2410.00037_Moshi: a speech-text foundation model for real-time dialogue¶
GitHub: github.com/kyutai-labs/moshi
组织: Kyutai(法国人工智能研究实验室)
引用: 157(2025-06-30)
在线体验:https://moshi.chat
Abstract¶
Keywords: speech, text, multimodal, foundation, spoken dialogue
Moshi 是一个语音对话模型,它能实现真正像人一样的语音对话,不需要传统的“语音活动检测→语音识别→文本对话→语音合成”的流程。
传统方法的问题是:
延迟高,互动不流畅;
中间用文字交流,会丢失情绪、语气等非语言信息;
需要人为分清“谁在说话”,但现实对话中常有打断、重叠等情况。
Moshi 用“语音生成语音”的方式解决这些问题:
它从语言模型出发,直接生成语音;
模型同时建模自己和用户的语音流,实现并行对话,不需要区分轮次;
还加入了“内心独白”机制,先生成文字,再辅助生成语音,提升语言质量;
最终实现了 160–200 毫秒低延迟的实时双工语音对话(双方可同时说话)。
1.Introduction¶
✅ 背景问题¶
传统语音助手(如 Siri、Alexa)通常流程是:
识别唤醒词;
将语音转为文字(ASR);
文字理解(NLU);
生成回答文字(NLG);
再转回语音(TTS);
这个流程存在三个问题:
延迟高(通常几秒,而自然对话反应时间是几百毫秒);
信息丢失(只处理文本,忽略情绪、语调、环境声等非文字信息);
回合式对话(你说完我说,不能打断、重叠说话,不自然)。
✅ Moshi的创新点¶
语音直达语音(Speech-to-Speech):
不再中间必须转成文字;
能处理情绪、口音、背景声等非文本内容;
实时处理对话,延迟只有 160 毫秒,比人类平均反应更快。
双流处理器(Multi-stream):
同时处理输入和输出语音;
不再区分“谁先说”,可以自然重叠说话、打断等。
三个主要组件:
Helium:7B 参数的大语言模型,负责文本推理;
Mimi:将语音转成离散音频token并还原的神经音频编码器;
Moshi 架构:一个层次化、流式音频语言模型,支持长时间上下文对话(比如连续5分钟)。
Inner Monologue 技术:
模型先预测文本,再生成音频;
提高语音的准确性与连贯性,还能实现流式语音识别(ASR)和语音合成(TTS)。
✅ 效果¶
Moshi 在语音理解、回答准确性、语音质量等方面效果领先;
同时支持流式交互,能自然应对重叠语音;
是第一个“全双工”(始终在听和说)的语音对话大模型。
3.Model¶
3.1 Overview¶
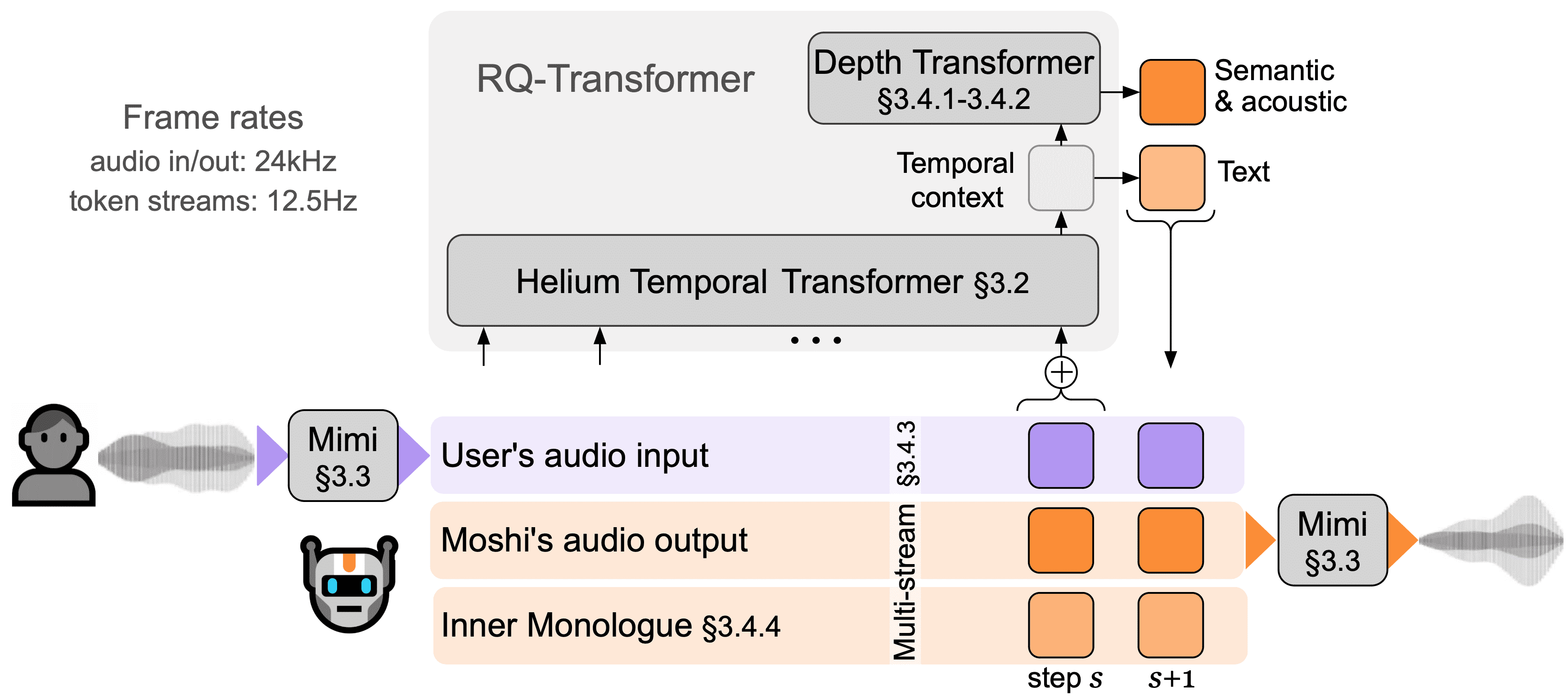
Figure 1:Overview of Moshi. Moshi is a speech-text foundation model which enables real-time spoken dialogue. The main components of Moshi’s architecture are: a bespoke text language model backbone (Helium, see Section 3.2); a neural audio codec with residual vector quantization and with semantic knowledge distilled from a self-supervised speech model (Mimi, Section 3.3); the streaming, hierarchical generation of semantic and acoustic tokens for both the user and Moshi, along with time-aligned text tokens for Moshi when using Inner Monologue (Section 3.4).
