2305.14387_AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback¶
引用: 636(2025-08-27)
组织:
Stanford
总结¶
总结
本文有简单讲解 PPO、Quark、PPO等强化学习内容
背景
使用人类反馈进行训练,存在三大核心挑战
数据收集成本高:获取真实人类反馈的成本昂贵,限制了研究和开发的可扩展性。
缺乏可信的评估机制:评估模型是否真正遵循了人类指令缺乏统一、可信的标准。
缺乏参考实现:现有方法(如 PPO、Expert Iteration 等)缺乏统一的实现方式,不利于比较和复现。
两两比较反馈(Learning from Pairwise Feedback, LPF)步骤
监督微调(SFT)
生成候选响应
生成候选响应
模型学习
Methods for learning from feedback
基于成对反馈的学习方法(learn from pairwise feedback) 注:本文使用
自然语言反馈(natural language feedback);
数值评分(numeric ratings);
执行轨迹(execution traces)。
四种基于替代奖励模型的方法
Best-of-n Sampling
也称为 重排序(re-ranking)。
在输入 x 下,从 SFT 模型中采样 n 个独立响应,然后选择 替代奖励最大 的响应。
优点是简单、效果不错,但 计算成本高,常用于推理阶段。
Expert Iteration
两步方法:
使用 Best-of-n 采样生成高质量样本。
使用这些样本对 SFT 模型进行微调。
Proximal Policy Optimization (PPO)
从当前策略中采样,并使用 重要性采样和剪切 进行梯度更新。
该方法在训练阶段表现良好,但实现复杂度较高。
Quark
受 奖励条件化(reward conditioning) 启发,Quark 通过分组训练 和 正则化 来改进可控生成。
与 Binary Reward Conditioning 不同,Quark 将样本按奖励值划分为多个组,加入 KL 散度 和 熵正则化,并在 多轮训练中重复。
初步分析表明,仅训练最高奖励组(top-quantile) 的方法效果优于训练所有组的方法。
AlpacaFarm
一个用于低成本模拟和研究基于人类反馈的大型语言模型(LLM)训练流程的工具
核心特点
模拟人类反馈:通过设计 LLM 提示词(prompt),模拟人类反馈。
自动评估机制:提出一种自动评估模型表现的方法,并验证其与真实人类指令的一致性。
提供参考实现:为多种基于反馈学习的方法(如 PPO、best-of-n、Expert Iteration 等)提供统一的代码实现,便于研究者比较和改进模型。
AlpacaFarm 并不以训练高性能模型为目标,而是以方法分析与模拟验证为目标,通过模拟数据来分析算法与超参数,并将所得见解迁移到实际的人类反馈设置中
Abstract¶
本章节主要介绍了 AlpacaFarm —— 一个用于低成本模拟和研究基于人类反馈的大型语言模型(LLM)训练流程的工具。文章指出,当前开发具有强指令跟随能力的 LLM(如 ChatGPT)涉及复杂的训练流程,尤其是使用人类反馈进行训练,但这一流程存在三大核心挑战:
数据收集成本高:获取真实人类反馈的成本昂贵,限制了研究和开发的可扩展性。
缺乏可信的评估机制:评估模型是否真正遵循了人类指令缺乏统一、可信的标准。
缺乏参考实现:现有方法(如 PPO、Expert Iteration 等)缺乏统一的实现方式,不利于比较和复现。
AlpacaFarm 的解决方案¶
为解决上述挑战,作者提出了 AlpacaFarm,其核心特点包括:
模拟人类反馈:通过设计 LLM 提示词(prompt),模拟人类反馈。与人工标注相比,成本降低约 50 倍,并且与人类判断高度一致。
自动评估机制:提出一种自动评估模型表现的方法,并验证其与真实人类指令的一致性。
提供参考实现:为多种基于反馈学习的方法(如 PPO、best-of-n、Expert Iteration 等)提供统一的代码实现,便于研究者比较和改进模型。
实验验证¶
文章进一步通过 端到端实验,验证了 AlpacaFarm 的有效性:
使用 10,000 对真实人类反馈数据,训练并评估了 11 个模型。
实验表明,使用 AlpacaFarm 训练的模型排名与使用真实人类数据训练的模型排名高度一致,说明其模拟效果可靠。
附加发现¶
使用奖励模型的方法(如 PPO)相比监督微调(Supervised Fine-tuning)具有明显优势。
作者提出的
1 Introduction¶
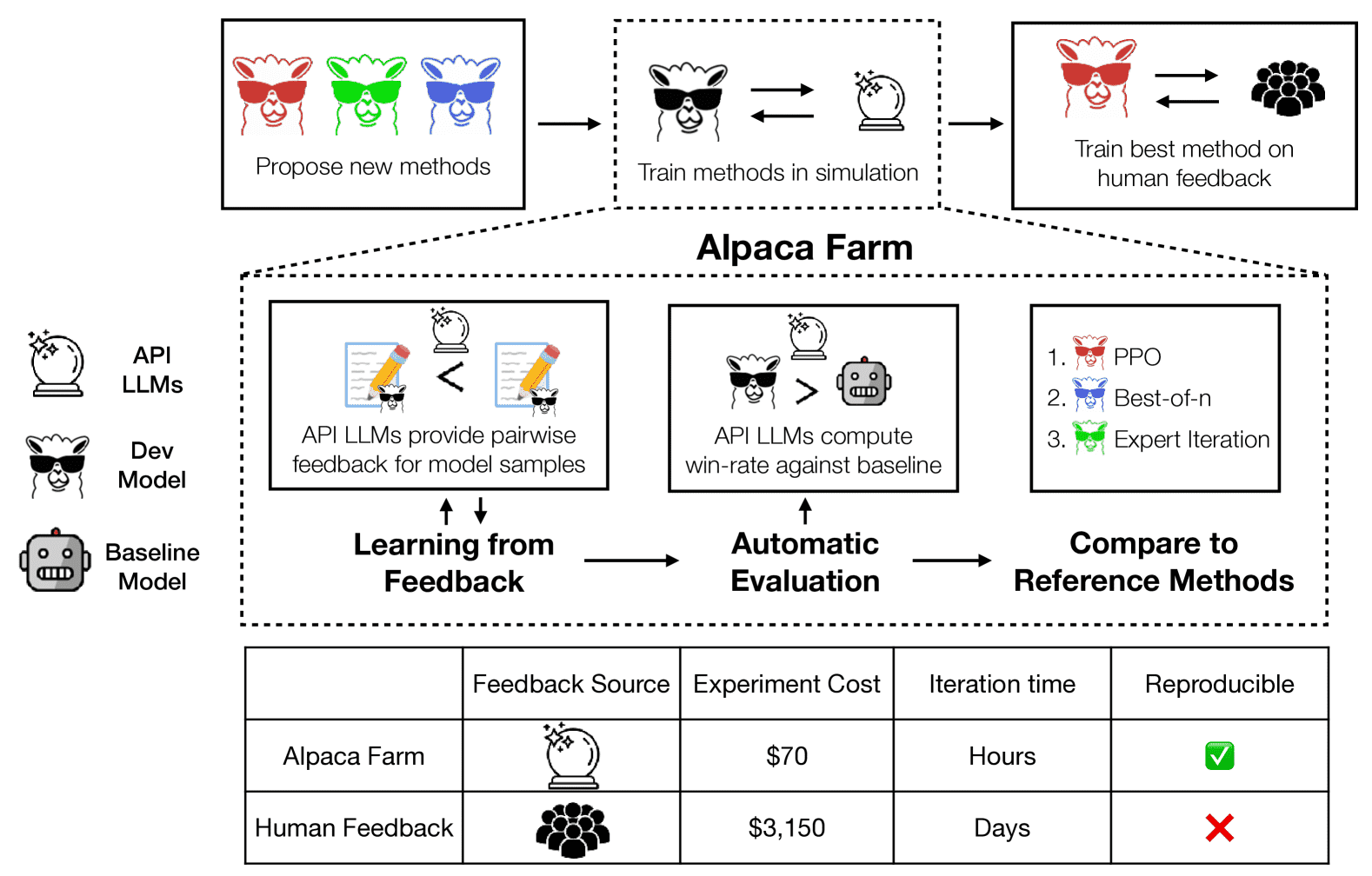
Figure 1:AlpacaFarm is a simulation sandbox that enables fast and cheap experimentation on LLMs that learn from human feedback. It simulates human feedback with (oracle) API LLMs, provides a validated evaluation protocol, and offers a suite of reference method implementations. Researchers can rapidly iterate on model development and transfer their methods to training on human data to maximize performance.
