2203.13366_RLP_P5: A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5)¶
引用: 660(2025-08-19)
组织:
Department of Computer Science, Rutgers University, NJ, US
GitHub: https://github.com/jeykigung/P5
Huggingface: https://huggingface.co/makitanikaze/P5
总结¶
重点说明
里面的几个图需要重点看
最后的附录中有用到的 prompt 集合(不过相对简单,但大体了解推荐相关的 prompt)
证明了在 A分类(如:Sport)中训练的模型可以 B分类(如:Beauty)数据集中有比较好的泛化能力(参见 figure 4)
标签
tag: Recommendation
tag: 推荐
简介
RLP: Recommendation as Language Processing
Personalized Foundation Models (PFM),
Universal Recommendation Engine (URE)
背景
推荐任务通常需要设计特定于任务的架构和训练目标。
因此,从一个任务学到的知识和表征难以迁移到另一个任务
推荐系统与自然语言处理的结合的四类研究方向:
可解释推荐
explainable recommendation
使用 NLP 模型生成推荐解释。
序列推荐作为语言建模:
sequential recommendation as language modeling
将用户交互历史视为词序列进行建模。
文本特征提取:
text feature extraction
提取文本编码以提升推荐性能。
对话推荐:
conversational recommendation
在交互式对话中理解用户意图并给出推荐。
多任务推荐预训练涵盖五个不同的任务系列
评分
顺序推荐
解释
评论
直接推荐
贡献
本文提出了一个灵活且统一的文本到文本推荐框架P5,它通过自然语言建模将多种推荐任务(如序列推荐、评论生成等)统一在一个共享框架下
关键创新
所有推荐相关数据(如交互记录、用户画像、商品信息)均转换为自然语言序列,以语言建模目标(如生成式任务)预训练单一模型。
支持多种下游任务(如评分预测、推荐理由生成),无需任务特定架构。
P5框架
一种统一的预训练、个性化提示和预测范式,其核心在于通过个性化提示(personalized prompts)生成大量可用于预训练的推荐任务数据
所有数据都被转化为统一的自然语言序列格式
数据包括:
user-item interactions,
user descriptions,
item metadata,
user reviews
自然语言中的丰富信息有助于P5捕捉更深层次的语义,从而实现更好的个性化和推荐效果
训练、验证、测试数据集准备方案
leave-one-out 评估策略
它模拟了“给定用户的历史行为,预测下一个可能交互的物品”的真实应用场景。
在 序列推荐任务(sequential recommendation) 中,用户的行为数据是按时间顺序排列的交互序列(例如一个用户先后点过、买过、看过的一系列物品)。
最后一个交互的物品(比如用户最后点击/购买的那个)被用作 测试集,即模型需要预测这个物品;
倒数第二个交互的物品 被用作 验证集,用于调参或模型选择;
之前的所有交互记录(除了最后两个)作为 训练集,让模型学习用户的行为模式。 数据集
Amazon
包含 29 类产品的用户评分和评论
本文采用其中三个数据集
Sports & Outdoors
Beauty
Toys & Games
Yelp
包含大量用户评分和评论,可用于商业推荐
评价指标
评分预测任务使用RMSE和MAE。
推荐任务使用HR@K(Hit Ratio)和NDCG@K(Normalized Discounted Cumulative Gain)。
解释生成和评论摘要任务使用BLEU-4和ROUGE(ROUGE-1、ROUGE-2、ROUGE-L)。
性能指标中RMSE和MAE越低越好,其余越高越好。
Abstract¶
长期以来,不同的推荐任务通常需要设计特定于任务的架构和训练目标。因此,从一个任务学到的知识和表征难以迁移到另一个任务,限制了现有推荐系统方法的泛化能力。例如,一个序列推荐模型很难被应用或迁移到评论生成任务中。
为了解决这一问题,论文认为语言可以描述几乎所有内容,并且语言建模是一种强大的媒介,能够统一表示各种问题或任务。基于此,作者提出了一个灵活且统一的文本到文本范式,名为“预训练、个性化提示、预测范式”(P5),用于推荐系统。
