2306.13394_MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models¶
引用: 1871(2025-07-24)
组织:
1Tencent Youtu Lab
2Xiamen University
GitHub: https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation
总结¶
简介
多模态大语言模型的综合评估基准
设计理念
全面性:涵盖感知和认知能力
感知包括粗粒度和细粒度对象识别
认知包括常识推理、数学计算、翻译和代码推理。
数据独立性:避免使用现有公开数据集,以防止数据泄露问题。
简洁指令:指令设计简洁且符合人类认知,以保证公平比较。
量化分析:通过“是/否”型回答,便于定量统计和评估。
MME Evaluation Suite
包含三个部分
指令设计(Instruction Design)
目标是引导模型仅输出“yes”或“no”两种答案
对于每张测试图像,研究人员手动设计两条指令,其中第一条问题的答案为“yes”,第二条为“no”。
只有当模型能正确回答两条问题时,才认为模型真正理解图像内容及其背后的知识
评估指标(Evaluation Metric)
Accuracy(准确率):基于每条问题的正确率。
Accuracy+(更严格的准确率):基于每张图像,要求两个问题都要正确回答
数据收集(Data Collection)
感知任务(Perception Tasks)
粗粒度识别(Coarse-Grained Recognition)
细粒度识别(Fine-Grained Recognition)
OCR
认知任务(Cognition Tasks)
常识推理(Commonsense Reasoning)
如,给出羽绒服图片,判断是否适合在寒冷天气穿着
数值计算(Numerical Calculation)
仅包含加法和乘法等简单问题
文本翻译(Text Translation)
代码推理(Code Reasoning)
目的:系统地评估多模态大语言模型(MLLMs)在视觉理解与认知推理上的综合能力。
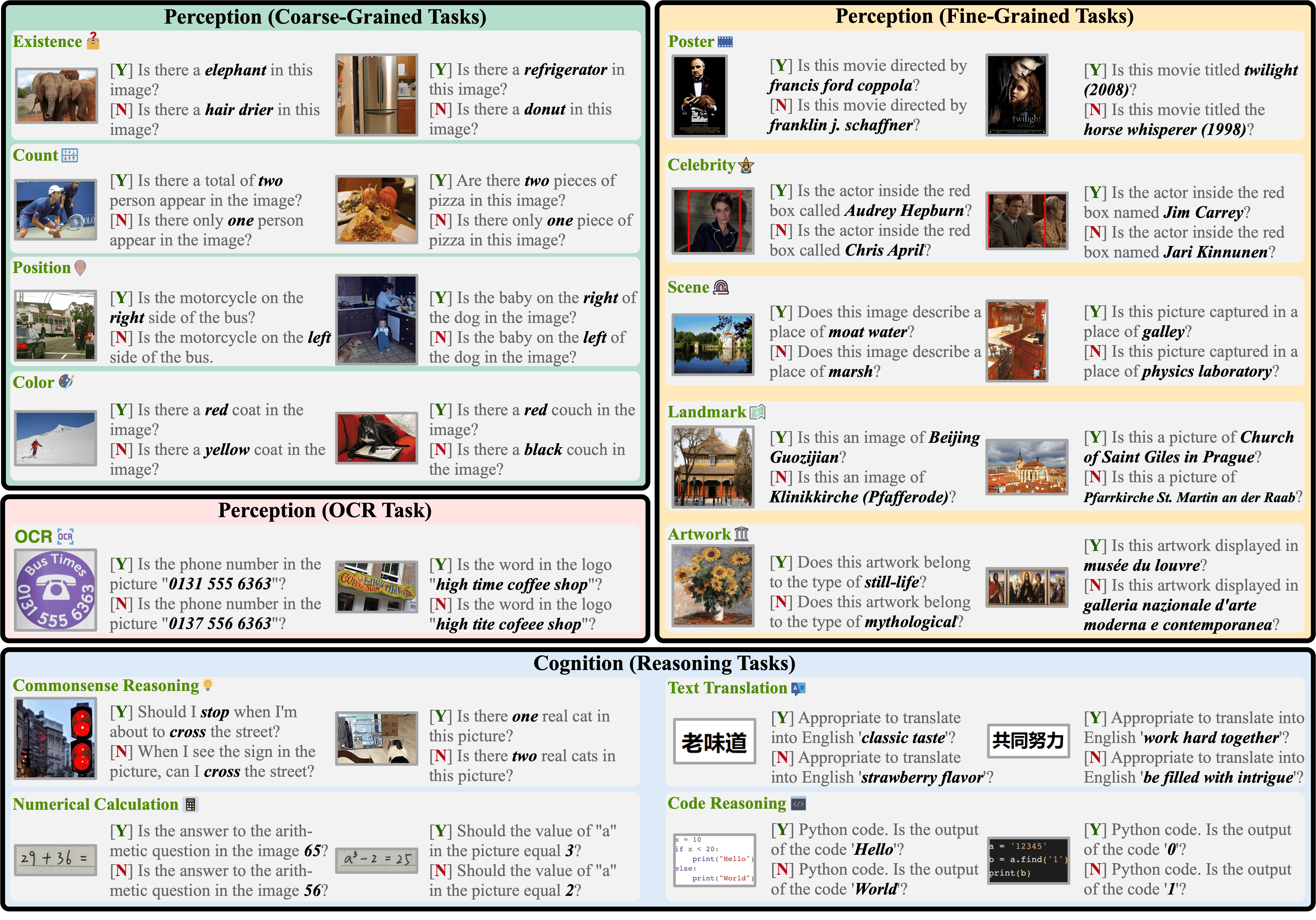
Figure 1:Diagram of our MME benchmark. It evaluates MLLMs from both perception and cognition, including a total of 14 subtasks. Each image corresponds to two questions whose answers are marked yes [Y] and no [N], respectively. The instruction consists of a question followed by “Please answer yes or no”. It is worth noting that all instructions are manually designed.
