2402.17753_LoCoMo❇️: Evaluating Very Long-Term Conversational Memory of LLM Agents¶
组织: University of North Carolina, Chapel Hill; University of Southern California; Snap Inc
官网: https://snap-research.github.io/locomo/
引用: 82(2025-07-13)
总结¶
简介
英文数据集
长期对话数据集
每个对话包含平均300轮、9,000个token,最长可达35个会话。
平均每段对话包含300轮、9209个token,跨越19.3个会话,覆盖数月时间
目标:以全面衡量模型在长期对话中的记忆能力
三种任务:
问答任务
该任务评估代理能否从长期历史对话中提取信息来回答问题
任务分为五类
单跳问题(Single-hop):答案仅依赖单个对话会话
多跳问题(Multi-hop):需要综合多个会话的信息
时序推理问题(Temporal reasoning):需要理解时间顺序和时间线索
开放领域知识问题(Open-domain knowledge):结合对话信息与常识/世界知识
对抗性问题(Adversarial questions):测试代理识别无法回答的问题的能力
评估方式为使用 F1 部分匹配,并尽量确保答案直接来自对话,以简化评估
事件总结
评估模型是否能理解并总结对话中事件之间的因果和时间关系
由于对话中存在时间与因果的引用关系,事件总结比传统文本更复杂
评估使用 FactScore 指标
将总结内容与参考事件图谱分解为原子事实,评估:
精确率(Precision):总结中的事实与参考事实的匹配数量
召回率(Recall):参考事实在总结中的覆盖率
F1 分数:综合精确率和召回率
多模态对话生成
该任务评估代理能否在长期对话中保持角色一致性与情节连贯性
评估方式包括:
MMRelevance:衡量生成对话与真实对话的多模态相关性
其他自然语言生成(NLG)指标
别人的总结¶