🔧 架构主要包括 5 个核心模块:¶
Helium(文本大模型)
从零构建的文本语言模型,提供强大的推理能力。
类似 ChatGPT 的文本理解和生成能力。
Mimi(音频编码器)
一个神经音频编解码器,将语音转换为语义+声学 token。
使用残差向量量化(RVQ)和知识蒸馏,压缩语音信息并保留关键特征。
Inner Monologue(内部独白机制)
在训练和生成过程中,同时处理文本、语义和声学 token。
让模型既能生成语音,又能利用文本的语言知识。
Multi-stream(多流架构)
同时处理“用户的语音输入”和“Moshi 的语音输出”。
不需要明确的轮流说话,支持双向实时语音对话(full-duplex)。
Depth Transformer(流式 Transformer)
用于处理长序列的语音和文本 token。
支持分层自回归建模和流式推理(边输入边生成)。
3.2 The Helium Text Language Model¶
3.2.1 Architecture¶
Helium 是一个基于 Transformer 的自回归文本语言模型(类似 GPT),它有以下特点:
改进架构:
使用 RMSNorm 替代 LayerNorm,提升训练稳定性。
使用 RoPE 位置编码,更好支持长上下文。
使用 FlashAttention 加速训练。
前馈网络改成 GLU(门控线性单元)+ SiLU 激活函数,增强非线性表达能力。
分词器:基于 SentencePiece 的 unigram 模型,词表大小为 32,000,专为英文设计,数字被拆成单个字符。
优化器:使用 AdamW 和 余弦学习率衰减。
上下文长度:最大 4096 tokens。
Helium 是 Moshi 模型的“文字理解大脑”,也是它预训练的基础。
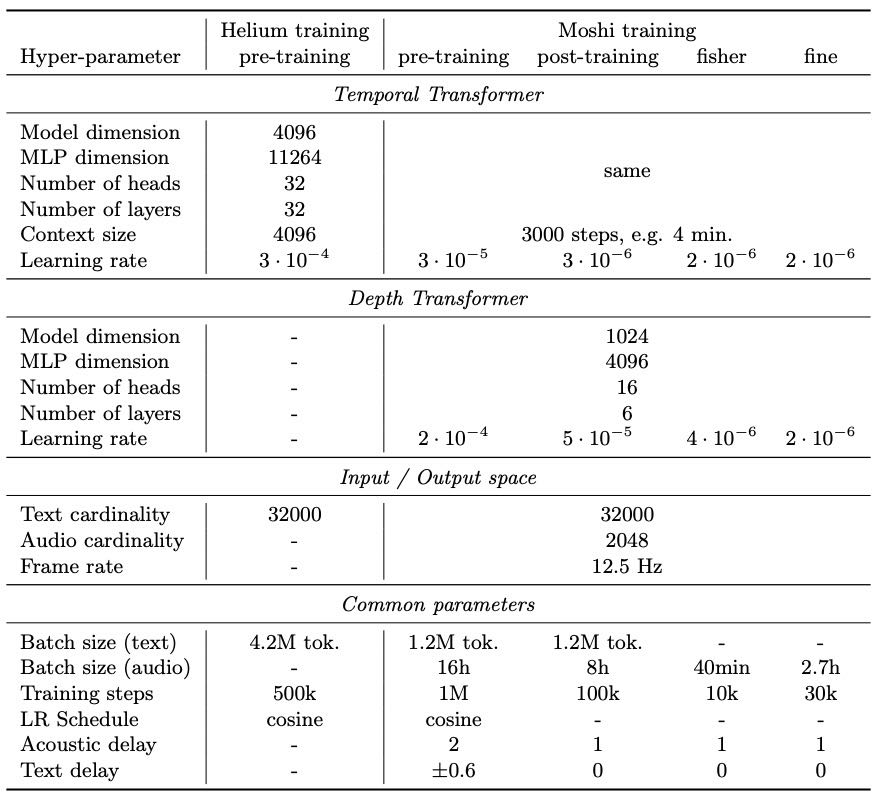
Table 1: Models’ hyper-parameters.
3.2.2 Pre-training data filtering¶
由于高质量文本数据量有限(如 Wikipedia、StackExchange),Helium 使用了大量网页爬虫数据(CommonCrawl)
但这些数据需要清洗:
去重:
使用 FNV-1a 哈希和 Bloom Filter 去除重复行;
用 fastText 分类器进一步清除“模糊重复”的内容(例如网页模板)。
语言识别:
用 fastText 判断文档语言,只保留英文,要求置信度 > 0.85。
质量过滤:
训练 fastText 分类器,学习区分高质量 vs 随机网页行;
打分并过滤掉低质量文档,保留更接近 Wikipedia、Wikibooks 等高质量来源的文本。
3.3 Audio Tokenization¶
备注
Mimi 是一个能同时编码语义与声学信息、并支持流式处理的神经音频编码器。
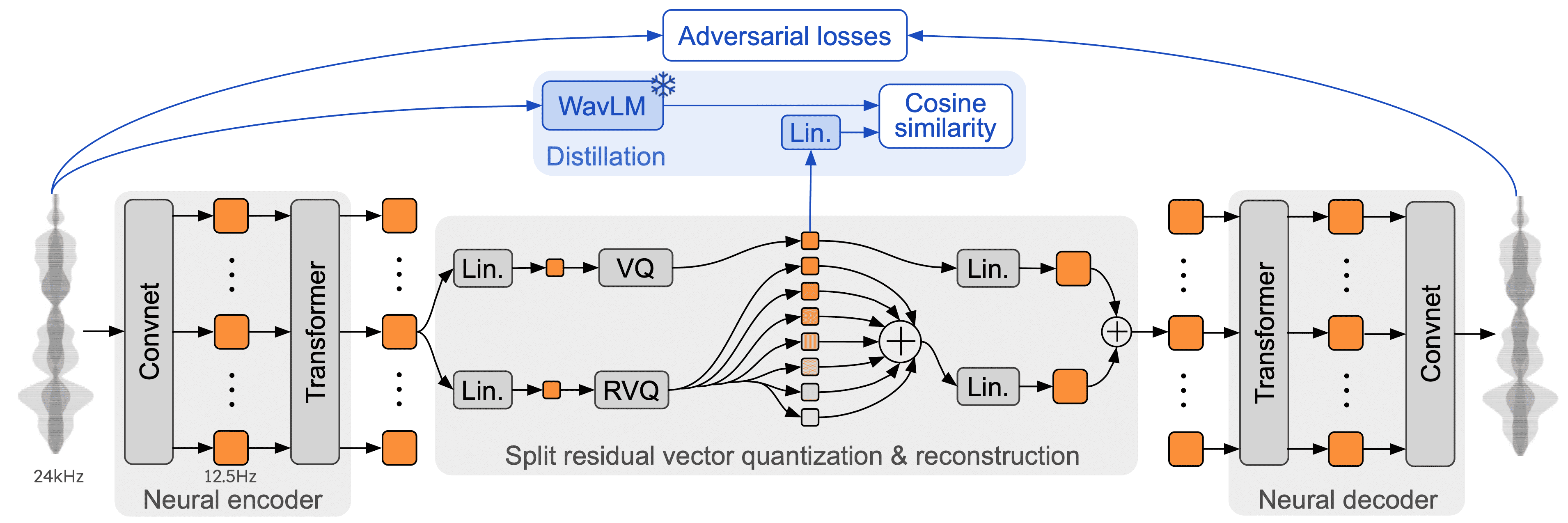
Figure 2:Architecture and training of Mimi, our neural audio codec, with its split residual vector quantization. During training (blue part, top), we distill non-causal embeddings from WavLM (Chen et al., 2022) into a single vector quantizer which produces semantic tokens, and is combined with separate acoustic tokens for reconstruction.