图 1 展示了 AlpacaFarm 的整体架构:
模拟人类反馈:通过 API LLM(如 GPT 系列)模拟“人类反馈”。
评估协议:提供经验证的评估流程,确保实验结果可信。
方法实现:提供一系列基础方法的实现,如 PPO、Expert Iteration 等。
快速迭代:支持研究人员快速开发和测试模型,并最终将方法迁移至真实人类数据训练中,以最大化模型性能。
研究背景:大语言模型与人类反馈¶
大语言模型(LLMs) 已展现出强大的遵循多样化、开放式指令的能力,这些能力通常被认为是通过预训练模型的微调(fine-tuning) 结合人类反馈(Human Feedback)实现的。
然而,LLM供应商并未公开训练方法的详细信息,导致该过程的可解释性与可复现性不足。
例如,OpenAI 模型中只有 Davinci003 使用了基于 PPO 的强化学习(RL),而 Davinci002 已具有良好的性能,这引发了对 RL 在训练中重要性的质疑。
👉 重点:当前方法的理解和改进依赖于训练过程的透明和开放,但因成本和复杂性,这一目标难以实现。
研究目标与挑战¶
作者提出,当前研究面临三大挑战:
数据标注成本高昂(Cost of Data Annotation)
缺乏自动化的模型评估方法(Lack of Automated Evaluation)
缺少现有方法的验证性实现(Absence of Validated Implementations)
为了解决这些问题,作者引入了 AlpacaFarm —— 一个用于低成本模拟人类反馈训练的沙盒框架。
AlpacaFarm 的三个核心功能¶
1. 模拟人类标注者,降低数据成本¶
AlpacaFarm 使用 大型语言模型(如 GPT-4)作为“模拟标注者”(Oracle API LLM),模拟人类进行成对比较(pairwise comparison)。
通过设计特定提示(prompt),AlpacaFarm 能以 1/45 的成本 模拟人类标注,并忠实反映人类标注者的质量判断、标注者间差异、风格偏好等关键特性。
👉 重点:模拟标注者极大降低了数据获取成本,同时保留人类反馈的多样性与真实性。
2. 自动化评估协议¶
由于人工评估成本高、不可重复、缺乏真实交互数据,难以评估开放式指令跟随的性能。
AlpacaFarm 提出一个自动评估协议,通过模拟标注者比较模型输出与基线模型输出的“胜率”(win-rate)来评估模型表现。
评估所用指令来自 Alpaca Demo 数据集,但由于数据保密限制,作者通过组合公开数据集构建了模拟指令集。
👉 重点:该评估方法与真实指令评估结果高度相关(系统排名的相关性高),验证了其有效性。
3. 提供可验证的参考实现(Reference Implementations)¶
AlpacaFarm 实现并测试了多种主流学习算法,包括:
PPO(Proximal Policy Optimization)
Expert Iteration
Quark
并发布参考实现,方便其他研究者复现与扩展。
实验结果显示:
使用 PPO + 替代奖励模型(surrogate reward model) 的方法在训练时最有效。
微调后的 LLaMA 7B 模型在与 Davinci003 的比较中,胜率从 44% 提高到 55%。
其他方法在更简单任务上表现良好,但在真实指令任务中表现较差,说明真实任务环境的测试至关重要。
👉 重点:AlpacaFarm 提供了可复现的实验基础,并验证了 PPO 在真实场景中的优越性。
端到端评估与结论¶
作者在 AlpacaFarm 中训练并评估了 11 种方法,并将它们与使用真实人类反馈训练的相同方法进行比较。
结果显示:
AlpacaFarm 中的方法排名与真实人类反馈下的排名高度一致(Spearman 相关系数 0.98)。
在 AlpacaFarm 中表现最佳的方法,在真实人类反馈下也取得了显著提升。
AlpacaFarm 能够模拟人类反馈的定性行为,如奖励模型的过度优化(over-optimization)。
👉 结论:AlpacaFarm 是一个有效的研究工具,可以帮助研究人员快速开发与评估基于人类反馈的指令跟随模型。
总结¶
本节主要阐述了 AlpacaFarm 的研究动机、目标、设计思路与初步实验结果。通过模拟人类标注者、自动化评估系统、以及提供参考实现,AlpacaFarm 为研究者提供了一个低成本、高效率、高可信度的实验平台,推动了对人类反馈学习方法的深入研究。
2 Background & problem statement¶
本节分为两个部分:2.1 学习遵循指令 和 2.2 问题陈述。该节主要用于介绍研究背景、任务设定以及 AlpacaFarm 框架所要解决的核心问题。
2.1 学习遵循指令¶
核心任务是“指令遵循”(Instruction Following),即给定用户指令 \(x \in \mathcal{X}\)(例如:“告诉我一些关于羊驼的事情”),模型需要生成高质量的响应 \(y \sim p_\theta(y|x)\),并通过未观察到的人类奖励函数 \(R(x, y)\) 评估响应质量。
在当前的研究中,许多方法通过人类反馈进行学习,尤其是两两比较反馈(Learning from Pairwise Feedback, LPF)已成为主流。LPF 的流程通常包括以下步骤:
监督微调(SFT):使用指令-响应对 \((x, y)\) 微调模型,得到 \(p_{\theta}^{\text{SFT}}(y|x)\)。
