2308.10144_ExpeL: LLM Agents Are Experiential Learners¶
引用: 300(2025-08-09)
作者: 无
Expel: Experience Learning
From Deepseek¶
论文背景与核心思想¶
该论文探讨了大语言模型(LLM)智能体通过经验学习(Experiential Learning)提升任务执行能力的方法。传统LLM在复杂任务中依赖静态知识或少量示例(few-shot),而ExpeL提出通过自主积累动态经验(如成功/失败的任务轨迹)来持续改进性能,无需人工干预或额外训练。
关键创新点¶
自主经验收集:
LLM智能体在任务尝试中自动记录详细经验(包括环境状态、动作、结果),形成可复用的任务解决范例。经验库(Experience Library):
结构化存储历史经验,支持高效检索。通过分析相似案例,智能体可快速适配新任务,避免重复错误。经验驱动的推理与规划:
在遇到新任务时,智能体从经验库中提取相关案例,生成更可靠的解决方案,显著减少幻觉(hallucination)。
Abstract¶
本文探讨了将大语言模型(LLMs)应用于决策任务的研究增长。随着研究兴趣的增加,LLMs 中嵌入的丰富世界知识被广泛用于提升决策任务的性能。然而,定制化 LLM 以适应特定任务存在两个主要问题:
微调模型代价高昂,并且可能影响模型的泛化能力;
最先进的模型如 GPT-4 和 Claude 仅通过 API 接口提供,其模型权重未公开。
这两个问题凸显了一种新方法的需求:无需更新模型参数即可从智能体经验中学习。为此,作者提出了经验学习智能体(ExpeL Agent)。该智能体能够自主收集经验并利用自然语言提取知识,在推理阶段通过反思过往经验做出更优决策。
实验结果表明,ExpeL 的学习效果显著增强,其性能随着经验的积累而不断提升。作者还通过定性观察和额外实验,探索了 ExpeL 的新兴能力及其在迁移学习中的潜力。
图片与引用总结¶
文中引用了 Tom Mitchell 对机器学习的经典定义:
“如果一个计算机程序在某个任务集合 T 上的表现(由性能指标 P 衡量)随着经验 E 的增加而提高,那么它就被称为从经验 E 中学习。”
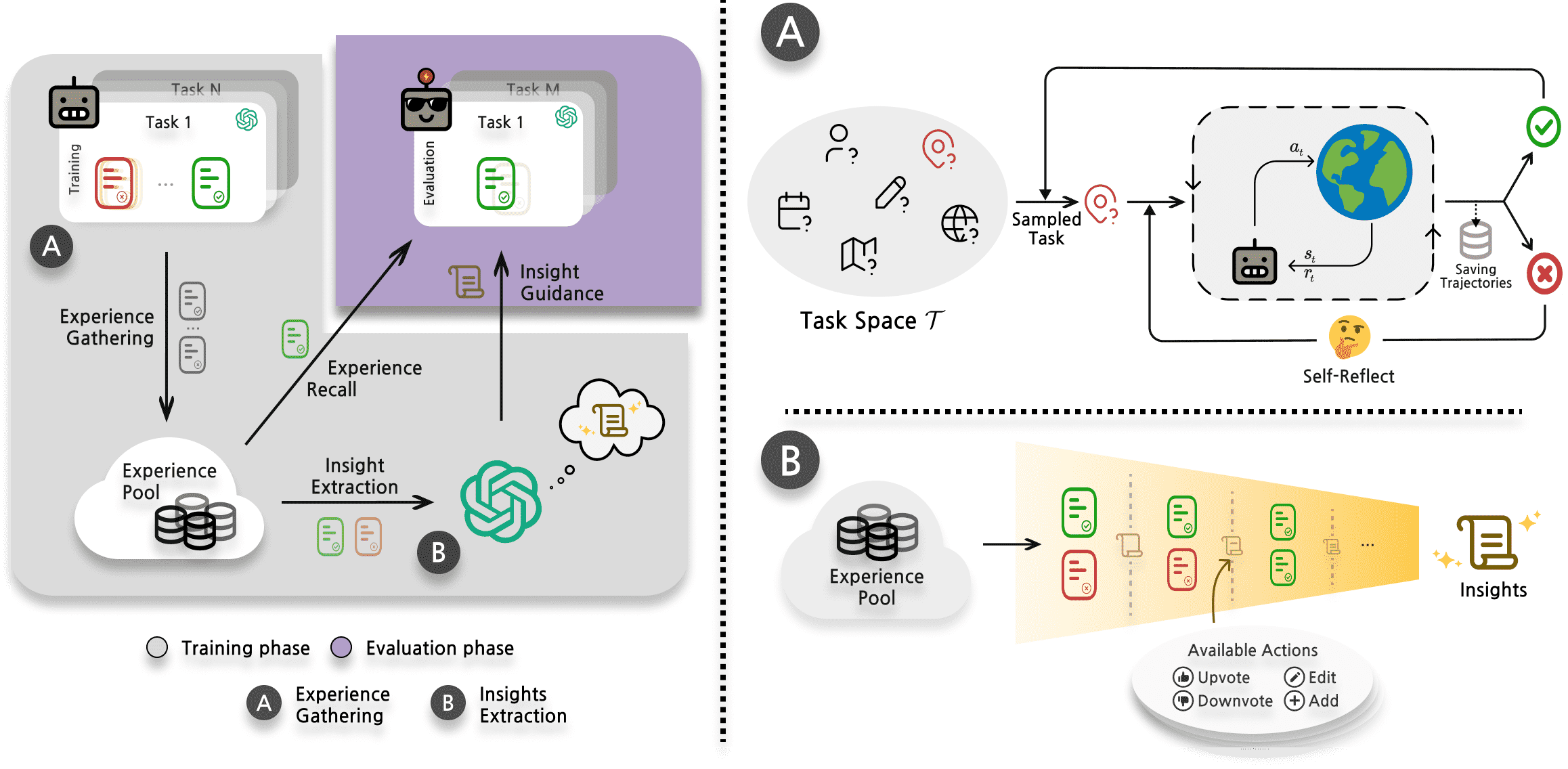
Figure 1:ExpeL Agent Overview.
