2303.08896_SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models¶
引入: 894(2025-08-06)
组织: ALTA Institute, Department of Engineering, University of Cambridge
总结¶
核心思想
一种基于采样的检测方法
如果模型对某个概念有准确的理解,那么多次采样生成的回复应该在内容和事实方面保持一致;
而如果包含虚假信息,不同采样结果会相互矛盾
五种检测变体:
BERTScore
QA(问答一致性)
n-gram 重合度
自然语言推理(NLI)
Prompt
LLM 总结¶
这篇文章《SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models》提出了一种名为 SelfCheckGPT 的方法,用于在没有外部资源的情况下,检测生成式大语言模型(LLMs)输出中的 幻觉(hallucinations)。所谓幻觉,指的是模型生成了看似合理但实际错误或虚构的信息。这类问题在大模型中尤为常见,尤其是在缺乏事实核查的情况下。
主要内容总结:¶
问题背景:
大型语言模型(如 GPT、LLaMA)在生成文本时,可能生成与事实不符的内容(即幻觉)。
现有的幻觉检测方法通常依赖外部资源(如知识库或事实检查系统),或者需要对模型进行微调(白盒方法),这些方法在资源受限或模型不可访问时难以应用。
SelfCheckGPT 的创新:
本文提出了一种 零资源(zero-resource) 且 黑盒(black-box) 的幻觉检测方法,无需访问模型的权重或依赖外部知识。
SelfCheckGPT 通过分析模型自身生成内容的 内部一致性(intra-consistency) 来检测幻觉。
具体来说,它利用了 自检(self-checking) 的思想,通过多次生成(如多次采样)来比较输出的一致性。如果多次生成的结果差异较大,说明模型可能在生成不准确或幻觉内容。
方法细节:
通过控制生成参数(如温度温度、top-k、top-p)生成多个版本的回答。
利用文本相似度(如 BERTScore)来衡量多个回答之间的一致性。
一致性越差,说明生成内容越可能存在幻觉。
实验与评估:
在多个基准数据集上验证了 SelfCheckGPT 的有效性。
实验结果表明,该方法在不依赖外部资源的情况下,能够有效检测幻觉,且性能优于一些基于外部资源的检测方法。
该方法对不同模型(如 GPT-3、LLaMA)和任务(如问答、摘要)都表现出良好的适应性。
意义与贡献:
提供了一种通用、实用的幻觉检测方法,适用于黑盒模型和资源受限的场景。
为实际部署中的模型可靠性提供了保障,特别是在高风险任务中(如医疗、法律)。
总结:¶
这篇文章提出了一种名为 SelfCheckGPT 的零资源黑盒幻觉检测方法,通过分析模型输出的一致性来识别可能的错误生成内容。该方法无需访问模型参数或依赖外部知识,具有广泛的应用前景,特别是在部署大语言模型时保障输出的可信度。
Abstract¶
这段内容主要介绍了“SelfCheckGPT”这一新型事实核查方法。文章指出,像GPT-3这样的生成式大语言模型虽然能够生成流畅且多样化的回复,但容易产生事实错误(即“幻觉”),从而影响用户对其输出的信任。现有的事实核查方法要么需要访问模型的概率分布(如ChatGPT可能不提供),要么依赖外部数据库,操作复杂。为了解决这些问题,作者提出了SelfCheckGPT,这是一种零资源、无需外部数据库的方法,适用于黑盒模型。
