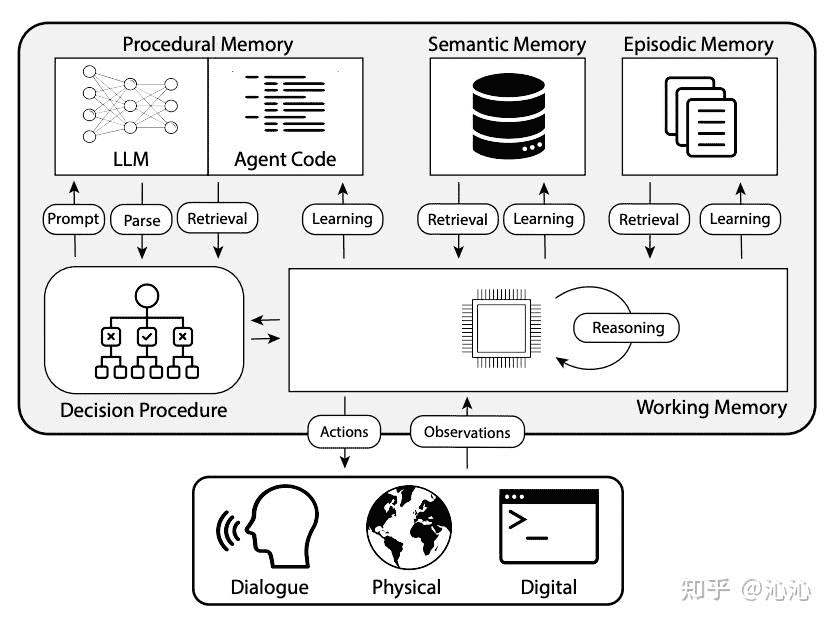
通用记忆¶
总结与展望¶
当前LLM Agent长记忆的研究正处于快速发展阶段,主要趋势包括:
• 多模态记忆:将文本、图像、音频等多种模态信息整合到统一的记忆表示中,以支持更丰富的Agent交互。
• 结构化记忆:从非结构化的对话历史中提取结构化知识(如实体、关系、事件),并以知识图谱等形式进行存储,以支持更复杂的推理和检索。
• 记忆的动态管理:开发更智能的记忆更新和遗忘机制,使Agent能够根据任务需求和时间推移,动态调整记忆的优先级和粒度。
• 效率与可扩展性:优化记忆系统的存储和检索效率,使其能够处理大规模、长时间的交互数据,并支持实时应用。
• 可解释性与可控性:提高记忆机制的透明度,使研究者和开发者能够理解Agent如何利用记忆进行决策,并对其记忆行为进行有效控制。
记忆类型¶
短期记忆(Short-Term Memory)¶
实时存储对话/任务上下文,让智能体“记住当前交互”,避免对话断层,提升连续交互体验 技术拆解:
上下文窗口机制:限制单次交互处理的 token 数(如 LLM 的max_context_size),用滑动窗口保留关键对话片段;
缓存:以对话 ID 为 Key,存储临时上下文(如用户最新提问、智能体回复草稿); 落地难点:窗口截断易丢失关键信息,缓存过期时间难平衡; 典型工具:Redis(KV 缓存)、LangChain
长期记忆¶
沉淀用户历史交互、行为习惯、画像标签,让智能体“记住老用户”,实现个性化服务
技术拆解:
Embedding:用 Sentence-BERT 将对话文本转向量,存入向量库(如 Milvus);
KG(知识图谱):构建用户 - 行为 - 标签三元组(如 Neo4j);
LLM+Prompting:通过 “回忆提示”(如根据用户历史,回答偏好…)激活长期记忆; 落地难点:知识图谱 schema 设计复杂,embedding 召回精度不足; 典型工具:Milvus(向量库)、Neo4j(图谱)
情节记忆(Episodic Memory)¶
记录具体事件的“时间、人物、内容”,让智能体可回溯关键事件(如故障、用户诉求) 技术拆解:
时序数据存储:用 InfluxDB 按时间戳存事件(如2025-07-11 10:00 发生XX故障);
事件序列模型:基于 LSTM 训练事件因果关系(如故障 A→操作 B→结果 C);
LLM+Prompting:通过事件摘要(如总结2025-07-11的关键事件)还原细节; 落地难点:时序数据量大导致存储压力,事件因果建模难; 典型工具:InfluxDB(时序库)、LSTM 模型
This refers to recalling specific past events.
