2410.00487_SELF-PARAM: Self-Updatable Large Language Models by Integrating Context into Model Parameters¶
引用: 2(2025-08-24)
组织:
1University of California San Diego,
2University of Illinois Urbana-Champaign
总结¶
总结
目标:将一段特定的知识或上下文 x 永久地、不可逆地融合到模型参数 θ 中,创建一个新的、独立的模型 θ’。目标是让模型内化这些知识,就像它从训练数据中学到的一样。
背景
整合新知识长期保留的2种方法:
无需额外模块或参数的方法
持续学习
模型编辑
知识蒸馏
需要额外模块或参数的方法
RAG
长上下文
记忆增强
SELF-PARAM
核心目标
不修改模型架构、不增加额外存储(即存储复杂度 𝒮 为零) 的情况下,将一段特定的上下文信息 x 直接“熔炼”进大语言模型(LLM)的参数中,得到一个更新后的模型 θ’
实现方式:
更新后的模型 θ’ 需要达到的效果是:
当用户只提供一个相关的提示 p 时,θ’ 生成的输出,
应该与原始模型 θ 在接收到“上下文 x + 提示 p”这个完整输入后生成的输出完全相同。
与 Prefix-Tuning 的关系¶
快速理解
Prefix-Tuning 是给模型一个可重用的、高效的“外部指令集”。模型本身没变,但学会了如何解读这个指令集。
上下文注入 是直接给模型**“动手术”**,改写它的“记忆”,让它从根本上变成一个知识更丰富的新模型。
核心目标与哲学
特性 |
上下文注入 (Context Injection) |
Prefix-Tuning |
|---|---|---|
目标 |
知识整合与模型更新。将一段特定的知识或上下文 |
条件生成与控制。为特定的任务(如摘要、情感分析)学习一个可训练的软提示(Soft Prompt/Prefix),作为模型输入的一部分。不改变原始模型 |
类比 |
给学生一本参考书让他学习并记住。之后即使没有那本书,他也能回答相关问题。知识成为了学生自身的一部分。 |
给演讲者一张提词卡。演讲者(模型)的能力没变,但根据提词卡(Prefix)的内容,他能做出更符合要求的演讲。提词卡和演讲者是分开的。 |
存储复杂度 |
𝒮 = 0。这是论文的核心目标之一。信息被吸收进模型参数后,原始的上下文 |
𝒮 > 0。必须存储学习到的 Prefix 参数。对于每个任务或每个上下文,都需要存储一套对应的 Prefix 向量。 |
Abstract¶
尽管大型语言模型(LLMs)取得了显著进展,但如何快速且频繁地整合小规模经验(如与周围物体的交互)仍然是一个重大挑战。在整合这些经验时,最关键的两个因素是:
有效性(Efficacy):模型能够准确记住近期事件的能力;
保留性(Retention):模型能够回忆长期过去经验的能力。
目前的方法主要有两种:
一种是通过持续学习、模型编辑或知识蒸馏等技术,将经验嵌入到模型参数中。但这些方法在处理快速更新和复杂交互时往往表现不佳;
另一种是依赖外部存储来实现长期保留,但这种方式会增加存储需求。
为此,本文提出了 SELF-PARAM(通过将上下文信息整合进模型参数来实现自更新的大型语言模型)。该方法不引入额外参数,同时保证了近最优的有效性和长期保留性。
重点突出:
SELF-PARAM 的训练目标是最小化原始模型(可以访问上下文信息)与目标模型(无法访问上下文)之间的KL散度;
通过生成与知识相关的多样化的问答对,并在这些数据集上最小化KL散度,从而更新目标模型,使模型在参数内部自然地吸收知识。
实验评估表明:
在问答任务和对话推荐任务中,SELF-PARAM 显著优于现有方法,即使在考虑非零存储需求的情况下也是如此;