其核心思想是:如果模型对某个概念有准确的理解,那么多次采样生成的回复应该在内容和事实方面保持一致;而如果包含虚假信息,不同采样结果会相互矛盾。作者使用GPT-3在WikiBio数据集上生成人物传记,并通过人工标注验证生成内容的事实性。实验结果显示,SelfCheckGPT能够有效检测句子层面的虚假信息,并在段落层面评估事实准确性。与现有方法相比,该方法在检测真假句子和评估段落事实性方面表现出更高的准确性。最后,作者公开了代码和数据集以供研究使用。
1 Introduction¶
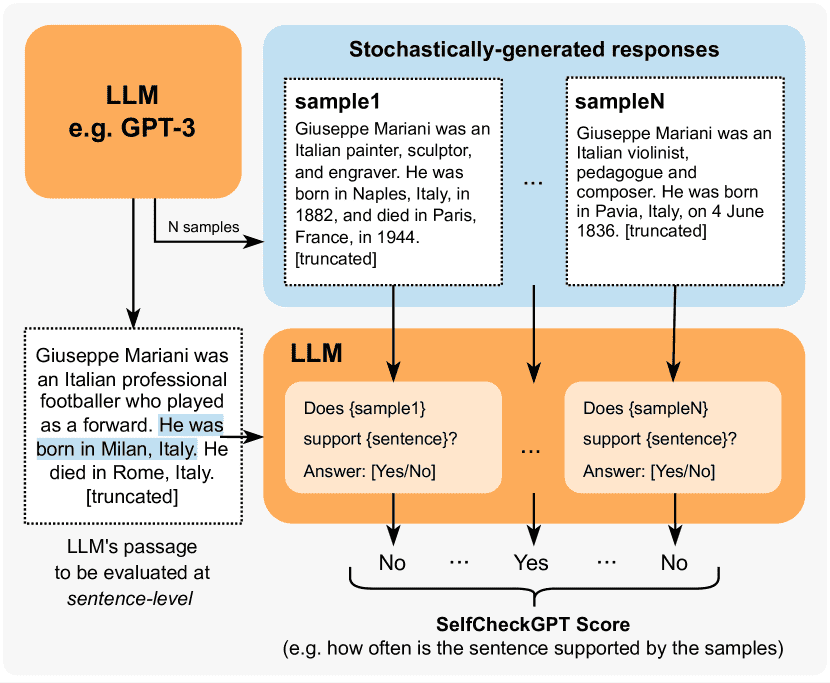
Figure 1:SelfCheckGPT with Prompt. Each LLM-generated sentence is compared against stochastically generated responses with no external database. A comparison method can be, for example, through LLM prompting as shown above.
本文介绍了一种名为 SelfCheckGPT 的新型大语言模型(LLM)幻觉检测方法。主要内容总结如下:
问题背景
尽管像 GPT-3 和 PaLM 这样的大型语言模型能够生成流畅、逼真的文本,但它们容易产生事实性幻觉(hallucination),即生成不真实或虚构的信息。当前缺乏有效的检测手段,尤其是在无法访问模型内部或外部数据库的情况下。现有方法的局限性
不确定性度量方法(如 token 概率或熵)需要访问模型内部的 token 级概率信息,而这种信息在通过 API 调用模型时通常不可用。
事实验证方法需要依赖外部数据库,但许多幻觉并不局限于已知事实的验证。
SelfCheckGPT 的核心思想
SelfCheckGPT 是一种基于采样的检测方法。其核心假设是:对于真实信息,LLM 在多次采样中生成的响应应具有一致性;而对于幻觉内容,不同采样响应之间可能出现不一致甚至矛盾。通过比较多个采样响应之间的一致性,可以判断生成内容是否为事实或幻觉。方法实现
SelfCheckGPT 不依赖外部数据库,仅使用 LLM 生成的响应进行比较,因此适用于黑盒模型。文章提出了五种检测变体:BERTScore
问答一致性
n-gram 重合度
自然语言推理(NLI)
LLM 提示方法
实验与结果
在对 GPT-3 生成的标注文章进行分析后,SelfCheckGPT 被证明是一种高效、实用的幻觉检测方法,其性能甚至优于部分灰盒方法,并为该领域提供了强有力的基线。贡献与意义
首次提出针对一般 LLM 生成内容的幻觉检测方法;
是首个适用于黑盒 LLM 的零资源检测方案;
为日益重要的 LLM 幻觉问题提供了新的研究方向和解决方案。
3 Grey-Box Factuality Assessment¶
本章节主要介绍了在“零资源”(即不使用外部数据库)且能完全访问模型输出分布的情况下,如何对大型语言模型(LLM)生成内容的**事实性(factuality)**进行评估的方法,称为“灰盒”(grey-box)方法。作者强调,这与需要访问模型内部状态的“白盒”方法不同,更为实用。
核心观点总结:¶
事实性的定义:
如果生成的语句基于有效信息(即未产生幻觉),则称为“事实性”语句。
评估时使用“零资源”设定,即不依赖外部数据库。
不确定性与事实性的关系:
LLM在预训练阶段通过大规模语料学习了语言结构、上下文推理和世界知识。
对于知名的实体(如“Lionel Messi”),模型有较高的确定性,输出的概率分布集中。
对于不熟悉的实体(如“John Smith”),模型不确定,输出的概率分布较平坦,容易生成不事实的内容(如错误的职业描述)。
基于概率的评估方法:
平均负对数概率(Avg(-log p)):衡量句子中所有词的概率平均值,越低表示越可能为事实性内容。
最大负对数概率(Max(-log p)):衡量句子中最不可能的词的不确定性,用于识别生成过程中的潜在问题。
