2310.06770_SWE-bench: Can Language Models Resolve Real-World GitHub Issues?¶
组织:
1.Princeton University,
2.Princeton Language and Intelligence,
3.University of Chicago
引用: 785(2025-07-17)
相关链接:
排行榜: swebench.com
总结¶
数据集
数据来源于 GitHub 上 12 个热门 Python 项目的实际问题(issue)和对应的代码提交PR
从最初约 9 万个 PR 中筛选出 2294 个有效任务实例
数据集地址
SWE-bench_Verified: huggingface
这个数据集是在原来 SWE-bench 数据集的基础上,人工过滤筛选
SWE-bench_Lite: huggingface
SWE-bench: huggingface
SWE-bench_Multilingual: huggingface
across 42 repositories and 9 programming languages
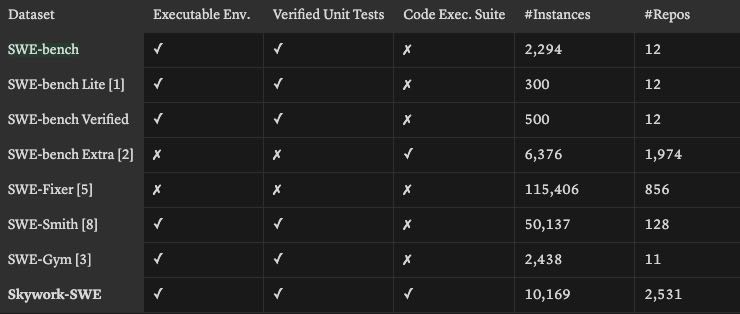
数据集统计
LLM 总结¶
文章提出了一种名为 SWE-bench 的基准测试框架,用于评估语言模型在处理实际软件工程问题上的效果。
总结如下:
研究背景:随着大型语言模型(如 GPT 系列、Codex 等)在代码生成和理解方面的能力不断提升,人们开始关注它们是否能够解决实际的软件工程问题,特别是 GitHub 上的 Issues。
SWE-bench 框架:作者提出了 SWE-bench,这是一个基于真实 GitHub Issues 的评估基准,包含多个经过验证的、具有挑战性的问题,涵盖不同编程语言和项目类型。
任务定义:模型的任务是根据用户提交的 Issue 描述,生成修复代码并提交到相应的仓库中,最后通过自动化测试验证修复是否成功。
实验与结果:文章对多个当前主流的语言模型进行了测试,结果显示,尽管部分模型在简单问题上表现良好,但在复杂或涉及深层理解的问题上仍然存在较大挑战。模型在代码生成准确性、上下文理解及测试通过率等方面的表现仍有提升空间。
挑战与限制:文章指出了语言模型在解决真实世界问题时面临的主要挑战,包括缺乏对项目结构的整体理解、对依赖关系的处理能力不足以及对上下文的误解等。
未来方向:作者认为,SWE-bench 为研究语言模型在软件工程领域的应用提供了统一的评估标准,并对未来的研究方向进行了展望,如结合代码理解和代码生成,提升模型的上下文感知能力等。
总结:本文通过 SWE-bench 基准测试,系统评估了语言模型在解决真实世界 GitHub Issues 上的能力,揭示了当前语言模型在实际软件工程任务中的优势与不足,为未来改进模型能力和构建更实用的软件开发辅助工具提供了方向。
Abstract¶
本文提出了一种用于评估语言模型在真实软件工程任务中表现的新框架 SWE-bench。主要观点和内容总结如下:
研究目标:随着语言模型的能力不断提升,现有的评估手段已难以跟上其发展速度。为推动语言模型的进一步发展,需要研究其能力的边界。软件工程被提出作为一个丰富、可持续且具挑战性的评估领域。
SWE-bench 框架:
包含约 22.9 万个软件工程问题,数据来源于 GitHub 上 12 个热门 Python 项目的实际问题(issue)和对应的代码提交(pull request)。
任务设置:给定代码库和问题描述,语言模型需要修改代码以解决问题。
任务难度:
问题往往涉及对多个函数、类甚至文件的协同修改。
要求模型理解上下文、与执行环境交互、处理长文本并进行复杂推理,远超传统代码生成任务。
评估结果:
当前最先进的专有模型以及作者优化的 SWE-Llama 模型仅能解决最简单的问题。
表现最好的模型 Claude 2 也仅能解决 1.96% 的问题,说明当前语言模型在真实软件工程任务中仍有较大提升空间。
意义与展望:
在 SWE-bench 上的进展将推动语言模型向更实用、更智能、更自主的方向发展。
1 Introduction¶
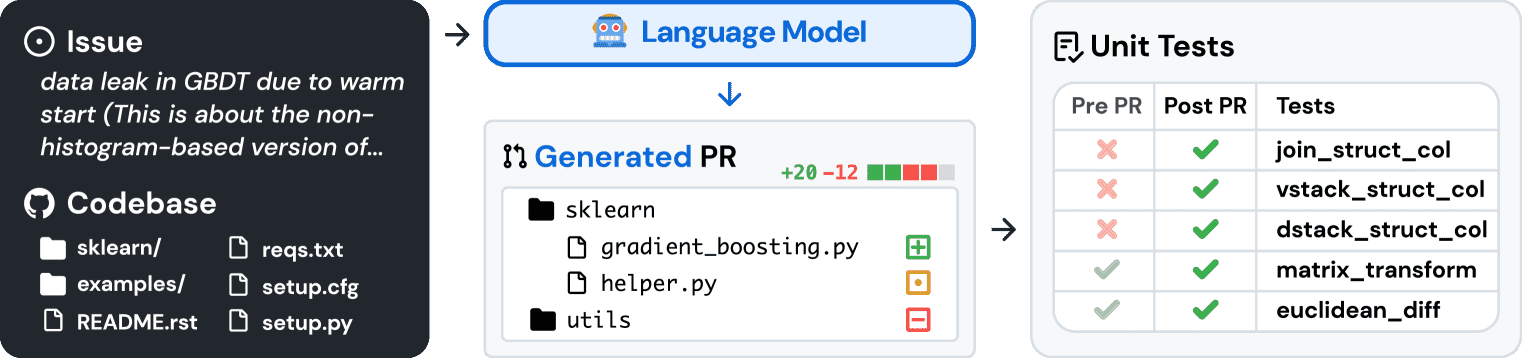
Figure 1: SWE-bench sources task instances from real-world Python repositories by connecting GitHub issues to merged pull request solutions that resolve related tests. Provided with the issue text and a codebase snapshot, models generate a patch that is evaluated against real tests.
