2507.07957_MIRIX: Multi-Agent Memory System for LLM-Based Agents¶
引用: 16(2025-12-12)
组织:
MIRIX AI
相关链接
总结¶
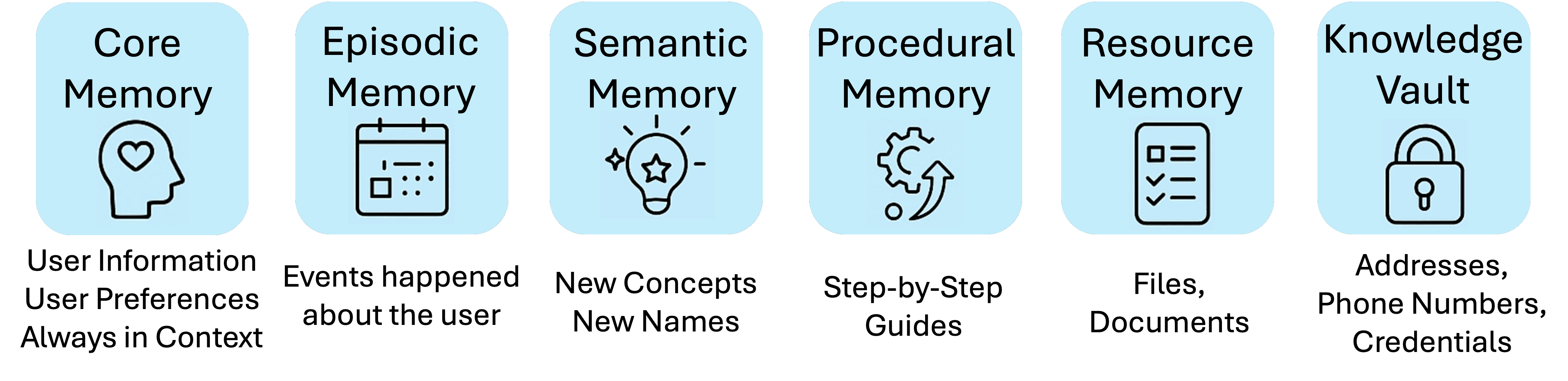
Figure 1:The six memory components of MIRIX, each providing specialized functionality.
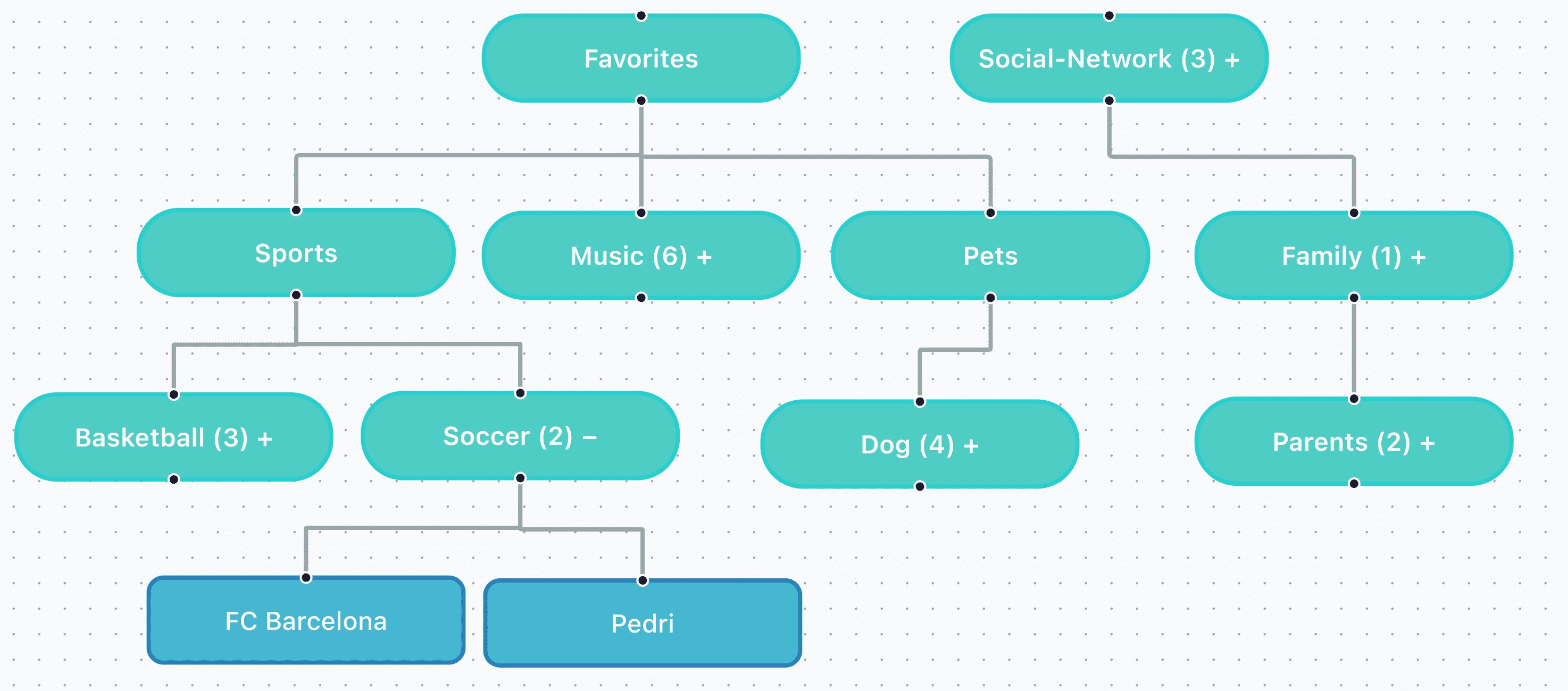
Figure 3:Tree Structure of an Example Semantic Memory.
