1804.07461_GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding¶
引用: 8979(2025-08-07)
组织:
1Courant Institute of Mathematical Sciences, New York University
2Paul G. Allen School of Computer Science & Engineering, University of Washington
3DeepMind
总结¶
简介
GLUE: General Language Understanding Evaluation(通用语言理解评估)
设计目标:
鼓励模型在不同任务之间共享通用的语言知识
推动跨任务、跨数据的通用语言理解
鼓励开发 样本高效且跨任务知识迁移能力强 的模型
核心目标**
多任务评估:涵盖多种语言理解任务(如文本分类、语义相似度、推理等),避免模型在单一任务上过拟合。
通用性:测试模型对语言多样性的处理能力,包括句法、语义、逻辑等。
推动研究:鼓励开发更强大的预训练模型(如BERT、RoBERTa等)。
数据集
Single-Sentence Tasks
CoLA(Corpus of Linguistic Acceptability):
判断句子语法是否合理(二分类)。
SST-2(Stanford Sentiment Treebank)
电影评论情感分析(正面/负面)。
Similarity and Paraphrase Tasks
MRPC(Microsoft Research Paraphrase Corpus):
判断句子对是否语义等价。
STS-B(Semantic Textual Similarity Benchmark):
计算句子对的相似度(1-5分)。
QQP(Quora Question Pairs):
判断两个问题是否语义相同。
Inference Tasks
MNLI(Multi-Genre Natural Language Inference):
判断句子对关系(蕴含/矛盾/中立)。
QNLI(Question Natural Language Inference):
问答式自然语言推理(源自SQuAD数据集)。
RTE(Recognizing Textual Entailment):
二分类的文本蕴含任务。
其他
WNLI(Winograd NLI):
共指消解任务(因数据问题已较少使用)。
评价指标
不同任务使用不同指标(如准确率、F1值、皮尔逊相关系数等)。
最终得分:所有任务得分的平均值(CoLA使用Matthews相关系数,其余多为准确率或F1)。
GLUE的影响与后续发展
推动预训练模型:BERT、RoBERTa、XLNet等模型均在GLUE上刷新记录。
升级版基准:
SuperGLUE(2019年提出):包含更难的任务(如阅读理解、指代消解)。
中文版本:CLUE(Chinese Language Understanding Evaluation)。
当前地位:随着模型性能的显著提升(如人类水平被超越),GLUE逐渐被更复杂的基准取代,但仍是NLP发展史上的重要里程碑。
Abstract¶
为了使自然语言理解(NLU)技术达到最佳的实用性,它必须能够以不局限于单一任务、体裁或数据集的方式处理语言。
为此,作者提出了通用语言理解评估(General Language Understanding Evaluation, GLUE)基准测试,这是一个用于评估模型在多种现有NLU任务上表现的工具集合。
GLUE 的设计目标之一是鼓励模型在不同任务之间共享通用的语言知识。为此,GLUE 包含了一些训练数据有限的任务,从而更有利于具备泛化能力的模型。
此外,GLUE 还包含了一个人工设计的诊断测试套件,能够对模型进行详细的语言学分析。
作者在当前的迁移学习和表示学习方法基础上评估了基准模型,发现在所有任务上进行多任务训练的效果优于为每个任务单独训练模型。然而,最佳模型的绝对性能仍然较低,这表明当前的通用NLU系统仍需进一步改进。
重点内容:¶
GLUE 的目标:推动跨任务、跨数据的通用语言理解。
GLUE 的设计特点:
包含多种NLU任务;
任务数据有限,强调模型泛化能力;
提供诊断测试套件,便于分析模型的语言理解能力。
实验结果:
多任务学习优于单任务学习;
最优模型性能仍不足,说明仍有改进空间。
不重要内容精简:¶
对具体任务和方法的详细描述未在摘要中展开,故未详细说明。
1 Introduction¶
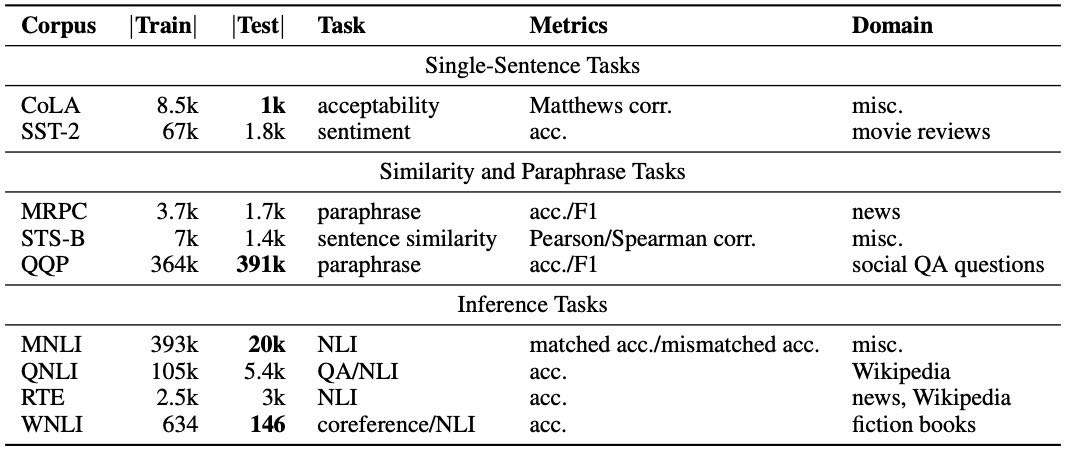
Table 1:Task descriptions and statistics. All tasks are single sentence or sentence pair classification, except STS-B, which is a regression task. MNLI has three classes; all other classification tasks have two. Test sets shown in bold use labels that have never been made public in any form.