该章节介绍了 SWE-bench 这一新型语言模型基准测试平台,旨在更真实地评估语言模型在软件工程任务中的能力。以下是主要内容的总结:
背景与动机:¶
语言模型(LMs)正被广泛应用于商业产品如聊天机器人和代码助手。
然而,现有基准测试(如 HumanEval)已趋于饱和,无法准确反映最先进的语言模型在真实应用场景中的表现。
构建有效的基准测试具有挑战性:任务需足够复杂以挑战现有模型,同时模型的输出需易于验证。
与其它任务相比,编程任务具有独特优势:生成的代码解决方案可通过运行单元测试来验证,因此非常适合基准测试。
SWE-bench 的设计:¶
SWE-bench 是一个基于真实软件工程场景的基准测试。
它从实际的 GitHub 项目中提取问题(如 bug 报告或功能请求),并将其与合并的 pull request(解决方案)关联,形成任务实例。
模型的任务是根据问题描述生成一个 代码补丁(patch),并使用项目的测试框架评估其有效性。
该基准测试包含来自 12 个不同仓库 的多样化问题,能够反映真实世界中复杂的代码问题。
SWE-bench 的优势:¶
真实场景:基于用户提交的 GitHub 问题和解决方案。
多样性:任务来自大量仓库,涵盖各种代码问题。
可扩展性:可自动持续更新任务实例,无需大量人工干预。
评估机制:通过运行测试框架验证模型生成的代码补丁是否有效。
实验结果:¶
在 SWE-bench 上评估了多个最先进的语言模型,结果表明这些模型在解决复杂问题上表现不佳。
例如,即使使用了 BM25 检索器的 Claude 2 模型,也仅能解决 1.96% 的问题。
这表明当前模型在处理真实世界代码问题方面仍存在较大差距。
补充贡献:¶
SWE-bench-train:发布了一个包含 19000 个非测试任务实例的训练数据集,用于推动开源模型在该领域的进步。
SWE-Llama 系列模型:基于 CodeLlama 进行了微调,包括 7b 和 13b 两个版本。
其中,SWE-Llama 13b 在某些设置下可与 Claude 2 竞争,并支持处理 超过 100000 token 的上下文。
总结:¶
SWE-bench 提供了一个更贴近真实软件工程任务的基准测试平台,揭示了当前语言模型在处理复杂代码问题上的局限性。同时,通过发布训练数据集和微调模型,为后续研究提供了重要资源,推动语言模型在软件工程领域的进一步发展。
2 SWE-bench¶
本节主要介绍了 SWE-bench(Software Engineering Benchmark)这一基准测试的构建过程、任务定义及其特点,并提出一个简化版本 SWE-bench Lite。以下是内容总结:
一、SWE-bench 概述¶
SWE-bench 是一个基于 GitHub 的真实软件工程任务基准,其目标是评估语言模型(LM)解决实际代码问题的能力。每个任务包括一个描述问题的 GitHub issue 和一个对应的已合并 Pull Request(PR),要求模型生成一个 PR 来修复该问题,并通过相关测试。
二、基准构建过程(Benchmark Construction)¶
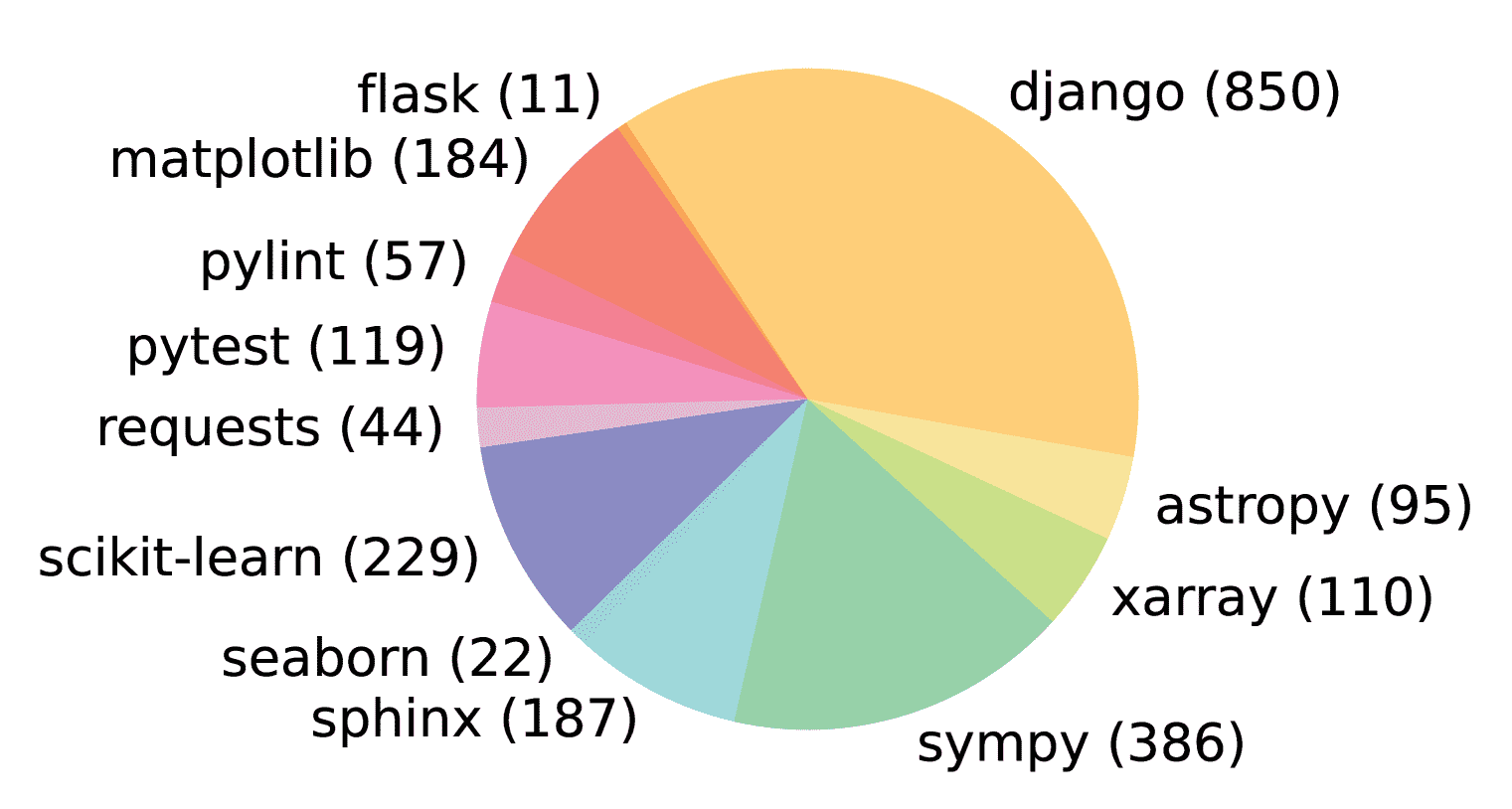
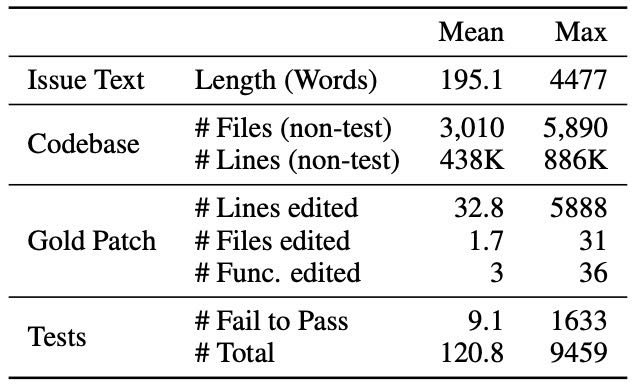
Table 1: Average and maximum numbers characterizing different attributes of a SWE-bench task instance. Statistics are micro-averages calculated without grouping by repository.