Mimi 是一个神经音频编码器(codec),用于把连续的语音波形信号转换为离散的 音频 token(tokenization),供后续模型处理。这类似于图像的离散化(如 VQ-VAE)或文字的分词。
它的核心功能包括:
高保真语音还原:音质清晰,适合语音合成;
嵌入语义信息:适合语言理解/对话生成任务;
可实时推理:可流式地进行语音 token 编码和解码。
**两类音频 token **
Acoustic token(声学 token):
表示语音的细节信息;
可以重建高质量音频;
用于 TTS 或音乐生成等任务;
Semantic token(语义 token):
表示语音的语言信息;
不能还原音频,但可表达内容含义;
类似“音频版文字 token”,可支持无文本语音生成。
混合 token 问题:
之前的模型通常先提取 semantic token,再用它引导生成 acoustic token;
但这种方式 不能实时运行,因为:
semantic token 是非因果(non-causal)的,必须整段语音提取;
分别使用两个编码器,计算开销大。
Mimi 的创新点:
借鉴 SpeechTokenizer 的思路,将语义信息“蒸馏”进因果模型生成的 token 中;
实现了 声学和语义 token 的统一建模,支持实时编码和解码;
既保留了语义信息,又能逐步生成高质量音频,适合流式语音生成任务。
3.3.1 Architecture¶
备注
Mimi 的基础架构是一种流式的神经音频编码器,结合残差量化、因果卷积和自动编码器设计,可高效将语音压缩成离散 token,同时保持高音质的还原能力。 Mimi 在因果自动编码器的基础上引入 Transformer、可控量化率和纯对抗训练等关键技术,不仅支持流式语音压缩,还显著提升了低比特率下的主观音质与语义保真。
这段内容详细描述了 Mimi 音频编码器的基础架构
核心思想是借鉴已有的高质量神经音频编码器(如 SoundStream 和 Encodec),并在此基础上加入残差量化器以提高压缩效率与重建质量。
🎯 目标
将 单声道语音波形(24kHz)压缩为可离散的、可用于神经网络处理的表示(即音频token),
并能流式实时还原为高质量语音。
架构组成
自动编码器 (Autoencoder)
编码器部分使用 SeaNet 架构,由一系列 残差卷积模块 构成:
解码器
使用反卷积(Transposed Convolution)逐步还原语音;
支持 流式语音重建。
残差向量量化器(RVQ)
将高维连续的 latent 表征转化为离散的 音频 token;
使用 Q 个量化器(多级量化),每个量化器有 NA 个词条;
输出为大小为 \(S \times Q\) 的离散索引矩阵,每个位置取值为 {1, …, NA};
这种离散表示称为 Acoustic Tokens(音频token);
RVQ 机制:逐层对残差进行量化,减少信息损失。
Transformer-based bottleneck.¶
目的:
增强压缩语音的表达能力,提升音质,并辅助语义信息提取(如语音转文字或理解)。
设计细节:
在quantization前后 各插入一个 Transformer 模块;
每个 Transformer:
8 层、8 个注意力头;
使用 RoPE(旋转位置编码);
上下文窗口为 250帧 ≈ 20 秒;
激活函数为 GELU;
维度为
model_dim=512,MLP层为2048;使用 LayerScale(对残差分量加权)初始化为 0.01;
全部使用因果掩码(causal masking),可流式处理。
效果:
有助于还原更高质量音频;
编码器侧 Transformer 还能提升语义 distillation 效果。
Causality and streaming.¶
整个架构为完全因果性设计,可以 边收音边编码并播放;
输入一段 80ms 音频帧,Mimi 即可生成对应 latent 表征 → 解码为 80ms 输出音频;
支持实时语音压缩与重建。
Optimization.¶
因引入 Transformer,需要:
使用 AdamW 优化器;
仅对 Transformer 参数加
weight_decay=0.05;
训练超参包括:
学习率:8e-4;
β1=0.5,β2=0.9;
EMA 权重衰减:0.99;
批次大小:128;
音频窗口:12秒,训练4M步;
Transformer上下文限制:10秒。
Quantization rate.¶
使用 8个量化器 (Q=8),每个有 2048 个词条 (NA=2048);
总帧率为 12.5Hz → 比特率约为 1.1kbps;
在进入量化器前将维度从 512 投影到 256,解码前恢复到 512;
训练时仅 50% 概率使用量化(其余直接用浮点表征):
避免过度依赖量化,提升模型鲁棒性;
实验证明:在低比特率下此策略能显著提升音质(尤其是客观指标)。
Adversarial-only training.¶
标准训练方式:
Mel谱重建损失(内容保真);
多尺度 STFT 判别器(感知音质);
实验突破:
尝试完全移除重建损失,仅保留:
特征损失(Feature loss);
判别器损失(Discriminator loss);
结果:虽然客观指标变差,但主观听感显著提升(参见 Table 4);
类似策略在带宽增强场景中也被成功验证(如 Tagliasacchi et al., 2020)。
3.3.2 Learning semantic-acoustic tokens with a split RVQ¶
为什么需要语义 token?
背景问题:
原始的 acoustic tokens(纯音频特征)能很好重建高质量音频,但 不能表达语言语义;
语义 tokens(如从自监督语音模型中提取)对语言内容建模更好,但无法还原高质量语音。
现有方法:直接把语义信息蒸馏到第一级 RVQ 中
蒸馏来源:使用 WavLM-large(微软自监督模型)提取 1024 维语义表示,采样率 50Hz;
目标对齐:Mimi 采样率为 12.5Hz,因此:
需将输入音频下采样到 16kHz;
WavLM 输出后再做非因果平均池化(
stride=4, kernel=8)→ 与 Mimi 输出对齐;
训练方式:
对 RVQ 的第一级输出做线性映射到 1024维;
与处理后的 WavLM 表征做余弦距离 loss(即 distillation loss);
问题:
语义蒸馏能增强语音的辨音能力(phonetic discriminability);
但却损害了音频重建质量,因为:
后续量化器的 residual 已被语义 token “污染”,难以还原真实音频;
第一级量化器要同时承载语义与音质,任务冲突。
创新方法:Split RVQ(分裂式残差向量量化器)
核心思想:将语义 token 和音频 token 分开量化!
用一个独立的普通 VQ专门做语义 token(用于蒸馏);
剩下的音频信息交由7 层 RVQ处理(不需要保留语义);
二者并行量化,结果再相加作为整体表示;
优势:
语义模块只学语义,不干扰音质重建;
RVQ 专注于音频细节保真;
提升语音辨识度与音质间的平衡。
3.4 Generative Audio Modeling¶
我们在原始的 Helium 模型基础上做了扩展,加入了对 Mimi 编码器生成的音频 token 的建模能力。为了实现更真实的对话效果,我们不仅建模一条音频流,而是同时建模两条音频流:一条代表用户说话,另一条代表系统(AI)说话。
此外,我们还引入了一个新功能叫 “内心独白”(Inner Monologue),即在系统端同时建模文字和音频,以提升对话质量。
3.4.1 Hierarchical autoregressive modeling with RQ-Transformer¶
这段内容讲的是如何用 RQ-Transformer(Residual Quantization Transformer) 对多模态(主要是音频token)进行高效建模
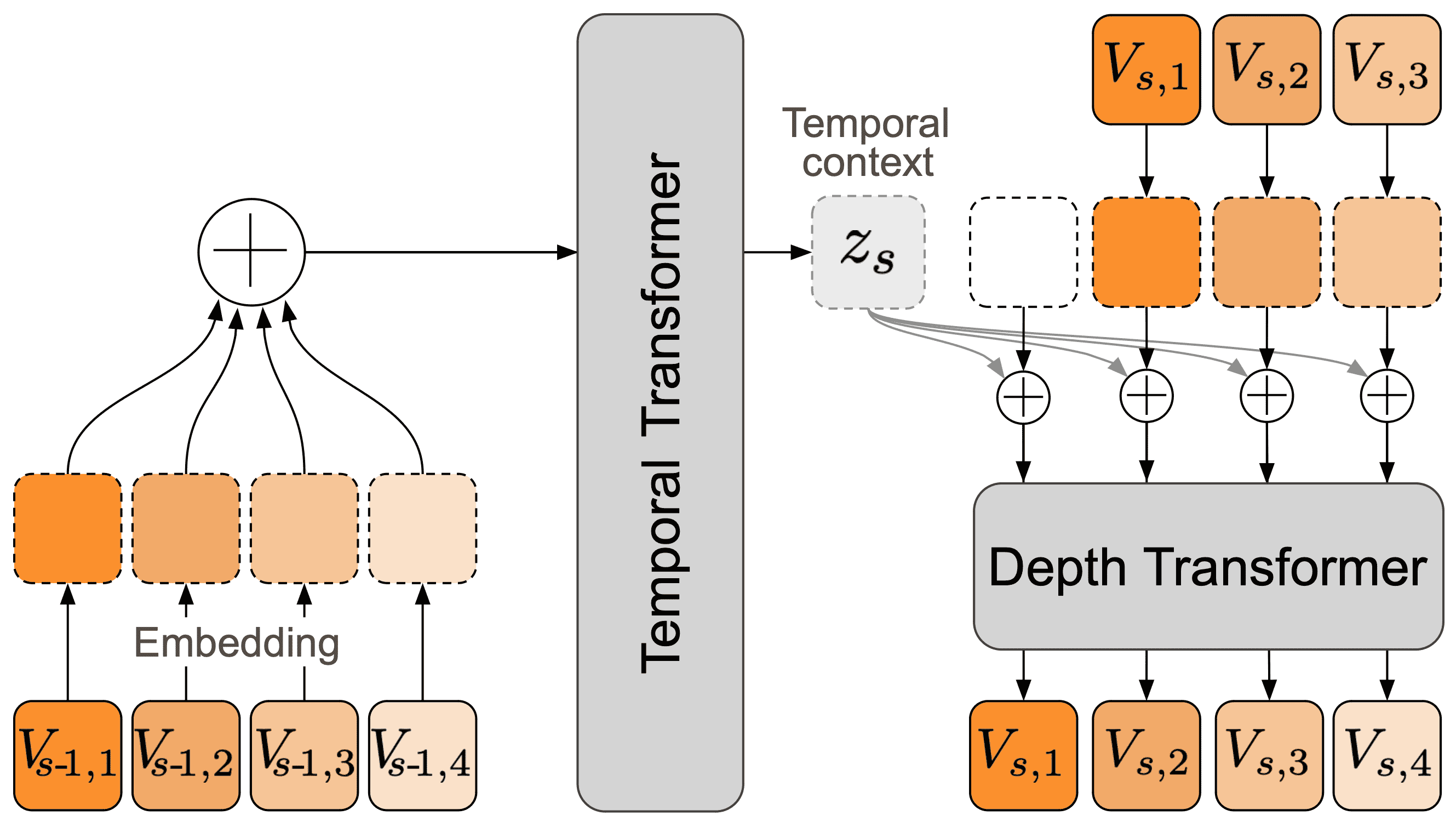
Figure 3:Architecture of the RQ-Transformer. The RQ-Transformer breaks down a flattened sequence of length K⋅S into S timesteps for a large Temporal Transformer which produces a context embedding used to condition a smaller Depth Transformer over K steps. This allows scaling to longer sequences by increasing S—or to a higher depth by increasing K— than modeling the flattened sequence with a single model. In this figure, we use K=4 for the sake of illustration.
