1911.00172_kNN-LMs: Generalization through Memorization: Nearest Neighbor Language Models¶
引用: 1034(2025-09-05)
组织:
†Stanford University
‡Facebook AI Research
总结¶
总结
kNN-LM 本质是
1.建立一个 k/v 缓存
表示函数 f(·):将上下文映射为固定长度的向量,例如在 Transformer 模型中,可以取某一层的注意力输出
对于上下文-目标对 (c_i, w_i)
k_i = f(c_i)
v_i = w_i
2.推理时
得到基于 LM 的输出分布 p_LM(y|x)
找出 f(x) 的 k 个最近邻 𝒩(根据距离函数 d(·,·),实验中使用的是 L² 距离)
将这些邻居的负距离转换为概率分布,并聚合所有邻居中相同目标词的概率 p_kNN(y|x)
最终的输出分布是 LM 分布与 kNN 分布的加权插值
p(y|x) = α * p_LM(y|x) + (1 - α) * p_kNN(y|x)
背景
传统神经语言模型(LMs)通常解决两个子问题:
将句子前缀映射为 固定维度的表示(representation)
利用这些表示来预测 下一个词
关键点
文本序列之间的相似性学习比直接预测下一个词更容易
kNN-LMs
定义
对已训练好的语言模型进行扩展,通过引入一个最近邻检索机制,无需额外训练(即语言模型的参数和表示保持不变)
这个扩展是通过一次前向遍历文本数据集(可能包含训练集)来完成的,得到的 上下文-目标词对 被存储在键值数据库中,并在推理时进行查询
kNN-LM 提高性能的三个关键原因:
Transformer LM 在学习上下文表示函数方面表现出色,能够捕捉隐式相似性;
尽管 Transformer 有能力记忆训练数据,但这样做会削弱其泛化能力;
kNN-LM 能在记忆训练数据的同时,保留有效的相似性函数,从而提升整体性能。
Abstract¶
本文提出了 kNN-LMs,这是一种通过将预训练的神经语言模型(LM)与 k近邻(kNN)模型 线性插值来扩展其能力的方法。
重点在于:近邻是根据预训练LM的嵌入空间中的距离计算得到,并且这些近邻可以来自任意文本集合,包括原始LM的训练数据。 实验部分,作者将此方法应用于一个强大的 Wikitext-103语言模型,并从原始训练集中选取近邻,最终取得了 15.79 的新 state-of-the-art perplexity 成绩,比之前提升了 2.9 个点,且无需额外训练。
此外,作者还指出:
该方法对于扩展到更大的训练集具有重要意义,
也可以通过简单地更换 近邻数据存储,实现 有效的领域适应(domain adaptation),同样无需进一步训练。
定性分析显示,该方法在预测 **罕见模式(如事实性知识)方面特别有效。
总结来说,文本序列之间的相似性学习比直接预测下一个词更容易,而近邻搜索是一种在长尾问题中有效提升语言建模性能的方法。
1 Introduction¶
传统神经语言模型(LMs)通常解决两个子问题:
将句子前缀映射为固定维度的表示(representation);
利用这些表示来预测下一个词(Bengio et al., 2003; Mikolov et al., 2010)。
