资源。
重点总结:
LARP 是为了解决语言代理在复杂环境中的适应性和长期记忆问题。
框架包含认知架构、环境交互模块和后处理方法。
强调代理与用户在开放世界中的沉浸式交互体验。
展示了语言模型在多个领域的潜在应用。
1 Introduction¶
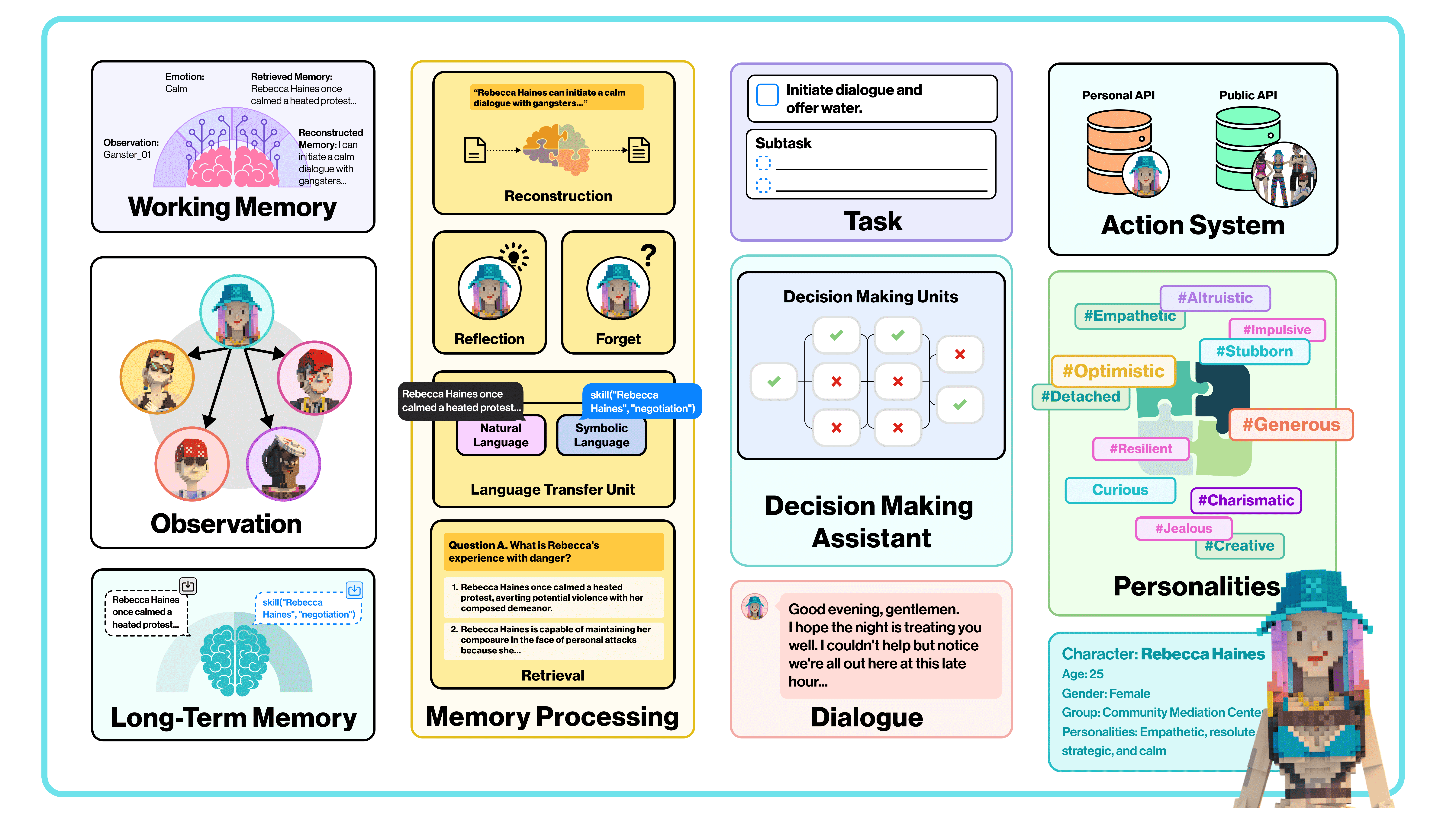
Figure 1:Cognitive Architecture of LARP Overview.
