2512.10696_Framework for Experience-Driven Agent Evolution¶
引用:
组织:
Google DeepMind
University of Illinois Urbana-Champaign
网站
数据集地址:reme.library 和 reme.website
总结¶
重点
强调 LLM Agent 需在部署期间持续检索、集成和更新记忆
图解¶
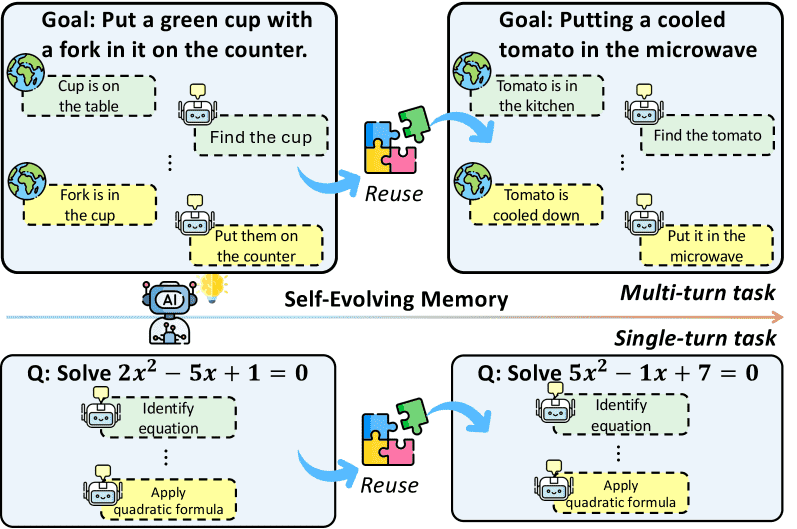
Figure 2:Illustration of different task types and experience reusing.
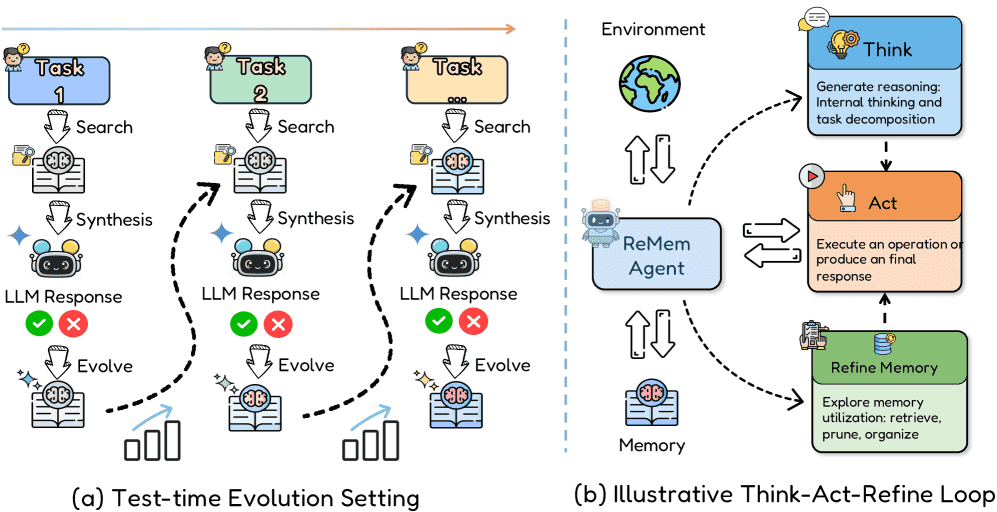
Figure 3:Overview of the ReMem agent framework.
Left: Test-time evolution process where the agent iteratively searches, synthesizes, and evolves its memory across multiple tasks.
Right: Agent architecture with three core modules—Think (reasoning and decomposition), Refine Memory (retrieve, prune, organize), and Act (execution)—that interact with the environment and learned memory.
From Moonlight¶
三句摘要¶
💡 Evo-Memory是一个全面的流式基准测试和框架,旨在解决现有LLM记忆评估在持续任务流中忽视测试时学习和经验重用能力的不足。
📊 该基准将数据集重构为顺序任务流,要求LLM在每次交互后搜索、适应和演化其记忆,并引入了ExpRAG基线和ReMem(action–think–memory refine)管道来促进持续改进。
🚀 实验结果表明,ReMem等自演化记忆方法在多轮任务中显著提升了性能,提高了效率,并增强了面对不同任务难度和失败经验时的鲁棒性,突显了动态记忆管理的关键作用。
关键词¶
Agentic Memory: 代理记忆(Agentic Memory)是指用于大型语言模型(LLM)代理的记忆机制。它对于代理维护跨交互的状态、积累经验、适应策略以及执行长期规划和解决问题至关重要。与仅限于检索对话历史的静态记忆不同,代理记忆强调动态地积累、整合和更新信息,以支持代理在持续任务流中的表现。
Test-time Learning: 测试时学习(Test-time Learning, TTL)是指模型在部署阶段(即推理或测试时)能够适应分布变化并进行自我改进的能力。它建立在测试时自适应(Test-time Adaptation, TTA)工作的基础上,允许模型通过在线优化来调整其行为,从而在部署过程中持续提升性能。本文将 TTL 的概念应用于 LLM 代理的记忆演化,以评估模型在实际应用中学习和适应的能力。
Self-evolving Agents: 自我演化代理(Self-evolving Agents)是指能够自主修改计划、综合反馈并协同演化的智能体。这种能力使得代理能够从与环境的互动中持续学习和进步,从而适应不断变化的任务和环境。本文提出的 Evo-Memory 基准正是为了评估 LLM 代理在测试时进行自我演化,特别是通过记忆的更新和重组来实现这种演化。
Evo-Memory: Evo-Memory 是本文提出的一套全面的流式(streaming)基准和框架,用于评估 LLM 代理的自我演化记忆能力。它将数据集结构化为连续的任务流,要求 LLM 在每次交互后搜索、适应和演化其记忆。Evo-Memory 旨在弥合静态对话记忆检索与跨演化任务流的经验积累和重用之间的差距,并提供一个统一的平台来评估不同记忆模块的适应性、效率和稳定性。
Experience Reuse: 经验重用(Experience Reuse)是指 LLM 代理从过去的交互或任务中学习到的知识、策略或解决方案,并在未来的任务中重新利用这些经验的能力。与仅仅检索过去的对话事实(Conversational Recall)不同,经验重用更侧重于抽象出推理策略,从而提升未来解决相似或相关问题的效率和效果。Evo-Memory 的一个核心目标就是评估和增强这种能力。
ReMem: ReMem 是本文提出的一个先进的、用于实现自我演化记忆的代理框架。它采用一种“行动-思考-记忆优化”(action–think–memory refine)的流水线,能够紧密整合推理、任务行动和记忆更新。ReMem 允许代理在解决问题的过程中主动评估、重组和演化其记忆,从而实现持续改进,它扩展了 ReAct 风格代理的行动空间,将记忆视为一个与推理实时交互的动态组件。
ExpRAG: ExpRAG(Experience Retrieval and Aggregation)是本文提出的一个用于经验重用的基线方法,它是一种任务级别的检索增强代理。ExpRAG 通过检索过去相似的任务经验,并将其作为上下文信息用于当前任务的推理,从而实现“一次性”的经验重用。它捕获了基于检索的上下文学习(in-context learning)方法在经验重用方面的行为,但缺乏迭代推理或推理时的自适应优化能力。
摘要¶