本文提出一个新假设:表示学习问题(representation learning problem)可能比预测问题(prediction problem)更容易。
例如,英语使用者知道“Dickens is the author of”和“Dickens wrote”在下一个词的分布上是相似的,即使他们并不知道具体的分布是什么。
我们提供了证据表明,现有的语言模型在第一个子问题(表示学习)上表现更好。通过在模型的前缀表示上使用一个 简单的最近邻(kNN)方案,可以 显著提升整体性能。
我们提出了 kNN-LM,这是一种通过 线性插值(linearly interpolating) 扩展已有语言模型的方法。
该方法将模型预测的下一个词的分布与一个 k最近邻(kNN)模型 的分布进行插值。
最近邻是根据 预训练的嵌入空间中的距离 来计算的,可以从任何文本集合中提取,包括模型原始训练数据。
这种方法允许模型 显式地记忆罕见模式,而不是隐式地存储在模型参数中。
当使用 相同的训练数据 来学习前缀表示和kNN模型时,模型性能显著提升,这进一步说明 预测问题比之前认为的更加具有挑战性。
为了验证该方法的有效性,我们进行了 广泛的实证评估:
在Wikitext-103 数据集上,使用原始数据集(未添加额外训练数据)进行 kNN-LM 增强,达到了新的最优困惑度(perplexity)15.79,比基线模型提升了 2.86(Baevski & Auli, 2019)。
该方法具有扩展性和灵活性,通过简单地调整最近邻数据库,可以高效地适应更大规模的训练集或跨领域任务。
例如,训练一个模型使用 1 亿词,然后使用 30 亿词的数据库进行 kNN 搜索,可以优于直接训练 30 亿词的模型。
同样,如果在数据库中加入域外数据,同一个语言模型可以适应多个领域,而无需进一步训练。
定性分析 也表明,该方法对于 长尾模式(如事实性知识) 特别有效,因为这些信息可以通过 显式记忆 更容易获取。
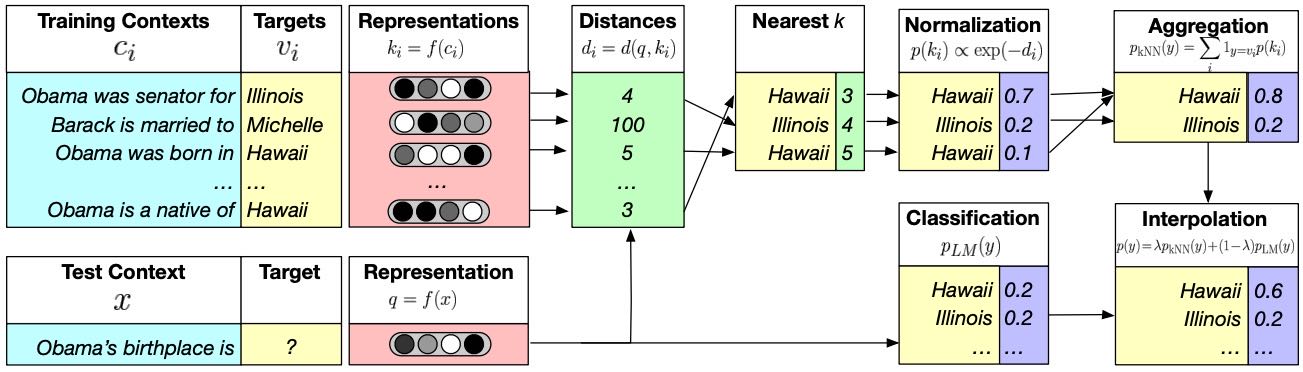
Figure 1: An illustration of 𝑘NN-LM. A datastore is constructed with an entry for each training set token, and an encoding of its leftward context. For inference, a test context is encoded, and the 𝑘 most similar training contexts are retrieved from the datastore, along with the corresponding targets. A distribution over targets is computed based on the distance of the corresponding context from the test context. This distribution is then interpolated with the original model’s output distribution.
