2405.16506_GRAG: Graph Retrieval-Augmented Generation¶
引用: 197(2025-08-02)
组织: Emory University
GitHub: https://github.com/HuieL/GRAG
总结¶
主要贡献
高效的文本子图检索
提出了一种分治策略,能够在线性时间内检索最优子图结构,从而提升检索效率
通过“自我图”(ego-graph)的初步检索和软剪枝机制,
高效近似地找到相关子图,避免了穷举子图的NP难问题
图上下文感知的生成机制
通过将文本图信息以文本视图和图视图两种互补的方式整合到LLMs中
使模型能更有效地理解并利用图的上下文信息
图信息的提示机制:设计了双通道提示方法,包括:
硬提示(hard prompts):将子图结构转换为层次化文本描述,保留拓扑信息
软提示(soft prompts):通过图编码器提取图的拓扑和文本信息,以结构化形式传递给LLMs
LLM 总结¶
文章《GRAG: Graph Retrieval-Augmented Generation》提出了一种新的信息检索与生成结合的方法——GRAG(图检索增强生成)。该方法将图结构数据引入传统的检索增强生成(RAG)框架中,以提升生成模型在处理复杂语义关系和多跳推理任务中的表现。
总结如下:
背景与动机:传统的RAG方法虽然在问答和内容生成方面表现出色,但在处理需要多跳推理或多实体关系理解的任务时存在局限。图结构能够更自然地表示实体之间的复杂关系,因此将其引入RAG框架具有重要意义。
方法概述:
GRAG通过构建知识图谱(KG)作为外部信息源,利用图检索技术(如子图检索、路径检索)从知识图谱中提取相关信息,并将这些信息注入到生成模型中,从而增强生成内容的准确性和相关性。关键技术:
图检索模块:用于从知识图谱中检索相关实体或路径。
图增强模块:将检索到的图结构信息编码并整合到生成模型中,使其能够在生成过程中利用图中的结构化信息。
生成模块:基于增强后的上下文生成高质量的回答或文本。
实验与结果:
GRAG在多个问答和生成任务上进行了评估,结果显示其在多跳推理任务、事实性问答和复杂语义理解方面优于传统RAG方法和其他基线模型。实验还表明,图结构的引入显著提升了模型的上下文理解能力和生成质量。总结与展望:
GRAG为融合结构化知识与生成模型提供了一个新的视角,展示了图检索在增强生成任务中的潜力。未来的研究可以进一步探索不同图检索策略、动态知识图谱更新以及跨模态图结构的融合。
总之,GRAG通过引入图结构和图检索机制,有效提升了生成模型在处理复杂语义和多跳推理任务中的能力,为下一代知识增强的生成系统提供了新的思路和方法。
Abstract¶
该论文提出了一种名为 GRAG(Graph Retrieval-Augmented Generation) 的新方法,旨在解决传统 RAG(Retrieval-Augmented Generation) 在处理网络化文档(如引用图、社交媒体、知识图谱等)时的局限性。与RAG仅关注单一文档不同,GRAG能够有效检索和利用文本子图结构,并将其整合到**大型语言模型(LLMs)**中,从而提升生成质量。
论文的主要贡献包括:
高效的文本子图检索:提出了一种分治策略,能够在线性时间内检索最优子图结构,从而提升检索效率。
图上下文感知的生成机制:通过将文本图信息以文本视图和图视图两种互补的方式整合到LLMs中,使模型能更有效地理解并利用图的上下文信息。
实验验证:在多个图推理基准测试中,GRAG在需要多跳推理的文本图场景中显著优于当前最先进的RAG方法。
最后,论文提供了数据集和代码,便于后续研究和验证。
总结:
GRAG通过引入图结构的检索与整合机制,有效克服了传统RAG在处理网络化文档时的不足,在图推理任务中展现出优越的性能。
1 Introduction¶
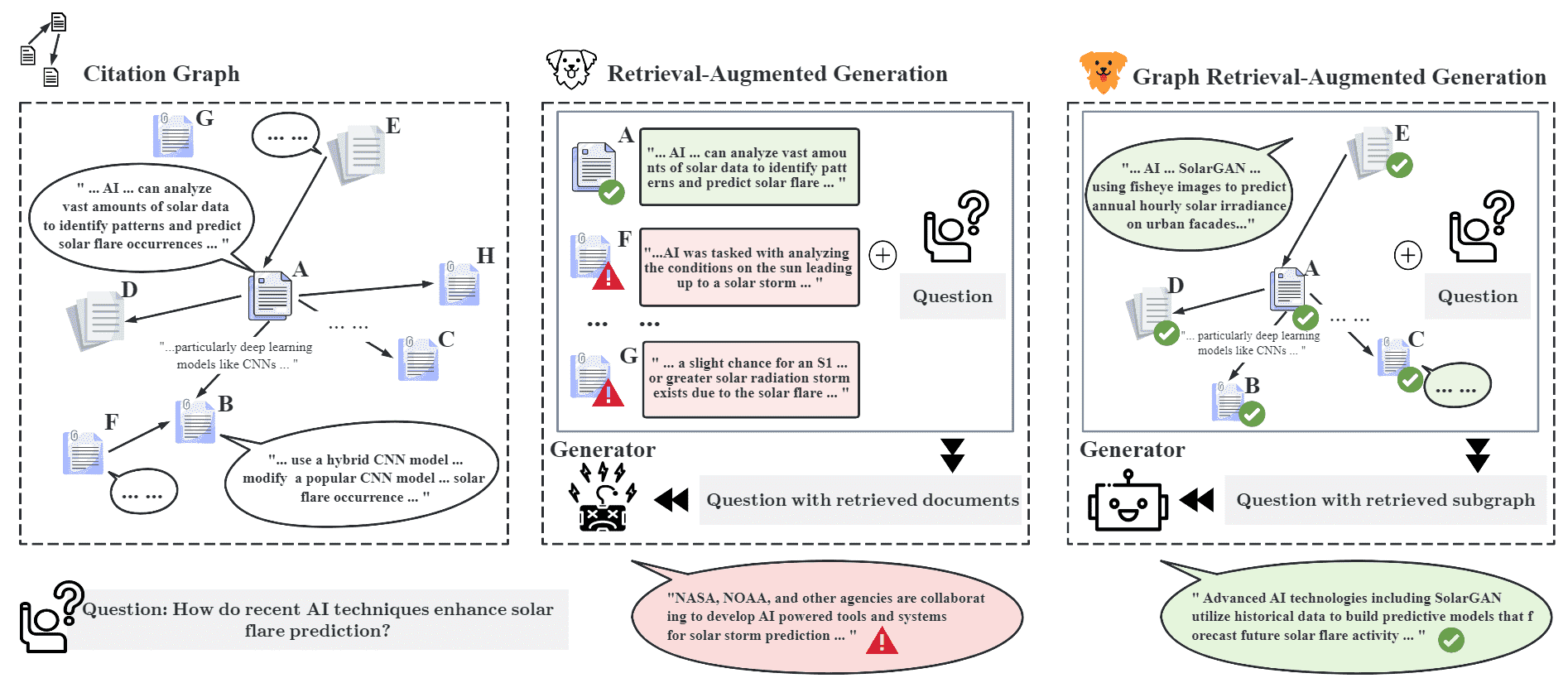
Figure 1:GRAG retrieves textual subgraphs relevant to the query, rather than discrete entities as in RAG. Entities with similar topics tend to have connections, which improves the precision and robustness of the retrieval phase.
