2505.06708_Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free¶
引用: 16(2025-12-04)
组织:
1Qwen Team, Alibaba Group
2University of Edinburgh(爱丁堡大学)
3Stanford University
4MIT
5Tsinghua University
总结¶
总结¶
关键点
引入门控机制,在 SDPA 输出之后,对输出进行非线性映射,并引入 Input-Dependent Sparsity,从而彻底消除 Attention Sink
总结-知乎¶
没有提出某种极其复杂的全新架构,而是通过大量的消融实验,在标准的 Transformer Attention 机制中引入了一个简单的门控机制,带来了意想不到的效果:不仅提升了模型性能,还显著增强了训练稳定性,并顺带解决了困扰 LLM 已久的Attention Sink 问题。
核心内容
当前的 Transformer 架构中,Attention 层的输出通常直接线性投影。作者提出在 Scaled Dot-Product Attention (SDPA) 的输出之后,直接加入一个 Sigmoid 门控机制。
核心收益:
性能提升:在 15B MoE 和 1.7B Dense 模型(训练数据达 3.5T token)上,PPL 和下游任务(MMLU, GSM8k 等)均有显著提升。
训练极其稳定:该机制几乎消除了训练过程中的 Loss Spikes,使得模型可以使用更大的学习率进行训练,这对于大规模模型训练至关重要。
消除 Attention Sink:这是个意外之喜。该机制引入了 Input-dependent sparsity,使得模型不再需要将注意力强行分配给首个 Token,从而天然地消除了 Attention Sink 现象。
长窗口外推能力增强:在进行长 Context 扩展(如使用 YaRN)时,Gated Attention 的表现显著优于 Baseline。
加入门控机制
作者尝试了在 Attention 的不同位置(Query, Key, Value, SDPA Output, Final Output)加入门控。最终发现在 SDPA 输出之后 (G_1) 加入门控效果最好。
Gating 如此有效主要归因于两点:非线性和稀疏性。
增加低秩映射的非线性
引入门控后,相当于在两个线性变换之间插入了一个非线性操作
这显著增加了 Attention 模块的表达能力。这也解释了为什么在 W_o 之后加门控 (G_5) 无效,因为它没有打破中间的线性瓶颈
引入 Input-Dependent Sparsity * 这是 Gating 区别于简单 LayerNorm 或激活函数的关键。 * Query-Dependent: 门控的分数 \(\sigma(XW_\theta)\) 是由当前 Token 的输入 X 决定的(即 Query 端的信息)。 * 过滤机制: 实验发现,训练好的门控分数大部分集中在 0 附近,具有很高的稀疏性。这意味着门控机制充当了一个“动态过滤器”,根据当前的 Query,选择性地让某些 Attention 结果通过,或者直接抑制(置零)。
意外之喜:彻底消除 Attention Sink
【定义】Attention Sink?
在之前的研究(如 StreamingLLM)中发现,Softmax 强制归一化导致模型必须把一部分注意力分数分配出去。
当当前 Token 找不到强相关的上下文时,模型倾向于把这些“无处安放”的注意力分数分配给第一个 Token(即使它没有实际语义),导致第一个 Token 拥有极高的 Attention Score,这就是 Attention Sink。
Gating 如何解决
使用了 Post-SDPA Gating 的模型,Attention Sink 现象完全消失了
原因推测:因为有了 Sigmoid 门控,模型有了“拒绝”的能力。
当上下文无关时,模型不需要通过 Softmax 强行找一个 Sink,而是可以通过门控将输出 Y 乘以一个接近 0 的系数,直接阻断信息流。
消除 Massive Activations
Gating 还显著减少了模型内部的异常大的激活值。
之前的研究认为 Massive Activations 是导致 BF16 训练不稳定的元凶之一。
Gating 通过稀疏化输出,天然抑制了这些异常值,解释了为什么训练稳定性得到了巨大提升。
实用的工程建议
架构改进性价比极高:
在 SDPA 后加一个 x * sigmoid(Linear(x)) 几乎不增加计算量(Latency < 2%),也不怎么增加显存,但能换来更好的 PPL 和更稳的训练。
这应该成为未来 LLM 的标准组件。
训练稳定性的新解法:
如果你在训练大模型时遇到 Loss Spike 或梯度爆炸,除了查数据和 LayerNorm,可以试试加 Gating。
它从原理上减少了激活值的漂移。
对 Attention 机制的再思考:
Softmax 的强制归一化(Sum=1)可能是一个过于强的归纳偏置。
Gating 实际上赋予了 Attention 机制 “Unnormalized” 的能力(即输出的总能量可以根据 Query 的需求动态调整),这比单纯的 Softmax 更加合理。
关键词
门控(Gate):就是用一个可学习的、输入相关的系数来动态调节信息流通,常见形式是乘性缩放(例如 Sigmoid 输出在 0–1 区间)。
归一化是统计型的幅度调节(弱条件化),门控是输入条件化、可学习的通道选择器(强条件化),能做更精准的过滤。
attention sink: 2023年底,MIT韩松团队发了一篇叫StreamingLLM的论文,发现了一个诡异的现象:大模型在处理长文本时,会把大量注意力”莫名其妙”地砸到第一个token上——哪怕这个token只是个没有任何语义的
