2308.08239_MemoChat: Tuning LLMs to Use Memos for Consistent Long-Range Open-Domain Conversation¶
引用: 58(2025-08-20)
组织:
1University of Warwick(华威大学, from British)
2Tecent YouTu Lab,
3King’s College London
总结¶
总结
三位专家手动标注了一个新的长程开放域对话数据集 MT-Bench+
MemChat
有效地使用自编备忘录(memos)来保持长程(long-range)一致开放域对话
核心思想
通过迭代的“ 记忆-检索-响应(memorization-retrieval-response) ”来实现长程对话的一致性
核心设计:
通过结构化记忆的即时使用,使模型在开放域对话中保持连贯性和长期一致性。
基于公开数据集构建训练指令
核心
在于构建并维护一个结构化的、实时更新的记忆库(on-the-fly memo),将对话历史按主题分类并总结,从而在后续对话中快速检索相关片段
三个阶段分别对应三个训练任务
Memo Writing(记忆编纂)
Memo Retrieval(记忆检索)
Chat w/ Memo(基于记忆的对话)
数据集
数据集重建
从三个公开对话数据集中重构了 10k 条用于训练 MemoChat 的指令数据:
TopicoQA:3.9k 个对话,涉及 4 个主题,平均 13 轮对话。
DialogSum:1.3 万个对话,单一主题,平均 5.5 轮,提供人工摘要。
Alpaca-GPT4:1.6k 个对话,人机交互,内容更复杂。
数据集MT-Bench+
三位专家手动标注了一个新的长程开放域对话数据集 MT-Bench+
基于 MT-Bench
包含 80 个两轮开放域问题
会扩展为四轮版本
每条对话流在最后添加了三种类型的问题:
Retrospection:要求模型从之前的对话中提取信息(如提取特定术语);
Continuation:基于已有知识继续生成内容(如完成故事);
Conjunction:跨话题生成响应(如结合两个任务)。
共构建了 54 个问题,每类 18 个。
Abstract¶
本研究提出 MemoChat,一个用于优化指令的流程,旨在使大语言模型(LLMs)能够通过 自我生成的备忘录(memos),在 长期、开放领域的对话中保持一致性。通过在对话中引入“记忆-检索-响应”的迭代循环,模型能够持续利用过去的对话信息,从而在长时间跨度内维持对话的一致性和连贯性。