本文总结如下:
1. 研究背景
大语言模型(LLMs)在多种推理任务中表现出色,包括基于图结构的数据处理。然而,由于训练数据的限制和缺乏实时知识,LLMs在事实准确性方面存在问题。为解决这一问题,研究者提出了检索增强生成(RAG),通过引入外部信息来提高模型输出的准确性和相关性。但传统的RAG方法主要基于文本相似性,仅关注独立文档,忽视了现实世界中文档之间的网络关系(如知识图谱、论文引用关系、社交媒体互动等),而这些结构信息在信息检索和文本生成中具有重要作用。
2. 提出问题
现有RAG方法无法有效利用文档间的网络结构(即“文本图”)。当LLMs需要从图结构中检索信息并生成答案时,如何整合这些结构信息成为一个关键挑战,包括:
检索阶段:如何高效地检索与查询相关的文本子图?
生成阶段:如何将子图的文本与拓扑信息传递给LLMs,并生成高质量的回答?
3. 本文贡献
为解决上述问题,作者提出了图检索增强生成(GRAG),其主要贡献包括:
问题定义与框架设计:提出了GRAG的概念,并设计了一个计算框架,扩展了传统RAG方法,使其能够处理图结构数据。
高效子图检索方法:提出了一种分而治之的策略,通过“自我图”(ego-graph)的初步检索和软剪枝机制,高效近似地找到相关子图,避免了穷举子图的NP难问题。
图信息的提示机制:设计了双通道提示方法,包括:
硬提示(hard prompts):将子图结构转换为层次化文本描述,保留拓扑信息;
软提示(soft prompts):通过图编码器提取图的拓扑和文本信息,以结构化形式传递给LLMs。
实验验证:在多跳图推理任务中,GRAG显著优于基于RAG的基线模型和微调后的LLMs,甚至在未微调的LLM上也表现更优。
4. 实验结果
实验结果验证了GRAG在图结构场景下的优越性能,特别是在需要多跳推理的任务中,GRAG能够更有效地利用图结构信息,提升回答的准确性和相关性。
总结
本文提出并验证了GRAG方法,通过结合图结构的拓扑关系与文本信息,有效提升了RAG在复杂图数据场景下的性能,为LLMs在图推理任务中的应用提供了新的思路和方法。
3 Problem Formalization¶