这项研究为大型语言模型的更高效和可扩展的经验整合奠定了基础,通过直接将知识嵌入模型参数来实现。
1 Introduction¶
在动态环境中,无论是虚拟世界(如视频游戏)还是现实世界中的人类社会,开发一个能够与对象有效交互的认知系统都面临重大挑战。文章将认知系统与其环境之间的交互定义为“经验”。为了保持功能性和适应性,认知系统必须持续进化,通过整合新经验并在与环境互动时反思过往经验(Wang et al., 2024d)。
在此进化过程中,系统面临的主要挑战是:如何吸收经验、如何适应变化,以及如何在未来回忆关键事件。这突出了系统必须具备的两个关键属性:
效能(Efficacy):系统必须对近期事件有精准的记忆,确保知识整合的准确性和效率。
保留能力(Retention):系统应具备强大的长期记忆能力,能有效回忆过去的经历。
实现长期保留的两种方法¶
为了实现长期保留,认知系统必须有效存储其经验。目前的方法可以根据是否引入额外模块或参数分为两类:
####(1)无需额外模块或参数的方法
这些方法将知识直接嵌入模型参数中,包括:
模型编辑(如 MEND、ROME、MEMIT、Model-Editing-FT):通过更新模型部分组件来插入或修改信息,适合处理事实性陈述,但对复杂经验的处理能力有限。
持续学习(Continual Learning):能处理更复杂的信息,但通常需要预训练或微调语料库,不适用于频繁更新,且依赖下一个词预测(NWP)损失函数,可能影响即时知识整合的效能。
知识蒸馏(Knowledge Distillation):主要针对事实或提示的蒸馏,对于复杂经验的整合效果有限。
####(2)需要额外模块或参数的方法
这些方法借助外部组件(如文本仓库、知识库或记忆模块)来存储过往经验,从而实现长期保留。例如:
MemoryLLM 和 Retrieval-Augmented Generation:允许模型在推理时访问外部信息,提升准确性与相关性,但依赖外部存储,导致存储需求高。如果模块规模较小,效果提升有限。
提出的新方法:SELF-PARAM¶
为了解决上述挑战,文章提出SELF-PARAM(Self-Evolvable Large Language Models with Parameter Integration)方法,具有以下优势:
零额外参数,即无需新增模块或参数;
高效整合上下文:通过定义“上下文注入有效”为模型在将上下文整合进参数后,能准确回答相关问题;
训练目标:最小化原始模型(有上下文)和目标模型(无上下文)之间的KL散度,从而让目标模型在没有上下文的情况下也能生成类似原始模型的响应;
训练数据构建:使用指令模型生成与上下文相关的问答对,并结合预训练数据集中的句子,形成目标句子集;
核心思想:通过足够多样的训练样本,使目标模型在参数中“内化上下文”,进而在未来生成准确响应。
实验与结果¶
文章通过以下任务验证了 SELF-PARAM 的有效性:
单上下文注入与批量上下文注入任务:测试模型在插入不同数量上下文后的表现。
顺序上下文注入任务:测试模型对知识的长期保留能力。
对话推荐任务:将用户与系统的对话注入模型,结果表明模型的推荐召回率显著优于其他基线模型。
实验结果表明,SELF-PARAM 在不引入额外参数的前提下,显著优于现有方法,实现了高效率与强保留能力的双重目标。
总结¶
本节重点介绍了认知系统在动态环境中的挑战,以及目前用于实现知识保留的两类方法的优缺点。随后提出了SELF-PARAM这一创新方法,通过最小化KL散度的方式,使得模型在无额外参数的情况下,实现高效的上下文注入和知识保留。实验部分进一步验证了该方法在多个任务中的优越表现。
3 Methodology¶
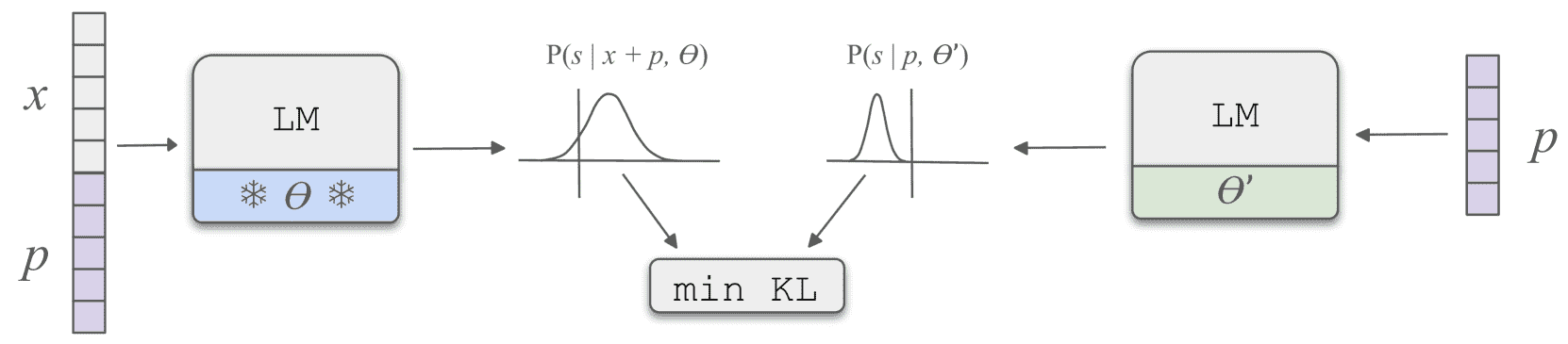
Figure 1: The Process of Context Injection.