本节介绍了自然语言理解(NLU)模型的现状与挑战,并提出了 GLUE(General Language Understanding Evaluation) 基准测试,旨在推动模型向更加通用的语言理解发展。
人类语言理解 vs. 当前 NLU 模型¶
人类的语言理解具有 通用性、灵活性和鲁棒性,而目前大多数 NLU 模型(在词以上层级)通常是为 特定任务 设计的,难以处理超出其训练领域(out-of-domain)的数据。为了实现超越“输入输出表面对应”的理解能力,作者认为必须开发 统一模型,能够在 多种任务和领域中学习并执行语言任务。
GLUE 基准的提出¶
为此,作者提出了 GLUE 基准,其包含多个 NLU 任务,如 问答、情感分析、文本蕴含等。GLUE 配套提供一个 在线平台,用于模型的评估、比较和分析。GLUE 对模型结构不做限制,只要能处理 单句或句对输入并输出预测结果 即可。对于训练数据较少或与测试集风格不一致的任务,GLUE 鼓励开发 样本高效且跨任务知识迁移能力强 的模型。
作者强调,GLUE 的数据集 并非为该基准专门创建,而是基于 NLP 社区普遍认可的已有数据集,这些数据集被认为是 具有挑战性和研究价值的。其中,四个数据集的测试集为私有,需通过指定平台提交预测结果进行评估。
探针任务与模型分析¶
为了理解模型所学习的知识,以及鼓励开发 语言语义上有意义的解决方案,GLUE 还提供了 专家手工构建的分析数据集。该数据集设计用于揭示模型在处理 世界知识和逻辑操作符等深层结构 时的挑战。
实验与基线结果¶
为评估 GLUE 的难度,作者进行了实验,使用了 简单基线模型与当前最先进的句子表示模型。结果发现,统一的多任务训练模型略优于单任务训练模型。其中,基于 ELMo 的模型表现最好,但其得分仍然较低。通过分析诊断数据集发现,基线模型在处理 强词法信号时表现良好,但在处理 深层逻辑结构时表现不佳。
GLUE 的内容总结¶
GLUE 包含以下四个部分:
九个句子或句对分类任务(除 STS-B 为回归任务),覆盖多种文本类型、数据规模和难度。
在线评估平台和排行榜,主要基于私有测试集,平台对模型结构无限制。
专家构建的诊断数据集,用于分析模型的语义理解能力。
多个主流句子表示模型的基线结果,为后续研究提供参考。
表格说明(Table 1)¶
表格列出了 GLUE 的九个任务及其统计信息,包括:
任务类别 |
任务名称 |
训练集规模 |
测试集规模 |
任务类型 |
评估指标 |
领域 |
|---|---|---|---|---|---|---|
单句任务 |
CoLA |
8.5k |
1k |
可接受性判断 |
Matthew 相关系数 |
多种 |
SST-2 |
67k |
1.8k |
情感分析 |
准确率(acc.) |
电影评论 |
|
句子相似性和句对任务 |
MRPC |
3.7k |
1.7k |
句对是否同义 |
准确率/F1 |
新闻 |
STS-B |
7k |
1.4k |
句子相似性 |
Pearson/Spearman 相关系数 |
多种 |
|
QQP |
364k |
391k |
问答是否同义 |
准确率/F1 |
社交问答 |
|
推理任务 |
MNLI |
393k |
20k |
文本蕴含 |
匹配/不匹配准确率 |
多种 |
QNLI |
105k |
5.4k |
问答/文本蕴含 |
准确率 |
Wikipedia |
|
RTE |
2.5k |
3k |
文本蕴含 |
准确率 |
新闻/Wikipedia |
|
WNLI |
634 |
146 |
共指/文本蕴含 |
准确率 |
小说 |
MNLI 有三个类别,其余均为二分类任务。
加粗测试集 表示其标签从未公开过,用于公平评估。
总结:本节介绍了 GLUE 基准的背景、目标、任务组成、评估机制和实验结果,强调其在推动通用语言理解模型研究方面的重要性。
2 相关工作总结¶
多任务学习(Multi-Task Learning)¶
Collobert 等人(2011) 提出了一种多任务学习模型,使用共享的句子理解组件,同时学习词性标注(POS tagging)、块划分(chunking)、命名实体识别(NER)和语义角色标注(SRL)等多个自然语言处理任务。这是早期多任务学习的典型应用。
近年来的研究 探索了利用核心NLP任务的标签来监督深度神经网络中下层的训练(例如 Søgaard & Goldberg, 2016;Hashimoto 等人, 2017),以及 自动学习任务间的共享机制 来优化多任务学习(Ruder 等人, 2017),这些方法提高了模型在多个任务上的泛化能力。
通用自然语言理解(NLU)系统的发展¶
除了多任务学习,许多研究聚焦于 句子到向量的编码器(sentence-to-vector encoders),例如 Le & Mikolov (2014) 和 Kiros 等人 (2015),这些模型尝试从句子中提取通用的语义表示。
研究同样利用了 未标注数据(如 Hill 等人, 2016;Peters 等人, 2018)、标注数据(如 Conneau & Kiela, 2018;McCann 等人, 2017),或两者的结合(如 Collobert 等人, 2011;Subramanian 等人, 2018)来训练这些编码器。
为了评估这些句子编码器的性能,研究者提出了一套标准的评估方法 SentEval(Conneau 等人, 2017;Conneau & Kiela, 2018),它是基于一系列已有的分类任务,这些任务通常以一个或两个句子作为输入。