该研究针对LLM Agent在超长期对话记忆方面的评估空白,提出了一个名为 LoCoMo 的数据集和一套全面的评估框架。LoCoMo数据集通过人机协作流水线生成,包含长达300轮、平均9K tokens的对话,跨越多达35个会话,并融入了人物角色和时间事件图,以模拟真实世界的复杂交互。评估框架涵盖问答、事件摘要和多模态对话生成任务,并细化了问答任务的推理类型(单跳、多跳、时间推理、开放域知识、对抗性问题)。研究发现,尽管长上下文LLMs和检索增强生成(RAG)技术能提升记忆能力,但在理解冗长对话、掌握长期时间因果动态以及避免幻觉方面仍远低于人类水平。特别是,时间推理和开放域知识问题对LLMs构成巨大挑战。该论文通过其提出的“反思与回应”(Reflect & Respond)机制,尝试赋予LLM Agent超长期记忆能力,该机制结合了短期会话摘要和从对话历史中提取的长期“观察结果”,并辅以时间事件图来确保对话的长期连贯性和因果一致性。
Abstract¶
本篇论文旨在研究大型语言模型(LLM)在非常长期对话中的长期记忆能力。现有研究多聚焦于不超过五个对话轮次(session)的对话评估,而对更长时间范围(如几十个会话)的研究仍属空白。为填补这一研究缺口,作者提出了一套人机协同的对话生成管道,用于生成高质量、长期的对话数据。该方法基于LLM智能体架构,并结合角色设定和时间事件图,使对话内容具有连贯性和事件基础。此外,智能体还被赋予图像生成与交互能力,以提升对话的多模态性。生成的对话会由人类标注者进行长期一致性检查和事件图匹配验证。
基于此管道,作者构建了一个名为LoCoMo的长期对话数据集。每个对话包含平均300轮、9,000个token,最长可达35个会话。基于该数据集,作者提出了一个综合评估基准,涵盖问答任务、事件总结和多模态对话生成,以全面衡量模型在长期对话中的记忆能力。
实验结果表明,尽管使用了长上下文处理和RAG(检索增强生成)等技术,当前LLM在理解和建模长期对话中的时间因果动态方面仍然存在明显挑战,远不及人类表现。论文最后提供了代码和数据资源,以促进后续研究。
1 Introduction¶
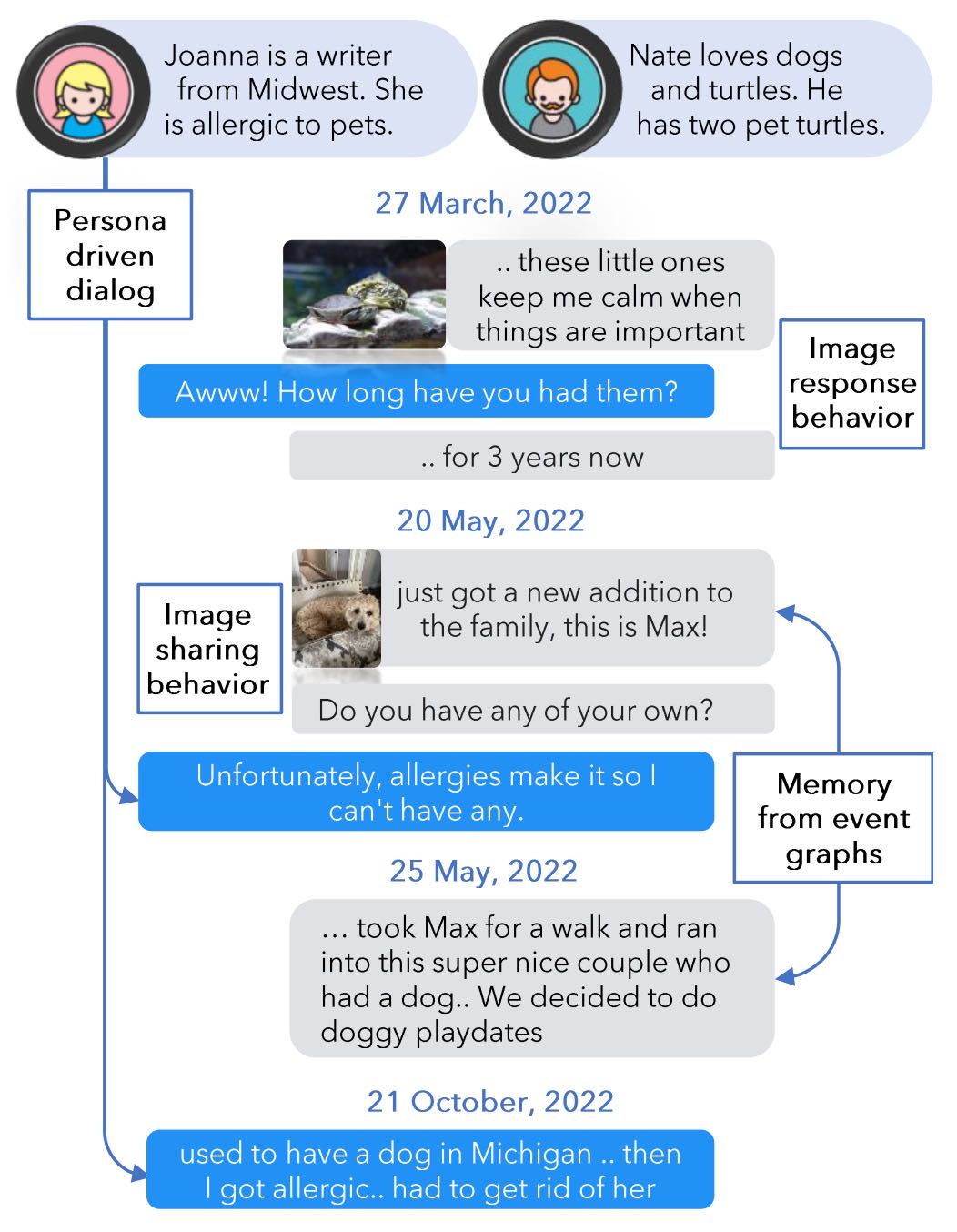
Figure 1: An example in LOCOMO.
本节主要介绍了LoCoMo这一全新的长时、开放域、多模态对话数据集,并提出了用于评估LLM代理在长对话中记忆能力的综合评估框架。
