2507.05595_PaddleOCR 3.0 Technical Report¶
引用: 12(2025-10-19)
组织: 百度
Document: https://paddlepaddle.github.io/PaddleOCR
Models & Online Demo: https://huggingface.co/PaddlePaddle
总结¶
三种主要解决方案
PP-OCRv5:用于多语言文本识别。
PP-StructureV3:用于分层文档解析。
PP-ChatOCRv4:用于关键信息提取。
PP-OCRv5
提供两种模型版本:
服务器版(默认):适用于配备 GPU 等加速硬件的系统,推理速度快、吞吐量高。
移动版:针对 CPU 环境优化,适配资源受限设备。
包含四个关键模块:
图像预处理模块(可选):用于图像旋转、几何畸变纠正,包括基于 PP-LCNet 的图像方向分类和基于 UVDoc 的图像展开模型。
文本检测模型:在 PP-OCRv4 的基础上进行了架构、知识蒸馏和数据增强的优化,采用更先进的 PP-HGNetV2 作为主干网络,提升了对复杂文本的检测能力。
文本行方向分类模型:自动识别并纠正文本行方向,确保后续识别模型接收标准可读文本。
文本识别模型:采用双分支结构(GTC-NRTR + SVTR-HGNet),兼顾准确性和推理效率,训练时使用 ERNIE-4.5-VL 生成高质量数据。
核心贡献
统一多语言建模:在一个模型中支持多种语言,模型体积小于 100MB,简化了工业部署。
复杂手写识别能力:相比之前模型,手写识别错误率降低 26%,适用于教育、金融、法律等领域。
历史文本与生僻字识别能力:通过网络优化和高质量数据集提升复杂场景下的识别准确性。
PP-StructureV3
包含五个模块:
预处理:包括图像方向分类和展开模型,与 PP-OCRv5 的预处理部分相同。
OCR:使用 PP-OCRv5 检测和识别文档中的所有文本内容。
布局分析:包含布局检测模型和区域检测模型,用于识别复杂文档(如多栏杂志、考试卷、手写文档)中的布局结构和元素位置。
文档元素识别:
表格识别:PP-TableMagic,支持结构化输出为 HTML。
公式识别:PP-FormulaNet_plus,可生成 LaTeX 公式。
图表解析:PP-Chart2Table,可将图表解析为 Markdown 表格。
印章识别:PP-OCRv4_seal,支持弯曲文本识别。
后处理:重构文档元素的关系(如图与表的关联、阅读顺序恢复),采用改进的 X-Y Cut 方法提升复杂布局的处理能力。
PP-ChatOCRv4
PP-Structure:作为文档解析模块,识别布局、文本和表格等结构。
向量检索模块:构建文本特征数据库,结合 RAG 技术提升关键信息检索效率。
大语言模型:当前使用 ERNIE-4.5-300B-A47B,通过精心设计的提示词提取信息。
PP-DocBee2:一种面向文档的多模态大模型,支持直接从图像中提取答案。
结果融合模块:融合文本与图像提取结果,生成最终输出。
Abstract¶
本技术报告介绍了 PaddleOCR 3.0,这是一个基于 Apache 许可证的开源 OCR 和文档解析工具包。随着大型语言模型(LLMs)时代对文档理解需求的增加,PaddleOCR 3.0 提出了三种主要解决方案:
PP-OCRv5:用于多语言文本识别。
PP-StructureV3:用于分层文档解析。
PP-ChatOCRv4:用于关键信息提取。
尽管这些模型的参数数量少于 1 亿个,但它们在准确性和效率方面与参数量达十亿级的视觉-语言模型(VLMs)相媲美,具有很强的竞争力。
此外,PaddleOCR 3.0 还提供了高质量的 OCR 模型库,并支持高效的训练、推理和部署工具。它兼容异构硬件加速,帮助开发者更轻松地构建智能文档应用。
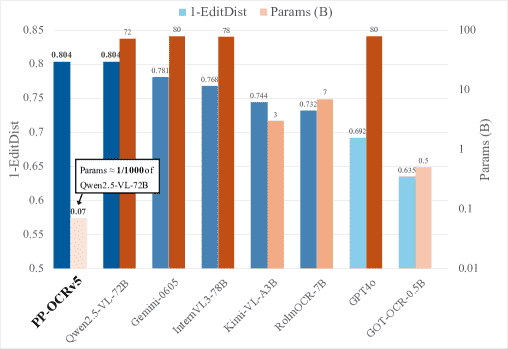
术语解释:
1-EditDist(1-Edit Distance):指的是编辑距离的倒数,数值越高,表示识别效果越好。这是衡量 OCR 模型性能的重要指标之一。
总结重点:
PaddleOCR 3.0 是一个轻量但高效的开源 OCR 工具包。
提出的三种模型(PP-OCRv5、PP-StructureV3、PP-ChatOCRv4)分别应对文本识别、文档结构解析和关键信息提取。
虽然参数较少,但性能可与大模型媲美。
提供一站式 OCR 解决方案,适合开发者快速开发智能文档应用。
1 Introduction¶
1.1 OCR 的重要性¶
光学字符识别(OCR)是一种基础技术,用于将包含文字的图像或扫描文档转换为结构化的机器可读文本。随着人工智能时代的到来,特别是大规模语言模型(LLMs)和检索增强生成(RAG)系统的兴起,OCR 的战略意义愈加突出。如今,OCR 不仅要求实现高精度的文字识别,还需成为高质量数据集构建、知识提取和视觉与语义层连接的关键技术。
重点强调:
OCR 是现代 AI 系统中的核心基础技术。
与 LLM 和 RAG 系统结合后,OCR 的作用已超越单纯的文字识别,成为知识管理和信息检索的重要环节。
1.2 OCR 技术的发展历程¶
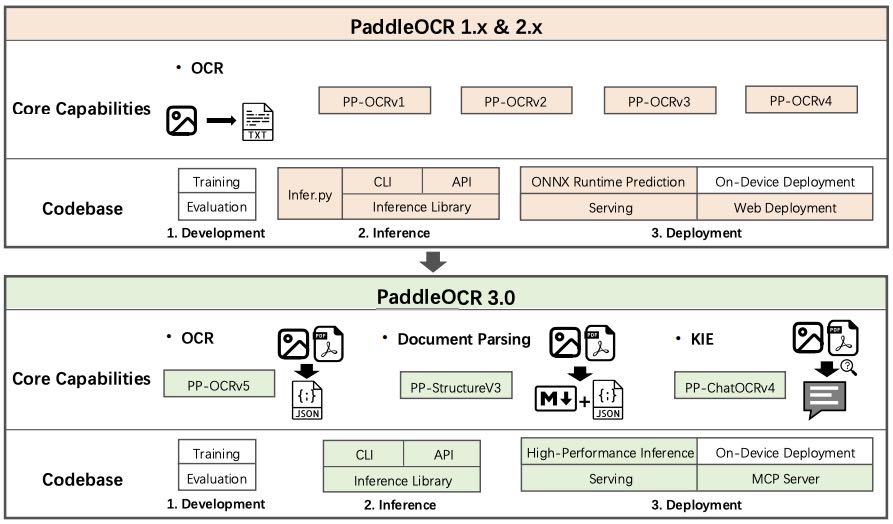
Figure 2: Evolution from PaddleOCR 1.x & 2.x to PaddleOCR 3.0. Different colors have been employed to denote areas with notable discrepancies between PaddleOCR 1.x & 2.x and PaddleOCR 3.0.
