2404.04475_AlpacaEval LC: A Simple Way to Debias Automatic Evaluators¶
引用: 421(2025-08-10)
组织:
1Stanford University
2Independent Researcher
总结¶
简介
LC AlpacaEval: Length-Controlled AlpacaEval
主要解决 LLM 评测时的长度偏差问题,并提出一种方法来控制长度偏差,从而提高自动评估的精度和一致性。
背景
自动评估工具(如AlpacaEval)存在长度偏差,偏好输出更长的模型。
Reference-free evaluation metrics(无参考评估指标)
用于在没有参考答案的情况下评估模型在开放生成任务上的表现
Chatbot Arena
一个基于用户选择的模型排名系统
Different length control methods
Length-controlled(LC):本文提出的方法。
Length-normalized(LN):通过长度函数归一化胜率。
有几种不同的归一化方法(例如,直接除以长度、长度的逻辑函数等)
性能较好,但不如 LC 严谨且解释性差
Length-balanced(LB):基于输出长度的分层平均胜率。
根据模型输出 (1) 比基线更长和 (2) 比基线更短的样本,分层计算平均胜率
缺点:鲁棒性。
具体来说,分层依赖于每个层内是否有足够的样本,否则估计值可能会迅速变得不稳定。
这可能会增加方差,例如,如果一个模型自然比另一个模型长,但也可能引入对抗性漏洞。
几种常见的自动化评估偏见:
长度偏见(length bias)
自我偏见(self-bias):模型倾向于对自己输出的评分更高
列表偏见(list bias):输出中包含列表的模型更可能被高估
当模型的回答中包含了列表(尤其是格式清晰、结构化的项目符号或编号列表)时,评估模型(或称“裁判模型”)会倾向于给这个回答更高的分数,即使这个列表本身可能并不完全准确、相关或全面。
列表偏见的本质是:自动化评估模型过度依赖“结构化格式”作为判断质量的主要指标,从而导致对包含列表的回答给出不公正的高评价。
贡献
提出一种基于回归的去偏方法,能够有效消除自动评估中对虚假变量(如长度)的依赖,同时保留其优点。
将方法应用于 AlpacaEval,得到 AlpacaEval-LC,提升了其鲁棒性和与人类评估的一致性。
AlpacaEval LC
提出了一种 回归方法,把 AlpacaEval 的评分拆解为 模型效应 + 长度效应 + 指令效应。
然后在计算时去掉“长度效应”,得到更公平的 长度控制胜率(LC win rate)。
Limitations
仅在 AlpacaEval 上测试,该基准使用的是相对简单的英文指令和特定提示语。
假设模型与基线具有相同长度,这可能过于简化。
未解决其他与 LLM-judge 相关的问题(如自我偏见、语义理解偏差等)。
From Deepseek¶
论文背景¶
随着大语言模型(LLMs)的快速发展,自动评估方法在模型输出质量评估中变得至关重要。然而,传统的自动评估器(如基于参考文本的指标或基于LLM的评判)可能存在偏见,例如偏好更长的回答、过度依赖特定关键词或受训练数据分布的影响。这些偏见会降低评估的可靠性,从而影响模型迭代和比较的公平性。
核心贡献¶
该论文提出了 AlpacaEval,一种简单而有效的方法,用于减少自动评估器的偏见。其主要创新点包括:
参考输出标准化:通过构建多样化的参考输出(reference responses)集合,减少评估对单一标准答案的依赖。
评估器去偏训练:利用对抗性训练或数据增强技术,使自动评估器(如基于LLM的评判者)对常见偏见(如长度偏好、风格差异)更鲁棒。
混合评估框架:结合自动评估与少量人类评估结果,校准自动评估器的偏差。
方法亮点¶
轻量高效:无需复杂架构调整,仅需对现有评估流程进行微调。
可扩展性:适用于多种自动评估器(如BERTScore、GPT-4作为评判者)。
透明性:通过分析偏见来源(如长度、词频),提供可解释的改进方向。
意义与应用¶
研究领域:为LLM评估提供更可靠的自动化工具有助于加速模型开发。
实践价值:适用于模型竞赛、企业级模型筛选等场景,减少对人类评估的依赖。
局限性¶
对参考输出的多样性敏感,若参考集本身存在偏差可能影响效果。
主要针对英语任务,多语言场景需进一步验证。
Abstract¶
这篇论文主要探讨了如何通过回归分析的方法来减少基于大语言模型(LLM)的自动评估工具(auto-annotators)中存在的偏差问题,特别是输出长度对评估结果的影响。以下是对论文的逐步解析:
1. 背景与问题¶
自动评估工具的普及:LLM-based auto-annotators因其成本低、可扩展性强,逐渐成为LLM开发流程中的重要组成部分,替代了传统的人工评估。
存在的偏差问题:这些自动评估工具可能会引入一些偏差(biases),比如对较长输出的偏好(length bias)。即使这种偏差是已知的,现有的自动评估指标中仍然存在这一问题。
案例研究:作者以AlpacaEval为例,这是一个用于评估指令微调LLM的快速、低成本的基准测试工具。虽然AlpacaEval与人类偏好高度相关,但它明显偏好输出更长的模型。
2. 研究目标¶
提出一种方法,用于控制自动评估中的偏差(特别是长度偏差),从而回答一个反事实问题:“如果模型和基线输出的长度相同,偏好结果会是什么?”
