2504.10147_PersonalRAG❇️: A Survey of Personalization: From RAG to Agent¶
引用: 4(2025-08-21)
组织:
City University of Hong Kong
Noah’s Ark Lab, Huawei China
GitHub: https://github.com/Applied-Machine-Learning-Lab/Awesome-Personalized-RAG-Agent
总结¶
总结
第一作者李晓鹏博士和他的导师赵翔宇来我们公司做过讲座
这篇文章是他们研究中的一个总纲
说明
本篇文章可以作为 记忆个性化RAG框架 的总纲
总结里面没有的细节找本文的各具体章节、然后找本文的原始论文、然后找索引中各具体论文
评估指标分类: 参见 表2
背景
RAG框架的三大核心阶段(可参考图1和表1)
预检索
查询重写(query rewriting)
直接个性化查询重写(Direct Personalized Query Rewriting)
通过模型直接调整查询,如使用强化学习、对话系统优化等方法
辅助个性化查询重写(Auxiliary Personalized Query Rewriting)
借助机制如检索、推理策略、外部记忆等
查询扩展(query expansion)
通过添加同义词、上下文信息等扩大原始查询的语义范围
个性化扩展结合用户标签、搜索历史等信息,以提升搜索体验
其他
查询消歧、自动补全
通过词嵌入、用户画像等方式提升个性化效果
说明
查询重写适用于查询不明确或存在歧义的场景,尤其在对话或多轮交互中效果显著。
查询扩展适用于查询本身相关但不够完整的情形,通过语义扩展提升结果覆盖度。
检索
Indexing(索引)
通过结构化数据提升检索效率。
个性化索引方法包括使用用户历史生成用户嵌入、引入知识图谱等,以增强个性化检索效果。
Retrieval(检索)
密集检索(Dense Retrieval)
通过嵌入用户偏好提升个性化匹配
稀疏检索(Sparse Retrieval)
BM25 结合用户行为权重
基于提示的检索(Prompt-based Retrieval)
通过个性化提示引导检索。
其他方法
如基于强化学习的检索优化、参数化检索
Post-retrieval(后检索)
重排序(Re-ranking)
摘要(Summarization)
压缩(Compression)
说明
索引阶段注重效率与语义理解的平衡。
检索阶段需在语义理解与计算成本之间权衡。
后检索方法应关注个性化内容的优化与简洁表达。
生成
Generation from Explicit Preferences(基于显式偏好的生成)
用户显式偏好包括人口统计、行为序列、写作风格等,
注入方式分为:
直接集成提示(Direct-integrated Prompting)
摘要增强提示(Summary-augmented Prompting)
通过提取用户偏好摘要提升生成效果
自适应提示(Adaptive Prompting)
通过自动化方式生成个性化提示
Generation from Implicit Preferences(基于隐式偏好的生成)
隐式偏好通过模型参数实现个性化
主要方法包括:
微调方法(Fine-tuning Based Methods)
如 LoRA、PLoRA、MiLP、Review-LLM 等
强化学习方法(Reinforcement Learning Based Methods)
如 P-RLHF、P-SOUPS、REST-PG、RewriterSlRl 等
通过奖励模型对齐用户偏好
说明
显式偏好适合信息明确、可解释性要求高的场景。
隐式偏好适合需要深度个性化、但难以提供显式输入的场景。
选择方法需结合具体应用场景和资源限制。
贡献
将RAG的能力扩展到个性化大语言模型代理(Personalized LLM-based Agents)
相比传统RAG具备更高级的功能,包括:
用户理解:深入理解用户的意图和需求
个性化规划与执行:根据用户目标生成和执行个性化策略
动态生成:基于实时上下文生成更贴合用户需求的内容
RAG 与 Agent 对比
RAG的结构与Agent的工作流具有高度一致性
RAG的查询重写阶段对应Agent的语义理解阶段
检索阶段对应Agent的规划与执行阶段
生成阶段对应Agent的生成阶段
个性化的重要性
有助于实现更加适应性和上下文感知的AI系统,是通向 通用人工智能(AGI) 的重要一步
被广泛应用于个性化推理、自适应决策、用户特定内容生成和交互AI系统等领域
用户个性化的分类
明确的用户画像(Explicit User Profile)
定义:用户主动提供的个人信息。
内容:包括人口统计信息(如年龄、性别、教育背景)和社会关系(如社交网络)。