该论文介绍了 Evo-Memory,一个用于评估 LLM Agent 在“Test-time Learning”(测试时学习)中自进化记忆(self-evolving memory)的综合性基准和框架。现有评估多集中于静态对话设置中的记忆被动检索,忽略了 LLM Agent 在持续任务流中积累和重用经验的动态能力。为弥补这一空白,Evo-Memory 提出了一种全新的视角,强调 LLM Agent 需在部署期间持续检索、集成和更新记忆。
核心问题与贡献:
问题陈述: 尽管 LLM 已在推理、规划和工具使用方面取得显著进展,但其记忆管理和进化能力仍未被充分探索。现有系统多停留在“Conversational Recall”(对话回忆),即被动地从对话中检索信息来回答查询,而非“Experience Reuse”(经验重用),即从积累的交互中学习以改进未来的推理或决策。这导致 LLM Agent 在处理连续任务流时常无法从过往经验中学习,失去宝贵的上下文洞察力。
主要贡献:
基准 (Benchmark): Evo-Memory 将数据集重构为序列化的任务流,要求 LLM 在每次交互后搜索、适应和进化记忆。它涵盖了多回合目标导向型(multi-turn goal-oriented)任务和单回合推理/问答(single-turn reasoning/QA)任务,旨在评估 LLM Agent 在部署期间积累知识和优化策略的能力,即“Test-time Evolution”。
框架 (Framework): 统一并实现了十余种代表性记忆模块(包括检索式、工作流式和分层记忆系统),并提供以记忆为中心的评估指标,用于分析适应性、效率和稳定性。
分析与洞察 (Analysis and Insights): 引入了 ExpRAG 作为检索和利用先前经验的基线方法,并提出了 ReMem——一种行动-思考-记忆精炼(action–think–memory refine)流水线,紧密整合推理、任务行动和记忆更新,以实现持续改进。
核心方法学(深入与技术细节):
论文将记忆增强型 Agent 形式化为一个元组 \((\mathcal{F}, \mathcal{U}, \mathcal{R}, \mathcal{C})\):
\(\mathcal{F}\) 是基础 LLM。
\(\mathcal{U}\) 是记忆更新流水线。
\(\mathcal{R}\) 是检索模块。
\(\mathcal{C}\) 是上下文构建机制,将检索到的内容转换为最终的工作上下文。
Agent 处理输入序列 \(\{x_1, x_2, \dots, x_T\}\),记忆状态 \(M_t\) 随历史演变。在时间步 \(t\),Agent 接收输入 \(x_t\),维护进化的记忆 \(M_t\),并执行以下循环:
Search (检索): Agent 根据当前输入 \(x_t\) 从记忆 \(M_t\) 中检索相关记忆条目: \(R_t = \mathcal{R}(M_t, x_t)\) 其中 \(\mathcal{R}\) 可以是相似性搜索、基于索引的查找或对存储嵌入的注意力机制。
Synthesis (合成): Agent 解释并将检索到的信息 \(R_t\) 重构为与当前输入 \(x_t\) 对齐的简洁工作上下文 \(\tilde{C}_t\)。这可能涉及构建结构化提示、选择关键记忆项或合并检索到的内容。最终输出由基础 LLM 生成: \(\hat{y}_t = \mathcal{F}(\tilde{C}_t)\) 其中 \(\tilde{C}_t = \mathcal{C}(x_t, R_t)\)。
Evolve (进化): 获得 \(\hat{y}_t\) 后,Agent 构建一个新的记忆条目 \(m_t = h(x_t, \hat{y}_t, f_t)\),其中 \(f_t\) 捕获了当前步骤的经验及反馈(如任务是否完成)。记忆随后通过 \(\mathcal{U}\) 更新: \(M_{t+1} = \mathcal{U}(M_t, m_t)\) \(\mathcal{U}\) 的具体实现因算法而异,例如直接追加、摘要压缩或替换。
ExpRAG (Experience Retrieval and Aggregation): 作为一种简单的基线方法,ExpRAG 是一个任务级别的检索增强型 Agent。每个记忆条目 \(m_i = S(x_i, \hat{y}_i, f_i)\) 编码了一个结构化的经验文本。在时间步 \(t\),Agent 根据检索分数 \(\phi\) 从记忆 \(M_t\) 中检索 \(k\) 个相似的经验: \(R_t = \text{Top-}k_{m_i \in M_t} \phi(x_t, m_i)\) 模型利用这些检索到的例子,遵循“in-context learning”原则生成输出: \(\hat{y}_t = \mathcal{F}(x_t, R_t)\) 并将新经验追加到记忆中: \(M_{t+1} = M_t \cup \{(x_t, \hat{y}_t, f_t)\}\) ExpRAG 通过检索和聚合执行一次性经验重用,捕捉了简单记忆扩展的行为,但缺乏迭代推理或适应性精炼。
