2501.01257_CodeForces: Benchmarking Competition-level Code Generation of LLMs on CodeForces¶
组织: Qwen Team
引用: 35(2025-07-24)
HuggingFace: https://huggingface.co/QwenLM/CodeElo
标题修改: CodeElo: Benchmarking Competition-level Code Generation of LLMs with Human-comparable Elo Ratings
总结¶
简介
一个非传统类型的代码评估基准,竞赛编程基准测试平台,旨在准确评估大型语言模型(LLMs)的推理能力
其目的是用于评估大型语言模型(LLMs)在编程竞赛水平上的代码生成能力,特别是在 CodeForces 平台上
贡献
提供了一套结构化的 CodeForces 问题集,包括比赛组别、难度评分和算法标签
首次引入零误判的评测方法,直接提交代码至平台,支持特殊判断器和一致性执行环境
首次为模型提供标准化、与人类可比的 Elo 评分
对比
竞争性代码基准
APPS,CodeContests,xCodeEval,TACO,LiveCodeBench,USACO
通用代码基准
HumanEval、MBPP、BigCodeBench
通用代码基准与竞争性代码基准的差异
任务复杂性:竞争性基准要求设计完整的算法和完整的代码,而通用基准通常只需实现特定功能的小函数。
问题难度:竞争性基准问题更复杂,需要高级推理能力,通用基准问题相对简单。
执行时间要求:竞争性基准不仅要求输出正确,还要求算法复杂度高效,而通用基准更关注输出正确性。
Abstract¶
本文提出了一种新的竞赛编程基准测试平台——CodeForces,旨在准确评估大型语言模型(LLMs)的推理能力,并通过与人类水平相当的标准ELO评分体系进行衡量。该基准首次实现了零误报,并支持基于CodeForces平台的特殊评测器。研究方法包括使用机器人将模型的解法直接提交至CodeForces平台进行测试,模拟人类选手参与。同时,研究团队开发了一个低方差的ELO评分系统,该系统与CodeForces平台对齐。测试了34种流行的LLM模型后发现,类似o1的推理模型(如o1-mini和QwQ-32B-Preview)表现优异,而大多数模型即使面对简单问题也表现不佳。作者计划公开发布该基准,希望其能推动模型测试的发展,并为提升LLMs的代码推理能力提供洞见。
1 Introduction¶
本文主要提出并介绍了 CodeForces 作为一个全新的基准测试平台,用于评估大语言模型(LLMs)在竞赛级编程中的推理能力。该基准填补了当前在编程评估方面标准化测试的空白,特别是在以下几个方面展现出独特优势:
1. 背景与动机¶
当前大型语言模型的推理能力不断提升,尤其在数学和编程领域表现突出。
然而,尽管已有多个数学评测基准(如 AIME、Omni-MATH),在编程评测方面缺乏标准化的高难度测试基准。
现有的编程评测基准(如 LiveCodeBench、USACO、CodeContests)存在以下问题:
测试用例不完整,导致误判率高;
不支持特殊判断器(Special Judge),无法处理答案不唯一的题目;
执行环境不一致,影响评测结果的准确性;
无法提供与人类相当的 Elo 评分,难以衡量模型的竞赛水平。
2. CodeForces 基准的特点¶
首次引入 CodeForces 基准,专门用于评估 LLM 的竞赛级编程能力。
关键创新点:
通过 自动提交模型生成的代码到 CodeForces 平台,获得官方测试结果,实现零误判;