在P5框架中,所有数据(如用户-物品交互、用户描述、物品元数据、用户评论等)都被转化为统一的自然语言序列格式。自然语言中的丰富信息有助于P5捕捉更深层次的语义,从而实现更好的个性化和推荐效果。
具体而言,P5在预训练阶段通过相同的语言建模目标学习不同的任务,因此它能够作为多种下游推荐任务的基础模型。P5还支持与其他模态的轻松集成,并能够通过提示(prompt)实现基于指令的推荐。P5推动推荐系统从浅层模型、深度模型向大模型演进,朝着通用推荐引擎的方向发展。
通过为不同用户设计自适应个性化提示,P5能够在零样本或少样本设置下进行预测,显著减少了对大量微调的依赖。论文在多个推荐基准数据集上进行了实验,验证了P5的有效性。
关键词(Keywords)¶
推荐系统(Recommender Systems)
自然语言处理(Natural Language Processing)
多任务学习(Multitask Learning)
个性化提示(Personalized Prompt)
语言建模(Language Modeling)
统一模型(Unified Model)
论文信息(Meta Information)¶
会议:第十六届ACM推荐系统会议(RecSys ‘22),2022年9月18日–23日,美国西雅图
期刊年份:2022
版权:ACM
DOI:10.1145/3523227.3546767
ISBN:978-1-4503-9278-5
论文集名称:Sixteenth ACM Conference on Recommender Systems (RecSys ’22)
总体总结(重点强调)¶
本文最重要的贡献是提出了一个统一的文本到文本推荐框架P5,它通过自然语言建模将多种推荐任务(如序列推荐、评论生成等)统一在一个共享框架下。P5利用语言的表达能力,实现了跨任务的知识迁移、零样本/少样本推荐、与多模态的集成等能力,是迈向“通用推荐引擎”的重要一步。
1. Introduction¶
本节回顾了推荐系统的发展趋势,并提出了一个统一的“预训练、个性化提示与预测范式”(P5)以应对未来推荐系统面临的多特征、多任务挑战。
推荐系统的特征建模与学习演进¶
推荐系统的特征工程和学习方法在过去几十年中从简单走向复杂。早期的系统主要依赖逻辑回归和协同过滤方法(Resnick et al., 1994; Sarwar et al., 2001 等),仅使用用户-物品交互数据建模用户行为。
随着发展,系统逐步引入了更多上下文特征(如用户画像、物品元数据),并使用了更复杂的模型,如因子分解机(Rendle, 2010)、GBDT(He et al., 2014)等。近年来,深度神经网络模型(如 Cheng et al., 2016; Guo et al., 2017; Zhang et al., 2017 等)进一步提升了模型对复杂、多样化特征的表达能力,从而在推荐准确率上超越了传统特征工程方法。
推荐任务的扩展¶
除了传统的评分预测和用户-物品匹配任务,近年来推荐系统扩展到了更多任务和场景,例如:
序列推荐(Sun et al., 2019; Hidasi et al., 2016)
对话式推荐(Zhang et al., 2018)
可解释推荐(Zhang et al., 2014a, 2020; Li et al., 2021)
虽然这些任务通常被分别处理,但已有研究趋势表明,通过多任务联合学习可以提取可迁移的表示(Shin et al., 2021b; Yuan et al., 2021 等)。然而,当前的推荐系统仍难以统一处理多样化的任务和特征,因此作者提出一个统一的框架来解决这一问题。
P5 方法概述(重点)¶
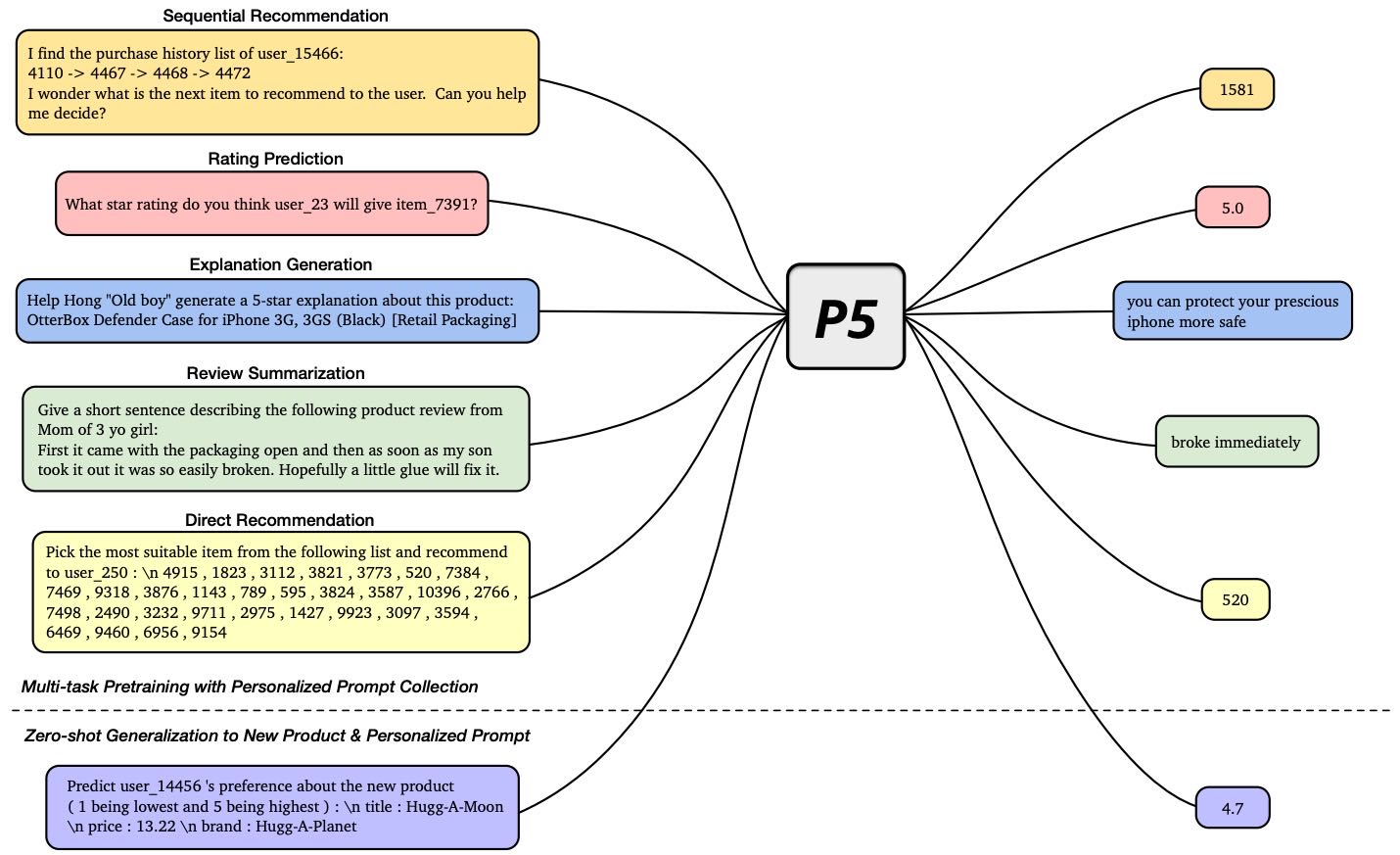
Figure 1: P5 pretrains on an encoder–decoder Transformer model that takes in textual inputs and produces target responses. We trained P5 on a multitask collection of personalized prompts. After multitask prompt-based pretraining on recommendation datasets, P5 achieves the capability of zero-shot generalization to unseen personalized prompts and new items.