ReMem (Synergizing Reasoning, Acting, and Memory): ReMem 是一种将推理、行动和记忆精炼统一在一个决策循环中的框架。它扩展了传统的 ReAct-style Agent,引入了第三个维度:记忆推理(memory reasoning)。在每个时间步 \(t\),给定当前输入 \(x_t\)、记忆状态 \(M_t\) 和之前在该步骤的推理轨迹 \(o^{1:n-1}_t\),Agent 选择三种操作之一 \(a^n_t \in \{\text{Think, Act, Refine}\}\)。然后执行操作并根据以下方式进行转换: \(o^n_t = \text{Agent}(x_t, M_t, a^n_t)\) 其中 \(o^n_t\) 表示在 \(n\) 次操作后在时间步 \(t\) 生成的输出,例如中间推理轨迹、外部行动或记忆精炼思考。
Think: 产生内部推理轨迹,帮助分解任务并指导后续行动。
Act: 在环境中执行操作或产生用户可观察的最终响应。
Refine: 对记忆执行元推理(meta-reasoning),以利用有用经验、清除噪声并重组 \(M_t\),更好地支持未来的推理和行动。 在一个步骤中,Agent 可以执行多轮 Think 和 Refine,并在选择 Act 操作后终止该步骤。这诱导了一个马尔可夫决策过程,其中在 \(n\) 次操作后,时间步 \(t\) 的状态为 \(s^n_t = (x_t, M_t, o^{1:n-1}_t)\)。通过将反射与记忆进化相结合,ReMem 为自适应、自改进的 LLM Agent 建立了新标准。
实验设置与结果:
数据集: Evo-Memory 在多样化的数据集上进行评估:
单回合 (Single-turn): MMLU-Pro (多学科推理), GPQA-Diamond (研究生级别问答), AIME-24/25 (奥林匹克数学问题), ToolBench (工具使用和 API 接地)。
多回合 (Multi-turn): Alf World (家庭指令遵循), BabyAI (接地导航), ScienceWorld (科学实验), Jericho (文本游戏), PDDL tasks (符号规划)。
评估指标: 答案准确率 (Answer accuracy)、成功率 (Success rate)、进度率 (Progress rate)、步骤效率 (Step efficiency)、序列鲁棒性 (Sequence robustness)。
LLM 基座 (Backbones): Gemini-2.5 系列 (Flash, Flash-Lite, Pro) 和 Claude 家族 (3.5-Haiku, 3.7-Sonnet)。
对比方法: ReAct, Amem, Self RAG, MemOS, Mem0, LangMem, Dynamic Cheatsheet (DC-Cu, DC-RS), Agent Workflow Memory (AWM),以及提出的 ExpRecent, ExpRAG, ReMem。
主要结果:
整体性能 (RQ1): ReMem 在单回合和多回合设置中都显示出一致的改进,尤其在多回合环境中性能提升更为显著,强调了持续适应在长任务序列中的价值。ExpRAG 作为简单基线也表现出色。
记忆改进分析 (RQ2): ReMem 的性能提升与数据集内部任务相似性呈强相关。任务结构相似度越高(例如 PDDL 和 Alf World),增益越大,表明重复的任务结构有利于记忆重用和泛化。ReMem 和 ExpRAG 还显著提高了步骤效率,减少了完成任务所需的步骤。
任务序列难度 (RQ3): 面对任务难度变化时(Easy→Hard 或 Hard→Easy),ReMem 展现出强大的鲁棒性和持续的高性能,表明其能够保留可迁移的知识。
反馈类型分析 (RQ4): 即使记忆中包含失败经验,ReMem 也能保持鲁棒性,通过主动精炼存储经验,处理不完善的经验。
随时间步的累积性能 (RQ5): ReMem 在所有交互式环境中都实现了更快的适应和更稳定的留存,在长任务序列中保持性能,验证了其在测试时学习中的鲁棒性。
结论: Evo-Memory 填补了 LLM Agent 自进化记忆评估的空白,通过将静态数据集转换为流式轨迹,系统地评估了 LLM 如何通过交互检索、适应和精炼记忆。研究结果表明,记忆能显著提升性能,但其稳定性和程序重用能力仍需改进。论文提出了 ExpRAG 和 ReMem,以推动 LLM 在构建可靠且持续改进的记忆能力方面的进展。
Abstract¶
本论文提出了一种名为 ReMe(Remember Me, Refine Me) 的新型框架,旨在提升大型语言模型(LLM)代理的程序性记忆能力,从而实现经验驱动的智能体演化。程序性记忆帮助代理“记住如何做”某事,理论上可以减少重复试错,但当前的代理记忆系统存在“被动积累”的问题,即将记忆视为静态、只读的存储,缺乏动态推理能力。
核心创新点(ReMe 的三大机制)¶
多维度经验提炼(Multi-faceted Distillation)
从历史经验中提取细粒度知识,包括:
识别成功模式(success patterns)
分析失败原因(failure triggers)
生成对比性见解(comparative insights)
重点内容:通过结构化方式提炼经验,提升记忆的可复用性和解释性。
上下文自适应复用(Context-Adaptive Reuse)
利用场景感知索引(scenario-aware indexing)机制,将历史经验适配到新任务中。
重点内容:解决传统记忆系统中“经验与新任务不匹配”的问题,增强泛化能力。
效用驱动优化(Utility-Based Refinement)
自动添加有效经验、删除过时记忆,保持记忆库的紧凑性与高质量。
