2312.04511_LLMCompiler: An LLM Compiler for Parallel Function Calling¶
引用: 91(2025-08-24)
组织
1UC Berkeley
2ICSI(International Computer Science Institute, 位于美国加州伯克利,成立于 1988 年)
3LBNL(Lawrence Berkeley National Laboratory, 美国顶尖国家实验室)
总结¶
总结
参见: 图1,
背景
现有的利用大语言模型 (LLMs) 调用多个函数的方法依赖于顺序和动态推理,这导致了在延迟、成本和准确性方面的效率低下。
贡献:
提出了一种将 LLM 与传统编译器结合的新思路。
实现了一种自动化的函数调用并行化方法,提升了 LLM 输出的实用性。
LLMCompiler
设计灵感来源于传统编译器
它包含三个关键组件:
Function Calling Planner(函数调用规划器)
分解查询任务并确定执行流程;
Task Fetching Unit(任务获取单元)
并行派遣函数调用;
Executor(执行器)
执行派遣的任务,并处理其依赖关系。
核心思想:并行执行函数调用
关键技术
依赖关系分析:
静态分析任务描述,构建函数调用的依赖图(DAG),识别可并行执行的独立调用。
动态调度器:
运行时管理函数执行顺序,优先调度无依赖的调用,并处理动态生成的中间结果。
错误处理与重试:
支持部分失败后的条件重试,确保鲁棒性。
Streamed Planner
背景: 当用户查询包含大量任务时,系统的“规划器”会产生不小的开销。
具体原因: 传统工作模式是,规划器必须一次性生成所有任务的完整依赖关系图后,才能交给“任务获取单元”和“执行器”去执行。
灵感来源: 借鉴现代计算机架构中的“指令流水线”思想。CPU不会等一条指令完全执行完再处理下一条,而是将指令处理分成多个阶段,并行工作,极大提高了效率。
工作流程: 规划器不再一次性输出全部结果,而是生成一个任务就立刻输出一个。对于每个任务,只要它的所有前置依赖都已被满足,“执行器”就可以立即开始执行这个任务,而无需等待其他任务被规划出来。
Abstract¶
核心问题¶
当前的大语言模型(LLMs)虽然具备一定推理能力,但仍存在一些根本性限制,如:
知识截止日期(无法获取最新信息)
数学计算能力不足
缺乏对私有数据的访问能力
为了解决这些问题,LLMs 通常通过调用外部函数来扩展其能力。这些函数可以帮助完成计算、数据检索等任务。然而,目前的函数调用方法通常采用顺序执行的方式,导致:
高延迟
高成本
准确性下降
解决方案:LLMCompiler¶
为了解决上述问题,本文提出了LLMCompiler,一种能够并行执行外部函数调用的系统,从而提高效率和准确性。
LLMCompiler 的设计灵感来源于传统编译器,它包含三个关键组件:
Function Calling Planner(函数调用规划器)
负责制定函数调用的执行计划,决定哪些函数可以并行执行,哪些需要依赖前一步的输出。
Task Fetching Unit(任务获取单元)
负责分发函数调用任务,将任务发送给执行器。
Executor(执行器)
负责并行执行函数调用任务,从而提升整体性能。
LLMCompiler 的一大优势是它自动优化函数调用流程,无需手动干预。它支持开源和闭源模型,具有广泛适用性。
实验结果¶
作者在多种不同函数调用模式的任务上对 LLMCompiler 进行了基准测试,结果表明:
延迟降低:高达 3.7 倍
成本节省:高达 6.7 倍
准确性提升:约 9%
这些结果表明,LLMCompiler 显著优于目前主流的 ReAct 方法。
代码开源¶
LLMCompiler 的代码已开源,可在以下链接访问:
https://github.com/SqueezeAILab/LLMCompiler
总结重点:¶
LLMCompiler 的优势在于并行执行函数调用,这是对传统顺序执行方式的重要改进。
自动优化、支持多模型、显著提升性能和准确性是其核心亮点。
实际测试结果非常有说服力,验证了其在效率和成本上的优势。
1. Introduction¶
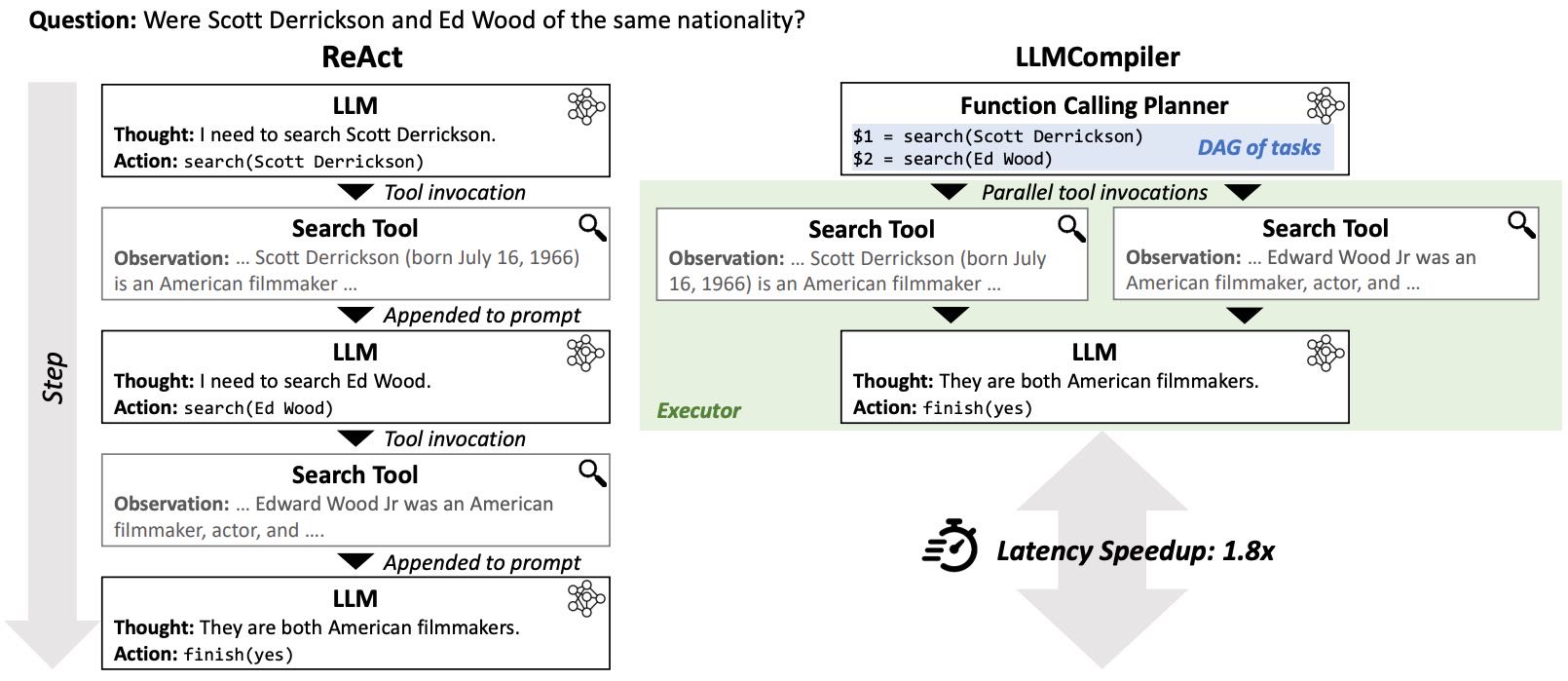
Figure 1. An illustration of the runtime dynamics of LLMCompiler, in comparison with ReAct
背景¶
近年来,大语言模型(LLMs)的推理能力取得了显著进步,使其应用范围从内容生成扩展到解决复杂问题。已有研究表明,LLMs的推理能力在提升复杂和逻辑任务准确性方面具有重要作用。此外,LLMs还可以调用外部工具(或函数),从而扩展其功能,这些工具可以从简单的计算器到更复杂的LLM基函数不等。
挑战¶
LLMs集成多种工具和函数调用的能力可能带来软件开发方式的根本性转变。然而,如何高效地结合多个函数调用成为一个关键挑战。目前,ReAct(Yao et al., 2022)是一个较为突出的方法,它通过调用函数、分析结果并决定下一步行动来实现任务解决。例如,在判断两位导演国家是否相同的问题中,ReAct会依次调用搜索工具,获取信息并逐步推理。
问题与不足¶
尽管ReAct是一个开创性的工作,并被集成到多个框架中,但其流程是顺序执行的:每一步都要等待前一步的结果,导致更高的延迟和成本。此外,重复调用LLM进行推理和操作步骤,以及将中间结果拼接到原提示中,可能会影响模型的推理流程,从而降低准确性。常见的失败案例包括重复调用同一函数或过早停止等问题。
解决方案与创新¶