SWE-bench 是通过一个三阶段的筛选流程构建而成,从最初约 9 万个 PR 中筛选出 2294 个有效任务实例。
阶段一:仓库选择与数据抓取
从 12 个流行的 Python 仓库中收集 PR,重点关注那些维护良好、测试覆盖率高的项目。阶段二:属性筛选
仅保留那些:解决了 GitHub issue;
修改了测试文件(表明用户贡献了测试用例)的 PR。
阶段三:执行筛选
对每个候选任务应用其 PR 的测试变更,并记录执行结果。仅保留那些:至少有一个测试从失败变为通过(fail-to-pass test);
无安装或运行时错误的任务。
最终得到 2294 个任务实例,这些实例广泛分布于多个流行的开源仓库中。
三、任务定义(Task Formulation)¶
输入:模型接收一个 GitHub issue 描述和完整的代码库。
输出:生成一个 patch 文件,对代码库进行修改,以解决该 issue。
评估方法:
使用
patch工具将生成的 patch 应用于原始代码;运行相关测试,如果 patch 成功应用并且所有测试通过,则视为解决问题成功。
评估指标为“问题解决率”(即解决的任务比例)。
四、SWE-bench 的特点(Features of SWE-bench)¶
真实软件工程任务
任务基于真实的大型代码库和 issue 描述,要求模型展示像经验丰富的软件工程师一样的技能,而不仅仅是生成简单代码片段。持续可更新
该基准的构建流程可以自动化应用到任何 GitHub 仓库,且几乎不需要人工干预,可以持续扩展新的任务实例。长输入和多样性
issue 描述平均约 195 个单词,代码库包含数千个文件。模型需从大量上下文中识别需要修改的少数关键代码行。鲁棒性评估
每个任务至少包含一个 fail-to-pass 测试,40% 的任务包含多个,并运行大量额外测试以验证原有功能未被破坏。跨上下文的代码编辑
不提供局部编辑提示,要求模型在大型代码库中找到多个修改点,平均每次修改 1.7 个文件、3 个函数、32.8 行代码。解决方案的广泛空间
任务允许模型自由探索,生成不同于参考 PR 的解决方案,适用于不同方法(如检索、长上下文模型、决策代理等)的对比。
五、SWE-bench Lite(简化版本)¶
由于 SWE-bench 的评估非常耗费资源且难度较高,作者创建了一个简化版本 SWE-bench Lite,包含 300 个更自包含的任务实例,主要用于评估功能性错误修复。
覆盖 11 个原始 12 个仓库中的大多数;
保留了与原始数据集相似的多样性和分布;
适合那些希望在短期内进行实验或优化的系统。
总结¶
本节详细介绍了 SWE-bench 的构建方法、任务定义和特点,强调其与传统 NLP 基准的不同之处,突出了其对真实软件工程能力的评估价值。同时,作者还提出一个简化版本 Lite,以促进该基准的广泛应用和研究。
3 SWE-Llama: Fine-tuning CodeLlama for SWE-bench¶
这一章主要介绍了 SWE-Llama 模型的构建过程,即通过微调 CodeLlama 模型来提升其在 SWE-bench 任务中的表现,特别是在解决 GitHub 实际问题方面的能力。以下是内容总结:
背景与动机
作者指出,为了公平评估开源模型在 SWE-bench 上的表现,需要将其与专有模型进行对比。
当前只有 CodeLlama 模型具备处理长上下文的能力,但其原始版本在执行复杂的、全局的代码修改任务上表现不佳,常输出占位符或无关代码。
模型微调
作者对 7 亿参数 和 13 亿参数 的 CodeLlama-Python 模型进行了监督微调,使其成为专门处理代码仓库编辑的模型。
微调后的模型能够在消费级硬件上运行,并有效解决 GitHub 上的问题。
训练数据
从 37 个流行 Python 仓库 中收集了 19000 个 issue-PR 对 作为训练数据。
与之前不同,这次不强制要求 PR 包含测试修改,从而构建了更大的训练集。
为防止数据污染,训练数据与评估数据使用的仓库完全不重叠。
训练细节
模型输入包括 GitHub 上的问题描述和相关代码文件,输出为目标补丁(“gold patch”)。
使用 LoRA 技术仅微调注意力机制的子层以节省内存。
为提升效率,排除了超过 30000 token 的训练样本,最终训练集规模缩减为 10000 个样本。
总结:本章节详细介绍了 SWE-Llama 模型的构建过程,包括训练数据的收集、微调方法与优化策略,目的是让 CodeLlama 更好地胜任解决真实 GitHub 问题的任务。
4 Experimental Setup¶
本章节介绍了SWE-bench实验的设置,主要包括输入构造方法、模型评估方式和使用的模型。
4.1 基于检索的方法¶
由于SWE-bench的每个实例包含一个简短的问题描述和一个庞大的代码库(平均约438k行代码),远超大多数语言模型的上下文窗口长度,因此需要选择合适的上下文提供给模型。
为解决这一问题,作者使用了两种检索策略:
稀疏检索(Sparse Retrieval)
使用BM25算法(Robertson et al., 2009)进行检索,选取与任务相关性高的文件作为上下文。实验中测试了三种不同的最大上下文长度,并选择模型在每种限制下表现最好的结果。结果显示,大多数模型在较短的上下文长度下表现最佳。“Oracle”检索(理想检索)
在此设置中,直接使用GitHub上实际修复该问题的补丁所涉及的文件作为上下文。这是一种理想化的设定,因为它假设模型知道哪些文件被修改过,这在实际情况中并不可行。此外,仅依赖这些被修改的文件可能无法完全理解软件行为。
实验结果(表3)显示,在27,000-token的上下文限制下,大约40%的实例中BM25检索出的文件包含了所有“oracle”文件;但在近一半的实例中,BM25并未检索到任何“oracle”文件。
