2508.18756_UltraMemV2: Memory Networks Scaling to 120B Parameters with Superior Long-Context Learning¶
引用:
1(2026-01-19)
组织:
ByteDance Seed
总结¶
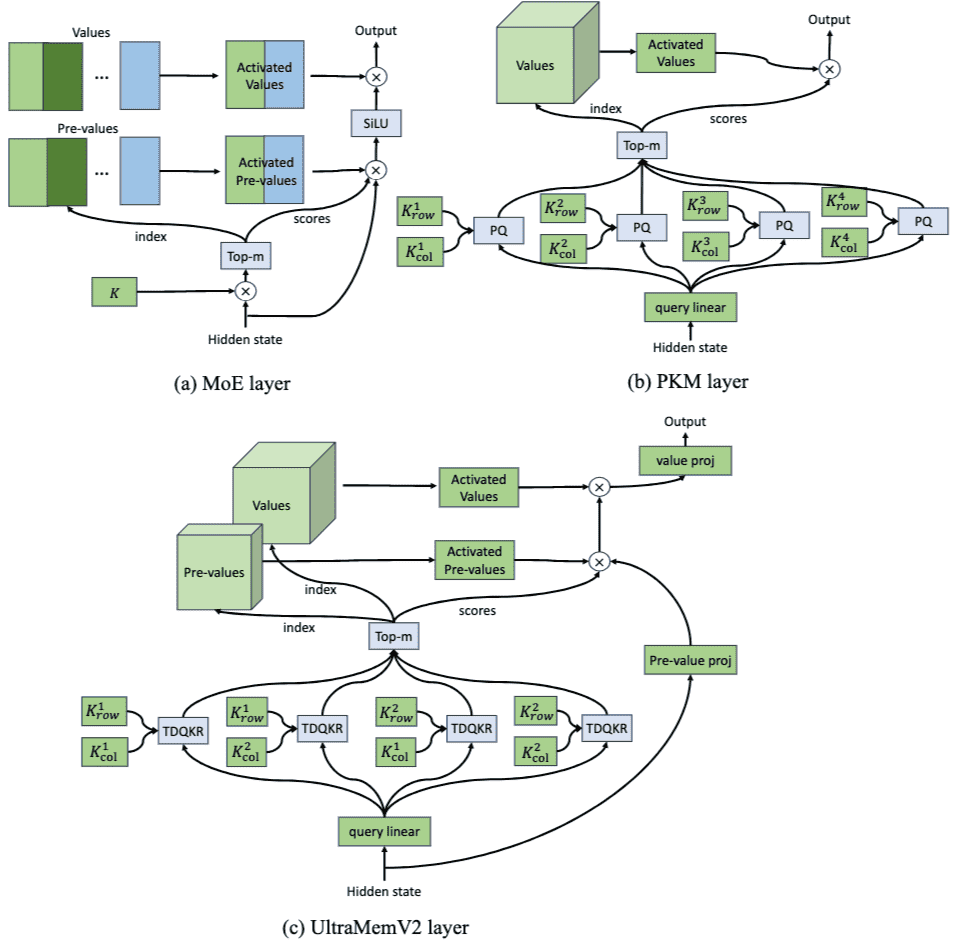
Figure 1 Overall structure of 3 sparse layers. (a) MoE layer; (b) Product Key Memory (PKM) layer; (c) UltraMemV2 layer
From Moonlight¶
三句摘要¶
⚙️ UltraMemV2是一种重新设计的内存层(memory-layer)架构,旨在弥合其与最先进的8-expert MoE模型之间的性能差距,同时解决MoE的高内存访问成本问题。
🚀 通过将内存层集成到每个Transformer块、简化值扩展并采用PEER等创新,UltraMemV2在显著降低内存访问成本的同时,实现了与MoE相当的性能,并在长文本记忆等任务上表现出色。
💡 实验证明UltraMemV2可扩展至120B总参数,并指出激活密度(activation density)对性能的影响大于总稀疏参数量,为高效稀疏计算提供了有竞争力的替代方案。
关键词¶
UltraMemV2: UltraMemV2 是一种重新设计的记忆层(memory-layer)架构,旨在缩小现有记忆层架构与最先进的 8 专家混合专家(MoE)模型之间的性能差距。它通过五项关键改进来实现这一目标:(1)架构集成:将记忆层更紧密地整合到每个 Transformer 块中;(2)简化值扩展:使用单一线性投影来简化隐式值扩展(IVE);(3)类专家值处理:采用 PEER [12] 的基于 FFN 的值计算;(4)优化初始化:采用原则性的参数初始化方法以防止训练发散;(5)计算重平衡:调整记忆层与 FFN 的计算比例。通过这些改进,UltraMemV2 在保持记忆层低内存访问优势的同时,实现了与 8 专家 MoE 模型相当的性能,尤其在记忆密集型任务上表现优越。
Memory Layer: 记忆层是一种模型架构,旨在通过激活大型参数表中的嵌入(embeddings)来扩展模型容量,同时实现比传统 MoE 模型显著更低的内存访问成本。与 MoE 的 FFN 类型专家不同,记忆层通过查询(query)与键(key)匹配来检索相关的值(value),从而实现内存访问与序列长度呈缓慢线性扩展的特性。
Mixture of Experts (MoE): 混合专家(MoE)模型是一种通过选择性地激活参数子集来提高效率的稀疏模型。它使用一个门控机制(gating mechanism)来决定哪些“专家”(通常是 FFN)应该被激活来处理输入 token。尽管 MoE 在参数数量和计算成本之间实现了有效解耦,但其在推理过程中存在高昂的内存访问成本,尤其是在仅有少量 token 激活所有专家的情况下。
Feed-Forward Network (FFN): 前馈神经网络(FFN)是 Transformer 模型中的一个标准组件,通常包含两个线性层和一个激活函数。在 MoE 模型中,每个“专家”通常就是一个 FFN。UltraMemV2 也借鉴了 PEER [12] 的思想,将 FFN 用于处理记忆层检索到的值(values)。
Activated Parameters: 激活参数是指在模型推理或训练过程中,由门控机制(gating mechanism)选择并实际参与计算的参数。在 MoE 模型中,这是指被选中的几个专家所拥有的参数。在记忆层模型(如 UltraMemV2)中,这通常指的是被 Top-M 函数选中的键(keys)和对应的值(values)相关的参数。论文强调,激活密度(activation density)比总稀疏参数数量对性能影响更大。
Memory Access Costs: 内存访问成本是指模型在运行时需要从内存中读取模型参数的开销。MoE 模型由于需要路由和加载多个专家,因此具有较高的内存访问成本,这在推理时尤其显著。记忆层架构(如 UltraMemV2)的主要优势之一就是显著降低内存访问成本,使其与序列长度呈缓慢线性增长。
Long-Context Learning: 长上下文学习能力是指模型理解和处理长输入序列(如长文档或对话历史)的能力。UltraMemV2 在这方面表现出色,相比 MoE 模型在长上下文记忆、多轮记忆和上下文学习等任务上取得了显著的性能提升。
Implicit Value Expansion (IVE): 隐式值扩展(IVE)是 UltraMem 架构中的一个技术,它通过因子分解(factorization)和 Tucker 分解(Tucker Decomposed)来创建大型值(value)内存池,并使用特定机制(如行键和列键)来检索。UltraMemV2 简化了 IVE,采用了单一线性投影来代替多重线性投影,并为每个 Tucker 秩使用独立的查询,以提高效率和性能。
PEER: PEER [12] 是一种改进的记忆层或稀疏模型架构,它提出使用一个具有单内部维度的 FFN 来替代传统的嵌入式值(value embedding)。UltraMemV2 采用了 PEER 的这一思想,将记忆层的值处理方式从简单的权重矩阵替换为 FFN,以提高参数效率和模型性能。
Tucker Decomposed Query-Key Retrieval (TDQKR): Tucker 分解查询-键检索(TDQKR)是 UltraMem 架构用于在大型记忆库中进行高效检索的关键技术。它利用 Tucker 分解来处理查询(query)和键(key),从而在保持较低计算成本的同时,能够检索到与输入相关的价值(value)。UltraMemV2 在此基础上进行了改进,简化了 IVE 过程。