左侧流程分为三个阶段:
经验收集:收集成功和失败经验;
知识提取:从经验中抽象出跨任务的通用知识;
经验应用:在评估任务中应用学到的见解并回忆成功经验。
右侧说明了关键机制:
(A) 通过 Reflexion 实现经验收集,智能体在失败后进行自我反思并重新尝试任务;
(B) 见解提取过程:根据成功/失败经验对现有见解列表进行动态更新,支持 ADD、UPVOTE、DOWNVOTE 和 EDIT 操作,重点在于提取常见失败模式或最佳实践。
总结重点¶
研究背景:LLMs 在决策任务中的应用快速增长,但存在微调成本高和模型权重不可访问的问题。
核心贡献:提出 ExpeL 智能体,不依赖模型微调,从经验中自主学习,提升性能和泛化能力。
方法创新:采用经验收集与反思机制,结合自然语言处理抽取见解,并通过动态更新机制增强智能体的知识库。
实验验证:性能随经验积累而提升,具备迁移学习潜力。
关键词:大语言模型(LLM)、决策任务、经验学习、ExpeL 智能体、无需微调学习。
1 Introduction¶
本节概述了将大语言模型(LLM)与自主智能体结合的研究背景,并提出了本文的核心贡献——ExpeL 智能体。
背景介绍¶
近年来,研究者将大语言模型(Large Language Models, LLM)引入自主智能体(autonomous agents),取得了诸多实际应用的进展。LLM 的一大优势在于其丰富的世界知识,使得它在多种场景中具有天然的多功能性。已有研究表明,LLM 能在多个领域(如科研、工业)中发挥重要作用。
当前方法的局限性¶
目前主要有两类方法用于增强智能体能力:
微调(Finetuning)方法:
通过大量环境交互或人工标注数据对 LLM 进行微调。
优点:可以显著提升模型在特定任务上的表现。
缺点:
需要访问模型的参数,计算成本高。
微调可能导致模型泛化能力下降(Du et al. 2022)。
限制了 LLM 的多功能性。
提示(Prompting)方法:
通过少量示例(in-context learning)增强 LLM 的序列决策能力。
优点:不需要修改模型参数,适用于封闭源代码模型(如 GPT-4)。
缺点:
受限于 LLM 的上下文窗口长度(context window size)。
智能体无法记住过去经验,只能通过少量示例学习。
本文提出的解决方案:ExpeL 智能体¶
为了解决上述方法的局限性,本文提出了ExpeL(Experiential Learning)智能体:
自主学习机制:ExpeL 通过试错方式在多个训练任务中积累经验。
知识总结与复用:从这些经验中提炼出自然语言形式的洞察,并在测试时将其作为上下文示例使用。
类比现实学习过程:类似于学生通过学习积累经验,最终在一次考试中应用所学。
关键特性:
无需参数更新,适用于封闭源模型(如 GPT-4、Claude)。
跨任务经验复用:强调多任务经验积累的重要性,提升整体性能。
数据高效:不需要大量标注数据或人工干预。
实验与贡献¶
作者通过多个领域的实验验证了 ExpeL 的有效性,并提出了以下关键贡献:
提出 ExpeL:一种无需梯度更新的 LLM 智能体,能通过经验自主学习。
广泛评估:在多种任务中验证了其学习能力和优于现有规划方法的性能。
迁移学习新场景:展示了 ExpeL 从源任务学习后能对目标任务产生正向迁移(forward transfer)。
意外能力:发现 ExpeL 智能体在训练过程中展现出一些未预期的能力。
未来展望¶
作者认为,随着规划算法和基础模型的进一步发展,ExpeL 的范式将能从中受益,展现出更大的潜力。
3 Preliminaries¶
复杂交互任务¶
本研究探讨的是复杂交互任务。在每一步时间步 \(i \in \{0, \dots, H\}\),智能体接收一个观察 \(o \in \mathcal{O}\),并基于其观察历史 \(H_t\) 选择一个动作 \(a \in \mathcal{A}\)。智能体的目标是完成某个目标 \(g \in \mathcal{G}\)。本文仅考虑确定性环境。
重点:
智能体在每一步决策时依赖于历史观察。
任务的目标性明确,且环境是确定性的,即相同输入始终产生相同输出。
大语言模型¶
大语言模型(LLM)是用于建模自然语言的统计模型,通常为神经网络。本文中使用的是自回归语言模型,例如 OpenAI、Brown 等人、Touvron 等人以及 Chowdhery 等人提出的模型。此类模型根据已有的 token 序列 \(\mathbf{x} = \{x_1, x_2, \dots, x_{l-1}\}\),预测下一个 token 的概率 \(p(x_l \mid x_{<l})\)。
此外,我们使用的是指令跟随型大语言模型,如 Thoppilan 等人、Chung 等人和 Wei 等人的模型。这些模型通常在格式化为(指令,输入,输出)的 NLP 任务上进行微调。这类模型能更好地遵循自然语言指令,从而减少对复杂的提示工程的依赖。
重点:
LLM 在自回归框架下工作,预测下一个词的概率。
指令跟随型模型经过特定任务微调,能够更自然地理解和执行语言指令。
这类模型减轻了对 prompt engineering 的需求。
ReAct 与 Reflexion¶
ReAct(Yao 等人)和 Reflexion(Shinn 等人)是两种增强 LLM 推理和自我改进能力的框架。
