2310.08560_MemGPT: Towards LLMs as Operating Systems¶
引用: 203(2025-08-09)
组织: 无
总结¶
简介
提出了虚拟上下文管理(virtual context management)技术
该技术灵感来源于传统操作系统中分层内存系统(hierarchical memory systems)的设计
主上下文(Main Context):相当于操作系统的“主存”
外部内存(External Memory):相当于“磁盘”
开发了 MemGPT 系统
MemGPT 智能地管理不同的存储层级,从而在 LLM 有限的上下文窗口内,有效扩展可用上下文
在两个关键任务中评估了 MemGPT 的效果:
文档分析
多会话聊天
MemGPT
主上下文由三部分连续组成
System instructions(系统指令)
只读部分
包含 MemGPT 的控制流程、不同层级记忆的使用说明以及如何使用 MemGPT 提供的函数(例如如何检索外部上下文数据)
这是固定的静态内容。
Working context(工作上下文)
固定大小、可读写的文本块,只能通过 MemGPT 函数调用修改
在对话场景中,用于存储用户的关键信息(如偏好、身份设定等),帮助模型维持对话的连贯性
FIFO Queue(先进先出队列)
保存消息的历史记录,包括用户与模型之间的对话、系统消息(如内存警告)以及函数调用的输入输出
队列的首项为系统消息,包含被移除消息的递归摘要(用于恢复被丢弃的信息)
From Deepseek¶
这是一篇探讨将大型语言模型(LLMs)类比为操作系统的研究论文,提出了一种名为 MemGPT(Memory-GPT)的新型架构,旨在通过模拟操作系统的内存管理机制来解决传统LLMs在长上下文和复杂对话中的局限性。以下是论文的核心内容简介:
1. 研究背景与问题¶
LLMs的局限性:传统LLMs(如GPT系列)受限于固定长度的上下文窗口,难以处理长对话或持续交互任务。虽然某些模型支持扩展上下文(如128K tokens),但实际性能仍会因信息分散或遗忘而下降。
操作系统的启发:操作系统通过分层内存管理(如主存、磁盘、缓存)高效处理资源。论文提出将类似思想引入LLMs,通过显式管理内存来优化长期信息存储与检索。
2. MemGPT核心思想¶
MemGPT将LLM视为操作系统的“中央处理器”,并为其设计虚拟化的内存层级:
主上下文(Main Context):相当于操作系统的“主存”,存储当前直接可用的信息(如对话中的最近消息)。
外部内存(External Memory):相当于“磁盘”,存储长期历史数据,通过内存管理指令(如保存、加载、搜索)动态交换信息。
内存管理单元(Memory Manager):由LLM自身控制,决定何时将信息存入外部内存或加载回主上下文。
3. 关键技术¶
自导向记忆操作:MemGPT通过插入特殊指令(如
/save、/recall)让模型主动管理内存,无需人工干预。函数调用机制:模型可调用外部API访问内存(如向量数据库),实现高效检索。
训练方法:通过合成数据训练模型学习内存管理策略,例如:
何时将信息移出主上下文以节省空间。
如何根据当前任务从外部内存检索相关内容。
4. 实验与结果¶
论文在两类任务上验证MemGPT的效果:
长对话问答:在多轮对话中,MemGPT通过动态加载历史信息,准确率比传统LLMs提升显著。
文档分析:处理长文档时,MemGPT能主动分段存储和检索内容,优于固定上下文窗口的基线模型。
5. 意义与展望¶
LLMs的系统化:MemGPT为LLMs引入了一种可扩展的“自我管理”范式,未来可能支持更复杂的多任务调度(如后台线程)。
应用场景:适合长周期交互场景(如个性化AI助手、持续学习系统)。
挑战:内存管理策略的优化、检索效率与延迟的平衡仍需进一步研究。
总结¶
MemGPT通过模拟操作系统的内存管理机制,赋予LLMs自主控制上下文的能力,为解决长上下文瓶颈提供了新思路。这一方向可能推动LLMs从“单次推理模型”向“持续运行系统”演进。
Abstract¶
