2311.12793_ShareGPT4V: Improving Large Multi-Modal Models with Better Captions¶
引用: 772(2025-07-22)
组织:
1University of Science and Technology of China
2Shanghai AI Laboratory
总结¶
简介
120 万条高质量、描述性强的图像描述文本
最初基于从 GPT4-Vision 中精选的 10 万条高质量描述,通过训练一个优秀的描述模型扩展至 120 万条
数据集
HuggingFace: https://huggingface.co/datasets/Lin-Chen/ShareGPT4V
ShareGPT4V:利用 GPT4-Vision 生成的 100K 高质量图像描述。
来源
COCO:50K张图像;
LCS(由LAION、CC-3M和SBU组成):30K张图像;
SAM:20K张图像;
TextCaps:500张图像;
WikiArt:500张图像;
从网络爬取的数据:1K张图像
ShareGPT4V-PT:通过训练 Share-Captioner 模型扩展生成的 1.2M 图像描述。
来源
COCO:118K张图像;
SAM:570K张图像;
LLaVA-1.5预训练数据:558K张图像。
贡献
基于该数据集开发了高性能多模态模型 ShareGPT4V-7B
LLM 总结¶
本文《ShareGPT4V: Improving Large Multi-Modal Models with Better Captions》提出了一种名为ShareGPT4V的方法,旨在通过改进图像的描述(captions)来提升大型多模态模型的性能。文章主要探讨了高质量、多样化和准确的图像描述对于训练多模态模型(如视觉-语言模型)的重要性,并提出了一种生成更优描述的策略。
总结如下:
背景与动机:当前多模态模型依赖大量图像-文本对进行训练,而现有的图像描述(captions)质量参差不齐,限制了模型的表现。因此,提升描述的质量和多样性对于模型性能至关重要。
方法:文章提出ShareGPT4V方法,通过结合先进的语言模型(如GPT-4V)来生成更准确、丰富、语义更丰富的图像描述。该方法不仅关注描述的准确性,还注重多样性,避免重复和泛化的描述。
实验与结果:在多个视觉-语言任务(如VQA、图像文本检索等)中,使用ShareGPT4V生成的描述训练的模型表现优于使用传统方法生成描述的模型,验证了该方法的有效性。
贡献:本文的主要贡献在于提出了一种新的图像描述生成框架,强调高质量描述在多模态学习中的关键作用,并为未来的研究提供了改进多模态模型训练数据质量的新思路。
总而言之,本文通过改进图像描述的质量和多样性,提升了多模态模型的效果,为相关领域提供了有价值的参考和方法。
Abstract¶
该论文摘要主要围绕大型多模态模型(LMMs)中的模态对齐问题展开,重点提出了一项新的解决方案——ShareGPT4V 数据集。以下是对摘要内容的总结:
问题背景:在多模态模型的训练中,高质量的图文对齐数据稀缺,限制了模型的性能提升。
解决方案:提出 ShareGPT4V 数据集,包含 120 万条高质量、描述性强的图像描述文本,涵盖世界知识、物体属性、空间关系和美学评价等信息,相较于现有数据集具有更高的多样性和信息量。
