2505.00675_❇️Rethinking Memory in AI: Taxonomy, Operations, Topics, and Future Directions¶
引用: 13(2025-08-29)
组织:
1The Chinese University of Hong Kong
2The University of Edinburgh(爱丁堡大学)
3HKUST(香港科技大学)
4Poisson Lab, CSI, Huawei UK R&D Ltd.
GitHub: https://github.com/Elvin-Yiming-Du/Survey_Memory_in_AI
总结¶
3. 主要发现与结论¶
本文的核心贡献在于提出并验证了一个全新的、以原子操作为中心的AI记忆框架。其主要发现和结论可概括为以下几点:
记忆框架的清晰化:
记忆类型:将AI记忆明确划分为参数化记忆(存储在模型权重中的知识)和上下文记忆(外部存储的显式信息)。
原子操作:定义了六大核心操作,分为管理类(巩固、索引、更新、遗忘)和利用类(检索、压缩)。
研究主题的深度解构:
长时记忆:研究集中在管理、利用和个性化上。论文发现,当前存在“检索-生成鸿沟”,即模型能高精度地检索到相关记忆,但在基于这些记忆生成高质量、连贯的回复时却表现不佳。这揭示了记忆利用环节的瓶颈。
长上下文:主要研究两大方面:参数化效率(如KV缓存优化)和上下文利用(如检索和压缩)。核心矛盾在于效率与表达能力的权衡,以及“迷失在中间”的信息定位难题。
参数化记忆修改:涵盖编辑、遗忘和持续学习。研究发现,当前方法在小模型上效果不错,但向大模型和批量/序列操作扩展时面临巨大挑战。同时,遗忘的基准(如TOFU)可能过于简单,无法反映真实挑战。
多源记忆:聚焦于跨文本整合(推理与冲突)和多模态协调(融合与检索)。主要挑战来自异质信息的冲突、冗余和缺乏来源归因,尤其是在处理多模态和动态信息时。
实践与未来方向: 文章总结了当前记忆在应用、产品和工具层面的实践,并从主题特定方向(如设计动态基准、解决检索-生成鸿沟)和更广阔的视角(如生物启发的记忆、多智能体系统中的记忆、记忆安全)提出了未来研究路线图。
4. 新颖概念的通俗解释¶
参数化记忆 vs. 上下文记忆:可以简单理解为“懂”和“知道”。参数化记忆是模型通过训练“内化”的知识(如“法国首都是巴黎”),无需查询,张口就来,但难以精确修改。上下文记忆是模型临时“查阅”的外部资料(如对话历史、上传的文档),可以随时增删,但需要额外步骤去“找”。
原子操作:这是构建AI记忆系统的“基本动作”。就像我们管理电脑文件(巩固=保存,索引=建立目录,更新=修改内容,遗忘=删除文件,检索=搜索文件,压缩=打包压缩),这些原子操作共同定义了记忆的完整生命周期。
检索-生成鸿沟:就像一个超级搜索引擎(检索能力强)给你找到了100篇最相关的资料(检索准确率高),但让你用这些资料写一篇深度分析报告(生成)时,你反而因为信息太多、太杂而写不好。模型目前就面临这个困境。
5. 优缺点与客观评价¶
优点:
框架创新性强: 首次从“原子操作”和“记忆表示”两个底层维度构建了一个统一、精细的AI记忆研究框架,为理解、设计和比较不同记忆系统提供了强大的理论工具。
系统性与全面性: 通过大规模文献检索和量化分析,将繁杂的记忆研究系统性地归入四个主题,并详细梳理了每个主题下的核心方法、数据集和挑战,覆盖面广。
分析深入且有洞见: 不仅仅是对文献的罗列,而是通过RCI、性能对比图等定量分析,揭示了“检索-生成鸿沟”、“效率与性能的权衡”等深层问题,极具启发性。
实用性强: 提供了详尽的论文列表、基准数据集、工具和应用实例(附录),对于研究人员和开发者都具有很高的参考价值。
缺点/局限性:
框架的静态性: 虽然提出了动态操作,但整个框架在描述时仍偏向于静态分类。对于不同操作之间如何相互影响、如何协同工作(例如,遗忘如何影响检索的精度),探讨得相对较少。
时间范围局限: 数据主要收集到2025年4月,对于之后快速发展的AI领域(特别是多模态和智能体方向)的最新进展可能无法完全覆盖。
技术细节深度不一: 为了保持宏观视角,对部分具体技术的深度剖析有所取舍。例如,在“长上下文”部分,对KV缓存优化的各种复杂技术细节讨论得相对简略。
6. 可能的后续研究方向¶
基于本文的分析,可以预见以下几个极具潜力的未来研究方向:
动态、统一的记忆基准测试: 开发能够同时评估多种记忆操作(如巩固、更新、遗忘)和多种记忆类型(参数化、非结构化、结构化)在长期动态交互中表现的基准,而不仅仅是静态的问答准确率。
弥合“检索-生成”鸿沟:探索新的机制,使模型在获得检索结果后,能进行更深层次的推理、筛选和整合,而不是简单地拼接信息。这可能涉及引入更精细的“记忆注意力”机制或“记忆推理”模块。
可扩展的参数化记忆修改:研究适用于百亿甚至千亿参数大模型的、低开销、高精度、支持大量序列操作的知识编辑与遗忘方法。这需要从根本上突破当前“定位-编辑”范式的扩展性瓶颈。
冲突感知的多源记忆融合:开发能够识别、归因并解决来自不同源头(参数 vs. 上下文,结构化 vs. 非结构化)记忆冲突的智能系统。重点在于建立“可信度”或“置信度”机制,让模型在不确定时能主动质疑或寻求更多证据。
生物启发的记忆架构:借鉴人类大脑的互补学习系统、记忆再巩固、分层记忆(K-Line理论) 等机制,设计出更鲁棒、更高效、更能平衡稳定性与可塑性的新一代AI记忆架构。
记忆安全与伦理:深入研究针对记忆操作的恶意攻击(如数据投毒、隐私窃取)以及系统性的健忘策略,确保AI系统既能记住必要的用户信息,又能可靠地忘记敏感或有害内容,这对于负责任地部署AI至关重要。
总结2¶
总结
总结
里面有各种表格&图片,把记忆相关的论文分门别类的列出来❇️❇️❇️
简介
本文是对记忆相关论文的综述
GitHub 上有收集到的相关论文❇️
后面可以按图索骥了
记忆不仅是存储,更是推理、规划与适应的关键使能者
不同类型的系统(知识型、用户型、任务型、多模态)对记忆的需求各不相同;
贡献
收集并标注了超过3万篇论文,使用基于GPT的筛选流程保留3,923篇高相关性论文
统一的分类框架
记忆分为两种形式。
参数记忆(Parametric Memory):知识隐式地编码在模型参数中
上下文记忆(Contextual Memory):外部信息显式存储,可结构化或非结构化
Unstructured Contextual Memory(无结构上下文记忆)
定义:一种通用的记忆系统,可以跨多种输入(如文本、图像、音频、视频)存储和检索信息
功能:支持将推理过程与感知信号结合,集成多模态上下文
Structured Contextual Memory(结构化上下文记忆)
定义:以预定义、可解释形式组织的记忆,如知识图、关系表或本体(ontologies)。
功能:支持符号推理和精确查询,常与预训练语言模型的关联能力互补。
六个基本的记忆操作
Consolidation(巩固):将短期记忆转化为长期记忆。
Updating(更新):根据新信息更新已有记忆。
Indexing(索引):为记忆建立索引,以便快速检索。
Forgetting(遗忘):选择性地删除或弱化不再相关的信息。
Retrieval(检索):从记忆中提取相关信息。
Compression(压缩):对记忆进行压缩,以提高存储效率或响应速度。
管理(Management):
整合(Consolidation):将新知识整合进持久记忆。
索引(Indexing):组织记忆以便检索。
分为三种范式
graph-based: 基于图的方法:如HippoRAG,构建轻量级知识图谱来显式揭示不同知识片段间的联系。
signal-enhanced: 信号增强的方法:如LongMemEval,用时间戳、事实内容和摘要来增强记忆键。
timeline-based approaches: 基于时间线的方法:如Theanine,沿着演化的时间和因果链组织记忆,支持基于相关性和时间线的检索,实现终身和动态个性化。
更新(Updating):根据新输入更新记忆
内在更新 (Intrinsic Updating):通过内部机制更新,无外部反馈。包括选择性编辑删除过时信息、递归摘要压缩对话历史、记忆混合与精炼合并过去和现在的表征、基于证据检索和验证的自我反思式记忆演化。
外在更新 (Extrinsic Updating):依赖外部信号(特别是用户反馈)更新。如存储用户修正到记忆中以实现持续改进,而无需重新训练。
遗忘(Forgetting):删除过时或错误的内容
自然遗忘:遵循艾宾浩斯遗忘曲线,记忆痕迹随时间逐渐衰减
主动遗忘:故意从记忆系统中移除特定信息(如出于隐私、安全、合规原因)
利用(Utilization):
检索(Retrieval):访问相关记忆。
以查询为中心:改进查询 formulation 和适应(如FLARE中的前向查询重写,IterCQR中的迭代精炼)
以记忆为中心:增强记忆候选的组织和排序(如更好的索引策略,重排序方法)
以事件为中心:基于时间和因果结构检索记忆(如LoCoMo, CC, MSC)
压缩(Compression):缩减记忆规模同时保留关键信息
Pre-input compression(输入前压缩):用于未使用检索的长上下文模型
Post-retrieval compression(检索后压缩):减少检索到的内容
记忆整合 (Memory Integration):
选择性地将检索到的记忆与模型上下文结合,以在推理过程中实现连贯推理或决策。
整合可能跨越多个记忆源和模态。
记忆接地生成 (Memory Grounded Generation):利用已整合的检索记忆内容来指导响应生成
自我反思推理:检索自我生成或结构化的记忆轨迹来指导中间推理步骤,增强解码过程中的多跳推理(如MoT, StructRAG)。
反馈引导修正:利用反馈记忆或记忆信息线索来约束生成,防止重复错误和提高输出鲁棒性(如MemoRAG, Repair)。
上下文对齐的长期生成:将压缩或提取的记忆摘要整合到生成过程中,以在长对话或长文档中保持连贯性(如COMEDY, MemoChat, ReadAgent)。
个性化 (Personalization)
模型级适应 (Model-Level Adaptation)
通过微调或轻量级更新将用户偏好编码到模型参数中
外部记忆增强 (External Memory Augmentation)
在推理时从外部记忆中检索用户特定信息来个性化LLM
局限
评估局限
当前长期记忆的评估受限于静态假设。
记忆操作评估不足
当前评估主要关注检索准确性和生成质量,但很大程度上忽略了记忆使用的过程方面(如巩固、更新、遗忘、选择性保留)
Parametric Memory Modification(参数化记忆修改)
Editing(编辑): 对模型参数进行局部修改,无需完全重新训练模型。
Unlearning(遗忘/反学习): 选择性移除模型中不需要的或敏感的信息。
Continual Learning(持续学习): 逐步吸收新知识,同时防止对旧知识的“灾难性遗忘”。
Practice
Applications(应用场景)
知识中心型系统(Knowledge-centric systems)
借助参数化记忆(parametric memory)将通用知识编码进模型权重中
用户中心型系统(User-centric systems)
依赖情境记忆(contextual memory)建模用户偏好和行为历史,实现个性化对话和自适应教学。
这类系统需要持续更新记忆以适应用户的动态需求。
任务导向型系统(Task-oriented agents)
使用结构化记忆(如键值存储、工作流图)来维护对话连续性,并支持长期推理
如项目管理或虚拟助手场景。
多模态系统(Multi-modal systems)
融合语言、视觉、音频等模态的参数化记忆和情境记忆
在自动驾驶和医疗决策等复杂环境中实现连贯交互
Products(产品应用)
用户中心型产品(User-centric products)
如 Replika(AI伴侣)、Amazon 推荐系统
利用持久化用户模型实现情感连续性和个性化推荐
任务导向型产品(Task-oriented products)
如 ChatGPT、Grok、GitHub Copilot、Coze
通过结构化记忆(如对话历史和任务表示)支持多轮对话和长期任务规划
Tools(工具与框架)
基础组件(Components):
包括向量数据库(如 FAISS)、图数据库(如 Neo4j)和大语言模型(如 Llama、GPT-4)。
检索机制(如 BM25、Contriever、OpenAI Embeddings)用于语义访问外部记忆。
重点:这些组件是构建记忆能力的基础,如语义相似性搜索、长期上下文理解等。
模块化框架(Frameworks):
提供可配置的记忆操作接口,如 LlamaIndex、LangChain、Graphiti、Letta 等。
重点:这些框架将复杂的记忆处理流程模块化,支持开发者构建多模态、持久化、可更新的记忆模块。
记忆层系统(Memory Layer Systems):
作为“记忆服务层”,提供调度、持久化和生命周期管理,例如 Mem0、Zep、Memary、Memobase。
重点:这类系统注重时间一致性、会话/话题索引和高效记忆检索,通常结合符号与亚符号记忆表示。
核心研究方向
长期记忆(Long-Term Memory)
关注多会话系统中的记忆管理与个性化,以及检索增强生成(RAG)、个性化代理和问答系统
长上下文记忆(Long-Context Memory)
涉及参数效率和上下文利用效果,如“KV缓存丢弃”与长上下文压缩
参数记忆修改(Parametric Memory Modification)
包括模型编辑、遗忘、持续学习等内存内部操作
多源记忆(Multi-Source Memory)
强调跨异构文本源和多模态输入的记忆整合
Open Challenges and Future Directions
专题方向
统一评估的必要性
长上下文处理:效率与表达性的平衡
参数化记忆修改的研究
多源整合:一致性、压缩与协调
更广泛的视角
时空记忆
参数知识的检索
终身学习
受生物学启发的记忆设计
K-Line理论与层级记忆
统一的记忆表示
多智能体系统中的记忆
记忆威胁与安全性
Abstract¶
Memory is a fundamental component of AI systems, underpinning large language models (LLMs)-based agents.
