2510.08842_Maple: A Multi-agent System for Portable Deep Learning across Clusters¶
引用: 0(2025-11-08)
组织:
Rutgers University, USA
总结¶
背景
跨集群资源的利用与挑战
硬件异构性
软件异构性
策略差异
启动脚本差异
Maple
一个基于模板的多智能体系统,用于根据自然语言描述自动生成可移植的DL启动脚本,解决跨平台部署的问题
四个协作智能体:
信息提取智能体:解析用户输入,识别关键参数。
模板检索智能体:查找最相关的脚本模板。
验证智能体:检查脚本的正确性和一致性。
调试智能体:在任务失败时分析并修复错误。
Abstract¶
国家网络基础设施中的GPU资源挑战¶
国家级的网络基础设施项目(如ACCESS和NAIRR试点)提供多个中小型GPU集群,以满足深度学习(DL)支持的科学与工程研究日益增长的需求。然而,跨GPU集群部署DL工作负载存在技术挑战,用户需要编写适应不同启动器、调度器、亲和性选项、DL框架参数和环境变量的启动脚本。这一过程容易出错,常让用户感到沮丧,从而影响研究效率或造成资源浪费。
Maple解决方案的提出¶
为了解决上述问题,本文提出Maple,一个多智能体系统,能够根据用户的自然语言输入生成正确的DL启动脚本。Maple由四个功能模块组成:
信息提取:解析用户输入的自然语言;
模板检索:根据提取的信息匹配合适的脚本模板;
脚本验证:验证生成的脚本是否正确;
错误纠正:自动修正可能的错误。
评估与性能表现¶
本文在美国的9个GPU集群上对Maple进行了评估,测试了5个代表性深度学习模型家族和4种并行训练范式。在总计567个测试用例中,Maple实现了超过95.6%的脚本生成准确率。借助多个语言模型(总参数量达100亿),Maple的表现可与最先进的GPT-5、Claude和Gemini等模型相媲美。
总结与价值¶
Maple展示了其在异构高性能计算(HPC)环境中实现可移植和可扩展分布式深度学习的实用价值,为科研用户提供了更高效、更便捷的脚本生成工具。
I Introduction¶
本节主要介绍了深度学习与科学计算融合的现状,以及当前在跨GPU集群部署深度学习工作负载时所面临的挑战,并引出了本文提出的解决方案——Maple系统。
1. 深度学习在科研中的应用与AI科学家的兴起¶
深度学习(DL)在多个科学领域取得了突破性进展,包括结构生物学、材料科学和气象预测等。研究人员正在开发“AI科学家”来自动化文献阅读、假设生成、实验设计与执行、结果评估和报告生成等任务。这些工作通常依赖于GPU集群进行模型开发与部署。
2. 跨集群资源的利用与挑战¶
美国的国家级网络基础设施项目(如ACCESS和NAIRR Pilot)提供了跨地理分布的GPU资源。然而,用户在多个GPU集群上运行深度学习任务时面临诸多挑战,包括:
硬件异构性:各集群可能使用不同型号的GPU(如NVIDIA A100、H100、Grace-Hopper或Intel Max),软件版本和驱动也存在差异。
软件异构性:不同集群使用不同的作业调度器(如Slurm、PBS)和Python包管理工具(如Anaconda、Virtual Environment),这影响了PyTorch等框架的兼容性。