数据来源与构建方法:该数据集最初基于从 GPT4-Vision 中精选的 10 万条高质量描述,通过训练一个优秀的描述模型扩展至 120 万条。
实验效果:
在 SFT(监督微调)阶段,将现有数据中的描述文本替换为 ShareGPT4V 的描述,显著提升了多个 LMM 模型(如 LLaVA-7B、LLaVA-1.5-13B 和 Qwen-VL-Chat-7B)在 MME 和 MMBench 等基准测试中的表现。
将 ShareGPT4V 应用于 预训练和 SFT 阶段,构建出 ShareGPT4V-7B 模型,在多数多模态基准上表现优异,证明了该数据集的有效性。
项目资源:项目网址为 https://ShareGPT4V.github.io,旨在为多模态模型研究社区提供重要资源。
图示说明:
图1(a) 展示了 ShareGPT4V 描述与现有 LMM 数据集中描述的对比,突出了其描述更详细、准确的特点。
图1(b) 展示了基于 ShareGPT4V 数据集训练的 ShareGPT4V-7B 模型在多个基准上的优异性能。

总结:该研究通过构建高质量的图文数据集 ShareGPT4V,有效提升了多模态模型在对齐和理解方面的表现,为多模态学习的发展提供了重要支持。
1 Introduction¶
本文旨在探讨多模态大模型(LMMs)在视觉与语言模态对齐方面的局限性,并提出通过高质量图像描述(caption)提升模型性能的解决方案。
1.1 多模态大模型的发展背景¶
近年来,大语言模型(LLMs)的发展推动了多模态模型的兴起。
多模态模型通常采用两阶段训练范式:预训练(pre-training) 和 监督微调(SFT),其中SFT阶段依赖于高质量的图像-文本对来提升模型的多模态推理能力。
然而,目前大多数模型所依赖的图像描述(captions)质量较低,通常是短而简略的,缺乏丰富的语义和上下文信息,导致模态对齐效果不佳。
1.2 问题提出与实验验证¶
作者通过实验验证了高质量图像描述在SFT阶段的重要性。他们仅用少量(如LLaVA-1.5中3.5%)由GPT4-Vision生成的高质量caption替换原有描述,就显著提升了多个LMM模型的性能。
实验结果表明:高质量的描述能够有效增强模型对图像内容的理解,从而改善视觉与语言的对齐效果。
1.3 数据集构建方法¶
基于上述发现,作者构建了一个大规模的高质量图像描述数据集 ShareGPT4V,分为两个阶段:
第一阶段:从多个数据源中收集约10万张图像,使用精心设计的提示词(prompt)引导GPT4-Vision生成高质量描述,平均长度为942个字符,涵盖世界知识、物体属性、空间关系、审美评估等丰富的语义。
第二阶段:利用第一阶段生成的高质量描述训练一个通用的描述生成模型,进一步扩展数据集至120万条高质量描述。
1.4 模型与实验结果¶
基于ShareGPT4V数据集,作者开发了一个先进的多模态大模型 ShareGPT4V-7B。
实验结果显示,该模型在11项主流多模态基准测试中均优于其他同规模模型,例如在MME基准中,总分为1943.8,比第二名的Qwen-VL-Chat-7B高出95.6分。
值得注意的是,尽管没有采用复杂的架构设计,该模型依然表现出色,说明高质量的训练数据是性能提升的关键。
1.5 主要贡献¶
揭示问题:指出当前多模态模型中图像描述质量低是影响模态对齐的关键因素,并通过实验验证了这一观点。
构建数据集:提出并构建了首个高描述性图像-文本数据集 ShareGPT4V,包括10万条GPT4-Vision生成的高质量描述和120万条由模型生成的高质量描述。
