2510.21618_❇️DeepAgent: A General Reasoning Agent with Scalable Toolsets¶
引用: 0(2025-12-14)
组织:
1Renmin University of China
2Xiaohongshu Inc.
链接:
总结¶
总结¶
引入了 自主记忆折叠机制,将历史交互压缩为结构化的情景记忆、工作记忆和工具记忆,在减少误差累积的同时保留关键信息。
提出了一种端到端的强化学习策略 ToolPO,利用大语言模型模拟的API,并通过工具调用优势归因,对调用工具的token进行细粒度奖励分配。
问题建模:
将智能体的任务建模为序列决策过程,智能体在每一步根据当前状态、用户问题和指令选择动作。
状态 s_t 由历史动作和观察结果组成,动作 a_t 包括四种类型:
内部思考(Internal Thought):由大模型生成推理步骤。
工具搜索(Tool Search):通过自然语言查询检索相关工具。
工具调用(Tool Call):执行具体工具并获取结果。
记忆压缩(Memory Fold):将历史信息压缩为结构化记忆。
框架结构
DeepAgent框架由主推理模型(LRM) 和 辅助机制 构成
主推理过程:由大模型驱动,统一完成任务分析、工具发现、动作执行和记忆管理,避免传统流程的僵化。
辅助机制:使用辅助LLM处理复杂交互,包括:
工具文档摘要;
工具调用结果去噪;
长期交互历史压缩。
这种分工使主模型专注于高层战略推理,提升系统稳定性和效率。
工具使用机制
工具搜索(Tool Search):
智能体生成查询语句 q_s,系统通过密集检索(dense retrieval)从工具库中找出最相关的 top-k 工具。
工具调用(Tool Call):
智能体生成结构化调用指令,系统执行后将结果反馈给主模型。
辅助LLM对结果进行摘要处理,确保信息简洁有效。
记忆压缩机制
智能体在推理过程中可主动触发记忆压缩,生成三种结构化记忆:
情节记忆(Episodic Memory, M_E):记录关键事件和决策点,提供长期任务视角。
工作记忆(Working Memory, M_W):保存当前子目标和短期计划,维持推理连续性。
工具记忆(Tool Memory, M_T):汇总工具使用情况,优化后续调用策略。
压缩过程由辅助LLM完成,输出结构化JSON格式,确保信息可控、可解析。
强化学习训练方法
基于ToolPO的端到端强化学习训练
工具模拟器(Tool Simulator):
使用辅助LLM模拟真实API响应,解决真实调用的不稳定性、延迟和成本问题
奖励机制与优势函数:
定义两种奖励:
任务成功奖励 \( R_{\text{succ}}(\tau) \):衡量最终任务完成质量。
动作奖励 \( R_{\text{action}}(\tau) \):评估工具调用和记忆压缩的效率。
基于这些奖励计算两种优势函数:
任务成功优势 \( A_{\text{succ}}(\tau_k) \):全局学习信号。
动作优势 \( A_{\text{action}}(\tau_k) \):仅作用于工具调用和记忆压缩动作,提供细粒度反馈。
优化目标(ToolPO):
结合全局与局部优势,使用裁剪代理目标函数(clipped surrogate objective) 进行策略优化,确保稳定更新。
图解¶
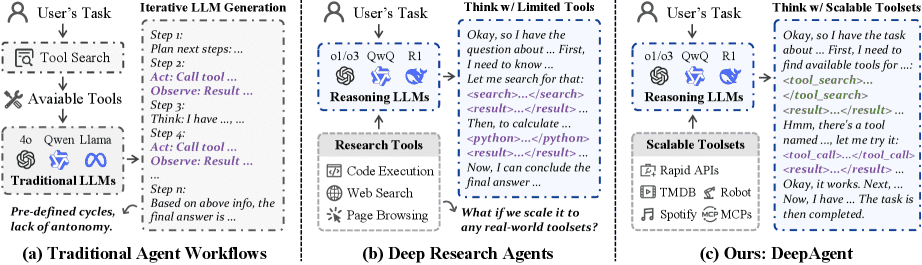
Figure 2. Comparison of agent paradigms
(a) Traditional agents with predefined workflows,
(b) Deep Research agents that can autonomously call limited tools
(c) Our DeepAgent, a fully autonomous reasoning agent that dynamically discovers and invokes helpful tools, all within a continuous agentic reasoning process.
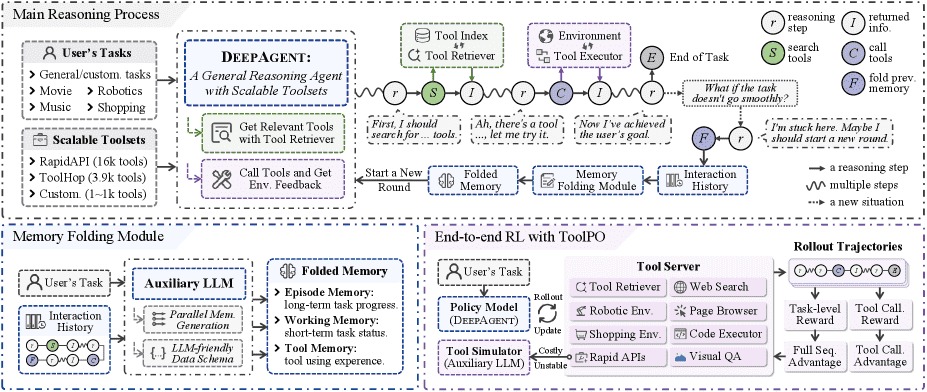
Figure 3. Overview of the DeepAgent framework.
The main reasoning model autonomously discovers tools, executes actions, and folds previous memory to restart with structured memories, all within a unified thinking process.
The DeepAgent is trained end-to-end with ToolPO, an RL method that uses a tool simulator to simulate large-scale real-world tool APIs, and rewards both final task success and correct intermediate tool calls through fine-grained advantage attribution.
