2510.14528_PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model¶
引用: 0(2025-10-19)
组织: 百度
总结¶
主要贡献
紧凑高效的视觉-语言模型架构(Compact yet Powerful VLM Architecture):
高质量数据构建方法论(High-quality Data Construction Methodology):
文档解析任务中的 SOTA 性能(SOTA Performance in Document Parsing):
PaddleOCR-VL
复杂任务拆分为两个阶段
第一阶段是布局分析(Layout Analysis)
第二阶段是元素级识别(Element-level Recognition)
一个先进的、高效的文档解析模型,在元素级和页面级识别方面表现出色。
该模型的核心组件为 PaddleOCR-VL-0.9B,采用了 NaViT风格的视觉编码器 和 ERNIE-4.5-0.3B语言模型 构建,能够准确识别包括文本、表格、公式和图表在内的复杂元素,并且支持100多种语言。
Training Recipe
PP-DocLayoutV2
第一阶段(RT-DETR):使用 PP-DocLayout_Plus-L 预训练权重
第二阶段(指针网络):冻结 RT-DETR 参数,独立训练指针网络。
PaddleOCR-VL-0.9B
阶段1:预训练对齐
阶段2:指令微调(Instruction Fine-tuning)
Abstract¶
本报告提出了一种名为 PaddleOCR-VL 的文档解析模型,该模型在性能和资源效率方面均达到**当前最佳(SOTA)**水平。其核心组件是 PaddleOCR-VL-0.9B,一个紧凑但功能强大的视觉-语言模型(VLM)。该模型通过结合 NaViT 风格的动态分辨率视觉编码器 和 ERNIE-4.5-0.3B 语言模型,实现了对文档中元素的高精度识别。
重点内容:¶
多语言支持:PaddleOCR-VL 支持 109 种语言,适应多种语言环境。
复杂元素识别能力强:模型在识别文本、表格、公式和图表等复杂文档元素方面表现出色。
资源效率高:在保持高性能的同时,资源消耗极低,适合部署在资源受限的场景。
广泛评估:通过在公共基准和内部基准上的全面评估,验证了其性能。
性能表现:在页面级文档解析和元素级识别任务中均达到 SOTA 水平。
高效推理:模型具有快速推理速度,适合实际应用。
非重点内容:¶
文章还展示了 PaddleOCR-VL 在 OmniDocBench v1.0 和 v1.5 上的性能图表,用于进一步说明模型的优越性。
总结:¶
PaddleOCR-VL 是一款高效、多语言、多元素识别能力强的文档解析模型,适合部署在实际应用中,具有广泛的应用前景。
1 Introduction¶
文档作为核心信息载体,其复杂性和规模呈指数级增长,使得文档解析成为不可或缺的关键技术。
文档解析的主要目标是实现对文档布局的深度结构和语义理解。具体任务包括识别文本块与列、区分公式、表格、图表和图像、确定正确的阅读顺序,以及检测关键元素(如脚注和图像标题)。这些能力为高效的信息检索和数据管理奠定了坚实基础。此外,高水平的文档解析还能增强大语言模型(LLMs)在结合“检索增强生成”(RAG)技术时对高质量知识的访问能力,从而提升其实际应用效果。
现代文档的复杂性带来了独特挑战:
现代文档通常包含密集的文本、复杂的表格或图表、数学表达式、多种语言以及手写内容,并具有多样化的布局结构。当前的研究主要遵循两种技术方法:
第一种方法采用基于专门模块化专家模型的流水线方法。虽然这些方法在性能上表现强劲,但它们在集成复杂度、误差传播和处理高度复杂文档时存在显著限制。
第二种方法是端到端的多模态模型方法,旨在简化流程并实现联合优化。然而,这类方法在处理长或复杂布局时可能出现文本顺序错误和幻觉生成,同时在长序列输出时计算开销大,限制了其实际部署。
为了解决上述问题,本文提出 PaddleOCR-VL:一种基于视觉-语言模型的高性能、资源高效的文档解析解决方案。