为了解决上述问题,作者受到传统编译器的启发,提出了一种新的框架——LLMCompiler。该框架借鉴了编译器优化指令执行的思想,通过识别可并行执行的函数调用并高效管理其依赖关系,从而优化LLM的执行效率。这与近年来将LLMs与计算机系统对齐的研究方向一致(如Karpathy, 2023; Packer et al., 2023)。
框架概述¶
LLMCompiler的核心思想是并行执行函数调用,通过三个关键组件实现:
Function Calling Planner(函数调用规划器):分解查询任务并确定执行流程;
Task Fetching Unit(任务获取单元):并行派遣函数调用;
Executor(执行器):执行派遣的任务,并处理其依赖关系。
实验与贡献¶
作者通过多个实验验证了LLMCompiler的有效性,主要贡献如下:
性能提升:在HotpotQA和电影推荐任务中,相比ReAct,LLMCompiler分别提升了1.80×/3.74倍的速度和3.37×/6.73倍的成本效率。
复杂模式支持:在设计的新基准ParallelQA中,LLMCompiler在多种非平凡调用模式下,实现了2.27倍的速度提升、4.65倍的成本降低,并提升了9%的准确性。
动态重规划能力:在需要根据中间结果进行多次重规划的“24点游戏”任务中,LLMCompiler比Tree-of-Thoughts方法快了2倍。
交互式决策效率:在WebShop任务中,LLMCompiler实现了最高101.7倍的速度提升,并提高了25.7%的成功率。
总结¶
LLMCompiler通过引入编译器思想,将LLMs的函数调用流程优化为并行执行,显著提升了推理效率、降低了成本,并在多个任务中提高了准确性。这一框架为未来LLM驱动软件系统的开发提供了新的方向。
2.1. Latency Optimization in LLMs(LLMs的延迟优化)¶
重点内容:
当前研究主要集中在通过模型设计**(如 Chen et al., 2023a; Dettmers et al., 2023; Kwon et al., 2022 等)**和系统优化(如 tgi、trt、Yu et al., 2022 等)来提升LLM推理效率。
然而,应用层的延迟优化研究较少,这在模型和推理流水线无法修改的“黑盒”场景下尤其重要。
最近提出的 Skeleton-of-Thought(Ning et al., 2023) 通过应用层的并行解码来减少延迟,但该方法局限于完全可并行的任务,无法处理任务之间存在依赖关系的问题,因此在如编程和数学推理等复杂任务中适用性有限。
LLMCompiler 的创新点在于:将输入查询转化为具有依赖关系的一系列任务,从而扩展了可处理的问题范围。
次要内容:
OpenAI 最新版本(1106)引入了并行函数调用功能,但该功能仅限于其自有模型。
随着开源模型的普及及参数高效微调技术的发展(如 Houlsby et al., 2019; Hu et al., 2022),开源社区对开源模型调用能力的需求日益增长。
LLMCompiler 支持开源模型的并行函数调用,具有更好的延迟和成本优势(将在第5节展示)。
2.2. Plan and Solve Strategy(计划与求解策略)¶
重点内容:
多项研究(如 Hao et al., 2023; Wang et al., 2023a 等)尝试通过将复杂查询分解为多个子任务,提升LLM在推理任务中的表现。
例如:Decomposed Prompting(Khot et al., 2023)将任务拆解为子任务并优化提示。
Step-Back Prompting(Zheng et al., 2023)从细节中抽象出高层概念以增强推理能力。
Plan-and-Solve Prompting(Wang et al., 2023a)通过将多步推理任务分解为子任务,减少错误并提高准确性。
这些方法主要目标是提高推理准确性,而 LLMCompiler 的目标是通过识别可并行的模式来减少延迟,同时保持准确性。
此外,TPTU、HuggingGPT 和 ViperGPT 等提出了端到端的计划与求解框架,但 LLMCompiler 的优势在于其通用性,支持规划与重规划、并行执行以及更广泛的问题领域(将在附录F中详细讨论)。
ReWOO(Xu et al., 2023)旨在通过将推理与执行分离来减少token使用和成本,但 LLMCompiler 不同之处在于:
支持并行函数调用以降低延迟和成本;
支持动态重规划,适合执行流程无法预先确定的任务(第5.3节)。
2.3. Tool-Augmented LLMs(工具增强的LLMs)¶
LLMs 的推理能力使其能够调用用户提供的函数并利用其输出完成任务。
本节对该领域的研究进行了简要介绍,更详细的讨论见附录 C.1。
总结¶
该节系统性地回顾了LLM在延迟优化、推理策略分解和工具增强方面的主要研究,并突出了 LLMCompiler 的几个关键优势:
解决任务依赖性问题,相比 Skeleton-of-Thought 等方法;
支持开源模型的并行调用,优于 OpenAI 的封闭方案;
通用性强,支持动态重规划与多领域问题;
兼顾效率与准确性,通过计划与并行执行减少延迟。
这些特点使 LLMCompiler 在当前 LLM 应用系统中具有显著的创新性与实用性。
3. Methodology¶
LLMCompiler 通过将任务分解为并行执行的步骤,提升了大型语言模型(LLM)在处理复杂问题上的效率。本节通过一个简单的两步并行任务示例来说明其核心组成和工作流程。
用户输入与任务分解示例¶
用户问题:“微软的市值需要增加多少才能超过苹果的市值?”