Parameter Initialization: 参数初始化是指在模型训练开始前,为模型的权重参数赋予初始值的过程。UltraMemV2 强调了其“原则性的参数初始化”的重要性,指出不当的初始化可能导致训练发散。论文中通过将记忆层输出的方差与 FFN 输出的方差相匹配来设计一种优化策略,以确保模型训练的稳定性。
Activation Density: 激活密度是指在模型中,给定计算预算或参数预算下,实际被激活的参数或特征的比例。论文发现,对于 UltraMemV2,激活密度(即每个记忆层中 Top-M 激活的值的数量)比总稀疏参数的数量对性能有更大的影响,这意味着更密集的激活(尽管是在稀疏模型框架内)可能带来更好的性能。
Product Key Memory (PKM): 产品键记忆(PKM)是一种早期的记忆层架构,它利用键的因子分解(key factorization)来构建一个大型内存。PKM 通过将输入的隐藏状态投影为查询(query),然后与多个小的、因子分解的键集(行键和列键)进行匹配,以从庞大的值池中检索信息。
Value Expansion: 值扩展是指在记忆层或 MoE 模型中,将低维度的输入信息映射到更高维度的表示空间的过程。在 PKM 和 UltraMem 等记忆层架构中,值扩展通常通过将输入隐藏状态与键进行匹配,并结合检索到的值来实现。UltraMemV2 通过简化 IVE 的线性投影来改进这一过程。
Query: 查询(query)是输入到记忆层(memory layer)中的一个表示,它被用来与记忆库中的键(keys)进行匹配。在 PKM 和 UltraMem 架构中,查询是通过输入隐藏状态通过线性层投影而得到的。
Key: 键(key)是记忆层中用于与查询(query)进行匹配的元素。通过查询与键的匹配得分,可以确定记忆库中最相关的部分。在 UltraMemV2 中,键包括行键(Krow)和列键(Kcol),它们与查询一起通过 Tucker 分解(TDQKR)进行检索。
Value: 值(value)是记忆层中存储的实际信息,当查询与键匹配时,这些值会被检索出来并用于计算模型的输出。在 UltraMemV2 中,值(V)可以通过 FFN 进行进一步处理,以生成最终的输出。
Top-M: Top-M 是一种在稀疏模型(如 MoE 和记忆层)中常用的操作,用于从一组计算得分的候选中选择得分最高的 M 个元素。在 MoE 中,它用于选择得分最高的 M 个专家;在记忆层中,它用于选择与查询匹配度最高的 M 个键,并检索对应的 M 个值。
Granularity: 粒度(Granularity)在 MoE 模型上下文中,通常指在处理每个 token 时激活的专家数量。研究表明,例如,8 专家 MoE 的粒度通常比 2 专家 MoE 具有更好的性能-效率权衡。UltraMemV2 的目标是达到与高粒度 MoE 模型相当的性能。
摘要¶
本文提出了UltraMemV2,这是一种重新设计的memory-layer架构,旨在弥合embedding-based sparse models与expert-based sparse models(如Mixture of Experts, MoE)之间的性能差距。尽管MoE模型通过选择性激活参数子集实现了显著的效率,但在推理过程中存在高内存访问成本。Memory-layer architectures则以极低的内存访问提供了替代方案,但之前的尝试(如UltraMem)仅能匹配2-expert MoE的性能,远低于先进的8-expert配置。UltraMemV2通过五项关键改进,首次使memory-layer architecture的性能与state-of-the-art的8-expert MoE模型相媲美,同时显著降低了内存访问成本。
核心方法学与技术细节
UltraMemV2在现有UltraMem架构的基础上进行了多项创新:
Architectural Integration (架构集成): UltraMemV2将memory layer集成到Transformer的每个block中。相比于MoE中通常在每个层都存在专家,这确保了稀疏参数的持续参与,并解决了早期UltraMem版本在连续训练(CT)阶段收益不如MoE的问题。实验表明,当每个Transformer block都包含UltraMemV2层时,模型性能提升与MoE保持一致。
Simplified Value Expansion (简化值扩展): 在UltraMem中,Implicit Value Expansion (IVE) 使用了多个线性层进行重映射。UltraMemV2移除了IVE中的多个线性层,仅使用单个共享的线性投影 \(W\)。修改后的公式为: \(o = \tilde{V}^T \times \hat{s} = W^T V^T \times \hat{s}^\diamond\) 此外,UltraMemV2为每个Tucker rank使用独立的queries,增强了query-key操作的准确性。这提高了参数效率,并将节省的参数容量重新分配给FFN,从而在保持相同参数量和计算量的前提下提升了性能。