重点内容:实现记忆系统的自我演化,避免冗余信息堆积。
实验与结果¶
实验平台:BFCL-V3 和 AppWorld
主要成果:ReMe 在代理记忆系统方面达到了新的 SOTA(State-of-the-Art)水平。
关键发现:存在显著的“记忆扩展效应”——
使用 ReMe 的 Qwen3-8B 模型表现优于未使用记忆的更大模型 Qwen3-14B。
表明自演化记忆系统可以作为高效计算路径,支持代理的持续学习(lifelong learning)。
总结¶
ReMe 是一个面向 LLM 代理的动态程序性记忆框架,通过提炼、复用、优化三个核心机制,解决了当前记忆系统静态、低效的问题。实验验证了其在多个任务上的优越性,并展示了记忆系统在模型规模受限时仍能通过经验积累提升性能。该工作为构建具备持续学习能力的智能代理提供了新思路和开源资源。
1 Introduction¶
1.1 背景与动机¶
本节介绍了从静态语言模型向自主代理(autonomous agents)的转变,这是人工智能领域的一个重要转折点。与传统模型不同,自主代理能够通过迭代推理和工具使用来处理复杂、动态的任务。为了在不重新训练参数的情况下实现持续优化,**程序性记忆(procedural memory)**成为代理演化的关键机制。程序性记忆通过积累高质量的问题解决经验,使代理能够复用过去的成功经验与教训,从而理论上减少重复试错,避免陷入局部最优。
图1展示了在股票交易任务中,有无经验记忆的代理完成任务的对比,突出了程序性记忆在任务执行中的优势。
1.2 理想程序性记忆系统的三大核心标准¶
一个理想的程序性记忆系统应满足以下三个核心标准:
高质量提取(High-quality Extraction)
从执行轨迹中提取通用、可复用的知识,而非原始、特定问题的观察。任务导向利用(Task-grounded Utilization)
检索出的记忆应能根据当前任务需求进行动态调整,以最大化其在新场景中的实用性。渐进式优化(Progressive Optimization)
记忆库应通过持续更新保持活力,自动强化有效条目、淘汰过时内容,防止记忆质量随时间下降。
1.3 当前方法的局限性¶
当前的程序性记忆框架大多采用“被动积累”的方式,将记忆视为静态存储,存在以下问题:
粗粒度经验:基于整个执行轨迹的经验可能包含无关信息,影响代理把握核心逻辑。
缺乏适应性:检索出的经验未经调整直接使用,导致在任务稍有变化时失效。
更新机制缺失:缺乏及时更新策略,记忆池逐渐混入无效或有害信息。
1.4 提出的方法:ReMe 框架¶
为解决上述问题,作者提出 ReMe(Remember Me, Refine Me),一种动态程序性记忆框架,实现从“被动存储”到“反馈驱动演化”的转变。该框架在记忆生命周期中引入以下创新:
多维度提炼策略(Multi-faceted Distillation)
通过成功模式识别、失败分析和对比洞察生成,将执行轨迹提炼为结构化、可复用的经验。任务导向复用流程(Task-grounded Reuse Pipeline)
采用使用场景索引策略进行检索,并结合重排序与自适应改写,使历史经验适配新任务。效用驱动优化机制(Utility-based Refinement)
跟踪经验在复用中的效用,定期淘汰低效条目,保持记忆库的紧凑与高效。
1.5 实验结果与贡献¶
在 BFCL-V3 和 AppWorld 基准测试中,ReMe 表现优异,达到最先进水平。特别值得注意的是:
ReMe 使 Qwen3-8B 模型超越了未使用记忆的更大模型 Qwen3-14B,在 Avg@4 和 Pass@4 上分别提升了 8.83% 和 7.29%。
这表明高质量的记忆机制可以替代模型规模,为资源高效的终身学习提供新路径。
1.6 主要贡献¶
提出 ReMe 框架,整合多维度经验提炼、上下文自适应复用、效用驱动优化,实现程序性记忆闭环。
发布 reme.library,一个从多种代理任务中构建的细粒度程序性记忆数据集,包含结构化成功模式与失败教训。
实验验证 ReMe 在多个基准任务上的显著性能提升,并揭示记忆-规模效应,即小模型通过记忆机制可超越大模型,验证了框架的计算效率与实用性。
3 Methodology¶
本节介绍了 ReMe 框架的三个核心阶段:经验获取(Experience Acquisition)、经验复用(Experience Reuse) 和 经验精炼(Experience Refinement),整体结构清晰,强调经验的结构化表示、动态更新与高效利用。
3.1 ReMe 概览¶
ReMe 框架分为三个阶段:
经验获取:通过分析代理生成的轨迹(成功与失败),提取可操作的知识并结构化存储。
经验复用:面对新任务时,从经验池中检索相关经验,增强代理的推理和任务解决能力。
经验精炼:持续优化经验池,加入新经验、淘汰旧经验,确保长期相关性和适应性。
3.2 经验获取¶
经验的结构化定义¶
经验 \( E \in \mathcal{E} \) 被定义为五元组: $\( E = \langle \omega, e, \kappa, c, \tau \rangle \)$ 其中:
\(\omega\):使用场景;
\(e\):核心经验内容;
\(\kappa\):关键词集合;
\(c \in [0,1]\):置信度;
\(\tau\):使用的工具。
经验池构建流程¶
轨迹收集:LLM 执行任务,生成多个轨迹(N 次采样),包括成功与失败路径。
经验总结:
成功模式识别:提取有效策略;
失败分析:总结教训;