记忆是人工智能系统的基本组成部分,是基于大语言模型(LLMs)代理系统的核心基础。
While prior surveys have focused on memory applications with LLMs (e.g., enabling personalized memory in conversational agents), they often overlook the atomic operations that underlie memory dynamics.
尽管以往的综述文章关注了LLMs中的记忆应用(例如在对话代理中实现个性化记忆),但它们往往忽略了支撑记忆动态的基本操作。
In this survey, we first categorize memory representations into parametric and contextual forms,
在本综述中,我们首先将记忆表示分为参数化(parametric)和上下文(contextual)两种形式。
参数化表示:记忆被编码在模型参数中,适用于长期记忆。
上下文表示:记忆通过外部上下文或缓存的方式引入,适用于短期或任务相关的记忆。
and then introduce six fundamental memory operations: Consolidation, Updating, Indexing, Forgetting, Retrieval, and Compression.
随后,我们提出了六个基本的记忆操作,这些操作对于理解记忆系统的功能至关重要:
Consolidation(巩固):将短期记忆转化为长期记忆。
Updating(更新):根据新信息更新已有记忆。
Indexing(索引):为记忆建立索引,以便快速检索。
Forgetting(遗忘):选择性地删除或弱化不再相关的信息。
Retrieval(检索):从记忆中提取相关信息。
Compression(压缩):对记忆进行压缩,以提高存储效率或响应速度。
We map these operations to the most relevant research topics across long-term, long-context, parametric modification, and multi-source memory.
我们将这些操作映射到与长期记忆、长上下文处理、参数修改以及多源记忆等研究主题相关的领域,展示了它们在不同应用场景下的适用性。
By reframing memory systems through the lens of atomic operations and representation types,
通过从基本操作和表示形式的角度重新审视记忆系统,
this survey provides a structured and dynamic perspective on research, benchmark datasets, and tools related to memory in AI,
我们提供了一个结构化且动态的视角,涵盖了记忆在AI中的研究、基准数据集和工具。
clarifying the functional interplay in LLMs based agents while outlining promising directions for future research.
这有助于澄清LLMs代理中各功能之间的相互作用,并为未来的研究指明了有前景的方向。
1 Introduction¶
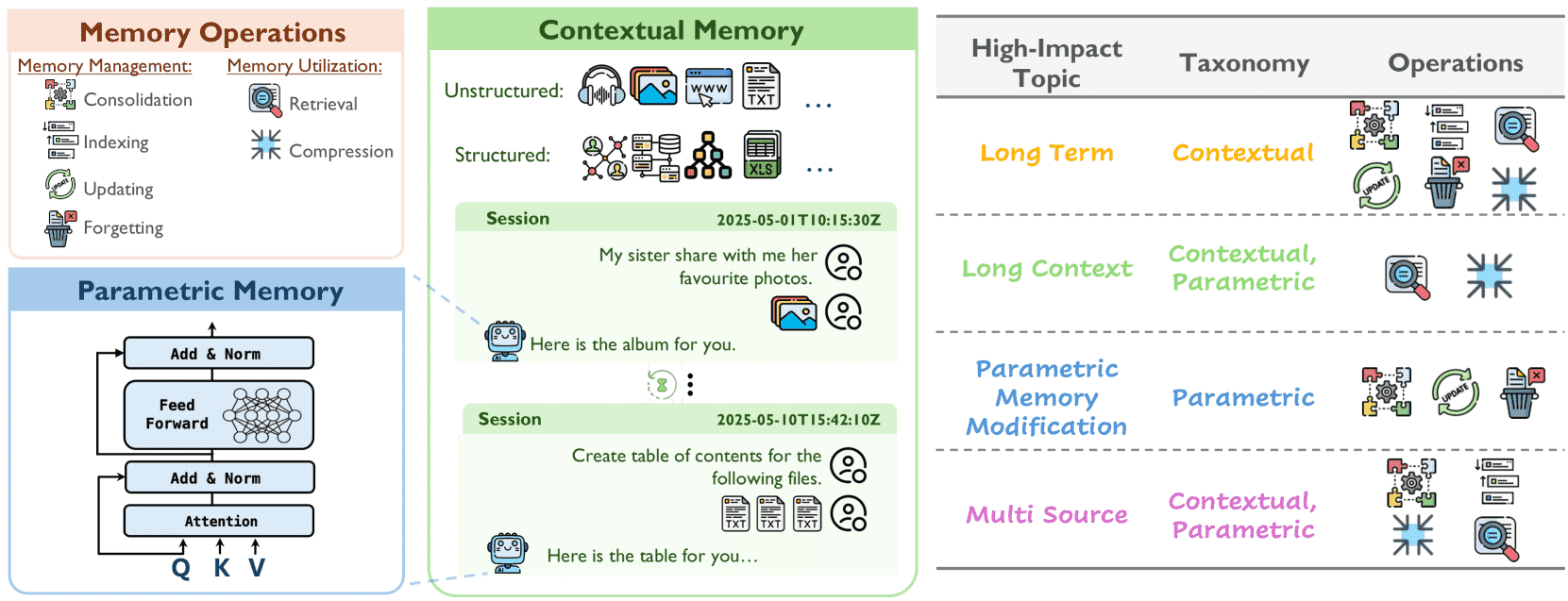
Figure 1:A unified framework of memory Taxonomy, Operations, and Applications in AI systems.
本节主要介绍了基于大语言模型(LLM)的系统中记忆(Memory)的重要性,并指出当前的研究在架构层面尚不完善。尽管已有研究在记忆的存储、检索和生成等方面取得了进展,但缺乏一个统一的框架来整合这些研究。
1.1 当前研究的局限性¶
最近的综述文章虽然提出了记忆的操作视角,但大多局限于特定子领域(如长上下文建模、长期记忆、个性化、知识编辑等),缺乏统一的操作框架。
现有研究未明确界定记忆研究的范围,也缺乏技术实现分析和实践基础(如基准测试和工具)。
1.2 本文的贡献¶
为填补上述空白,作者提出了一个统一的分类框架,将记忆分为两大类:
1.2.1 记忆类型划分¶
参数记忆(Parametric Memory):知识隐式地编码在模型参数中。
上下文记忆(Contextual Memory):外部信息显式存储,可结构化或非结构化。
时间维度:记忆可分为长期记忆(Long-term)(如多轮对话、长期观察)和短期上下文(Short-term)(如当前对话或任务上下文)。
1.2.2 记忆操作划分¶
基于上述类型,作者将记忆操作分为两类:
管理(Management):
整合(Consolidation):将新知识整合进持久记忆。
索引(Indexing):组织记忆以便检索。
更新(Updating):根据新输入更新记忆。
遗忘(Forgetting):删除过时或错误的内容。
利用(Utilization):
检索(Retrieval):访问相关记忆。
压缩(Compression):缩减记忆规模同时保留关键信息。
1.3 核心研究方向¶
通过初步研究,作者总结出四个核心方向,分别从时间、上下文、模型内部、多模态等角度探讨记忆:
长期记忆(Long-Term Memory):关注多会话系统中的记忆管理与个性化,以及检索增强生成(RAG)、个性化代理和问答系统。
长上下文记忆(Long-Context Memory):涉及参数效率和上下文利用效果,如“KV缓存丢弃”与长上下文压缩。
参数记忆修改(Parametric Memory Modification):包括模型编辑、遗忘、持续学习等内存内部操作。
多源记忆(Multi-Source Memory):强调跨异构文本源和多模态输入的记忆整合。
1.4 数据与分析方法¶
作者从多个顶会(如NeurIPS, ICLR, ICML等)中收集并标注了超过3万篇论文,使用基于GPT的筛选流程保留3,923篇高相关性论文。
提出了 **相对引用指数(RCI)**作为时间归一化的引用度量指标,用于识别有影响力的工作。
通过统一的分类与操作框架对这些论文进行系统分析。
1.5 论文结构¶
第2节介绍记忆的分类和核心操作。
第3节映射高影响力研究方向,并总结关键方法和数据集。
第4节讨论实际应用及工具。
第5节对比人类与AI记忆系统的异同。
第6节展望未来研究方向。
小结¶
本节为全文奠定了基础,明确提出了当前研究的不足,并构建了一个统一的分类与操作框架,为后续章节的深入分析提供了清晰的结构。重点在于记忆的分类、操作、研究方向和数据支持,为读者理解AI中的记忆机制和研究现状提供了全面的概述。
2 Memory Foundations¶
2.1 Memory Taxonomy(记忆分类)¶
本节从记忆表示的角度出发,将记忆分为Parametric Memory(参数记忆) 和 Contextual Memory(上下文记忆) 两类,后者又进一步分为无结构与有结构两种形式。
Parametric Memory(参数记忆)¶