支持特殊判断器,处理答案不唯一的题目;
执行环境完全一致,与人类选手相同,确保评测公正;
提供标准化的 Elo 评分系统,基于模型表现估算其在 CodeForces 上的 Elo 等级,且具有较低方差,更具参考性。
3. 评测结果与发现¶
测试了 30 个开源和 3 个闭源 LLM 模型,其中:
OpenAI o1-mini 表现最佳,Elo 评分为 1578,超过 90% 的人类选手;
QwQ-32B-Preview(类似 o1)在开源模型中表现突出,Elo 评分为 1261,处于人类前 60%;
多数模型表现较差,与人类选手相比处于前 10% 以下;
模型表现分析:
擅长 数学和实现类问题;
不擅长 动态规划(DP)和树结构问题;
最佳表现语言是 C++,而非普遍使用的 Python,这与以往基准测试不同。
4. 主要贡献¶
提供了一套结构化的 CodeForces 问题集,包括比赛组别、难度评分和算法标签;
首次引入零误判的评测方法,直接提交代码至平台,支持特殊判断器和一致性执行环境;
首次为模型提供标准化、与人类可比的 Elo 评分;
通过详尽实验分析,为未来模型改进和研究提供洞察。
总结¶
本文提出的 CodeForces 基准填补了当前在竞赛级编程评测方面的空白,为评估和提升 LLM 在复杂推理和编程任务中的能力提供了可靠、标准化的手段。未来有望推动更先进的 LLM 在编程领域的应用与发展。
2 Related Work¶
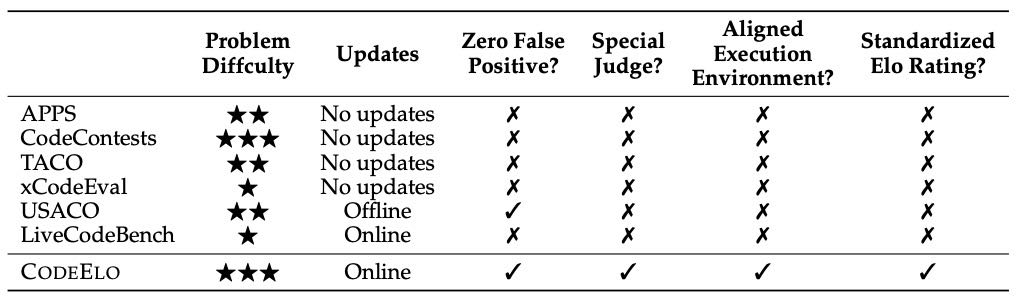
Table 1: Comparison between CODEELO and other competition code benchmarks.
本节总结了与作者工作相关的现有代码基准测试工具,并重点对比了CodeForces基准与其他竞争性代码基准以及其他通用代码基准的优劣。
首先,作者回顾了六个代表性竞争性代码基准:
APPS:2021年提出,收集自Codewars、AtCoder、Kattis和CodeForces。
CodeContests:2022年提出,包含CodeForces的问题、解决方案和测试用例。
xCodeEval:2023年提出,一个多语言、多任务的大规模代码基准,问题也来自CodeForces。
TACO:2023年提出,整合了CodeContests和APPS的问题,并新增了从多个竞赛平台收集的问题。
LiveCodeBench:2024年提出,主要从LeetCode和AtCoder抓取问题,每月更新以避免重复问题,但来自CodeForces的内容较少。
USACO:2024年提出,包含美国计算机奥林匹克竞赛(USACO)的问题与测试用例,通过发布新版本来更新。
作者还通过表格对这些基准进行了比较,发现它们的共同特点是:从开放的在线编程竞赛平台抓取题目,进行离线评估。然而,存在以下问题:
测试用例质量不高:多数平台隐藏真实测试用例,现有基准常需人工生成测试用例,但不如原生用例(通常由高水平选手设计,具有对抗性)可靠,导致误判率高。
不支持Special Judge:无法处理多种正确输出形式的问题。
依赖本地运行环境:运行时间是算法竞赛的重要指标,不同机器性能差异可能影响结果。
缺乏标准化Elo评分:无法提供类似人类选手的标准化评分体系。
相比之下,作者提出的CodeForces基准具有明显优势,包括在线评估、真实测试用例、支持Special Judge、在线运行环境和标准化Elo评分等。
此外,作者还比较了通用代码基准(如HumanEval、MBPP、BigCodeBench)与竞争性代码基准的差异,主要体现在:
任务复杂性:竞争性基准要求设计完整的算法和完整的代码,而通用基准通常只需实现特定功能的小函数。
问题难度:竞争性基准问题更复杂,需要高级推理能力,通用基准问题相对简单。
执行时间要求:竞争性基准不仅要求输出正确,还要求算法复杂度高效,而通用基准更关注输出正确性。
综上,作者指出目前的竞争性代码基准存在诸多局限,而CodeForces基准在问题质量、评估机制和标准化方面具有显著优势。
3 CodeForces Benchmark¶
本章节介绍了基于 CodeForces 平台构建的编程竞赛级别代码生成基准(CodeForces Benchmark)。该基准旨在更准确地评估大型语言模型(LLMs)在生成高质量竞赛代码方面的性能。主要内容包括:
问题收集:
所有测试问题均来自 CodeForces 的官方竞赛平台,且主要选取近期的比赛以避免数据污染。
问题最初以 HTML 格式存储,解析后提取出问题描述、输入输出格式、示例、注释等部分,便于测试时灵活构造提示。
保留原始 HTML 格式以确保信息和公式展示的清晰性,方便模型处理。
分类与标签:
竞赛难度分级:CodeForces 将竞赛划分为 Div. 1 到 Div. 4,Div. 1 最难,Div. 4 最易。还有一些混合等级(如 Div. 1+2)和全球赛。
问题难度评分:每道题都有一个难度评分,表示某评分的选手首次尝试通过该题的概率为 50%。评分基于大量用户的实际表现计算得出。
算法标签:每个问题平均有 3.9 个标签,涵盖其涉及的主要算法类型。这些标签对模型和人类在测试时不可见,不能作为提示。
评估方法:
提交与评判机制:
将模型生成的代码直接提交至 CodeForces 官方平台进行评判,确保结果准确。
通过自动提交机器人完成提交,并解析反馈结果。只有通过全部测试用例的代码才被视为“接受”。
Elo 评分系统:
采用与 CodeForces 官方相似的 Elo 评分系统,用于量化模型的编程能力。
模型在每个竞赛中的表现被独立评估,通过计算模型在该竞赛中相对于人类参赛者的表现,得出其 Elo 评分。
使用二分法求解模型的期望评分,确保计算高效准确。
Elo 评分的优势:
相比传统的 pass@n(如 pass@1)指标,Elo 评分考虑了多次尝试、尝试失败的惩罚以及问题难度的影响。
鼓励模型挑战更难的问题,提供更全面的评估结果,并降低评估的方差。
总结来说,该章节详细介绍了 CodeForces 基准的构建过程,包括问题收集、分类体系和评估方式,特别是通过官方平台直接评判和 Elo 评分系统,实现了对模型代码生成能力的更精确、更公平的评估。
4 Evaluation on Existing LLMs¶
本章对现有的大语言模型(LLMs)在编程竞赛问题上的表现进行了评估,主要基于 CodeForces 平台的数据。以下是该章节的总结:
4.1 实验设置¶
研究者选取了 2024 年 5 月到 11 月之间的 CodeForces 比赛数据,共计 54 场比赛、387 道题目。排除了难度较高的 Div.1 比赛,专注于其他难度等级。每道题允许模型最多尝试 8 次,失败尝试计入罚分,但不计时间惩罚,以模拟真实比赛环境。测试语言为 C++,因为该语言在竞赛环境中表现最佳。所有模型都采用相同的思维链(Chain-of-Thought, CoT)提示方式进行推理。
4.2 Elo 评级¶
根据实验结果,模型的表现被转化为 Elo 评级,以衡量其与人类参赛者的相对水平。其中,专有模型中 o1-mini 表现最优,Elo 评级为 1578,而开源模型中 QwQ-32B-Preview 表现最佳,Elo 评级为 1261。研究还发现,模型规模越大,表现越好,且高于 500 Elo 的开源模型均为 30B 及以上规模。然而,即使是表现最好的开源模型,其 Elo 评级仍低于人类参赛者的前 80%。