大语言模型与AI代理的发展¶
大语言模型 (LLMs) 是一种能够执行多种自然语言处理任务的机器学习模型,包括文本生成、语言翻译和对话式问答等。其中“大”指的是模型在学习过程中可以更新的参数数量庞大。近年来,随着预训练生成模型技术的进步以及大规模综合数据集的建设,一些领先的大语言模型参数数量已达到数百亿级别(如Touvron et al., 2023;Brown et al., 2020等)。这些模型的广泛应用推动了人工智能实体(通常称为代理,Agent)的发展。在人工智能领域,代理指能够通过传感器感知环境、做出决策并通过执行器做出反应的人工智能实体。近年来,随着大语言模型和代理技术的发展,一个新趋势是将二者结合,形成语言代理 (Language Agent),即融合语言模型与代理设计的智能实体(Wang et al., 2023a;Xi et al., 2023等)。
游戏与语言代理的结合¶
作为与计算机密切相关的重要行业,游戏产业与语言代理的发展日益融合。特别是文本游戏和对抗游戏中已有大量关于语言代理应用的研究(如Dambekodi et al., 2020;OpenAI et al., 2019)。随着LLM能力的增强,开放世界游戏成为了语言代理应用的新前沿。这类游戏场景复杂、动态且具有高度互动性,适合模拟人类行为的通用语言代理发挥作用。尽管已有研究提出了一些适用于开放世界游戏(如Minecraft)的通用语言代理架构(Lin et al., 2023;Park et al., 2023),但当前通用语言代理在开放世界环境中的实际应用仍面临诸多挑战,包括环境理解、长期记忆、行为一致性以及与环境的持续学习等。
LARP框架的提出¶
为解决上述挑战,本文提出了一个面向开放世界游戏的角色扮演代理框架,命名为LARP(Language Agent for Role Play)。该框架采用模块化设计,融合记忆处理、决策制定及与环境的持续交互能力。LARP基于认知心理学设计了一个复杂的认知架构,使代理具备高可玩性和独特性。为了增强角色扮演的真实感,LARP通过游戏环境的数据和上下文对代理进行约束,结合预设个性、知识、规则、记忆和行为限制,形成特定场景下的语言代理实例。
与传统依赖单一大型语言模型的通用代理框架不同,LARP采用多个小型语言模型,这些模型经过领域微调,分别处理不同任务。这种设计为开发开放世界角色扮演游戏的语言代理提供了新的思路和实践经验。
总结¶
本章主要介绍了大语言模型与代理技术的发展趋势,指出了在开放世界游戏领域中语言代理面临的挑战,并提出了LARP框架作为解决方案。LARP通过结合认知心理学、模块化设计及多模型协作策略,为构建更真实、更具个性化的游戏代理提供了新思路。
3 Cognitive Architecture¶