OCR 技术的发展反映了计算机视觉与自然语言处理的整体演进。早期的 OCR 系统依赖于手工特征和规则启发式方法,在受控条件下表现良好,但在面对复杂多样的真实场景时快速失效。深度学习(特别是卷积神经网络)的出现推动了数据驱动的 OCR 时代,显著提升了识别的准确性、鲁棒性和适应性。
重点强调:
传统 OCR 无法应对复杂文档类型和多样性需求。
深度学习推动 OCR 技术进入新阶段。
1.3 当前 OCR 面临的新挑战¶
随着大模型应用的普及,OCR 需要处理更广泛的文档类型,包括手写文本、多语言内容、罕见字符、表格与图像嵌套的复杂布局。此外,OCR 通常需支持下游任务,如文档理解、关键信息提取(KIE)和语义搜索,成为端到端智能工作流的一部分。
重点强调:
OCR 需要适应多样化和复杂化的文档需求。
支持文档理解与语义处理是当前 OCR 发展的重要方向。
1.4 LLM 与 RAG 对 OCR 的新要求¶
近年来,大模型和 RAG 技术的快速发展重塑了信息检索和知识管理的格局。OCR 不再只是数据采集工具,而是构建高质量语料库、支持模型训练和推理的关键环节。OCR 输出的准确性和完整性直接影响到 LLM 和 RAG 的性能与可信度。
重点强调:
OCR 是 LLM 和 RAG 系统中不可或缺的“数据源头”。
OCR 质量直接影响模型推理的准确性与可靠性。
1.5 当前 OCR 的局限性¶
尽管 OCR 技术取得了长足进步,但实际部署中仍面临诸多挑战。例如,处理低质量扫描、复杂背景、非标准字体、多模态文档(图文混排)等都对 OCR 提出更高要求。此外,面对全球语言、书写风格的多样性,OCR 需要在视觉建模和语言理解能力之间取得平衡。
重点强调:
实际部署中存在 OCR 无法很好应对的多模态、多语言问题。
工业界对轻量化、可扩展的 OCR 解决方案需求迫切。
1.6 PaddleOCR 的发展背景¶
作为开源 OCR 项目,PaddleOCR 从 2020 年起持续推动 OCR 技术的发展。其核心特点是全面覆盖、端到端流程和轻量高效。PP-OCR 系列不断迭代,从 v1 到 v4 不断提升识别性能、扩展语言支持,并引入文档结构理解能力(如 SLANet 表格识别)。
重点强调:
PaddleOCR 通过持续迭代,成为 OCR 领域的重要开源项目。
PP-OCRv1 到 v4 逐步提升了 OCR 的准确率和适用性。
1.7 PaddleOCR 的应用与影响¶
PaddleOCR 在学术和工业界都得到了广泛应用,并拥有活跃的开发者社区。截至 2025 年 6 月,其 GitHub 已获 5 万星标,并作为多个项目的 OCR 引擎(如 MinerU、RAGFlow、UmiOCR)。PaddleOCR 在高质量数据集构建、文档解析、智能归档等任务中发挥核心作用,并广泛支持 LLM 和 RAG 的数据流程。
重点强调:
PaddleOCR 是当前 OCR 技术中应用最广泛的开源项目之一。
其模块化架构与丰富 API 支持多种 AI 场景的集成。
1.8 用户反馈与未来需求¶
随着用户基数的增长,PaddleOCR 的社区反馈也更加丰富。用户对 OCR 提出更高要求,包括更精准的手写识别、多语言与罕见字符支持、复杂布局解析以及智能化信息提取等。这些需求也受到 LLM 和 RAG 应用规模扩大的推动。
重点强调:
用户反馈推动 OCR 技术的进一步发展。
面向 LLM 和 RAG 的需求是技术演进的关键驱动力。
1.9 PaddleOCR 3.0 的核心技术创新¶
