2506.05813_MAPLE: Multi-Agent Adaptive Planning with Long-Term Memory for Table Reasoning¶
引用: 0(2025-10-31)
组织:
1Department of Data Science & AI, Monash University(澳大利亚)
总结¶
MAPLE
MAPLE: Multi-agent Adaptive Planning with Long-term mEmory
包含四大核心组件(重点内容):
Solver(求解器):执行逐步推理,通过与表格的实时互动进行动态操作。其输入包括当前环境、问题、历史操作和记忆;输出为中间操作结果或最终答案。
Checker(检查器):对答案进行多维度的验证,包括答案类型检查、格式验证和证据支撑验证,输出结构化反馈。
Reflector(反思器):在答案验证失败时进行错误诊断,生成改进计划,推动系统自我优化。
Archiver(归档器):通过总结经验、检索相关记忆、演化记忆结构,实现长期记忆管理与知识积累。
Memory Summarization(记忆总结):将问题、答案、反馈等信息浓缩为结构化记忆;
Memory Retrieval(记忆检索):分为Solver-time(推理时)和Archiver-time(管理时)两种模式,支持经验指导与记忆优化;
Memory Evolution(记忆演化):通过语义聚类和连接更新记忆,实现知识的动态优化。
数据集
在WiKiTQ和TabFact两个数据集上测试得到显著效果提升
WikiTQ:这是一个广泛使用的表格问答数据集,由14,149个训练对和4,344个测试对组成。问题需要不同层次的推理,答案可以是单个值、列表或根据表格推导出的结果。
TabFact:这是一个事实验证数据集,包含来自不同领域的表格和与之配对的自然语言陈述,每个陈述被标记为“yes”或“no”。任务是判断陈述是否与表格一致。
主要贡献
提出一种反馈驱动的多代理框架(MAPLE),实现自适应推理规划。
专门的验证和反思机制,提供有针对性的诊断反馈。
结构化的长期记忆系统,用于经验提炼和错误分类。
在WiKiTQ和TabFact基准上的SOTA性能。
展望
两个有前景的研究方向
增强基础推理能力
开发用于复杂数值操作的专用工具
未来的研究应探索更为复杂的记忆管理策略,例如引入“遗忘机制”或采用分层组织的记忆结构。
缺点
由于其多轮次、多智能体的架构,MAPLE的计算成本高于单次推理方法。每轮推理都需要调用多个大语言模型(LLM),这增加了推理时间和计算成本
记忆表示方式
自然语言表示(如 Reflexion、Voyager、Generative Agents):强调语义丰富性和可解释性。
向量嵌入表示(如 MemoryBank、A-MEM、ChatDev):支持基于相似性的高效检索。
结构化表示(如 ChatDB、DB-GPT):支持符号推理和精确查询。
表格推理(Table Reasoning)
表格推理的研究主要分为两类:微调方法 和 提示方法。
微调方法(如 TAPAS、Pasta、TUTA、TAPEX):通过专门的训练目标,使预训练语言模型适应表格语义。
提示方法(如 Chain-of-Thought、Least-to-Most、Binder、Chain-of-Table、ReAcTable、Table-Critic):基于任务分解,利用少量训练数据进行推理,部分方法引入了智能体协作或 ReAct 风格的推理机制。
Abstract¶
本文探讨了基于表格的问题回答(Table-based question answering)这一任务,指出当前的大型语言模型(LLMs)在进行单次推理时难以完成所需的复杂推理。现有方法如Chain-of-Thought(思维链)和问题分解(question decomposition)虽然在一定程度上提升了推理能力,但存在两个关键问题:缺乏错误检测机制,且无法复用问题解决经验,与人类处理问题的方式形成鲜明对比。
为了解决这些问题,作者提出了MAPLE(Multi-agent Adaptive Planning with Long-term mEmory),这是一个模仿人类问题解决过程的新型框架,通过多个专门的认知代理(cognitive agents)在反馈驱动的循环中协同工作,从而提升推理效率和准确性。
MAPLE包含四大核心组件(重点内容):
Solver:使用ReAct范式进行推理,结合推理与行动;
Checker:负责答案验证,检测推理过程中可能存在的错误;
Reflector:进行错误诊断和策略修正,提升后续推理的正确性;
Archiver:管理长期记忆,用于经验的复用与演化,使系统能够不断积累和优化问题解决经验。