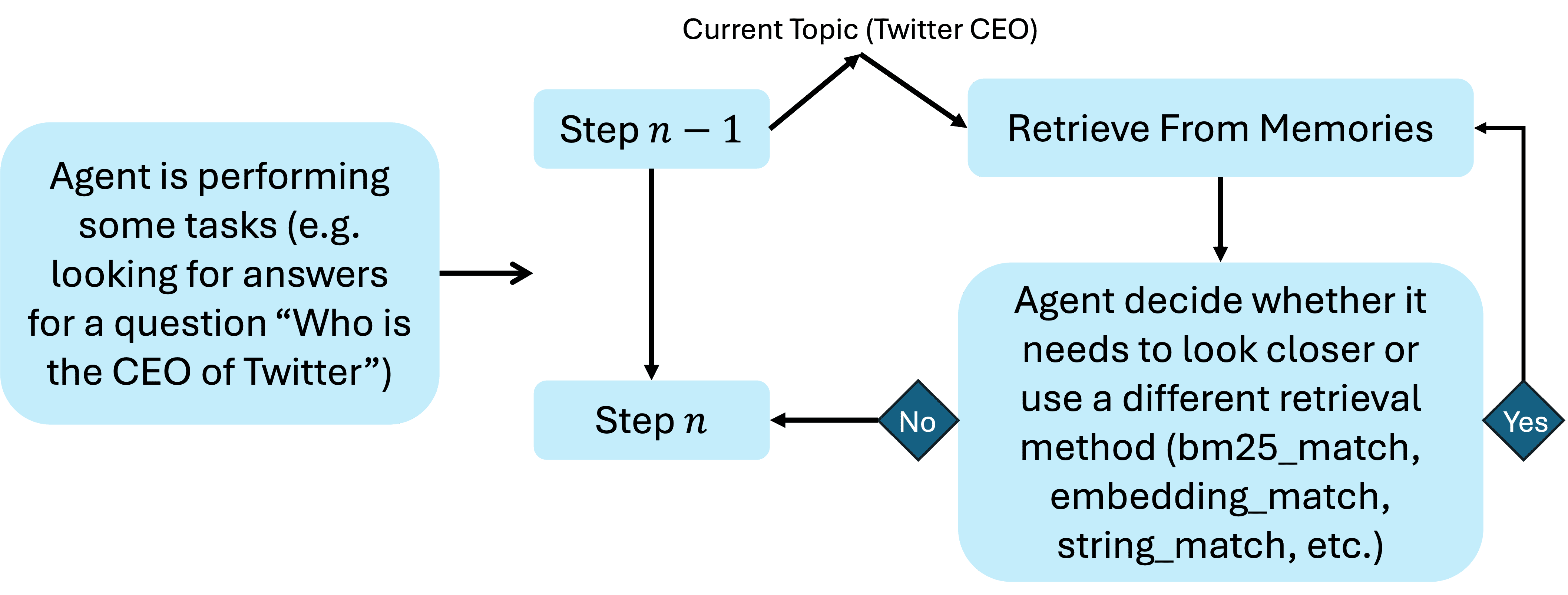
Figure 5:Demonstration of Active Retrieval.
From Moonlight¶
三行摘要¶
💡 MIRIX是一个为LLM代理设计的模块化多智能体记忆系统,它通过六种专门的记忆类型(Core, Episodic, Semantic, Procedural, Resource Memory, Knowledge Vault)和一个协调的多智能体框架,帮助LLM实现对多模态和用户特定信息的持久化、推理和检索。
⚙️ 该系统采用创新的“主动检索”机制,自动生成话题并从记忆组件中检索相关信息,并通过Meta Memory Manager与多个Memory Managers的协作来高效管理和更新动态异构记忆,从而支持大规模多模态输入的抽象化处理。
🚀 在ScreenshotVQA和LOCOMO这两个挑战性基准测试中,MIRIX均显著超越现有系统,在ScreenshotVQA上准确率比RAG基线高35%且存储需求减少99.9%,在LOCOMO上达到了85.4%的SOTA性能,并且提供了一个由MIRIX驱动的个人助手应用程序。
关键词¶
MIRIX: MIRIX 是一个模块化的、多智能体(multi-agent)的记忆系统,旨在为基于大型语言模型(LLM)的智能体提供真正持久、个性化且可检索的记忆能力。它超越了传统的文本记忆,整合了丰富的视觉和多模态体验,通过六种精心设计的专业记忆类型(Core, Episodic, Semantic, Procedural, Resource, Knowledge Vault)以及一个动态协调这些记忆更新和检索的多智能体框架,实现了在真实世界场景中对用户数据的长期持久化、推理和准确检索。
LLM-Based Agents: 基于大型语言模型(LLM)的智能体是指利用大型语言模型作为核心驱动力,以执行复杂任务、进行交互或提供服务的 AI 系统。这些智能体通常需要具备理解、生成自然语言、进行推理、规划和执行多步骤任务的能力。本文的研究重点在于增强这类智能体的记忆能力,使其能够更持久、个性化地服务用户。
Memory System: 记忆系统是 AI 智能体能够持久化、检索并利用过去用户特定信息的能力。在本文中,作者认为现有 LLM 智能体的记忆系统存在局限性,如记忆组件结构单一、缺乏多模态支持、扩展性和抽象能力不足等。MIRIX 作为一种新的记忆系统,旨在通过其模块化、多类型的架构来解决这些挑战,使智能体能够真正“记住”信息。
Core Memory: 核心记忆是 MIRIX 系统中存储高优先级、持久化信息的部分,这些信息在智能体与用户互动时应始终保持可见。它包含两个主要区块:persona(智能体的身份、语气或行为特征)和 human(关于用户的持久性事实,如姓名、偏好、自我认知属性)。当核心记忆接近容量上限时,系统会触发重写过程以保持紧凑性。
Episodic Memory: 叙事记忆(Episodic Memory)用于捕获带有时间戳的事件和与时间相关的用户行为、经历或活动。它类似于一个结构化的日志或日历,允许智能体推理用户的日常习惯、信息的时效性以及情境感知式的后续跟进。每一条记录包含事件类型、摘要、详细信息、参与者(用户或助手)以及时间戳。
Semantic Memory: 语义记忆(Semantic Memory)维护的是独立于特定时间或事件的抽象知识和事实信息。它充当一个知识库,存储关于世界或用户社交图谱的通用概念、实体和它们之间的关系。例如,“哈利·波特由 J.K. 罗琳创作”或“约翰是用户的朋友,他喜欢慢跑并居住在旧金山”都属于语义记忆的范畴。
Procedural Memory: 程序记忆(Procedural Memory)存储的是结构化的、目标导向的过程,例如操作指南、工作流程或交互式脚本。这类记忆既不依赖时间(非叙事性),也不属于抽象事实(非语义性),而是代表了可调用以协助用户完成复杂任务的可行动知识。例如,“如何填写差旅报销单”、“设置 Zoom 会议的步骤”等。
Resource Memory: 资源记忆(Resource Memory)用于存储用户当前正在处理但又不适合其他记忆类别的完整或部分文档、对话记录或多模态文件。如果用户正在阅读一份详细的野餐计划或项目提案文档,代理可以从资源记忆中存储和检索这些信息,以确保在长时间任务中的上下文连续性。
Knowledge Vault: 知识库(Knowledge Vault)是一个安全存储位置,用于存放用户的详细且敏感的原始信息,如证书、地址、联系方式和 API 密钥。这些信息通常不直接用于对话层面的推理,但对于执行身份验证任务或存储长期标识符至关重要。高敏感度的条目会受到访问控制,并被排除在常规检索之外,以防止滥用或泄露。
Multi-Agent Framework: 多智能体框架(Multi-Agent Framework)是一种系统架构,它不依赖于单一的、包罗万象的智能体,而是由多个专门的、协同工作的智能体组成,共同完成复杂任务。在 MIRIX 中,系统包含六个负责管理不同记忆类型的专门记忆管理器(Memory Managers),以及一个负责任务路由的元记忆管理器(Meta Memory Manager),共同构成了一个协调且高效的工作流程。
Active Retrieval: 主动检索(Active Retrieval)是 MIRIX 提出的一种核心机制,用于解决显式触发记忆检索的局限性。在用户提问或智能体执行下一步操作前,系统首先根据当前输入和上下文推断出一个“主题”(topic),然后利用该主题从各个记忆组件中检索相关信息。检索到的内容会被注入到系统提示中,确保模型能够利用最新、个性化或情境化的信息来生成回应,消除了用户需要主动要求“搜索记忆”的必要。