为了实现这一目标,作者 精心设计了针对每个不同阶段的微调指令,这些指令是从多个公开数据集中 重新构造而来的,目的是训练模型 如何以结构化的方式记忆和检索对话历史。
为了评估模型在长期对话中的一致性表现,作者邀请专家手动标注测试集,并设计了专门的评估问题。在三种不同的测试场景中,涉及开源模型和通过API访问的聊天机器人,实验结果显示 MemoChat 显著优于多个强基线模型,验证了其有效性。
重点:
MemoChat 的核心是通过“记忆-检索-响应”的机制提高长对话一致性。
微调指令是根据公共数据集重新构建的,专门用于训练结构化记忆和检索能力。
实验表明,MemoChat 在多个测试场景中均优于强基线模型。
专家标注的测试集用于评估对话一致性,增强了评估的可信度。
1 Introduction¶
1. 大型语言模型(LLMs)的变革作用¶
近年来,大型语言模型(Large Language Models, LLMs)引发了深刻的技术变革,彻底改变了我们的生活方式。LLMs 已成为连接学术界与工业界在人工智能领域的新平台。尤其是,它们在模拟人类认知过程方面表现出色,能够生成类人对话,成为构建高质量人机对话系统的基础。
2. 长距离开放域对话的挑战¶
与传统对话系统不同,现代人机对话的趋势是长距离、话题多样的开放域对话。传统对话系统多围绕单一话题进行短对话,而当前对话可能涉及多个轮次和多个主题。例如,图1展示了一个超过20轮的对话,涵盖了如“量子物理”、“日本商务礼仪”、“多项式数学问题”等多个话题。
图1中还展示了对话中的长距离问题,例如要求模型回溯“日本商务礼仪”或“量子物理”的历史信息。这种类型对话对传统方法提出了挑战,因为传统模型难以在长时间跨度内保持上下文一致性。
为应对这一问题,已有研究提出两种主要方法:
扩展输入文本窗口:例如使用位置插值(positional interpolation)方法,使得模型支持更长的上下文。但输入窗口无法无限扩展。
使用外部记忆机制:通过外部存储(如 DPR、FAISS)来保存和检索历史对话信息。但这种方法可能导致记忆误差积累。
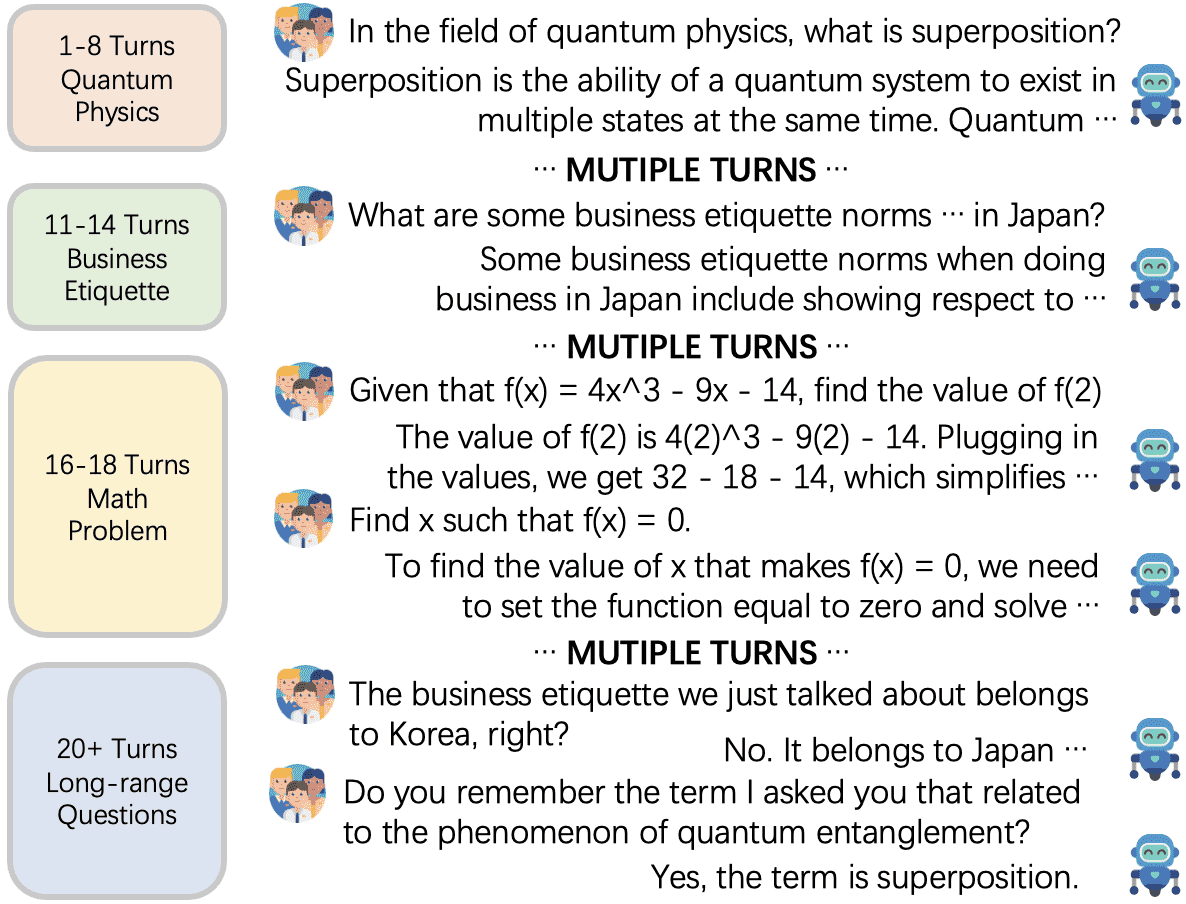
Figure 1:An example of a long-range open-domain conversation. It contains multiple topics.