本节内容对文本图(Textual Graphs)和文本子图(Textual Subgraphs)进行了形式化定义,并提出了基于图的检索增强生成(Graph Retrieval Augmented Generation,GRAG)任务的数学模型。以下是主要内容的总结:
文本图的定义:
文本图 \( G = (V, E, \{T_n\}_{n \in V}, \{T_e\}_{e \in E}) \),由节点集 \( V \) 和边集 \( E \) 构成,每个节点和边都带有自然语言属性(文本信息)\( T_n \) 和 \( T_e \)。
文本子图的定义:
文本子图是原始文本图的一个子结构,形式化定义为
\( g = (V', E', \{T_n\}_{n \in V'}, \{T_e\}_{e \in E'}) \)
其中 \( V' \subseteq V \),\( E' \subseteq E \),即子图的节点集和边集是原始图的幂集中的元素。
GRAG 任务的目标:
将图的上下文信息集成到检索和生成两个阶段中,以提升生成结果与图中嵌入知识的相关性。
在给定查询 \( q \) 和文本图 \( G \) 的情况下,目标是检索出一个最优的子图 \( \hat{g} \in \mathcal{S}(G) \),使得基于该子图的语言模型输出更符合预期。
GRAG 的概率模型:
GRAG 的目标是通过最优子图 \( \hat{g} \) 来增强语言模型的生成能力。最终输出序列 \( Y \) 的概率分布为:
\(p_\theta(Y \mid [q, G]) = \prod_{i=1}^{n} p_\theta(y_i \mid y_{<i}, [q, \hat{g}])\)
其中,\( y_{<i} \) 表示前缀词元,\( [q, \hat{g}] \) 表示查询与最优子图信息的拼接。
示意图说明:
提供了 GRAG 方法的流程图(图2),用于直观展示图信息如何被检索并整合到生成过程中。
总结:本节从数学角度形式化了文本图和文本子图的结构,并提出了 GRAG 模型的目标和基本框架,强调了在生成过程中利用图中检索到的最有信息子图的重要性。
4 Methodology¶
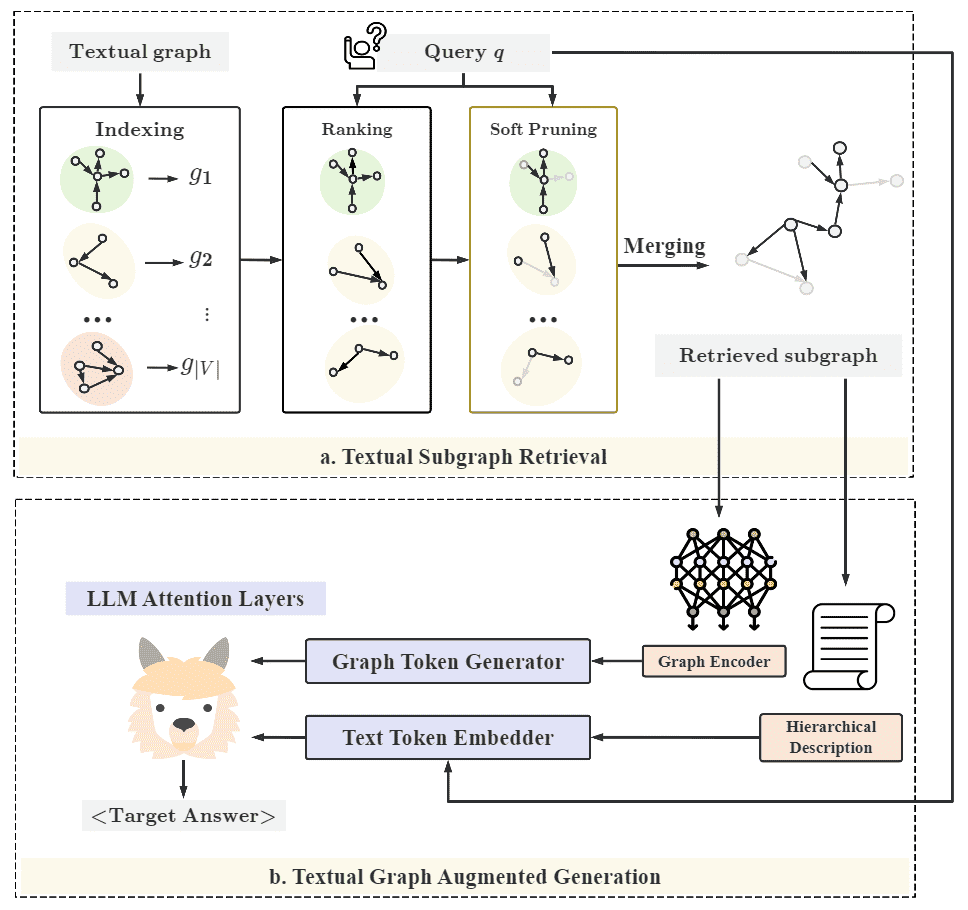
Figure 2:Illustration of our GRAG approach.