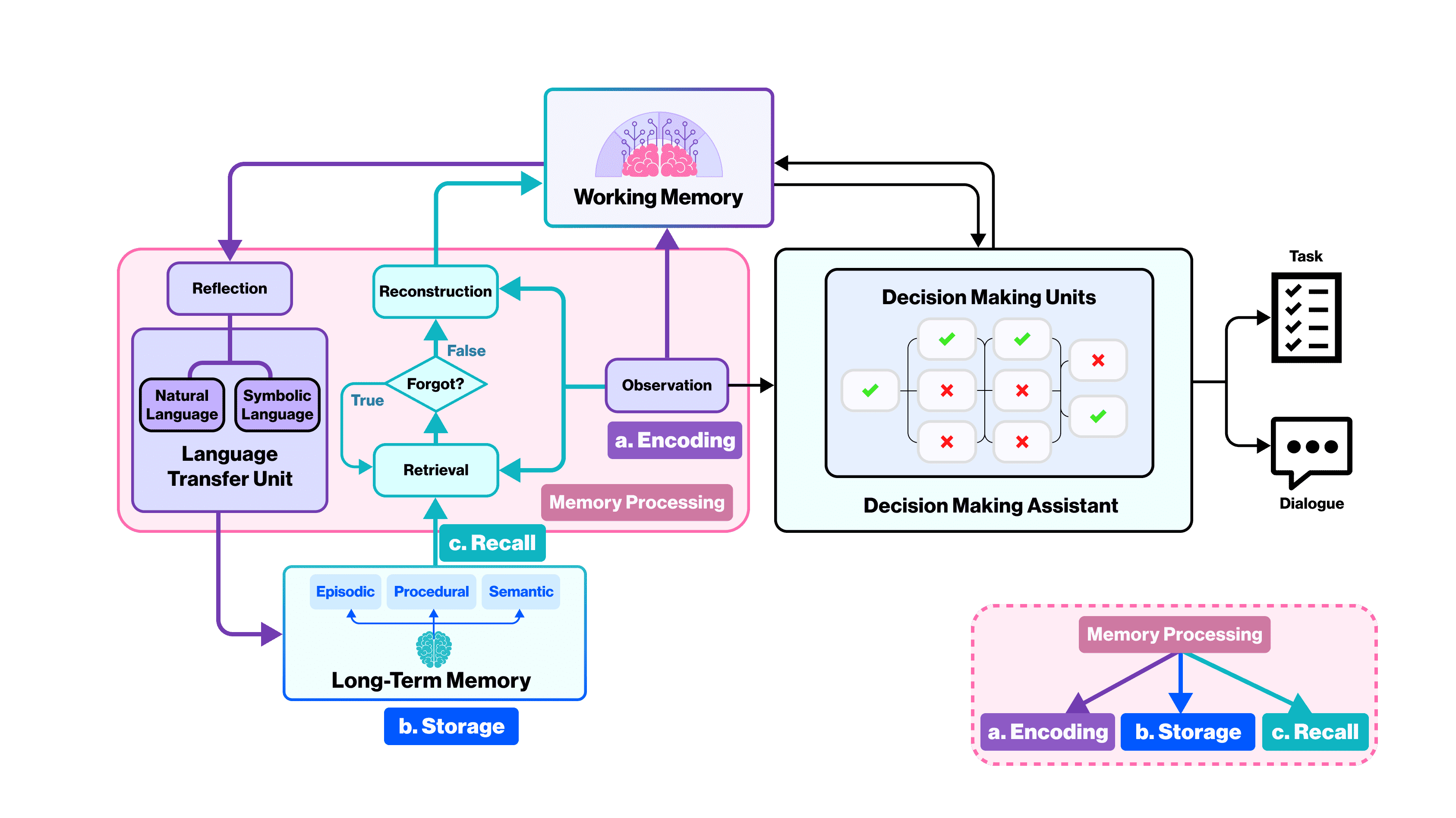
Figure 2:Cognitive Workflow of LARP.
认知架构是开放世界游戏中角色扮演语言代理(LARP)的基本组成部分,提供了逻辑框架和自我认知能力。该架构包括四个主要模块:
长期记忆(Long-term Memory):存储容量大,用于存储重要记忆。
工作记忆(Working Memory):容量有限的临时缓存,用于支持复杂认知任务和交互任务。
记忆处理(Memory Processing):核心模块,负责记忆的编码、存储与回忆。
决策模块(Decision Making):根据检索到的信息生成后续行为或对话。
3.1 长期记忆¶
长期记忆在认知科学中分为两类:
陈述性记忆(Declarative Memory):
语义记忆(Semantic Memory):关于世界的一般知识,如游戏规则和世界观,分为外部数据库存储和符号语言存储。
情景记忆(Episodic Memory):个体经历的特定事件,如与其他玩家或代理的互动,采用向量数据库存储,并引入衰减参数模拟记忆遗忘。
程序性记忆(Procedural Memory):自动化的技能,如游泳、骑车等,以API形式在系统中表示,分为公共API和个人API,后者可通过学习扩展。
我们提出了一种基于问题的查询方法(Question-based Query),通过自问生成查询,结合向量相似性搜索与谓词逻辑,提高语义和情景记忆的检索效率。
3.2 工作记忆¶
工作记忆用于支持复杂认知任务和交互任务,是短期记忆的实现形式。其容量与人类相似,约为7±2项,持续时间在几秒至一分钟之间。在LARP中,工作记忆作为数据缓存,用于提取信息并注入到提示上下文中。其提取过程在记忆处理和决策模块中有进一步描述。
3.3 记忆处理¶
记忆处理模块处理已存储和待存储的记忆,包含三个阶段:
编码(Encoding):将输入信息转化为长期记忆内容。通过语言转换系统,将自然语言与概率编程语言(PPL)和逻辑编程语言对齐,实现记忆的结构化表示。
存储(Storage):已在长期记忆模块中详细说明。
回忆(Recall):从长期记忆中提取信息,包括向量相似性搜索和谓词逻辑搜索。
我们采用**自问策略(Self-Ask Strategy)**生成查询,并结合以下三种方法进行检索:
生成逻辑编程查询。
基于关键词提取的向量相似性搜索。
基于问题-答案对的语义匹配。
此外,我们还模拟了记忆重构和遗忘过程,利用Wickelgren幂律公式计算遗忘概率:
其中,\( \lambda \) 为重要性评分,\( N \) 为检索次数,\( t \) 为上次检索后的时间,\( \alpha \) 和 \( \beta \) 为缩放参数,\( \psi \) 为遗忘速率。通过多次记忆重构和遗忘,系统可模拟记忆扭曲现象。