PaddleOCR-VL 结合了强大的布局分析模型与紧凑且高效的视觉-语言模型 PaddleOCR-VL-0.9B:
首先,PaddleOCR-VL 进行布局检测和阅读顺序预测,以获取各个元素(如文本块、表格、公式、图表)的坐标和阅读顺序。
与依赖 grounding 和序列输出的多模态方法(如 MinerU2.5、Dolphin)相比,该方法在推理速度、训练成本和新布局类别扩展性方面具有优势。
其次,根据位置信息对元素进行分割,并输入 PaddleOCR-VL-0.9B 进行识别。该视觉-语言模型专为资源高效推理设计,在文档解析中的元素识别任务中表现出色。其结合了 NaViT 风格的动态高分辨率视觉编码器与轻量级 ERNIE-4.5-0.3B 语言模型,显著提升了识别能力和解码效率。
为了训练一个强大的多模态模型,我们开发了一套高质量的训练数据构建流程:
通过公开数据获取和数据合成,收集了超过 3000 万条训练样本;
设计了提示工程,引导通用大模型进行自动标注,基于专家模型的识别结果;
同时进行数据清洗,去除低质量或不一致的标注(如模型幻觉造成的错误);
构建了一个评估引擎,将元素细分为更详细的类别,通过自动评估分析模型在不同类别上的表现,从而进行有针对性的困难样本挖掘;
最后,对少量边界情况样本进行人工标注,完成训练数据构建。
PaddleOCR-VL 在多个公开基准(如 OmniDocBench v1.0/1.5、olmOCR-Bench)和内部基准测试中均取得 SOTA(当前最优)性能:
显著优于现有的基于流水线的解决方案;
在与领先的视觉-语言模型(VLM)的对比中表现出强劲竞争力;
并在推理延迟和吞吐量方面表现出更高的效率。
PaddleOCR-VL 的主要贡献包括:
紧凑高效的视觉-语言模型架构(Compact yet Powerful VLM Architecture):
提出一种专为资源高效推理设计的视觉-语言模型,结合 NaViT 风格的动态高分辨率视觉编码器与轻量级语言模型 ERNIE-4.5-0.3B,显著提升了模型在元素识别与解码效率方面的表现。该架构在保持高精度的同时降低了计算需求,非常适合实际文档处理应用。高质量数据构建方法论(High-quality Data Construction Methodology):
提出一套系统且全面的高质量数据构建方法,为高效且稳健的文档解析提供了坚实的数据基础。该方法不仅支持按需构建高质量数据,还为高质量数据的自动生成提供了新的思路。文档解析任务中的 SOTA 性能(SOTA Performance in Document Parsing):
PaddleOCR-VL 在文档解析任务中达到最先进的性能。它在识别复杂文档元素(如文本、表格、公式、图表)方面表现出色,适用于包括手写文本和历史文档在内的多种复杂内容类型。支持 109 种语言,涵盖主要全球语言及多种脚本语言(如俄语、阿拉伯语、印地语),具有广泛的多语言和全球化文档处理能力。
此总结全面覆盖了原文内容的重点与结构,便于快速理解该论文的研究背景、方法创新与实际贡献。
2 PaddleOCR-VL¶
2.1 架构¶
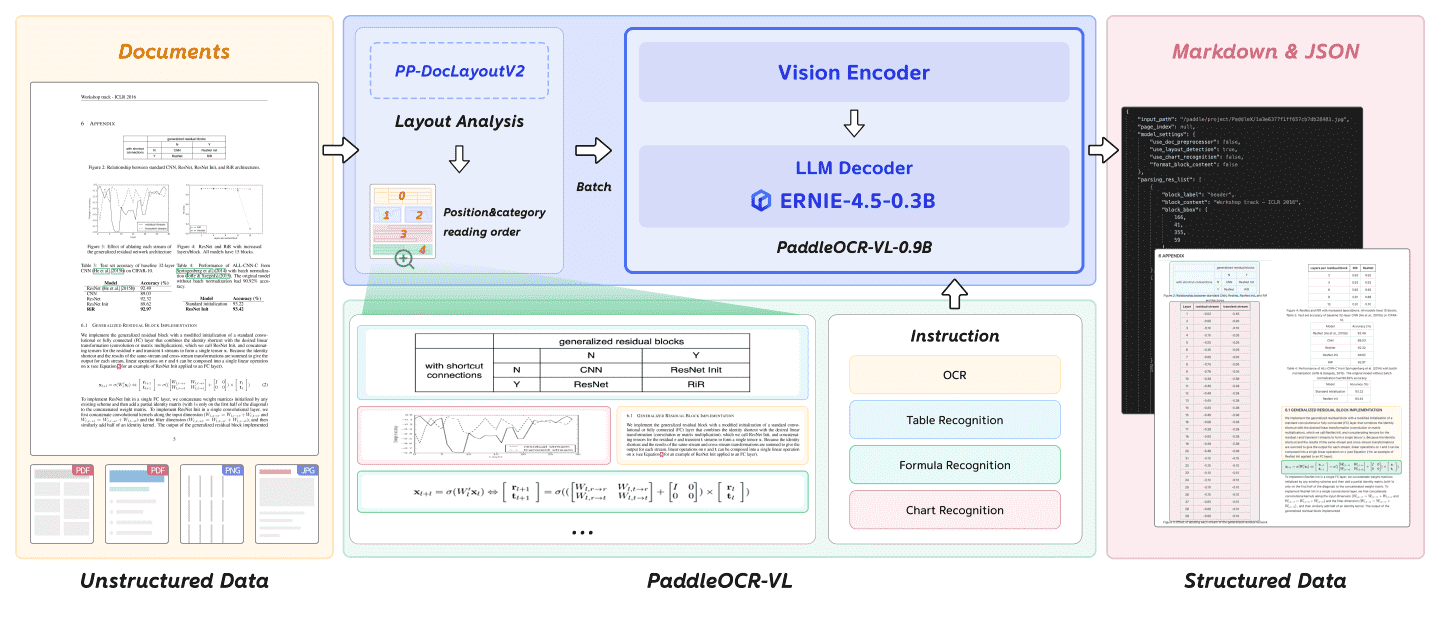
Figure 2: The overview of PaddleOCR-VL.
PaddleOCR-VL 将文档解析这一复杂任务拆分为两个阶段:第一阶段是布局分析(Layout Analysis),第二阶段是元素级识别(Element-level Recognition)。整体结构如图2所示。
第一阶段使用 PP-DocLayoutV2 模型进行布局分析,包括定位语义区域和预测阅读顺序。
第二阶段使用 PaddleOCR-VL-0.9B 进行细粒度的识别,支持文本、表格、公式和图表等多种内容。
最后通过一个轻量级的后处理模块,将两个阶段的输出整合为结构化的 Markdown 和 JSON 格式。
2.1.1 布局分析(Layout Analysis)¶
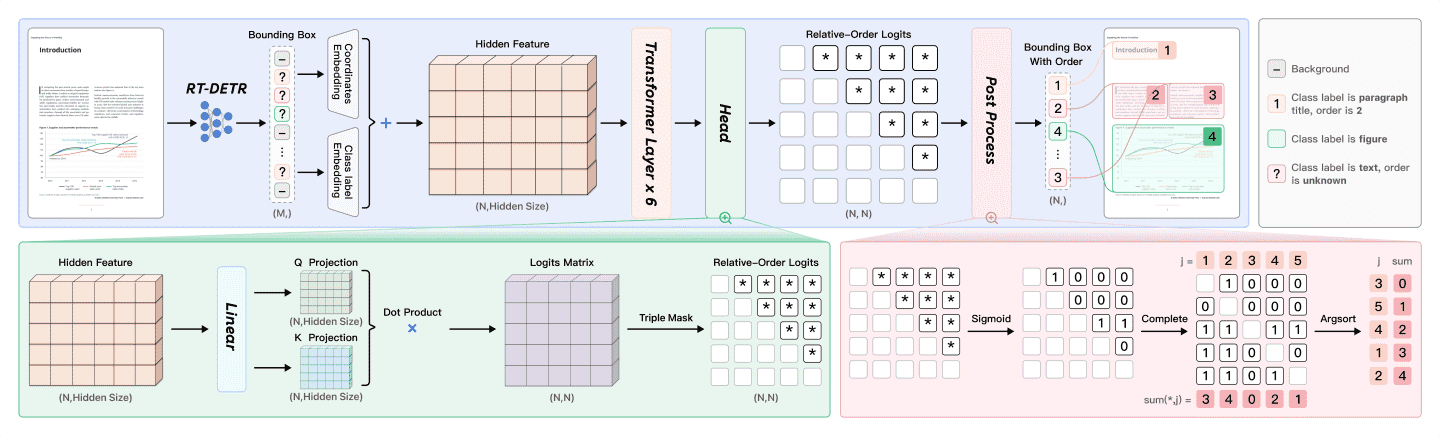
Figure 3: Architecture of layout analysis model.