对比分析:识别成功与失败的关键差异。
经验验证:使用 LLM-as-a-Judge 评估经验的可操作性与价值。
去重与存储:去除冗余经验,按场景 \(\omega\) 的嵌入向量索引,存入向量数据库。
3.3 经验复用¶
检索机制¶
使用 embedding 模型(如 text-embedding-v4)对任务查询进行编码;
计算余弦相似度,检索 Top-K 相关经验。
后续处理¶
重排序(Reranking):使用 LLM 对检索结果进行上下文感知的重排序。
重写(Rewriting):将多个经验整合为任务导向的指导信息,提升适应性。
作用¶
经验复用不仅是知识检索,更是连接过去与当前任务的“认知桥梁”,在利用已有经验的同时鼓励创新思维。
3.4 经验精炼¶
动态更新机制¶
经验添加策略:
全量添加:无论成功与否都加入经验池;
选择性添加:仅添加成功轨迹的经验。
实验表明选择性添加更优,因失败经验在实时任务中往往缺乏足够上下文。
失败反思机制:
遇到失败时,LLM 分析失败原因,生成改进建议;
若后续执行成功,则将经验加入池中;
最多允许 3 次自我反思,避免陷入死循环。
经验删除策略(基于效用):
记录经验被检索次数 \(f(E)\) 与成功贡献次数 \(u(E)\);
若 \(u(E)/f(E) \leq \beta\) 且 \(f(E) \geq \alpha\),则删除该经验。
公式如下: $\( \phi_{\text{remove}}(E) = \begin{cases} \mathds{1}\left[\frac{u(E)}{f(E)} \leq \beta\right], & \text{if } f(E) \geq \alpha, \\ 0, & \text{otherwise}. \end{cases} \)$
表1:ReMe 与基线模型在 BFCL-V3 和 AppWorld 上的性能对比¶
模型 |
方法 |
BFCL-V3 |
AppWorld |
平均 |
|---|---|---|---|---|
Qwen3-8B |
无记忆 |
40.33 |
14.97 |
27.65 |
Qwen3-8B |
ReMe(动态) |
45.17 |
24.70 |
34.94 |
Qwen3-14B |
ReMe(动态) |
55.00 |
34.32 |
44.66 |
Qwen3-32B |
ReMe(动态) |
56.17 |
42.02 |
49.10 |
关键结论:
ReMe(尤其是动态版本)在多个模型规模下均显著优于基线方法;
动态更新机制(添加 + 删除)提升了经验池质量,从而提升任务成功率;
随着模型规模增大,ReMe 的优势更加明显。
总结¶
ReMe 提出了一个结构化、动态更新的经验记忆框架,涵盖经验的获取、复用与精炼全过程。其核心亮点包括:
结构化经验表示:便于检索与复用;
多阶段处理机制:从经验提取到动态优化;
基于效用的经验管理:确保经验池质量;
实验证明有效:在多个任务和模型规模下均表现优异。
该方法为代理系统从试错学习向策略推理的进化提供了坚实基础。
4 Experiments¶
4.1 实验设置¶
数据集¶
实验基于两个工具增强型基准:BFCL-V3 和 AppWorld。
BFCL-V3:从基础多轮任务中随机选取50个任务构建初始经验池,其余150个任务作为评估集。
AppWorld:使用90个训练任务进行经验获取,测试集为168个任务的test-normal集。
评估指标¶
Avg@4:4次独立任务尝试的平均成功率。
Pass@4:4次尝试中至少一次成功的概率。
所有结果为3次独立运行的均值与标准差。
基线方法¶
对比三种基线方法:
No Memory(无记忆)
A-Mem:动态组织记忆的代理记忆系统。
LangMem:LangChain的长期记忆模块,用于提取重要信息优化代理行为。
所有方法在任务开始时仅进行一次经验检索,且仅在成功轨迹中添加新经验。
实现细节¶
使用 Qwen3系列模型 作为LLM执行模块(LLM_execute),经验总结模块(LLM_summ)与LLM_execute相同。
经验索引使用Qwen3-Embedding(维度1024)。
经验获取阶段:N=8,temperature=0.9。
经验复用阶段:top-K=5,检索最相关5条经验。
ReMe(动态)与ReMe(固定)的区别在于经验池是否在执行中动态更新。
经验精炼阶段:删除阈值α=5,效用阈值β=0.5。
最大迭代次数为30次。
4.2 主要结果¶
性能表现¶
表1展示了ReMe在不同Qwen3模型上的表现:
ReMe在BFCL-V3和AppWorld上均优于No Memory和基线方法。
Qwen3-8B + ReMe在Pass@4和Avg@4上分别提升7.29%和8.83%。
ReMe(动态)在两个基准上表现稳定,尤其在AppWorld上LangMem性能下降明显。
模型规模与记忆机制的对比¶
小模型+ReMe可超越大模型无记忆系统:
Qwen3-8B + ReMe > Qwen3-14B(无记忆)
Qwen3-14B + ReMe > Qwen3-32B(无记忆)
动态 vs 固定版本¶
ReMe(动态)始终优于ReMe(固定),说明任务执行中动态更新经验池的重要性。
ReMe降低了运行结果的标准差,提升输出稳定性。
表2:经验提取粒度消融实验¶
粒度 |
Qwen3-8B |
Qwen3-14B |
|---|---|---|
Avg@4(%) |
Pass@4(%) |
Avg@4(%) |
