2603.02766_EvoSkill: Automated Skill Discovery for Multi-Agent Systems¶
引用:
组织:
1Sentient,
2Virginia Tech
链接:
图解¶
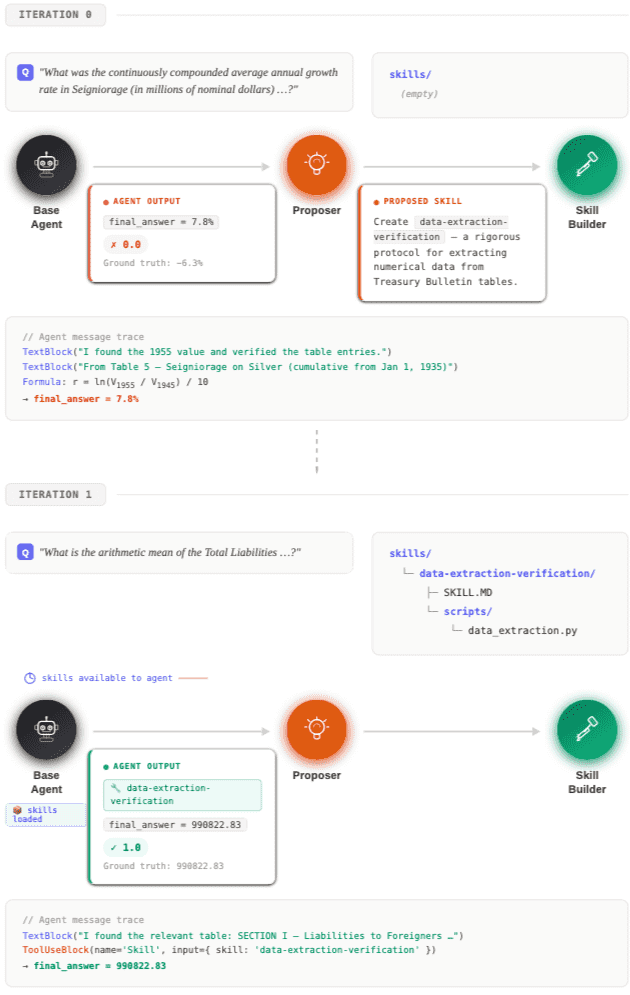
Figure 1: Overview of the EvoSkill loop.
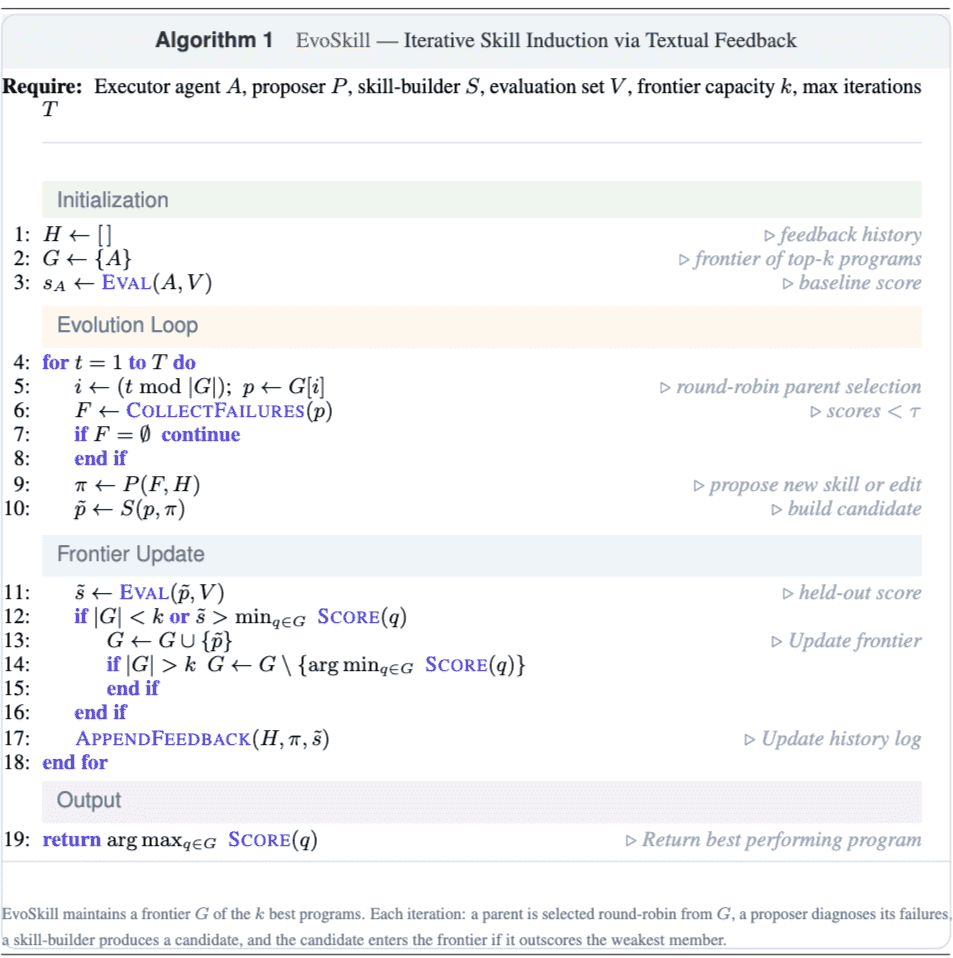
Algorithm 1 EvoSkill — Iterative Skill Induction via Textual Feedback
总结¶
📝 论文解读:EvoSkill —— 多智能体系统的自动化技能发现框架¶
一、 背景、目的与核心问题¶
背景: 当前,以代码为核心的智能体(Coding Agents,如Claude Code, OpenHands等)展现出了极强的通用问题解决能力。然而,通用性并不意味着它们具备处理垂直领域专业任务所需的“领域专家经验”。为了弥补这一鸿沟,业界开始引入“智能体技能”——即可复用的工作流、代码和指令集。但目前大多数技能依赖人工编写,不仅耗时费力,且难以规模化。
研究目的: 本文提出了 EvoSkill,一个自我进化的自动化框架。旨在通过分析智能体执行任务时的失败案例,自动发现、迭代并提炼出结构化的“技能”,从而赋予智能体特定领域的专业能力。
核心问题: 现有的进化优化方法(如提示词或代码优化)通常停留在底层构件层面,高度依赖特定模型和任务,缺乏泛化性和可复用性。EvoSkill 试图在更高的抽象层级——“技能”层面进行优化,解决自动技能生成与跨任务复用的难题。
二、 研究方法与核心机制¶
EvoSkill 的核心思想是基于文本反馈的迭代式失败分析。在底层大模型(LLM)权重完全冻结的情况下,它通过多智能体协作来更新技能库。
1. 框架架构(三大核心智能体):
执行者 (Executor, AA): 在当前技能库的加持下执行任务。
提议者 (Proposer, PP): 分析执行者的失败日志、预测答案和真实标签,诊断失败原因,并提出创建新技能或修改现有技能的高维建议。