LLM 总结¶
该论文章节介绍了 MME(Multimodal Massive Evaluation),这是一个针对多模态大语言模型的综合评估基准。文章的主要目的是提出MME作为评估多模态模型在处理图像和文本任务方面性能的工具。
核心内容总结如下:¶
背景与动机:
随着多模态大语言模型(Multimodal LLMs)的快速发展,评估模型在不同任务上的综合能力变得尤为重要。
现有的评估基准通常局限于单一任务或特定领域,缺乏对多模态模型进行全面、系统评估的能力。
因此,作者提出MME,以提供一个覆盖多种视觉语言任务、具有挑战性的评估框架。
MME的构成:
MME包含多个任务类别,涵盖从基础理解到复杂推理的多种能力,例如:图像描述生成、视觉问答、文本到图像生成、多模态逻辑推理等。
该基准集整合了多个现有数据集,并新增了部分高质量标注数据,以增强评估的全面性和多样性。
评估维度:
MME从多个维度评估模型性能,包括准确性、鲁棒性、可解释性、泛化能力等。
提供了定量指标和定性分析,使研究者可以全面了解模型的优缺点。
实验与分析:
作者在多个领先的多模态大语言模型上进行了测试,验证了MME的有效性和区分能力。
实验结果显示,当前模型在某些任务上表现良好,但在复杂推理和跨模态理解方面仍存在明显不足。
意义与贡献:
MME为多模态大语言模型的研究和开发提供了统一、系统的评估平台。
有助于推动模型在多模态任务中的性能提升和实际应用。
总结:¶
这篇文章提出MME作为多模态大语言模型的综合评估基准,旨在全面衡量模型在视觉与语言联合任务中的能力。它通过整合多种任务和评估指标,为研究者提供了一个更具挑战性和现实意义的测试平台,有助于推动多模态AI技术的发展。
Abstract¶
本文提出首个全面的多模态大语言模型(MLLM)评估基准MME,旨在填补当前对MLLM性能评估不足的问题。MME由厦门大学为学术研究收集,包含14个子任务,涵盖感知和认知能力的评估。为了避免数据泄露问题,所有指令-答案对均由人工设计,指令简洁,便于公平比较不同模型,而无需依赖复杂的提示工程。通过对30个先进MLLM的全面评估,研究发现现有模型仍有较大提升空间,并揭示了未来的优化方向。该评估体系及相关在线排行榜已开源发布在GitHub。
1 Introduction¶
本章节主要介绍了多模态大语言模型(MLLM)的发展及其带来的新兴能力,同时指出了当前对MLLM进行全面评估的不足,并提出了一种新的评估基准——MME(Multimodal Large Language Model Evaluation Benchmark),以全面衡量MLLM在感知和认知能力上的表现。
主要内容总结:¶
MLLM的发展与能力:
大语言模型(LLM)的兴起推动了多模态领域的快速发展,MLLM通过将LLM作为“大脑”,能够处理多模态信息并进行推理。
MLLM继承了LLM的三大能力:指令跟随、上下文学习(ICL)和链式推理(CoT),并将其扩展到多模态任务中。例如,Flamingo支持多模态的ICL,PaLM-E实现了OCR-free的数学推理,GPT-4V和MiniGPT-4具备多模态指令跟随能力。
MLLM在多种复杂推理任务中表现出色,预示着人工智能进入了一个新的发展阶段。