开始符。 低秩瓶颈: 一个模型从 1024 维特征跳到 64 维,之后再跳回 1024 维。中间那个 64 维的“狭窄地带”,就是低秩瓶颈。
在自编码器(autoencoder)中,中间层的隐藏向量本来就是一个低秩瓶颈。图像、语音、文本都会被挤进低维语义空间再展开。这个过程逼模型捕捉主要因素,而不是噪声。
LoRA(Low-Rank Adaptation)方法就利用低秩瓶颈来做参数高效微调。把一个大矩阵拆成两个小矩阵,中间的维度 r 就是瓶颈。
模型被迫放弃那些不重要、不可泛化的细节,只保留能解释大结构的核心成分。这和你把一幅 4K 图像压缩成一张素描草图有点像:画面失真了,但结构保住了。
这种压缩让模型在处理复杂关系时,有机会“重新组织”信息,因为它从高维掉到低维,再被投射回去。就像你把一堆没看懂的笔记全部重写一遍,反而更清晰。
门控思想的历史脉络
1997–2014:循环神经网络中的门控 LSTM(1997)与 GRU(2014)用「输入门、遗忘门、输出门」来控制信息随时间的流动与保留,解决长序列中的梯度消失问题。
2015:Highway Networks 在深层前馈网络里用门控(transform gate/carry gate)控制跨层信息流,缓解深层训练困难。
2017:Transformer 与自注意力 把序列建模从「按时间步传递」切换到「内容对齐」:用查询(Q)去选择键(K)对应的值(V),显著提升长距离依赖的建模能力。
2017–2022:前馈层的门控(GLU/SwiGLU) 在 FFN 中引入门控(GLU、GELU、SwiGLU),提升表达力与训练性能,成为现代 LLM 的「标配」。
2019–2021:稀疏与专家路由(MoE) MoE 用门控做路由(选择专家),在保持计算预算的前提下提高模型参数与容量。
2021–2024:在注意力层尝试门控的工作 如 Switch Heads、Native Sparse Attention 等,混合了「门控」和「路由/稀疏模式」。
但「门控本身到底起什么作用」一直没被系统性地剥离出来
2022–2024:长上下文与位置编码问题 RoPE 插值(PI、YaRN 等)把上下文长度扩展到 32k、64k、128k;同时暴露出模型对位置缩放的脆弱性(性能骤降、注意力模式僵化)。
Qwen 的注意力门控:把门控单独拿出来系统测试,发现一个简单的改动(在 SDPA 输出后做门控)能带来性能、稳定性与长上下文泛化的系统性提升,并给出清晰的机制解释。
三行摘要¶
📝 该论文系统研究了Softmax注意力中的门控机制,发现SDPA后应用head-specific sigmoid门控可显著提升LLMs的性能和训练稳定性。
💡 这种有效性归因于在value和output投影之间引入非线性,以及应用query-dependent的稀疏门控分数来调制SDPA输出。
🚀 稀疏门控机制不仅通过减少对初始tokens的过度关注而缓解了“注意力沉淀”(attention sink)现象,还显著增强了长上下文(long-context)外推性能。
摘要¶
这篇论文系统性地研究了门控机制在标准 Softmax Attention 中的作用,揭示了它对模型性能、训练稳定性以及注意力动态的显著影响。作者通过对 15B Mixture-of-Experts (MoE) 模型和 1.7B 密集模型(在 3.5 万亿 token 数据集上训练)的 30 多个注意力门控变体进行全面比较,发现一个简单的修改——在 Scaled Dot-Product Attention (SDPA) 之后应用一个 head-specific 的 Sigmoid 门控——能够持续提升性能。这种修改还增强了训练稳定性,允许使用更大的学习率,并改善了模型的可扩展性。
动机: 尽管门控机制已广泛应用于从 LSTM (Hochreiter & Schmidhuber, 1997) 到最新状态空间模型 (Gu & Dao, 2023) 和线性注意力 (Hua et al., 2022) 等多种架构中,但现有文献很少系统性地探究门控的具体效果。例如,Switch Heads (Csordas et al., 2024a;b) 引入 Sigmoid 门控来选择注意力头专家,但作者发现即使只选择单个专家,性能增益仍然显著,这表明门控本身具有独立于路由机制的内在价值。Native Sparse Attention (NSA) (Yuan et al., 2025) 也未区分门控机制与稀疏注意力设计本身的贡献。因此,有必要严格解耦门控机制的效果。
核心方法和实验: 作者在 Transformer 的注意力层中探索了门控机制的五个关键方面:
位置 (Positions):如图 1 (left) 所示,门控可应用于 Q、K、V 投影之后 (G4, G3, G2),Scaled Dot Product Attention (SDPA) 输出之后 (G1),以及最终密集输出层之后 (G5)。
粒度 (Granularity):Headwise (一个标量门控分数调制整个注意力头的输出) 和 Elementwise (门控分数是与输出 Y 相同维度的向量,实现更细粒度的调制)。
头部特异性 (Head Specificity):Head-Specific (每个注意力头有独立的门控分数) 和 Head-Shared (门控参数 \(W_\theta\) 和分数在头部间共享)。
作用类型 (Multiplicative or Additive):乘法门控 \(Y' = Y \odot \sigma(XW_\theta)\) 和加法门控 \(Y' = Y + \sigma(XW_\theta)\)。
激活函数 (Activation Function):主要考虑 SiLU 和 Sigmoid。