🔧 问题背景:¶
音频比文字更长:比如用 Mimi 编码器编码音频时,每秒要处理 100 个 token(远高于文字的 3~4 个 token),所以用传统方法处理音频,计算量太大,不适合实时对话生成。
音频是多通道的(比如多个 codebook),相比单一路的文字,还更复杂。
🧠 目标:¶
我们不只建模一条序列,而是建模多条子序列(比如多个音频 codebook 的输出 + 可选的文字 token)。
每个时间步包含多个子 token。
🌲 解决方案:RQ-Transformer(分层自回归建模)¶
备注
RQ-Transformer 通过时间-层次解耦的双 Transformer 架构,高效地建模语音 token 的时序与结构特性,并用参数定制化优化每个子序列的生成质量,同时保证推理效率。
关键思想:把每一帧的音频 token 序列拆成两维建模:
RQ-Transformer 由两个 Transformer 模型组成
时间维(Temporal Transformer):处理每个时间步的上下文(例如从第1秒到第s-1秒说了什么)。
深度维(Depth Transformer):在当前时间步内,预测多个 codebook 的 token(比如音频的多个“子通道”)。
重点
时间变换器 (Temporal Transformer) 的步数始终等于 S ,而不是 K⋅S,所以计算量 较小且稳定
深度变换器 (Depth Transformer) 的步数最多为 K,即每个时间步中最多预测 K 个子 token。
🧱 定义:¶
Temporal Transformer 表示为函数 \(\mathrm{Tr}_{\mathrm{Temp}}\)
Depth Transformer 表示为 \(\mathrm{Tr}_{\mathrm{Depth}}\)
对于每一个时间步 \(s \in [1, S]\),我们用以下公式表示该步所有子序列的联合状态。 \(V_s = (V_{s,1}, ..., V_{s,K})\)
🧠 Temporal Transformer 的工作方式¶
在时间步 \(s\),Temporal Transformer 接收历史所有步的输出作为输入:
\(z_s = \mathrm{Tr}_{\mathrm{Temp}}(V_0, ..., V_{s-1}) \in \mathbb{R}^d\)
这个 \(z_s\) 是当前时间步的上下文向量。
🧱 Depth Transformer 的工作方式¶
对于每一个子序列索引 \(k > 1\),Depth Transformer 接收:
上下文向量 \(z_s\)
当前步之前的所有子序列 token:\((V_{s,1}, ..., V_{s,k-1})\)
并输出一个 logits 向量:
\(l_{s,k} = \mathrm{Tr}_{\mathrm{Depth}}(z_s, V_{s,1}, ..., V_{s,k-1}) \in \mathbb{R}^{N_k}\)
对于第一个子序列 \(k = 1\),使用一个独立的线性层:
\(l_{s,1} = \mathrm{Lin}(z_s) \in \mathbb{R}^{N_1}\)
整合¶
我们训练这三个模块(Temporal Transformer、Depth Transformer 和线性层 Lin)来使 softmax 后的结果逼近真实的 token 分布: \( \begin{cases} \mathrm{softmax}(l_{s,1}) \approx \mathbb{P}(V_{s,1} \mid V_0, ..., V_{s-1}) \\ \mathrm{softmax}(l_{s,k}) \approx \mathbb{P}(V_{s,k} \mid V_0, ..., V_{s-1}, V_{s,1}, ..., V_{s,k-1}), \quad \text{if } k > 1 \end{cases} \)
⚙️ 模型效率设计¶
Temporal Transformer 的步数始终为 S(音频的时间步数)
而不是 \(K \cdot S\),因此计算量不随 codebook 数增加而线性上升。
每步输入为上一时间步 \(V_{s-1}\) 所有子序列对应的 K 个 embedding 向量之和。
Depth Transformer 最多运行 K 次(每个时间步内预测 K 个子 token)
每步输入为 \(z_s + \text{embedding}(V_{s,k-1})\)
3.4.2 Audio modeling¶
这段讲的是如何用 RQ-Transformer 来建模音频 token,
特别是用 Mimi 编码器生成的多子序列(codebooks)音频 token。
🎯 目标:¶
音频经过 Mimi 编码器后,被分成 Q=8 条子序列(即 8 个 codebook),每秒 12.5 步(frame)。
其中,第 1 条子序列代表 语义信息(semantic),其余是 声学特征(acoustic features)。
🧠 做法:¶
把这些音频子序列插入到我们之前定义的多序列 \(V\) 中,交给 RQ-Transformer 来建模。
🔁 Acoustic Delay(声学延迟):¶
原本是直接把 V=A(即当前时间步的语义和声学 token 都一起输入),但这种方式生成效果不太好。
改进方案:延迟声学 token 的输入,比如把第 s 步的声学 token 放到第 s+1 步再输入。
为什么要延迟?
