2601.02163_EverMemOS: A Self-Organizing Memory Operating System for Structured Long-Horizon Reasoning¶
引用: 0(2026-01-13)
组织:
1EverMind
2Shanda Group
总结¶
图解¶
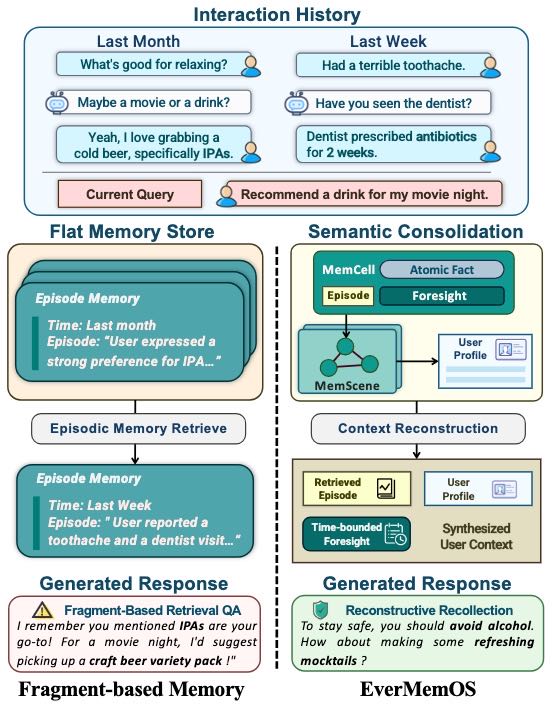
Figure 2: Comparison of typical fragment-based memory and EverMemOS in an interactive chat scenario.
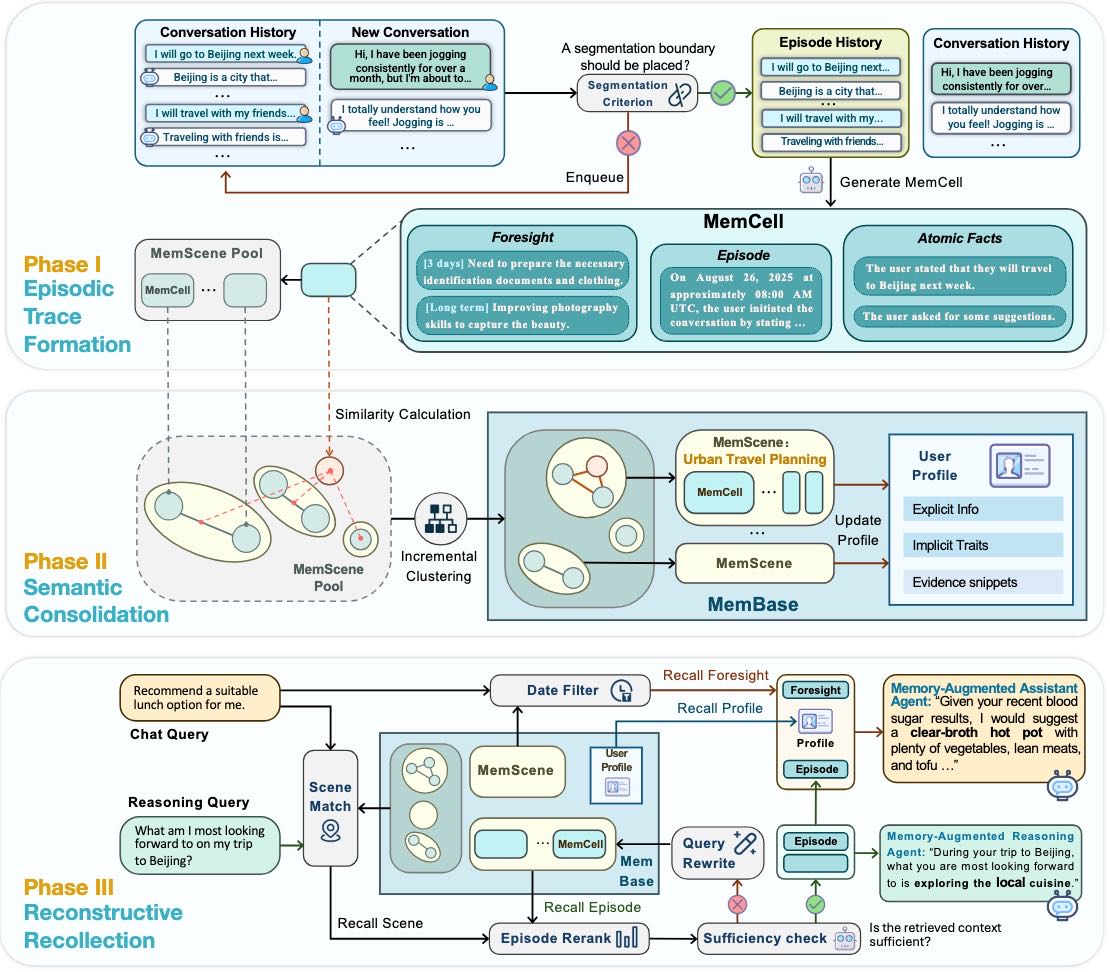
Figure 3: The EverMemOS workflow mirrors an engram-inspired memory lifecycle
图解
Episodic Trace Formation segments continuous dialogue into MemCells with episodes, atomic facts, and time-bounded foresight.