门控机制的通用形式为: \(Y' = g(Y, X, W_\theta, \sigma) = Y \odot \sigma(X W_\theta)\) 其中 \(Y\) 是被调制的输入,\(X\) 是用于计算门控分数的另一个输入(通常是预归一化后的隐藏状态),\(W_\theta\) 是可学习的门控参数,\(\sigma\) 是激活函数(如 Sigmoid),\(Y'\) 是门控输出。
实验设置:
模型:15B MoE 模型 (15A2B,激活参数 2.54B) 和 1.7B 密集模型。
训练数据:3.5 万亿 token 的高质量数据集,包括多语言、数学和通用知识内容。
注意力机制:Group Query Attention (GQA)。
超参数:上下文长度 4096。MoE 模型采用 128 个专家,top-8 Softmax 门控,fine-grained experts (Dai et al., 2024),global-batch LBL (Qiu et al., 2025) 和 z-loss (Zoph et al., 2022)。
评估指标:困惑度 (PPL),以及 Hellaswag, MMLU, GSM8k, HumanEval, C-eval, CMMLU 等少样本基准测试。
主要发现:
SDPA 输出门控 (G1) 和 Value 层门控 (G2) 最有效:在 SDPA 输出 (G1) 或 Value 映射 (G2) 之后插入门控能取得最佳 PPL 降低和基准测试性能提升。G1 表现更优。
Head-Specific 门控至关重要:当不同注意力头拥有各自独立的门控分数时,性能提升最显著。共享门控分数会导致性能下降。
乘法门控优于加法门控:虽然加法门控也能提升性能,但乘法门控效果更好。
Sigmoid 激活函数表现更佳:SiLU 激活函数的效果不如 Sigmoid。
提升训练稳定性与可扩展性:门控机制显著减少了训练过程中的 loss spikes,使得模型在更大批次大小和学习率下也能稳定训练,从而提升了模型的可扩展性。
效果分析: 作者将门控机制的有效性归因于两个关键因素:
引入非线性 (Non-Linearity):
在 Multi-Head Attention 中,Value 投影 \(W_V\) 和输出层 \(W_O\) 形成一个低秩线性映射。具体地,对于第 \(k\) 个头的第 \(i\) 个 token 的输出 \(o_i^k\) 可以表示为: \(o_i^k = \left(\sum_{j=0}^i S_{ij}^k \cdot X_j W_V^k \right) W_O^k = \sum_{j=0}^i S_{ij}^k \cdot X_j (W_V^k W_O^k)\) 由于 \(d_k < d_{model}\),\((W_V^k W_O^k)\) 构成一个低秩线性映射。
在 G2 位置(Value 投影之后)添加门控对应于修改: \(o_i^k = \left(\sum_{j=0}^i S_{ij}^k \cdot \text{Non-Linearity-Map}(X_j W_V^k)\right) W_O^k\)
在 G1 位置(SDPA 输出之后)添加门控对应于修改: \(o_i^k = \text{Non-Linearity-Map}\left(\sum_{j=0}^i S_{ij}^k \cdot X_j W_V^k\right) W_O^k\)
在 \(W_V\) 和 \(W_O\) 之间引入非线性(通过门控或 GroupNorm)可以提高这种低秩线性变换的表达能力。这也是为什么 G5 位置(在最终输出层之后)的门控无效,因为它未能解决 \(W_V\) 和 \(W_O\) 之间非线性的缺失问题。
引入输入依赖的稀疏性 (Input-Dependent Sparsity):
稀疏的门控分数:有效的门控(尤其是在 G1 位置的 SDPA 输出门控)表现出非常低的平均门控分数,且分数分布高度集中在 0 附近,这表明门控分数本身具有显著的稀疏性。
Head-Specific 稀疏性:强制跨注意力头共享门控分数会增加整体门控分数,并降低性能增益,这强调了为不同注意力头应用独立门控分数的重要性。
Query-Dependency 稀疏性:G1 的门控分数(依赖于当前查询的隐藏状态)比 G2 的门控分数(依赖于过去键和值的隐藏状态)更低、更稀疏,且性能更优。这暗示门控分数的稀疏性在查询依赖时更有效,可以过滤掉与查询不相关的上下文信息。
稀疏性提升性能:当通过修改激活函数 (NS-Sigmoid) 或使用 input-independent 门控来减少门控分数的稀疏性时,模型性能会下降。这验证了门控分数稀疏性的重要性。
消除“注意力汇聚”现象 (Attention-Sink-Free):
“注意力汇聚” (attention sink) 指的是初始 token disproportionately 占据大量注意力分数 (Xiao et al., 2023)。
稀疏的、输入依赖的、head-specific 的 SDPA 输出门控能够有效地过滤掉与当前查询 token 不相关的上下文信息,从而显著缓解了注意力汇聚现象。基线模型的第一 token 平均注意力分数高达 46.7%,而门控模型仅为 4.8%。
门控也降低了模型中的“massive activations”,这可能解释了训练稳定性的提升:减少大规模激活使得模型在 BF16 训练时不易出现数值误差。同时,作者观察到“massive activations”并非“注意力汇聚”的必要条件。
促进长上下文外推 (Long-Context Extrapolation):
在 RULER (Hsieh et al., 2024) 基准测试上,注意力汇聚消除的特性使得门控模型在上下文长度扩展方面表现出显著优势。在 64k 和 128k 上下文长度下,门控模型大幅优于基线模型。
作者推测,基线模型可能依赖注意力汇聚模式来调整注意力分数分布。当通过 YaRN (Peng et al., 2023) 等技术修改 RoPE 基时,注意力汇聚模式可能难以适应,导致性能显著下降。而门控模型主要依赖输入依赖的门控分数来控制信息流,使其对这些变化更具鲁棒性。