定义:参数记忆是指隐式存储在模型内部参数中的知识,通过预训练或后训练获得,并在推理时通过前馈计算访问。
优点:能够快速、无上下文依赖地检索事实和常识知识,是模型的一种即时、长期且持久的记忆形式。
缺点:缺乏透明性,难以根据新经验或任务上下文进行选择性更新。
参考文献:Berges et al.(2024)、Wang et al.(2024c)等。
Contextual Memory(上下文记忆)¶
上下文记忆是补充模型参数的显式外部信息,分为无结构和有结构两种形式:
Unstructured Contextual Memory(无结构上下文记忆)
定义:一种通用的记忆系统,可以跨多种输入(如文本、图像、音频、视频)存储和检索信息。
功能:支持将推理过程与感知信号结合,集成多模态上下文。
时间划分:分为短期记忆(如当前对话上下文)和长期记忆(如跨会话的对话记录和持久知识)。
参考文献:Zhong et al.(2024)、Wang et al.(2025a)等。
Structured Contextual Memory(结构化上下文记忆)
定义:以预定义、可解释形式组织的记忆,如知识图、关系表或本体。
功能:支持符号推理和精确查询,常与预训练语言模型的关联能力互补。
时间划分:可以是短期(推理时构建的局部记忆)或长期(跨会话的结构化知识存储)。
参考文献:Oguz et al.(2022)、Lu et al.(2023)等。
2.2 Memory Operations(记忆操作)¶
为实现动态记忆(而非静态存储),AI系统需要记忆的生命周期操作,这些操作可归纳为两大类:
Memory Management(记忆管理):决定如何存储、维护和删除记忆。
Memory Utilization(记忆利用):决定如何检索和压缩记忆以用于推理。
2.3 Memory Management(记忆管理)¶
记忆管理包含四个核心操作,分别处理记忆的存储、更新与删除:
1. Consolidation(记忆整合)¶
功能:将短期经历整合为持久记忆,通常用于构建模型参数、知识图或知识库。
应用场景:持续学习、个性化、记忆库构建。
公式表示:
$\( \mathcal{M}_{t+\Delta_t} = \texttt{Consolidate}(\mathcal{M}_t, \mathcal{E}_{[t,t+\Delta_t]}) \)$参考文献:Squire et al.(2015)、Wang et al.(2024j)等。
2. Indexing(索引)¶
功能:构建辅助代码(如实体、属性、表示)作为记忆访问点,提升检索效率和语义连贯性。
应用场景:支持符号、神经和混合记忆系统的规模化检索。
公式表示:
$\( \mathcal{I}_t = \texttt{Index}(\mathcal{M}_t, \phi) \)$参考文献:Maekawa et al.(2023)。
3. Updating(更新)¶
功能:重新激活旧记忆并用新知识临时修改,维护记忆一致性。
实现方式:
参数记忆:定位-编辑机制。
上下文记忆:摘要、剪枝或精炼。
公式表示:
$\( \mathcal{M}_{t+\Delta_t} = \texttt{Update}(\mathcal{M}_t, \mathcal{K}_{t+\Delta_t}) \)$参考文献:Kiley and Parks(2022)、Bae et al.(2022)等。
4. Forgetting(遗忘)¶
功能:选择性抑制过时、无关或有害的记忆内容。
实现方式:
参数记忆:使用去学习技术。
上下文记忆:时间删除或语义过滤。
公式表示:
$\( \mathcal{M}_{t+\Delta_t} = \texttt{Forget}(\mathcal{M}_t, \mathcal{F}) \)$参考文献:Davis and Zhong(2017)、Wang et al.(2009)等。
风险与挑战¶
遗忘和更新操作可能引入安全风险,比如记忆被篡改或毒化,需在第6节中进一步讨论。
2.4 Memory Utilization(记忆利用)¶
记忆利用涉及如何在推理中使用已存储的记忆,主要包括两个操作:
1. Retrieval(检索)¶
功能:根据输入查询从记忆中识别并访问相关信息,支持下游任务(如响应生成、视觉定位、意图预测)。
输入类型:可包括简单查询、多轮对话、视觉内容等。
检索条件:通常使用相似度函数
sim(),选取与查询相似度高于阈值 \(\tau\) 的记忆片段。公式表示:
$\( \texttt{Retrieve}(\mathcal{M}_t, \mathcal{Q}) = m_{\mathcal{Q}} \in \mathcal{M}_t \quad \text{with } \text{sim}(\mathcal{Q}, m_{\mathcal{Q}}) \geq \tau \)$参考文献:Du et al.(2024)、Wang et al.(2025a)等。
2. Compression(压缩)¶
功能:在模型输入窗口有限的前提下,通过压缩保留关键信息、去除冗余。
分类:
Pre-input compression(输入前压缩):用于未使用检索的长上下文模型。
Post-retrieval compression(检索后压缩):减少检索到的内容,可通过上下文压缩或参数压缩实现。
公式表示:
$\( \mathcal{M}_t^{comp} = \texttt{Compress}(\mathcal{M}_t, \alpha) \)$参考文献:Yu et al.(2023)、Xu et al.(2024a)等。
总结¶
本章系统地介绍了AI系统中记忆的基础理论和操作机制,涵盖记忆的分类(参数与上下文)、记忆管理(整合、索引、更新、遗忘)和记忆利用(检索、压缩)。重点在于理解记忆的动态管理流程及其在不同任务中的应用,同时指出操作中可能存在的风险。
3 From Operations to Key Research Topics¶
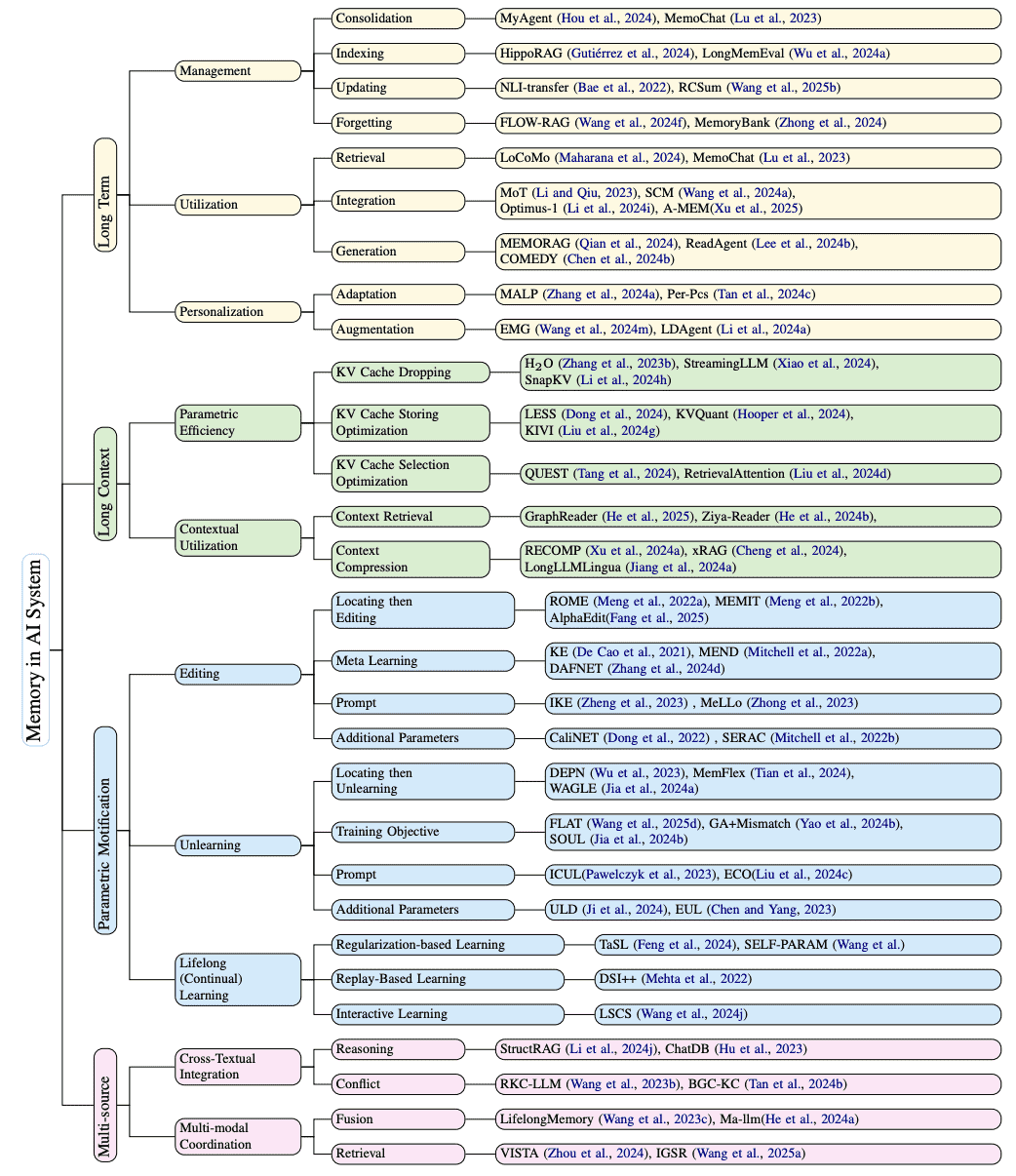
Figure 2: Operation-driven key research topics in AI systems.
分析了现实系统中如何通过核心操作来管理和利用内存,并围绕四个关键研究主题展开讨论,分别是长期记忆(Long-term Memory)和长上下文(Long-context)。文章通过 相对引用指数(RCI) 识别出具有影响力的成果,并借助图示和表格展示不同内存类型与操作之间的关系。以下是对本章内容的结构化总结。
3.1 长期记忆 (Long-term Memory)¶
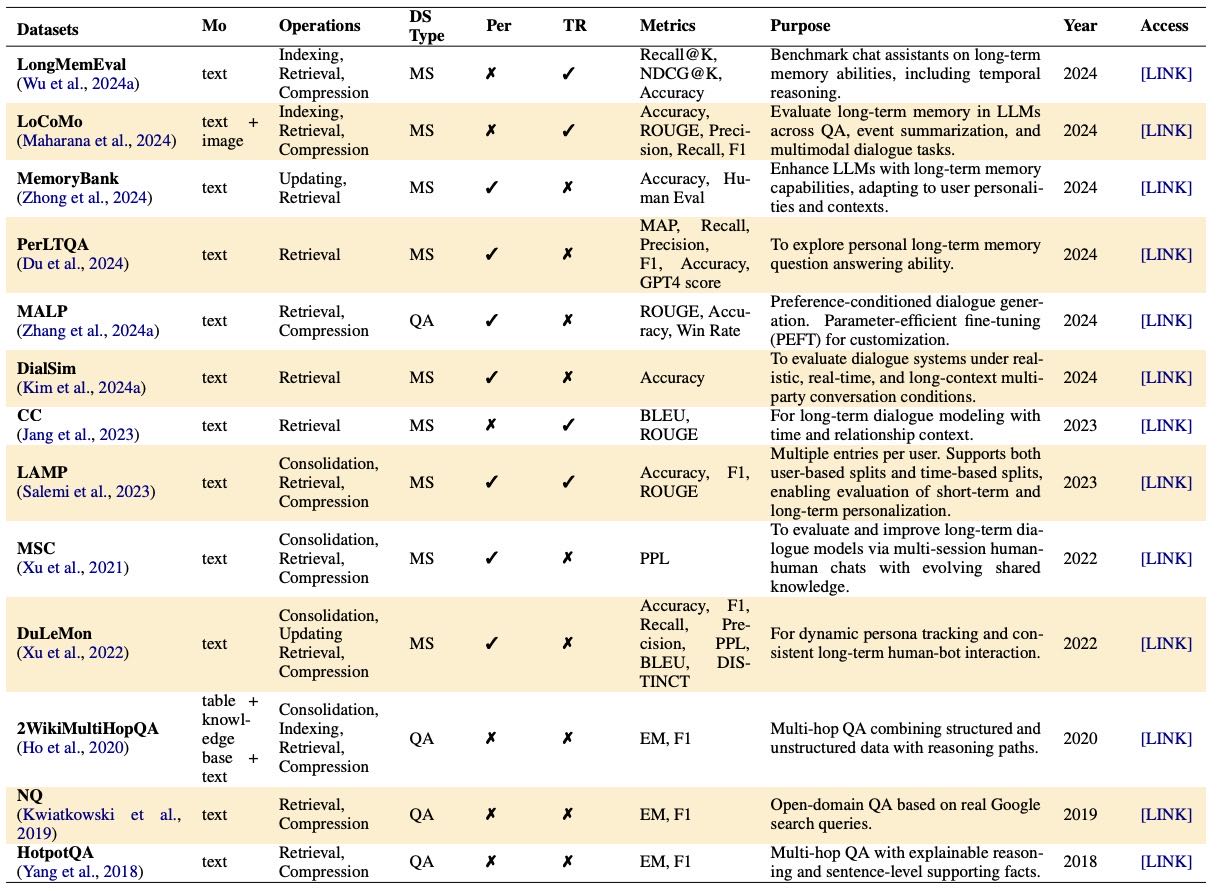
Table 4:Datasets used for evaluating long-term memory. “Mo” denotes modality. “Ops” denotes operability (placeholder). “DS Type” indicates dataset type (QA – question answering, MS – multi-session dialogue). “Per” and “TR” indicate whether persona and temporal reasoning are present.
