2510.12422_VideoLucy: Deep Memory Backtracking for Long Video Understanding¶
组织:
1Huazhong University of Science and Technology
2NUS
3S-Lab, NTU
4Shanghai AI Lab
Code&Dataset: https://videolucy.github.io/
总结¶
标签
tag: prompt
remark: prompt(代表论文中有好的 prompt)
VideoLucy
灵感来源于人类的记忆回溯过程。
该框架采用了分层记忆结构和基于智能体的迭代回溯机制,能够从整体到细节、逐步挖掘视频中与问题相关的信息,从而实现对视频内容的强时间理解能力和前所未有的细粒度感知。
整体方法分为三个核心部分:分层记忆结构、角色增强的智能体 和 迭代回溯机制。
分层记忆结构(Hierarchical Memory Structure)
定义不同层级的记忆粒度和时间范围。
随着记忆层级加深,时间范围缩小,细节程度提高。
实现方式:
将视频划分为多个短片段(clip),每个片段通过 MLLM 模型生成文本描述。
通过调整片段数量 \( K \),控制记忆的时间范围:
\( K=1 \):整个视频的概览。
\( K=N \):每一帧的详细描述。
记忆回溯机制(Memory Backtracking Mechanism)
通过代理系统迭代挖掘与问题相关的深层记忆。
从模糊的全局记忆逐步深入到具体的细节记忆,直到获得足够信息来回答问题。
角色增强的智能体(Agents with Empowered Roles)
描述生成代理(Captioning Agent)
使用 MLLM 生成视频片段的文本描述。
功能:将视觉信息转化为文本,作为系统“眼睛”。
定位代理(Localization Agent)
使用 LLM 理解问题并定位相关时间片段。
功能:筛选干扰记忆,聚焦关键时间点。
指令生成代理(Instruction Agent)
分析当前记忆中缺失的关键信息,生成引导性描述指令。
功能:指导描述代理深入挖掘相关信息。
回答代理(Answering Agent)
判断当前记忆是否足以回答问题。
功能:具备推理能力,决定是否继续探索记忆。
迭代回溯机制(Iterative Backtracking Mechanism)
核心思想:通过多阶段迭代流程,动态探索与问题相关的深度记忆,实现广度与深度的信息收集。
问题背景:
若直接使用完整记忆,计算和存储成本高,且可能超出 LLM 上下文限制
用户问题通常聚焦关键时间点,大量无关记忆会干扰系统性能
优势:
模拟人类回忆过程,逐步深入挖掘相关信息。
在较低资源消耗下实现问题相关记忆的全面搜索与整合。
长视频基准
MLVU:涵盖九个任务,评估全局与局部视频理解,视频时长从3分钟到2小时不等。
Video-MME:包含2700个问题,覆盖短(<2分钟)、中(4~15分钟)、长(30~60分钟)视频,评估不依赖字幕的结果。
LVBench:专为超长视频理解设计,包含1492个问题,平均视频时长4101秒,支持6种任务。
EgoMem:❇️本文提出的长视频理解新基准,用于进一步性能比较。
评估维度:
时间理解能力
细节感知能力(尤其是短暂出现的视觉特征)
数据构成:
包含42个视频,平均每个视频约6.33小时
总共504个问答对
设计了6种问答形式,评估模型对第一视角日常记录中复杂、时间演化事件的理解
相关研究
MLLM
帧采样(Frame Sampling)