From Moonlight¶
三句摘要¶
🤖 DeepAgent 提出了一种端到端的深度推理Agent,它在一个连贯的推理过程中自主思考、发现工具并执行操作,旨在解决现有Agent在可扩展工具集和长周期交互方面的限制。
🧠 该Agent通过自主记忆折叠机制将交互历史压缩为结构化的情景、工作和工具记忆,并通过ToolPO这一强化学习策略进行高效训练,该策略利用LLM模拟API和工具调用优势归因来确保稳定性和准确性。
🏆 在ToolBench、GAIA等八个基准测试中,DeepAgent在通用工具使用任务和下游应用方面均显著优于基线,尤其在开放集工具检索场景中展现出卓越的性能和可扩展性。
关键词¶
Large Reasoning Models: 大型推理模型(LRMs)是指在数学、编程和科学推理等领域展现出强大问题解决能力的大型语言模型。它们通过逐步的“慢思考”过程来解决复杂问题,与传统的“快思考”模型不同。这些模型在仅依赖参数化知识时存在局限性,无法直接与现实世界互动,因此常被整合到工具增强的推理方法中。
Autonomous Agents: 自主智能体(Autonomous Agents)是指能够通过调用外部工具与环境互动来完成现实世界任务的、由大型语言模型驱动的系统。与遵循预定义工作流程的传统代理不同,自主智能体被设计为能够自主思考、动态发现工具并执行动作,从而实现更高级别的自动化和决策能力。
Tool Retrieval: 工具检索(Tool Retrieval)是指在代理执行任务的过程中,动态地搜索和发现可用工具的能力。当代理需要执行某项功能但其内在知识不足时,它会生成一个查询来从工具集中查找最相关的工具。DeepAgent 使用基于密集检索的方法,通过计算查询与工具文档之间的余弦相似度来检索工具。
Memory Mechanism: 记忆机制(Memory Mechanism)是指代理用于管理和利用其交互历史和内部状态的系统。DeepAgent 引入了一种“自主记忆折叠”(Autonomous Memory Folding)机制,通过将过去的思考和交互历史压缩成结构化的记忆(包括 the episodic, working, and tool memories),来管理长距离交互产生的海量上下文,减少信息过载和错误累积。
Reinforcement Learning: 强化学习(Reinforcement Learning, RL)是一种机器学习方法,代理通过与环境互动来学习最优策略,以最大化累积奖励。DeepAgent 使用一种名为 ToolPO 的端到端强化学习策略来训练其工具使用能力。这种方法利用 LLM 模拟的 API 来提高训练的稳定性和效率,并使用工具调用优势归因(tool-call advantage attribution)来为正确的工具调用提供更精细的学习信号。
DeepAgent: DeepAgent 是本文提出的一个端到端的深度推理代理。它能够在一个统一的推理过程中自主地思考、发现工具、执行动作,并管理记忆。DeepAgent 的目标是克服现有代理在自主性、动态工具发现、记忆管理和推理深度方面的局限,使其能够处理大规模工具集和长距离交互的真实世界任务。
Autonomous Memory Folding: 自主记忆折叠(Autonomous Memory Folding)是 DeepAgent 的一项核心技术,用于解决长距离交互带来的上下文长度爆炸和信息累积问题。当代理需要时,它可以触发此机制,将之前的交互历史压缩成结构化的“情景记忆”(episodic memory)、“工作记忆”(working memory)和“工具记忆”(tool memory),从而在不丢失关键信息的前提下,重置其思维状态,避免陷入错误的探索路径,并提高推理效率。
ToolPO: ToolPO(Tool Policy Optimization)是 DeepAgent 使用的一种端到端的强化学习训练方法,专门为通用的工具使用代理设计。它解决了现实世界 API 训练中的不稳定性和成本问题,通过使用 LLM 模拟的 API 进行高效训练。同时,它采用了工具调用优势归因(tool-call advantage attribution),将奖励更精细地分配给导致正确工具调用的特定 token,从而提供更有效的学习信号。
LLM-simulated APIs: LLM 模拟的 API(LLM-simulated APIs)是在强化学习训练过程中使用的一种技术。由于直接与成千上万个真实的、可能不稳定的 API 进行训练是不可行的,DeepAgent 使用一个辅助 LLM 来模拟真实世界 API 的响应。这种方法提供了一个稳定、高效且低成本的训练环境,使得代理能够进行鲁棒的 RL 训练。
Long-horizon interactions: 长距离交互(Long-horizon interactions)是指代理在完成一个任务时需要与环境进行一系列连续的、可能很长时间的互动。这种场景会产生大量的交互历史,导致上下文长度爆炸和错误累积。DeepAgent 的自主记忆折叠机制旨在解决这一挑战,通过压缩历史信息,使代理能够更有效地处理长距离交互任务。
摘要¶
DeepAgent 是一种端到端(end-to-end)的深度推理Agent,旨在解决大型推理模型(LRMs)在现实世界任务中对外部工具和长时序交互的需求。现有Agent框架通常遵循预定义的工作流程,限制了自主性和全局任务完成能力。DeepAgent通过将自主思考、工具发现和行动执行整合到一个连贯的推理过程中,克服了这些限制。
核心问题与贡献:
统一的推理过程: DeepAgent提出了首个将思考、工具发现和行动执行统一在一个连贯的Agentic推理过程中的框架,使LRMs能够驾驭任意规模的工具集,并泛化到复杂的现实任务。
自主记忆折叠机制: 为解决长时序交互中的上下文长度爆炸和错误累积问题,DeepAgent引入了一种自主记忆折叠(Autonomous Memory Folding)机制。该机制能够将过去的交互历史压缩成结构化的情景记忆(episodic memory)、工作记忆(working memory)和工具记忆(tool memory),减少错误累积,同时保留关键信息。这使得Agent能够“喘息”并重新思考策略。
ToolPO强化学习策略: 为了高效稳定地教授Agent通用工具使用能力,DeepAgent开发了一种端到端强化学习策略,命名为ToolPO。该策略利用LLM模拟的API来增强训练的稳定性和效率,并通过工具调用优势归因(tool-call advantage attribution)为正确的工具调用token分配细粒度的奖励,解决稀疏奖励问题。