重要性:是个性化最直接、最明确的来源之一。
用户历史行为(User Historical Interactions)
定义:用户过去的行为数据。
内容:如浏览记录、点击行为、购买历史等。
作用:通过这些行为数据可以推断用户的兴趣和偏好,从而提升个性化效果。
重要性:是理解用户长期偏好的关键。
用户生成内容(User Historical Content)
定义:用户自己产生的文本内容。
内容:如聊天记录、邮件、评论、社交媒体互动等。
特点:属于隐式个性化,提供更自然的个性化依据。
重要性:有助于捕捉用户的真实表达和潜在需求。
基于角色的用户模拟(Persona-Based User Simulation)
定义:利用**大语言模型(LLM)**模拟用户进行个性化交互。
作用:生成基于特定用户角色的回应,提升交互的真实性和针对性。
重要性:是智能体实现个性化的重要方式之一。
个性化整合的作用
动态匹配用户偏好:使模型的输出更贴合用户当前的状态和需求。
增强用户中心性:让回答更加以用户为中心,提升交互体验。
提高适应性:系统能够根据不同的用户表现出不同的行为和输出。
Abstract¶
个性化在现代AI系统中的重要性¶
个性化已成为现代人工智能系统中的一个关键能力,使得系统能够根据用户的个人偏好、上下文和目标提供定制化的交互体验。近年来,研究重点转向了基于检索增强生成(RAG)的框架及其在个性化场景中的发展,尤其是演进为更高级的基于代理(Agent)的架构,以提升用户满意度。
本文的主要贡献¶
本文系统地探讨了在RAG框架的三大核心阶段(预检索、检索和生成)中实现个性化的研究进展。在此基础上,进一步将RAG的能力扩展到个性化大语言模型代理(Personalized LLM-based Agents)。这些代理系统相比传统RAG具备更高级的功能,包括:
用户理解:深入理解用户的意图和需求
个性化规划与执行:根据用户目标生成和执行个性化策略
动态生成:基于实时上下文生成更贴合用户需求的内容
研究内容与结构¶
对于RAG中的个性化以及基于代理的个性化,文章提供了:
形式化定义
对近期文献的全面回顾
关键数据集与评估指标的总结
此外,文章还深入探讨了该领域中的基本挑战、限制因素以及有前景的研究方向。
关键术语¶
大语言模型(Large Language Model)
检索增强生成(Retrieval-Augmented Generation)
代理(Agent)
个性化(Personalization)
小结¶
本摘要系统性地介绍了个性化在现代AI系统中的核心作用,尤其聚焦于RAG及其向代理系统的演进。文章不仅回顾了现有研究,还指出了未来研究方向,并提供了丰富的资源支持,具有较强的学术参考价值。
1. Introduction¶
背景与问题
大语言模型(LLMs):在AI应用中取得了重大突破,实现了前所未有的自然语言理解和生成能力,但在实际应用中存在响应过时和生成谬误(hallucinations)的问题,限制了信息生成的准确性。
检索增强生成(RAG):作为解决上述问题的框架,通过从外部语料库(如Google、Bing、科学数据库、企业数据库等)中检索信息,确保生成结果是基于可靠知识且最新的。
RAG的结构与智能代理的工作流具有高度一致性:RAG的查询重写阶段对应代理的语义理解阶段,检索阶段对应代理的规划与执行阶段,生成阶段对应代理的执行阶段,这表明RAG的架构与代理工作流正在深度融合,成为智能自治系统的重要支撑。
个性化的重要性
为了进一步提升这些智能系统的性能,个性化成为关键。它有助于实现更加适应性和上下文感知的AI系统,是通向**通用人工智能(AGI)**的重要一步。
个性化被广泛应用于个性化推理、自适应决策、用户特定内容生成和交互AI系统等领域。
当前研究缺乏对个性化RAG与代理系统(agentic RAG)的系统性比较分析,现有的综述要么关注通用RAG方法,要么关注代理系统,鲜有研究专门探讨个性化在其中的整合机制。
本文贡献
全面综述:系统性地回顾了个性化如何整合到RAG(包括预检索、检索、生成)和代理RAG(理解、规划、执行、生成)的各个阶段。
数据与评估:总结了相关子任务中使用的关键数据集、基准和评估指标,以支持未来研究。
研究局限与未来方向:指出当前研究的局限性,并提出未来改进的方向,以解决现有挑战。
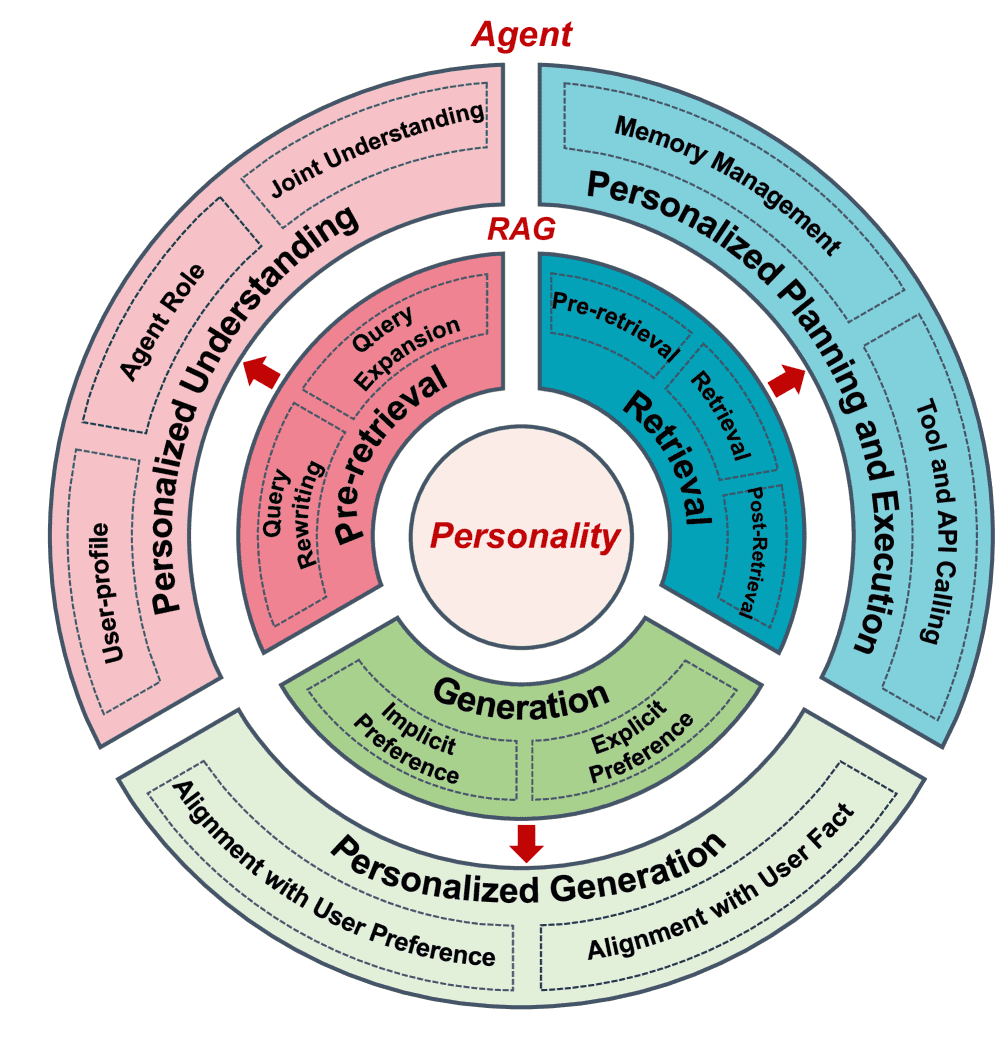
Figure 1.Correlation between personalization and RAG with agent flow.
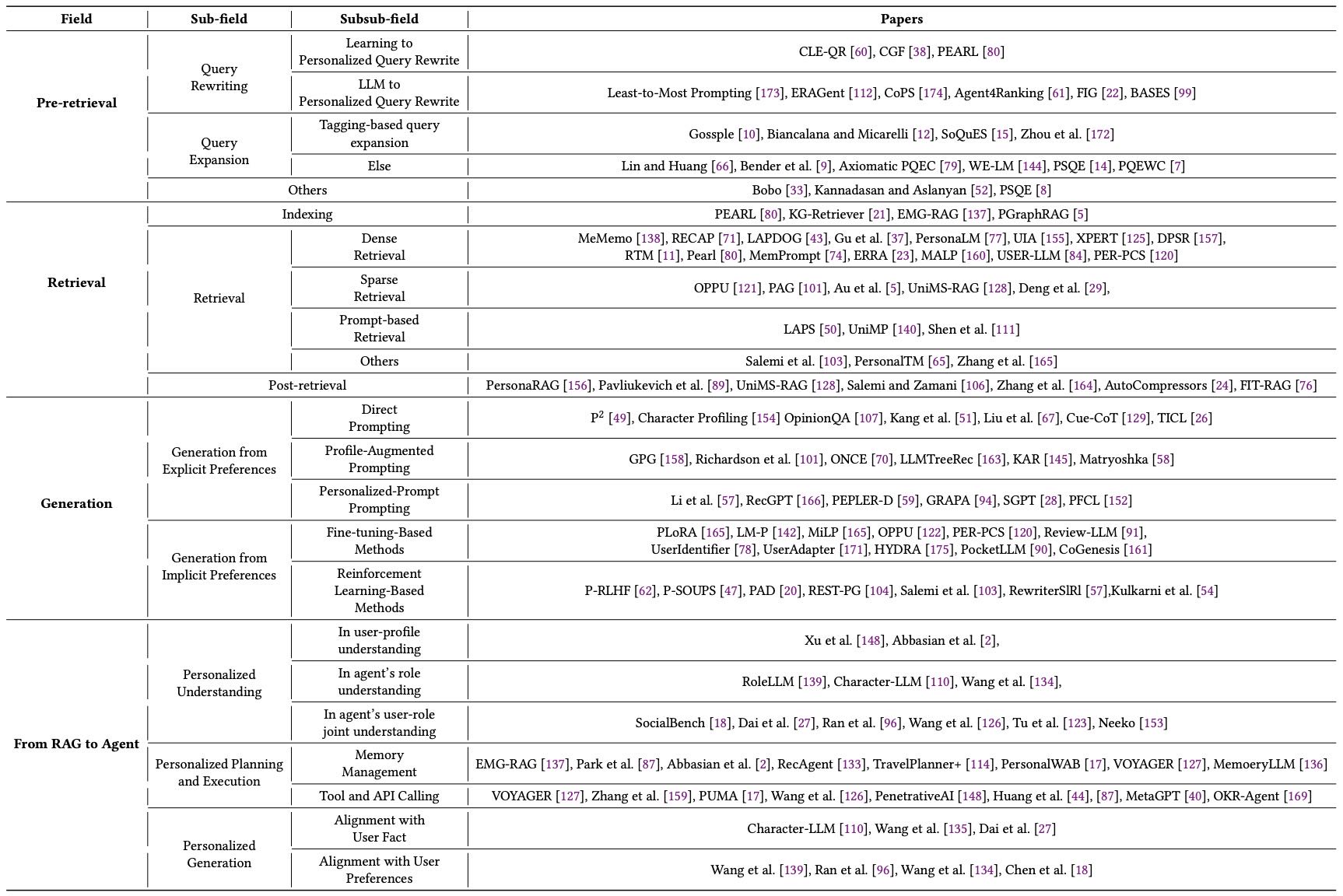
Table 1. Overview of Personalized RAG and Agent.