Adaptive Keyframe Sampling (AKS) 方法在固定 token 预算下优化帧的相关性和覆盖性,从而提升问答性能,强调了信息预过滤的重要性。
token 压缩(Token Compression)
VideoChat-Flash 提出了一种分层 token 压缩方法,并结合多阶段学习策略,在高压缩率下仍保持良好性能。
增强记忆的方法(Memory-Augmented Methods)
LangRepo 提出了一种结构化的语言库框架,通过写/读操作迭代更新多尺度视频块并剪枝冗余文本。
TTM 受神经图灵机启发,使用外部记忆模块压缩历史帧为紧凑 token,降低计算复杂度。
Agent-based Systems
VideoAgent:使用 LLM 作为核心智能体,迭代定位并整合关键信息。
DrVideo:将长视频转换为文本文档,采用基于智能体的循环机制检索关键帧并增强数据。
VideoTree:通过迭代关键帧优化和树状聚合,构建查询自适应的分层视频表示,提升推理效率。
Abstract¶
本章介绍了当前基于智能体的视频理解系统在处理长视频时所面临的两个主要挑战:一是这些系统通常逐帧建模和推理,难以捕捉连续帧之间的时间上下文信息;二是为了降低密集帧级描述的成本,系统常采用稀疏采样,可能导致关键信息丢失。
为了解决这些问题,作者提出了 VideoLucy,一种基于深度记忆回溯的长视频理解框架。该框架受人类从粗到细回忆过程的启发,采用分层记忆结构,在不同层级上明确界定记忆的细节程度和时间范围。通过基于智能体的迭代回溯机制,VideoLucy能够系统地挖掘与问题相关的深层次全局视频信息,直到收集到足够信息以生成高置信度的答案。这种设计不仅提升了对连续帧时间关系的理解能力,也有效保留了关键细节。
此外,作者还提出了一个新的长视频理解基准 EgoMem,用于全面评估模型对长时间展开的复杂事件的理解能力,以及在极长视频中捕捉细粒度信息的能力。
实验结果表明,VideoLucy表现出色,基于开源模型构建的VideoLucy在多个长视频理解基准上显著优于现有最先进方法,甚至超越了如 GPT-4o 这样的最新闭源模型。作者承诺将公开代码和数据集。
1 Introduction¶
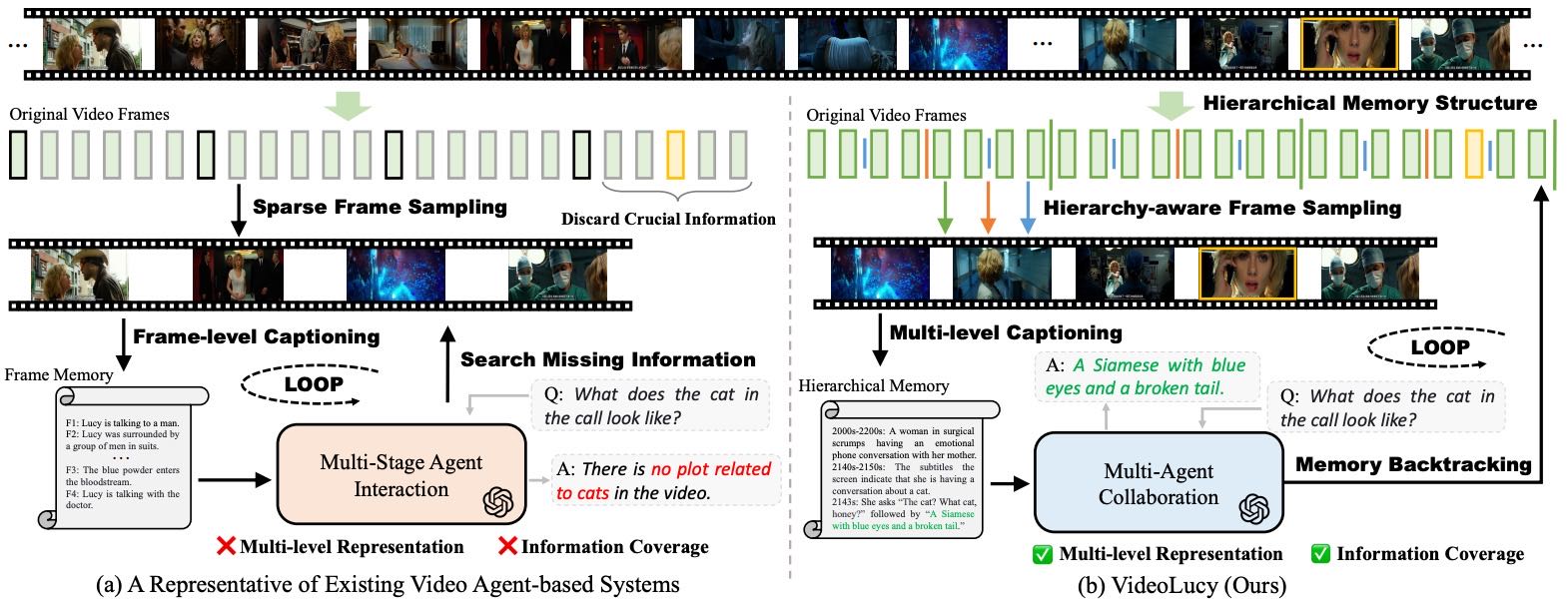
Figure 1: Comparison between our VideoLucy with existing video agent-based systems
核心问题:长视频理解(Long Video Understanding)¶
本节首先指出,长视频理解是一个备受关注的任务,其核心目标是基于视频的全部内容,准确、客观地回答各种用户问题。这要求系统具备对视频中几乎所有细节的全面记忆和理解能力,否则容易因信息缺失导致回答错误。
作者通过电影《露西》(Lucy)中的情节类比,说明理想系统应具备像主角Lucy那样“回忆生命中每一个细节”的能力,强调了全面记忆在视频理解中的重要性。
现有方法:基于代理的系统(Agent-based Systems)¶
近年来,基于代理的系统成为长视频理解的一种有前景的方法。与传统多模态大语言模型(MLLMs)相比,这类系统利用大语言模型(LLMs)的推理、规划和记忆能力,通过迭代搜索和整合关键信息,实现对长视频的更深入理解。
但这些系统仍面临两个主要挑战:
缺乏时间上下文建模能力
多数系统基于单帧建模和推理,难以捕捉连续帧之间的时间关系。
例如,DrVideo 通过初始帧级文档检索关键帧,再通过多阶段代理交互更新信息,但在涉及时间连续性的问题上表现较弱。