PaddleOCR 3.0 是一次重大版本升级,旨在全面增强 OCR 的识别精度和文档解析能力。主要创新包括:
PP-OCRv5 高精度文字识别流水线
采用先进模型架构与训练策略,支持印刷体、手写体、多语言文档的高精度识别。
支持简体中文、繁体中文、拼音、英文、日文等语言的统一识别。
保持云与边缘部署的高效性。
PP-StructureV3 文档解析方案
集成布局分析、表格识别和结构提取,支持表单、发票、学术文献等复杂文档的结构化处理。
PP-ChatOCRv4 深度语义集成系统
轻量 OCR 模型与 LLM 结合,支持关键信息提取、上下文感知问答和文档理解,适用于 RAG 和智能文档代理。
专用任务支持
印章识别、公式识别、图表分析等模块增强其在科研与工业场景中的适用性。
重点强调:
PaddleOCR 3.0 代表 OCR 技术的新里程碑。
聚焦复杂场景下的识别与解析能力,支持 LLM 和 RAG 的深度集成。
1.10 PaddleOCR 3.0 的开放与扩展性¶
PaddleOCR 3.0 不仅在技术上有所突破,还在开放性、易用性和扩展性方面持续优化。新版提供更清晰的 API 和 CLI,保持向后兼容性。部署方面,其架构更加模块化,便于与 LLM 系统集成。
重点强调:
PaddleOCR 3.0 以开放、模块化和可扩展为核心设计理念。
有助于推动 OCR 在 AI 生态中的广泛应用。
1.11 PaddleOCR 3.0 的愿景与影响¶
PaddleOCR 3.0 旨在成为文档 AI 领域的智能、高效、开放基础设施。它不仅推动智能自动化与知识驱动 AI 系统的发展,还在视觉与语言交叉领域激发新的研究和应用前景。
重点强调:
PaddleOCR 3.0 是 OCR 技术演进的重要节点。
对智能文档处理、知识管理、AI 自动化等领域具有深远影响。
总结来看,本文介绍了 OCR 技术的重要性、发展历程、当前挑战以及 PaddleOCR 项目的发展与演进,重点展示了 PaddleOCR 3.0 的核心技术创新和应用前景。文章结构清晰,逻辑层层递进,全面呈现 OCR 技术在现代 AI 体系中的关键作用。
2 Core Capabilities¶
PaddleOCR 3.0 包含三项核心能力:PP-OCRv5、PP-StructureV3 和 PP-ChatOCRv4。本节分别介绍了这些能力所解决的问题、模型方案细节及其性能表现。
2.1 PP-OCRv5¶
PP-OCRv5 是一个高精度、轻量级的OCR系统,适用于多种场景,支持包括简体中文、繁体中文、拼音、英文和日文在内的多语言识别。它提供两种模型版本:
服务器版:适用于配备 GPU 等加速硬件的系统,推理速度快、吞吐量高。
移动版:针对 CPU 环境优化,适配资源受限设备。
默认情况下,文中提到的 PP-OCRv5 指的是服务器版本。
系统框架¶
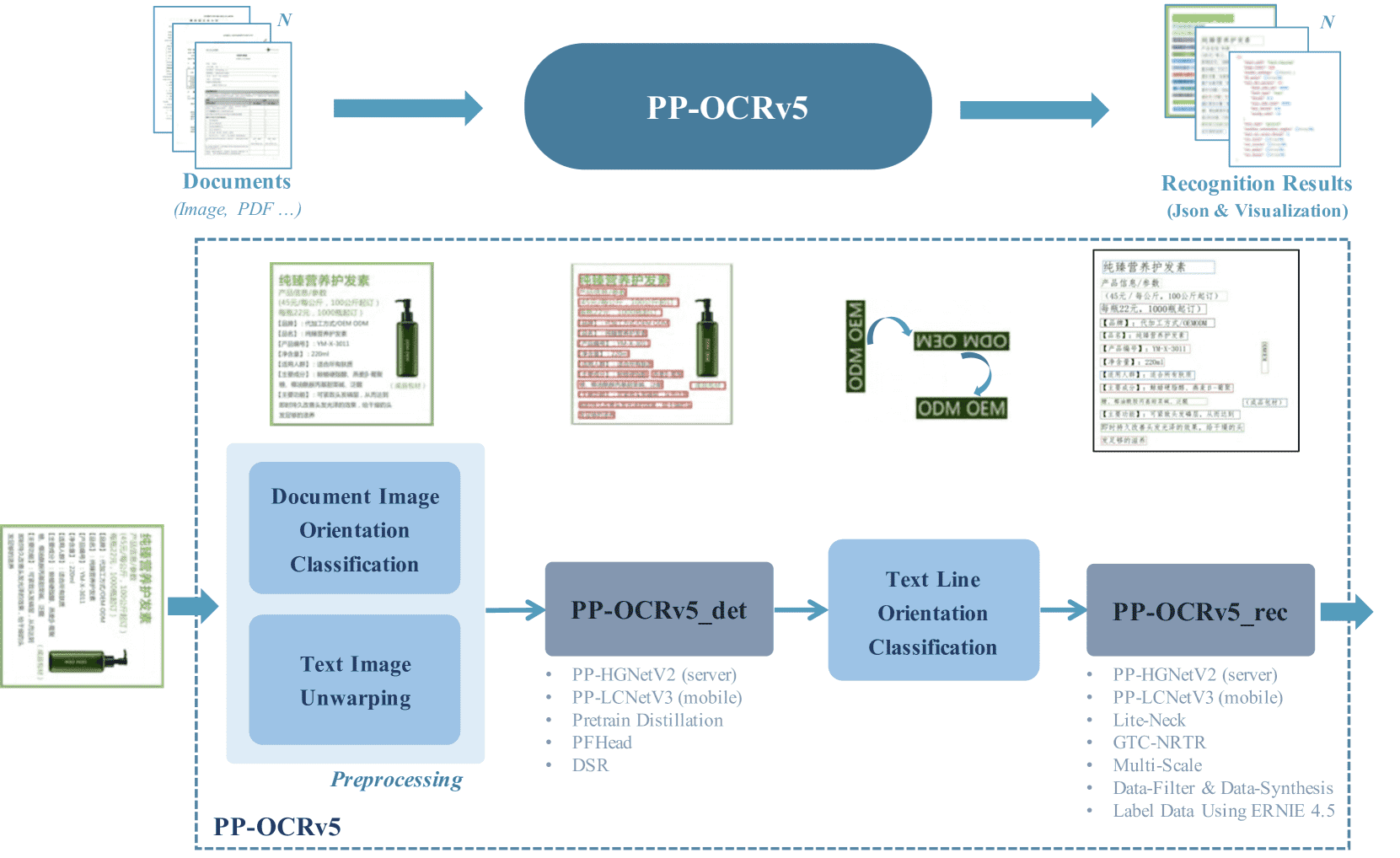
Figure 3: Pipeline of PP-OCRv5. The pipeline includes image preprocessing, text region detection, text line orientation classification, and text recognition, ultimately extracting the text from images and outputting it as structured textual content.
PP-OCRv5 包含四个关键模块:
图像预处理模块(可选):用于图像旋转、几何畸变纠正,包括基于 PP-LCNet 的图像方向分类和基于 UVDoc 的图像展开模型。
文本检测模型:在 PP-OCRv4 的基础上进行了架构、知识蒸馏和数据增强的优化,采用更先进的 PP-HGNetV2 作为主干网络,提升了对复杂文本的检测能力。
文本行方向分类模型:自动识别并纠正文本行方向,确保后续识别模型接收标准可读文本。
文本识别模型:采用双分支结构(GTC-NRTR + SVTR-HGNet),兼顾准确性和推理效率,训练时使用 ERNIE-4.5-VL 生成高质量数据。
核心贡献¶
统一多语言建模:在一个模型中支持多种语言,模型体积小于 100MB,简化了工业部署。
复杂手写识别能力:相比之前模型,手写识别错误率降低 26%,适用于教育、金融、法律等领域。
历史文本与生僻字识别能力:通过网络优化和高质量数据集提升复杂场景下的识别准确性。
性能评估¶
在 17 个不同场景(包括中文、英文、拼音、古籍等)中测试,PP-OCRv5 在平均 1-edit distance 指标上超越了多个大模型(如 GPT-4o、Gemini 等),特别是在中文场景中表现突出。尽管模型规模较小(仅 0.07B 参数),却在多个关键指标上领先。
2.2 PP-StructureV3¶
PP-StructureV3 是一个文档图像解析系统,能够将文档图像或 PDF 文件解析为结构化数据(如 JSON、Markdown)。
系统框架¶
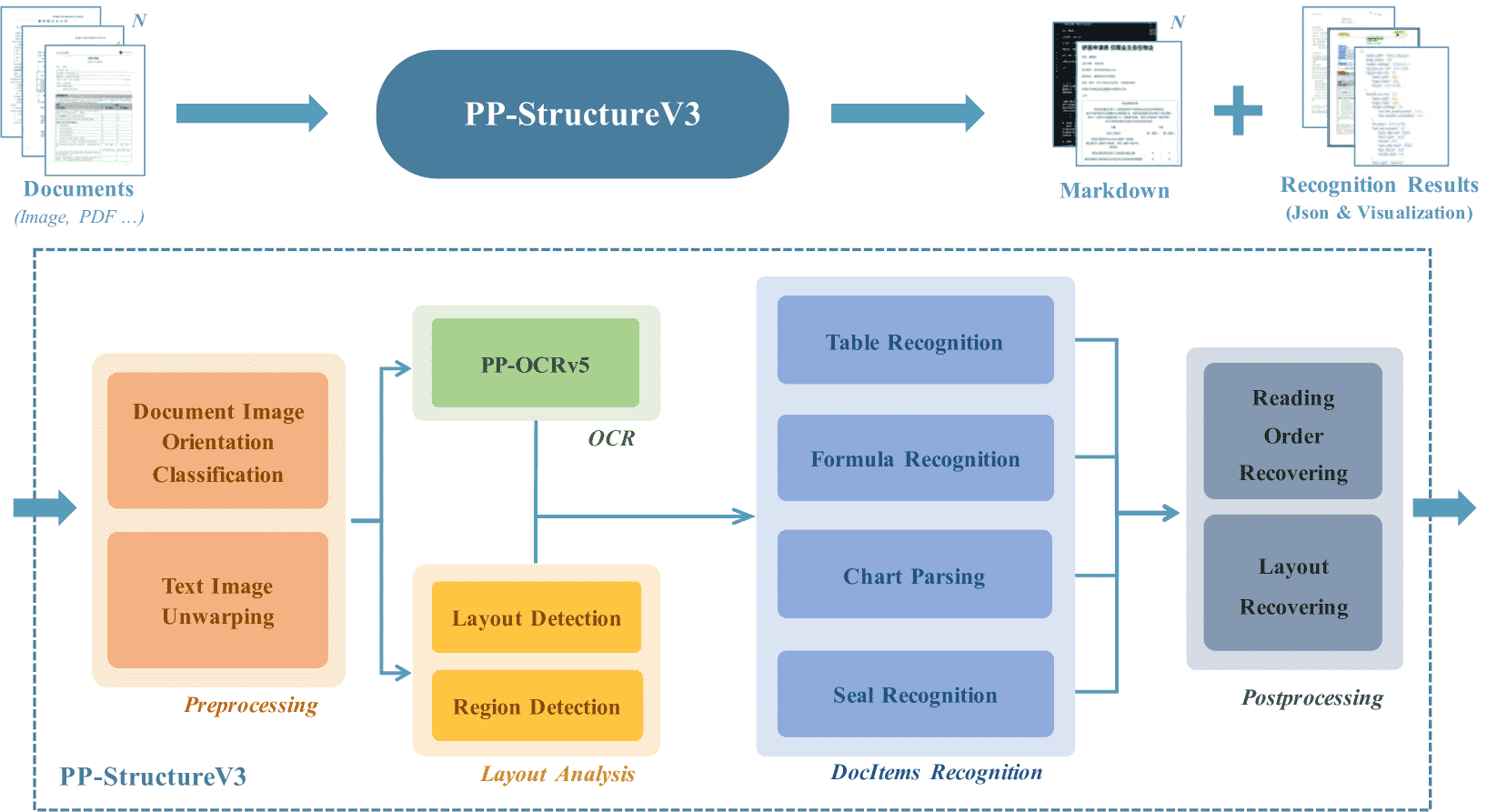
Figure 8: Pipeline of PP-StructureV3. The pipeline includes Preprocessing, OCRv5, Layout Analysis and Document Items Recognition and Postprocessing. It effectively parses content from images and outputs it as structured data.
PP-StructureV3 包含五个模块:
预处理:包括图像方向分类和展开模型,与 PP-OCRv5 的预处理部分相同。
OCR:使用 PP-OCRv5 检测和识别文档中的所有文本内容。
布局分析:包含布局检测模型和区域检测模型,用于识别复杂文档(如多栏杂志、考试卷、手写文档)中的布局结构和元素位置。
文档元素识别:
表格识别:PP-TableMagic,支持结构化输出为 HTML。
公式识别:PP-FormulaNet_plus,可生成 LaTeX 公式。
图表解析:PP-Chart2Table,可将图表解析为 Markdown 表格。
印章识别:PP-OCRv4_seal,支持弯曲文本识别。
后处理:重构文档元素的关系(如图与表的关联、阅读顺序恢复),采用改进的 X-Y Cut 方法提升复杂布局的处理能力。
性能评估¶
在 OmniDocBench 基准上,PP-StructureV3 在中英文文档解析任务中表现最优,优于其他主流工具和多模态大模型(如 GPT-4o、InternVL3-78B 等)。
2.3 PP-ChatOCRv4¶
PP-ChatOCRv4 是一个文档关键信息提取系统,结合 OCR、VLM 和 LLM 技术,能够从复杂布局、多页 PDF、生僻字等挑战性场景中提取关键信息。
系统框架¶
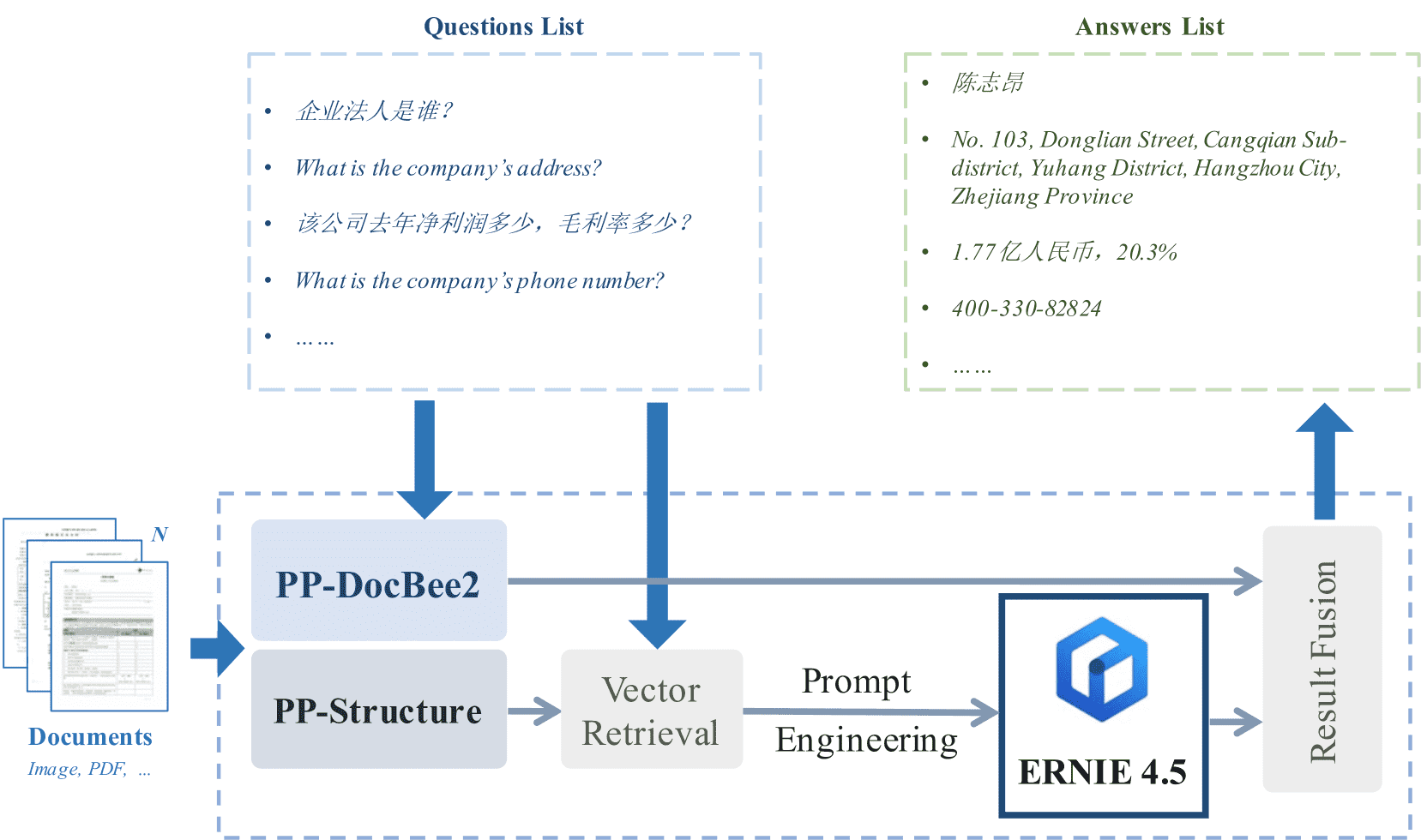
Figure 9: Pipeline of PP-ChatOCRv4.