受多任务提示式训练的启发(Aribandi et al., 2022; Sanh et al., 2022 等),本文提出了 P5(Pretrain, Personalized Prompt & Predict)范式,其核心思想是:
将推荐任务建模为基于自然语言的提示任务;
利用统一的序列到序列(seq2seq)框架处理多种推荐任务;
使用个性化提示模板将用户-物品信息和特征整合成模型输入。
P5 的主要优势包括:
语言环境融合:将所有推荐任务转化为自然语言处理任务,借助个性化提示模板,无需为不同特征设计专用编码器,从而充分利用语言模型的语义和知识;
多任务统一架构:采用共享的编码器-解码器结构,使用统一的语言建模损失,将所有任务视为条件文本生成问题,简化了模型设计;
零样本泛化能力:通过指令式提示训练,P5 能够在未见过的个性化提示或新领域物品上实现良好的性能。
总结:本节系统回顾了推荐系统的演进,指出现有系统在多任务和多特征处理上的不足,并提出 P5 范式作为未来推荐系统发展的一个统一、灵活的技术路线。
3. Personalized Prompt Collection¶
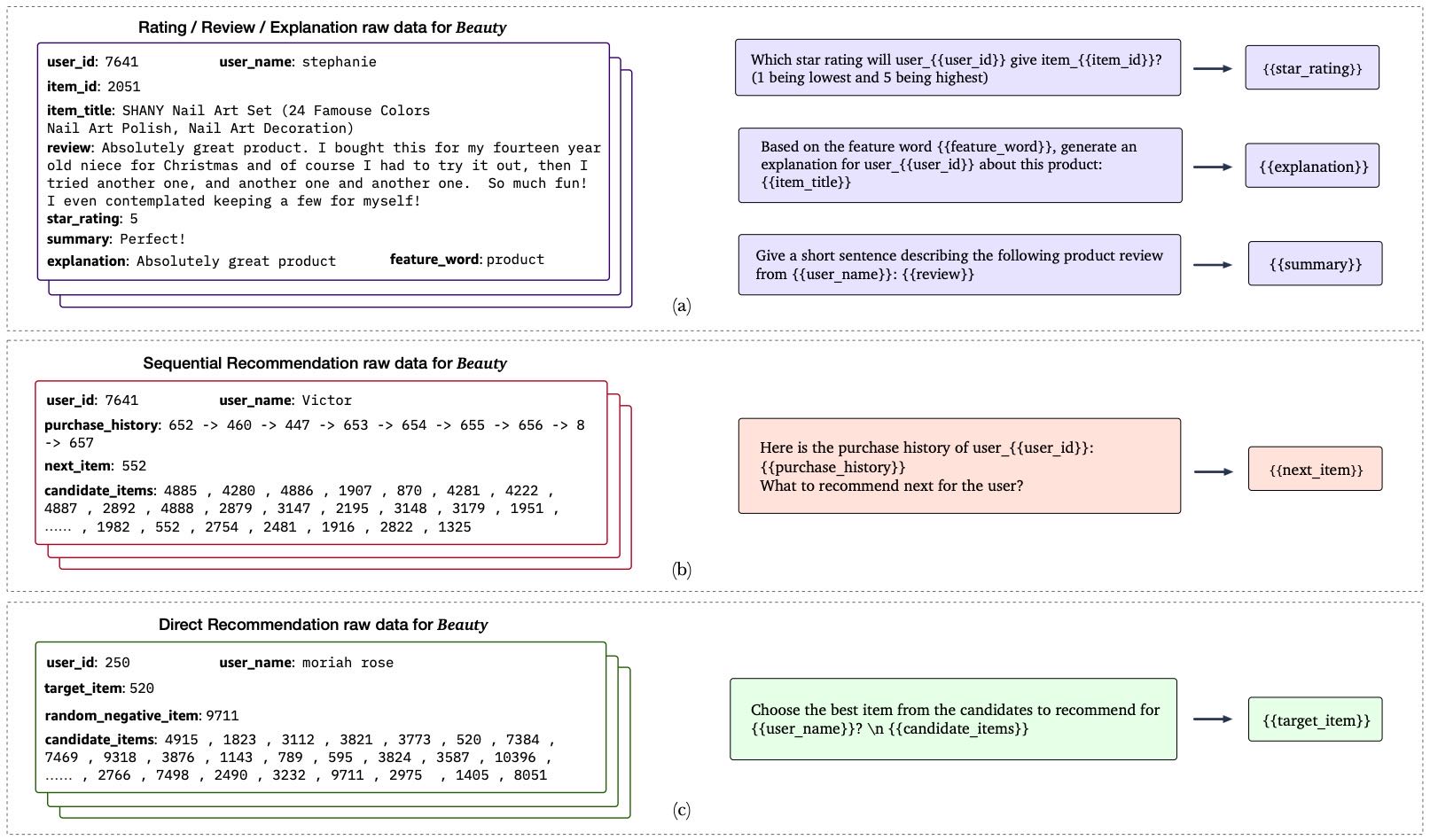
Figure 2.Building input–target pairs from raw data according to our designed personalized prompt templates
本节介绍为实现推荐系统中的多任务提示式预训练(P5)而创建的个性化提示模板集合。该集合覆盖了五大任务类别:评分预测、序列推荐、解释生成、评论任务和直接推荐。每个任务家族下包含多个个性化提示,用于帮助模型从用户和商品的不同角度挖掘信息。提示由输入模板、目标模板和相关元数据组成,而个性化提示进一步引入了针对不同用户和商品的个性化字段,这些字段可以是用户ID、性别、年龄,或商品ID、描述信息等。
评分预测任务家族(Rating Prediction)¶
该任务家族设计了三类提示:
直接预测评分:基于用户和商品信息,预测1到5之间的评分;
预测用户是否会给商品某个评分:输出“是”或“否”;
预测用户是否喜欢某个商品:将4分及以上视为“喜欢”,低于4分为“不喜欢”。
序列推荐任务家族(Sequential Recommendation)¶
该任务家族包含以下三类提示:
基于用户历史行为直接预测下一个项目;
从候选列表中选择下一个可能的项目(只有一个正样本);
预测用户是否会在下一步与该项目互动。
解释生成任务家族(Explanation)¶
该任务要求模型生成文本解释,用于说明用户对某一商品的偏好。包含两类提示:
直接生成解释句,包括用户/商品信息;
基于特征词生成解释(如参考Li等人2021年工作),可能结合评论标题和评分信息。
评论相关任务家族(Review)¶
该任务家族设计了两类提示:
将评论摘要成更短的评论标题;
基于评论内容预测评分。
直接推荐任务家族(Direct Recommendation)¶
该任务家族包含两类提示:
预测是否推荐该商品给用户(输出“是”或“否”);
从候选列表中选择最合适的商品进行推荐。
提示构建与训练数据准备¶
利用这些提示,我们可直接从原始数据中构建输入-目标对。如图2所示,只需将模板中的字段替换为原始数据中对应的信息,即可生成训练对或零样本测试提示。
用户和商品的多模态语义将通过训练数据和预训练任务被浓缩到模型中;
评分/评论/解释任务共享相同的数据;
序列推荐和直接推荐则取决于是否将交互历史作为输入;
在预训练过程中,会混合不同任务家族的输入-目标对;
为了增强P5模型的鲁棒性和零样本泛化能力,每个原始数据仅采样部分个性化提示;
在需要候选列表的任务中,还会随机选择一组负样本。
重点总结¶
个性化提示模板是本节核心,用于构建多任务推荐系统的输入;
五个任务家族覆盖了推荐系统的多个关键任务,每个任务家族下都设计了多样化的提示;
模型通过输入-目标对进行训练,结合用户和商品的多模态信息;
训练策略强调鲁棒性和泛化能力,通过采样和负样本增强效果;
图2提供了部分示例提示,完整提示集合可在附录中找到。
4. The P5 Paradigm and Model¶
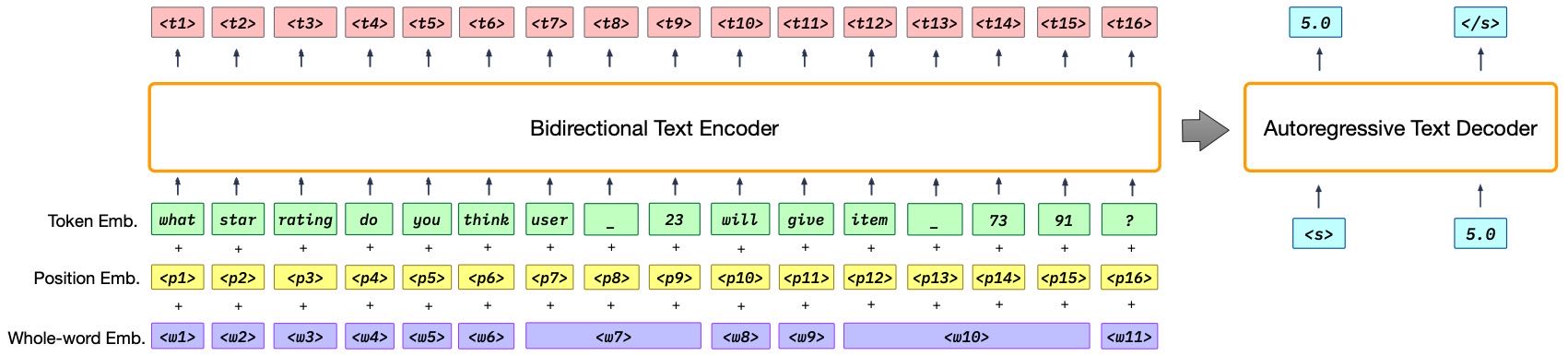
Figure 3.An illustration of the P5 architecture.
4.1. P5架构¶
P5(Pretrain, Personalized Prompt, and Predict Paradigm)是一种统一的预训练、个性化提示和预测范式,其核心在于通过个性化提示(personalized prompts)生成大量可用于预训练的推荐任务数据。这些数据覆盖了多种推荐任务,并通过统一的输入-目标令牌序列格式(input–target token sequences)共享,从而打破了传统任务之间的界限。P5通过在一个统一的条件生成框架下同时预训练多个推荐任务,提升模型对所有相关任务的理解和表现能力。此外,P5在预训练阶段沉浸于完整的语言环境中,期望其具备零样本泛化能力,即在没有见过的个性化提示和详细物品描述下,也能进行有效推理和预测。