核心概念¶
长期记忆 指的是智能体(如AI模型)在与环境交互(如多轮对话、浏览模式、决策路径)中获取的信息的持久化存储。它支持记忆管理、利用和个性化等能力,使智能体能够执行复杂任务。
关键区别:本节讨论的是上下文长期记忆(可以是结构化的或非结构化的),它与通过持续学习存储在模型权重中的参数记忆不同。
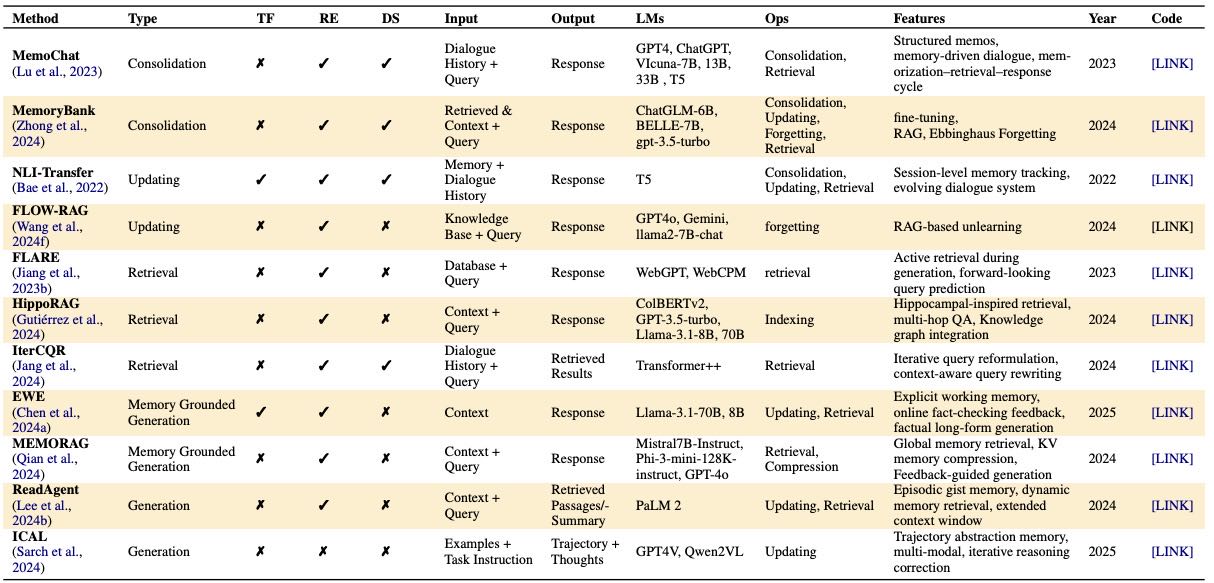
Table 9:Overview of methods for long-term memory in memory management and utilization. “TF” (Training Free) denotes whether the method operates without additional gradient-based updates. “RE” (Retrieval Module) denotes whether the method needs Retrieval. “DS” (Dialogue System) denotes whether the method aims for a dialogue task.
3.1.1 管理 (Management)¶
管理涉及对已获取经验的巩固、索引、更新和遗忘等操作。
两种实例化形式:
积累的多轮对话历史。
自主智能体的长期观察和决策。 这些记忆通常由大语言模型(LLM)编码,并存储在外部的记忆库中,供未来访问和重用。记忆会随着新信息的加入而更新,并会修剪过时或无关的内容。
四个子操作:
记忆巩固 (Memory Consolidation):将短期记忆转化为长期记忆的过程。常用摘要总结技术来生成非结构化的记忆表示(如MemoryBank, ChatGPT-RSum)。也有工作利用LLM提示来识别和结构化相关信息(Lu et al., 2023),或通过建模时间相关性来加强记忆(MyAgent),甚至模仿人类的情景记忆(什么-哪里-何时)来分层组织知识以进行行动规划(Park et al., 2025)。
记忆索引 (Memory Indexing):构建记忆表示以支持高效准确检索的基础过程。分为三类范式:
基于图的方法:如HippoRAG,构建轻量级知识图谱来显式揭示不同知识片段间的联系。
信号增强的方法:如LongMemEval,用时间戳、事实内容和摘要来增强记忆键。
基于时间线的方法:如Theanine,沿着演化的时间和因果链组织记忆,支持基于相关性和时间线的检索,实现终身和动态个性化。
记忆更新 (Memory Updating):指外部记忆为未见信息创建新条目,或将新内容与现有记忆表征重组和整合的过程。分为两大范式:
内在更新 (Intrinsic Updating):通过内部机制更新,无外部反馈。包括选择性编辑删除过时信息、递归摘要压缩对话历史、记忆混合与精炼合并过去和现在的表征、基于证据检索和验证的自我反思式记忆演化。
外在更新 (Extrinsic Updating):依赖外部信号(特别是用户反馈)更新。如存储用户修正到记忆中以实现持续改进,而无需重新训练。
记忆遗忘 (Memory Forgetting):移除已巩固的长期记忆表征的过程。
自然遗忘:遵循艾宾浩斯遗忘曲线,记忆痕迹随时间逐渐衰减。
主动遗忘:故意从记忆系统中移除特定信息(如出于隐私、安全、合规原因)。这在处理敏感或有害内容时尤为重要(Chen et al., 2024b; Mitchell et al., 2022b等)。
3.1.2 利用 (Utilization)¶
利用指根据当前输入和相关记忆内容生成响应的过程,通常涉及记忆路由、整合和读取。
三个子操作:
记忆检索 (Memory Retrieval):根据给定查询选择最相关的记忆条目。分为三类范式:
以查询为中心:改进查询 formulation 和适应(如FLARE中的前向查询重写,IterCQR中的迭代精炼)。
以记忆为中心:增强记忆候选的组织和排序(如更好的索引策略Wu et al., 2024a,重排序方法Du et al., 2024)。
以事件为中心:基于时间和因果结构检索记忆(如LoCoMo, CC, MSC)。 其他技术如多跳图遍历(Gutiérrez et al., 2024)和记忆图演化(Qian et al., 2024)也丰富了检索过程。
记忆整合 (Memory Integration):选择性地将检索到的记忆与模型上下文结合,以在推理过程中实现连贯推理或决策。整合可能跨越多个记忆源和模态。分为两种策略:
静态上下文整合:在推理时检索和组合静态记忆条目以丰富上下文和提高推理一致性(如EWE, Optimus-1)。
动态记忆演化:强调记忆在交互过程中增长、适应和重构(如通过动态链接或受控记忆更新),例如A-MEM, Synapse, R2I, SCM。
记忆接地生成 (Memory Grounded Generation):利用已整合的检索记忆内容来指导响应生成。分为三种方法:
自我反思推理:检索自我生成或结构化的记忆轨迹来指导中间推理步骤,增强解码过程中的多跳推理(如MoT, StructRAG)。
反馈引导修正:利用反馈记忆或记忆信息线索来约束生成,防止重复错误和提高输出鲁棒性(如MemoRAG, Repair)。
上下文对齐的长期生成:将压缩或提取的记忆摘要整合到生成过程中,以在长对话或长文档中保持连贯性(如COMEDY, MemoChat, ReadAgent)。
3.1.3 个性化 (Personalization)¶
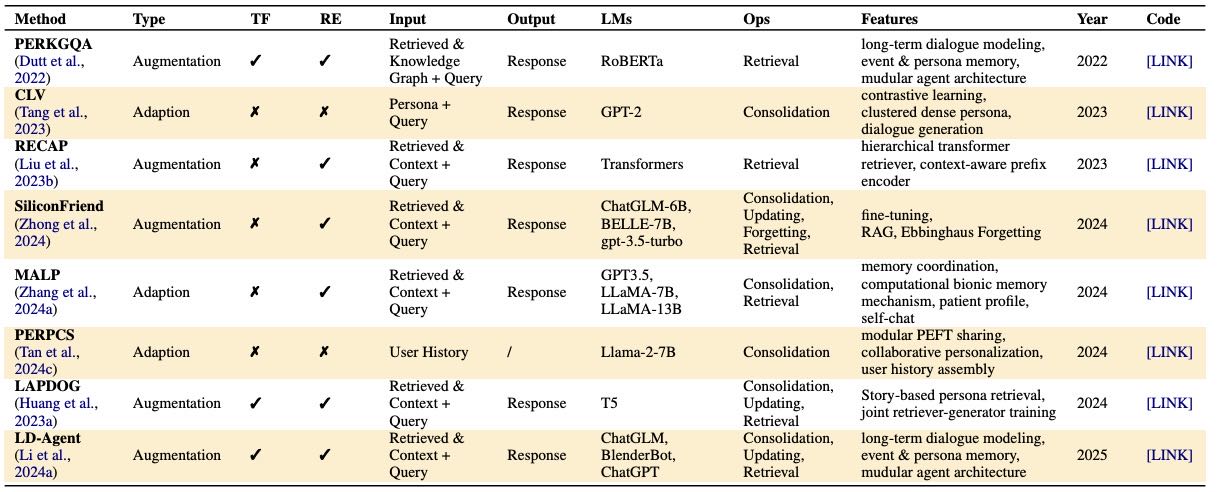
Table 8:Overview of methods for long-term memory in personalization. “TF” (Training Free) denotes whether the method operates without additional gradient-based updates. “RE” (Retrieval Module) denotes whether the method needs Retrieval.
个性化是长期记忆的关键但具有挑战性的方面,受限于数据稀疏性、隐私和用户偏好变化。当前方法可分为两类:
模型级适应 (Model-Level Adaptation):通过微调或轻量级更新将用户偏好编码到模型参数中。
一些方法在潜在空间中嵌入用户特征(如CLV使用对比学习聚类人物描述来指导生成)。
其他采用参数高效策略(如RECAP通过前缀编码器注入检索到的用户历史,Per-Pes组装模块化适配器来反映用户行为)。
在专业领域(如医疗对话),MaLP引入了双过程记忆来建模短期和长期个性化。
外部记忆增强 (External Memory Augmentation):在推理时从外部记忆中检索用户特定信息来个性化LLM。基于记忆格式分为:
结构化记忆:如用户档案或知识图谱(用于构建个性化提示LaMP,或用于个性化问答PerKGQA)。
非结构化记忆:如对话历史和叙述性人物(检索以丰富稀疏档案LAPDOG,并通过双重学习与输入上下文对齐Fu et al., 2022)。
混合方法:如SiliconFriend和LD-Agent,跨会话维护持久记忆。
局限性:这些方法通常将长期记忆视为被动缓冲区,其用于主动规划和决策的潜力尚未被充分探索。
3.1.4 讨论 (Discussion)¶
评估局限:当前长期记忆的评估受限于静态假设。
基于知识的QA任务评估模型对事实知识的检索和推理能力,但通常假设静态记忆内容,忽略了更新、选择性保留和时间连续性等动态操作。
多轮对话基准(如LoCoMo, LongMemEval)更好地反映了真实世界的记忆使用(跨会话检索、记忆更新、事件推理),但大多数评估仍将对话历史视为静态上下文, narrowly focusing on QA accuracy while overlooking dynamic memory operations such as indexing, consolidation, forgetting, or user-specific adaptation.