ReAct 将观察、动作和思考显式地交织在一起,为鲁棒的规划和推理提供了基础。
Reflexion 在 ReAct 的基础上增加了反思步骤,在每次任务尝试前进行反思,从而提升模型的适应性学习过程。
重点:
ReAct 通过整合观察、动作和思考,提升模型的推理能力。
Reflexion 在 ReAct 的基础上增加了反思机制,进一步增强模型的学习能力。
4 ExpeL: An Experiential Learning Agent¶
章节总结¶
本章节介绍了 ExpeL(经验学习)智能体,一种基于大型语言模型(LLM)的智能体结构。ExpeL 的核心思想是:通过对经验的自主收集与归纳,提高 LLM 在任务中的表现,而无需更新模型参数。该方法借鉴了人类学习的机制,并结合了自主智能体与基于提示(prompt-based)方法的优势。
4.1 收集经验¶
重点内容:
ExpeL 的训练阶段通过试错法收集经验。每个任务可以最多重试 Z 次。
每次尝试中,智能体会生成一个轨迹 τ,如果任务成功则将该轨迹加入经验池 ℬ;如果失败,则通过自我反思生成反思内容 ν,并将其加入下一次尝试的上下文中。
该过程不仅增加了成功案例的数量,还提供了成功与失败的对比,为后续的洞见提取提供数据支持。
次要内容:
使用 Reflexion 框架进行重试与反思。
伪代码见 Algorithm 1。
4.2 从经验中学习¶
重点内容:
ExpeL 模拟人类学习的两种方式:
经验召回:从经验池中检索与当前任务相似的成功轨迹作为示例。
洞见提取:通过比较成功与失败的轨迹,归纳出可复用的“好做法”。
经验召回机制:
使用 Faiss 向量库和 all-mpnet-base-v2 嵌入器,基于任务相似性检索 top-k 成功轨迹。
任务相似性检索减少了对模型外推能力的依赖。
洞见提取机制(见图 2):
提供一系列操作符(ADD、EDIT、UPVOTE、DOWNVOTE)供模型使用。
每个洞见的“重要性计数”会随着操作动态变化,确保洞见的可靠性。
使用 LLMinsights 模型(如 gpt-4)进行洞见生成与更新。
次要内容:
洞见的初始集合为空,通过迭代机制构建。
洞见生成伪代码见 Algorithm 2。
4.3 任务推理¶
重点内容:
在任务推理阶段,智能体会结合以下内容做出决策:
提取的洞见:将所有洞见 ι 拼接为上下文。
任务相似性检索的示例:从经验池中检索 top-k 相似任务的成功轨迹。
这种结合方式提高了模型在新任务中的表现,尤其在少样本设定下效果显著。
次要内容:
提示模板见图 3。
伪代码见 Algorithm 3。
4.4 迁移学习¶
重点内容:
ExpeL 也支持跨任务迁移学习,即在源任务中积累的知识可用于目标任务。
通过在目标任务中加入少量示例,对从源任务中提取的洞见进行“微调”,使其更适用于新任务。
该机制降低了对目标任务数据的需求,提升了模型在数据有限环境中的适应性。
次要内容:
微调提示模板见图 4。
ExpeL 在不同任务域(如 HotpotQA、ALFWorld、WebShop)中表现优于 ReAct 和 Act,如图 5 所示。
4.5 ExpeL 的优势¶
重点内容:
可解释性强:所有经验与洞见以自然语言形式呈现,用户可查看、修改或删除有害内容。
数据与计算效率高:比微调模型需要更少的训练数据与计算资源。
灵活性强:不依赖特定 LLM,可与现有策略(如 ReAct)无缝结合,提升其性能。
支持持续改进:随着基础模型的更新,ExpeL 的性能也能提升。
支持跨领域迁移:通过少量示例即可实现从源任务到目标任务的知识迁移。
次要内容:
ExpeL 不依赖部署时的重试,适合对重试有严格限制的场景。
实验表明,gpt-4 在洞见提取上优于 gpt-3.5-turbo。
总结¶
ExpeL 通过经验收集、洞见提取与任务推理,构建了一个具有人类学习特点的 LLM 智能体。其优势在于可解释性强、资源消耗低、灵活且可迁移,在多个任务域中均表现出色。该方法为 LLM 智能体的持续学习和跨任务适应提供了一种有效路径。
5 Experiments¶
5.1 实验设置¶
本实验基于四个文本类基准测试平台,分别是:
HotpotQA:知识密集型任务,要求代理通过搜索 API(Wikipedia Docstore API)进行推理和问答。
ALFWorld 和 WebShop:需要代理在家庭和电商网站中进行多步骤交互式任务决策。
FEVER:事实验证任务,同样使用与 HotpotQA 相同的 API,可以用于知识迁移。
实验使用 四折交叉验证,报告平均结果和标准误差。评估指标为“成功率”,具体如下:
HotpotQA 和 FEVER:精确匹配;
ALFWorld:任务在限定时间内完成;
WebShop:购买符合所有属性的商品。
部分环境还提供了额外指标,如 WebShop 的 平均奖励(r ∈ [0,1]),以及 ALFWorld 的任务类型得分分解。
使用的基线模型包括 ReAct 和 Act(Yao et al. 2023),其中 Act 不包含推理步骤。所有代理在评估阶段使用 gpt-3.5-turbo-0613,文本生成使用 temperature=0 和 贪心解码。模仿学习(IL)结果来自 ReAct 论文。更多实验细节见附录 D。
5.2 主要结果¶
Experiential Learning(经验学习)¶