3. 本文提出的 MemoChat 方法¶
本文关注的是如何构建具备记忆能力的聊天机器人。与现有方法不同,本文不依赖外部工具进行记忆的创建与检索,而是提出一种简化流程,仅使用 LLMs 本身来实现记忆增强。
提出的方法名为 MemoChat,其核心思想是通过“记忆-检索-响应”(memorization-retrieval-response)循环来实现长距离对话的一致性。具体来说,MemoChat 通过**即时记忆(on-the-fly memo)**来帮助 LLMs 在对话过程中保持上下文一致性。
为实现此目标,作者:
不依赖外部API,而是基于公开数据集进行指令微调(instruction tuning),训练开源 LLMs 适应 MemoChat 的流程。
构建专家标注的测试集,专门评估长距离对话的一致性。
使用强大的 LLM 作为评估者,对结果进行综合评估。
文献参考:
OpenAI (2023)
Google (2023)
Adlakha et al. (2022)
Chen et al. (2021)
Ghosal et al. (2023)
Zheng et al. (2023)
4. 本文的贡献(重点)¶
本论文的主要贡献包括:
提出 MemoChat 指令微调框架:通过即时记忆机制,使 LLM-powered 聊天机器人能够在长距离开放域对话中保持一致性。
基于公开数据集构建训练指令:帮助开放源码 LLMs 适应 MemoChat 的流程。
构建专家标注的评估集:作为评估响应一致性的基准,实验验证了 MemoChat 在开源与 API 类聊天机器人上的有效性。
总结要点¶
LLMs 正在重塑人机对话系统,尤其在长距离多话题对话中表现出潜力。
传统方法(扩展上下文窗口、外部记忆)各有不足,存在扩展限制或误差积累问题。
本文提出的 MemoChat 方法简化流程,仅依赖 LLM 自身能力,通过“记忆-检索-响应”循环实现对话一致性。
重点贡献在于构建了一个高效、可评估的对话系统框架,并提供了评估基准和实验验证。
3 Methodology¶
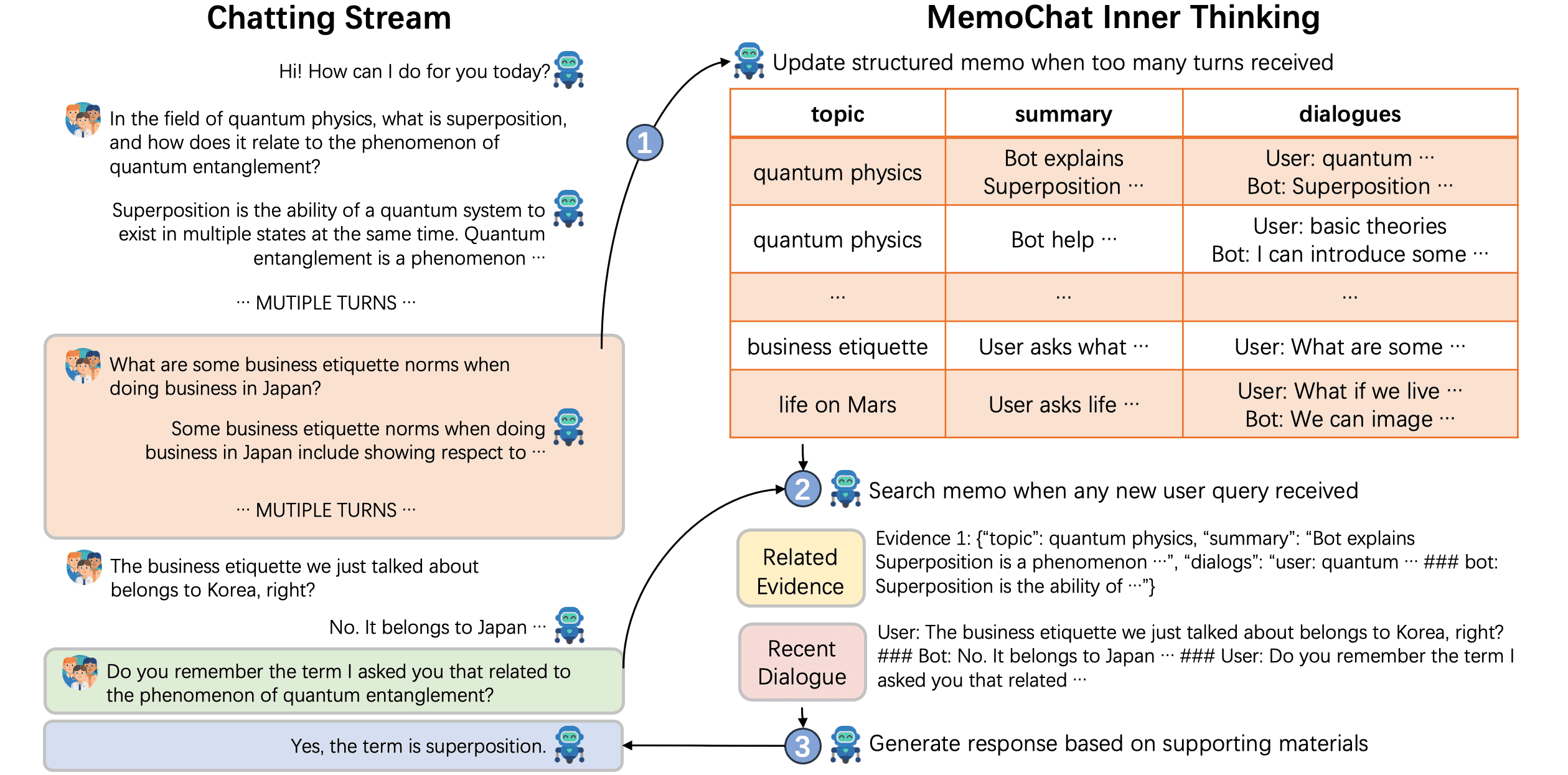
Figure 2: The overall architecture of our proposed MemoChat pipeline. While maintaining a chatting stream between the human user and the chatbot (left part), the chatbot will have a memo-equipped inner thinking (right part).
