2112.08679_SimGCL: Are Graph Augmentations Necessary? Simple Graph Contrastive Learning for Recommendation¶
引用: 872(2025-09-13)
组织:
The University of Queensland(Australia)
Shandong University
Griffith University(Australia)
GitHub: https://github.com/Coder-Yu/QRec
总结¶
背景
基于CL的推荐模型通常包含两个步骤:
图增强(Graph Augmentation)
通过结构扰动(如边删除)对用户-项目二部图进行增强
对比学习
最大化不同增强图之间节点表示的一致性
InfoNCE(Information Noise-Contrastive Estimation)
一个在自监督学习(尤其是对比学习)中极为重要的损失函数。
它源于噪声对比估计(NCE)的思想,核心目的是通过比较正负样本来学习有效的表示。
核心直觉非常简单:“拉近”相似(正)样本的表示,“推远”不相似(负)样本的表示。
图增强推荐:鼓励同一节点在不同增强图中的表示具有一致性,同时区分不同节点之间的表示
InfoNCE 是现代对比学习算法的基石,被用于众多开创性的工作中:
CPC (Contrastive Predictive Coding): 最初提出 InfoNCE 的论文,用于语音、文本和视频的无监督表示学习。
MoCo (Momentum Contrast): 使用一个动量更新的编码器和一个大容量的队列来构建庞大且一致的负样本库。
SimCLR (A Simple Framework for Contrastive Learning): 证明了强大的数据增强和非线性投影头的重要性,使用同一个批次内的其他样本作为负样本。
CLIP (Contrastive Language-Image Pre-training): 将 InfoNCE 应用于多模态领域,拉近匹配的图像-文本对,推远不匹配的对。
SimGCL
核心思想
直接在嵌入空间中进行扰动,以实现更高效的数据增强
具体来说,SimGCL 对每个节点的嵌入向量添加小幅度的随机噪声
其中噪声 Δ 满足两个约束条件:
模长固定
方向一致
通过 嵌入空间扰动 实现图对比学习,有效调节表示的均匀性,从而提升推荐性能。
SimGCL 为图对比学习在推荐系统中的应用提供了一种轻量级、高效且有效的解决方案。
两个关键发现
CL 通过学习更均匀分布的用户/项目表示,隐式缓解了流行度偏差(popularity bias),这是其性能提升的关键
图增强(Graph Augmentation)在其中的作用被高估,实际上只起到了微不足道的作用
提出了一种无需图增强的简单对比学习方法
主要贡献
实验性揭示了CL提升推荐性能的原因:其本质在于 InfoNCE 损失的作用,而非图增强
提出了一种简单但有效的图增强无关的CL方法,通过噪声增强实现表征均匀性,为传统图增强方法提供了一个更优替代方案
Abstract¶
核心内容总结:
近年来,对比学习(Contrastive Learning, CL)在推荐系统领域引起了广泛研究兴趣,因其能够从原始数据中提取自监督信号,正好契合了推荐系统处理数据稀疏性问题的需求。当前基于CL的推荐模型通常包含两个步骤:
图增强(Graph Augmentation):通过结构扰动(如边删除)对用户-项目二部图进行增强;
对比学习:最大化不同增强图之间节点表示的一致性。
尽管这一方法已被证明有效,但其性能提升的内在机制仍不清晰。