首先,作者指出当前尽管在基于LLM的对话模型和检索增强生成(RAG)技术方面取得了一些进展,但针对非常长的对话(例如跨越数月、数百轮次)的系统性评估仍然不足。已有对话数据集的平均对话长度较短,缺乏对长期记忆能力的有效测试,而LoCoMo填补了这一空白。
LoCoMo数据集的特点包括:
平均每段对话包含300轮、9209个token,跨越19.3个会话,覆盖数月时间;
支持多模态对话,包括图像的分享和回应;
通过LLM生成对话初稿,再由人工校对以修正长期不一致性和增强对话连贯性;
对话内容围绕角色的个性特征、生活事件的时间线以及历史对话的反思和回应机制构建。
评估框架方面,作者提出了三种任务来全面评估模型在长对话中的表现:
问答任务(QA):测试模型是否能“回忆”过去的对话内容,分为单跳、多跳、时间推理、常识/世界知识和对抗性问题等类型;
事件图总结任务:评估模型是否能理解并总结对话中事件之间的因果和时间关系;
多模态对话生成任务:评估模型是否能生成与对话历史一致的回应,包括对图像的反应。
实验结果表明:
长上下文LLM和RAG在QA任务中提升显著(22-66%),但与人类表现仍有较大差距(低56%),特别是在时间推理方面差距达73%;
长上下文LLM在对抗性问题和事件图总结任务中表现较差,容易将对话或事件错误地分配给错误的角色;
RAG在质量和上下文理解之间取得平衡,特别当对话被转化为角色生活的数据库形式时,表现更优。
综上,本节强调了LoCoMo在真实长对话模拟、多模态交互和长期记忆评估方面的创新性,并提出了新的评估任务,为未来对话系统的开发和评估提供了重要基础。
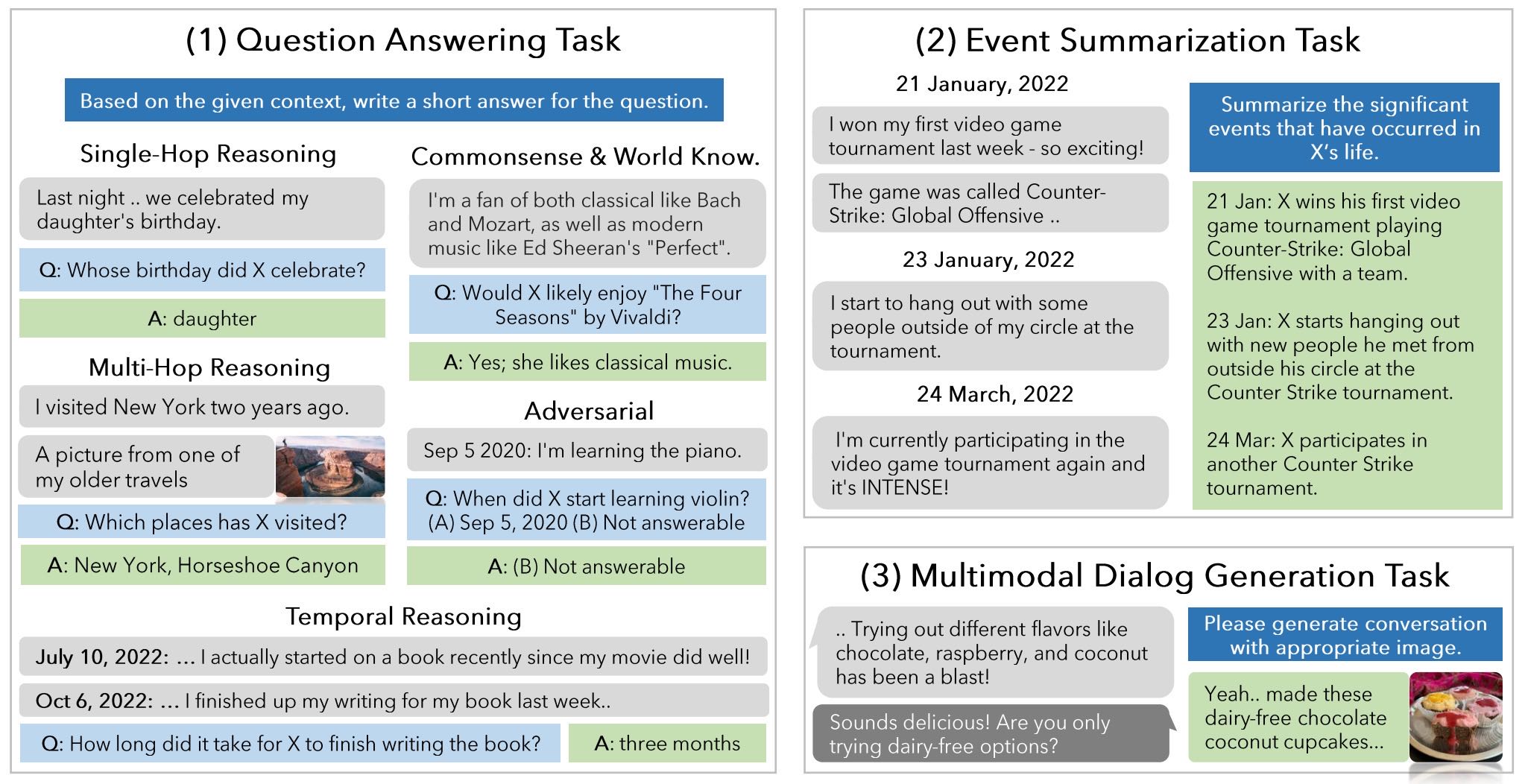
Figure 2: Overview of our evaluation framework. We propose three tasks: question answering, event summarization and multimodal dialog generation to evaluate models’ comprehension in very long-term dialogues.