ExpeL(经验学习代理)在所有环境中都优于基线代理。
当限制为仅使用抽象见解或经验检索时,HotpotQA 和 ALFWorld 表现出明显差异:
HotpotQA 中,见解更重要(36% vs 31%);
ALFWorld 中,经验更重要(50% vs 55%);
WebShop 需要两者结合,表现接近(37% vs 38%,平均得分 0.675 vs 0.67)。
这表明抽象与记忆的协同作用对经验学习至关重要,ExpeL 显著优于单模式代理。
跨任务学习(Cross-task Learning)¶
ExpeL 与 Reflexion 代理(Shinn et al. 2023)在 HotpotQA 上表现相当(40% vs 39%),在 ALFWorld 上甚至更好(54% vs 59%),且无需重复尝试。
Reflexion 依赖多次任务执行来优化见解(R1, R2, R3);
ExpeL 通过跨任务经验积累实现提升。
WebShop 任务表现仍略逊于 Reflexion,仍有改进空间。
5.3 代理行为分析¶
通过手动分析轨迹,观察到 ExpeL 的一些显著行为变化:
假设构建与约束适应(Hypothesis Formulation & Constraints Adaptation):
ExpeL 能在最终步骤重新评估整个轨迹并完成任务,而非放弃。
在 HotpotQA 中,代理会根据已有观察推断答案,而不是回复“未知”。
世界模型信念更新(World Model Belief Update):
ExpeL 能根据经验更新对环境的信念,避免无效行动。
例如,在 ALFWorld 中,代理更新了对锅的位置的先验(从抽屉改为炉灶),更高效地找到目标。
自我纠正(Self-correction):
ExpeL 能识别并纠正错误操作(如在 ALFWorld 中错误拿起物品后放回并继续任务)。
这种行为由生成的见解推动,如“如果不进展任务,应重新评估并考虑其他操作”。
5.4 知识迁移(Transfer Learning)¶
实验中将 HotpotQA 作为源任务,FEVER 作为目标任务,验证知识迁移效果。
使用 gpt-4-0613 从 HotpotQA 提取见解并适配到 FEVER 任务。
比较了 ExpeL Transfer 与 ReAct、Act 以及无任务演示的 ExpeL 的迁移效果。
关键发现:使用少量示例进行见解微调(fewshot finetuning)在迁移中效果显著,ExpeL Transfer 取得 70% 的成功率,明显优于基线。
5.5 带任务重试的 ExpeL(ExpeL with Task Reattempts)¶
在 R0 的失败检查点上进行任务重试,评估 ExpeL 的鲁棒性。
结果表明,ExpeL 与 Reflexion 结合后,在 ALFWorld 中成功率逐步提升,最多达到 64.2%。
表明 ExpeL 与 Reflexion 在该环境中具有协同效应。
5.6 消融实验(Ablation Studies)¶
经验数量对性能的影响¶
比较了以下三种设定:
只使用初始 fewshot 示例;
使用 ReAct 收集经验(无重试);
使用 Reflexion 收集多样化经验(成功/失败对)。
结论:更多多样化经验有助于 ExpeL 提升性能,尤以 Reflexion 收集的经验最优。
见解提取机制的消融¶
关键发现:
代理自动生成的见解优于人工构建的(如 39% vs 32%);
加入反思(Reflection)反而有害,可能引入幻觉;
使用更强大的 LLM(如 gpt-3.5)生成见解效果更好。
上下文示例选择策略的消融¶
比较了三种方式:
任务相似度检索(ExpeL);
推理相似度检索;
随机抽样。
结果:任务相似度最佳,随机抽样最差,说明精准匹配上下文示例对性能至关重要。
总体总结:¶
本章全面评估了 ExpeL 模型在多个文本环境中的性能表现和行为特性。核心结论如下:
ExpeL 通过经验抽象与检索显著提升推理和任务完成能力;
与 Reflexion 等机制结合可实现跨任务学习与重试自适应;
多样化经验和高质量 LLM 生成的见解是模型性能提升的关键;
ExpeL 在多个任务中均优于基线模型,验证了其作为“经验型学习代理”的有效性。
(注:文中部分链接和图像因格式限制未完整呈现,建议参考原文获取更详细内容。)
6 Conclusion and Limitations¶
局限性¶
在本研究中,我们主要关注基于文本观察的任务,这在现实场景中存在一定限制。因此,引入图像观察将使本方法更具普遍适用性。使用视觉语言模型(Vision-Language Models)或图像描述模型(captioning models)来扩展大型语言模型(LLM)以支持图像输入,可能是一个有潜力的研究方向。
此外,我们在实验中使用了闭源的API LLM来验证方法的有效性,但在某些应用场景中,这些模型可能不可用。未来可以进一步探索基于开源LLM的智能体(LLM agents),这应是另一项具有前景的研究方向(Zeng et al., 2023)。
另外,我们提取的洞察信息并未超过当前LLM的token限制,因此可以直接放入智能体的上下文窗口中。但对于真正具有终身学习能力的智能体来说,可能需要额外的检索步骤来管理上下文窗口的大小,以确保其效率和可行性。