SentEval 和 GLUE 的比较:
两者都基于现有的分类任务。
SentEval 仅评估句子到向量的表示,适合评估独立句子的任务。
GLUE 更加通用,允许使用任意的表示形式或上下文建模方法,包括完全不依赖向量或符号表示的模型,因此更适合评估需要跨句子上下文建模的任务,如机器翻译、问答和自然语言推理。
GLUE 和 SentEval 的任务选择差异¶
SentEval 的任务偏向于情感分析,例如 MR、SST、CR 和 SUBJ,这些任务较为简单或与情感相关,缺乏多样性。
部分任务已被基本解决,如 MPQA 和 TREC 问题分类,评估这些任务的信息量较低。
GLUE 的目标是构建一个既多样又具有挑战性的基准测试集,以推动通用自然语言理解方法的发展。
其他相关基准¶
decaNLP(McCann 等人, 2018) 是另一个基于多任务的 NLP 基准,它将多个任务(如摘要和语义解析)转换为问答形式进行评估。
然而,与 GLUE 相比,decaNLP 缺少排行榜和错误分析工具,并且其目标更为宏大但当前实用性较低。
GLUE 追求的是在一组明确任务上表现优异的方法,而 decaNLP 则试图将 NLU 所有任务统一到问答框架下,目标更具理想性。
3 Tasks¶
GLUE基准包含九项英语句子理解任务,涵盖广泛的领域、数据量和难度。其目标是推动通用自然语言理解(NLU)系统的开发。GLUE的设计要求模型在多个任务间共享大量知识,同时保留一些任务特定的组件。尽管可以针对每个任务单独训练模型,不进行预训练或使用外部知识来源,但鉴于其中包含一些数据稀缺的任务,这种方法最终将难以竞争。文中对九项任务进行了描述,详见 表1,附录A提供了更多细节。除非另有说明,任务均以准确率(accuracy)评估,且类别平衡。
3.1 Single-Sentence Tasks¶
CoLA¶
CoLA(语言接受度语料库)包含来自语言学书籍和期刊的英语句子可接受性判断。每个例子标注了该句子是否语法正确。评估指标为Matthews相关系数(Matthews Correlation Coefficient),适用于不平衡二分类任务,取值范围为-1到1。使用作者提供的私有测试集进行评估,报告的是测试集中领域内和领域外部分的综合表现。
SST-2¶
SST-2(斯坦福情感树库)包含电影评论中的句子及其情感标注。任务是预测句子的情感倾向,分为积极和消极两类。仅使用句子级别的标签。
3.2 Similarity and Paraphrase Tasks¶
MRPC¶
MRPC(微软研究复述语料库)包含从新闻中自动提取的句子对,标注了是否语义等价。由于类别不平衡(68%为正类),评估时同时报告准确率和F1分数。
QQP¶
QQP(Quora问题对数据集)包含Quora上提取的问题对,任务是判断两个问题是否语义等价。类别分布不平衡(63%为负类),因此也报告准确率和F1分数。使用作者提供的私有测试集,且测试集的标签分布与训练集不同。
STS-B¶
STS-B(语义文本相似性基准)由新闻标题、视频图像描述、自然语言推理数据中的句子对组成。每个句子对标注有1至5的相似性分数。评估指标为皮尔逊(Pearson)和斯皮尔曼(Spearman)相关系数。
3.3 Inference Tasks¶
MNLI¶
MNLI(多体裁自然语言推理语料库)包含多个来源的句子对,标注为“蕴含”、“矛盾”或“中性”。评估使用标准测试集,并区分匹配域(in-domain)和不匹配域(cross-domain)。还推荐使用SNLI(55万条数据)作为辅助训练数据。
QNLI¶
QNLI(问答推理)由斯坦福问答数据集(SQuAD)转换而来。任务是判断上下文句子是否包含问题的答案。经过转换后,任务变成句子对分类问题。此过程去除模型需选择准确答案的要求,同时去除了词法重叠作为提示的简化设定。注意早期版本的QNLI存在优化空间,随后被改进。
RTE¶
RTE(文本蕴含识别)数据集来自多个年度挑战任务。本文将多个RTE数据集合并为二分类任务(蕴含/非蕴含)。构建基于新闻和维基百科的句子对。
WNLI¶
WNLI(Winograd NLI)基于Winograd Schema挑战,属于阅读理解任务。任务是判断代词替换后的句子是否与原句蕴含。转换为句子对分类任务后,评估方式与QNLI类似。测试集不平衡,且开发集存在对抗性样本,部分训练与开发实例共用假设句。
3.4 Evaluation¶
GLUE的评估方式借鉴了SemEval和Kaggle平台。评估时需运行模型在测试数据上,并将结果上传至GLUE官方网站(gluebenchmark.com)进行评分。网站显示每个任务的得分和任务得分的宏观平均值,用于确定模型在排行榜中的位置。对于使用多种评估指标的任务(如准确率和F1),采用指标的无权重平均值作为该任务的最终得分。网站还提供诊断数据集的粗粒度和细粒度结果,详情见附录D。
重点总结:
GLUE包含9项任务,涵盖单句理解、语义相似性、推理任务。
任务设计强调跨任务共享知识,适合评估通用NLU模型。
重点任务包括:CoLA(语法性判断)、SST-2(情感分析)、STS-B(相似性评分)、MNLI(自然推理)。
评估方式统一,采用宏观平均分,并支持多指标任务的平均处理。
数据集部分不平衡,需特别注意评估指标(如F1、Pearson/Spearman)。
此章节为GLUE基准任务的全面介绍,为后续模型评估和比较提供了标准化框架。
4 Diagnostic Dataset¶
4 诊断数据集(Diagnostic Dataset)¶
背景与目标¶