稀疏采样导致信息丢失
为降低密集帧级描述的计算成本,系统通常采用稀疏采样(如每秒0.125帧)。
例如,VideoTree 在 Video-MME 数据集上采用稀疏采样,虽然节省资源,但会丢失大量关键细节。
提出方法:VideoLucy¶
为解决上述问题,作者提出 VideoLucy,一个基于深度记忆回溯的长视频理解框架。其核心设计灵感来自人类认知过程:从粗略到精细地回忆信息。
核心设计:¶
分层记忆结构(Hierarchical Memory Structure)
定义不同层级的记忆粒度和时间范围。
随着记忆层级加深,时间范围缩小,细节程度提高。
记忆回溯机制(Memory Backtracking Mechanism)
通过代理系统迭代挖掘与问题相关的深层记忆。
从模糊的全局记忆逐步深入到具体的细节记忆,直到获得足够信息来回答问题。
这种设计使 VideoLucy 能够实现对视频内容的全面记忆和时间理解,正如电影中的 Lucy 所说:“我能感受到我大脑最深处的记忆。”
新基准:EgoMem¶
作者还提出一个新的长视频理解基准 EgoMem,基于 EgoLife 数据集构建。
评估维度:
时间理解能力
细节感知能力(尤其是短暂出现的视觉特征)
数据构成:
包含42个视频,平均每个视频约6.33小时
总共504个问答对
设计了6种问答形式,评估模型对第一视角日常记录中复杂、时间演化事件的理解
实验结果与优势¶
作者进行了大量实验验证 VideoLucy 的优越性:
基于开源模型(如 Qwen2.5-VL-7B)构建的 VideoLucy,在多个长视频理解基准(如 LVBench)上显著优于现有最先进方法。
在 LVBench 上,VideoLucy 达到 58.8% 的准确率,比 GPT-4o 高出 9.9%。
消融实验和“视频中的针”实验(needle in a video haystack)进一步验证了其分层记忆结构和细节感知能力的有效性。
总结¶
本节介绍了长视频理解任务的挑战,指出现有基于代理系统的局限性,并提出了 VideoLucy 框架。该框架通过分层记忆结构和记忆回溯机制,实现了对视频内容的全面记忆与时间理解。同时,作者构建了新的评估基准 EgoMem,并通过实验验证了 VideoLucy 的优越性能,为未来长视频理解研究提供了新方向。
2 Method¶
本节介绍了 VideoLucy,一个用于长视频理解的深度记忆回溯框架。该框架能够根据问题动态回溯视频的全面且深入的记忆,从而实现准确回答。整体方法分为三个核心部分:分层记忆结构、角色增强的智能体 和 迭代回溯机制。
2.1 分层记忆结构(Hierarchical Memory Structure)¶
核心思想:¶
设计一种符合人类从粗到细回忆模式的分层记忆结构,以高效建模长视频中的丰富信息。
重点内容:¶
多层级表示(Multi-level Representation)
长视频的问题时间跨度差异大,有的关注单帧细节,有的需要整体理解。
因此,记忆结构应具备多粒度建模能力,即支持从粗略到精细的多层次表示。
全面信息覆盖(Comprehensive Information Coverage)
现有方法常采用稀疏采样,导致信息丢失。
为应对问题信息需求的不确定性,记忆结构应尽可能覆盖视频的全部内容。
实现方式:¶
将视频划分为多个短片段(clip),每个片段通过 MLLM 模型生成文本描述。
通过调整片段数量 \( K \),控制记忆的时间范围:
\( K=1 \):整个视频的概览。
\( K=N \):每一帧的详细描述。
分层结构:¶