图1总结:kNN-LM 的工作原理是:
构建一个数据存储库,包含每个训练词及其左上下文的编码。
推理时,对测试上下文进行编码,检索出最相似的 k 个训练上下文 及其目标词。
根据上下文与测试上下文的距离,计算目标词的分布,并与模型原始的输出分布进行 插值。
2 Nearest Neighbor Language Modeling¶
语言模型的基本任务¶
语言模型(LM)的任务是对词序列进行概率分配。给定一个上下文序列 c_t = (w₁, …, w_{t−1}),自回归语言模型估计 p(w_t | c_t),即在给定上下文时下一个词 w_t 的概率分布。
kNN-LM 模型概述¶
kNN-LM 是对已训练好的语言模型进行扩展,通过引入一个最近邻检索机制,无需额外训练(即语言模型的参数和表示保持不变)。这个扩展是通过一次前向遍历文本数据集(可能包含训练集)来完成的,得到的上下文-目标词对被存储在键值数据库中,并在推理时进行查询,如图1所示(见原文)。
数据存储 (Datastore)¶
表示函数 f(·):将上下文映射为固定长度的向量,例如在 Transformer 模型中,可以取某一层的注意力输出。
键值对 (k_i, v_i):对于训练数据中的每个上下文-目标对 (c_i, w_i),我们构建一个键值对,其中键 k_i = f(c_i),值 v_i = w_i。
数据库定义:(𝒦, 𝒱) 是所有 (f(c_i), w_i) 的集合,即:
\[ (\mathcal{K}, \mathcal{V}) = \{(f(c_i), w_i) | (c_i, w_i) \in \mathcal{D}\} \tag{1} \]
推理过程 (Inference)¶
在测试阶段,给定输入上下文 x,模型会:
生成基于 LM 的输出分布 p_LM(y|x) 和上下文表示 f(x)。
查询数据库,找出 f(x) 的 k 个最近邻 𝒩(根据距离函数 d(·,·),实验中使用的是 L² 距离)。
通过 softmax 将这些邻居的负距离转换为概率分布,并聚合所有邻居中相同目标词的概率:
最终的输出分布是 LM 分布与 kNN 分布的加权插值,公式如下:
λ 是一个调节参数,用于平衡模型与最近邻检索的结果。
实现细节 (Implementation)¶
由于数据库可能包含数十亿个训练样本,为了高效检索,作者使用了 FAISS(一个高效的高维向量检索库)。FAISS 通过聚类和向量压缩技术加速搜索,实验表明使用 L² 距离比内积距离效果更好。
总结¶
kNN-LM 是一种通过最近邻检索增强的语言模型,无需重新训练。它通过在推理阶段引入训练数据的键值数据库,结合 LM 原始预测和最近邻匹配结果,提升模型对罕见词、新词或特定领域词的生成能力。数据存储和检索是其实现的关键,而 FAISS 提供了高效的检索支持。与之前基于缓存的模型不同,kNN-LM 强调通过记忆训练样本来提升泛化能力。
3 Experimental Setup¶
数据¶
实验中使用了以下英文语料库:
Wikitext-103 是 Merity 等人(2017)提出的一个标准基准,用于自回归语言建模,词汇表大小为 250K(词级)。训练集包含 103M 个 token,开发集和测试集各 250K 个 token。
Books 是 Toronto Books Corpus(Zhu 等人,2015),包含 7 亿个 token。保留完整的书籍用于验证和测试。
Wiki-3B 是英文维基百科,包含约 28.7 亿个 token。保留完整的文章用于验证和测试。
Wiki-100M 是 Wiki-3B 的一个随机子集,包含 1 亿个 token,由完整文章组成。
除了 Wikitext-103,其他语料的文本使用 byte-pair encoding(BPE) 进行分词,子词词汇表大小为 29K,来源于 BERT(Devlin 等人,2019)。
模型架构¶
kNN-LM 可以与任何生成固定大小上下文表征的模型兼容。本研究使用了 仅解码器的 Transformer(Vaswani 等人,2017),这是目前最先进的语言建模架构。