本节介绍一个小型的手动构建测试集,用于分析模型在特定语言现象上的表现。该数据集受到 FraCaS 套件(Cooper 等,1996)和 Build-It-Break-It 竞赛(Ettinger 等,2017)的启发。与主要基准数据集(反映实际应用场景分布的例子)不同,诊断数据集聚焦于一组预定义的语言现象,旨在测试模型对这些关键语言特性是否具备理解能力。这些现象被完整列出在 表2 中。
数据集内容¶
每个例子是一个自然语言推理(NLI)句子对,并带有标注的语言现象标签。
NLI 任务非常适合这种分析,因为它可以评估句子理解中的多种能力,例如句法歧义消解、常识推理等。
为保证多样性,数据集涵盖多种语言现象,并基于来自多个领域(如新闻、Reddit、维基百科、学术论文)的真实句子构建。
与 FraCaS 不同,FraCaS 的设计目标是测试语言理论,使用的是极简且统一的例子,而本数据集更强调实际语言现象的覆盖。
数据集的一个示例可在 表3 中查看。
标注过程(Annotation Process)¶
初始目标是一组语言现象,大致参考了 FraCaS 使用的现象。
每个例子通过找到一个原始句子,并对其进行两种方式的编辑,形成一个句子对。
编辑过程尽量保留词汇和结构的重叠,以减少表面线索(superficial cues)。
标注过程中,每个句子对的两个句子轮流作为前提,生成两个标注样本,总共 1100 个标注实例。
尽可能为一个源句创建多个具有不同推理标签(entailment, neutral, contradiction)的句子对,以保证语言表面相似但推理关系不同。
最终标签分布为:42% 包含(entailment)、35% 中性(neutral)、23% 矛盾(contradiction)。
评估指标(Evaluation)¶
由于诊断数据集的类别分布不均衡,使用 R₃(Gorodkin, 2004)指标进行评估,这是 Matthews 相关系数 的三类扩展版本。
为验证数据中不存在可被模型利用的表面线索(artifacts),作者复现了 Gururangan 等(2018)的方法,使用 fastText 分类器仅根据假设句子预测推理标签。
在诊断数据集上的准确率接近随机(32.7% 对 SNLI,36.4% 对 MNLI),说明数据不含可被利用的表面线索。
为评估人类表现,作者请六位 NLP 研究人员标注 50 个句子对(共 100 个推理实例,随机采样)。
标注者之间的一致性较高,Fleiss’s κ 为 0.73。
平均 R₃ 得分为 0.80,远高于第 5 节中描述的任何基线系统,说明数据集具有良好的区分能力。
预期用途(Intended Use)¶
该数据集不用于衡量整体性能,而是为模型提供分析工具。
由于数据集中的例子是手动挑选的,并且 NLI 任务本身无自然输入分布,因此其性能不能反映实际应用场景下的泛化能力。
作者建议在模型之间比较诊断集上的性能,但不应在不同任务类别之间进行比较。
数据集的主要用途包括:
错误分析
定性模型比较
对抗样本开发
总结¶
本节呈现了一个小型但精心设计的诊断数据集,用于评估模型对关键语言现象的理解能力。该数据集设计合理、标注严谨,并通过严格的审计确保无表面线索,能够作为模型分析和研究的有效工具。
5 Baselines¶
5 Baselines 总结¶
本节主要介绍了在GLUE任务上用于对比的基线模型(baselines),包括基于多任务学习的模型及其多个变体,以及基于近期预训练方法的模型。所有模型均使用 AllenNLP 库实现,原始代码可在指定 GitHub 仓库中找到。
架构(Architecture)¶
基线模型的核心架构是基于 句子到向量(sentence-to-vector)编码器 的结构。简单模型使用:
BiLSTM:两层、1500 维(每方向),配合 max pooling
词嵌入:300 维的 GloVe 词向量(基于 840B Common Crawl)
对于单句任务(如 SST-2、CoLA),模型直接编码句子并传入分类器;
对于句子对任务(如 MRPC、STS-B),分别编码两个句子,然后拼接以下特征:
[u; v; |u−v|; u*v],并输入一个 512 维的多层感知机(MLP)分类器。
重点内容:
引入了基于注意力机制的变体模型(+Attn),使用了 Seo 等人的方法,通过词对间的注意力交互,再使用 BiLSTM 和 max pooling,突破了 sentence-to-vector 的范式,更充分地建模句子之间的交互关系。
预训练(Pre-Training)¶
作者进一步将基线模型与以下两个近期的预训练方法结合:
ELMo:使用两个双向语言模型(BiLM)在 Billion Word Benchmark 上训练。每个词通过上下文生成嵌入,方法是将各层隐状态线性组合。论文中使用 ELMo 替代了其他词嵌入方式。
CoVe:基于一个用于英德翻译的双层 BiLSTM 编码器,将 CoVe 向量与 GloVe 向量拼接使用。
重点内容:
ELMo 和 CoVe 的加入显著提升了模型在多个 GLUE 任务上的表现,说明上下文信息对自然语言理解任务的重要性。
训练(Training)¶
训练策略为:
使用共享的 BiLSTM 句子编码器和注意力 BiLSTM。
分类器为任务独立训练。
每个训练回合从任务池中按训练样本数量比例采样任务进行训练。
使用 Adam 优化器,初始学习率为
1e-4,批量大小为 128。以宏平均分(macro-average score)为验证指标,当学习率低于
1e-5或 5 次验证无提升时停止训练。
单任务模型:
每个任务独立训练,不共享参数。
与多任务模型设置相同,但不进行超参调优,因此不追求任务最优。
重点内容:
多任务训练在多个任务中表现优于单任务模型,说明共享结构和参数有助于提升整体性能。
ELMo 和 CoVe 的加入进一步提升了多任务模型的表现。
句子表示模型(Sentence Representation Models)¶
作者还评估了以下几种训练好的句子向量表示模型:
CBoW(GloVe 的平均)
Skip-Thought
InferSent(Conneau 等,2017)
DisSent(Nie 等,2017)
GenSen(Subramanian 等,2018)
这些模型仅用于生成句子表示,作者在每个任务上单独训练分类器。
重点内容:
GenSen 和 InferSent 表现较好,GenSen 在多个任务上达到 66.2 的平均分,说明这些模型在生成通用句子表示方面具有优势。
相比之下,基于 ELMo 和多任务训练的模型(如 +Attn, ELMo)在多任务平均得分上达到 70.0,表现更优。
总结¶
本节全面评估了多种基线模型在 GLUE 任务上的性能,重点包括:
句子到向量编码器(如 BiLSTM)及其变体(+Attn)
预训练模型(ELMo、CoVe)
多任务与单任务训练策略
现成句子表示模型(如 InferSent、GenSen)
通过对比不同配置的模型,作者展示了上下文信息(如 ELMo)和任务间共享结构(如多任务训练)对自然语言理解任务的显著提升作用。
6 Benchmark Results¶
6 Benchmark Results(基准测试结果)¶
本节介绍了对多个模型在GLUE任务上的基准测试结果。作者训练了每种模型的三个版本,并选择在开发集上宏平均性能最佳的那一轮进行评估(详见附录表6)。对于单任务和句子表示模型,作者分别评估了每个任务表现最好的版本。最终结果展示在表4中。
主要发现¶
多任务训练优于单任务训练:
对于使用注意力机制或ELMo的模型,多任务训练在整体表现上优于单任务训练。
注意力机制在单任务训练中效果甚微甚至有负面影响,但在多任务训练中表现出帮助。
ELMo优于GloVe和CoVe:
使用ELMo嵌入比使用GloVe或CoVe嵌入在单句任务中表现更好。
CoVe嵌入的效果则不稳定,有时优于GloVe,有时不如。
预训练句子表示模型表现良好:
从CBoW到Skip-Thought,再到Infersent和GenSen,模型表现逐步提升。
Infersent在GLUE任务上的表现可与直接训练模型相媲美,而GenSen则超越了除两个最佳模型之外的所有模型。
任务差异性:
在CoLA任务中,句子表示模型表现远远不如直接在该任务上训练的模型。
在STS-B任务中,直接训练的模型表现不如最佳句子表示模型。
在WNLI任务中,所有模型的表现甚至不如最频繁类别猜测(65.1%),因此使用了最频繁类别的预测结果。
在RTE任务中,即使是最优的基线模型仍存在改进空间。
总体结论:
当前的模型和方法在解决GLUE任务上仍存在较大挑战,尚未达到理想水平。
表5总结:诊断集结果¶
表5展示了模型在诊断集上的表现,使用的是R3系数(相关性系数),已乘以100表示。模型结果分为粗粒度类别和细粒度类别:
粗粒度类别包括:
词汇语义(LS)
语义结构(PAS)
逻辑(L)
知识与常识(K)
细粒度类别包括:
全称量化(UQuant)
词形否定(MNeg)
双重否定(2Neg)
代词/共指(Coref)
限制性(Restr)
向下单调性(Down)
表格展示了不同模型在不同任务子类中的表现,例如:
在单任务训练中,加入ELMo或CoVe对某些任务有帮助,但并不稳定。
使用注意力机制+ELMo在多个任务中表现最好。
预训练模型(如GenSen)在多数任务上表现优于单任务训练模型。
CBoW和Skip-Thought表现较差,但InferSent和GenSen表现显著提升。
结论¶
本节展示了不同模型在GLUE任务上的表现,体现出:
多任务训练和预训练句子表示模型的优势。
ELMo和注意力机制的有效性。
当前模型在某些任务(如RTE和WNLI)上仍存在明显不足。
这表明GLUE任务仍是当前NLP领域的一个挑战性基准,未来模型和方法仍有很大发展空间。
7 Analysis¶
7 分析¶
7.1 Coarse Categories(粗略类别)¶
本部分通过在诊断集上评估每个模型的 MNLI 分类器,分析其语言能力。结果显示(见表5),所有模型的整体表现较低,最高总分为 28,仍表示较差的绝对性能。
模型在谓词-论元结构(Predicate-Argument Structure)上的表现较高,而在逻辑(Logic)上的表现较低,但不同类别之间数据可比性不高。
与主基准测试不同,在诊断集上,多任务模型的性能几乎总是低于单任务模型。这可能是因为当前的多任务训练机制简单,MNLI 与其他任务之间存在破坏性干扰。
使用 GLUE 任务训练的模型大多优于预训练的句子表示模型,GenSen 除外。另外,使用注意力机制对诊断得分的影响大于使用 ELMo 或 CoVe,这表明注意力机制在 NLI 的泛化方面尤为重要。
7.2 Fine-Grained Subcategories(细粒度子类别)¶
大多数模型对全称量化(universal quantification)的处理相对较好。例如,模型通常依赖“all”这样的词汇线索来取得良好表现。
同样,在形态否定(morphological negation)的例句中,词汇线索也提供了较强的信号。