问题背景¶
大型语言模型(LLMs)虽然在人工智能领域引发了革命性变化,但受限于有限的上下文窗口,在处理长时间对话或文档分析等任务时存在明显不足。
解决方案:虚拟上下文管理¶
为了解决这一限制,作者提出了虚拟上下文管理(virtual context management)技术。该技术灵感来源于传统操作系统中分层内存系统(hierarchical memory systems)的设计,通过页面置换机制在物理内存和磁盘之间切换,为用户提供扩展的虚拟内存的幻觉。
基于此,作者开发了 MemGPT 系统。MemGPT 智能地管理不同的存储层级,从而在 LLM 有限的上下文窗口内,有效扩展可用上下文。
评估与应用¶
作者在两个关键任务中评估了 MemGPT 的效果:
文档分析:
MemGPT 能够分析规模远超 LLM 上下文窗口限制的文档,显著提升了处理长文本任务的能力。多会话聊天:
MemGPT 能够创建具有记忆能力的对话代理,支持与用户进行长期互动、反思和动态演变,从而实现更自然和连贯的对话体验。
开源资源¶
MemGPT 的代码和实验数据已开源,访问地址为 https://research.memgpt.ai。
会议信息¶
本文发表于 机器学习领域顶级会议 ICML,说明其研究具有前沿性和学术价值。
1 Introduction¶
近年来,大型语言模型(LLMs)及其基于 Transformer 架构(Vaswani 等,2017;Brown 等,2020;Ouyang 等,2022)已成为对话式人工智能的核心,广泛应用于消费和企业场景中。然而,这些模型通常具有固定长度的上下文窗口,这严重限制了它们在处理长对话或长文档推理时的应用能力。例如,当前主流的开源 LLM 通常只能处理几十轮对话或短文档内容,否则就会超出最大输入长度(Touvron 等,2023)。
扩展上下文长度的挑战¶
直接扩展 Transformer 模型的上下文长度会带来计算时间和内存成本的二次增长,这是由于 Transformer 的自注意力机制所导致。因此,设计支持长上下文的新架构成为一个关键的研究挑战(Dai 等,2019;Kitaev 等,2020;Beltagy 等,2020)。尽管已有研究致力于开发更长的模型(Dong 等,2023),但即使解决了计算问题,近年来的研究表明,长上下文模型在有效利用额外上下文方面仍然存在困难(Liu 等,2023a)。因此,考虑到训练先进 LLM 所需的高昂资源以及长上下文扩展的边际收益递减,迫切需要其他技术来支持长上下文处理。
本文的贡献:MemGPT¶
本文研究了如何在保持固定上下文模型的前提下,提供“无限上下文”的假象。我们的方法借鉴了虚拟内存分页的思路:通过在主内存和磁盘之间交换数据,应用程序可以处理远超可用内存的数据集。我们利用 LLM 代理的函数调用能力(Schick 等,2023;Liu 等,2023b),提出了 MemGPT——一个受操作系统启发的 LLM 系统,用于虚拟上下文管理。
通过函数调用,LLM 代理可以读写外部数据源、修改自己的上下文,并选择何时返回用户响应。这些能力使得 LLM 能够在上下文窗口(类比操作系统中的“主内存”)和外部存储之间**“分页”信息**,从而实现类似于分层内存系统的功能。此外,函数调用还可以用于控制流程,协调上下文管理、响应生成和用户交互之间的切换,使得代理可以在单个任务中迭代地修改其上下文内容,从而更有效地利用其有限的上下文窗口。
MemGPT 的设计原理¶
在 MemGPT 中,我们将上下文窗口视为一种受限的内存资源,并设计了一个分层内存系统,类似于传统操作系统中的多级内存(Patterson 等,1988)。在操作系统中,应用程序通过虚拟内存访问比实际物理内存更大的内存空间,通过分页机制将溢出数据写入磁盘,并在需要时通过“页故障”恢复数据。MemGPT 通过一个“LLM 操作系统”(即 MemGPT 本身)来实现类似的机制:允许 LLM 管理其上下文中的内容,将缺失的历史数据检索到当前上下文中,并将不相关的数据移出到外部存储系统。图 3 展示了 MemGPT 的各个组件。