这样可以减弱每个时间点内部不同子序列之间的依赖,让模型更容易学习。
大模型专注于时间上的语义变化,小模型处理细节特征,更高效。
文中引用了多个论文,也实验证明延迟后生成质量更高。
🚀 创新点:¶
首次实现了语义与声学 token 的联合流式生成(以前是先生成语义,再补声学)。
在 Depth Transformer 中,为每个子序列 使用了独立的参数,提升了建模质量。
3.4.3 Multi-stream modeling¶
这段话讲的是 多音频流建模(Multi-stream modeling),用于模拟一个包含双方对话的真实交流场景。
在对话中,只建模一个人的音频是不够的。所以,Moshi 框架扩展到了双人的音频建模:
输入是两个音频流:一个是 Moshi(模型)的说话音频,另一个是用户的说话音频。
对这两个音频流都加入“音频延迟”(为了考虑说话的先后顺序),然后合并起来作为模型的输入。
图中展示的是这个合并后的序列,模型逐步处理每一步的音频“Token”。
推理时,Moshi 部分(图中虚线以下)是模型生成的,而用户部分(虚线以上)是实际输入的。
这种方式可以让模型处理“双方讲话可能重叠”的情况。
这段在讲如何让模型能听懂和应对两人交谈、甚至是说话重叠的对话场景。
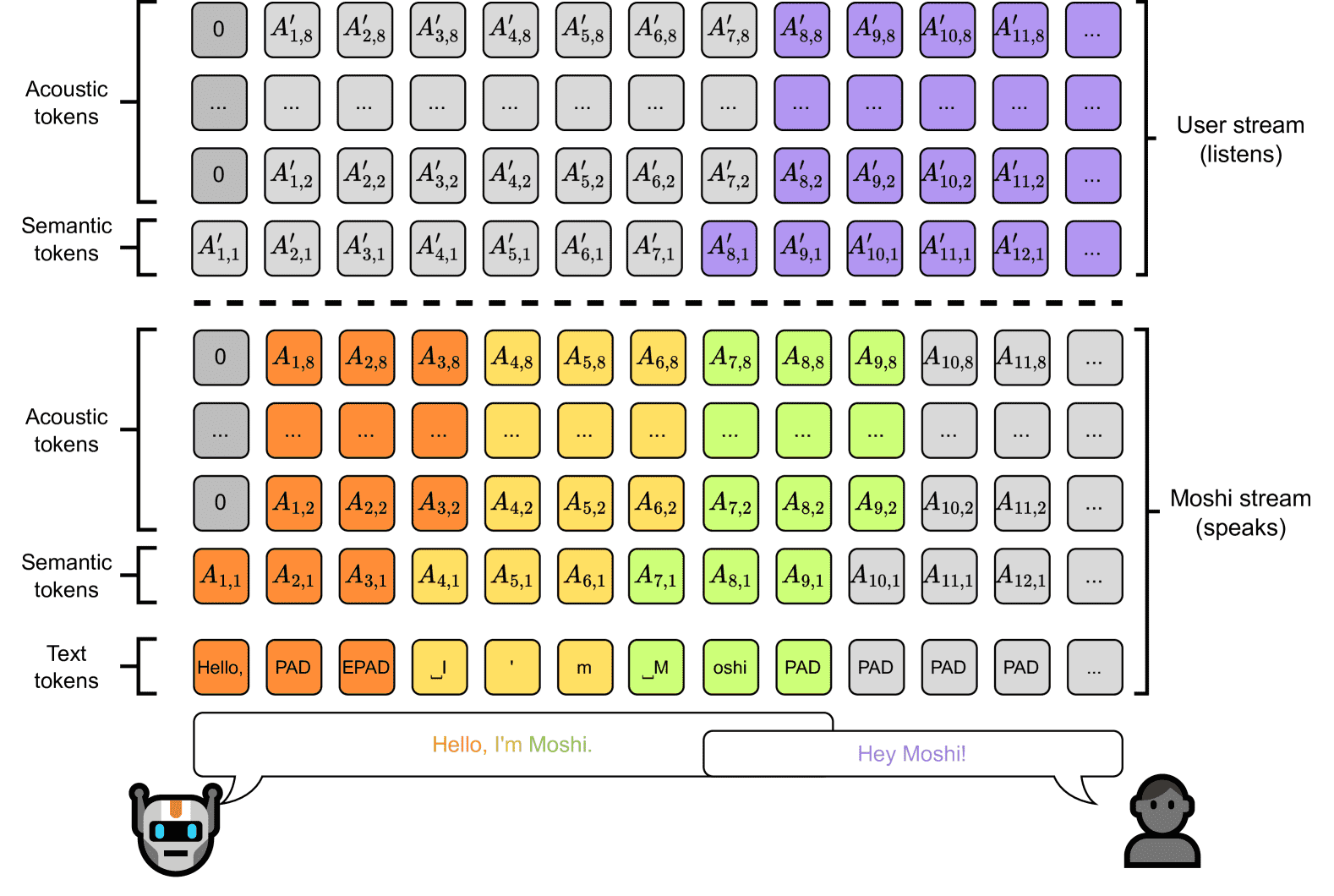
Figure 4:Representation of the joint sequence modeled by Moshi. Each column represents the tokens for a given step in the joint sequence (Vs,k) described in Equation 6 with an acoustic delay τ=1, e.g. the input of the Temporal Transformer for this step. Tokens are predicted from bottom to top in the Depth Transformer. At inference time, tokens under the dashed line (corresponding to Moshi) are sampled, while those above are fed from the user. This design allows for our model to handle overlapping speech turns.
3.4.4 Inner Monologue(内心独白)¶
主要讲的是 Moshi 模型如何通过“内心独白”(Inner Monologue)机制,同时建模文本与语音流,提高语音生成质量,并实现可切换的流式语音识别(ASR)和语音合成(TTS)功能。
核心思想:Moshi 让模型“听见自己在说什么”
什么是 Inner Monologue(内心独白)?
模型在说话时,不只生成语音,还生成对应的文字(用 Whisper 识别自己说的话)。
这个文字流(文本 token)作为一种“语言支架”,帮助模型说得更清楚、更符合语言规范。
这个机制只对 Moshi 自己使用,对用户的语音流不做实时转写。
因为实时转录难度高,且这不符合我们端到端的语音到语音建模目标
Aligning text and audio tokens.¶
目标:将文本 token 与每秒 12.5 帧的音频 token 对齐
模型使用 Whisper 给出的单词时间戳,把文本 token 精准对齐到这些帧。
为了让模型知道哪里是“空白”或“说完了”,引入了两种特殊 token:
PAD:表示填充(静音)EPAD:表示某个词结束
在英语中对话语料中,约65%的帧都是填充帧(PAD token),说明词之间的停顿是常见现象。
Deriving streaming ASR and TTS.¶
一套机制,切换成流式 ASR 或 TTS
通过控制文本 token 和语音 token 的“谁在前谁在后”,可以让模型:
只生成文本 → 流式语音识别(ASR)
只用文本来引导语音 → 流式语音合成(TTS)
不用改模型结构或训练数据,只改一个“延迟”参数。
Joint sequence modeling for Moshi.¶
每一时刻,模型预测一个包含多个流的“联合序列”,包括:
Moshi 的文本 token
Moshi 的语义 token
Moshi 的延迟音频 token
用户的语义 token
用户的延迟音频 token
总共有
2Q+1条流(Q=8),如图4所示。给定延迟步数 \(\tau\),语音分帧维度 \(Q\),第 \(s\) 步的联合序列 \(V_s\) 包括以下内容:
公式: \( \left\{ \begin{array}{lll} V_{s,1} &= W_s & \text{aligned text tokens.} \\ V_{s,2} &= A_{s,1} & \text{semantic tokens of Moshi.} \\ V_{s,1+q} &= A_{s-\tau,q} \quad \text{if} \quad s \geq \tau+1, 1 < q \leq Q & \text{delayed acoustic tok. of Moshi.} \\ V_{s,1+Q+1} &= A^{\prime}_{s,1} & \text{semantic tokens of other.} \\ V_{s,1+Q+q} &= A^{\prime}_{s-\tau,q} \quad \text{if} \quad s \geq \tau+1, 1 < q \leq Q & \text{delayed acoustic tok. of other.} \\ \end{array} \right. \)
其中 \( K = 2Q + 1 \quad \text{with } Q = 8 \)
参数说明
\(V_{s,k}\):第 \(s\) 个时间步、第 \(k\) 个子序列的 token。
\(W_s\):对齐的文本 token 序列(Moshi 说的文字)。
\(A_{s,1}\):Moshi 的语义 token(表示语义内容)。
\(A_{s-\tau,q}\):Moshi 的延迟音频 token,第 \(q\) 个(表示具体发音细节),仅在 \(s \geq \tau + 1\) 且 \(1 < q \leq Q\) 时有效。
\(A'_{s,1}\):对方说话者的语义 token。
\(A'_{s-\tau,q}\):对方说话者的延迟音频 token,第 \(q\) 个,条件同上。
\(\tau\):延迟步数(控制文本和音频之间的时间差)。
\(Q\):每个时间步包含的音频 token 数量,实验中取 \(Q=8\)。
\(K = 2Q + 1\):总的子序列流数量,包括文本流、两个说话者的语义流和音频流。
Inference of Moshi.¶
只生成 Moshi 的文本和语音部分,用户部分用真实音频代替。
模型可以同时听和说,也可以静音(生成“自然的静音波形”)。
利用文本流控制行为,比如插入
EPAD可以让 Moshi 立即开口说话。
🎯 总结一句话:¶
Moshi 在生成语音时,也生成自己说的文字,通过这种“内心独白”机制提高语音质量,并可以灵活切换成语音识别或语音合成。
4. Datasets and Training¶
4.1 Text Data¶