Expert-like Value Processing (类专家值处理): 采纳了PEER [12] 的思想,将value embedding替换为具有一个inner dimension的FFN。这相当于用“数百万个1-inner-dim专家”替换了简单的embedding值。原始PEER公式为: \(o = W^T V^T \times (\sigma(Px) \otimes \hat{s}^\diamond)\) UltraMemV2进一步发现,对两个并行结果同时应用激活函数可能导致信息损失。因此,移除了PEER FFN中的激活函数,最终的输出公式简化为: \(o = W^T V^T \times ((Px) \otimes \hat{s}^\diamond)\) 这使得PEER与SwiGLU FFN结构非常相似,其中 \(V, Px, \hat{s}\) 分别对应于 \(W_3, W_2x, \sigma(W_1x)\)。PEER的引入显著提升了模型的训练效率和下游任务表现。
Optimized Initialization (优化初始化): 针对UltraMemV2层参数的初始化,特别设计了标准差,以防止训练发散。目标是使memory layer输出激活的方差不随层数增加而发散,且不至于过大。通过使memory layer的初始化激活方差与FFN的激活方差保持一致,推导出了”Values”和”Pre-values”的初始化标准差 \(\sigma_V\): \(\sigma_V^2 = \sqrt{\frac{0.2 \cdot k_{inner} \cdot h}{k \cdot n_{head} \cdot (1 + \sigma_s^2) \cdot d_{prev} \cdot d_v \cdot L}}\) 其中,\(k_{inner}\) 是FFN inner dimension与hidden size的比值,\(h\) 是hidden size,\(k\) 是top-k参数,\(n_{head}\) 是头数,\(d_{prev}\) 是”Pre-values”的维度,\(d_v\) 是”Values”的维度,\(L\) 是层数,\(\sigma_s\) 是top-k分数的标准差。
Computational Rebalancing (计算再平衡): 调整了memory layer与FFN之间的计算比例。通过细致的消融研究,确定了最佳的memory computational proportion (MCP)。当keys维度 \(D_k\) 增加时,memory layer的计算量增加,FFN的计算量相应减少。研究发现,17.0%的MCP是最佳配置。此外,还对 \(D_v\) 和 \(D_p\) (value和pre-value维度) 的大小和比例进行了探索,发现 \(D_p:D_v = 1:3\) 的配置效果最佳,同时较小的 \(D_v\) 和 \(D_p\) 总和能够促进更精细的内存划分和更好的性能。
其他研究与发现
辅助损失 (Auxiliary Losses):研究发现,UltraMem中用于约束Tucker core非最大特征值的惩罚损失在UltraMemV2中是冗余的,因为Tucker core的特征谱自然呈现出显著的衰减,主要特征值远大于次要特征值。移除此损失甚至能带来轻微的性能提升。对于平衡损失(balance loss),其有效性与激活值的数量 (TopM) 相关:当激活值较少时有益,但当激活值较多时则可能 detrimental。
共享内存 (Shared Memory):探索了跨层共享value table的策略。虽然共享内存能够提升模型容量,但需要权衡FFN inner dimension的缩小。实验比较了Ring-based和Block-wise共享策略,发现S9-Ring配置在下游任务表现最佳,而S6-Block作为工程上更友好的替代方案也取得了显著提升。
Value Learning Rate Schedule (值学习率调度):与UltraMem中高初始学习率并衰减的策略不同,UltraMemV2发现,在足够长的训练周期内,保持恒定、适中的学习率(例如,主模型学习率的1倍)可以获得更好的最终性能,并简化了超参数调整。
实验结果与优势
UltraMemV2在高达2.5B激活参数(总参数120B)的模型上进行了验证,并在多个基准测试上与MoE模型进行了比较。
性能对等性:UltraMemV2在相同的计算和参数预算下,实现了与8-expert MoE模型相当的性能。在私有和开源数据集上的广泛评估均支持这一结论。
长上下文任务的卓越性能:UltraMemV2在内存密集型任务上表现出显著优势,包括长上下文记忆化 (+1.6点)、多轮记忆化 (+6.2点) 和in-context learning (+7.9点)。
设计原则:研究表明,activation density(即每个memory layer激活的values数量)对性能的影响大于总的稀疏参数数量。这意味着激活更多values比简单增加总参数量更有效。
局限性:UltraMemV2在训练早期阶段的表现不如MoE,需要更多高质量的数据才能赶上。其最佳性能也依赖于在模型的每个block中都放置memory layer。
总结
UltraMemV2成功地将memory-layer architectures的性能提升到与当前最先进的MoE模型相媲美的水平。它为高效稀疏计算提供了一个引人注目的替代方案,尤其擅长处理长上下文和记忆密集型任务。未来的工作将侧重于改善其早期训练动态,并进一步探索其在不同下游应用中的架构权衡。
Abstract¶
本论文研究了Mixture of Experts(MoE)模型与新型内存层架构UltraMemV2之间的性能对比。MoE模型通过仅激活部分参数实现了较高的计算效率,但在推理过程中存在较高的内存访问开销。相比之下,内存层架构(memory-layer architectures)具有极低的内存访问需求,但此前的方案(如UltraMem)仅能与2-expert MoE模型性能相当,远低于当前主流的8-expert MoE模型。
UltraMemV2 是作者提出的一种改进型内存层架构,旨在弥补这一性能差距。其主要改进包括:
将内存层嵌入到每个Transformer块中,增强模型整体的表达能力;