3.1 问题建模(Formulation)¶
本节将“长程开放式对话”建模为生成式问答(Generative Question Answering, GQA)任务,目标是基于当前用户问题 𝒙q 和过往对话历史 𝒙h,生成最可能的回答 Y^:
为提升回答的一致性,作者提出 MemoChat 框架,将对话流程分解为“记忆—检索—响应”三阶段循环。模型不再直接依赖全部对话历史,而是通过构建结构化的记忆(memo),从中检索与当前问题相关的历史片段(𝒙h’),再基于该信息生成回答。具体流程如下:
记忆构建:将对话历史 𝒙h 转换为结构化记忆 𝒙m,通过函数 f 建立。
记忆检索:基于当前问题 𝒙q 和记忆 𝒙m,通过函数 g 检索出相关历史 𝒙h’。
生成回答:基于当前问题 𝒙q 和检索到的 𝒙h’ 生成回答 Y^:
3.2 MemoChat 实现机制¶
MemoChat 的整体框架如图2所示,其核心在于构建并维护一个结构化的、实时更新的记忆库(on-the-fly memo),将对话历史按主题分类并总结,从而在后续对话中快速检索相关片段。
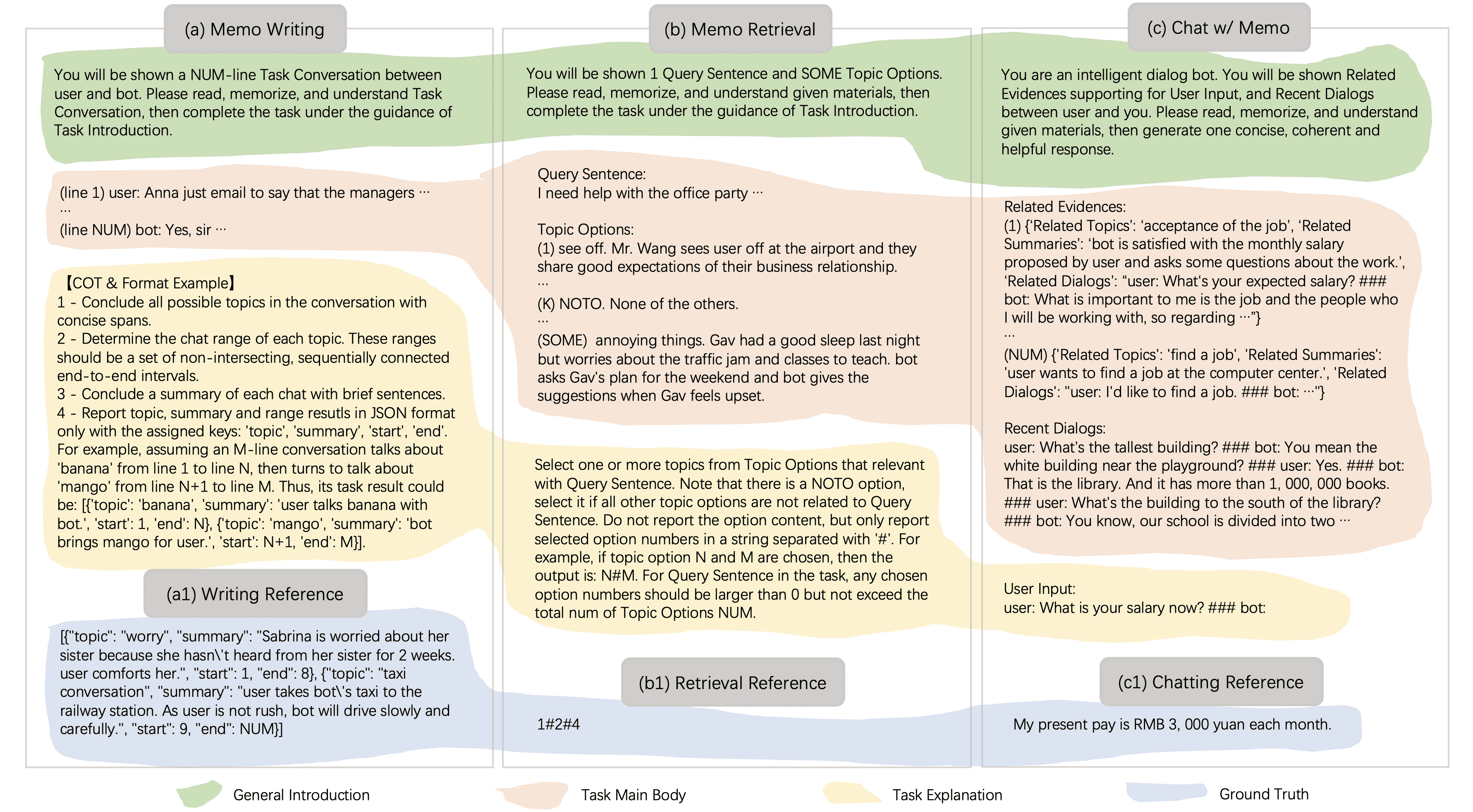
Figure 3:Instruction templates in MemoChat (better view in colors). Three instructions are carefully designed to serve MemoChat inner thinking pipeline including “Memo Writing”, “Memo Retrieval” and “Chat w/ Memo”, partitioned by gray boxes. The organization of all instructions consists of general task introduction (green area), main body of task-oriented inputs (bisque area), and detailed task explanation (yellow area). Ground-truth answers are provided during fine-tuning (blue area). More specific examples are provided in Appendix B.
图3展示了用于指导模型内部推理的指令模板,包括三个关键指令:“记忆编纂”(Memo Writing)、“记忆检索”(Memo Retrieval)和“基于记忆的对话”(Chat w/ Memo)。每个指令由三部分组成:
任务描述(绿色区域);
任务输入(米色区域);
任务解释(黄色区域);
标注答案(蓝色区域)用于微调。
指令结构设计¶
MemoChat 的三个阶段分别对应三个训练任务:
Memo Writing(记忆编纂):
输入一段对话,模型需将其按主题分类,生成每个子对话的摘要(summary)。
输出为 JSON 格式,包含“topic”、“summary”和“dialogues”。
结合 Chain-of-Thought(CoT)与 In-Context Learning(ICL)进行任务解释。
Memo Retrieval(记忆检索):
输入当前用户问题和多个主题选项(包括一个“NOTO”选项),模型需选出与问题相关的主题。
“NOTO”选项用于处理用户突然开启新话题的情况。