检索与生成的错配:揭示了利用瓶颈。
最新模型在检索指标(如Recall@5)上表现优异(>90%),但生成指标(如F1)却落后超过30个百分点。
原因:紧凑的记忆格式比冗长的条目更利于生成;记忆与查询之间的时间距离增加会导致生成质量下降即使检索准确;检索更多项目会引入噪声损害解码;多语言评估中存在语言差距(英语优于中文)。
结论:当前系统可以检索相关记忆内容,但在有效组织和利用它进行下游生成任务方面仍然不足。
记忆操作评估不足:当前评估主要关注检索准确性和生成质量,但很大程度上忽略了记忆使用的过程方面(如巩固、更新、遗忘、选择性保留)。需要能够评估记忆可靠性、时间适应性和多会话对话一致性的综合基准。
出版趋势:
检索和生成在文献中占主导地位(尤其在NLP领域)。
核心操作如巩固和索引在ML中受到更多关注,而遗忘仍未得到充分探索。
个性化主要限于NLP(由于实际应用需求)。
就引用影响而言,巩固、检索和整合起着关键作用(由记忆感知微调、摘要、检索增强生成和提示融合的进步驱动)。
未来方向:
设计动态统一的基准,评估不同记忆类型上的记忆操作,并捕捉超越对话的长期时间动态。
通过增强记忆格式化、控制检索粒度和建模时间可靠性来解决检索-生成脱节问题。
通过跨会话记忆重用和自适应用户建模,推进个性化的、以记忆为中心的智能体。
3.2 长上下文 (Long-context)¶
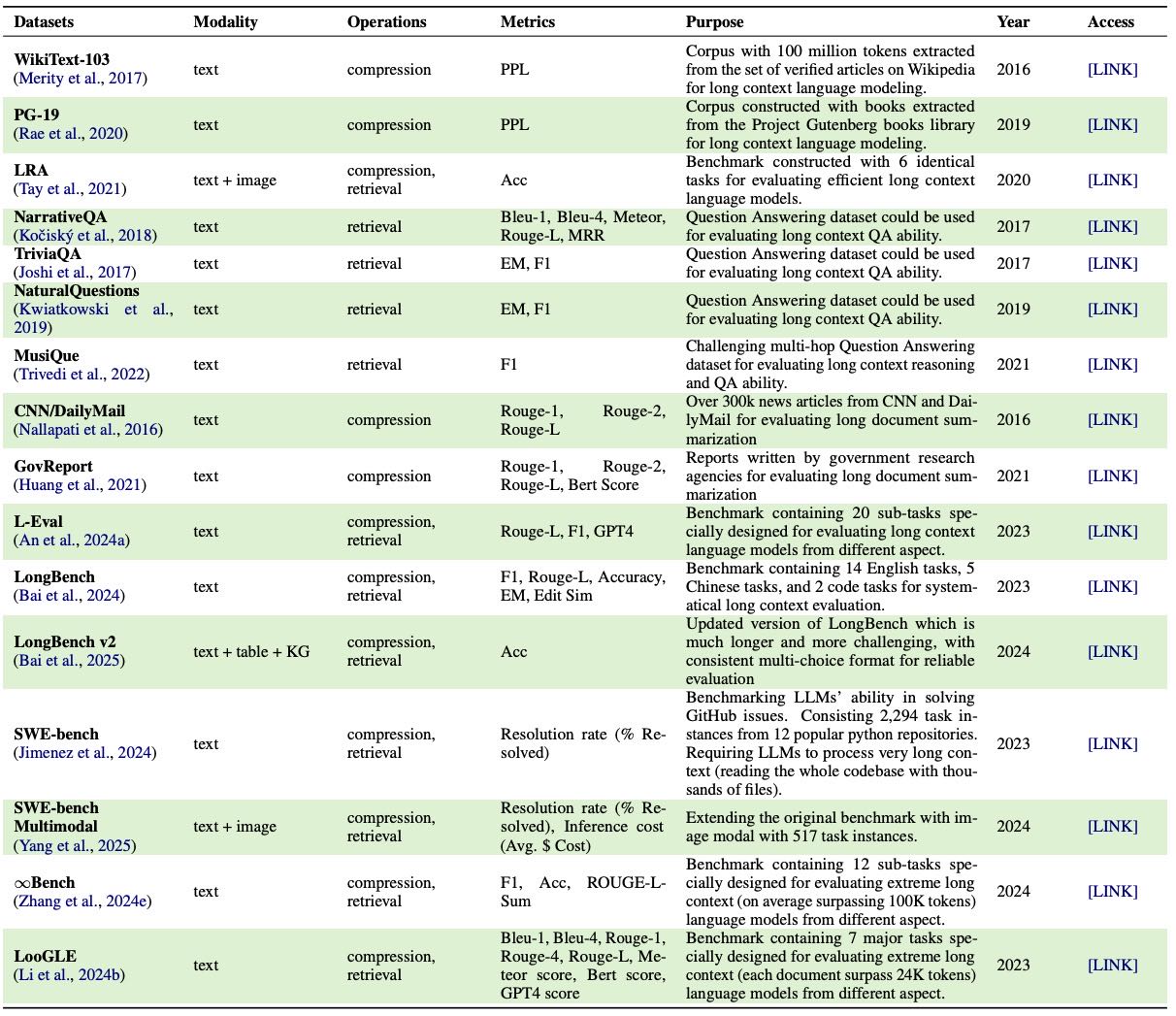
Table 5: Datasets for long-context memory evaluation.
核心内容: 本节开篇指出,在 conversational search(会话式搜索)中,管理海量、多源的外部内存给“长上下文语言理解”带来了巨大挑战。尽管模型设计和长上下文训练的进步已让大语言模型(LLMs)能处理数百万个输入token,但如何在这种超长上下文中有效管理内存仍然是一个复杂的问题。
这些挑战主要分为两方面:
参数效率 (Parametric Efficiency): 专注于优化KV缓存(一种参数化内存),以实现高效的长上下文解码。
上下文利用 (Contextual Utilization): 专注于优化LLMs本身,以管理各种外部内存(上下文内存)。
本节将系统回顾应对这些挑战的研究工作。相关数据集和重点工作的总结详见论文中的表格。
Figure 5: 该图展示了本节所讨论的重点论文(RCI > 1)的发表统计情况,反映了该领域的研究热度和发展趋势。
3.2.1 参数效率 (Parametric Efficiency)¶
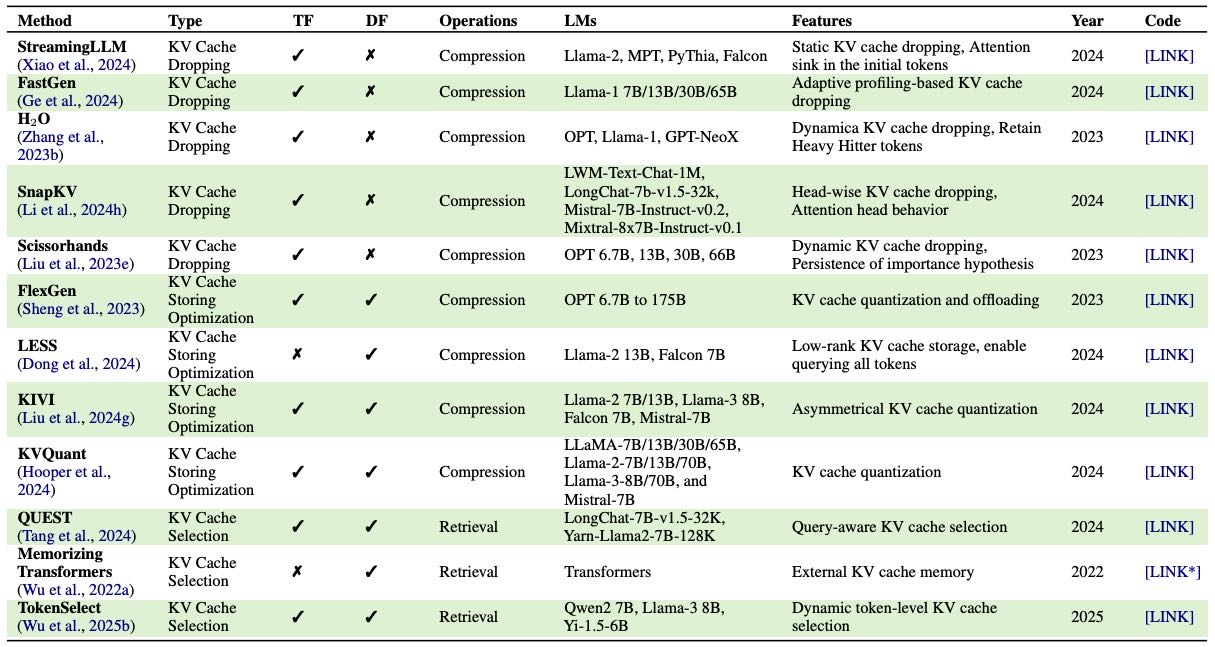
Table 10:Overview of methods for long-context memory in Parametric Efficiency. “TF” (Training Free) denotes whether the method operates without additional gradient-based updates. “DF” (Dropping Free) denotes whether the method able to maintain all the KV cache without dropping. [LINK]* indicates unofficial implementations.
核心内容: 为了管理海量多源外部内存,LLMs必须被优化以高效处理长上下文。本小节讨论从内存视角优化长上下文处理的方法,重点是键值缓存(KV Cache)优化。
问题:KV缓存通过存储过去的键值对作为外部参数化内存,来避免重复计算。但随着上下文变长,存储这些内存的需求呈二次方增长,难以处理极长上下文。
KV缓存丢弃 (KV Cache Dropping)¶
目标:通过消除不必要的KV缓存来减小缓存大小。
静态丢弃: 按固定模式选择要丢弃的缓存。
例子: StreamingLLM 和 LM-Infinite 使用一种Λ形稀疏模式;LCKV 只保留最顶层的KV缓存。
动态丢弃: 更灵活,根据查询(如H2O, FastGen)或模型在推理时的行为(如注意力权重,SnapKV, HeadKV)来决定丢弃哪些缓存。
合并法: 由于直接丢弃可能导致信息丢失,一些方法选择合并相似的KV缓存(如MiniCache, InfiniPot)或使用特殊token存储(如Activation Beacon),而不是直接丢弃。
KV缓存存储优化 (KV Cache Storing Optimization)¶
目标: 认识到丢弃可能造成信息损失,转而关注如何用更小的空间占用保存全部KV缓存。
方法: 将不重要的缓存条目压缩成低维表示(如LESS, Eigen),或对KV缓存进行动态量化以减少内存分配(如FlexGen, Atom, KVQuant)。
优缺点: 相比丢弃法,性能下降更小,但由于内存增长的二次方特性,优化空间仍有限。未来需权衡内存成本和性能下降。
KV缓存选择 (KV Cache Selection)¶
目标: 选择性加载所需的KV缓存来加速推理,专注于KV缓存的内存检索。
方法: 采用查询感知的缓存选择(如QUEST, TokenSelect)或近似最近邻(ANN)搜索(如RetrievalAttention)来检索关键的KV缓存。
外部存储: 将KV缓存存入外部内存,推理时再检索相关部分(如Memorizing Transformers, LongLLaMA, ReKV)。
优势: 灵活性高,避免了驱逐缓存,并能与存储优化技术结合。
3.2.2 上下文利用 (Contextual Utilization)¶
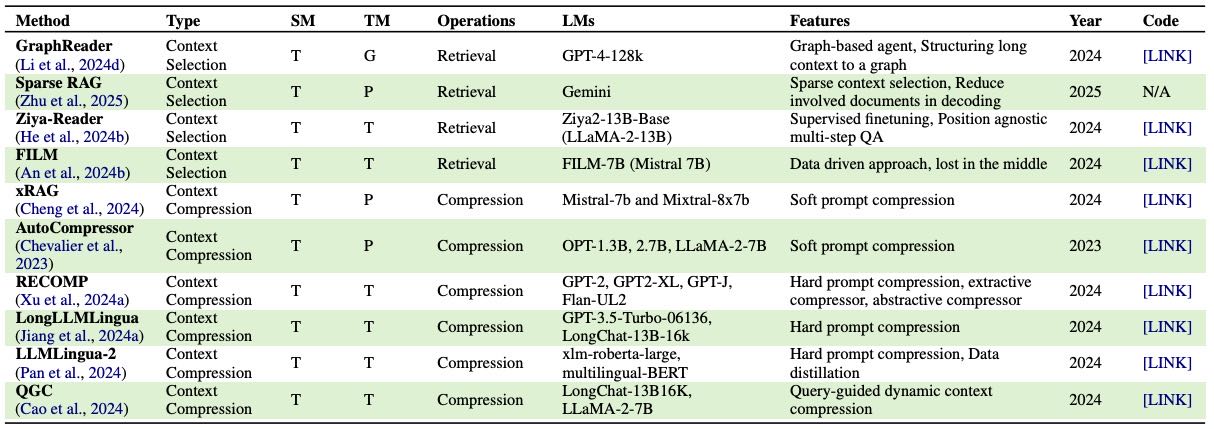
Table 11:Overview of methods for long-context memory in Contextual Utilization. “SM” (Source Modal) denotes the source modality of contextual memory. “TM” (Target Modal) denotes target modality (processed for selection / after compression) of contextual memory (T – Text, G – Graphs, P – Parametric).