总体重点:¶
核心主题:RAG与个性化、代理系统的融合是当前AI发展的重要方向。
重点内容:
RAG的结构与智能代理工作流的一致性(结构对齐);
个性化在RAG和代理流程各阶段中的整合机制;
当前研究的不足与未来研究方向。
次要内容:具体论文的引用和各子任务的技术分类(如查询重写、生成方法等)可以作为参考,但不是重点。
2. What is Personalization¶
本节主要介绍了个性化(Personalization)在当前研究中的定义及其在**RAG(检索增强生成)和智能体(Agents)**中的应用方式。重点在于将用户特定信息整合到模型预测和内容生成中,以匹配用户的偏好。
个性化的基本定义¶
个性化是指根据个体的偏好来定制模型的预测或生成内容。在RAG和智能体中,它体现在将用户信息融入RAG流程的不同阶段或智能体内部,从而实现更符合用户需求的响应。
用户个性化的分类¶
用户个性化可以分为以下四种类型:
1. 明确的用户档案(Explicit User Profile)¶
定义:用户主动提供的个人信息。
内容:包括人口统计信息(如年龄、性别、教育背景)和社会关系(如社交网络)。
重要性:是个性化最直接、最明确的来源之一。
2. 用户历史行为(User Historical Interactions)¶
定义:用户过去的行为数据。
内容:如浏览记录、点击行为、购买历史等。
作用:通过这些行为数据可以推断用户的兴趣和偏好,从而提升个性化效果。
重要性:是理解用户长期偏好的关键。
3. 用户生成内容(User Historical Content)¶
定义:用户自己产生的文本内容。
内容:如聊天记录、邮件、评论、社交媒体互动等。
特点:属于隐式个性化,提供更自然的个性化依据。
重要性:有助于捕捉用户的真实表达和潜在需求。
4. 基于角色的用户模拟(Persona-Based User Simulation)¶
定义:利用**大语言模型(LLM)**模拟用户进行个性化交互。
作用:生成基于特定用户角色的回应,提升交互的真实性和针对性。
重要性:是智能体实现个性化的重要方式之一。
个性化整合的作用¶
将上述个性化信息整合到RAG和智能体的工作流程中,可以实现以下目标:
动态匹配用户偏好:使模型的输出更贴合用户当前的状态和需求。
增强用户中心性:让回答更加以用户为中心,提升交互体验。
提高适应性:系统能够根据不同的用户表现出不同的行为和输出。
总结¶
本节重点介绍了个性化在RAG和智能体中的实现方式,强调了整合用户信息(包括显式和隐式信息)的重要性,并分类讨论了四种主要的个性化类型。这些方法共同作用,使系统能够更灵活、更精准地满足不同用户的需求。
3. How to Adopt Personalization¶
本节讨论了在检索增强生成(RAG)流程中引入个性化信息(personalized information, 记作 \( p \))的整体过程。作者提出了一种数学表达方式来描述个性化信息在整个 RAG 流程中的作用:
其中:
\( q \) 为原始查询;
\( p \) 为个性化信息;
\( \mathcal{Q} \) 表示查询处理阶段;
\( \mathcal{R} \) 表示检索阶段;
\( \mathcal{C} \) 表示文档语料库;
\( \mathcal{G} \) 表示生成阶段,参数为 \( \theta \);
最终输出为个性化生成结果 \( g \)。
个性化信息的作用阶段¶
个性化信息 \( p \) 贯穿整个 RAG 流程,具体体现在以下三个阶段:
预检索阶段(Pre-retrieval Phase)
在查询处理阶段 \( \mathcal{Q} \),个性化信息用于优化原始查询 \( q \),例如通过**查询重写(query rewriting)或查询扩展(query expansion)**等方式,使检索更贴近用户个人背景或需求。检索阶段(Retrieval Phase)