简化值扩展机制,使用单一的线性投影代替原有复杂结构;
采用基于FFN的值处理机制,借鉴自PEER方法;
采用更合理的参数初始化策略,提升训练稳定性;
重新平衡内存与FFN计算的比例,优化整体计算效率。
实验结果显示,UltraMemV2在相同计算量和参数规模下,达到了与8-expert MoE模型相当的性能,同时显著降低了内存访问开销。在对内存需求较高的任务上,UltraMemV2表现尤为突出:
在长上下文记忆任务中提升+1.6点;
在多轮记忆任务中提升+6.2点;
在上下文学习任务中提升+7.9点。
作者还在最大达1200亿参数、激活参数达25亿的模型上验证了方法的有效性,并指出:激活密度(activation density)对模型性能的影响大于总稀疏参数数量。
结论:UltraMemV2成功将内存层架构的性能提升至与当前最先进的MoE模型相当的水平,为高效稀疏计算提供了一个有竞争力的替代方案。
1 Introduction¶
核心问题与背景¶
本节首先指出,大语言模型(LLMs)在自然语言处理(NLP)任务中取得了显著成功,但其参数数量和计算复杂度的指数增长,给资源受限的部署带来了巨大挑战。为了解决这一问题,研究者提出了混合专家模型(Mixture of Experts, MoE),通过选择性激活专家子集,在不显著增加计算成本的前提下,实现参数规模的扩展。
MoE 的优势与瓶颈¶
MoE 的优势在于:
参数与计算解耦:只激活部分专家,降低推理时的计算开销。
性能-效率平衡:研究表明,激活8个专家时性能最佳,显著优于激活更少专家的配置。
但 MoE 也存在明显问题:
内存访问成本高:由于路由机制导致的专家切换,尤其在少量 token 激活所有专家时,会带来显著的内存访问开销。
替代方案:Memory-layer 架构¶
为解决 MoE 的内存瓶颈,研究者提出了基于内存层(Memory-layer)的稀疏模型架构,如 UltraMem[18]。其特点包括:
激活嵌入向量而非 FFN 专家,从大型参数表中提取信息。
内存访问随序列长度缓慢线性增长,优于 MoE 的非线性访问。
Over-tokenized Transformer也被视为一种 Memory-layer 架构。
但现有 Memory-layer 模型仍存在性能差距:
仅能匹配 MoE 中激活2个专家的性能,远低于8个专家的 SOTA 表现。
UltraMemV2 的提出与创新点¶
为弥合这一差距,作者提出 UltraMemV2,一种重新设计的 Memory-layer 架构,融合了以下五项关键创新:
结构整合:将 Memory 层紧密集成进每个 Transformer 块。
简化值扩展(IVE):使用单一线性投影替代复杂扩展机制。
专家式值处理:引入 PEER 的 FFN 结构进行值计算。
优化初始化:设计合理的参数初始化策略,防止训练发散。
计算再平衡:调整 Memory 与 FFN 的计算比例。
实验结果与贡献¶
作者通过全面评估验证了 UltraMemV2 的有效性:
性能与 MoE-8 相当,同时保留 Memory-layer 的内存优势。
在长上下文记忆、多轮记忆、上下文学习等任务上表现更优(分别提升 +1.6、+6.2、+7.9 点)。
可扩展性强:支持高达 25 亿激活参数,总参数达 1200 亿。
激活密度(top-m)比总稀疏参数数更重要。
主要贡献总结¶
架构创新:首次提出在性能上能与 8-expert MoE 竞争的 Memory-layer 架构。
全面分析:通过消融实验和对比分析,揭示 UltraMemV2 在不同任务和训练阶段的表现优势与权衡。
大规模验证:验证 UltraMemV2 在大规模下的有效性,并提出激活密度与参数数量之间的设计原则,为未来 Memory-layer 架构提供指导。
总结:本节系统地指出了 MoE 的局限性,提出了 UltraMemV2 这一改进型 Memory-layer 架构,并通过结构创新与实验验证,展示了其在性能、效率与可扩展性方面的优势。
3 Approach¶
3.1 Preliminary(预备知识)¶
本节回顾了三种常见的内存扩展结构:MoE(Mixture of Experts)、PKM(Product Key Memory)和 UltraMem,它们的目标是在不显著增加计算成本的前提下扩展模型容量。
MoE Layer(专家混合层)¶
结构:通过门控机制选择性激活部分专家参数。
输入:隐藏状态 \(\mathbf{x} \in \mathbb{R}^{D_{\text{in}}}\)
公式:
路由得分计算: $\( \mathbf{s} = \mathbf{x} \times \mathbf{K}^T \quad \text{(式1)} \)$
选择 Top-M 个专家: $\( \mathcal{I} = \text{Top-M}(\mathbf{s}) \)$
输出计算: $\( \mathbf{o} = \sum_{i \in \mathcal{I}} s_i \cdot (\text{SiLU}(\mathbf{x} \mathbf{U}_i) \times \mathbf{V}_i^T) \quad \text{(式2)} \)$
特点:稀疏激活,计算效率高。
PKM Layer(乘积键内存层)¶
结构:使用键的因子化来构建大规模内存。
输入:隐藏状态 \(\mathbf{x}\)
公式:
查询生成: $\( \mathbf{s}_{\text{row}} = \sigma_{\text{TopM}}(\mathbf{K}_{\text{row}} q_{\text{row}}(\mathbf{x})), \quad \mathbf{s}_{\text{col}} = \sigma_{\text{TopM}}(\mathbf{K}_{\text{col}} q_{\text{col}}(\mathbf{x})) \quad \text{(式3)} \)$