方法学详情:
DeepAgent将Agent的任务建模为一个序列决策过程。在每一步\(t\),Agent的状态\(s_t\)由所有先前的行动及其结果观察历史组成。Agent由参数为\(\theta\)的策略\(\pi\)驱动,根据当前状态、用户问题和指令选择一个行动\(a_t\),即\(a_t \sim \pi_\theta(\cdot|s_t, Q, I)\)。行动类型包括:
内部思考(Internal Thought, \(a^t_{think}\)): LRM生成的文本推理步骤,用于分析问题或规划下一步。
工具搜索(Tool Search, \(a^t_{search}\)): 自然语言查询\(q_s\),以从工具集中找到相关工具。
工具调用(Tool Call, \(a^t_{call}\)): 调用特定工具\(\tau\)并传入参数。
记忆折叠(Memory Fold, \(a^t_{fold}\)): 压缩交互历史\(s_t\)为结构化的记忆摘要。
目标是学习最优策略\(\pi^*_\theta = \arg \max_{\pi_\theta} E_{\tau \sim \pi_\theta} [R(\tau)]\),以最大化轨迹\(\tau\)的预期累积奖励。
自主工具搜索与调用:
DeepAgent的主LTM通过生成特定文本提示来执行所有操作。当Agent认为需要工具时,它生成一个包含查询\(q_s\)的工具搜索提示:<tool_search> q_s </tool_search>。系统通过密集检索(dense retrieval)操作:首先,使用嵌入模型\(E\)预计算每个工具文档\(d_i\)的嵌入\(E(d_i)\),构建索引。在推理时,系统根据查询\(q_s\),通过余弦相似度\(\text{sim}(E(q_s), E(d_i))\)排名检索出Top-k工具(\(\text{T}_{\text{retrieved}} = \text{top-k}_{\tau_i \in \text{T}}(\text{sim}(E(q_s), E(d_i)))\))。检索到的工具文档由辅助LLM处理(过长则摘要),然后返回给主LTM。
执行工具时,Agent生成结构化调用提示:<tool_call> {"name": "tool_name", "arguments": ...} </tool_call>。框架解析此调用,执行工具,捕获输出,并由辅助LLM摘要后反馈给推理上下文。
自主记忆折叠与脑启发式记忆模式:
Agent可以在推理过程的任何逻辑点触发记忆折叠,例如完成子任务或意识到探索路径错误时,通过生成特殊token:<fold_thought>。系统检测到此token后,辅助LLM(参数为\(\theta_{aux}\))处理整个先前的交互历史\(s_t\),并并行生成三个结构化记忆组件:\((M_E, M_W, M_T) = f_{\text{compress}}(s_t; \theta_{aux})\)。
这些压缩后的情景记忆(\(M_E\))、工作记忆(\(M_W\))和工具记忆(\(M_T\))随后替换原始交互历史。
情景记忆(\(M_E\)): 记录任务的关键事件、主要决策点和子任务完成情况,提供长期上下文。
工作记忆(\(M_W\)): 包含最新信息,如当前子目标、遇到的障碍和短期计划,确保推理的连续性。
工具记忆(\(M_T\)): 整合所有工具相关交互,包括已使用的工具、调用方式和有效性,通过结构化JSON模式确保稳定性和可解析性。
ToolPO端到端强化学习训练: ToolPO为通用工具使用Agent设计。为了克服与数千个真实API交互训练的不稳定、延迟和高成本问题,DeepAgent开发了一个基于LLM的工具模拟器,模仿真实API的响应,提供稳定高效的训练环境。 ToolPO定义了两个奖励组件:
整体任务成功奖励(\(R_{\text{succ}}(\tau)\)): 反映最终结果的质量,分配给轨迹中的所有生成token,提供全局学习信号。
工具调用奖励(\(R_{\text{action}}(\tau)\)): 反映中间行动的质量。它由正确工具调用的奖励和有效记忆折叠的奖励组成:\(R_{\text{action}}(\tau) = \lambda_1 \sum_{t=1}^T C(a^t_{\text{call}}) + \lambda_2 S_{\text{pref}}(\tau)\),其中\(C(a^t_{\text{call}})\)在工具调用正确时为1,否则为0;\(S_{\text{pref}} = (L(\tau_{\text{direct}}) - L(\tau_{\text{fold}})) / (L(\tau_{\text{direct}}) + L(\tau_{\text{fold}}))\)是鼓励高效记忆折叠的偏好分数(\(L(\tau)\)表示轨迹长度)。 基于这些奖励,ToolPO计算两种组相对优势:
任务成功优势(\(A_{\text{succ}}(\tau_k)\)): \(R_{\text{succ}}(\tau_k) - \frac{1}{K} \sum_{j=1}^K R_{\text{succ}}(\tau_j)\),归因于轨迹中的所有生成token。
行动层面优势(\(A_{\text{action}}(\tau_k)\)): \(R_{\text{action}}(\tau_k) - \frac{1}{K} \sum_{j=1}^K R_{\text{action}}(\tau_j)\),仅归因于构成工具调用和记忆折叠行动的特定token,提供更具针对性的学习信号。 给定token \(y_i\)的总体优势为:\(A(y_i) = A_{\text{succ}}(\tau_k) + M(y_i) \cdot A_{\text{action}}(\tau_k)\),其中\(M(y_i)\)是掩码,如果\(y_i\)是工具调用或记忆折叠token序列的一部分,则为1,否则为0。 ToolPO通过裁剪代理目标函数(clipped surrogate objective function)优化策略: \(L_{\text{ToolPO}}(\theta) = E_{\tau_k} \left[ \sum_{i=1}^{|\tau_k|} \min \left( \rho_i(\theta) A(y_i), \text{clip}(\rho_i(\theta), 1 - \epsilon, 1 + \epsilon) A(y_i) \right) \right]\) 其中\(\rho_i(\theta) = \frac{\pi_\theta(y_i|y_{<i},s)}{\pi_{\theta_{\text{old}}}(y_i|y_{<i},s)}\)是token \(y_i\)的概率比。