实验在WiKiTQ和TabFact两个数据集上进行,结果表明MAPLE在多个大语言模型(LLM)基础上,均取得显著性能提升,达到当前最优水平(SOTA)。作者表示将在论文被接收后公开代码与数据。
1 Introduction¶
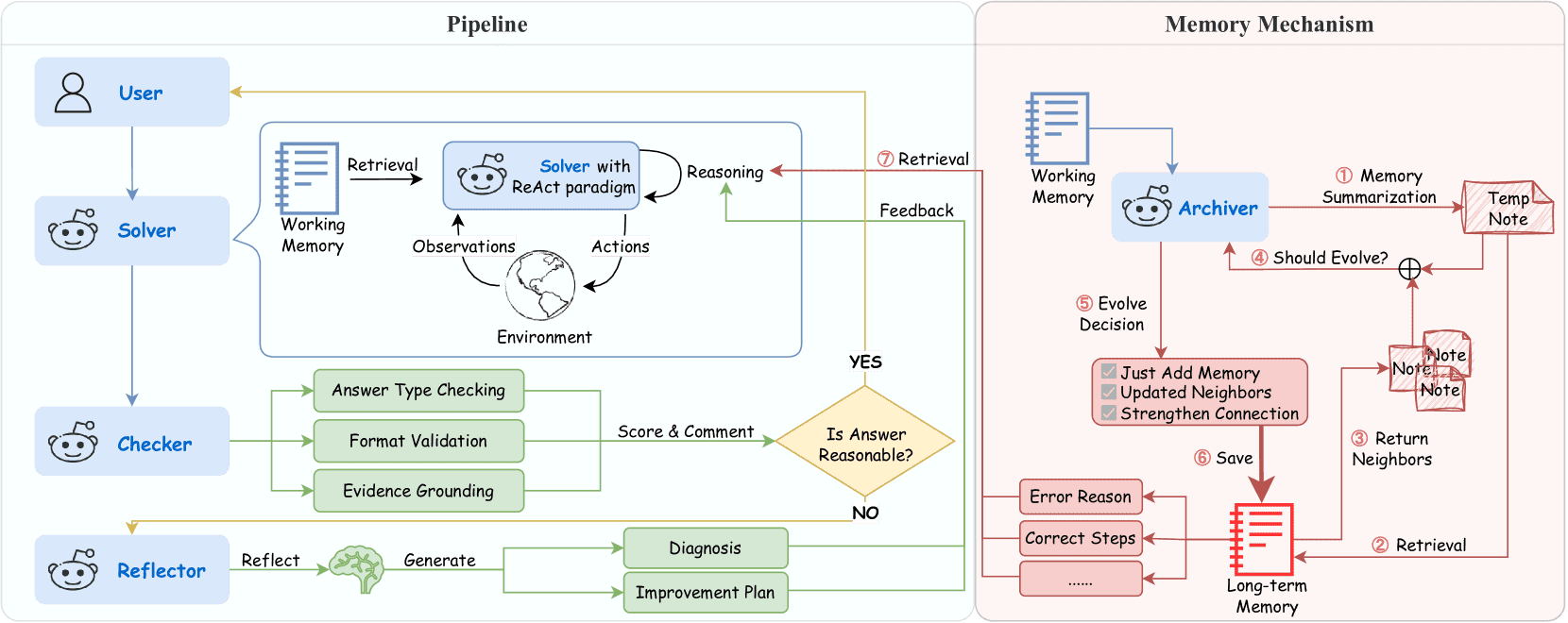
Figure 1: The MAPLE framework pipeline. 4 agents work collaboratively in a feedback loop: the Solver conducts iterative reasoning using ReAct, the Checker evaluates answer quality, the Reflector diagnoses errors and suggests improvements, and the Archiver manages an evolving long-term memory. This architecture enables dynamic adaptation both within tasks and across similar problems, mirroring human cognitive problem-solving processes.
背景与挑战¶
表格是半结构化数据中最常见形式之一,广泛应用于科学研究到商业分析等多个领域。然而,从表格中回答问题存在独特挑战,包括:在结构化数据上进行多步骤推理、识别单元格之间的隐含关系、以及对上下文进行精确解释。这些挑战使得表格问答(Table QA)对**大语言模型(LLMs)**尤为困难,因为LLMs需要在处理表格结构的同时进行复杂的推理,而当前的LLMs在单次前向推理中很难实现这一点。
现有方法的局限性¶
当前的表格推理框架存在以下限制:
单次前向方法(如Cheng et al. 和 Ye et al.)缺乏错误检测机制,容易导致错误传播。
ReAct方法(如Wang et al. 和 Zhang et al.)虽然提供了环境反馈,但缺乏系统的验证机制。
多代理方法(如Ye et al. 和 Yu et al.)主要关注输出优化,而非全面的推理改进。
经验无法复用:现有系统在问题解决完成后丢弃经验,无法实现跨任务的知识积累。
这与人类的解题过程形成鲜明对比:人类在处理复杂表格问题时,会系统地执行解决方案、验证结果、反思错误,并积累经验用于未来问题的解决。
MAPLE 框架的提出¶
为了解决上述问题,作者提出了MAPLE(Multi-agent Adaptive Planning with Long-term mEmory)框架,该框架通过反馈驱动的多代理协作来模仿人类的认知过程。框架结构如图1所示,包含四个专用代理:
Solver(求解者):通过ReAct进行迭代推理。
Checker(检查者):评估答案质量。
Reflector(反思者):诊断错误并提出改进建议。
Archiver(归档者):管理长期记忆,用于跨任务学习。
该架构能够在任务内和任务间实现动态适应,模拟人类的认知流程。
实验与贡献¶
在WiKiTQ和TabFact这两个基准数据集上的实验验证了MAPLE的显著优势,其表现优于现有方法。消融研究进一步验证了每个组件对整体性能的贡献。记忆分析表明,逻辑推理错误和数值操作失败占剩余挑战的80%左右,为未来研究提供了重要方向。
作者的主要贡献包括:
提出一种反馈驱动的多代理框架(MAPLE),实现自适应推理规划。
专门的验证和反思机制,提供有针对性的诊断反馈。
结构化的长期记忆系统,用于经验提炼和错误分类。
在WiKiTQ和TabFact基准上的SOTA性能。
这些创新解决了当前方法的根本性局限,构建了一个模拟人类认知过程的系统,同时提升了复杂表格推理任务的性能。
2 MAPLE Framework¶
2.1 Overview¶
本节概述了MAPLE框架中各个智能体(Agent)的功能、输入输出和核心作用。与传统单次推理方法不同,MAPLE借鉴人类的解题过程,设计了一个模块化、反馈驱动的多智能体系统,用于提升表格推理任务的适应性和学习能力。
Solver(求解器):执行逐步推理,通过与表格的实时互动进行动态操作。其输入包括当前环境、问题、历史操作和记忆;输出为中间操作结果或最终答案。
Checker(检查器):对答案进行多维度的验证,包括答案类型检查、格式验证和证据支撑验证,输出结构化反馈。
Reflector(反思器):在答案验证失败时进行错误诊断,生成改进计划,推动系统自我优化。
Archiver(归档器):通过总结经验、检索相关记忆、演化记忆结构,实现长期记忆管理与知识积累。
该框架的核心创新在于引入了反馈驱动的多轮推理循环,使得系统能通过迭代不断优化推理策略。