生成候选响应:对每个指令 \(x\),从 \(p_{\theta}^{\text{SFT}}(y|x)\) 中采样两个响应 \(y_0, y_1\)。
人类两两比较:人类标注者对这两个响应进行比较,给出二元偏好标签 \(z \in \{0, 1\}\),表示哪一响应更好。
模型学习:基于这些两两比较的数据集 \(\mathcal{D}_{\text{pairwise}} = \{(x^{(j)}, y_0^{(j)}, y_1^{(j)}, z^{(j)})\}\) 进行训练。
在模型训练完成后,通常使用两两模型评估(Pairwise Model Evaluation)来比较模型与参考模型 \(p_{\text{ref}}\) 的性能,通过计算模型的胜率(Win Rate)来衡量其表现。
重点:本节强调了 LPF 的流程及其在当前指令遵循模型(如 Alpaca、InstructGPT)中的核心地位。
2.2 问题陈述¶
AlpacaFarm 的目标是提供一个低成本的模拟框架,用于研究和开发指令遵循模型。该框架包含三个核心组成部分:
低成本的两两反馈生成器:用模拟偏好 \(z_{\text{sim}} \sim p_{\text{sim}}(z|x, y_0, y_1)\) 替代真实的人类偏好 \(z_{\text{human}} \sim p_{\text{human}}(z|x, y_0, y_1)\),目标是低成本地模拟真实人类反馈的关键特征,如响应质量、标注者一致性、风格偏好等。
自动化的模型评估机制:设计评估数据集,使得模型在模拟数据上的排名与人类在真实任务上的排名高度一致。例如,使用 Alpaca Demo 作为真实指令数据源。
参考方法的实现与比较:开发并评估六种 LPF 方法,提供可复现、高性能的参考实现,供研究者作为基线进行比较与改进。
核心目标是构建一个模拟框架,用于在低成本环境下研究和开发 LPF 方法,并通过模拟结果指导真实世界中的方法改进。
重点:AlpacaFarm 并不以训练高性能模型为目标,而是以方法分析与模拟验证为目标,通过模拟数据来分析算法与超参数,并将所得见解迁移到实际的人类反馈设置中。
后续章节概览¶
3 章节:详细介绍 AlpacaFarm 的构建过程,包括模拟反馈和评估机制的设计。
4 章节:验证 AlpacaFarm 模拟器的有效性。
5 章节:在 AlpacaFarm 框架下对参考方法进行基准测试与分析。
总结¶
本节明确了 AlpacaFarm 所研究的核心任务(指令遵循),介绍了 LPF 的基本流程与数据形式,并提出了 AlpacaFarm 框架的三个核心目标:低成本模拟反馈、自动化评估、参考方法实现。其核心目的是通过模拟手段加速方法研究,并将研究结果迁移到真实的人类反馈场景中。
3 Constructing the AlpacaFarm¶
3.1 指令跟随数据¶
在定义如何模拟成对反馈之前,首先需要一个大规模、多样化的指令集合 x,以便构建 AlpacaFarm 的其余部分。
我们选用 Alpaca 数据集作为起点,因为它包含 52k 个 (x, y) 示例,并且训练后的模型在指令跟随任务上表现良好。
为了适配人类反馈学习方法,我们参考 [Ouyang22] 的数据划分方式,将 Alpaca 数据集划分为四个部分(总共 42k 条指令),余下 10k 用于未来用途:
监督微调 (SFT) 集:10k 用于微调后续步骤中使用的基线指令跟随模型。
成对偏好 (PREF) 集:10k 条指令,用于收集成对反馈数据。
无标签集:20k 条指令,供 PPO 等算法使用。
验证集:2k 条数据,用于开发和调优。
3.2 设计模拟成对偏好 psim¶
在拥有 Alpaca 指令数据的基础上,我们设计了模拟成对偏好的系统。我们的核心思想是通过提示 OpenAI API 大语言模型来生成模拟注释器。
虽然使用 LLM 模拟人类注释已成为趋势,但将其用于模拟环境面临额外挑战。我们的模拟偏好 psim 不仅需要与人类偏好 phuman 高度一致,还需体现人类反馈的其他特性,如注释者之间的差异(inter-annotator variability)和注释者内部的不一致性(intra-annotator variability)。
基础 GPT-4 提示设计¶
我们首先设计一个基础提示,提供适当的响应指南、上下文示例,并利用批量生成降低成本。我们对 GPT-4 进行一次提示查询(记作 \(psim^{GPT-4}\)),发现其与人类注释者的一致率与人类之间的一致率相近(65% vs 66%),但尚不能充分反映人类注释的变异性,特别是在奖励过度优化问题上存在差异。
模拟人类变异性¶
为了更真实地模拟人类注释者,我们从两个方面增强模拟器:
模拟注释者之间的差异:我们通过使用不同 API 模型、不同提示格式、不同批量大小和上下文示例来构建多个“注释者”。
模拟注释者内部的差异:我们通过在 25% 的情况下随机翻转偏好来引入噪声。
最终我们构建了 13 个模拟注释器,并在附录中详细描述。使用模拟偏好标注 1000 个输出仅需 6 美元,成本是人工标注的 50 分之一。在 第4节中,我们通过实际的人类偏好数据验证了模拟偏好的一致性与变异性。
3.3 设计自动评估¶
为了让研究人员开发 LPF 方法时能够快速迭代并可靠比较,我们设计了自动评估协议。评估面临两个挑战:
如何量化不同模型输出的质量?
使用哪些指令才能代表真实的人类交互?