MemGPT 的关键机制¶
内存层级系统:LLM 的上下文(类比物理内存)由系统指令、工作上下文和 FIFO 队列组成。LLM 的输出(completion tokens)被解释为函数调用。
函数调用执行器:负责在主上下文和外部上下文(如归档存储和回溯存储数据库)之间移动数据。
函数链:LLM 可以通过输出中加入特殊参数(
request_heartbeat=true)请求连续的 LLM 推理,从而串联多个函数调用,实现多步检索,以回答用户查询。
评估与实验¶
为了验证 MemGPT 的有效性,我们在两个领域进行了实验:
文档分析:现代 LLM 在处理长文本文件(如法律合同、科研论文)时容易超出输入限制,MemGPT 通过外部检索和上下文管理显著提升了处理能力。
对话代理:传统 LLM 由于上下文窗口有限,无法在长对话中保持上下文一致性、角色一致性和长期记忆,MemGPT 通过动态管理上下文,显著改善了对话体验。
在上述两个设置中,MemGPT 都成功克服了固定上下文长度的限制,优于现有基于 LLM 的方法。
总结¶
本章介绍了当前 LLM 在处理长上下文任务中的局限性,并提出 MemGPT 作为解决方案。MemGPT 借鉴操作系统中的虚拟内存概念,通过分层内存管理和函数调用机制,使 LLM 能够在有限上下文中模拟“无限上下文”的行为,从而在文档分析和对话代理等任务中显著提升性能。
2 MemGPT (MemoryGPT)¶
MemGPT 是一种受操作系统启发的多层级记忆架构系统,旨在扩展大型语言模型(LLM)的上下文处理能力。MemGPT 的设计核心在于区分两种主要记忆类型:
Main context(主上下文):对应于物理内存(类似 RAM),包含当前在 LLM 模型上下文窗口内的提示词(prompt tokens),可以直接被 LLM 在推理过程中访问。
External context(外部上下文):对应于磁盘存储,包含超出 LLM 上下文窗口的信息。这些信息必须通过显式操作(如调用 MemGPT 提供的函数)才能被加载到主上下文中,并传递给 LLM 处理。
MemGPT 提供了若干函数调用接口,允许 LLM 自主管理其内存,而无需用户干预。这种机制使得语言模型能够在上下文受限的情况下,动态调整其对信息的访问和存储策略。
2.1 Main context (prompt tokens)¶
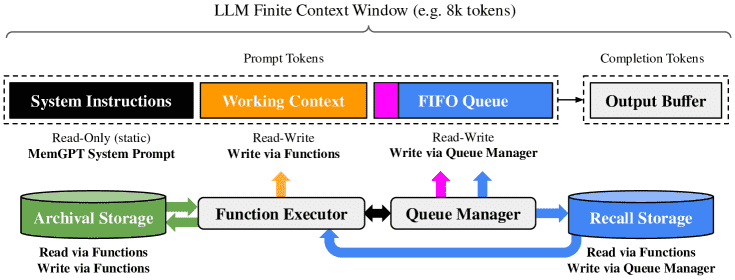
Figure 3: In MemGPT, a fixed-context LLM processor is augmented with a hierarchical memory system and functions that let it manage its own memory.
主上下文由三部分连续组成:
System instructions(系统指令):只读部分,包含 MemGPT 的控制流程、不同层级记忆的使用说明以及如何使用 MemGPT 提供的函数(例如如何检索外部上下文数据)。这是固定的静态内容。
Working context(工作上下文):固定大小、可读写的文本块,只能通过 MemGPT 函数调用修改。在对话场景中,用于存储用户的关键信息(如偏好、身份设定等),帮助模型维持对话的连贯性。
FIFO Queue(先进先出队列):保存消息的历史记录,包括用户与模型之间的对话、系统消息(如内存警告)以及函数调用的输入输出。队列的首项为系统消息,包含被移除消息的递归摘要(用于恢复被丢弃的信息)。
重点:这一结构使得模型能够在有限的上下文窗口中,通过维护工作上下文和消息队列,动态管理信息的可见性与存储。
2.2 Queue Manager(队列管理器)¶
队列管理器负责管理 消息的缓存与溢出处理,是 MemGPT 的核心组件之一。其主要功能包括:
消息处理:每当系统接收到新消息,队列管理器会将其添加到 FIFO 队列中,然后将当前上下文拼接后传递给 LLM 生成输出(completion tokens)。同时,输入和输出都会被写入 recall storage(回忆存储),即 MemGPT 的消息数据库。