本文通过实验揭示了以下两个关键发现:
CL 通过学习更均匀分布的用户/项目表示,隐式缓解了流行度偏差(popularity bias),这是其性能提升的关键;
图增强(Graph Augmentation)在其中的作用被高估,实际上只起到了微不足道的作用。
基于上述发现,作者提出了一种简单但有效的对比学习方法,摒弃图增强,转而通过在嵌入空间中添加均匀噪声来构建对比视图。
实验部分在三个基准数据集上进行,结果表明:
该方法虽然形式简单,但可以平滑地调节表示的均匀性;
在推荐准确率和训练效率方面,优于基于图增强的对比学习方法。
关键词(Keywords)
Self-Supervised Learning(自监督学习)
Recommendation(推荐)
Contrastive Learning(对比学习)
Data Augmentation(数据增强)
会议信息(Journal & Conference Info)
会议名称:第45届ACM SIGIR信息检索国际会议(2022年,西班牙马德里)
出版信息:《Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval》
版权信息:ACM
DOI:10.1145/3477495.3531937
ISBN:978-1-4503-8732-3
CCS分类:信息系统 > 推荐系统
总结
本文通过系统实验揭示了对比学习在推荐系统中提升性能的本质机制,指出其关键在于均匀表示的学习而非图增强。基于此,作者提出了一种无需图增强的简单对比学习方法,在多个指标上表现优越。结论具有重要的理论和实际意义,值得在推荐系统研究中深入思考与应用。
1. Introduction¶
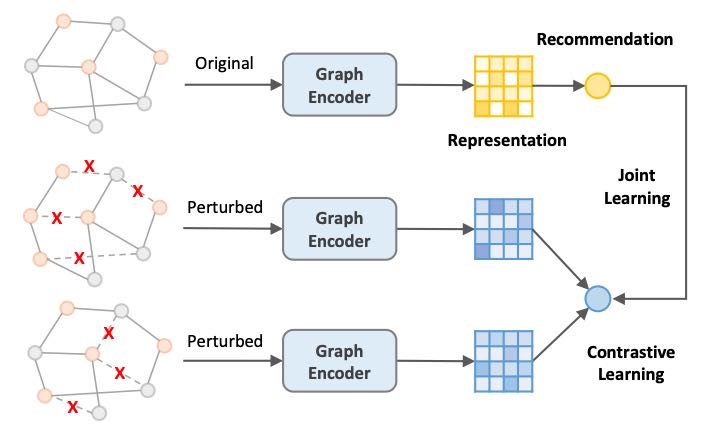
Figure 1: Graph contrastive learning with edge dropout for recommendation.
近年来,对比学习(Contrastive Learning, CL)在深度表征学习中重新受到关注,广泛应用于多个研究领域。由于CL能够在无需标注数据的情况下提取通用特征,并以自监督的方式正则化表征,因此在推荐系统等数据稀疏场景中具有天然优势。近期研究(如 Wu et al., 2021;Yu et al., 2021 等)尝试将CL应用于推荐系统,提出在用户-项目二分图中通过结构扰动(如随机边/节点丢弃)生成不同的图视图,并最大化这些视图下表征的一致性。这种CL任务作为辅助任务,与推荐任务联合优化(见图1)。
尽管CL在推荐中表现出色,但其性能提升背后的原因尚不明确。直觉上,人们认为通过丢弃冗余和杂质信息,对比不同图增强可以捕捉原始交互中的关键信息。然而最新研究(如 Yu et al., 2021a;Zhou et al., 2021b)却发现,即使使用极高丢弃率(如90%)的图增强,也能带来良好的性能,这一现象既反直觉又难以解释。
为了解决这一疑问,作者首先分别在有/无图增强的设置下进行了实验比较,结果发现即使不使用图增强,性能仍然可观。进一步分析CL与非CL方法的嵌入空间分布后发现,真正影响推荐性能的是对比损失(如InfoNCE),而非图增强本身。优化InfoNCE损失能够学习到更均匀分布的用户/项目表征,从而在一定程度上缓解流行度偏差问题。
尽管图增强并非无效——适度扰动有助于学习对干扰因素不变的表征——但它存在两个主要问题:效率低(需频繁重建图邻接矩阵)和鲁棒性差(关键边/节点丢失可能导致图结构断裂)。因此,作者提出一个重要问题:是否存在更有效、高效的数据增强方法?