不同模型在弱点方面也存在差异。双否定(double negation)对仅使用 GloVe 嵌入的 GLUE 训练模型来说尤其困难,但使用 ELMo 或 CoVe 可以在一定程度上缓解这一问题。
注意力机制对整体结果影响复杂。具有注意力机制的模型在向下单调性(downward monotonicity)任务中表现较弱。研究发现这些模型对上位词/下位词替换(hypernym/hyponym substitution)和词语删除(word deletion)敏感,但预测方向错误(仿佛词语处于向上单调性上下文中)。这一现象与 McCoy & Linzen(2019)的研究一致,即模型倾向于使用前提与假设之间的子序列关系作为启发式快捷方式。
限制性例子(restrictivity examples)通常依赖于量化词作用范围的细微差别,几乎所有模型在此类任务上的表现都很差。
总结¶
总体来看,超越向量表示的模型结构(如注意力机制)可能有助于模型在领域外数据上的表现。此外,迁移学习方法(如 ELMo 和 CoVe)编码了它们监督信号中的语言信息。
然而,模型表示能力的提升可能导致过拟合,例如注意力模型在向下单调性语境中的失败。
作者认为该平台和诊断集在未来类似的分析中将非常有用,以便模型设计者更好地理解其模型的泛化行为和隐式知识。
8 Conclusion¶
8 结论¶
本文介绍了GLUE(General Language Understanding Evaluation),这是一个用于评估和分析自然语言理解(NLU)系统的平台及资源集合。
重点指出,模型在多个任务上联合训练时,整体表现优于为每个任务单独训练的模型表现的总和,这表明多任务学习的潜力。
文中进一步确认了注意力机制和迁移学习方法(如ELMo)在NLU系统中的有效性,这些方法结合使用后在GLUE基准上优于当前最佳的句子表示模型,但仍存在改进空间。
通过在诊断数据集上的评估发现,这些模型在许多语言现象上表现不佳(甚至是显著失败),这为未来的研究提供了可能的方向。
最后,作者总结道,如何设计通用的NLU模型仍然是未解的问题,并认为GLUE平台为解决这一挑战提供了良好的研究基础。
Acknowledgments¶
致谢¶
本节主要表达了对在研究过程中提供帮助和支持的个人、机构的资金支持的感谢。
重点内容:
早期阶段的反馈与评论:作者感谢 Ellie Pavlick、Tal Linzen、Kyunghyun Cho 和 Nikita Nangia 在本工作的早期阶段提出的宝贵意见,这些反馈对研究的推进有重要帮助。
私有评估数据的获取:作者特别感谢 Ernie Davis、Alex Warstadt 以及 Quora 的 Nikhil Dandekar 和 Kornel Csernai 提供了私有评估数据的访问权限,这对于研究的可靠性和全面性具有重要意义。
资金支持:
SB 收到的支持:来自 Google、腾讯(Tencent Holdings)和三星研究院(Samsung Research)的资助。
AW 收到的支持:来自 AdeptMind 以及美国国家科学基金会(NSF)的研究生研究奖学金。
总结:
本节内容虽然简短,但涉及了对多方支持的感谢,尤其是早期反馈和私有数据的获取对研究工作的开展至关重要。资金支持方面则体现了项目获得了学术界和工业界的双重认可。
Appendix A Additional Benchmark Details¶
QNLI(问答自然语言推理)¶
本节重点介绍了 QNLI(Question-NLI) 数据集的构建方法,以确保数据的平衡性。
为构建一个平衡的数据集,作者采取了如下策略:
选择非答案对:挑选所有与问题最相似的句子不是答案句子的样本对。
选择近似干扰对:同时挑选同样数量的样本对,这些样本中,正确答案的句子确实是最相似的,但还有一个干扰句子紧随其后,相似度也非常高。
上述方法中使用了相似度度量:基于 CBoW 词袋模型和预训练的 GloVe 词向量表示句子,以此作为判断句子相似度的标准。
此外,该方法的思路与以下研究密切相关:
White 等人(2017)的工作:他们也尝试将现有数据集转换为NLI(自然语言推理)格式。
Dagan 等人(2006)提出的文本蕴含(textual entailment)概念:他们认为,许多NLP任务可以转化为文本蕴含问题,从而统一处理。
重点内容总结:
QNLI数据集构建的核心在于数据平衡,包括“非答案对”和“干扰答案对”。
使用 CBoW + GloVe 表示来判断句子相似性。
与文本蕴含和NLI格式转换的研究密切相关,体现了将多种NLP任务统一为推理任务的思路。
Appendix B Additional Baseline Details¶
Appendix B Additional Baseline Details(附录B 其他基线细节)¶
B.1 Attention Mechanism(注意力机制)¶
本节介绍了论文中所使用的注意力机制的实现方式:
给定两个序列的隐藏状态:u₁, u₂, …, u_M 和 v₁, v₂, …, v_N,首先计算一个矩阵 H,其中 H_ij = u_i ⋅ v_j,即u_i和v_j之间的点积。
对于每个u_i,通过在H的第i行上进行softmax操作,得到注意力权重α_i。
基于注意力权重,计算出一个上下文向量ṽ_i,即对v_j进行加权求和,得到ṽ_i = Σ α_ij * v_j。
将[u₁; ṽ₁], …, [u_M; ṽ_M]作为输入,通过一个带有最大池化的BiLSTM处理,得到新的表示u’。
类似地处理v_j,得到v’。
最终将[u’; v’; |u’ − v’|; u’ * v’]作为特征,输入到一个分类器中进行判断。