为了解决端到端方法(如基于视觉语言模型 VLM)在长序列自回归过程中存在的高延迟、内存消耗大以及多列和图文混合布局的不稳定问题,PaddleOCR-VL 采用了一个独立的轻量级模型 PP-DocLayoutV2 来专门处理布局分析。
模型结构¶
PP-DocLayoutV2 由两部分组成:
RT-DETR 检测模型:负责布局元素的定位与分类。
指针网络(Pointer Network):用于对检测出的元素进行排序,预测其阅读顺序。
关键技术细节¶
使用 类别的阈值筛选 来选择用于排序的前景候选框。
通过 2D 位置编码 和 类别标签嵌入 对候选框进行嵌入。
在 encoder attention 中引入 几何偏置机制(来自 Relation-DETR),显式建模元素之间的几何关系。
使用 成对关系头(Pairwise Relation Head) 生成 N×N 的相对顺序矩阵。
最终通过 确定性 win-accumulation 解码算法 恢复一致的阅读顺序。
优势¶
相比其他专用模型(如 LayoutReader),PP-DocLayoutV2 在参数更少的情况下实现了更高的性能,主要归功于 RT-DETR 的高效扩展与指针网络的结合。
2.1.2 元素级别识别(Element-level Recognition)¶
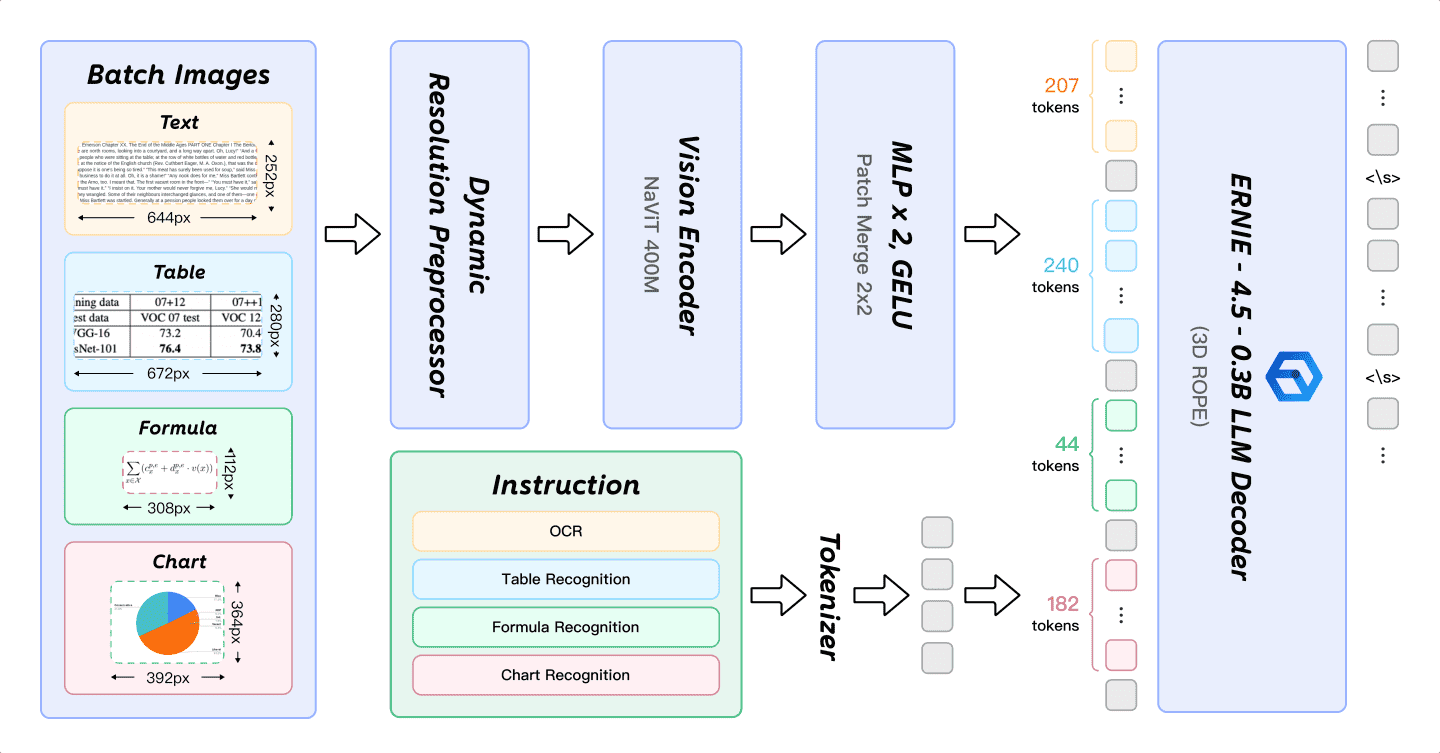
Figure 4: Architecture of PaddleOCR-VL-0.9B.