最后,与强化学习方法不同,提示技术(prompting techniques)目前缺乏理论支撑,这可能会对最终策略的效率产生影响。未来研究可以探索这些方法的结合,从而获得更有效和最优的解决方案。
总结¶
我们提出了一种新的学习型LLM智能体——ExpeL。该智能体能够自主从一系列训练任务中积累经验,并在没有访问模型参数的情况下,提升其解决评估任务的能力。我们通过实验展示了ExpeL在性能上的提升,相较于传统的ReAct和Act智能体具有优势。
我们还研究了迁移学习场景,发现从一系列源任务中提取的洞察可以帮助ExpeL更好地解决目标任务。此外,我们还观察到训练结束后智能体出现了一些意想不到的能力。
我们相信,自主从经验中学习是构建类人智能体的重要一步,而ExpeL则是朝这一目标迈出的关键一步。
Acknowledgement¶
本研究得到了以下项目的资助支持:国家重点研发计划项目(2022ZD0114900)、国家自然科学基金项目(62022048、U2336214、62332019)以及清华大学郭强研究院的支持。
重点内容:本论文的研究工作受到多个国家级科研项目的支持,显示了研究的重要性和权威性。
精简内容:具体资助项目编号和机构名称列出,便于读者查阅相关项目信息。
Appendix B Broader Impacts¶
本部分主要探讨了研究工作的更广泛影响,特别是围绕大型语言模型(LLM)智能体的应用所带来的潜在风险与应对措施。
研究指出,如果赋予这些自主运行的程序(即LLM智能体)互联网访问权限,可能会带来不可预见的负面影响。这种风险是重点内容之一,因为随着LLM能力的增强,其自主行为可能对现实世界产生实际影响,例如传播错误信息、执行不当任务或引发安全问题。
为应对上述风险,文章提到了**基于人类反馈的强化学习(RLHF)**作为一种可能的缓解手段,并引用了 Nakano 等人(2021)和 Ouyang 等人(2022)的研究作为支持。这是本节的另一个重点,说明已有技术手段可以用于提升LLM行为的安全性与可控性。
总体而言,该章节强调了LLM智能体的潜在危害与应对策略,突出了技术发展与伦理安全之间的平衡问题。
Appendix C Computational Resources¶
本节简要介绍了实验所使用的计算资源,具体如下:
硬件配置:所有的实验均在一台台式机上完成。
CPU:使用的是 Intel(R) Core(TM) i9-9900K,主频为 3.60GHz,包含 16 个核心。
内存(RAM):配置了 64GB 的内存,能够支持大规模数据处理和模型训练。
GPU:使用了一块 NVIDIA GeForce RTX 2080 Ti 显卡,提供强大的图形处理能力和深度学习加速。
重点内容:
实验所用的硬件配置较为高端,尤其是在 GPU 方面,RTX 2080 Ti 是一款适合深度学习和高性能计算的显卡,对于模型训练和推理具有重要意义。
16 核 CPU 和 64GB 大内存也确保了系统在处理复杂任务时的稳定性与效率。
非重点内容:
实验平台为台式机,未涉及分布式计算或其他更复杂的硬件环境,说明实验规模相对较小或对计算资源的需求在单机范围内即可满足。
Appendix D Environment Details¶
D.1 评估任务集(Evaluation Task Set)¶
本文在所有实验中采用四折交叉验证(four-fold validation)的方式进行训练与评估。每折训练一半数据,测试另一半数据,结果取四折的均值和标准误差,以提高结果的可靠性。
对于HotpotQA任务,使用了包含100个验证任务的distractor dev split数据集(Yang et al. 2018),与ReAct和Reflexion方法相同。对于ALFWorld任务,使用了134个可解任务(Shridhar et al. 2021)。对于WebShop任务,同样采用了100个任务,与ReAct和Reflexion一致。
重点内容:评估任务集的设置保证了结果的可比性和一致性,特别是任务数量与已有的研究方法保持一致。
D.2 提示与少量样本(Prompts/Fewshot Examples)¶
本文在适当阶段使用了ReAct和Reflexion的提示和少量样本(fewshot examples)(Yao et al. 2023b;Shinn et al. 2023)。
对于WebShop任务,额外添加了一个样本,使其总共包含两个fewshot例子,以提高模型的指导性。完整的提示模板可以在附录F中找到,并承诺开源代码和实现细节。
重点内容:提示和样本设置对模型表现有直接影响,作者在保持标准样本的基础上进行了适度扩展。
D.3 WebShop环境特定细节(WebShop Environment Specific Detail)¶
本文对WebShop环境进行了细微修改,以保证实验的确定性和可复现性。原始版本中,商品价格和价格约束是通过均匀随机抽样生成的;本文改为使用平均值,以确保每次运行环境的一致性。
另外,为了适应大语言模型(LLM)的更大的上下文窗口,将每页显示的商品数量从3个扩展到10个,以增加观察数据的丰富性。
重点内容:环境的修改重点在于提高实验的可复现性和适应更大上下文窗口的LLM。
D.4 WebShop奖励函数(WebShop Reward Function)¶
