2010.10783_SGL: Self-supervised Graph Learning for Recommendation¶
引用: 32(2025-09-09)
组织:
Shanghai Jiao Tong University
Huawei Noah’s Ark Lab
GitHub: https://github.com/wujcan/SGL
总结¶
背景
图卷积网络(GCN)方法,如 PinSage 和 LightGCN,通过利用高阶邻居信息取得了良好效果。
然而,存在两个关键问题:
高连接度(高阶)的节点在表示学习中占据主导地位,削弱了对低度节点(长尾物品)的推荐效果;
更倾向于推荐这些热门商品,而忽视那些连接数少、不活跃的“长尾商品”
传统的邻居聚合机制容易放大观测边中的噪声,导致推荐结果不稳定
用户与商品的交互行为中天然存在噪音(比如误点、冲动消费、虚假点击)
GCN通过聚合邻居信息来学习,这个过程会放大这些噪音数据的影响
SGL
核心思路:
在传统的、有监督的推荐任务(主任务)基础上,增加一个辅助的自监督学习(SSL)任务。
这个自监督任务的目标是通过一种叫“自我判别”(self-discrimination)的方法来增强(reinforce)节点表示的学习,使其更准确、更稳定。
设计了三种具体的数据 augmentation(增强)方法来生成不同的“视角”
节点丢弃(Node Dropout): 随机屏蔽掉图中一部分节点。
边丢弃(Edge Dropout): 随机屏蔽掉图中一部分交互关系(边)。
随机游走(Random Walk): 通过随机游走为每个节点生成一个子图,不同的游走路径会生成不同的子图视角。
SGL有一个额外的隐藏优势:
它能够自动挖掘“难负例”(hard negatives)。
在对比学习中,负例是与当前样本不相似的样本。
而“难负例”是指那些与当前样本相似但确实不同的样本(例如,两款外观相似的手机),学会区分它们对模型来说挑战更大,收益也更高。
SGL通过其图结构上的操作,可以自动产生这样的效果。
消融测试
三种SGL变体:
SGL-ND:基于节点丢弃(Node Dropout)。
SGL-ED:基于边丢弃(Edge Dropout)。
SGL-RW:基于随机游走(Random Walk)。
对比结果
SGL-ED 表现最佳
SGL-RW 次之
SGL-ND 相对不稳定
结论
LightGCN 只推荐高频物品,导致长尾物品被忽视。
SGL 减少了高频组对 Recall 的贡献,提升了对长尾物品的推荐能力。
Abstract¶
该研究主要探讨了在用户-物品图上进行表示学习以提升推荐系统性能的方法。当前推荐系统中的图卷积网络(GCN)方法,如 PinSage 和 LightGCN,通过利用高阶邻居信息取得了良好效果。然而,作者指出这些方法存在两个关键问题:
高度节点影响过大:高连接度(高阶)的节点在表示学习中占据主导地位,削弱了对低度节点(长尾物品)的推荐效果;
对“热门商品”的偏见(High-degree Node Bias): 在图(graph)中,连接数多的节点(如热门商品、活跃用户)在信息传播中影响力过大。
这使得模型会更倾向于推荐这些热门商品,而忽视那些连接数少、不活跃的“长尾商品”(low-degree / long-tail items),导致推荐多样性下降。
对噪声敏感:传统的邻居聚合机制容易放大观测边中的噪声,导致推荐结果不稳定。
对“交互噪音”的脆弱性(Vulnerability to Noise): 用户与商品的交互行为中天然存在噪音(比如误点、冲动消费、虚假点击)。
GCN通过聚合邻居信息来学习,这个过程会放大这些噪音数据的影响,从而降低模型的鲁棒性(Robustness),学到的表示可能不准确。
解决方案的核心思路:在传统的、有监督的推荐任务(主任务)基础上,增加一个辅助的自监督学习(SSL)任务。这个自监督任务的目标是通过一种叫“自我判别”(self-discrimination)的方法来增强(reinforce)节点表示的学习,使其更准确、更稳定。
“自我判别”如何操作:对比学习(Contrastive Learning)。他们会为一个节点生成多个不同的“视角”(views),然后让同一个节点的不同视角在表示空间里尽可能接近,而让不同节点的视角尽可能远离。这就是“最大化相同节点不同视角之间的一致性”。
设计了三种具体的数据 augmentation(增强)方法来生成不同的“视角”,这些方法都是通过随机地改变图结构来实现的:
节点丢弃(Node Dropout): 随机屏蔽掉图中一部分节点。
边丢弃(Edge Dropout): 随机屏蔽掉图中一部分交互关系(边)。
随机游走(Random Walk): 通过随机游走为每个节点生成一个子图,不同的游走路径会生成不同的子图视角。
这些操作从不同角度“变化”图的结构,从而生成多个“视角”表示,然后通过最大化同一节点在不同视角之间的相似度,以及最小化与其他节点的相似度,来优化表示学习。
作者在 LightGCN 的基础上实现了 SGL 模型
发现SGL有一个额外的隐藏优势:它能够自动挖掘“难负例”(hard negatives)。在对比学习中,负例是与当前样本不相似的样本。而“难负例”是指那些与当前样本相似但确实不同的样本(例如,两款外观相似的手机),学会区分它们对模型来说挑战更大,收益也更高。SGL通过其图结构上的操作,可以自动产生这样的效果。