在模型架构方面,P5基于编码器-解码器结构(Encoder-Decoder Framework),使用Transformer模块作为编码器和解码器。输入的令牌序列首先通过嵌入(Embeddings)、位置编码(Positional Encodings)和全词嵌入(Whole-word Embeddings)进行处理,以捕捉位置信息和个性化信息。例如,为避免分词导致的上下文断裂,P5引入全词嵌入来帮助模型识别关键字段。此外,P5避免使用大量额外的独立用户/物品标识符,而是采用多个子词(sub-word units)来表示用户或物品,从而减少额外词汇的数量。
编码器接收三种嵌入的加和作为输入,输出上下文相关的表示。解码器则基于已生成的令牌和编码器的输出,预测下一个令牌的概率分布。P5的训练目标是最小化负对数似然(negative log-likelihood),其目标函数如下:
该目标函数适用于所有推荐任务,实现了统一模型、统一损失函数和统一数据格式。
4.2. 使用预训练P5进行推荐¶
在预训练完成后,P5可通过个性化提示直接执行不同任务,包括评分、解释、评论、序列推荐和直接推荐。对于评分、解释和评论等任务,P5采用贪心解码(greedy decoding)生成答案。而对于序列推荐和直接推荐任务,由于其输出为物品列表,P5使用波束搜索(beam search)生成多个可能的推荐项。
序列推荐:使用波束搜索生成潜在的下一物品列表,并在所有物品中进行评估。
直接推荐:从业务设定的候选集 \(\mathbf{S} = \{S_1, \cdots, S_m\}\) 中预测正例物品。同样采用波束搜索生成高分目标物品列表进行评估。
波束搜索的通用解码过程如下:
其中,\(B\) 表示波束大小,\(\mathbf{C}\) 是推荐物品列表。
总结¶
P5架构:基于Transformer的编码器-解码器结构,通过统一的输入格式和共享目标函数,实现跨任务的统一学习。
个性化提示设计:结合位置编码、全词嵌入等技术,增强模型对用户和物品的识别能力。
多任务推荐能力:通过预训练模型,P5在不同推荐任务中表现优异,支持零样本推荐,具备良好的泛化能力。
解码策略:根据任务类型选择不同解码方式(贪心解码 vs 波束搜索),适应多样化的推荐输出需求。
5. Experiments¶
5.1 实验设置¶
1. 数据集
作者在四个真实世界的数据集上进行了广泛的实验,包括来自Amazon平台的Sports、Beauty和Toys & Games三个商品类别,以及Yelp平台的商业推荐数据。
数据集的统计信息如表1所示,涵盖了用户数、物品数、评论数及稀疏度等指标。
2. 任务划分
对于评分预测、解释生成和评论任务,作者将每个数据集随机划分为训练集(80%)、验证集(10%)和测试集(10%),确保每个用户和物品在训练集中至少有一个实例。
对于序列推荐任务,作者采用用户的最后一项作为测试数据,倒数第二项为验证数据,其余为训练数据。
这是序列推荐里常见的 leave-one-out 评估策略。它模拟了“给定用户的历史行为,预测下一个可能交互的物品”的真实应用场景。
在 序列推荐任务(sequential recommendation) 中,用户的行为数据是按时间顺序排列的交互序列(例如一个用户先后点过、买过、看过的一系列物品)。
最后一个交互的物品(比如用户最后点击/购买的那个)被用作 测试集,即模型需要预测这个物品;
倒数第二个交互的物品 被用作 验证集,用于调参或模型选择;
之前的所有交互记录(除了最后两个)作为 训练集,让模型学习用户的行为模式。
3. 实现细节
作者使用预训练的T5模型(T5 Small和T5 Base)作为P5的基础,并使用SentencePiece对词进行分词,词汇表大小为32,128。
P5-S(Small)版本包含6层Transformer,参数量为60.75M;P5-B(Base)版本包含12层Transformer,参数量为223.28M。
作者对P5进行了10个epoch的预训练,使用AdamW优化器,最大输入长度为512,学习率为1e-3,并使用了5%的warmup策略。
对于评分预测任务,将原始整数评分转换为小数以避免过度拟合;对于序列推荐任务,使用波束搜索(beam search)进行预测。
4. 评价指标
评分预测任务使用RMSE和MAE。
推荐任务使用HR@K(Hit Ratio)和NDCG@K(Normalized Discounted Cumulative Gain)。
解释生成和评论摘要任务使用BLEU-4和ROUGE(ROUGE-1、ROUGE-2、ROUGE-L)。
性能指标中RMSE和MAE越低越好,其余越高越好。
5.2 多任务基线¶
为了展示P5在多种推荐任务中的能力,作者选择了代表性的方法作为基线进行比较。
1. 评分预测和直接推荐¶
MF (Matrix Factorization) 和 MLP (Multi-Layer Perceptron) 作为评分预测基线。
BPR-MF (Bayesian Personalized Ranking - Matrix Factorization)、BPR-MLP 和 SimpleX (基于对比学习的协同过滤模型) 作为直接推荐基线。
2. 序列推荐¶
Caser:使用卷积神经网络建模用户兴趣。
HGN:通过分层门控网络学习长期和短期用户行为。
GRU4Rec:使用GRU建模用户点击历史。
BERT4Rec:模仿BERT的掩码语言模型进行序列推荐。
SASRec:使用自注意力机制建模序列推荐。