现有评估方法的局限性:
当前对MLLM的评估方法存在局限性:
方法一依赖传统多模态数据集,但难以反映MLLM的新兴能力。
方法二使用开放式评估数据,存在数据不可公开或数量过少的问题。
方法三仅关注单一方面,如幻觉或鲁棒性,无法全面评估模型。
因此,迫切需要一种更全面、公正的评估基准。
MME评估基准的设计理念:
MME是符合四个关键设计目标的多模态大语言模型评估基准:
全面性:涵盖感知和认知能力,感知包括粗粒度和细粒度对象识别,认知包括常识推理、数学计算、翻译和代码推理。
数据独立性:避免使用现有公开数据集,以防止数据泄露问题。
简洁指令:指令设计简洁且符合人类认知,以保证公平比较。
量化分析:通过“是/否”型回答,便于定量统计和评估。
MME的评估结果与实验:
在MME上,对30种先进的MLLM模型进行了零样本评估,结果显示各模型在感知和认知任务上的表现存在显著差异。
通过实验,作者总结出MLLM在实际使用中暴露的四大问题,如基本指令执行能力差、感知与推理能力不足、对象幻觉等,这些发现对模型优化具有指导意义。
贡献总结:
提出了MME这一新的、全面的多模态大语言模型评估基准。
评估了30种最新的MLLM模型,展示了其在MME上的表现。
总结了实验中发现的问题,为MLLM的发展和优化提供了参考。
总之,本章节重点提出了MME评估基准的设计背景、目标及其在实验中的应用,并为多模态大语言模型的评估和发展提供了新的思路和方向。
2 MME Evaluation Suite¶
本章节介绍了MME评估套件(MME Evaluation Suite)的设计与实现,主要包含三个部分:指令设计(Instruction Design)、评估指标(Evaluation Metric) 和 数据收集(Data Collection),目的是系统地评估多模态大语言模型(MLLMs)在视觉理解与认知推理上的综合能力。
2.1 指令设计(Instruction Design)¶
为便于量化性能评估,指令设计的目标是引导模型仅输出“yes”或“no”两种答案。每条指令由两个部分组成:一个简洁的问题和一个明确的回答指示“Please answer yes or no.”。
对于每张测试图像,研究人员手动设计两条指令,其中第一条问题的答案为“yes”,第二条为“no”。只有当模型能正确回答两条问题时,才认为模型真正理解图像内容及其背后的知识,而非随机猜测。这种设计有助于评估模型是否具备真正的理解能力。
2.2 评估指标(Evaluation Metric)¶
由于模型的输出仅限于“yes”或“no”,因此可以方便地计算以下两个评估指标:
Accuracy(准确率):基于每条问题的正确率。
Accuracy+(更严格的准确率):基于每张图像,要求两个问题都要正确回答。
两个指标的随机猜测准确率分别为 50% 和 25%。其中,Accuracy+ 是一个更严格的评估指标,更能反映模型对图像的综合理解能力。
此外,还计算了子任务得分,每个子任务的得分是 Accuracy 与 Accuracy+ 的总和。感知任务和认知任务的总分分别为 2000 和 800。每个子任务的满分为 200。