策略差异:如最大运行时间、作业提交工具等也各不相同。
启动脚本差异:由于以上异构性,用户需要为每个集群编写特定的启动脚本,这非常耗时,尤其对HPC经验有限的用户而言是巨大障碍。
文中通过一个ViT训练脚本的对比示例(表I)说明了在不同集群(Perlmutter和Polaris)上启动脚本的差异。
3. 现有解决方案及其局限性¶
为了解决跨平台部署的问题,已有多种基础设施方案被提出,如:
网格计算(Grid Computing):如TeraGrid和Open Science Grid,通过配置文件定义命令。
分布式计算框架:如Hadoop、Spark使用JVM实现跨平台。
云服务与容器技术:如AWS使用虚拟机,Kubernetes、Docker、Kubeflow用于容器化和部署。
Diamond服务:提供容器镜像和作业管理功能,支持GPU集群上的DL训练。
然而,这些方案主要从软件环境层面解决问题,并未解决跨集群异构性下启动脚本的可移植性问题。
4. 本文的解决方案:Maple系统¶
将深度学习工作负载启动脚本的生成视为一个代码生成问题。作者尝试了现代代码生成工具,但发现其在生成DL启动脚本方面能力有限,主要因为缺乏对集群特定调度器、启动器、框架、节点配置和策略等知识的掌握。
为解决这一问题,作者提出了Maple——一个基于模板的多智能体系统,用于根据自然语言描述自动生成可移植的DL启动脚本。Maple的核心是通过从真实应用中收集的启动脚本模板库进行生成,并包含以下四个协作智能体:
信息提取智能体:解析用户输入,识别关键参数。
模板检索智能体:查找最相关的脚本模板。
验证智能体:检查脚本的正确性和一致性。
调试智能体:在任务失败时分析并修复错误。
这些智能体共同构建了一个自动化工作流,以最少的人工干预生成可移植的脚本。
5. 评估与实验¶
作者构建了一个包含567个测试用例的评估集,覆盖9个美国政府资助的集群、5个深度学习模型家族、4种主流DL框架和并行范式。实验结果表明,Maple在所有测试用例中平均准确率为95.6%(模型参数约为100亿)。
此外,Maple的模板库还能显著提升当前最先进的大语言模型(如GPT-5、Claude Sonnet4、Gemini等)在DL脚本生成任务上的表现,其准确率可与Maple媲美(尽管这些模型参数量约为1000亿)。
6. 论文结构简介¶
第II节(Background):介绍分布式深度学习在GPU集群上的背景。
第III节(System Design):描述Maple的系统设计。
第IV节(Implementation):详细介绍实现细节。
第V节(Experiments):展示实验结果。
第VI节(Error Analysis):分析常见错误。
第VII节(Related Work):讨论相关工作。
第VIII节(Conclusion):总结与展望。
总结¶
本节概述了深度学习在科研中的广泛应用,以及当前在跨集群部署中因硬件/软件异构性带来的挑战。作者提出Maple系统,通过多智能体协作和模板库,解决启动脚本的可移植性问题。实验表明,该系统具有很高的准确性和实用性,为未来AI科学家的自动化部署提供了重要支持。
II Background¶
GPU集群的重要性¶