S3-Rec:使用自监督目标增强序列推荐模型。
3. 解释生成¶
Attn2Seq:使用注意力机制生成评论。
NRT:基于GRU的解释生成模型。
PETER:使用Transformer架构生成解释,还有一个带提示特征词的变体 PETER+。
4. 评论相关任务¶
使用预训练的 T5 和 GPT-2 模型作为基线。
对于评论偏好预测任务,仅使用T5进行比较。
5.3 不同任务下的性能比较(RQ1)¶
作者在五个任务类别上对P5进行了多任务学习能力的验证,并在零样本基础上评估了其性能。
1. 评分预测¶
P5在评分预测任务中表现优于大多数基线方法,尤其是在零样本提示下也能保持较高性能。
P5-B比P5-S表现略好,但P5-S在部分任务上略有优势,这可能与任务复杂度有关。
2. 序列推荐¶
P5在序列推荐任务中表现优异,尤其是在P5-B版本中,效果显著优于其他基线。
某些数据集上,P5-S甚至优于P5-B,显示出小模型在特定任务上的潜力。
3. 解释生成¶
P5在解释生成任务中表现良好,尤其是在带特征词提示的任务中(Prompt 3-9 & 3-12)。
P5在直接解释生成任务(Prompt 3-3)中优于所有基线方法。
4. 评论相关¶
P5在评论偏好预测和总结任务中表现优于T5和GPT-2,尤其是P5-S在小型数据集上表现突出。
5. 直接推荐¶
P5在直接推荐任务中表现优异,尤其是在Top-1推荐任务中,性能远超SimpleX。
5.4 对未见过的提示与新领域的零样本泛化能力(RQ2)¶
1. 转移到未见过的个性化提示¶
P5在未见过的提示任务中也能保持良好的性能,部分任务甚至优于训练时的提示。
表明多任务提示预训练提升了模型的鲁棒性和泛化能力。
2. 转移到新领域的物品¶
作者收集了三个领域共741个用户的数据进行跨领域评估。
P5在跨领域评分预测、偏好预测和带特征词的解释生成任务中表现良好,但在无提示的直接解释生成任务中效果较差。
举例说明P5在零样本转移任务中能生成合理解释。
备注
三个领域的测试集,先在一个测试集做训练,然后对另一类测试集中的数据进行测试 得到的结论:在零样本转移任务中能生成合理解释
5.5 模型规模的消融实验(RQ3)¶
作者比较了P5-S和P5-B在不同任务上的表现。
P5-S虽然参数量为P5-B的四分之一,但在部分任务(如序列推荐、直接推荐)上表现更优。
P5-B在用户和物品数量较多的数据集(如Sports)上表现更好。
结论:模型规模应根据数据集规模调整,小数据集可以用小模型,大数据集则需大模型。
5.6 任务扩展的消融实验(RQ3)¶
作者比较了多任务预训练(P5-S)和单任务预训练(P5-SN)的效果。
P5-S在推荐任务中表现略优于P5-SN,但在文本生成任务(如解释生成、评论摘要)中,P5-SN表现更好。
多任务建模在推荐任务中平衡了不同任务,提升了性能。
5.7 提示规模的消融实验(RQ3)¶
作者减少了预训练提示的数量,验证了提示数量对P5性能的影响。
P5-S在大多数任务上的表现优于提示数量较少的P5-PS,尤其是在零样本任务中。
结论:高质量的个性化提示越多,越有助于模型性能的提升,特别是零样本任务。
5.8 如何实现个性化(RQ4)¶
作者比较了两种个性化方法:独立额外token(P5-I)和默认方法(使用SentencePiece进行子词分词,P5-S)。
P5-I在回归任务和评论摘要任务中表现与P5-S相当,但在序列推荐和直接推荐任务中显著逊色。
原因是P5-I引入了大量额外token,难以训练,而P5-S通过协作学习优化了子词间的潜在关联。
结论:默认方法在推荐和整体性能上更优,并且保持了较小的学习空间。
总结¶
本节通过多个实验验证了P5方法在多种推荐任务中的有效性。无论是评分预测、序列推荐、解释生成还是评论任务,P5在多数情况下均优于基线方法。同时,作者通过消融实验分析了模型规模、任务扩展、提示数量和个性化策略对模型性能的影响,为P5方法的改进和应用提供了丰富参考。
6. Conclusions and Future Work¶
在本论文中,我们提出了 P5,一个将不同推荐任务统一到一个 共享的语言建模与自然语言生成框架 中的模型。通过设计一组包含五个推荐任务家族的个性化提示(prompt),我们将用户-物品交互、用户描述、物品元数据和用户评论等原始数据转换为统一的 输入-目标(input-target)文本对 格式。然后我们在完整的语言环境中对 P5 进行预训练,以帮助其发现各种推荐任务中的更深层次语义信息。
根据我们的实验结果,P5 在所有五个任务家族中均能超越或达到现有代表性方法的性能。此外,P5 展现出良好的泛化能力,能够在零样本条件下(zero-shot transfer)对新物品、新领域以及新的个性化提示进行有效推荐。
未来工作¶
未来,我们将继续探索扩大 P5 的模型规模,并尝试采用更强大的基础模型(如 GPT-3、OPT 和 BLOOM)来提升其性能。此外,P5 是一个高度灵活的范式,具有进一步扩展到多种模态和更多任务的潜力,例如:
会话式推荐(conversational recommendation)
对比式推荐(comparative recommendation)
跨平台推荐(cross-platform recommendation)
甚至各种搜索任务,通过将用户查询整合进 P5 系统中