实验在ToolBench、API-Bank、TMDB、Spotify、ToolHop等通用工具使用任务以及ALFWorld、WebShop、GAIA、Humanity’s Last Exam (HLE)等下游应用上进行,结果表明DeepAgent在所有场景中均优于基线,尤其在开放式工具检索场景中表现出色,验证了其在复杂现实任务中的通用工具使用能力和高适应性。
Abstract¶
本节为论文的摘要部分,简要介绍了研究背景、问题、方法、实验结果与贡献。
研究背景与问题¶
当前的大规模推理模型在解决问题方面表现出色,但在实际应用中,往往需要借助外部工具并进行长期交互。现有的智能体(agent)框架通常依赖预定义的工作流程,限制了其自主性和全局任务完成能力。
提出方法:DeepAgent¶
为此,作者提出了 DeepAgent,一个端到端的深度推理智能体,能够在单一、连贯的推理过程中实现自主思考、工具发现与动作执行。
记忆机制创新:为应对长期交互带来的挑战(如多次调用工具导致的上下文长度爆炸和交互历史积累),DeepAgent引入了自主记忆折叠机制,将历史交互压缩为结构化的情景记忆、工作记忆和工具记忆,在减少误差累积的同时保留关键信息。
强化学习策略:为了高效稳定地训练通用工具使用能力,作者提出了一种端到端的强化学习策略 ToolPO,利用大语言模型模拟的API,并通过工具调用优势归因,对调用工具的token进行细粒度奖励分配。
实验与结果¶
作者在8个基准任务上进行了大量实验,包括通用工具使用任务(如ToolBench、API-Bank、TMDB、Spotify、ToolHop)和下游应用任务(如ALFWorld、WebShop、GAIA、HLE)。实验结果表明,DeepAgent在有标签工具和开放集合工具检索场景下均优于基线方法。
贡献与意义¶
本研究推动了面向真实世界应用的更通用、更强能力的智能体的发展。代码和演示已开源,便于复现与进一步研究。
1. Introduction¶
背景与问题¶
随着大语言模型(LLMs)的快速发展,基于LLM的智能代理(LLM-powered agents)在信息检索、软件工程和个人助理等领域得到了广泛应用。然而,目前大多数代理框架依赖于预定义的工作流程,例如ReAct和Plan-and-Solve方法,它们通过结构化的规划过程和“推理-行动-观察”循环来完成任务。尽管这些方法在简单任务中表现良好,但在面对复杂现实问题时存在以下关键限制:
缺乏执行步骤和整体流程的自主性;
无法在任务执行过程中动态发现新工具;
无法完全自主管理交互式记忆;
在任务整体推理上缺乏深度和连贯性。
这些缺陷严重限制了代理在复杂任务中的表现,尤其是在需要广泛使用工具和长期环境交互的场景中。
相关研究与局限¶
近年来,大推理模型(LRMs)在数学、编程和科学推理等领域展示了通过“慢思考”逐步解决问题的能力。然而,许多现实任务仍需依赖外部工具完成。虽然已有研究尝试将工具使用整合进推理过程(如Search-o1、DeepResearcher、ToRL),但这些方法通常仅限于预定义的有限工具集(如网页搜索、代码执行等),限制了其在更广泛复杂任务中的适用性。
DeepAgent的提出¶
为解决上述问题,本文提出DeepAgent,一种端到端的深度推理代理,能够在单一、连贯的推理过程中动态检索和调用工具。与传统方法不同,DeepAgent不依赖预定义流程,而是通过自主思考、工具搜索和执行操作完成任务,具备全局任务视角,工具调用也根据需要动态发现,从而充分发挥推理模型的自主能力。
核心创新点¶
自主记忆折叠机制与类脑记忆架构:
DeepAgent引入了自主记忆折叠策略,可将历史交互和思考整合为结构化记忆,提升推理效率并防止陷入错误路径。该机制结合类脑记忆设计(包括情景记忆、工作记忆和工具记忆),确保压缩后的记忆稳定且可用。端到端强化学习训练方法(ToolPO):
为提升DeepAgent对工具使用的掌握能力,提出ToolPO方法,解决传统代理强化学习中的两个关键问题:使用LLM模拟API替代真实API,提高训练稳定性与效率;
通过工具调用优势归因机制,对正确调用的具体token进行精确奖励分配,提升中间步骤的准确性。
实验与结果¶
DeepAgent在多个基准任务上进行了广泛测试:
通用工具使用任务:ToolBench、API-Bank、TMDB、Spotify、ToolHop;
下游应用任务:ALFWorld、WebShop、GAIA、Humanity’s Last Exam(HLE)。
实验结果表明,DeepAgent在所有场景中均表现出色,显著优于现有方法。
主要贡献总结¶
提出首个在统一推理过程中实现自主思考、工具发现与执行的代理框架;
引入类脑记忆架构与自主记忆折叠机制,增强代理的策略调整能力;
提出ToolPO强化学习方法,提升大规模工具训练的稳定性与工具调用准确性;
在8个基准任务上验证了DeepAgent的卓越性能与广泛适用性。
框架概览¶
如图3所示,DeepAgent的核心推理模型在统一思考过程中自主发现工具、执行动作,并通过记忆折叠机制重启推理。整个系统通过ToolPO方法进行端到端训练,利用工具模拟器模拟真实API,并通过细粒度奖励机制优化最终任务完成与中间工具调用的准确性。
3. Methodology¶
本节介绍了DeepAgent框架的核心方法,包括任务建模、框架结构、工具使用机制、记忆压缩机制以及强化学习训练方法。以下是对各子章节的结构化总结:
3.1. 问题建模(Problem Formulation)¶
重点内容:
将智能体的任务建模为序列决策过程,智能体在每一步根据当前状态、用户问题和指令选择动作。
状态 \( s_t \) 由历史动作和观察结果组成,动作 \( a_t \) 包括四种类型:
内部思考(Internal Thought):由大模型生成推理步骤。
工具搜索(Tool Search):通过自然语言查询检索相关工具。
工具调用(Tool Call):执行具体工具并获取结果。
记忆压缩(Memory Fold):将历史信息压缩为结构化记忆。
目标是通过学习策略 \( \pi_\theta \) 最大化期望累积奖励 \( R(\tau) \),即:
非重点内容:
奖励函数的具体定义未展开,仅说明其用于评估任务完成质量。
3.2. DeepAgent框架概述(Overview of the DeepAgent Framework)¶
重点内容:
DeepAgent框架由主推理模型(LRM) 和 辅助机制 构成:
主推理过程:由大模型驱动,统一完成任务分析、工具发现、动作执行和记忆管理,避免传统流程的僵化。
辅助机制:使用辅助LLM处理复杂交互,包括:
工具文档摘要;
工具调用结果去噪;
长期交互历史压缩。
这种分工使主模型专注于高层战略推理,提升系统稳定性和效率。
非重点内容:
框架图(图3)未详细解读,仅说明其结构逻辑。
3.3. 自主工具搜索与调用(Autonomous Tool Search and Calling)¶
重点内容:
工具搜索(Tool Search):
智能体生成查询语句 \( q_s \),系统通过密集检索(dense retrieval)从工具库中找出最相关的 top-k 工具。
使用嵌入模型 \( E \) 计算相似度 \( \text{sim}(E(q_s), E(d_i)) \),并返回结果。
工具调用(Tool Call):
智能体生成结构化调用指令,系统执行后将结果反馈给主模型。
辅助LLM对结果进行摘要处理,确保信息简洁有效。
非重点内容:
具体的工具调用格式(如JSON结构)未详细展开。
3.4. 自主记忆压缩与类脑记忆结构(Autonomous Memory Folding and Brain-Inspired Memory Schema)¶
重点内容:
记忆压缩机制(Memory Folding):
智能体在推理过程中可主动触发记忆压缩,生成三种结构化记忆:
情节记忆(Episodic Memory, \( M_E \)):记录关键事件和决策点,提供长期任务视角。
工作记忆(Working Memory, \( M_W \)):保存当前子目标和短期计划,维持推理连续性。
工具记忆(Tool Memory, \( M_T \)):汇总工具使用情况,优化后续调用策略。
压缩过程由辅助LLM完成,输出结构化JSON格式,确保信息可控、可解析。
非重点内容:
记忆压缩的具体数据结构(附录D)未展开。
3.5. 基于ToolPO的端到端强化学习训练(End-to-end RL Training with ToolPO)¶
重点内容:
训练数据来源:
包括ToolBench、ALFWorld、WebShop、WebDancer、WebShaperQA、DeepMath等多领域任务,覆盖工具使用、数学推理、现实交互等能力。
工具模拟器(Tool Simulator):
使用辅助LLM模拟真实API响应,解决真实调用的不稳定性、延迟和成本问题。
奖励机制与优势函数:
定义两种奖励:
任务成功奖励 \( R_{\text{succ}}(\tau) \):衡量最终任务完成质量。
动作奖励 \( R_{\text{action}}(\tau) \):评估工具调用和记忆压缩的效率。
基于这些奖励计算两种优势函数:
任务成功优势 \( A_{\text{succ}}(\tau_k) \):全局学习信号。
动作优势 \( A_{\text{action}}(\tau_k) \):仅作用于工具调用和记忆压缩动作,提供细粒度反馈。
优化目标(ToolPO):
结合全局与局部优势,使用裁剪代理目标函数(clipped surrogate objective) 进行策略优化,确保稳定更新。
非重点内容:
数学公式推导细节(如概率比 \( \rho_i(\theta) \))未深入解释。
总结¶
本章系统介绍了DeepAgent的自主推理方法,涵盖任务建模、框架结构、工具使用机制、类脑记忆结构以及强化学习训练策略。核心创新点包括:
统一推理流程:主模型自主完成任务分析、工具调用与记忆管理;
结构化记忆压缩:通过类脑记忆机制提升长期推理能力;
端到端强化学习(ToolPO):结合任务成功与动作质量的双重奖励机制,实现高效策略优化。
这些设计使DeepAgent在多个任务中表现出优于传统工作流方法的性能(如表1和表2所示)。
4. Experimental Settings¶
4.1. 任务与数据集(Tasks and Datasets)¶
本节介绍了用于评估模型性能的两类任务:通用工具使用和下游应用。
通用工具使用(General Tool-Use)¶
该部分选取了四个具有代表性的工具使用基准,用于评估模型在多工具、多步骤调用场景下的表现:
ToolBench(G3子集):基于超过16,000个真实API,测试模型在大规模工具集下的多步骤调用能力。
API-Bank:包含314个对话样本和753次API调用,用于评估工具调用的规划、检索与执行能力。
RestBench:包含来自TMDB电影数据库(54个工具)和Spotify音乐播放器(40个工具)的REST风格任务,模拟典型Web服务场景。
ToolHop:一个需要3到7步连续调用的多跳推理数据集,共3,912个本地可执行工具。
实验设置分为两种:已知真实工具和需从完整工具集中检索工具。
下游应用(Downstream Applications)¶
该部分选取了四个需要特定领域工具集的复杂任务,用于评估模型在真实应用场景中的长期规划与交互能力:
ALFWorld:基于文本的具身智能任务,使用9种基本动作完成目标。
WebShop:模拟在线购物环境,通过“搜索”和“点击”完成购买任务。
GAIA:复杂信息检索任务,配备网页搜索、浏览、视觉问答、代码编译和文件读取等工具。
Humanity’s Last Exam(HLE):高难度推理任务,提供代码、搜索、浏览和视觉问答工具。
这些任务强调模型在复杂现实场景中的长期规划与鲁棒交互能力。
4.2. 基线方法(Baselines)¶
本节列出了用于对比的两类基线方法:
(1)基于工作流的方法(Workflow-based Methods)¶
ReAct:采用“推理-行动-观察”循环进行任务处理。
CodeAct:将行动表示为可执行的Python代码。
Plan-and-Solve:先制定高层计划,再逐步执行。
Reflexion:通过失败后的语言自我反思提升性能。
AgentLM:通过指令微调提升大语言模型的代理能力。
(2)推理中的自主工具使用(Autonomous Tool Usage within Reasoning)¶
WebThinker:将推理与网页搜索、深层网络探索结合。
HiRA:采用分层代理架构,包括任务分解、路由和执行模块。
OpenAI Deep Research:基于推理模型的代理系统。