长范围粗略记忆(Long-range Coarse Memory):覆盖大时间跨度,信息较粗略。
短范围精细记忆(Short-range Fine Memory):聚焦更小时间范围,描述更详细。
帧级超精细记忆(Frame-level Ultra-fine Memory):对单帧或极短片段进行细致描述。
示例:¶
图2展示了该结构的示意图:随着记忆层级加深,每秒捕捉的帧数增加,时间跨度缩短,从而实现从整体到细节的渐进式记忆。
2.2 角色增强的智能体(Agents with Empowered Roles)¶
核心思想:¶
通过提示工程赋予不同智能体特定角色,协同完成记忆回溯任务。
各智能体功能:¶
描述生成代理(Captioning Agent)
使用 MLLM 生成视频片段的文本描述。
功能:将视觉信息转化为文本,作为系统“眼睛”。
定位代理(Localization Agent)
使用 LLM 理解问题并定位相关时间片段。
功能:筛选干扰记忆,聚焦关键时间点。
指令生成代理(Instruction Agent)
分析当前记忆中缺失的关键信息,生成引导性描述指令。
功能:指导描述代理深入挖掘相关信息。
回答代理(Answering Agent)
判断当前记忆是否足以回答问题。
功能:具备推理能力,决定是否继续探索记忆。
2.3 迭代回溯机制(Iterative Backtracking Mechanism)¶
核心思想:¶
通过多阶段迭代流程,动态探索与问题相关的深度记忆,实现广度与深度的信息收集。
问题背景:¶
若直接使用完整记忆,计算和存储成本高,且可能超出 LLM 上下文限制。
用户问题通常聚焦关键时间点,大量无关记忆会干扰系统性能。
机制流程(见算法1):¶
稀疏粗略记忆初始化(Sparse Coarse Memory Initialization)
初始化记忆列表 \( CM \),使用粗粒度划分(时间跨度 \( T_c \))生成初始记忆。
利用定位代理筛选出与问题最相关的时间段,形成初始相关集合 \( S_{rt} \)。
问题引导的深度与广度记忆探索
定位代理找出最相关的时间段。
指令代理分析当前描述中缺失的关键信息,生成描述指令。
描述代理生成两种描述:
整体更新当前记忆(current-depth memory)。
细分片段并生成更详细描述(deeper memory)。
更新记忆列表,加入新生成的描述。
多智能体驱动的迭代循环
回答代理判断是否能自信回答问题。
若不能,则继续迭代探索,直到满足以下任一条件:
能自信回答。
达到最大迭代次数(防止超时)。
优势:¶
模拟人类回忆过程,逐步深入挖掘相关信息。
在较低资源消耗下实现问题相关记忆的全面搜索与整合。
总结¶
VideoLucy 的核心设计思想是模拟人类回忆过程,通过分层记忆结构实现对长视频的多层次、全面建模;通过角色增强的智能体分工协作,完成记忆生成、定位、分析与回答任务;通过迭代回溯机制动态探索问题相关记忆,逐步构建出足够支持回答的上下文信息。整个系统在保证效率的同时,实现了对长视频的深入理解与准确问答。
3 EgoMem Benchmark¶
本节介绍了作者构建的一个用于超长视频理解的新基准测试——EgoMem,其目标是评估模型在处理长视频时对**瞬时信息(细节感知)和连续事件(事件理解)**的记忆建模能力。
主要内容如下:¶
数据来源:基于EgoLife视频资源,作者为每天的长视频手动标注了问答对,重点考察跨时间事件理解和瞬时视觉特征感知。
问题设计:
针对事件理解,设计了六种不同类型的问题,以全面、有效地评估模型在真实场景下的表现,避免模型走“捷径”。