评估协议¶
我们通过测量模型 pθ 与参考模型 pref 的“胜率”来量化其输出质量,即在某条指令 x 上,pθ 的输出被偏好于 pref 输出的期望频率。这种方法易于理解,便于跨模型比较,并可复用我们在成对反馈中构建的流程。
我们使用 13 个模拟注释器(不添加额外噪声)进行评估,记为 \(psim^{eval}\)。参考模型我们选择 Davinci003,因为它性能稳定,与我们微调的模型相似。
评估指令¶
指令跟随要求覆盖多样化的现实交互。我们结合多个开源评估数据集,并参考 Alpaca Demo 的实际交互方式构建评估数据集。由于隐私原因,我们不直接发布 Demo 数据,而是将其用于指导如何组合现有数据。
我们构建了一个包含 805 条指令的评估集,其中包括:
252 条来自 self-instruct 测试集;
188 条来自 Open Assistant 测试集;
129 条来自 Anthropic 的 helpful 测试集;
80 条来自 Vicuna 测试集;
156 条来自 Koala 测试集。
我们在文中提供了示例指令和指令动词分布图(图2),展示了评估指令的多样性。我们发现跨数据集的组合对于模拟真实交互非常重要,这一点在第4.4节中进一步验证。
3.4 AlpacaFarm 中的参考方法¶
最后,AlpacaFarm 定义了一系列经过验证的 LPF 指令跟随方法。详细方法描述见附录 A,此处仅做简要概述。
所有 LPF 方法都从在监督数据上进行初步微调开始,接下来我们介绍三种直接操作成对反馈的基线方法:
Binary FeedME:在每对比较中仅对较优输出进行监督微调。
Binary reward conditioning:在微调前添加一个标记表示输出是否被偏好,并在推理时使用该标记。
Direct Preference Optimization (DPO):基于 Bradley–Terry 模型最大化偏好对数似然,隐式定义奖励模型。
此外,还有几种方法不直接操作成对数据,而是先用 SFT 模型和成对反馈训练一个替代奖励模型,再基于该奖励模型进行优化:
Best-of-n 采样:从 SFT 模型中独立采样 n 次,返回奖励最高的输出(n 通常为 1024)。
Expert iteration:训练时扩展 Best-of-n,生成新指令的最佳输出并进行微调。
Proximal Policy Optimization (PPO):一种流行的强化学习方法,最大化替代奖励,同时对参数施加 KL 惩罚。
Quark:使用奖励的上分位数据训练,最小化微调模型与 SFT 初始化之间的 KL 散度,同时最大化模型熵。
这些方法提供了丰富的研究基线,用于在 AlpacaFarm 中测试和比较各种 LPF 方法。
4 Validating the AlpacaFarm simulator¶
在完成模拟器定义与方法的设定后,作者对 AlpacaFarm 进行了系统性验证。
4.1 实验细节(Experimental details)¶
模型设置(Models)¶
基线模型:作者以 LLaMA 7B 为基础,通过 SFT 10k 对其进行微调。
偏好来源:从 SFT 10k 的输出中采集 模拟偏好 和 真实人类偏好(PREF 分割)。
训练流程:
对于六种参考方法(PPO 等),分别在 模拟偏好 下训练,并使用 模拟评估器 评估结果模型(M_sim)。
部分模型在真实人类偏好(phuman)下训练,评估使用 真实人类评估器 评估的模型(M_human)。
对照模型:还评估了 GPT-4、ChatGPT、Davinci001、Alpaca 7B 等标准模型。
推理设置:所有模型使用 温度 0.7 进行采样,best-of-n 采样使用 温度 1.0 以提升多样性。
人类标注(Human annotation)¶
通过 Amazon Mechanical Turk 招募了 34 名标注员,筛选出 16 名与作者标注一致性 高于 70% 的合格标注员。
每次标注任务支付 时薪 \(21**,标注成本约为 **\)3000(PREF 数据集),单个模型在 805 条指令上的评估成本为 $242。
标注任务为:给定一条指令 x 和两个响应 y0、y1,选择更优的响应。
4.2 AlpacaFarm 的端到端验证(End-to-end validation)¶
本节核心:验证 AlpacaFarm 模拟排名与人类真实排名的一致性。
图3 显示了在模拟器和真实人类评估中,不同方法的胜率排名。通过 Spearman 相关系数 0.98 表明,AlpacaFarm 模拟排名与人类排名高度一致。
结论:AlpacaFarm 能够忠实模拟人类交互过程中的排名,降低了真实人类数据的使用成本,使研究者可以在低成本环境中开发模型后再迁移至真实场景。
例外情况(Rank Mismatches)¶
SFT10k vs SFT52k:人类偏好 SFT10k(44.3%),但模拟偏好 SFT52k(39.2%)。
ChatGPT vs PPO:人类偏好 PPO(55.1%),但模拟偏好 ChatGPT(61.4%)。
尽管存在差异,但这些差异幅度较小,说明模拟器整体表现良好。
4.3 验证配对偏好组件(Validating the pairwise preferences component)¶
本节重点验证 AlpacaFarm 中模拟标注者(simulated annotators) 的行为是否接近真实人类标注者。
模拟标注者的标注一致性(Agreement with Human Annotators)¶
模拟标注者(psim-ann)与人类多数标注的一致性为 65%,与真实人类标注的一致性(66%)基本一致。
模拟标注者成本仅为人类标注的 1/25(\(12/1000 vs \)300/1000)。
噪声处理:在训练过程中引入噪声(label flip),以模拟人类标注的非一致性行为,从而更真实地反映模型训练过程。
模拟标注者复制过优化现象(Replicating Over-Optimization)¶
训练模型时,使用真实人类偏好和 AlpacaFarm 模拟偏好时,均观察到 过优化现象(模型优化奖励后性能下降)。
相比之下,使用单一 GPT-4 提示进行标注时,无过优化现象,模型性能持续提升。
结论:AlpacaFarm 的标注者通过引入标注者间变异性(inter-annotator variability),成功模拟了人类标注的动态特性。
方差分析(Variance Analysis)¶
AlpacaFarm 标注者的方差(0.26 - 0.43)与人类标注者(0.35)接近,远高于单一 GPT-4 标注者(0.1)。
结论:AlpacaFarm 的设计良好,能够模拟真实标注环境中的噪声和多样性。
4.4 验证评估协议(Validating the evaluation protocol)¶
本节验证 AlpacaFarm 的评估数据是否能代表真实用户行为。
数据来源:使用 Alpaca Demo 的真实用户交互数据(200 条指令),确保不包含隐私、毒性内容等。
评估模型:使用与图3相同的 11 个模型。
结果:AlpacaFarm 评估数据与真实用户交互数据的 胜率相关性为 r² = 0.97。
结论:AlpacaFarm 的评估数据可以作为真实用户交互的有效替代,支持在模拟环境中进行模型评估。