Semantic Consolidation organizes MemCells into MemScenes and updates a user profile.
Reconstructive Recollection performs MemScene-guided retrieval to compose the necessary and sufficient context.

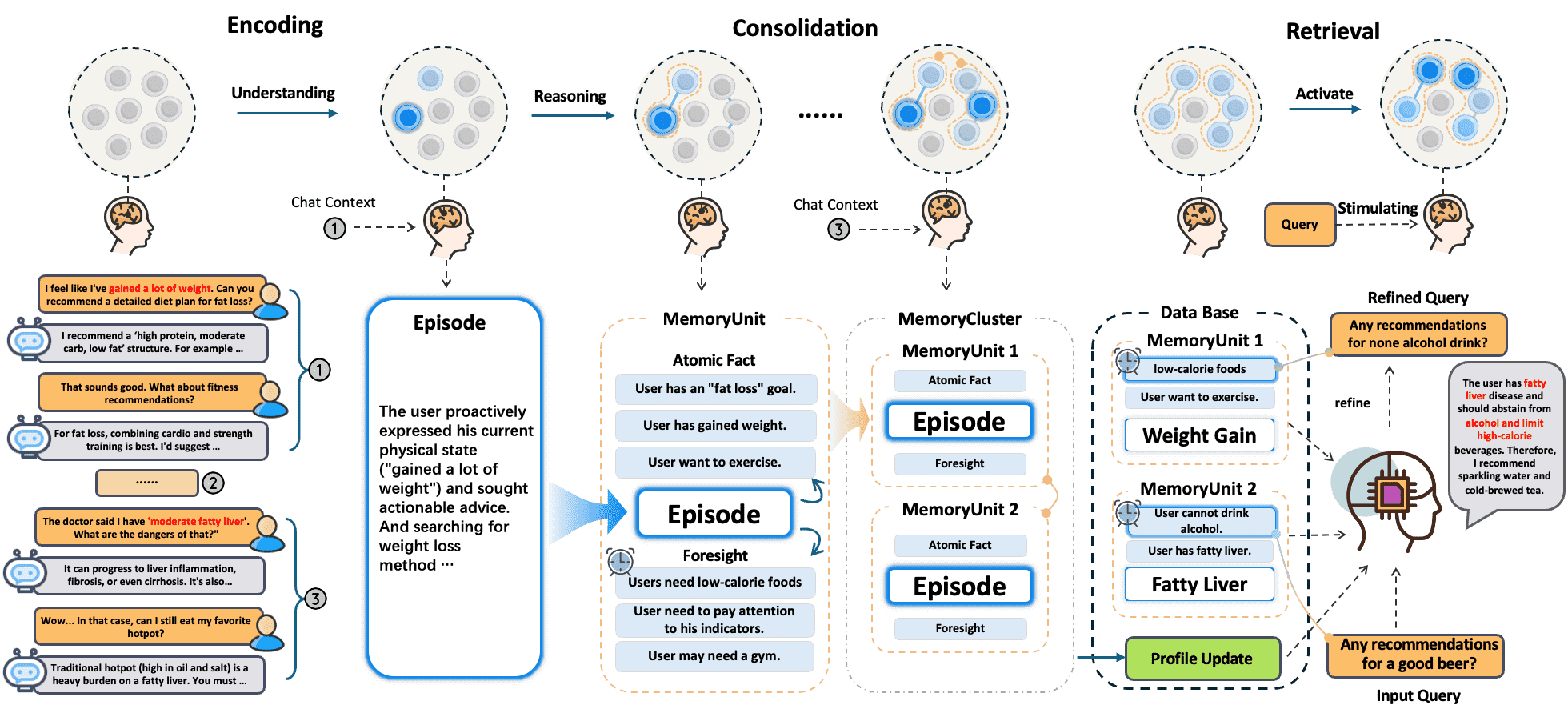
Figure 7: Case studies illustrating Profile, Foresight, and Episode capabilities in Memory-Augmented Chat.