本节介绍了 GRAG 方法的实现方式,主要围绕文本子图检索和生成过程展开,具体总结如下:
概述¶
GRAG 采用分而治之的策略,解决文本子图检索的问题。该方法基于一个重要假设:关键子图由重要节点及其部分邻居构成。具体流程分为两步:
检索:搜索重要节点的ego-graph(K-hop邻域图);
剪枝与融合:将检索到的子图合并,并通过软剪枝去除冗余的节点与边,最终生成一个近似最优的子图结构。
相比直接在所有子图中搜索(搜索空间为 \(2^{|V|+|E|}\)),GRAG 仅搜索 \(|V|\) 个 ego-graph,显著提高了效率。
此外,为保留图的文本信息和拓扑结构,GRAG 采用双视图方法:
图视图:将子图表示为软提示(soft prompt),保留文本连接关系;
文本视图:将子图转换为层次文本描述作为硬提示(hard prompt),保留连接的叙述方式。
4.1 文本子图检索¶
目标:给定一个文本图 \(G\),找出一个子图 \(\hat{g}\),最大化其对后续生成任务的帮助(即最大化 \(f(\hat{g})\))。
关键假设:子图可以看作是若干关键节点的K-hop邻域的并集。
公式建模:
\(\max_{\hat{g}} f(\hat{g}) = \max_{V_{\text{key}}} f\left(\bigcup_{v \in V_{\text{key}}} G[\mathcal{N}_K^*(v)]\right)\)
其中
\(V_{\text{key}}\) 是关键节点集合,
\(\mathcal{N}_K^*(v)\) 是节点 \(v\) 选择的K-hop邻域。
近似策略:将联合优化问题近似为对每个节点邻域独立评分的加总问题,将原NP难问题转化为线性复杂度问题。
文本子图索引(Indexing)¶
编码方法:使用预训练语言模型(如 SentenceBERT)将节点和边的文本属性编码为向量。
图嵌入生成:对所有节点和边的嵌入进行均值池化,得到子图 \(g\) 的嵌入表示 \(z_g \in \mathbb{R}^d\)。
公式:
\(z_g = \text{POOL}(\text{PLM}(\{T_n\}_{n \in V_g}, \{T_e\}_{e \in E_g}))\)
所有子图嵌入存储在索引库中,用于后续检索。
文本子图排序(Ranking)¶
查询编码:使用相同的PLM对查询 \(q\) 进行编码,得到 \(z_q\)。
相似度排序:计算每个子图与查询的余弦相似度 \( \text{cos}(z_q, z_g) \),选出与查询语义最相关的Top-N个子图。
公式: $\( \mathcal{S}_N(G) = \text{Top-N}_{g \in \mathcal{S}(G)} \text{cos}(z_q, z_g) \)$
文本子图软剪枝(Soft Pruning)¶
目的:去除检索子图中与查询不相关的节点和边。
方法:使用两个MLP网络分别对节点和边进行剪枝:
对节点和边嵌入与查询嵌入的差异进行建模,输出一个缩放因子 \(\alpha\)。
距离查询越远,\(\alpha\) 越接近0,对应节点或边被有效“掩码”。
公式: $\( \alpha_n = \text{MLP}_{\phi_1}(z_n \ominus z_q), \quad \alpha_e = \text{MLP}_{\phi_2}(z_e \ominus z_q) \)$