开发模型:基于该数据集开发了高性能多模态模型 ShareGPT4V-7B,在多个基准测试中表现出色,证明了高质量描述的有效性。
总结¶
本文强调了高质量图像描述在多模态模型中的关键作用,并通过构建高质量数据集和开发先进模型,展示了提升多模态模型性能的新路径。该研究为未来多模态模型的发展提供了重要的数据资源和方法参考。
3 ShareGPT4V Dataset¶
1. 数据集概述¶
ShareGPT4V 数据集分为两个部分:
ShareGPT4V:利用 GPT4-Vision 生成的 100K 高质量图像描述。
ShareGPT4V-PT:通过训练 Share-Captioner 模型扩展生成的 1.2M 图像描述。
该数据集在图像来源多样性、描述生成质量、样本数量和描述长度等方面优于现有主流数据集(如 COCO-Caption、BLIP-LCS、LLaVA-23K)。
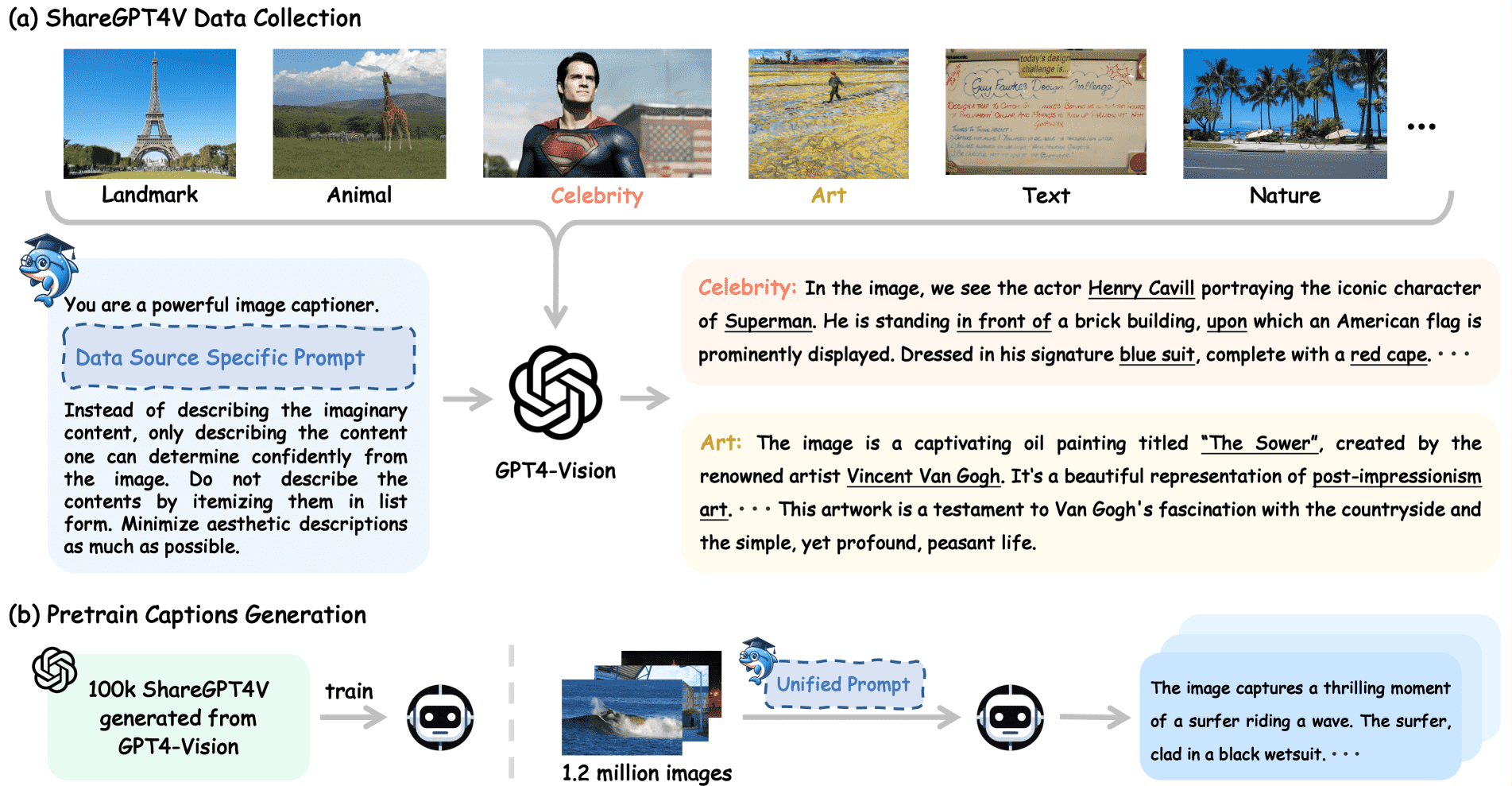
Figure 3: An overview for crafting the ShareGPT4V dataset. (a) We illustrate the procedure for collecting highly descriptive captions from GPT4-Vision via various image sources and data-specific prompts, resulting in 100K high-quality captions that encapsulate a wide array of information conveyed by the images. (b) We delineate the process of utilizing the seed captions to train a general captioner and then employing this captioner to generate 1.2M high-quality captions for pre-training usage.
2. 数据收集(ShareGPT4V)¶
图像来源:从多个公开数据源(如 COCO、LCS、艺术作品、地标等)收集约 100K 幅图像,以增强数据的多样性和覆盖性。
提示设计:为每类图像设计了基本提示和特定提示,确保生成的描述不仅包含外观信息,还涵盖相关知识和美学分析。
质量验证:通过替换现有 LMM 的 SFT 数据集中的描述并进行性能测试,验证了 GPT4-Vision 生成的描述在 SFT 阶段的有效性。
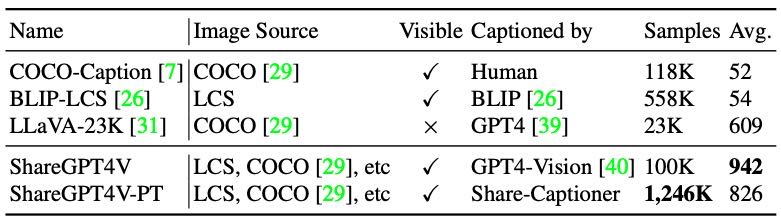
Table 1. Comparison of widely-used caption datasets and ShareGPT4V. ‘LCS’ abbreviates the LAION, CC, and SBU datasets. The ‘Visible’ column denotes the image visibility during captioning, and the last column shows the average character number of the caption.