图片理解
旨在将外部上下文直接注入到语言模型的参数中,从而使其在不提供原上下文的情况下,也能正确回答与该上下文相关的问题。
目标:
给定一个原始语言模型 \( \theta \) 和一个上下文 \( x \),我们希望获得一个新的模型 \( \theta' \),使得当模型 \( \theta' \) 接收一个提示 \( p \) 时,其输出与模型 \( \theta \) 接收 \( x + p \) 时的输出相同。也就是说,\( \theta' \) 应该能够模拟 \( \theta \) 在拥有上下文 \( x \) 时的行为。
数学表达:
令 \( P(s|x+p, \theta) \) 表示模型 \( \theta \) 在输入 \( x + p \) 时对句子 \( s \) 的概率分布,而 \( P(s|p, \theta') \) 是模型 \( \theta' \) 在输入 \( p \) 时的输出分布。我们希望通过最小化两者的 KL散度,使 \( \theta' \) 能够准确地模拟 \( \theta \) 在上下文 \( x \) 下的行为。
3.1 Definition of Context Injection(上下文注入的定义)¶
核心定义:¶
Context Injection 是将特定的上下文 \( x \) 注入到语言模型中,使其能够独立生成与该上下文相关的正确回答的过程。
举个例子:
原始模型 \( \theta \) 在没有上下文的情况下,对于问题 \( p \) 会生成不准确的答案 \( a_1 \)。
当上下文 \( x \) 被加入提示中(即输入 \( x + p \)),模型 \( \theta \) 能正确生成 \( a_2 \)。
目标是将上下文 \( x \) 注入模型中,使得新模型 \( \theta' \) 在仅输入 \( p \) 时也能生成正确答案 \( a_3 \)。
两个关键性质:¶
Efficacy(有效性):模型 \( \theta' \) 能够准确回答与上下文 \( x \) 相关的问题。
Retention(保留性):模型在多次注入不同上下文后,仍能保留先前注入的信息。
最终目标:在不增加存储复杂度的前提下,最大化这两个性质。
3.1.1 The Process of Context Injection(上下文注入的过程)¶
核心思想:¶
通过最小化 KL 散度,使新模型 \( \theta' \) 能在不提供上下文 \( x \) 的情况下,模拟原始模型在上下文 \( x \) 下的行为。
优化目标: $\( \theta' = \arg\min_{\hat{\theta}} \mathbb{E}_s [KL[P_\theta(s|x) \| P_{\hat{\theta}}(s)]] \)$
其中 \( s \) 是任意句子,包括与上下文相关和不相关的句子。在实际中,我们通过采样生成目标句子集合 \( \mathcal{E} \) 来近似这个目标。
3.2 Construction of Target Sentence Set(目标句子集的构建)¶
目标句子集包含两部分:¶
与上下文相关的句子(用于注入上下文 \( x \)):
使用指令模型(如 GPT-4o-mini 或相应的 Instruct 模型)生成 QA 对,用于训练模型回答与上下文 \( x \) 相关的问题。
与上下文无关的句子(用于保留模型原有能力):
从 SlimPajama 数据集中随机采样,防止模型在注入上下文后丢失通用语言能力。
作用:通过平衡这两类句子,模型既能学习新知识,又能保持对通用语言的理解和生成能力。
3.3 Discussion(讨论)¶
3.3.1 性能提升的原因(Where does the performance gain come from?)¶
与传统的 NWP(Next-Word Prediction) 相比,我们提出的方法通过训练 多样化的QA对,鼓励模型真正理解知识,而不仅仅是记忆特定的输入形式。