由于 kNN-LM 并未改变原有的语言模型结构,我们直接采用了 Baevski & Auli(2019)中描述的模型和优化方法,并将其用于 kNN-LM 的推理。
该模型包含 16 层,每层有 16 个自注意力头,隐藏层维度为 1024,前馈网络维度为 4096,总共有 247M 可训练参数。
对于 Wikitext-103,每个样本处理 3072 个 token 的上下文,其他语料则为 1024 个 token。
对于 Wikitext-103 的实验,采用了 自适应输入 和 自适应 softmax(Grave 等人,2017b),并使用 参数绑定(Press & Wolf,2017);其他数据集则未使用这些方法。
评估¶
语言模型的训练目标是最小化训练语料的负对数似然,并通过 困惑度(Perplexity) 来评估,即负对数似然的指数形式。
根据 Baevski & Auli(2019),每个测试样本评估 512 个 token。
对于 Wikitext-103,每个样本额外提供最多 2560 个 token 的上下文;其他语料则提供最多 512 个 token 的上下文。
kNN-LM¶
kNN-LM 使用的 key 是 Transformer 语言模型最后一层中输入到前馈网络的 1024 维表征(经过自注意力和 LayerNorm,详见第 5 节)。
我们对训练集进行一次前向传播以保存 key 和 value。
对于 Wikitext-103,每个目标 token 至少提供 1536 个 token 的上下文;其他语料至少提供 512 个 token 的上下文。
然后使用 FAISS 构建索引,从 103M 个 key 中随机采样 1M 个用于聚类,学习 4096 个聚类中心。为提高效率,key 被量化为 64 字节。
在推理阶段,检索 k=1024 个最近邻,索引在搜索时查找 32 个聚类中心以加速查找。
对于 Wikitext-103,我们使用 全精度 key 计算平方 L2 距离;而对于其他数据集,直接使用 FAISS 的 L2 距离(非平方)在量化 key 上计算,以加快评估速度。
在验证集上调整了插值参数 λ,相关代码可在 GitHub 上获取。
计算成本¶
尽管 kNN-LM 不需要额外训练(已有语言模型即可),但它仍引入了一定的计算开销。
存储 key 和 value 需要一次训练集的前向传播,这大约仅占一次训练 epoch 的一小部分成本。
对于 Wikitext-103,构建包含 103M 条目的缓存,在单个 CPU 上耗时约 2 小时。
在验证集上运行,检索 1024 个 key 耗时约 25 分钟。
需要注意的是,构建大规模缓存的计算成本与条目数线性增长,但该过程易于并行化,且不需要 GPU。
4 Experiments¶
4.1 使用训练数据作为数据存储¶
本实验的核心是:使用训练语言模型(LM)时所用的训练数据本身作为检索的数据存储。我们通过在 Wikitext-103 和 Books 数据集上的实验,评估了 𝑘NN-LM 方法的性能。
重点内容:¶
Wikitext-103 实验结果(表 1):
基线模型(Baevski & Auli, 2019)的测试集 perplexity 为 18.65。
加入 𝑘NN-LM 后,perplexity 降至 16.12,提升显著。
与已有方法(如 Transformer-XL、Phrase Induction)相比,𝑘NN-LM 明显更优。
将 𝑘NN-LM 与 Continuous Cache 结合使用,性能进一步提升至 15.79,比基线模型提升了 2.86。
Books 数据集实验结果(表 2):
基线模型测试集 perplexity 为 11.89。
加入 𝑘NN-LM 后,perplexity 降至 10.89,说明方法在不同领域都有效。
Continuous Cache 小结:
Continuous Cache 是一种从测试文档中检索邻居的方法,与 𝑘NN-LM 是互补的技术。
与之前的工作相比,其在本模型中的提升效果较小,可能是因为自注意力机制的语言模型已经可以完成部分查询功能。
4.2 无需训练获得更多数据¶
本部分探讨的核心问题是:是否可以通过从大规模语料中检索邻居,替代语言模型在这些数据上的训练?