本文对此问题给出了肯定答案。基于“表征分布的均匀性是关键”的发现,作者提出了一种无需图增强的CL方法,通过向原始表征中添加随机均匀噪声,实现表征层面的数据增强。这种方式在保持对比视图差异性的同时,能够控制噪声幅度以保留可学习的不变性,且相比图增强更易于实现、计算高效。
本文的主要贡献包括:¶
实验性揭示了CL提升推荐性能的原因:其本质在于InfoNCE损失的作用,而非图增强;
提出了一种简单但有效的图增强无关的CL方法,通过噪声增强实现表征均匀性,为传统图增强方法提供了一个更优替代方案;
在三个基准数据集上进行了全面实验验证,结果表明该方法在推荐准确率和模型训练效率方面均优于基于图增强的CL方法。
总结来看,该引言部分系统回顾了CL在推荐系统中的应用背景,指出现有方法的不足,提出了新的问题,并引出了本文的创新方法与贡献。
2. Investigation of Graph Contrastive Learning in Recommendation¶
在本章节中,作者对图对比学习(Graph Contrastive Learning, Graph CL)在推荐系统中的作用进行了系统性研究。主要分为三个部分:图对比学习在推荐中的应用、图增强的必要性分析,以及InfoNCE损失对性能的影响。
2.1. 图对比学习在推荐中的应用(Graph CL for Recommendation)¶
作者以SGL(Simple Graph Contrastive Learning)模型为例,分析了图对比学习在推荐系统中的核心思想和实现方式。SGL通过图增强(如节点/边丢弃)来生成两个不同的图表示,并采用InfoNCE损失函数来鼓励同一节点在不同增强图中的表示具有一致性,同时区分不同节点之间的表示。
模型整体训练目标为:
其中:
\(\mathcal{L}_{\text{rec}}\) 是传统的推荐损失(如BPR);
\(\mathcal{L}_{\text{cl}}\) 是对比学习损失(InfoNCE),其数学表达为:
文中进一步说明了图编码器LightGCN的基本结构,其节点表示通过多层图卷积进行信息传播。SGL通过在不同增强后的图中应用LightGCN,得到每个节点的两个表示,并将其输入对比学习损失函数进行联合优化。
2.2. 图增强的必要性(Necessity of Graph Augmentation)¶
作者探究了图对比学习中图增强的必要性。为此,他们提出了SGL-WA,即不使用图增强的对比学习版本。实验在Yelp2018和Amazon-Book两个数据集上进行,并对比了多个SGL变体的性能。结果如表1所示:
方法 |
Yelp2018 |
Amazon-Book |
|---|---|---|
LightGCN |
0.0639/0.0525 |
0.0410/0.0318 |
SGL-ND |
0.0644/0.0528 |
0.0440/0.0346 |
SGL-ED |
0.0675/0.0555 |
0.0478/0.0379 |
SGL-RW |
0.0667/0.0547 |
0.0457/0.0356 |
SGL-WA |
0.0671/0.0550 |
0.0466/0.0373 |
CL Only |
0.0245/0.0190 |
0.0314/0.0258 |
实验结果显示:
SGL-WA在不使用图增强的情况下,性能优于部分使用图增强的变体(如SGL-ND和SGL-RW);
CL Only(仅使用对比损失)性能较差,说明推荐任务中仅依赖对比学习是不够的;
图增强(尤其是节点丢弃和随机漫步)可能导致了图结构的严重破坏,从而影响表示学习。
作者进一步通过可视化节点表示的分布发现,SGL-WA的特征分布更加均匀。这表明对比学习本身(特别是InfoNCE损失)在提升推荐性能中起到了关键作用,而图增强可能反而引入了噪声或干扰。
2.3. InfoNCE损失的影响(InfoNCE Loss Influences More)¶
