2601.07372_Engram: Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models¶
引用:
0(2026-01-19)
组织:
1Peking University
2DeepSeek-AI
链接:
总结¶
关键信息
条件记忆(conditional memory)。其核心思想是,LLMs在处理语言信号时面临两种本质上不同的子任务:需要深度、动态计算的组合推理(compositional reasoning)和能够通过廉价查找实现的知识检索(knowledge retrieval)。
Engram模块,具体实现条件记忆(Conditional Memory)的模块。一个将经典N-gram嵌入现代化为O(1)查找的条件记忆实例化。Engram的设计旨在将静态模式存储与动态计算分离,从而提升模型的效率和能力。
图表¶
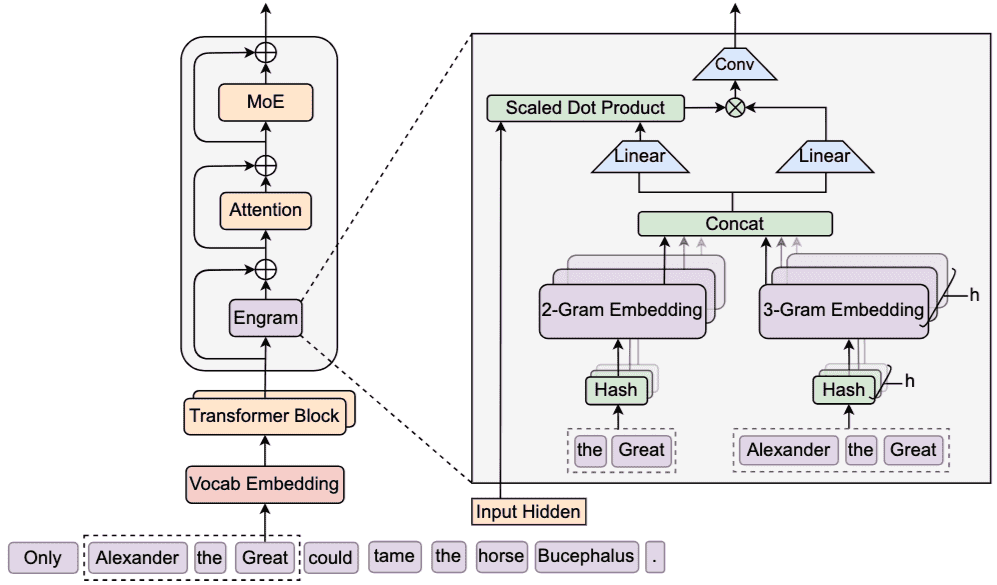
Figure 1 | The Engram Architecture.
说明
The module augments the backbone by retrieving static 𝑁-gram memory and fusing it with dynamic hidden states via context-aware gating.
This module is applied only to specific layers to decouple memory from compute, leaving the standard input embedding and un-embedding module intact.
图解
在主干网络中插入 Engram 模块,用于检索静态 N-gram 记忆。
通过上下文感知门控机制融合查找到的信息。
仅在特定层使用,保持输入嵌入与输出解嵌入模块不变。
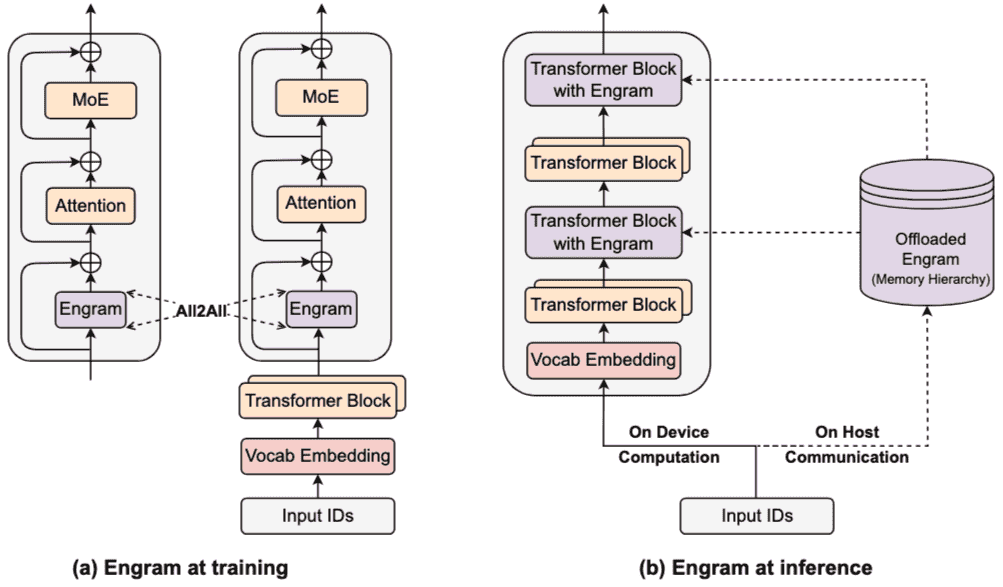
Figure 2 | System implementation of Engram.
说明
a) Training Phase:
The massive embedding tables are sharded across available GPUs.
An All-to-All communication primitive is employed to retrieve active embedding rows across devices.
b) Inference Phase:
Engram tables are offloaded to host memory.
By exploiting the deterministic retrieval logic, the host asynchronously prefetches and transfers embeddings,
overlapping communication with the on-device computation of preceding Transformer blocks.
图解
(a) 训练阶段:嵌入表跨 GPU 分片,All-to-All 通信收集活跃行。
(b) 推理阶段:嵌入表卸载到主机内存,异步预取与计算重叠。
From Moonlight¶
三句摘要¶
🤔 本文引入了条件记忆(conditional memory)作为LLMs的一种新的稀疏性轴,通过Engram模块实现,该模块利用可扩展的O(1)查找来高效处理静态模式,从而解决模型通过计算模拟知识检索的低效问题。
📈 论文制定了稀疏性分配问题,发现U形缩放定律指导MoE专家和Engram记忆之间的最优容量分配,使得混合模型(如Engram-27B/40B)在通用推理、代码和数学任务上超越了同参数同FLOPs的MoE基线。
⚙️ 机制分析显示,Engram通过减轻早期层静态重建任务,有效“深化”了网络并增强了长上下文能力;其确定性寻址还支持从主机内存进行运行时预取,实现了显著的效率提升。
关键词¶
Conditional Memory: 论文提出的核心概念,作为一种与现有“条件计算”(Conditional Computation)并行的“稀疏性轴”,旨在解决大型语言模型(LLM)中通过计算模拟知识检索的低效问题。它通过结构化地分离静态知识存储与动态计算,依赖于稀疏查找(sparse lookup)操作来检索固定知识的嵌入向量,从而提高模型的知识获取和利用效率。
Engram: 论文提出的具体实现条件记忆(Conditional Memory)的模块。它对经典的 N-gram 嵌入进行了现代化改造,支持高效的 O(1) 时间复杂度查找,能够根据局部上下文(N-gram)检索静态嵌入向量。Engram 模块被集成到 Transformer 主干网络中,与条件计算(如 MoE)协同工作,共同提升模型的整体性能。
Sparsity Allocation: 论文中提出的一个问题框架,用于在给定的总参数量和训练计算量约束下,优化模型容量在 MoE 专家(计算)和 Engram 记忆(存储)之间的分配比例。通过对该问题的研究,论文揭示了一个“U形”的稀疏性分配法则(U-shaped scaling law),表明混合使用条件计算和条件记忆比纯粹的条件计算能获得更好的性能。
Mixture-of-Experts (MoE): 一种已广泛应用的扩展 LLM 容量的方法,其核心思想是通过条件计算,为每个输入 token 仅激活模型参数的一个稀疏子集(专家)。MoE 允许模型在参数量急剧增加的同时,保持每 token 的计算量相对恒定。本文将 Engram 作为 MoE 的补充,提出一种结合两者的稀疏性分配策略。
N-gram: 指由 N 个连续的词语或 token 组成的序列。在自然语言处理中,N-gram 模型(如 2-gram, 3-gram)常用于捕捉局部语言模式和依赖关系。Engram 模块在此基础上,利用 N-gram 作为查找静态嵌入的键(key),并对其进行压缩和哈希处理,以实现高效的知识检索。
Lookup: 指通过一个键(key)在存储系统中检索对应值的操作。在 Engram 模块中,局部上下文(N-gram)被用作键,通过哈希函数映射到存储在嵌入表中的静态向量(值)。这种 O(1) 时间复杂度的查找操作是 Engram 实现高效知识检索的关键机制。
Conditional Computation: 指在模型推理过程中,根据输入的不同,仅激活模型参数的一个子集来执行计算。Mixture-of-Experts (MoE) 是条件计算的一个典型例子。与此相对,论文提出的条件记忆(Conditional Memory)通过查找操作引入了另一种形式的稀疏性,即激活(检索)内存中的特定信息,而非计算参数。
Scaling Law: 描述模型性能、容量或效率如何随规模(如参数量、训练数据量、计算量)变化的规律。论文通过研究 Sparsity Allocation 问题,发现了 MoE 与 Engram 混合模型的一种“U形”稀疏性分配法则,表明存在一个最优的容量分配比例,使得在固定总参数和计算量下,性能达到最优。