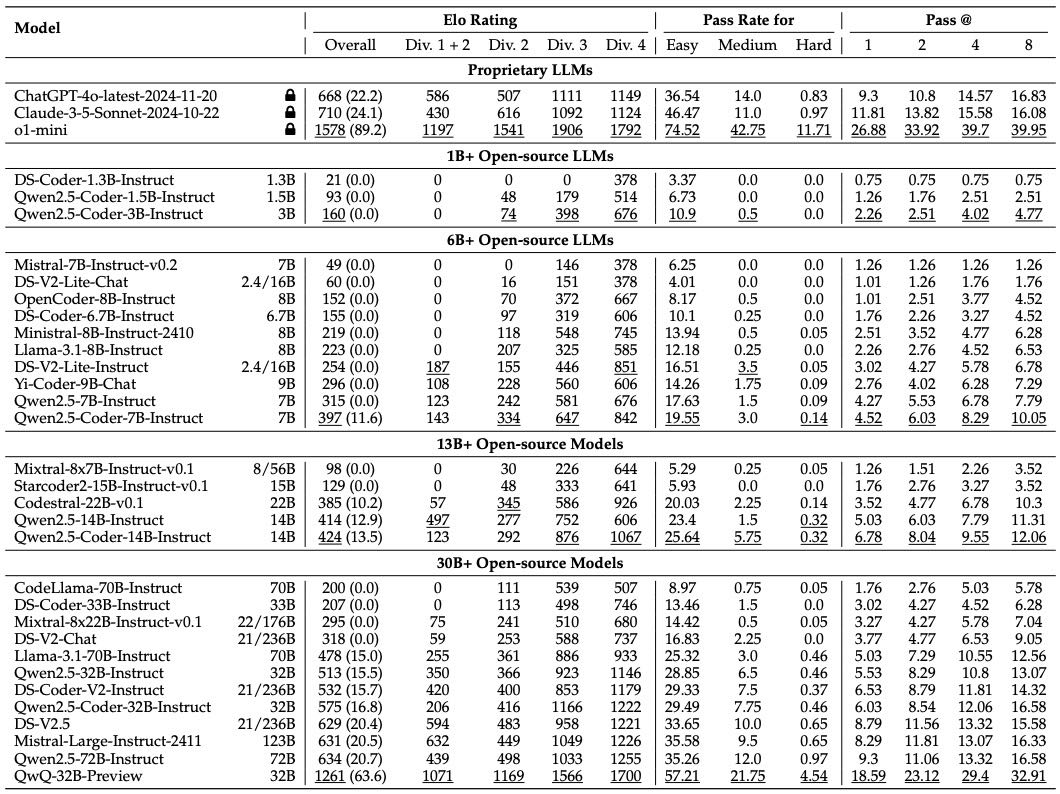
Table 3: Main results of different LLMs on CODEELO. The number in parentheses after the overall Elo rating shows the percentile rank among human participants. The underlined numbers represent the best scores within the same model size range.
4.3 主要结果¶
模型表现对比¶
研究测试了 30 个开源模型和 4 个专有模型,对它们的 Elo 评级、通过率(Pass Rate)和不同尝试次数下的通过率(Pass@n)进行了详细分析。
小模型(1B 以下)几乎无法解决任何问题;
中等规模模型(6B 以上)表现显著提升,尤其是 30B 以上的大模型;
QwQ-32B-Preview 和 o1-mini 表现最佳,显示出长推理链(Long CoT)模型在解决困难编程问题上的优势;
模型的性能与其规模呈正相关,但即便如此,它们的表现仍远不及中等水平的人类参赛者。
比赛难度与模型表现¶
在难度较低的比赛中(如 Div.4),模型的平均表现较好;
o1-mini 在 Div.3 中表现最佳,符合其较高的 Elo 评级;
模型在与自身能力匹配的比赛中表现最佳,说明比赛难度对模型表现有显著影响。
题目难度与通过率¶
题目被划分为简单(800~1000)、中等(1000~1300)和困难(1300~3500)三个级别;
大多数模型在简单题目上表现不佳,中等题目能区分出部分先进模型;
在困难级别上,几乎所有模型都难以通过,显示出当前模型在解决高水平编程问题上的局限性。
Pass@n 指标¶
Pass@n 指标衡量模型在 n 次尝试中的通过率;
大多数模型的通过率随着尝试次数增加而提高,说明多样化的尝试有助于提高成功率;
尽管 Pass@n 与 Elo 评级相关,但由于计算方式不同,它们并不完全一致。
总结¶
本章通过系统的实验设置和多维度指标(Elo 评级、通过率、Pass@n)评估了当前主流 LLM 在 CodeForces 竞赛级编程问题上的表现。结果显示,虽然大模型在编程任务上已有显著提升,但与人类顶尖选手相比仍有较大差距。研究也揭示了模型规模与性能之间的正相关性,并突出了长推理链模型在处理复杂问题中的优势。这些结果为未来模型的优化与评估提供了重要参考。
5 Analysis Experiments¶
本章节主要分析了不同模型在编程竞赛题目上的表现,重点从算法类别、编程语言选择以及评分标准差三个方面进行了实验和探讨:
不同算法下的模型表现(Performance Across Algorithms)
研究选取了16类常见算法标签,每类包含至少30道题,评估模型在不同算法上的通过率(pass@1)。
模型在数学(Ma.)、实现(Im.)、排序(So.)等算法上表现较好,通过率较高。
相对而言,模型在动态规划(DP)、DFS相关(DFS)、树结构(Tr.)等算法上表现较差,部分模型甚至在某些类别上完全无法解决问题。
专有模型(如 o1-mini)在多数算法上优于开源模型,尤其是在高参数模型(如30B+)中表现更佳。
C++ 与 Python 的性能对比(Comparison between C++ and Python)
尽管大多数模型在未指定语言的情况下倾向于选择 Python(使用率超过95%),但实验发现在 CodeForces 上,使用 C++ 时模型的性能更优。