作者指出,对比学习在视觉领域的研究(如Wang and Isola, 2020)表明,InfoNCE损失会推动特征在单位超球面上更加对齐和均匀。作者将该观点引入推荐系统中,并通过特征可视化验证了这一现象。
通过t-SNE将高维表示降维到二维空间,并使用KDE进行密度估计,作者发现:
LightGCN的表示分布高度聚集,表明其存在表示退化的问题;
SGL-WA和SGL-ED的表示分布更均匀,说明对比学习有助于缓解表示退化;
使用信息熵分析(通过公式推导)发现,优化InfoNCE损失等价于最小化节点之间的余弦相似度,从而使得表示更加分散,增强泛化能力。
作者还指出:
InfoNCE损失具有去偏作用,能够缓解推荐系统中的流行度偏差问题;
但过度的均匀化可能导致推荐性能下降,因为它忽略了用户-物品之间的交互关系;
因此,对比学习的性能增益在一定范围内有效,但需注意平衡表示的均匀性和相关性。
总结¶
本章节的核心观点是:
图对比学习显著提升了推荐系统的性能,尤其在防止表示退化和缓解流行度偏差方面表现突出;
图增强的作用可能被高估,部分增强策略反而破坏了图结构;
InfoNCE损失是提升性能的关键因素,其核心机制是通过最小化节点之间的余弦相似度,使表示分布更均匀;
未来应进一步探索更稳健的对比学习方式,避免过度依赖图增强,并平衡均匀性与相关性。
这一研究对图对比学习在推荐系统中的应用提供了深入理解,并为后续方法优化提供了理论支持。
3. SimGCL: Simple Graph Contrastive Learning for Recommendation¶
本章介绍了SimGCL(Simple Graph Contrastive Learning)——一种用于推荐系统的简单图对比学习方法。SimGCL通过调节表示的均匀性来提升推荐性能,避免了传统图增强方法的复杂性与计算开销。
3.1. 动机与建模¶
传统的图增强方法,例如节点删除或边扰动,操作复杂且耗时。SimGCL 的核心思想是 直接在嵌入空间中进行扰动,以实现更高效的数据增强。
具体来说,SimGCL 对每个节点的嵌入向量添加小幅度的随机噪声,生成两个增强后的表示:
其中噪声 Δ 满足两个约束条件:
模长固定(即 \( \|\Delta\|_2 = \epsilon \));
方向一致(即 Δ 与原始嵌入在同一象限中),以保证增强后的表示与原表示保持相似,避免信息丢失。
SimGCL 使用 LightGCN 作为图编码器,逐层传播节点信息并加入扰动。最终的节点表示由多层扰动后的表示平均得到。与 SGL 和 LightGCN 不同,SimGCL 跳过输入层的嵌入,以提升性能。
SimGCL 的损失函数结合了 BPR 损失 和 对比学习损失,使用 Adam 优化器进行联合优化。
3.2. 调节表示的均匀性¶
SimGCL 通过两个超参数调节表示的均匀性:
λ:对比学习损失中的权重;
ε:噪声的幅度。
研究发现,ε 是调节均匀性的主要手段。更大的 ε 会导致增强表示偏离原始表示更远,从而提升表示空间的均匀性。这种均匀性越强,推荐系统对长尾用户和物品的鲁棒性也越高。
作者通过 Wang & Isola (2020) 提出的均匀性度量公式(基于高斯核的对数平均)验证了 SimGCL 的效果。实验表明:
SimGCL 能够在更早的训练阶段达到更高的均匀性;
即使 ε 很小(如 0.01),SimGCL 的均匀性也优于 SGL;
随着 ε 增大,SimGCL 的表示分布更均匀,推荐性能显著提升。
3.3. 时间复杂度与性能对比¶
SimGCL 相比传统图增强方法(如 SGL-ED)具有更低的计算开销,原因如下:
无需重复构建图结构,仅在训练开始时构建一次邻接矩阵;
增强操作在嵌入空间中完成,避免了复杂的图结构扰动;
GPU 加速图卷积计算,而 SGL-ED 的图扰动需在 CPU 上完成,效率更低。
作者通过理论分析与实验验证了 SimGCL 的时间复杂度优势,并将其与其他方法(如 LightGCN、SGL-ED)在多个基准数据集上进行比较。结果表明:
SimGCL 在 Recall 和 NDCG 指标上均优于现有方法;
在 1、2、3 层结构下均表现优异,性能提升显著(如在 Amazon-Book 数据集上 Recall 提升 28.6%);
SimGCL 不仅性能优异,而且训练效率更高,适合实际部署。
小结¶
本章提出 SimGCL 方法,通过 嵌入空间扰动 实现图对比学习,有效调节表示的均匀性,从而提升推荐性能。SimGCL 相比传统方法:
更简单高效:无需图结构扰动;
更稳健:对长尾用户和物品有更好的推荐能力;
更有效:在多个数据集上均表现优异。
SimGCL 为图对比学习在推荐系统中的应用提供了一种轻量级、高效且有效的解决方案。
4. Experimental Results¶
4.1. 实验设置¶
数据集:本文使用了三个公开基准数据集(Douban-Book, Yelp2018, Amazon-Book)进行实验,分别包含用户、物品和交互数量的不同规模。为了评估 Top-N 推荐效果,去除了 Douban-Book 中评分低于 4 的记录,并将其他评分设置为 1。数据集按 7:1:2 的比例划分为训练集、验证集和测试集。评估使用 Recall@20 和 NDCG@20 两个指标,并在所有物品上进行了 5 次实验以保证结果的可靠性。
基线方法:除了 LightGCN 和 SGL 变体外,还比较了几种基于数据增强的推荐方法,包括 Mult-VAE、DNN+SSL、BUIR 和 MixGCL。这些方法使用了不同的自监督或对比学习策略。
超参数:为了保证实验的公平性,所有方法使用相同的嵌入大小(64)、L2 正则化参数(1e-4)、批量大小(2048)和 Adam 优化器(学习率 0.001)。SimGCL 和 SGL 使用温度参数 τ=0.2,该值在 SGL 原始论文中被验证为最佳值。
4.2. SGL 与 SimGCL 的全面比较¶
本节从推荐性能、收敛速度、运行时间以及去偏能力四个方面对 SGL 与 SimGCL 进行比较。
4.2.1. 性能比较¶
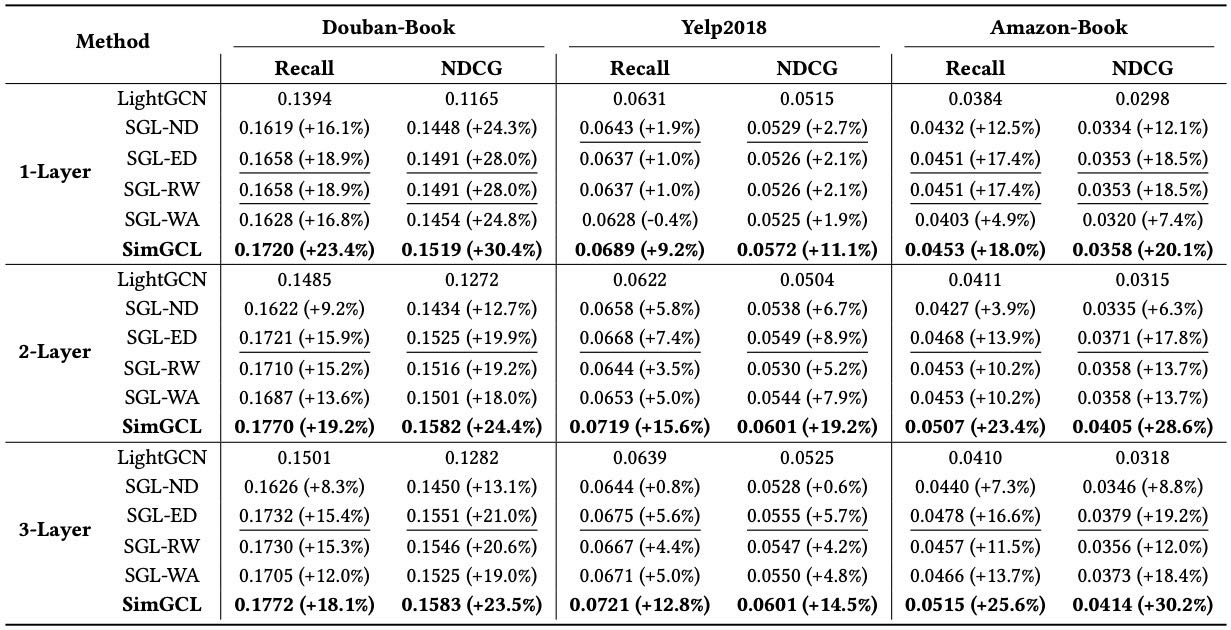
Table 3.Performance Comparison for different CL methods on three benchmarks.
SimGCL 在所有数据集上均优于 SGL 和 LightGCN,尤其在 Amazon-Book 数据集上,Recall 和 NDCG 分别提升了 25.6% 和 30.2%。
SGL 的变体中,SGL-ED 稳定性最好,而 SGL-ND 表现最差。这说明 SGL 的性能提升主要依赖于对比学习损失(CL loss),而非图增强本身。
SimGCL 在 Yelp2018 和 Amazon-Book 上显著优于 SGL 变体,表明其基于噪声的图增强方法更有效。
4.2.2. 收敛速度比较¶
SimGCL 较 SGL 收敛更快。在 Douban-Book、Yelp2018 和 Amazon-Book 上,SimGCL 分别在第 10、11 和 25 个 epoch 达到最佳性能,而 SGL-ED 则需 14 至 38 个 epoch。
SimGCL 的快速收敛归因于噪声提供了类似动量的梯度增量,从而加快训练过程。此外,SimGCL 的收敛速度明显优于 LightGCN,后者的收敛需数百个 epoch 才能完成。
4.2.3. 运行时间比较¶
SimGCL 的运行时间比 SGL-ED 快得多。例如,在 Amazon-Book 上,SGL-ED 比 LightGCN 慢 5.7 倍,而 SimGCL 仅慢 2.4 倍。
SimGCL 的运行效率远高于 SGL-ED,且在较少的 epoch 数下即可达到最佳性能,因此总体上更高效。
4.2.4. 去偏能力比较¶