相关工作: 论文回顾了门控机制在神经网络(如 LSTMs, GRUs, Highway Networks, SwiGLU, SSMs, Linear Attention)中的应用。特别提到了 Forgetting Transformer (Lin et al., 2025) 也应用了 Softmax Attention 的门控并取得了显著改进,以及 Quantizable Transformers (Bondarenko et al., 2023) 发现门控可以缓解注意力集中和隐藏状态中的离群值。在注意力汇聚方面,论文讨论了其发现 (Xiao et al., 2023; Sun et al., 2024; Gu et al., 2024) 并指出其与这些工作的区别,例如大规模激活并非注意力汇聚的必要条件。
局限性: 论文主要集中于通过一系列消融研究来分析注意力门控的原因和影响,但对于非线性对注意力动态和整体训练过程的更广泛影响仍有待深入探索。此外,尽管观察到消除注意力汇聚有助于长上下文扩展,但论文并未提供严格的理论解释,说明注意力汇聚如何影响模型泛化到更长序列的能力。
总而言之,该工作通过深入的实证研究,不仅验证了门控机制在提升 Transformer 模型性能和稳定性方面的有效性,更揭示了其背后的非线性引入、稀疏性调制以及注意力汇聚消除等核心机制,为未来基础模型的架构设计提供了宝贵的见解。作者也发布了相关的代码和模型。
关键词¶
门控机制: 门控机制是一种在神经网络中用于控制信息流动的计算单元。在该论文中,门控机制被形式化为 \(Y' = Y \odot \sigma(XW_\theta)\),其中 \(Y\) 是待调制的输入,\(\sigma(XW_\theta)\) 是由另一个输入 \(X\) 和可学习参数 \(W_\theta\) 计算得到的门控分数(通常使用 sigmoid 等激活函数),\(\odot\) 表示逐元素乘法。门控分数作为一个动态滤波器,选择性地放大或抑制 \(Y\) 中的信息,从而更精细地控制信息在模型中的传播。论文中重点研究了在 Transformer 的注意力层中引入门控机制,尤其是在缩放点积注意力 (SDPA) 的输出之后,发现这种机制能带来显著的性能提升。
Softmax注意力: Softmax注意力是 Transformer 模型中核心的注意力机制,其计算公式为 \(\text{Attention}(Q, K, V) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V\)。它首先计算查询 (Q) 和键 (K) 之间的相似度得分,然后通过 softmax 函数将其归一化为注意力权重,最后用这些权重对值 (V) 进行加权求和。这种机制允许模型根据输入序列中不同部分的关联程度来分配注意力。本论文在此基础上,探讨了在 Softmax 注意力机制中引入门控变体的影响。
缩放点积注意力 (SDPA): 缩放点积注意力 (Scaled Dot-Product Attention, SDPA) 是 Transformer 模型中实现注意力机制的具体计算方法。它首先通过点积计算查询 (Q) 和键 (K) 之间的相似度,然后将结果除以键向量维度的一半(\(\sqrt{d_k}\))进行缩放,以防止点积过大导致 softmax 函数的梯度过小。接着,通过 softmax 函数得到归一化的注意力权重,最后将这些权重应用于值 (V) 向量,得到加权平均的输出。论文中的研究发现,在 SDPA 的输出之后应用门控机制(G1 位置)能带来最佳的性能提升。
注意力汇聚 (Attention Sink): 注意力汇聚(Attention Sink,或称注意力陷阱)是指在 Transformer 模型中,尤其是在处理长序列时,最早的几个 tokens(通常是第一个 token)会不成比例地获得极高的注意力分数,并且这种现象在模型的浅层和深层都可能存在。这导致模型将过多的计算资源和注意力集中在不必要的信息上,限制了模型对序列中其他重要信息的有效关注,尤其影响长上下文的处理能力。本论文发现,通过在 SDPA 输出后应用稀疏门控机制,能够有效缓解甚至消除注意力汇聚现象。
非线性: 非线性是神经网络模型学习复杂模式的关键。在 Transformer 的注意力层中,标准的注意力计算(特别是 Query, Key, Value 的线性投影和最终的输出层)会经过多层线性变换。论文指出,连续的线性层(如值投影 \(W_v\) 和输出投影 \(W_o\))可以合并为一个低秩线性映射。通过在这些线性变换之间引入门控机制,可以有效地注入非线性,从而增强低秩映射的表达能力,提升模型性能。例如,在 SDPA 输出后或值投影之后加入门控,都能引入这种有益的非线性。
稀疏性: 稀疏性是指在一个向量或矩阵中,大部分元素的值为零或接近于零。在本论文中,稀疏性主要体现在门控分数上。研究发现,当门控分数(特别是 SDPA 输出处的门控分数)具有高度的输入依赖性且表现出显著的稀疏性时(即大多数门控分数接近于零),模型性能提升最为显著。这种稀疏门控机制可以根据查询 (query) 的内容,动态地过滤掉与当前查询不相关的信息,从而使注意力更加聚焦,并有助于消除“注意力汇聚”现象。
头特定门控: 多头注意力机制允许模型并行地从不同的表示子空间学习信息。头特定门控 (Head-Specific Gating) 指的是为多头注意力中的每一个注意力头分配独立的门控参数和门控分数。这意味着每个注意力头都可以学习一个针对自身特点的、动态的调节器。论文实验表明,与共享门控参数(Head-Shared Gating)相比,头特定门控能够带来更大的性能提升,因为它允许每个头更精细地控制其输出,更好地捕捉输入中的不同模式。