Infrastructure-aware Efficiency: 指模型设计应考虑其在实际硬件基础设施(如 GPU、CPU、内存层次结构)上的运行效率。Engram 的确定性寻址机制允许在推理时将大量参数(嵌入表)卸载到 CPU 内存(Host Memory),并利用前置计算来掩盖通信延迟,从而在不显著影响吞吐量的情况下,实现巨大的参数扩展。
Multi-branch Architecture: 一种先进的 Transformer 主干网络结构,其中残差流被分成多个并行分支,信息流通过可学习的连接权重进行调节。Engram 模块被设计成可以有效地集成到这种多分支架构中,通过参数共享和分支特异性的门控机制,提高了模型的表达能力和计算效率。
Context-aware Gating: 一种门控机制,用于动态地调整从 Engram 检索到的静态嵌入向量与当前 token 的隐藏状态之间的融合比例。该机制利用当前 token 的隐藏状态(经过多层注意力聚合的全局上下文)作为查询(Query),检索到的嵌入作为键(Key)和值(Value)的来源,计算一个门控信号(𝛼𝑡),以确保检索到的信息与上下文一致,并抑制噪声。
Tokenizer Compression: 一种预处理技术,用于最大化词汇表(vocabulary)的语义密度。标准分词器可能为同义词分配不同的 ID。论文提出的词汇投影层(vocabulary projection layer)创建一个从原始 token ID 到规范 ID 的映射函数 P,将语义上等价但 ID 不同的词语映射到同一个规范 ID,从而减少实际使用的有效词汇量,增强 N-gram 查找的语义一致性。
Multi-head Hashing: Engram 模块中用于处理 N-gram 键的哈希技术。为了减少哈希冲突(collisions)并提高检索的鲁棒性,论文对每个 N-gram 订单(order)采用了 K 个独立的哈希头(hash heads)。每个哈希头将压缩后的上下文映射到一个嵌入表(embedding table)的索引,从而构建最终的记忆向量。
Representational Alignment: 用于衡量不同模型或同一模型不同层之间表示(representations)的相似性。论文使用 CKA (Centered Kernel Alignment) 度量来分析 Engram 模型与其 MoE 基线模型在不同层级的表示是否对齐。结果表明,Engram 模型的早期层级在功能上类似于 MoE 基线模型更深层级的表示,表明 Engram 增强了模型的“有效深度”(effective depth)。
Effective Depth: 指模型能够进行多步信息处理或推理的能力。Engram 模块通过将静态知识检索的任务从早期层级中剥离出来,使这些层级不必再花费计算资源去“记忆”和“重构”静态信息,从而将宝贵的计算深度留给更复杂的推理任务。这使得模型在功能上等同于拥有更深的计算网络。
Latency Masking: 指在系统中,利用计算时间来隐藏通信(如数据传输)所带来的延迟。Engram 模块在推理时,可以将嵌入表的访问操作卸载到 Host Memory(CPU 内存),并通过将其放置在 Transformer 主干网络的特定层,利用前面 Transformer 块的计算时间来异步加载所需的嵌入数据,从而掩盖 PCIe 总线传输的延迟,避免 GPU stalls。
Host Memory Offloading: 指将模型的大部分参数(例如,Engram 的大型嵌入表)存储在 CPU 主内存(DRAM)中,而不是 GPU 的显存(HBM)中。由于 Engram 的查找是确定性的,其索引可以预先计算,因此系统可以异步地从 Host Memory 加载数据,有效地绕过 GPU 内存容量的限制,使模型能够拥有远超 GPU 显存容量的参数规模。
摘要¶
大型语言模型(LLMs)的现有稀疏化方法主要集中在条件计算(Mixture-of-Experts, MoE)上,但本研究提出了一种补充性的稀疏轴:条件记忆(conditional memory)。其核心思想是,LLMs在处理语言信号时面临两种本质上不同的子任务:需要深度、动态计算的组合推理(compositional reasoning)和能够通过廉价查找实现的知识检索(knowledge retrieval)。当前LLMs通过计算来模拟知识检索,导致在处理本地、静态且高度模式化的信息(如N-gram、命名实体、固定短语)时效率低下,浪费了计算资源和网络深度。
为了解决这一问题,本研究引入了Engram模块,一个将经典N-gram嵌入现代化为O(1)查找的条件记忆实例化。Engram的设计旨在将静态模式存储与动态计算分离,从而提升模型的效率和能力。
核心方法:Engram架构 Engram模块增强了Transformer骨干网络,通过两个主要阶段处理每个位置\(t\)的输入:检索(retrieval)和融合(fusion)。
稀疏检索通过哈希N-gram(Sparse Retrieval via Hashed N-grams)
Tokenizer Compression:为了最大化语义密度,Engram首先通过一个词汇表投影层\(P: V \rightarrow V'\)将原始token ID \(x_t\)映射到规范化ID \(x'_t = P(x_t)\)。这利用了NFKC(Normalization Form Compatibility Composition)和小写转换等规范化文本等价性,实践中可将128k词汇表的有效词汇量减少23%。然后,从这些规范化ID构建后缀N-gram \(g_{t,n} = (x'_{t-n+1}, \dots, x'_t)\)。
Multi-Head Hashing:为解决所有N-gram组合空间参数化的不可行性,Engram采用基于哈希的方法。对于每个N-gram阶数\(n\),使用\(K\)个不同的哈希头来缓解冲突。每个头\(k\)将压缩后的上下文映射到嵌入表\(E_{n,k}\)(素数大小为\(M_{n,k}\))中的一个索引:\(z_{t,n,k} \triangleq \varphi_{n,k}(g_{t,n})\),其中\(e_{t,n,k} = E_{n,k}[z_{t,n,k}]\)。\(\varphi_{n,k}\)实现为轻量级乘法-异或哈希。最终的记忆向量\(e_t \in \mathbb{R}^{d_{mem}}\)通过拼接所有检索到的嵌入得到:\(e_t \triangleq \parallel_{n=2}^N \parallel_{k=1}^K e_{t,n,k}\)。
上下文感知门控(Context-aware Gating)
检索到的嵌入\(e_t\)作为上下文无关的先验知识。为了增强表达能力并解决哈希冲突或多义性带来的噪声,Engram采用上下文感知门控机制。当前的隐藏状态\(h_t\)(通过先前的注意力层聚合了全局上下文)用作动态查询(Query),而检索到的记忆\(e_t\)则作为键(Key)和值(Value)的来源:\(k_t = W_K e_t\), \(v_t = W_V e_t\)。