检索模块 \( \mathcal{R} \) 使用个性化信息 \( p \) 从语料库 \( \mathcal{C} \) 中获取更相关的文档,提升检索的精准度和相关性。生成阶段(Generation Phase)
在生成阶段 \( \mathcal{G} \),检索到的文档信息与个性化信息 \( p \) 一起,结合给定的 prompt,被输入至生成模型中,生成最终的个性化响应 \( g \)。生成模型的参数为 \( \theta \)。
重点总结¶
个性化信息 \( p \) 在 查询处理、检索、生成 三个阶段均发挥关键作用。
个性化不是简单添加信息,而是结构化嵌入到全流程中,从而提升系统的个性化能力。
作者指出,Agent 系统 可以看作是 RAG 框架的一种 专门应用形式,其中个性化信息的引入方式与 RAG 类似。
小结¶
本节强调了在 RAG 框架中引入个性化的方式和路径,说明个性化信息如何通过各个模块提升系统的表现。理解这一流程对于设计和实现个性化增强的 RAG 系统具有重要意义。
4. Where to Adopt Personalization¶
本章节围绕个性化技术在信息检索和生成系统中的应用展开,重点讨论了个性化在预检索(Pre-retrieval)、检索(Retrieval)、生成(Generation)以及从RAG到Agent的演进这四个阶段的实现方式与技术策略。
4.1. Pre-retrieval(预检索阶段)¶
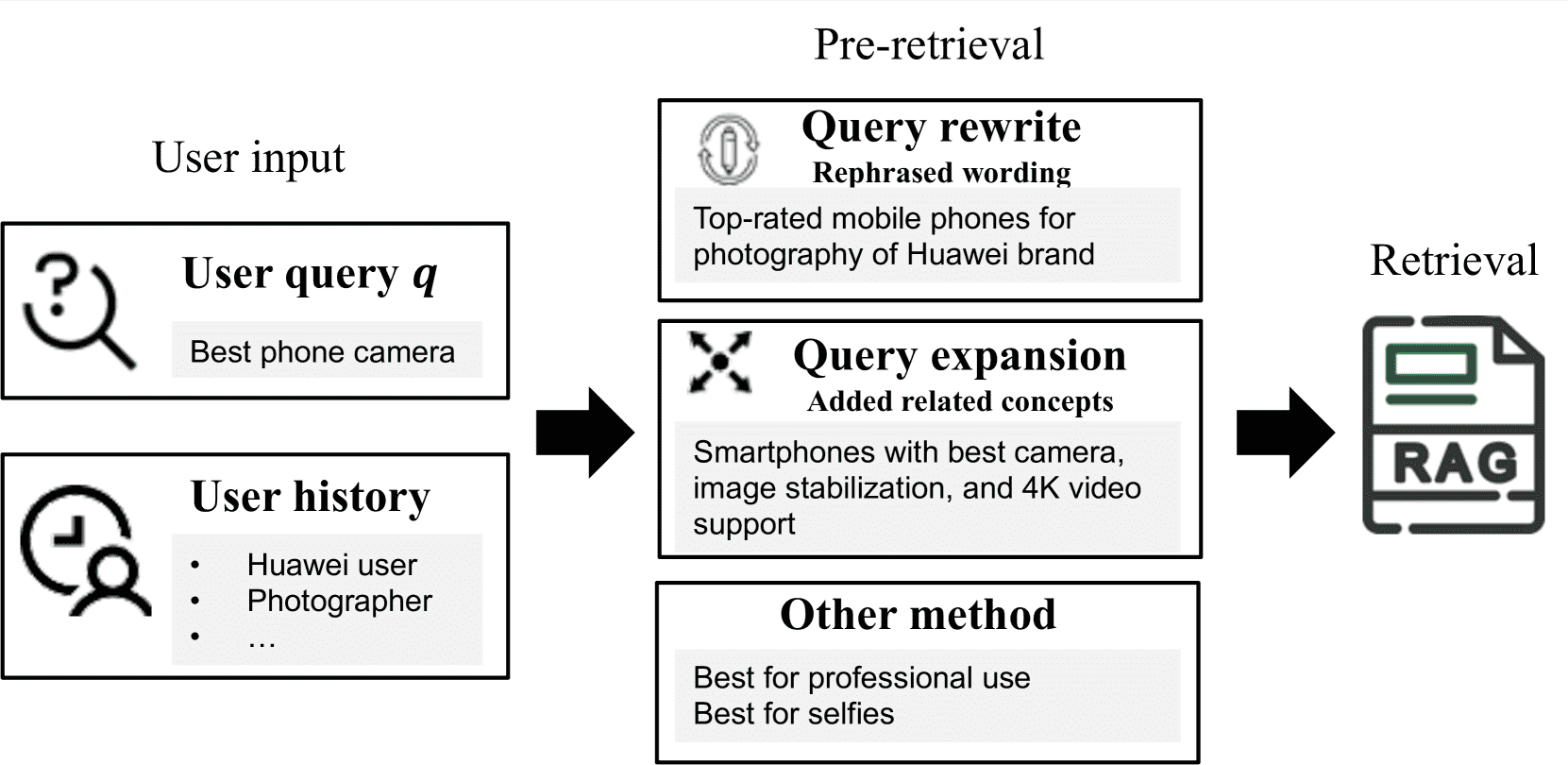
Figure 2.Overview of the personalized pre-retrieval stage.
4.1.1. Definition(定义)
预检索阶段是信息检索系统中优化用户查询以提高检索相关性的重要步骤。该阶段通过引入个性化信息改进原始查询,公式表示为:
\( q^{*} = \mathcal{Q}(q, p) \)
其中 \( q \) 是原始查询,\( p \) 是个性化信息,\( q^{*} \) 是优化后的查询。
4.1.2. Query Rewriting(查询重写)
查询重写的目标是提升检索效果,分为两类:
直接个性化查询重写(Direct Personalized Query Rewriting):通过模型直接调整查询,如使用强化学习、对话系统优化等方法(如 CLE-QR、CGF、PEARL、Li et al. 等工作)。
辅助个性化查询重写(Auxiliary Personalized Query Rewriting):借助机制如检索、推理策略、外部记忆等,如 ERAGent、CoPS、Agent4Ranking 等。
4.1.3. Query Expansion(查询扩展)
查询扩展通过添加同义词、上下文信息等扩大原始查询的语义范围。个性化扩展结合用户标签、搜索历史等信息,以提升搜索体验。主要包括:
基于标签的扩展(Tagging-based Query Expansion):如 TagMap、TagRank、SoQuES 等。
其他扩展策略:如基于用户历史、社交网络、语义相似性等方法(如 WE-LM、PSQE、PQEWC)。
4.1.4. Others(其他)
包括查询消歧、自动补全等内容,如 Bobo、PSQE 等研究,通过词嵌入、用户画像等方式提升个性化效果。
4.1.5. Discussion(讨论)
查询重写适用于查询不明确或存在歧义的场景,尤其在对话或多轮交互中效果显著。
查询扩展适用于查询本身相关但不够完整的情形,通过语义扩展提升结果覆盖度。
4.2. Retrieval(检索阶段)¶
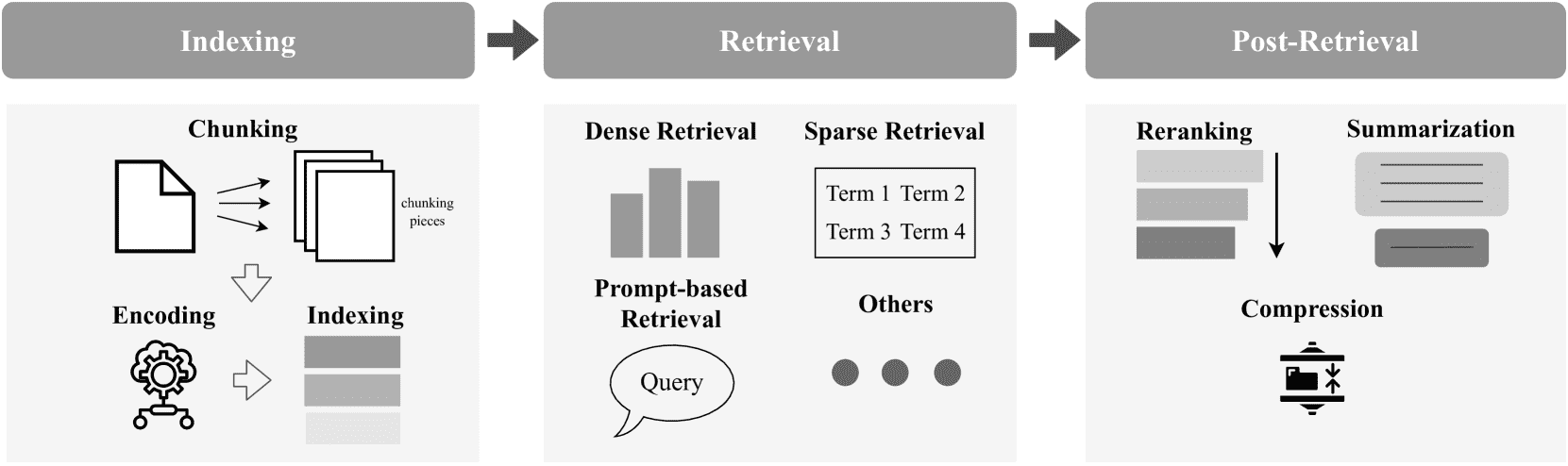
Figure 3.Overview of the personalized retrieval stage.