LLMCompiler 将该问题分解为以下任务:
$1 = search(Microsoft Market Cap)
$2 = search(Apple Market Cap)
\(3 = math(\)1 / $2)
\(4 = llm(\)3)
这些任务构成一个任务依赖图(DAG),如图 2 所示。
LLMCompiler 的核心组件包括:
Function Calling Planner(功能调用规划器):负责根据用户输入,生成任务及其依赖关系。它利用 LLM 的推理能力,将自然语言问题分解为一系列可执行的子任务,并标注其依赖关系。
Task Fetching Unit(任务获取单元):根据依赖关系,从 Planner 获取任务,并将适合并行执行的任务发送给 Executor。它还负责将前序任务的输出代入后续任务的占位符中。
Executor(执行器):异步执行任务,使用用户提供的工具(如计算器、搜索工具或 API)来完成具体操作。每个任务都有独立的内存来存储中间结果。
用户只需提供工具定义和可选的上下文示例给 Planner,即可使用 LLMCompiler。
3.1. Function Calling Planner(功能调用规划器)¶
该组件是 LLMCompiler 的核心,负责生成任务及其依赖关系。例如,在图 2 中,任务 \(1 和 \)2 是独立的搜索任务,可以并行执行;而任务 \(3 依赖于这两个任务的输出。因此,规划器会自动识别这些依赖关系,生成一个 **有向无环图(DAG)**,并使用占位符变量(如 \)1、$2)表示后续任务中需要用到的中间结果。
Planner 依赖于 LLM 的推理能力,并通过预定义的提示(prompt)来指导其生成符合语法的任务序列。此外,用户还可以提供工具定义和上下文示例,以帮助 Planner 更准确地理解任务结构。这些信息会在第 4.1 节详细讨论。
3.2. Task Fetching Unit(任务获取单元)¶
该单元类似于现代计算机架构中的“指令获取单元”,负责按需获取任务并发送给执行器。其核心功能有两点:
根据依赖关系决定任务是否可执行,并按照贪心策略尽可能并行地调度任务;
将占位符替换为真实值。例如,任务 \(3 中的变量 \)1 和 $2 会分别被替换为微软和苹果的实际市值。
该单元不需要专用的 LLM,只需一个简单的调度与队列机制即可实现。
3.3. Executor(执行器)¶
执行器负责异步执行任务,并将其分配给相应的工具。由于 Task Fetching Unit 保证了发送给执行器的任务是独立的,因此可以并发执行。
工具可以是:
简单函数(如数学运算)
搜索工具(如维基百科搜索)
API 调用
甚至定制的 LLM agent
每个任务都有独立的内存存储中间结果,类似于传统顺序框架中将观察结果汇总为一个提示(prompt)的方式。任务执行完成后,其结果将作为输入传递给依赖它的后续任务。
3.4. 动态重规划(Dynamic Replanning)¶
在某些情况下,执行过程会根据中间结果动态调整,类似于程序中的“分支”操作。例如,在运行时根据条件判断选择执行哪条路径。
对于简单的分支(如 if-else),可以静态编译并动态选择路径;但对于更复杂的分支,可能需要根据中间结果进行重新规划(replanning)。
动态重规划的流程如下:
Executor 将中间结果返回给 Function Calling Planner;
Planner 根据新信息生成新的任务序列;
新任务被发送至 Task Fetching Unit,再由 Executor 执行;
循环该过程,直到最终结果生成。
这种机制在如“24 点游戏”这类需要多步推理和动态路径选择的问题中尤为重要,相关案例将在第 5.3 节展示。
4.LLMCompiler Details¶
4.1. 用户提供的信息(User-Supplied Information)¶
LLMCompiler 需要用户提供两类信息:
工具定义(Tool Definitions)
用户需要明确告诉 LLM 可以使用的工具,包括每个工具的描述和参数规范。这是 LLMCompiler 能够正确调用外部工具的基础。这一要求与 ReAct 和 OpenAI 函数调用框架类似,属于必要输入,因此是重点内容。Planner 的上下文示例(In-context Examples for the Planner)
用户可以可选性地提供 Planner 如何行为的示例,例如对于图 2 中的场景,提供任务之间依赖关系的示例。这些示例有助于 Planner 更好地理解工具的使用方式,并生成正确格式的任务依赖图。虽然这部分是可选项,但它可以显著提升 Planner 的质量和适应性,因此也是重要内容。
附录 G 中提供了评估中使用的示例,作为参考。
4.2. 流式Planner(Streamed Planner)¶
在处理复杂查询时,Planner 会生成多个任务,这可能会带来显著的延迟,因为 Task Fetching Unit 和 Executor 需要等待 Planner 生成完整依赖图后才能开始处理任务。为了解决这一性能瓶颈,LLMCompiler 引入了流式Planner。
流式Planner 的机制
Planner 以流式方式异步输出任务依赖图,而不是一次性生成。一旦某个任务的依赖关系被解析完成,Executor 就可以立即处理该任务,从而提升整体执行效率。这一机制类似于现代计算机系统中的指令流水线,是本节的重点内容。实验结果
表 C.1 展示了在不同基准测试中,LLMCompiler 在开启和关闭流式Planner 机制下的延迟对比。结果显示,流式机制显著降低了系统延迟,特别是在 ParallelQA 基准中,延迟减少了高达 1.3 倍。
延迟改善的原因在于,在 ParallelQA 中使用的数学工具执行时间较长,擅长“隐藏”Planner 的延迟,而在 HotpotQA 和 Movie Recommendation 中使用的是搜索工具,执行时间较短,因此延迟优化效果不明显。这部分是对优化效果的精简讲解。
总结:LLMCompiler 通过用户提供的工具定义和可选的 Planner 示例,构建任务依赖图;通过引入流式Planner,提升了系统在处理复杂任务时的效率和响应速度。
5. Results¶