基于熵(Entropy)的评估方法:
熵(Entropy):衡量输出分布的不确定性,熵值越高表示模型越不确定。
平均熵(Avg(H)):衡量句子整体的不确定性。
最大熵(Max(H)):识别句子中最不确定的词,可能揭示模型的“幻觉”位置。
总结:¶
本节提出了一套基于模型输出分布的不确定性指标,用于在无外部资源帮助的情况下判断LLM生成内容的事实性。通过分析概率和熵,可以识别出模型在哪些地方不确定,从而推断其是否可能产生不事实(虚假)内容。这些方法对检测模型幻觉具有实际应用价值。
4 Black-Box Factuality Assessment¶
本章节主要讨论在无法获取大语言模型(LLM)内部输出概率信息(如token-level概率)的情况下,如何对模型生成内容的事实性进行评估。该情境下,灰盒方法(grey-box methods)受限,因此提出使用黑盒方法(black-box approaches)来评估事实性,即使只能获取文本输出也能适用。
其中,一种简单的黑盒方法是使用“代理模型”(Proxy LLM),即另一个可以完全访问的LLM(如LLaMA),来近似估算目标黑盒模型(如ChatGPT)的输出概率。这种方法可以弥补无法直接获取模型概率信息的不足。
最后,作者提出了一种新的黑盒方法——SelfCheckGPT,将在后续章节中进行介绍。
5 SelfCheckGPT¶
SelfCheckGPT 是一种用于检测大型语言模型(LLM)生成内容中幻觉(hallucination,即模型生成的不准确或虚构信息)的黑盒零资源方法。其核心思想是通过比较同一查询下生成的多个响应来测量一致性,从而判断哪些句子可能是幻觉。
核心概念¶
黑盒零资源:无需访问模型内部参数(黑盒),也无需额外训练数据或标注(零资源)。
基本流程:
给定用户查询,生成一个主响应 \( R \)。
对同一查询生成 \( N \) 个额外的随机样本响应 \( \{S^1, S^2, ..., S^N\} \)。
通过比较 \( R \) 和样本 \( S^n \) 的一致性,计算每个句子的幻觉分数 \( \mathcal{S}(i) \)(0.0表示可信,1.0表示可能是幻觉)。
五种变体方法¶
1. SelfCheckGPT with BERTScore¶
原理:用BERTScore(基于RoBERTa-Large的语义相似度)比较主响应句子 \( r_i \) 与每个样本 \( S^n \) 中最相似的句子。
公式: $\( \mathcal{S}_{\text{BERT}}(i) = 1 - \frac{1}{N} \sum_{n=1}^N \max_k \mathcal{B}(r_i, s^n_k) \)$
若 \( r_i \) 与多个样本中的句子相似,则分数低(可信);否则分数高(可能是幻觉)。
2. SelfCheckGPT with Question Answering (MQAG)¶
原理:通过生成多选题(问题 \( q \) 和选项 \( \mathbf{o} \))测试一致性:
从主响应 \( R \) 生成问题。
用样本 \( S^n \) 回答问题,比较答案是否匹配。
分数:
统计匹配数 \( N_{\text{m}} \) 和不匹配数 \( N_{\text{n}} \),计算不一致分数: $\( \mathcal{S}_{\text{QA}}(i, q) = \frac{N_{\text{n}}}{N_{\text{m}} + N_{\text{n}}} \)$
最终分数是所有问题的平均(公式6)。
3. SelfCheckGPT with n-gram¶
原理:用样本训练一个 \( n \)-gram语言模型,计算主响应句子的概率:
低概率(高负对数概率)表示可能是幻觉。
两种分数:
平均负对数概率(公式7)。