最终子图融合:对剪枝后的Top-N个子图进行合并,得到最终的查询相关子图 \(\hat{g}\),复杂度为线性。
总结¶
GRAG 方法通过分而治之的策略,结合高效检索与软剪枝机制,实现对文本子图的快速、有效的检索与优化,为下游生成任务提供高质量的图结构输入。其核心优势在于:
显著降低搜索空间(从指数级降至线性);
双视图设计兼顾拓扑结构与文本信息;
软剪枝机制提升子图与查询的相关性。
4.2 Textual Graph Augmented Generation¶
本节提出了“文本图增强生成”(Textual Graph Augmented Generation)方法,旨在为大语言模型(LLM)提供两种互补的文本图视图:文本视图和图视图,从而增强其在生成任务中的推理能力。
1. 文本视图(Text View of Textual Graphs)¶
该方法通过将检索到的子图结构化为层次结构,帮助LLM更好地保留图的拓扑信息。由于图中可能包含额外边(非父子关系),这与树结构不同,因此提出了一种基于广度优先搜索(BFS)和先序遍历的算法,将图分解为一个树结构和一个额外边集合。通过这种方式,可以将图转换为具有层次结构的文本描述,从而实现图与文本之间的无损转换。
最终,将该文本描述与原始查询拼接,形成一个“硬提示”输入到LLM中,以引导其生成过程。
2. 图视图(Graph View of Textual Graphs)¶
为了保留图的结构信息,使用图神经网络(GNN)对图进行编码。为了避免无关节点对生成结果的影响,引入了软剪枝机制,通过学习的相关性缩放因子控制GNN中的信息传递。接着,使用多层感知器(MLP)将图嵌入对齐到LLM的文本向量空间中,从而实现图结构与LLM的融合。
3. 生成阶段(Generation Phase)¶
在生成阶段,结合了两种提示方式:一个是图结构的软提示(由GNN编码并经过MLP对齐),另一个是文本视图的硬提示(由文本结构化描述和查询组成)。最终的生成结果通过联合概率模型进行建模,将这两个提示信息融合,从而提升生成结果的准确性和结构感知能力。
总结¶
本节的核心贡献在于通过文本视图和图视图的结合,构建了一个增强的图检索与生成框架,使LLM能够更好地理解图的结构和语义信息,从而在复杂任务中实现更高质量的生成输出。
5 Experiments¶
总结:第五章 实验部分¶
本章详细介绍了 GRAG(Graph Retrieval-Augmented Generation)方法在图结构数据上的实验设置、主要结果、讨论及消融研究。
5.1 实验设置¶
数据集:实验在 GraphQA 基准上的两个子数据集 WebQSP 和 ExplaGraphs 上进行,前者侧重多跳图推理,后者侧重常识推理。两者的图结构特征差异显著(WebQSP 图较大,ExplaGraphs 图较小)。
评估指标:对于 WebQSP,使用 F1 Score、Hit@1 和 Recall;对 ExplaGraphs 使用 Accuracy。
对比方法:比较了多种主流的 RAG 检索方法(如 BM25、MiniLM、LaBSE、E5 等)以及 LLM 基线模型(冻结 LLM 和 LoRA 微调的 LLM)。
实验模型:使用 Llama2-7b 作为基础模型,详细设置见附录。