门控标量\(\alpha_t \in (0, 1)\)的计算方式为:\(\alpha_t = \sigma\left(\frac{\text{RMSNorm}(h_t)^\top \text{RMSNorm}(k_t)}{\sqrt{d}}\right)\)。
门控输出定义为\(\tilde{v}_t = \alpha_t \cdot v_t\),确保语义对齐:如果检索到的记忆\(e_t\)与当前上下文\(h_t\)矛盾,门控\(\alpha_t\)趋近于零,有效抑制噪声。
短深度因果卷积(Short Depthwise Causal Convolution)
为了扩展感受野并增强模型的非线性,Engram引入了一个短的、深度因果卷积。设\(\tilde{V} \in \mathbb{R}^{T \times d}\)是门控值序列,最终输出\(Y\)计算为:\(Y = \text{SiLU}(\text{Conv1D}(\text{RMSNorm}(\tilde{V}))) + \tilde{V}\)。
Engram模块通过残差连接集成到骨干网络中:\(H^{(\ell)} \leftarrow H^{(\ell)} + Y\),之后是标准的Attention和MoE层。
与多分支架构的集成(Integration with Multi-branch Architecture) Engram模块与先进的多分支骨干网络集成,采取参数共享策略:一个单一的稀疏嵌入表和一个值投影矩阵\(W_V\)在所有\(M\)个并行分支中共享,而\(M\)个不同的键投影矩阵\(\{W_K^{(m)}\}_{m=1}^M\)用于实现分支特定的门控行为。对于第\(m\)个分支的隐藏状态\(h_t^{(m)}\),分支特定的门控信号计算为:\(\alpha_t^{(m)} = \sigma\left(\frac{\text{RMSNorm}(h_t^{(m)})^\top \text{RMSNorm}(W_K^{(m)}e_t)}{\sqrt{d}}\right)\)。检索到的记忆由这些独立门控调制后应用于共享的值向量:\(u_t^{(m)} = \alpha_t^{(m)} \cdot (W_V e_t)\)。
系统效率:解耦计算与记忆(System Efficiency: Decoupling Compute and Memory) Engram的确定性检索机制允许参数存储与计算资源解耦。在训练期间,大规模嵌入表通过分片在多个GPU上进行模型并行。在推理期间,由于记忆索引在正向传播前已知,系统可以异步地从主机内存(host memory)通过PCIe预取(prefetch)嵌入,并与GPU上先前的Transformer block的计算重叠,从而隐藏通信延迟。Engram模块被放置在特定层中,以利用计算窗口进行预取。此外,自然语言N-gram遵循Zipfian分布,允许采用多级缓存层次结构,将频繁访问的嵌入缓存到更快的存储层(如GPU HBM),而稀有模式则存储在较慢但容量更大的介质(如NVMe SSD)中。
稀疏性分配问题与扩展定律(Sparsity Allocation and Scaling Laws) 本研究通过Sparsity Allocation问题量化了Engram与MoE的协同作用:在固定总参数预算下,如何在MoE专家和Engram记忆之间分配容量。
计算匹配公式:定义了总可训练参数\(P_{tot}\)、每token激活参数\(P_{act}\)和非激活参数\(P_{sparse} \triangleq P_{tot} - P_{act}\)。\(P_{act}\)和\(P_{tot}\)在不同模型间保持固定。MoE中非选择专家参数贡献给\(P_{sparse}\),Engram中增加嵌入槽数量增加\(P_{tot}\)但不增加\(P_{act}\)。
分配比例:分配比例\(\rho \in [0, 1]\)定义为分配给MoE专家容量的非激活参数预算分数:\(P_{\text{MoE}}^{\text{(sparse)}} = \rho P_{sparse}\), \(P_{\text{Engram}} = (1 - \rho) P_{sparse}\)。\(\rho=1\)是纯MoE模型。
U形扩展定律:实验结果揭示了验证损失与分配比例\(\rho\)之间的U形关系。即使将MoE分配减少到40%,Engram模型也能达到与纯MoE基线相当的性能。最佳性能点位于\(\rho \approx 75\%-80\%\),表明将20%-25%的稀疏参数预算重新分配给Engram能带来最佳结果。这证实了两个模块的结构互补性:MoE主导的模型缺乏专用记忆导致计算效率低下,而Engram主导的模型缺乏条件计算能力则无法处理动态推理任务。
无限记忆状态下的Engram:在放宽记忆预算的情况下,Engram表现出清晰且一致的对数线性(log-linear)扩展行为,即增加记忆槽数量会持续改进验证损失,而无需额外计算。这表明Engram提供了一个可预测的扩展旋钮,并且比OverEncoding等直接平均方法解锁了更大的扩展潜力。
大规模预训练(Large Scale Pre-training) 在2620亿token上训练了四个模型:Dense-4B、MoE-27B、Engram-27B(iso-参数和iso-FLOPs MoE-27B)和Engram-40B。Engram-27B通过将72个MoE专家减少到55个,并将释放的参数(5.7B)分配给Engram记忆模块(\(\rho=74.3\%\))来实现与MoE-27B的总参数和激活参数匹配。Engram-40B进一步将Engram记忆扩展到18.5B参数。
结果:Engram-27B在所有基准测试中始终优于iso-参数和iso-FLOPs的MoE-27B基线。增益不仅限于知识密集型任务(如MMLU:+3.0),在通用推理(如BBH:+5.0)、代码(HumanEval:+3.0)和数学(MATH:+2.4)领域也观察到显著改进。Engram-40B的进一步扩展降低了预训练损失,并在大多数基准测试中提升了性能,表明其扩展潜力尚未完全饱和。
长上下文训练(Long Context Training) Engram通过将本地依赖建模卸载给静态查找,保留了宝贵的注意力容量来管理全局上下文。
实验设置:在预训练之后,使用YaRN策略进行上下文窗口扩展训练(32768 tokens)。通过控制基线模型损失(”Iso-Loss”设置)而不是训练步数,进行严格的架构效率比较。
结果:在”Iso-Loss”设置下(Engram-27B (46k) vs. MoE-27B (50k),两者预训练损失相同),Engram在复杂检索任务(如Multi-Query NIAH: 97.0 vs. 84.2; VT: 87.2 vs. 77.0)上表现出显著增益。在”Iso-FLOPs”设置下,Engram-27B (50k)进一步扩大优势。即使是早期停止的Engram-27B (41k)也与完全训练的MoE-27B (50k)高度竞争,表明了Engram架构的内在优越性。
分析(Analysis)
Engram是否等效于增加模型深度?