得分聚合: $\( \mathbf{S}_{\text{grid}} = \sigma_{\text{TopM}}(\mathbf{s}_{\text{row}} + \mathbf{s}_{\text{col}}^\top) \quad \text{(式4)} \)$
输出计算: $\( \mathbf{o} = \sum_{i \in \mathcal{I}} \mathbf{S}_{\text{grid}}^i \mathbf{V}_i \quad \text{(式5)} \)$
特点:通过因子化键实现大规模内存,支持多头机制。
UltraMem Layer¶
结构:结合 MoE 和 PKM 的特点,使用 Tucker 分解和隐式值扩展(IVE)。
输入:隐藏状态 \(\mathbf{x} \in \mathbb{R}^{D_i}\)
公式:
查询生成: $\( \mathbf{S}_{\text{row}} = \mathbf{K}_{\text{row}} q_{\text{row}}(\mathbf{x}), \quad \mathbf{S}_{\text{col}} = \mathbf{K}_{\text{col}} q_{\text{col}}(\mathbf{x}) \quad \text{(式6)} \)$
得分计算: $\( \mathbf{S}_{\text{grid}} = \sigma_{\text{TopM}}(\mathbf{S}_{\text{row}}^\top \times \mathbf{C} \times \mathbf{S}_{\text{col}}) \quad \text{(式7)} \)$
Shuffle 操作: $\( \hat{\mathbf{s}} = \texttt{Shuffle}(\texttt{vec}(\mathbf{S}_{\text{grid}})) \quad \text{(式8)} \)$
输出计算: $\( \mathbf{o} = \sum_p \mathbf{W}_p^\top (\mathbf{V}^\top \times \hat{\mathbf{s}}_p) \quad \text{(式9)} \)$
特点:支持大规模参数扩展,适合长上下文建模。
3.2 Overall Structure(整体结构)¶
提出改进结构:UltraMem-V2(如图1(c)所示)
与 UltraMem 的对比改进:
每个 Transformer 块包含 FFN 和 UltraMem-V2 层。
移除 IVE 中的多个线性层,仅保留一个线性层;为每个 Tucker 秩使用独立查询。
引入 PEER(Parameter Efficient Embedding Remapping),将嵌入值替换为具有一个内维的 FFN。
改进参数初始化方法。
调整内存层的计算比例。
3.3 Different view in Implicit Value Expansion(IVE 的新视角)¶
核心思想:IVE 实际上实现了多头机制,无需显式定义。
公式:
多头得分计算: $\( \mathbf{S}_{\text{grid}} = \sigma_{\text{TopM}}([\mathbf{S}_{\text{row}}^{i\top} \mathbf{C}^{i,j} \mathbf{S}_{\text{col}}^{j}]) \quad \text{(式11)} \)$
输出计算简化为: $\( \mathbf{o} = \mathbf{W}^\top (\mathbf{V}^\top \times \hat{\mathbf{s}}) \quad \text{(式12)} \)$
优势:减少线性层数量,提升推理速度。
3.4 Million of 1-inner-dim experts instead of embeddings(用 1 内维专家替代嵌入)¶
引入 PEER 方法:将值替换为具有一个内维的 FFN。
公式:
输出计算: $\( \mathbf{o} = \mathbf{W}^\top (\mathbf{V}^\top \times ((\mathbf{P} \mathbf{x}) \otimes \hat{\mathbf{s}})) \quad \text{(式15)} \)$
与 SwiGLU FFN 的类比:
\(\mathbf{V} \leftrightarrow \mathbf{W}_3\),
\(\mathbf{P} \mathbf{x} \leftrightarrow \mathbf{W}_2 \mathbf{x}\),
\(\hat{\mathbf{s}} \leftrightarrow \sigma(\mathbf{W}_1 \mathbf{x})\)
改进:去除激活函数以避免信息损失。
3.5 Improved initialization(改进初始化)¶
目标:确保训练稳定,输出激活方差不随层数增加而发散。
方法:
初始化标准差设计需满足:
输出激活方差稳定;
方差不过大。
与 FFN 初始化保持一致。
具体推导:见附录6。
3.6 Auxiliary losses(辅助损失)¶
说明:本节介绍的两个辅助损失在 UltraMemV2 中未使用,实验表明无提升。
Tucker Core Penalty Loss(Tucker 核惩罚损失)¶
目的:约束 Tucker 核的奇异值,防止其退化为秩1矩阵。
公式: $\( \mathcal{L}_{\text{aux}} = \frac{\alpha}{r-1} \sum_{i=2}^{r} \left( \max(0, \lambda_i - \tau) \right)^2 \quad \text{(式17)} \)$