5.2 主要结果¶
GRAG 表现优于基线:GRAG 在所有指标上均显著优于未微调和微调的 LLM,以及传统 RAG 方法。例如,在 WebQSP 上,GRAG 的 Hit@1 达到 0.7236,远高于冻结 LLM 的 0.4148。
微调效果有限:即使对 LLM 进行微调(LoRA),GRAG 的提升幅度较小,说明 GRAG 本身是提升图推理能力的有效策略。
图信息压缩的重要性:直接将图的全部文本信息作为上下文输入 LLM 性能较差,表明需要通过检索机制过滤冗余信息。
跨数据集迁移能力:GRAG 在 WebQSP 上训练后,在 ExplaGraphs 上的准确率提升了 33.77%,显示其良好的迁移能力。
模型规模不一定带来性能提升:在未使用检索增强的情况下,更大的 LLM(如 Llama2-13B)在图任务上表现略差于较小模型(如 Llama2-7B)。
5.3 讨论¶
子图大小 K 的影响:子图越大会增加计算开销,且可能引入信息过平滑问题。2-hop 子图在性能和效率上表现最佳。
幻觉评估:GRAG 的生成结果在人工评估中具有较高的真实性(79% 引用了图中真实实体),优于其他 RAG 方法。
与 RAG 的对比:传统 RAG 方法仅依赖文本检索,忽略了图的拓扑结构。GRAG 通过直接检索子图并将其结构信息嵌入生成过程,取得了最佳效果。
5.4 消融研究¶
图结构编码的重要性:若不将图信息编码(w/o Graph Encoder),生成性能显著下降(Hit@1 从 0.7275 降至 0.5835),说明 LLM 仅靠文本描述不足以理解图结构。
软剪枝的作用:去除不相关实体(Soft Pruning)对性能提升至关重要,尤其在稠密图中效果更明显。
文本属性的关键性:仅依赖图的结构信息(软 token)无法有效提升生成质量,必须结合节点与边的文本描述。
总体结论¶
GRAG 通过引入图检索机制,将图的拓扑结构和文本信息有效整合到大语言模型中,显著提升了图推理任务的性能。相比传统的 RAG 和 LLM 微调方法,GRAG 在多个数据集上表现更优,具有较好的可迁移性、可解释性和抗冗余能力。
6 Conclusion¶
本章总结了论文的主要贡献和实验结果。论文提出了基于图的检索增强生成模型(GRAG),扩展了传统的检索增强生成(RAG)方法,适用于图结构数据场景。GRAG通过检索与查询相关的文本子图来增强大语言模型(LLM)的生成能力,并提出了一种分治策略,利用 K-hop 邻域图和软剪枝技术来高效近似最优子图。该方法为 LLM 提供了两种互补的图视角——图视角和文本视角,从而实现对图上下文的全面理解。
实验结果表明,GRAG 在需要多跳推理的文本图任务中显著优于基线 LLM 和基于 RAG 的方法。此外,GRAG 不仅解决了子图搜索这一 NP 难问题,还证明了在无需微调的情况下,通过 GRAG 增强的冻结 LLM 在性能上可媲美甚至超越微调模型,同时降低了训练成本。
7 Limitations¶
本章节讨论了GRAG方法的局限性。尽管GRAG为图上下文感知生成提供了一个有效的框架,但其文本子图检索的效率高度依赖于初始节点排序和剪枝机制的质量。当图结构复杂或节点重要性难以评估时,可能导致检索性能不佳。
Acknowledgments¶