加速预测收敛(Accelerated Prediction Convergence):通过LogitLens分析,Engram模型在早期层表现出系统性更小的KL散度,表明模型在网络层次结构中更早地完成了特征组合,更快地达到高置信度的有效预测。
表征对齐和有效深度(Representational Alignment and Effective Depth):CKA分析显示Engram层的表征与MoE模型更深层的表征高度相似。软对齐指数\(a_j = \frac{\sum_{i \in \mathcal{I}_j} S_{i,j} \cdot i}{\sum_{i \in \mathcal{I}_j} S_{i,j}}\)(其中\(\mathcal{I}_j = \text{argtop}_k(S_{i,j})\))显示\(a_j > j\),意味着Engram通过显式查找绕过早期特征组合,从而增加了模型的有效深度。
结构消融和层敏感性(Structural Ablation and Layer Sensitivity)
放置权衡:在Layer 2注入Engram能获得最佳单层性能,这表明一层注意力已足够提供有意义的上下文,并且仍足够早以替代骨干网络底层局部聚合。将相同记忆预算分配到Layer 2和Layer 6的两个模块能进一步提升性能,结合了早期干预和后期丰富的上下文门控。
组件重要性:多分支骨干网络内的分支特定融合、上下文感知门控和tokenizer compression对性能提升贡献最大。移除这些组件会导致验证损失大幅下降。轻量级深度卷积的影响较小。
敏感性分析(Sensitivity Analysis)
在推理时完全抑制Engram稀疏嵌入输出的消融实验表明,事实知识基准测试遭受灾难性崩溃(仅保留29%-44%的原始性能),证实Engram模块是参数知识的主要存储库。相反,阅读理解任务具有显著的弹性(保留81%-93%),表明上下文依赖任务主要依靠骨干网络的注意力机制。
系统效率(System Efficiency)
将100B参数的Engram层完全卸载到主机内存中,对端到端吞吐量的影响微乎其微(在8B骨干网络上峰值仅为2.8%)。这证实了早期密集块的计算强度提供了足够的时间窗口来掩盖检索延迟。
案例研究:门控可视化(Case Study: Gating Visualization)
门控标量\(\alpha_t\)的可视化显示,门控机制在完成本地、静态模式(如多token命名实体“Alexander the Great”、“the Milky Way”,或中文习语“四大发明”、“张仲景”)后会一致性地激活。这表明Engram成功识别并处理了模式化的语言依赖,有效减轻了Transformer骨干网络记忆这些静态关联的负担。
结论 Engram作为一种条件记忆的实例化,为Transformer模型提供了一个补充性的稀疏轴。通过制定Sparsity Allocation问题,本研究发现混合分配MoE专家和Engram记忆的稀疏容量,严格优于纯MoE基线。Engram有效地“深化”了网络,减轻了早期层对静态知识重建的负担,从而释放了注意力容量以专注于全局上下文和复杂推理。其确定性寻址方式允许存储和计算解耦,实现了将大规模参数表卸载到主机内存而几乎不产生推理开销。研究认为条件记忆功能是下一代稀疏模型不可或缺的建模原语。
Abstract¶
本论文提出了一种新的稀疏建模机制——条件记忆(conditional memory),作为MoE(Mixture-of-Experts)之外的另一条稀疏性路径。作者设计了一个名为 Engram 的模块,将经典的NN-gram嵌入方法现代化,实现了 𝒪(1) 的快速知识检索,从而弥补了Transformer在知识检索上的不足。
核心贡献与发现:¶
提出“稀疏分配问题”(Sparsity Allocation Problem):在神经计算(MoE)和静态记忆(Engram)之间进行资源分配,发现存在一个U型缩放律(U-shaped scaling law),用于优化两者之间的平衡。
Engram模块的扩展能力:成功将Engram扩展到270亿参数,在相同参数量和FLOPs条件下,优于传统的MoE模型。
性能提升表现:¶
知识检索任务:如MMLU(+3.4)、CMMLU(+4.0)显著提升;
推理能力:BBH(+5.0)、ARC-Challenge(+3.7)提升更大;
代码与数学任务:HumanEval(+3.0)、MATH(+2.4)也有明显提升。
机制分析:¶
减轻早期层负担:Engram让模型的前几层不再需要重复学习静态知识,相当于“加深”了用于复杂推理的网络深度;
注意力资源释放:通过将局部依赖交给Engram查找,注意力机制可以专注于全局上下文,显著提升长文本检索能力(如Multi-Query NIAH从84.2提升到97.0)。
效率与部署优势:¶
基础设施感知设计:Engram的确定性寻址机制支持从主机内存中预取数据,运行时开销极低。
总结:¶
Engram为稀疏模型提供了一种全新的建模原语,不仅提升了模型性能,还优化了计算与内存的使用效率。作者认为,条件记忆将成为下一代稀疏模型中不可或缺的组成部分。
GitHub开源地址:https://github.com/deepseek-ai/Engram
1 Introduction¶
核心观点:¶
本文提出了一种新的稀疏性设计思路——条件记忆(conditional memory),作为对当前主流的条件计算(conditional computation)范式(如Mixture-of-Experts, MoE)的补充。这种新方法旨在更好地匹配语言建模任务中组合推理与知识检索两种本质不同的子任务。
1.1 背景与动机¶
稀疏性在智能系统中的重要性:从生物神经网络到现代大语言模型(LLMs),稀疏性是设计的重要原则。
MoE 的现状:MoE 通过条件计算实现模型容量扩展,已成为前沿模型的标准架构(如 DeepSeek、Gemini、Kimi 等)。
MoE 的局限性:
语言建模包含两类任务:
组合推理(需要深度动态计算)
知识检索(如命名实体、固定模式等,具有局部性、静态性和重复性)
当前模型缺乏原生的知识检索机制,只能通过多层注意力和FFN模拟,造成计算资源浪费。
关键数据支持:Table 3 显示,识别一个常见多词实体需要消耗多个早期层的计算资源。
1.2 条件记忆(Conditional Memory)的提出¶
核心思想:引入一种新的稀疏机制——条件记忆,通过稀疏查找操作检索静态知识嵌入(embedding)。
实现方式:借鉴经典的 NN-gram 模型,使用局部上下文作为键(key),通过常数时间 \(\mathcal{O}(1)\) 的查找操作从大规模嵌入表中检索信息。
Engram 模块:作为条件记忆的实现,结合现代技术(如 tokenizer 压缩、多头哈希、上下文门控、多分支融合)进行优化。
1.3 稀疏性分配问题(Sparsity Allocation)¶
研究问题:在固定参数预算下,如何在 MoE 专家(计算)与 Engram 记忆(查找)之间分配容量?
实验发现:存在一个 U 型缩放规律,表明即使简单的查找机制,作为一等建模原语,也能显著提升模型性能。
1.4 Engram-27B 的实验结果¶
模型规模:Engram-27B 是一个 270 亿参数的模型。
性能提升(对比 MoE 基线):
知识密集型任务(如 MMLU、CMMLU、MMLU-Pro):+3.4 ~ +4.0
推理任务(如 BBH、ARC-Challenge、DROP):+3.3 ~ +5.0
代码与数学任务(如 HumanEval、MATH、GSM8K):+2.2 ~ +3.0
1.5 机制分析¶
LogitLens 与 CKA 分析:
Engram 减轻了主干网络在早期层重建静态知识的负担,释放了深度用于复杂推理。
注意力机制得以专注于全局上下文,提升了长上下文任务表现。
长上下文任务表现(如 LongPPL、RULER):
Multi-Query NIAH:97.0 vs. 84.2
Variable Tracking:89.0 vs. 77.0
1.6 高效部署与内存优化¶
Engram 的部署优势:
使用确定性 ID,支持运行时预取(prefetching),通信与计算可并行。