From https://mp.weixin.qq.com/s/Z5ASlcQOv_Sh4sNRRsXwFg
From Moonlight¶
三句摘要¶
✨ EverMemOS是一个受“engram”启发的自组织记忆操作系统,旨在通过模拟记忆生命周期,解决LLMs长期推理中记忆碎片化的问题。
💡 系统通过“Episodic Trace Formation”将对话转化为
MemCells,继而通过“Semantic Consolidation”将MemCells组织成MemScenes并更新用户档案,最后通过“Reconstructive Recollection”进行必要上下文的智能检索。🚀 实验结果表明,EverMemOS在
LoCoMo、LongMemEval和PersonaMem-v2等记忆增强推理任务上显著优于现有SOTA方法,验证了其生命周期记忆组织策略的有效性。
关键词¶
EverMemOS: EverMemOS 是一个自组织的记忆操作系统,它为大型语言模型(LLMs)设计了一个计算记忆的生命周期,旨在解决 LLM 在长期交互中保持连贯性、整合不断演进的经验以及解决冲突的问题。它通过将对话流转化为结构化的记忆单元(MemCells)和场景(MemScenes),并在此基础上进行记忆的构建、组织和检索,以支持长期推理。
Long-Horizon Reasoning: 长期推理是指在跨越较长时间段(几天、几个月甚至几年)的交互或任务中,LLM 能够保持连贯性、一致性并有效利用过去的信息进行决策或回答问题的能力。这是 EverMemOS 旨在解决的核心问题,因为传统的 LLM 受限于有限的上下文窗口,难以处理跨越长距离的信息。
Memory Operating System: 记忆操作系统(Memory Operating System, MoS)是指一类将记忆管理提升到系统级运行时的框架,它负责记忆的存储、检索、过滤和更新等一系列操作,为 LLM 提供一个结构化、高效的记忆管理解决方案。EverMemOS 是一个具体的记忆操作系统实现。
Engram: Engram(脑科学中的“印迹”)是 EverMemOS 的灵感来源,它指的是生物体中存储记忆的物理或生化痕迹。EverMemOS 借鉴了 Engram 的概念,将其转化为计算记忆的生命周期模型,强调从零散的经验中形成稳定、结构化的记忆表示,并经历形成、巩固和提取的过程。
Lifecycle: 生命周期(Lifecycle)是 EverMemOS 记忆管理的核心概念,它描述了记忆从形成到最终被使用的完整过程。EverMemOS 将这一生命周期划分为三个阶段:记忆痕迹形成(Episodic Trace Formation)、语义整合(Semantic Consolidation)和重构性回忆(Reconstructive Recollection),模拟了生物记忆的处理流程。
Episodic Trace Formation: 记忆痕迹形成是 EverMemOS 生命周期中的第一阶段。它负责将 LLM 与用户之间的无界对话流(interaction history)转化为离散的、稳定的记忆单元,称为 MemCells。这个过程旨在从嘈杂的对话数据中提取出有语义的信号,并封装成结构化的记忆表示。
MemCell: MemCell 是 EverMemOS 的核心记忆单元,是连接低级数据和高级语义的桥梁。每个 MemCell 是一个元组 (E, F, P, M),包含:E(Episode,事件叙述)、F(Atomic Facts,原子化事实)、P(Foresight,包含时间有效性区间的未来预测)以及 M(Metadata,时间戳、来源指针等元数据)。它将记忆从静态记录转化为时间上下文丰富的表示。
Episode: Episode(事件)是 MemCell 的一个组成部分,它对发生的事件进行简洁的第三人称叙述,作为记忆的语义锚点。它旨在通过重写对话历史来消除冗余和歧义,形成一个清晰、稳定的事件描述。
Atomic Facts: 原子化事实(Atomic Facts)是 MemCell 的另一个组成部分,它是由事件叙述(Episode)提取出的离散的、可验证的陈述。这些事实用于实现高精度的记忆匹配和检索。
Foresight: Foresight(远见/预测)是 MemCell 的一个组成部分,它包含前瞻性的推断(如计划、临时状态等)。每个 Foresight 都带有明确的有效性时间区间 [tstart, tend],以支持 LLM 的时间感知能力,帮助模型预测未来的状态或规划行动。