例如:当上下文是 “David likes apples.” 时,模型在 NWP 损失下可能无法回答 “What fruit does David like?”,而我们的方法由于训练了多种形式的问答对,能更好地泛化。
3.3.2 计算成本分析(Analysis of the Computational Cost)¶
成本增加:相比传统微调方法,我们的方法需要额外生成 QA 对和计算原始模型的 Logits,因此计算成本大约是传统方法的两倍。
成本合理性:尽管成本较高,但实验表明我们的方法在准确性和保留性上表现更优,因此是值得的。
3.3.3 幻觉缓解(Hallucination Mitigation)¶
由于我们鼓励模型在没有原始上下文的情况下生成回答,存在“幻觉”(Hallucination)的风险。
缓解措施:
过滤掉需要依赖原始上下文的提示(如总结上下文、生成标题等)。
仅保留基于固定事实的问答对(如“What language was used…?”),以减少模型生成错误回答的可能性。
使用 KL 散度优化目标,而非直接预测目标句子,也可以减少幻觉。
总结:¶
本节提出了一个名为 Context Injection 的方法,通过将外部上下文注入语言模型参数中,使得模型在不提供原始上下文的情况下也能正确回答相关问题。该方法通过最小化 KL 散度的方式优化新模型,使其行为等价于原始模型在上下文输入下的行为。目标句子集由与上下文相关的 QA 对和与上下文无关的句子组成,以兼顾新知识的注入和原有语言能力的保持。尽管该方法引入了一定的计算成本,但其在准确性和保留性上的提升证明了其有效性。此外,通过精心设计的数据集和优化方式,有效缓解了模型幻觉问题。
4 Experiments¶
论文作者在“实验”部分通过四种任务评估了其提出的方法 SELF-PARAM 的性能,分别对应不同的上下文注入方式和评估维度。
4.1 单上下文注入(Single Context Injection)¶
实验设置:¶
数据集:使用 PwC 数据集,包含(上下文,问题,答案)三元组。
方法:对每个上下文进行注入,然后提问模型并计算 QA-F1 得分。
模型:OpenLLaMA-3B-v2、Mistral-7B、Llama3-8B。
对比基线:Base(原始模型)、FT (C)(仅对上下文微调)、FT (S)(对生成的问答对微调)。
结果:表格 1 显示,SELF-PARAM 表现最优,尤其在 Llama3-8B 上接近 Base,C+Q(提供上下文和问题的上限性能)。
总体表现比较:¶
重点结论:
SELF-PARAM 显著优于所有微调基线。
与 FT (C) 相比,SELF-PARAM 能更好地融合并使用知识。
与 FT (S) 相比,SELF-PARAM 的训练目标(最小化 KL 散度)能更有效地接近 Base,C+Q 的性能上限。
4.2 批量上下文注入(Batch Context Injection)¶
实验设置:¶
数据集与模型:沿用 PwC 数据集与前三模型。
任务:一次性注入 100 或 500 个上下文,并测试模型对所有相关问题的回答性能。
对比基线:除 FT 基线外,还引入了 MemoryLLM、InfLLM、DPR、BM25、RAPTOR 等方法。
性能指标:QA-F1 得分与存储复杂度(Storage Complexity)。
总体表现比较:¶
重点结论:
SELF-PARAM 在所有模型和上下文规模下表现最佳,接近 Base,C+Q 上限。
与 FT (C) 和 FT (S) 相比,SELF-PARAM 不仅注入有效,还能保留上下文的通用性。
与 MemoryLLM、DPR、BM25 等方法相比,SELF-PARAM 不需要额外存储模块,具有零存储复杂度(Storage Complexity 为 0)。
结论:SELF-PARAM 在批量上下文注入任务中具有明显的性能优势与存储效率。
4.3 顺序注入(Sequential Injection)¶
实验设置:¶
任务:评估模型在多次上下文注入后是否能保留之前的上下文。
方法:顺序注入 20 个上下文,每注入一次就评估模型对之前所有问题的回答性能。