4.2.1. Definition(定义)
检索是根据优化后的查询 \( q^{*} \) 从知识库 \( \mathcal{C} \) 中找到最相关文档 \( D^{*} \),个性化信息 \( p \) 通过个性化检索函数 \( \mathcal{R} \) 被整合进流程,公式表示为:
$\( D^{*} = \mathcal{R}(q^{*}, \mathcal{C}, p) \)$
4.2.2. Indexing(索引)
索引阶段通过结构化数据提升检索效率。个性化索引方法包括使用用户历史生成用户嵌入、引入知识图谱(KG-Retriever、EMG-RAG、PGraphRAG)等,以增强个性化检索效果。
4.2.3. Retrieval(检索)
个性化检索方法分为四类:
密集检索(Dense Retrieval):如 MeMemo、PersonaLM、XPERT 等,通过嵌入用户偏好提升个性化匹配。
稀疏检索(Sparse Retrieval):如 BM25 结合用户行为权重,如 OPPU、PAG、UniMS-RAG。
基于提示的检索(Prompt-based Retrieval):如 LAPS、UniMP,通过个性化提示引导检索。
其他方法:如基于强化学习的检索优化(Salemi 等)、参数化检索(PersonalTM、Zhang 等)。
4.2.4. Post-retrieval(后检索)
后检索方法用于优化检索结果,包括:
重排序(Re-ranking):如 PersonaRAG、UniMS-RAG 等,提升结果排序。
摘要(Summarization):如 Zhang et al. 提出的个性化摘要框架。
压缩(Compression):如 AutoCompressor、FIT-RAG,提升检索效率。
4.2.5. Discussion(讨论)
索引阶段注重效率与语义理解的平衡。
检索阶段需在语义理解与计算成本之间权衡。
后检索方法应关注个性化内容的优化与简洁表达。
4.3. Generation(生成阶段)¶
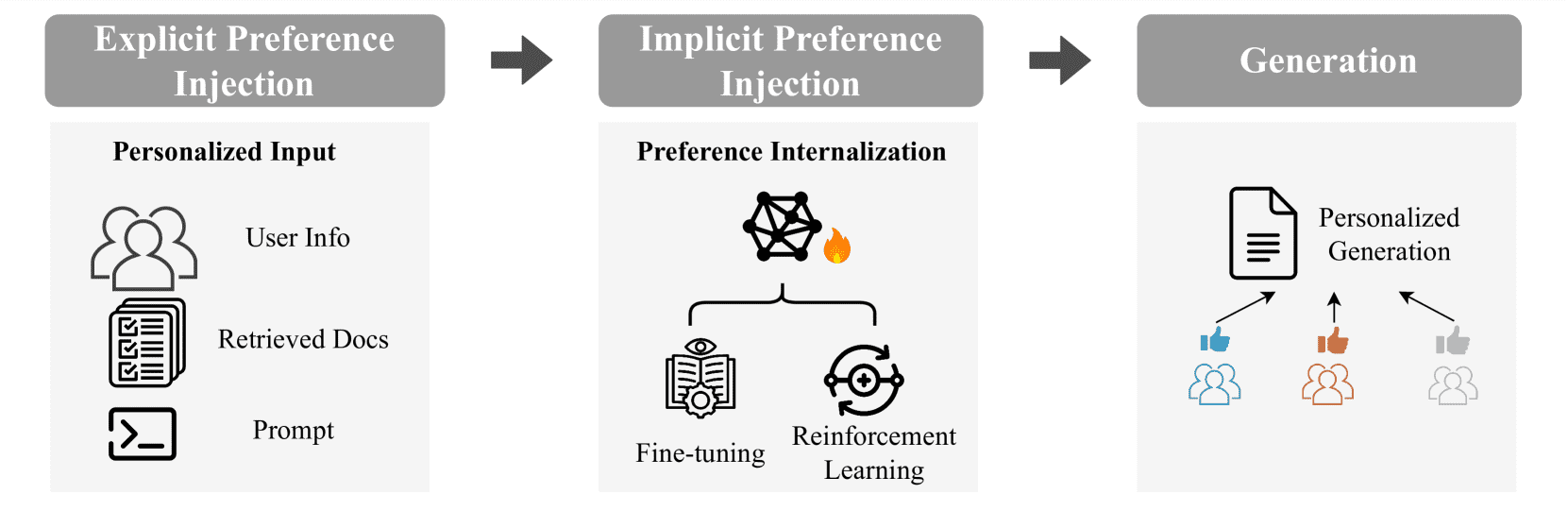
Figure 4.Overview of the personalized generation stage.