总结¶
本章通过三方面验证 AlpacaFarm 模拟器的有效性:
端到端验证:模拟排名与人类排名高度一致(Spearman = 0.98),证明 AlpacaFarm 可用于替代真实人类数据。
配对偏好验证:模拟标注者在标注一致性、成本、过优化现象等方面与人类标注者高度匹配。
评估协议验证:AlpacaFarm 的评估数据与真实用户行为高度相关(r² = 0.97),可作为真实评估的替代方案。
这些结果表明,AlpacaFarm 是一个低成本、高保真的模拟框架,可广泛用于研究基于人类反馈的模型训练方法。
5 Benchmarking reference methods on the AlpacaFarm¶
表2:AlpacaFarm 上基线和 LHF 方法的评估结果¶
表2展示了参考方法在 AlpacaFarm 上的评估结果,包括模拟训练和评估(Simulated Win-rate)以及使用人类反馈训练和评估(Human Win-rate)的情况。所有方法的胜负率是相对于 Davinci003 模型计算得出的。
对于未标注星号(*)的方法,左列为模拟训练和评估的胜负率,右列为使用人类反馈训练和评估的胜负率。
对于标注星号的方法,左列为模拟评估结果,右列为人类评估结果。
GPT-4 和 ChatGPT 的输出被限制为 1000 个字符以内,以与其他方法保持一致。
Quark 和 Binary Reward Conditioning 在开发中表现不佳,因此未进行人类评估。
方法 |
模拟胜负率 (%) |
人类胜负率 (%) |
|---|---|---|
GPT-4*† |
79.0±1.4 |
69.8±1.6 |
ChatGPT*† |
61.4±1.7 |
52.9±1.7 |
PPO |
46.8±1.8 |
55.1±1.7 |
DPO |
46.8±1.7 |
- |
Best-of-1024 |
45.0±1.7 |
50.7±1.8 |
Expert Iteration |
41.9±1.7 |
45.7±1.7 |
SFT 52k |
39.2±1.7 |
40.7±1.7 |
SFT 10k |
36.7±1.7 |
44.3±1.7 |
Binary FeedME |
36.6±1.7 |
37.9±1.7 |
Quark |
35.6±1.7 |
- |
Binary Reward Conditioning |
32.4±1.6 |
- |
Davinci001* |
24.4±1.5 |
32.5±1.6 |
LLaMA 7B* |
11.3±1.1 |
6.5±0.9 |
5.1 比较 LPF 方法¶
监督微调(SFT)效果显著¶
SFT 显著提升了模型的表现,将 LLaMA 7B 的模拟胜负率从 11% 提高到 37%,人类胜负率从 7% 提高到 44%。
但从 SFT 10k 到 SFT 52k 的提升不大,说明增加数据量对性能的提升有限。
PPO 在 LPF 中表现最佳¶
PPO 在模拟和人类反馈中均表现优异,模拟胜负率为 47%,人类胜负率为 55%。
PPO 在人类反馈中略优于 ChatGPT,这可能与 ChatGPT 的输出长度被限制有关。
Best-of-n 性能突出¶
Best-of-n 采样方法在 PPO 之外表现最佳,说明奖励模型的学习信号是有效的。
该方法也表明 LPF 方法可以从奖励模型中获益。
Expert Iteration 和 Quark 表现较弱¶
Expert Iteration 与 Best-of-n 相比落后 3-6%,说明从 Best-of-n 的改进中获益并非易事。
Quark 的训练过程中样本奖励有所提升,但整体表现不如 SFT 基线。
直接从成对反馈学习的方法表现不佳¶
Binary Reward Conditioning 和 Binary FeedME 未能超过 SFT 10k 基线,表明构建替代奖励模型可能是 LPF 的关键。
计算成本¶
大多数方法在单台 8×A100 机器上训练时间少于 2 小时。
Best-of-n 和 Expert Iteration 的计算成本较高,主要在于解码大量样本。
5.2 模型输出分析¶
PPO 和 Best-of-n 在模拟和人类反馈中均表现出明显提升。为了理解这些提升的原因,我们分析了模型输出的变化。
PPO 和 Best-of-n 的输出长度显著增加。例如,SFT 10k 的平均输出长度为 278 个字符,Best-of-16 为 570 个字符,PPO 为 637 个 token。
表 3 展示了 PPO 训练前后输出的示例,显示输出内容更详细、更具解释性。
5.3 使用 AlpacaFarm 直接训练用于人类部署的模型¶
AlpacaFarm 的主要目标是提供一个模拟器,用于开发最终在人类反馈上训练的模型。
我们比较了在 AlpacaFarm 上使用模拟偏好训练的 PPO 模型与使用 GPT-4 模拟器训练的 PPO 模型在人类评估中的表现。
结果显示,使用 AlpacaFarm 训练的模型在人类评估中表现较差(43%),而使用 GPT-4 训练的模型表现更好(50%)。
与初始 SFT 模型(44%)和人类训练的 PPO(55%)相比,模拟训练的模型存在约 5% 的性能差距。
这些结果表明,模拟器设计中存在“真实性-性能”的权衡:
更真实的模拟器会导致模型过度优化,从而训练效果变差。
AlpacaFarm 的标准成对评估器适合方法开发和选择,但在直接部署模型时,使用一致性更高的模拟器(如 GPT-4)能显著提升真实评估表现。
7 Limitations and future directions¶
本节总结了 AlpacaFarm 模拟器的当前限制,并提出了未来的研究方向。整体上,AlpacaFarm 在模拟人类反馈方面展现出了实用性和有效性,但仍存在一些需要关注的问题。
Validation(验证)¶
尽管第4节验证了 AlpacaFarm 的有效性,但仍存在一些验证设置上的限制:
指令的简单性:所使用的指令(包括来自真实世界的示例)相对简单,并且是单轮的。这可能无法全面反映复杂的实际应用场景。
模型基础一致:所有微调模型均以 LLaMA 7B 为基础模型,缺乏在不同基础模型上的验证,可能限制了 AlpacaFarm 的通用性。
人类验证的局限性:人类验证基于13名众包标注者,数据量较小,可能无法代表更广泛的人类偏好,并且可能存在偏见,例如偏好更长的输出(如第C.2节所述)。
尽管这些限制不会显著削弱 AlpacaFarm 的实用性,但作者建议用户在使用任何模拟器时保持警惕,并期待随着更多数据集和基础模型的出现,进一步验证 AlpacaFarm。
此外,成对比较的评估方法即使使用人类标注者,也可能难以深入理解模型之间的差异。
Assumption of an oracle LLM(对“全知大语言模型”的假设)¶
AlpacaFarm 假设可以访问一个比被研究模型更强大的“全知大语言模型”(oracle LLM),用于近似人类反馈。这种假设在研究环境中可能成立,但在开发最先进的模型时并不现实。
作者认为,未来的一个重要方向是研究使用同一模型进行模拟和学习的可能性,这可能带来更实际和有效的学习方法。
AlpacaFarm for fine-grained development(用于细粒度开发的 AlpacaFarm)¶