模型:使用 Mistral-7B,通过 LoRA 进行微调。
结果:通过图 2 展示 QA-F1 得分随注入次数的变化。
结果与讨论:¶
重点结论:
随着注入次数增加,性能略有下降,但 SELF-PARAM 在 20 次注射后仍保持约 0.3 的 QA-F1 得分,远高于基线约 0.14。
对角线性能表明模型在多次更新后仍能保留早期知识。
结论:SELF-PARAM 表现出良好的长期记忆能力。
4.4 对话推荐(Conversational Recommendation)¶
实验设置:¶
任务:将对话数据注入模型,用于生成电影推荐。
数据集:INSPIRED(731 轮对话)、REDIAL(7415 轮对话)。
模型:Mistral-7B-instruct-v0.2。
对比基线:FT (C)、FT (S)、DPR、BM25、RAPTOR。
评价指标:Recall@1(r1, r2, r3, r4)。
总体表现比较:¶
重点结论:
SELF-PARAM 在所有场景和数据集中表现最优。
与 FT (C) 和 FT (S) 相比,SELF-PARAM 不仅能有效整合对话知识,还能保持模型原有能力。
与 DPR、BM25 等方法相比,SELF-PARAM 不依赖外部检索模块,具备更低的复杂度。
结论:SELF-PARAM 在对话推荐任务中表现出色,展示了其在交互式任务中的潜力。
4.5 消融研究(Ablation Study)¶
训练目标的消融研究:¶
对比使用 NWP 损失对原始上下文(FT (C))和生成的问答对(FT (S))进行微调的效果。
结论:FT (S) 表现优于 FT (C),但仍远低于 SELF-PARAM,说明训练目标的设计是性能提升的关键。
目标句子集合构建模型的消融研究:¶
替换 gpt-4o-mini 为对应 instruct 模型生成目标句子。
结论:性能基本持平,说明 SELF-PARAM 的优势不依赖于使用更强大模型来生成目标句子,具备方法独立性。
总结¶
论文在实验部分通过 四个任务(单上下文、批量注入、顺序注入、对话推荐)全面评估了 SELF-PARAM 的性能。核心结论如下:
性能方面:SELF-PARAM 显著优于所有基线模型,尤其在注入效率和知识保留方面表现突出。
存储效率方面:SELF-PARAM 不需要额外存储模块,具备零存储复杂度,适合资源受限场景。
泛化能力:无论是问答还是对话推荐,SELF-PARAM 都能有效吸收并应用新知识,且不影响模型原有能力。
训练目标设计:通过最小化 KL 散度,使模型在更新知识时保持稳定性与一致性。
这些实验结果验证了 SELF-PARAM 在自更新大语言模型领域的有效性与创新性。
5 Conclusion and Future Work¶
总结部分¶
本文针对一个关键挑战进行了研究,即如何在不增加存储复杂度的前提下,高效地将小规模经验整合进大型语言模型(LLM),并且实现长期保留。为此,作者提出了SELF-PARAM(自更新型大语言模型与参数整合),这是一种通过最小化原始模型与目标模型之间的KL散度,将经验直接嵌入模型参数的新方法。原始模型具有上下文信息,目标模型则不包含上下文。
通过在多种任务中进行全面评估,包括单次上下文注入、批量上下文注入、连续注入以及对话推荐,研究发现,SELF-PARAM在即时知识整合和多次注入后的知识保留方面,均优于现有的基线方法。值得注意的是,SELF-PARAM在实现这些进步的同时,不需要额外参数或外部存储模块,从而保持了模型的完整性与在动态环境中的可扩展性。
这部分的重点在于:SELF-PARAM方法在保持模型结构不变的前提下,实现了高效的上下文整合与长期记忆能力,这是LLM适应动态任务和个性化应用的重要一步。
未来工作部分¶
本研究的发现表明,SELF-PARAM有潜力提升LLM的适应性与效率。未来的工作可以从以下几个方向展开:
扩展至更大规模的模型:研究如何在更复杂的LLM架构中应用SELF-PARAM,并评估其效果。
整合更多样化经验类型:探索如何将不同形式的知识(如多模态或结构化数据)整合进模型。