与人类选手类似,C++ 在竞赛场景中因运行效率更高而更受欢迎,模型在使用 C++ 时的 Elo 排名也普遍更高。
该发现表明,模型在面对对运行效率敏感的问题时,应被训练为优先选择 C++,以提升性能。同时,这与 APPS 和 LiveCodeBench 等主要使用 Python 的基准测试不同。
评分标准差分析(Rating Variance)
模型在不同比赛中的评分存在较大波动,标准差通常在300到500之间。
由于模型通常只能解决少量问题,解决一道额外题可能显著提高其评分,因此评分波动较大。
通过增加测试的比赛数量(如本实验中的54场比赛),可以有效降低评分标准差(降至约50),从而更稳定地评估模型性能。
使用小提琴图(violin plot)可以直观展示模型在不同比赛中的评分分布,便于性能比较。
总结:
本章通过实验证明了模型在不同算法上的表现存在显著差异,C++ 在竞赛环境中比 Python 表现更好,且通过增加测试规模可以降低评分波动,从而更准确地评估模型的编程能力。这些发现对模型训练和评估方法的改进具有指导意义。
6 Discussion¶
本章“讨论”部分主要阐述了本文工作的贡献及其局限性,具体内容总结如下:
6.1 贡献(Contributions)¶
高质量的在线可更新测试题集
提供了一套高质量的编程问题数据集,涵盖CodeForces平台上的完整问题,并支持在线更新。相较于其他基准,本数据集包含更详细的信息,如比赛难度等级、问题标签等,有助于更全面地评估模型性能。直接平台提交的评估方法
采用直接向CodeForces平台提交代码的方式进行评估,这在竞争性编程问题中尤为关键。由于许多问题需要特殊判断器(special judge)和隐藏测试用例,传统方法易导致环境不一致和结果偏差。本方法能更准确反映模型真实能力。人类可比的Elo评分体系
首次为现有模型提供与人类水平相当的Elo评分,从而衡量AI模型在编程竞赛中的表现。研究发现,类o1的推理模型在本基准上表现出明显优势,且在不同比赛难度、标签维度上的详细结果可为模型开发者提供优化方向。揭示前人研究未关注的问题
例如,尽管Python是当前LLM最熟悉的语言,但在CodeForces上,模型在C++语言下的表现更好。这表明,仅使用Python进行评估可能无法充分激发模型的最佳性能,提示开发者应重视C++代码生成能力,尤其是在效率要求高的场景下。
6.2 局限性(Limitations)¶
提交次数限制
为避免对CodeForces平台造成影响,每个问题仅允许提交8次。虽然实际比赛中用户可多次尝试,但该限制可能导致模型的Elo评分略低于真实水平。但此设置在公平性与平台可用性之间做了权衡。依赖CodeForces平台进行评测
相比于传统离线评测方式,本研究依赖于CodeForces平台的在线评测机制,原因是隐藏测试用例和特殊判断器无法被访问或复制。虽然理想情况下希望实现全自主评测,但这些资源的不可获取性使得平台依赖成为必要。
总结来看,本文提出了一种更具实用性与准确性的编程竞赛代码生成评估方法,推动了NLP领域在代码生成方向的研究进展,同时也明确指出了当前方法在评估机制和平台依赖方面的局限性。
7 Conclusion¶
本文总结如下:
本研究提出了 CodeForces 基准测试集,这是一个由 Codeforces 平台上的编程问题组成的数据集,具备详细的问题信息和独特的判断方法。该方法通过将解决方案提交至 Codeforces 平台获取判断结果,从而实现了 零误报、支持特殊判断器 和 一致的执行环境,这是前所未有的。