多头注意力: 多头注意力 (Multi-Head Attention) 是 Transformer 模型中注意力机制的一种扩展。它将输入的 Q、K、V 向量分别投影到多个低维空间,并在每个子空间中独立计算注意力(即多个“头”),然后将所有头的输出拼接起来,再经过一个线性投影。这种机制使得模型能够同时关注来自不同表示子空间的信息,增强了模型的表达能力。本文在多头注意力的背景下,研究了在各个注意力头应用门控机制的效果。
混合专家模型 (MoE): 混合专家模型 (Mixture-of-Experts, MoE) 是一种模型架构,它由多个“专家”子网络组成,并通过一个“门控网络”(router)来决定在处理特定输入时激活哪些专家。与传统的稠密模型相比,MoE 模型在训练时可以激活的参数量远小于总参数量,这使得在不显著增加计算成本的情况下,模型规模可以做得非常大。本论文在 15B 参数的 MoE 模型上进行了大量实验,以验证门控注意力机制在其上的有效性。
训练稳定性: 训练稳定性指的是在模型训练过程中,损失函数能够平稳下降,避免出现剧烈波动、梯度爆炸或消失等问题。论文发现,引入门控机制,特别是 SDPA 输出处的门控,能够显著改善模型的训练稳定性,几乎消除了损失尖峰,并允许使用更大的学习率。这被归因于门控机制引入的非线性和稀疏性,可能有助于减少巨大的激活值,从而降低数值不稳定性。
上下文长度扩展: 上下文长度扩展 (Context Length Extension) 指的是模型在处理超出其训练时固定上下文长度的序列时的能力。当序列长度超出训练时的范围时,模型的性能通常会急剧下降。本论文研究表明,通过在注意力层中引入门控机制(尤其是 SDPA 输出处的门控),模型在长上下文设置下表现出更好的性能,并且在进行上下文长度扩展(如使用 YaRN 方法)时,相比于基线模型,性能下降幅度更小,显示出对上下文长度扩展的更好适应性。
Abstract¶
本论文主要研究了门控机制(gating mechanisms)在softmax注意力机制中的应用与效果。尽管门控机制在LSTM、Highway Network、状态空间模型、线性注意力等模型中被广泛使用,但现有研究很少系统地分析门控机制的具体作用。
为此,作者进行了系统性的实验,研究了多种带有门控机制的softmax注意力变体。实验涵盖了30种不同的注意力变体,在150亿参数的MoE模型和17亿参数的密集模型上进行训练,训练数据量高达3.5万亿token。
核心发现:¶
作者提出了一种简单但有效的改进方法:在Scaled Dot-Product Attention (SDPA)之后加入一个头特定(head-specific)的sigmoid门控机制。该方法带来了以下优势:
性能提升
训练更稳定
可容忍更大的学习率
更好的扩展性
门控机制有效的原因:¶
通过对比不同门控位置和计算方式,作者总结出两个关键因素:
在softmax注意力的低秩映射中引入非线性
使用与查询相关的稀疏门控分数来调节SDPA输出
其他重要发现:¶
该稀疏门控机制有助于缓解“注意力沉降”(attention sink)问题
提升了长上下文外推能力(long-context extrapolation)
开源信息:¶
为了促进后续研究,作者公开了相关代码和模型。
1 Introduction¶
1.1 门控机制在神经网络中的应用¶
门控机制(Gating Mechanism)是神经网络中广泛应用的一种技术,最早在LSTM(Hochreiter & Schmidhuber, 1997)、Highway Networks(Srivastava et al., 2015)和GRU(Dey & Salem, 2017)等模型中被提出,用于控制时间步或层之间的信息流动,改善梯度传播。这一机制在现代模型中依然常见,如状态空间模型(State-Space Models)和注意力机制(Attention Mechanisms)中,门控常用于调节token混合组件的输出。
1.2 门控机制研究的不足¶
尽管门控机制在实践中取得了成功,但其功能和影响尚未被充分理解,尤其是在与其他架构因素混杂时,难以评估其真实贡献。例如:
Switch Heads(Csordas et al., 2024a, b)中引入的sigmoid门控原本用于选择top-K注意力头专家,但实验发现即使只保留一个专家,性能依然显著提升,说明门控本身具有内在价值。
Native Sparse Attention (NSA)(Yuan et al., 2025)虽然展示了整体性能提升,但未能区分门控机制与稀疏注意力设计的独立贡献。
这些例子表明,有必要系统地分离门控机制与其他架构组件的影响。
1.3 本文研究方法与发现¶
本文聚焦于标准softmax注意力机制(Vaswani, 2017)中的门控机制(见第2.2节),在注意力层的不同位置引入门控操作(如图1所示):
G2(G₂):值(Value)投影之后
G3(G₃):键(Key)投影之后
G4(G₄):查询(Query)投影之后
G1(G₁):缩放点积注意力(SDPA)输出之后
G5(G₅):最终输出层之后
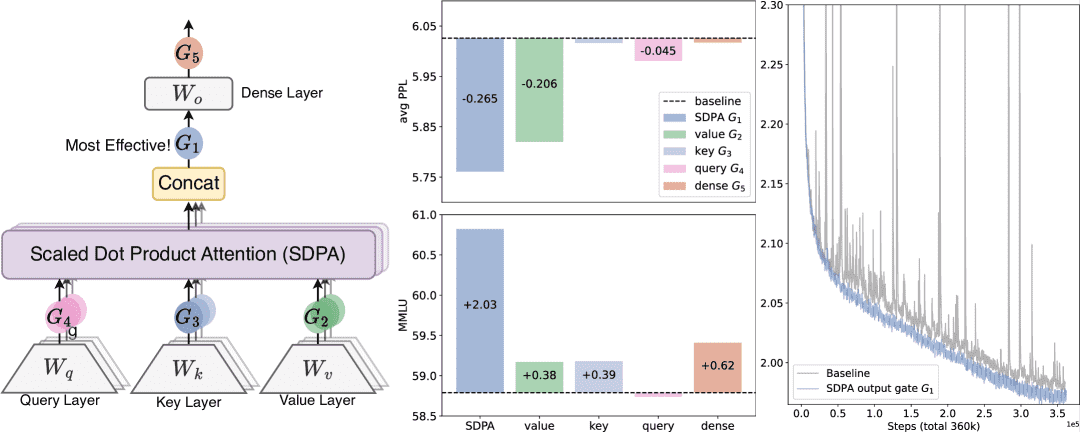
Figure 1:Left: Investigated positions for applying gating operations.; Middle: Performance comparison (Test PPL and MMLU) of 15B MoE models with gating applied at various positions. Right: Training loss comparison (smoothed, 0.9 coeff.) over 3.5T tokens between baseline and SDPA-gated 1.7B dense models under identical hyperparameters.