ScreenshotVQA: ScreenshotVQA 是论文中为评估 MIRIX 在处理大规模多模态输入方面的能力而创建的一个新的数据集。该数据集包含用户近一个月的高分辨率电脑截图,数量高达近 20,000 张,要求智能体从这些视觉历史记录中提取信息、建立记忆并回答相关问题,这极大地挑战了现有记忆系统的能力。
LOCOMO: LOCOMO 是一个长篇、多轮对话的基准数据集,用于评估 LLM 智能体的长期对话记忆能力。论文中,MIRIX 在此数据集上进行了评估,其中要求智能体只能通过检索到的记忆来回答问题,而不能直接访问原始对话文本,从而检验了系统从对话中提炼和路由关键信息到记忆中的能力。
Multimodal Input: 多模态输入(Multimodal Input)是指 AI 系统接收和处理的多种类型的数据,例如文本、图像、音频、视频等。MIRIX 的一个关键创新在于其能够处理多模态输入,特别是通过屏幕截图来捕捉视觉信息,使其记忆系统能够理解和记忆用户界面的布局、视觉内容等非文本信息,从而在实际应用中更加实用。
摘要¶
MIRIX是一种新颖的、模块化的多agent记忆系统,旨在提升LLM-based agents的长期推理和个性化能力。该系统通过解决现有记忆系统在扁平结构、多模态支持不足、以及缺乏抽象和可扩展性方面的局限性,使得LLM能够真正记住用户特定信息。
1. 核心方法论 (Core Methodology)
MIRIX的核心是一个由六种专业记忆组件和多agent框架构成的架构,用于动态控制、更新和检索信息。
六种记忆组件 (Six Memory Components):
Core Memory: 存储高优先级、持久性的信息,始终对agent可见。它分为两个主要区块:
persona(编码agent的身份、语气或行为配置文件)和human(存储用户的持久性事实,如姓名、偏好)。当记忆大小超过90%容量时,系统会触发重写过程以保持紧凑性。Episodic Memory: 捕获带有时间戳的用户特定事件和经验,反映用户的行为、活动或互动。作为结构化日志或日历,它帮助agent推理用户日常、事件发生时间,并进行上下文相关的后续操作。每个条目包含
event_type(如user_message,inferred_result)、summary、details、actor(user或assistant)和timestamp(例如”2025-03-05 10:15”)。Semantic Memory: 维护独立于特定时间或事件的抽象知识和事实信息。它作为通用概念、实体和关系(关于世界或用户社交图谱)的知识库。每个条目包含
name、summary、details和source(如user_provided,Wikipedia)。与Episodic Memory不同,Semantic Memory条目旨在持久存在,除非概念上被覆盖。Procedural Memory: 存储结构化的、目标导向的流程,如操作指南、工作流和交互脚本。这些是可操作的知识,用于帮助用户完成复杂任务。每个条目包含
entry_type(workflow,guide,script)、description(目标或功能)和steps(指令列表,可选JSON格式)。Resource Memory: 处理用户正在积极使用的完整或部分文档、转录或多模态文件,但不属于其他记忆类别。每个条目包含
title、summary、resource_type(如doc,markdown,pdf_text,image,voice_transcript)和content。Knowledge Vault: 作为安全存储凭证、地址、联系信息和API密钥等逐字敏感信息的存储库。每个条目包含
entry_type、source、sensitivity(low,medium,high)和secret_value。高敏感度条目受访问控制保护。
Active Retrieval 机制: 为解决LLM依赖参数知识而非记忆的问题,MIRIX引入了Active Retrieval。该机制分两阶段操作:
Agent根据输入上下文生成一个“当前话题”(current topic)。
该话题用于从每个记忆组件中检索相关记忆。检索结果(例如每个组件中最相关的10个条目)会被注入到系统prompt中,并带有来源标签(如
<episodic_memory>...</episodic_memory>)。 这种机制无需用户显式触发记忆访问,确保模型自动整合最新、个性化或上下文信息。 此外,系统支持多种检索函数,包括embedding_match、bm25_match和string_match,并计划扩展更多专业检索策略。
多agent工作流 (Multi-Agent Workflow): MIRIX采用模块化的多agent架构,由一个中央的
Meta Memory Manager和六个专业的Memory Managers(每个负责一种记忆类型)组成,共八个agent。记忆更新工作流 (Memory Update Workflow):
当接收到新输入时,系统首先对记忆库进行自动搜索。
检索到的信息连同用户输入传递给
Meta Memory Manager。Meta Memory Manager分析内容,确定相关记忆组件,并将输入路由给相应的Memory Managers。Memory Managers并行更新各自的记忆,同时避免冗余信息。更新完成后,它们向
Meta Memory Manager报告,后者发送确认。
对话检索工作流 (Conversational Retrieval Workflow):
Chat Agent收到用户查询时,首先对记忆库进行自动粗粒度搜索,获取各组件的高级摘要。Chat Agent分析查询,确定需要更精确搜索的记忆组件,并选择合适的检索方法。获取相关结果后,整合信息并合成最终响应。
如果查询涉及记忆更新(如提供新事实),
Chat Agent会直接与相应Memory Managers交互以进行精确更新。