重点内容:¶
实验设置:
使用在 Wiki-100M 上训练的模型,从更大规模的 Wiki-3B(30 倍数据量)中构建数据存储。
将其与直接在 Wiki-3B 上训练的模型进行比较。
实验结果(表 3):
直接在 Wiki-3B 上训练的模型测试集 perplexity 为 15.17。
而在 Wiki-100M 上训练的模型,通过从 3B 数据中检索邻居,perplexity 降至 13.73,优于直接训练在 3B 上的模型。
这表明:通过检索大规模语料中的邻居,可以替代部分训练过程。
数据存储大小的影响(图 2):
随着数据存储规模的增加,模型性能持续提升,未出现饱和。
即使仅使用 1.6B 数据(不到 3B 的一半),模型性能也优于直接训练在 3B 上的模型。
数据存储越大,模型对 𝑘NN-LM 的依赖程度也越高(λ 增大)。
4.3 领域自适应¶
本部分研究的是:𝑘NN-LM 在不同领域之间的适应能力。
重点内容:¶
实验设置:
在 Wiki-3B 上训练的模型在 Books 领域的测试集 perplexity 为 34.84,表现较差。
但当在 Books 领域构建一个数据存储并使用 𝑘NN-LM 时,perplexity 降至 20.47。
实验结果(表 4):
原始模型在 Books 上的性能较差,但在加入 Books 数据存储后显著提升。
性能接近在 Books 上训练的模型(11.89),说明通过数据存储的检索,可以实现跨领域的性能提升。
结论:
𝑘NN-LM 允许一个模型在多个领域中使用,只需为每个领域构建一个数据存储,无需重新训练模型。
总结¶
𝑘NN-LM 显著提升了语言模型的性能,尤其在使用大规模数据存储的情况下。
无需训练即可使用更多数据,通过检索大规模语料,可以替代部分训练过程。
跨领域适应能力强,只需为新领域构建数据存储,即可显著提升模型性能。
与 Continuous Cache 等技术具有互补性,可以进一步提升模型表现。
总之,𝑘NN-LM 是一种有效的语言模型扩展方法,能够在不增加训练成本的前提下,通过检索机制显著提升语言建模效果。
5 Tuning Nearest Neighbor Search¶
本节《5 Tuning Nearest Neighbor Search》探讨了在 kNN-LM 模型中对近邻搜索进行调优的关键问题,主要包括 表示函数的选择、邻居数量、插值参数 λ 以及 相似度计算的精度。以下是该节内容的总结:
Key Function(关键函数)¶
kNN-LM 中,使用语言模型(LM)的中间状态作为上下文 c 的表示 f(c),用于相似度搜索。不同的中间状态对最终性能有显著影响。
主要结论:
使用 最终层前馈网络(FFN)的输入 作为表示函数 f(c),并 在层归一化之后,效果最好(perplexity 为 16.06)。
与之相对,多头自注意力(MHSA)的输入以及模型输出 也有帮助,但效果略差。
说明 前馈网络更关注预测任务,而 自注意力层更关注输入表示。
图3:展示 Transformer 模型的层结构。
表5:不同表示方式在 Wikitext-103 上的验证结果,显示了不同 f(·) 的 performance(以 perplexity 为指标)。
Number of Neighbors per Query(每个查询的邻居数量)¶
每个查询返回 top-k 个邻居。
图4 显示,随着 k 的增加,模型性能单调提升。
即使使用较小的 k(如 k=8),也能达到 SOTA 表现。
表明,增加邻居数量可以带来更好效果,但计算成本也会上升。
Interpolation Parameter(插值参数 λ)¶
使用 λ 来平衡基础模型分布和 kNN 搜索的分布:最终输出为 λp_kNN + (1−λ)p_base。
最优值:
对于 Wikitext-103,λ=0.25 表现最佳。
对于 领域适应(domain adaptation),λ=0.65 更优。
图5 显示了 λ 对 in-domain 和 out-of-domain 的影响,说明 提高 λ 有助于跨领域任务的性能提升。
Precision of Similarity Function(相似度函数的精度)¶
在 FAISS 中,近邻搜索使用 量化键 计算 L2 距离。
实验发现,使用全精度键并计算平方 L2 距离,可以将 Wikitext-103 的 perplexity 从 16.5 提升到 16.06。
表明 精度对性能有显著影响,尤其是在相似度计算这一关键步骤中。
总结:该节通过一系列实验,系统性地探索了 kNN-LM 中近邻搜索的调优方法,指出了表示函数的选择、邻居数量、插值参数 λ 和相似度计算精度对模型性能的关键影响。其中,FFN 输入(层归一化后)是最优表示函数,增加邻居数量和调整 λ 有助于提升性能和领域适应能力,而提升相似度计算的精度也能带来显著的性能提升。
6 Analysis¶
定性分析¶
为了理解为什么 kNN-LM 能提高性能,作者手动检查了那些 \(p_{kNN}\) 显著优于 \(p_{LM}\) 的案例。表 6 展示了其中一个例子(详见附录 A 中的更多案例)。该例子显示,kNN-LM 在多个检索到的邻居中匹配了三元组 impact on the,但将几乎全部权重放在了最相关的邻居上,因此比 n-gram LM 提供了更多的价值。
总体来看,我们发现 kNN-LM 最有帮助的案例通常包含稀有模式,例如事实性知识、人名和训练集中几乎重复的句子。在这些情况下,通过 f(⋅) 将训练和测试实例映射到相似的表示中,比在模型参数中隐式记忆下一个词更容易。
表中展示了一个典型例子,在该测试上下文中,\(p_{kNN}\) = 0.998,而 \(p_{LM}\) = 0.124,说明 kNN-LM 对正确目标词的置信度远高于 LM。尽管训练集中存在一些局部 n-gram 匹配,但最近邻搜索在匹配上下文的相关性上表现出更高的置信度。
简单表示 vs 神经表示¶
我们发现许多长尾现象表现为稀有 n-gram(如人名),于是提出一个问题:是否可以用 n-gram 模型与 Transformer LM 进行插值,替代 kNN-LM?