应用于更广泛的任务:比如将SELF-PARAM扩展到多轮对话场景中,以增强模型在实际应用中的表现力和实用性。
未来的研究方向强调的是扩展性与泛化能力,确保SELF-PARAM不仅在当前任务中有效,也能在更广泛的应用场景中发挥作用。
Ethics Statement¶
本研究中,我们使用了公开可用的数据集(PwC、INSPIRED 和 REDIAL),这些数据集中不包含个人身份识别信息(PII),确保符合数据隐私标准和许可协议。这一做法是重点内容,因为数据隐私和合规性是研究中必须严格遵守的核心要求。
通过将上下文知识直接嵌入模型参数中,存在数据泄露的潜在风险。这是本段的重点内容,说明了研究中潜在的风险点。为应对这一问题,我们采用了严格的安全措施,并建议在部署时进一步加强安全保障。此处强调了安全措施的重要性,并指出后续部署中也需保持警惕。
所有方法和数据处理流程均符合相关法律框架和伦理准则,我们通过透明的报告和适当的引用保持了研究的诚信。这部分内容说明了研究的整体合规性和透明性,是研究可信度的重要保障。
总体而言,虽然我们的方法增强了大型语言模型的能力,但我们仍致力于推动人工智能领域的公平性、安全性和负责任的创新。这是对研究整体目的和价值观的总结,强调了技术进步与社会责任并重的立场。
Reproducibility Statement¶
本节对论文中提到的实验设置和实现细节进行了总结,以便读者能够复现相关结果。
目标句子集的构建(Target Sentence Set Construction)¶
文章在附录 §A.3 中详细描述了目标句子集的构建过程,这是后续实验的基础。这部分内容对于理解模型在特定上下文中更新参数的方式非常重要,建议读者重点阅读。
单上下文注入(Single Context Injection)¶
在 §4.1 中,作者介绍了单上下文注入的实验数据集设置。该实验旨在研究模型在接收单个上下文信息时的表现。实现细节则在附录 §A.2 中给出,包括模型的训练和评估配置。虽然数据集设置是重点,但实现细节相对标准化,可简要浏览。
批量上下文注入(Batch Context Injection)¶
与单上下文注入类似,§4.2 描述了批量上下文注入的实验数据集配置,用于评估模型在多个上下文信息同时输入时的性能。实现细节同样参考附录 §A.2。本部分重点在于数据集设置和实验设计,实现部分可略读。
顺序注入(Sequential Injection)¶
在 §4.3 中,作者探讨了顺序注入的场景,即模型在连续接收多个上下文信息时的表现。数据集设置在该小节中给出,实现细节依旧在附录 §A.2 中统一说明。顺序注入是模型动态更新能力的重要体现,建议重点阅读。
会话推荐(Conversational Recommendation)¶
§4.4 介绍了基于上下文的会话推荐任务,旨在评估模型在对话场景中结合历史上下文生成推荐结果的能力。数据集设置在该小节详细说明,实现细节与之前部分一致,位于附录 §A.2。该任务具有较强的应用背景,是论文的重要实验部分,值得重点关注。
总结来看,所有实验的实现细节均集中在附录 A.2 中,而各个实验任务的数据集设置和方法描述则分别在 §4.1 至 §4.4 中给出。建议读者优先阅读各实验任务的主节(§4.1–§4.4)中的数据集部分,以及附录中的实现细节部分,以全面理解模型的运行方式和实验结果的可靠性。
Appendix A Additional Settings¶
A.1 补充实验设置¶
A.1.1 对话推荐任务的评估指标¶
本节延续 He 等人(2023)的研究,基于代码库 https://github.com/AaronHeee/LLMs-as-Zero-Shot-Conversational-RecSys,在四种不同过滤条件下,使用 Recall@1 作为评估指标。这些条件主要围绕推荐结果的后处理步骤,特别是对 OOV(Out-Of-Vocabulary)项 和 已呈现项(Seen Items) 的过滤。以下是四种指标的简要描述:
指标描述¶
r1(无过滤)
✗ 过滤 OOV 项?