本节评估了 LLMCompiler 在多种模型和问题类型中的表现。主要使用了 GPT 系列的闭源模型和 LLaMA-2 开源模型,并特别强调 LLMCompiler 在开放源模型中实现并行函数调用的能力。讨论了从简单的“完全并行模式”到更复杂的“依赖模式”,包括动态依赖图的动态重规划问题。最后,展示了 LLMCompiler 在 WebShop 决策任务中的应用。
5.1. 完全并行函数调用¶
这是最简单的情况,LLM 用于独立任务(例如并行搜索或分析)。传统方法如 ReAct 需要顺序执行,导致 延迟增加 和 token 消耗增加。这里通过两个基准测试展示了 LLMCompiler 的优势:
HotpotQA:评估多跳推理,包含 1500 个比较两个实体的问题,属于 2 路完全并行任务。
Movie Recommendation:需要从四部电影中选出最相似的电影,属于 8 路完全并行任务。
结果表明,LLMCompiler 相比 ReAct 和 OpenAI 的并行函数调用方法,速度更快,token 消耗更少,成本更低。表格数据显示速度提升可达 3.74x,token 成本降低可达 6.73x。
5.2. 带依赖关系的并行函数调用¶
在更复杂的情况下,任务之间存在依赖关系,类似于传统代码执行中的依赖链。为此,设计了一个自定义的 ParallelQA 基准测试,包含三种依赖模式(见图 3(b) 和 (c))。
使用两种工具:搜索工具和数学工具,其中数学工具的参数依赖于搜索工具的输出。
结果表明,LLMCompiler 相比 ReAct 在 速度 和 准确性 上都有显著提升,尤其在 LLaMA-2 模型上,速度提升可达 2.27x,token 成本降低 4.65x。
LLMCompiler 能够一次性规划所有任务,而 OpenAI 的并行函数调用方法则需要多次调用 LLM,效率较低。
5.3. 带重规划的并行函数调用¶
在某些任务中,依赖图需要根据中间结果动态生成。以 Game of 24 为例,目标是使用四个数字和基本算术操作得到 24。
LLMCompiler 支持“再规划”策略,即在每一轮中,通过“topk 选择”保留最有希望的方案,然后触发 Planner 生成新的计划。
与基线方法相比,LLMCompiler 在 gpt-4 上实现了 2.89x 的速度提升,且成功率略有提高。在 LLaMA-2 上,速度提升为 2.01x,成功率保持稳定。
5.4. 应用:LLMCompiler 在交互式决策任务中的表现¶
本部分评估了 LLMCompiler 在 WebShop 任务中的效果,WebShop 是一个模拟在线购物环境的交互任务,要求模型选择最合适的商品。
LLMCompiler 使用两个工具:search(搜索商品列表)和 explore(点击链接获取商品详细信息)。
与三种基线方法(ReAct、LATS、LASER)相比,LLMCompiler 显示出显著的性能提升:
在 gpt-3.5-turbo 上,LLMCompiler 相比 ReAct 和 LATS 的成功率为 28.4% 和 6% 的提升。
在 gpt-4 上,相对于 ReAct 和 LASER,成功率分别提升了 20.4% 和 5.6%。
延迟方面,LLMCompiler 相比 LATS 和 LASER 分别实现了 101.7x 和 2.69x 的速度提升。
总结¶
LLMCompiler 在多种任务中表现优异,从简单的完全并行任务到复杂的依赖关系任务,再到动态重规划任务和交互式决策任务。相比传统方法如 ReAct 和 OpenAI 的并行函数调用,LLMCompiler 具有以下优势:
更高的准确性(提升 7-8%)
更低的延迟(最高达 3.74x 速度提升)
更少的 token 消耗和成本(最高可降低 6.73x)
更强的动态任务处理能力(可支持 Game of 24 等需要重规划的复杂任务)
在交互式任务中表现突出(如 WebShop)
这些结果显示了 LLMCompiler 在提高大规模语言模型效率方面的潜力。
6. Conclusions¶
现有方法的问题¶
现有的利用大语言模型 (LLMs) 调用多个函数的方法依赖于顺序和动态推理,这导致了在延迟、成本和准确性方面的效率低下。
LLMCompiler 的提出¶
为了解决这些问题,作者提出了一种名为 LLMCompiler 的受编译器启发的框架。该框架支持在多种 LLM 上进行高效的并行函数调用,包括开源模型如 LLaMA-2 和 OpenAI 的 GPT 系列。
核心组件¶
LLMCompiler 通过以下三个核心组件工作:
Planner(规划器):将用户输入分解为具有定义依赖关系的任务。
Task Fetching Unit(任务获取单元):并发地获取这些任务。
Executor(执行器):并发地执行这些任务。
实验结果¶
LLMCompiler 在多个指标上表现显著提升:
延迟:提升最高达 3.7 倍;
成本效率:提升最高达 6.7 倍;
准确性:提升最高达 约 9%;
对比 OpenAI 的并行函数调用功能:LLMCompiler 在延迟方面表现更优。
未来期望¶
作者希望未来基于 LLMCompiler 的研究能够进一步提升 LLM 在执行复杂、大规模任务时的能力和效率,从而推动 LLM 应用的未来发展。
致谢(Acknowledgements)¶
作者感谢多个个人和机构的支持,包括:
Minwoo Kang 的宝贵反馈;
Furiosa 团队的慷慨支持;
微软通过其“加速基础模型研究项目”的支持,特别是 Sean Kuno;
Google Cloud、Google TRC 团队,尤其是 Jonathan Caton;
David Patterson 教授 的支持;
Keutzer 实验室 由 Intel 公司、Intel One-API、VLAB 团队、BDD 和 BAIR 资助;
三星,包括 Dongkyun Kim 和 David Thorsley;
Ellick Chan、Saurabh Tangri、Andres Rodriguez、Kittur Ganesh 的支持;
韩国高级研究基金会 对 Sehoon Kim 和 Suhong Moon 的支持;
Amir Gholami 由 三星 SAIT 资助;
Michael W. Mahoney 感谢 J. P. 摩根大通 Faculty Research 奖励 以及 DOE、NSF 和 IARPA 的资助。