4.3.1. Definition(定义)
生成阶段基于检索结果 \( D^{*} \)、提示信息和用户偏好 \( p \),生成个性化内容 \( g^{*} \),公式表示为:
$\( g^{*} = \mathcal{G}(D^{*}, \text{prompt}, p, \theta) \)$
4.3.2. Generation from Explicit Preferences(基于显式偏好的生成)
用户显式偏好包括人口统计、行为序列、写作风格等,注入方式分为:
直接集成提示(Direct-integrated Prompting):如 P2、Character Profiling、Cue-CoT 等。
摘要增强提示(Summary-augmented Prompting):如 GPG、ONCE、Matryoshka,通过提取用户偏好摘要提升生成效果。
自适应提示(Adaptive Prompting):如 Li et al.、RecGPT、SGPT,通过自动化方式生成个性化提示。
4.3.3. Generation from Implicit Preferences(基于隐式偏好的生成)
隐式偏好通过模型参数实现个性化,主要方法包括:
微调方法(Fine-tuning Based Methods):如 LoRA、PLoRA、MiLP、Review-LLM 等。
强化学习方法(Reinforcement Learning Based Methods):如 P-RLHF、P-SOUPS、REST-PG、RewriterSlRl 等,通过奖励模型对齐用户偏好。
4.3.4. Discussion(讨论)
显式偏好适合信息明确、可解释性要求高的场景。
隐式偏好适合需要深度个性化、但难以提供显式输入的场景。
选择方法需结合具体应用场景和资源限制。
4.4. From RAG to Agent¶
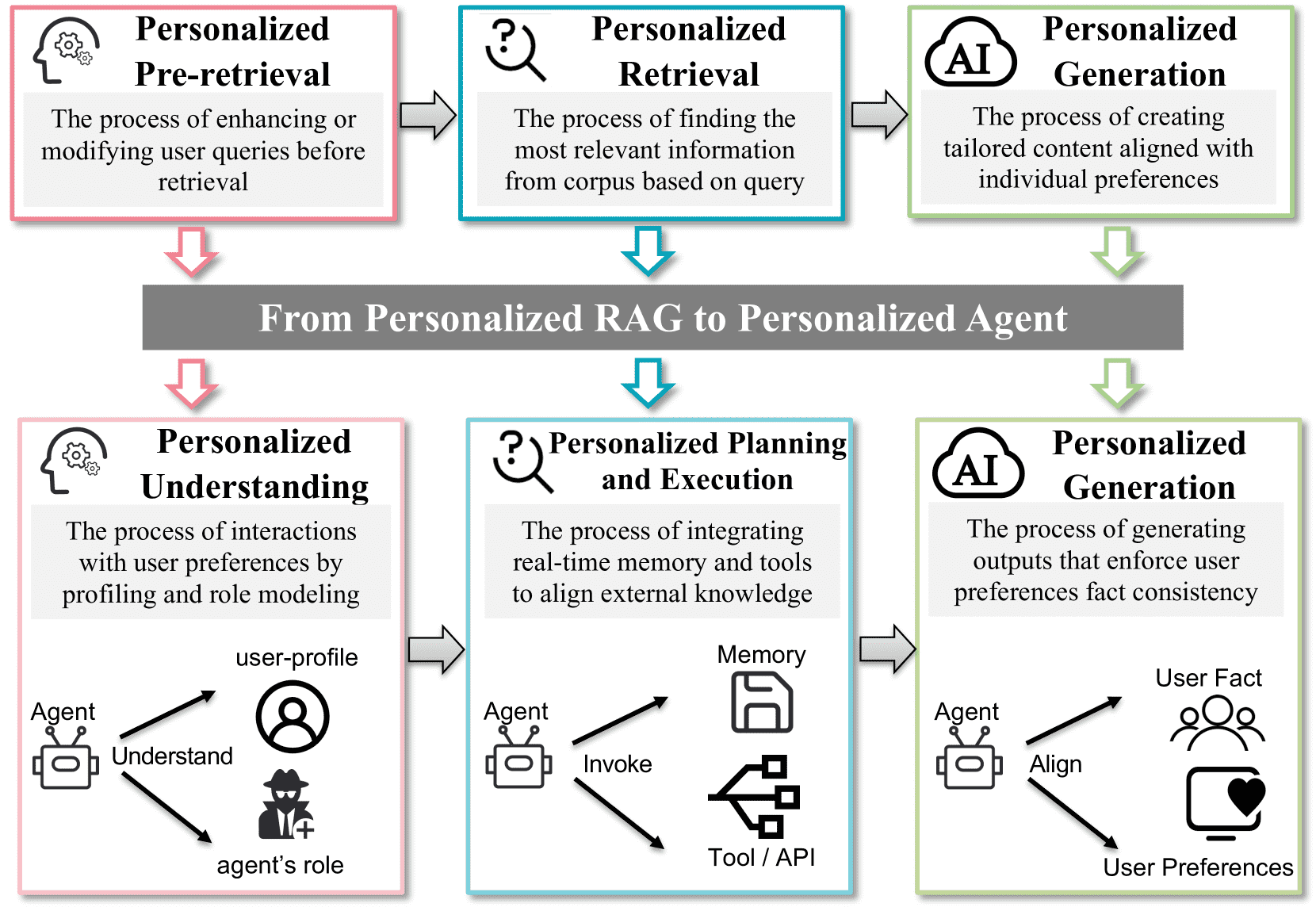
Figure 5.Overview of transition from personalized RAG to personalized agent.
4.4.1. Definition(定义)¶
核心内容: 本节给出了个性化基于LLM的智能体的定义,并提出了一个核心观点:智能体可以看作是“个性化RAG++”,是RAG系统深度个性化发展的必然结果。
详细解读:
定义:一个个性化的LLM智能体是一个系统,它能动态地整合用户背景、记忆、外部工具或API,以支持高度个性化和目标导向的交互,并以目标驱动的方式解决问题。
与RAG的关联:作者认为,个性化RAG的演进在结构上与智能体架构趋同。他们从三个关键角度进行了分析,这三个角度正好对应RAG的三个阶段(4.1, 4.2, 4.3),但功能更强大:
个性化理解:对应RAG的“查询理解与重写”,但更进一步,能进行动态用户画像和角色建模,理解隐含的用户偏好。
个性化规划与执行:对应RAG的“检索”,但超越了静态文档检索,能进行实时记忆管理和复杂的工具调用,动态整合外部知识。
个性化生成:对应RAG的“生成”,但超越了静态模板,能动态整合用户偏好和事实对齐,使输出更具情境适应性。
核心比喻:智能体是 “个性化RAG++” 。这个“++”体现在:
用持续记忆(Persistent Memory)替换静态索引:记忆是动态的、可更新的,记录了用户的交互历史和历史偏好,而RAG的索引通常是静态的文件库。
用工具API作为动态知识连接器:智能体可以主动调用API、使用工具来获取实时、动态的信息或执行动作(如订机票、查天气),而RAG通常只能从固定的知识库中检索信息。
结论:当RAG系统需要更深度的个性化(如用户状态跟踪、自适应工具使用、情境感知生成)时,它们就自然而然地具备了智能体的能力。
4.4.2. Personalized Understanding¶
核心内容: 本节深入探讨了智能体如何准确理解用户,并将其分为三个逐层递进的子能力。
详细解读: 个性化理解指智能体通过整合用户意图识别和情境分析来准确解读用户输入的能力。这确保了交互既有意义又情境得当。
它包含三个层面:
用户画像理解(User-profile Understanding):
智能体需要建模和理解用户的 偏好、背景和意图。
例如:
理解物理世界以更好地执行任务。
在医疗健康领域,用户的个人资料直接决定智能体的行为和建议。这是最基础的能力。
角色理解(Role Understanding):
智能体需要理解 它自身被赋予的角色。
研究通过增强LLM的角色扮演能力来实现这一点,
例如:
RoleLLM:一个评估和提升LLM角色扮演能力的基准。