实验结果:
将 1000 亿参数的表卸载到主机内存,仅带来 <3% 的开销。
意义:Engram 有效绕过 GPU 内存限制,支持参数的激进扩展。
总结:¶
本节提出了条件记忆作为稀疏性设计的新维度,通过 Engram 模块实现高效的静态知识检索,与 MoE 的动态计算形成互补。实验证明,这种设计不仅提升了模型效率与性能,还优化了长上下文处理能力,并具备良好的部署效率。
2 Architecture¶
2.1 Overview¶
Engram 是一个条件记忆模块,旨在通过将静态模式存储与动态计算结构分离,来增强 Transformer 架构。给定输入序列 \( X = (x_1, \dots, x_T) \) 和第 \(\ell\) 层的隐藏状态 \( \mathbf{H}^{(\ell)} \in \mathbb{R}^{T \times d} \),Engram 在每个位置 \( t \) 上执行两个功能阶段:
检索(Retrieval):从静态存储中提取与当前上下文相关的嵌入向量。
融合(Fusion):将这些嵌入向量与当前隐藏状态结合,通过门控机制和轻量卷积进行动态调制。
模块结构分为以下四个子部分,分别在后续小节中展开。
2.2 Sparse Retrieval via Hashed N-grams¶
Tokenizer Compression(重点)¶
传统子词分词器(如 SentencePiece)可能导致语义等价词被分配不同 ID(如 “Apple” vs. “␣apple”)。
Engram 引入一个词汇投影函数 \( \mathcal{P}: V \to V' \),将原始 token ID 映射为规范 ID(基于 NFKC、小写等归一化),实现语义压缩。
实验显示,对于 128k 的词表,该方法可减少 23% 的有效词表大小(见附录 C)。
对位置 \( t \) 的 token,其规范 ID 为 \( x'_t = \mathcal{P}(x_t) \),形成后缀 N-gram:
$\( g_{t,n} = (x'_{t-n+1}, \dots, x'_t) \)$
Multi-Head Hashing(重点)¶
所有可能的 N-gram 组合空间太大,无法直接参数化。
采用 多头哈希机制,每个 N-gram 阶数 \( n \) 有 \( K \) 个哈希头,每个头将压缩后的上下文映射到嵌入表 \( \mathbf{E}_{n,k} \) 中的索引: $\( z_{t,n,k} \triangleq \varphi_{n,k}(g_{t,n}), \quad \mathbf{e}_{t,n,k} = \mathbf{E}_{n,k}[z_{t,n,k}] \)\( 其中 \) \varphi_{n,k} $ 是轻量级乘法-XOR 哈希函数。
最终记忆向量 \( \mathbf{e}_t \in \mathbb{R}^{d_{\text{mem}}} \) 是所有头和阶数的拼接: $\( \mathbf{e}_t \triangleq \mathop{\|}_{n=2}^{N} \mathop{\|}_{k=1}^{K} \mathbf{e}_{t,n,k} \)$
2.3 Context-aware Gating(重点)¶
门控机制设计¶
检索到的嵌入 \( \mathbf{e}_t \) 是上下文无关的先验,可能因哈希冲突或一词多义而引入噪声。
引入上下文感知门控机制,灵感来自注意力机制:
当前隐藏状态 \( \mathbf{h}_t \) 作为 Query。
检索到的记忆 \( \mathbf{e}_t \) 生成 Key 和 Value: $\( \mathbf{k}_t = \mathbf{W}_K \mathbf{e}_t, \quad \mathbf{v}_t = \mathbf{W}_V \mathbf{e}_t \)$
使用 RMSNorm 稳定梯度,计算门控系数: $\( \alpha_t = \sigma\left( \frac{\text{RMSNorm}(\mathbf{h}_t)^\top \text{RMSNorm}(\mathbf{k}_t)}{\sqrt{d}} \right) \)$
门控输出为: $\( \tilde{\mathbf{v}}_t = \alpha_t \cdot \mathbf{v}_t \)$
卷积增强¶
为扩大感受野和增强非线性,引入深度可分离因果卷积(kernel size=4,dilation=最大 N-gram 阶数)。
最终输出为: $\( \mathbf{Y} = \text{SiLU}\left( \text{Conv1D}(\text{RMSNorm}(\tilde{\mathbf{V}})) \right) + \tilde{\mathbf{V}} \)$
Engram 模块通过残差连接集成到 Transformer 中: $\( \mathbf{H}^{(\ell)} \leftarrow \mathbf{H}^{(\ell)} + \mathbf{Y} \)$
注意:Engram 并非应用于每一层,其放置位置受系统延迟限制(见 2.5 节)。
2.4 Integration with Multi-branch Architecture(重点)¶
采用多分支架构(如 MHC [xie2025mhcmanifoldconstrainedhyperconnections]),信息流由可学习连接权重控制。
Engram 模块结构上与拓扑无关,但为适应多分支需优化结构。
参数共享策略¶
所有分支共享一个稀疏嵌入表和一个 Value 投影矩阵 \( \mathbf{W}_V \)。
每个分支使用不同的 Key 投影矩阵 \( \mathbf{W}_K^{(m)} \),以实现分支特异性门控行为。
第 \( m \) 个分支的门控信号为: $\( \alpha_t^{(m)} = \sigma\left( \frac{\text{RMSNorm}(\mathbf{h}_t^{(m)})^\top \text{RMSNorm}(\mathbf{W}_K^{(m)} \mathbf{e}_t)}{\sqrt{d}} \right) \)$
最终输出为: $\( \mathbf{u}_t^{(m)} = \alpha_t^{(m)} \cdot (\mathbf{W}_V \mathbf{e}_t) \)$
设计允许将投影矩阵融合为一个 FP8 矩阵乘法,提升 GPU 利用率。
默认使用 M=4 的 MHC 架构进行实验。
2.5 System Efficiency: Decoupling Compute and Memory(重点)¶
训练阶段优化¶
大规模嵌入表通过模型并行分布在多个 GPU 上。
使用 All-to-All 通信原语在前向传播中收集活跃行,在反向传播中分发梯度。
总内存容量随加速器数量线性扩展。
推理阶段优化¶
Engram 的检索索引仅依赖输入 token 序列,具有确定性,支持异步预取。
推理时将嵌入表卸载到主机内存(host memory),利用 PCIe 异步传输。
Engram 模块放置在特定层中,利用前序层的计算时间缓冲通信延迟。
硬件-算法协同设计:Engram 放置过深可延长计算窗口,但建模性能偏好早期干预。
多级缓存层次结构¶
N-gram 分布具有 Zipfian 特性(少数模式高频访问)。
提出多级缓存机制:
高频嵌入缓存在 GPU HBM 或 Host DRAM。
低频嵌入存储在 NVMe SSD 等高容量低速介质。
此设计使 Engram 可扩展至大规模记忆容量,同时保持低延迟。
如需进一步分析实验结果或模型性能,请继续提问。
3 Scaling Laws and Sparsity Allocation¶
本节探讨了 Engram(作为条件记忆的一种实现)与 MoE(专家条件计算)之间的结构互补性,以及在参数和计算资源受限的情况下,如何最优地分配稀疏容量。研究围绕两个核心问题展开:
有限资源下的最优分配:在总参数量和训练计算量固定的情况下,如何在 MoE 专家和 Engram 嵌入之间分配稀疏容量?
无限记忆模式下的缩放行为:当内存预算放宽时,Engram 自身的缩放行为如何?