作者强调,结论并不代表其资助方的立场或政策,也不应被理解为任何官方的背书。
本节重点介绍了 LLMCompiler 的创新性设计及其在效率和准确性上的显著提升。其通过任务分解与并发执行机制,有效解决了现有 LLM 多函数调用方法的局限性。作者对未来的 LLM 应用发展充满期待,并表达了对多方支持的感谢。
A. Accuracy Analysis: ReAct vs. LLMCompiler¶
本节重点分析了 ReAct 和 LLMCompiler 在准确性上的对比,揭示了 ReAct 的两个常见失败模式:提前终止(Premature Early Stopping) 和 重复调用函数(Repetitive Function Calls)。这两个问题显著降低了 ReAct 的准确性,而 LLMCompiler 能有效解决这些问题,从而提升了整体性能。
1. 电影推荐任务中的提前终止问题¶
在 Movie Recommendation 任务中,ReAct 常常在未完成所有 8 部电影搜索前就提前终止,导致其准确率显著低于 LLMCompiler(68.60 vs. 77.13)。图 A.1 显示了 ReAct(左图)与 LLMCompiler(右图)的函数调用次数分布。可以看出,约85%的 ReAct 示例在未完成所有搜索前就提前退出,而 LLMCompiler 几乎全部完成了 8 次搜索(99%)。即使通过添加提示语来改进 ReAct(中间图),其函数调用次数虽然有所增加,但仍然无法完全覆盖所有搜索,改进后的准确率也只是从 68.60 提升到 72.47,提升有限。
图 A.2 进一步验证了提前终止对准确性的影响:ReAct 的函数调用次数越少,准确率越低。相反,LLMCompiler 保证了所有电影的完整搜索,从而实现了更高且更稳定的准确率。
重点结论:ReAct 的提前终止严重影响准确性,LLMCompiler 通过强制完成全部搜索有效避免了这一问题。
2. HotpotQA 中的重复函数调用问题¶
另一个 ReAct 的典型失败模式是 重复调用函数,这常常导致 无限循环 或 超出上下文长度限制。这一问题在 HotpotQA 任务中尤为明显,因为该任务本质上是 2 路并行搜索。在图 A.3 中,可以看到 ReAct 有约 10% 的示例调用函数超过 4 次,这通常意味着 系统进入无意义的循环或发散状态。相比之下,LLMCompiler 几乎所有示例都只调用 2 次函数,符合任务的并行结构。
图 A.4 显示了不同函数调用次数对应的准确率。对于 ReAct,调用 4 次及以上 的示例准确率往往低于 10%,而通过 LLMCompiler 处理这些示例时,准确率提升至约 50%。这表明,LLMCompiler 有效避免了重复调用带来的负面影响。
重点结论:ReAct 的重复调用问题会严重降低准确率,而 LLMCompiler 通过控制函数调用次数,避免了这一问题。
3. 小结¶
ReAct 的主要问题:提前终止和重复调用函数是其性能受限的两个关键原因。
LLMCompiler 的优势:通过强制完成所有必要操作(如搜索所有电影、控制并行调用次数)来提升准确率。
实验结果支持:在 Movie Recommendation 和 HotpotQA 任务中,LLMCompiler 的准确率均高于 ReAct,证明其方法更稳定、更可靠。
4. 补充:流式处理对延迟的影响(附录)¶
表 C.1 比较了在 Planner 模块中使用和不使用 流式处理(Streaming) 的延迟。结果显示,流式处理显著降低了任务执行时间,尤其在 ParallelQA 任务中效果明显。这是因为流式处理允许 Task Fetching Unit 在 Planner 生成任务的同时立即开始执行,有效隐藏了 Planner 的执行时间。
任务 |
不使用流式处理(秒) |
使用流式处理(秒) |
延迟提升倍数 |
|---|---|---|---|
HotpotQA |
4.00 |
3.95 |
1.01× |
Movie Rec. |
5.64 |
5.47 |
1.03× |
ParallelQA |
21.72 |
16.69 |
1.30× |
重点结论:流式处理在 LLMCompiler 中起到了优化延迟的关键作用,尤其是在需要大量函数调用的任务中效果显著。
B. Failure Case Analysis of LLMCompiler¶
本节深入分析了LLMCompiler在ParallelQA数据集上的失败情况。这些失败案例主要可以归因于 Planner(规划器)、Executor(执行器)或最终输出过程中的问题。
其中,最终输出过程的失败是指LLM无法根据工具执行所收集的观察结果(这些结果已包含在上下文中)提供正确的答案。在总共10.6%(36个案例)的失败案例中,Planner、Executor和最终输出过程分别贡献了8%、64%和28%的失败。
Planner 的失败(8%)¶
Planner的失败是LLMCompiler特有的问题。例如,Planner可能会错误地将输入和输出进行映射,将错误的标识符作为后续任务的输入,从而构建出错误的DAG(有向无环图)。然而,在具备充分的工具定义和上下文示例的情况下,Planner的错误显著减少(在我们的评估中总共只有3个实例),这体现出LLM在将问题分解为复杂多任务依赖方面的能力。
Executor 的失败(64%)¶
Executor是导致失败的主要原因,占所有失败的64%。常见问题包括数学工具选择了错误的属性,或在单位转换中处理不当。这些问题并不是LLMCompiler独有的,也出现在ReAct系统中。
最终输出过程的失败(28%)¶
最终输出过程的失败占28%,主要表现为未能从收集到的观察结果中得出正确结论,例如无法从数据中挑选出最小属性。虽然这类问题也出现在ReAct中,但LLMCompiler在这些方面失败率略低,因为它只向每个工具提供相关的上下文,有助于更准确地提取信息。
我们相信,通过优化Agent scratchpad的结构,而不是简单地附加观察结果,可以进一步减少最终输出过程中的失败率。
总结来看,LLMCompiler的失败主要集中在Executor和最终输出过程中,而Planner的失败率较低且可通过上下文优化显著降低。与ReAct相比,LLMCompiler在某些方面表现更优,但仍存在改进空间。