最后,在本工作中,我们设计了显式提示(explicit prompts),因为它们直观、灵活,且接近人类之间的自然交流方式,从而实现了基于指令的推荐。未来,我们也将研究提示搜索(prompt search)和/或隐式提示(latent prompts)技术,以生成更高效的指令提示,或结合检索增强生成(retrieval-enhanced generation)方法,进一步提升 P5 在下游任务中的性能。
Acknowledgment¶
本研究部分得到了美国国家科学基金会(NSF)IIS 1910154、2007907 和 2046457 项目的资助。文中所表达的观点、发现、结论或建议均为作者个人观点,不一定反映资助方的意见。
D FULL LIST OF PERSONALIZED PROMPTS FOR AMAZON DATASETS¶
D.1 Task Family 1: Rating Prediction¶
Prompt ID: 1-1
Input template: Which star rating will user_{{user_id}} give item_{{item_id}}? (1 being lowest and 5 being highest)
Target template: {{star_rating}}
Prompt ID: 1-2
Input template: How will user_{{user_id}} rate this product: {{item_title}}? (1 being lowest and 5 being highest)
Target template: {{star_rating}}
Prompt ID: 1-3
Input template: Will user_{{user_id}} give item_{{item_id}} a {{star_rating}}-star rating? (1 being lowest and 5 being highest)
Target template: {{answer_choices[label]}} (yes/no)
Prompt ID: 1-4
Input template: Does user_{{user_id}} like or dislike item_{{item_id}}?
Target template:
{{answer_choices[label]}} (like/dislike) – like (4,5) / dislike(1,2,3)
Prompt ID: 1-5
Input template: Predict the user_{{user_id}} s preference on item_{{item_id}} ({{item_title}})
-1 \n -2 \n -3 \n -4 \n -5
Target template: {{star_rating}}
Prompt ID: 1-6
Input template: What star rating do you think {{user_desc}} will give item_{{item_id}}? (1 being lowest and 5 being highest)
Target template: {{star_rating}}
Prompt ID: 1-7
Input template: How will {{user_desc}} rate this product: {{item_title}}? (1 being lowest and 5 being highest)
Target template: {{star_rating}}
Prompt ID: 1-8
Input template: Will {{user_desc}} give a {{star_rating}}-star rating for {{item_title}}? (1 being lowest and 5 being highest)
Target template: {{answer_choices[label]}} (yes/no)
Prompt ID: 1-9
Input template: Does {{user_desc}} like or dislike {{item_title}}?
Target template:
{{answer_choices[label]}} (like/dislike) – like (4,5) / dislike(1,2,3)
Prompt ID: 1-10
Input template: Predict {{user_desc}} s preference towards {{item_title}} (1 being lowest and 5 being highest)
Target template: {{star_rating}}
D.2 Task Family 2: Sequential Recommendation¶
Prompt ID: 2-1
Input template: Given the following purchase history of user_{{user_id}}:
{{purchase_history}}
predict next possible item to be purchased by the user?