PaddleOCR-VL-0.9B 是第二阶段的核心模型,负责细粒度识别。其架构设计参考了 LLaVA,采用以下组件:
预训练视觉编码器(NaViT 风格,初始化于 Keye-VL 的视觉模型):支持原生高分辨率输入,避免图像失真。
动态分辨率预处理器:适应不同分辨率的输入图像。
2层 MLP 投影器(随机初始化):将视觉特征映射到语言模型的嵌入空间。
预训练语言模型(ERNIE-4.5-0.3B):具有较小的参数量,推理效率高,并引入 3D-RoPE 增强位置表示。
优势¶
支持任意分辨率输入,显著减少图像失真和幻觉。
在视觉与语言模型之间取得良好平衡。
实现了文档解析的高性能与低资源消耗。
2.2 训练方法(Training Recipe)¶
本节分别介绍 PP-DocLayoutV2 和 PaddleOCR-VL-0.9B 的训练细节。
2.2.1 布局分析训练¶
PP-DocLayoutV2 的训练采用 两阶段策略:
第一阶段(RT-DETR):
使用 PP-DocLayout_Plus-L 预训练权重。
在自建的数据集上训练 100 个 epoch,该数据集包含超过 2 万个高质量样本。
目标是完成布局检测与分类任务。
第二阶段(指针网络):
冻结 RT-DETR 参数,独立训练指针网络。
使用 广义交叉熵损失(Generalized Cross Entropy Loss),提高在混合标注数据下的鲁棒性。
学习率为 2e-4,使用 AdamW 优化器训练 200 个 epoch。
2.2.2 元素级识别训练¶
PaddleOCR-VL-0.9B 的训练分为两个阶段,具体设置如下表所示:
阶段 |
阶段1 |
阶段2 |
|---|---|---|
训练样本 |
29M |
2.7M |
最大分辨率 |
1280×28×28 |
2048×28×28 |
序列长度 |
16384 |
16384 |
可训练组件 |
所有组件 |
所有组件 |
批量大小 |
128 |
128 |
数据增强 |
是 |
是 |
最大学习率 |
5×10⁻⁵ |
5×10⁻⁶ |
最小学习率 |
5×10⁻⁶ |
5×10⁻⁷ |
训练轮数 |
1 |
2 |
阶段1:预训练对齐¶
目标是使视觉信息与文本表示对齐。
使用 2900 万高质量图像-文本对进行训练,一个 epoch。
提高模型对视觉与语义之间关系的理解。
使用动态分辨率支持更丰富的视觉输入。
阶段2:指令微调(Instruction Fine-tuning)¶
旨在将模型的通用能力适配到具体的文档元素识别任务。
使用 270 万精心构建的样本,训练 2 个 epoch。
数据集涵盖多种文档类型、语言和视觉复杂度,贴近真实应用场景。
微调任务包括以下四类:
OCR 识别:识别和提取页面级文本(字符、词、段落等)。
表格识别:解析表格结构,生成 OTSL 格式的结构化内容。
公式识别:识别数学公式并转换为 LaTeX 格式,区分行内公式与独立公式。
图表识别:识别各类图表(柱状图、折线图、饼图等),并转换为 Markdown 表格。
总结¶
PaddleOCR-VL 的整体架构通过将布局分析与元素识别分离,实现了更高的稳定性与准确性。PP-DocLayoutV2 提供了高效的布局分析能力,而 PaddleOCR-VL-0.9B 结合视觉与语言模型,在多语言、多元素文档解析任务中表现出色。训练方面,通过分阶段的优化策略和高质量数据集,模型在不同文档任务上均取得了优异的性能。
3 Dataset¶
本节介绍了PaddleOCR-VL-0.9B训练数据集的构建方法。该数据集具有高质量和多样性,构建过程如图5所示。主要包括以下几个步骤:数据收集、自动标注、以及难例挖掘,每一步都对模型的性能和鲁棒性至关重要。
图5: PaddleOCR-VL-0.9B训练数据的构建过程。
3.1 数据收集¶
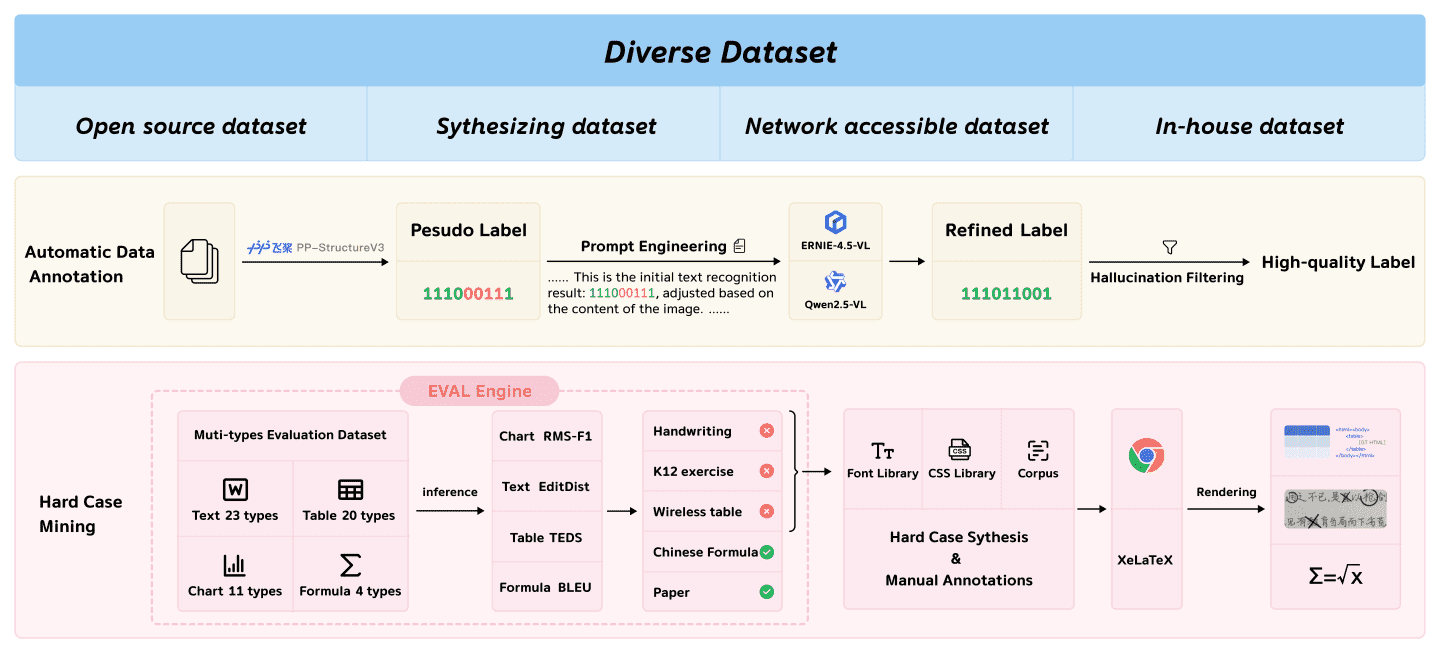
Figure 5: The construction process of training data for PaddleOCR-VL-0.9B.