3.4 决策模块¶
决策模块根据观察信息和工作记忆生成最终的行为决策或对话内容。其核心是可编程单元的有序集群,每个单元处理工作记忆和上下文信息,并实时更新工作内存。单元类型包括:
简单的信息处理单元(如情感计算)。
复杂单元(如意图分析、输出格式化),可使用特定微调的语言模型。
单元的执行顺序由语言模型助理决定。最终输出可用于指导NPC的行为或对话内容。
图3展示了回忆过程的详细控制流程:通过自问生成查询,使用逻辑编程、关键词匹配和语义相似性等方法进行检索,最终生成决策或输出内容。
4 Environment Interaction¶
在开放世界游戏中进行角色扮演的语言智能体,仅依靠认知架构根据当前观察生成任务是不够的。因为在自由行动和内容丰富的开放世界中,智能体需要通过连接内部状态与外部环境进行交互。
重点讲解: 已有不少研究尝试让语言智能体与开放世界游戏环境进行交互(如Wang et al., 2023d;Zhu et al., 2023;Yang et al., 2023;Wang et al., 2023e)。例如:
Voyager 采用“自动课程”的概念,通过将环境观察内容和状态输入 GPT-4,从中获取目标,并生成实现目标的功能代码。它还提出了“技能库”方法,以“技能描述-代码”键值对形式存储,从而实现技能的高效扩展。
Octopus 使用视觉语言模型(VLM)获取观察信息。但这种方法的缺点是数据特征维度高,控制性差,且VLM的使用成本高,游戏中先验知识的收集也较为困难。
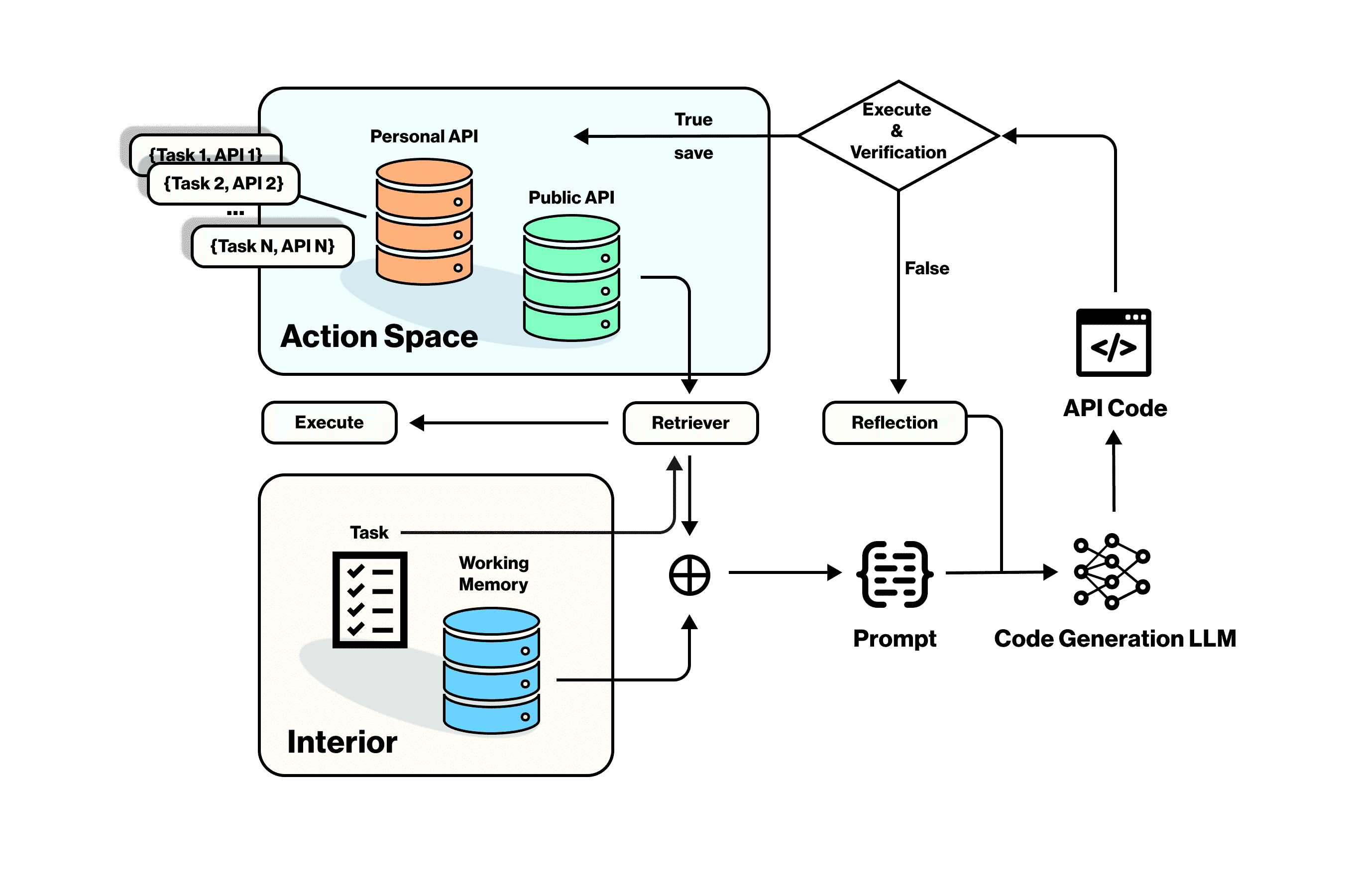
Figure 4:Environment Interaction.
图4展示了系统与环境交互的基本流程:
Interior(内部):包括智能体的工作记忆和基于当前情境生成的待执行任务。
Action Space(动作空间):是智能体在游戏世界中可执行的动作API集合,分为公共API(通用基础动作)和个人API(存储在个人库中的任务-API对)。
个人API库中的任务-API对,便于快速决策和API复用。
重点讲解: 整个系统将任务或子任务与工作记忆结合,通过检索器在个人API库和公共API库中查找对应动作。若动作已存在,则直接执行;若不存在,系统则会结合整个动作空间和内部信息,使用微调后的语言模型(LLM)生成结构化代码。生成的代码在验证成功后,将作为新的(任务,API)对存入个人API库供后续使用。若验证失败,则会触发反思模块,生成新的代码块(Shinn et al., 2023)。
代码生成与模型优化¶
系统还会将生成的“提示-代码”对作为训练集,用于微调代码生成的语言模型(Patil et al., 2023)。