Target template: {{next_item}}
Prompt ID: 2-2
Input template: I find the purchase history list of user_{{user_id}}:
{{purchase_history}}
I wonder which is the next item to recommend to the user. Can you help me decide?
Target template: {{next_item}}
Prompt ID: 2-3
Input template: Here is the purchase history list of user_{{user_id}}:
{{purchase_history}}
try to recommend next item to the user
Target template: {{next_item}}
Prompt ID: 2-4
Input template: Given the following purchase history of {{user_desc}}:
{{purchase_history}}
predict next possible item for the user
Target template: {{next_item}}
Prompt ID: 2-5
Input template: Based on the purchase history of {{user_desc}}:
{{purchase_history}}
Can you decide the next item likely to be purchased by the user?
Target template: {{next_item}}
Prompt ID: 2-6
Input template: Here is the purchase history of {{user_desc}}:
{{purchase_history}}
What to recommend next for the user?
Target template: {{next_item}}
Prompt ID: 2-7
Input template: Here is the purchase history of user_{{user_id}}:
{{purchase_history}}
Select the next possible item likely to be purchased by the user from the following candidates:
{{candidate_items}}
Target template: {{next_item}}
Prompt ID: 2-8
Input template: Given the following purchase history of {{user_desc}}:
{{purchase_history}}
What to recommend next for the user? Select one from the following items:
{{candidate_items}}
Target template: {{next_item}}
Prompt ID: 2-9
Input template: Based on the purchase history of user_{{user_id}}:
{{purchase_history}}
Choose the next possible purchased item from the following candidates:
{{candidate_items}}
Target template: {{next_item}}
Prompt ID: 2-10
Input template: I find the purchase history list of {{user_desc}}:
{{purchase_history}}
I wonder which is the next item to recommend to the user. Try to select one from the following candidates:
{{candidate_items}}
Target template: {{next_item}}
Prompt ID: 2-11
Input template: User_{{user_id}} has the following purchase history:
{{purchase_history}}
Does the user likely to buy {{candidate_item}} next?
Target template: {{answer_choices[label]}} (yes/no)
Prompt ID: 2-12
Input template: According to {{user_desc}} s purchase history list:
{{purchase_history}}
Predict whether the user will purchase {{candidate_item}} next?
Target template: {{answer_choices[label]}} (yes/no)
Prompt ID: 2-13
Input template: According to the purchase history of {{user_desc}}:
{{purchase_history}}
Can you recommend the next possible item to the user?
Target template: {{next_item}}
D.3 Task Family 3: Explanation Generation¶
Prompt ID: 3-1
Input template: Generate an explanation for user_{{user_id}} about this product: {{item_title}}
Target template: {{explanation}}
Prompt ID: 3-2
Input template: Given the following review headline
{{review_headline}}
can you help generate an explanation of user_{{user_id}} for item_{{item_id}}?
Target template: {{explanation}}
Prompt ID: 3-3
Input template: Help user_{{user_id}} generate a {{star_rating}}-star explanation about this product:
{{item_title}}
Target template: {{explanation}}
Prompt ID: 3-4
Input template: Generate an explanation for {{user_desc}} about this product: {{item_title}}
Target template: {{explanation}}
Prompt ID: 3-5
Input template: Based on the following review headline:
{{review_headline}}
Generate {{user_desc}} s purchase explanation about {{item_title}}
Target template: {{explanation}}
Prompt ID: 3-6
Input template: Help {{user_desc}} generate a {{star_rating}}-star explanation for item_{{item_id}}
Target template: {{explanation}}
Prompt ID: 3-7
Input template: Predict the star rating, then use {{feature_word}} as feature word to generate user_{{user_id}} s purchase explanation for item_{{item_id}}
Target template: {{star_rating}}, {{explanation}}
Prompt ID: 3-8
Input template: What score will {{user_desc}} rate item_{{item_id}}?
Then give an explanation for the rating score. (1 being lowest and 5 being highest)
Target template: {{star_rating}}, {{explanation}}
Prompt ID: 3-9
Input template: Based on the feature word {{feature_word}}, generate an explanation for user_{{user_id}} about this product:
{{item_title}}
Target template: {{explanation}}
Prompt ID: 3-10
Input template: Given the word {{feature_word}}, can you help generate an explanation for {{user_desc}} about the product:
{{item_title}}
Target template: {{explanation}}
Prompt ID: 3-11
Input template: Using the word {{feature_word}}, write a {{star_rating}}-star explanation for user_{{user_id}} about item_{{item_id}}
Target template: {{explanation}}
Prompt ID: 3-12
Input template: According to the feature word {{feature_word}}, generate a {{star_rating}}-star explanation for {{user_desc}} about item_{{item_id}}
Target template: {{explanation}}
D.5 Task Family 5: Direct Recommendation¶
Prompt ID: 5-1
Input template: Will user_{{user_id}} likely to interact with item_{{item_id}}?
Target template: {{answer_choices[label]}} (yes/no)
Prompt ID: 5-2
Input template: Shall we recommend item_{{item_id}} to {{user_desc}}?
Target template: {{answer_choices[label]}} (yes/no)
Prompt ID: 5-3
Input template: For {{user_desc}}, do you think it is good to recommend {{item_title}}?
Target template: {{answer_choices[label]}} (yes/no)
Prompt ID: 5-4
Input template: I would like to recommend some items for user_{{user_id}}. Is the following item a good choice?
{{item_title}}
Target template: {{answer_choices[label]}} (yes/no)
Prompt ID: 5-5
Input template: Which item of the following to recommend for {{user_desc}}?
{{candidate_items}}
Target template: {{target_item}}
Prompt ID: 5-6
Input template: Choose the best item from the candidates to recommend for {{user_desc}}?