GPU集群在现代深度学习(DL)驱动的科学与工程中扮演着关键角色。全国范围内的网络基础设施项目(如ACCESS和NAIRR Pilot)提供了跨多个计算中心的GPU资源。此外,美国能源部(DOE)也在投资建设顶级计算设施,例如ALCF Aurora和NERSC Perlmutter。这些GPU密集型集群通常具有高度异构的硬件和软件环境,用户在不同平台间迁移时面临诸多困难,基础设施方面也难以提供统一的用户体验。
OpenFold团队的迁移案例¶
OpenFold团队最初在NERSC Perlmutter上进行AlphaFold2的复现研究,该系统使用SLURM作业调度器,每节点配备4块NVIDIA A100 GPU。由于节点时间耗尽,他们被迫迁移到TACC Lonestar6继续实验。Lonestar6同样使用SLURM,但每节点配备3块A100 GPU,且软件环境不同(Perlmutter支持Anaconda,而TACC推荐使用原生Python构建),导致团队必须重新配置依赖项,并通过试错法开发训练脚本。随后,DOE又为该项目分配了20万节点时数,以便在ALCF Polaris上继续蛋白质相互作用研究,该系统使用PBS调度器,每节点同样有4块A100 GPU。团队不得不将训练脚本适配到PBS,同时替换掉原来的srun启动器为mpiexec。
异构性带来的挑战¶
上述案例仅展示了在现代GPU集群之间迁移DL工作负载时的一些实际障碍。异构性体现在硬件和软件两个层面:
硬件异构性:
不同系统使用不同GPU型号(如NVIDIA A100/GH200与Intel Max系列),通信方式也不同(如NVLink、InfiniBand与Xe Link)。
每个系统连接GPU的方式和每节点GPU数量不同,这影响DL工作负载的数据共享与通信方式。
软件异构性:
作业调度系统不同(如Slurm、PBS或自定义队列系统),每个系统有其特定的语法和提交格式。
通信库不同(如MPI、NCCL、oneCCL)。
编译器版本、CUDA工具包、Python版本和模块管理系统在不同集群中也存在差异,通常需要用户从头构建依赖项。
脆弱的执行环境¶
由于上述各层面的异构性,分布式DL工作的执行环境变得非常脆弱。最明显的体现是启动脚本(launch script),它是用户与复杂系统之间的接口。用户必须在启动脚本中指定调度器选项、节点数、GPU映射和通信后端等信息,且每个脚本需要根据不同系统的配置进行调整。在跨集群实验中,调度器、模块环境或通信库的微小差异都可能导致在某一台机器上运行正常的脚本在另一台机器上失败。这些不一致使得启动脚本成为跨集群DL工作中的常见失败点,迫使用户反复调试底层配置问题,而不是专注于实验本身。
合作与系统设计动机¶
为解决这些问题,研究团队与多家美国主要超级计算中心合作,包括TACC、NERSC、ALCF、NCSA、PSC和普渡大学。广泛的生产级GPU集群覆盖增强了所提系统(Maple)的通用性和适应性。这些挑战直接推动了系统设计的动机,即构建一个更易于跨集群迁移和运行DL工作负载的解决方案。
III System Design¶
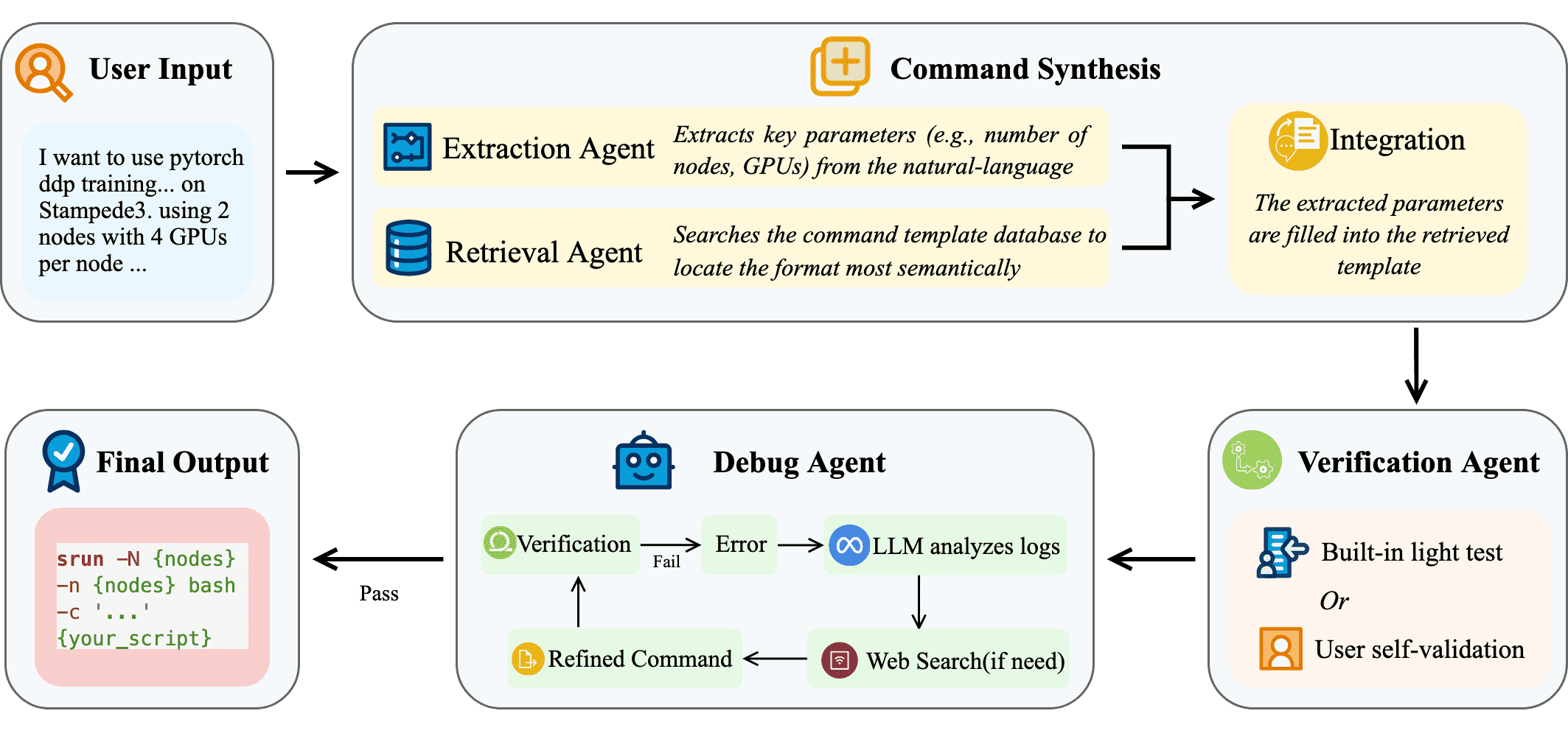
Figure 1:Overview of the system workflow.