3.1 MoE 与 Engram 的最优分配比例¶
计算匹配公式(Compute-matched formulation)¶
研究使用三个参数指标来分析 MoE 与 Engram 的权衡:
Ptot:总可训练参数(不包括词表嵌入和语言模型头)
Pact:每个 token 激活的参数,决定了训练计算量(FLOPs)
Psparse = Ptot - Pact:未激活参数,代表“免费”的可扩展参数预算(如未选中的专家或未检索的嵌入)
在固定 Ptot 和 Pact 的前提下,MoE 的 Pact 由 top-k 个选中的专家决定,而未选中的专家属于 Psparse;Engram 则通过固定数量的检索槽位实现,扩展槽位数会增加 Ptot,但不增加 Pact。
分配比例 ρ 的定义¶
定义分配比例 ρ ∈ [0,1] 表示将 Psparse 中的多少比例分配给 MoE:
ρ = 1:纯 MoE 模型
ρ < 1:减少 MoE 专家数量,将参数重新分配给 Engram 嵌入槽位
实验设置¶
在两个计算预算下进行实验,保持 Ptot / Pact ≈ 10:
C = 2×10²⁰ FLOPs:Ptot ≈ 5.7B,Pact = 568M,MoE 基线有 106 个专家
C = 6×10²⁰ FLOPs:Ptot ≈ 9.9B,Pact = 993M,MoE 基线有 99 个专家
通过调整专家数量和 Engram 槽位数量来构建不同 ρ 的模型,训练流程和超参数保持一致。
结果与分析¶
验证损失与 ρ 的关系呈 U 形:表明存在一个最优分配比例。
Engram 在 ρ ≈ 40% 时仍能保持与纯 MoE 相当的性能,说明 Engram 可以有效替代部分 MoE 专家。
最优 ρ 约为 75%–80%,此时验证损失最低。例如在 10B 参数规模下,验证损失从 1.7248 降低到 1.7109。
结论:
MoE 过多(ρ 接近 100%):模型缺乏静态模式记忆,需通过深度计算重建,效率低。
Engram 过多(ρ 接近 0%):模型失去条件计算能力,影响动态推理任务。
3.2 无限记忆模式下的 Engram 表现¶
实验设置¶
固定 MoE 主干:Ptot ≈ 3B,Pact = 568M,训练 100B token
Engram 槽位数 MM 从 2.58×10⁵ 到 1.0×10⁷(增加约 130 亿参数)
对比基线:OverEncoding(通过平均词嵌入集成 NN-gram)
结果¶
Engram 随着槽位数增加,验证损失持续下降,且呈幂律关系(log 空间下为线性),说明其具有可预测的缩放能力。
Engram 比 OverEncoding 更高效:在相同内存预算下,Engram 能实现更大的性能提升。
结论:Engram 提供了一个与 MoE 条件计算互补的、可扩展的稀疏容量维度。
总结¶
本节通过理论建模与实验验证,揭示了 MoE 与 Engram 在参数与计算资源分配上的互补性:
在有限资源下,存在一个最优的 MoE 与 Engram 分配比例(ρ ≈ 75%–80%),能显著提升模型性能。
在无限内存条件下,Engram 展现出良好的缩放行为,且比传统方法更高效。
整体结论:Engram 作为“条件记忆”,与 MoE 的“条件计算”形成结构互补,为大模型提供了一个新的稀疏性扩展维度。
4 Large Scale Pre-training¶
章节概述¶
本节通过训练四种不同结构的语言模型(Dense-4B、MoE-27B、Engram-27B、Engram-40B),在相同训练数据和激活参数条件下,比较它们在多个任务上的表现,验证Engram架构的有效性。
4.1 实验设置¶
训练数据与模型配置¶
所有模型均在 2620亿token 上预训练,使用DeepSeek-v3的tokenizer(词汇量128k)。
模型结构统一为:30层Transformer,隐藏层大小2560,每层包含MLA注意力(32头)和mHC连接的FFN,扩展率为4。
优化器为Muon,超参数详见附录A。
四种模型配置:¶
Dense-4B:标准密集FFN,总参数4.1B。
MoE-27B:使用DeepSeekMoE模块,72个路由专家+2个共享专家,top-6激活,总参数26.7B,激活参数与Dense-4B一致。
Engram-27B:基于MoE-27B改造,将专家数从72减至55,释放参数用于构建5.7B的Engram记忆模块(ρ=74.3%),总参数保持26.7B。
Engram模块配置:第2、15层插入,最大NN-gram=3,8头,维度1280。
优化设置:Embedding使用Adam优化,学习率×5,无权重衰减;卷积参数初始化为0以保持初始恒等映射。
Engram-40B:Engram模块扩展至18.5B,总参数39.5B,其余配置与Engram-27B一致。
评估协议¶
评估涵盖以下任务:
语言建模:The Pile测试集与验证集的loss。
知识与推理:MMLU、MMLU-Redux、MMLU-Pro、CMMLU、C-Eval、AGIEval、ARC、TriviaQA、PopQA、CCPM、BBH、HellaSwag、PIQA、WinoGrande。
阅读理解:DROP、RACE、C3。
代码与数学:HumanEval、MBPP、CruxEval、GSM8K、MGSM、MATH。
4.2 实验结果¶
表1:预训练性能对比(关键结果)¶
模型 |
总参数 |
激活参数 |
Pile Loss |
MMLU Acc. |
MMLU-Pro Acc. |
CMMLU Acc. |
BBH EM |
GSM8K EM |
MATH EM |
|---|---|---|---|---|---|---|---|---|---|
Dense-4B |
4.1B |
3.8B |
2.091 |
48.6 |
21.1 |
47.9 |
42.8 |
35.5 |
15.2 |
MoE-27B |
26.7B |
3.8B |
1.960 |
57.4 |
28.3 |
57.9 |
50.9 |
58.4 |
28.3 |
Engram-27B |
26.7B |
3.8B |
1.950 |
60.4 |
30.1 |
61.9 |
55.9 |
60.6 |
30.7 |
Engram-40B |
39.5B |
3.8B |
1.942 |
60.6 |
31.3 |
63.4 |
57.5 |
62.6 |
30.6 |
关键发现:¶
稀疏模型优于密集模型:
在相同激活参数下,MoE、Engram等稀疏模型在所有任务上显著优于Dense-4B。
Engram优于MoE:
Engram-27B在知识密集型任务(如MMLU、CMMLU)和推理任务(如BBH、DROP)上均优于MoE-27B。
示例提升:
MMLU:+3.0
BBH:+5.0
GSM8K:+2.2
MATH:+2.4
Engram-40B进一步提升:
虽然部分任务未完全超越Engram-27B,但训练后期loss持续下降,表明训练未饱和,未来有望进一步提升。
表2:长上下文性能对比(补充结果)¶
模型 |
LongPPL (32k) |
RULER Accuracy (32k) |
|---|---|---|
MoE-27B (50k steps) |
4.38 |
100.0 |
Engram-27B (41k steps) |
4.37 |
99.6 |
Engram-27B (46k steps) |
4.19 |
97.6 |
Engram-27B (50k steps) |
4.14 |
99.3 |
关键发现:¶
Engram-27B在更少训练步数下表现接近MoE-27B:
使用82%的FLOPs(41k vs 50k)达到相近LongPPL,但RULER准确率更高。
Engram-27B在相同训练步数下显著优于MoE:
在LongPPL和RULER多个指标上均优于MoE-27B。
总结¶
Engram架构在相同激活参数下优于MoE和Dense模型,尤其在知识密集型和推理任务上表现突出。
Engram-40B通过扩大记忆模块,在更多任务上进一步提升性能,但训练尚未完全收敛。
Engram在长上下文任务中也展现出优势,在更少计算资源下达到相近或更优性能。
这些结果验证了Engram通过引入外部记忆机制,提升了模型的表示效率,为稀疏模型设计提供了新方向。
5 Long Context Training¶
本节通过实证方法验证了Engram架构在长上下文训练中的结构优势。通过将局部依赖建模卸载到静态查找中,Engram保留了注意力机制用于处理全局上下文的能力。作者通过长上下文扩展训练(long-context extension training)验证了Engram在长距离检索和推理任务中的显著提升。
5.1 实验设置¶
训练细节¶
作者采用了DeepSeek-V3中提出的上下文扩展策略,使用YaRN方法在32768 token的上下文窗口中训练5000步(共300亿高质量长上下文token)。超参数设置为:
scale \( s = 10 \)