2. 应用与用例 (Application & Use Cases)
MIRIX应用程序: 开发了一个跨平台应用,支持实时屏幕监控。它每1.5秒捕获一次屏幕截图,丢弃视觉相似的图像,每收集20张独特截图(约60秒)触发一次记忆更新。采用流式上传策略和Gemini API(支持Google Cloud URL加载图像),显著降低了端到端延迟(从约50秒降至5秒以下)。应用提供聊天界面和记忆可视化功能(如Semantic Memory的树状结构和Procedural Memory的列表视图)。
可穿戴设备记忆系统: MIRIX适用于AI眼镜、AI pins等可穿戴设备,通过连续收集和处理音频、视觉场景和用户查询等数据流,实现实时记忆形成和个性化。支持本地/云端混合记忆管理。
Agent记忆市场 (Agent Memory Marketplace): 设想一个去中心化生态系统,将个人记忆视为一种新的数字资产。包含AI Agents基础设施、隐私保护记忆基础设施(端到端加密、细粒度权限控制、去中心化存储)和记忆市场与社交功能(记忆的通证化交易、专家社区、粉丝经济和交友应用)。
3. 实验结果 (Experimental Results)
MIRIX在两个严苛的基准测试中表现出色:
ScreenshotVQA: 一个要求从多达20,000张高分辨率电脑截图序列中提取信息和构建记忆的多模态基准。
对比基线: Gemini(长上下文基线,将图像缩小到256×256像素)和SigLIP(RAG基线,检索最相关的50张高分辨率图像)。
结果: MIRIX在准确率上比RAG基线高35%,同时存储需求减少99.9%;比长上下文Gemini基线准确率高410%,存储减少93.3%。MIRIX通过存储SQLite数据库中的提取信息而非原始图像,实现了存储效率的大幅提升。
LOCOMO: 一个长对话文本输入基准测试。
对比基线: A-Mem, LangMem, Zep, Mem0, Memobase等,并使用gpt-4.1-mini作为统一的骨干模型。同时与Full-Context方法(被视为性能上限)进行比较。
结果: MIRIX达到85.38%的总准确率,超越现有最佳方法8.0%,并接近Full-Context方法的上限。
Single-Hop和Temporal: 表现显著优于基线,验证了分层记忆存储的有效性。
Multi-Hop: 表现出最大增益,比所有基线高出24点以上,因为它能显式存储整合事件,避免查询时的信息拼接。
Open-Domain: 表现良好,但与基线差距较小,与Full-Context的差距显示了RAG方法在全局理解方面的固有局限性。
4. 总结与未来工作 (Conclusion and Future Work)
MIRIX通过其结构化、组合式的记忆架构(六种专业记忆组件和多agent管理框架),显著提升了LLM-based agents的长期推理和个性化能力。实验证明了其在多模态和长文本对话任务上的优越性能和存储效率。MIRIX还提供了一个个人助手应用程序,使更多用户能体验到先进的记忆能力。未来的工作包括构建更具挑战性的真实世界基准,并持续改进MIRIX及其个人助手应用。
Abstract¶
虽然AI代理的记忆能力正受到越来越多关注,但目前的解决方案依然存在根本性限制。大多数方法依赖于平面化、狭隘范围的记忆组件,限制了它们在个性化、抽象化以及长期可靠回忆用户特定信息方面的能力。为此,本文提出 MIRIX——一种模块化、多代理的记忆系统,通过解决该领域最关键的挑战(使语言模型真正具备记忆能力)重新定义AI记忆的未来。与之前的方法不同,MIRIX 不仅限于文本,而是融合了丰富的视觉和多模态体验,使得记忆在现实场景中真正具有实用性。
MIRIX 包含六种结构化明确的记忆类型:核心记忆(Core)、情景记忆(Episodic)、语义记忆(Semantic)、程序记忆(Procedural)、资源记忆(Resource Memory) 和 知识库(Knowledge Vault),并结合一个多代理框架,动态控制和协调记忆的更新与检索。这一设计使代理能够大规模地持久化存储、推理和准确检索多样化的长期用户数据。
验证实验¶
我们通过两个具有挑战性的设置验证了MIRIX的性能:
在 ScreenshotVQA 上的验证:该多模态基准包含近20,000张高分辨率计算机截图,要求深度的情境理解,且目前没有任何现有记忆系统可以应用。MIRIX 在准确率上比 RAG 基线高出 35%,并且将存储需求减少了 99.9%。
在 LOCOMO 上的验证:该长文本对话基准采用单模态文本输入,MIRIX 达到了 85.4% 的最先进性能,远超现有基线。
这些结果表明,MIRIX 为增强型大语言模型代理(LLM Agents)设定了新的性能标准。
应用体验¶
为了使用户能够体验我们的记忆系统,我们提供了一个由 MIRIX 驱动的打包应用程序。该应用能够实时监控屏幕、构建个性化记忆库,并提供直观的可视化和本地安全存储,确保用户隐私。
重点总结:
MIRIX 是一种模块化、多代理的记忆系统,解决了当前AI记忆的核心问题。
它包含六种结构化记忆类型,结合动态代理机制,支持长期、多样化的记忆处理。
在 ScreenshotVQA 和 LOCOMO 上的实验验证了其卓越的性能与存储效率。
提供了实际应用版本,具备隐私保护和视觉化功能,方便用户体验。
1 Introduction¶
1.1 研究背景与动机¶
重点内容:
近年来,大型语言模型(LLM)代理的研究主要集中在复杂任务执行能力的提升,如代码调试、仓库管理、自主浏览网页等。
但记忆(memory)这一基础维度却鲜有研究。记忆对于实现一致、个性化交互、学习反馈、避免重复提问等至关重要。
当前大多数LLM代理状态不持久,除了当前提示窗口外,无法保留长期记忆,除非用户显式提供上下文。这极大地限制了其在实际场景中的长期使用。