4.3. 实现细节(Implementation Details)¶
本节介绍了模型架构、训练参数和实验平台:
主模型:使用QwQ-32B作为DeepAgent的主干模型。
辅助模型:Qwen2.5-32B-Instruct用于主实验结果。
生成参数:最大生成长度81,920 token,温度0.7,top_p 0.8,top_k 20,重复惩罚1.05。
工具实现:
网页搜索与浏览:Google Serper API 和 Jina Reader API。
视觉问答:Qwen2.5-VL-32B-Instruct。
工具检索:使用bge-large-en-v1.5模型。
训练设置:使用ToolPO算法训练100步,batch size为64,λ1=λ2=1,rollout size K=8,最大序列长度32,768。
硬件平台:所有实验在64块NVIDIA H20-141GB GPU上进行。
此外,附录C提供了更详细的实现说明。
图表说明¶
图4:展示了训练过程中的奖励得分(a)和验证得分(b)变化趋势。
表3:对DeepAgent各组件进行了消融实验,结果显示完整模型(DeepAgent-32B-RL)在多个任务上表现最佳,平均得分为48.1。移除关键组件(如训练、记忆折叠、工具模拟、工具优势归因)均导致性能下降。
5. Experimental Results¶
5.1. Main Results on General Tool Usage Tasks¶
重点内容:
DeepAgent 的端到端推理优于基于工作流的方法
DeepAgent 在多个任务中显著优于传统预定义流程方法。例如,在 TMDB 和 Spotify 的 labeled-tool 任务中,DeepAgent-32B-RL 的成功率分别为 89.0% 和 75.4%,远超基线的 55.0% 和 52.6%。在开放集场景中表现稳健
在需要动态发现工具的开放集任务(如 ToolBench 和 ToolHop)中,DeepAgent 分别达到 64.0% 和 40.6% 的成功率,远超基线的 54.0% 和 29.0%,显示其在真实复杂场景中的可扩展性和鲁棒性。ToolPO 训练策略进一步提升性能
使用基于 LLM 的工具模拟器和细粒度优势归因的 ToolPO 策略,使 DeepAgent 在 ToolBench 和 Spotify 上分别提升了 6.0% 和 5.2% 的成功率。
5.2. Main Results on Downstream Applications¶
重点内容:
自主推理范式优于工作流方法
在复杂任务(如 GAIA 和 WebShop)中,DeepAgent 和 HiRA 明显优于 CodeAct,说明长期交互任务需要深度代理推理能力。DeepAgent 在多个应用任务中表现最佳
DeepAgent 在 GAIA 和 ALFWorld 上分别达到 53.3 和 91.8% 的成功率,优于其他 32B 模型(如 HiRA),得益于其将动作无缝整合进推理过程的能力。ToolPO 提升下游任务性能
ToolPO 训练使 GAIA 成功率提升 6.6%,ALFWorld 提升 3.7%,验证了其对复杂任务推理和工具使用的增强效果。
5.3. Analysis of Training Dynamics¶
重点内容:
ToolPO 提升训练稳定性和上限
与 GRPO 相比,ToolPO 在奖励和验证分数上表现更优,训练波动更小,说明使用工具模拟器和过程监督有助于更稳定地训练工具使用能力。
5.4. Ablation Studies¶
重点内容:
ToolPO 训练至关重要
移除 ToolPO 使平均得分从 48.1 降至 44.3,说明其在增强工具使用和任务完成中的核心作用。记忆折叠机制有效
缺乏记忆折叠机制导致平均得分下降至 44.2,尤其在 GAIA 上从 53.3 降至 44.7,验证其对长期交互的重要性。训练策略贡献显著
移除工具模拟器或优势归因均导致性能下降,说明两者分别提升了训练稳定性和学习信号的精确性。
5.5. Effectiveness of Tool Retrieval Strategies¶
重点内容:
动态工具发现优于预检索方法
在所有框架中,推理过程中自主检索工具均优于预检索方法,尤其在大规模工具集(如 ToolBench 和 ToolHop)上表现更优。DeepAgent 更适合动态检索
结合自主工具检索,DeepAgent 平均得分达 52.6,远超最佳工作流方法的 28.5,说明其架构更适合动态工具发现。
5.6. Scaling Analysis of Action Limits¶
重点内容:
DeepAgent 在不同动作限制下均优于 ReAct
在 WebShop 和 GAIA 上,DeepAgent 始终优于 ReAct,且随着动作限制增加,性能差距扩大,说明其能更有效地选择关键动作。动作限制增加提升性能
更多动作允许更深入的推理和探索,尤其对复杂任务更有利。
5.7. Generalization Across Different Backbones¶
重点内容:
DeepAgent 在不同模型主干上均表现优异
使用 Qwen3-30B 和 Qwen3-235B 作为主干时,DeepAgent 均显著优于 ReAct 和 Plan-and-Solve,说明其推理方法具有良好的泛化能力。与更大模型结合效果更佳
所有方法在使用更大模型时性能提升,但 DeepAgent 提升幅度最大,尤其在复杂任务上表现突出。
总结:
第五章通过多个维度验证了 DeepAgent 在工具使用和复杂任务处理上的优越性。其核心优势包括:
端到端推理优于传统工作流;
动态工具发现机制在开放集任务中表现稳健;
ToolPO 训练策略显著提升性能;
自主记忆折叠机制增强长期交互能力;
架构设计使其在不同模型主干和动作限制下均表现优异。
6. Conclusion¶
本章节总结了DeepAgent的核心贡献与实验成果:
DeepAgent概述:提出了一种端到端的推理代理模型,将思考、工具发现与执行统一为一个连贯的代理推理过程。
关键技术:
自主记忆折叠机制:为支持长期交互,该机制将交互历史压缩为结构化记忆,使代理能够“暂停思考”并重新评估策略,这是本节强调的重点之一。
ToolPO算法:一种端到端的强化学习方法,利用大语言模型(LLM)模拟API进行稳定训练,并通过细粒度优势归因机制,实现对工具调用的精准信用分配,这也是核心技术亮点。