✗ 过滤 Seen 项?
描述:不进行任何后处理,保留所有推荐结果,包括 OOV 项和 Seen 项。该指标用于衡量模型在无约束情况下的推荐上限。
r2(仅过滤 Seen 项)
✗ 过滤 OOV 项?
✓ 过滤 Seen 项?
描述:仅过滤已呈现的项,保留 OOV 项。这样可以避免重复推荐,提高用户获取新建议的可能性。
r3(仅过滤 OOV 项)
✓ 过滤 OOV 项?
✗ 过滤 Seen 项?
描述:仅过滤不在候选集中的 OOV 项,保留所有 Seen 项。这保证了推荐项的有效性,避免无效推荐。
r4(过滤 OOV 和 Seen 项)
✓ 过滤 OOV 项?
✓ 过滤 Seen 项?
描述:同时过滤 OOV 和 Seen 项,只保留新的、有效的推荐项。这是最严格的评估方式,确保推荐结果在实际场景中的适用性。
总结表¶
指标 |
过滤 OOV 项? |
过滤 Seen 项? |
描述 |
|---|---|---|---|
r1 |
✗ |
✗ |
不过滤任何项,作为性能上限 |
r2 |
✗ |
✓ |
仅过滤已呈现项,保留 OOV 项 |
r3 |
✓ |
✗ |
仅过滤 OOV 项,保留已呈现项 |
r4 |
✓ |
✓ |
同时过滤 OOV 和已呈现项,保留新且有效项 |
表5:对话推荐任务中 Recall@1 指标总结
补充说明¶
OOV 项:不在候选集中的推荐项,可能无效或无关,需过滤以提升推荐质量。
Seen 项:对话中已提到的推荐项,过滤可避免重复推荐,提升用户体验。
评估意义:
r1:展示模型的最大潜力(无约束);
r2、r3:分别从 Seen 项和 OOV 项角度评估推荐质量;
r4:最贴近实际场景的评估,强调推荐的新颖性和有效性。
这四个指标从不同维度全面评估推荐系统的性能,有助于分析模型的优势与局限性。
A.2 实现细节¶
所有实验均在 8 块 NVIDIA RTX A6000 GPU 上进行:
SELF-PARAM:每个实验使用 2 块 GPU;
基线模型:每个实验使用 1 块 GPU;
学习率:设为 \( 2 \times 10^{-5} \);
训练轮数:
单上下文注入(Single Context Injection)和批量上下文注入(Batch Context Injection):50 轮;
顺序注入(Sequential Injection):20 轮;
对话推荐(Conversational Recommendation):1 轮;
KL 散度计算:使用 PyTorch 库中的
torch.nn.functional.kl_div函数;模型训练设置:
对于 OpenLLaMA-3B-v2:仅训练 MLP 层;
对于 Mistral-7B、Mistral-7B-instruct-v0.2、Llama3-8B:使用 LoRA(低秩适配) 进行参数微调,配置如下:
{ "inference_mode": false, "r": 8, "lora_alpha": 32, "lora_dropout": 0.1, "target_modules": [ "q_proj", "v_proj", "k_proj", "up_proj", "down_proj", "gate_proj" ] }
A.3 目标句子集的构建¶
在使用上下文查询指令模型时,使用的提示模板如下:
给定一个上下文,请尽可能全面地生成相关的问答对,以项目符号形式列出。
示例:
上下文:一个小海滨城镇以其色彩斑斓的海玻璃海滩而闻名,并每年举办一场以庆祝这一独特特征为主题的艺术和环保节。
问题:每年吸引游客的特色是什么?
答案:独特的海玻璃海滩。问题:城镇的年度节日庆祝什么?
答案:海玻璃这一自然现象。问题:节日中有哪些活动?