PP-Structure:作为文档解析模块,识别布局、文本和表格等结构。
向量检索模块:构建文本特征数据库,结合 RAG 技术提升关键信息检索效率。
大语言模型:当前使用 ERNIE-4.5-300B-A47B,通过精心设计的提示词提取信息。
PP-DocBee2:一种面向文档的多模态大模型,支持直接从图像中提取答案。
结果融合模块:融合文本与图像提取结果,生成最终输出。
性能评估¶
在自定义的多场景数据集(638 张文档图像 + 1196 个问答对)上测试,PP-ChatOCRv4 在 Recall@1 指标上达到 85.55%,优于 GPT-4o、Qwen2.5-VL-72B 等模型。
总结¶
PaddleOCR 3.0 通过 PP-OCRv5、PP-StructureV3 和 PP-ChatOCRv4 三大核心能力,实现了从文本识别、文档解析到关键信息提取的完整流程。其优势体现在:
高精度与轻量化:PP-OCRv5 表现优异,参数少但性能领先。
多语言与多模态支持:可处理中英文、拼音、古籍等复杂场景。
工业级部署能力:模块化设计、轻量模型和高效推理,适合移动和边缘设备。
结构化输出与智能提取:PP-StructureV3 和 PP-ChatOCRv4 实现了从图像到结构化数据的端到端处理。
这些能力共同推动了 OCR 技术在实际应用中的广泛部署与落地。
3 Codebase Architecture Design¶
本节介绍 PaddleOCR 3.0 的整体架构设计,重点包括训练工具包与推理库的结构设计及其改进。
3.1 Overall Architecture(整体架构)¶
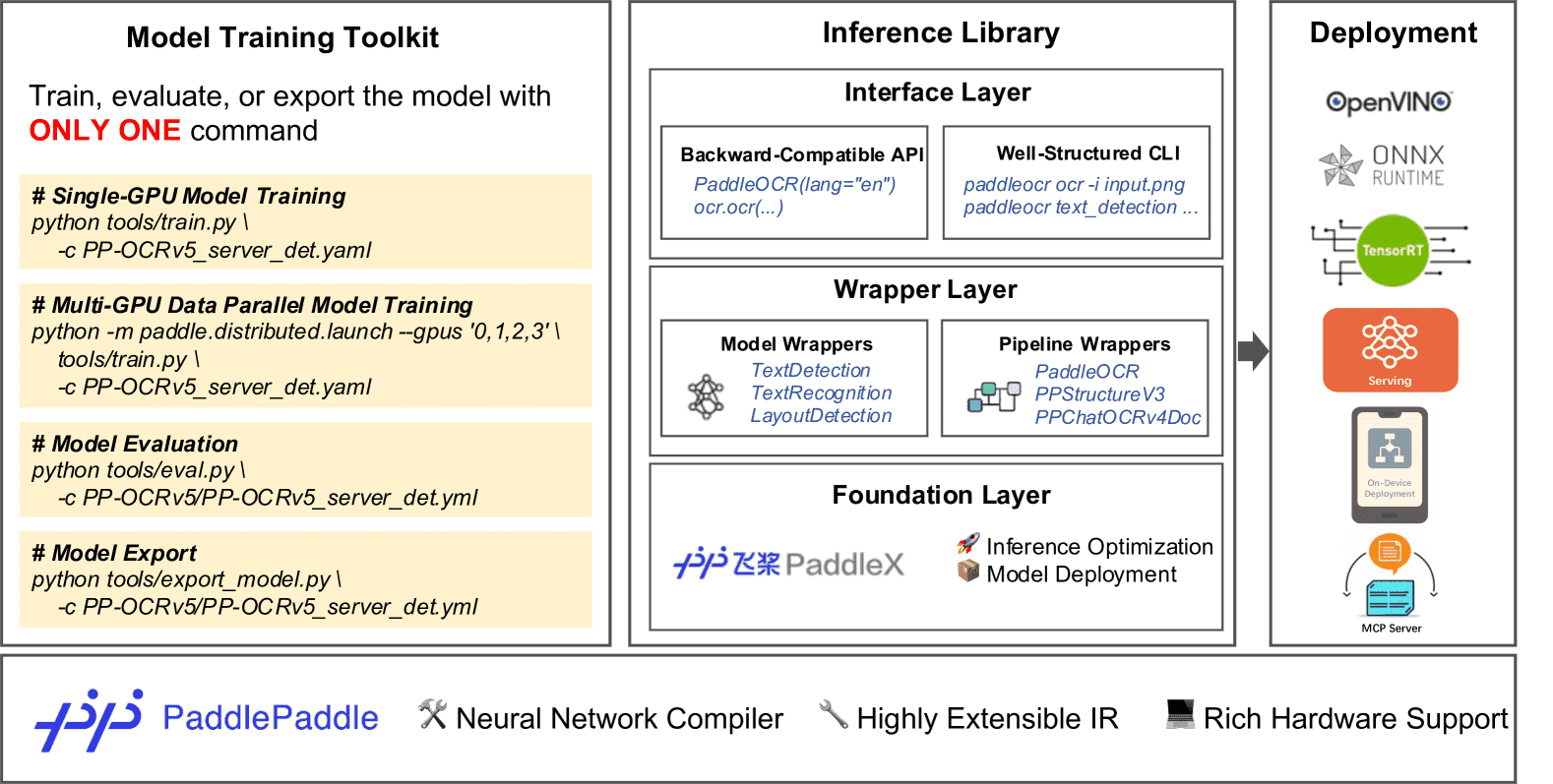
Figure 10: Overall Architecture of the PaddleOCR 3.0 Codebase.