检索仅基于“topics”和“summaries”,以提高效率。
Chat w/ Memo(基于记忆的对话):
输入当前问题、最近对话和检索到的相关历史信息,模型基于这些上下文生成回答。
此任务帮助模型在长程对话中保持一致性。
数据集重构¶
作者从三个公开对话数据集中重构了 10k 条用于训练 MemoChat 的指令数据:
TopicoQA:3.9k 个对话,涉及 4 个主题,平均 13 轮对话。
DialogSum:1.3 万个对话,单一主题,平均 5.5 轮,提供人工摘要。
Alpaca-GPT4:1.6k 个对话,人机交互,内容更复杂。
各任务数据来源如下(见表1):
任务 |
数据量 |
平均 token 数 |
数据来源 |
|---|---|---|---|
Memo Writing |
3,046 |
951.92 |
TopicoQA 1,790 / DialogSum 1,256 |
Memo Retrieval |
3,654 |
329.86 |
TopicoQA 1,719 / DialogSum 1,935 |
Chat w/ Memo |
3,300 |
273.04 |
DialogSum 1,602 / Alpaca-GPT4 1,698 |
此外,还构建了 400 条用于评估的测试指令,分别对应三个任务。
面临的挑战¶
作者列出了在构建 MemoChat 指令时遇到的三大挑战:
Prompt Copy(提示复制):模型可能会直接复制提示中的示例格式作为回答。为避免此问题,建议使用虚拟变量替换具体数字,防止答案泄露。
Catastrophic Forgetting(灾难性遗忘):当“Chat w/ Memo”数据量较少时,模型可能生成重复或早期停止的回答。建议通过添加适量对话数据(如 Alpaca-GPT4)来保持模型对话能力。
Prompt Misplacement(提示错位):若输入中“任务输入”和“任务解释”的顺序调换,模型表现会下降。任务解释应置于末尾,有助于模型更好地理解任务。
小结¶
本节提出了 MemoChat 框架,通过“记忆—检索—响应”的三阶段机制,提升了长程开放式对话中回答的一致性。通过设计三种结构化指令任务,结合自建指令数据集,实现了对 LLM 的有效微调。作者还指出了在实践过程中可能遇到的三大挑战,并提供了对应的解决策略。
4 Experiments¶
4.1 实验设置¶
数据集¶
除了使用重建的指令数据集外,作者还邀请了三位专家手动标注了一个新的长程开放域对话数据集 MT-Bench+,以验证响应一致性。该数据集基于 MT-Bench(Zheng 等,2023),包含 80 个两轮开放域问题,扩展为四轮版本,并通过采样生成长度为 12~15 轮的对话流。每条对话流在最后添加了三种类型的问题:
Retrospection:要求模型从之前的对话中提取信息(如提取特定术语);
Continuation:基于已有知识继续生成内容(如完成故事);
Conjunction:跨话题生成响应(如结合两个任务)。
共构建了 54 个问题,每类 18 个。
基线模型¶
实验中使用了多个基线模型,包括:
Fastchat-T5-3B 和 Vicuna-7B/13B/33B:基于 Flan-T5 和 Llama 的人类对齐版本;
ChatGPT-2k:使用 2k 文本窗口的 gpt-3.5-turbo API;
MPC-ChatGPT 和 MemoryBank-ChatGPT:分别引入 MPC 和 MemoryBank 方法增强记忆能力;