3 Generative Pipeline for LoCoMo¶
这一章节介绍了 LoCoMo 的生成管道(generative pipeline),旨在构建具有长期对话记忆的大型语言模型(LLM)虚拟代理。主要内容总结如下:
3. LoCoMo 的生成管道概述¶
LoCoMo 的生成管道由两个主要部分组成:虚拟代理的架构和人类验证与编辑。整个流程的目标是生成具有长期一致性、多模态交互能力的虚拟对话内容。具体包括以下几个部分:
虚拟代理的构建:为两个代理(ℒ₁ 和 ℒ₂)分配独特的角色(persona)和时间事件图(temporal event graph),并赋予记忆与反思模块,以支持长期对话记忆和多模态交互(如图像分享与反应)。
对话生成与编辑:通过人类标注者对生成的对话进行筛选和修改,以确保长期一致性和内容质量。
3.1 角色设定(Persona)¶
每个代理被赋予一个详细的角色设定,包括目标、经历、日常习惯、人际关系等信息。
初始角色设定从 MSC 数据集中选取,随后通过 GPT-3.5 扩展为完整的角色背景。
3.2 时间事件图(Temporal Event Graph)¶
为每个代理构建一个时间事件图 𝒢,反映其现实生活中的因果事件序列。
事件之间具有因果关系,并分布在 6 到 12 个月的时间跨度内。
事件生成采用分批次迭代方式,以平衡推理效率和事件连贯性。
每个代理的时间图包含最多 25 个事件,确保对话中能自然引入长期记忆。
3.3 虚拟代理架构¶
虚拟代理基于 Park 等人(2023)提出的架构,包含以下两个主要功能模块:
1. 反思与回应(Reflect & Respond)¶
代理结合短期记忆(会议摘要)和长期记忆(过往对话观察)来生成回应。
每次会议后生成摘要,存储在短期记忆中,用于后续对话参考。
每个对话回合被记录为长期记忆中的观察,用于未来对话的反思。
代理在生成回应时,还会考虑时间事件图中发生在上一次会议和当前会议之间的事件。
2. 图像分享与图像反应(Image Sharing & Image Reaction)¶
代理支持图像分享和图像反应,增强对话的多模态性。
图像分享流程包括:生成图像描述 → 提取关键词 → 通过关键词搜索图像 → 分享图像。
图像反应流程包括:生成图像描述 → 对图像生成回应。
图像及描述也会被存储到长期记忆中,供未来对话使用。
3.4 人类验证与编辑(Human Verification & Editing)¶
人类标注者对生成的对话进行后期处理,包括:
修正对话中的长期不一致问题;
删除或替换不相关的图像;
检查对话内容与时间事件图之间的对齐性。
标注者平均编辑了约 15% 的对话回合,并替换了约 19% 的图像。
总结¶
本章节详细介绍了 LoCoMo 系统的生成流程,通过结合角色设定、时间事件图、多模态交互和人类编辑,构建了一个能够进行长期连贯对话的虚拟代理系统。该流程不仅提升了对话的自然性和一致性,还引入了图像交互,使系统更加贴近真实的人际交流体验。
4 LoCoMo Evaluation Benchmark¶
本章节介绍了 LoCoMo 评估基准(LoCoMo Evaluation Benchmark),旨在评估大型语言模型(LLM)在长期对话记忆方面的表现。该基准包含三个主要任务,分别从不同角度测试对话代理在长期对话中的记忆能力与信息处理能力:
1. 问答任务(Question Answering Task)¶
该任务评估代理能否从长期历史对话中提取信息来回答问题。任务分为五类:
单跳问题(Single-hop):答案仅依赖单个对话会话;
多跳问题(Multi-hop):需要综合多个会话的信息;
时序推理问题(Temporal reasoning):需要理解时间顺序和时间线索;
开放领域知识问题(Open-domain knowledge):结合对话信息与常识/世界知识;
对抗性问题(Adversarial questions):测试代理识别无法回答的问题的能力。
评估方式为使用 F1 部分匹配,并尽量确保答案直接来自对话,以简化评估。同时标注答案所在的对话轮次 ID,并评估 RAG 模型的上下文检索准确性。
2. 事件总结任务(Event Summarization Task)¶
该任务测试代理对事件序列及其因果关系的理解能力。对话构建基于一个时间事件图谱 𝒢,代理需根据所给时间范围对事件进行总结,并与图谱中的事件对比。
由于对话中存在时间与因果的引用关系,事件总结比传统文本更复杂。评估使用 FactScore 指标,将总结内容与参考事件图谱分解为原子事实,评估:
精确率(Precision):总结中的事实与参考事实的匹配数量;
召回率(Recall):参考事实在总结中的覆盖率;
F1 分数:综合精确率和召回率。
这与其他传统摘要评估指标(如 BLEU、ROUGE)不同,更加关注事实准确性。
3. 多模态对话生成任务(Multi-Modal Dialogue Generation Task)¶