3. 方法:回归分析控制偏差¶
步骤1:使用广义线性模型(GLM)拟合自动评估工具的偏好结果。模型的输入包括:
需要控制的变量(mediators):比如长度差异(length difference)。
其他相关特征:可能影响偏好的其他因素。
步骤2:在GLM中,将长度差异设为零(即假设模型和基线的输出长度相同),重新预测偏好结果,从而得到“长度控制后的偏好”(length-controlled preferences)。
4. 效果验证¶
减少长度偏差:通过这种方法,可以降低模型通过增加输出长度(verbosity manipulation)来“刷分”的可能性,提高评估的鲁棒性。
提升相关性:作者发现,长度控制后的AlpacaEval与LMSYS Chatbot Arena(另一个评估基准)的Spearman相关系数从0.94提升到了0.98,表明其与人类偏好的相关性更强。
核心要点总结¶
问题:自动评估工具(如AlpacaEval)存在长度偏差,偏好输出更长的模型。
方法:用回归分析(GLM)控制长度差异的影响,反事实预测“如果长度相同,结果会怎样”。
“反事实预测”(Counterfactual Prediction),是因为它回答了一个 “如果……将会怎样?”(What if…?) 的问题,而这个问题的场景是与事实相反的、假设性的。
反事实是指:我们在脑海中构建了一个假设的、未曾发生过的世界。在这个世界里,模型A和模型B的回复长度完全相同(L_A = L_B)。
效果:减少偏差后,评估更鲁棒,且与人类偏好的相关性更高。
意义:为自动评估中的偏差控制提供了一种简单有效的解决方案,并推动了更公平的模型评估。
1 Introduction¶
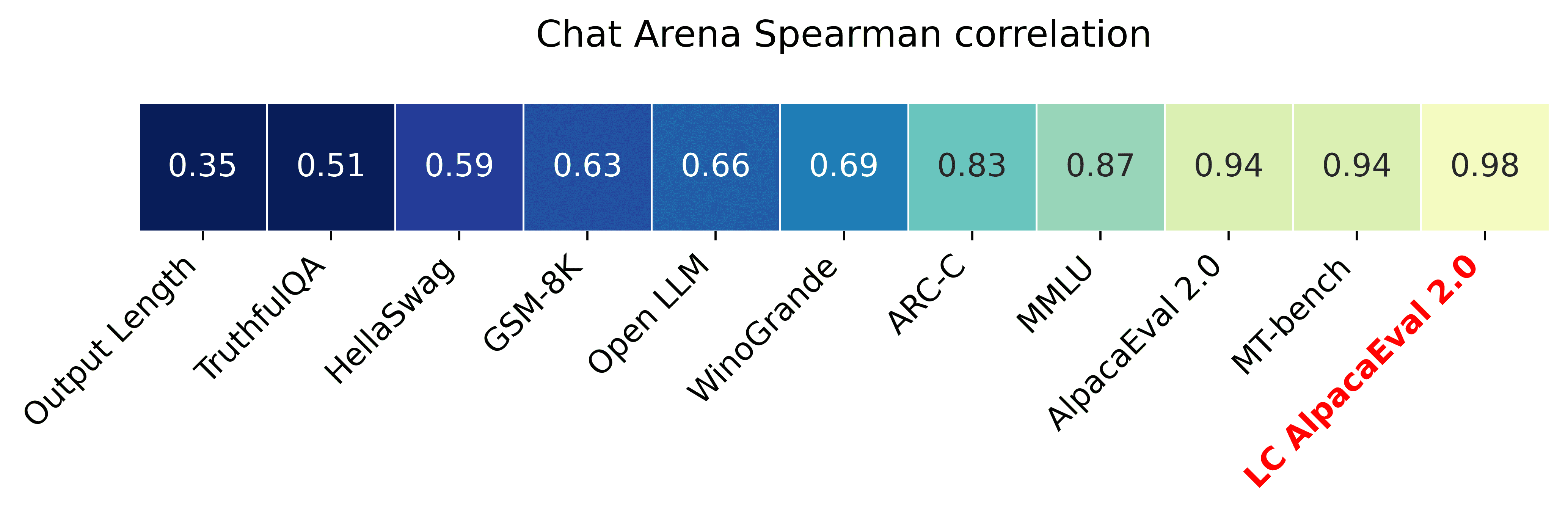
Figure 1:AlpacaEval length-controlled increases correlation with the LMSYS Chatbot Arena from 0.94 to 0.98. It is currently the automatic benchmark with the highest correlation with Chatbot Arena.
本节主要介绍了当前自然语言处理(NLP)系统开发中对自动评估方法的需求、现有方法的局限性,以及本文提出的一种基于回归去偏的自动评估方法,并重点介绍了其在 AlpacaEval 基准上的应用与改进。
1.1 自动评估的背景与挑战¶
在闭合任务(如多项选择 QA)中,评估相对简单且容易信任,例如 Novikova 等(2017)和 Yeh 等(2021)的工作。然而,在开放生成任务(如语言模型的指令遵循)中,传统的基于参考答案的评估方法(如 BERTScore)面临困难,因为难以收集覆盖所有有效输出的参考答案集。
1.2 基于大语言模型的无参考评估方法¶
近年来,研究者提出了多种无参考的自动评估方法,例如:
AlpacaEval (Li 等, 2023)
MTBench (Zheng 等, 2023)
WildBench (Lin 等, 2024)