MemoChat:基于上述模型,使用本文提出的指令数据集进行微调。
GPT-4 被用作评估者,但未作为训练模型,以避免数据泄漏。
评估指标¶
本文使用四组评估指标:
Memo Writing(摘要写作):
使用 NER 模型评估主题识别,指标包括 Precision (P)、Recall (R) 和 F1-score;
摘要生成则使用 BertScore 进行语义相似度评估。
Memo Retrieval(记忆检索):
使用常规 F1-score 评估检索准确性。
Chat with Memo(带记忆的对话):
使用 BertScore 评估生成回答与参考答案的相似度。
长程响应一致性:
使用 GPT-4 评分机制,以 1~100 的整数评分响应与历史对话的一致性(faithfulness)。
超参数与训练设置¶
训练使用全参数微调(而非轻量训练如 LoRA),在单台服务器上进行,配有 900G CPU 内存和 8 张 A100 40G GPU。使用 Deepspeed 和 Flash Attention 加速训练。每个模型的训练超参数、批次大小、梯度累积等设置详见表 2。
4.2 实验结果¶
Memo 生成与检索能力¶
表 3 显示,模型在“Memo Writing”和“Memo Retrieval”任务上的表现。关键发现如下:
大模型表现更优:ChatGPT 和 GPT-4 在零样本任务中表现突出;
微调显著提升性能:使用 1k 和 10k 数据进行微调后,模型在 F1-score 和 BertScore 上均有显著提升;
Vicuna-33B 的表现:在充分微调后,Vicuna-33B 的性能接近甚至超过 GPT-4;
例外情况:Vicuna-7B 和 T5-3B 在部分任务上表现略差。
响应一致性¶
表 4 显示了模型在“Retrospection”、“Continuation”和“Conjunction”任务上的 GPT-4 评分。主要结论包括:
MemoChat 显著提升一致性:相比 MPC 和 MemoryBank,MemoChat 在平均评分上提升 7~19.5;
训练数据规模影响显著:10k 数据比 1k 数据训练效果更好,尤其是在大模型上;
13B 模型在部分任务上优于 33B:当训练数据不足时,Vicuna-13B (1k) 在 Retrospection 任务上的得分更高;
GPT-4 仍具备优势:在 Cross-topic 任务上,ChatGPT 表现更优,可能与其更强的长文本理解能力有关。
案例分析¶
图 4 通过一个具体案例展示了不同模型在处理长程对话任务时的表现:
在涉及机器学习和反垄断法的对话中,ChatGPT 由于上下文窗口限制无法正确回答 Retrospection 问题;
MemoChat 能够准确回溯并完成跨主题任务;
在 Conjunction 任务中,MemoChat-ChatGPT 和 MemoChat-Vicuna-33B 能较好地结合两个主题,GPT-4 分别给它们 100 和 90 分,而 ChatGPT 仅得 1 分。

Figure 4:Case analysis of different types of testing questions with different chatbots. We show the key points (in bold) in the answers, and some parts of the answer context are replaced by ellipsis due to length limitation.