Semantic Consolidation: 语义整合是 EverMemOS 生命周期中的第二阶段。它负责将离散的 MemCells 组织成更高阶的结构,即 MemScenes(记忆场景),从而将短暂的经验转化为稳定的长期知识。这个过程还包括更新用户画像(User Profile),以保持跨交互的一致性。
MemScene: MemScene(记忆场景)是 EverMemOS 中由多个相关 MemCells 组织而成的高阶语义结构。它通过聚类的方式将零散的事件和事实聚合起来,形成主题性的、稳定的知识簇。MemScenes 有助于 LLM 整合分散的证据,并进行更连贯的推理。
User Profile: 用户画像(User Profile)是 EverMemOS 在语义整合阶段生成和维护的关于用户信息的简洁表示。它整合了从 MemScenes 中提炼出的稳定用户特征和临时状态,帮助 LLM 了解用户的偏好、历史以及当前状况,从而提供个性化的服务。
Reconstructive Recollection: 重构性回忆是 EverMemOS 生命周期中的第三阶段。它不是简单的静态查找,而是基于“必要性和充分性”原则,主动构建完成当前查询所需的最小化上下文。这个过程通过 MemScene 指导检索,并可能进行查询重写,以确保检索到的信息既必要又充分。
Necessity and Sufficiency: 必要性和充分性原则是重构性回忆阶段的核心指导思想。它要求在检索信息时,仅包含完成特定任务所必需的最少信息,并且这些信息必须足以完成任务,避免检索过多无关或冗余的内容,提高效率和准确性。
摘要¶
EverMemOS 是一项旨在解决大型语言模型 (LLMs) 在长期交互中保持连贯行为和支持长程推理 (long-horizon reasoning) 挑战的自组织记忆操作系统。传统的 LLM 记忆系统通常以孤立记录的形式存储信息并检索片段,导致难以整合不断演进的经验并解决冲突。为了应对这一局限性,EverMemOS 从生物学中“记忆痕迹” (engram) 的生命周期中汲取灵感,将计算记忆建模为一个动态的生命周期。
核心方法论
EverMemOS 采用三阶段工作流程:
Episodic Trace Formation (情景痕迹形成): 此阶段将无序的交互流转化为离散、稳定的记忆痕迹,称为 MemCells。一个 MemCell
c是一个四元组(E, F, P, M),其中:E (Episode):事件的简洁第三人称叙述,作为语义锚点。它通过对话重写 (rewriting process) 解决冗余和歧义。F (Atomic Facts):从E中提取的离散、可验证的事实,用于高精度匹配。P (Foresight):前瞻性推断 (prospections),例如计划或临时状态,并带有有效性区间[tstart, tend],以支持时间感知。M (Metadata):包括时间戳和源指针的上下文信息。 此阶段具体分为三个步骤:Contextual Segmentation (上下文切分):使用一个 Semantic Boundary Detector 处理滑动窗口 (sliding window) 中的交互。当检测到话题转换时,将累积的对话轮次封装为原始情景历史。此步骤通过 LLM prompting 实现。
Narrative Synthesis (叙事合成):将情景历史合成为高保真的 Episode (E),生成简洁的第三人称叙述,并解决共指 (coreferences),建立稳定的语义锚点。
Structural Derivation (结构派生):从重写的 Episode
E中提取 Atomic Facts(F)以实现精确匹配,并生成带有推断有效性区间[tstart, tend]的 Foresight 信号(P)。这些组件与 MetadataM一起打包形成最终的 MemCellc。
Semantic Consolidation (语义整合): 此阶段将 MemCells 组织成更高阶的结构,以将瞬时情景转化为稳定的长期知识,灵感来源于生物学中的系统整合 (systems consolidation)。
Incremental Semantic Clustering (增量语义聚类):当新的 MemCell