重点内容:注意力机制的构建过程(计算H矩阵、softmax、上下文向量)和最终特征向量的构造方式是重点内容,说明了模型如何融合两个序列的信息。
B.2 Training(训练)¶
本节介绍了模型的训练方式和优化策略:
模型中使用BiLSTM编码句表示,并在所有任务中共享编码器和后处理的BiLSTM注意力模块,而分类器则是为每个任务单独训练的。
每次训练更新时,按任务的训练样本数量比例随机选择任务进行训练。
对每个任务的损失函数进行反比例缩放(样本越多,损失权重越小),从而提升整体性能。
使用Adam优化器,初始学习率为10⁻³,批量大小为128,使用梯度裁剪(gradient clipping)防止梯度爆炸。
验证时使用所有任务的宏平均(macro-average score)作为评估指标,每10000次更新进行一次验证。
如果验证性能不再提升,将学习率除以5。
当学习率低于10⁻⁵ 或连续5次验证未提升时,停止训练。
重点内容:任务共享的结构设计、损失函数的加权方式、优化器参数和学习率调整策略是训练过程的关键,体现了多任务学习的灵活性与稳定性。
B.3 Sentence Representation Models(句表示模型)¶
本节介绍了论文中评估的几种句子表示方法:
CBoW(词袋模型):对句子中所有词的GloVe嵌入取平均。
Skip-Thought(Kiros等人,2015):基于序列到序列模型,通过中间句生成上下文句子,预训练于多本书籍语料(TBC)。
InferSent(Conneau等人,2017):基于BiLSTM和最大池化,训练于语义相似度任务(MNLI和SNLI)。
DisSent(Nie等人,2017):同样基于BiLSTM和最大池化,训练于根据句间关系(如因果关系)对句子进行分类。
GenSen(Subramanian等人,2018):基于序列到序列模型,训练目标包括语义相似度(MNLI/SNLI)、Skip-Thought任务和句法结构任务。
作者在这些模型的冻结状态上训练任务特定的分类器,并使用SentEval提供的默认参数进行实验,相关代码和细节可在GitHub上找到(https://github.com/nyu-mll/SentEval)。
重点内容:这些模型代表了不同层次的句表示方法,从简单的词袋到复杂的多任务训练模型,说明了实验对比的全面性。
Appendix C Development Set Results¶
Appendix C Development Set Results 总结¶
本节内容主要说明的是,由于GLUE网站限制用户每天最多提交两次结果,以防止对私有测试数据过度拟合,因此为了给未来在GLUE上的研究提供参考,作者在表6中展示了其基线模型在**开发集(development set)**上取得的最佳结果。
重点内容如下:
提交限制:GLUE网站限制每天最多提交两次,这是为了防止研究者通过对测试数据的反复尝试而过拟合。
开发集结果展示:由于测试数据受限,作者选择在开发集上展示其基线模型的最佳表现,以提供一个参考标准。
表6的作用:表6中总结了不同模型在开发集上的性能,为后续研究提供了基准。
不重要内容说明:
本节文字简短,重点在于说明原因和展示方式,没有涉及具体模型细节或结果分析。
Appendix D Benchmark Website Details¶
Appendix D Benchmark Website Details(附录 D 基准网站详情)¶
本节主要介绍了 GLUE 基准测试平台的网站实现细节和展示方式,重点包括网站技术架构和排行榜展示。
技术实现¶
GLUE 的在线平台使用了 React、Redux 和 TypeScript 进行前端开发。后端数据存储使用了 Google Firebase,评测脚本的部署和运行则通过 Google Cloud Functions 实现。当用户提交模型结果时,系统会自动运行评测脚本,并将结果更新到排行榜中。
排行榜展示¶
图 1 展示了基准网站的排行榜界面。图中提供了每个提交结果的扩展视图,包括:
模型的简要描述:以文本形式介绍模型的基本信息;
参数数量:展示模型的参数规模,便于比较不同模型的复杂度。
图 1 的作用是直观呈现当前排行榜上各模型的性能和特性,方便用户快速理解不同模型的表现和差异。
重点总结¶
技术架构 是本节的重点,详细说明了 GLUE 平台所使用的技术栈,包括 React、Redux、TypeScript、Firebase 和 Cloud Functions,突出了系统的可扩展性与自动化;
排行榜展示方式 也是重点内容,图 1 显示了用户提交模型后,平台如何展示模型的详细信息和性能表现;
较为次要的信息是网站的前端和后端技术细节,但这些细节对于理解平台的运行机制起到了支持作用。
Appendix E Additional Diagnostic Data Details¶
本节总结如下:
附录 E:额外的诊断数据细节¶
本节介绍了一个用于分析语言模型在自然语言理解不同层面表现的数据集。该数据集可用于分析从词义、句法结构到高水平推理和世界知识应用的多方面内容。
1. 数据集目的与分类¶
数据集并非用于基准测试,而是作为分析工具,帮助研究者了解模型在不同语言现象上的表现,例如错误分析、模型对比和对抗样本的构建。
作者将语言现象分为四类:词义(Lexical Semantics)、谓词-论元结构(Predicate-Argument Structure)、逻辑(Logic)和知识(Knowledge),并进一步细分为多个子类别,以便更细致地分析模型的表现。