总结¶
本章实验围绕 MemoChat 的构建与评估展开,重点考察其在长程开放域对话中的 响应一致性 和 记忆使用能力。通过构建 MT-Bench+ 数据集和引入多种基线,实验结果表明:
大模型在零样本和微调任务中表现更优;
MemoChat 显著提升了模型的记忆使用和长程响应一致性;
在充分微调后,某些开源大模型(如 Vicuna-33B)的性能接近甚至超越 GPT-4;
仍存在跨话题理解和长文本生成的挑战,GPT-4 在某些任务上仍具优势。
5 Conclusion¶
本文提出了 MemoChat,这是一种用于训练大语言模型(LLMs)进行即时结构化记忆使用的指令微调流程,旨在实现一致且长期的开放域对话。该流程可以分解为“记忆-检索-回应”(memorization-retrieval-response)的循环结构。
重点内容:
MemoChat的核心设计:通过结构化记忆的即时使用,使模型在开放域对话中保持连贯性和长期一致性。
三个可训练指令:基于公开数据集,作者精心设计了三个可训练的指令模块:
结构化写作(structured writing):帮助模型生成结构清晰的记忆内容。
快速检索(fast retrieval):提升模型从已存储记忆中快速获取相关信息的能力。
记忆交互(interations with memos):增强模型与结构化记忆之间的互动能力。
下游评估数据集:作者构建了一个专家标注的下游评估集,用于进一步验证方法的有效性。
实验验证:在三种测试场景和多种基于LLM的聊天机器人上进行的实验,验证了 MemoChat 的有效性,说明该方法在提升对话连贯性与一致性方面具有显著优势。
精简内容:
本文强调了结构化记忆在开放域对话中的重要性,并提出了一个系统化的训练流程来实现这一目标。
Appendix A Basic Published Datasets¶
本节总结了论文中使用的三个基础公开数据集,它们用于MemoChat流水线中的指令重建。这些数据集分别是:
TopicoQA¶
这是一个以对话形式组织的数据集,内容围绕多个主题展开。每个对话中,会涉及多个话题切换,并通过“start”和“end”字段标记每个话题的对话范围。例如:
A 问:“Which of the four Galilean moons is the closest to Jupiter?”
B 回答:“Io.”
后续问题可能转向“谁发现的?”、“它是否属于某个专辑?”等,涉及多个主题如“Io (moon)”、“Galilean moons”、“Bohemian Rhapsody”等。
重点说明:
该数据集的特点是对话中话题切换频繁,适合用于训练模型在多话题对话中的上下文理解和话题识别能力。
通过“start”和“end”字段,可以清晰划分出每个话题的起止位置。
DialogSum¶
该数据集包含带有对话摘要的对话样本,每个对话都配备了多个不同角度的摘要以及对应的主题。例如:
对话中A要求B将一份备忘录打印并分发给所有员工。
提供的三个摘要分别从“沟通方式”、“公司政策”、“听写”等角度总结对话内容。
重点说明:
该数据集的重点在于多视角对话摘要生成,适合用于训练模型生成不同角度的摘要。
可用于训练模型理解对话的主要意图,并根据不同需求生成不同风格的摘要。
Alpaca-GPT4¶
该数据集由GPT-4生成的指令-输出对组成,用于训练语言模型理解并执行多样化的任务。例如:
用户提问:“列举展示强大领导力的行为。”
GPT-4输出一个包含10点行为特征的列表,如“清晰沟通”、“持续学习”等。
重点说明:
该数据集强调指令理解和任务执行能力,适合用于训练模型对各种指令的准确响应。
有助于模型在实际对话中更好地理解用户需求并生成相关回复。
表5:三类数据集示例(Table 5)¶
表5展示了上述三个数据集的示例内容,由于页面限制,部分内容被省略。该表用于说明论文中采用的基础数据集,并展示它们在格式和内容上的差异。
图5:指令设计挑战示例(Figure 5)¶
图5通过配图说明了在指令设计中常见的三个挑战:
Prompt Copy(提示复制):指令设计不当导致模型直接复制之前的提示语,缺乏创新。
Catastrophic Forgetting(灾难性遗忘):模型在训练后忘记之前学到的知识。
Prompt Misplacement(提示错位):模型未能正确理解当前任务,导致输出与上下文不一致。
重点说明:
每个挑战都配对了“劣质设计”和“优质设计”,用灰色和绿色框区分。
绿色框中展示了优化后的指令设计,强调了关键特征(加粗显示)。