轨迹级 |
43.00+2.67 |
60.00+0.45 |
关键点级 |
44.50+4.17 |
65.77+6.22 |
关键点级经验提取显著优于轨迹级,说明细粒度知识总结更有效。
案例分析¶
图1展示了ReMe在BFCL-V3任务中的推理改进:
无经验时,代理因虚构股价失败。
使用ReMe后,代理正确获取实时股价,成功完成交易。
4.3 消融研究¶
提取粒度消融¶
关键点级经验提取显著优于轨迹级,说明细粒度知识更利于迁移。
核心组件消融(表3)¶
组件 |
Avg@4 |
Pass@4 |
|---|---|---|
全量添加 |
40.83% |
62.00% |
选择性添加 |
44.33% |
64.66% |
+失败反思 |
45.00% |
64.66% |
+效用删除 |
45.17% |
68.00% |
选择性添加比全量添加更优,强调经验质量。
失败反思和效用删除进一步提升性能。
检索键消融¶
使用LLM生成的“使用场景”作为检索键效果最佳。
原始任务描述或关键词检索效果较差。
4.4 更多分析¶
LLM_summ能力提升的影响(表4)¶
LLM_execute |
LLM_summ |
Avg@4 (%) |
Pass@4 (%) |
|---|---|---|---|
Qwen3-8B |
Qwen3-8B |
44.50 |
65.77 |
Qwen3-8B |
Qwen3-14B |
46.33 (+1.83) |
66.00 (+0.23) |
Qwen3-8B |
Qwen3-32B |
47.83 (+3.33) |
68.00 (+2.23) |
LLM_summ能力越强,性能提升越明显,说明高质量经验总结至关重要。
检索经验数量的影响(图4)¶
检索数量K从0到10,性能先升后降。
K=5达到最佳平衡,过多经验引入噪声。
错误分析(图5)¶
ReMe将失败案例从62个减少到47个。
减少了推理错误(22→14)和动作遗漏错误,说明经验帮助代理更准确地进行多步推理和任务流程识别。
总结¶
ReMe通过动态经验池、细粒度经验提取、选择性添加、失败反思和效用删除等机制,显著提升了代理在BFCL-V3和AppWorld上的任务成功率。实验表明,经验机制不仅提升性能,还增强模型稳定性,甚至使小模型超越大模型的表现。
5 Conclusion¶
本节是对全文工作的总结。
主要内容:
作者提出了 ReMe,一个动态的程序性记忆框架,能够使智能体的推理能力从盲目的试错逐步演进为有策略的经验复用。ReMe 通过在细粒度层面上从先前的轨迹中提炼结构化知识,使智能体能够利用关键经验,从而避免了粗粒度方法中可能出现的经验干扰问题。此外,ReMe 通过有效的经验精炼机制,维护了一个高质量的经验池,支持智能体的持续进化。
重点内容强调:
ReMe 的核心贡献:提出了一种新的记忆机制,使智能体能够从历史经验中提取结构化知识,提升决策效率。
优势:相比粗粒度方法,ReMe 更能避免经验之间的干扰,保持经验质量。
实验验证:大量实验表明 ReMe 显著优于多个基线模型,消融实验进一步验证了 ReMe 中每个核心组件的有效性。
说明: 本节未涉及具体数学公式、算法步骤或表格数据,主要为方法论和实验结果的总结性陈述。
Limitations¶
本节讨论了本文提出的 ReMe 框架在代理自演化过程中所面临的一些局限性,并提出了未来可能的改进方向。
1. 固定的经验检索策略¶
当前 ReMe 使用的是固定检索策略,即在每个任务开始时仅检索一次经验。
问题:这种策略缺乏灵活性,无法根据任务执行过程中的上下文变化动态调整经验的使用。
未来方向:设计一种上下文感知的动态检索机制,可以更有效地整合新经验,提升系统的适应性和知识利用率。
2. 经验验证机制的局限性¶
目前的经验验证主要依赖于LLM-as-judge(大语言模型作为评判者)的方法来过滤低质量经验。
问题:虽然该方法有效,但可能忽略经验质量与相关性的细微差异,评估不够全面。
未来方向:探索更复杂和精确的经验评估技术,以提升经验筛选的准确性和适应性。
3. 模型规模与总结能力的关系¶
实验结果(见第4.4节)表明:更大规模的总结器模型在代理推理中带来了更显著的性能提升。
原因:更强的总结能力有助于提取更高质量的经验知识。
未来方向:研究在小模型上也能实现高效总结的先进策略,从而提升代理的自演化能力。
重点内容总结:
ReMe 的经验检索和验证机制仍有改进空间;
更灵活的检索和更精细的验证方法是未来研究重点;
模型总结能力对代理性能影响显著,值得进一步优化。
Appendix A Dataset Details¶
BFCL-V3¶
重点内容:
BFCL-V3(Berkeley Function Calling Leaderboard V3)是一个用于评估大语言模型(LLM)在函数调用和工具使用方面能力的基准测试,尤其关注多轮对话和多步骤任务的处理能力。
包含超过1800个测试任务,要求模型生成精确的API调用,支持多种编程语言(如Python、Java、JavaScript),并能处理并行函数调用等复杂交互。
评估方式包括:
抽象语法树(AST)匹配:用于检查生成的代码是否在语法上正确。
可执行测试:验证函数调用是否能产生预期的功能输出。
任务成功标准:代理(agent)必须正确调用所需函数并产生预期输出。
非重点内容精简:
该数据集由 patilberkeley 提出,主要用于衡量模型在真实编程任务中的表现。
AppWorld¶
重点内容:
AppWorld 是一个用于评估函数调用和交互式编程代理能力的模拟环境,模拟了9个日常应用程序(如邮件、Spotify、Venmo),共涉及457个API,并模拟了约100个用户的行为。
评估机制基于状态单元测试,确保任务完成的准确性。
提供两个核心评估指标:
任务目标完成率(TGC):代理通过所有任务测试的百分比。
场景目标完成率(SGC):代理完成整个场景中所有任务的百分比。
实验中采用TGC指标,用于衡量任务的成功率。
非重点内容精简:
AppWorld 由 trivedi2024appworld 提出,构建了一个贴近现实的API交互环境。
Appendix B Baseline Details¶
本节详细介绍了两个用于增强语言模型代理记忆能力的基线系统:LangMem 和 A-Mem,并辅以图表说明其在不同任务中的应用和表现。
LangMem¶
LangMem(LangChain2025)是LangChain的长期记忆模块,能够从对话中提取关键信息并存储,以便未来检索使用。
它提供了与任何存储系统兼容的功能原语,并与LangGraph的存储层有原生集成,使代理能够持续学习和改进。
在实验中,我们采用了LangMem的情景记忆(episodic memory)实现,该机制帮助代理从过往经验中学习。
图6展示了在BFCL-V3任务中,不同记忆索引方式的示例,说明LangMem在记忆组织上的灵活性。
重点:LangMem通过结构化记忆提取和存储机制,增强了代理的长期学习能力。
A-Mem¶
A-Mem(Xu2025mem)是一个为LLM代理提供“代理式记忆”(agentic memory)的系统,使代理能够自主管理其长期知识。
它为代理构建了一个以记忆为中心的知识图谱,能够根据代理的目标和交互行为,主动决定哪些信息需要存储、回忆或更新。
在实验中,我们基于其开源代码复现了A-Mem,并对提示进行了微调,以提取程序性记忆(procedural memories)。
图7和图8分别展示了A-Mem在BFCL-V3和AppWorld任务中的经验示例,说明其在不同任务环境下的记忆构建能力。
图9比较了**轨迹级(trajectory-level)和关键点级(keypoint-level)**的经验粒度,表明A-Mem在记忆抽象和提取方面的优势。
重点:A-Mem通过主动记忆管理机制,提升了代理在复杂任务中的决策与适应能力。
总结¶
本附录通过介绍LangMem和A-Mem两个记忆增强系统,展示了如何通过结构化记忆机制提升LLM代理的学习与决策能力。
LangMem侧重于记忆的提取与存储,适用于通用代理系统集成。
A-Mem则强调代理对记忆的自主管理,具备更强的智能性和适应性。
图表辅助说明了两种方法在实际任务中的记忆组织方式和粒度差异。
Appendix C Implementation Details¶
C.1 经验获取(Experience Acquisition)¶
本节描述了经验获取的具体实现步骤,主要包括以下三个关键环节:
1. 轨迹采样与筛选¶
对每个任务查询,采样 8 条轨迹(NN=8),以获得多样化的潜在解决方案,包括高奖励和低奖励结果。
在每组相同任务对应的轨迹中,按奖励排序,仅保留最低分和最高分的轨迹用于后续经验提取。
2. 成功模式识别¶
成功轨迹定义:奖励超过预设阈值(经验设定为 1.0)的轨迹。
使用 LLM(记为 LLM_summ)分析这些成功轨迹,识别促成任务成功的关键点。
3. 失败原因分析¶
对失败轨迹,同样使用 LLM_summ 分析,识别导致失败的最早关键步骤。
4. 对比洞察生成¶
当两条轨迹之间存在显著奖励差异时,使用 LLM_summ 提取区分高分与低分尝试的具体决策或动作。
5. 经验验证¶
为过滤无效经验,使用一个“LLM-as-a-Judge”提示(见表9)对生成的经验进行有效性验证。
重点内容总结:
使用 LLM_summ 对采样轨迹进行分析,提取成功/失败原因和对比洞察。
通过设定奖励阈值筛选轨迹,并使用 LLM 进行经验验证。
表6-9提供了具体的提示模板和验证机制。
C.2 经验检索(Experience Retrieval)¶
本节描述了在新任务到来时,如何从经验库中检索相关经验。
1. 检索方法¶
使用 LLM_execute(LLM_{execute})根据新任务查询 q_new,从经验库中检索最相关的经验 ℰ_r。
检索依据是当前任务查询与经验中“使用场景”字段 w 的余弦相似度:
2. 相似度计算¶
使用 Qwen3-Embedding 模型 ϕ(·) 对“使用场景”字段 w 和新任务查询 q_new 进行向量化表示。
余弦相似度计算公式如下:
3. 检索策略探索¶
在正文第 4.3 节进一步探讨了多种经验索引策略。
图6展示了不同检索键(retrieval keys)之间的差异。
重点内容总结:
使用余弦相似度匹配新任务与已有经验,基于 Qwen3-Embedding 向量表示。
检索结果为 top-k 个最相关经验。
图6和正文4.3节展示了不同检索策略的比较。
如需进一步了解具体提示模板(表6-9)或检索键对比(图6),可参考附录 E 和附录 B 的相关内容。
Appendix D Experience Examples¶
本节主要介绍 ReMe 方法如何从历史轨迹中提取关键点级(keypoint-level)经验,并通过图示进行说明。
1. ReMe 方法的经验提取示例¶
ReMe 的核心在于从历史任务执行轨迹中提取出关键操作步骤,形成结构化的经验知识。
论文分别展示了在 BFCL-V3 和 AppWorld 两个任务环境下的经验示例,分别见图7和图8。