重点讲解: 在代码成功执行并验证之后,系统还会通过**强化学习人类反馈(RLHF)**的方式将结果反馈给模型,以进一步提升模型能力。
总结¶
本节主要讨论了语言智能体在开放世界游戏中如何通过与环境交互来实现任务执行。系统通过任务分解、API检索与代码生成、验证与反馈等机制,实现高效、可扩展的交互策略。关键在于构建可扩展的API库、优化代码生成过程,并通过RLHF持续提升模型性能。
5 Personalities¶
重要性¶
文章指出,多样化个性特征在提升语言代理(language agents)在角色扮演中的认知能力中起着至关重要的作用。通过调整不同的个性设定,语言模型能更好地理解多元视角,展现不同的文化背景和社会群体。在复杂情境中扮演不同角色时,模型不仅需要深入理解,还需以独特的方式做出回应和表达。这要求模型具备类似人类的思维过程和广泛多样的个性特征。理解多样的语言表达、处理多文化内容、展现不同的思想、观点、情绪与态度,都需要模型具备这些多样化的个性特征。因此,本节将深入探讨其具体实现方法。
LARP 的实现策略¶
LARP 采用了一种策略:模拟多个经过不同对齐(alignment)微调的模型集群,以应对代理在角色扮演中所展现出的多样化观点。这些模型可以应用于不同模块中。在训练阶段,我们预训练了多个不同规模的基模型(base models),这些模型的预训练数据集包含了不同文化和群体的视角。预训练完成后,这些基模型通过监督式微调(SFT),在一系列关于角色和人设的指令数据集上进行优化,从而增强其遵循指令和角色扮演的能力。该指令数据集是基于SOTA模型生成的问答对,通过数据蒸馏方法建立的,并在人类反馈的基础上进行了评估、修改和优化。
动态能力扩展(LoRAs)¶
为了增强模型集群的多样性,文章提到可以创建多个数据集,并针对不同能力(如反思、代码生成、意图分析等)微调出多个LoRAs(低秩适配)。这些LoRAs可以动态地与不同规模的基模型结合,从而形成一个具有多样化能力和个性特征的模型集群。这些能力覆盖了语言风格、情绪表达、动作生成、反思能力、记忆重建等多个方面。
数据质量挑战¶
文章重点指出,获取高质量数据是微调语言模型、构建角色扮演所需LoRAs的主要挑战之一。成功的微调需要精心构建的高质量数据集,这些数据集必须细致捕捉角色的多个方面,包括语言风格、行为方式、个性特征、惯用语、背景故事等。数据集的构建需要大量的文学创作、剧本编写和角色研究,以确保生成的语言不仅符合角色的个性特征,还能与用户进行恰当的互动。
后处理模块¶
为丰富代理的多样性,文章设置了几个后处理模块,包括动作验证模块和冲突识别模块。
动作验证模块属于环境交互模块的一部分,用于检查生成的动作是否可以在游戏中正确执行。