{{candidate_items}}
Target template: {{target_item}}
Prompt ID: 5-7
Input template: Pick the most suitable item from the following list and recommend to user_{{user_id}}:
{{candidate_items}}
Target template: {{target_item}}
Prompt ID: 5-8
Input template: We want to make recommendation for user_{{user_id}}.
Select the best item from these candidates:
{{candidate_items}}
Target template: {{target_item}}
D.6 Task Family Z: Zero-Shot Generalization¶
Prompt ID: Z-1
Input template: Given the facts about the new product, do you think user {{user_id}} will like or dislike it?
title: {{item_title}}
brand: {{brand}}
price: {{price}}
Target template: {{answer_choices[label]}} (like/dislike) – like
(4,5) / dislike (1,2,3)
Prompt ID: Z-2
Input template: Here are the details about a new product:
title: {{item_title}}
brand: {{brand}}
price: {{price}}
What star will {{user_desc}} probably rate the product? -1 -2 -3 -4 -5
Target template: {{star_rating}}
Prompt ID: Z-3
Input template: Predict user_{{user_id}} 's preference about the new product (1 being lowest and 5 being highest):
title: {{item_title}}
price: {{price}}
brand: {{brand}}
Target template: {{star_rating}}
Prompt ID: Z-4
Input template: Will {{user_desc}} like or dislike the following product?
title: {{item_title}}
price: {{price}}
brand: {{brand}}
Target template:
{{answer_choices[label]}} (like/dislike) – like (4,5) / dislike (1,2,3)
Prompt ID: Z-5
Input template: Generate a possible explanation for {{user_desc}} s preference about the following product:
title: {{item_title}}
brand: {{brand}}
price: {{price}}
Target template: {{explanation}}
Prompt ID: Z-6
Input template: Based on the word {{feature_word}}, help user_{{user_id}} write a {{star_rating}}-star explanation for this new product:
title: {{item_title}}
price: {{price}}
brand: {{brand}}
Target template: {{explanation}}
Prompt ID: Z-7
Input template: For the new product {{item_title}}, we would like to know whether {{user_desc}} will love it.
If you think the user will love it, please help explain why.
Target template: {{explanation}}
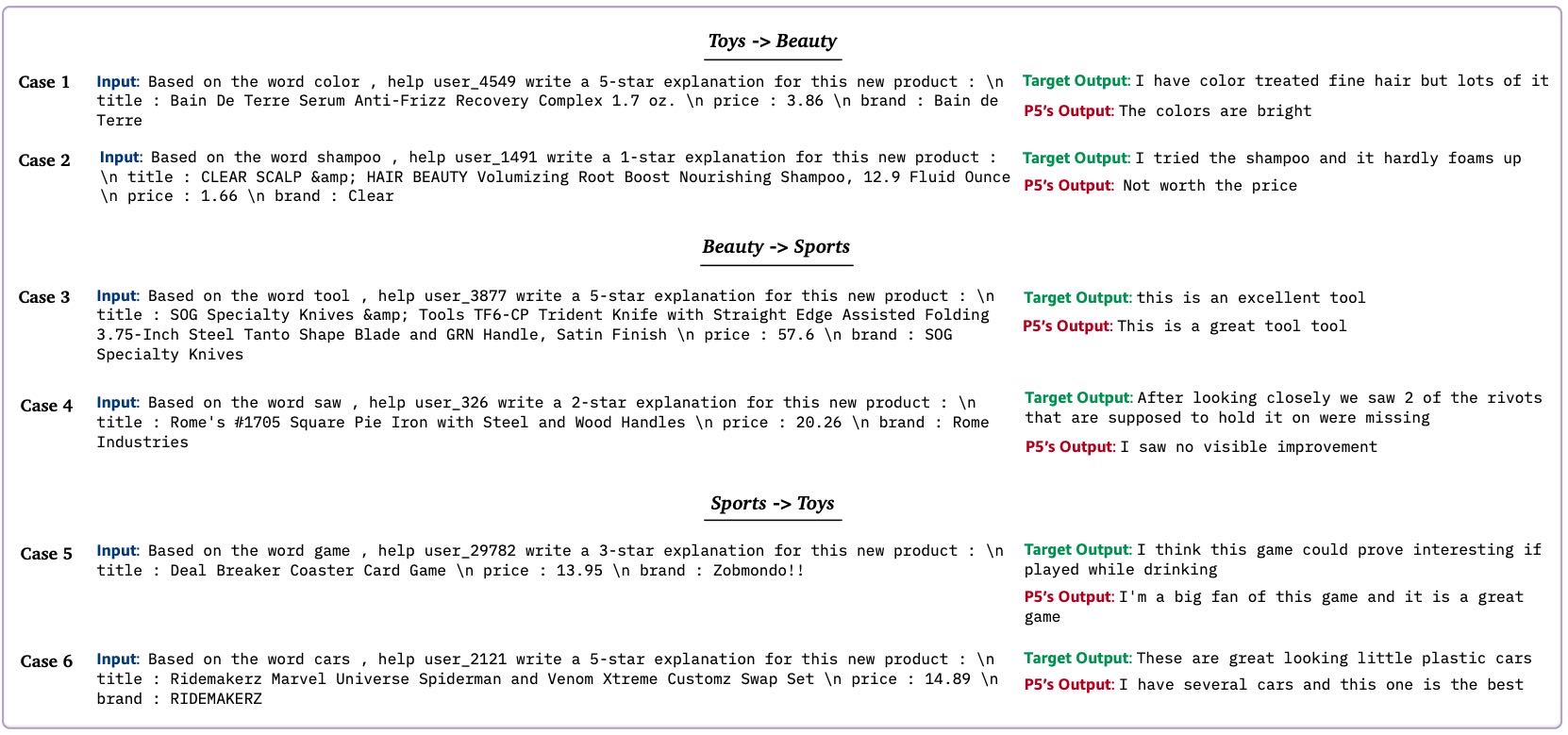
Figure 4: Example cases of zero-shot domain transfer on Z-6 task. We demonstrate three transfer directions: Toys to Beauty, Beauty to Sports, and Sports to Toys.