12.5% 来自高质量数据源:Wikipedia、Wikibooks、Wikisource、Wikinews、StackExchange、科学文章(peS2o)。
87.5% 来自 CommonCrawl 网络数据,使用特定过滤方法筛选。
Wikipedia 用了 5 个不同年份的数据(2017、2018、2019、2021、2022)。
4.2 Audio Data¶
700万小时音频(以英语为主)通过 Whisper large-v3 转录,用于预训练(不区分说话人)。
Fisher 数据集(2000小时电话对话,左右声道分开录)用于训练模型能“听说同步”(多流能力)。
170小时高质量多说话人对话用于微调多流 TTS 模型,不直接训练 Moshi,但对其提升效果。
所有音频处理为单声道、24kHz采样率。
为生成时间戳,使用 whisper-timestamped 工具。
4.3 Speech-Text Instruct Data¶
文本指令集(如 Open Hermes)不适合 TTS,因此使用 Helium 生成真实对话的文字,再用多流 TTS 合成语音。
合成语音数据达 2万小时,Moshi 的声音来自同一个演员(录了70+种说话风格),用户声音随机。
对话生成方式包括:
根据 Wikipedia/StackExchange 生成知识问答类对话;
让用户请求 Moshi 用特定声音(如愤怒或像海盗)说话;
角色扮演情景(如“开心的侦探”);
训练 Moshi 识别错误、拼写问题、误导性提问(如“埃菲尔铁塔在北京吗?”);
生成安全对话,避免 Moshi 回答不当或不合规内容。
4.4 Training Stages and Hyper-parameters¶
Helium pre-training.¶
使用纯文本训练语言模型 Helium,共训练 50 万步。
用 AdamW 优化器 + 余弦学习率调度 + warmup。
每批数据包含 420 万个 token,运行在 H100 GPU 上。
Moshi pre-training.¶
Temporal Transformer 初始化自 Helium,Depth Transformer 随机初始化。
数据:单通道的音频序列 + 随机延迟的文本(mask 掉30%)。
总共训练 100 万步,其中一半 batch 是纯文本以防遗忘。
使用两个优化器分别处理文本与音频,调节学习率以保持平衡。
Moshi post-training.¶
使用说话人分离(diarization),将音频分成主说话人和其他人两个通道。
文本只保留主说话人内容。
固定延迟为 0,训练 10 万步,批次为 8 小时音频。
Moshi finetuning.¶
真实多说话人对话
使用 Fisher 数据集,让模型学习真实多轮对话。
批量大小为 40 分钟音频,训练 1 万步。
不再使用纯文本 batch。
instruct
使用合成 instruct 数据集,把主说话人设置为“助手”。
批量大小为 2.7 小时音频,训练 3 万步。
增强用户音频流:随机调整音量、加背景噪音、模拟回声和混响等。
TTS Training.¶
使用延迟 2 秒的音频流进行训练,目标是生成 instruct 微调数据。
注意:Moshi 本身并未使用该 TTS 的有监督多流数据进行训练。
Training loss.¶
同时对文本 token 和音频 token 建模。
文本 loss 与音频 loss 加权求和(文本重要性高,语义音频 token 权重为 100,其他为 1)。
5. Evaluation¶
5.1 Text Language Modeling¶
评估方法:
他们用多个常见的语言理解测试(比如 ARC、TriviaQA、MMLU 等)来评估文本训练的模型 Helium,
涵盖常识推理、问答、多项选择题等任务。
部分测试用 5-shot 方式(给模型看几个示例后再答题),其余用 0-shot(直接答题)。
对比模型:
用了一些参数量约 70 亿、训练数据量相近(<2.5 万亿 token)的现有大模型(比如 MPT、Falcon、Llama 2、OLMo)作为基线,
还包括算力用得更多的 Mistral 和 Gemma。
评估结果:
在大多数测试中,Helium 的表现和这些对比模型相当,
甚至在部分任务(如 ARC、Open-Book QA)中超过了用更多算力训练的模型,说明它的预训练数据质量很好。
5.2 Audio Tokenization¶
这段内容讲的是一个叫 Mimi 的音频编码器的评估方式与结果
一、评估方式¶
语义评估(Semantic)
用 ABX 错误率衡量语音中相似音素(如“beg”和“bag”)的区分能力,来判断 Mimi 的语义 token 是否适合语言建模。
音质评估(Acoustic)
使用三种方法来评估还原音频的质量:
自动指标:VisQOL(有参考音)、MOSNet(无参考音);
人工听感:MUSHRA(请20人评分)。
二、对比方法和模型¶
对比了三个已有方法:
RVQGAN:只能编码音频,不含语义信息;
SpeechTokenizer 和 SemantiCodec:同时编码语义和音频信息。
三、主要结果¶
语义方面:
Mimi 原始语义 token 区分音素的能力不强;
通过将 WavLM 知识“蒸馏”进 Mimi(即借助大模型提升小模型),其语义表现明显提升;
不过,语义更强会牺牲一部分音质;
使用“语义/音频分离量化”结构后,能较好地平衡语义与音质。
音质方面:
加入 Transformer 解码器后,音质显著提升;
虽然自动指标(VisQOL、MOSNet)提升有限,但人工听感(MUSHRA)评分提升很大;
Mimi 即使在低码率下,音质也优于其它方案,而且支持实时处理(全因果、低帧率);
四、讨论总结¶
Mimi 优势:语义强、音质高、支持实时对话(低延迟);
问题发现:自动评估指标(尤其是 VisQOL 和 MOSNet)与人真实感知音质有时不一致;
结论:目前仍缺乏稳定可靠的自动音质评估方法,这对音频建模是一个挑战。
5.3 Ablations on Generative Modeling¶
这段内容讲的是 Moshi 模型在语音生成方面的 消融实验(Ablation Studies),目的是优化生成效果和响应速度。
实验目的:¶
测试不同模型结构(比如 RQ-Transformer)和延迟模式(delay patterns)对生成语音效果的影响。
所有模型都使用 Helium 作为文本处理模块,并在音频数据上预训练。
度量方式:¶
困惑度(perplexity):衡量模型预测的准确性(适用于相同延迟模式下的模型)。
Whisper转录 + 文本评分模型(LiteLlama):用来评估不同延迟模式下生成语音的可懂性和一致性。
文本长度(字符数):长文本通常表示模型输出质量更好,短的说明模型可能“哑了”。
主要发现:¶
RQ-Transformer 模块的作用:
在标准延迟
[0,1,2,3,4,5,6,7](总延迟640ms)下,RQ-Transformer 效果提升不大。但在更低延迟
[0,2,2,2,2,2,2,2](240ms)下,使用 RQ-Transformer 大幅提高性能,因此在实时对话中是关键模块。
不同延迟模式的对比:
最小延迟
[0,0,0,0,0,0,0,0](80ms)效果差;增加一点延迟(80ms 或 240ms)能明显提升语音质量;
说明在实时性和质量之间要权衡。
训练策略优化:
给 语义 token的损失权重提高到 100,其他仍为 1,能让语音更易懂。