2.2 Agent Roles¶
本节详细定义了MAPLE中每个智能体的功能及其协同机制,通过Algorithm 1描述了完整的自适应推理流程。
2.2.1 Solver¶
核心功能:通过ReAct范式进行逐步推理,动态与表格环境交互。
输入包括当前环境、问题、历史操作和双记忆系统(工作记忆和长期记忆)。
输出为操作后的表或最终答案。
特点是具有实时反馈机制,根据表状态调整策略,实现动态适应。
2.2.2 Checker¶
关键作用:对答案进行结构化验证,提升回答的准确性与合理性。
验证维度包括:
答案类型(如问题要求数量,输出不能是国家名);
格式要求(如仅输出结果而非过程);
证据支撑(答案必须基于表格数据)。
输出为评分和反馈,用于驱动系统自我修正。
2.2.3 Reflector¶
创新点:引入元认知能力,对推理错误进行诊断并生成改进方案。
输入包括问题、答案、验证反馈和推理轨迹。
输出为诊断结果(d)和改进计划(p)。
通过反馈回路驱动Solver进行有目的的调整,避免盲目重复错误。
2.2.4 Archiver¶
核心贡献:实现长期记忆管理,促进经验复用与知识积累。
包括三个模块:
Memory Summarization(记忆总结):将问题、答案、反馈等信息浓缩为结构化记忆;
Memory Retrieval(记忆检索):分为Solver-time(推理时)和Archiver-time(管理时)两种模式,支持经验指导与记忆优化;
Memory Evolution(记忆演化):通过语义聚类和连接更新记忆,实现知识的动态优化。
总体结构总结¶
MAPLE框架通过多智能体协作,构建了一个具备自适应推理、多轮反馈、经验复用与知识积累能力的表格推理系统。其核心结构包括:
Solver负责推理;
Checker负责验证;
Reflector负责反思与改进;
Archiver负责记忆管理与演化。
各组件通过Algorithm 1中定义的自适应推理循环紧密协作,实现从任务中学习并持续优化,克服了传统系统无法适应和学习的局限。
重点概括:
MAPLE通过模块化设计和反馈驱动机制,实现表格推理的持续优化。
双记忆系统(短期与长期)推动经验积累与复用。
元认知能力(Reflector)和结构化验证(Checker)提升了系统的自我修正能力。
记忆演化机制(Archiver)使系统具备长期知识积累和动态优化能力。
3 Experiments¶
3.1 实验设置¶
本节介绍了实验的基本设置,包括使用的数据集、基线方法、模型和评估指标。
数据集¶
WikiTQ:这是一个广泛使用的表格问答数据集,由14,149个训练对和4,344个测试对组成。问题需要不同层次的推理,答案可以是单个值、列表或根据表格推导出的结果。
TabFact:这是一个事实验证数据集,包含来自不同领域的表格和与之配对的自然语言陈述,每个陈述被标记为“yes”或“no”。任务是判断陈述是否与表格一致。
基线方法¶
实验对比了三类方法:
标准推理:模型直接生成答案,包括端到端问答、少量样本问答、思维链(Chain-of-Thought)等。
基于程序的推理:模型生成可执行的代码(如Binder、Dater)来解答问题。
ReAct式推理:结合推理与行动,使用外部工具辅助(如Chain-of-Table、ReAcTable)。
实现细节¶
实验使用了两种最先进的大语言模型:
LLaMA3.3-70B-Instruct
Qwen2.5-72B-Instruct
所有模型在两个NVIDIA A100 GPU上运行,表格输入被转换为markdown格式。使用上下文提示(in-context prompting)并附带任务特定示例。
评估指标¶
WikiTQ:计算denotation accuracy,即预测答案与标准答案是否匹配,不考虑形式差异。
TabFact:使用精确字符串匹配评估二分类结果(“yes”或“no”)。
表2:表格推理准确率¶
方法 |
LLaMA3.3-70B |
Qwen2.5-72B |
|---|---|---|
WiKiTQ |
74.01 |
73.39 |
TabFact |
90.66 |
86.02 |
此表显示,MAPLE在两个数据集和两种模型上均超越所有基线方法。在WikiTQ上,提升最高达8.26%,TabFact上提升7.41%。这表明MAPLE在表格推理任务中具有显著优势。
3.2 主要结果¶
实验结果表明,MAPLE在两个标准数据集上均表现优于所有对比方法。特别是在WikiTQ上,其推理能力在需要组合推理的任务中表现突出;在TabFact上,证明了其在二分类事实验证任务中的强适应性。无论使用哪种基础模型,MAPLE都保持领先,说明其设计具有泛化性。
此外,MAPLE通过动态规划、多轮反馈、多角色协作和长期记忆机制,显著提升了系统的推理能力。