核心内容: 除了优化模型本身获得长上下文能力,优化上下文内存的利用是另一大挑战。
上下文检索 (Context Retrieval)¶
目标: 增强LLM从上下文内存中识别和定位关键信息的能力。
图方法: 将文档分解成图结构以有效选择上下文(如CGSN, GraphReader)。
Token级选择: 修剪和选择最重要的token(如TRAMS, Selection-p)。
片段级选择: 根据任务重要性选择相关上下文片段(如NBCE, FragRel, Sparse RAG)。
训练法: 用专门数据训练LLM,提高其上下文选择能力(如Ziya-Reader, FILM)。
外部向量缓存: 将外部内存编码到向量空间并存储,有效更新和检索以实现长期记忆利用(如MemGPT, Neurocache, AWESOME)。
上下文压缩 (Context Compression)¶
目标: 利用内存压缩操作优化上下文内存利用,主要分两类:
软提示压缩: 将输入token块压缩成推理阶段的连续向量(如AutoCompressors, xRAG),或在训练阶段将任务特定的长上下文编码到微调模型的参数内存中(如YORO)。
硬提示压缩: 直接将长输入块压缩成更短的自然语言块。
丢弃法: 选择性修剪信息量少的token(如Selective Context)或块(如Semantic Compression)。
摘要法: 通过抽象关键信息来压缩长输入(如RECOMP, LLMLingua系列)。
混合法: 结合丢弃和摘要(如TCRA-LLM)。
3.2.3 讨论 (Discussion)¶
迷失在上下文中 (Lost in the Context)¶
尽管模型声称能处理百万级token,但在执行任务(如问答)时,LLMs仍会丢失上下文中间位置的关键信息(“中间迷失”问题)。
在需要基于上下文进行推理的复杂场景中,LLMs也难以有效聚合不同部分的内存。
此外,检索到的无关信息会误导模型,损害生成质量。因此,有效的上下文利用(检索与压缩)是解决这些限制的关键。
压缩率与性能下降的权衡 (Trade-off between compression rate and performance drop)¶
压缩是长上下文内存中的主要操作,用于平衡效率(压缩率)和有效性(性能下降)。
不同策略的优劣:
KV缓存丢弃法:压缩率高,但信息损失大,性能下降明显。
KV缓存存储优化法:在有效性和效率间取得了最佳权衡(见图6)。
上下文内存压缩法:效果通常不如参数内存压缩(如LLMLingua2性能相对较差)。
Figure 6: 直观展示了不同压缩方法在压缩率和性能(在LongBench基准上的表现)之间的权衡关系。
发表趋势 (Publication Trending)¶
NLP社区更关注上下文内存的利用。
ML社区更专注于通过参数化内存提高效率。
KV缓存存储优化是当前讨论的焦点,因为它能平衡效率与有效性,并与其他长上下文方法兼容。
上下文检索受到的关注相对较少,部分原因是其与“长期记忆”、“多源记忆”等主题有重叠。
未来方向: 在复杂环境(如多源内存)中的上下文利用仍是关键且缺乏有影响力工作的研究方向,对智能体发展至关重要。
总结与未来方向:
在KV缓存优化中平衡内存使用和性能下降是一个重要的未来研究方向。
复杂环境下的上下文利用是推动智能体发展的关键研究方向。
3.3 Parametric Memory Modification(参数化记忆修改)¶
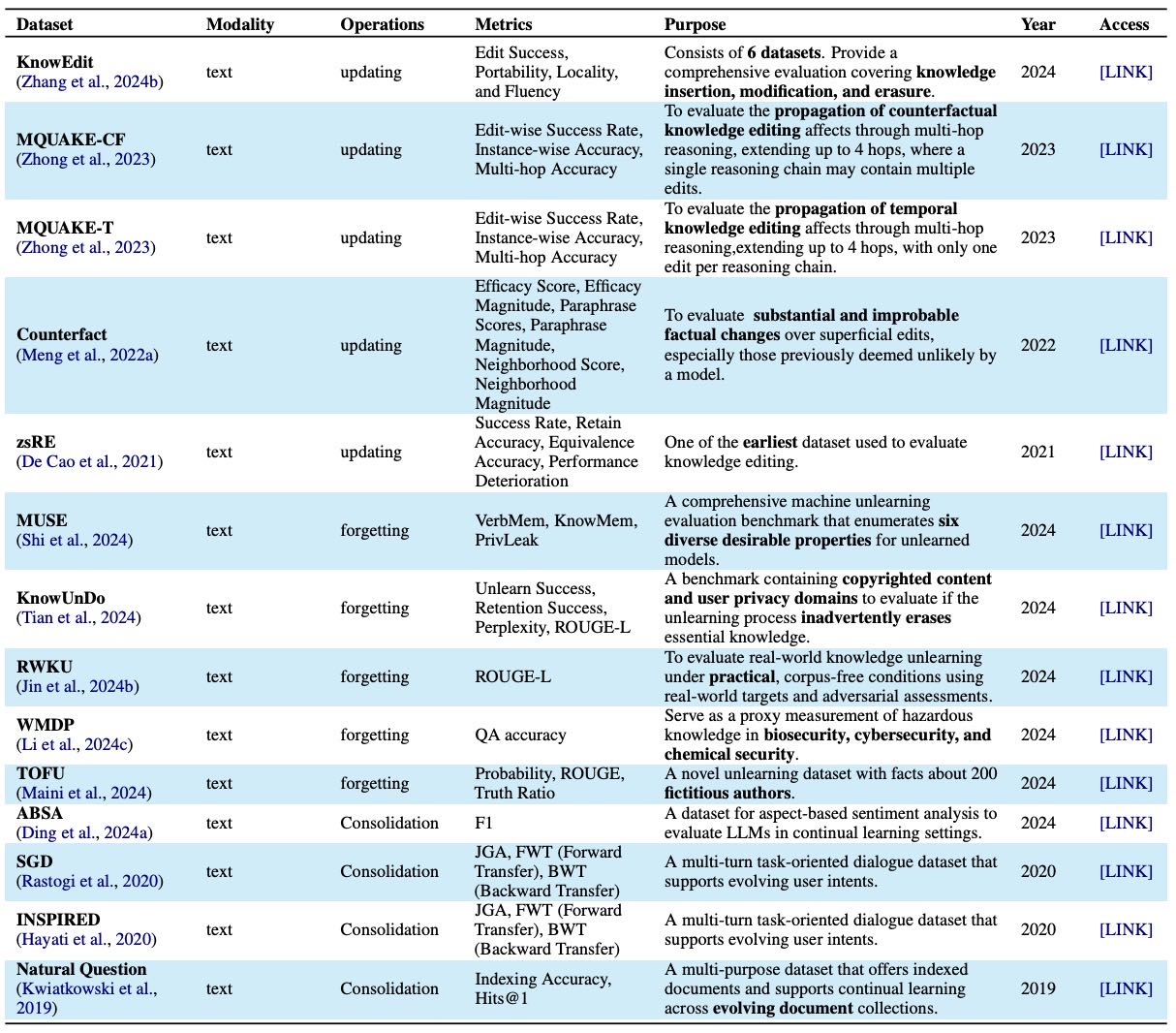
Table 6: Datasets for parametric memory evaluation.
核心概念: 参数化记忆是指编码在LLM模型参数内部的知识。修改这些记忆对于让模型动态适应新知识、纠正错误或忘记敏感信息至关重要。
主要方法分类:
Editing(编辑): 对模型参数进行局部修改,无需完全重新训练模型。
Unlearning(遗忘/反学习): 选择性移除模型中不需要的或敏感的信息。
Continual Learning(持续学习): 逐步吸收新知识,同时防止对旧知识的“灾难性遗忘”。
本节将系统回顾这三类方法,并在后续小节中进行详细分析和比较。相关数据集和方法总结见论文中的表格。
3.3.1 Editing(编辑)¶
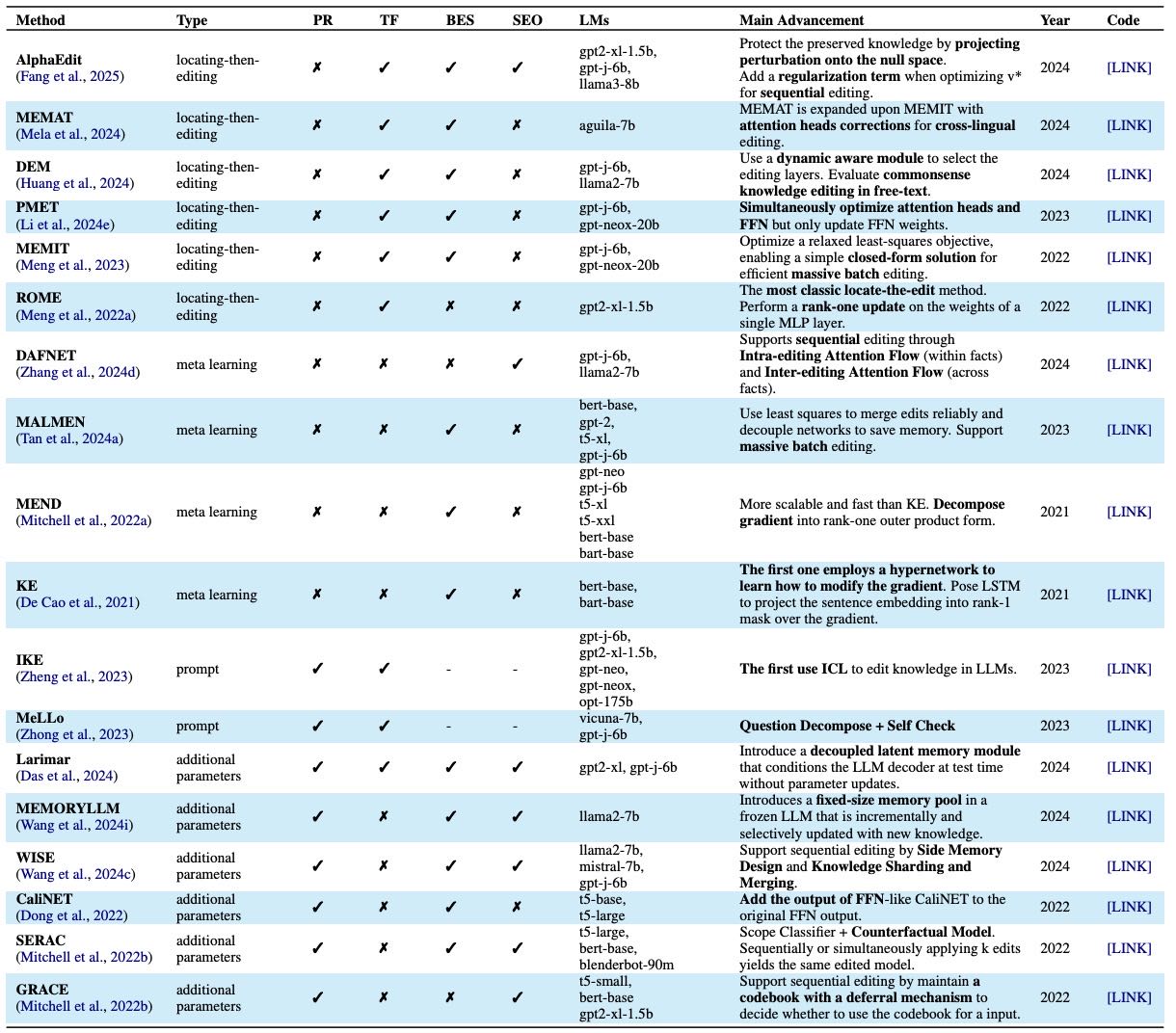
Table 12:Overview of methods for parametric memory optimization in editing. “PR” (Parametric Reserving) indicates whether the method avoids direct modification of the model’s internal weights. “TF” (Training-Free) denotes whether the method operates without traditional iterative optimization. “BES” (Batch Editing Support) reflects the method’s ability to handle multiple edits simultaneously. “SEO” (Sequential Editing Optimization) specifies whether the method introduces mechanisms tailored for sequential Editing. “LMs” lists the language models used for empirical evaluation.