并通过理论分析指出 SGL 能够自动挖掘硬负样本(hard negatives),从而提高模型性能。实验部分在三个基准数据集上验证了 SGL 的有效性,其主要优势体现在:
提升推荐准确率,尤其是在长尾物品推荐方面;
增强模型对交互噪声的鲁棒性。
关键词(Keywords)
协同过滤(Collaborative Filtering)
图神经网络(Graph Neural Network)
自监督学习(Self-supervised Learning)
长尾推荐(Long-tail Recommendation)
其他信息(Footnotes & Metadata)
会议信息:SIGIR 2021(第44届ACM SIGIR国际信息检索研究与发展会议)
会议时间与地点:2021年7月11-15日,虚拟举办(加拿大)
出版信息:会议论文集《Proceedings of SIGIR ’21》
核心贡献总结
这篇论文的核心是提出了一个通用的、即插即用的自监督学习框架(SGL),用来增强基于GCN的推荐模型。
解决了什么问题? 解决了GCN推荐模型固有的 流行度偏见 和 对噪音敏感 的问题。
如何解决的? 通过在传统推荐损失基础上,引入一个 基于图数据增强的对比学习任务 作为辅助任务。
效果如何? 既提高了整体精度,又特别惠及了长尾商品,还让模型更抗噪。
简单来说,它就像是给推荐模型增加了一个“自学”任务,通过让模型学习“从不同角度观察同一个节点还能认出它”来获得更强大、更通用的表示能力。
1. Introduction¶
摘要概述¶
这段文字是一篇关于推荐系统研究的论文的引言部分。它主要阐述了:
背景:基于图的协同过滤推荐模型(GCNs)是目前的主流且有效的方法。
问题:但当前的模型存在三个主要缺陷:监督信号稀疏、数据分布倾斜(对长尾物品不友好)、交互数据中存在噪音。
解决方案:本文提出通过自监督学习(SSL) 来弥补上述缺陷。具体方法是引入一个辅助任务——节点自判别,通过数据增强(对图结构进行操作)和对比学习来为模型提供额外的训练信号。
贡献:该方法(名为SGL)是模型无关的,能有效提升推荐精度(尤其是长尾物品),并增强模型鲁棒性。文章还提供了理论分析。
逐部分详解¶
1. 研究背景与发展¶
核心主题:从用户-物品的交互数据中学习高质量的表示(向量)是协同推荐的关键。
技术演进:
初期:矩阵分解(MF)。只为每个用户和物品的ID分配一个嵌入向量,简单但信息有限。
发展:加入交互历史。利用用户过去交互过的物品来丰富其表示,比MF更有效。
当前主流:基于图卷积网络(GCNs) 的方法。将用户和物品看作一个二分图,利用图结构(即高阶连接关系,如“朋友的朋友”)来学习节点表示,性能最佳。
2. 现有模型的问题¶
尽管GCNs很有效,但它们存在三大局限性:
稀疏监督信号 (Sparse Supervision Signal)
问题:模型依赖已观察到的交互数据(如用户点击、购买记录)作为监督信号来学习。但这些数据只占所有可能交互的极小一部分(比如,一个用户可能只接触过百万商品中的几十个),导致信号稀疏,不足以学出非常好的表示。
倾斜的数据分布 (Skewed Data Distribution)
问题:交互数据通常遵循幂律分布(二八法则),即少数热门物品(高频物品)占据了大部分交互,而大量物品是很少被交互的长尾物品。
后果:在GCN的邻居聚合过程中,热门物品会频繁出现,对模型学习的影响更大,导致模型偏向于为热门物品生成更好的表示,而牺牲了长尾物品的推荐效果。
交互中的噪音 (Noises in Interactions)
问题:推荐系统大多依赖隐式反馈(如点击、浏览),而非显式反馈(如五星好评)。用户可能误点或不喜欢某个商品,这些不可靠的交互就是噪音。
后果:GCN的邻居聚合会放大这些噪音的影响(因为噪音会通过图结构传播),使得模型学习更加不稳定和脆弱。
3. 本文解决方案:引入自监督学习 (SSL, Self-Supervised Learning)¶
核心思想:将计算机视觉(CV)和自然语言处理(NLP)中成功的自监督学习(SSL) 技术引入推荐系统。
什么是SSL?:通过设计一个辅助任务,从数据本身(尤其是未标注的数据)中提炼出额外的信号来帮助模型学习。
例子1 (NLP):BERT通过随机遮盖句子中的词,并预测它,来学习词汇间的依赖关系。
例子2 (CV):RotNet通过旋转图片,并让模型识别旋转角度,来提升图像表示能力。
SSL的优势:可以充分利用未标注的数据空间,对下游任务(如推荐)带来显著提升。
4. 具体方法:SGL (Self-supervised Graph Learning)¶
挑战:推荐数据是离散且互联的(图结构),不同于CV/NLP。
辅助任务设计:节点自判别——判断两个表示是否来自同一个节点。
两个关键组件:
数据增强:为每个节点生成多个“视图”。
对比学习:最大化同一节点不同视图之间的一致性,同时最小化不同节点之间的一致性。
如何增强?:对图的邻接矩阵(即结构)进行三种操作:
节点丢弃:随机屏蔽一些节点。
边丢弃:随机丢弃一些交互边(用户-物品连接)。
随机游走:从图中采样不同的子图。
如何解决前述三个问题?