Balance Loss(平衡损失)¶
目的:防止专家激活不平衡。
公式: $\( \mathcal{L}_{\text{balance}} = \beta N \cdot \sum_{n=1}^{N} f_n \cdot p_n \quad \text{(式19)} \)\( 其中: \)\( f_n = \frac{\text{Count}_n}{T}, \quad p_n = \frac{1}{T} \sum_t \mathbf{P}_{\text{row/col}}^n \quad \text{(式20)} \)$
结论:UltraMem 的并行方式不依赖专家激活平衡,因此该损失无明显效果。
总结¶
本章系统介绍了 UltraMemV2 的基础结构、改进点、数学建模和实现细节。重点包括:
三种内存结构(MoE、PKM、UltraMem)的对比与公式推导;
UltraMemV2 的五大改进:结构优化、IVE 简化、PEER 引入、初始化改进、计算比例调整;
IVE 的多头机制解释;
PEER 与 FFN 的类比与改进;
初始化与辅助损失的分析。
这些改进使得 UltraMemV2 能够在保持高效计算的同时,扩展至 120B 参数,并在长上下文任务中表现优异。
4 Experiments¶
4.1 与MoE的对比¶
实验目标¶
验证UltraMemV2在以下方面与MoE模型的对比表现:
性能一致性:UltraMemV2在训练后期可达到与MoE相当或更优的性能。
架构优势:UltraMemV2在长上下文记忆、多轮记忆和上下文学习任务中表现优异。
参数效率:通过激活密度而非参数总量提升性能。
数据与模型配置¶
训练数据:
私有数据:3.9T tokens预训练(PT)+ 500B高质量长上下文tokens继续训练(CT)
开源数据:OLMoE的1T tokens
模型配置:
UltraMemV2-2.5B/120B-top256:从120B稀疏参数中激活2.5B,每层激活256个值
UltraMemV2-2.5B/60B-top768:从60B稀疏参数中激活2.5B,每层激活768个值
MoE对比模型:SeedMoE-2.5B/30B、SeedMoE-2.5B/60B
开源模型:OLMoE、Memory+、UltraMem
关键发现¶
训练阶段依赖性:
初期训练(1.6T PT):UltraMemV2表现略逊于SeedMoE
后期训练(+250B CT):UltraMemV2性能反超,尤其在数学推理、代码生成和推理任务上
长期训练(3.9T PT + 500B CT):UltraMemV2在HardBench上表现更优
扩展行为:
增加激活值密度(top768 vs top256)比增加稀疏参数总量(60B vs 120B)更有效
激活密度提升带来性能增益,但也增加推理延迟
长上下文任务优势:
UltraMemV2在长上下文记忆任务上显著优于SeedMoE:
长上下文记忆:23.5 vs 21.9
多轮记忆:31.2 vs 25.0
上下文学习:29.5 vs 21.6
开源模型对比:
在227M/1.2B和1B/7B参数配置下,UltraMemV2显著优于Memory+和UltraMem,与OLMoE性能相当
表格数据¶
表1:不同训练阶段的性能对比(OpenBench和HardBench)
表2:长上下文任务性能对比
表3:开源模型在多个基准测试中的表现
4.2 结构消融实验¶
4.2.1 PEER¶
方法:用FFN替代值嵌入(value embedding)
配置:
Baseline:N=789 keys, Dv=288, TopM=48
PEER:N=558 keys, Dp=288, TopM=24
结果:
PEER在训练损失和下游任务准确率上均优于Baseline
证明FFN-based值处理在参数效率和效果上更优
4.2.2 单一投影器与多查询¶
改进:
使用单一投影器减少激活
使用多查询提升查询-键匹配精度
结果:
训练1.5T tokens后,损失降低0.0026,Open-Benchmark准确率提升0.7点
4.2.3 单头 vs 多头¶
配置:
单头:Dk和TopM翻倍
双头:原始配置
结果:
单头配置损失降低8e-4,准确率提升0.2点
增加查询/键维度比增加头数更有效
4.2.4 内存计算比例¶
目标:确定Dk(键维度)的合理配置
实验:调整Dk,保持总计算量不变
结果:
17%内存计算比例为最优配置
推荐Dk = h/2(h为隐藏层大小)
4.2.5 Dv和Dp的配置¶
实验:
Dv + Dp越小,内存划分越精细
设置Dp:Dv = 1:3时性能最优
结论:
更小的Dv和Dp有助于提升性能,但会增加训练和推理开销
4.2.6 UltraMemV2层数¶
实验:插入2、5、10、20个UltraMemV2层
结果:
验证集损失无明显差异,但Open-Benchmark准确率持续提升(+2.3, +0.9, +1.1)
MoE每层都有稀疏参数,而UltraMemV2间隔插入更高效
4.2.7 辅助损失¶
Tucker核心惩罚损失¶
发现:
λ1(最大特征值)远大于λ2(次大特征值),惩罚损失无必要
去除惩罚损失后模型性能略有提升(0.3点)
平衡损失¶
实验:
TopM=47时平衡损失提升性能
TopM=94时平衡损失反而降低性能
结论:
平衡损失在稀疏激活时有效,密集激活时无效
4.2.8 共享内存¶
策略:
Sgg-NoRing:邻近层共享
Sgg-Ring:环形共享
Sgg-Block:块内共享
结果:
S9-Ring在训练损失和准确率上最优
S6-Block在工程实现上更友好,性能略逊于S9-Ring
4.2.9 值学习率调度¶
实验:
Baseline:4x→1x线性衰减
Constant 1x:恒定1x
Constant 1.5x:恒定1.5x
结果:
短期训练(<400B tokens):Baseline最优
长期训练(1.4T tokens):Constant 1x最优,准确率提升0.4点
结论:恒定学习率在长期训练中更优,简化训练流程
总结¶
UltraMemV2在多个方面展现出与MoE相当或更优的性能,尤其在长上下文任务中表现突出。通过结构优化(如PEER、单头、共享内存)和训练策略改进(如恒定学习率),UltraMemV2在保持参数效率的同时提升了模型性能。消融实验验证了各项改进的有效性,并为后续模型设计提供了指导。
5 Conclusion¶
主要成果与贡献¶
本论文提出了 UltraMemV2,这是一种新型模型架构,首次在性能上达到了与顶级8专家MoE(Mixture of Experts)模型相当的水平。通过在模型的各个部分引入新的“记忆层”(memory layers),UltraMemV2 成为构建大规模、高效率AI模型的一种有力新选择。
作者总结了几个关键发现:
性能匹配MoE:UltraMemV2 在标准测试中表现与强MoE模型相当。
记忆密集型任务表现优异:在长文档理解和多轮对话等需要强记忆能力的任务上,UltraMemV2 显著优于MoE模型。
训练流程简化:相比MoE模型,UltraMemV2 不需要复杂的训练设置,训练过程更简单。
设计启示:研究发现,激活更多值(激活更多参数)比单纯增加稀疏参数数量更有效,这是一个重要的架构设计经验。
局限性(Limitations)¶
尽管UltraMemV2表现出色,但也存在一些限制:
训练初期表现不佳:在训练初期阶段,UltraMemV2 的性能不如MoE模型。
依赖大量高质量数据:需要大量高质量数据才能追上MoE模型的表现。
架构依赖性强:其最佳性能依赖于在每个模型块中都插入记忆层。
未来工作方向¶
未来的研究应聚焦于:
改进UltraMemV2在训练初期的动态表现;
进一步探索不同下游任务中的架构权衡,以提升其适用性。
总结¶
UltraMemV2验证了记忆层架构在构建高效、强大模型中的潜力。它不仅在性能上与MoE模型媲美,还在特定任务上实现了超越。尽管存在一些限制,但其结构设计和训练效率为未来的大规模AI模型开发提供了重要方向。
6 Optimized Initialization¶
本章主要介绍 UltraMem-V2 模型中用于控制输出方差的优化初始化方法,目标是使每一层的输出方差保持稳定,避免随着网络深度增加而发散。内容分为三个小节。
6.1 UltraMem-V2 层输出的方差¶
重点内容:
输入来自 LayerNorm 的输出,均值为 0,方差为 1。
根据中心极限定理(CLT),”pre value proj” 输出的均值为 0,方差为 0.4。
“Activated Pre values” 的方差为 σ_V²。
两个张量相乘后,方差变为 0.4 × σ_V² × d_prev。
经过 top-k 分数加权后,方差变为 (0.4 + 0.4 × σ_s²) × σ_V² × d_prev。
最终输入到 “value proj” 的方差为:
\[ (0.4 + 0.4 × σ_s^2) × σ_V^4 × d_{prev} × k × n_{head} \]最终输出方差(使用 CLT 推导)为:
\[ σ_{mem}^2 = (0.16 + 0.16 × σ_s^2) × σ_V^4 × d_{prev} × k × n_{head} × d_v / h \tag{22} \]
6.2 top-k 分数的方差¶
重点内容:
TDQKR 模块包含复杂的操作(如 Tucker 分解和 SVD),难以直接推导其方差。
采用统计方法:生成大量符合查询和键归一化输出分布的随机数据,输入 TDQKR 模块。
通过调整查询和键的归一化初始化,使得 top-k 分数的均值约为 1。
在此条件下统计 top-k 分数的方差,并代入公式 (22)。
6.3 初始化标准差的计算¶
重点内容:
目标是控制最终输出的方差,使其与 FFN 输出方差一致。
首先推导 FFN 的输出方差:
FFN 输入为 LayerNorm 输出,均值 0,方差 1。
Swish 激活函数输入的方差为 0.4。
使用截断正态分布估计 Swish 输出的均值和方差:
\[ μ_{gate} = μ_{swi} + \frac{φ(α) - φ(β)}{Z} σ_{swi} \tag{23} \]\[ σ_{gate}^2 = σ_{swi}^2 \left[1 - \frac{βφ(β) - αφ(α)}{Z} - \left(\frac{φ(α) - φ(β)}{Z}\right)^2 \right] \tag{24} \]FFN 内部激活的方差为 0.16。
最后一层线性层的初始化标准差乘以因子 1/√(2L),以防止输出方差随层数增加而发散。
得到 FFN 输出方差为:
\[ σ_{ffn}^2 = \frac{0.064 × k_{inner}}{2L} \tag{25} \]
令 σ_mem = σ_ffn,推导出 “Values” 和 “Pre-values” 的初始化方差:
\[ σ_V^2 = \sqrt{ \frac{0.2 × k_{inner} × h}{k × n_{head} × (1 + σ_s^2) × d_{prev} × d_v × L} } \tag{26} \]
总结¶
本章围绕 UltraMem-V2 的初始化优化展开,重点在于:
利用 CLT 推导各模块输出的方差;
通过统计方法估计 top-k 分数的方差;
基于 FFN 输出方差作为参考,推导出 “Values” 和 “Pre-values” 的初始化标准差;
保证网络输出方差在多层堆叠下保持稳定,避免梯度爆炸或消失。