4.2 输入格式¶
检索到的文件与问题描述、任务指令、文档和示例补丁文件一起,构成了模型的输入格式。更详细的实例示例见附录D。
4.3 评估的模型¶
由于SWE-bench需要处理长文本,只有少数模型具备足够长的上下文窗口。评估的模型包括:
ChatGPT-3.5(gpt-3.5-turbo-16k-0613)
GPT-4(gpt-4-32k-0613)
Claude 2
SWE-Llama(7b和13b版本)
表2显示了不同模型在不同上下文长度限制下的问题解决率。Claude 2表现相对较好,而Llama系列在较长上下文下表现下降显著。
表4比较了不同模型在不同上下文长度下的覆盖率。具有更长上下文窗口的模型(如GPT-4)在覆盖实例数方面具有明显优势。值得注意的是,不同模型对token的计算方式不同,因此token长度具有一定的相对性。
总结¶
本章节重点介绍了实验中的上下文选取方法、输入格式和模型选择。由于上下文窗口的限制,模型在处理长代码库时面临挑战,而BM25检索能够在一定程度上缓解这一问题,但其效果在不同模型和任务中仍有较大差异。
5 Results¶
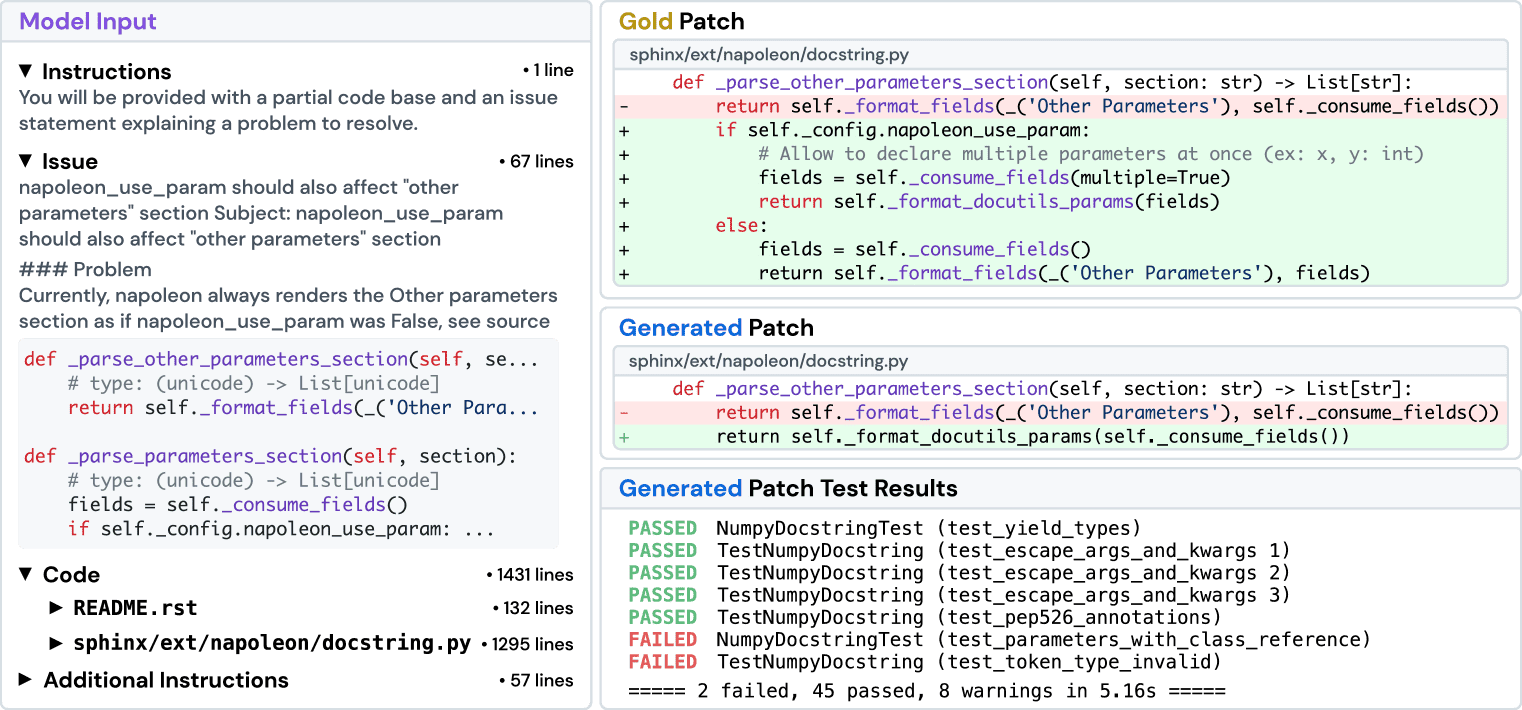
Figure 6: We show an example of an formatted task instance, a model prediction, and the testing framework logs. In the patches, red highlights are deletions. Green highlights are additions.
本文第五章“结果”部分主要探讨了不同检索机制和提示方式对语言模型解决真实GitHub问题(SWE-bench任务)的表现影响,并分析了模型性能和任务难度之间的关系。以下是该章节的主要内容总结:
整体模型表现较差:
多数模型在解决真实GitHub问题方面表现不佳。
最好的模型Claude 2在BM25检索机制下仅能解决1.96%的问题;在“Oracle”(理想检索)设置下提升至4.8%。
检索机制的重要性:
通过“Oracle”检索(即模型获取所有相关文件信息)进行对比,发现在此设置下所有模型的性能都有所提升。
结果表明,检索结果的质量对模型解决问题的能力有显著影响。
不同模型对比:
表5展示了多个模型在BM25检索下的表现,Claude 3 Opus表现最好,解决了3.79%的问题;SWE-Llama系列模型表现较差。
图4显示了不同模型在不同仓库中的解决率,尽管趋势相似,但解决的问题实例有较大差异。
问题难度差异:
仓库难度不同,模型在不同仓库中的表现也有差异。
含有图片的问题更难解决,因为需要多模态模型或外部工具处理。
上下文长度与性能关系:
模型性能随着上下文长度增加而下降,尤其是在BM25检索设置下。
图5显示Claude 2的性能随上下文长度增加而显著下降,其他模型也有类似趋势。
表6显示,在“Oracle-collapsed”设置(仅保留PR中修改的代码段)下,模型性能有所提升。
问题解决时间与难度无关:
模型在2023年之前和之后解决的问题表现基本相同,表明模型并未利用训练数据“作弊”解决近期问题。
微调模型对上下文敏感:
SWE-Llama系列模型在使用BM25检索时表现较差,因为它们是在“Oracle”检索设置下微调的,与实际任务的上下文存在差异。
生成补丁比生成整个文件更容易:
模型在生成补丁文件表现优于生成整个文件。
表8显示,模型生成的补丁文件通常较短、较简单,通常只修改单个文件,而理想补丁涉及更多复杂修改。
定性分析:
作者对SWE-Llama和Claude 2生成的补丁进行了定性分析,发现模型倾向于生成简单、直接的代码,而忽略了代码风格和代码库的整体结构。
模型在解决具体问题时往往不够全面,没有像人类那样进行结构优化和前瞻性修改。
总体结论: 当前语言模型在解决真实世界GitHub问题方面仍面临较大挑战,尤其是在处理复杂上下文、多模态信息和代码结构优化方面。尽管“Oracle”检索设置下性能有所提升,但整体解决率仍然较低,表明模型在生成高质量、符合实际需求的代码补丁方面还有较大提升空间。
7 Discussion¶
本章节主要讨论了SWE-bench任务的局限性与未来改进方向,并总结了研究的贡献与意义。
主要内容总结如下:
局限性与未来方向
当前SWE-bench任务实例仅限于Python语言,未来希望扩展到更多编程语言和领域。
实验部分旨在建立基础的、直接的解决方法作为基准,但并非限制未来研究只能采用类似方法。鼓励探索其他方法,如基于智能体的方法或增强工具的大型语言模型。
当前评估依赖于基于执行的代码测试,但这种方法不足以完全保证模型生成代码的可靠性。研究发现,自动化生成的代码在完整性、效率和可读性上常不如人工编写的代码。
结论
实际的软件开发过程远比代码补全复杂。SWE-bench通过开源协作流程,构建了一个更贴近真实开发环境的基准测试平台。
这种更现实的环境有助于激发创新解决方案,并可直接应用于开源软件开发。
作者希望SWE-bench及其他贡献能为未来更实用、智能和自主的大型语言模型发展提供有价值的资源。
8 Ethics Statement¶
本章节为 “伦理声明”(Ethics Statement),主要阐述了 SWE-bench 数据集在伦理和数据使用方面的合规性。以下是总结内容:
数据来源合法合规:SWE-bench 数据完全来源于具有适当许可证的公开仓库,这些许可证允许软件使用,并符合贡献规范。具体许可证信息可在表12中查到。
用户隐私保护:在数据收集和评估过程中,未收集任何 GitHub 用户的个人信息,任务实例仅使用通过 GitHub 公共 API 和网站公开的数据。