补充监督信号:对比学习任务提供了额外的、来源于数据本身的监督信号,弥补了交互信号的稀疏性。
缓解数据倾斜:特别是边丢弃操作,可以有意地减少与热门节点相连的边,从而削弱其影响力,让模型更多关注长尾节点。
增强鲁棒性:为节点生成基于不同邻居结构的多个视图,模型不再过度依赖某几条边,从而对噪音更不敏感。
理论发现:文中的对比学习范式有一个“副作用”——它会自动挖掘难以区分的负样本(Hard Negatives),这不仅能提升效果,还能加速训练。
5. 实验与贡献总结¶
通用性:SGL是模型无关的,可以套用在任何图推荐模型上。本文选择在轻量且高效的LightGCN上进行实现。
实验结果:在三个基准数据集上验证了SGL的有效性,显著提高了推荐精度,尤其是在长尾物品上,并增强了抗噪音能力。
三大贡献:
提出了SGL新范式。
从理论上了分析了其挖掘困难负样本的作用。
进行了广泛的实验验证。
2. Preliminaries¶
总体概括¶
这段文字描述的是如何利用图卷积网络(GCN)来构建一个推荐系统。其核心思想是:将用户和物品之间的关系看作一个图(Graph),然后使用GCN技术在这个图上学习用户和物品的表示向量,最后用这些向量来预测用户是否会喜欢某个物品。
逐段详解¶
1. 问题定义与图构建¶
我们有两类实体:用户(𝒰) 和 物品(ℐ)。
观测到的交互(𝒪+) 是指用户和物品之间发生过的行为,比如用户购买了一件商品、给一部电影打了分等。
y_ui = 1就表示用户u和物品i有过交互。这些关系被构建成一个二分图(Bipartite Graph)
𝒢。节点(𝒱):图中包含所有用户和所有物品。
边(ℰ):如果用户
u和物品i有过交互(即y_ui = 1),那么他们之间就有一条边。
简单理解: 把整个推荐系统想象成一张网,用户和物品是网上的点,用户购买过哪个物品,就用线把对应的点和物品点连起来。
2. GCN的核心操作:邻居聚合¶
公式 (1) & (2) 解释: GCN的工作方式是分层的(一层一层地计算)。它的核心思想是:一个节点的特征(表示向量)应该由其邻居节点的特征来丰富和更新。
Z(l):第l层所有节点的表示向量(嵌入向量)。Z(0):最初始的表示向量,通常是随机生成的可训练参数(比如每个用户、每个物品都有一个独立的ID嵌入向量)。
每一层 l 的操作都包含两个步骤(对应函数 f_aggregate 和 f_combine):
聚合(Aggregate):对于一个中心节点(例如用户
u),首先将它的所有邻居(例如用户u购买过的所有物品i)在上一层的表示向量z_i(l-1)聚合起来。聚合方式可以是求平均、求和、取最大值等。f_aggregate({z_i(l-1) | i ∈ 𝒩_u})
结合(Combine):然后将聚合后的邻居信息与中心节点自己上一层的表示向量
z_u(l-1)结合起来,生成节点u在第l层的新表示向量z_u(l)。f_combine(z_u(l-1), 聚合结果)
重要特性: 第 l 层的节点表示,已经融合了该节点**l 跳(l-hop)以内所有邻居的信息**。例如,第1层包含了直接邻居的信息,第2层包含了邻居的邻居(二阶邻居)的信息。
3. 生成最终表示向量¶
公式 (3) 解释: 经过L层GCN后,每个节点都有了L+1个表示向量(从第0层到第L层)。我们需要将这些不同层的表示合并成一个最终的表示向量用于预测。常见的方法有:
最后一层(Last-layer):只使用第L层的输出作为最终表示。简单,但可能丢失初始信息。
拼接(Concatenation):将每一层的表示向量拼接成一个很长的向量。保留所有信息,但维度会变大。
加权和(Weighted Sum):将各层表示加权求和,权重可以学习得到。一种灵活折中的方案。
简单理解: 每一层都捕获了不同范围(“朋友圈”大小)的信息,最后需要把这些信息综合起来,形成一个更全面、更准确的代表该用户或物品的“个人简历”。
4. 预测与模型训练¶
公式 (4) & (5) 解释:
预测(Prediction):得到用户
u的最终表示向量z_u和物品i的最终表示向量z_i后,最常用的预测方式是求它们的内积(Inner Product)y^_ui = z_u^T · z_i。内积值越大,说明用户和物品的向量越相似,表示用户越可能喜欢该物品。这种方式计算高效,特别适合做大规模推荐检索。训练(Training - 损失函数):模型需要学习参数,所以需要一个目标(损失函数)来优化。这里选择了 BPR(Bayesian Personalized Ranking)损失。
思想:对于一個用户
u,他希望模型对他交互过的物品(正样本i) 的打分,要远高于他未交互过的物品(负样本j) 的打分。做法:从训练数据
𝒪中采样大量的三元组(u, i, j),其中(u, i)是观测到的交互(正样本),(u, j)是未观测到的(作为负样本)。BPR损失函数会努力让(y^_ui - y^_uj)这个差值越大越好(用Sigmoid函数衡量),从而学会区分用户喜欢和不喜欢的东西。
简单理解: 训练模型的原则就是——“让模型猜用户喜欢的东西的分数越来越高,猜用户不喜欢的东西的分数越来越低”。
总结¶
这段话清晰地勾勒出了GCN用于推荐系统的标准流程:
建图:用用户-物品交互数据构建一个二分图。
传播:在图上运行GCN,通过多层“聚合-结合”操作,使每个节点(用户/物品)的表示向量包含其高阶邻居的信息。
读出:合并所有层的表示,生成每个用户和物品的最终向量。
预测:用用户和物品向量的内积来预测他们之间发生交互的可能性。
训练:使用BPR损失函数,通过比较正样本和负样本的分数来训练模型参数。
3. Methodology¶
核心思想概括¶
这段文字描述了一种自监督学习(SSL) 技术,用于增强基于图神经网络(GCN)的推荐系统。其核心思想是:
问题:传统的推荐系统GCN模型(如LightGCN)严重依赖用户-物品交互数据(即图结构)。数据稀疏时,模型性能会受限。
解决方案:引入一个自监督的辅助任务,与主推荐任务共同训练(多任务学习)。这个辅助任务不需要额外的人工标注数据,而是从图数据本身创造监督信号。
如何实现:
数据增强:对用户-物品交互图进行随机“破坏”,生成同一个节点的多个不同“视图”。
对比学习:让同一个节点在不同视图下的表示(正样本对)尽可能相似,而不同节点的表示(负样本对)尽可能不同。
效果:通过这个辅助任务,模型能学习到更鲁棒、更具区分性的节点表示,从而减轻数据稀疏问题,提升主推荐任务的性能。
各部分详解¶
1. 整体流程 (Section 3 开头部分)¶
SGL:Self-supervised Graph Learning,即自监督图学习范式。