为了确保数据集的广泛性和多样性,数据主要从以下四类来源获取:
开源数据集: 作为数据集的基础,我们系统性地整合了多个知名的公开数据集。文本数据来自CASIA-HWDB,数学公式数据来自UniMER-1M和MathWriting,图表相关数据则来自ChartQA、PlotQA、Chart2Text等多个来源。这些数据集均经过初步筛选和清洗,以去除低质量和噪声数据。
合成数据集: 由于公开数据在类型分布上通常不平衡,我们采用合成生成策略,低成本生成大量缺失类型的数据,确保模型在解析文档时具有无偏的表现。
网络可访问数据集: 为了提高模型在真实世界非结构化文档上的泛化能力与鲁棒性,我们收集了大量来自互联网的公开文档。这些文档涵盖学术论文、报纸、扫描的手写文件、考试卷、幻灯片等,极大地丰富了训练数据在风格、结构和领域上的多样性,降低了模型对干净标准数据的过拟合风险。
内部数据集: 通过多年OCR领域的积累,我们拥有涵盖多种数据类型的内部数据集。这些数据在训练中被精确控制比例使用,成为模型高性能的重要保障。
3.2 自动数据标注¶
在获得原始数据后,我们采用了自动化标注流程进行大规模标签生成。首先,使用专家模型PP-StructureV3进行初步处理,生成可能包含误差的伪标签。然后,通过提示工程(prompt engineering)生成包含原始图像和伪标签的提示,提交给更先进的多模态大语言模型(如ERNIE-4.5-VL和Qwen2.5VL),通过分析图像内容优化标签。最后,系统会进行一次幻觉过滤,剔除可能由大模型生成的错误内容,确保生成标签的高质量与可靠性。
3.3 难例挖掘¶
为了解决模型在某些复杂场景下的性能瓶颈,我们提出了难例挖掘策略。首先,我们构建了一个评估引擎,并通过人工标注创建了大量高质量的评估数据。这些评估数据按类型分为四类:
文本数据:包括中文、英文、打印体、手写体、日文、拉丁文、表情符号等23个类别;
表格数据:包括有限表格、无限表格、手写表格、清单、发票、旋转表格等20个类别;
公式数据:包括中英文公式、手写体与打印体、简单与复杂公式等4个类别;
图表数据:包括中英文图表、折线图、柱状图等11个类别,涵盖多种来源以覆盖不同文档类型。
在评估数据上进行推理后,我们通过专业度量指标(如文本的EditDist、表格的TEDS、图表的RMS-F1、公式的BLEU)精准识别模型表现较差的难例。最后,系统利用字体库、CSS库、语料库等资源和渲染工具(如XeLaTeX、网页浏览器)生成大量高质量的难例,从而提升模型在复杂场景下的性能。
4 Evaluation¶
4.1 页面级评估¶
本节主要评估 PaddleOCR-VL 的端到端文档解析能力,使用三个主要基准:OmniDocBench v1.5、OmniDocBench v1.0 和 olmOCR-Bench,以衡量其在真实文档场景下的综合表现。
OmniDocBench v1.5¶
OmniDocBench v1.5 是一个扩展数据集,包含 1,355 页文档,涵盖中英文平衡的数据,并加入了更多公式等元素。评估方法更新,公式使用 CDM 方法评估。PaddleOCR-VL 在多个关键指标上表现优异,例如 TextEdit 编辑距离最低(0.035)、Formula-CDM 最高(91.43)、Table-TEDS 和 Table-TEDS-S 分别为 89.76 和 93.52,以及 Reading Order 编辑距离最低(0.043)。这些结果表明 PaddleOCR-VL 在文本识别、公式识别和复杂表格结构分析方面具有显著优势。
OmniDocBench v1.0¶
OmniDocBench v1.0 包含 981 页 PDF,涵盖 9 种文档类型、4 种布局风格和 3 种语言类别。PaddleOCR-VL 表现突出,平均整体编辑距离为 0.115,并在中文和英文文本编辑距离上分别达到 SOTA(0.062 和 0.041),展现出优异的文本和公式处理能力。尽管在英文表格 TEDS 表现稍弱,但该数据集存在标注错误,而中文表格 TEDS 表现为 92.14,优于大多数模型。阅读顺序编辑距离也优于其他模型,尤其在中文方面。
olmOCR-Bench¶
olmOCR-Bench 包含 1,402 份 PDF 和 7,010 个测试案例。该数据集通过机器可验证的单元测试评估模型性能。PaddleOCR-VL 在该基准上表现优异,总体通过率为 80.0 ± 1.0,在 ArXiv (85.7)、Headers and Footers (97.0) 等类别中领先,显示出其在复杂文档类型上的强大能力。
4.2 元素级评估¶
本节聚焦于 PaddleOCR-VL 在文本、表格、公式和图表等具体元素上的识别能力,利用多个公共和内部数据集进行评估。
4.2.1 文本识别¶
OmniDocBench-OCR-block:从 OmniDocBench v1.5 提取文本子图像,形成 17,148 个图像测试集。PaddleOCR-VL 在多种文档类型(如学术文献、书籍、杂志等)中均表现最优。
In-house-OCR:包含 107,452 个高质量标注样本,涵盖 109 种语言和多种文本类型。PaddleOCR-VL 在多语言和文本类型方面的编辑距离显著优于其他模型。
Ocean-OCR-Handwritten:包含 400 个中英文手写样本。PaddleOCR-VL 在手写文本的编辑距离、F1 分数、Precision、Recall 等指标上均领先。
4.2.2 表格识别¶
OmniDocBench-Table-block:从 OmniDocBench v1.5 中提取 512 个表格进行测试。PaddleOCR-VL 在 TEDS(0.9195) 和 Overall Edit Distance(0.0561) 上表现最佳。
In-house-Table:包含 20 种表格类型(如中英文混合、学术论文表格、低质量表格等)。PaddleOCR-VL 在 Overall TEDS(0.8699)、Structural TEDS(0.9066) 等指标上达到最优。