3.3 评估代理贡献¶
为了验证各个代理(Solver、Checker、Reflector、Archiver)在框架中的作用,进行了消融实验,使用LLaMA3.3-70B模型在WikiTQ上进行测试。结果如下:
设置 |
准确率(LLAMA3.3-70B) |
|---|---|
基线 |
45.58 |
+ Solver |
63.81 |
+ Solver & Checker |
65.91 |
+ Solver & Checker & Reflector |
71.09 |
+ Solver & Checker & Reflector & Archiver |
74.01 |
结果显示,每个代理的加入都有明显提升。特别是引入Archiver的长期记忆机制后,最终达到74.01%的准确率,验证了模块化设计的有效性。
3.4 记忆分析与系统行为¶
错误分布¶
实验分析了LLM在表格推理中的错误类型,发现:
逻辑推理错误(40.4%) 和 计数与聚合错误(38.7%) 是主要问题,占总体错误的80%以上。
计算与比较错误仅占4.1%,说明迭代验证机制有效减少了简单错误。
这些发现表明,未来提升方向应集中在增强LLM的逻辑推理能力,并引入外部工具辅助精确计算与聚合操作。
记忆动态与相似度阈值分析¶
通过调整相似度阈值(δ),观察到记忆系统的动态变化:
低阈值(δ=0.3):记忆量大但存在冗余。
中等阈值(δ=0.7):记忆演化率和效率达到峰值,是知识演化的最优范围。
高阈值(δ>0.9):记忆量减少,演化效率下降,影响推理效果。
不同数据集的最优阈值略有差异:
WikiTQ:在δ=0.3时准确率最高。
TabFact:在δ=0.5时表现最佳。 这表明检索时应使用较低阈值,而记忆演化时使用中等阈值,以兼顾多样性与一致性。
理论意义¶
实验结果支持了认知科学中的“近似学习理论”,即最优知识获取发生在新信息与已知信息既不完全相似也不完全不同时。MAPLE的记忆演化机制为此提供了实证支持。
总结¶
实验部分系统地验证了MAPLE框架在表格推理任务中的优越性,从模型性能、代理贡献到记忆机制均进行了深入分析。结果显示,MAPLE通过多代理协作、长期记忆机制和多轮反馈,有效提升了表格推理的准确率和鲁棒性,具有较高的实用价值和理论意义。
4 Conclusion¶
本文提出了 MAPLE,一个用于表格推理的多智能体框架,结合了自适应规划与长期记忆演化。通过将推理过程分解为由不同智能体负责的专门功能,我们的方法通过一个反馈驱动的循环,实现了策略的动态优化。
在 WiKiTQ 和 TabFact 数据集上的实验表明,该方法显著优于现有技术,消融研究也验证了各个组件的价值。我们对记忆的分析表明,剩余错误中的近 80% 来源于逻辑推理错误以及计数/聚合操作,这提示出两个有前景的研究方向:增强基础推理能力 和 开发用于复杂数值操作的专用工具。
此外,MAPLE 所展示的原理不仅限于表格推理任务,还可能对那些依赖于验证、反思和经验积累的知识密集型任务产生积极影响。这是本文的重要推广价值所在。
Limitations¶
尽管MAPLE取得了令人鼓舞的成果,但仍存在几个需要承认的限制。
首先,由于其多轮次、多智能体的架构,MAPLE的计算成本高于单次推理方法。每轮推理都需要调用多个大语言模型(LLM),这增加了推理时间和计算成本。这一特性对实时应用或资源受限系统的部署提出了挑战,这是当前需要重点关注的问题。
其次,虽然我们的记忆进化机制在实验中表现出有效性,但其长期的可扩展性尚未得到充分验证。随着记忆库的不断增长,保持记忆的一致性以及防止知识稀释变得越来越困难。未来的研究应探索更为复杂的记忆管理策略,例如引入“遗忘机制”或采用分层组织的记忆结构。
最后,目前的框架仅专注于基于表格的推理,尚未整合外部知识。这使其难以应对需要表格中未明确给出信息的问题。将外部知识收集能力整合到MAPLE中,是未来有潜力的研究方向,有助于提升其对复杂问题的处理能力。
Appendix B Cognitive Architecture¶
本节介绍 MAPLE 的认知架构,重点在于其如何通过内存模块、动作模块和规划模块实现多步推理、验证与反思。图3展示了 MAPLE 的内存结构和信息流动,通过不同颜色箭头表示不同操作过程:
绿色箭头(→):表示推理过程,智能体在工作内存中读取和更新信息,完成多步骤任务。
橙色箭头(←):表示从长期记忆中检索信息,支持当前推理。
红色箭头(→):表示学习过程,将新知识写入长期记忆。
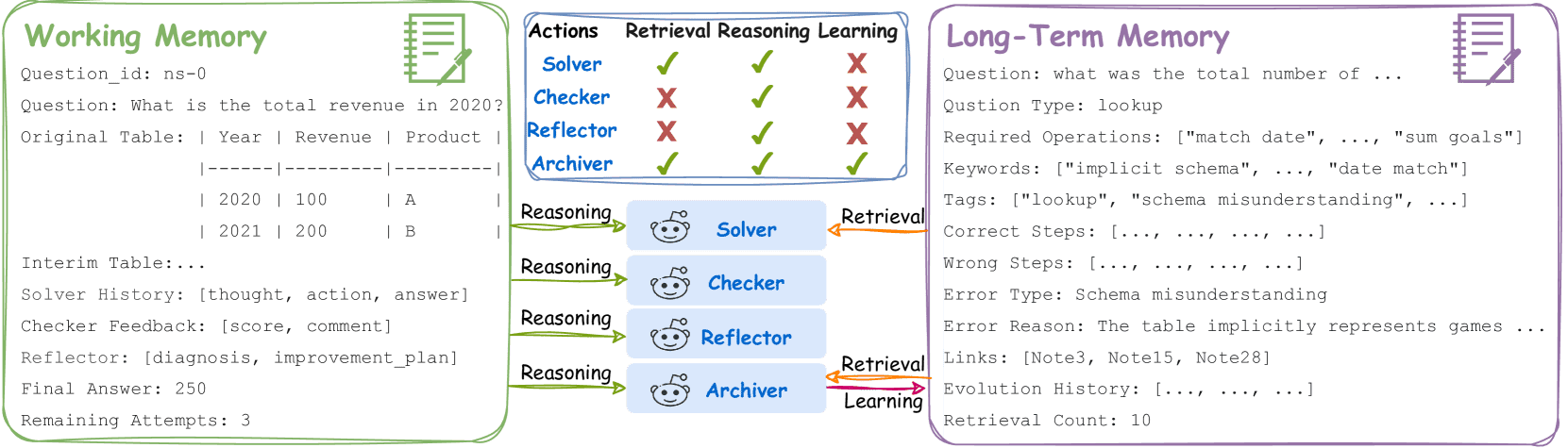
Figure 3:Overview of the memory structures and information flows in MAPLE.