\( \alpha = 1 \)
\( \beta = 32 \)
缩放因子 \( f = 0.707 \)
模型配置¶
比较了四种模型配置:
MoE-27B 和 Engram-27B 的最终预训练检查点(50k步)
Engram-27B 的两个中间检查点(41k步和46k步)
为了控制变量,所有模型使用相同的上下文扩展训练协议。特别地,Engram-27B (46k) 与 MoE-27B (50k) 具有相同的预训练损失,构成“等损失(Iso-Loss)”设置,确保性能差异源于架构而非初始质量。
评估基准¶
使用 LongPPL 和 RULER 评估长上下文能力:
LongPPL:涵盖四类数据:长书、论文、代码库、长思维链(CoT)轨迹
RULER:包含14个子集,归为8类任务,包括“针在干草堆中”(Needle-in-a-Haystack)、多跳变量追踪(VT)、常见词提取(CWE)、问答(QA)等
5.2 实验结果¶
1. 超越注意力机制的长上下文能力¶
实验发现,Engram模型在预训练过程中,即使架构和计算预算固定,其长上下文性能仍随预训练进展单调提升。这表明长上下文性能与基础模型的建模能力密切相关,因此在比较架构时应控制基础模型损失,而非仅对齐训练步数。
2. 控制变量下的架构优势¶
在控制基础模型能力的前提下,Engram相比MoE展现出显著优势:
等损失设置(46k vs. 基线):Engram在复杂检索任务中显著优于MoE,例如:
多查询NIAH:97.0 vs. 84.2
多跳变量追踪(VT):87.2 vs. 77.0
等FLOPs设置(50k vs. 基线):Engram在所有任务中表现最佳,进一步拉大差距。
极端设置(≈82%计算量):Engram-27B (41k) 在LongPPL上与MoE相当,在RULER上超越MoE,说明Engram架构具有内在优势。
3. 表示对齐与收敛速度分析(图4)¶
LogitLens分析(图4a):Engram在早期层的KL散度更低,说明其预测收敛更快。
CKA相似性热图(图4b-c):Engram的浅层与MoE的深层功能等价,相当于“增加了模型深度”。
表3:实体解析示例¶
展示了模型如何通过不同层逐步整合上下文,构建“戴安娜王妃”的内部表示。Engram在第6层即可准确生成“Diana, Princess of Wales”,而早期层逐步从“国家”到“公主头衔”再到具体人物进行推理。
总结¶
本节通过严格的控制实验验证了Engram架构在长上下文训练中的优势。其通过静态查找处理局部依赖,释放注意力机制用于全局上下文建模,从而在相同或更少计算资源下,显著优于MoE架构。实验结果表明,Engram不仅提升了长上下文任务的性能,还加快了模型收敛速度,并增强了表示能力。
6 Analysis¶
以下是对论文第6章 Analysis 的结构化总结,按照原文标题和结构进行组织,重点内容详细讲解,次要内容精简处理,同时保留数学公式、算法步骤和表格数据的关键信息。
本章从多个角度深入分析 Engram 的内部机制,包括其功能等价性、模块设计、参数敏感性、系统效率以及一个案例研究。
6.1 Engram 是否等价于增加模型深度?¶
6.1.1 加速预测收敛¶
使用 LogitLens 方法分析模型各层预测的演化过程。通过将中间层的隐藏状态投影到最终的 LM Head,计算中间输出分布与最终输出分布之间的 KL 散度,衡量中间表示的“预测准备度”。
结果:Engram 的 KL 散度显著低于 MoE 基线,尤其在早期层表现更明显。Engram 曲线下降更快,说明其能更快完成特征组合,提前达到高置信度预测。
结论:Engram 通过显式知识查找机制,减少了模型在早期层的计算负担,从而加速了预测收敛。
6.1.2 表征对齐与有效深度¶
使用 CKA(Centered Kernel Alignment) 比较不同模型层之间的表征相似性。定义如下:
其中 \( K = XX^\top \), \( L = YY^\top \) 是 Gram 矩阵,HSIC 是 Hilbert-Schmidt 独立性准则。
进一步定义软对齐索引 \( a_j \):
结果:Engram 层的表示与 MoE 更深层的表示更相似。例如,Engram-27B 第5层的表示与 MoE 第12层最接近。
结论:Engram 在早期层即可达到 MoE 深层的表示能力,验证了其“功能上等价于增加模型深度”的假设。
6.2 结构消融与层敏感性分析¶
参考配置¶
使用 12 层 3B MoE 模型作为主干,插入两个 Engram 模块(共 1.6B 参数),分别位于第2层和第6层。
验证损失从 1.808 降低到 1.768,显著优于基线。
内存注入位置的影响¶
实验方法:固定 Engram 总参数量,将其集中为单个模块,遍历插入层(1~12)。
结果:第2层插入效果最佳(验证损失 1.770),深层插入效果下降。
分析:第2层已具备足够的上下文用于门控,同时仍处于早期,能有效替代底层局部特征提取。
进一步优化:将 1.6B 参数拆分为两个模块(第2层和第6层),性能进一步提升(验证损失 1.768)。
各组件重要性分析¶
关键组件:
多分支融合(multi-branch integration)
上下文感知门控(context-aware gating)
tokenizer 压缩
消融结果:移除上述任一组件都会导致显著性能下降。
次要组件:
轻量级深度卷积影响较小。
使用 4-gram 效果略差,可能因稀释了 2/3-gram 的容量。
6.3 参数敏感性分析¶
实验方法¶
推理时完全抑制 Engram 的稀疏嵌入输出,保留主干不变。
分析模型在不同任务上的表现变化。
结果¶
事实性知识任务(如 TriviaQA):性能下降至 29–44%,说明 Engram 是知识存储的核心。
阅读理解任务(如 C3):性能保留 81–93%,说明这些任务依赖主干的注意力机制。
结论¶
Engram 主要负责存储静态知识,而上下文理解仍由主干完成。
6.4 系统效率¶
实验设置¶
使用 nano-vLLM 实现推理引擎。
在 Dense-4B 和 Dense-8B 模型中插入一个 100B 参数的 Engram 层,嵌入表全部驻留在主机内存。
异步预取嵌入,与第一层计算重叠。
结果(见表4)¶
模型 |
配置 |
吞吐量(tok/s) |
|---|---|---|
4B-Dense |
基线 |
9,031.62 |
+100B Engram (CPU Offload) |
8,858.28 |
|
8B-Dense |
基线 |
6,315.52 |
+100B Engram (CPU Offload) |
6,140.02 |
结论:即使将 100B 参数完全卸载到 CPU 内存,吞吐量下降仅 2.8%,说明 Engram 的稀疏激活机制对系统效率影响极小。
进一步说明:该实验为保守基线,实际中可通过缓存高频项进一步优化。
6.5 案例研究:门控可视化¶
方法¶
可视化 Engram 的门控标量 \( \alpha_t \in [0,1] \),表示 Engram 激活程度。
选择与语义模式匹配最相关的门控值进行展示。
结果¶
Engram 在识别局部静态模式时激活(红色),如英文中的多词实体(“Alexander the Great”)、固定短语(“By the way”),以及中文中的成语和历史人物(“四大发明”、“张仲景”)。
图示:热图中颜色越深表示激活越强,Engram 能有效识别并检索静态语言模式。
结论¶
Engram 成功识别并处理了静态语言依赖,减轻了 Transformer 主干的记忆负担。
总结¶
本章系统分析了 Engram 的多个核心机制:
功能等价性:Engram 在早期层即可达到 MoE 深层的表示能力,相当于“增加模型深度”。
结构设计:Engram 模块应插入早期层,多模块分层插入效果更佳;多分支融合、上下文门控和 tokenizer 压缩是关键组件。
参数敏感性:Engram 主要负责存储事实性知识,而阅读理解任务依赖主干。
系统效率:即使将 100B 参数卸载到 CPU,吞吐量下降极小,验证了其高效性。
可视化验证:Engram 能有效识别并激活静态语言模式,提升模型效率。
这些分析全面验证了 Engram 的设计目标:通过显式知识查找机制,提升模型效率与性能,同时保持系统可扩展性。
8 Conclusion¶
本节总结了论文的核心贡献与实验发现,强调了**条件记忆(conditional memory)作为一种新的稀疏性维度,与当前主流的条件计算(MoE)**范式形成互补,旨在解决通过动态计算模拟知识检索所带来的效率问题。
核心思想与实现方式¶
作者提出了一种名为 Engram 的模块,作为条件记忆的具体实现。Engram 对传统的神经网络 n-gram 嵌入进行了现代化改进,使得模型能够在常数时间 \( O(1) \) 内进行静态模式的查找,从而实现高效的知识检索。
稀疏分配问题与U型缩放规律¶