WebShop引入了一种奖励函数,用于评估选中的商品与目标商品之间的相似性,其值范围为0到1,计算公式如下:
其中,\(r_{\text{type}}\) 是根据文本匹配程度(TextMatch)定义的权重值,具体如下:
若 TextMatch = 0,\(r_{\text{type}} = 0\)
若 TextMatch < 0.1,\(r_{\text{type}} = 0.1\)
若 TextMatch ≤ 0.2 且查询不匹配、类别不匹配,\(r_{\text{type}} = 0.5\)
其他情况,\(r_{\text{type}} = 1\)
“TextMatch”衡量了选中商品和目标商品标题中代词、名词和专有名词的重合度(Liu et al. 2023b)。
重点内容:奖励函数是WebShop评估体系的核心,它综合了属性匹配、选项匹配和价格约束,并根据文本匹配程度进行加权。
D.5 基础语言模型(Base Language Model)¶
所有实验通过 Langchain(Chase, 2023) 调用 OpenAI API 实现。在经验收集阶段(Reflexion),使用了 gpt-3.5-turbo-0613 和 gpt-3.5-turbo-16k-0613(后者用于超过上下文限制的情况);在洞察提取阶段(insight extraction)使用了 gpt-4-0613。评估阶段的所有代理均使用 gpt-3.5-turbo-0613。
实验时间范围为 2023年7月10日至2023年8月10日。
重点内容:模型选择和API调用方式对实验的性能和结果有直接影响,作者在不同阶段使用了适当的模型版本以兼顾性能与上下文限制。
Appendix E Environment, Agent, Retrieval Parameters¶
检索参数(Retrieval Parameters)¶
向量数据库(Vectorstore):使用 Faiss,这是一个高效相似性搜索的库。
检索器类型(Retriever type):采用 kNN(k近邻算法) 进行检索。
嵌入模型(Embedder):使用 all-mpnet-base-v2,这是一种广泛使用的文本嵌入模型。
智能体超参数(Agent Hyperparameters)¶
最大反思重试次数(Max Reflection Retries):设置为 3,表示在反思阶段最多尝试 3 次。
反思语言模型(Reflection LLM):使用 gpt-3.5-turbo-0613。
策略语言模型(Policy LLM):同样使用 gpt-3.5-turbo-0613。
洞察提取语言模型(Insight Extraction LLM):使用更强大的 gpt-4-0613。
解码温度(Decoding Temperature):设置为 0,表示使用确定性解码(无随机性)。
解码策略(Decoding Strategy):使用 greedy(贪心) 策略,每次选择最可能的输出。
HotpotQA 专用参数(HotpotQA-specific Parameters)¶
洞察提取中的成功示例数量 L:设置为 8。
最大环境步数 H:设置为 7,表示智能体在环境中最多尝试 7 步。
最大少样本示例数量 k:设置为 6。
最大反思少样本示例数量 k_reflections:设置为 2。
WebShop 专用参数(WebShop-specific Parameters)¶
洞察提取中的成功示例数量 L:设置为 4。
最大环境步数 H:设置为 15。
最大少样本示例数量 k:设置为 2。
最大反思少样本示例数量 k_reflections:设置为 2。
每页搜索的商品数量:设置为 10,这是 WebShop 任务的特定参数。
ALFWorld 专用参数(ALFWorld-specific Parameters)¶
洞察提取中的成功示例数量 L:设置为 8。
最大环境步数 H:设置为 20。
最大少样本示例数量 k:设置为 2。
最大反思少样本示例数量 k_reflections:设置为 2。
FEVER 专用参数(FEVER-specific Parameters)¶
最大环境步数 H:设置为 7。
最大少样本示例数量 k:设置为 3。
总结¶
该附录详细列出了实验中使用的参数配置,包括通用的检索和智能体参数,以及各个特定任务(HotpotQA、WebShop、ALFWorld、FEVER)的专用参数。参数设置涉及模型选择、环境交互限制、少样本学习和反思机制等方面,重点突出在不同任务中如何适配智能体的行为和学习策略。
Appendix F Prompt Templates¶
F.1 策略/执行者提示模板(Policy/Actor Prompt Templates)¶
策略/执行者提示模板主要来源于 ReAct(Yao 等人 2023b),并进行了少量修改,以适应 ExpeL 智能体从中提取的洞察。
重点内容:
来源与调整:这些模板基于 ReAct 的设计,进行了微调以更好地匹配 ExpeL 智能体的特定任务需求。
模板示例:
图7:ExpeL HotpotQA 执行模板:展示如何在 HotpotQA 任务中设计策略/执行者的输入提示。
图8:ExpeL ALFWorld 执行模板:用于 ALFWorld 环境中的执行模板,可能涉及导航或交互任务。