目标:通过自监督学习来“增强”主监督任务(即点击/购买预测)。
** pretext task / 辅助任务**:从输入数据内部的关联中构建监督信号。在这里,这个关联就是“同一个节点在不同视图下应该保持一致”。
方法组合:将数据增强(创建不同视图)和对比学习(比较视图间的相似性)结合起来,与经典的GCN模型通过多任务学习的方式进行结合。
理论分析:作者会从梯度角度分析,揭示该方法与“困难负样本挖掘”的联系。
图1说明:上图是主监督任务(标准的图卷积和预测),下图是自监督辅助任务(对图结构进行增强并做对比学习)。
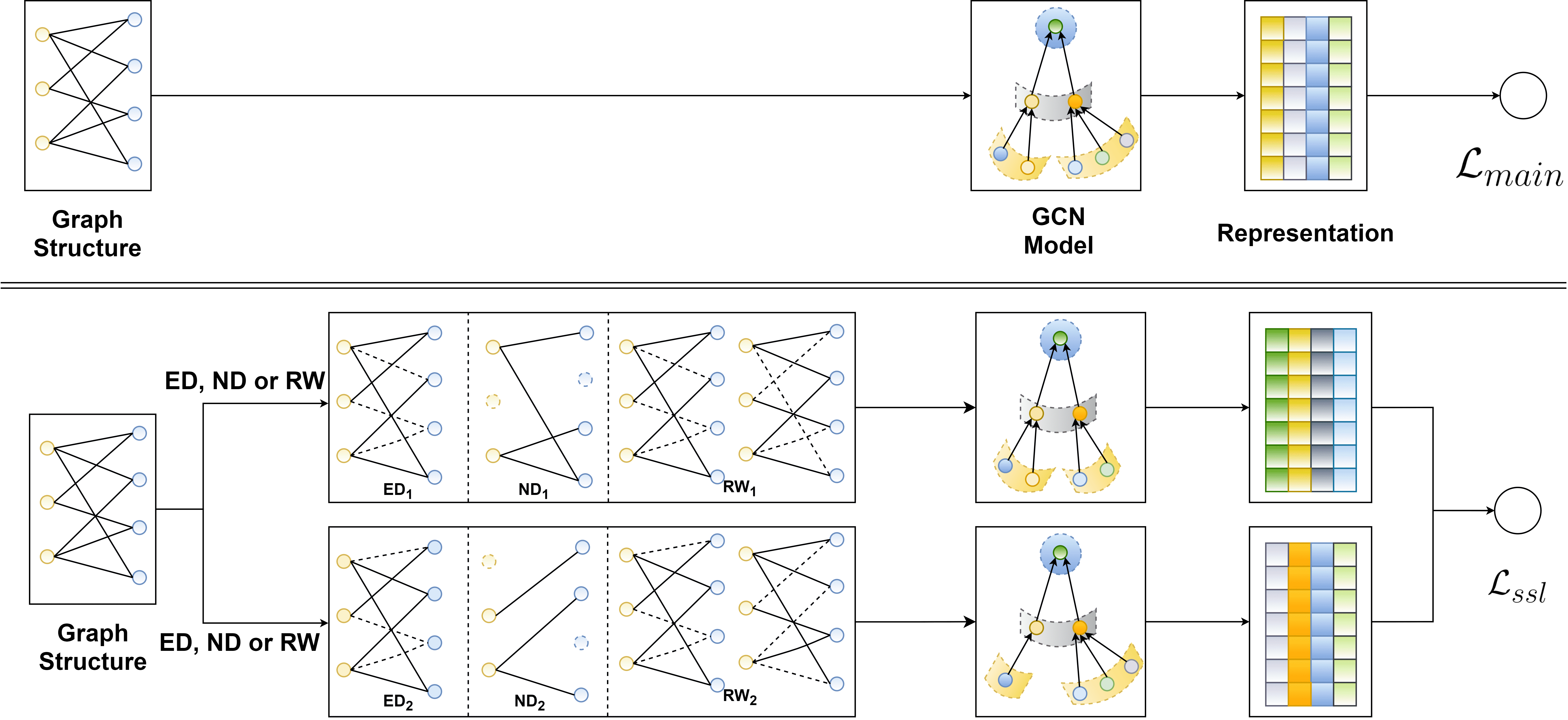
Figure 1.The overall system framework of SGL.
The upper layer illustrates the working flow of the main supervised learning task
The bottom layer shows the working flows of SSL task with augmentation on graph structure.
2. 图结构的数据增强 (Section 3.1)¶
为什么不能直接用CV/NLP的方法?
用户和物品的特征是离散的(如ID),图像的那些增强方法(裁剪、旋转)不适用。
用户和物品在图中是相互连接的,而非独立的个体。
为什么要在图上做增强?
图中包含着丰富的协同过滤信号(例如,历史物品代表用户兴趣,相似用户有相似行为)。增强可以挖掘图结构的内在模式,帮助学习更好的表示。
三种增强操作符:
节点丢弃(Node Dropout, ND):随机丢弃一部分节点及其连边。目标是让模型不过度依赖少数关键节点,对结构变化更鲁棒。
边丢弃(Edge Dropout, ED):随机丢弃一部分边。目标是让模型关注局部结构模式,对噪声交互(如误点击)更鲁棒。
随机游走(Random Walk, RW):与ED和ND的关键区别。ED和ND在每个训练周期(epoch)生成一个固定的子图用于所有层。而RW在每一层都随机丢弃不同的边,相当于为每一层生成一个不同的子图。这使得节点间的连通路径更加多样化(见图2)。
共同形式:公式(6)概括了增强过程。
s1和s2是两个独立的随机采样函数,分别作用于原图G,生成两个增强后的子图视图Z1和Z2。H是图卷积操作。
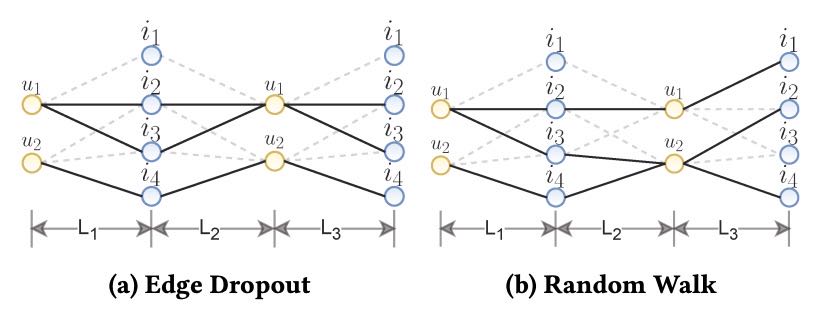
Figure 2.A toy example of higher-order connectivity in a three-layer GCN model with Edge Dropout (left) and Random Walk (right). For Random Walk, the graph structure keeps changing across layers as opposed to Edge Dropout. As a result, there exists a three-order path between node u_1 and i_1 that does not exist in Edge Dropout.