这些图展示了 ReMe 如何将原始操作序列转化为结构化的经验条目,包括关键动作、上下文信息和执行结果。
2. 经验粒度的影响分析¶
为了进一步研究经验粒度对性能的影响,作者对比了两种经验获取方式:
轨迹级(trajectory-level):记录完整的操作流程,包含所有细节。
关键点级(keypoint-level):仅保留关键动作和决策点,忽略次要步骤。
相关对比实验在正文第 4.3节(见 Section 4.3)的消融实验中进行了详细分析。
3. 不同粒度经验的结构与内容对比¶
图9展示了两种粒度经验在结构和内容上的差异:
轨迹级经验:
特点:记录完整操作流程,细节丰富。
优点:适合需要精确步骤的任务。
缺点:信息冗余,泛化能力弱。
关键点级经验:
特点:聚焦关键动作,省略非必要步骤。
优点:结构清晰,便于迁移和复用。
缺点:可能丢失部分上下文信息。
总结¶
本节通过图示和对比分析,展示了 ReMe 提取关键点级经验的能力,并说明了其相较于轨迹级经验在结构化和泛化方面的优势。相关实验和性能对比详见正文第4.3节。
Appendix E Additional Experimental Results¶
E.1 Retrieval Key Analysis(检索键分析)¶
核心内容总结:¶
本节对四种检索键策略(任务查询、泛化查询、查询关键词、使用场景)在不同模型规模(Qwen3–8B、Qwen3–14B、Qwen3–32B)下的性能进行了对比实验,评估指标为 Avg@4 和 Pass@4。
实验设置:基于 BFCL-V3 基准测试,在 ReMe(fixed) 设置下进行。
关键发现:
简单的检索方法(如原始任务查询、关键词)性能较低。
LLM 生成的检索键(尤其是“使用场景”字段)表现最佳,Avg@4 和 Pass@4 分数普遍最高或接近最高。
模型规模影响:随着模型参数量增加,整体性能提升,但“使用场景”策略在所有模型中均保持领先。
表格数据(Table 5):¶
模型 |
检索键类型 |
Avg@4 |
Pass@4 |
|---|---|---|---|
Qwen3-8B |
任务查询 |
44.00% |
63.33% |
泛化查询 |
42.50% |
63.77% |
|
查询关键词 |
44.22% |
65.33% |
|
使用场景(最优) |
44.50% |
65.77% |
|
Qwen3-14B |
任务查询 |
50.11% |
71.77% |
泛化查询 |
50.49% |
72.22% |
|
查询关键词 |
51.16% |
71.11% |
|
使用场景(最优) |
51.89% |
72.44% |
|
Qwen3-32B |
任务查询 |
56.22% |
72.22% |
泛化查询 |
55.33% |
73.33% |
|
查询关键词 |
56.89% |
74.44% |
|
使用场景(次优) |
56.05% |
74.89% |
结论:LLM 生成的“使用场景”检索键在大多数情况下表现最优,尤其在小模型上提升显著,说明其对检索质量有重要影响。
E.2 Prompt Examples for Experience Extraction(经验提取的提示示例)¶
本节提供了用于经验提取的四个提示模板,分别用于:
成功模式识别(Table 6)
失败分析(Table 7)
对比洞察生成(Table 8)
经验验证(Table 9)
重点内容:¶
1. 成功模式识别(Success Pattern Recognition)¶
目标:从成功轨迹中提取可复用的步骤级经验。
分析框架:
步骤模式分析
决策点识别
技术有效性分析
可复用性提取
输出格式:JSON 对象,包含
when_to_use,task_query,generalized_query,experience,tags,confidence,tools_used等字段。
2. 失败分析(Failure Analysis)¶
目标:从失败轨迹中提取教训,防止重复错误。
分析框架:
失败点识别
错误模式分析
替代方案建议
预防策略提取
输出格式:与成功模式识别类似,但强调失败教训。
3. 对比洞察生成(Comparative Insights Generation)¶
目标:比较高分与低分步骤序列,提取性能提升的关键因素。
分析框架:
性能因素识别
方法差异分析
效率分析
优化建议
输出格式:JSON 对象,强调性能提升策略。
4. 经验验证(Experience Validation)¶
目标:验证提取经验的质量,确保其可操作性、准确性、相关性、清晰性和独特性。
验证标准:
可操作性
准确性
相关性
清晰度
独特性
输出格式:JSON 对象,包含
is_valid,score,feedback,recommendations。
小结:¶
这些提示模板设计规范,结构统一,强调经验的结构化提取与验证。
输出格式统一为 JSON,便于后续处理和系统集成。
每个模板都包含明确的分析框架和输出格式,有助于提升经验提取的一致性与实用性。
总结¶
本附录通过实验和提示模板两个方面,验证了 ReMe 框架中经验检索与提取机制的有效性:
E.1 检索键分析:LLM 生成的“使用场景”字段在检索性能上优于传统方法,尤其在小模型中提升显著。
E.2 提示模板:提供结构化、标准化的经验提取与验证流程,涵盖成功、失败、对比分析及质量验证,确保经验的实用性与可操作性。
这些补充实验和模板设计为 ReMe 框架的实际应用提供了坚实基础。