4.2.3 公式识别¶
PaddleOCR-VL 在 OmniDocBench-Formula-block 和 In-house-Formula 中表现突出。在 OmniDocBench-Formula-block 中 CDM 为 0.9453,而在 In-house-Formula 中达到 0.9882,优于多个大型模型。
4.2.4 图表识别¶
由于公开数据集质量有限,仅在内部图表数据集 In-house-Chart 上评估。PaddleOCR-VL 在 RMS-F1 指标上达到 0.8440,优于多个 OCR VLM 和大型多模态模型。
4.3 推理性能¶
为了提升推理效率,PaddleOCR-VL 引入了多线程异步执行机制,将推理流程分为数据加载、布局模型处理和 VLM 推理三个阶段,分别运行在不同线程中。通过队列传递数据实现并发执行,并在 VLM 推理阶段采用批量处理机制,提高并行效率。
在 OmniDocBench v1.0 数据集上,PaddleOCR-VL 在单卡 A100 GPU 上处理 512 份 PDF 文件,端到端推理时间最短(800.9 秒),页面吞吐量(1.2241 pages/s)和 Token 吞吐量(1881.2 tokens/s) 均优于其他模型。同时,GPU 显存占用最低(43.7 GB),比 dots.ocr 节省约 40%,并在性能与资源利用之间取得良好平衡。
总结:PaddleOCR-VL 在多个文档解析任务中均达到 SOTA 表现,特别是在文本、表格、公式和图表的识别方面,且推理性能优异,具有高性能与高效率的双重优势,非常适合实际应用中的大规模文档理解场景。
5 Conclusion¶
本报告介绍了PaddleOCR-VL,这是一个先进的、高效的文档解析模型,在元素级和页面级识别方面表现出色。该模型的核心组件为 PaddleOCR-VL-0.9B,采用了 NaViT风格的视觉编码器 和 ERNIE-4.5-0.3B语言模型 构建,能够准确识别包括文本、表格、公式和图表在内的复杂元素,并且支持100多种语言。
PaddleOCR-VL 具备快速推理和低资源消耗的特性,使其非常适合实际部署。在多个基准测试中,它优于现有的流水线解决方案,并能有效应对手写内容和历史文档等具有挑战性的内容,还能够将图表图像转换为结构化数据。
其广泛的多语言支持和强大的性能,有望推动多模态文档处理技术的发展与应用,为自动化分析和信息检索带来创新。这将显著提升 RAG(检索增强生成)系统 的性能和稳定性,使从复杂文档中提取信息更加高效,为未来的AI应用提供更可靠的数据支持。
Appendix A Training Dataset Details¶
本章介绍了PaddleOCR-VL-0.9B模型在文本、表格、公式和图表任务中所使用的训练数据集的构建方法。该两阶段方法在数据收集方面具有独特优势,尤其在获取孤立元素图像及其标注方面比收集完整文档页面更为可行。以下是各部分数据的构建细节:
A.1 文本¶
我们构建了一个包含2000万高质量图文对的大规模文本训练数据集。该数据集通过以下关键步骤生成:
自动标注:
采用轻量级文档结构模型(如PP-StructureV3)与多模态大模型(如ERNIE-4.5-VL、Qwen2.5-VL)结合的方式,生成伪标签并通过多粒度合并形成高质量标注。高质量OCR数据合成:
针对低质量标注场景(如潦草手写、密集模糊文本),通过合成生成大量图像数据,使用多种CSS样式、字体和语料库提升模型在复杂场景下的识别能力。
数据标注层级包括文本行、文本块和文本页,覆盖109种语言,如中文、英文、法语、印地语等,并包含多种场景(论文、报纸、手写、古籍、身份证、车票等)以及多种文本形式(印刷、手写、扫描、艺术字体等)。
A.2 表格¶
我们构建了一个包含5500万高质量图像-表格对的大规模表格数据集。构建策略包括自动标注、潜在标注挖掘和高质量数据合成。使用OTSL作为表格格式目标,而非传统HTML。
自动标注:
使用PP-StructureV3定位表格,并结合多阶段标注流程(如ERNIE-4.5-VL生成伪标签、再由更大模型验证),并通过N-gram分析和HTML验证确保标注质量。潜在标注挖掘:
从公共数据(如arXiv)中提取表格及其HTML源码,通过正则匹配与上下文对齐构建准确的数据对。高质量表格合成:
设计了一个表格合成工具,能随机生成多样表格,也能按需求生成特定类型表格。工具使用LLM生成语料,通过结构、字体、样式参数生成图像,合成效率达每小时10000个样本,生成550万训练样本。
该数据集覆盖多种表格类型和识别场景,为表格识别任务提供有力支持。
A.3 公式¶
公式数据集通过源代码渲染、自动标注、长尾数据合成和公共数据收集等策略构建,涵盖教育辅材、试卷、论文、课件、论文、财务报告和手写笔记等多种场景。
源代码渲染:
从arXiv抓取论文源码,提取LaTeX公式,使用MinHash去重和KaTeX归一化,再通过引擎渲染为图像。自动标注:
使用PP-StructureV3识别公式区域,通过大模型生成LaTeX代码。针对中文公式(约占1%),使用PP-OCRv5识别字符,使用LaTeX渲染引擎进行过滤和验证。长尾数据合成:
针对难以识别的公式类型(如竖式、带删除线的公式、带注释的公式),通过规则生成LaTeX代码并使用逆渲染生成图像。公共数据收集:
从已有公开数据集(如UniMER-1M、MathWriting)中收集高质量公式数据,涵盖真实文档和手写公式,增强模型的泛化能力。
A.4 图表¶
我们构建了一个包含80万高质量图像-图表对的双语(中英文)图表数据集,涵盖学术论文、财务报告和网页等多种来源的图表类型。采用公共数据收集、自动标注、数据合成和长尾数据增强四类策略。
公共数据收集与清洗:
从ChartQA、PlotQA、Chart2Text等多个公开数据集中收集样本,通过数据清洗和过滤,保留高质量的22万个样本。自动标注:
基于视觉大模型ERNIE-4.5-VL开发两阶段标注流程:首先提取坐标轴标签,再通过标签匹配查询数据点,最后进行一致性检查。数据合成:
使用三阶段合成流程,利用LLM生成多样化数据表和图表代码,结合matplotlib和seaborn进行渲染,控制图表的视觉风格,提升模型泛化能力。长尾数据增强:
从具有独特视觉特征的图表(种子图表)出发,使用LLM复制并修改渲染代码,生成多样化的增强样本。
最终数据集覆盖多种图表类型和应用场景,为图表识别与理解任务提供坚实基础。
总结:
本附录详细介绍了PaddleOCR-VL-0.9B模型在文本、表格、公式和图表任务中所使用的高质量训练数据集的构建方法。通过自动化标注流程、合成数据生成、长尾数据增强和多模态模型的结合,实现了大规模、多语言、多场景的数据覆盖,为模型训练与性能提升提供了坚实的数据基础。
Appendix B Supported Languages¶
本节主要介绍了 PaddleOCR-VL 所支持的全球语言种类。以下是重点内容的总结:
1. 语言支持总数¶
PaddleOCR-VL 共支持 109 种语言,展示了其广泛的多语言识别能力。
2. 语言识别准确率¶
表 6(Table [6])中列出了不同语言的 文本行识别准确率,用于评估模型在不同语言上的表现(具体内容略)。
3. 语言类别与具体支持语言对照表(Table A1)¶
表 A1(Table [A1])详细列出了每个语言类别及其对应的 具体支持语言,这是本节的重点内容。具体包括以下类别:
语言类别 |
具体支持语言 |
|---|---|
中文 |
中文 |
英文 |
英语 |
韩语 |
韩语 |
日语 |
日语 |
泰语 |
泰语 |
希腊语 |
希腊语 |
泰米尔语 |
泰米尔语 |
泰卢固语 |
泰卢固语 |
阿拉伯语系 |
阿拉伯语、波斯语、维吾尔语、乌尔都语、普什图语、库尔德语、信德语、俾路支语 |
拉丁字母语言 |
包含法语、德语、意大利语、西班牙语、葡萄牙语、荷兰语、瑞典语等 40 多种语言(详见表 A1) |
西里尔字母语言 |
包含俄语、白俄罗斯语、乌克兰语、保加利亚语、蒙古语、哈萨克语、吉尔吉斯语、塔吉克语等 30 多种语言 |
天城文语言 |
包含印地语、马拉地语、尼泊尔语、比哈尔语、梵语等 12 多种语言 |
总结:¶
本节详细介绍了 PaddleOCR-VL 所支持的 109 种语言,并按语言类别分类列出具体支持的语言。
语言识别准确率和 语言类别对照表 是重点内容。
模型在多种语言体系(如阿拉伯语系、拉丁字母、西里尔字母、天城文等)中均有较强支持,体现了其在全球化文档处理中的广泛适用性。
Appendix C Inference Performance on Different Hardware Configurations¶
在本节中,作者测量了 PaddleOCR-VL 在不同硬件配置下的推理性能,并在表 A2 中进行了总结。结果显示,PaddleOCR-VL 在各类硬件和后端配置下均表现出稳定且高效的推理性能,说明该系统可以灵活地适应各种计算环境。此外,作者还表示正在集成FastDeploy 后端,预计在未来的版本中将进一步提升推理效率。
表 A2:端到端推理性能¶
硬件 |
后端 |
总时间 (秒) ↓ |
页面/秒 ↑ |
Token/秒 ↑ |
平均 VRAM 使用 (GB) ↓ |
|---|---|---|---|---|---|
A100 |
vLLM |
800.9 |
1.2241 |
1881.2 |
43.7 |
SGLang |
917.6 |
1.0684 |
1641.5 |
49.8 |
|
A10 |
vLLM |
1238.0 |
0.7921 |
1217.2 |
14.1 |
SGLang |
1429.9 |
0.6858 |
1055.8 |
20.0 |
|
RTX 3060 |
vLLM |
2749.1 |
0.3568 |
548.2 |
11.9 |
SGLang |
2792.4 |
0.3513 |
540.8 |
11.8 |
|
RTX 5070 |
vLLM |
1292.9 |
0.7584 |
1165.5 |
8.9 |
RTX 4090D |
vLLM |
845.3 |
1.1597 |
1781.8 |
16.7 |
SGLang |
951.8 |
1.0303 |
1586.1 |
21.8 |
重点内容讲解:¶
总时间 (Total Time):数值越小越好,表示模型推理所需时间越短。A100 和 RTX 4090D 的表现较好,RTX 3060 表现最差。
页面/秒 (Pages/s) 和 Token/秒 (Tokens/s):这两个指标越大表示处理速度越快。A100 和 RTX 4090D 的处理速度明显高于中低端显卡。
平均 VRAM 使用 (Avg. VRAM Usage):VRAM 使用越低越好,特别是对于资源有限的应用场景。RTX 5070 的 VRAM 使用最低,仅为 8.9GB。
硬件与后端组合:不同后端(如 vLLM 和 SGLang)在相同硬件上的性能略有差异,但整体趋势相似(如 A100 的 vLLM 性能优于 SGLang)。
简要结论:¶
高端 GPU(如 A100、RTX 4090D):在推理速度和 token 处理能力上表现优异,适合需要高性能的部署场景。
中低端 GPU(如 RTX 5070、A10):在性能和资源使用之间取得良好平衡,适合资源有限但需稳定运行的环境。
RTX 3060:性能最弱,适合轻量级任务或训练资源受限的场景。
后端选择:vLLM 通常在推理速度上略优于 SGLang,但具体差异因硬件而异。
总结¶
本节通过实测数据展示了 PaddleOCR-VL 在多种硬件和后端配置下的推理性能。其优异的适应性和稳定性,加上未来计划集成的 FastDeploy 后端,使其成为一个高效、灵活的多语言文档解析系统,适用于不同计算环境和应用场景。
Appendix D Real-world Samples¶
本附录展示了PaddleOCR-VL在多种具有挑战性场景下的解析与识别能力,覆盖文档结构、布局、阅读顺序、文本、表格、公式以及图表等多个方面。