B.1 记忆模块¶
MAPLE 的架构包含两个互补的内存模块:短期工作记忆(working memory)和长期记忆(long-term memory),分别用于动态推理和知识积累。
工作内存(Working Memory)¶
作用:存储当前任务相关的所有信息,如原始表格、问题、操作历史、验证反馈、反思分析等。
结构:采用 Shared Message Pool 架构,所有智能体可异步发布和订阅信息,支持灵活的多对多协作。
特点:
所有信息以自然语言表示,便于与大语言模型交互。
智能体(Solver、Checker、Reflector、Archiver)在推理过程中读写共享内存,确保上下文一致性。
长期记忆(Long-term Memory)¶
作用:存储任务间积累的知识,用于持续改进和经验重用。
结构:
每个记忆条目包含问题类型、操作步骤、错误类型、诊断信息等字段。
采用混合存储格式:结构化元数据用于基于嵌入的检索,自然语言描述用于可解释性。
创新点:
选择性集成机制:通过密度过滤,避免记忆饱和,保留多样性推理模式。
记忆演化策略:在任务完成后选择性更新或演化记忆,而非无差别更新,提升效率与一致性。
应用:
Archiver 代理在任务中检索相关记忆辅助 Solver,在任务结束后选择性更新长期记忆。
B.2 动作模块(Action Module)¶
动作模块将智能体的决策转化为具体操作,位于架构的最下层,直接与环境交互,并受内存和规划模块影响。
分类¶
外部动作(External Actions):如与机器人交互、网站导航等。MAPLE 不涉及此类动作。
内部动作(Internal Actions):操作对象为内部内存系统,分为三类:
检索(Retrieval):从长期记忆中读取相关经验。
推理(Reasoning):通过 LLM 处理当前信息,更新工作内存。
学习(Learning):将新知识写入长期记忆。
智能体动作模式¶
Solver 与 Checker:主要进行推理动作,读写工作内存。
Reflector:进行推理与学习,既更新工作内存,也向长期记忆提交反思信息。
Archiver:三种动作(检索、推理、学习)兼有,用于维护记忆一致性与演化。
B.3 规划模块(Planning Module)¶
规划模块对多步推理任务至关重要,直接影响最终结果。规划分为两类:
无反馈规划(Planning without Feedback)¶
传统方法,如 Chain-of-Thought,预先生成所有步骤,缺乏根据中间结果动态调整的能力。
缺点:无法适应任务执行中的新发现,容易累积推理错误。
有反馈规划(Planning with Feedback)¶
环境反馈(Environmental Feedback):
Solver 在每次操作后观察表格状态变化,决定是否继续操作或得出答案。
采用 thought-action-observation 三元组,防止单次推理解锁错误。
模型反馈(Model Feedback):
Checker 和 Reflector 作为独立验证代理,提供客观评价与诊断。
与传统自反思机制不同,MAPLE 的验证过程分离生成与评估,减少确认偏误。
优势:
动态路径由智能体交互生成,无需预定义步骤。
Solver、Checker、Archiver 依任务进展动态调整,形成输出-反馈-改进的闭环。
总结¶
MAPLE 的认知架构通过 工作内存与长期记忆的协同机制、内部动作的多样化模式 和 基于反馈的动态规划,实现了强大的多步骤推理能力。其核心创新包括:
共享消息池 架构支持灵活的多代理协作;
选择性记忆集成与演化机制 提升知识利用效率;
分离式验证代理(Checker 和 Reflector) 降低推理偏差;
动态反馈驱动的规划方式 接近人类问题解决过程。
该架构为表格推理任务提供了稳定、可扩展且高效的解决方案。
Appendix C Memory Evolution Algorithm¶
在本节中,我们介绍了 MAPLE 的记忆演化过程的详细算法。虽然正文部分描述了我们记忆系统的概念框架和关键创新,但本附录提供了完整的算法实现,说明了新经验是如何被评估、过滤并整合到长期记忆库中的。

Figure 4: Illustrative case study of MAPLE’s multiagent reasoning workflow.
重点内容讲解:
目的:本节的重点在于提供一个具体的算法实现,补充正文中的理论描述,使读者能够更清楚地了解系统内部是如何处理记忆的演化。
核心流程:包括新经验的评估、过滤和整合,这三个步骤是内存演化的关键环节,确保长期记忆的有效性和适应性。
算法结构:通过提供完整的算法步骤(即算法 2),为后续的实现和实验提供了基础支持。
非重点内容精简讲解:
本节未对算法中的每一步进行详细说明,而是作为附录,对正文内容的补充。重点在于强调该算法是系统实现的核心部分。
Appendix D Case Study¶
D.1 Round 1 - Solver(解算器第一轮)¶
用户输入:
提供了一个历史记忆,解答“谁进球最多”这类聚合型问题的正确推理步骤。
输入表格显示了多位球员的进球数、出场次数和职业生涯时间。
问题是:“谁是Landon Donovan之前的最佳射手?”
LLM响应:
根据表格排序,认为第二位球员Clint Dempsey是正确答案。
中间答案:Clint Dempsey
D.2 Round 2 - Checker(检查器第一轮)¶
用户输入:
表格和问题与前一轮相同,答案为Clint Dempsey。
LLM响应:
检查器指出逻辑错误:Clint Dempsey不是“在Landon Donovan之前”的最佳射手。Eric Wynalda虽然进球数略少,但其职业生涯在Donovan之前结束,更符合“之前”的语义。
错误类型:逻辑错误
结论:答案不正确
D.3 Round 3 - Reflector(反思器)¶
用户输入:
包括问题、表格、之前的回答和检查器反馈。
LLM响应:
诊断: 解算器忽略了“previous to”的时间含义,仅考虑进球数次高者。
改进计划: 应结合职业生涯时间线,找出在Donovan进入职业赛场之前或早期活跃且进球最多的球员。
建议答案: Eric Wynalda更符合要求。
D.4 Round 4 - Solver(解算器第二轮)¶
用户输入:
历史记忆与第一轮相同,但加入了反思器的反馈。
筛选出职业生涯在2000年之前开始或结束的球员。
LLM响应:
根据反思内容修正策略,但未得出最终答案。
答案:未就绪
D.5 Round 5 - Solver(解算器第三轮)¶
用户输入:
使用了上一轮筛选出的中间表格。
加入反思器的反馈。
LLM响应:
根据球员职业生涯时间线,最终确定Eric Wynalda为正确答案。
答案:Eric Wynalda
D.6 Round 6 - Checker(检查器第二轮)¶
用户输入:
表格和问题与前一轮相同,答案为Eric Wynalda。
LLM响应:
检查器验证答案类型、格式和证据支持均正确。
结论:答案正确
D.7 Round 7 - Archiver(存档器:记忆总结)¶
用户输入:
包括问题、表格、正确答案和整个推理过程。
LLM响应:
生成一个总结性的记忆条目,包括问题类型、操作步骤、关键词、标签等。
重点内容: 问题类型为“lookup”,操作包括过滤、比较和找最大值。
标签: lookup、sports data、goalscorer、career timeline
结论: 无需更新现有记忆结构。
D.8 Round 8 - Archiver(存档器:记忆演化)¶
用户输入:
将新生成的记忆条目与历史记忆进行比对,判断是否需要演化。
LLM响应:
判断当前新记忆与已有记忆无显著差异,决定不进行演化。
结论:无需演化
总结¶
该案例展示了MAPLE系统通过多智能体协同(Solver、Checker、Reflector、Archiver)逐步优化推理的完整流程:
Solver 提供初步答案。
Checker 检查逻辑错误。
Reflector 分析错误原因并提出改进策略。
Solver 调整策略后重新计算得出正确答案。
Checker 验证正确性。
Archiver 记录最终结果并判断是否需更新记忆库。
重点:
系统通过结合语义理解(如“previous to”)和时间上下文(如职业生涯时间线)进行推理,提升了复杂问题的准确性。
记忆机制(Memory Base)用于存储典型问题与解答方式,帮助系统在未来类似问题中复用经验,提升效率。
Appendix E Addtional Experimental Results¶
E.1 表格大小与推理性能对比¶