D. Experimental Details¶
实验场景¶
本文的实验评估了两种常见的场景:
基于 API 的闭源模型:使用 OpenAI 提供的 GPT 模型。
开源模型与内部服务框架结合:使用开源模型 LLaMA-2,并部署在 2 块 A100-80GB GPU 上,采用 vLLM 框架进行服务。
模型选择与发布时间¶
闭源模型:
HotpotQA 和 Movie Recommendation:使用
gpt-3.5-turbo(1106 版本)。ParallelQA:使用
gpt-4-turbo(1106 版本)。Game of 24:使用
gpt-4(0613 版本)。
实验时间:
HotpotQA、Movie Recommendation 和 ParallelQA 实验均在 2023 年 11 月进行,即在 GPT-3.5 和 GPT-4 Turbo 推出后。
Game of 24 的实验则从 2023 年 9 月至 10 月进行。
开源模型部署¶
使用 LLaMA-2(由 Touvron 等人于 2023 年提出)。
部署环境:2 块 A100-80GB GPU,使用 vLLM 框架。
所有实验均使用 温度为 0,表示生成过程是确定性的,除了 Game of 24 中的 Thought Proposer 和 State Evaluator 使用温度 0.7 以引入一定随机性。
实验设置与对比¶
重复运行:
对于 OpenAI 模型,即使温度为 0,输出仍存在随机性,因此进行了 3 次运行,并报告了平均准确率。
样本数量(Few-shot):
ReAct:3 个样本。
OpenAI 并行函数调用:1 个样本。
LLMCompiler:5 个样本。
所有方法在 HotpotQA、Movie Recommendation 和 ParallelQA 中使用相同的样本,以保证公平对比。
Game of 24 的 Planner 使用 2 个上下文示例。
指令提示(Instruction Prompt):
跨不同方法使用相同的指令提示,以确保公平。
例外是 ReAct†(第 5.1 节)使用了额外的 ReAct 特定提示。
WebShop 实验设置¶
使用 gpt-4-0613,具有 8k 上下文窗口。
使用 gpt-3.5-turbo,具有 16k 上下文窗口。
总结重点¶
实验涵盖了闭源 API 和开源模型两种典型部署方式。
跨模型(ReAct、OpenAI 并行调用、LLMCompiler)进行了系统的对比,确保在样本数量、提示和运行次数方面保持一致性。
Game of 24 是唯一使用非零温度的实验,以测试模型在探索性推理中的表现。
WebShop 实验特别强调了上下文窗口的配置,以适应任务需求。
E. Analysis¶
E.1. Parallel Speedup Modeling¶
本节主要分析 LLMCompiler 在并行任务中未能达到理论最大加速比的原因,并提出了一个理论模型来分析其延迟表现。
主要问题分析¶
LLMCompiler 在并行工作负载中表现出更低的延迟,但没有达到理想中的 N 倍加速比(N 代表并行任务数)。
主要原因有两个:
Planner 和 Final Answering 的开销无法并行化:
在 Movie Recommendation 实验中,Planner 平均耗时 1.88 秒,Final Answering 耗时 1.62 秒,合计已占总延迟的超过一半。
Straggler Effect(拖尾效应):
最慢任务的平均延迟为 1.13 秒,是所有任务平均延迟(0.61 秒)的近 2 倍。
模型定义与对比¶
模型组件:Planner、Task Fetching Unit 与 Executor。
Planner 生成 N 个任务,每个任务对应一个 Ei,由 Executor 执行。
延迟模型定义为:
ReAct 的总延迟: $\( TR = \sum_{i=1}^N \left( T^R_P(P_i) + T(E_i) \right) \)$ (即按顺序执行所有任务的总延迟)
LLMCompiler 的总延迟: $\( TC = \sum_{i=1}^N T^C_P(P_i) + \max_{k} T(E_k) \)$ (即 Planner 生成所有任务的延迟 + 最慢任务的执行延迟)
引入流式依赖图的 LLMCompiler: $\( TSC = \sum_{i=1}^N T^C_P(P_i) + T(E_N) \)$ (流式机制提升了任务依赖处理效率,TSC ≤ TC)
加速比分析¶
加速比 γ 定义为: $\( \gamma = \frac{TR}{TC} \)$
最大加速比 γmax:
当 Executor 延迟远大于 Planner 时,理论上最大加速比为 N。
最小加速比 γmin:
当 Planner 延迟是主要因素,且 ReAct 与 LLMCompiler 的 Planner 延迟相似时,γmin ≈ 1。
结论¶
要显著提升延迟性能,LLMCompiler 需要:
降低 Planner 的开销
减少拖尾任务的影响
E.2. Latency versus Number of Parallelizable Tasks¶
本节展示了 LLMCompiler 在不同并行任务数下的延迟表现,并与 ReAct 对比。
弱扩展(Weak Scaling)分析¶
理想情况下,当任务数增加时,系统延迟应保持恒定(即理想并行)。
ReAct 的延迟随着任务数线性增长(因为串行执行)。
LLMCompiler 的延迟增长缓慢(因并行执行),但仍略微上升,这是由于 Planner 无法并行化导致的开销。
结论¶
LLMCompiler 在并行任务中能显著减少延迟,但 Planner 的串行开销仍是瓶颈。
E.3. Additional Experiments on the HotpotQA Bridge Benchmark¶
本节通过在 HotpotQA Bridge Benchmark 上的实验,进一步验证了 LLMCompiler 在处理顺序任务时的性能优势。
实验设置¶
HotpotQA 的“bridge”部分测试的是顺序推理任务,例如:
“谁饰演了 Corliss Archer,并曾担任什么政府职位?”