该任务评估代理能否在长期对话中保持角色一致性与情节连贯性。对话话题随时间推进,涉及角色的事件变化(如受伤后康复等),代理需在生成对话时与设定的事件图谱和角色设定保持一致。
评估方式包括:
MMRelevance:衡量生成对话与真实对话的多模态相关性;
其他自然语言生成(NLG)指标。
总结¶
LoCoMo 评估基准通过三个任务(问答、事件总结、多模态对话生成)全面测试了 LLM 代理在长期对话中对记忆的存储、检索、推理与生成能力。评估设计注重事实准确性与长期一致性,并结合多种评估指标,力求客观衡量代理的长期记忆表现。
5 Experimental Setup¶
本章节主要介绍实验设置和不同模型在问答、事件摘要和多模态对话生成任务中的表现,具体总结如下:
1. 实验设置概述¶
任务类型:实验包含三个任务:问答(Question Answering)、事件摘要生成(Event Summarization)和多模态对话生成(Multi-modal Dialogue Generation)。
图像处理方式:
在问答和事件摘要任务中,图像被替换为其描述文字(captions),模型仅基于纯文本对话进行推理。
多模态对话生成任务中直接使用图像输入。
模型类型:
评估了三种模型类型:
基础模型(Base LLMs):如 Mistral-7B、Llama-70B-chat、GPT-3.5-turbo 和 GPT-4-turbo。
长上下文模型(Long-context LLMs):如 GPT-3.5-turbo-16k。
检索增强生成模型(RAG):结合 DRAGON 检索器和 GPT-3.5-turbo-16k 作为阅读器,从对话历史或摘要中检索相关信息。
2. 问答任务(Question Answering)¶
模型类型:
基础模型:在问答表现上表现一般,F1 分数较低。
长上下文模型:随着上下文长度的增加(从 4K 到 16K),性能显著提升。例如,GPT-3.5-turbo-16k 在 16K 上下文时,整体 F1 分数达到 37.8。
RAG 模型:通过检索对话历史、观察信息或摘要来增强上下文,不同检索单位(dialog、observation、summary)和 top-k 值对结果有影响。其中,“observation”在不同 top-k 值下的表现较优,最高整体 F1 分数为 41.4。
性能指标:使用 F1-score 和 Recall@k(k 为检索数量)评估模型表现,分数越高越好。
3. 事件摘要生成任务(Event Summarization)¶
模型设置:使用问答任务中的 基础模型 和 长上下文模型,但不使用 RAG,因为摘要需要对整个对话有全面理解。
实现方式:
使用 增量摘要(incremental summarization):每次对前一阶段的对话生成摘要,然后将该摘要用于下一阶段的摘要生成。
引用文献:Chang et al. (2023) 的方法。
未展示具体指标,但强调了摘要任务的挑战性在于需要对长对话整体进行理解,而非局部检索。
4. 多模态对话生成任务(Multi-modal Dialogue Generation)¶
数据生成:
通过自动化流程生成 50 次对话,用于训练数据(未进行人工筛选)。
模型训练:
使用 MiniGPT-5 进行训练,共训练三种版本:
Base:仅基于先前对话。
+ summary:结合先前对话和全局摘要。
+ observation:结合先前对话和从对话历史中检索到的观察信息。
初始化方式:
使用在 MMDialog 上微调的 MiniGPT-5 检查点进行初始化。
5. 总结¶
本实验比较了多种模型在长对话任务中的表现:
基础模型受限于上下文长度,性能较低。
长上下文模型随着上下文增加,表现显著提升。
RAG 模型通过引入检索机制,能够有效提升问答性能。
事件摘要需要模型对整体对话有全面理解,因此未使用 RAG,而是采用增量摘要方法。
多模态对话生成使用图像和文本结合,训练时引入摘要和观察信息,以提升模型对上下文的理解能力。
6 Experimental Results¶
本章总结了对大型语言模型(LLM)在长对话记忆评估任务中的实验结果,涵盖问答任务、事件图总结任务和多模态对话生成任务。以下是对各部分的总结:
6.1 问答任务(Question Answering Task)¶
主要发现:
上下文长度限制影响模型表现:
拥有有限上下文窗口的LLM(如GPT-4-turbo)在处理极长对话时表现不佳,尽管它是表现最好的模型(得分32.4),但仍远低于人类基准(87.9)。
长上下文模型容易产生幻觉(Hallucinations):
GPT-3.5-turbo-16K(16K上下文)在对抗性问题上的准确率低至2.1%,远低于Llama-2-Chat(22.1%)和GPT-4-turbo(70.2%),表明长上下文模型容易受误导生成错误信息。
RAG(检索增强生成)的有效性与挑战:
将对话作为观察记录并进行检索,能提高模型表现(如GPT-3.5-turbo使用Top 5观察记录时提升5%)。
但检索内容过多或噪音过高会降低效果。
使用会话摘要作为上下文未能显著提升性能,可能是因为信息丢失。
难点分析:
时间推理问题:LLM难以正确理解对话中的时间概念,类似问题也存在于其他时间推理基准中。
开放域知识问题:LLM在开放域知识任务中表现不佳,引入不准确的检索内容反而会导致性能下降。
6.2 事件图总结任务(Event Summarization Task)¶
主要发现:
增量总结表现最佳:
GPT-3.5-turbo在召回率和F1分数上表现最好,尽管GPT-4-turbo在精确度上有5.3%的提升,但召回率较低。
该任务需要模型理解事件间的时间依赖和因果关系(见图7)。
长上下文模型未必更优:
GPT-3.5-turbo-16K(16K上下文)在精确度和召回率上均低于GPT-3.5-turbo(4K上下文),表明长上下文模型未必能更好地利用其上下文。
这与问答任务中的发现一致,说明模型可能并未有效利用更长的上下文。
商业模型优势明显:
GPT-4-turbo和GPT-3.5-turbo在ROUGE和FactScore指标上显著优于开源模型(如Llama-2-Chat)。
常见错误类型(手动分析):
缺失关键信息;
生成不准确或无关的细节(幻觉);
误解对话中的幽默或讽刺;
说话人归属错误;
将不重要的对话误认为重要事件。
6.3 多模态对话生成任务(Multi-Modal Dialog Generation Task)¶
主要发现:
上下文引入提升性能:
在训练中加入上下文信息(如观察记录)能显著提升多模态对话生成效果。例如,引入观察记录中的视频游戏比赛体验信息,使生成的对话和图像更贴合说话人的人设。
MM-Relevance分数随对话历史增长而下降:
对话历史越长,MM-Relevance分数越低(见图4B),表明模型难以处理长对话中的多模态信息。
RAG缓解性能下降:
检索增强生成(RAG)方法能在一定程度上缓解MM-Relevance分数的下降趋势,表明结合检索信息有助于模型生成更相关的内容。
总体结论¶
本章通过对三种任务的全面实验,揭示了LLM在长对话记忆任务中的关键挑战与表现差异:
上下文长度限制与幻觉问题影响模型在问答和事件总结任务中的表现;
RAG方法在特定设置下有效,但存在噪音和信息丢失问题;
多模态对话生成中,上下文引入和RAG方法有助于提升生成质量;
时间推理、开放域知识和对话理解(幽默、讽刺等)是当前LLM难以克服的难点。
这些发现为改进LLM在长对话场景中的表现提供了明确方向。
7 Conclusion¶
本章总结了研究的主要成果与发现。作者构建了一个名为LoCoMo的人机协作数据集,包含50段高质量的超长对话,每段平均包含300轮对话、约9000个token,跨越最多35次会话。同时,提出了一套包含三项任务的评估框架,用于评估模型在长对话中的表现。实验结果表明,尽管是大型语言模型(LLMs),在处理长对话中的长期叙事理解以及对话事件之间的时间和因果关系方面仍存在显著困难。
8 Limitations¶
该章节总结了研究中存在的一些局限性,主要包括以下几点:
混合人机生成数据:数据集主要来源于大型语言模型(LLM)生成的文本,尽管有人类标注者参与验证和编辑以增强真实性,但该数据集可能仍无法完全反映真实的在线对话的细微差异。
多模态行为的探索有限:数据集中的图片来自网络,缺乏个人照片中常见的视觉一致性(如外表、家庭环境、宠物等),因此在大多数情况下,图片可以被其文字描述替代,只有在需要OCR(光学字符识别)的场景下才例外。
语言限制:目前的生成对话流程仅支持英语,但理论上可以通过使用掌握其他语言的LLM和相应翻译来扩展语言支持。
依赖闭源LLM:在生成对话数据时使用了最先进的商业闭源LLM,虽然能够生成更真实的对话,但这也限制了可复现性和开源性。研究者计划公开代码,以便未来与开源LLM结合使用。
长文本生成的评估挑战:LLM倾向于生成冗长的回复,即使提示要求简短回答,这使得评估其回答的准确性变得困难。该研究的评估框架也面临同样的问题。
整体而言,作者诚实地指出了研究中由于技术、资源和方法带来的限制,并提出了相应的改进方向。
9 Broader Impacts¶
该章节“9 Broader Impacts”主要探讨了论文所提出的生成代理框架在伦理和实际应用中可能带来的广泛影响,总结如下:
生成代理的伦理风险:作者借鉴并改进了Park等人提出的生成代理框架,致力于生成高度真实感的长期对话。然而,这种真实感可能导致用户与代理之间形成“寄生式社会关系”,从而对用户的现实生活产生负面影响。因此,作者建议在实际部署时应明确声明对话来自生成模型,以避免误导用户。
多模态大语言模型的风险:文中使用的多模态大模型可以根据对话内容生成图像,这种能力可能被滥用,导致虚假信息和社交偏见的传播。特别是当代理被诱导重复错误信息或危险观点时,风险更大。