本节介绍了 Maple 的系统设计,它是一个多代理系统,旨在通过用户的自然语言输入,自动生成可在不同 GPU 集群上运行的深度学习(DL)启动脚本。Maple 的设计目标是实现脚本的可移植性,并通过多代理协作方式简化用户的操作。
III-A User Input(用户输入)¶
系统的工作流程从用户输入开始。用户输入可以是简短的任务描述,也可以是另一个机器上运行成功的脚本。无论哪种形式,用户输入必须包含足够的信息,以便 Maple 生成对应的启动脚本。这些关键信息包括目标机器、DL 框架、并行策略、节点数和每节点 GPU 数量。如果信息缺失,Maple 会提示用户提供缺失内容。
III-B Script Synthesis(脚本合成)¶
III-B1 Extraction Agent(提取代理)¶
提取代理负责从用户输入中提取关键信息,包括目标机器、DL 框架、并行策略等。Maple 使用了一个小型的解码器-only 小型语言模型(SLM),该模型专门训练用于识别自然语言中的关键参数。提取代理还会将各种数值和符号表达统一为中间格式,以确保后续处理的统一性。
III-B2 Retrieval Agent(检索代理)¶
检索代理根据提取到的信息,从模板库中选择最相关的脚本模板。模板选择基于目标机器名称、DL 框架和并行策略等参数。Maple 使用了轻量级的嵌入模型,以语义方式匹配用户任务描述与预验证的模板,这种方式比简单的关键词匹配更准确,支持快速检索,即便模板库扩展到数百个平台和配置时也能保持高效。
III-B3 Template Repository(模板库)¶
模板库是 Maple 的核心组件,它反映了 GPU 集群在硬件和软件上的多样性。模板库中的 35 个脚本模板来自 9 个不同的 GPU 集群,涵盖了多种 GPU 类型、调度器、DL 框架和并行策略。这些模板均来自实际成功的运行,具有高度的可执行性。模板库在生成阶段提供验证模板,在调试阶段作为参考,帮助修正失败脚本。随着时间推移,新修正的脚本可被加入模板库,系统可不断自我完善。
示例模板包括:
LS6-DDP:基于 Slurm 的配置,用于 Lonestar6 上使用
torchrun进行数据并行训练。Aurora-DDP:基于 PBS 和 MPI 的模板,用于 Aurora 上的分布式数据并行执行。
DeltaAI-Deepspeed:基于 DeepSpeed 和 Intel MPI 的配置,用于多节点启动。
III-B4 Script Synthesis(脚本生成)¶
最终,检索出的模板与提取的参数结合,生成一个或多个候选启动脚本,供后续验证使用。
III-C Verification Agent(验证代理)¶
生成的脚本需要经过验证。用户可以在目标集群上运行验证,Maple 也提供自动化验证功能。验证代理使用一组 DL 工作负载 mini-app 来测试脚本的正确性。这些 mini-app 涵盖 PyTorch、Deepspeed、Accelerate 等框架,并支持数据并行、完全分片并行(FSDP)和 3D 并行等策略。如果验证失败,验证代理会将错误信息传递给调试代理。
III-D Debug Agent(调试代理)¶
当验证失败时,调试代理被激活。它通过集成的 LLM 分析错误日志,识别可能原因,并提出脚本修正建议。调试代理还能从多个数据源(如集群文档、GitHub 问题、Stack Overflow)中检索相关信息,辅助定位和解决错误。虽然调试能力受限于已有知识库,但实验表明 Maple 能解决超过 90% 的启动脚本错误,大大减少了人工调试工作量。如果无法解决,用户仍需联系专家或开发者。
III-E Final Output(最终输出)¶
最终阶段输出一个已验证、可直接运行的启动脚本。用户可以直接执行该脚本,也可以将其保存以备复用,或嵌入到 Slurm 脚本中用于批量提交任务。
总结¶
Maple 系统通过多代理协作(提取、检索、验证、调试代理)实现了从用户自然语言输入到生成可运行脚本的完整流程。其关键设计包括:
自然语言处理:使用 SLM 提取关键参数。
模板库:包含大量可运行模板,支持异构集群。
自动验证与调试:使用 mini-app 和 LLM 降低人工干预。
持续学习:新脚本可加入模板库,系统持续优化。
这一设计显著提升了深度学习任务在不同 GPU 集群间的可移植性与开发效率。
IV Implementation¶