LLMCompiler 利用其 replanning 能力,先找到演员,再查找其政府职位。
实验结果¶
性能对比表(Table E.2):
LLMCompiler 相比 ReAct,在准确率上提高了 4%,比 ReAct† 提高了 3%。
延迟分别为 4.70 秒,明显优于 ReAct 的 7.07 和 6.42 秒。
原因分析:
ReAct 存在重复调用函数和过早停止的问题,即使优化后(ReAct†)仍有 5% 的失败案例。
LLMCompiler 的 replanning 机制有效避免了此类问题。
结论¶
LLMCompiler 不仅适用于并行任务,也能高效且准确地处理顺序任务。
其 replanning 机制显著提升了准确性和效率。
总结¶
本章节通过模型分析与实验验证,全面展示了 LLMCompiler 在大规模语言模型推理中的延迟优化能力,特别是在并行与顺序任务中的表现优势。主要结论如下:
LLMCompiler 的并行化机制显著降低延迟,但受 Planner 串行开销和拖尾效应限制。
引入流式依赖图机制可进一步优化任务调度效率。
LLMCompiler 的 replanning 能力使其在顺序推理任务中也优于 ReAct。
未来改进方向包括降低 Planner 开销和减少拖尾任务的影响。
如需进一步分析模型细节或实验数据,可参考附录 E.1 与表格 E.3。
G. User-Supplied Examples for LLMCompiler Configuration¶
LLMCompiler 提供了一个简单的接口,允许通过提供工具定义和上下文中的示例来定制框架以适应不同的使用场景。本节展示了如何通过**少量提示语(prompts)**来配置框架,用于“电影推荐”和“24点游戏”两个基准任务。
G.1 电影推荐示例提示语(Movie Recommendation Example Prompts)¶
重点内容:
该部分展示了如何通过一系列搜索操作(search)来实现电影推荐功能。
问题:找一部与《碟中谍》、《沉默的羔羊》、《美国丽人》、《星球大战IV:新希望》类似的电影。
选项:包括《王牌大贱谍》、《阿廖沙与巨龙》、《冷血》、《罗塞塔》等。
操作步骤(示例提示语):
分别对题目中提到的电影进行搜索(search)操作。
也对选项中的电影进行搜索。
最后通过“finish()”给出最终答案。
总结:
该示例通过一系列的搜索操作,模拟了推荐系统的行为,说明了如何通过配置 Planner 来实现特定任务。重点是通过少量的搜索操作对电影进行匹配和推荐。
G.2 24点游戏示例提示语(Game of 24 Example Prompts)¶
重点内容:
该部分展示了如何通过状态生成、评估和选择操作,来解决 24 点游戏问题。
示例1:初始状态为空¶
问题:给定数字 “1 2 3 4”,初始状态为空。
操作步骤:
生成一个可能的思路(thought proposer)。
评估这个思路的状态(state evaluator)。
从中选择 Top-k 操作(top kselect)。
最终通过 finish() 结束。
示例2:已有多个状态¶
问题:同样给定数字 “1 2 3 4”,但已有多个状态:
如 “1+2=3(剩下 3, 3, 4)”
“2-1=1(剩下 1, 3, 4)”
等等
操作步骤:
对每个状态分别生成思路(thought proposer)。
对每个思路进行状态评估(state evaluator)。
从所有思路中选择 Top-k 作为下一步操作(top kselect)。
最终通过 finish() 结束。
总结:
该示例展示了 LLMCompiler 如何通过并行调用多个函数(如 proposer、evaluator、selector)来处理状态空间较大的问题,如 24 点游戏。重点在于状态生成、评估与选择的流程,体现了框架的灵活性与扩展性。
整体总结:
本节通过两个具体的任务示例,展示了如何通过配置 LLMCompiler 的 Planner 来完成不同的任务。两个示例都使用了少量提示语实现了复杂任务的处理,突出了 LLMCompiler 的可定制性和并行操作能力。
H. Pre-defined LLMCompiler Planner Prompts¶
该部分介绍了 LLMCompiler Planner 的预定义提示(Prompt),用于指导 Planner 如何拆分任务、生成依赖图,并确保语法格式的正确性。该提示内包含了一系列具体规则:
任务格式要求:每个任务应单独一行,以数字编号开头,使用
$符号表示中间变量。输入/输出类型和描述:每个动作都包含输入/输出类型和描述,必须严格遵守这些类型。
遵循指南:动作描述中包含指南,必须严格按照指南执行动作。
动作类型限制:每个动作必须是预定义的类型之一,并遵守 Python 的命名习惯。
唯一且递增的 ID:每个动作必须有唯一的、递增的 ID。
输入来源限制:输入可以是常量或前面动作的输出,如果是后者,必须使用
$id格式表示。最大化并行性:生成的计划应尽量提高并行性。
仅使用预定义动作类型:如果无法用现有动作解决查询,则调用 finish 动作。
禁止解释或注释:生成的计划中不能包含解释性内容。
禁止引入新动作:不能添加超出预定义范围的动作。
finish() 函数的定义¶
Planner 中还包含一个内置的 finish 函数,用于终止计划生成。该函数在以下两种情况下被调用:
计划已足够解决问题。
当前计划无法继续,并需要重新规划。
当 Planner 输出 finish 函数时,计划生成将终止。该函数的作用包括:
收集并整合之前动作的结果。
调用 LLM agent 执行
join操作,以最终确定答案或等待计划执行完成。
join必须是计划中的最后一个动作,并在以下两种场景中调用:
(a) 如果可以通过收集任务输出来生成最终答案。
(b) 如果在执行计划之前无法确定答案。
更多 finish 函数的使用示例请参考附录 G。