这些方法虽然与人类评估表现出较高的相关性,但它们往往依赖于虚假相关性(spurious correlations),比如输出长度、列表形式或位置偏差等,这会影响评估的准确性与公平性。
1.3 本文的研究目标¶
为了解决上述问题,本文提出一个关键挑战:如何对现有的自动评估指标(如 AlpacaEval)进行去偏处理,消除其对虚假变量的依赖,从而实现更准确的开放生成任务评估。
1.4 方法概要¶
本文提出一种基于回归的去偏策略,利用观测性因果推断的基本方法,将虚假相关变量(如输出长度)视为因果图中的非期望中介变量,通过回归调整来消除其影响。
这一方法简单、可解释,并能保留自动评估的其他优良特性。
1.5 应用与实验¶
将该方法应用于 AlpacaEval,得到改进后的版本 AlpacaEval-LC(Length-Controlled AlpacaEval)。
实验结果显示:
AlpacaEval-LC 与 LMSYS Chatbot Arena 的相关性从 0.94 提高到 0.98(见图 1),是当前与人类评估最相关的自动基准。
相比原始 AlpacaEval 和 MTBench,AlpacaEval-LC 对长度操纵(如增加输出长度来“刷分”)更加鲁棒。
1.6 本文贡献¶
本文的主要贡献包括:
提出一种基于回归的去偏方法,能够有效消除自动评估中对虚假变量的依赖,同时保留其优点。
将方法应用于 AlpacaEval,得到 AlpacaEval-LC,提升了其鲁棒性和与人类评估的一致性。
实验验证 AlpacaEval-LC 与 LMSYS Chatbot Arena 之间具有更强的相关性,表明其在自动评估中的有效性。
图 1 展示了 AlpacaEval-LC 与 LMSYS Chatbot Arena 的相关性显著提升,是本文核心实验结果的直观体现。
2 Background and Problem Setting¶
本章节主要介绍了与本研究相关的背景知识,包括无参考评价方法、AlpacaEval、Chatbot Arena以及成对评估问题的定义,为后续的去偏实验奠定了理论基础。
Reference-free evaluation metrics(无参考评估指标)¶
重点内容:
无参考评估指标用于在没有参考答案的情况下评估模型在开放生成任务上的表现。这类方法历史悠久,包括早期的统计方法(如 Louis & Nenkova, 2013)和近年来基于神经网络的监督学习方法(如 Kryscinski et al., 2020; Sinha et al., 2020; Goyal & Durrett, 2020)。
近年来,随着大语言模型(LLMs)的发展,研究者开始尝试将LLM作为零样本、无参考的评估工具(如 Zheng et al., 2023; Dubois et al., 2023; Li et al., 2023; Lin et al., 2024),特别是在对话系统中。
在对话场景中,AlpacaEval 和 MT-bench 是两个著名的基准测试,它们利用基于 GPT-4 的语言模型评估较弱模型的输出质量。
次要内容:
某些指标虽然准确性较高,但容易受到伪相关性的干扰,如困惑度和文本长度(Durmus et al., 2022)。
AlpacaEval¶
重点内容:
AlpacaEval 是一个基于LLM的自动评估指标,用于评估模型在805个代表用户交互的指令上的表现。
对于每个指令,基线模型 b 和被评估模型 m 都生成响应,然后由 GPT-4 turbo 评估器进行成对比较,并输出偏好被评估模型的概率。
胜率(win rate) 是 AlpacaEval 的核心指标,表示自动评估器在所有805个指令中倾向于被评估模型的期望概率。
AlpacaEval 拥有可解释的属性:
值域为 [0%, 100%];
模型与基线互换时,结果对称(如:AlpacaEval(b, m) = 100% - AlpacaEval(m, b));
模型与自身比较时结果为 50%;
任何后续修正应保持这些属性。
次要内容:
AlpacaEval 最初是为 Alpaca 模型和 AlpacaFarm 模拟器设计的;
作者尝试通过随机化模型与基线的顺序来控制偏见,但并未完全解决长度、风格等偏见;
后续研究表明,这些未控制的偏见可以被AI系统利用,从而在排行榜上获得不公平优势。
Chatbot Arena¶
重点内容:
Chatbot Arena 是一种通过真实用户交互进行成对比较的评估方法,可视为 AlpacaEval 的“银标准”。
用户在不知情的情况下,对两个匿名模型的响应进行评估,并给出偏好。
所有比较结果通过 Elo 评分系统 进行建模,最终转化为模型的分数。
该方法具有难以饱和、真实用户驱动的优点,但缺点是成本较高,不适合模型开发阶段使用。
次要内容:
尽管 Chatbot Arena 尽可能反映用户偏好,但仍然可能存在表面特征偏好等偏见。
Setup(问题设定)¶
重点内容:
成对评估问题定义如下:
给定一个指令 \(x\),基线模型生成响应 \(z_b\),被评估模型生成响应 \(z_m\);
人类标注者给出偏好 \(y \in \{0,1\}\)(0 表示基线更好,1 表示被评估模型更好);
一个自动替代方法(如 AlpacaEval)是一个函数 \(f(z_m, z_b, x)\),用于预测人类偏好 \(p(y | z_m, z_b, x)\);
AlpacaEval 的当前指标是胜率(win rate),即模型 m 相对于基线 b 的平均偏好概率,定义为: $\( \mathrm{winrate}(m,b) = 100 \cdot \mathbb{E}_x[f(z_m, z_b, x)] \)$
总结:
本章通过介绍现有的无参考评估方法、AlpacaEval 的实现机制、Chatbot Arena 的人类评估方式,以及成对评估的数学定义,为后续研究模型评估中的偏见问题提供了理论基础与实验框架。
3 Length-Controlled AlpacaEval¶
核心问题: 自动评测(如 AlpacaEval)在比较模型输出质量时,常常受到一些“虚假的相关因素”影响。 例如:输出的长度往往与“是否赢得比较”相关(长的回答更可能被认为更好),但这并不代表模型本身质量更高。 然而,一旦开发者意识到长度影响评价结果,他们可能会专门调节输出长度,从而让“长度”不再能反映真实的质量差异。
研究问题: 如果模型 m 的输出和基线模型 b 的输出长度相同,那么 AlpacaEval 的胜率会是多少?