本研究得到了美国国家科学基金会(NSF)和美国国立卫生研究院(NIH)的多项资助支持,具体包括:NSF资助编号2414115、2403312、2007716、2007976、1942594、1907805,以及NIH资助编号R01AG089806和R01CA297856。
Appendix A Appendix¶
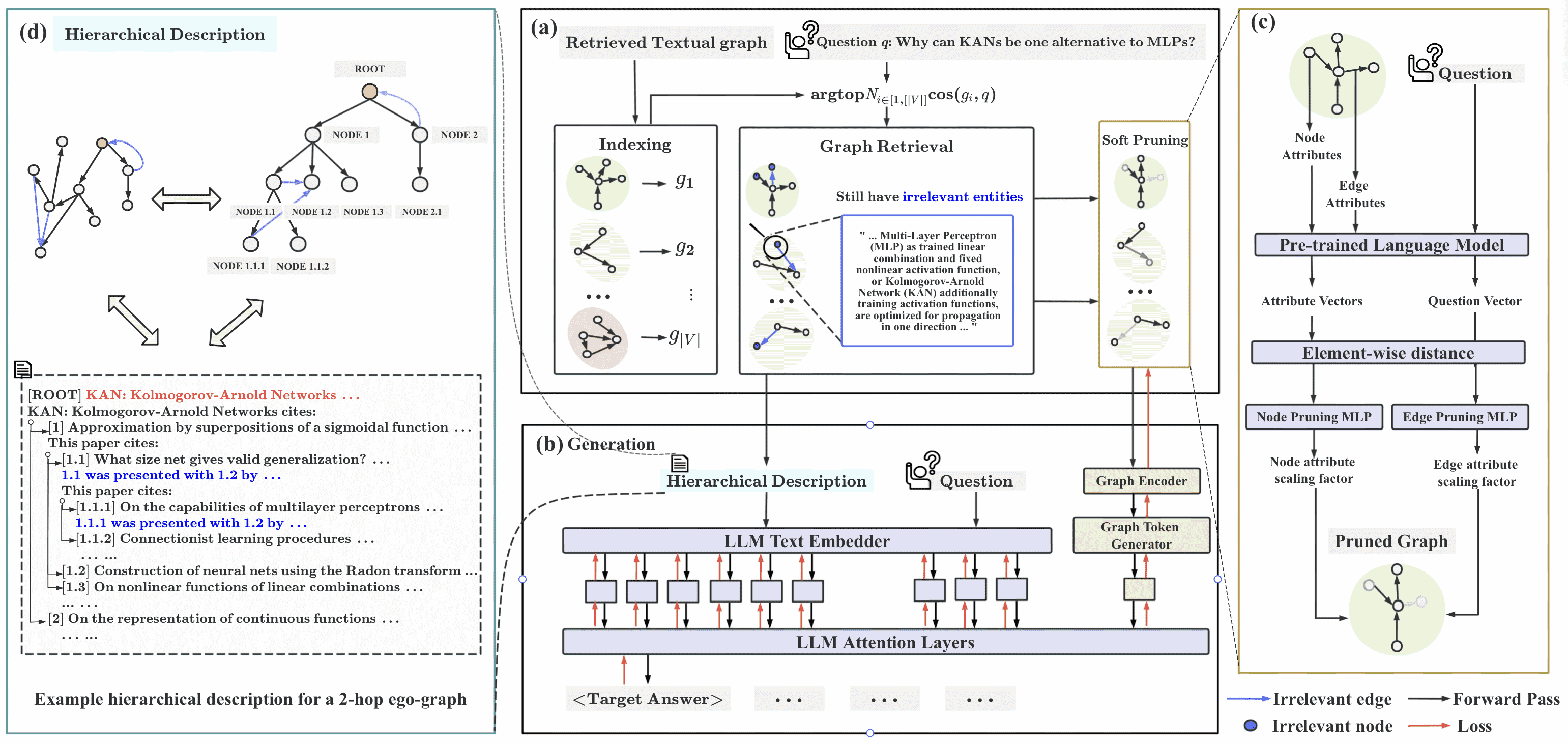
以下是对所提供论文附录章节内容的总结:
附录A 总结¶
A.1 层次化描述¶
本节介绍了如何将图结构转化为层次化的文本形式。以2-hop ego图为例,该图被转换成一个嵌套、缩进的列表结构,反映出图中的层级关系。每个节点及其子节点之间的连接通过缩进方式表示,同时保留了图中的文本信息(如节点标题或内容)。这种层次化结构能够清晰地展示节点之间的连接关系,有利于后续的检索和生成任务。
A.2 检索器对比¶
本节列出了多种用于RAG(检索增强生成)框架的检索器模型,包括:
BM25:基于统计的检索模型,使用词频、反文档频率等指标。
MiniLM-L12-v2:SentenceTransformer模型,用于聚类和语义搜索。
LaBSE:基于BERT的跨语言检索模型。
mContriever-Base:使用对比学习的双编码器架构。
E5-Base:使用对比预训练的双编码器模型,优化相关性对。
G-Retriever:基于图结构检索,使用Prize-Collecting Steiner Tree方法构建子图。
这些模型在不同数据集上的性能在表中进行了比较。
A.3 实现细节¶
数据划分:ExplaGraphs为60%/20%/20%,WebQSP为60%/5%/35%。
实验环境:基于Linux服务器,配备4块NVIDIA A10G GPU。
文本编码:使用SentenceBert对问题和图属性进行编码。
图编码:使用GAT(Graph Attention Network)模型,4层,每层4个头,隐藏维度为1024。
大语言模型(LLM):使用Llama-2-7b-hf,LoRA微调参数设置为秩8、缩放因子16、Dropout 0.05。
优化器:使用AdamW,学习率为1e-5,权重衰减0.05。
每个模型在ExplaGraphs上进行3次实验(top-3, top-5, top-10),在WebQSP上进行5次(top-3到top-20)。
A.4 实验分析¶
评估指标:包括Hit@1、F1分数、召回率和准确率(Acc)。
检索实体数量的影响:随着检索数量增加,模型性能通常先提升后趋于稳定甚至下降。例如,BM25在WebQSP上的Hit@1从top-3的0.3722提升到top-20的0.4287,但LaBSE在top-15后性能开始下降。这说明过多的检索结果可能引入噪声,影响生成质量。
小图限制:在ExplaGraphs数据集上,由于图规模较小,大多数模型的性能提升有限,而GRAG通过有效利用图拓扑信息,突破了这一瓶颈。
总结¶
本附录详细描述了论文中提出的GRAG(Graph Retrieval-Augmented Generation)方法的技术细节和实验设置,包括层次化图描述、多种检索器模型的比较、模型实现参数,以及对检索实体数量对性能影响的分析。实验表明,在适当数量的检索实体下,模型性能最佳,过多检索反而可能引入噪声。GRAG通过有效利用图结构信息,在小图任务中表现出更强的性能优势。