基于平台的判断结果,作者还开发了一个与 Codeforces 平台一致但方差更低的 Elo 分数计算系统。在对 30 个开源和 3 个专有大语言模型(LLMs)进行测试后发现,o1-mini 和 QwQ-32B-Preview 表现突出,但大多数模型在最简单的问题上也表现不佳,处于人类参赛者的最低 20% 水平。
进一步分析发现,不同模型在不同算法标签上的表现存在差异,且在 C++ 上的表现优于 Python,这与之前的一些基准测试结果相反。
作者已公开了 CodeForces 基准测试集,希望该基准能够为自然语言处理(NLP)社区提供一个测试 LLMs 在代码生成和复杂推理能力方面的新工具,并为未来研究提供有价值的见解。
8 Ethical Statement¶
本章节为论文的伦理声明部分,主要内容总结如下:
平台使用规范:该基准测试基于 CodeForces 平台进行判断,所有实验过程均严格遵守 CodeForces 的《用户条款》和《AI 使用限制规定》。
使用范围限制:该基准仅用于学术研究,强调应以有限方式使用,避免影响平台正常用户的访问体验。
仅限虚拟参与:该基准仅适用于虚拟参与模式,不能用于正式比赛中的测试。
伦理考量与后续计划:出于伦理考虑,作者将在开源完整的提交与评估框架前,进行全面的风险评估,并寻求 CodeForces 平台的授权。因此,当前版本论文中未包含完整的框架代码。
建议与致谢:在框架正式开放前,作者建议其他研究人员独立复现本文提出的方法进行评估。同时,作者对 CodeForces 平台的创建者 Mike Mirzayanov 表示高度感谢。
Appendix A Model Cards¶
本附录列出了所有测试的模型信息,包括模型的简称、引用来源以及HuggingFace的端点链接。主要内容包括:
模型覆盖范围:涵盖了多种大语言模型(LLMs)和代码生成模型,包括Claude、ChatGPT、o1、Qwen、DeepSeek、Llama、Mistral、Mixtral、OpenCoder、Yi-Coder、Starcoder2等系列。
模型规模和变体:
包括不同参数规模的Qwen(如1.5B、3B、7B、14B、32B、72B)。
深度寻求(DeepSeek)系列,包括DS-Coder和DS-V2系列。
Llama系列,包含Llama-3.1的不同版本。
Mistral和Mixtral系列,涵盖多种参数配置。
公开访问性:大部分模型在HuggingFace平台上有公开的访问端点,方便研究人员和开发者进行测试和使用。
引用与来源:每个模型都标注了对应的引用文献,表明其来源和相关研究。
总结:本附录为读者提供了详细的模型列表和来源信息,为研究和比较不同模型在代码生成任务上的表现提供了数据支持。
Appendix B Decoding Hyperparameters¶
本附录描述了模型解码过程中使用的超参数设置。对于专有模型,使用默认参数的API调用。对于开源模型,推理设置为:温度(temperature)为0.7,top_p为0.8,top_k为20,重复惩罚(repetition_penalty)为1.1。所有模型的最大输出token数设置为4,096,但QwQ-32B-Preview模型例外,其最大输出token数设置为32,768。
Appendix C Analysis of Our Elo Rating Calculation System¶
本附录分析了作者提出的Elo评分计算系统,并与CodeForces平台原有的评分系统进行了对比与数学验证。
评分方法:作者提出的方法是,针对每个模型在每个比赛后计算期望评分,并对所有比赛的评分取平均。假设每个模型在不同比赛中的评分是独立同分布(IID)的,因此平均评分的期望值保持不变,而方差会随着比赛数量 \( k \) 增加而减小,具体为 \( \text{Var}(r)/k \)。这表明,随着比赛数量趋近于无穷大,评分结果会趋于稳定。