在第4节中,AlpacaFarm 表现出在模型选择和模拟过优化等行为上的有效性。然而,作者发现:
学习算法的超参数设置不同:与使用真实人类反馈训练相比,模拟反馈下的学习算法需要不同的超参数设置。例如,由于替代奖励模型的值尺度变化,RLHF 中的 KL 正则化系数范围也发生了变化。
这表明,即使使用模拟反馈,也需要对训练过程中的超参数进行细致调整,这对实际应用提出了更高要求。
Simulated annotators(模拟标注者)¶
模拟标注者是 AlpacaFarm 的核心组成部分。第4.3节和附录C表明:
与人类标注者的一致性较高:模拟标注者与人类标注者在偏好上高度一致,且表现出类似偏见,如偏好更长的输出或列表形式。
存在特定偏见:例如,模拟标注者倾向于优先选择提示中先出现的输出,或偏好与模拟器相同模型生成的输出。
缓解措施:通过随机化输出顺序、统一训练数据等方式,作者试图减少这些偏见,但仍可能存在未识别的其他偏见。
如果需要更高质量的自动标注器,可以参考 AlpacaEval 工具。
Future directions(未来方向)¶
作者指出,AlpacaFarm 显著降低了基于成对反馈的学习方法的研究与开发成本与迭代时间。此外:
蓝本作用:AlpacaFarm 为构建其他需要人类监督的 AI 研究模拟器提供了蓝图。
扩展方向:未来可以将这种模拟方法扩展至其他领域数据,以及不同形式的人类反馈学习方法,如评分反馈、文本反馈等。
总结来看,AlpacaFarm 是一个有用的工具,但仍需在模型多样性、标注者偏见、模拟与现实一致性等方面进一步改进和拓展。
Acknowledgments and Disclosure of Funding¶
本部分主要列出了研究过程中提供支持的机构和个人,并披露了相关的资助来源。
重点内容包括:
计算资源支持:作者感谢 斯坦福大学基础模型研究中心(CRFM)、斯坦福大学人文与人工智能中心(Stanford HAI) 和 Stability AI 提供的计算支持。这一部分强调了计算资源在研究中的重要性。
数据收集支持:数据收集工作得到了 天桥与Chirs Chen研究所(Tianqiao & Chrissy Chen Institute) 和 开放慈善基金(Open Philanthropy) 的资助。说明了数据收集环节的资金来源,体现了研究的多方面支持。
个人资助情况:
XL(作者之一)获得了 斯坦福大学研究生奖学金(Stanford Graduate Fellowship) 的支持。
RT(作者之一)获得了 美国国家科学基金会(NSF)GRFP奖学金(编号 DGE 1656518)。
YD(作者之一)获得了 Knights-Hennessy奖学金。
不重要内容(如重复描述等)已适当精简。整体上,该章节对研究的资助来源进行了全面且清晰的说明,有助于读者了解研究背景和资源支持情况。
Appendix A Reference LPF methods on AlpacaFarm¶
本附录详细描述了在 AlpacaFarm 框架中所采用的 人类反馈学习方法(Learning from Human Feedback, LPF),并提供了对这些方法的自定义修改。更多关于 超参数调优、实验细节和进一步消融实验 的内容,请参见 附录 B
一、API 基线方法¶
在 人类 和 模拟反馈流程 中,我们评估了以下来自 OpenAI API 的方法:
GPT-4
ChatGPT
Davinci001
Davinci003(作为基线模型)
所有模型输出均以 温度 0.7 和 top-p 1.0 进行采样。
对于文本模型,我们使用与 AlpacaFarm 中其他参考方法 相同的提示词。
对于对话模型(ChatGPT、Davinci003),我们做了两点修改:
这些模型需要 对话格式的提示,而其他模型使用的是 纯文本格式。
这些模型生成的输出 长度远超 其他模型(限制为 300 个 token),因此我们在 系统提示中加入长度限制(ChatGPT 限制为 1000 字符,GPT-4 限制为 500 字符),以减少输出长度,同时保持与原始提示词效果相近。
二、直接从成对反馈中学习的方法(Methods that directly learn from pairwise feedback)¶
这些方法 不引入替代奖励模型,而是 直接使用成对反馈数据 进行训练。
1. Binary FeedME¶
FeedME 起源于 OpenAI 的方法,通过监督微调,仅使用人类评分 7/7 的生成样本。
我们将其适配为 成对反馈设置(pairwise feedback setting),称为 Binary FeedME。
该方法对每个偏好对中的 首选响应(chosen response) 进行监督微调。
2. Binary Reward Conditioning¶
基于 可控生成中的条件化方法,我们提出 Binary Reward Conditioning。
通过在输入中添加 正/负控制标记,对 SFT 模型进行微调。
对于每个数据 (x, y₀, y₁, z),我们将 [x, y_z] 与 正标记 关联,[x, y_{1−z}] 与 负标记 关联,从而构建一个 两倍大小的演示数据集。
测试时,模型在 正标记条件下 生成输出。
3. Direct Preference Optimization (DPO)¶
DPO 通过最大化 Bradley–Terry 模型下的偏好对数似然 来优化。
该方法 不显式构建奖励模型,而是通过 当前策略 隐式定义奖励模型。
目标函数如下:
该方法在实验中表现良好,且计算效率较高。
三、优化替代奖励函数的方法(Methods that optimize a surrogate reward function)¶
这类方法首先 构建一个替代奖励模型(surrogate reward model),再基于该模型进行训练或推理。
替代奖励模型的训练目标¶
替代奖励模型 \( \hat{R}_\phi \) 通过最大化成对反馈下的对数似然进行训练:
该模型可能会导致 过度优化(over-optimization),即模型学会利用奖励模型,而非实现真实奖励。
下面介绍四种基于替代奖励模型的方法:
1. Best-of-n Sampling¶
也称为 重排序(re-ranking)。
在输入 x 下,从 SFT 模型中采样 n 个独立响应,然后选择 替代奖励最大 的响应。
优点是简单、效果不错,但 计算成本高,常用于推理阶段。
2. Expert Iteration¶
两步方法:
使用 Best-of-n 采样生成高质量样本。
使用这些样本对 SFT 模型进行微调。
相较于多轮迭代,我们只进行 一轮专家迭代。
有关多轮迭代的实验结果,请参见 附录 B
3. Proximal Policy Optimization (PPO)¶
PPO 是一种广泛应用的 强化学习(RL)算法,用于训练 InstructGPT 和 ChatGPT。
目标函数为:
每一步包括:从当前策略中采样,并使用 重要性采样和剪切 进行梯度更新。
该方法在训练阶段表现良好,但实现复杂度较高。
4. Quark¶
受 奖励条件化(reward conditioning) 启发,Quark 通过分组训练 和 正则化 来改进可控生成。