构建者 (Skill-Builder, SS): 将提议者的抽象建议具象化为实际的“技能文件夹”(包含触发元数据、指令文档
SKILL.md和辅助脚本)。
2. 进化循环:
前沿维护: 系统维护一个容量为 \(K\) 的“帕累托最优前沿”,用于保存历史上表现最好的 \(K\) 个智能体程序配置。
失败驱动: 每次迭代中,系统采用轮询法从前沿选出一个父本程序,在训练集上运行。收集得分低于阈值的“失败样本”。
文本反馈下降: 提议者根据失败样本和历史反馈记录 \(\mathcal{H}\) 生成优化建议;构建者生成新的候选程序。
验证与淘汰: 候选程序必须在独立的验证集上取得比当前前沿中最差程序更高的分数,才能将其淘汰并进入前沿。
3. 数据与环境设置:
数据被大模型分类器分为训练集(用于发现失败)、验证集(用于前沿淘汰选择)和测试集(最终评估)。
程序配置通过 Git 分支进行版本控制,确保每次技能的变异都可追溯且轻量化。
三、 关键数据与主要发现¶
实验使用了两个极具挑战性的基准测试,并测试了跨任务的零样本迁移能力:
1. OfficeQA (基于美国财政部数据的接地推理基准):
数据: 包含约89,000页复杂的表格和文本,人类平均解题需50分钟。
结果: 使用极少量数据(10%训练集),EvoSkill 将 Claude Opus 4.5 的准确率从 60.6% 提升至 65.8%。通过合并多次独立运行发现的技能,准确率进一步提升至 67.9% (+7.3%)。
2. SealQA (带有噪声检索的搜索增强QA基准):
结果: 在面对充满冲突和噪声的网络搜索结果时,EvoSkill 将准确率从 26.6% 大幅提升至 38.7% (+12.1%)。
3. 零样本迁移:
发现: 将在 SealQA 上进化出的“搜索持久性协议”技能,不加任何修改地直接应用于 BrowseComp 基准测试,准确率从 43.5% 提升至 48.8% (+5.3%)。这直接证明了 EvoSkill 发现的技能具有强大的跨任务泛化能力。
四、 新颖概念通俗解释¶
1. 技能抽象
通俗解释: 过去优化大模型应用,往往是在“改提示词”或“改两行代码”,这就像为了让学生数学考高分,你只教他背某一题的答案(死记硬背,换个题型就不会了)。EvoSkill 的“技能抽象”则是给学生总结一套“解题方法论”(比如:如何提取图表数据、如何进行多源交叉验证)。这种“技能”是一个包含触发条件、操作手册和工具箱的独立文件夹,不仅当下有用,遇到类似的新问题也能直接拿来用。