最大负对数概率(公式8,更关注最不可信的词)。
4. SelfCheckGPT with NLI¶
原理:用自然语言推理(NLI)模型(如DeBERTa-v3-large)判断主响应句子 \( r_i \) 是否与样本 \( S^n \) 矛盾。
分数: $\( \mathcal{S}_{\text{NLI}}(i) = \frac{1}{N} \sum_{n=1}^N P(\text{contradict} | r_i, S^n) \)$
高分数表示 \( r_i \) 与多个样本矛盾。
5. SelfCheckGPT with Prompt¶
原理:直接提示LLM(如GPT-3)判断句子 \( r_i \) 是否被样本 \( S^n \) 支持。
分数:
将回答(Yes/No/N/A)映射为数值,取平均(公式11)。
需注意:小模型(如LLaMA)可能效果不佳。
关键点总结¶
一致性假设:若信息在多个样本中一致出现,则更可能是事实;否则可能是幻觉。
适用场景:无需外部知识或标注,仅需同一模型的多组生成结果。
方法选择:
BERTScore:适合语义相似度检测。
QA:适合可转化为问题的内容。
n-gram:简单快速,但依赖表面统计。
NLI:适合逻辑矛盾检测。
Prompt:依赖大模型能力,成本较高。
通过这五种方法,SelfCheckGPT可以灵活检测生成文本中的幻觉,适用于不同需求和资源场景。
6 Data and Annotation¶
本章主要介绍了用于评估幻觉检测方法的数据构建与标注过程。具体内容如下:
数据生成:由于目前没有标准的幻觉检测数据集,作者使用GPT-3模型(text-davinci-003版本)基于WikiBio数据集中的概念生成维基百科风格的段落。从WikiBio测试集中选取了238篇最长的20%的条目作为输入,生成了共1908个句子,平均每段184.7个token的合成数据。
标注标准:对生成的段落进行逐句标注,标注类别包括:
Major Inaccurate(严重不实):句子完全不相关,属于幻觉。
Minor Inaccurate(轻微不实):句子部分不实,但与主题相关。
Accurate(准确):句子内容准确无误。
标注流程如图3所示。
标注结果与一致性分析:
761句(39.9%)被标记为严重不实;
631句(33.1%)被标记为轻微不实;
516句(27.0%)被标记为准确。
201句由两位标注者标注,采用更严格标签处理分歧。使用Cohen’s κ计算标注者一致率,三类标签的κ值为0.595(中等一致性),两类标签(真实 vs 不实)的κ值为0.748(相当一致)。
段落层面评分:通过句子评分的平均值得到段落层面的事实性评分。如图4所示,大部分段落评分集中在1.0,被定义为“完全幻觉”,即段落内容完全不真实。
检测性能初步展示:通过图5的PR曲线展示了检测非事实与事实句子的性能。
总结来说,本章构建了一个高质量的人工标注数据集,为后续幻觉检测模型的评估奠定了基础,并通过标注一致性和评分分布分析验证了数据的有效性和可靠性。
7 Experiments¶
本节总结如下:
7 实验¶
本节主要评估了 SelfCheckGPT 检测生成式大语言模型(LLM)中幻觉(hallucination)的能力,实验围绕两个核心任务展开:句子级别的幻觉检测 和 段落级别的事实性排序,并进行了多个消融实验。
7.1 句子级别的幻觉检测¶
主要实验设置:¶
生成数据使用 GPT-3(text-davinci-003),使用温度0.0和温度1.0分别生成确定性和随机性样本。
代理模型使用 LLaMA(30B参数)。
SelfCheckGPT 方法包括 BERTScore、QA、NLI、Prompt、n-gram 等。
主要发现:¶
LLM 的概率 p 与事实性显著相关:
用 GPT-3 生成文本时,句子概率(特别是最大概率)在检测非事实句子上表现优异。