关键公式:
输出方差公式 (22)
FFN 输出方差公式 (25)
初始化标准差公式 (26)
7 Evaluation Benchmark¶
7 评估基准(Evaluation Benchmark)¶
本章节介绍了用于评估 UltraMemV2 模型的多个基准测试,包括 开放基准(Open Benchmark)、困难基准(Hard Benchmark) 和 长上下文基准(Long-context Benchmark)。这些基准测试旨在全面评估模型在不同任务和场景下的性能。
开放基准(Open Benchmark)¶
开放基准测试涵盖了多个领域,包括:
这些任务覆盖了代码生成、数学问题求解、常识推理、多跳推理等多个方面,具有广泛的代表性。
困难基准(Hard Benchmark)¶
该基准包含更具挑战性的任务,但论文中未详细列出具体任务内容,仅指出其难度高于开放基准。
长上下文基准(Long-context Benchmark)¶
表9展示了长上下文评估任务及其描述,主要包括以下几类:
任务名称 |
描述 |
|---|---|
长上下文记忆(Long-context memorizing) |
评估模型在长上下文条件下理解和记忆信息的能力 |
多轮对话记忆(Multi-round memorizing) |
评估模型在多轮对话中保持上下文理解和记忆的能力 |
上下文学习(In-context learning) |
评估模型在给定较长任务示例下的学习和推理能力 |
推理(Reasoning) |
评估模型在长上下文中的推理能力 |
定位关键信息(Find needle) |
评估模型在大量信息中快速定位特定信息的能力 |
键值检索(Key-val retrieval) |
在大量键值对中,评估模型根据给定键进行检索的能力 |
多跳推理(Multi-hop reasoning) |
评估模型在不同上下文片段之间建立逻辑联系,从而回答问题或做出决策的能力 |
这些任务特别关注模型在处理长文本、多轮对话、信息检索和复杂推理方面的表现,是评估 UltraMemV2 长上下文能力的核心指标。
开源模型实验中的评估任务¶
在开源模型的实验中,作者评估了以下任务:
Arc-C、Arc-E
CommonSenseQA
Hellaswag
MMLU-var
OpenbookQA
PIQA
SCIQ
Winogrande
这些任务主要集中在常识推理、语言理解、多选问答等方面,用于对比 UltraMemV2 与其他开源模型的性能。
总结¶
本章系统地介绍了 UltraMemV2 的评估体系,包括三个主要基准:
开放基准:涵盖代码、数学、知识和推理任务,适用于通用能力评估;
困难基准:用于测试模型在复杂任务上的表现;
长上下文基准:重点评估模型在长文本、多轮对话、信息检索和多跳推理等方面的能力。
通过这些多样化的评估任务,论文全面验证了 UltraMemV2 在大规模参数设置下的性能优势,尤其是在长上下文建模方面的突出表现。
8 Open-source model hyperparameters¶
8 开源模型的超参数设置¶
本节主要介绍了 UltraMemV2 系列开源模型的超参数配置,包括不同模型在参数数量、内存层结构、键值维度等方面的差异。重点内容如下:
模型配置概述¶
表10展示了多个模型的配置信息,包括:
层数(Layer):如 OLMoE-227M/1.2B 和 UltraMemV2-227M/1.2B 均为20层。
隐藏层大小(Hidden size):如768或2048。
注意力头数(Attn head):如12或16。
内存层参数(Mem layer):包括内存层的数量(如4或20)、键数量(Key number)、键维度(DkDₖ)、值维度(DvDᵥ)和预值维度(DpDₚ)。
激活函数(act):未具体说明,但不同模型使用相同的激活函数。
参数总量(param):以百万(M)或十亿(B)为单位。
关键对比与分析¶
Memory+-227M/1.2B 与 UltraMem-227M/1.2B 的对比
两者共享值(value)维度,因此值数量相同。
Memory+ 使用更多的键(knum = 1138),而 UltraMem 的键数量较少(knum = 808),但键维度(kdim)更小。
这种设计使得 Memory+ 在键的存储上更丰富,而 UltraMem 更注重值的表达能力。
UltraMemV2 的改进
UltraMemV2-227M/1.2B 在内存层中引入了更复杂的结构(Mem layer = 20),键数量进一步减少(knum = 360),但键维度(kdim = 192)和值维度(vdim = 192)保持合理。
引入了 pre-vdim(DpDₚ = 192),增强了模型的表达能力。
参数总量与 UltraMem 基本一致(225M),但性能更优。
OLMoE-1B/7B 与 UltraMemV2-1M/7B 的对比
OLMoE-1B/7B 是一个更大的模型,隐藏层大小为2048,参数总量为1070M(约1B)。
UltraMemV2-1M/7B 在保持相似参数总量(1079M)的前提下,引入了内存层(Mem layer = 16),键数量为528,值维度更大(vdim = 512)。
这表明 UltraMemV2 在更大规模模型中依然保持了内存网络的优势。
总结¶
本节通过表格详细列出了不同模型的超参数配置,重点在于:
内存层的设计:键数量(knum)和值维度(vdim)是影响模型性能的关键因素。
参数总量控制:尽管引入了内存机制,UltraMemV2 在参数总量上与基线模型(如 OLMoE)基本一致。
模型扩展性:UltraMemV2 在更大规模模型(如1B/7B)中依然有效,表明其良好的扩展性。
这些配置为后续实验和性能分析提供了基础。