Episodic memory in humans: when a person recalls a particular event (or “episode”) experienced in the past.
Episodic memory in agents: the CoALA paper defines episodic memory as storing sequences of the agent’s past actions.
This is used primarily to get an agent to perform as intended.
In practice, episodic memory is implemented as few-shot example prompting. If you collect enough of these sequences, then this can be done via dynamic few-shot prompting. This is usually great for guiding the agent if there is a correct way to perform specific actions that have been done before. In contrast, semantic memory is more relevant if there isn’t necessarily a correct way to do things, or if the agent is constantly doing new things so the previous examples don’t help much.
回忆具体的过去事件。 人类中的情境记忆: 当一个人回忆曾经经历过的特定事件(或“情境”)。 代理中的情境记忆: CoALA 论文将情境记忆定义为存储代理过去行动的序列。 在实践中,情境记忆通常通过few-shot示例提示实现。
语义记忆(Semantic Memory)¶
存储“常识、行业知识、概念定义”,让智能体具备基础认知(如“北京是中国首都”)
技术拆解:
知识图谱:用 Schema 定义概念关系(如城市-属于-国家),导入维基百科 / 行业文档;
SFT(监督微调):用带知识标签的数据集微调 LLM(如常识问答数据集);
LLM+Prompting:通过知识问答提示(如根据常识,回答…)调用记忆;
落地难点:知识图谱构建耗时,SFT 数据标注成本高;
典型工具:Neo4j(图谱)、HuggingFace SFT训练框架
This is someone’s long-term store of knowledge.
Semantic memory in humans: it’s composed of pieces of information such as facts learned in school, what concepts mean and how they are related.
Semantic memory in agents: the CoALA paper describes semantic memory as a repository of facts about the world.
Today, this is most often used by agents to personalize an application.
Practically, we see this being done by using an LLM to extract information from the conversation or interactions the agent had. The exact shape of this information is usually application-specific. This information is then retrieved in future conversations and inserted into the system prompt to influence the agent’s responses.
对知识的长期存储。 人类中的语义记忆: 它由在学校学到的事实、概念的意义和它们之间的关系等信息组成。 代理中的语义记忆: CoALA 论文将语义记忆描述为世界事实的存储库。 在实践中通过使用 LLM 从与代理的对话或交互中提取信息来完成的。信息的具体形式通常是应用特定的。然后,这些信息在未来的对话中用rag的方式融入进来
工作记忆(Working Memory)¶
动态管理“当前任务的目标、步骤、依赖”,让智能体像人类一样“边想边做”,协调多任务
技术拆解:
任务调度能力:用 DAG(有向无环图)定义任务依赖(如 Airflow);
状态追踪能力:通过 Redis 存储任务状态(如任务A:执行中/已完成);
落地难点:任务依赖复杂导致死锁,状态同步延迟;
典型工具:Airflow(任务调度)、Redis(状态存储)
短期记忆和工作记忆这两个术语有时可以互换使用,它们都指在短时间内存储信息。然而,工作记忆与一般的短期记忆有所不同,因为工作记忆具体涉及的是被心理操控的信息的临时存储。
短期记忆是指,例如,当一个人有意识地处理并记住一个新认识的人的名字、一个统计数据或一小段时间内的其他细节时,就会用到它。这些信息可能会被保存在长期记忆中,也可能在几分钟内就被遗忘。
短期记忆包括记住
• 一分钟前见过的人的样子
• 查找后立即显示当前温度
• 电影中刚刚发生了什么
工作记忆是指,信息(例如,一个人正在阅读的句子中的前几个单词)被保存在脑海中,以便能够在当下运用。
工作记忆包括记住
• 您在心算过程中计算出的数字
• 读书时句子开头提到的人
• 在脑海中记住一个概念(例如球 )并将其与另一个概念( 橙色 )结合起来
程序性记忆(Procedural Memory)¶
固化“标准化操作流程”(如开票、运维脚本),让智能体自动执行重复性任务
技术拆解:
规则系统:用 JSON/YAML 写流程规则(如if 条件A then 执行步骤1);
强化学习:让智能体在模拟环境中试错学习流程(如 OpenAI Gym);
LLM+Prompting:通过流程执行提示(如按开票流程处理)触发记忆;
落地难点:规则冲突(如多条规则触发),强化学习环境与实际差异大;
典型工具:Drools(规则引擎)、OpenAI Gym(强化学习环境)
This term refers to long-term memory for how to perform tasks, similar to a brain’s core instruction set.