Character-LLM:一个可训练的、能根据预定义角色定制回复的智能体框架。
通过“心理访谈”来评估角色扮演中的人格保真度,增强AI角色的真实感和一致性。
用户-角色联合理解:
这是最高层次的理解,要求智能体在动态环境中 综合考虑用户本身和它自己所扮演的角色。
研究通过社会性评估、融入多模态数据、人格指示信息以及文化维度(如中文语境下的评估基准)来实现,使交互更加精细和适应性强。
4.4.3. Personalized Planning and Execution(个性化规划与执行)¶
核心内容: 本节阐述了智能体如何为用户制定并执行个性化计划,其两大核心支柱是记忆管理和工具调用。
详细解读: 个性化规划与执行是指设计和实施专门为个人独特背景和目标量身定制的策略或行动的过程。它需要智能体动态整合长期记忆、实时推理和外部工具使用。
记忆管理:有效的记忆系统让智能体整合用户的 历史偏好、行为模式和情境习惯。
EMG-RAG:结合可编辑记忆图和RAG来维护动态用户画像。
记忆流与周期性反思:模拟人类-like的行为,通过反思记忆来提炼洞察。
领域应用:
在医疗健康中,整合多模态用户数据优化治疗建议;
在推荐系统(RecAgent)中,使用分层记忆结构建模用户跨域交互模式;
在旅行规划(TravelPlanner+)中,使用记忆增强的LLM生成更相关的个性化行程。
工具和API调用:集成外部工具将智能体的能力超越纯语言推理,使其能够与真实世界互动并执行个性化任务。
VOYAGER:通过自动API课程学习和技能库构建,实现终身学习。
机器人:LLM引导机器人进行工具介导的技能发现,完成新物体操作任务。
PUMA:个性化网页智能体通过自适应API编排在电商任务中提升性能。
移动交互:使用少量示例(few-shot)学习来操作多样的UI。
核心挑战在于“工具落地机制”,即将语言计划转化为可执行的API序列,同时保持个性化约束。
总结:现代智能体通过 记忆增强架构 和 工具API集成 这两大策略实现高级个性化。
4.4.4. Personalized Generation(个性化生成)¶
核心内容: 在完成个性化规划和准备后,本节关注智能体如何最终生成既 符合事实 又 贴合用户偏好 的输出。
详细解读: 个性化生成是确保输出结果不仅事实正确,而且与用户独特偏好、个性特质和情境需求产生共鸣的能力。它是连接智能体推理和最终用户感受的桥梁。
与用户事实对齐(Alignment with User Fact):
强调回复的 准确性、一致性和事实基础,确保其可信度。
挑战在于平衡角色真实性和避免“幻觉”。
Character-LLM:使用记忆增强架构在保持角色特质的同时减少幻觉。
量化研究:研究在计算受限的边缘设备上如何保持人格一致性。
多模态一致性:确保角色扮演中文本和图像输出的一致性。
与用户偏好对齐:
确保生成的内容反映用户的个性化人格、价值观和交互风格。
要求智能体能动态解读隐含的用户线索并相应调整。
研究通过 基准测试、心理学量表数据集、心理访谈量化和社会适应性评估 等方法来度量和提升偏好对齐。
4.4.5. Discussion(讨论)¶
核心内容: 本节总结了从RAG演进到智能体所带来的 挑战和未来研究方向。
详细解读:
个性化理解的挑战:
实时适应性与泛化能力不足:当前系统(如RoleLLM)在处理 动态变化的用户状态、演进中的偏好或多会话交互 时存在困难。
文化局限性:基于特定区域数据训练的智能体难以泛化到不同的社会文化语境。
未来方向:探索结合 持续学习机制 和 隐私保护的联邦学习(privacy-preserving federated learning) 的混合架构。
个性化规划与执行的挑战:
可扩展性问题:在复杂环境中,依赖 预定义API分类 限制了在新场景中发现新工具的能力。
冷启动问题:在需要快速掌握技能的领域(如医疗)问题仍然存在,如:API响应延迟可能影响决策效率。
未来方向:开发 元推理架构,能根据情境紧急程度和置信度动态决定是使用记忆还是调用工具。
个性化生成的挑战:
过拟合风险:过度适应用户档案可能会 强化用户的认知偏见。
缺乏伦理边界检测:系统可能在不经意间模仿并传播有害的刻板印象。
未来方向:集成 价值对齐的强化学习 和 人在回路的验证机制,在保持个性化的同时防止有害的定制。
5. Evaluation and Dataset¶
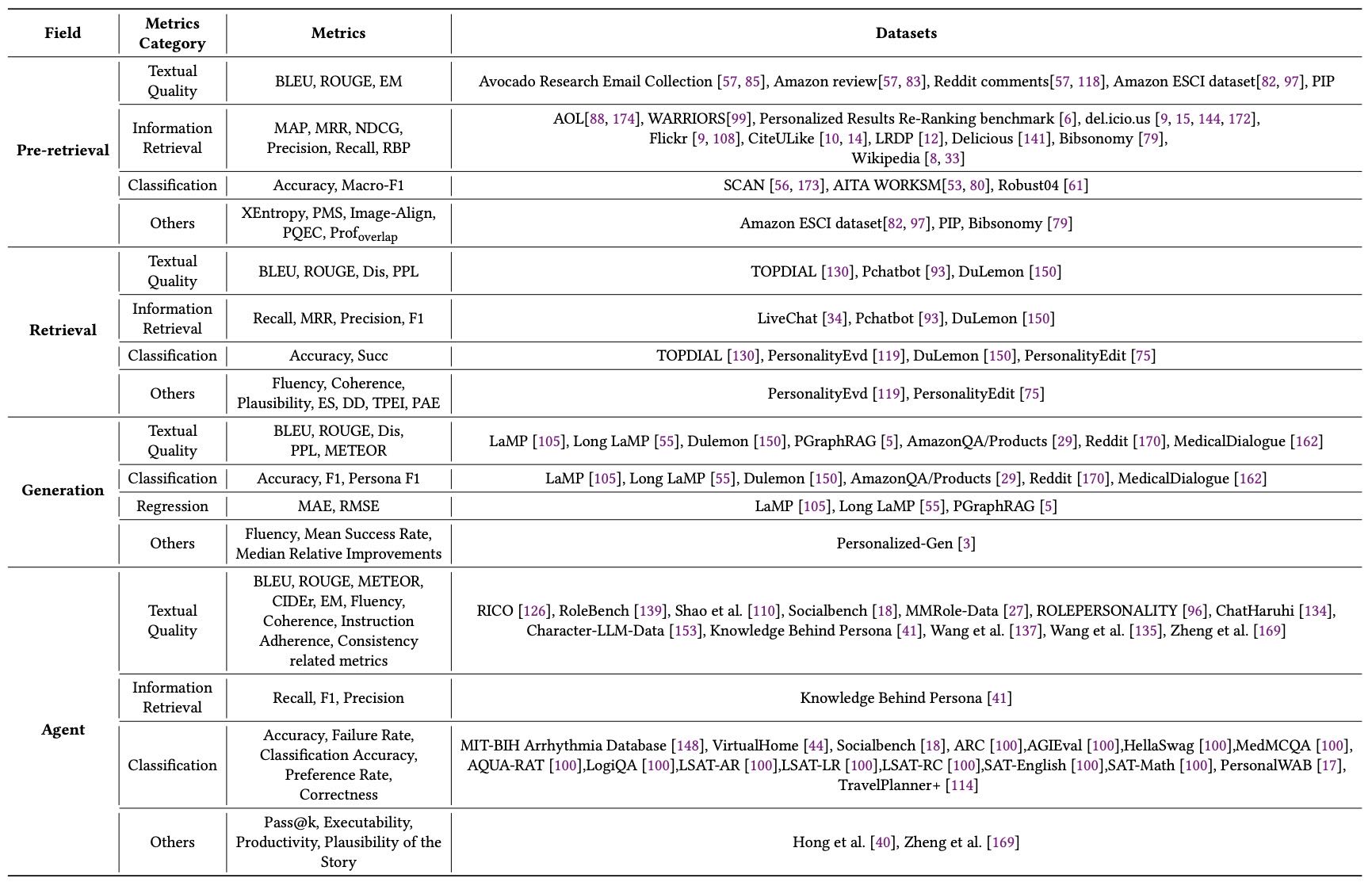
Table 2. Datasets and metrics for personalized RAG and Agent.