图 8 显示,使用 n-gram LM 进行插值几乎没有带来改善(仅提升了 0.2 perplexity 点,类似 Bakhtin et al. 2018 的结果),这表明仅靠 n-gram 无法有效提升。这一结果强调了使用神经网络学习出的表示函数 f(⋅) 的重要性,它可以更有效地衡量不同上下文之间的相似性。
图 7 对比了在 Wikitext-103 上使用 Transformer LM 和 n-gram LM 进行插值的结果,kNN-LM 明显降低了 perplexity,说明神经表示不仅匹配了局部上下文,也捕捉了更深层的语义。
隐式记忆 vs 显式记忆¶
如果神经表示函数对 kNN-LM 至关重要,那么是否可以用神经网络隐式地记忆训练数据来替代 kNN-LM 的显式记忆?
为了测试这一点,作者训练了一个没有 dropout 的 Transformer LM。图 8 显示,这个模型最终训练损失降为 0,表明它可以对训练集中的每个例子做出完美预测,即模型已完全记忆训练数据。然而,这种记忆导致模型过拟合,验证集的 perplexity 显著升高(28.59),远高于普通 Transformer LM(17.96)。
相比之下,普通 Transformer LM(含 dropout)的训练损失略高,但泛化能力更强。这表明 Transformer 模型确实具备记忆训练数据的能力,但强制记忆反而损害了其泛化性。
接着,作者测试了将“记忆化”LM 与原 LM 插值的效果,结果仅提升了 0.1 perplexity,而 kNN-LM 提升了 1.9,说明仅仅具备记忆能力并不足够,还需要一个有效的相似性函数。
结论¶
基于以上实验,作者提出了 kNN-LM 提高性能的三个关键原因:
Transformer LM 在学习上下文表示函数方面表现出色,能够捕捉隐式相似性;
尽管 Transformer 有能力记忆训练数据,但这样做会削弱其泛化能力;
kNN-LM 能在记忆训练数据的同时,保留有效的相似性函数,从而提升整体性能。
这些发现表明,kNN-LM 的成功不仅在于记忆能力,更在于如何利用神经表示进行更有效的上下文匹配和推理。
8 Conclusion and Future Work¶
本节总结了本文提出的方法 kNN-LMs 的优势,并提出了未来的研究方向。
核心贡献¶
作者提出了一种新的语言模型方法 —— kNN-LMs,该方法在测试时直接查询训练样本,从而显著优于标准语言模型。这种方法不仅效果明显,而且具有通用性,可以应用于任何神经网络语言模型。
方法的启发¶
该方法的成功表明,在上下文中学习相似性函数可能比直接从上下文预测下一个词更容易。这一观察为语言建模的研究提供了一个新的视角。
未来工作方向¶
作者指出未来的工作应集中在以下两个方面:
显式训练相似性函数:当前的 kNN-LMs 依赖于模型隐式的相似性判断,未来可以设计专门的模型或损失函数来显式学习上下文之间的相似性。
减少数据库大小:当前方法依赖于一个较大的数据存储库来查询训练样本,未来的工作应探索如何在不牺牲性能的前提下,减小数据存储的规模。
致谢¶
作者感谢了匿名审稿人以及 Sida Wang、Kartikay Khandelwal、Kevin Clark 和 FAIR Seattle 团队的成员,对他们的有益讨论和评论表示感谢。这部分内容较为次要,属于学术论文的常规致谢部分,简洁带过即可。
Appendix A Appendix¶
概述¶