门控形式包括逐元素(elementwise)和头级(headwise)、头特定(head-specific)和头共享(head-shared)、加法(additive)和乘法(multiplicative)等。
主要发现如下:
G1(SDPA输出后的头特定门控)效果最佳:带来显著性能提升(如PPL降低0.2,MMLU提升2分)。
训练稳定性提升:G1门控几乎消除了损失尖峰(loss spikes),允许使用更大的学习率,增强模型可扩展性。
1.4 门控机制有效性的三大因素¶
非线性增强表达能力(Non-Linearity)
注意力机制中,值投影(Wv)和输出投影(WO)两个线性层可合并为一个低秩线性变换。
在G1或G2位置引入门控,可为该低秩变换引入非线性,提升表达能力(见第4.1节)。
输入依赖的稀疏性(Sparsity)
非线性门控变体虽然普遍有效,但其效果差异与门控得分的稀疏性密切相关。
稀疏门控在SDPA输出上引入输入依赖的稀疏性,有助于模型聚焦关键信息(见第4.2节)。
消除注意力沉降(Attention Sink)
注意力沉降是指初始token在注意力得分中占据主导地位的现象,通常由softmax的非负归一化导致。
在SDPA输出应用稀疏门控后,无论是稠密模型还是MoE模型(训练3.5T token),均未出现注意力沉降。
这些模型在长度泛化任务(如RULER)中表现优异,提升超过10分(见第4.3和4.4节)。
1.5 总结与贡献¶
本文系统研究了标准注意力机制中门控机制的作用,揭示了其在以下方面的关键影响:
提升模型性能(PPL、MMLU)
增强训练稳定性
引入非线性和稀疏性,提升表达能力
消除注意力沉降,提升长上下文泛化能力
作者表示将开源无注意力沉降的模型,以推动未来研究。
2 Gated-Attention Layer¶
2.1 Preliminary: Multi-Head Softmax Attention(多头Softmax注意力机制)¶
本节回顾了Transformer中标准的多头注意力机制,分为四个阶段:
QKV线性投影:¶
输入 \( X \in \mathbb{R}^{n \times d_{\text{model}}} \) 被线性变换为查询(Q)、键(K)和值(V),使用可学习的权重矩阵 \( W_Q, W_K, W_V \in \mathbb{R}^{d_{\text{model}} \times d_k} \):
缩放点积注意力(SDPA):¶
计算查询与键之间的相似度,使用softmax归一化后对值进行加权求和:
其中,\(\frac{QK^T}{\sqrt{d_k}}\) 是缩放后的点积相似度矩阵,softmax确保每行的注意力权重非负且和为1。
多头拼接:¶
多头注意力机制将上述过程并行应用于 \( h \) 个头,每个头有独立的投影矩阵 \( W_q^i, W_k^i, W_v^i \),最终将各头输出拼接:
其中,\(\text{head}_i = \text{Attention}(QW_Q^i, KW_K^i, VW_V^i)\)
最终输出层:¶
拼接后的输出通过一个线性变换层 \( W_o \in \mathbb{R}^{hd_k \times d_{\text{model}}} \) 得到最终输出:
图示说明:图2展示了注意力机制中“注意力沉降”(attention sink)现象,即模型在多个层中将大量注意力分配给第一个token。引入门控机制后,这种现象显著缓解。
2.2 Augmenting Attention Layer with Gating Mechanisms(在注意力层中引入门控机制)¶
本节提出了一种门控机制,用于增强注意力层的表达能力,形式如下:
其中:
\( Y \) 是待调制的输入;
\( X \) 是用于计算门控分数的输入(通常为归一化后的隐藏状态);
\( W_\theta \) 是门控参数;
\( \sigma \) 是激活函数(如sigmoid);
\( Y' \) 是门控后的输出;
\( \sigma(XW_\theta) \) 作为动态滤波器,控制信息流。
门控机制的五种变体研究:¶
位置(Positions)
研究门控在注意力层中不同位置的应用效果:G2-G4:在QKV投影之后;
G1:在SDPA输出之后;
G5:在最终多头输出之后。
粒度(Granularity)
Headwise:每个头一个标量门控分数;
Elementwise:每个维度一个门控分数,实现细粒度控制。
头特定或共享(Head Specific or Shared)
Head-Specific:每个头有独立的门控参数;
Head-Shared:所有头共享同一组门控参数。
乘法或加法门控(Multiplicative or Additive)
乘法门控:\( Y' = Y \cdot \sigma(X\theta) \)
加法门控:\( Y' = Y + \sigma(X\theta) \)
激活函数(Activation Function)
主要使用 Sigmoid(输出在[0,1]之间)和 SiLU(用于加法门控,因其输出无界);
也尝试了 Identity Mapping 和 RMSNorm(用于分析门控机制的有效性)。
默认设置:除非另有说明,论文中使用的是头特定、乘法门控、Sigmoid激活函数。
总结¶
本章系统介绍了标准的多头注意力机制,并在此基础上提出了门控注意力机制。通过在不同位置、不同粒度、不同方式下引入门控,论文探索了如何增强注意力机制的非线性表达能力,缓解“注意力沉降”问题,并提升模型的灵活性与表现力。
3 Experiments¶
3.1 实验设置¶
模型架构与训练设置¶
实验在两种模型上进行:
MoE模型(15A2B):总参数150亿,激活参数25.4亿,使用128个专家,top-8 softmax门控机制,细粒度专家(Dai et al., 2024),全局批次LBL(Qiu et al., 2025),z-loss(Zoph et al., 2022)。
密集模型:总参数17亿。
模型使用组查询注意力(GQA)(Ainslie et al., 2023),训练数据为3.5万亿高质量token的子集,涵盖多语言、数学和通用知识内容,上下文长度设为4096。
其他超参数使用AdamW优化器默认值,门控机制引入的延迟小于2%。
评估¶
在多个基准任务上测试模型的few-shot性能,包括:
Hellaswag(英文理解)
MMLU(通用知识)
GSM8k(数学推理)
HumanEval(代码生成)
C-eval 和 CMMLU(中文能力)
同时报告语言模型在多个测试集上的困惑度(PPL),涵盖英文、中文、代码、数学、法律、文学等领域。