目标: 不进行全模型重训练,更新参数化记忆中的特定知识。
主要技术路线:
直接修改权重(Locating-then-editing):
策略: 先通过归因或追踪技术定位特定知识存储在模型的哪些参数中,然后直接修改这些被识别出的参数。
例子: Meng et al. (2022a, 2023) 等人的工作。
元学习(Meta-learning):
策略: 训练一个“编辑器”网络,让它学会预测应该如何修改原模型的权重才能实现目标编辑。这种方法更快速、鲁棒。
例子: De Cao et al. (2021), Mitchell et al. (2022a) 等人的工作。
不修改原始权重的方法:
基于提示(Prompt-based): 通过设计特殊的提示词(Prompt) 或上下文学习(ICL)来间接地引导模型输出,不触动模型本身。
添加额外参数(Additional-parameter): 在原始模型之外添加新的、可调整的参数模块来改变模型行为,保持原有权重不变。
现状: 这些方法在效率和可扩展性上各有不同,但目前大多专注于实体级别(如修改某个名人的出生地)的编辑。
3.3.2 Unlearning(遗忘/反学习)¶
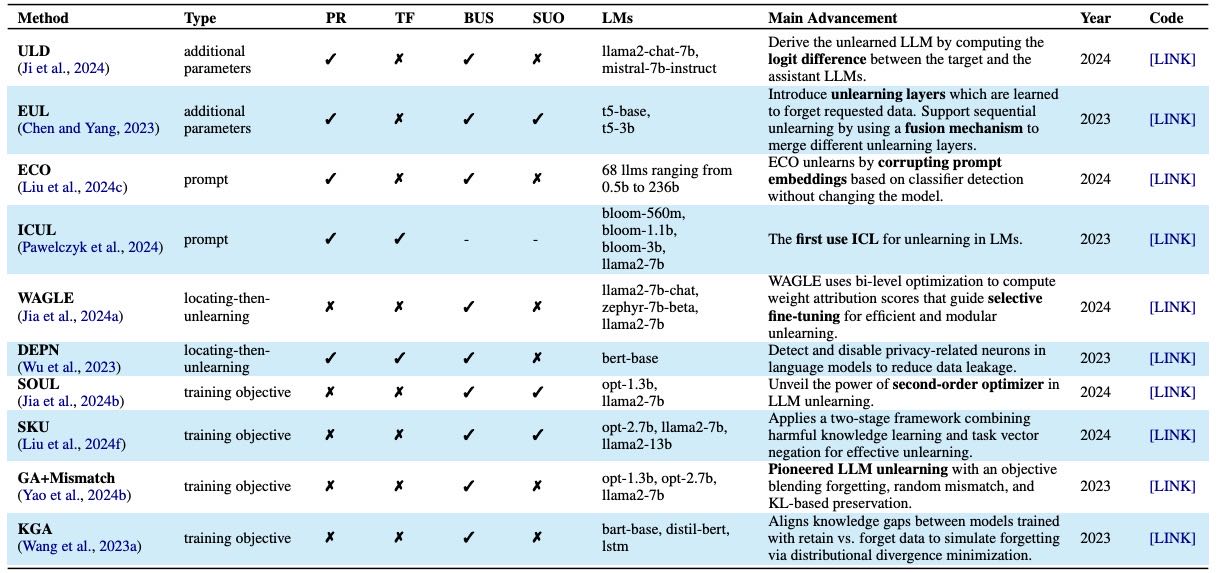
Table 13:Overview of methods for parametric memory optimization in unlearning. “PR” (Parametric Reserving) indicates whether the method avoids direct modification of the model’s internal weights. “TF” (Training-Free) denotes whether the method operates without traditional iterative optimization. “BUS” (Batch Unlearning Support) reflects the method’s ability to handle multiple edits simultaneously. “SUO” (Sequential Unlearning Optimization) specifies whether the method introduces mechanisms tailored for sequential Editing. “LMs” lists the language models used for empirical evaluation.
目标: 选择性移除特定记忆,同时保留其他无关的知识。
主要技术路线:
添加额外参数: 添加新的模块(如logit差异模块或“遗忘层”)来调整输出,避免重训练整个模型。
基于提示: 通过操纵输入或使用ICL提示从外部触发“遗忘”行为。
定位后遗忘(Locating-then-unlearning): 先定位到需要遗忘的记忆所在的参数,然后进行针对性的更新或失活。
基于训练目标: 修改训练时的损失函数或优化策略,明确地鼓励模型“忘记”特定信息。
核心挑战: 在给定明确遗忘目标时,精确擦除相关记忆,同时保留非目标知识,平衡效率与精度。
3.3.3 Continual Learning(持续学习)¶
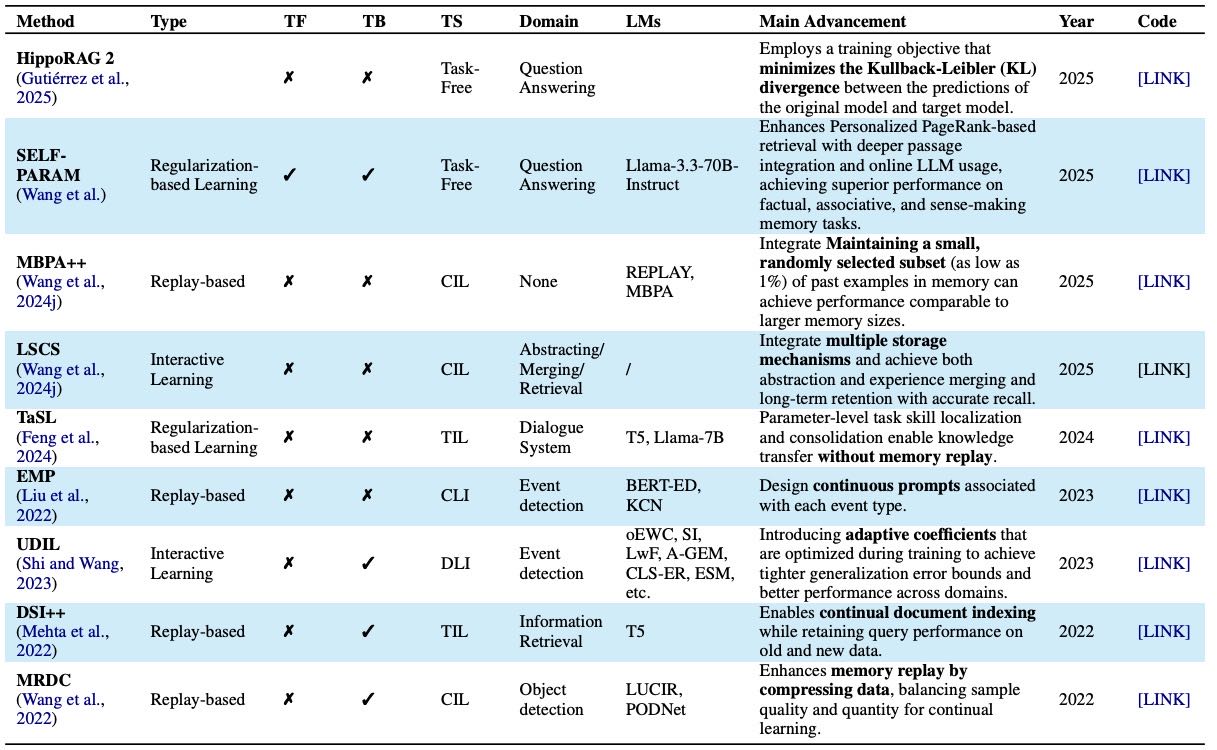
Table 14:Overview of methods for parametric memory modification in continual learning. “TB” denotes the task boundary whether exists. “TS” denotes the task settings including TIL (Task Incremental Learning), CIL (Class Incremental Learning), DIL (Domain Incremental Learning), Task-Free.