Procedural memory in humans: remembering how to ride a bike.
Procedural memory in Agents: the CoALA paper describes procedural memory as the combination of LLM weights and agent code, which fundamentally determine how the agent works.
In practice, we don’t see many (any?) agentic systems that update the weights of their LLM automatically or rewrite their code. We do, however, see some examples of an agent updating its own system prompt. While this is the closest practical example, it remains relatively uncommon.
如何执行任务的长期记忆,类似于大脑的核心指令集。 人类中的程序性记忆: 记住如何骑自行车。 agent中的程序性记忆: 将程序性记忆描述为 LLM 权重和agent代码的组合,基本上决定了agent的工作方式。 实际上,我们并没有看到许多(如果有的话)代理系统会自动更新它们的 LLM 权重或重写它们的代码。然而,我们确实看到一些代理在更新自己的系统提示时的例子。虽然这是最接近的实际例子,但仍然相对罕见。 一般不修改。
感觉记忆(Sensory Memory)¶
感觉记忆是心理学家对刚刚经历的感官刺激(例如视觉和听觉)的短期记忆。
对刚刚看到的东西的短暂记忆被称为图像记忆,
基于声音的类似记忆被称为回声记忆。
其他感官也被认为存在其他形式的短期感觉记忆。
与感官相关的记忆也可以长期保存。
视觉空间记忆是指物体在空间中如何排列的记忆——当一个人想起去杂货店该往哪个方向走时,就会用到这种记忆。
听觉记忆 、 嗅觉记忆和触觉记忆分别指储存的声音、气味和皮肤感觉等感官印象。
图示¶
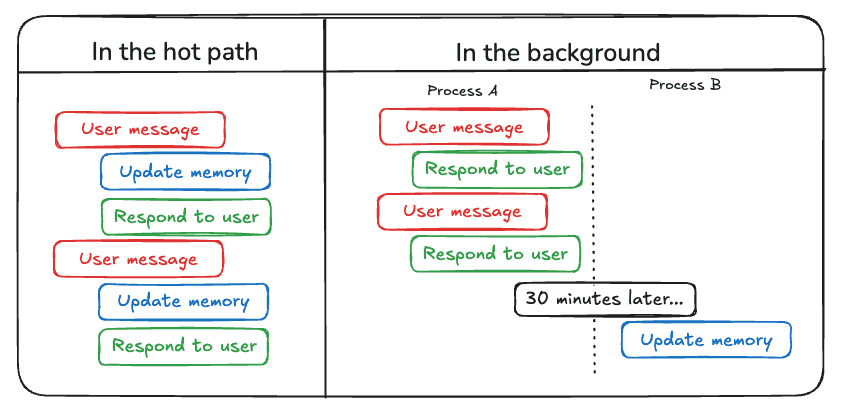
Update memory “in the hot path”/“in the background”.
长记忆的必要性与挑战¶
LLM Agent的记忆能力是其实现自主性、适应性和持续学习的关键。传统的LLMs在处理长序列输入时,受限于其固定上下文窗口,无法有效保留历史信息。这导致Agent在多轮对话或复杂任务中出现重复、矛盾或遗忘关键信息的情况。长记忆机制的引入,旨在赋予Agent跨越时间维度的信息存储、检索和利用能力,使其能够:
• 维持对话连贯性:记住用户偏好、历史对话内容和上下文,提供更自然、个性化的交互体验。
• 支持复杂任务执行:在多步骤、长时间的任务中,记住中间状态、规划结果和执行细节,避免重复劳动和错误。
• 实现持续学习与适应:通过积累经验和知识,不断优化自身行为和决策,提升Agent的智能水平。
然而,实现高效、可扩展的长记忆机制面临诸多挑战,包括:
• 记忆表示:如何有效地表示和组织海量的历史信息,使其既能被LLM理解,又能高效检索。
• 记忆检索:如何在庞大的记忆库中快速、准确地找到与当前任务或对话相关的记忆片段。
• 记忆更新与管理:如何动态地添加、修改、删除记忆,保持记忆库的实时性和一致性,并处理记忆冲突。
• 计算效率:长记忆机制可能引入显著的计算和存储开销,如何在保证性能的同时优化效率。
• 幻觉与一致性:如何确保检索到的记忆是准确的,并避免LLM基于错误记忆产生幻觉。
参考¶
【定义】Cattell–Horn–Carroll理论¶
简称 CHC 理论,可以把它想成一棵长得很讲道理的树:根扎在统计数据里,枝叶伸向现实中的认知能力
一个综合性的智力理论,它将人类认知能力描绘成一个三层级的层级结构,目前被广泛认为是智力领域的主流理论之一