D.1 综合文档解析(Comprehensive Document Parsing)¶
本节展示了PaddleOCR-VL对各种类型文档的整体解析能力。通过图 A5 到 A8 的示例,模型能够将书籍、教科书、学术论文、研究报告(包含图表识别)、财务报告、幻灯片、试卷、笔记、竖排书籍、古籍、证书、报纸和杂志等多种文档转换为Markdown格式输出。
重点内容:模型在处理不同文档结构时的通用性和稳定性表现优秀,尤其在复杂格式下的输出结构清晰。
D.2 布局检测(Layout Detection)¶
图 A9 至 A11 展示了PaddleOCR-VL在复杂或困难排版下的布局识别能力。
重点内容:模型能够准确识别不同文档中的区域划分,即使在排版混乱的情况下也能保持较高的识别精度。
D.3 阅读顺序(Reading Order)¶
图 A12 和 A13 展示了PaddleOCR-VL在复杂布局中的阅读顺序识别能力。
重点内容:模型能够正确识别报告、教材、报纸、杂志、竖排文档等文档的阅读顺序,确保信息的逻辑性和可读性。
D.4 文本识别(Text Recognition)¶
D.4.1 多语言文本识别(Multilingual Text Recognition)¶
图 A14 至 A19 展示了模型对多种语言(如法语、印度语、克罗地亚语、西班牙语、英语、阿拉伯语、德语、中文、俄语、日语、泰语、韩语)的识别能力。
重点内容:PaddleOCR-VL具备强大的多语言处理能力,适用于国际化文档的解析需求。
D.4.2 手写文本识别(Handwriting Text Recognition)¶
图 A20 和 A21 展示了模型对混合印刷/手写文本及手写公式的识别效果。
重点内容:模型能够处理手写体内容,适用于笔记、表单等非标准化输入场景。
D.4.3 竖排文本识别(Vertical Text Recognition)¶
图 A22 展示了模型对竖排文本的识别能力。
重点内容:PaddleOCR-VL在竖排文档(如古代书籍、竖排杂志)中依然保持高识别准确率。
D.5 表格识别(Table Recognition)¶
图 A23 和 A24 展示了模型对各种表格格式的识别能力,包括学术论文表格、财务报告表格、带水印表格、带图像表格、带公式的表格及表格照片。
重点内容:模型具备处理复杂表格结构的能力,能够识别表格中的内容并以结构化方式输出。
D.6 公式识别(Formula Recognition)¶
图 A25 展示了模型对英文数学公式的识别能力,包括印刷体、手写体、屏幕截图以及竖排公式。
图 A26 展示了对中文公式(含中文字符)的识别能力。
重点内容:PaddleOCR-VL在公式识别方面表现突出,能够准确解析多种来源(印刷、手写、屏幕截图)的公式。
D.7 图表识别(Chart Recognition)¶
图 A27 至 A29 展示了PaddleOCR-VL在图表识别方面的优越性能,包括饼图、柱状图、折线图、柱折混合图、热力图等。
重点内容:目前许多专家级OCR视觉语言模型(如MinerU2.5、dots.ocr、MonkeyOCR)缺乏图表解析能力,而PaddleOCR-VL填补了这一空白。
总结¶
本附录通过多个实际案例展示了PaddleOCR-VL在文档解析任务中的全面性和鲁棒性。模型在处理复杂布局、多语言、手写体、竖排文本、表格、公式和图表等方面均表现出色,具备广泛的实际应用价值。
Appendix E Compare with Others¶
E.1 Layout Detection(布局检测)¶
PaddleOCR-VL 在处理具有复杂布局的 PDF 页面时表现出色,明显优于目前最先进的(SOTA)模型。这从图 A30 和图 A31 中可以清晰看出,PaddleOCR-VL 能够更精准地识别页面中的复杂结构和特殊元素,表现优于其他解决方案。
E.2 Text Recognition(文本识别)¶
E.2.1 Multilingual Text Recognition(多语言文本识别)¶
PaddleOCR-VL 在多语言文本识别方面具有极高的识别精度。图 A32 至图 A34 显示,PaddleOCR-VL 在识别俄语、印地语等语言时的表现优于 MinerU2.5 和 MonkeyOCR 等模型,后者常将非英语语言误判为英语。
E.2.2 Handwriting Text Recognition(手写文本识别)¶
在手写文本识别方面,PaddleOCR-VL 同样表现出色,能够更准确地识别手写字符。图 A35 和图 A36 展示了其识别效果优于其他模型,尤其在字符缺失或多变的手写体中表现稳定。
E.2.3 Vertical Text Recognition(竖排文本识别)¶
对于竖排文本,PaddleOCR-VL 能够准确识别,而其他模型在此类任务中常出现识别困难。图 A37 展示了 PaddleOCR-VL 在识别中文竖排文本等方面的卓越能力。
E.3 Table Recognition(表格识别)¶
在表格识别任务中,PaddleOCR-VL 显示出较高的解析准确率。图 A38 和图 A39 表明,PaddleOCR-VL 能够更完整地还原表格结构,而其他模型在此类复杂表格处理中普遍表现不佳。
E.4 Formula Recognition(公式识别)¶
图 A40 显示,PaddleOCR-VL 在复杂数学公式识别中表现出色,能够正确解析公式结构和符号。相比之下,其他 SOTA 模型在面对复杂数学符号时经常产生错误或不完整的输出。
E.5 Chart Recognition(图表识别)¶
PaddleOCR-VL 在图表识别方面也具有优势。图 A41 和图 A42 显示,PaddleOCR-VL 能够准确识别图表结构和内容,优于多模态大语言模型如 Qwen2.5VL-72B 和 GPT-4o。
总结¶
PaddleOCR-VL 在多个文档处理任务中均表现优异,包括复杂布局检测、多语言与手写文本识别、竖排文本处理、表格与公式解析,以及图表识别。它在多个方面超越了当前主流模型,尤其在处理复杂、多样的文档内容时展现出强大的适应性和准确性。