重点: 这些分类并非基于某一种特定的语言学理论,而是基于语言学家在句法和语义研究中普遍关注的问题。
2. 数据集统计信息¶
表 7 展示了粗粒度分类下的数据量和标签分布,包括中性(Neutral)、矛盾(Contradiction)和蕴含(Entailment)的比例:
分类 |
数据量 |
% 中性 |
% 矛盾 |
% 蕴含 |
|---|---|---|---|---|
词义 |
368 |
31.0 |
27.2 |
41.8 |
谓词-论元结构 |
424 |
37.0 |
13.7 |
49.3 |
逻辑 |
364 |
37.6 |
26.9 |
35.4 |
知识 |
284 |
26.4 |
31.7 |
41.9 |
重点: 数据分布具有一定的任意性,因此建议将模型在同一类别下的表现进行比较,而非跨类别比较。
E.1 词义(Lexical Semantics)¶
该类别关注词语层面的意义。
词义蕴含(Lexical Entailment)¶
词语之间的蕴含或矛盾关系,如“狗”蕴含“动物”,“猫”与“狗”矛盾。该类现象常与**单调性(Monotonicity)**相关。
形态否定(Morphological Negation)¶
通过词形变化表达否定意义,如“agree”与“disagree”,“ever”与“never”。
事实性(Factivity)¶
某些结构在句子中对命题的真假有固定关系,例如:
“I recognize that X” → 蕴含 X
“I believe that X” → 不蕴含 X
对称性/集体性(Symmetry/Collectivity)¶
句子中的关系是否对称,如“John married Gary”蕴含“Gary married John”,而“John likes Gary”不蕴含“Gary likes John”。
冗余(Redundancy)¶
单词在句子中是否可被省略而不影响语义。
专有名词(Named Entities)¶
关注名称的语义,如“Baltimore Police”与“Police of the City of Baltimore”等价。
量词(Quantifiers)¶
如“every”、“some”、“no”等,用于表示量化的逻辑结构。
重点: 词义分析是理解句子语义的基础。
E.2 谓词-论元结构(Predicate-Argument Structure)¶
关注句子内部结构的组合关系,包括句法歧义、语义角色和指代关系。
句法歧义(Syntactic Ambiguity)¶
如相对子句(Relative Clauses)和并列结构(Coordination Scope)可能带来歧义。
介词短语(Prepositional Phrases)¶
介词短语的依附问题常困扰句法分析器,涉及句法与语义的交叉。
核心论元(Core Arguments)¶
动词的选择性论元,如主语与宾语的互换性。
句法变换(Alternations)¶
包括主动/被动、所有格/部分格、名词化、与格等句法变换。
省略/隐含(Ellipsis/Implicits)¶
语句中某些成分被省略,模型需根据上下文推断其意义。
指代/共指(Anaphora/Coreference)¶
多个表达指向同一实体或事件,如代词“he”、“they”等。
交集性(Intersectivity)¶
形容词修饰的交集性或非交集性,影响蕴含关系。
限制性(Restrictivity)¶
名词修饰语是否用于限定或补充实体信息。
重点: 谓词-论元结构是句子结构理解的核心,涉及句法与语义的融合。
E.3 逻辑(Logic)¶
关注句子中可形式化为逻辑推理关系的结构。
命题结构(Negation, Double Negation, Conjunction, Disjunction, Conditionals)¶
自然语言中的否定、双重否定、合取、析取和条件句等对应逻辑运算。
量词逻辑(Quantification)¶
“all”、“some”、“no”等词表示的普遍性和存在性量化。
单调性(Monotonicity)¶
判断量词或逻辑结构对子句变换的敏感度。如“a”为上升单调,“no”为下降单调,“exactly one”为非单调。
更复杂的逻辑结构(Intervals/Numbers, Temporal)¶
如数字推理(“more than 2”蕴含“more than 1”)和时间推理(“before”蕴含“after”)。
重点: 逻辑推理能力是语言模型理解复杂语义关系的重要基础。
E.4 知识(Knowledge)¶
关注世界知识和常识的使用,涉及事实性知识和普遍常识。
世界知识(World Knowledge)¶
如地理、法律、文化等事实性知识,例如“Mt. Fuji 在日本”而不是“在尼泊尔”。
常识(Common Sense)¶
如对社会行为和物理现象的普遍理解,例如“理发”蕴含“剪发”,“震惊”与“预期相反”。
重点: 模型若缺乏常识或世界知识,将难以正确理解语义关系。
总结¶
本节详细介绍了 GLUE 诊断数据集的分类、统计信息和子类别,旨在帮助研究者从多个语言理解和推理层面评估模型的能力。数据集不用于基准测试,而是用于错误分析、模型比较和对抗样本生成。分类涉及词义、句法结构、逻辑推理和知识应用,每个类别下都有详细的子类和示例,涵盖自然语言处理中的多个核心问题。
总结重点:
数据集是分析工具,非基准测试;
分类涵盖词义、句法结构、逻辑和知识;
每个类别下有大量子类和示例,便于模型分析;
强调逻辑推理与常识理解的重要性。