针对细节感知,标注了关于视频中某些瞬时片段的视觉细节问题,用以测试模型是否能捕捉到关键的细节信息。
数据规模:
包含42个视频,平均每个视频时长6.33小时。
总共包含504个问题。
更多细节见附录。
图3说明:¶
展示了EgoMem基准中的问题类型和示例,图中六种问题类型用于评估模型对跨时间事件的理解,还有一个细节感知任务用于评估模型对瞬时视觉特征的捕捉能力。所有问题均为人工标注,并附有充分的证据描述。
重点总结:
EgoMem是一个面向长视频理解的新基准,强调事件的连续性理解与细节的瞬时感知。
问题设计多样且人工标注,具有高真实性和挑战性。
数据集规模大、视频时长极长,对模型记忆建模能力提出更高要求。
4 Experiments¶
实现细节¶
VideoLucy 是一个基于智能体的系统,仅需一个大语言模型(LLM)和多模态语言模型(MLLM)分别用于文本理解和视觉描述。与多数依赖昂贵闭源模型 API 的方法不同,本文统一使用开源模型 Qwen-2.5-VL-7B 和 DeepSeek-R1,以确保结果的可复现性和低成本。不同视频基准测试中,时间范围参数(Tc、Tf、Tuf)设置不同。更多细节(尤其是智能体提示)见附录。
评估基准与指标¶
实验主要在三个主流长视频基准上进行:
MLVU:涵盖九个任务,评估全局与局部视频理解,视频时长从3分钟到2小时不等。
Video-MME:包含2700个问题,覆盖短(<2分钟)、中(4~15分钟)、长(30~60分钟)视频,评估不依赖字幕的结果。
LVBench:专为超长视频理解设计,包含1492个问题,平均视频时长4101秒,支持6种任务。
EgoMem:本文提出的新基准,用于进一步性能比较。
默认评估指标为准确率(Accuracy)。
4.1 与其他方法的主比较¶
Video-MME 比较(表1)¶
在 Video-MME 基准上,VideoLucy 表现显著优于其他智能体系统,平均准确率比此前最佳模型 MemVid 高8.5%。在长视频理解方面,VideoLucy 使用7B模型仍优于所有开源 MLLM,甚至接近商业模型 Gemini 1.5 Pro。
LVBench 比较(表2)¶
在 LVBench 上,VideoLucy 总体准确率达58.8%,比此前最佳模型 AdaReTaKe-72B 高5.5%。在关键信息检索(KIR)任务中,准确率高达75.6%,远超其他模型。
MLVU 比较(表3)¶
在 MLVU 基准上,VideoLucy 同样表现优异,说明其对各种时长视频具有良好的适应性,适用于实际中视频时长未知的场景。
EgoMem 比较(表4)¶
在本文提出的 EgoMem 基准上,现有 MLLM 表现较差,而 VideoLucy 凭借记忆回溯机制,在事件理解和细节感知方面显著优于其他方法,总体准确率达56.7%,比 VideoChat-Flash 高10.3%。
4.2 消融与分析¶
“视频中的针”实验¶
通过在长视频中插入短片段并测试模型识别能力,验证其对细节事件的感知能力。结果显示,VideoLucy 明显优于现有模型,且性能几乎不受视频长度影响。
记忆回溯中的信息丰富性与相关性¶
通过计算 Shannon 熵和使用 LLM 评估相关性,验证记忆在回溯过程中信息的丰富性和与问题的相关性。结果显示,两者在回溯过程中持续提升,证明方法有效。
不同组件的影响¶
实验分为四组:仅使用视频摘要、依赖粗粒度记忆、细粒度访问、超细粒度访问。结果显示,深入访问帧级记忆效果最佳。此外,迭代次数设为5次时性能最佳,因此设为默认值。
4.3 定性比较¶
长视频事件理解比较(图7)¶