2.3 数据收集(Data Collection)¶
数据集分为感知任务和认知任务两大类:
2.3.1 感知任务(Perception Tasks)¶
感知是 MLLMs 的基础能力,缺乏感知能力容易导致“幻觉”(hallucination)问题,即模型基于想象而非图像内容进行回答。
粗粒度识别(Coarse-Grained Recognition):包括识别对象的存在、数量、颜色和位置。数据来自 COCO 数据集,但指令和答案是人工设计的,确保不在训练集出现。每个子任务包含 30 张图像和 60 条指令-答案对。
细粒度识别(Fine-Grained Recognition):测试模型的知识储备能力,包括识别电影海报、名人、场景、地标和艺术品。各子任务分别包含 147、170、200、200、200 张图像,指令人工设计,例如通过在图像中加红框并询问“红框中的人是否是[名人名]”。
OCR(Optical Character Recognition):测试模型的光学字符识别能力,作为文本相关任务(如翻译、理解)的基础。数据来自公开数据集,指令与答案人工设计,共 20 张图像和 40 条指令-答案对。
2.3.2 认知任务(Cognition Tasks)¶
认知任务评估模型在感知图像后进行逻辑推理的能力,是 MLLM 相比传统方法更具优势的方面。要求模型结合指令、图像内容与语言模型中的知识进行综合判断。
常识推理(Commonsense Reasoning):评估模型对日常常识的理解。例如,给出羽绒服图片,判断是否适合在寒冷天气穿着。图像和指令均人工设计,共 70 张图像和 140 条指令-答案对。
数值计算(Numerical Calculation):模型需识别图像中的数学问题并输出答案。当前版本仅包含加法和乘法等简单问题,共 20 张图像和 40 条指令-答案对。
文本翻译(Text Translation):模型需将中文文本翻译为英文。考虑到当前 MLLM 的能力,仅设置基础翻译问题,未来将扩展。共 20 张图像和 40 条指令-答案对。
代码推理(Code Reasoning):模型需理解图像中的代码并完成逻辑运算。当前版本仅包含基础代码问题,共 20 张图像和 40 条指令-答案对。
总结¶
MME 评估套件通过精心设计的指令、严格的评估指标和多样化的数据集,系统评估了 MLLMs 在视觉感知和认知推理方面的综合能力。该套件不仅涵盖了基础的图像识别与 OCR 任务,还包括高级的常识推理、数值计算、翻译和代码理解任务,为 MLLM 的发展提供了全面的评估框架。
3 Experiments¶
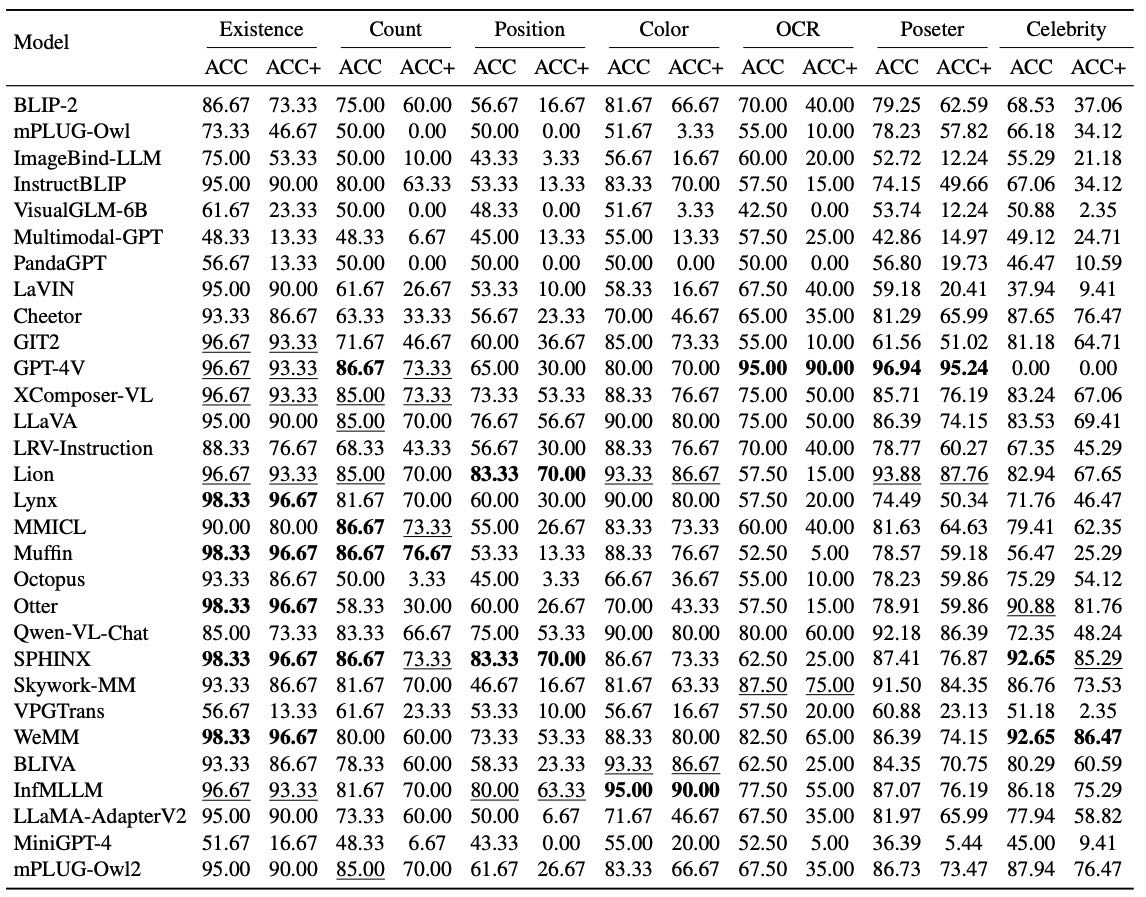
Table 1. Evaluation results on the subtasks of existence, count, position, color, OCR, poster, and celebrity. The top two results on each subtask are bolded and underlined, respectively.