无人类参与:整个 SWE-bench 的构建和评估过程中,未涉及任何形式的人类受试者参与,包括众包或雇佣人工任务工人。
公平的数据筛选标准:在基于流行度筛选 GitHub 仓库时,未使用任何歧视性或偏见性的启发式方法。
开放共享与透明度:SWE-bench 将开源所有任务实例、收集与评估基础设施、实验结果、SWE-Llama 模型的微调训练数据及模型权重,并提供详尽的文档和反馈渠道,以提高可用性和可维护性。
无直接有害影响:SWE-bench 本身不包含任何立即有害的见解。
社会影响讨论:文章在附录 E 中进一步讨论了 SWE-bench 的潜在社会影响。
该声明体现了 SWE-bench 在数据伦理、隐私保护和开放科学方面的高标准与透明实践。
9 Reproducibility Statement¶
本章《可复现性声明》主要说明了作者在提交工作中为确保研究可复现所采取的一系列措施。具体内容总结如下:
代码提交:作者已将完整的源代码以压缩包的形式提交,并进行了匿名化处理,便于评审与复现。
代码组织:代码库按论文中的不同贡献模块组织,例如数据集收集、评估、开源模型推理、SWE-Llama训练等,结构清晰。
文档说明:代码中包含详细的内联文档,说明各部分代码的功能和使用方法,便于理解与使用。
数据提供:作者提交了完整的2294个SWE-bench任务实例,涵盖论文中提到的所有组件,为复现实验提供数据支持。
技术细节补充:在附录A.2和A.4中,作者进一步补充了数据收集流程和评估方法的技术细节,这些内容与论文正文中的第2节形成互补,有助于理解代码实现的逻辑。
未来开放计划:作者计划在伦理声明所讨论的框架下,将SWE-bench作为开源项目正式发布,提供详尽的文档、代码说明和使用指南,以促进社区使用和持续维护。
可维护性与可复现性:SWE-bench的数据收集框架将作为开源代码的一部分发布。由于其良好的可维护性设计,作者相信该基准具备高度的可复现性。
Appendix¶
附录部分提供了关于数据集构建过程、评估流程以及SWE-bench基准测试更详细的说明和特征描述。
Appendix A Benchmark Details¶
本部分总结了论文附录 Appendix A: Benchmark Details 的主要内容,涵盖了数据收集、任务实例构建、执行验证及持续更新等关键流程。
A.1 High Level Overview¶
数据来源:
从 GitHub 上下载量排名前 100 的 PyPI 包中提取 Merged 的 Pull Request(PR),作为任务实例的基础。筛选条件包括:PR 已合并(Merged)
PR 解决了相关 Issues
PR 引入了新的测试(测试文件路径含关键词如 “test”)
任务实例构建:
每个任务实例包括以下内容:代码库(Codebase): 通过 PR 的 base commit 和仓库信息(owner/name)重建代码状态
问题描述(Problem Statement): 整合所有相关 Issues 的标题和描述,排除 PR 合并后的内容以防信息泄露
测试补丁(Test Patch): 从 PR 中提取的测试代码变更
解决方案补丁(Gold Patch): 从 PR 中提取的代码修复变更

Figure 7: SWE-bench task instance example.
执行验证:
为确保任务实例的可用性,通过执行验证:创建虚拟环境并安装代码库
运行测试 T 两次:一次在未应用补丁时,一次在应用补丁后
若测试状态从失败变为通过,则认为该任务有效
排除非实质性的补丁(如测试依赖新定义的函数或类)
持续更新:
SWE-bench 支持扩展,可轻松添加新仓库和语言。其设计具有时间鲁棒性,便于根据新模型的训练时间更新任务集。
A.2 Construction Process¶
字段描述:
任务实例包含多个字段,如:base_commit:PR 所在的原始提交 IDproblem_statement:自然语言描述的任务目标patch:解决方案的 .patch 格式补丁test_patch:用于验证的测试补丁FAIL_TO_PASS:执行后状态从失败变为通过的测试列表env_install_commit:安装依赖的提交版本等
问题描述(problem_statement)生成:
从 PR 的标题、正文和提交信息中提取相关 Issues
按关键词(如 “closes”, “fixes”)匹配 Issues 并收集其描述
提取 Issues 的标题和正文,组合成自然语言的问题描述
从 PR 评论中提取可能的提示信息(hints_text)
代码库管理:
代码库内容不直接存储,而是通过
repo和base_commit信息重建使用 GitHub 镜像仓库确保代码历史不变,避免原始仓库修改导致任务失效
镜像保留原始提交哈希、历史、分支和标签
补丁提取与验证:
解析 PR 的 diff 数据,提取测试和解决方案补丁
补丁采用 .patch 格式,包含文件路径和修改内容(以
+表示新增,-表示删除)对提取的补丁进行验证,确保其行为与原始 PR 一致
其他字段处理:
created_at:用于时间分析version:根据代码库发布时间或版本信息生成env_install_commit:用于创建可靠执行环境
A.3 Execution-Based Validation¶
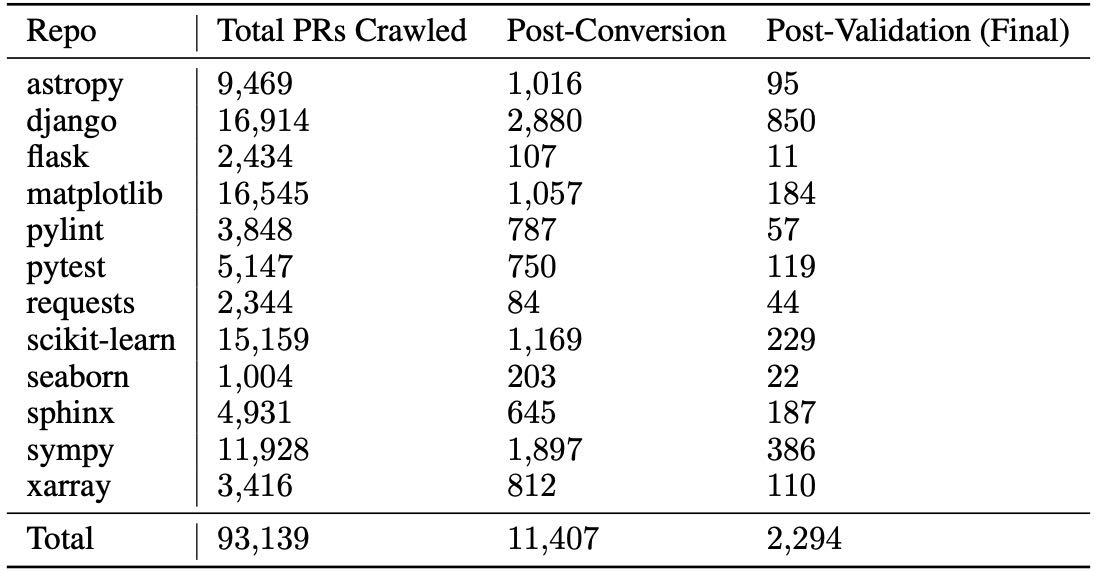
Table 10: Statistics for how many candidate task instances were kept after the completion of a stage across the construction and validation procedures.