3. 对比学习 (Section 3.2)¶
正负样本对定义:
正样本对:同一个节点(如用户u)在两个不同增强视图下的表示
(z‘_u, z’‘_u)。负样本对:不同节点(如用户u和用户v)的表示
(z’_u, z‘’_v)。
目标:最大化正样本对的相似性,最小化负样本对的相似性。
损失函数:使用InfoNCE损失(公式10)。它本质是一个基于softmax的损失,分子是正样本对的相似度,分母是正样本对与所有负样本对相似度的总和。
τ是温度参数,控制分布的尖锐程度(后面理论分析会重点讲)。最终损失:用户侧和物品侧的对比损失相加
L_ssl = L_ssl_user + L_ssl_item。
4. 多任务训练 (Section 3.3)¶
总损失函数:
L = L_main + λ1 * L_ssl + λ2 * ||Θ||^2L_main:主推荐任务的损失(如BPR损失)。L_ssl:自监督对比损失。||Θ||^2:L2正则化项,防止过拟合。λ1,λ2:超参数,控制各部分的重要性。
替代方案:也可以先预训练(只用
L_ssl),再微调(只用L_main)。
5. SGL的理论分析 (Section 3.4) - 这是最难也是最重要的部分¶
核心问题:SGL为什么有效?
答案:对比学习任务具有自动挖掘困难负样本的能力,从而提供了更有意义的梯度来指导模型优化。
如何证明?
梯度分解:作者推导了对比损失
L_ssl对节点表示z’_u的梯度(公式12)。这个梯度可以分解为正样本节点u的贡献c(u) 和所有负样本节点v的贡献c(v) 之和。关注负样本贡献:负样本v的梯度贡献
c(v)的模长(大小)近似于一个函数g(x) = sqrt(1-x²) * exp(x/τ),其中x是正样本u和负样本v的表示之间的余弦相似度。分析函数
g(x):x ~ 1:困难负样本(与正样本很相似,难以区分)。x ~ -1:简单负样本(与正样本完全不同,很容易区分)。通过绘制
g(x)的函数曲线(图3),作者发现:当
τ较大(=1)时,g(x)曲线平缓,所有负样本贡献的梯度大小差不多。当
τ较小(=0.1)时,g(x)曲线非常尖锐:x值很高(非常困难的负样本)的梯度贡献巨大,而简单负样本(x为负)的梯度贡献几乎为0。
结论:小的温度参数
τ使得对比学习过程能够自动地重点关注那些困难负样本,从而获得更大、更有效的梯度来更新模型,让学习到的表示更具区分度,加速模型收敛。这相当于一种隐式的困难负样本挖掘策略。
6. 复杂度分析 (Section 3.5)¶
空间复杂度:SGL没有引入任何额外的可训练参数,所以和基础的LightGCN一样。
时间复杂度:主要增加来自两部分:
构建增强图:需要为每个epoch生成两个子图并计算归一化邻接矩阵。
计算对比损失:需要计算大批量中所有样本对的相似度。
结论:虽然SGL比LightGCN更耗时(论文中以Yelp2018数据集为例,耗时约为3.7倍),但鉴于其能显著提升效果和收敛速度,这个开销是可以接受的。
总结¶
这段方法论描述了一个巧妙且强大的框架:
创造性地将SSL应用于图推荐:通过图结构上的数据增强(ND, ED, RW)来生成自监督信号。
通过多任务学习整合:将对比学习作为辅助任务与主任务联合训练,提升主任务性能。
提供了深刻的理论解释:从梯度层面证明了SGL的有效性源于其自动聚焦困难负样本的能力,这是通过调节温度参数
τ来实现的。实践上可行:虽然增加了计算成本,但仍在可接受范围内,且收益显著。
简单来说,SGL让推荐模型不仅学习“用户A是否喜欢物品B”这个主任务,还同时学习“不管图怎么变,用户A还是用户A”这个辅助任务,从而学到一个更本质、更鲁棒的用户/物品表示。
4. Experiments¶
本节通过大量实验验证了**SGL(Self-supervised Graph Learning)**在推荐系统中的优越性,并探讨其有效性的原因。主要研究问题包括:
RQ1:SGL在Top-K推荐任务中相比现有最先进的协同过滤(CF)模型表现如何?