这里的目标是把这个问题转化成一个**回归建模(regression-based estimator)**来做偏差修正。
Length control via regression¶
作者提出用回归模型把 AlpacaEval 的得分拆解成三个部分:
模型身份 (Model identity)
输出来自 baseline b 还是被评测模型 m。
这显然会影响胜率(评测模型更好时,胜率更高)。
输出长度 (Length of output)
长度会影响评判结果,既影响人类,也影响自动评价模型。
所以需要单独建模。
指令难度 (Instruction difficulty)
不同任务难度不同,比如 baseline 在编程任务可能比其他任务表现好。
“任务难度”本身不由模型决定,但在回归时作为一个控制变量,可以减少噪音,提高估计精度。
流程:
拟合一个模型,把“胜出概率”解释为这三部分的组合。
在估计时人为把长度的贡献设为 0,从而得到“长度控制后”的胜率。
The regression model¶
作者用逻辑回归公式来建模胜率概率:
对应三部分:
模型项 (Model term): \(\theta_m - \theta_b\)
长度项 (Length term): 标准化后的长度差,并经过 \(\tanh\) 限制(防止极端差异无限放大)。
指令项 (Instruction term): \((\psi_m - \psi_b)\gamma_x\),即任务难度修正。
性质:
恒等性 (identity):同一个模型比自己 → 胜率 = 0.5。
对称性 (symmetry):交换 m 和 b → 胜率互补 (p vs. 1-p)。
这些保证了回归模型的合理性。
Obtaining length corrected (LC) win rate¶
当人为设定 len(zm) = len(zb) 时,长度项变为 0。 于是长度校正后的胜率就是:
即:去掉长度效应后,只保留模型效应和指令效应。
Training¶
使用标准的广义线性模型 (GLM),损失函数是交叉熵。
参数数量:每个模型有 \(\theta_m, \phi_{m,b}, \psi_m\),每个指令有一个 \(\gamma_x\)。 → 总参数量约为 3M + N,而样本量是 M × N(远大于参数量)。
训练细节:
交叉验证 (5-fold CV) + L2 正则化,防止过拟合。
指令难度 \(\gamma_x\) 先统一估计,然后固定,再对每个模型单独拟合。这样保证 leaderboard 上旧模型的分数不会因新模型加入而改变。
对长度系数 \(\phi_{m,b}\) 加弱正则化,避免有人利用“故意截断”来攻击(比如把模型答得差的地方都缩短,让“长度修正”自动帮它加分)。
✅ 总结一句话: 这部分提出了一种 回归方法,把 AlpacaEval 的评分拆解为 模型效应 + 长度效应 + 指令效应。 然后在计算时去掉“长度效应”,得到更公平的 长度控制胜率(LC win rate)。
4 Results¶
本节展示了作者对 AlpacaEval-LC 进行的评估结果。由于 AlpacaEval 存在明显的长度偏差问题,且被广泛用于评估大语言模型(LLM)的生成质量,因此作者提出了新的评估方法 AlpacaEval-LC 来修正这一偏差。评估主要从以下几个方面展开:
4.1 AlpacaEval-LC decreases length gameability(AlpacaEval-LC 降低了长度可操控性)¶
重点内容:
一个理想的评估指标不应因模型输出的长度变化而大幅波动。
作者通过让模型分别以“尽可能详细”(verbose)和“尽可能简洁”(concise)的方式生成回复来测试长度可操控性。
原始 AlpacaEval 在长度变化下表现出非常高的敏感性。例如,GPT-4 模型在不同提示下的胜率从 22.9% 跳变到 64.3%,表明其评估结果严重依赖输出长度。
AlpacaEval-LC 显著降低了这种敏感性,GPT-4 的胜率范围缩小为 41.9% 到 51.6%。
三点提示下的胜率标准差从 25% 降至 10%,表明评估结果更加稳定。
结论: AlpacaEval-LC 有效降低了输出长度对评估结果的干扰,符合评估应关注“内容质量”而非“风格”的目标。
4.2 AlpacaEval-LC increases correlation with Chatbot Arena to 0.98(AlpacaEval-LC 提高了与 Chatbot Arena 的相关性)¶