在筛选了所有符合条件的Pull Request(PR)并将其转化为候选任务实例之后,下一步是通过执行验证每个任务实例的可用性。该过程分为三个主要步骤:
构建可执行环境(Executable Contexts)
为每个仓库的发布版本创建独立的虚拟环境。选择以发布版本为单位构建环境,是在安装成功率和人工维护成本之间取得平衡的结果。通过查看仓库的README、CONTRIBUTING等文档,确定Python版本、依赖和安装命令。验证引擎(Validation Engine)
验证引擎用于验证候选任务实例是否可用。具体步骤包括:按版本分组任务实例;
对每个任务实例在对应的conda环境中执行以下操作:
恢复基础提交,确保代码库处于初始状态;
运行安装命令;
应用测试补丁并运行测试,记录测试结果;
应用解决方案补丁并重新运行测试;
如果任一阶段失败,该任务实例将被丢弃。
验证日志检查(Examining Validation Logs)
验证过程中会产生两个测试结果日志(log_pre 和 log_post):首先检查log_pre中是否存在ImportError或AttributeError,这些错误可能表明依赖命名错误;
然后检查测试结果,确保应用补丁后,至少有一个测试状态从“失败”变为“通过”,否则任务实例也被丢弃。
最终,通过执行验证后保留的任务实例被保存为开源的JSON文件,并生成对应的测试结果结构(FAIL_TO_PASS、PASS_TO_PASS等),用于后续评估时直接使用,避免重复运行测试。
A.4 评估流程(Evaluation Procedure)¶
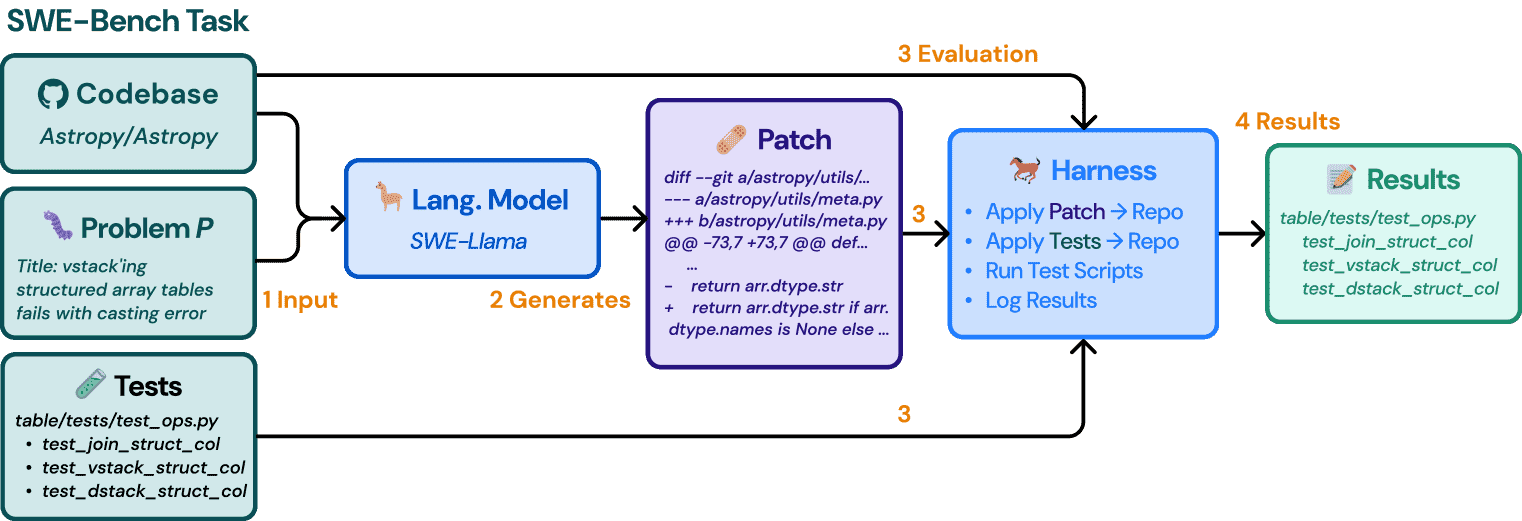
Figure 8: Visualization of the evaluation pipeline at an individual task instance level. During evaluation, the Patch is model generated. A prediction .patch must be applied successfully and produce the same results as the corresponding task instance’s D for task completion.