本节讨论了从 RAG(检索增强生成)到高级 Agent(智能代理)系统的人格化研究中,评估模型所依赖的多样化数据集和指标。通过将指标分类为多个关键类型,能够更系统地衡量不同任务下的模型表现。
1. 评估指标分类¶
文本质量(Textual Quality)
用于评估生成文本的流畅性和一致性,常用指标包括 BLEU、ROUGE、METEOR 等。这些指标广泛应用于生成任务和对话系统中。信息检索(Information Retrieval)
用于衡量检索系统的效果,如 MAP、MRR、Recall、F1 等。这些指标在个性化推荐、文档检索等场景中尤为重要。分类(Classification)
用于评估模型在分类任务中的表现,常用指标包括 Accuracy、F1、Failure Rate 等。适用于个性化意图识别、角色分类等任务。回归(Regression)
用于量化预测任务中的误差,如 MAE、RMSE。常见于需要预测连续数值的个性化场景,例如模型性能评分。其他(Others)
包括一些特定领域或任务的评估指标,如 Fluency、Pass@k、Executability、Plausibility 等。这些指标更关注生成内容的可执行性、合理性或故事性。
2. 应用场景与任务分类¶
评估指标和数据集按照任务阶段和系统类型进行分类,包括:
预检索(Pre-retrieval)
主要评估系统在检索前的文本质量,例如使用 BLEU、ROUGE 等评估生成的查询重写是否准确。相关数据集包括 Avocado Research Email Collection、Amazon Review、Reddit Comments 等。检索(Retrieval)
评估系统在检索过程中的表现,使用 MAP、MRR、Recall 等指标。数据集如 AOL、WARRIORS、del.icio.us、CiteULike 等广泛用于个性化检索研究。生成(Generation)
评估生成内容的质量和准确性,使用 BLEU、ROUGE、Dis、PPL、METEOR 等指标。数据集如 LaMP、Long LaMP、DuLemon、AmazonQA 等被广泛用于对话式生成任务。Agent(智能代理)
评估代理系统的综合表现,包括 指令遵循、一致性、生成质量 等,使用 BLEU、ROUGE、CIDEr、EM、Fluency 等指标。相关数据集如 RICO、RoleBench、ChatHaruhi 等。
3. 数据集汇总¶
为了全面评估个性化系统,文中总结了大量数据集,涵盖多个领域和任务。例如:
文本生成与对话:如 TOPDIAL、DuLemon、LaMP、PGraphRAG。
个性化推荐与信息检索:如 AOL、WARRIORS、del.icio.us、CiteULike。
分类与角色识别:如 SCAN、AITA WORKSM、PersonalityEvd。
Agent 与角色扮演:如 RoleBench、RICO、Character-LLM-Data。
医学与虚拟环境:如 MedicalDialogue、VirtualHome、MIT-BIH Arrhythmia Database。
4. 总结¶
本节系统整理了个性化系统评估的关键指标与常用数据集,覆盖了从 RAG 到智能代理的多个阶段与任务。这些指标和数据集为研究人员提供了基准,帮助他们评估和优化个性化的模型设计,从而在虚拟环境和现实世界任务中实现更高效、自然的交互。
6. Challenges and Future Directions¶
本章节总结了个性化RAG(Retrieval-Augmented Generation)和基于智能体(Agent-based)系统在当前研究和应用中面临的关键挑战,并指出了未来可能的研究方向。
• 平衡个性化与可扩展性(Balancing Personalization and Scalability)¶
重点内容:
将用户个性化数据(如偏好、历史记录和上下文信号)整合到RAG过程中,通常会增加计算复杂度,导致系统在大规模部署时难以维持效率和扩展性。
未来方向:
研究轻量级、自适应的嵌入方法和混合框架,使得用户画像和实时上下文信息能够无缝融合,从而在个性化和系统效率之间取得平衡。
• 有效评估个性化效果(Evaluating Personalization Effectively)¶
重点内容:
当前常用的评估指标(如BLEU、ROUGE)和人工评估方法,无法充分捕捉输出结果与用户动态偏好的细微对齐程度,缺乏针对个性化效果的专门衡量标准。
未来方向:
需要开发专门的基准和评估指标,评估长期用户满意度和系统的适应能力,以提升个性化系统在现实场景中的实用价值。
• 通过设备-云协作保障隐私(Preserving Privacy through Device–Cloud Collaboration)¶
重点内容:
个性化检索通常涉及处理敏感用户数据,隐私问题突出,尤其是在全球范围内对数据保护(如欧盟的GDPR)日益重视的大背景下。
未来方向:
有望通过设备端和云端的协作方式解决隐私问题。例如,使用设备上的小型语言模型处理敏感数据,而云端的大模型提供更广泛的上下文知识,从而兼顾隐私和性能。
• 个性化智能体规划(Personalized Agent Planning)¶
重点内容:
目前智能体规划研究仍处于早期阶段,主要集中在构建基础框架(如GUI智能体)和跨领域应用方面,个性化方法尚未广泛融入。
未来方向:
探索如何将个性化支持集成到现有智能体框架中,以提升用户体验,是未来有前景的研究方向。
• 保障系统的伦理与一致性(Ensuring Ethical and Coherent Systems)¶
重点内容:
数据处理中的偏见、用户画像中的隐私问题,以及检索与生成阶段之间的一致性问题仍未得到充分解决。
未来方向:
应优先研究伦理保障机制、隐私保护技术以及跨阶段的优化方法,以构建值得信赖、统一的个性化系统。
总结:
个性化RAG与智能体系统在提升用户体验方面具有巨大潜力,但其发展仍面临诸多挑战,包括效率与扩展性、评估标准、隐私保护、个性化智能体设计以及伦理一致性等问题。未来的研究应围绕这些关键问题展开,以推动更加智能、高效、安全和可信赖的个性化系统发展。
7. Conclusion¶
本文探讨了从检索增强生成(RAG)到基于大语言模型(LLM)的智能体(Agents)的个性化发展路径,详细说明了在预检索、检索和生成阶段的适配与改进,并进一步扩展到智能体能力的实现。通过回顾最新文献、数据集和评估指标,文章突出了在提升用户满意度方面,定制化AI系统所取得的进展与多样性。
重点强调的是,当前仍存在若干关键挑战,包括可扩展性、有效的评估机制以及伦理问题,这些问题凸显了对创新解决方案的迫切需求。未来的研究应集中于轻量化框架、专用基准测试和隐私保护技术,以推动个性化AI的发展。
此外,相关的论文和资源已在线整理,以便于今后的研究工作。