各 RVQ 层用 独立的参数 (depthwise)代替共享参数,减少相互干扰,效果更好。
Inner Monologue 的重要性:
即使是纯语音到语音生成,也发现加入 文本思考链(Inner Monologue) 显著提升生成语音的质量和长度。
最终做法:
预训练阶段使用音频延迟2,微调阶段降低为1,实现 160ms的理论延迟,兼顾了质量和实时性。
5.4 Audio Language Modeling¶
这段内容主要讲的是 Moshi 模型在语音语言建模方面的表现评估。
📊 1. 评估指标(Metrics)¶
使用“textless NLP”指标来测试 Moshi 理解语音的能力:
sWUGGY:测词汇识别能力(如能否区分”oxidation”和虚构词”accidation”)。
sBLIMP:测语法判断能力。
Spoken StoryCloze:测常识推理能力,看是否能判断一段故事结尾是否合理。
Spoken Topic-StoryCloze:难度更低,干扰项更容易区分,得分更高。
计算时采用负对数似然(越小越好),对每一时刻的多个 token 加权求和(语义 token 权重为100,音频 token 为1)。
忽略文本 token,仅评估未转录的音频片段。
⚖️ 2. 对比模型(Baselines)¶
分三类进行对比:
音频起步模型:如 GSLM、AudioLM、TWIST-1.3B,从零开始训练,只用音频。
文本预训练再转音频:如 TWIST-13B、VoxtLM、Spirit-LM(Speech Only)。
多模态联合训练:语音+文本一起训练。
Moshi 分三个阶段对比:初始模型、多流后训练、有无真人录音语音合成。
🏆 3. 结果(Results)¶
Moshi 即使在“冷启动”(纯音频起步)下,也在大多数指标上超过其他模型,尤其在 sTopic-StoryCloze 上表现突出。
多模态训练能提升常识推理能力,但对词汇/语法判断能力(sWUGGY/sBLIMP)有时反而不利。
推测是因为在用户通道引入了噪声和混响条件,影响了细粒度词汇判断。
Moshi 在 MMLU(文本问答)上得分比 Spirit-LM 高 12 分,表明其通用知识和文本理解更强。
Moshi 是唯一一个同时集成 语义+音频 token 的端到端生成模型,不像其他模型要靠额外 vocoder。
💬 4. 讨论(Discussion)¶
虽然 textless NLP 指标推动了早期研究,但对对话型模型(如 Moshi)不总是有效指导。
常识判断和语法判断的分数常不一致,可能是训练中音频条件太多样。
sWUGGY 分数下降不代表 Moshi 真正词汇能力下降,因为实际语音输出的多样性并没变差。
所以接下来会用“语音问答”继续评估 Moshi 的知识和语言能力。
5.5 Spoken Question Answering¶
🌟 评估方法:¶
用三个语音问答数据集(Spoken Web Questions、Llama Questions 和音频版 TriviaQA)测试 Moshi。
模拟用户提问方式:把问题的音频 token 加入模型输入流,最后用一个特殊 token 触发回答。
🆚 对比模型:¶
和 Spectron、SpeechGPT 及其他语音模型(如 GSLM、AudioLM、TWIST)进行对比。
比较时分两类:
纯音频模型:和不使用“内心独白”的 Moshi 对比。
文本转语音模型:和使用“内心独白”的 Moshi 对比。
也和文本模型 Helium 比较,以观察是否因训练语音数据导致知识损失。
📈 结果总结:¶
Moshi 表现最好,尤其在加入“内心独白”(Inner Monologue)后,准确率提升近三倍,几乎不增加推理成本。
它是唯一支持“流式”语音交互的模型,其它模型必须先生成整段文本再转语音。
如果预训练时不保留部分纯文本数据,会造成性能下降,说明保持文字知识很重要。
🧠 讨论:¶
虽然 Moshi 很强,但还是略逊于纯文本模型 Helium(如 MMLU 分数下降)。
特别在 TriviaQA 上差距较大,原因可能是:
问题太复杂(多句子结构);
太书面化,而 Moshi 是在更口语风格数据上微调的。
改进建议:在微调中引入更多复杂语法结构,有望弥补这部分差距。
5.6 Quality and Statistics of Generated Dialogues¶
评估指标:
不只是评估单轮问答,还通过外部语言模型对对话的语言质量打分,并分析“轮流说话”相关指标,包括:
IPU(说话片段):被两侧至少 0.2 秒的静音分隔的连续语音。
Pause(停顿):同一说话人两个 IPU 之间的静音。
Gap(间隙):不同说话人之间的静音。
Overlap(重叠):两人同时说话的时间。
使用 DialoGPT 模型,通过计算 perplexity(困惑度)来评价语义质量。
实验设置:
从 Fisher 数据集中随机选 1000 个 10 秒语音片段,用 Moshi 模型生成 32 个续说结果(不同温度设置下)。
对比基线:
与 dGSLM 模型比较(同样是端到端语音生成模型),
dGSLM 用的是 50 个语音片段,每个生成 50 次,并与一个传统级联系统(ASR + LM + TTS)对比。
结果总结:
Moshi 的语言质量跟传统级联系统相当,甚至在 perplexity 上表现更好,
说明它生成的语言更贴近 DialoGPT 的训练数据,比真实对话还“更规范”。
相比之下,dGSLM 模型无法生成连贯的语音。
5.7 Streaming ASR and TTS¶
📌 方法概述:¶
Inner Monologue 模型通过控制文字和音频 token 的“延迟”来实现流式 TTS 和 ASR。
流式 TTS:音频 token 延迟 2 秒,模型可以提前看到部分文本(lookahead),推理时对文本部分使用强制教师(teacher forcing)。
流式 ASR:文本 token 延迟 2 秒,模型先听一段音频再开始生成文本,推理时对音频部分使用强制教师。
📊 评估方式:¶
TTS 生成的音频用 HuBERT-Large 模型转写成文本,然后计算词错误率(WER)。
只评估时长在 4~10 秒之间的音频,方便和 Vall-E 等模型对比。
数据集:LibriSpeech test-clean(但模型训练时没用这个数据集)。
✅ 实验结果:¶
TTS WER:
Moshi:4.7%(好于 Vall-E 的 5.9%,不如 NaturalSpeech 3 的 1.81%)
Moshi 只用 2 秒延迟,Vall-E 和 NaturalSpeech 3 要看完整文本。
ASR WER:
Moshi:5.7%
对比模型 Streaming FastConformer:3.6%
Moshi 还能提供精度达 80ms 的对齐信息。
💡 说明:¶
实验目的是展示 Inner Monologue 的灵活性,而不是追求最好结果。
LibriSpeech 评估集不适合展示 Moshi 的全部能力,比如多说话人建模和长对话生成等。
更全面的流式 TTS 评估将在后续工作中进行。
5.8 Compressing Moshi and Impact on Speech Quality¶
这段内容主要讲的是对 Moshi 模型进行压缩(量化)后对其语言理解能力和语音合成质量的影响。
🌟 背景¶
大模型太大,难以部署在资源有限的设备上。为此,**后训练量化(PTQ)**是一种常见的压缩方法,可以大幅减小模型体积,但可能会损失性能。