c到来时,系统计算其嵌入 (embedding) 并检索最近的 MemScene centroid。如果相似度超过阈值τ,c被同化,并且场景表示增量更新;否则,会实例化一个新的 MemScene。这是一个实时维护主题结构的在线 (online) 过程。Scene-Driven Profile Evolution (场景驱动的用户画像演进):场景层面的整合也用于更新紧凑的 User Profile (用户画像)。当一个新的 MemCell 被同化到一个 MemScene 中时,EverMemOS 会通过对这些场景摘要进行 prompting 来更新简洁的场景摘要和刷新用户画像,而不是基于单独的对话轮次。User Profile 维护了显式事实 (explicit facts) 和隐式特质 (implicit traits),通过场景摘要进行在线更新,并结合时新性感知更新 (recency-aware updates) 和冲突追踪 (conflict tracking)。
Reconstructive Recollection (重建性回忆): 此阶段的检索不是静态查找,而是一个积极的重建过程,遵循必要性和充分性原则 (principle of necessity and sufficiency)。给定一个查询
q,EverMemOS 执行以 MemScenes 为指导的代理式检索 (agentic retrieval)。MemScene Selection (记忆场景选择):首先通过融合 MemCells 的 Atomic Facts
F上的稠密检索 (dense retrieval) 和 BM25 稀疏检索 (sparse retrieval),并通过 Reciprocal Rank Fusion (RRF) 计算查询与所有 MemCells 之间的相关性。然后根据其组成 MemCells 的最大相关性对每个 MemScene 进行评分,并选择一小组最高评分的 MemScenes。Episode and Foresight Filtering (情景与前瞻过滤):在选定的 MemScenes 中,汇集其组成 MemCells 中的 Episodes,并重新排序以选择紧凑的集合用于下游推理。然后应用 Foresight Filtering,仅保留有效区间
[tstart, tend]满足当前时间tnow的 Foresight (丢弃已过期或未到期的 Foresight)。Agentic Verification and Query Rewriting (代理式验证与查询重写):检索到的上下文由一个基于 LLM 的验证器 (verifier) 评估其充分性。如果被认为不充分,系统会触发一个查询重写 (query rewriting) 步骤以补充检索;否则,上下文将传递给下游模块。
实验评估
EverMemOS 在 LoCoMo 和 LongMemEval 这两个长程记忆增强推理基准测试上进行了评估,并在 PersonaMem-v2 上进行了用户画像研究。实验结果表明,EverMemOS 在整体准确性上显著优于最先进的方法,例如在 LoCoMo 上相对提高了9.2%,在 LongMemEval 上相对提高了6.7%。特别是在需要整合分散证据的复杂推理任务上,如 LoCoMo 的多跳 (multi-hop) 和时间性 (temporal) 问题,以及 LongMemEval 的知识更新 (knowledge update) 任务,EverMemOS 展现出显著优势,这验证了 MemScenes 的有效性。
消融研究 (Ablation study) 证实了 MemScenes、MemCells 和情景切分的重要性,去除这些结构会导致性能逐步下降。EverMemOS 也展示了有利的准确性-效率权衡 (accuracy-efficiency trade-off),其 Reconstructive Recollection 阶段的代理式充分性检查 (agentic sufficiency check) 确保了上下文由必要且充分的证据构成,避免了固定预算检索中常见的噪声积累。此外,用户画像的引入显著提升了 PersonaMem-v2 上的整体准确性,表明语义整合能够提供超越情景检索的补充信号。通过案例研究 (case study),EverMemOS 还展示了其在情景记忆召回、纵向用户画像建模和经验驱动的前瞻性推理方面的连贯、经验感知行为。
尽管 EverMemOS 在文本对话场景中表现出色,但其在多模态或具身 (embodied) 环境中的扩展、端到端效率的进一步提升以及在超长交互时间线上的压力测试仍是未来的研究方向。