图9:ExpeL WebShop 执行模板:针对 WebShop 领域的执行模板,可能用于模拟购物或商品搜索。
图10:ExpeL FEVER 执行模板:适用于 FEVER 事实验证任务的执行模板。
非重点内容:
附录主要通过图表展示不同任务下的执行模板结构,具体细节在图中体现,文本部分仅作说明。
F.2 迁移学习提示模板(Transfer Learning Prompt Template)¶
本部分未提供具体内容,仅作为标题列出,推测是用于迁移学习任务的提示模板部分,可能包括如何将已有的知识或策略从一个任务迁移到另一个任务的提示设计。由于没有详细内容,无法进一步总结。
Appendix G Example Insights¶
G.1 HotpotQA insights(重点部分)¶
图11展示了一个从 HotpotQA 任务中提取出的见解示例,其中一些关键见解被特别强调。特别指出见解2和4,它们建议将复杂问题拆解为多个简单问题,类似于 Auto-GPT 的机制。
见解8与“突发能力”有关,已在第5.3节和图16、17中进一步讨论和展示。
图12则展示了一些手工编写(hand-crafted)的见解。这些见解是通过对 Reflexion(Shinn 等,2023)在 HotpotQA 上的成功与失败轨迹进行人工分析后得出的。
从中可以看出,GPT-4-0613 能提取出与手工编写见解相似的内容(如见解3和6),这表明 GPT-4-0613 所支持的 ExpeL 方法展现出类似人类的抽象能力。
例如,见解3和6强调在放弃之前应穷尽所有步骤,并在第一次搜索无效时尝试多样化的关键词,以提高结果质量。
总结:HotpotQA 的见解主要集中在问题拆解、搜索策略优化以及错误处理策略上,展示了 GPT-4-0613 在提取与人类一致的抽象规则方面的能力。
G.2 ALFWorld insights¶
图13展示了 ALFWorld 环境中由代理提取出的见解。部分特别有意义的见解被以紫色突出显示。
说明:这部分内容相对简洁,主要展示 ALFWorld 环境中见解的可视化结果,未详细说明具体见解内容。
G.3 WebShop insights¶
图14展示了 WebShop 环境中由代理提取出的见解,同样有重点见解以紫色展示。
说明:这部分也是以图示为主,没有详细文字描述见解内容。
G.4 FEVER insights¶
图15展示了 FEVER 环境中提取出的见解,部分被标记为“迁移型见解”(transferred insights)。
说明:FEVER 任务涉及事实核查,这些见解可能是从其他任务迁移而来的,有助于代理在新任务中快速适应。
总体总结:
本附录通过多个任务(HotpotQA、ALFWorld、WebShop、FEVER)展示了 ExpeL 代理在任务执行过程中所提取的见解。
HotpotQA 是重点部分,展示了 GPT-4-0613 在提取关键策略(如问题拆解、搜索优化)方面的强大能力,并与人类手工总结的见解具有一致性。
其他任务的见解主要通过图表形式展示,未作详细解释,但强调了 ExpeL 在不同任务环境中的适应性和策略提取能力。
通过这些见解,ExpeL 展现出类似于人类的抽象学习与经验积累能力,支持其作为“经验型学习代理”的核心理念。
Appendix H Emergent Abilities Showcase¶
H.1 HotpotQA,形成分析性推理与环境约束意识¶
在 HotpotQA 任务中,ExpeL 展现了其能够适应环境并进行推理判断的能力。通过两个具体例子(图16和图17)进行展示:
图16:ExpeL 能够重新评估其行为路径,进行推理并形成合理的猜测,从而成功回答问题。相比之下,传统的 ReAct 代理在面对类似情况时选择了放弃。图中紫色框中提供了一个可能影响其行为路径的关键洞察。
图17:ExpeL 再次展现了其基于轨迹观察进行推理和判断的能力,通过已有信息做出合理猜测。同样,紫色框中提供了相关的关键洞察能力分析。
重点总结:ExpeL 在 HotpotQA 中表现出更强的环境适应性与推理能力,能够有效处理复杂问题,而 ReAct 则缺乏这种能力。
H.2 ALFWorld,世界模型信念更新¶
在 ALFWorld 环境中,ExpeL 展示了其更新世界模型信念与自我纠正的能力,这两个能力是其新兴能力的重要体现。
图18:世界模型信念更新
ExpeL 通过经验更新其先验知识,例如将锅的可能位置从“台面”更新为“炉灶”,从而成功完成任务。紫色框中提供了相关影响因素的分析。图19:自我纠正
ExpeL 具备识别并纠正错误的能力,例如在错误拿取花瓶后将其放回。而在同样的任务中,ReAct 代理虽然有时能识别错误(例如拿错了物品),但从未将其纠正,导致任务失败。这说明 ExpeL 的自我纠正机制具有明显优势。
重点总结:ExpeL 在 ALFWorld 中展现出动态更新世界模型和错误纠正能力,而 ReAct 代理在这方面表现出明显的局限性。
总体总结¶
通过在 HotpotQA 和 ALFWorld 中的两个案例分析,ExpeL 展现了多项新兴能力,包括:
环境适应与推理能力
动态更新世界模型的信念
自我识别与纠正错误的能力
这些能力使得 ExpeL 在复杂任务中表现优于传统方法(如 ReAct),在实际应用中具有更高的鲁棒性和适应性。
Appendix I Example Trajectories¶