在关于“智力”定义的长期争论中,CHC理论通常被视为一种“狭义”智力理论。它主要聚焦于能够被标准化智力测验测量和量化的心理能力,而不是涵盖适应性、智慧或创造力等更宽泛的日常概念。这种“操作化”的定义使其在科学研究中更为严谨和可验证
背景:核心内容与演变¶
雷蒙德·卡特尔 (Raymond Cattell): 最早提出了流体智力(Gf) 和晶体智力(Gc) 的划分。
流体智力涉及解决新问题的推理能力,会随年龄增长而下降;面对新问题、没学过的规则时的推理、抽象和模式发现
晶体智力则指通过学习获得的知识,可以持续增长;包括词汇、常识、文化经验和长期积累的技能
约翰·霍恩 (John Horn):
扩展了理论,在Gf-Gc基础上增加了更多广泛能力,如引入了如视觉加工、听觉加工、短时记忆、处理速度等一批“广义能力”。
约翰·卡罗尔 (John B. Carroll):
提出了包含一般智力(g)、广泛能力和狭义能力的“三阶层理论”。
三层层级系统¶
层级 |
能力分类 |
具体描述 |
|---|---|---|
最高层 |
一般智力 (g) |
覆盖所有认知能力的最高通用能力,位于模型顶端。 |
中间层 |
Broad 能力(约 10 种) |
包括流体推理(Gf)、晶体知识(Gc)等多种独立又相关的广泛认知能力。 |
基础层 |
Narrow 能力(80 + 种) |
70多种具体、狭窄的认知技能,是广泛能力在特定任务中的具体表现。 |
核心Broad能力¶
流体推理(Gf):不依赖既有知识的抽象问题解决能力,如逻辑推理、归纳/演绎思维,随年龄增长先升后降,与神经生理基础关联紧密。
晶体智力(Gc):通过教育、文化与经验积累的知识和技能,如词汇、常识、语言理解,通常随年龄稳定增长或保持稳定。
数量推理(Gq):处理数字、数学关系与运算的能力,涵盖计算、数学问题解决等。
读写能力(Grw):阅读解码、阅读理解、写作表达等语言相关的习得能力。
短时记忆(Gsm):对信息的即时存储与操作能力,如数字广度、工作记忆任务表现。
长时存储与提取(Glr):长时记忆中信息的编码、存储与提取效率,包括联想记忆、自由回忆等。
视觉加工(Gv):处理空间关系、图形识别、心理旋转等视觉信息的能力。
听觉加工(Ga):辨别声音模式、语音感知、听觉序列记忆等听觉相关能力。
加工速度(Gs):快速准确完成简单认知任务的效率,如符号匹配、快速命名。
决策/反应时速度(Gt):快速做出简单决策的反应效率,区别于复杂任务的加工速度。
核心Narrow能力¶
如
在 Gv 下,会细分为心理旋转、空间关系、视觉记忆;
在 Gc 下,会有词汇量、阅读理解、一般知识等。它们直接对应测试题目和具体表现。
CHC 理论的意义¶
第一,它把“智力不是单一数值”这件事结构化了,而不是停留在口号层面。
第二,它与现实测验高度兼容。WAIS、WISC、Woodcock–Johnson 等主流智力量表,基本都在 CHC 框架下设计或重新解释。
第三,它在发展和教育上很有解释力:儿童的 Gf 往往先发展,Gc 随着学习和文化积累不断增长;老年阶段,Gc 相对稳定,而 Gf 和 Gs 更容易下降。
总结¶
CHC 理论以层级化、多维度的视角重构了智力的结构,既保留了一般智力的核心地位,又细化了不同认知领域的具体能力,为智力评估、教育与临床实践提供了系统的理论支撑,是当前心理测量领域的主流框架之一。
Reciprocal Rank Fusion (RRF) 算法¶
目标:把多个排序结果合成一个更稳健的排序
核心思想:一个文档在多个列表中排名都靠前,那么它就应该在最终结果中排名非常靠前;反之,如果一个文档只在一个列表中排名很高,但在其他列表中根本找不到,那它的最终排名应该被抑制。
RRF 是一种用于合并多个相关文档排序列表的简单而强大的算法。它最初由信息检索领域的研究人员提出,主要用于解决两个问题:
多检索系统/模型结果融合:当你使用不同的搜索引擎、模型或查询方法(如关键词搜索、向量搜索)对同一个问题进行检索时,每个系统都会返回一个排序结果列表。如何将这些列表合并成一个最终的、更优的排序列表?