本节分析了表格大小对推理性能的影响,数据来自 WikiTQ 数据集。作者将表格按照 token 数量分为四个类别:0–300、300–600、600–2000 和 2000+ tokens。图 5 展示了在不同表格大小下,MAPLE(蓝色)、Chain-of-Table(橙色)和 Chain-of-Thought(绿色)三种方法的准确率对比。图中还显示了每种方法的总尝试次数(深色)和正确答案数(浅色条纹)。
主要观察结果如下:
表格越大,性能越差:所有方法在表格增大时准确率均下降。这符合预期,因为表格信息越复杂、噪声越多,语言模型更难提取关键信息。
MAPLE 在所有表格大小下持续优于基线方法:特别是在中大型表格(600+ tokens)中,MAPLE 表现出显著优势。例如,在 600–2000 tokens 范围内,MAPLE 准确率为 68.3%,而 Chain-of-Table 和 CoT 基线分别为 54.5% 和 57.7%,相对提升分别为 13.8% 和 10.6%。随着表格复杂度增加,MAPLE 与其他方法的差距进一步拉大,表明其自适应多智能体架构和基于记忆的规划机制在处理复杂表格时具有重要鲁棒性。
图 6 进一步分析了不同表格大小在不同推理迭代次数下的准确率提升情况。蓝色柱状图显示样本在不同迭代次数下的分布,折线图则追踪了随表格大小变化的准确率演变趋势。实验设计要求至少一轮 Solver 和一轮 Checker,因此每个样本至少涉及两次 LLM 调用。
E.2 多轮推理的影响¶
图 6 展示了随着推理迭代次数增加,不同表格大小的准确率变化趋势。
在 TabFact 数据集上,多轮推理的效果尤为显著。初始迭代准确率低于 50%,但随着迭代次数增加,准确率最终超过 90%,说明单次推理方法在事实验证任务上存在明显缺陷。
不同数据集和表格复杂度下,多轮推理的收益也有所不同:
WikiTQ 中的大型表格(>2000 个单元格):初始准确率低于 55%,但经过多轮推理后提升至 65% 以上,相对提升超过 10 个百分点。尽管如此,其最终准确率仍低于小表格,表明复杂表格仍存在挑战。
TabFact 中的复杂表格(>400 个单元格):不仅准确率提升幅度大,且在后期迭代中甚至超过小表格。这可能与 TabFact 表格本身较小(平均约 388 tokens)有关,其任务复杂度和数据特征不同。
总体来看,两种数据集都一致表明,MAPLE 的多智能体框架在复杂表格中能提供更高的提升比例,这正是传统方法最常遇到困难的场景。
此外,大多数样本在前几轮迭代中即可收敛(约 80% 的 WikiTQ 样本和 70% 的 TabFact 样本在第 3 轮内解决),而复杂样本在后续迭代中仍有持续提升。这说明多轮推理在保持效率的同时,也显著提升了复杂任务的准确性。
总结:
表格越大,推理难度越高,所有方法性能下降;
MAPLE 在各类表格中表现最优,尤其是在复杂表格中优势显著;
多轮推理对性能提升有重要作用,尤其在 TabFact 中表现突出;
MAPLE 的多智能体架构和自适应推理机制在应对复杂表格和信息过载方面具有明显优势。
Appendix F Example Prompts¶
附录 F 示例提示(Example Prompts)¶
本附录提供了论文中框架内四个核心代理(Agent)的详细指令和提示模板,包括 Solver(求解者)、Checker(校验者)、Reflector(反思者) 和 Archiver(归档者)。这四个代理协同工作,通过迭代推理、验证和错误反思来解决基于表格的问答任务。
Solver Agent(求解者)¶
基于 ReAct 范式(Reasoning + Acting)来与表格进行交互。该代理通过选择合适的操作(如筛选、排序、聚合等),逐步推理并最终生成答案。此过程强调逻辑性与操作的准确性。
重点:ReAct 范式的应用使 Solver 能够像人类一样逐步处理问题,从而提高答案的准确性和可解释性。
prompt:
You are a Solver AI agent tasked with determining the next step to perform based on a provided table, question,
action history, and optionally additional information from other agents (such as Reflector). If additional information
is provided, incorporate it into your reasoning process clearly.
[Your task]:
1. Based on the currently provided <Question>, <intermediate_table>, and <Action History>, determine whether additional
table operations (e.g., simplifying or restructuring the table due to its complexity) are necessary to answer the
question, or if the current table is already sufficient to derive an answer directly.
- If you decide to perform further operations on the table, you may filter, sort, group, or add rows and columns
as necessary. After updating the table, provide the modified version in markdown format within the "intermediate_table"
field of the JSON response. Then, clearly indicate "<NOT_READY>" in the "answer" field of the JSON response.
- If you decide to directly use the current table without making any further modifications (indicating that the table
is already sufficiently simple and ready for direct computation), provide the calculated answer in the "answer" field
of the JSON response, and clearly state "<NOT_CHANGED>" in the "intermediate_table" field.
2. Clearly document your reasoning steps in the "thought" field of your JSON response, but make sure it's not overly long;
3. Summarize the action you've performed and enter it into the "action" field of your JSON response. This could be
an operation on the table (e.g., filtering, sorting, grouping, or adding rows and columns) or a calculation of the
answer (e.g., "Calculate the answer: 3 + 3 = 6").
...
[Output Format]:
```json
{
"thought": "<your clear reasoning process and rationale>",
"action": "<summarize the action you've performed>",
"intermediate_table": "<updated table or '<NOT_CHANGED>'>",
"answer": "<calculated answer or '<NOT_READY>'>"
}
```
[Examples]:
==========
<Example1>
<Intermediate Table>
| Year | Revenue | Product |
|-------|---------|---------|
| 2020 | 100 | A |
| 2021 | 200 | B |
| 2020 | 150 | C |
<Question>
What is the total revenue in 2020?