代理替代人类的潜在问题:生成代理可能被用于替代真实人类参与某些研究或过程,尤其是在难以收集长期人类互动数据的情况下。但作者强调,若研究结果可能影响现实决策,这种替代应谨慎对待,以免对人类造成实际影响。本文仅是关于长期对话中模型理解能力的研究,不涉及现实政策建议,作者也建议其他研究者避免据此提出政策性建议。
总体而言,该章节强调了生成代理技术在推动对话研究的同时,所涉及的伦理风险和社会责任,并提出了一些应对措施和使用建议。
Appendix Overview¶
该段落主要概述了附录的结构和内容,并配合一个图表说明LoCoMo数据集中人物设定生成相关的信息。以下是内容总结:
附录结构:
附录A:介绍了LoCoMo数据集中生成式流程的细节。
附录B:提供了LoCoMo数据集的统计数据、数据发布的许可证以及标注人员的详细信息。
附录C:描述了实验设置和实现细节。
附录D:展示了在LoCoMo基准上评估的额外结果。
图5说明:
图5展示了一个用于从初始人物设定(pc)生成扩展人物陈述(p)的提示语(prompt)。
同时提供了LoCoMo数据集中人物陈述的示例,用于说明虚拟代理在对话生成流程中的人物设定生成方式。
总结:该段落和图表为论文的附录部分提供了结构说明,并具体解释了LoCoMo数据集中人物设定生成的方法和示例,增强了论文的技术细节和数据背景的可理解性。
Appendix A Generative Pipeline for LoCoMo¶
本附录描述了LoCoMo数据集生成流程的主要组成部分,包括角色设定(Persona)、时间事件图(Temporal Event Graph)和人类过滤(Human Filtering)三个部分:
角色设定(Persona):
每个虚拟代理(agent)被赋予一个独特的角色设定(persona),该设定通过从MSC数据集中选取初始角色属性,利用GPT-3.5-turbo模型扩展生成完整的角色描述。
生成过程使用了提示词(prompt)和上下文示例,确保角色设定的多样性和合理性。
示例和提示词见图5和图6。
时间事件图(Temporal Event Graph):
基于角色设定,使用迭代方式生成事件图,图中包含因果关联的事件。
初始生成三个与角色相关的独立事件,之后逐步生成由已有事件引发的新事件,从而形成因果链。
虚拟代理架构包括“反思与回应”(Reflect & Respond)和“图像分享与回应”(Image Sharing & Response)两个机制。
反思与回应:结合短期记忆(当前会话摘要)和长期记忆(关于角色的观察性陈述)生成回复。
图像分享与回应:支持生成图像描述并基于图像进行对话互动。
相关提示词和示例见图7至图10。
人类过滤(Human Filtering):
生成的对话内容经过人类标注者编辑,以提高数据质量和一致性。
编辑任务包括:删除无关图像、补充图像上下文、替换不匹配图像、修正对话一致性、确保对话与事件图一致、删除未出现在对话中的事件等。
图11展示了一些编辑示例。
总结:LoCoMo数据集的生成依赖于角色设定、时间事件建模和多轮对话生成,同时通过人类标注进行后期修正,以确保数据的连贯性、合理性和多样性,适用于评估大型语言模型在长期对话中的记忆能力。
Appendix B Dataset¶
本章总结如下:
附录B:数据集¶
B.1 数据集统计¶
本部分介绍了LoCoMo数据集的统计信息,包括对话和评估基准的数据规模与特点。
对话统计:
总对话数:50个。
平均每个对话包含19.3个会话(session)。
平均每个会话包含15.8轮对话(turn)。
平均每个对话包含约9,209.2个token。
每轮对话的平均token数约为30.2个(对话内容)和18.2个(观察内容)。
每个会话的总结平均长度为127.4个token。
问答评估基准统计:
单跳检索:2,705个问题(占36%)。
多跳检索:1,104个问题(占14.6%)。
时间推理:1,547个问题(占20.6%)。
开放域知识:285个问题(占3.9%)。
对抗性问题:1,871个问题(占24.9%)。
总问题数:7,512个。
事件总结统计:
每个对话平均包含24.2个事件。
事件总结的平均长度为896.5个token。
多模态对话生成统计:
每个对话平均包含32.3张图片。
B.2 数据集授权¶
LoCoMo数据集将采用 CC BY-NC 4.0 DEED 许可协议发布,允许在非商业用途下使用,并需注明出处。
B.3 标注人员信息¶
本数据集由内部标注人员完成标注。由于信息保密原因,无法提供标注人员的人口统计信息。
总结:
本章提供了LoCoMo数据集的详细统计信息,涵盖对话结构、评估任务分布、事件总结及多模态内容。同时明确了数据集的授权方式,并说明了标注人员的信息保密情况。这些内容为理解数据规模和使用限制提供了重要参考。
Appendix C Experimental Setup¶
本节总结了论文中关于实验设置的附录内容,主要包括基线方法、不同任务的实验配置以及实现细节。
1. 基线方法(Baselines)¶