重点内容:
如果评估方法能更好地反映人类偏好,则其与 Chatbot Arena(一个基于用户选择的模型排名系统)的相关性应该更高。
作者使用 Spearman 相关系数(而非 Pearson)来衡量,因为 Chatbot Arena 的排名与 ELO 分数呈对数线性关系。
原始 AlpacaEval 与 Chatbot Arena 的相关性为 0.94,而 AlpacaEval-LC 提高到了 0.98,是目前已知的相关性最高的评估方法。
作者指出,专有模型(如 Claude-2.1)在 AlpacaEval-LC 中排名提升显著,而许多经过 RLHF 优化的开源模型排名下降。
这表明,开源模型可能在训练中利用了 AlpacaEval 的长度偏差,而 AlpacaEval-LC 修正了这一偏差,使其更贴近人类偏好。
结论: AlpacaEval-LC 不仅减少了长度偏差,还更好地反映了人类对模型性能的真实偏好。
4.3 AlpacaEval-LC is interpretable and robust(AlpacaEval-LC 是可解释且鲁棒的)¶
重点内容:
可解释性: AlpacaEval-LC 的胜率具有自然的对称性,例如 winrate(m, b) = 100% - winrate(b, m),这与许多其他长度修正方法不同,使其更容易被理解和解释。
鲁棒性: 作者测试了对抗性攻击,例如对模型输出进行截断(仅保留与基线长度相近的部分),发现 AlpacaEval-LC 在未进行正则化时仍能抵御攻击(对抗性胜率从 3.7% 提升至 25.9%)。
通过引入对模型参数的正则化(regularization),对抗性优势被进一步削弱至 12.2%,同时对正常模型无显著影响。
作者还展示了其 GLM(广义线性模型)可以预测任何模型对之间的胜率,为模型评估提供了更灵活的工具。
结论: AlpacaEval-LC 在保证可解释性的同时具备较强的鲁棒性,能够有效抵御对抗性攻击。
4.4 Different length control methods(不同的长度控制方法)¶
重点内容:
作者比较了几种不同的长度控制方法,包括:
Length-controlled(LC):本文提出的方法。
Length-normalized(LN):通过长度函数归一化胜率。
Length-balanced(LB):基于输出长度的分层平均胜率。
评估指标:
Chatbot Arena 相关性(↑)
长度可操控性(↓)
对抗性胜率优势(↓)
方法 |
Chatbot Arena 相关性 |
长度可操控性 |
对抗胜率增益 |
|---|---|---|---|
原始胜率 |
0.94 |
26% |
0.0 |
Length-controlled (LC) |
0.98 |
10% |
8.5 |
Length-normalized (LN) |
0.96 |
15% |
3.6 |
Length-balanced (LB) |
0.95 |
15% |
40.8 |
LC 在所有指标上表现最优,尽管其对抗性增益略高,但整体优势显著。
LB 虽然能改善某些指标,但缺乏鲁棒性。
LN 性能较好,但不如 LC 严谨且解释性差。
结论: AlpacaEval-LC 在多个维度上均优于其他方法,是最适合用于实际评估的长度控制方式。
总结¶
本节系统评估了 AlpacaEval-LC 的性能,验证其在以下几个方面的优势:
降低长度偏差:输出长度对评估结果的影响显著减小。
提高与人类偏好的一致性:与 Chatbot Arena 相关性从 0.94 提升至 0.98。
可解释性强:胜率具有对称性和自然解释性。
鲁棒性强:能有效抵御对抗性攻击。
方法优越性:在多种长度控制方法中,AlpacaEval-LC 表现最佳。
作者还开源了所有代码,便于社区进一步验证和使用。
5 Discussion¶
Table 2: LLM judges self-bias but the ranking is surprisingly stable¶
表 2 展示了在 AlpacaEval 数据集上,不同 LLM 作为评估者(judge)时所生成的排行榜。重点在于模型的排名在不同 judge 下保持稳定,这说明尽管存在自我偏见(self-bias),但模型间的总体表现仍然具有一定的一致性。
模型 |
gpt-4-1106 |
claude-3-opus |
mistral-large |
|---|---|---|---|
gpt-4-1106 |
50.0 |