消息检索:当通过 MemGPT 函数调用需要检索外部存储的消息时,队列管理器会将这些消息重新插入到 FIFO 队列的末尾,以恢复其在 LLM 上下文中的可见性。
重点:队列管理器还负责 上下文溢出控制(context overflow control),具体通过 队列驱逐策略(queue eviction policy) 实现:
当主上下文的 token 数量超过 LLM 上下文窗口的 “警告阈值”(如 70%),队列管理器会插入一条系统消息,提示 LLM 需要进行内存管理(例如将关键信息保存到工作上下文或归档存储)。
当超过 “刷新阈值”(如 100%),队列管理器会执行 队列刷新(flush):移除部分消息,并用这些消息生成一个新的递归摘要。被移除的消息虽不再在上下文中可见,但会永久存储在回忆存储中,并可通过函数调用访问。
重点总结:队列管理器通过自动化的驱逐与摘要机制,使得 LLM 能够在有限的上下文窗口中保持对长对话或大量信息的处理能力。
2.3 Function executor(函数执行器,处理 completion tokens)¶
MemGPT 通过 函数调用机制 在主上下文与外部上下文之间移动数据。LLM 可以自主决定何时将数据在不同上下文之间移动(例如,当对话历史过长时),并修改其主上下文以反映当前任务的理解变化。
重点:我们通过在系统指令中提供 明确的指令说明,指导 LLM 如何与 MemGPT 的记忆系统交互。这些指令包括:
对记忆层级的详细说明及其用途;
函数的调用格式(包括自然语言描述)。
在每次推理周期中,LLM 处理器接收主上下文(拼接成字符串)作为输入,并生成输出字符串。MemGPT 会解析该输出字符串,验证函数参数的正确性,若验证通过则执行该函数。执行结果(包括运行时错误)会反馈给 LLM,形成一个 反馈循环,使系统能够从行为中学习并调整策略。
重点补充:MemGPT 通过 上下文容量的预警机制 和 分页检索机制,确保在检索外部信息时不会超出上下文窗口的限制,从而确保模型的有效性与稳定性。
2.4 Control flow and function chaining(控制流与函数链)¶
在 MemGPT 中,事件驱动 LLM 推理,事件可以是:
用户消息(聊天应用中);
系统消息(如主上下文容量警告);
用户交互(如登录、文件上传);
定时事件(允许 MemGPT 在无用户干预的情况下运行)。
MemGPT 使用解析器将事件转化为纯文本消息,然后将其添加到主上下文中,作为 LLM 的输入。
重点:很多实际任务需要 连续调用多个函数(例如分页查询、多文档信息整合)。为此,MemGPT 提供了 函数链机制(function chaining):
函数可以带有 立即返回控制权的标志,表示执行完该函数后继续执行下一条函数,不中断 LLM 的推理流程。
若未设置此标志(即 yield),MemGPT 会暂停 LLM 推理,直到下一个外部事件触发(例如用户消息或定时中断)。
示例说明:图 4 展示了一个对话片段,MemGPT(左侧)更新了工作上下文中的信息,说明其可以在主上下文中动态修改存储内容。
总结¶
MemGPT 通过 多层级记忆结构、队列与上下文管理机制,以及 函数调用与链式执行,使得 LLM 在有限的上下文窗口中能够自主管理信息,实现更长的对话历史和更复杂的任务处理。其核心价值在于为 LLM 提供了类似操作系统的功能,使其具备自我管理、自我扩展的能力。
3 Experiments¶
3.1 MemGPT 用于对话代理¶
实验目标¶
对话代理(如虚拟助手、个性化聊天机器人)需要在长期交互中保持对话的一致性和吸引力。传统模型受固定上下文长度限制,难以处理长期对话。因此,MemGPT 的目标是通过无限上下文机制提升对话的一致性和互动性。
评估标准¶
一致性(Consistency):MemGPT 是否能够记住过去的对话内容,并在后续对话中保持一致性?
吸引力(Engagement):MemGPT 是否能够根据长期对话内容个性化回复,从而提升用户体验?