4. 总体实验效果¶
在多个基准测试(如 LLaVA-Bench、MME、MMBench、VizWiz 等)中,ShareGPT4V-7B 在 11 个任务中表现优于其他模型,尤其在使用较小参数量(7B)的情况下依然取得优异成绩。
小结¶
ShareGPT4V 数据集通过 GPT4-Vision 生成高质量描述,并结合 Share-Captioner 进行成本可控的扩展,显著提升了多模态模型在微调和预训练阶段的表现。该数据集在多个方面优于现有主流数据集,并在多个基准上验证了其有效性。
4.1 模型架构¶
ShareGPT4V-7B 的架构借鉴了 LLaVA-1.5 的设计,主要包括三个核心组件:
视觉编码器:采用 CLIP-Large 模型,输入分辨率为 336×336,将图像编码为 576 个视觉 token。
投影器:由两层多层感知机(MLP)组成,用于连接视觉和语言模态。
大语言模型(LLM):基于开源模型 Vicuna-v1.5,源自 LLaMA2,模型规模为 7B。
尽管模型规模较小,但得益于高质量训练数据,ShareGPT4V-7B 在性能上优于许多使用更大模型或更多数据训练的 LMM。
4.2 预训练¶
预训练阶段使用了 ShareGPT4V 数据集的预训练子集(ShareGPT4V-PT),并采用了同时微调视觉编码器、投影器和大语言模型的方法。这与以往仅微调 MLP 或冻结视觉编码器的做法不同,目的是让语言模型更好地理解视觉嵌入,并促使视觉编码器生成与描述更一致的视觉表示。
超参数设置:学习率为 2e-5,批量大小为 256,训练步数约为 4700。
优化策略:实验发现仅微调视觉编码器后半部分的层可以获得最佳效果,并保持较高的训练效率。
4.3 监督微调(SFT)¶
本研究的核心目标是验证高质量描述对多模态对齐的有效性,而非设计全新的 SOTA 模型。因此,研究者在 LLaVA-1.5 提供的 665k 监督数据中,将其中 23k 低质量描述替换为 ShareGPT4V 中随机采样的 23k 高质量描述。
数据来源:包括公开的学术任务型数据和对话及复杂推理任务数据。
微调策略:冻结视觉编码器,仅微调投影器和语言模型,以提升训练效率和公平比较。
超参数设置:学习率为 2e-5,批量大小为 128,训练步数约为 5200。
总结¶
ShareGPT4V-7B 是一项基于高质量多模态数据(ShareGPT4V)的轻量级多模态模型研究。通过合理的架构设计、视觉与语言模态的同步微调,以及高质量描述在监督微调中的应用,该模型在模型规模较小的情况下仍能取得优于许多大模型的性能,验证了高质量数据在提升多模态对齐中的关键作用。
5 Experiments¶
该论文的第五章“实验(Experiments)”主要从以下几个方面对提出的ShareGPT4V-7B模型进行了全面评估和分析:
1. 实验基准(Benchmarks)¶
为全面评估ShareGPT4V-7B模型的性能,作者在11个与视觉问答(VQA)相关的基准数据集上进行了测试。这些数据集涵盖了传统VQA任务和为大模态模型(LMMs)设计的现代多模态任务,包括LLaVA(in the wild)、MME、MMBench、SEED、MM-Vet、Q-Bench等。这些任务测试了模型在对话、复杂推理、细节描述、感知和认知等能力上的表现。
2. 定量比较(Quantitative Comparison)¶
在这些基准上,ShareGPT4V-7B模型在11个任务中取得了9个最佳成绩。尤其在LLaVA (in the wild)、MME、MMBench、SEED和QBench等任务中,ShareGPT4V-7B表现优于之前最先进的模型(如LLaVA-1.5-13B和Qwen-VL-Chat)。尽管模型参数规模较小(7B),但通过高质量的图像描述(captions)训练,其性能优于许多参数更大、训练数据更多的模型。
3. 多模态对话能力(Multi-modal Dialogue)¶
作者通过图示展示了ShareGPT4V-7B在多模态对话场景中的表现,能够理解图像细节并具备一定的美学评估能力,进一步证明了高质量描述数据对模型的增强作用。
4. 消融实验(Ablations)¶
(1)ShareGPT4V数据集的有效性¶
通过表格4和5的消融实验,作者验证了ShareGPT4V数据集在预训练(pre-training)和监督微调(SFT)阶段对模型性能的提升作用。使用ShareGPT4V数据显著提升了MME、MMBench和SEED等任务的得分,尤其在感知能力(MME-P)方面提升显著。
(2)预训练描述质量的影响¶
通过对比BLIP生成的描述与ShareGPT4V-PT生成的高质量描述的实验结果,发现后者带来的性能提升更加显著,证明了高质量描述在预训练中的关键作用。
(3)预训练数据量的影响¶