50.0 |
50.0 |
claude-3-opus |
40.4 |
43.3 |
47.5 |
mistral-large |
32.7 |
28.2 |
45.5 |
gpt-4-0613 |
30.2 |
20.5 |
34.3 |
gpt-3.5-turbo |
19.3 |
16.7 |
28.9 |
要点总结:
表中每一行代表一个模型的胜率(win rate),即在与不同 judge 模型比较时获胜的概率。
虽然存在一定的自偏(如 claude-3-opus 偏向 gpt-4-1106,mistral-large 偏向前两个模型),但模型的排名总体稳定。
这一结果说明模型之间的性能差异大于自偏的影响。
Other biases¶
除了长度偏见(length bias),作者还提到其他几种常见的自动化评估偏见:
自我偏见(self-bias):模型倾向于对自己输出的评分更高(Zheng et al. 2023)。
列表偏见(list bias):输出中包含列表的模型更可能被高估(Dubois et al. 2023)。
作者指出,这些偏见可以通过在回归模型中加入对应的特征(如列表数量、模型输出长度等)来建模,从而进行控制。
重点总结:
自我偏见存在,但通常小于模型之间的性能差异。
作者的初步研究表明,不同评估者对模型排名影响较小(见表 2)。
可以通过扩展回归模型来控制其他类型的偏见。
Length-controlling in RLHF¶
作者指出他们的研究与 RLHF(Reinforcement Learning from Human Feedback)中减少奖励模型偏见的工作密切相关。
相关工作:
Shen et al. (2023)、Chen et al. (2024)尝试训练一个与长度无关的奖励模型,通过同时预测奖励与长度来解耦。
Park et al. (2024)将这种思想推广到隐式奖励模型中。
区别:
这些方法通常用于训练阶段,而 AlpacaEval 使用的是封闭源模型作为评估者,无法直接应用。
作者的方法:
提出一种后处理(post-hoc)去偏方法,可以在 RLHF 设置中使用,具有潜力,期待未来进一步探索。
重点总结:
作者的去偏方法可以在 RLHF 框架中使用。
与现有方法不同,其方法适用于封闭源模型的自动评估场景。
Limitations¶
作者提到了当前方法的几个限制:
仅在 AlpacaEval 上测试,该基准使用的是相对简单的英文指令和特定提示语。
假设模型与基线具有相同长度,这可能过于简化。
未解决其他与 LLM-judge 相关的问题(如自我偏见、语义理解偏差等)。
尽管有上述限制,去偏后的 AlpacaEval-LC 与人工评估(Chatbot Arena)的关联性显著增加,表明该方法是朝正确方向迈出的一步。
重点总结:
方法尚未扩展到更复杂或多语言场景。
但实验证明其有效性和稳定性,初步验证了去偏方法的可行性。
Conclusion¶
作者提出了一个简单有效的方法,用于减轻 AlpacaEval 中的长度偏见:
使用广义线性模型(GLM)预测自动评估者的偏好,并控制输出长度。
通过预测模型在相同长度下的偏好,获得去偏后的评估结果。
实验表明,去偏后的评估(AlpacaEval-LC)与人工评估更一致、长度偏见更小、且难以被“操控”。
重点总结:
方法简单但有效,显著减少了长度偏见。
与 Chatbot Arena 的相关性增强,验证了其可靠性。
为自动评估系统的公平性和稳定性提供了新思路。
Acknowledgments¶
最后作者致谢了以下贡献者和组织:
Xuechen Li、Rohan Taori、Tianyi Zhang:帮助维护 AlpacaEval。
Viet Hoang Tran Duong:提出考虑长度平衡的胜率。
Twitter ML 社区:强调长度控制的重要性。
用户社区:贡献了100+模型到 AlpacaEval。
OpenAI、Together AI:提供 API 生成输出和评估模型。
Open Philanthropy、Tianqiao and Chrissy Chen Institute:提供研究资助。
重点总结:
作者对社区与平台的支持表达了感谢,强调了开源与合作的重要性。
总体总结¶
本节讨论了 AlpacaEval 中 LLM 自动评估的偏见问题,提出了一个基于回归模型的去偏方法,验证了方法的有效性,并指出其在 RLHF 中的潜在用途。尽管方法存在一些限制,但实验证明其能够显著提升评估的公平性和与人工评估的一致性,是值得进一步研究的方向。