与 Binary Reward Conditioning 不同,Quark 将样本按奖励值划分为多个组,加入 KL 散度 和 熵正则化,并在 多轮训练中重复。
初步分析表明,仅训练最高奖励组(top-quantile) 的方法效果优于训练所有组的方法。
Appendix B Details on methods implementation and hyperparameters¶
B.1 PPO(近端策略优化)¶
本节介绍了在对语言模型进行微调时,对PPO的实现细节和超参数设置所做的调整。
主要修改:
优势归一化方式:
传统实现中会对每个小批量(minibatch)进行优势归一化。
但作者发现这种方法在小批量情况下会导致训练不稳定。
因此改为对每个PPO步骤中获得的整个rollout批次进行优势归一化。
价值模型初始化:
不再使用SFT(监督微调)模型初始化价值模型,而是使用奖励模型进行初始化。
这种做法更符合近期实践,且实验表明基于奖励模型初始化的效果优于基于SFT模型的效果。
超参数设置:
批次大小:每个PPO步骤使用512的批次,其中每个梯度更新使用256个rollout,进行2个epoch。
学习率:峰值为10⁻⁵,并在整个训练过程中线性衰减到0。
梯度裁剪:使用欧几里得范数剪切,阈值为1。
训练步数:对无标签数据进行10次完整训练,共390个PPO步骤。
GAE参数:λ 和 γ 均设为1。
KL正则化系数:使用固定值(非自适应),人为调参后确定:人类偏好用0.02,模拟数据用0.002。
早停与奖励尺度:KL正则化系数的选择依赖于早停策略和替代奖励的尺度。
性能观察:
性能通常在训练初期就达到峰值(见图5(c))。
B.2 Quark¶
本节描述了Quark方法的重新实现和关键修改。
主要修改:
Rollout池的处理方式:
原始Quark会不断积累rollout并存入池中,训练过程中池会持续增长。
作者发现这种方式会导致训练过程中的计算开销逐渐增加,因为每次生成新rollout后都要重新排序。
因此改为在每次生成新batch的rollout后,丢弃旧的rollout,即将rollout池重置。
这样可以保持计算开销一致且可预测。
训练数据的选择策略:
原本Quark基于多个bins(分组)进行训练,但作者发现这样会影响奖励优化的效率。
改为仅使用奖励最高的bin(即论文中提到的“最佳分位”变体)进行训练。
初步实验表明,该变体在简单情感任务中可能损失一些困惑度(perplexity),但可通过增大KL正则化系数进行补偿。
熵惩罚的使用:
原始Quark中引入了熵惩罚,但作者发现这对指令跟随任务并无明显帮助。
即使是小的熵惩罚项,也会对文本生成的流畅性产生显著负面影响。
超参数设置:
KL正则化系数:0.05
学习率:峰值为3×10⁻⁶,线性衰减到0
批次大小:每个Quark步骤使用512的rollout批次,每个epoch使用256的梯度更新批次,共2个epoch
梯度裁剪:阈值为1
训练步数:同样进行10轮完整训练,共390步
B.3 直接偏好优化(DPO)¶
本节介绍了在噪声模拟偏好数据上运行DPO时的设置。
关键参数设置:
β参数:设为0.1,这是偏好优化中的核心参数。
训练轮数:1111个epoch(注意:这里可能为笔误,正常应为11或111个epoch)
批次大小:64
学习率:前3%的训练时间进行线性预热(warm-up),达到峰值1e-5,之后线性衰减到0
说明:
该设置用于验证DPO在模拟偏好数据(含噪声)下的性能。
总结¶
本附录详细描述了PPO、Quark和DPO三种方法在实现过程中的关键修改和超参数设置。每个方法都做了适应性调整以提升训练稳定性、效率和最终效果。PPO和Quark在rollout池管理和优势归一化方面有显著优化,DPO则在学习率调度和β参数设置上进行了针对性配置。这些细节对实验的可复现性和结果的可靠性至关重要。
Appendix C Pairwise preference simulation¶
C.1 模拟标注者的详细信息¶
本节介绍了用于模拟标注者的一系列设计与实现细节,所有标注者均通过 OpenAI API 生成标注结果。标注者的设计基于 Alpaca 数据集和 self-instruct 框架,并通过 GitHub 仓库 https://github.com/tatsu-lab/alpaca_farm 提供了所有的提示模板。
随机顺序¶
为了减少标注者对“第一输出”的偏好,对每个标注者而言,两个输出的顺序是随机化的。实验证明随机化对缓解模型偏向性非常重要。
带与不带输入的提示¶
部分指令包含输入,部分不包含。为此,每个标注者使用两种提示:一种用于有输入的指令,一种用于无输入的指令。两者的区别仅在于上下文示例是否包含输入。
GPT-4 的批处理¶
由于 GPT-4 处理长提示成本较高,因此采用 批处理 来提高效率。每个批处理最大包含 5 个标注任务,实验中发现最多可处理 20 个任务而不显著影响性能。为提升标注性能,还采用带索引的格式和上下文示例来辅助标注。
提升 ChatGPT 的解析性¶
ChatGPT 更难用作模拟标注者,常出现无法解析结果的问题。为此,作者采用两种技巧:
对关键词赋权:对“Neither”、“Both”等干扰词施加负权,对目标输出词施加正权,以引导输出方向。
要求生成 JSON 结果:要求 ChatGPT 输出包含解释(Chain of Thought)和布尔偏好的 JSON 格式,便于解析。
C.2 AlpacaFarm 的模拟标注者池¶
评估标注者池(p_sim^eval)¶
为了模拟人类标注者的偏差与方差,作者构建了13 个不同阶段的模拟标注者,其差异在于:
模型类型:5 个基于 GPT-4,4 个基于 ChatGPT,4 个基于 Davinci003。
上下文示例数量:不同示例数量影响标注结果。
提示格式:不同批大小、输出格式(JSON vs 纯文本)等。
偏好设定:2 个 GPT-4 标注者被设定为偏好“长输出”和“短输出”。
采样方式:所有标注者使用温度 1.0 的随机采样,以模拟人类的不一致性。
训练标注者池(p_sim^ann)¶
训练使用的标注者与评估标注者相同,但增加了25% 的随机翻转概率。通过将 p_sim^eval 与一个独立的伯努利随机变量(概率为 0.5)混合,只需标注一半输出即可达到训练目标,成本和时间降低一半。
GPT-4 标注者¶
GPT-4 标注者采用批量提示(批大小为 5),且使用温度 0,即确定性标注,以确保一致性。
C.3 额外结果分析¶
模拟标注者的偏差与方差(图 7)¶
图 7 展示了模拟标注者的偏差(y 轴)与方差(x 轴)。相较于人类标注者(基准点),单个模拟标注者方差较低(< 0.2),而人类方差约为 0.35。通过使用标注者池(绿色点)和加入噪声(橙色点),模拟结果更接近人类的偏差和方差。作者认为,这种设计有助于模拟人类的过优化行为。
标注者方差的主要来源(图 8)¶
图 8 为标注者之间的一致性热力图。可以看出,不同模型(GPT-4、ChatGPT、Davinci003)之间的标注者差异显著,是模拟标注者方差的主要来源。标注者池在保持低偏差的同时表现出高方差,符合人类行为特征。
模拟与人类偏好的一致性(图 9)¶
图 9 显示,人类与模拟标注者都偏好较长的输出和包含列表的输出。具体来说,人类选择长输出和含列表输出的比例分别为 62% 和 69%,而模拟标注者分别为 64% 和 63%。这表明,模拟标注者较好地捕捉了人类的风格偏好。