本部分通过几个示例展示 \(p_{kNN}\) 和 \(p_{LM}\) 在目标词概率判断上的差异。重点在于 \(p_{kNN}\) 比 \(p_{LM}\) 能更准确地将更高的概率质量分配给正确的目标词。
表6: \(p_{kNN}\) 的优势¶
测试上下文:描述了加里波利战役对澳大利亚和新西兰国家认同的意义,以及每年在纪念日举行的活动。
\(p_{kNN}\) = 0.995,\(p_{LM}\) = 0.025
目标词:honour(纪念)
训练集上下文:
最相似的训练上下文与测试上下文几乎一致,且目标词也为 honour,概率为 0.995。
其他训练上下文如:
celebrate(庆祝),概率 0.0086
honour(纪念),概率 0.0000041
重点:\(p_{kNN}\) 能够通过找到与测试上下文高度一致的训练上下文,将更高的概率质量分配给正确的目标词,而 \(p_{LM}\) 则概率较低。
表7: \(p_{kNN}\) 的精准匹配¶
测试上下文:描述 U2 乐队在 PopMart 巡演的时间范围。
\(p_{kNN}\) = 0.959,\(p_{LM}\) = 0.503
目标词:1998
训练集上下文:
唯一匹配的上下文是描述 PopMart 巡演的日期范围,目标词为 1998,概率为 0.936。
其他上下文如:
2002(概率 0.0071)
1998(概率 0.0015)
98(概率 0.00000048)
重点:尽管目标词在多个上下文中出现,但 \(p_{kNN}\) 通过精确匹配,将最高概率分配给了唯一相关的训练上下文。
表8: \(p_{kNN}\) 的推理能力¶
测试上下文:描述了 Gauthier 在 1909 年首次在意大利帕维亚演出 Bizet 的作品。
\(p_{kNN}\) = 0.624,\(p_{LM}\) = 0.167
目标词:Carmen(歌剧作品)
训练集上下文:
有多个上下文提到 Bizet 的作品:
Carmen(概率 0.356)
opera(概率 0.0937)
Carmen(概率 0.0686)
重点:\(p_{kNN}\) 能够推理出 Bizet 的著名作品是 Carmen,而非其他模糊的词汇。
表9: \(p_{kNN}\) 在模糊情况下的表现¶
测试上下文:描述了 Mycena maculata 的特征。
\(p_{kNN}\) = 0.031,\(p_{LM}\) = 0.007
目标词:develops(发展)
训练集上下文:
多个词都可能是合适的延续词(如 develops, generally, has, can),但 \(p_{kNN}\) 将最高概率分配给了 develops(0.031)。
对比之下,\(p_{LM}\) 的概率更低。
重点:尽管上下文存在不确定性,\(p_{kNN}\) 仍能识别最相关的上下文并赋予最高概率,而 \(p_{LM}\) 的表现更差。
总结¶
核心观点:\(p_{kNN}\) 模型在多个例子中展现出比 \(p_{LM}\) 模型更高的性能,尤其是在上下文匹配和推理能力方面。
重点内容:
\(p_{kNN}\) 能通过找到与测试上下文高度一致的训练样本,准确分配高概率。
在多个模糊或重复的上下文中,\(p_{kNN}\) 能排除干扰,选出最相关的上下文。
即使测试上下文存在不确定性或多个合理词,\(p_{kNN}\) 仍能选择最合适的词。
次要内容:具体上下文的描述和概率数值的展示,用于支持上述观点。