事实性句子的 AUC-PR 可达 53.97,远优于随机基线(27.04)。
概率(log-p)方法优于熵(H)方法。
代理 LLM 表现较差:
使用 LLaMA 等代理模型时,熵方法比概率表现更好。
但整体性能仍低于 GPT-3,尤其在概率较低时效果差。
其他代理模型(如 GPT-NeoX、OPT-30B)几乎与随机基线无异。
SelfCheckGPT 方法显著优于 LLM 概率/熵方法:
SelfCheckGPT-Prompt 在所有设置中表现最佳,AUC-PR 达 93.42。
即使是最简单的 Unigram (max) 方法也优于灰盒(grey-box)方法。
低计算成本的 Unigram (max) 方法通过识别低频词实现有效检测。
n-gram 方法性能随 n 增加而下降:
1-gram 表现最好,5-gram 逐渐变差。
最大 n-gram 计分法优于平均分。
NLI 方法性能接近 Prompt 方法:
NLI 方法在黑盒和灰盒方法中效果最好。
虽然 Prompt 方法稍强,但计算成本高;NLI 方法在性能与效率之间取得良好平衡。
7.2 段落级别的事实性排序¶
方法:¶
将段落中所有句子的句子级别得分取平均,作为段落级别评分。
与人工评分使用 Pearson 和 Spearman 相关性进行衡量。
结果:¶
SelfCheckGPT 方法在段落级别上与人工评分高度相关。
SelfCheckGPT-Prompt 表现最佳,Pearson 相关性达到 78.32。
代理 LLM 方法(如 LLaMA)相关性明显较低。
7.3 消融实验¶
1. 使用外部知识 vs. SelfCheck¶
使用维基百科等外部知识(如 WikiBio)时,部分方法(如 NLI、Prompt)性能提升,但 n-gram 方法反而下降。
SelfCheckGPT 在大多数情况下表现优于或接近使用外部知识的方法。
但外部知识依赖性强,不适用于所有应用场景。
2. 样本数量对性能的影响¶
随着样本数量增加,性能逐渐提升,但收益递减。
n-gram 方法需要更多样本才能达到性能稳定。
3. 不同 LLM 用于 SelfCheckGPT-Prompt 的对比¶
GPT-3 可以在少量样本(如 4 个)下自我检测,优于 unigram 方法。
ChatGPT 在上下文中的判断略优于 GPT-3,但差距不大。
总结¶
SelfCheckGPT 在句子和段落级别的幻觉检测中表现优异,优于基于 LLM 概率和熵的基线方法。
Proxy LLM 方法性能较差,说明模型生成风格差异较大,影响检测效果。
NLI 和 Prompt 方法在性能与计算成本之间取得较好平衡。
SelfCheckGPT 在无需外部知识的情况下仍能有效检测幻觉,适合资源受限的场景。
消融实验表明,样本数量、方法选择和 LLM 类型对最终效果有显著影响。
以上内容总结了 SelfCheckGPT 在幻觉检测任务中的实验设置、主要方法及其性能表现,为后续研究和实际应用提供了参考依据。
8 Conclusions¶
本论文总结了以下几点:
研究创新性:本文是首个针对通用大语言模型(LLM)响应中幻觉(hallucination)检测任务的研究。
方法提出:作者提出了 SelfCheckGPT,这是一种零资源方法,适用于任何黑盒LLM,无需依赖外部资源。
方法有效性:实验表明,SelfCheckGPT在句子和段落级别上均优于多种灰色盒和黑盒的基线检测方法,展示了其优越性能。
数据集发布:为进一步推动研究,作者还发布了一个标注数据集,专门用于GPT-3的幻觉检测,包含句子级别的事实性标签。
Limitations¶