🧠 语言能力方面(MMLU 测试):¶
Helium 模型(Moshi 的文本基础模型) 较为耐量化,4bit 后性能只下降不到2分,模型变小3.4倍。
Moshi 模型(语音模型) 较敏感,4bit 后性能下降 5~10分,8bit 时只下降2分,可接受。
用较大的量化块(block size = 256)会影响性能,小块(如32)更好。
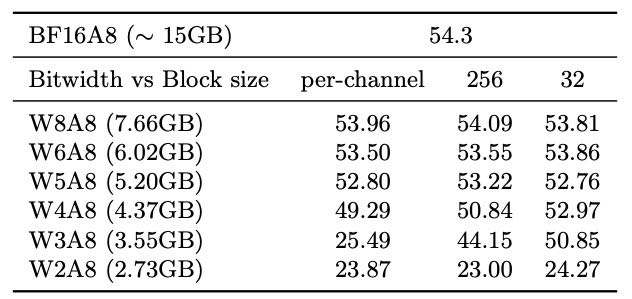
Table 10: Linguistic impact of model compression on Helium, as measured by MMLU
🔊 音频质量方面(MOSNet指标 + 熵谱分析):¶
用 4bit量化 时,语音质量基本没有明显下降。
低于4bit(如3bit, 2bit) 会出现严重问题,如:
杂音(noisy)
含糊语音(gibberish)
重复模式(repetitive)
MOSNet 对这些问题不敏感,但通过分析熵谱可以识别这些问题。
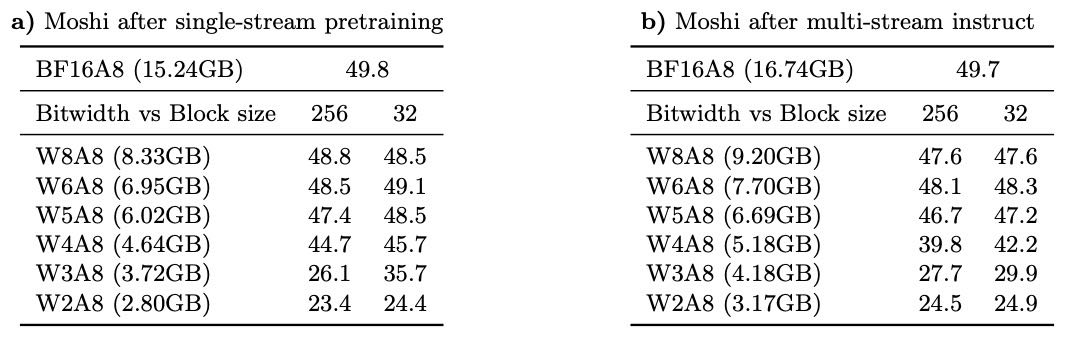
Table 11: Linguistic impact of model compression on Moshi, measured by MMLU for different quantized Moshi on the text tokens generated by Inner Monologue directly
✅ 总结建议:¶
对 Moshi 使用 8bit 或 4bit 量化比较安全;
不建议使用 2bit 或 3bit 量化,会严重影响语音质量;
Helium 可更激进地压缩,而 Moshi 更需谨慎。
6.Safety¶
6.1 Toxicity Analysis¶
研究人员过去几年主要关注文本生成模型中的偏见和有害内容问题,但对语音模型的安全性研究还不够。由于语音中包含语调、讽刺等非文字信息,语音模型和文本模型不容易直接对比。
为了方便比较,他们这里只分析语音模型 Moshi 生成的文本是否存在有害内容(比如仇恨、自残、武器、犯罪、性、毒品等),使用的是一个名为 ALERT 的安全性评估标准。
结果显示,Moshi 的整体安全分为 83.05,相比 GPT-4(99.18)、GPT-3.5(96.95)等大模型略低,处于中等水平。工业界模型因为有更多人工标注和安全优化,表现更好是正常的。
6.2 Regurgitation Analysis¶
“复读”指模型在生成内容时,重复训练数据中见过的内容,这是过拟合的表现之一。
对于语音模型,复读不仅是文字,也可能包括声音的语调、语速、甚至背景音乐,这会带来版权或隐私问题(比如生成某人声音未经授权)。
评估方法:
研究者挑选了训练数据中最常出现的一段 16 秒音频片段,然后测试不同模型是否会在生成中重复这段内容。
他们使用了一套匹配系统,对比生成结果与这段音频的匹配度(不仅比声音,还比文字),再进行人工审核确认。
实验结果:
温度(temperature)越高 → 生成越随机 → 复读概率更高。
去重数据集 → 可以有效消除复读风险。
微调(fine-tuning) 后也能降低复读概率,但不能完全防止。
总结:
模型复读是现实风险。
去重训练数据是目前最有效的防护手段之一。
对语音模型来说,这不仅是技术问题,也是法律和伦理问题。
6.3 System Voice Consistency¶
问题背景:
语音到语音模型存在一个潜在风险:误用或模仿用户的声音。
模型应该坚持使用系统预设的目标声音,而不是学着模仿用户的声音。
评估方法:
生成 100小时 的对话,参与者为:
Moshi 模型;
一个合成的第二说话人。
使用 WavLM(一个说话人识别模型)提取每段语音的“说话人特征”(嵌入)。
对比 Moshi 的每段话与两个基准声音的相似度:
和它自己最开始的声音比;
和另一个说话人的声音比。
排除前 15 秒的片段,避免把第一句作为比较目标。
结果:
在 10,382 段对话中,98.7% 的语音更接近系统自己的声音;
仅有 1.3% 的语音更接近另一个说话人的声音,说明误模仿的情况非常少。
结论:
通过在训练时选择一个固定的目标声音,并在生成时坚持使用它,
Moshi 可以有效防止模仿用户声音,保障了声音一致性和语音安全性。
6.4 Identification of the Content Generated by Moshi: Watermarking¶
这段内容讲的是:如何识别一段音频是不是 Moshi 生成的,
主要探索了两种方式:索引查找(indexing)和水印(watermarking)
🔹一、索引匹配法(Indexing)
只适用于可以访问生成服务器的情况(比如 Moshi 官方 Demo)。
本质是:对生成音频做指纹匹配,比对数据库中有没有一样的记录。
优点:准确;缺点:只能在封闭系统中用,开放模型没法应用。
🔹二、水印法(Watermarking)
目的是在生成音频中加入人耳听不出来的“隐形标记”,便于事后识别是否为 Moshi 生成。
Evaluation of signal-based watermarking.¶
在音频信号中加入微弱变化(如微小频率抖动)。
使用 Facebook 的开源工具 Audioseal 测试:
➡️ 结论:信号水印对压缩非常不鲁棒,容易被“无意压缩”抹掉,不适合实际部署。
Exploration on generative-based watermarking for audio.¶
类似文本水印,在生成过程中控制采样概率,用哈希函数控制生成结果有“特定偏好”,可被事后检测。
优点:更稳,适用于开源模型。
问题:
音频生成后需要重新编码为 token 才能检测,但这种 codec 编解码过程不稳定(非幂等);
少量时序变化(比如延迟 20ms)就会导致 token 不一致;
导致水印检测失败。
Discussion on generative audio watermarking.¶
只对前几层 token 加水印 → 更稳定。
引入新损失函数,增强 codec 编解码过程的稳定性。
学习鲁棒性编码器(类似图像水印)。
对文本添加水印 → 但容量小,仅适合长对话,且需依赖语音转文本准确度。
在训练数据中加入隐性水印(radioactive data) → 模型会“潜移默化”学到,可用于后期追溯。
小结¶
Moshi 团队尝试了传统信号水印,但发现容易被压缩等操作抹掉;
也尝试了生成过程加水印,结果不稳定;
未来方向:更稳定的编码方式 + 数据级水印 是可能的突破点;
同时指出:即使模型开源,也要防止水印机制被轻易移除。
7.Conclusion¶
我们提出了 Moshi,是第一个实时、全双工的语音对话系统。
它由以下几个关键部分组成:
Helium:一个7B参数的文本大模型,在同类开源模型中表现优秀;
Mimi:一个高质量、低码率、低帧率的音频编解码器,能将语音转换成适合语言建模的离散单元;
多流架构:支持语音到语音的自然对话生成;
Inner Monologue(内心独白)技术:通过先生成文本再生成语音,提高了语音生成质量,还能支持流式生成。
实验表明,Moshi 在语音问答和对话建模上效果优异,语音一致性好、无毒性内容。整套系统的理论延迟为 160毫秒,可以持续进行复杂对话达5分钟。
我们开源了 Mimi 和 Moshi,希望推动语音交互技术发展。同时指出,Inner Monologue 还能广泛应用于流式TTS和ASR。