使用电影《Lucy》作为测试材料,模型需回答跨时间事件理解问题。VideoLucy 能准确捕捉事件关系,而其他模型常给出不完整或错误答案。
长视频细节感知比较(图8)¶
模型需回答关于短暂片段的细节问题。VideoLucy 在提取和呈现细节方面表现优异,而其他模型难以捕捉细微信息。此外,VideoLucy 提供了推理过程,增强了结果的可解释性和可信度。
总结:VideoLucy 在多个长视频理解基准上表现优异,尤其在长视频和超长视频任务中显著优于现有方法,且具备良好的可解释性和适应性。
6 Conclusion¶
本节总结了论文的核心贡献与实验成果:
VideoLucy框架:作者提出了一种新的视频理解框架 VideoLucy,其灵感来源于人类的记忆回溯过程。该框架采用了分层记忆结构和基于智能体的迭代回溯机制,能够从整体到细节、逐步挖掘视频中与问题相关的信息,从而实现对视频内容的强时间理解能力和前所未有的细粒度感知。
EgoMem基准数据集:为了评估模型在超长视频中进行时间和细粒度理解的能力,作者提出了一个新的基准数据集 EgoMem。
实验结果:大量实验表明,VideoLucy 在多个基准测试中达到了最先进的性能,不仅显著优于以往方法,甚至超过了某些强大的商业模型。
研究意义:本研究验证了结构化、类人记忆机制在复杂视频理解任务中的有效性,为未来相关研究提供了新的方向和基础。
重点内容:VideoLucy 的设计思想(类人记忆回溯)、EgoMem 数据集的提出、以及其在性能上的突破。
次要内容:实验细节和具体指标未展开描述。
7 Acknowledgments.¶
本节简要列出了为本研究提供资金支持的机构,包括国家自然科学基金(项目编号:U22B2053)和湖北省自然科学基金(项目编号:2022CFA055)。该部分内容为常规性的资助声明,未涉及具体研究细节,因此不做进一步展开。
Appendix A Appendix¶
A.1 技术细节¶
不同基准的设置¶
VideoLucy在不同视频基准上的设置因视频长度分布而异,主要涉及记忆时间范围的配置和帧采样率的设定。例如:
MLVU:根据视频长度分为短(0-600秒)、中(600-1200秒)、长(1200-3600秒)和超长(>3600秒)四类,时间范围和帧采样率随长度增加而调整。
Video-MME:沿用官方划分的短、中、长三类,时间范围和帧采样率也相应调整。
LVBench:专为长视频理解设计,分为中(3600-5400秒)和长(>5400秒)两类。
EgoMem:由于视频极长且长度相近,不进行划分,统一设置时间范围和帧采样率。
Captioning Agent¶
负责描述视频片段,根据问题动态生成指令。
该代理的主要功能是充当系统的“眼睛”,能够根据指定指令的要求描述给定的视频剪辑。
Localization Agent¶
定位代理:用于在稀疏粗略记忆初始化阶段找到与问题最相关的三个时间段,并在记忆回溯过程中找到最相关的时间段。
初始化阶段参见表5,还用于在记忆回溯过程中搜索当前记忆列表中最相关和最有趣的单个时间段,之后后续指令代理将生成相应的指令来检索补充信息
Table 5:The designed prompts for the localization agent in the sparse coarse memory initialization stage. Given the current memory list and the question, we obtain the most relevant three time periods.