数据集和任务设计¶
使用并扩展了 Multi-Session Chat (MSC) 数据集,包含多个会话的对话记录。
设计了两项任务:
Deep Memory Retrieval(DMR)任务:测试 MemGPT 在多轮对话中对长期记忆的调用能力。
Conversation Opener 任务:测试 MemGPT 是否能根据用户的历史对话生成个性化、吸引人的开场白。
实验结果¶
DMR 任务结果(表 2):
MemGPT 明显优于固定上下文模型(如 GPT-3.5、GPT-4),在准确率和 ROUGE-L 评分上分别达到 93.4% 和 0.827。
这表明 MemGPT 的“无限上下文”机制能有效提升对话一致性。
Conversation Opener 任务(表 3):
MemGPT 生成的开场白在多个指标上表现良好,甚至优于人工编写的开场白。
表明 MemGPT 能根据长期记忆生成更自然、更吸引用户的对话内容。
重点结论¶
MemGPT 在长期对话中表现出显著优势,特别是在记忆调用和个性化表达方面,远超固定上下文模型。这说明 MemGPT 的“无限上下文”架构对构建高质量对话代理具有重要意义。
3.2 MemGPT 用于文档分析¶
实验目标¶
在文档分析任务中,传统模型受制于有限的上下文长度,难以处理超长文档或多文档推理。MemGPT 旨在通过存储和检索机制解决这一问题,实现跨文档的问答和信息提取。
实验设计与任务¶
多文档问答任务(Document QA):MemGPT 与固定上下文模型在多文档问答任务中进行对比。
使用 NaturalQuestions-Open 数据集,结合 Wikipedia 文档进行问答。
MemGPT 通过分页检索机制,从存档存储中调取多文档信息,实现更长范围的上下文理解。
嵌套键值检索任务(Nested KV Retrieval):测试 MemGPT 的多跳检索能力,即在多层嵌套结构中查找信息。
任务设计:每个键值对中的值可能是另一个键,需多次查询才能找到最终值。
MemGPT 通过重复调用存储查询,实现多跳检索,而固定模型无法处理超过 2 层的嵌套结构。
实验结果¶
文档 QA 任务(图 5):
固定模型性能受限于上下文长度,而 MemGPT 通过分页检索机制,能处理更大范围的文档信息。
MemGPT 使用 GPT-4 时表现最佳,远超 GPT-3.5 和 GPT-4 Turbo。
嵌套 KV 任务(图 7):
MemGPT 是唯一能在多层嵌套中完成检索的模型。
即使在 4 层嵌套中,MemGPT 也能找到最终答案,而 GPT-4 在 3 层后表现下降,GPT-3.5 在 1 层后就无法完成任务。
重点结论¶
MemGPT 在文档分析任务中展现出了 跨文档推理 和 多跳检索 的能力,突破了传统模型上下文长度和信息检索的限制。它能够处理更复杂的信息查询任务,为构建基于 LLM 的“操作系统级”AI 提供了基础。
补充说明:实现细节与数据公开¶
模型设置:
GPT-4、GPT-4 Turbo、GPT-3.5 Turbo 等模型的上下文长度和版本均有明确说明。
数据公开:
公开了扩展的 MSC 数据集、嵌套 KV 检索任务数据集,以及包含 2000 万篇 Wikipedia 文章嵌入的数据库。
代码与实验工具已开源,可在 https://research.memgpt.ai 获取。
总结¶
本文通过两个关键领域的实验验证了 MemGPT 在处理长期对话和多文档推理任务中的有效性:
在对话代理任务中,MemGPT 显著提升了对话的一致性和互动性;
在文档分析任务中,MemGPT 通过灵活的存储与检索机制,突破了传统模型的上下文限制,展现出跨文档、多跳检索的能力。
这些实验结果表明,MemGPT 为构建具备“无限记忆”能力的 LLM 应用系统提供了重要基础。
5 Conclusion¶
在本文中,作者介绍了MemGPT,这是一种受操作系统启发的新型大语言模型(LLM)系统,旨在解决LLM上下文窗口有限的问题。MemGPT通过设计类似于传统操作系统的内存分层体系和控制流机制,为LLM提供了“更大的上下文容量”的虚拟体验。
重点内容讲解:¶
MemGPT的灵感来源与设计:
MemGPT的架构借鉴了操作系统的内存管理机制(如分页、分层存储),为LLM提供了一种内存分层管理的解决方案,使模型能够高效地在内存中“加载”和“卸载”上下文信息,从而突破固定上下文长度的限制。应用领域与实验验证:
作者在两个典型场景中验证了MemGPT的效果:文档分析:MemGPT能够处理远超当前LLM上下文限制的长文本,通过智能地将相关信息“调入”或“调出”内存,实现了对长文档的有效处理。
会话代理:在长时间对话中,MemGPT能够保持长期记忆、一致性与演化能力,从而显著提升了对话系统的性能与用户体验。
MemGPT的潜力:
实验表明,MemGPT证明了操作系统技术(如内存分层管理、中断机制)可以有效增强LLM的能力,即使在上下文长度受限的情况下,也能“突破瓶颈”。
未来研究方向:¶
扩展应用领域:将MemGPT应用于更多需要处理大规模、无界上下文的场景。
技术融合:结合数据库、缓存系统等不同类型的存储技术,提升MemGPT的效率和扩展性。
优化算法:进一步改进控制流和内存管理策略,提升系统智能和响应速度。
总结¶
MemGPT通过引入操作系统的核心理念,为LLM提供了在有限资源下实现更强功能的新路径。这项工作不仅展示了LLM在受限条件下的扩展潜力,也为未来的AI系统设计提供了跨领域整合的全新思路。
6 Appendix¶
6 附录总结¶
本章节主要介绍了 MemGPT 模型在不同任务中所使用的提示词(prompts)和指令(instructions),以及相关的评估方法。内容按照任务类型和功能用途进行了分节说明,重点讲解了 DMR(对话记忆恢复)、文档分析和 K/V(键值)任务的提示词设计和评估方式。
6.1 提示词和指令总结¶
6.1.1 MemGPT 指令(DMR)¶
核心内容:MemGPT 在对话和聊天任务中使用了特定的指令,要求模型完全沉浸于角色中,不提及自己是 AI,回答时基于核心记忆和对话检索(conversation_search)。
基线方法:基线模型则接收了简化的系统提示,要求回答用户关于之前对话的问题,并从对话摘要中获取信息。
重点:MemGPT 通过角色沉浸和记忆管理实现更自然和准确的对话回复,而基线方法则依赖于对话摘要。
6.1.2 LLM Judge(DMR / 开场)¶
功能:用于评估 DMR 任务中模型回答的正确性。
方法:给 LLM 提供问题、黄金答案和生成答案,判断生成答案是否“正确”或“错误”。
判断标准:只要生成答案提到黄金答案中的关键信息,即使更长或有额外内容,也视为“正确”;如果未提及关键信息或完全不相关,则视为“错误”。
重点:LLM Judge 的评估标准宽松,但强调回答必须与对话内容一致,不能仅依赖角色信息。
6.1.3 自我指令的 DMR 数据集生成¶
方法:使用原始 MSC 数据集和用户角色信息,生成用于测试对话记忆的问答对。
关键要求:问题必须依赖对话记录(chat log),不能仅通过角色简介(persona)回答。
例子:例如,根据对话记录生成“记得我们第一次去冲浪时,午餐吃了什么?”这样的问题。
重点:数据集设计强调真实性与记忆测试的合理性,避免基线模型通过角色信息“作弊”。
6.1.4 文档分析指令¶
任务设定:MemGPT 在文档分析任务中需从其“归档记忆”中检索并回答问题。
提示词:明确指出答案必定在归档记忆中,要求持续检索直到找到答案。
基线方法:给定文档列表,要求从其中提取答案,并提供答案与对应的文档内容。
重点:MemGPT 强调持续检索的必要性,而基线方法则依赖于给定文档的查找能力。
6.1.5 LLM Judge(文档分析)¶
评估方式:用于评估文档分析任务中模型是否正确引用文档内容作答。
判断标准:若答案与文档内容一致,并且提供了正确的文档引用,则为“CORRECT”,否则为“INCORRECT”。
重点:强调答案必须基于文档内容,而不是模型自身的知识库。
6.1.6 K/V 任务指令¶
任务目标:从键值对中查找嵌套的值,直到找到最终值。
MemGPT 的提示词:强调必须持续检索,直到验证某个值不是键为止。
基线方法:提供 JSON 格式的数据,要求进行嵌套查找并返回最终值。
重点:该任务检验模型的嵌套检索能力,MemGPT 特别强调了“持续检索”的策略。
总体总结¶
本章内容聚焦于 MemGPT 模型在多个任务(DMR、文档分析、K/V)中使用的提示词和评估方法,强调了模型在记忆管理、持续检索和角色沉浸方面的优势。相比基线方法,MemGPT 的设计更注重真实对话场景和长期记忆的维护,通过 LLM Judge 进行严格评估,确保了模型回答的正确性和可靠性。