I. ParallelQA Benchmark Generation¶
本章节介绍了ParallelQA这一自定义基准的构建过程,其灵感来源于IfQA基准(Yu等人,2023)。ParallelQA共包含113个示例,目的是通过数学问题和不同实体的事实细节来回答问题,从而测试系统在并行搜索与数学运算的整合能力。此类任务需要混合使用搜索与数学运算,且这些操作在不同任务之间存在依赖关系。
重点内容讲解:¶
问题示例:如“如果德克萨斯州和佛罗里达州合并为一个州,以及加利福尼亚州和密歇根州合并为一个州,那么这两个新州中人口密度最高的是多少?”这一问题需要四个并行的搜索任务,随后基于搜索结果执行相互依赖的数学计算,且这些任务可以并行执行。
主要目标:评估框架将输入问题分解为多个子任务,并根据观察结果生成最终答案的能力。
数据构建方法:
精心选择了56个来自不同领域的实体,这些实体的属性可以通过维基百科搜索获取。
最小化工具执行失败,以确保基准的可靠性。
设计了多样化的执行模式:包括一元和二元数学运算,在搜索实体信息后进行。
并行任务数量范围:每个问题可包含2至5个最大可并行任务。
任务依赖结构:例如图3(b)和(c)分别包含2和3个函数调用之间的连接(joins),以增加问题复杂性。
数据来源与标注:所有113个示例由GPT-4生成,并经过人工标注,以确保质量和准确性。
精简讲解内容:¶
构建过程中注重任务之间的复杂依赖关系,以模拟真实场景下的问题解决需求。
通过多样化的任务结构和复杂度,该基准能够全面测试系统在任务分解、规划与执行方面的能力。
J. Details of the Game of 24 and the Tree-of-Thoughts Approach¶
24点游戏简介¶
24点游戏是一个考验数学推理能力的游戏,玩家需要通过加、减、乘、除四种基本运算,组合给定的四个数字,使其结果为24。规则要求每个数字只能使用一次。例如,给定数字2、4、4、7,一个可能的解法是 \(4 \times (7 - 4) \times 2 = 24\)。
这个任务对于大语言模型(LLM)而言是一项非平凡的推理挑战。即使像GPT-4这样的先进模型,在使用思维链(Chain-of-Thought)提示策略时,其成功率也仅有4%(Yao等人,2023b)。
思维树(Tree-of-Thoughts,ToT)方法的实现步骤¶
ToT方法通过多步骤推理来解决问题,其核心思想是利用LLM生成可能的“思维”(部分解),然后通过一个状态评估器筛选出最有希望的解。
思维生成(Thought Proposer)
在每一步中,LLM 会生成若干“思维”,每个思维是一个部分解,即对两个数进行一次算术操作后的结果(例如:7 - 4 = 3)。这个操作会消耗两个数字,并将结果作为新元素,与剩下的数字一起进入下一步。状态评估(State Evaluator)
所有生成的“思维”会被状态评估器评估,判断其是否有潜力在后续操作中得到24。评估结果分为三类:sure(确定):几乎可以肯定能继续得到24;
likely(可能):有一定可能性;
impossible(不可能):无法继续得到24。
只有被标记为 likely 的思维才会进入下一步,从而形成一棵搜索树。
搜索树结构
每个节点代表一个可能的操作提案。
树从根节点开始,通过每次运算生成子节点,逐步向下展开。
每一步保留前5个最有潜力的状态,以减少搜索空间并提高效率。
图 J.6 说明¶
图中展示了24点游戏中ToT方法的运行过程。以输入四个数(2, 4, 4, 7)为例:
初始状态:输入 2, 4, 4, 7。
可能的操作:例如 7-4=3(剩余 2, 3, 4),7/2=3.5(剩余 3.5, 4, 4)等。
评估:每个状态被评估其是否“有潜力”继续运算到24。
保留状态:每一步只保留前5个最有潜力的“思维路径”。
总结重点¶
24点游戏是一个对LLM数学推理能力具有挑战性的任务。
ToT方法通过思维生成和状态评估两步机制,构建一棵搜索树,逐步逼近目标。
关键点:
思维生成(LLM生成部分解)
状态评估(筛选出有潜力的路径)
每轮保留前5个最有希望的状态,提高效率
优势:相比传统思维链,ToT通过并行探索多个可能路径,提升了复杂问题的求解能力。
K. Details of WebShop Experiments¶
K.1. WebShop环境¶
WebShop环境是一个模拟的在线购物平台,旨在测试智能体能否根据给定的指令找到最匹配的商品。例如,若指令是“寻找一张黑色、皇后尺寸、价格低于140美元的床”,智能体的任务就是精准地找到符合这些条件的商品。每件商品都有一个奖励值,该奖励值反映了商品与指令的匹配程度,评估标准包括价格、商品选项及其他商品页面中的详细信息。
重点内容:
任务目标:根据指令精准匹配商品。
评估指标:
成功率(success rate):选择商品满足所有要求的实验比例。
平均得分(average score):所有实验中奖励值的平均数。
K.2. 基线方法¶
除了本文提出的ReAct方法外,还使用了两个基线方法进行比较:LASER 和 LATS。
LASER(Ma et al., 2023)
采用状态探索的方式完成任务。在WebShop中,不同的页面(如搜索页、商品页、商品详情页)被视为不同的状态,智能体通过执行动作(如搜索、选择商品、查看详情、翻页等)在状态之间进行转换。因此,WebShop的探索被抽象为在状态空间图中进行搜索的问题。LATS(Zhou et al., 2023a)
使用一种改进的蒙特卡洛树搜索(MCTS)方法,构建决策树,评估可能动作的成功概率,通过探索与利用的平衡选择动作。智能体会根据环境反馈动态调整策略,从成功与失败中学习,从而优化决策过程。虽然这种方法能处理复杂的在线购物任务,但因为树搜索过程较为详尽,因此执行速度较慢。
重点内容:
基线方法:LASER(状态探索)、LATS(树搜索 + 反馈学习)。
对比目的:用于衡量本文方法(如ReAct、LLMCompiler)的性能优势。