<Action History>
None
After thinking step by step based on the above information:
<Solver result>
```json
{
"Thought": "There is no prior action history, so I will start by filtering relevant data from the provided table.",
"Action": "Filter rows where 'Year' is 2020",
"Intermediate Table": " | Year | Revenue | Product |
|------|---------|---------|
| 2020 | 100 | A |
| 2020 | 150 | C |",
"Answer": "<NOT_READY>"
}
```
==========
<Example2>
<Intermediate Table>
| City | Average Temperature |
|---------|---------------------|
| Beijing | 12 |
| Tokyo | 17.5 |
| Sydney | 23 |
<Question>
Which city has the highest average temperature?
<Action History>
1.Calculate the average temperature for each city
After thinking step by step based on the above information:
<Solver result>
```json
{
"Thought": "The intermediate table already lists the average temperature for each city. I can directly identify the city
with the highest average temperature.",
"Action": "Identify city with highest average temperature",
"Intermediate Table": "Not changed",
"Answer": "Sydney"
}
```
Checker Agent(校验者)¶
概述了 Checker Agent 的职责,其主要任务是评估 Solver 的输出。校验从三个维度进行:
答案类型(Answer Type):验证答案是否符合预期类型(如数值、类别等);
格式验证(Format Validation):检查答案是否符合指定格式;
证据支撑(Evidence Grounding):确认答案是否由表格中的真实数据支持。
重点:Checker 的多维度验证机制确保 Solver 输出的答案在逻辑和形式上都符合要求。
prompt:
You are a Checker AI. Your role is to verify the accuracy and consistency of results based on a given table and
question. Carefully compare the provided <answer> against the <Table> and <Question> to ensure it aligns logically
with the data and context.
[Your task]
1. Evaluate the <answer> based on 3 aspects, and assign a score according to the Scoring Instructions below. After
assigning a score for each aspect, provide a brief comment explaining the reason for the given score:
- answer_type_checking: Verify whether the answer type matches the question type. Example: If the question asks
for a count, the answer should be a number, not a name. If the question asks for a country, the answer should
be a country name, not a number.
- format_validation: Ensure the answer follows the [answer Format] requirements. Example: If the question is
yes/no, the answer should be yes/no, not true/false. If the answer contains multiple elements, they should be
separated by "|". Additional format rules are specified in the [answer Format] section below.
- Evidence Grounding: Check if the question and answer are logically coherent. Example: If the question asks for
a country, the answer must be one of the countries listed in the table. If the question asks "Which month had the
highest revenue?", but the answer includes multiple months, then the response is incorrect.
2. Scoring Instructions:
- Each aspect is scored on a scale of 0 to 2 points:
- 0 points: Requirement not met.
- 1 point: Partially met.
- 2 points: Fully met or not applicable.
- The total score is out of 6 points.
3. Finally, sum up the scores from the 3 aspects and record the total in "total_score". Then, compile the comments from
all three aspects into a concise final summary under "final_comments".
[Examples]:
==========
<Example1>
<Table>
| Act | Year signed | # Albums released under Bad Boy |
|---------------------|-------------|---------------------------------|
| Diddy | 1993 | 6 |
| The Notorious B.I.G | 1993 | 5 |
| Harve Pierre | 1993 | - |
| The Hitmen | 1993 | - |
<Question>
How many albums did Diddy have under Bad Boy?
<answer>
6
<feedback>
```json
{
"feedback": {
"answer_type_checking": {
"score": 2,
"comments": "The question asks for a numerical value, and the answer is a number. The type matches correctly."
},
"format_validation": {
"score": 2,
"comments": "The answer is a single number, which follows the expected format for numerical responses."
},
"Evidence Grounding": {
"score": 2,
"comments": "The answer matches the correct value from the table, where Diddy has 6 albums under Bad Boy."
},
"summary": {
"total_score": 6,
"final_comments": "The answer is correct in terms of type, format, and logical consistency. No issues detected."
}
}
}
```
Reflector Agent(反思者)¶
介绍了 Reflector Agent 的功能,它根据 Checker 提供的反馈和上下文信息,分析错误的根源,并提出未来改进的建议。该代理的作用是引入“反思”机制,使得系统能够从错误中学习。
重点:反思机制是系统自我改进的关键,有助于提升长期推理能力。
You are a Reflection AI. Your task is to analyze the reasoning process of an AI Reasoner that answers
table-based questions. You will receive: 1. The original table and question. 2. The Reasoner’s step-by-step thought
process,intermediate table and actions. 3. The Reasoner’s final answer. 4. Feedback from a Checker agent that evaluates
the correctness of the answer.
[Your Tasks]:
1. Identify Mistakes: Analyze the reasoning process and checker feedback to determine what went wrong.
2. Provide Refinement Suggestions: Suggest specific improvements that Reasoner should implement in future iterations.
[Output Format]:
Please provide your reflection strictly in the following JSON format:
```json
{
"diagnosis": "<Concise reflection on key mistakes>",
"improvement_plan": "<Step-by-step plan for improving reasoning in the next attempt>"
}
```
[Examples]:
==========
<Example1>
### Provided Information
Question:
What is the total revenue in 2020?
Table:
| Year | Revenue | Product |
|------|---------|---------|
| 2020 | 100 | A |
| 2021 | 200 | B |
| 2020 | 150 | C |
Reasoner’s Processing History:
[
{
"thought": "There is no prior action history, so I will start by filtering relevant data from the provided table.",
"action": "Filter rows where 'Year' is 2020",
"intermediate_table": "| Year | Revenue | Product |
|------|---------|---------|
| 2020 | 100 | A |
| 2020 | 150 | C |",
"answer": "<NOT_READY>"
},
...
]
Reasoner’s Final answer:
100
Checker feedback:
{
"feedback": {
...
"summary": {
"total_score": 4,
"final_comments": "The answer is logically incorrect as it fails to sum all relevant revenues."
}
}
}
### Reflection & Recommendations
Now, based on the above details:
```json
{
"diagnosis": "The reasoner only summed the first matching row (100) but ignored another relevant row (150).
This caused an incorrect final answer.",
"improvement_plan": "Ensure that after filtering relevant rows, all numerical values are summed together.