2. 文本反馈下降
通俗解释: 传统的梯度下降是通过数学微调模型参数来减少错误。而“文本反馈下降”则是让大模型阅读自己做错的题目和标准答案,用自然语言写出“我为什么错了、下次应该怎么做”的反思报告,然后根据这份文本报告去修改“技能库”。这是一种基于人类自然语言逻辑的“进化”,而不是数字层面的计算。
3. 帕累托前沿
通俗解释: 就像一个只保留“最强王者”的有限候补室。系统不会保留所有尝试过的技能组合,而是只保留表现最好的前 \(K\) 个版本。任何新产生的技能,只有在测试中打败了候补室里最弱的那一个,才能把它踢出去并取而代之。这保证了系统的高效和持续进化。
五、 优缺点评价与未来研究方向¶
优点:
高度创新性与实用性: 突破了传统提示词工程的局限,实现了从“底层微调”到“高层技能获取”的跨越,非常契合当前 Agent 的发展趋势。
模型无关与参数冻结: 不需要微调底层大模型(如 GPT-4 或 Claude)的权重,大幅降低了计算成本和部署门槛。
卓越的泛化能力: 论文通过扎实的实验(特别是 SealQA 到 BrowseComp 的零样本迁移)证明了该框架发现的技能不是“过拟合”的死记硬背,而是真正具有通用价值的“能力”。
局限性:
计算成本与时间开销: 尽管没有进行参数训练,但多智能体(执行者、提议者、构建者)的反复调用和长文本反思需要消耗大量的 API Token 和时间。
评估指标的局限性: 对于开放式任务,自动评分机制(基于精确匹配和模糊容差)可能无法完全捕捉智能体回答的语义正确性。
随机性控制: 论文提到由于 Opus 4.5 的计算成本高昂,部分实验仅运行了一次,缺乏多种随机种子下的方差分析。
未来研究方向:
多模态技能扩展: 将 EvoSkill 应用于视觉、代码等多模态混合任务中,发现跨模态的复合技能。
构建共享技能库: 探索建立去中心化或全局的“技能集市”,不同用户的智能体可以上传、下载、组合彼此发现的技能。
跨模型迁移研究: 验证在 Claude 上进化出的技能,是否能够零样本迁移到 GPT 或开源模型(如 Llama)的智能体上。