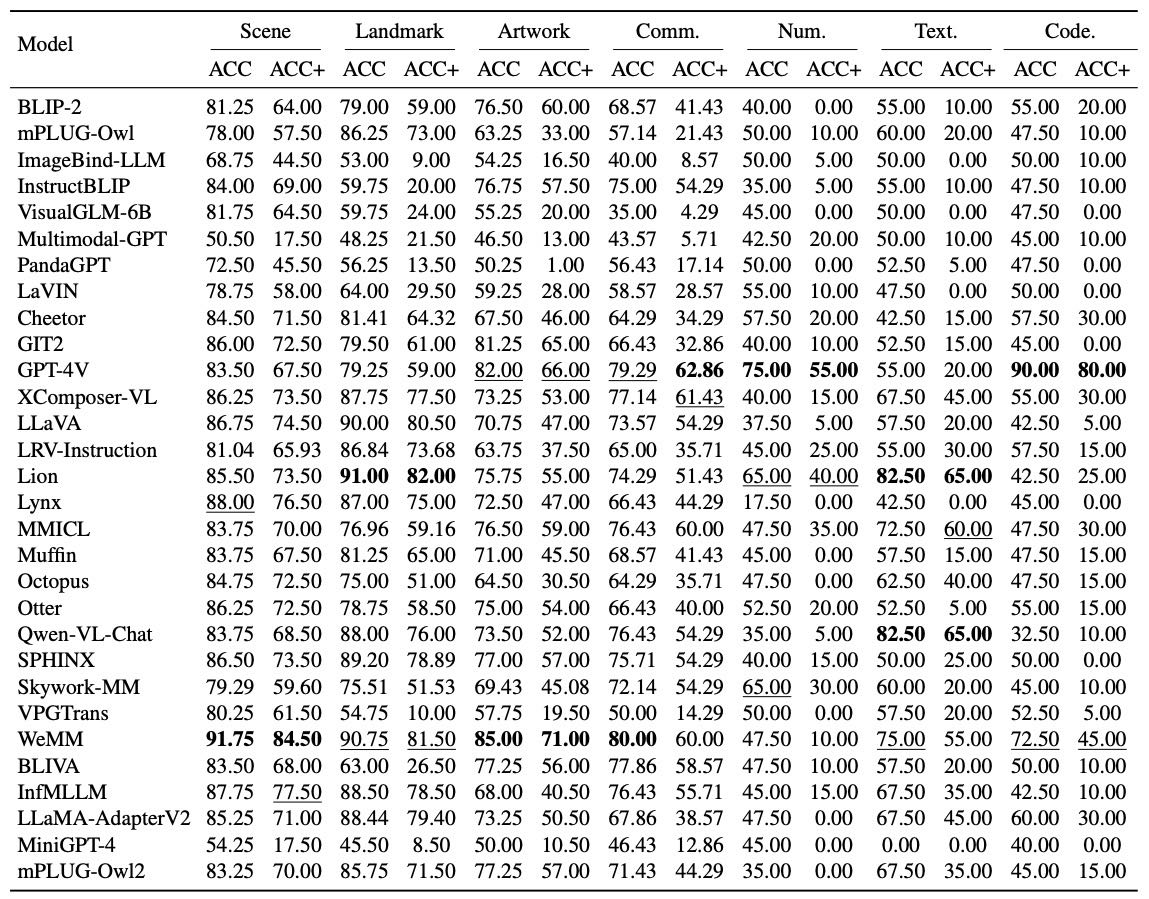
Table 2. Evaluation results on the subtasks of scene, landmark, artwork, commonsense reasoning, numerical calculation, text translation, and code reasoning. The top two results on each subtask are bolded and underlined, respectively.