1.2 现有记忆系统的局限性¶
重点内容:
一些记忆增强系统被提出,如使用知识图谱(如 Zep、Cognee)或扁平化记忆结构(如 Letta、Mem0、ChatGPT)。
知识图谱适合表示实体间结构化关系,但难以建模事件序列、情感状态、长文档或多模态输入(如图像)。
扁平化记忆系统(如 Letta 和 Mem0)虽然有一定应用,但面临以下挑战:
缺乏组合记忆结构:大多数系统将所有历史数据存储在一个扁平数据库中,缺乏按记忆类型(如程序性、情景性、语义性)分类的结构,导致检索效率和准确性下降。
多模态支持差:文本为主的记忆机制无法处理大量非语言输入(如图像、界面布局、地图)。
可扩展性与抽象化问题:存储原始输入(尤其是图像)会导致存储需求过高,缺乏有效的抽象层级来总结并保留关键信息。
1.3 本文提出的系统:MIRIX¶
重点内容:
本文提出MIRIX(Multi-Agent Memory System for LLM-Based Agents),这是一个模块化、全面的记忆系统,包含六种记忆组件(如图1):
Core Memory:核心记忆,用于存储用户偏好等关键信息。
Episodic Memory:情景记忆,存储用户特定事件和经历。
Semantic Memory:语义记忆,捕捉概念和命名实体。
Procedural Memory:程序性记忆,记录任务执行步骤。
Resource Memory:资源记忆,存储用户提供的文档、文件等媒体。
Knowledge Vault:知识库,保存必须精确存储的重要信息(如地址、电话号码等敏感事实)。
每种记忆组件内部采用层次化结构,例如情景记忆包含摘要和细节字段,语义记忆按名称和描述组织信息。
由于管理这种结构化且异构的记忆系统对单个代理来说困难,本文采用多代理架构:
为每种记忆组件设计一个Memory Manager(记忆管理器)。
一个Meta Memory Manager(元记忆管理器)负责任务的路由。
附加一个Chat Agent,用于演示如何访问和使用这些记忆。
补充说明:
提出了主动检索机制(Active Retrieval):在回答问题或执行下一步前,代理必须生成一个主题(topic),并将检索到的信息作为系统提示输入模型。
设计了多种检索工具,以便代理在不同情境中选择合适的工具。
1.4 实验与评估¶
重点内容:
实验一:多模态输入挑战
构建了一组包含5,000到20,000张高分辨率截图的基准数据集,来源于三位博士生一个月的电脑使用记录。
每张截图分辨率为2K到4K,要求代理从这些视觉历史中提取信息并构建记忆。
该任务对现有长上下文模型(如 Gemini)也构成挑战。
实验二:LOCOMO 数据集评估
在长对话数据集 LOCOMO 上进行评估(约26,000 token/对话)。
限制 Chat Agent 只能使用检索到的记忆回答问题,不能访问原始对话文本。
该设置用于测试系统是否能有效提取和路由关键信息。
实验结果:
相比RAG和长上下文基线,MIRIX分别提高了35%和410%,同时存储需求分别减少了99.9%和93.3%。
在 LOCOMO 上,MIRIX 达到85.38%的准确率,比现有最佳方法高出8.0%,接近长上下文模型的上限。
1.5 应用与贡献¶
重点内容:
为提高记忆系统的实用性,作者还开发了一个由 MIRIX 驱动的个人助理应用,在用户授权下捕捉屏幕内容,并持续构建记忆。
该应用允许用户通过记忆系统与助理进行更智能的互动,体现了系统的现实可应用性。
贡献总结:
分析现有记忆系统的不足,提出由六种记忆组件和八个代理组成的新型记忆系统。
构建新型多模态内存建模基准,要求代理从大量屏幕截图中理解用户行为。
实验验证:MIRIX 在新基准和 LOCOMO 上显著优于现有方法。
构建并开源个人助理应用,使用户能在实际场景中体验高级记忆功能。
该章系统性地介绍了 MIRIX 的研究背景、系统设计、实验方法和主要贡献,为后续章节的深入展开打下了坚实基础。
2 Application & Use Cases¶
2.1 MIRIX 应用¶
为了展示记忆系统(Memory System)的完整功能,开发了一个跨平台的应用程序,前端基于 React-Electron,后端使用 Uvicorn 服务器。该应用支持直接安装,用户可通过 ScreenShots 选项卡激活屏幕监控功能。该功能使代理(agent)能够观察用户的屏幕活动,并动态更新其记忆,逐步构建对用户上下文的理解。代理可以根据积累的记忆回答相关问题。
Memory Updates(记忆更新)¶
每 1.5 秒截取一张屏幕图像,去除视觉上重复的截图,保留 20 张唯一截图后启动记忆更新流程(约每 60 秒一次)。
为了降低延迟,采用 流式上传(streaming upload)策略:截图一旦生成即上传,而非等待整批处理。
利用 Gemini API 支持从 Google Cloud URL 加载图像的特性,实现高效的图像传输,显著减少端到端延迟(从大约 50 秒降低到 5 秒以下)。
Chat Interface(聊天界面)¶
用户可通过聊天界面与代理交互,代理可访问所有累积的记忆,以提供更智能、个性化的回应。
图 2 示例展示了用户查询过去行为,代理基于记忆内容生成回答的场景。
Memory Visualization(记忆可视化)¶
随着屏幕观察时间的延长,代理将知识组织为结构化记忆组件。
语义记忆(Semantic Memory)以树状结构组织(如图 3 所示),程序性记忆(Procedural Memory)则以列表形式呈现(如图 4 所示)。
2.2 可穿戴设备上的记忆系统¶
可穿戴设备市场近年来迅速发展,智能个人助理类产品(如 AI 眼镜、AI 针等)已成为趋势。尽管这些设备支持语音、视觉捕捉和实时反馈,但普遍缺乏长期记忆能力,无法持续学习用户习惯和行为。
MIRIX 记忆系统非常适合集成到这类设备中:
通过持续采集音频、视觉和用户查询,实现实时记忆构建。
示例应用包括:AI 眼镜可自动总结会议、记住常去地点、识别重复视觉模式,甚至回溯过去对话。
记忆系统包含程序性、情景性、语义性和资源性记忆模块,适合轻量级设备。
程序性记忆:学习用户习惯(如日常路线、会议结构)。
语义记忆:存储用户偏好、环境与日常模式。
情景记忆:记录时间戳事件(如“上周会议我看到了什么”)。
考虑硬件限制(计算与存储资源有限),系统支持混合本地/云端存储,关键信息本地存储,大规模记忆可按需云端调用。
总结:此记忆系统可作为可穿戴 AI 代理的“认知核心”,实现个性化、连续性与边缘智能。随着市场发展,具备持久结构化记忆将成为下一代 AI 助手的重要差异点。
2.3 代理记忆市场(Agent Memory Marketplace)¶
我们设想未来,个人记忆将作为新的数字资产类别存在。AI 时代中,记忆不再是静态的事件记录,而是可共享、可个性化、可货币化的动态知识库。Agent Memory Marketplace 是一个去中心化的生态系统,支持 AI 代理之间记忆的交换、复用与共建。
核心理念:¶
人类记忆将成为 AI 时代最有价值的资产,因为它包含主观体验、偏好、互动和情境,既高度个人化,又可被 AI 系统复用。
市场结构分为三层:¶
AI 代理基础设施
支持长期、交互式的智能代理系统,包括:
个人 AI 助手与伙伴(个性化、持续学习)
AI 可穿戴设备(如智能眼镜、AI 针)中扩展记忆采集
多代理系统(共享记忆访问,实现协同智能)
隐私保护记忆基础设施
为增强信任与用户接受度,系统包含:
端到端加密
细粒度隐私控制(用户可选择共享、交易或限制记忆)
去中心化存储(抗审查、分布式存储)
记忆市场与社交功能
一个点对点的生态系统,用于记忆共享、聚合与交易,包括:
记忆社交与交易(如生产力技巧、小众工作流或生活建议)
专业社区(如金融、教育、宠物护理领域的共享记忆)
粉丝经济与约会应用(用户可订阅名人记忆的 AI 代理人,或通过 AI 代理人进行预约会互动)
总结:我们设想一个未来,个人记忆不再只是过去事件的记录,而是成为活跃的数字资产。通过结合长期 AI 代理、隐私保护基础设施与去中心化市场,我们构建了一个安全、有意义、协作性强的生态系统,使记忆不仅能被用户自身利用,还能赋能协作、个性化与经济价值。
3 Methodology¶
3.1 Memory Components¶
本节提出了一种模块化的记忆架构,包含六个不同的记忆组件:Core Memory、Episodic Memory、Semantic Memory、Procedural Memory、Resource Memory 和 Knowledge Vault。每个组件在结构和功能上都经过定制,用于捕捉用户交互和世界知识的不同方面,从而支持代理在时间与任务上的有效检索、推理与行动。
Core Memory(核心记忆)¶
功能:存储高优先级、持久性信息,这些信息应始终对代理可见。
结构:分为
persona和human两个块。persona描述代理的身份、语气和行为模式;human存储用户的基本信息(如姓名、偏好等)。容量管理:当内存使用超过 90% 时,系统会触发有控制的重写机制,确保信息紧凑但不丢失关键内容。
Episodic Memory(情景记忆)¶
功能:记录带时间戳的事件和用户互动,支持代理理解用户的日常行为、近期活动和上下文相关的后续响应。
结构:每个条目包括
event_type(如用户消息、系统通知)、summary(简洁描述)、details(扩展信息)、actor(用户或代理)和timestamp。用途:代理可以通过时间索引追踪变化,识别正在进行中的任务或待处理动作。
Semantic Memory(语义记忆)¶
功能:保存抽象知识和事实性信息,与具体时间和事件无关。
结构:包括
name(概念标识)、summary(定义)、details(背景信息)、source(来源,如用户提供或推断)。用途:支持代理进行常识、社会关系、地理等领域的推理。
Procedural Memory(程序记忆)¶
功能:存储结构化的、目标导向的过程或操作指南,如“如何填写报销单”、“如何设置Zoom会议”。
结构:每个条目包括
entry_type(如工作流、指南)、goal(目标描述)和steps(步骤列表,可为JSON格式)。用途:用于任务拆解、自动化和执行复杂用户目标。
Resource Memory(资源记忆)¶
功能:存储用户正在处理但不适合其他记忆类型的文档、多模态文件或长文本。
结构:包括
title、summary(概述)、resource_type(如文档、图片)和content(全文或摘录)。用途:支持长周期任务的上下文连续性。
Knowledge Vault(知识库)¶
功能:安全存储敏感信息,如密码、地址、API密钥等。
结构:包括
entry_type(如凭证、API密钥)、source(来源)、sensitivity_level(敏感等级)和secret_value。用途:支持执行需要认证的任务,高敏感信息通过访问控制保护。
3.2 Active Retrieval and Retrieval Design(主动检索与检索设计)¶
许多记忆增强系统中,记忆检索需要显式触发,否则模型会依赖其参数知识,可能导致过时或错误的回答。
Active Retrieval(主动检索)¶
机制:分为两个阶段:
代理根据输入上下文生成一个“当前话题”;
用该话题从六个记忆组件中检索相关内容,并将结果注入系统提示中。
示例:用户询问“Twitter的CEO是谁?”时,代理自动检索记忆中对应的信息,并根据来源(如
<episodic_memory>)标记内容,确保模型使用最新、个性化信息回应。
检索方法¶
支持多种检索策略:
embedding_match(嵌入匹配)、bm25_match(BM25匹配)、string_match(字符串匹配)等,未来将继续扩展。