PaddleOCR 3.0 的整体架构如图 10 所示。其底层基于 PaddlePaddle 框架(Ma et al., 2019),该框架具备神经网络编译器,可优化性能、提供高度可扩展的中间表示(IR)并支持广泛的硬件兼容性。
在 PaddlePaddle 的基础上,PaddleOCR 3.0 构建了两个核心组件:
模型训练工具包(Training Toolkit)
提供从模型训练到导出的完整流程支持,包括文本检测和文本识别等模型。
支持将动态图模型转换为静态图格式,提升模型在推理和部署场景中的适应性。
用户可通过单个命令执行训练、评估和导出任务,并支持通过配置参数满足不同需求(如指定预训练模型路径或自定义数据集目录)。
推理库(Inference Library)
推理库设计为轻量且高效的结构,支持加载官方发布模型和用户自定义训练模型。
支持 8 种端到端推理模型流水线,并可灵活集成到实际应用中。
作为部署能力的基础,支持高性能推理、服务化部署、移动端部署以及通过 Model Context Protocol (MCP) 服务器运行。
其具体设计将在下一小节详细介绍。
3.2 Inference Library Design(推理库设计)¶
本节重点阐述 PaddleOCR 3.0 推理库的设计动机和结构组成,并解决 PaddleOCR 2.x 版本中存在的问题。
PaddleOCR 2.x 的主要问题¶
参数命名空间混乱:所有命令行参数共享一个命名空间,新增功能需手动添加参数,导致维护困难。
配置方式不灵活:参数仅通过函数参数配置,缺乏可复用性和可移植性,不利于配置管理与版本控制。
模块职责不清:推理库直接基于训练工具包构建,导致训练与推理入口点重叠,用户容易混淆,且模块化和可维护性差。
PaddleOCR 3.0 的改进方案¶
为解决上述问题,PaddleOCR 3.0 推理库基于 PaddleX 3.0 工具包 构建,该工具包提供了丰富的推理优化和部署功能,并考虑了向后兼容性,降低用户从 PaddleOCR 2.x 迁移的成本。新推理库采用三层架构设计:
接口层(Interface Layer)
提供统一的 Python API 和 CLI 命令行工具。
Python API:所有 OCR 任务均可通过统一接口调用,并保留了关键方法和参数的向后兼容性。
CLI:相比 PaddleOCR 2.x,CLI 完全重新设计,采用子命令方式区分不同任务,提升用户交互体验。
封装层(Wrapper Layer)
提供对 PaddleX 核心组件的 Pythonic 封装,如模型和流水线。
支持统一的接口和灵活的配置管理。
同时兼容 PaddleOCR 2.x 的参数方式,并引入 PaddleX 风格的配置文件机制,实现配置的可移植性与可复用性。
基础层(Foundation Layer)
依赖于 PaddleX 3.0 工具包,是 PaddleOCR 3.0 的核心基础。
提供推理优化和模型部署能力,并与训练工具包解耦。
通过将推理库从训练脚本中分离,明确了训练与推理的职责边界,减少了冗余入口点,提升了系统的模块化和可维护性。
架构优势¶
该分层架构确保了上层组件只依赖于下层抽象,具备低耦合、高模块化和易于维护的特点,为系统的长期演进打下了坚实基础。
4 Deployment¶
本节概述了 PaddleOCR 3.0 的部署能力,如图11所示。PaddleOCR 3.0 提供了灵活且全面的部署选项,包括高性能推理、服务部署和设备端部署,以支持多种应用场景。在实际生产环境中,OCR系统不仅需要保证识别准确率,还要满足延迟、吞吐量和硬件兼容性等要求。PaddleOCR 通过可配置的部署工具,简化了跨平台的集成,并提供了一个 MCP 服务器,方便与大语言模型(LLM)应用集成。
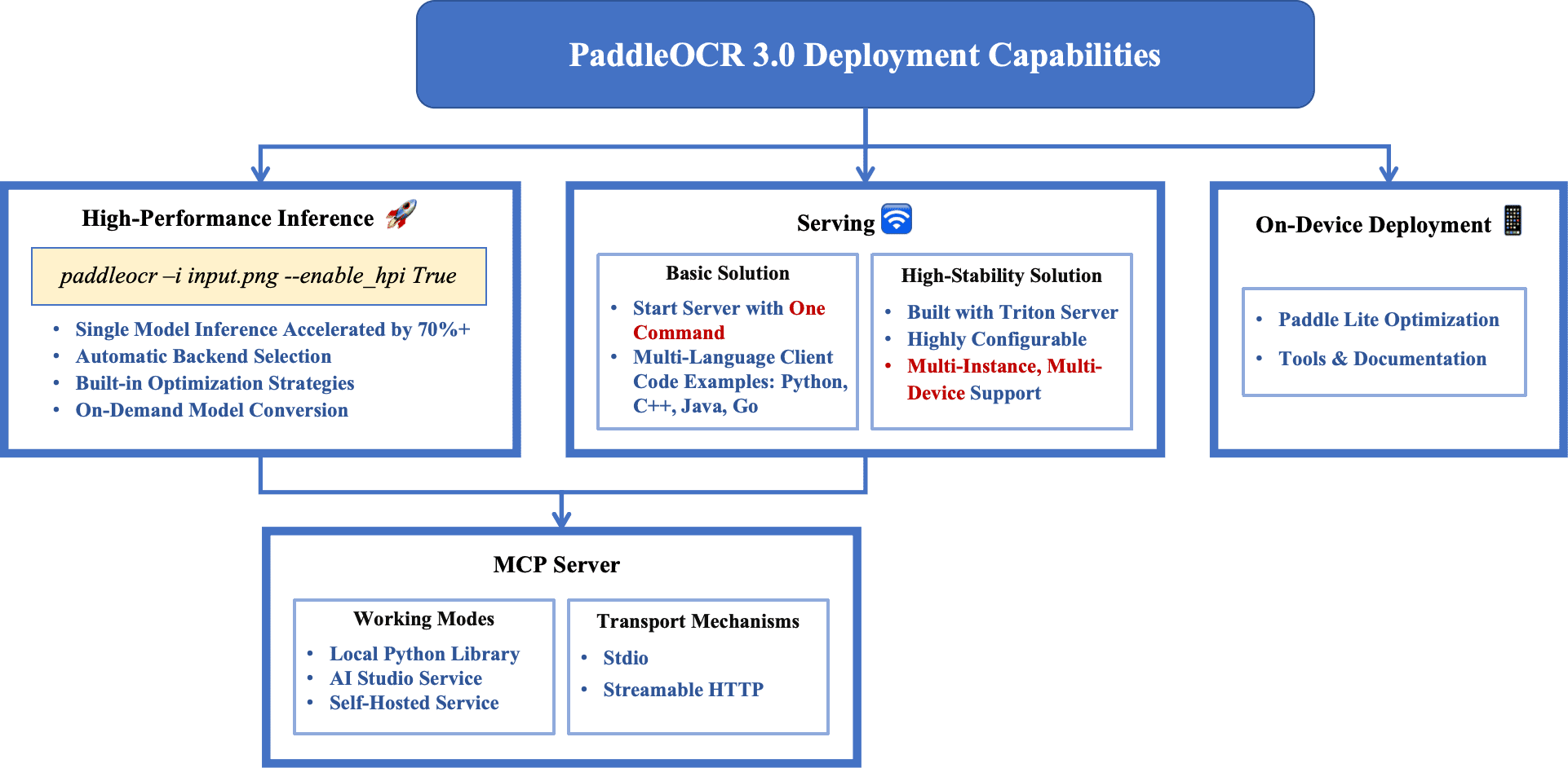
Figure 11: Overview of the deployment capabilities of PaddleOCR 3.0. PaddleOCR 3.0 provides high-performance inference, serving, and on-device deployment capabilities. Additionally, it enables users to easily deploy an MCP server based on PaddleOCR.