原始系统对比:CodeForces平台的评分系统是通过维护每个参赛者的评分历史来更新评分的。初始评分为零,每次比赛后根据表现计算期望评分 \( E(r_i) \),并将当前评分向期望评分移动一半距离,即 \( r_i = \frac{r_{i-1} + E(r_i)}{2} \)。由于每个比赛独立且 \( E(r_i) \) 与评分 \( r \) 分布相同,长期来看,评分的期望值会收敛于真实期望 \( r \),方差也会收敛于 \( \text{Var}(r) \)。
结论:尽管两种方法在计算方式上有所不同,但通过数学推导,作者证明了两种方法在期望值上是等价的,且作者的方法通过增加比赛数量可以显著降低评分的方差,使其结果更加稳定和可靠。
Appendix D Human-comparable Elo Rating¶
本章节《可与人类相比的Elo评分》介绍了该基准测试的一个优势:提供了可与人类参赛者比较的标准化Elo评分。通过从CodeForces平台上公开可用的用户评分数据中计算出所有人类参赛者的各百分位Elo评分,并以表格形式展示(见表6)。该表格列出了从第1百分位到第100百分位的人类参赛者的Elo评分,评分范围从最低的348分到最高的4009分。通过这些数据,可以直观地比较模型在竞赛级别编程中的表现与不同水平人类参赛者的相对位置。
Appendix E Problem Demonstration¶
本附录展示了CodeForces中一个竞赛编程问题的示例。该问题包含以下部分:标题、时间限制、内存限制、问题描述、输入格式、输出格式、测试用例示例以及(可选的)备注。图中的问题链接为 https://codeforces.com/contest/2034/problem/E,可供进一步查阅。此示例展示了竞赛级编程题的典型结构和信息内容。
Appendix F Special Judge¶
本章节《附录F:特殊判题器(Special Judge)》主要讨论了在编程竞赛中,某些题目可能对同一输入存在多个正确输出的情况,并介绍了如何处理这些情况的判题方式。
要点总结:¶
问题背景:
编程竞赛中,大多数题目对每个输入只有一个正确输出,可以通过与标准答案对比直接判断。
但有一部分题目允许对同一输入存在多个正确输出,因此不能仅通过比较输出与标准答案来判断正确性。
特殊判题器(Special Judge)的作用:
用于验证这些允许多种正确输出的题目的解是否符合题意。
它类似一个逻辑单元测试,但因为情况复杂,编写难度较大。
研究结果:
作者进行了实证研究,发现100个随机选择的问题中有30个需要使用特殊判题器。
早期的代码生成评估基准无法处理这类问题,因此无法全面评估模型的性能。
改进的评估方法:
提出的评估方法能够支持需要特殊判题器的问题,也支持交互式问题(Interactive Problems)。
对于这些类型的问题的支持,是全面评估模型能力、获得人类级别评分(如Elo评分)的关键。
案例示例:
图5展示了一个需要特殊判题器的问题示例。例如,输入为”abc”时,可能的输出包括”abb”、”acc”、”aac”等,但不能是”abc”本身。
因此,不能简单地将输出与标准答案比较,而是需要一个逻辑判断器来验证该输出是否满足题目要求。
CodeForces平台通过在官方平台上运行提交的代码来处理这类问题,提供了对这类题目的首次支持。
结论:¶
作者强调,支持需要特殊判题器和交互式问题的能力,是评估模型在编程竞赛级别代码生成能力的重要组成部分。这一方法能够更全面、准确地衡量模型的表现。