本节讨论了研究中存在的几个局限性。首先,研究中使用的238篇GPT-3生成文本主要集中在WikiBio数据集中的个人描述,未来可以扩展到更多概念,如地点和物体,以便更全面地研究大语言模型(LLM)的幻觉现象。其次,研究是在句子层面评估事实性,但一个句子可能同时包含事实和非事实信息,因此可借鉴Min等人(2023)提出的将句子分解为原子事实的方法,以实现更细粒度的评估。最后,研究中表现最好的SelfCheckGPT方法虽然效果突出,但计算成本较高,未来需要优化其效率,以降低实际应用中的计算负担。
Ethics Statement¶
本章节的伦理声明指出,本研究关注大语言模型(LLM)产生的幻觉问题。如果未能检测到这些幻觉内容,可能会导致错误信息的传播,从而带来潜在的负面影响。因此,识别和处理幻觉内容在伦理上具有重要意义。
Acknowledgments¶
本研究得到了剑桥大学出版社与评估部门(CUP&A)以及剑桥英联邦、欧洲与国际信托基金的支持。作者还感谢匿名审稿人提供的宝贵意见。
Appendix A Models and Implementation¶
以下是该论文章节内容的总结:
本附录部分介绍了模型和实现细节,主要包括以下三个部分:
熵的计算(Entropy)
定义并实现了输出分布的熵公式:
$\( \mathcal{H}_{ij}=2^{-\sum_{\tilde{w}\in\mathcal{W}}p_{ij}(\tilde{w})\log_{2}p_{ij}(\tilde{w})} \)\( 其中 \)\mathcal{W}\( 表示词汇表中所有可能的词,\)p_{ij}(\tilde{w})\( 是在位置 \)ij\( 生成词 \)\tilde{w}$ 的概率。该公式用于衡量语言模型输出的不确定性。代理大语言模型(Proxy LLMs)
作者使用了几种不同规模的代理大语言模型进行实验,包括:LLaMA 系列:LLaMA-7B、LLaMA-13B、LLaMA-30B
OPT 系列:OPT-125M、OPT-1.3B、OPT-13B、OPT-30B
GPT 系列:GPT-J-6B、GPT-NeoX-20B
SelfCheckGPT 的系统组成
问答生成系统:G1 和 G2 是基于 T5-Large 模型,并分别在 SQuAD 和 RACE 数据集上微调得到。
回答系统 A:基于 Longformer 模型,在 RACE 数据集上微调。
可答性判断系统 U:同样是 Longformer,但在 SQuAD2.0 数据集上微调。
用于提示的 LLM:作者使用了 GPT-3(text-davinci-003)和 ChatGPT(gpt-3.5-turbo),其中 GPT-3 被用于生成 WikiBio 数据集中的文本。
该附录为论文中的分析和实验提供了具体的模型实现和配置信息。
Appendix B SelfCheckGPT with QA¶
本节对 SelfCheckGPT 的 QA(Question Answering)方法进行了扩展,重点介绍了如何结合 贝叶斯定理 和 软计数(soft counting) 来提升模型对生成文本中幻觉(hallucination)的检测能力。总结如下:
1. 两阶段的 QA 生成方法¶
G1:生成问题 \( q \) 和标准答案 \( a \)。
G2:生成干扰答案 \( \mathbf{o}\_{\backslash a} \),形成包含正确答案的四个选项 \( \mathbf{o} = \{a, \mathbf{o}\_{\backslash a}\} \)。
为了过滤掉无意义或无法回答的问题,引入了一个可回答性评分 \( \alpha \)。该评分由一个分类模型 \( P_U \) 输出,范围在 0.0(不可回答)到 1.0(可回答)之间。
2. 贝叶斯方法的应用(SelfCheckGPT-QA)¶
定义句子为非事实(Non-factual, F)或事实(Factual, T)的概率,并使用贝叶斯公式推导:
\[ P(F|L_m, L_n) = \frac{P(L_m, L_n|F)P(F)}{P(L_m, L_n|F)P(F) + P(L_m, L_n|T)P(T)} \]假设 \( P(F) = P(T) \),简化为:
\[ P(F|L_m, L_n) = \frac{P(L_m, L_n|F)}{P(L_m, L_n|F) + P(L_m, L_n|T)} \]对于非事实句子,其概率为:
\[ P(L_m, L_n|F) = (1-\beta_1)^{N_m} \cdot \beta_1^{N_n} \]对于事实句子,其概率为:
\[ P(L_m, L_n|T) = \beta_2^{N_m} \cdot (1-\beta_2)^{N_n} \]最终简化为:
\[ P(F|L_m, L_n) = \frac{\gamma_2^{N_n}}{\gamma_1^{N_m} + \gamma_2^{N_n}} \]其中 \( \gamma_1 = \frac{\beta_2}{1 - \beta_1}, \gamma_2 = \frac{\beta_1}{1 - \beta_2} \),实验中 \( \beta_1 = \beta_2 = 0.8 \)。
3. 软计数(Soft Counting)的引入¶
传统的硬计数(hard counting)只考虑是否可回答,而软计数使用可回答性评分 \( \alpha \) 来加权计数,从而更精细地评估匹配和不匹配的答案数量。
匹配答案数量的软计数为:
\[ N'_m = \sum_{n\ s.t.\ a_n \in L_m} \alpha_n \]不匹配答案数量的软计数为:
\[ N'_n = \sum_{n\ s.t.\ a_n \in L_n} \alpha_n \]
使用软计数后,最终的 QA 检测评分公式为:
\[ \mathcal{S}_{\text{QA}} = \frac{\gamma_2^{N'_n}}{\gamma_1^{N'_m} + \gamma_2^{N'_n}} \]
4. 实验结果¶
实验结果显示,引入贝叶斯方法和软计数显著提升了 SelfCheckGPT 在检测文本中幻觉的表现。在句子级别和段落级别的幻觉检测任务中,组合了贝叶斯和软计数的方法(+ Bayes + α)均优于只使用硬计数的方法。
方法 |
句子级别 |
段落级别 |
|---|---|---|
SimpleCount |
83.97 |
57.39 |
+ Bayes |
83.04 |
56.43 |
+ Bayes + α |
84.26 |
61.07 |
总结¶
本节通过引入两阶段的 QA 生成、贝叶斯概率模型和软计数机制,有效提升了 SelfCheckGPT 在检测生成式语言模型输出中幻觉的能力。实验表明,贝叶斯方法和软计数的结合是关键因素,能够更准确地区分事实与非事实信息。
Appendix C SelfCheckGPT with Prompt¶
本章节主要介绍了在使用 SelfCheckGPT-Prompt 方法时,对 GPT-3 和 ChatGPT 的实验设置与成本分析,并展示了两者的预测结果对比。
主要内容总结:¶
实验设置:
使用了主文中提供的提示模板(Prompt Template),分别在 GPT-3 (text-davinci-003) 和 ChatGPT (gpt-3.5-turbo) 上进行实验。
对于 ChatGPT,使用标准的系统消息 “You are a helpful assistant.” 进行初始化。
成本分析:
当时的 API 费用为:每 1,000 个 token,GPT-3 为 \(0.020,ChatGPT 为 \)0.002。
处理全部 1908 个句子和 20 个样本的预估成本为:GPT-3 约 \(200,ChatGPT 约 \)20。