表1:门控变体性能与结果¶
训练15A2B MoE模型于4000亿token上,比较不同门控方法的PPL和基准任务表现。主要变体包括:
门控位置:SDPA输出、value输出、key输出、query输出、dense输出。
门控粒度:head-wise vs. head-shared。
门控方式:乘法 vs. 加法。
激活函数:sigmoid vs. SiLU。
结果显示:
SDPA输出和value输出的门控效果最佳。
head-wise门控引入参数少但提升显著。
sigmoid激活优于SiLU。
乘法门控优于加法门控。
3.2 主要结果¶
3.2.1 MoE模型的门控注意力机制¶
在MoE模型(15A2B)上进行实验,使用学习率从2e-3线性预热到3e-5,bsz=1024,训练10万步。
关键发现:
SDPA和value输出门控最有效
在SDPA输出(G1)或value映射(G2)插入门控能显著降低PPL并提升基准任务表现。head-wise门控更优
head-wise门控仅引入少量参数(<2M),但提升显著;而head-shared门控效果较差。乘法门控优于加法门控
加法门控虽优于基线,但不如乘法门控有效。sigmoid激活更优
使用SiLU替代sigmoid会降低性能。
总结:
在value层(G2)和SDPA输出(G1)添加门控可降低PPL超过0.2,优于参数扩展方法。
G1在PPL和基准任务上表现最佳。
只要不同头使用不同门控分数,激活函数和粒度影响较小。
3.2.2 密集模型的门控注意力机制¶
在密集模型(1.7B)上验证SDPA输出门控的有效性。训练时调整FFN宽度以保持参数总量不变。
训练设置:
4000亿token:最大学习率4e-3,bsz=1024。
3.5万亿token:最大学习率4.5e-3,bsz=2048。
增加层数、学习率和batch size以测试门控对训练稳定性的提升。
关键发现:
门控在多种设置下均有效
在不同模型配置(row 1 vs. 2)、训练数据(row 3 vs. 4)、超参数(row 11 vs. 13)中,SDPA输出门控均带来提升。门控提升训练稳定性
在3.5万亿token设置中,门控显著减少loss spike。
当学习率提升时,基线模型无法收敛(row 6, 12),而加入门控后仍能稳定训练并提升性能。
门控支持更大batch size和学习率
在48层、1T token、bsz=4096设置中,门控模型在高学习率下仍能稳定训练并提升性能(row 13 vs. 14)。
总结¶
SDPA element-wise门控 是最有效的注意力增强方法。
在MoE和密集模型中均能显著提升性能,尤其在降低PPL和提升few-shot任务表现方面。
门控机制还能提升训练稳定性,支持更大batch size和学习率,有助于模型扩展。
4 Analysis: Non-Linearity, Sparsity, and Attention-Sink-Free¶
本节通过一系列实验探讨为何如此简单的门控机制能显著提升性能和训练稳定性。主要结论如下:
门控操作增强非线性,带来性能提升(见4.1节);
最有效的SDPA逐元素门控引入了强输入依赖的稀疏性,从而缓解“注意力沉降”现象(见4.2节)。
4.1 非线性提升注意力中低秩映射的表达能力¶
重点内容:
非线性增强表达能力:在注意力机制中,WV(值投影)和WO(输出投影)之间是线性映射,引入非线性可以提升模型表达能力。实验表明,门控机制通过在WV和WO之间引入非线性激活函数(如Sigmoid、SiLU),有效缓解了低秩问题,从而提升了性能。
不同门控位置的效果:
G1位置(SDPA输出):在SDPA输出后加入门控(如Sigmoid),对应公式(8),即在加权求和后应用非线性映射,效果最佳。
G2位置(值投影后):在值投影后加入门控(如Sigmoid),对应公式(7),即在加权求和前应用非线性映射,效果次之。
实验结果(见表3):
使用Sigmoid门控在G1位置(第2行)可显著降低PPL(从6.026降至5.761),并提升多个基准任务的性能。
使用SiLU门控在G1位置(第4行)也有提升,但不如Sigmoid明显。
在G5位置(WO之后)加入门控无效(表1第9行),因为未在WV和WO之间引入非线性。
总结:有效的门控变体之所以性能提升,主要归因于在WV和WO之间引入了非线性。G1和G2位置均可引入非线性,但G1位置效果更优。
4.2 门控引入输入依赖的稀疏性¶
重点内容:
门控得分稀疏性:SDPA输出门控(G1位置)的平均门控得分最低,且分布集中在0附近,说明其具有强稀疏性,与性能提升一致。
头特异性稀疏性的重要性:
若强制所有注意力头共享门控得分(第4行),整体门控得分升高,性能下降。
表明每个注意力头应有独立的门控得分,以捕捉输入的不同方面。
查询依赖性的重要性:
值门控(G2位置)得分高于SDPA输出门控(G1位置),且性能较差,说明查询依赖的稀疏性更有效。
SDPA输出门控基于当前查询的隐藏状态计算门控得分,能过滤与当前查询无关的信息。
稀疏性降低性能下降:
使用NS-sigmoid函数(将门控得分限制在[0.5, 1.0])去除稀疏性后,性能下降(第7行),说明稀疏性对性能提升至关重要。
总结:门控机制通过引入输入依赖、头特异性的稀疏性,有效过滤无关上下文信息,从而提升模型性能。
4.3 SDPA输出门控减少注意力沉降¶
重点内容:
注意力沉降现象:指模型在生成过程中过度关注初始token,影响长上下文建模。
门控机制的作用:
SDPA输出门控(G1位置)显著降低了对第一个token的注意力得分,并减少了隐藏状态中的大规模激活(见表4“F-Attn”和“M-Act”列)。
头特异性门控效果最佳,而共享门控或仅在值投影后门控效果较差。
输入依赖性的重要性:
输入无关门控(第6行)或NS-sigmoid门控(第7行)均导致注意力沉降和大规模激活加剧。
训练稳定性提升:
稀疏性减少了模型中的大规模激活,从而降低BF16训练中的数值误差风险。
大规模激活主要来自早期层(如第5层),通过残差连接传播至后续层,门控机制有助于缓解这一问题。
总结:SDPA输出门控通过引入输入依赖、头特异性的稀疏性,有效缓解注意力沉降,提升训练稳定性。
4.4 SDPA输出门控有助于上下文长度扩展¶
重点内容:
实验设置:将训练好的模型扩展至更长上下文(32k → 128k),使用YaRN方法进行扩展。
实验结果(见表5):
在32k上下文内,门控模型略优于基线。
扩展至128k后,基线模型性能显著下降,而门控模型下降幅度较小。
在64k和128k上下文中,门控模型显著优于基线。
原因分析:
基线模型依赖注意力沉降来调整注意力得分分布,而YaRN等方法在不重新训练的情况下难以适应这种变化。