I.1 HotpotQA,一个 ExpeL 与 ReAct 示例轨迹¶
在 HotpotQA 环境中,ExpeL 和 ReAct 被分配了相同的任务进行比较。
ExpeL 的轨迹(图20):展示了 ExpeL 通过有效的查询策略成功完成任务。这是本节的重点内容,说明 ExpeL 在处理复杂问答任务时具备较高的效率。
ReAct 的轨迹(图21):显示了 ReAct 未能切换查询策略,从而导致任务失败。这表明在策略灵活性方面,ReAct 存在一定的局限性。
本节重点强调了 ExpeL 在查询策略上的优势,而 ReAct 的表现则显示出不足。
I.2 ALFWorld,一个 ExpeL 与 ReAct 示例轨迹¶
在 ALFWorld 环境中,ExpeL 和 ReAct 同样执行相同任务。
ExpeL 的轨迹(图22):展示了 ExpeL 在该环境中具有高效的任务执行能力。
ReAct 的轨迹:由于未提供详细描述和标注图像,其表现无法深入分析。
重点在于强调 ExpeL 在 ALFWorld 环境中表现出色,而 ReAct 的表现则缺乏详细说明。
I.3 WebShop,一个 ExpeL 与 ReAct 示例轨迹¶
在 WebShop 环境中,ExpeL 与 ReAct 的轨迹如下:
ExpeL 的轨迹(图23):展示了 ExpeL 能够识别可能的候选商品并正确选择合适选项,体现出其在实际交互任务中的准确性和判断力。
ReAct 的轨迹:同样由于图像未标注,其具体表现未作说明。
本节重点在于 ExpeL 在商品筛选与选择上的表现,是其在 WebShop 环境中的关键优势点。
I.4 FEVER,一个 ExpeL 与 ReAct 示例轨迹¶
在 FEVER 环境中,ExpeL 与 ReAct 的轨迹如下:
ExpeL 的轨迹(图24):展示了 ExpeL 在该任务中具备查询优化能力,能够有效地改进查询以提高任务完成的准确性。
ReAct 的表现:未做具体说明。
本节重点在于 ExpeL 在查询优化方面的优势,这是其在事实核查任务中的关键能力。
总结¶
本附录通过不同环境(HotpotQA、ALFWorld、WebShop、FEVER)中 ExpeL 与 ReAct 的示例轨迹,展示了 ExpeL 在多个方面(如查询策略、任务执行效率、商品筛选、查询优化)上的优势。而 ReAct 在某些环境中表现欠佳,尤其是在策略调整和任务完成方面存在一定的局限性。
Appendix J Additional Quantitative Results¶
表 5:环境特定分数¶
ALFWorld 的成功率(SR %) 按不同环境分解,展示了各方法在不同任务(如 put、clean、heat 等)中的表现。其中,ExpeL(ours)在大多数环境中都表现出色,尤其是在 put 环境中达到了 83% 的成功率,显著高于其他方法。
WebShop 的平均奖励(𝑟 score) 中,ExpeL(ours)也取得了最高分 0.701,优于其他方法,包括 ReAct(0.665)和 Insights-only(0.675)。
从整体来看,ExpeL 的两种变体(Insights-only 和 Retrieve-only)表现均优于 Prompt-based 的方法,体现出经验学习机制的优势。
图 25、26、27:训练与评估结果分解¶
为 HotpotQA、ALFWorld 和 WebShop 三个任务分别提供了任务结果(成功、失败、中止)的分解图。
这些图表提供了更直观的数据展示,方便观察不同方法在训练和评估阶段的表现差异。但内容较为图示化,具体细节较少,属于辅助性材料。
表 6:附加统计指标¶
提供了不同方法在三个基准(HotpotQA、ALFWorld、WebShop)中每条轨迹的平均统计信息。
重点指标包括:
思考次数(Number of thoughts):ExpeL(5.02)在 HotpotQA 中略高于 ReAct(5.19)和 Insights-only(5.28),说明其在生成思考时的效率较高。
动作次数(Number of actions):ExpeL(14.3)在 ALFWorld 中动作效率较高。
观察次数(Number of observations):ExpeL 在 HotpotQA(5.02)和 ALFWorld(18.32)中观察次数适中。
无效动作次数(Number of invalid actions):ExpeL 的无效动作次数(2.32)在 ALFWorld 中控制得不错,优于其他方法。
Token 使用量:ExpeL 使用的 Token 数量最高,但这也反映了其更复杂的思考和推理机制。这说明其虽然效率稍低,但更有深度。
思考 Token / 动作 Token / 观察 Token:ExpeL 的思考 Token 数(262.66)在 ALFWorld 中较高,说明其在生成计划时更详细。
总结¶
本节补充了论文的定量结果,重点通过 表 5 和 表 6 展示了 ExpeL 在不同任务和环境中的卓越表现,尤其是在成功率、奖励分数、动作效率和 Token 使用方面。
通过这些数据,可以看出 ExpeL 相比基线方法具有明显优势,尤其是在结合经验学习机制后,能够更有效地完成复杂任务。
图形部分(图 25–27)虽然提供了任务结果的分布,但由于是图示,核心信息并不如表格详细,因此略作简要提及。