RQ2:在协同过滤中使用自监督学习带来了哪些优势?
RQ3:不同设置如何影响SGL的有效性?
4.1. Experimental Settings¶
数据集¶
实验在三个真实世界的推荐数据集上进行:
数据集 |
用户数 |
物品数 |
交互数 |
密度 |
|---|---|---|---|---|
Yelp2018 |
31,668 |
38,048 |
1,561,406 |
0.00130 |
Amazon-Book |
52,643 |
91,599 |
2,984,108 |
0.00062 |
Alibaba-iFashion |
300,000 |
81,614 |
1,607,813 |
0.00007 |
Yelp2018 和 Amazon-Book 采用 10-core 设置,Alibaba-iFashion 更稀疏,随机采样 300k 用户。
评估指标¶
将用户交互按 7:1:2 分为训练集、验证集和测试集。使用 All-ranking 协议计算 Recall@20 和 NDCG@20。
对比模型¶
NGCF:基于图卷积的协同过滤模型。
LightGCN:简化版 GCN,提高推荐性能。
Mult-VAE:基于变分自编码器的推荐模型。
DNN+SSL:基于深度神经网络和自监督学习的推荐模型。
SGL变体¶
提出三种SGL变体:
SGL-ND:基于节点丢弃(Node Dropout)。
SGL-ED:基于边丢弃(Edge Dropout)。
SGL-RW:基于随机游走(Random Walk)。
超参数设置¶
所有模型使用 Xavier 初始化,Adam 优化器,学习率 0.001,批量大小 2048。
SGL 超参数包括对比损失系数 λ₁、温度 τ 和采样比例 ρ。
4.2. Performance Comparison (RQ1)¶
4.2.1. 与 LightGCN 的比较¶
表3展示了 SGL 与 LightGCN 在不同图层数下的性能比较。
SGL 显著优于 LightGCN:在大多数情况下,SGL 的 Recall 和 NDCG 指标优于 LightGCN,尤其在 Amazon-Book 和 Alibaba-iFashion 数据集上提升显著。
SGL-ED 表现最佳:在 10/18 个案例中 SGL-ED 表现最好,SGL-RW 次之,SGL-ND 相对不稳定。
模型深度提升性能:增加图层数(1~3)提升了 SGL 的性能,表明 SGL 能缓解 GCN 的过平滑问题。
4.2.2. 与 SOTA 模型比较¶
表4展示了 SGL 与其他 SOTA 模型的对比结果:
模型 |
Yelp2018 |
Amazon-Book |
Alibaba-iFashion |
|---|---|---|---|
SGL-ED |
0.0675 |
0.0555 |
0.1126 |
LightGCN |
0.0639 |
0.0525 |
0.1078 |
NGCF |
0.0579 |
0.0477 |
0.1043 |
DNN+SSL |
0.0483 |
0.0438 |
0.0712 |
SGL-ED 超越所有基线,尤其在 Amazon-Book 上表现最佳。
DNN+SSL 在 Amazon-Book 表现不错,但在其他数据集上不如 SGL-ED,说明基于图的 SSL 更有效。
p 值 < 0.05 表明 SGL-ED 的改进在统计上显著。
4.3. Benefits of SGL (RQ2)¶
4.3.1. 长尾推荐¶
LightGCN 只推荐高频物品,导致长尾物品被忽视。
SGL 减少了高频组对 Recall 的贡献,提升了对长尾物品的推荐能力。
4.3.2. 训练效率¶
SGL 收敛更快:SGL 在 Yelp2018 和 Amazon-Book 上分别在 18 和 16 个 epoch 达到最优,而 LightGCN 需要 720 和 700 个 epoch。
InfoNCE 损失和动态硬负采样是 SGL 高效训练的关键。
4.3.3. 对噪声的鲁棒性¶
SGL 比 LightGCN 更鲁棒:在加入 5%~20% 噪声时,SGL 性能下降更少。
在 Amazon-Book 上,即使加入 20% 噪声,SGL 仍优于干净数据下的 LightGCN。
4.4. Study of SGL (RQ3)¶
4.4.1. 温度 τ 的影响¶
τ 过小或过大都会影响性能:τ = 0.1~1.0 为最佳区间。
τ 控制负样本的难易区分度,对训练稳定性至关重要。
4.4.2. 预训练的影响¶
SGL-pre 表现略差于联合训练的 SGL-ED,但优于 LightGCN。
自监督任务提供了更好的初始化,但联合训练可进一步提升性能。
4.4.3. 负样本设计的影响¶
区分节点类型(SGL-ED-batch)优于不区分(SGL-ED-merge)。
使用 mini-batch 的 SGL 可有效替代全局负样本。
总结¶
本章通过大量实验验证了 SGL 的有效性:
性能优越:SGL 在多个数据集上超越现有 SOTA 模型。