总结¶
本节通过表格和图示,系统介绍了用于模型训练的三个基本公开数据集,并指出在指令设计过程中可能遇到的挑战。通过这些内容,论文强调了话题识别、多视角总结和指令理解在构建高质量对话系统中的重要性。
Appendix B Involved Prompts¶
作为补充,本文列出了在中间的“Memo相关的调优”(intermediate memo-related tuning)和下游的“回应一致性检查”(downstream response consistency checking)中所使用的完整Prompt示例。表6、表7、表8和表9分别对应“Memo Writing”(撰写Memo)、“Memo Retrieval”(检索Memo)、“Chat w/ Memo”(使用Memo进行对话)任务以及下游的回应一致性检查任务的完整指令。如图3所示,所有指令均采用相似的结构,包括:任务的一般性介绍、任务特定输入的内容主体以及任务的详细说明。在调优过程中,还提供了真实标签(ground truth),用于模型训练和评估。
重点内容:¶
表6至表9:分别对应不同阶段和任务的完整Prompt模板,是调优和评估的重要组成部分。
统一的指令结构:所有任务指令都遵循相同的格式,便于模型理解与学习。
地面真值的使用:在调优过程中提供真实数据,有助于提升模型在长期对话中的一致性表现。
Appendix C Instruction Design Challenges¶
1. 引言¶
本附录提供了在前面章节中讨论的指令设计挑战的具体示例。例如,“Prompt Copy”、“Catastrophic Forgetting”和“Prompt Misplacement”在图5中有图示说明。
2. Prompt Copy(提示复制)¶
为避免“Prompt Copy”挑战,使用虚拟变量(Dummy Variables)代替数字,可以防止模型直接复制格式要求中的值。例如,“Memo Writing”和“Memo Retrieval”中的行号或选项ID可能导致模型走捷径,虚拟变量能促使模型真正理解提示内容。子图1a和1b分别展示了“Memo Writing”和“Memo Retrieval”中的“Prompt Copy”挑战。通过用虚拟变量“M”和“N”替换实际数字,可以生成合理的内容。
3. Catastrophic Forgetting(灾难性遗忘)¶
第二个挑战是“Catastrophic Forgetting”,即当各种指令类型不平衡时,模型的响应会崩溃。如子图2所示,当“Chat w/ Memo”数据量显著小于其他数据时,模型的输出会变成无意义的重复。通过补充足够的对话语料库可以显著减少此类问题。
4. Prompt Misplacement(提示错位)¶
第三个挑战是“Prompt Misplacement”,即提示内容的关键部分应放在末尾。否则,模型可能进行自然文本生成而非执行与备忘录相关的任务。子图3展示了当“Memo Writing”中的详细任务说明放在任务内容之前时,模型可能无法正确执行任务。
5. 示例任务说明¶
a. Memo Writing(摘要写作)¶
提供了一个完整的Memo Writing指令示例,包括20轮用户与机器人对话的示例任务,以及需要执行的任务说明(如总结话题、确定对话范围等),以及期望的JSON格式结果。
b. Memo Retrieval(摘要检索)¶
这是一个完整的Memo Retrieval指令示例。要求从5个主题选项中选择与查询句子相关的主题,并以“#”分隔的形式输出选择的选项编号,且包含排除性选项“NOTO”。
c. Chat w/ Memo(带备忘的对话)¶
这是一个完整的“Chat w/ Memo”指令示例。模型需根据提供的背景信息和最近对话生成自然、连贯且有帮助的回复。示例中包括相关背景、最近对话和用户输入,并给出了正确的回应示例。
d. GPT4评估提示¶
提供了一个GPT4评估提示的示例。要求模型作为公正的评审者,评估某个对话回复是否忠实于背景对话内容。给出的格式包括背景对话、用户问题和模型回复,并要求进行评分(1-100)。
总结¶
本附录详细探讨了指令设计中的三个主要挑战:“Prompt Copy”、“Catastrophic Forgetting”和“Prompt Misplacement”,并通过具体的任务示例(Memo Writing、Memo Retrieval 和 Chat w/ Memo)进行了说明。最后还提供了GPT4用于评估回复质量的提示示例,强调了评估的客观性和格式要求。