以下内容提供了该视频在不同时段的大致描述:
{当前记忆列表(时间段 + 描述)}
现在,有一个关于该视频的问题:
{问题}
请仔细阅读上述视频内容描述和问题。由于这些描述大多比较粗略,部分细节信息缺失,因此我的任务是:**尽力找出与问题相关的时间段,并对这些时间段的视频内容进行更细致的观察和描述**。
为了帮助我完成这一任务,你的任务是:
**根据提供的粗略视频描述,判断该问题是否可以通过重新观察视频中三个时间段的内容,从而更有把握地给出答案。**
如果可以,请尽可能找出与问题相关的时间段,并提供这些时间段,以便我可以再次回看这些片段,获取更多信息,从而更准确地回答问题。
例如,以下问题不需要整体理解整个视频,只需重新观察三个时间段,就能获得更准确的答案:
(i) 在普京接受安东尼·布林肯和玛丽·约万诺维奇采访之间,他的领带是什么颜色?
(ii) 视频中81分38秒时,守门员是如何阻止利物浦的射门得分的?
(iii) 是谁打碎了魔镜?
相反,以下问题因为需要对整个视频有整体理解,仅观察几个片段难以得到更准确答案:
(i) 比赛的下半场发生了什么?
(ii) 这个视频是关于什么的?
(iii) 视频的主角一共去了哪些地方?
你的输出必须采用**严格规范的字典格式**,包含以下三个键值对:
```json
{
"Flag": bool值,若你非常有把握能根据要求提供时间段,则为 true,否则为 false,
"Time Period": 若 Flag 为 true,则填入最相关的三个时间段,格式为 [(开始时间, 结束时间)];若为 false,则填入 "No Time Periods",
"Reason": 字符串,说明你选择这些时间段的理由。
}
```
Instruction Agent¶
为了最大限度地减少 LLM 调用,我们将两个进程合二为一,使上述两个智能体的功能(定位 Agent+指令 Agent)能够通过一个设计的提示同时实现,如表6
指令代理:生成指令以获取问题相关的补充信息。
Table 6:The designed prompts for the localization and instruction agents in the memory backtracking stage. Given the current memory list and the question, we obtain the single most relevant period and corresponding instruction.