实验部分总结¶
在实验部分,研究者评估了 30 个当前主流的多模态大语言模型(MLLMs) 在 MME 基准 上的表现,涵盖了 感知(Perception) 和 认知(Cognition) 两大类任务。
3.1 感知能力评估¶
感知任务包括 10 个子任务,主要从 粗粒度识别(coarse-grained recognition)、细粒度识别(fine-grained recognition) 和 OCR(光学字符识别) 三个方面进行评估。
粗粒度识别 包括对象存在性、数量、位置和颜色等任务。模型在对象存在性任务上表现较好,如 Otter、Lynx、WeMM 等模型得分最高;但在 对象位置识别 上表现较弱,说明当前模型对位置信息的敏感度仍有限。
细粒度识别 包括海报识别、名人识别、场景识别、地标识别、艺术作品识别等任务:
GPT-4V、Lion、Qwen-VL-Chat 在海报识别上表现出色;
WeMM、SPHINX、Otter 在名人识别上领先;
WeMM、InfMLLM、Lynx 在场景识别上首次进入前三;
Lion、WeMM、LLaVA 在地标识别中表现突出;
WeMM、GPT-4V、GIT2 在艺术作品识别中领先。
OCR 任务 中,GPT-4V 显著领先,得分为 185,远超其他模型。
总体排名前三位 的模型是 WeMM、InfMLLM、SPHINX,紧随其后的是 Lion、LLaVA 和 XComposer-VL。
3.1.2 认知能力评估¶
认知任务包括 常识推理、数值计算、文本翻译和代码推理 四个子任务。
常识推理 中,GPT-4V、WeMM 和 XComposer-VL 显著领先。
数值计算 中同样 GPT-4V 表现最佳,但在 文本翻译 上略有不足。
代码推理 是 GPT-4V 的强项,得分高达 170,远超其他模型。
整体认知任务排名前三 的模型为 GPT-4V、Lion 和 WeMM。
总结¶
该实验全面评估了 30 个 MLLMs 在 MME 基准上的表现,揭示了各模型在感知和认知任务中的优势与不足。研究发现:
模型在 粗粒度识别(如对象存在、数量)上表现较强;
在 位置识别 等任务上仍有较大提升空间;
GPT-4V 在 OCR 和代码推理 上具有明显优势;
WeMM、Lion、InfMLLM 等模型在多个任务中表现出色;
当前 MLLMs 在 认知类任务(尤其是常识推理、翻译)上仍有提升空间。
该研究为 MLLMs 的发展提供了重要的评估视角和改进建议。
4 Analysis¶
本章节分析了多模态大语言模型(MLLMs)在实际应用中存在的一些常见问题,主要总结为以下四点:
不遵循指令:尽管指令设计简洁明确,部分模型仍会忽略指令要求,自由作答。例如,指令要求“请回答是或否”,但模型给出的是陈述句而非“yes”或“no”。这种现象表明模型在指令理解与执行方面仍有不足,尤其在经过指令微调后更应具备这种基本能力。
感知能力不足:模型在图像识别方面表现不稳定。例如,模型错误识别香蕉数量或图像中的文字,导致答案错误。同时,感知能力对指令的细微变化非常敏感,有时仅一字之差就会导致完全不同的结果。
推理能力缺失:尽管模型在某些情况下能够正确感知信息,但在逻辑推理过程中仍会出现错误。例如,模型识别出图像不是办公室场景,却仍回答“是”;或虽正确计算了数值,但最终答案错误。这表明模型在推理链的连贯性上存在问题。引入类似“让我们一步步思考”的推理提示(CoT)可能有助于改善这一问题。
对象幻觉:当指令中提及图像中并不存在的物体时,模型可能会“想象”该物体存在,并据此给出“是”的回答。这种现象导致模型在某些测试中的准确率仅为50%左右,甚至在更严格的标准下为0%。因此,抑制模型的幻觉问题已成为提升其可靠性的关键任务。
总体而言,这些发现揭示了当前MLLMs在指令遵循、感知、推理和可靠性方面仍存在的缺陷,为后续改进模型性能提供了研究方向。
5 Conclusion¶
本文总结部分指出,该研究提出了首个针对多模态大语言模型(MLLM)的评估基准MME,并突出了其在任务类型、数据来源、指令设计和定量统计方面的四个显著特点。作者在MME上评估了30种先进的MLLM,实验结果表明这些模型仍有较大的提升空间。此外,文章还总结了实验中暴露出的常见问题,为MLLM的未来发展提供了有价值的指导。