论文通过提出稀疏分配(Sparsity Allocation)问题,揭示了一个U型缩放规律(U-shaped scaling law)。该规律表明:将稀疏资源在 MoE 专家和 Engram 记忆之间进行混合分配,其效果显著优于纯 MoE 基线模型。
基于这一规律,作者将 Engram 模型扩展至 270 亿参数(27B),并在多个领域(如知识检索、推理、代码生成、数学问题解决)中展现出优越性能。尤其值得注意的是,Engram 在通用推理、编程和数学任务中带来的提升甚至超过了其在知识检索任务中的表现。
机制分析与架构优势¶
通过机制分析,作者发现 Engram 实际上起到了“加深网络”的作用。它通过将早期层从静态模式重建任务中解放出来,使注意力机制能够专注于全局上下文和复杂推理任务。这种架构上的变化显著提升了模型处理长上下文任务的能力,在 LongPPL 和 RULER 等长文本评估任务中表现优异。
效率设计与未来展望¶
Engram 强调了基础设施感知效率(infrastructure-aware efficiency)的重要性。其确定性寻址机制使得存储与计算可以解耦,从而可以将大规模参数表卸载到主机内存中,几乎不增加推理开销。
最后,作者展望未来,认为条件记忆将成为下一代稀疏模型中不可或缺的建模原语(modeling primitive)。
总结:本节系统总结了 Engram 模块的设计理念、实验证据、机制分析与效率优势,提出了稀疏模型设计的新方向,强调了条件记忆在性能与效率上的双重价值。
Appendix A Detailed Model Architecture and Hyper Parameters¶
附录 A:详细模型架构与超参数¶
本节提供了多个模型(Dense-4B、MoE-27B、Engram-27B 和 Engram-40B)的架构细节和训练超参数,重点在于模型结构、参数分布、优化策略以及 Engram 模型特有的配置。
1. 模型参数与结构¶
项目 |
Dense-4B |
MoE-27B |
Engram-27B |
Engram-40B |
|---|---|---|---|---|
总参数量 |
4.1B |
26.7B |
26.7B |
39.5B |
激活参数量 |
3.8B |
- |
- |
- |
总训练 Token 数 |
262B |
- |
- |
- |
层数(Layers) |
30 |
- |
- |
- |
维度(Dimension) |
2560 |
- |
- |
- |
前置稠密层(Leading Dense Layers) |
- |
1 |
1 |
1 |
路由专家数(Routed Experts) |
- |
72 |
55 |
55 |
每步激活专家数(Active Experts) |
- |
6 |
6 |
6 |
共享专家数(Shared Experts) |
- |
2 |
2 |
2 |
Dense-4B 是一个全连接模型,参数量约 41 亿,训练时激活参数略少(38 亿),训练 Token 总数为 2620 亿。
MoE-27B 是一个混合专家模型,总参数约 267 亿,每步激活 6 个专家,共 72 个专家。
Engram 系列(27B 和 40B):
使用 Engram 架构,包含 Engram 层(位于第 2 到第 15 层);
支持多头 Engram(Engram Num Head = 8);
使用 mHC 扩展机制(Expansion Rate = 4);
Engram Vocab Size 分别为 226 万和 724 万;
Engram Layer 位于第 2 到第 15 层;
Engram 结合 mHC(combine mHC = True);
使用 tokenizer 压缩(tokenizer compression = True);
使用卷积初始化为零(Conv Zero Init = True);
Engram 的学习率乘数为 5 倍(Lr Multiplier = x5);
Engram 的权重衰减为 0。
2. 训练配置¶
项目 |
数值 |
|---|---|
序列长度(Sequence Length) |
4096 |
词表大小(Vocab Size) |
129,280 |
批量大小(Batch Size) |
1280 |
训练步数(Training Steps) |
50,000 |
主干优化器(Backbone Optimizer) |
Muon [jordan2024muon] |
嵌入层优化器(Embedding Optimizer) |
Adam [kingma2014adam] |
基础学习率(Base Learning Rate) |
4e-4 |
学习率调度器(Lr Scheduler) |
Step Decay [bi2024deepseek] |
权重衰减(Weight Decay) |
0.1 |
所有模型使用相同的训练设置,包括序列长度、词表大小、批量大小等。
主干网络使用 Muon 优化器,嵌入层使用 Adam。
学习率调度采用 Step Decay,基础学习率为 4e-4,权重衰减为 0.1。
3. Engram 模型特有配置¶
项目 |
Engram-27B |
Engram-40B |
|---|---|---|
Engram 维度(dmemd_mem) |
1280 |
1280 |
Engram 词表大小 |
2,262,400 |
7,239,680 |
Engram 多头数(Num Head) |
8 |
8 |
Engram 层位置 |
[2,15] |
[2,15] |
Engram n-gram 范围(NN-gram) |
[2,3] |
[2,3] |
Engram 是否结合 mHC |
True |
True |
Engram tokenizer 压缩 |
True |
True |
Engram 卷积初始化为零 |
True |
True |
Engram 学习率乘数 |
x5 |
x5 |
Engram 权重衰减 |
0.0 |
0.0 |
Engram 嵌入层优化器 |
Adam [kingma2014adam] |
- |
Engram 模型在架构上引入了额外的 Engram 层,用于处理 n-gram 信息(n=2 和 3);
使用多头机制(8 头);
Engram 层位于第 2 到第 15 层;
Engram 的词表远大于主词表(分别为 226 万和 724 万);
Engram 的嵌入层使用独立的 Adam 优化器,学习率乘数为 5,权重衰减为 0。
总结¶
本节通过表格详细列出了多个模型的架构参数和训练配置,重点包括:
模型结构差异:Dense、MoE 和 Engram 的结构特点;
参数分布:总参数量、激活参数量、专家数量等;
Engram 特有配置:Engram 层、n-gram、多头机制、mHC 扩展等;
训练设置:统一的训练参数,Engram 的嵌入层使用独立优化器;
关键技术引用:如 MLA 注意力机制、Muon 优化器、Step Decay 学习率调度等。
这些信息为模型的性能分析、训练策略和结构设计提供了重要参考。
Appendix B Full Benchmark Curves¶
图8展示了预训练最后10k步的基准曲线。由于缺乏详细的文本描述和数学公式,无法进一步分析其结果或方法。建议参考图中的说明以获取更多信息。
Appendix C Case Study of Tokenizer Compression¶
本节通过一个具体案例,展示了分词器压缩的效果和过程。重点内容如下:
1. 压缩效果分析¶
表6列出了通过分词器压缩算法合并的前5个最频繁的token,并展示了每个token的合并次数、规范化后的token以及原始token列表。
压缩比达到了23.43%,说明在128k词汇量的分词器中,通过合并重复或相似token,显著减少了总token数量。
2. Top-5 合并token分析¶
第1位:空白字符(如空格、换行、制表符等)被统一压缩为
'␣',共合并了163次,说明空白字符在文本中出现频率极高,且形式多样。第2至第5位:字母(如
'a','o','e','i')及其大小写、带重音的形式被合并,表明语言中字母的变体较多,但语义相同或相近,适合合并。
3. 数学与算法要点¶
虽然本节未详细列出压缩算法的数学公式,但从合并策略来看,应是基于频率统计和字符相似性进行的合并。
合并过程中可能使用了归一化规则,例如将不同形式的空格统一为一个符号,或将不同重音的字母统一为基本字母。
4. 表格数据总结¶
排名 |
合并次数 |
规范化token |
原始token示例 |
|---|---|---|---|
1 |
163 |
|
|
2 |
54 |
|
|
3 |
40 |
|
|
4 |
35 |
|
|
5 |
30 |
|
|
5. 总结¶
本案例展示了通过归一化和合并重复token,可以有效压缩分词器的词汇表。
空白字符和字母变体是压缩的主要对象,压缩比达23.43%,说明该方法在实际应用中具有显著效果。
(注:文档末尾为LaTeXML生成信息,可忽略。)