目前有一个总时长为 {video length} 秒的视频。
以下内容给出了该视频在特定时间段内的大致画面描述:
{当前记忆列表(时间段 + 描述)}
现在,有一个关于该视频的问题:
{问题}
请仔细阅读上述视频内容描述和问题。你**不需要回答这个问题**。
你的第一个任务是:**根据各时间段的视频内容,找出与该问题最相关的单个时间段**,并且你认为**如果进一步细化该时间段的视频内容描述,可以让该问题的答案更加明确**。
特别注意,你需要从**以下时间段之外的部分**中选择最相关的一个时间段:
{已检索的时间段}
此外,假设现在有一个**字幕生成模型**,它可以根据你的指令对指定视频片段进行描述。
你的第二个任务是:**思考在你所选的视频时间段中,你希望该模型重点描述哪些具体内容**,并给出你的指令。
例如,假设整个视频片段是关于一场足球比赛中的一次进攻,而你希望模型重点关注足球在进攻过程中的传球情况,那么你可以给出的指令是:
> “请非常仔细地观察该视频中的所有细节,并提供一个详细且客观的画面描述。如果该视频片段展示的是一场足球比赛中的一次进攻,请特别关注这次进攻过程中足球的传球情况。”
请注意,你应当**参考上述示例的语言结构**来组织你的指令。
你的输出必须采用**严格规范的字典格式**,包含以下三个键值对:
```json
{
"Time Period": [(开始时间, 结束时间)], // 填入与问题最相关的单个时间段
"Instruction": "字符串,需用双引号括起,表示你给字幕模型的详细指令",
"Reason": "字符串,需用双引号括起,说明你选择该时间段及指令的理由"
}
```
Answering Agent¶
回答代理:基于当前记忆和问题进行推理,判断是否能提供自信答案。
目前有一个总时长为 `{video length}` 秒的视频。
以下内容给出了该视频在若干时间段内的大致画面描述:`{Current Memory List (Time Period + Description)}`。
现在,关于该视频的内容描述,有一个问题:`{Question}`。请认真阅读给定的视频内容描述与该问题,并判断你是否**仅凭目前提供的描述**就能**准确**回答该问题。
* 如果你可以**绝对有把握**地回答该问题,请回答并同时给出你所引用的视频时间段。你给出的答案必须在视频描述中有**完全且绝对客观的支持**,不得进行任意推测或臆断。
* 如果你认为当前的视频内容描述**仍不足以准确回答**该问题,请不要回答问题,直接说明原因。
请以**严格规范的字典格式**输出,包含以下四个键值对:
```json
{
"Confidence": 布尔值。如果你对答案有把握则为 true,否则为 false,
"Answer": "字符串(必须用双引号括起)"。当 "Confidence" 为 true 时填入答案内容;当 "Confidence" 为 false 时填入 "No Answer"。
"Time Period": 列表。当 "Confidence" 为 true 时,填入与答案对应的视频时间段,每一项格式为 (开始时间, 结束时间);当 "Confidence" 为 false 时填入 "No Time"。
"Reason": "字符串(必须用双引号括起)"。说明你做出该判断的理由。你的推理必须能够为你的结论提供绝对支持。
}
```
A.2 EgoMem基准细节¶
手动注释过程¶
构建全天事件序列,标注每个事件的开始和结束时间及描述。
事件理解任务:通过事件子序列提取和设计六种类型的问题-答案对。
细节感知任务:从已标注的事件序列中识别瞬时视觉特征,创建问题并设计干扰项。
详细注释内容¶
以A6 SHURE第1天的视频为例,展示了手动标注的事件序列和六种类型的问题-答案对,包括事件顺序、时间判断、时间对齐、事件上下文、事件修正和事件重建。
A.3 消融研究细节¶
针在视频 haystack 中的实验:使用来自LVBench和MLVU的10个长视频,以及5个短视频作为“针”,每个短视频有4个问题-答案对。
回溯中的信息丰富性和相关性实验:展示了Shannon熵计算代码和相关性评估者的提示设计。
A.4 附加实验¶
验证了VideoLucy框架对不同MLLM和LLM的适应性,结果显示不同组合均表现良好,更强大的模型性能更优。
A.5 失败案例分析¶
案例1:由于粗略记忆中未包含具体出生日期的线索,系统无法定位相关时间段。
案例2:由于MLLM的幻觉现象,对象被错误识别,导致错误答案。
A.6 更广泛的影响¶
积极影响:教育、医疗、内容产业、科研等领域的应用。
负面影响:隐私和数据安全风险、信息真实性挑战、劳动力市场结构变化、伦理和法律问题。
治理框架:技术、政策和社会协调的多层次治理框架。
A.7 限制¶
视频MLLM的准确性:影响后续回溯过程。
LLM的能力:文本理解和指令遵循能力影响系统性能。
推理时间:相比端到端视频MLLM,需要更多时间,但可通过存储记忆减少时间开销。
A.8 推理时间¶
推理开销:主要来自MLLM处理短视频片段和LLM推理长文本上下文。
效率比较:VideoLucy平均需要6.3次LLM调用,显著少于VideoAgent(14.1次)和VideoTree(9.6次)。