评估流程用于评估语言模型生成的补丁是否能够解决任务实例。流程如下:
模型生成补丁
语言模型基于给定的问题描述和代码库,生成一个.patch文件。评估步骤
将代码库恢复到任务实例的初始提交;
激活对应的可执行环境;
依次应用测试补丁和模型生成的补丁;
如果补丁应用失败,尝试自动修复(如移除多余上下文、重新计算补丁头);
运行测试脚本并生成结果日志。
评估指标计算
解析模型补丁的测试结果日志,生成测试到状态的映射;
与真实结果中的FAIL_TO_PASS和PASS_TO_PASS进行比对;
若所有对应测试均通过,则认为该任务被成功解决,否则得分为0。
A.5 Evaluation Test Set Characterization¶
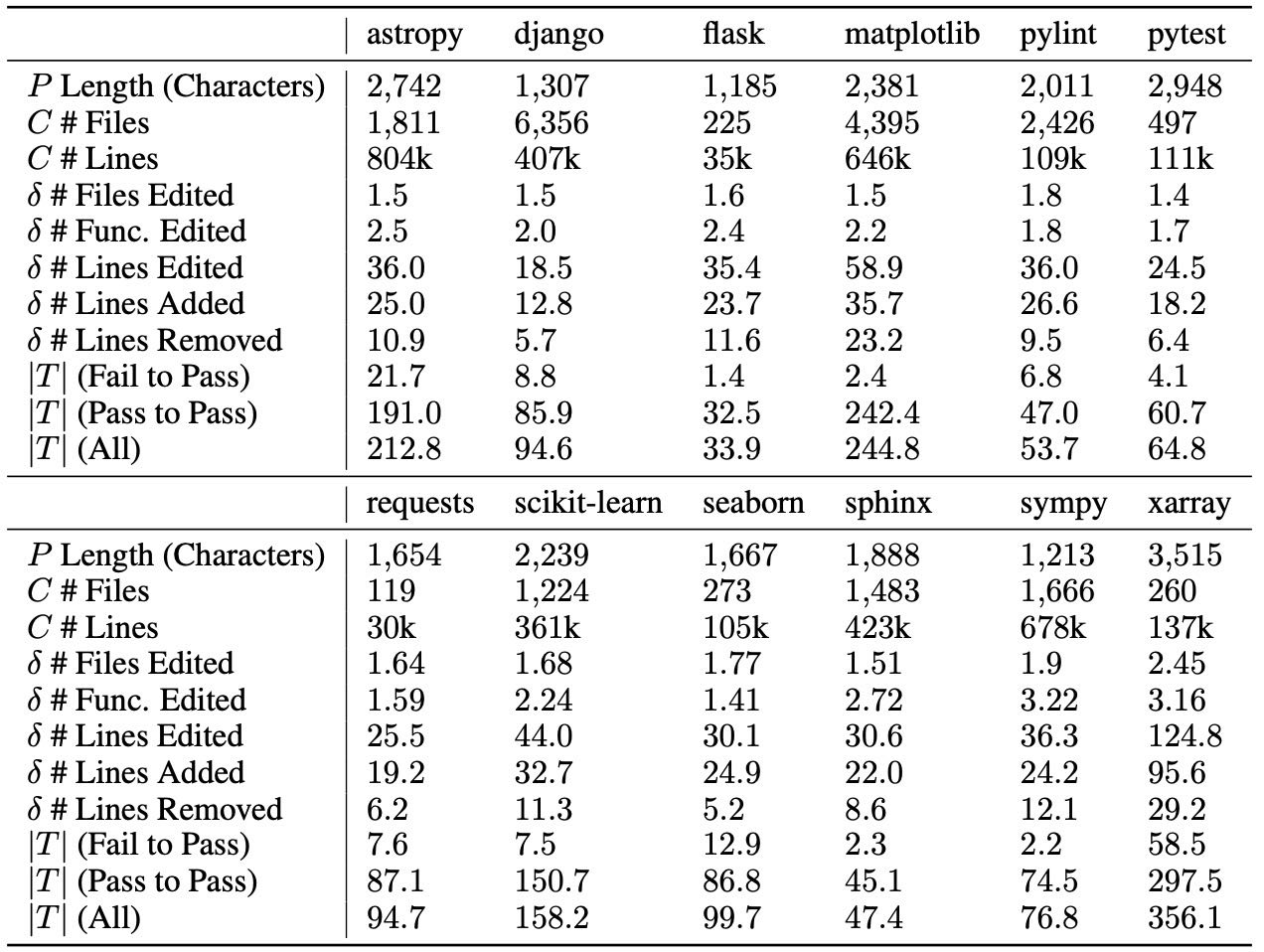
Table 11: Average numbers characterizing different attributes of a SWE-bench task instance grouped by repository.
表格理解:
δ # Lines Added,
δ # Lines Removed,
|T| (Pass to Pass).
表格理解:
多维度的统计分析,包括
代码长度、文件数量、函数数量、修改行数、新增/删除行数以及测试数量等。
提出了三个新的统计指标:
新增行数(Lines Added)、删除行数(Lines Removed) 和 Pass to Pass 测试数量。
本章详细描述了 SWE-bench 评估测试集的各项特征,包括任务难度、代码修改规模、测试要求、问题类型和模型表现。通过这些分析,可以看出:
SWE-bench 任务具有多样性和复杂性,涉及各种开源项目的不同问题。
补丁生成任务对模型提出了较高的要求,特别是在格式化和代码一致性方面。
不同模型的性能差异显著,提示未来在模型训练和优化方面仍有改进空间。
A.6 Development Set Characterization¶
为了在最终测试集上运行之前,对模型进行评估和超参数调优,论文提供了与测试集类似的一个开发集(development set)。该开发集包含 225 个任务实例(约为测试集的 10.1%),来源于 6 个开源仓库,且这些仓库的许可证允许此类使用。开发集的收集方法、过滤标准与测试集完全一致,并额外过滤了2019年1月11日之前创建的实例。

Table 15: Summary and licenses for all GitHub repositories that development task instances were extracted from.