无权重且健壮:RRF 不需要知道每个底层系统的得分(如BM25分数、余弦相似度),也不需要调优复杂的权重,仅根据每个文档在各个列表中的排名位置就能进行有效融合。
公式¶
其中:
\( d \):某一个文档。
\( k \):要融合的排序列表的总数(例如,2个搜索引擎,k=2)。
\( i \):第 \( i \) 个排序列表。
\( r_i(d) \):文档 \( d \) 在第 \( i \) 个列表中的排名。排名通常从1开始计数(即第一名r=1,第二名r=2)。
\( c \):一个常数(通常设为 \( c = 60 \)),主要用于平滑,防止对排名非常靠后的文档(r很大)给予过大的惩罚。
常数 \( c \) 确保了即使一个文档在某个列表中排名靠后(比如第100名),它的贡献 \( \frac{1}{100+60} \approx 0.00625 \) 仍然是一个小但非零的值,而不是可以忽略不计。
计算步骤¶
输入:接收 \( k \) 个已经排好序的文档列表。
遍历所有不重复文档:找出这 \( k \) 个列表中出现的所有唯一文档。
计算每个文档的RRF得分:
对于每个文档 \( d \),遍历每一个列表 \( i \)。
如果列表 \( i \) 中包含文档 \( d \),则获取其排名 \( r_i(d) \),并计算贡献值 \( \frac{1}{r_i(d) + c} \)。
如果列表 \( i \) 中不包含文档 \( d \),则该项贡献为 0(或者可以认为 \( r_i(d) = \infty \),贡献为0)。
将所有 \( k \) 个列表的贡献值相加,得到 \( RRFscore(d) \)。
输出:将所有文档按照其 \( RRFscore \) 从高到低排序,生成最终的融合排序列表。
优点与缺点¶
优点:¶
简单有效:算法逻辑简单,易于实现,不需要复杂的参数调优。
无权重/分数归一化需求:不关心底层系统使用的具体评分尺度(如0-1, 或0-1000),只依赖排名,避免了分数标准化的问题。
鼓励一致性和多样性:倾向于提升在多个来源中都排名靠前的文档的排名(一致性),同时也能将不同来源中的优质结果(如文档C)纳入最终列表(多样性)。
健壮性强:对单一列表的噪声或异常结果有一定的抵抗能力。
缺点:¶
忽略原始分数信息:完全抛弃了原始的相关性分数,而这些分数可能包含更细粒度的信息。例如,列表A中第一和第二名的分数可能相差很大,但RRF对此不敏感。
常数 \( c \) 的选择:虽然通常设为60,但这个值可能在不同数据集和场景下需要调整。
列表长度影响:通常只考虑每个列表的前N个结果(如top 100),因为排名太靠后的文档贡献极小。这个N的选择会影响结果。
应用场景¶
混合检索(Hybrid Search):这是目前最主流的应用场景。将关键词检索(如BM25) 和向量检索(如Embedding) 的结果进行融合。RRF完美解决了两种检索机制得分体系不同、难以直接加权融合的问题。
元搜索引擎(Meta-Search Engine):聚合多个独立搜索引擎(如Google, Bing)的结果。
多特征/多模型排序融合:在机器学习排序中,可以使用不同模型生成多个候选列表,然后用RRF进行初步融合。
检索增强生成(RAG)系统:在RAG中,从知识库中检索相关文档时,经常使用RRF来融合不同检索方法得到的结果,以提供更全面、准确的上下文给大模型。
总结¶
Reciprocal Rank Fusion(RRF)是一个基于排名的、无需权重的结果列表融合算法。它通过累加每个文档在不同列表中排名的倒数(经过平滑)来计算其重要性,从而高效、健壮地生成一个更优的统一排序列表。 它的简单性和在实践中表现出的有效性,使其在现代信息检索,尤其是混合搜索和RAG系统中,成为一个非常受欢迎和实用的工具。