3.3 Multi-Agent Workflow(多代理工作流)¶
为管理复杂且多样化的用户交互,系统采用模块化的多代理架构,由Meta Memory Manager(元记忆管理器)与六个Memory Managers(记忆管理器)协同工作。
Memory Update Workflow(记忆更新流程)¶
流程:
接收用户输入后,系统首先在记忆库中进行搜索;
搜索结果与用户输入一起传递给Meta Memory Manager;
Meta Memory Manager 分析内容,决定哪些记忆组件需要更新,并将输入路由给相应的Memory Managers;
各Memory Managers 并行更新各自的内存,避免重复信息;
更新完成后,向Meta Memory Manager 报告,完成更新确认。
Conversational Retrieval Workflow(对话检索流程)¶
流程:
Chat Agent(聊天代理)接收用户查询后,首先进行初步搜索,获取所有记忆组件的高阶摘要;
分析查询内容,确定需要更精确搜索的记忆组件,并选择合适的检索方法;
整合搜索结果并生成最终回应;
若用户查询涉及更新记忆(如提供新事实),Chat Agent 可直接与相关 Memory Manager 交互,进行精准更新。
图表说明¶
图5(Active Retrieval):展示了代理如何根据用户输入生成话题,并从各记忆组件中检索内容。
图6(Memory Update Workflow):展示了从用户输入到记忆更新的完整流程。
图7(Query Workflow):展示了代理如何根据用户查询执行检索并生成回应的过程。
总结¶
本章详细介绍了 MIRIX 系统的多模块记忆架构和多代理系统设计,每个记忆组件针对不同类型的用户信息做专门设计,通过“主动检索”和“多代理工作流”实现高效、准确、上下文感知的记忆管理与响应能力。系统强调自动化、模块化与安全性,适用于复杂任务和长期交互场景。
4 Experiments¶
本节详细介绍了 MIRIX 在两个数据集上的实验设置、评估指标和结果。通过与现有记忆系统和基线方法的对比,MIRIX 展示了其在多种任务上的优越性能和高效性。
4.1 实验设置 (Experimental Setup)¶
4.1.1 数据集 (Datasets)¶
ScreenshotVQA¶
数据收集:作者创建了一个新数据集,收集了三位计算机科学和物理专业的博士生的屏幕截图。
数据生成方式:通过脚本每秒截图一次,若当前图像与上一帧相似度超过 0.99,则跳过。
数据量:三位学生分别使用电脑的时间为1天、20天和1个月,生成了5886、18178和5349张图像。
问题生成:每位学生手动创建一定数量的问题,并经双人验证确保可回答性,最终分别生成11、21和55个问题。
LOCOMO¶
来源:沿用 Mem0 中的 LOCOMO 数据集,用于与 MIRIX 的横向比较。
数据结构:包含10次对话,平均每次对话600轮、26000个token,200个问题。
问题类型:包括单跳、多跳、时间顺序和开放域问题。
特别说明:排除“对抗性”问题类别,以保证公平性。
4.1.2 评估指标与实现细节 (Evaluation Metrics and Implementation Details)¶
评估指标 (Evaluation Metrics)¶
主指标:LLM-as-a-Judge,使用 GPT-4.1 作为裁判,评估生成的回答是否成功回答了问题。
重要性:该指标是核心,用于量化不同方法的性能差异。
ScreenshotVQA 的实现细节¶
模型:使用 Gemini-2.5-flash-preview-04-17。
原因:Gemini 与 Google Cloud 集成良好,支持异步图像上传和检索,加快处理速度。
操作流程:每步需要多次函数调用,包括主记忆管理器和其他记忆管理器。
LOCOMO 的实现细节¶
模型选择:使用 gpt-4.1-mini,因其在函数调用上优于 gpt-4o-mini(数据来自 Berkeley 函数调用基准)。
基线方法:在统一模型下复现了 LangMem、RAG-500、Mem0 和 Zep。
代码来源:使用 Mem0 和 Zep 的官方代码库。
结果复现:所有基线运行一次,MIRIX 和 Full-Context 运行三次并取平均。
代码与数据:公开结果和代码可在 GitHub 上访问。
4.2 ScreenshotVQA 上的实验结果 (Experimental Results on ScreenshotVQA)¶
对比方法:
Gemini:长上下文基线,直接输入所有截图,图片被压缩到 256×256,最多包含3600张。
SigLIP:检索增强基线,用 SigLIP 检索前50张相关图像,再由 Gemini 生成答案。
评估指标:
Accuracy:通过 LLM-as-a-Judge 评估。
Storage:按像素大小计算存储开销(Gemini)或原始图像大小(SigLIP)或提取信息的大小(MIRIX)。
主要结论:
MIRIX 在准确率上显著优于 Gemini 和 SigLIP,同时存储成本大大降低。
Gemini:由于图片压缩,存储开销仍较大。
SigLIP:存储开销极高(15GB+),但准确率略高于 Gemini。
MIRIX:存储极小(仅 15.89MB),准确率最高(59.50%),比 SigLIP 高35%,比 Gemini 高410%。
4.3 LOCOMO 上的实验结果 (Experimental Results on LOCOMO)¶
对比方法:
A-Mem、LangMem、Zep、Mem0、Memobase(均基于 gpt-4.1-mini 实现)。
另外报告了 Mem0 原论文中基于 gpt-4o-mini 的结果。
主要结论:
总体表现:MIRIX 在所有类别中表现最优,平均得分 85.38,比最强开源方法(LangMem)高出 8 分以上。
单跳与时间顺序:MIRIX 表现优异,但略低于 Full-Context。部分问题因上下文歧义导致误差(如计划与实际事件混淆)。
多跳推理:MIRIX 表现最佳,比其他方法高出 24 分以上。原因在于其存储了整合事件,无需查询时拼接信息。
开放域:MIRIX 表现良好,但与 Full-Context 仍有差距。这是因为开放域问题需要更全局的理解,而 MIRIX 依赖 RAG 检索,存在瓶颈。
总结:
MIRIX 在 LOCOMO 数据集上实现了 SOTA 性能,尤其在多跳推理方面表现突出。
其模块化设计、智能路由机制和分层存储策略是性能提升的关键。
总结¶
本章通过对 ScreenshotVQA 和 LOCOMO 两个数据集的实验验证,全面评估了 MIRIX 在 图像问答 和 对话记忆系统 任务中的性能。实验结果表明:
MIRIX 在存储效率和准确率方面远超现有基线(如 Gemini、SigLIP)。
在对话记忆任务中,MIRIX 在多跳推理上表现突出,显著优于 Mem0、LangMem 等主流系统。
虽然在某些任务(如开放域、单跳)上仍有改进空间,但整体表现已达到当前最优。
6 Conclusion and Future Work¶
在本研究中,我们提出了 MIRIX,这是一种新型的记忆架构,旨在提升基于大语言模型(LLM)的智能体在长期推理和个性化能力方面的表现。与目前主要依赖扁平存储或有限记忆类型的现有记忆系统不同,MIRIX 采用了结构化和组合式的方法,集成了六个专门的记忆组件:核心记忆(Core)、情景记忆(Episodic)、语义记忆(Semantic)、程序性记忆(Procedural)、资源记忆(Resource) 和 知识库(Knowledge Vault)。这些组件由各自的记忆管理器管理,并在**元记忆管理器(Meta Memory Manager)**的协调下协同工作。
重点内容:
我们设计了一项具有挑战性的多模态基准测试,该测试基于真实用户活动的高清截图,以严格评估 MIRIX 的性能。实验结果显示,与检索增强生成和长上下文基线相比,MIRIX 在准确性和存储效率方面都取得了显著提升。在 LOCOMO 基准测试中的实验进一步验证了 MIRIX 在长对话场景中达到了当前最优的性能。
此外,为了让更多用户能够实际体验 MIRIX 的能力,我们开发并发布了一款由 MIRIX 驱动的个人助手应用,使用户能够在日常场景中获得一致且记忆增强的交互体验。我们希望这项工作能够为构建更加稳健、可扩展且类似人类的记忆系统铺平道路。
未来工作:
我们计划构建更具挑战性的现实世界基准,以全面评估 MIRIX 的性能。同时,我们将持续改进 MIRIX 及其相关的个人助手应用,以为用户提供更优质的服务体验。
Appendix A Full Experimental Results with Different Runs¶
本节报告了 MIRIX 和 Full-Context 方法在使用 gpt-4.1-mini 时的多次运行结果,完整结果见 表3。文中指出,尽管不同运行之间存在一些变化,但 MIRIX 在所有运行中都保持了 最先进的性能。
主要内容总结:¶
实验设计与数据来源:
使用 gpt-4.1-mini 作为基础模型。
对 MIRIX 和 Full-Context 方法分别进行了 三次独立运行。
全部预测结果与 LLM-Judge 评分数据存放于公开 GitHub 仓库中,地址为:
重点表格:Table 3
表中比较了不同方法在 LOCOMO 数据集 上的表现,按照问题类型分为:
Single Hop(单跳)
Multi-Hop(多跳)
Open Domain(开放领域)
Temporal(时间相关)
Overall(整体)
每个指标的得分使用 LLM 作为评估者(LLM-Judge)进行打分,百分比越高越好。
表中重点方法表现对比:
MIRIX 的表现非常突出:
三次运行的平均得分为:
Single Hop:85.0%
Multi-Hop:83.7%
Open Domain:65.6%
Temporal:88.3%
Overall:85.3%
在所有指标上均优于大多数基线方法,特别是在 Multi-Hop 和 Temporal 任务上表现尤其优异。
Full-Context 的表现接近上限:
文中提到,由于 LOCOMO 数据集的平均长度仅为 9k token,Full-Context(即直接使用完整上下文)几乎可以看作是性能上限。
MIRIX 能够在大多数任务中接近甚至略超 Full-Context,表明其在记忆系统设计上的显著进步。
其他方法表现:
Zep:使用 gpt-4.1-mini 时仅得 49.09%,作者怀疑其实现可能存在问题,因此未报告。
Memobase 和 Zep 在 Temporal 任务上表现较好,但整体表现不如 MIRIX。
LangMem、Mem0 等方法的表现中等,低于 MIRIX。
结论:
尽管多次运行间存在轻微波动,MIRIX 在所有运行中都保持了 SOTA 表现。
实验结果展示了 MIRIX 在多跳推理、时间任务和长文本处理等方面的优势。
与 Full-Context 接近的性能表明,MIRIX 在有效记忆管理和上下文压缩方面取得了重要进展。
补充说明:¶
LLM-Judge 评分方式:使用 LLM 作为评分器对生成结果进行判断,这种方式已成为当前评估 LLM 系统性能的常用方法。
公开数据与复现支持:作者提供了完整的评估结果和预测输出,方便后续研究者进行复现与比较。
总结:¶
本附录通过多轮实验验证了 MIRIX 在多类型任务中的鲁棒性和优越性能,特别是在记忆管理和上下文压缩方面表现出色。与 Full-Context 接近的表现表明,MIRIX 已经接近当前 LLM 处理长文本任务的理论上限。