SimGCL 通过对比学习损失(InfoNCE loss)有效缓解了流行度偏差,尤其在推荐长尾物品方面表现突出。
SimGCL 的推荐效果主要来源于“非热门”物品,而 LightGCN 倾向于推荐热门物品。SGL 变体的表现介于两者之间。
SimGCL 在推荐长尾物品上的优势符合推荐系统的实际需求,能够更好地提升用户体验。
4.3. 参数敏感性分析¶
4.3.1. λ 的影响¶
λ 是对比学习损失的权重。随着 λ 的增加,SimGCL 的性能先提升后下降。在不同数据集上,λ 的最佳值为 0.2、0.5、2。
λ 调整在一定程度上可以调节模型性能,但其调节粒度不如 ϵ 精细,说明 ϵ 对性能有更直接的影响。
4.3.2. ϵ 的影响¶
ϵ 是噪声的幅度。较小的 ϵ(约 0.1)有助于模型稳定和去偏,但过大的 ϵ 会导致节点之间的相似性丢失,从而影响推荐效果。
嵌入初始化使用均匀分布(如 Xavier)比高斯分布提升了 3%-4% 的性能,说明初始化方式对模型也有一定影响。
4.4. 与其他方法的性能比较¶
SimGCL 在 Recall 和 NDCG 指标上显著优于 Mult-VAE、DNN+SSL、BUIR 和 MixGCF。
LightGCN、MixGCF 和 SimGCL 均基于图卷积机制,因此在建模图数据上优于基于 VAE 的 Mult-VAE。
DNN+SSL 在没有用户/物品特征的条件下表现不佳,BUIR 由于使用 Siamese 结构并忽略负样本,导致其性能不稳定。
SimGCL 在长尾物品推荐能力上优于所有基线方法,说明其设计更贴合推荐系统的实际需求。
4.5. 不同噪声类型的性能比较¶
SimGCL 使用的是均匀分布噪声(Uniform noise),还测试了高斯噪声(Gaussian noise)、对抗噪声(Adversarial noise)和正向均匀噪声(Positive uniform noise)。
高斯噪声(SimGCLg)与均匀噪声(SimGCLu)表现相近,因为归一化后高斯分布接近均匀分布。
对抗噪声(SimGCLa)表现较差,因为其仅关注对比学习损失,而推荐任务的损失主导了优化过程。
正向均匀噪声(SimGCLp)略有下降,说明 SimGCLu 的方向性约束有助于生成更有效的增强样本。
总结¶
SimGCL 在多个方面优于 SGL 和其他对比方法:
性能:SimGCL 在推荐精度、长尾物品推荐方面表现更优。
效率:SimGCL 收敛更快且运行时间更短。
去偏能力:SimGCL 能有效缓解流行度偏差,提升个性化推荐效果。
参数鲁棒性:SimGCL 对噪声参数(ϵ)较敏感,但可通过合理设置获得稳定性能。
泛化能力:SimGCL 在不同噪声类型下均表现良好,尤其在基于对比学习的推荐任务中具有广泛适用性。
6. Conclusion¶
本文重新审视了基于Dropout的对比学习(CL)在推荐系统中的应用,并探讨了它如何提升推荐性能。研究发现,在CL推荐模型中,CL损失函数是核心因素,而图增强仅起到了次要的作用。
通过优化CL损失,可以引导表示分布更加均匀,这种均匀性有助于缓解推荐场景中的偏差问题。为了进一步简化和提升效果,作者提出了一种不依赖图增强的CL方法,它能够以更直接的方式调节表示分布的均匀性。
该方法通过对不同数据增强的表示加入有方向的随机噪声,能够在对比学习中显著提升推荐效果。大量实验结果表明,与基于图增强的方法相比,新方法在效果上更优,同时训练时间也大幅减少。
重点总结如下:
CL损失是提升推荐性能的核心,图增强作用较小;
表示分布的均匀性有助于缓解推荐偏差;
提出的新方法无需图增强,使用随机噪声调节表示分布;
实验结果显示新方法在性能和效率上均优于现有方法。
Acknowledgement¶
本研究得到了澳大利亚研究理事会的资助,具体包括未来研究员奖学金(项目编号:FT210100624)、发现项目(项目编号:DP190101985)以及早期职业研究员发现奖(项目编号:DE200101465)。以上资助对本工作的顺利开展起到了重要作用。