实验发现,仅使用100K高质量描述数据即可带来显著性能提升,且随着数据量增加到1000K以上,模型性能趋于饱和,说明高质量描述数据在少量情况下即可有效对齐模态。
(4)视觉编码器中可学习块数的影响¶
通过调整预训练阶段中视觉编码器(ViT)中可学习的Transformer块数,发现解锁后半部分的块数可以显著提升模型性能,尤其是在MME感知任务和MMBench、SEED等基准上。
总结¶
第五章通过多角度的实验验证了ShareGPT4V-7B模型在多模态任务中的优越性。作者强调,尽管模型参数规模较小,但高质量的图像描述数据在预训练和微调阶段发挥了关键作用,能够有效提升模型在多个基准任务中的表现。此外,实验还揭示了数据质量、数据量、模型结构等因素对模型性能的影响,为后续研究提供了有价值的参考。
6 Conclusion¶
本研究总结如下:
本文提出了 ShareGPT4V,这是一个具有突破性的大规模图文数据集,包含 120 万个详细且信息丰富的图像描述,其内容的丰富性和多样性超越了现有数据集,涵盖了世界知识、物体属性、空间关系和美学评估等多个方面。该数据集由 10 万个高质量的 GPT4-Vision 生成的描述 用于监督微调(SFT),并通过通用描述模型扩展至 120 万个,用于预训练。研究通过在最新的语言-视觉模型(LMMs)上进行 SFT 实验,验证了 ShareGPT4V 的有效性,并进一步展示了基于该数据集训练的 ShareGPT4V-7B 模型 所取得的卓越性能。作者承诺将 ShareGPT4V 全面公开,希望其成为推动 LMMs 领域发展的基础性资源。
Appendix A Data Sources¶
本章节主要介绍了ShareGPT4V和ShareGPT4V-PT两个模型所使用的数据来源及其组成。
ShareGPT4V的数据来源包括总计100K张图像,分别来自以下几个数据集:
COCO:50K张图像;
LCS(由LAION、CC-3M和SBU组成):30K张图像;
SAM:20K张图像;
TextCaps:500张图像;
WikiArt:500张图像;
从网络爬取的数据:1K张图像(包括地标和名人的图像各500张)。
ShareGPT4V-PT的预训练数据则由预训练的Share-Captioner模型生成。该预训练数据集包含从已有公开数据集中选取的1.2M张图像,具体来源包括:
COCO:118K张图像;
SAM:570K张图像;
LLaVA-1.5预训练数据:558K张图像。
总体而言,两个模型的数据来源都具有多样性,并且在数据规模和图像类型上有所不同,以满足不同的训练需求。
Appendix B Caption Analysis¶
本章节对 GPT4-Vision 和 Share-Captioner 生成的图像描述(caption)进行了分析,主要从两个方面展开:
图示分析(Figure 7)
通过可视化展示两个模型生成的描述中的“核心名词-动词对”,可以发现 Share-Captioner 生成的描述在多样性和语言表达方面与 GPT4-Vision 的表现相当,说明 Share-Captioner 能够生成高质量、内容丰富的图像描述。词汇构成分析(Table 7)
对两个模型生成描述的词汇组成进行了统计比较,结果显示两者的描述在名词(n.)、形容词(adj.)、副词(adv.)、动词(v.)、数字(num.)和介词(prep.)的比例上非常接近。Share-Captioner 生成的描述在信息量方面与 GPT4-Vision 基本相当,表明其具有良好的语言结构和表达能力。
综上所述,Share-Captioner 在图像描述的多样性和语言质量上与 GPT4-Vision 表现相当,具有较高的生成能力。
Appendix C Prompts¶
本章节介绍了用于指导 GPT-4 Vision 生成详细图像描述的提示词(Prompts)。由于图像来源多样,研究者期望每张图像都能获得高度内容相关且详尽的描述。为此,研究人员设计了一种结构化的提示方式:以通用描述的“基础提示”开头和结尾,并在中间插入针对具体数据源的“数据特定提示”。通过这种方式,能够提升生成描述的相关性和准确性。文中提到的图 8 展示了这种提示结构的具体示例。
Appendix D Examples¶
本附录展示了三种模型在生成图像描述和多轮对话中的表现示例:
图9 展示了由 Share-Captioner 生成的图像描述示例,其中描述中准确且细致的部分以蓝色突出显示。
图10 展示了由 ShareGPT4V 生成的图像描述示例,同样,描述中准确且细致的部分也被标记为蓝色。
图11 则提供了一个 ShareGPT4V-7B 的多轮对话示例,其中在对话中生成的详细且准确的部分同样以蓝色强调。
这些示例用于直观展示不同模型在图像理解与描述生成方面的性能表现。