自监督学习提升推荐质量:有助于长尾推荐、提高训练效率、增强模型鲁棒性。
设计合理:SGL 中的自监督任务设计(如边丢弃、动态硬负采样等)对性能提升至关重要。
具有通用性:SGL 可作为其他推荐模型的增强方法,提升其初始化与泛化能力。
6. Conclusion and Future Work¶
在本研究中,我们识别了在一般监督学习框架下基于图的推荐方法的局限性,并探索了自监督学习(Self-Supervised Learning, SSL)在解决这些局限方面的潜力。我们提出了一种模型无关的框架——SGL(Self-supervised Graph Learning),以在用户-项目图上通过自监督学习辅助监督推荐任务。
从图结构的角度出发,我们设计了三种不同方面的数据增强方法来构建辅助的对比任务。我们在三个基准数据集上进行了广泛的实验,验证了我们方法在长尾推荐、训练收敛速度以及对噪声交互的鲁棒性方面的优势。
这项工作是对将自监督学习应用于推荐系统的初步尝试,为未来的研究开辟了新的可能性。在未来的工作中,我们希望将SSL更深入地融入推荐任务中。我们计划超越图结构上的随机选择,探索如**反事实学习(counterfactual learning)**等新视角,以识别有影响力的数据点,从而构建更强大的数据增强方法。
此外,我们将重点关注推荐系统中的预训练与微调机制,即训练一个能够捕捉跨多个领域或数据集的用户通用和可迁移模式的模型,并在新领域或数据集上进行微调。另一个有前景的研究方向是进一步挖掘SSL在解决长尾问题方面的潜力。
我们希望SGL的发展能够有助于提高推荐模型的泛化性和迁移能力。
致谢:
本研究得到了国家自然科学基金(U19A2079, 61972372)和国家重点研发计划(2020AAA0106000)的支持。
Appendix A Gradient of InfoNCE Loss w.r.t. node representation¶
1. InfoNCE 损失函数的表达式¶
对于用户 u,其对比损失函数定义为:
其中 \( s_u^{\prime} \) 和 \( s_u^{\prime\prime} \) 是归一化后的用户表示。
归一化形式为:\( s_u^{\prime} = \frac{z_u^{\prime}}{\| z_u^{\prime} \|} \),\( s_u^{\prime\prime} = \frac{z_u^{\prime\prime}}{\| z_u^{\prime\prime} \|} \)。
重点在于展示了归一化如何影响梯度计算。
2. 关于 \( z_u^{\prime} \) 的梯度推导¶
利用链式法则,梯度可分解为:
归一化梯度项: $\( \frac{\partial s_u^{\prime}}{\partial z_u^{\prime}} = \frac{1}{\| z_u^{\prime} \|} (I - s_u^{\prime} s_u^{\prime T}) \)$
其中 \( I \) 是单位矩阵,\( s_u^{\prime} s_u^{\prime T} \) 是一个秩1矩阵。
该式说明归一化会引入一个投影矩阵,即从 \( z_u^{\prime} \) 的梯度方向减去其在 \( s_u^{\prime} \) 方向上的投影。
3. 关于 \( s_u^{\prime} \) 的损失梯度¶
定义:
\( P_{uv} = \frac{\exp(s_u^{\prime T} s_v^{\prime\prime} / \tau)}{\sum_{v \in \mathcal{U}} \exp(s_u^{\prime T} s_v^{\prime\prime} / \tau)} \)
\( P_{uu} \) 是正样本的概率。
意义:
正样本的梯度项为 \( s_u^{\prime\prime T} (P_{uu} - 1) \)
负样本的梯度项为 \( s_v^{\prime\prime T} P_{uv} \)
4. 最终的梯度表达式¶
重点总结:
梯度由正样本和负样本两部分组成。
通过投影矩阵 \( I - s_u^{\prime} s_u^{\prime T} \),梯度最终只作用于与表示方向垂直的维度,这有助于保持表示的归一化性质。
5. 推导的数学意义¶
该推导表明,在 InfoNCE 损失中使用归一化表示时,梯度会受到两个关键因素影响:
归一化对梯度方向的限制:梯度被投影到与表示方向垂直的空间。
正负样本的相对概率 \( P_{uv} \):影响梯度的强度和方向。
通过这种形式的梯度更新,模型能够更好地学习表示的结构,特别是在使用余弦相似度时。
总结¶
本附录详细推导了 InfoNCE 损失函数对节点表示的梯度。重点如下:
使用余弦相似度时,归一化会导致梯度被投影到与表示方向垂直的空间;
梯度由正样本和负样本项组成,分别通过 \( P_{uu} \) 和 \( P_{uv} \) 表示;
最终的梯度形式保留了归一化带来的结构约束,有助于模型学习更具区分性的节点表示。