本节讨论 Maple 系统的实现细节,主要包括每个智能体(agent)的模型选择和**模板库(template repository)**的实现方式。
模型选择(Model Selection for Each Agent)¶
如图1所示,Maple 由四个智能体组成:提取智能体(extraction agent)、检索智能体(retrieval agent)、验证智能体(verification agent) 和 调试智能体(debug agent)。每个智能体根据任务需求选择合适的模型。
1. 提取智能体(Extraction Agent)¶
使用模型:Llama-3.2-1B
作用:从各种输入(如自然语言描述、BASH 脚本等)中提取关键信息,如目标机器、启动器、节点数、GPU 数量和深度学习框架。
选择依据:实测显示其在信息提取任务上具有足够的准确率,且模型大小适中。
2. 检索智能体(Retrieval Agent)¶
使用模型:all-MiniLM-L6-v2
作用:将用户输入与模板库中的脚本模板进行匹配。
特点:参数量仅为 22M,模型小,推理效率高,准确率仍有保障。
3. 验证智能体(Verification Agent)¶
使用方式:不依赖 LLMs,而是使用小型应用程序(mini-apps)
作用:验证生成脚本的正确性。
小型应用程序特点:
基于 GPT-2 训练代码开发,支持 DDP、FSDP、ZeRO-3 等并行策略。
包含一次 allreduce 和一次 allgather 通信,计算量小。
足够用于测试生成脚本在分布式训练中的正确性。
4. 调试智能体(Debug Agent)¶
使用模型:Llama-3-8B-Instruct
作用:分析错误日志、提出修正建议、生成测试脚本。
特点:支持在线检索(如 GitHub Issues、Stack Overflow),可获取最新的问题解决信息。
优势:能够诊断本地知识库中尚未收录的新出现的框架或硬件问题。
重点强调:上述模型均基于 Maple 的实际需求选择,可根据需要通过 API 替换为更大模型(如 GPT-5、Gemini)。
模板库(Template Repository)¶
实现方式:JSON 文件格式
优势:易于扩展
内容:
支持主流框架:PyTorch、DeepSpeed、Accelerate。
包含主要的并行策略:DDP、FSDP[[45]]、ZeRO[[28]]。
特点:所有模板均在实际系统中验证过,而非基于合成示例,确保其在真实场景中的可用性。
小结¶
本节详细说明了 Maple 系统中四个智能体的模型选择依据和功能,以及模板库的实现方式。重点在于:
每个智能体根据任务需求选择合适模型,兼顾准确率与效率。
模型和模板库均可扩展或替换,系统设计灵活。
模板库基于真实场景构建,保障生成脚本的实用性。
V Experiments¶
本章总结了 Maple 实验设计与结果,分为三个主要部分:跨平台并行化验证、可移植性与调试验证,以及模型尺寸比较。整体上,实验通过与多个主流大语言模型(LLMs)对比,展示了 Maple 在生成深度学习启动脚本方面的高效性、可移植性和调试能力。
V-A 跨平台与并行化验证¶
实验目的¶
评估 Maple 在多 GPU 集群和多种并行训练策略下的执行能力。
实验设置¶
基准模型:GPT-2(轻量、跨框架支持)
集群数量:9 个异构集群
并行策略:PyTorch DDP、FSDP、DeepSpeed ZeRO-3、Accelerate DDP
实验结果¶
成功率:Maple 在 36 个测试案例中成功生成 33 个脚本,成功率达 91.7%
失败案例:主要集中在 Aurora(Accelerate DDP 与 PBS 调度器冲突)、Vista 和 DeltaAI(ZeRO-3 编译错误)
对比模型:主流 LLMs(如 GPT-5、Claude、Gemini 等)在没有模板检索的情况下表现很差(最高 22.2%)
模板检索的作用:当结合模板检索时,大多数模型(包括 GPT-5)的准确率提升至 92%,表明模板检索是关键因素
V-B 可移植性与调试验证¶
实验目的¶
测试 Maple 在不同深度学习模型与任务上的可移植性与调试能力,尤其在未见过的模型和任务上表现。
实验设置¶
模型选择:涵盖多种类型(语言模型、视觉模型、经典 CNN):GPT-2 XL、Llama-3.1-8B、BERT-base、ViT-base、ResNet-18