A.7 SWE-BENCH LITE CHARACTERIZATION¶
本节介绍了SWE-bench Lite,这是用于更高效评估语言模型在SWE-bench任务上的表现的一个子集。
备注
原文的 pdf 这一节断开了,不知道为啥
Appendix B Additional Details on Training SWE-Llama¶
本章节详细描述了SWE-Llama模型的训练细节,主要包括以下内容:
优化方法:
使用LoRA(Low-Rank Adaptation)进行微调,参数设置为秩r=16,alpha=16,dropout=0.05,应用于每个注意力子层的查询、键、值和输出投影矩阵。
训练参数:
学习率设为6e-4,每梯度步长使用32个序列作为批量大小。
最大训练轮数为44轮。
训练过程:
每50个训练步保存一次模型检查点。
根据验证集上100个实例的验证损失选择最佳检查点。
训练时间和资源:
SWE-Llama 7b:基于CodeLlama-Python 7b初始化,在4块NVIDIA A100 GPU上训练了20小时。
SWE-Llama 13b:基于CodeLlama-Python 13b初始化,在8块NVIDIA A100 GPU上训练了47小时。
技术支持:
使用DeepSpeed Ulysses和Flash Attention技术以支持长上下文训练。
总结:本节全面介绍了SWE-Llama模型的训练配置、优化方法、训练资源及时间消耗,展示了模型训练的高效性和技术实现的先进性。
Appendix C Additional Results¶
本附录部分提供了关于SWE-bench基准测试中语言模型在解决GitHub实际问题方面的补充结果,涵盖了不同检索方法、模型性能对比、时间分析、补丁生成的细粒度分析等多个方面,总结如下:
C.1 Results with “Oracle” Retrieval¶
方法:使用“Oracle”检索方法(即仅提供参考解决方案中修改的文件)。
主要发现:
“Oracle”检索相比 BM25 检索显著提升了模型表现,说明提供更准确的上下文有助于模型生成更有效的补丁。
总体结论¶
Oracle 检索显著提升了模型性能,说明准确的上下文对生成有效补丁至关重要。
SWE-Llama 系列在大多数指标上表现优于 GPT 和 Claude,尤其是在大规模补丁生成和多文件处理方面。
模型仍面临挑战:包括代码依赖关系的理解、长序列生成的准确性、幻觉问题等。
未来方向:提供执行环境和反馈机制,有助于模型通过测试结果逐步优化补丁生成,提高解决真实世界问题的能力。
C.7 Software Engineering Metrics¶
本章节《C.7 软件工程度量》总结了作者在代码生成领域中使用软件工程度量(如圈复杂度和Halstead复杂度)来评估大型代码块在复杂代码库中集成效率和复杂性的初步研究。
主要观点如下:
传统NLP评估的局限性:
传统的自然语言处理(NLP)任务通常使用语义相似度评分来评估生成文本的流畅性和表层相似性,但这类方法在代码生成中可能不适用。软件工程度量(如McCabe的圈复杂度和Halstead复杂度)基于抽象语法树(AST)等逻辑抽象结构,能更准确地度量代码的复杂性、效率和可读性。SWE-bench任务的适用性:
相比于代码竞赛中规模较小的任务,SWE-bench任务足够复杂,能够为软件工程工具提供有意义的反馈,帮助评估代码补丁的复杂度及其对整个代码库的影响。度量方法与实验设计:
作者使用Radon开源软件包,直接从源代码中计算圈复杂度和Halstead复杂度。研究聚焦于Claude 2在psf/requests仓库中的补丁预测结果,将模型生成的补丁应用到代码库,计算修改函数的复杂度指标,并与标准参考补丁进行对比。结论与意义:
软件工程度量可以提供关于模型生成代码质量的自动、结构化反馈,使研究者能够从逻辑复杂性和可维护性等维度评估模型性能,而不仅仅是依赖代码长度或表面相似性。这为评估代码生成模型的能力打开了新的视角。
Appendix D Additional Experimental Details¶
D.1 检索细节¶
稀疏检索:在检索过程中,对文档进行轻微增强,即在文件内容前添加文件路径,以便能够根据直接在问题中提到的文件名进行更有效的检索。
Oracle 检索:Oracle 检索直接从参考解决方案的补丁文件中提取文件路径,不包含测试文件。
D.2 推理设置¶
由于生成补丁的成本较高,每个实例仅生成一个补丁文件。
为了评估模型性能,使用贪婪解码(greedy decoding)而不是采样方法,这一做法与 Pass@1 和 SWE-bench 等代码生成评估标准一致。
D.3 提示模板示例¶
模型使用统一的提示模板,根据具体模型略有调整。模板包括以下部分:
问题描述(
<issue>标签内)代码库片段(
<code>标签内)补丁文件格式示例(
<patch>标签内),展示如何指定文件名、行号、增删内容等信息。
模型的任务是基于提供的代码和问题描述,生成符合 Git 应用格式的补丁文件。
补充说明¶
实验中调整指令或示例的行数对整体性能影响不大,除非特别指出(如第5节所述实验结果)。
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
{ISSUE TEXT}
</issue>
<code>
[start of README.md]
{README.md text}
[end of README.md]
[start of file\_1.py]
{file\_1.py text}
[end of file\_1.py]
...
</code>
Here is an example of a patch file. It consists of changes to the code base. It specifies the file names, the line numbers of each change, and the removed and added lines. A single patch file can contain changes to multiple files.
<patch>
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 \* err
- if e2 > -dy:
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+ points.append((x, y))
return points
</patch>
I need you to solve the provded issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the format shown above.
Respond below:
Appendix E Societal Impact¶
本章节《附录E 社会影响》主要探讨了代码推理能力作为大语言模型(LM)基础技能之一,可能引发的机器自动化软件工程的未来发展趋势及其潜在的社会影响。作者指出,这一趋势带来了一系列重要的问题,特别是在AI安全领域,例如如何确保AI生成的代码符合人类意图,以及在代码代理误解人类目标时应采取哪些防护措施。
为在受控环境中观察这些问题并探索解决方案,作者提出SWE-bench可能作为一个测试平台,用于设计安全、稳健的措施,以实现对齐、可验证和安全的AI驱动软件工程。
Appendix F In-depth Analysis of SWE-Llama Generations¶
本章节对SWE-Llama模型在解决编程问题时的生成样本进行了深入分析,主要总结了以下几点观察:
在多行和多文件修改上表现不佳:
模型在处理需要进行多行或跨多个文件修改的任务时存在困难。例如,在Table 25和Table 26中,SWE-Llama生成的补丁未能以最简洁和高效的方式解决问题,并引入了新的代码风格不一致问题。
模型的补丁虽然能够通过部分测试,但与参考解决方案相比,显得冗余或不够优雅。例如,在Table 26中的问题中,SWE-Llama的补丁未能完全利用已有函数的参数来解决类型问题,而参考补丁则更直接地修改了参数列表,减少了代码复杂度。
在理解代码库上下文方面存在不足:
SWE-Llama在某些情况下未能充分理解代码库的上下文,导致生成的补丁不准确。例如,在Table 27和Table 28中,模型未能识别到问题的根本原因,而是直接对问题描述中提到的特定代码进行了修改,忽略了代码库中其他依赖部分的逻辑。
在Table 29和Table 34中,模型对问题的分析不够全面,甚至导致了原本正确功能的失效。例如,在Table 34中,模型的补丁虽然解决了输出符号翻转的问题,但引入了新的错误,影响了模型的稳定性。
在处理复杂逻辑时表现不稳定:
在某些复杂逻辑任务中,SWE-Llama生成的补丁未能覆盖所有边界条件。例如,在Table 30和Table 31中,模型虽然能够通过部分测试,但其补丁在代码风格和代码库一致性方面存在不足,可能在未来引发新的问题。
在Table 32中,SWE-Llama生成的补丁比参考补丁更简洁,但在代码风格上与代码库不一致,这可能会影响代码的可维护性。
在处理图像和外部依赖时表现不足:
在Table 28中,问题描述中包含了图像和第三方库的使用。SWE-Llama未能正确理解这些信息,导致无法生成有效的解决方案,突显了模型在处理视觉信息和外部依赖时的局限性。
在处理长上下文任务时存在挑战:
在Table 34中,问题涉及对代码库中多个部分的修改。SWE-Llama未能充分理解这些修改对代码库其他部分的影响,导致生成的补丁不仅未能解决问题,还破坏了原有的功能。这表明,模型在处理长上下文任务时需要进一步提升其对代码结构的整体理解能力。
总体来看,SWE-Llama在解决编程问题时表现出一定的能力,尤其是在简单和直接的问题上。然而,模型在处理复杂的逻辑、多文件修改、长上下文任务以及对代码库上下文的深入理解方面仍存在明显不足。这些分析结果为模型的进一步改进提供了方向,特别是在提升代码理解和上下文处理能力方面。