实验验证:在多种通用工具使用任务和下游应用中进行了广泛实验,结果表明DeepAgent在多个基准上显著优于现有代理模型,尤其在需要动态发现工具、面对大规模工具集的开放场景中表现突出,这是作者重点强调的成果部分。
整体来看,本节突出了DeepAgent在结构设计、学习方法和实际应用中的创新与优势。
Appendix A Datasets¶
A.1 训练数据¶
本节介绍了用于训练模型的多样化数据集,涵盖四个任务类别,旨在培养模型的综合能力。
1. 通用工具使用(General Tool-Use)¶
重点内容:从 ToolBench 数据集中选取了 1,000 个标注工具使用样本和 1,000 个工具检索样本。
目的:提升模型对多种工具的通用使用能力,并通过检索机制应对大规模工具集。
2. 真实世界交互(Real-World Interaction)¶
重点内容:从 ALFWorld 和 WebShop 各取 500 个样本。
目的:训练模型在真实环境中有效交互、管理状态转换并达成用户目标。
3. 深度研究能力(Deep Research)¶
重点内容:使用 WebDancer(200 个)和 WebShaperQA(500 个)样本。
目的:增强模型通过网页搜索和浏览获取深度信息的能力。
4. 数学推理(Mathematical Reasoning)¶
重点内容:从 DeepMath 数据集中收集 900 个问题。
目的:强化模型使用代码解决复杂数学问题的能力。
总结:训练数据覆盖广泛任务,强调工具使用、环境交互、信息检索与数学推理,旨在打造多功能智能代理。
A.2 基准测试(Benchmarks)¶
本节介绍用于评估模型性能的多个基准测试,分为通用工具使用和下游应用两类。
通用工具使用(General Tool-Use)¶
ToolBench(重点):
包含超过 16,000 个真实 REST API,涵盖 49 个类别。
测试集包含 100 个案例,评估单工具与多工具组合使用能力。
API-Bank(重点):
包含 73 个 API 工具和超过 2,200 个对话样本。
提供可运行的评估系统,测试 API 调用、检索与规划能力。
TMDB 和 Spotify(次要):
RestBench 的子任务,分别测试电影数据库和音乐播放器的多步骤 API 调用。
ToolHop(重点):
多跳推理数据集,包含 995 个复杂问题,每任务需调用 3~7 个工具。
下游应用(Downstream Applications)¶
ALFWorld:
文本环境中的具身智能任务,测试基础动作(如移动、拾取)完成目标的能力。
WebShop(重点):
模拟电商购物环境,包含 12,087 个任务,测试搜索与选择操作的交互能力。
GAIA(重点):
面向通用 AI 助手的复杂任务基准,包含 466 个真实问题,需多模态、代码执行等综合能力。
Humanity’s Last Exam (HLE)(重点):
包含 2,500 个高难度、跨学科问题,测试模型的深度推理与多模态理解能力,强调非依赖外部搜索的内在能力。
总结:基准测试覆盖广泛,从工具使用到复杂现实任务,强调模型在多工具调用、环境交互、信息检索、数学推理和深度理解方面的综合表现。
总体评价:
本附录详细介绍了训练数据与评估基准,强调模型在多种任务场景下的泛化能力与复杂推理能力,尤其突出工具调用、真实环境交互与深度信息处理等关键能力。
Appendix B Baselines¶
本节介绍了与本文提出的方法进行对比的多个基线代理(Baseline Agents),并详细说明了它们的核心思想与工作机制。以下是各方法的简要总结:
ReAct(Reasoning and Acting)¶
由 Yao 等人(2022b)提出,是一种结合推理(Reasoning)与行动(Acting)的通用范式。该方法通过提示语言模型生成“思考—行动—观察”交错的步骤序列,逐步完成任务。重点在于其将推理与操作结合的能力,是许多后续方法的基础。
CodeAct¶
由 Wang 等人(2024a)提出,其核心是将代理的行为表示为 Python 代码,并在解释器中执行。该方法的优势在于通过代码作为动作空间,能够灵活调用各种工具、API 和系统功能。
Plan-and-Solve(计划与求解)¶
由 Wang 等人(2023)提出,采用两阶段策略解决复杂问题:
首先制定详细的分步计划(不使用工具);
然后执行该计划,完成具体计算或操作。
该方法强调结构化问题解决流程。
Reflexion¶
由 Shinn 等人(2023)提出,通过语言形式的自我反思(verbal self-reflection)来提升代理的学习能力。在任务失败后,代理会分析失败原因并将其记录在记忆中,以提升后续表现。
AgentLM¶
由 Zeng 等人(2024)提出,是一种通过指令微调(instruction tuning)提升大语言模型(LLM)代理能力的方法。其核心是使用一个轻量级、专门构建的数据集 AgentInstruct 对 LLM 进行微调。
WebThinker¶
由 Li 等人(2025b)提出,是一种面向复杂信息检索任务的深度研究代理。其特点在于通过“思考—搜索—撰写”循环自主浏览网络,收集并整合信息。
HiRA(Hierarchical Reasoning Agent,分层推理代理)¶
由 Jin 等人(2025a)提出,采用分层代理架构解决复杂、多模态任务。其核心机制是将高层规划与底层执行分离:由规划器分解任务,再由多个执行代理(如搜索、编码代理)完成具体操作。
OpenAI Deep Research¶
由 OpenAI(2025)开发,是 ChatGPT 中的一项功能,用于对复杂主题进行深入研究。它通过广泛浏览网络资源,合成信息并生成结构化、详细的回答,相比普通查询更耗时但更深入。
总结:
本节介绍了当前主流的智能代理方法,涵盖了推理、行动、代码执行、自我反思、分层架构等多个方向。其中,ReAct、CodeAct、HiRA 和 WebThinker 是具有代表性的结构化代理框架,而 AgentLM 和 Reflexion 则侧重于通过微调或反思机制提升代理能力。这些方法为本文提出的新方法提供了重要的对比基础。
Appendix C Implementation Details¶
模型配置与使用¶
主推理模型:
表1和表2使用 QwQ-32B(Team, 2024)。
表5使用 Qwen3-30B-A3B-Thinking-2507 和 Qwen3-235B-A22B-Thinking-2507(Yang et al., 2025a)。
辅助模型:
使用 Qwen2.5-32B-Instruct(Qwen et al., 2024)完成以下任务:
过滤冗长的工具搜索结果和执行输出(所有基线模型均使用)。
在 ToolPO 训练中模拟 RapidAPI。
从交互历史生成折叠记忆。
基线模型:
使用 QwQ-32B 或 Qwen2.5-32B-Instruct 作为基础模型。
文本生成参数:
最大 token 数:81,920。
温度:0.7,top_p:0.8,top_k:20,重复惩罚:1.05。
最大动作数限制:50。
工具与 API 实现¶
网页搜索与浏览:
使用 Google Serper API 进行网络搜索。
使用 Jina Reader API 进行页面内容解析。
视觉问答(VQA)工具:
基于 Qwen2.5-VL-32B-Instruct(Bai et al., 2025),输入为问题和图像,输出为模型生成的答案。
工具检索:
使用 bge-large-en-v1.5(Xiao et al., 2024)进行语义匹配。
工具文档格式:
所有工具文档遵循 OpenAI 函数定义格式,包括名称、描述、参数类型与要求,用于构建工具索引和提示输入。
训练设置¶
训练方法:
使用 ToolPO 算法,训练步数:100 步。
批量大小:64,λ₁ = λ₂ = 1,rollout 大小 K = 8。
最大序列长度:32,768,最大动作数:50。
训练框架:
基于 VeRL(Sheng et al., 2024)进行多节点分布式训练。
硬件配置:
所有实验在 64 块 NVIDIA H20-141GB GPU 上运行。
重点内容总结¶
模型选择:主模型和辅助模型均选用高性能大模型,确保推理与辅助任务的高效执行。
工具集成:采用标准化 API 和函数格式,提升工具调用与检索效率。
训练优化:结合 ToolPO 与 VeRL 框架,实现大规模分布式训练,适应长序列和多动作任务。
硬件支持:使用高规格 GPU 集群,支撑复杂模型训练与推理需求。
Appendix D Memory Schema¶
本节介绍了受大脑记忆机制启发设计的记忆架构,包含三个核心组件:情景记忆、工作记忆和工具记忆。每种记忆都有其特定的JSON结构,以确保信息在压缩和展开过程中保持稳定,避免信息丢失,并支持长期推理能力。
情景记忆结构(Episodic Memory Schema)¶
重点内容:
情景记忆用于记录任务的高层次进展,包括关键事件、决策和结果。它帮助代理保持长期上下文,并反思整体策略。
结构组成:
task_description:对任务目标和整体推理过程的概括。key_events:按步骤记录关键事件,包括:step:步骤编号description:具体行动或决策及其背景和推理outcome:行动结果、观察反馈、新信息或任务状态变化
current_progress:当前任务完成情况与剩余工作概述
总结: 这是代理的“任务历史摘要”,用于长期回顾与策略调整。
工作记忆结构(Working Memory Schema)¶
重点内容:
工作记忆是代理的短期记忆缓冲区,用于维持当前推理上下文,确保在记忆折叠过程中保持推理连贯性。
结构组成:
immediate_goal:当前子目标的清晰描述current_challenges:当前面临的主要障碍或困难next_actions:计划采取的下一步行动,包括:type:类型(工具调用 / 规划 / 决策)description:具体行动描述
总结: 这是代理的“当前任务状态快照”,支持短期推理与行动规划。
工具记忆结构(Tool Memory Schema)¶
重点内容:
工具记忆记录代理使用工具的经验,包括使用频率、成功率、参数组合、常见错误等。它帮助代理优化工具使用策略。
结构组成:
tools_used:每个工具的使用记录,包括:tool_name:工具名称success_rate:成功使用率effective_parameters:有效参数组合common_errors:常见错误类型response_pattern:典型输出模式experience:使用经验总结
derived_rules:从经验中提炼出的规则,例如:“当条件X发生时,优先使用工具Y”
“工具Z在参数A设为B时效果最佳”
总结: 这是代理的“工具使用知识库”,支持持续学习与优化。
整体总结:
本附录定义了三种记忆结构的JSON格式,分别用于支持代理的长期任务回顾、短期推理维持和工具使用优化。这些结构化记忆机制共同构成了一个稳定、可扩展的类脑记忆系统。
Appendix E Case Study¶
本节通过一个详细的案例,展示了 DeepAgent 框架在处理需要多工具协同、多步骤操作的复杂任务时的有效性。该案例列在表6中,重点说明了 DeepAgent 如何自主选择工具、执行顺序操作,并整合结果以提供用户查询的完整解决方案。
案例概述¶
用户请求包括三个任务:
在 Vimeo 上搜索与“纪录片”相关的视频;
获取“电影”类别相关的人员信息,用于邀请嘉宾;
提供一个 YouTube 视频 ID 为 ‘UxxajLWwzqY’ 的流媒体链接。
DeepAgent 的处理流程¶
第一步:搜索纪录片视频¶
DeepAgent 首先搜索可用工具,选择了
search_videos工具。使用关键词“documentary”进行搜索,并按“most_liked”排序。
成功返回多个受欢迎的纪录片视频。
第二步:寻找电影类别的相关人员¶
发现没有直接搜索“人员”的工具,于是通过“cinema”标签搜索视频。
使用
get_videos_by_tag工具,获取带有“cinema”标签的视频及其创作者信息。成功识别出两位潜在嘉宾:“John Doe”和“Jane Smith”。
第三步:获取 YouTube 视频链接¶
使用
search_for_youtube_v3工具验证视频 ID 是否存在。确认有效后,构建标准 YouTube 流媒体链接:
https://www.youtube.com/watch?v=UxxajLWwzqY
最终输出结果¶
DeepAgent 将三部分信息整合后,给出如下回答:
Vimeo 上的纪录片:包括自然和太空类纪录片;
电影类嘉宾推荐:John Doe 和 Jane Smith,并附上其 Vimeo 资料;
YouTube 视频链接:成功生成指定视频的播放链接。
总结¶
该案例充分展示了 DeepAgent 在以下方面的能力:
自主工具选择:根据任务需求灵活选用不同工具;
多步骤任务处理:协调多个工具完成复杂任务链;
结果整合能力:将分散信息整合为结构化、可操作的输出。
此案例验证了 DeepAgent 在处理多工具、多步骤任务中的高效性与实用性。