门控模型依赖输入依赖的门控得分控制信息流,因此对上下文扩展更鲁棒。
总结:门控机制使模型在长上下文场景下更具鲁棒性,尤其在上下文扩展至128k时表现更优。
总结¶
本章通过分析门控机制的非线性、稀疏性和注意力沉降缓解机制,揭示了其提升性能和训练稳定性的原因:
非线性增强表达能力:在WV和WO之间引入非线性激活函数,提升模型表达能力。
输入依赖的稀疏性:门控机制引入稀疏性,过滤无关上下文信息,提升性能。
缓解注意力沉降:通过稀疏性减少对初始token的关注,提升长上下文建模能力。
提升训练稳定性:减少大规模激活,降低数值误差风险。
支持上下文扩展:门控机制使模型在长上下文扩展中更具鲁棒性。
这些分析为理解门控注意力机制的有效性提供了理论和实验支持。
6 Conclusion¶
6 结论¶
本章节总结了对标准 softmax 注意力中门控机制作用的系统性研究,指出其在模型性能、训练稳定性以及注意力动态方面的显著影响。
主要发现:¶
通过对 15B 参数的 MoE 模型和 1.7B 参数的稠密模型,共计 30 多种变体,在高达 3.5T token 数据上的大量实验验证,作者发现:
在缩放点积注意力后使用 sigmoid 门控,带来了最显著的性能提升。
该门控机制的优势(重点内容):¶
增强非线性:使注意力输出更具非线性特性,提升模型表达能力。
引入输入依赖的稀疏性:根据输入动态调整注意力权重,提高效率。
消除“注意力沉降”(attention sink)问题:这是影响长序列建模效率的关键问题。
支持上下文长度扩展:模型在未重新训练的情况下,也能有效处理更长的输入序列。
意义与贡献:¶
作者发布了首个无注意力沉降现象的模型,为后续研究提供了基准。
这些实证结果为下一代先进基础模型的设计与工程实现提供了重要参考。
总结:本节强调了门控机制在注意力机制中的关键作用,提出了一种简单但有效的改进方法,并展示了其在多个维度上的显著优势。
Limitations¶
局限性¶
本节标题保持不变,内容总结如下:
文章指出,尽管通过一系列消融实验对注意力门控机制的原因和影响进行了分析,但研究仍存在一些局限性。
重点内容:
作者指出,注意力机制中的非线性因素对模型注意力动态和整体训练过程的影响尚未被深入探讨。这是一个重要的研究空白,因为非线性可能在注意力机制的复杂行为中起到关键作用。
次要内容(精简):
此外,虽然实验发现去除“注意力沉没点”(attention sinks)有助于提升模型在长上下文扩展任务中的表现,但文章未能提供关于这些沉没点如何影响模型对长序列泛化能力的严格理论解释。
Appendix A Supplement Experiments¶
A.1 Switch Head 基线实验¶
本节详细探讨了 Switch Head 方法在注意力机制中的应用。核心思想是通过引入稀疏激活机制(每个 token 从 key/value/output 专家池中选择 top-k 专家),从而在参数总量不变的情况下提升模型性能。
实验结果(表6):¶
Switch kv, 8top8:增加 38M 参数,PPL 为 5.847,MMLU 为 59.17。
Switch kv, 4top4:增加 13M 参数,PPL 为 5.935,MMLU 为 58.14。
Switch v, 4top4:增加 13M 参数,PPL 为 5.820,MMLU 为 59.02。
Switch v, 8top2:增加 25M 参数,PPL 为 5.870,MMLU 为 59.10。
Switch v, 1top1(等同于 value 层的门控机制):仅增加 3M 参数,PPL 为 5.808,MMLU 为 59.32,表现最佳。
关键发现:¶
引入门控机制本身对性能提升有显著作用,尤其是 Switch v, 1top1 在参数最少的情况下表现最优。
增加激活的专家数量(如从 4top4 到 8top8)对 PPL 有一定提升,但对整体基准测试的增益不明显。
A.2 稀疏门控得分的进一步讨论¶
本节分析了门控得分的稀疏性对注意力输出的影响。
图4:门控前后隐藏状态的均值变化¶
门控后隐藏状态的均值从 0.71 降至 0.05,说明门控得分普遍较小。
门控后的隐藏状态与基线相似,表明门控可能起到了类似“注意力沉降”(attention sink)的作用,过滤了无关信息。
图5:门控前后低于阈值的隐藏状态比例¶
门控显著提高了隐藏状态的稀疏性。
当将门控得分与原始隐藏状态相乘时,稀疏性提升更明显,说明稀疏门控得分是增强稀疏性的关键因素。
A.3 层级大规模激活与注意力沉降现象¶
本节比较了不同门控配置下模型中出现的 大规模激活(massive activations)和 注意力沉降(attention sinks)现象。
不同配置的对比:¶
基线(Baseline):第6层后出现大规模激活和注意力沉降。
SDPA 输出门控:激活值较小,无注意力沉降。
仅在 value 层应用门控:激活值与 SDPA 门控类似,但仍有部分注意力沉降。
跨头共享门控得分 或 降低门控稀疏性:激活和注意力沉降现象与基线相似。
关键结论:¶
足够的注意力稀疏性有助于缓解大规模激活和注意力沉降。
大规模激活并非注意力沉降的必要条件。
需要进一步研究稀疏性、激活值和注意力沉降之间的关系,尤其是在更大更深的模型中。
A.4 更多层级门控得分分析¶
本节分析了在 SDPA 输出门控基础上,两种额外约束下的门控得分分布:
跨头共享门控得分:大多数层的门控得分上升,说明不同头需要不同的稀疏性。
限制门控得分最小值:影响门控的稀疏程度。
图7:不同约束下的门控得分分布¶
跨头共享门控得分会提高大多数层的得分,表明头特定的门控机制更为重要。
A.5 其他训练稳定化尝试¶
本节探讨了除门控机制外的其他方法来稳定训练,尤其是防止残差连接中的大规模激活。
尝试的方法:¶
Sandwich Normalization 和 门控机制:都能有效消除大规模激活并提升训练稳定性。
引入裁剪操作(clip):限制注意力和 FFN 层输出的范围(如 -clip 到 clip)。
实验结果:¶
即使设置 clip 值为 300 或 100,在学习率为 8e-3 的情况下,模型仍无法收敛。
表明预归一化模型的训练不稳定性不仅源于残差中的大激活值,还可能来自任何层的大输出。
结论:¶
需要进一步研究训练不稳定的根本原因,而不仅仅是限制激活值。
总结¶
本附录通过多个补充实验,深入探讨了 门控注意力机制 在稀疏性、非线性、训练稳定性等方面的表现。核心发现包括:
门控机制本身 是提升性能的关键,尤其在减少注意力沉降和大规模激活方面。
稀疏性 对模型表现有积极影响,但不同头需要不同的稀疏策略。
训练稳定性 不仅与激活值有关,还涉及更复杂的因素,需要进一步研究。