由于成本较高,关于 LLM 选择的消融实验(Ablation Study)只在 4 个样本上进行。
预测结果对比(表 6):
两模型在判断句子是否被支持(Yes/No)时的预测结果如下:
模型 |
预测为 Yes |
预测为 No |
|---|---|---|
GPT-3 |
3179 |
367 |
ChatGPT |
1038 |
3048 |
GPT-3 更倾向于判断句子为 “支持”(Yes),而 ChatGPT 更倾向于判断为 “不支持”(No)。
总结:¶
本附录提供了 SelfCheckGPT-Prompt 方法在不同大语言模型上的实验细节、成本估算及结果对比,为读者理解模型表现和经济性提供了参考。
Appendix D Additional Experimental Results¶
附录 D 补充实验结果总结¶
本节提供了与主文中实验结果互补的额外实验结果,重点评估了 SelfCheckGPT 方法在不同 n-gram 模型、代理大型语言模型(LLM)和不同模型规模下的性能表现。
1. n-gram 模型对检测效果的影响¶
使用 Avg(-logp) 和 Max(-logp) 两种方法评估不同 n-gram 模型在句级(sentence-level)和段落级(passage-level)上的检测效果。
表格结果显示:
句级非事实检测(Non-factual detection):
使用 Max(-logp) 方法时,2-gram 和 3-gram 表现相对较好,AUC-PR 分别达到 85.26 和 84.97。
Avg(-logp) 方法中,3-gram 和 4-gram 的 AUC-PR 分别达到 83.56 和 83.80。
段落级排名性能(Passage-level ranking):
Max(-logp) 方法中,1-gram 的 Pearson 和 Spearman 相关系数分别为 64.71 和 64.91,表现优于其他 n-gram。
随着 n-gram 增大,性能在某些指标上有波动,表明存在性能下降或过拟合的风险。
2. 代理 LLM 对检测效果的影响¶
评估了使用不同规模的代理 LLM(如 LLaMA、OPT、GPT-J、NeoX)在 Avg(ℋ) 和 Max(ℋ) 方法下的检测效果。
LLaMA 30B 和 OPT 30B 是表现较好的模型:
Avg(ℋ) 方法中,LLaMA 30B 在句级检测中 AUC-PR 达到 80.80,段落级 Spearman 相关系数为 39.49。
Max(ℋ) 方法中,LLaMA 30B 的 AUC-PR 为 80.92,Spearman 相关系数为 38.94。
较小模型(如 OPT 125m)性能较差,Spearman 相关系数甚至为负值(-37.18)。
3. 不同模型方法的对比¶
SelfCheckGPT-BERTScore, SelfCheckGPT-QA, SelfCheckGPT-1gram(max) 和 SelfCheckGPT-NLI 四种方法在段落级上的检测结果与人类评分进行了对比。
散点图显示了各方法与人类评分的相关性(Pearson 和 Spearman)。部分方法与人类评分一致性较高,但某些方法(如 SelfCheckGPT-NLI)相关性较低。
4. 样本数量对检测效果的影响¶
图 8 展示了 SelfCheckGPT 方法在句级非事实检测中的 AUC-PR 与样本数量的关系。
随着样本数量的增加,检测性能逐渐稳定,说明该方法具有较好的可扩展性。
总结¶
本节补充实验结果展示了 SelfCheckGPT 在不同 n-gram 设置、代理 LLM 规模和模型方法下的检测性能。结果显示,LLaMA 30B 在大多数情况下表现最佳,Max(-logp) 方法在句级检测中优于 Avg(-logp),但在段落级排名上两者性能接近。此外,样本数量对方法性能有一定影响,但整体表现较为稳定。