冲突识别模块位于认知架构中,用于检查决策和对话是否与角色关系、个性特征或游戏世界观存在冲突。如果检测到冲突,该模块将采取拒绝结果或重写内容等措施,以防止代理偏离角色设定。
总结¶
本节围绕如何通过构建多样化个性特征的语言模型集群,来增强角色扮演代理(agent)的多样性与智能性展开讨论。重点内容包括:
使用多个不同对齐方式的模型进行微调,提升角色扮演能力;
利用 LoRAs 实现灵活的功能扩展,构建多样化模型集群;
数据质量是关键挑战,需通过人工反馈和创作构建高质量角色数据集;
通过后处理模块(动作验证、冲突识别)确保代理行为符合角色设定,避免“出戏”。
6 Discussions¶
6.1 多智能体协作与智能体社会关系构建¶
本节指出,单个语言智能体在所提出的框架下进行角色扮演,不足以解决开放世界游戏中生成丰富内容的问题。为了让由智能体支持的每个角色真正“活”起来,需要建立一个强大的社会网络。一种可行的方法是,在大语言模型驱动的智能体之上构建合适的社会机制和行为,以确保经过大量角色扮演推理后,NPC(非玩家角色)仍能保持其理性和逻辑性。这一部分强调的是多智能体之间的协作与社交关系对内容丰富度和沉浸感的重要性。
6.2 模型集群的置信度 vs. 评估与反馈系统¶
本节讨论了将语言模型与认知科学结合的方法,使语言智能体更贴近人类的真实认知过程。这种方法能有效缓解单一大模型因数据不足而难以提升角色扮演效果的问题。同时,由于认知系统仅包含领域任务,微调的小规模模型也能达到令人满意的效果,相较于微调大模型,节省了成本。
然而,由于语言模型输出具有随机性,各任务生成结果的累积偏差可能影响整个认知架构的准确性。这使得难以判断一个存在偏差的智能体是否仍可被认为是可信的类人智能体。因此,需要构建相应的评估与度量框架,对认知系统的偏差进行约束和收敛。通过为整个系统建立测量与反馈机制,评估每个逻辑单元的逻辑偏差,可以提升系统的鲁棒性,并减少单个系统偏差对整体的影响。这是本节的重点,强调了系统评估机制对智能体可靠性的重要性。
7 Conclusion¶
在本研究中,作者提出了一种面向开放世界游戏的语言代理框架,并从三个方面对该框架进行了详细阐述:认知架构、环境交互以及与多种价值观的对齐。重点在于:
认知架构:作者采用了更为复杂精细的认知科学方法,使代理能够做出更为合理的决策。同时,引入了后处理约束机制,以防止代理行为过于自由,从而使其在角色扮演情境中更接近真实人类的行为。
环境交互与与多种价值观的对齐(这两方面未在原文中展开具体细节,因此此处精简处理):研究还关注了代理与环境的互动方式,以及在多样化的价值体系下的行为适应。
最后,作者指出,该工作在开放世界游戏中具有巨大的潜力,有望为这一传统领域注入新的活力,并最终提供类似于《西部世界》(Westworld)中那种沉浸式的游戏体验。