在LoCoMo数据集上,对话包含自然语言和图像,涉及高阶推理和多模态共指消解。研究发现,使用BLIP-2生成图像描述,并结合先进大语言模型(LLMs)进行推理,可以有效处理多模态共指问题。因此,问答和事件摘要任务主要使用LLMs进行,仅在多模态对话生成任务中直接使用图像。
1.1 问答任务¶
实验采用三种方法:
Base:在受限上下文窗口中使用LLM直接完成任务,早期对话会因窗口限制被省略。
Long-context:使用拥有更大上下文窗口的LLM,尽可能暴露更多对话内容。
RAG(检索增强生成):从对话历史、观察或会话总结中检索相关内容。观察基于对话中每个说话者的断言,会话总结则为每场对话的简要总结。
使用的模型包括 Mistral-7B、LLaMA-70B、gpt-3.5-turbo 和 gpt-4-turbo,检索模型为 DRAGON。未报告部分开源模型的性能,原因在于其在短上下文中的表现可能存在波动。
1.2 事件摘要任务¶
同样采用 Base 和 Long-context 配置,但不使用 RAG。与问答任务不同,事件摘要需要对整个对话有全面理解。研究采用迭代方式,先为前一节对话生成摘要,再基于该摘要生成下一节的摘要。同时,通过一个示例输入和输出引导模型提取重要人生事件。
1.3 多模态对话生成¶
使用 MiniGPT-5 模型,在50个自动生成的对话上进行训练,未经过人工筛选。训练数据包括以下三种变体:
Base:仅使用前文对话。
+summary:使用前文对话和全局对话摘要。
+observation:使用前文对话和从历史中检索到的相关观察。 模型均基于 MiniGPT-5 在 MMDialog 数据集上的预训练参数。
2. 实现细节(Implementation Details)¶
使用 OpenAI API 和 Huggingface 平台进行实验,温度(temperature)设为 0,top-p 为 1,以确保生成结果的确定性。
所有实验(包括 RAG 模型、MiniGPT-5 训练和推理)均在 NVIDIA A6000 服务器上使用 FP32 精度完成。
对于 MiniGPT-5,模型训练了 10 个周期,耗时约 30 小时,使用原始代码库推荐的超参数。
评估中使用标准的 Python 库计算以下指标:
BLEU
ROUGE
BertScore
FactScore
总结¶
本节详细描述了实验设置,针对问答、事件摘要和多模态对话生成任务分别设计了不同的基线方法和模型配置,并提供了具体的实现细节和评估指标,为实验结果的可信性和可复现性提供了保障。
Appendix D Results¶
总结内容如下:¶
1. 表6:MiniGPT-5多模态对话生成性能比较¶
表6比较了MiniGPT-5模型在不同训练变体下的多模态对话生成性能。性能评估指标包括BLEU-1/2、Rouge-L 和 MM-R。结果显示:
基础模型(Base) 表现为 BLEU-1/2 为 57.1/34.2,Rouge-L 为 12.4,MM-R 为 56.1。
在基础上加入**摘要(+ summary)**时,top-k=1时性能最优,BLEU-1/2 为 58.2/34.1,Rouge-L 为 12.8,MM-R 为 56.9。
加入**观察(+ observation)**时,top-k=5 时性能最佳,BLEU-1/2 为 59.7/35.1,Rouge-L 为 13.6,MM-R 为 57.8。
2. D.1 事件总结任务(Event Summarization Task)¶
该部分通过表7展示了LLMs在事件总结任务中常见的五类错误:
信息缺失(Missing information):关键事件细节缺失,模型未能建立因果和时间联系。
幻觉(Hallucination):添加了不存在的或来自其他事件的信息。
对话提示误解(Misunderstanding of dialog cues):将轻松语句误解为严肃陈述。
说话人归属错误(Speaker attribution):事件被错误地归因于错误的说话人。
显著性错误(Saliency):模型将对话中不重要的互动视为重要。
这些错误示例基于 gpt-3.5-turbo 的预测生成,反映了当前LLMs在长对话事件总结中的主要问题。
3. D.2 多模态对话生成任务(Multimodal Dialog Generation Task)¶
部分D.2介绍了LoCoMo基准中MiniGPT-5模型在多模态对话生成任务上的评估结果,其性能数据详见表6。
总体总结:¶
MiniGPT-5模型在多模态对话生成任务中,通过引入摘要和观察信息,提升了生成性能。
top-k=5 时的“+ observation”变体表现最佳。
在事件总结任务中,LLMs主要存在信息缺失、幻觉、误解提示、说话人归属错误和显著性判断错误等问题。
本附录内容旨在评估LLMs在长对话场景中的表现,揭示其在多模态对话生成和事件总结任务中的优劣点。
以上内容是对附录D章节内容的总结。