总结¶
本节详细介绍了 AlpacaFarm 中用于模拟标注者的实现方法,并通过多个维度(模型选择、提示设计、采样方式、偏差与方差)验证了其对人类行为的拟合效果。结果显示,模拟标注者在偏好一致性、方差和偏差等方面表现良好,尤其在使用标注者池和加入噪声后,能够更真实地模拟人类标注行为,为基于人类反馈的模型训练提供了可靠的实验环境。
Appendix D Details on human data collection¶
Qualification(资格审核)¶
在本研究中,我们通过 25 个资格审核示例 对标注人员进行资格审核。这些例子由一个 OPT 6B 模型 生成,该模型在本项目早期开发阶段被研究使用。
论文的五位学生作者共同标注了一个共享的 成对偏好数据集。我们从该共享集中挑选了 25 个问题,其中大多数作者对正确标注达成了一致意见。我们使用这25个问题作为资格测试,并根据标注人员与学生作者之间的一致性,选出了 一致性最高的16位标注人员。
重点说明:我们对资格审核阶段与正式标注阶段的标注人员支付了 相同的报酬,以确保公平。
在实际标注过程中,我们还将每位标注人员的偏好与 GPT-4 的偏好进行了比较。我们发现有一位标注人员与 GPT-4 的一致性仅为 约50%,明显低于其他标注人员,因此我们 中止了与其合作,并删除了其标注数据。
Annotation guideline(标注指南)¶
我们的标注指南和标注界面分别显示在 图10 和 图11 中(由于无法展示图片,建议查阅原文获取视觉信息)。
在标注过程中,我们发现有些成对样本之间的差异非常微小,例如 标点符号不同 或 编辑距离极小。因此,我们指导标注人员在这种情况下,如果差异非常小,可以选择 “略微更好”或“略微更差” 的标签。
重点说明:在收集的偏好数据中,大约 18% 的标注为“略微更好”。在我们的 LPF(Learn from Preference) 实验中,我们将这些“略微更好”的选项与普通偏好标签 合并处理(二值化)。
但我们仍然 发布了更细粒度的标签作为资源,并将其进一步研究留给了未来的工作。
总结:本附录详细介绍了人类数据收集的流程,包括标注人员的筛选机制、标注指南的设计以及对差异极小样本的处理方式。强调了标注质量控制的重要性,并展示了数据处理中的方法与权衡。
Appendix E Additional results¶
E.1 模拟标注者中的标签噪声消融分析(Label noise ablations for simulated annotators)¶
本节研究了在模拟数据中影响模型“过度优化”(overoptimization)的关键因素,特别是标签噪声(label noise)和模拟标注者随机性(randomization across annotators)之间的关系。
重点内容:
实验设计:
作者对比了三种不同的模拟标注策略:psimGPT-4:使用 GPT-4 提示生成的固定标签,仅添加标签噪声。psimeval:使用模拟标注者生成的标签,但不加标签噪声。psimann:使用模拟标注者并添加标签噪声。
核心结论:
如图12所示,添加标签噪声是引发“过度优化”的关键因素。未添加标签噪声的两个方法(psimGPT-4和psimeval)的“胜率”(win-rate)随着样本数的增加而持续上升,表明没有出现过优化现象。而添加了标签噪声的方法(psimann)则表现出明显的“过优化”现象。标签噪声比例的影响:
如图13所示,作者测试了不同比例的标签噪声(0%、17.5%、25%、35%),发现25% 是最小能引发过优化的比例。随着标签噪声比例的增加,过优化现象也呈现单调递增趋势。
E.2 理解计算成本(Understanding computational cost)¶
本节讨论了不同方法的计算成本,主要关注训练时间和推理时间。
重点内容:
训练时间对比:
监督微调(SFT)方法(如 Binary Reward Conditioning 和 Binary FeedME)训练速度快,10k 条指令训练时间通常少于一小时。
PPO(策略梯度)方法:训练在80-40步时表现最佳,仅需不到2小时的计算资源。
DPO(直接偏好优化)方法:在半台设备上训练一轮(1 epoch)不到3小时。
推理成本:
Best-of-n 采样:推理成本高,但无训练成本。作者发现 n=16 是最优值。这意味着推理时需进行约16倍的计算。
Expert Iteration 方法:需要对未标注数据进行 Best-of-16 样本生成,耗时约4小时。
总结: 虽然某些方法在推理时成本较高,但整体来看这些方法在现代计算资源下是可行的。
E.3 模型输出的附加分析(Additional analysis of model outputs)¶
本节通过定性分析和输出长度比较,探讨了不同训练方法对模型输出内容和长度的影响。
重点内容:
输出长度变化:
对比方法: 作者对比了 SFT 10k、PPO_human、PPO_sim 等方法的输出示例,发现经过 LPF(Learned Preference Fine-tuning)训练后,模型输出通常变得更长。
数据支持: 在表6和表7中,作者展示了模型输出的平均字符数。结果显示,不论是基于真实人类偏好还是模拟偏好训练的 LPF 模型,输出长度普遍增加。
输出内容质量:
输出变长:输出更详细,可能更符合人类偏好(如更长的回答更可能被选中)。
潜在问题: 但输出中也存在幻觉(hallucinations),例如对“谁建立柏林?”的问题,PPO_sim 模型给出了错误的历史叙述。
总结: 虽然 LPF 方法可以提高输出长度和某些人类偏好指标,但其是否提升了输出的准确性和真实性仍需进一步验证。
总体总结¶
本附录重点探讨了:
标签噪声是引发模型“过优化”的关键因素,模拟标注者的随机性作用较小。
不同方法在计算成本上的差异,部分方法(如 SFT、DPO)效率高,而 Best-of-n 和 Expert Iteration 推理成本较高。
模型输出在长度和内容上的变化趋势,特别是在 LPF 训练后输出更长,但可能伴随幻觉问题。
这些分析为理解模型行为和优化方法提供了实证支持。
Appendix F Additional Analysis on Training and Evaluation Instructions¶
本节提供了对 Alpaca 训练指令分布和 AlpacaFarm 评估指令分布的进一步分析。具体内容如下:
图 14 展示了 52,000 条 Alpaca 训练指令的分布情况。
图 15 展示了 805 条 AlpacaFarm 评估指令的分布情况。
在图表中:
内层显示了指令的动词分布(root verb distribution)。
外层显示了指令的直接主语分布(direct subject distribution)。
重点内容:¶
研究发现,训练分布与评估分布都覆盖了多样化的指令类型,并且这两个分布在高层次上是一致的(match at a high level)。这表明 AlpacaFarm 评估指令的设计在一定程度上能够代表 Alpaca 训练数据中所涵盖的指令范围。
精简内容:¶
图表的生成时间为 2024 年 1 月 8 日,并通过 LaTeX 工具生成,末尾附有工具标识。这些技术细节对于理解数据的呈现方式有帮助,但并非本节的核心内容。