答案:玻璃艺术展览、环保工作坊和本地音乐表演。问题:节日中工作坊的目的是什么?
答案:提升游客的环保意识。问题:节日对当地经济有什么影响?
答案:通过吸引游客促进本地商业发展。
实际应用中,上下文部分将被替换为输入的动态内容。
这一构建方式用于生成基于上下文的问答对,辅助模型理解并生成更准确的推荐建议。
Appendix B Additional Experiments¶
B.1 目标句子集多样性对模型性能的影响¶
在本节中,作者研究了在训练过程中目标句子集(即问题-答案对)的多样性对模型性能的影响。当前训练目标(公式 [3])在每个上下文中使用 50 对问题-答案对,训练 1 个 epoch。在探索过程中发现,如果使用 10 对问题-答案对 训练 5 个 epochs,模型性能显著下降。
模型 & 上下文数量 |
50 对 QA(1 epoch) |
10 对 QA(5 epochs) |
|---|---|---|
OpenLlama-3B-v2 & 100 |
0.5082 |
0.4203 |
OpenLlama-3B-v2 & 500 |
0.5048 |
0.4203 |
Mistral-7B & 100 |
0.4521 |
0.3891 |
Mistral-7B & 500 |
0.4384 |
0.3813 |
表6 显示,在相同上下文数量下,使用较少的问题-答案对进行多轮训练的效果显著低于使用更多对进行一次训练的效果。这表明:目标句子集的多样性对模型性能有显著影响,多样性不足可能导致性能下降。
此外,作者还提供了多个图表(图3至图5),展示了不同设置下的 QA-F1 分数变化趋势。这些图形进一步支持了上述结论。
图3:不使用 SlimPajama 数据集进行训练时的性能表现。
图4:在目标句子集上微调后的性能表现。
图5:在上下文上微调后的性能表现。
B.2 顺序注入的消融实验¶
在这一部分,作者进行了顺序注入的消融实验,验证不同设置对模型性能的影响。主要考虑了以下三种设置:
1. 不使用 SlimPajama(SELF-PARAM w/o SlimPajama)¶
此设置下,实验跳过了使用 SlimPajama 数据集进行训练的步骤,仅使用目标句子集进行注入。结果显示(见图3),模型的泛化能力在约20步注入后明显下降,QA-F1 分数降至 0.3 以下。相比之下,使用 SlimPajama 的 SELF-PARAM 方法能保持 QA-F1 分数在 0.5 左右。这说明:使用 SlimPajama 对维持模型的通用能力至关重要。
2. 在上下文上微调(Finetuning on the Context, FT(C))¶
此设置下,作者在每个上下文上使用 LoRA 微调 Mistral-7B 模型,并在每一步合并 LoRA 权重。结果显示(见图4),FT(C) 的效果非常差,模型几乎无法保留注入的知识。这表明:仅在上下文上微调难以有效注入和保留知识。
3. 在目标句子集上微调(Finetuning on the Target Sentence Set, FT(S))¶
此设置下,模型在由 gpt-4o-mini 构建的目标句子集上进行微调,实验设置与 SELF-PARAM 一致。结果显示(见图5),FT(S) 的知识保留能力与 SELF-PARAM 相当,但注入效率较低。例如,在注入第20个上下文后,FT(S) 的 QA-F1 分数从 0.36 降到 0.31,而 SELF-PARAM 从 0.5 降到 0.33。因此,FT(S) 的知识保留能力虽好,但注入效率不如 SELF-PARAM。
总结¶
B.1 节 强调了目标句子集的多样性对模型性能的重要性。使用更少的问题-答案对进行多轮训练的效果不如使用更多对进行单次训练。
B.2 节 通过消融实验验证了不同训练设置的有效性:
不使用 SlimPajama 会显著降低模型的泛化能力;
仅在上下文中微调(FT(C))效果极差;
在目标句子集上微调(FT(S))虽然保留能力与 SELF-PARAM 相当,但注入效率较低。
整体来看,SELF-PARAM 方法在保持模型泛化能力的同时,能高效地注入和保留新知识,是一种较为理想的上下文注入方法。