图11展示了 PaddleOCR 3.0 的部署能力:支持高性能推理、服务部署和设备端部署,并允许用户基于 PaddleOCR 部署 MCP 服务器。
4.1 高性能推理(High-Performance Inference)¶
PaddleOCR 3.0 提供了高性能推理功能,用户无需手动调优底层配置即可提升运行时性能。该功能对关键模型有显著加速作用。例如:
在 NVIDIA Tesla T4 设备上,启用高性能推理后:
PP-OCRv5_mobile_rec 的单模型推理延迟减少 73.1%
PP-OCRv5_mobile_det 的延迟减少 40.4%
关键特性包括:
自动选择推理后端:根据运行环境和模型特性,自动选择合适的推理引擎,支持 Paddle Inference、OpenVINO、ONNX Runtime 和 TensorRT。
内置优化策略:如多线程和 FP16 推理,以更好地利用硬件资源。
按需模型转换:支持将 PaddlePaddle 的静态图模型自动转换为 ONNX 格式,以兼容其他推理引擎。
用户只需开启 enable_hpi 开关即可实现加速,底层优化由 PaddleOCR 自动处理。对于高级用户,还支持通过 Python 参数或配置文件进行细粒度调优。
4.2 服务部署(Serving)¶
PaddleOCR 3.0 支持构建可扩展且生产就绪的 OCR 服务,提供两种部署方案:
• 基础服务(Basic Serving)¶
基于 FastAPI 的轻量级解决方案,适合快速验证和低并发场景。
用户可通过 CLI 一键运行任意 pipeline 服务。
提供了七种编程语言的客户端调用示例(Python、C++、Java、Go、C#、Node.js、PHP),方便集成到自有应用中。
• 高稳定性服务(High-Stability Serving)¶
基于 NVIDIA Triton Inference Server,适合对稳定性与性能要求更高的场景。
可配置多 GPU 多实例运行,充分利用计算资源。
两种服务接口相似,用户可从基础服务起步,按需升级到高稳定性方案,迁移成本低。
4.3 设备端部署(On-Device Deployment)¶
为了支持资源受限的设备部署,PaddleOCR 3.0 提供了在移动平台部署 PP-OCR 模型 的能力。通过配套工具和文档,支持模型优化与 Paddle-Lite 运行时集成,实现移动端 OCR 任务的高效运行。
4.4 MCP 服务器(MCP Server)¶
PaddleOCR 3.0 提供了轻量级的 MCP 服务器,可将 OCR 和 PP-StructureV3 流水线作为工具集成到任何兼容 MCP 的主机中。
MCP 服务器基于 PaddleOCR 推理库构建,支持其各类推理和部署方式,当前运行模式包括三种:
• 本地模式(Local)¶
在本地机器上运行 PaddleOCR pipeline,适合离线使用或数据隐私要求高的场景。
可启用高性能推理加速。
• AI Studio 模式(AI Studio)¶
通过 PaddlePaddle AI Studio 提供的云服务运行。
适合快速尝试功能、验证方案或零代码开发场景。
• 自托管模式(Self-Hosted)¶
连接到用户自建的 PaddleOCR 服务。
支持流水线服务部署,适合需要自定义服务配置的场景。
无论选择哪种模式,设置 PaddleOCR MCP 服务器都非常简便。附录中提供了示例配置文件供参考。此外,MCP 服务器支持 stdio 和 Streamable HTTP 传输方式,适用于多种部署场景。凭借其灵活架构和多模式支持,PaddleOCR MCP 服务器能够有效满足不同用户(包括开发者和企业)的多样化部署需求。
总结¶
PaddleOCR 3.0 的部署能力非常全面,涵盖了:
高性能推理:自动优化、多引擎支持、延迟显著降低
服务部署:支持 FastAPI 和 Triton,灵活满足不同性能需求
设备端部署:适合移动端和资源受限设备
MCP 服务器:便于与 LLM 集成,支持多种部署模式,提供高度灵活性和扩展性
这些特性使得 PaddleOCR 3.0 不仅在模型性能上表现出色,也具备良好的生产环境部署能力,适用于广泛的应用场景。
5 Conclusion¶
PaddleOCR 长期专注于 OCR(光学字符识别)和文档解析领域,致力于提供更有价值的技术解决方案。PaddleOCR 3.0 是一次重要的升级,其中引入的 PP-OCRv5、PP-StructureV3 和 PP-ChatOCRv4 等技术将在大规模模型时代发挥重要作用,是本章节的重点内容。
未来,PaddleOCR 将继续扩展模型功能,计划推出包括多语言文本识别模型、多模态 OCR 模型以及文档解析模型等新功能,这些内容虽然目前为规划阶段,但体现了项目的发展方向。
最后,作者呼吁用户如果发现 PaddleOCR 3.0 有帮助,或希望在项目中使用它,请引用该技术报告。
Appendix A Acknowledgments¶
核心内容:感谢所有贡献者(个人和开源社区),强调他们的贡献对项目成功的重要作用。
重点人物:列出大量项目核心参与者和开源社区支持者。
图示展示:通过图12可视化项目的主要贡献者,增强社区认同感。
Appendix B Usage of command and API details¶
B.1 通过命令行(CLI)运行推理¶
PaddleOCR 3.0 提供了方便的 CLI 接口,用户可以通过命令行快速体验以下模型的推理能力:
PP-OCRv5:适用于文本识别的 OCR 模型。
PP-StructureV3:用于文档结构分析的模型。
PP-ChatOCRv4:结合 OCR 与大语言模型(LLM)的交互式 OCR 模型。
示例命令:¶
运行 PP-OCRv5 推理:
paddleocr ocr -i test.png \ --use_doc_orientation_classify False \ --use_doc_unwarping False \ --use_textline_orientation False
该命令对
test.png进行 OCR 推理。--use_doc_orientation_classify:是否启用文档方向分类(默认关闭)。--use_doc_unwarping:是否启用文档展开功能(默认关闭)。--use_textline_orientation:是否启用文本行方向识别(默认关闭)。
运行 PP-StructureV3 推理:
paddleocr pp_structurev3 -i test.png \ --use_doc_orientation_classify False \ --use_doc_unwarping False
用于分析文档结构,输出如表格、图像、段落等布局信息。
运行 PP-ChatOCRv4:
paddleocr pp_chatocrv4_doc -i test.png \ -k number \ --qianfan_api_key your_api_key \ --use_doc_orientation_classify False \ --use_doc_unwarping False
需要先获取 Qianfan API Key。
通过 OCR 和 LLM 的结合,实现交互式文档理解。
B.2 通过 Python API 运行推理¶
除了 CLI,PaddleOCR 3.0 还提供了简洁的 Python API,方便用户集成到自己的项目中。以下是几种模型的 Python 使用示例:
1. PP-OCRv5 示例:¶
from paddleocr import PaddleOCR
ocr = PaddleOCR(
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False
)
result = ocr.predict(input="test.png")
for res in result:
res.print()
res.save_to_img("output")
res.save_to_json("output")
初始化 PaddleOCR 实例,可以配置是否使用文档方向分类、文档展开、文本方向识别等功能。
调用
predict方法进行推理,结果可通过print输出或保存为图像和 JSON。
2. PP-StructureV3 示例:¶
from paddleocr import PPStructureV3
pipeline = PPStructureV3(
use_doc_orientation_classify=False,
use_doc_unwarping=False
)
output = pipeline.predict(input="test.png")
for res in output:
res.print()
res.save_to_json(save_path="output")
res.save_to_markdown(save_path="output")
初始化 PPStructureV3 实例。
调用
predict方法进行文档结构分析,结果可保存为 JSON 或 Markdown 格式。
3. PP-ChatOCRv4 示例:¶
from paddleocr import PPChatOCRv4Doc
chat_bot_config = {
"module_name": "chat_bot",
"model_name": "xxx",
"base_url": "https://qianfan.baidubce.com/v2",
"api_type": "openai",
"api_key": "your_api_key"
}
retriever_config = {
"module_name": "retriever",
"model_name": "embedding-v1",
"api_key": "your_api_key"
}
pipeline = PPChatOCRv4Doc(
use_doc_orientation_classify=False,
use_doc_unwarping=False
)
visual_predict_res = pipeline.visual_predict(
input="test.png",
use_common_ocr=True,
use_seal_recognition=True,
use_table_recognition=True
)
vector_info = pipeline.build_vector(visual_info_list, retriever_config=retriever_config)
chat_result = pipeline.chat(
key_list=["number of people"],
visual_info=visual_info_list,
vector_info=vector_info,
chat_bot_config=chat_bot_config,
retriever_config=retriever_config
)
print(chat_result)
需要配置 chat_bot_config 和 retriever_config,包括模型名、API 地址和 Qianfan API Key。
调用
visual_predict进行图像识别,并结合 OCR 与大模型进行交互推理。最终通过
chat方法生成对话式输出结果。
重点总结:
CLI 使用:适合快速体验模型功能,适合新手用户。
Python API 使用:适合集成项目,提供了更灵活的配置和高级功能(如结构分析、交互式对话)。
所有模型均支持关闭文档方向分类、文档展开等辅助功能,提升使用效率。
PP-ChatOCRv4 需要额外配置 API Key,并依赖大模型支持,功能最为强大,适合复杂文档的理解与交互场景。
Appendix C More details on MCP host configuration¶
本附录提供了 Claude for Desktop 中 MCP 主机配置 的几个示例,展示如何连接到 PaddleOCR MCP 服务器。每个可配置的参数可以通过两种方式指定:
通过环境变量(
env字段)通过命令行参数(
args字段)
1. 使用本地 Python 库¶
这是本地部署的示例,使用本地的 PaddleOCR 库运行 OCR 服务。
配置结构:
mcpServers: 定义 MCP 服务器配置paddleocr-ocr: OCR 服务名称command: 执行命令为paddleocr_mcpargs: 命令行参数(例如:--device "gpu:1")env: 环境变量PADDLEOCR_MCP_PIPELINE: OCR 管道类型(这里是"OCR")PADDLEOCR_MCP_PPOCR_SOURCE: 源类型(这里是"local",表示本地)
重点:此配置适合本地开发和测试,支持 GPU 加速。
2. 使用 PaddlePaddle AI Studio 服务¶
此示例展示了如何连接到 PaddlePaddle 提供的 AI Studio 服务。
配置结构:
mcpServers:paddleocr-ocr:command: 执行命令为paddleocr_mcpargs: 命令行参数(例如:--timeout "60")env: 环境变量PADDLEOCR_MCP_PIPELINE:"OCR"PADDLEOCR_MCP_PPOCR_SOURCE:"aistudio"(表示使用 AI Studio 服务)PADDLEOCR_MCP_SERVER_URL: 服务的 URL(需替换为实际 URL)PADDLEOCR_MCP_AISTUDIO_ACCESS_TOKEN: 访问令牌(需替换为实际令牌)
重点:适用于使用 PaddlePaddle 提供的云端 OCR 服务,需要填写服务地址和访问令牌。
3. 使用自托管服务¶
此示例展示了如何连接到用户自己托管的 OCR 服务。
配置结构:
mcpServers:paddleocr-ocr:command: 执行命令为paddleocr_mcpargs: 命令行参数(无)env: 环境变量PADDLEOCR_MCP_PIPELINE:"OCR"PADDLEOCR_MCP_PPOCR_SOURCE:"self_hosted"(表示使用自托管服务)PADDLEOCR_MCP_SERVER_URL: 自托管服务的 URL(需替换为实际 URL)
重点:适用于企业或高级用户自建 OCR 服务的情况,配置简洁,只需指定服务地址。
总结¶
本附录提供了三种配置方式,分别适用于本地开发、云端服务(AI Studio)和自托管服务。
每种配置方式都包含命令、参数和环境变量,用户可以根据需求选择合适的配置。
重点内容:
环境变量和命令行参数是配置的核心。
不同的 OCR 源类型(
local、aistudio、self_hosted)决定了服务的来源。自托管服务需要用户自行部署并提供服务地址。
以上为 Appendix C 的内容总结,保持了原文结构并对重点内容进行了强调。