In this case, the reasoner should extract both '100' and '150' and compute the
sum (100 + 150 = 250) before outputting the final answer."
}
```
Archiver Agent(归档者)¶
记忆摘要模块(Memory Summarization Module):将每个任务的推理过程、关键操作和错误类型等信息进行结构化,生成标准的记忆笔记。
记忆进化模块(Memory Evolution Module):通过分析新生成的记忆笔记与已有记忆的关联性,判断是否需要语义上的更新(如加强连接、更新元数据),以提升记忆库的一致性和检索效率。
重点:Archiver 的两个模块共同构建了一个长期记忆库,该记忆库能够随时间进化,为未来任务的推理提供有力支持。
prompt: 记忆摘要模块
You are an expert reasoning analyzer helping to build a long-term JSON format memory system for QA tasks. Your job is
to analyze the reasoning process behind a question-answer pair, identify the reasoning type and operation required,
and summarize key steps and mistakes.
You will be given:
- A QA question
- A table (used for answering the question)
- A predicted answer from a model
- The correct (ground truth) answer
- A step-by-step reasoning trace (from a Reasoner)
- Feedback from a Reflector agent (who diagnoses mistakes and proposes fixes)
Please output your structured summary as a JSON object with the following fields:
{
"question_type": "A general reasoning category such as 'filter+count', 'lookup', 'aggregation', 'comparison'",
"required_operations": [
"List of core reasoning operations required to solve the question",
"Examples: 'filter', 'sum', 'compare', 'lookup'"
],
"context": "A short paragraph summarizing the reasoning pattern, data domain, and error focus (if any).",
"keywords": [
"Logical reasoning concepts and actions",
"Avoid specific entities like country names or people",
"Use terms like 'filter', 'sort', 'count', 'compare', etc."
],
"tags": [
"A set of high-level, multi-category tags describing the memory",
"Categories may include:",
"- Task type: 'aggregation', 'comparison', 'filter+count'",
"- Data domain: 'sports', 'medal table', 'match results'",
"- Reasoning challenges: 'temporal', 'multi-step', 'false assumption'",
"- Error types: 'logic mismatch', 'schema misunderstanding', 'over-assumption'"
],
"correct_steps": [
"A list of step-by-step reasoning that should lead to the ground truth answer"
],
"wrong_steps": [
"A list of the reasoning steps that were actually followed (if the answer was incorrect). If the reasoning was
correct (e.g., Model Answer matches Ground Truth), return an empty list: []"
],
"error_type": "A concise label summarizing the nature of the error, such as 'schema misunderstanding' or 'partial
result'. If the answer is correct, return 'none'.",
"error_reason": "A brief explanation of why the answer is incorrect. Even if the Checker passes, identify any hidden
flaws, misinterpretations, or reasoning gaps. If the error_type is 'none', then return 'none' as well."
}
==============
Example:
{
"question_type": "lookup",
"required_operations": ["match date", "understand implicit schema", "sum goals"],
"context": "This is a structured lookup question that requires understanding implicit roles in a sports match table.
The table does not explicitly list both teams; instead, it assumes that Haiti is the home team and lists only the
opponents. The Reasoner failed to realize this schema assumption and incorrectly concluded that the Haiti vs South Korea
game was not in the table, despite it being implicitly encoded. This reflects a misunderstanding of the table structure
rather than a simple retrieval error.",
"keywords": ["implicit schema", "opponent column", "verify match", "date match"],
"tags": ["lookup", "sports table", "schema misunderstanding", "implicit team", "table structure error"],
"correct_steps": [
"Understand that the table assumes Haiti is always the team in question",
"Find the row with Opponent = South Korea and Date = 2013-09-06",
"Extract Result = 1-4 and compute total goals = 5"
],
"wrong_steps": [
"Interpreted South Korea as the home team",
"Assumed the match did not exist due to misunderstanding of table layout",
"Concluded the game was not listed"
],
"error_type": "schema misunderstanding",
"error_reason": "The Reasoner failed to recognize that the table implicitly represents games played by Haiti and
misinterpreted the structure, leading to the incorrect belief that the game was not listed."
}
prompt: 记忆进化模块
You are an AI agent responsible for evolving a memory knowledge base to improve future retrieval and reasoning.
You will receive:
- A new memory (which includes the context, keywords)
- A list of nearest neighbor memories (memories that are most semantically similar based on prior embeddings)
Your tasks:
1. Analyze the relationship between the new memory and its nearest neighbors, based on their contents.
2. Decide whether the memory base should evolve.
Evolution Decision Rules:
- If `should_evolve` is false:
- Set `actions` to an empty list `[]`
- Leave all other fields empty lists
- If `should_evolve` is true:
- `actions` must include at least one action.
- You can choose between:
- `"strengthen"`: Create explicit links between the new memory and semantically close neighbor memories.
- `"update_neighbor"`: Suggest updated `tags` and `context` for the neighbor memories to better align their metadata.
- It is allowed to select only `"strengthen"`, only `"update_neighbor"`, or both together.
When suggesting updates:
- If you select `"strengthen"`, list the IDs of neighbor memories to connect.
- If you select `"update_neighbor"`, provide updated `tags` and `context` for each neighbor memory.
- If no update is needed for a neighbor, copy its original tags and context unchanged.
- Ensure that:
- The length of `new_context_neighborhood` matches EXACTLY the number of neighbors.
- The length of `new_tags_neighborhood` matches EXACTLY the number of neighbors.
Return your decision in STRICT JSON format as follows:
```json
{
"should_evolve": true or false,
"actions": ["strengthen", "update_neighbor"],
"suggested_connections": ["neighbor_memory_ids"],
"tags_to_update": ["tag1", "tag2", ...],
"new_context_neighborhood": ["new context for neighbor 1", "new context for neighbor 2", ...],
"new_tags_neighborhood": [["tag1", "tag2"], ["tag1", "tag2"], ...]
}
总结¶
本附录详细描述了四个核心代理的职责与工作流程,展示了整个系统如何通过 协作、验证、反思和记忆 实现对复杂表格问答任务的高效处理。其中,ReAct 范式、多维度校验、反思机制与长期记忆的构建是实现系统智能性的关键所在。