任务:涉及 DDP 和 FSDP 等多种并行训练方法,且脚本生成需更复杂调整(如参数顺序、路径设置等)
实验结果¶
无模板检索:¶
Maple:首次生成成功 33/45(73.3%),5 次调试后达 43/45(95.6%)
对比模型:GPT-5(28.9%)、Claude(33.3%)、Gemini(28.9%)等表现较差,GPT-4 Mini 全部失败
失败原因:多为启动脚本中的参数错误(如调度器选项、通信库选择等)
有模板检索:¶
Maple 与主流模型:成功率均达到 95.6%
性能优势:
响应速度:Maple 平均响应时间 4.7 秒,远快于其他模型(如 GPT-5 24 秒、Gemini 9.1 秒)
输出简洁性:Maple 生成脚本简洁、结构清晰,而其他模型常生成冗长脚本
调试能力:Maple 能自动修复常见错误(如 CUDA 版本不匹配、环境变量缺失等),仅在 Intel GPU 集群上因官方 PyTorch 脚本问题失败
V-C 模型尺寸比较¶
模型尺寸对比¶
Maple:由三个小型模型组成(MiniLM、LLaMA-3.2-1B、LLaMA-3.1-8B-instruct),总参数量 <10B
主流大模型:如 GPT-5、Gemini、Nova 等均超过 100B,Qwen-2.5-VL-72B 等在 70B 左右
优势总结¶
轻量部署:Maple 可在本地 HPC 集群上运行,无需联网,保障隐私与安全性
高效成本:小模型降低了部署和运行的成本,适合大规模部署
性能均衡:尽管模型小,但 Maple 的多代理结构结合模板检索,实现了与大型模型相当甚至更优的准确率
总结¶
Maple 通过多代理结构(提取、检索、调试)和模板检索机制,在多集群、多任务的深度学习工作负载中展现出优异的可移植性、调试能力和生成准确率。相比主流大语言模型,Maple 以更小的模型尺寸实现了相近甚至更高的性能,适用于 HPC 场景下的高效、安全部署。实验结果表明,Maple 在跨平台深度学习脚本生成领域具有显著优势。
VI Error Analysis¶
本节总结了使用 Maple 在异构 HPC 系统上运行分布式深度学习任务时所遇到的错误类型,并分析了其原因及 Maple 如何帮助定位和修复这些错误。主要内容分为以下四个部分:
VI-D 未解决的问题(Unresolved Cases)¶
重点内容:
部分问题无法通过 Maple 解决,原因在于底层框架或驱动本身的限制,而非配置错误。
典型例子:
Delta-AI(NVIDIA GH200):DeepSpeed Zero-3 无法运行,原因是官方未支持最新 GPU 架构,无法编译 fused-adam 等 CUDA 内核。
Intel XPU:PyTorch 原生 DDP 不兼容,缺少对 Intel 后端的上游支持。
总结:
这些问题需要等待官方框架或驱动更新才能解决,突显了某些可移植性障碍的系统性挑战,超出了当前自动化工具的解决范围。
总结¶
尽管 Maple 在自动化和可移植性方面取得了显著进展,但分布式深度学习任务在异构 GPU 集群中仍然对环境变化和用户配置高度敏感。本节错误分析强调了当前工具的局限性,并指出了智能、自适应工具在弥合这些差距中的重要性。
VIII Conclusion¶
本节总结了全文的研究成果和实验结果,强调了 MapLe 系统在分布式深度学习(DL)任务中的有效性与创新性。
首先指出,由于系统异构性和用户配置的复杂性,跨现代 GPU 集群运行分布式深度学习工作负载是一项复杂且容易出错的任务。这为自动化的工具提出了需求。
重点内容:本文提出了 Maple,一个多智能体系统,能够自动生成、验证并优化深度学习任务的启动脚本。Maple 通过结构化模板检索、验证和基于大型语言模型(LLM)的调试功能,弥补了用户意图与系统执行之间的差距。这一设计减少了手动调整的需要,提高了实验的可重复性。
实验结果:Maple 在九个生产级 GPU 集群上进行了测试,支持常见的并行化策略,并能处理广泛的深度学习模型。它简化了调试过程,生成了结构清晰、准确的启动脚本,适用于不同水平的高性能计算(HPC)用户。
重点数据:在 567 个测试案例中,Maple 的准确率超过 95%,性能可与最先进的大模型相比。此外,Maple 在内存效率方面表现更优,其模型参数为 100 亿,而性能相当的模型通常需要数百亿参数。
总结:Maple 是一个高效、可靠、易于使用的工具,适用于分布式深度学习任务的脚本生成,具有广泛的实用价值和研究意义。