目标: 让模型能够持续地学习新知识(实现长期记忆),同时缓解灾难性遗忘(即学了新的,忘了旧的)。
主要技术路线:
基于正则化(Regularization-based):
策略: 在更新模型时约束对重要权重的更改,以保护已有的关键记忆。
例子: EWC, TaSL, SELF-PARAM, POCL 等方法。
基于回放(Replay-based):
策略: 在学习新知识时,重新引入一部分过去的样本(数据) 来“复习”旧知识,从而强化记忆。
例子: DSI++ 利用生成式记忆产生伪查询来辅助学习。
智能体范式(Agent-based):
策略: 将持续学习扩展到交互环境中,智能体通过实时体验逐步获取和巩固记忆。
例子: LifeSpan Cognitive System (LSCS) 研究了如何将外部记忆持续编码到模型参数中。
3.3.4 Discussion(讨论)¶
SOTA Solution Analysis(顶尖方案分析)¶
实验设置: 作者在常用的编辑数据集(CounterFact, ZsRE)和遗忘数据集(ToFU)上测试了各类别的顶尖方法。
关键发现:
Prompt-based方法整体表现最强。
Meta-learning方法普遍表现不如其他方法。
所有方法在ZsRE数据集上的表现都比在CounterFact上差,主要原因是特异性(Specificity) 得分低(即编辑不够精确,影响了无关内容)。
大多数方法在ToFU(遗忘)基准上得分都很高,作者认为这个基准可能不够有挑战性,需要开发更难的新基准。
Scaling Challenges(扩展性挑战)¶
编辑次数: 除了MemoryLLM,大多数方法只能顺序编辑1k-5k次,远未达到实际应用的需求。顺序遗忘的研究更是稀少。
模型规模:
非Prompt类方法(如直接改权重)大多在中小模型(≤20B参数) 上测试,因为计算成本高,难以扩展到超大模型。
Prompt类方法则更常在大模型上评估,因为它们依赖模型强大的指令遵循和上下文学习能力。
核心问题: 如何平衡模型大小与编辑/遗忘的有效性和效率,是一个亟待解决的问题。
Publication Trending(发表趋势)¶
关注度: Editing(编辑) 领域受到的关注最多,尤其是“定位后编辑”和“添加参数”这两种方法。
社区差异: NLP社区更关注编辑,而ML社区对三者分布更均匀。
影响力: “定位后编辑”领域产生了多篇极具影响力的论文(RCI方差高)。
研究潜力: Unlearning(遗忘) 方法虽然数量少,但已显示出潜力;Continual Learning(持续学习) 则相对探索不足。
核心总结(你的总结很棒,完全正确)¶
当前编辑方法的精确性(特异性) 不足。
当前的遗忘基准(如ToFU)太简单,无法反映真实世界的挑战。
未来的持续学习需要避免在交互中覆盖模型参数中持久的长期记忆。
3.4 多源记忆 (Multi-source Memory)¶
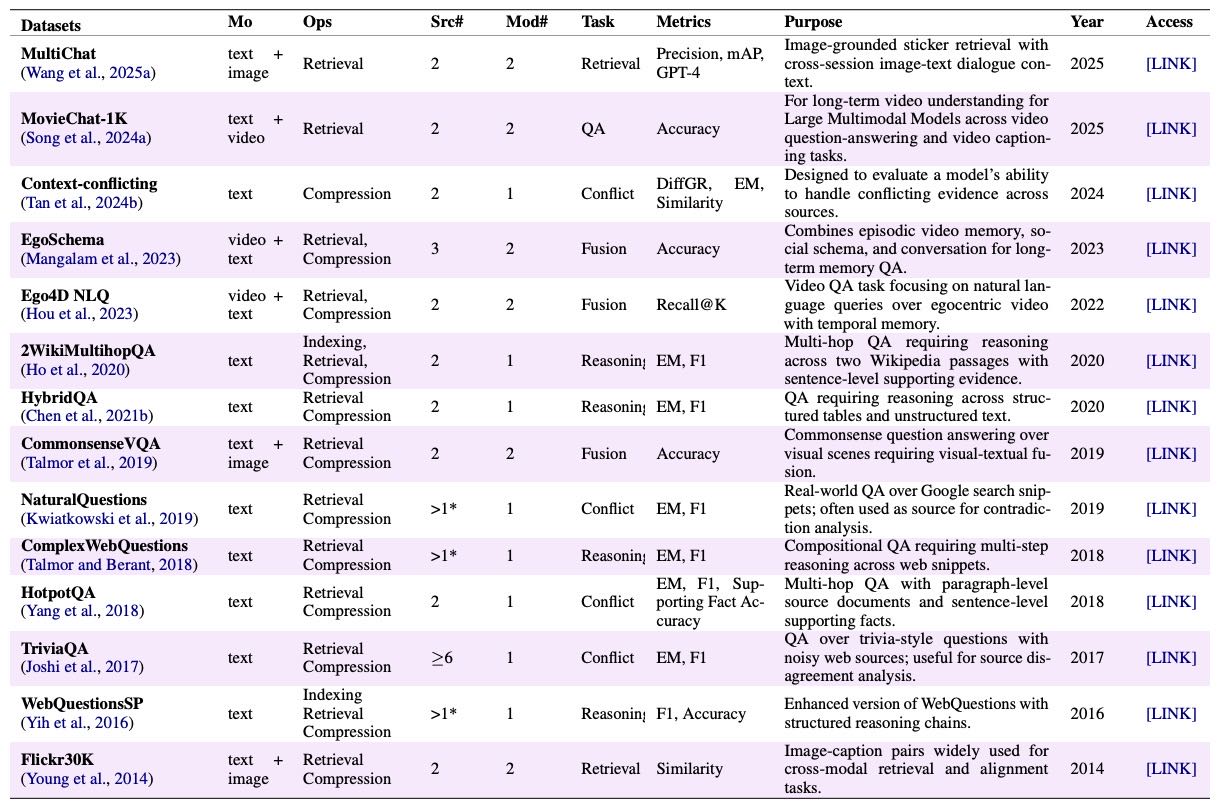
Table 7:Datasets used for evaluating multi-source memory. “Mo” denotes data modality. “Ops” indicates operations. “Src#” = number of information sources per instance; “Mod#” = number of modalities; “Task” = retrieval, fusion, reasoning, or conflict resolution.
本节核心思想: 在现实世界中,AI系统需要同时处理内部参数和多种外部知识(如数据库、图表、文本、音频、图像、视频等)。多源记忆就是研究如何让AI有效地整合和利用这些不同来源、不同格式的信息。本节从两个维度探讨其关键挑战:跨文本整合 和 多模态协调。
3.4.1 跨文本整合 (Cross-textual Integration)¶
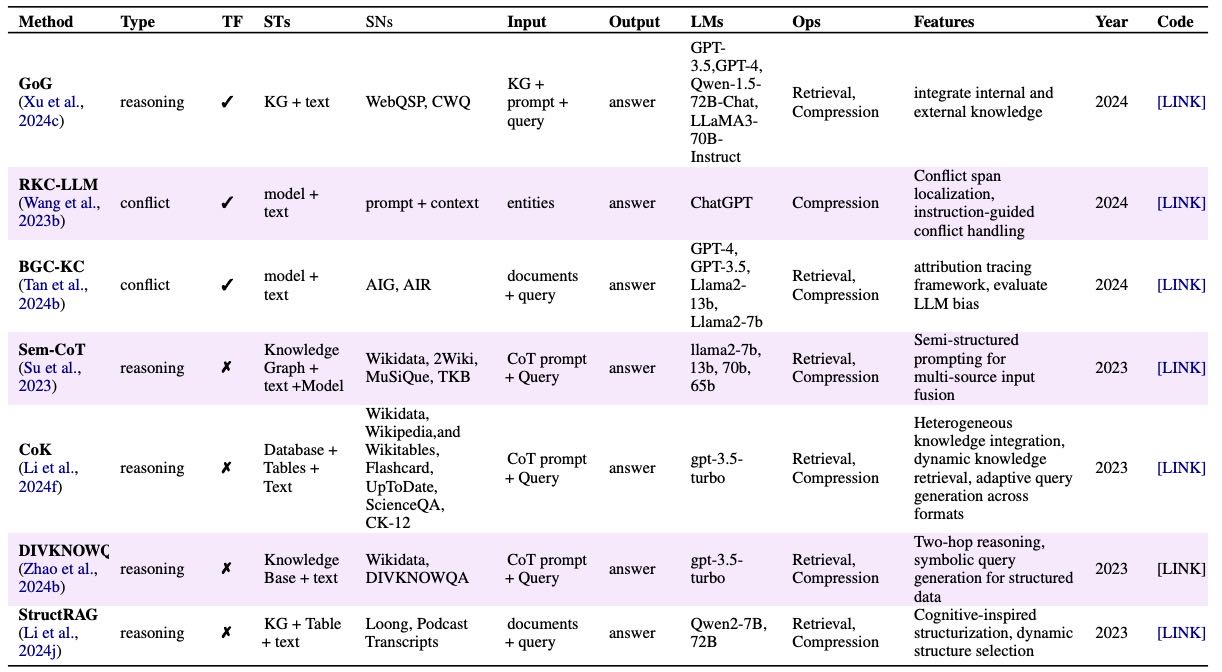
Table 15:Overview of methods for multi-source memory in cross-textual integration. “TF” (Training Free) denotes whether the method operates without additional gradient-based updates. “STs” denotes the source types. “SNs” denotes the source dataset names.
本小节核心思想: 让AI能够从多个文本来源中进行深度推理,并解决不同来源信息之间的冲突,从而给出更准确、有根据的回答。它分为两个子部分:推理 和 冲突。
推理 (Reasoning)¶
目标: 整合不同格式的记忆(如结构化的数据库和非结构化的文本),生成在事实和语义上都一致的回答。
方法分类:
操作结构化记忆: 像操作数据库一样精确地使用符号化的记忆(例如:ChatDB, Neurosymbolic)。
动态整合参数化记忆: 灵活地整合针对特定领域训练的内部模型参数(例如:EMAT)。
多文档推理: 从多个不同的文档来源中获取信息进行推理(例如:DelTA, dynamic-MT)。
异构知识整合: 同时从结构化和非结构化来源中检索信息(例如:StructRAG, GoG)。
现存挑战: 虽然已有进展,但如何实现对异构(不同质)多源记忆的统一推理仍然是一个重大挑战。特别是如何有效整合内部参数化记忆与外部知识源。
冲突 (Conflict)¶
定义: 指在检索和推理来自不同表征的记忆时,出现的事实或语义上的不一致。例如,内部模型记忆的知识与外部检索到的知识矛盾,或者数据库里的数据和文本描述对不上。
当前研究重点: 主要是识别和定位这些不一致。
RKC-LLM: 提供一个评估框架,用来测试模型发现上下文矛盾的能力。
BGC-KC: 指出模型更倾向于相信自己的内部知识,而不是检索到的内容。这说明了标明信息来源和校准信任的重要性。
现存挑战: 现有的冲突解决方法大多局限于静态场景或单源推理,还不够强大。
3.4.2 多模态协调 (Multi-Modal Coordination)¶
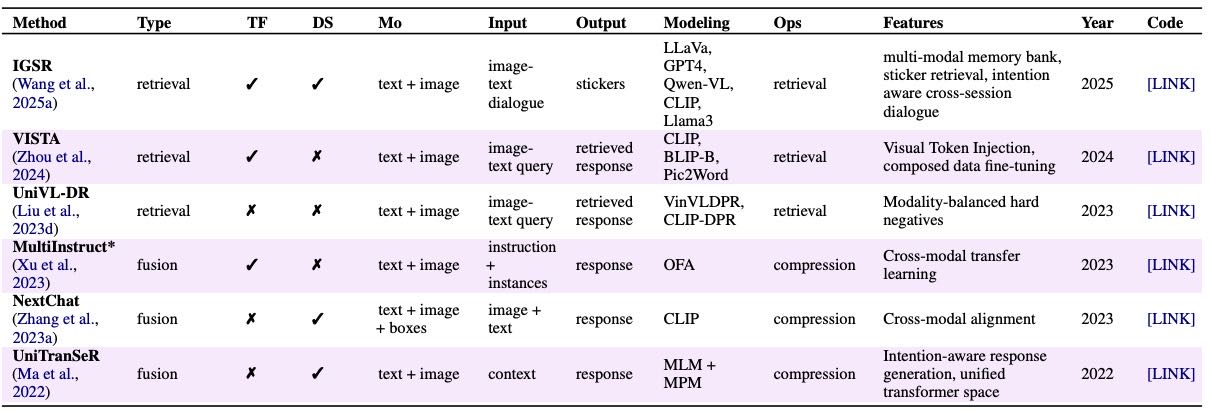
Table 16:Overview of methods for multi-source memory in Multi-modal Coordination. “TF” (Training Free) denotes whether the method operates without additional gradient-based updates. “DS” (Dialogue System) denotes whether the method aims for a dialogue task. “Mo” denotes data modality (T – Text, I – Images, B – Box (Position)).
本小节核心思想: 当记忆系统包含多种模态(如文本、图像、音频、视频)时,核心挑战在于如何融合和检索这些不同形式的信息。
融合 (Fusion)¶
定义: 将检索到的不同模态的信息进行对齐和整合。
方法分类:
统一语义投射: 将不同模态的信息(如图片、文字)映射到同一个语义空间中进行处理(例如:UniTransSeR, PaLM-E)。
长期跨模态记忆整合: 建立持久的记忆库,长期积累和整合多模态知识(例如:LifelongMemory记录病历,MA-LMM理解长视频)。
现存挑战: 当前方法在长期多模态记忆管理方面不足,例如如何动态更新记忆和保持不同来源间的一致性。
检索 (Retrieval)¶
定义: 从存储的记忆中访问跨模态的知识。
主流方法: 基于嵌入相似度计算。使用多模态模型(如CLIP, QwenVL)将不同模态的内容投射到共享的语义空间,然后计算它们的向量相似度来检索(例如:VISTA, UniVL-DR)。
进阶方法: 一些工作开始引入更多上下文,例如IGSR在多轮对话中根据“意图”来检索表情包。
现存挑战:
当前方法大多停留在浅层的相似度匹配,缺乏基于记忆的、具有推理能力的检索。
对音频和传感器信号等模态的探索仍然不足,而这些对于具身智能(如机器人)至关重要。
3.4.3 讨论 (Discussion)¶
本节是对前述内容的总结和趋势分析。
多源记忆整合趋势 (Trends in Multi-Source Memory Integration)¶
总体趋势: 领域正从静态的检索管道转向动态的、对上下文敏感的记忆系统,以支持跨任务和会话的、基于时间的推理。
跨文本整合趋势:
早期: 使用符号记忆(如数据库),通过显式查询访问,透明但扩展性差(如ChatDB)。
近期: 使用非结构化记忆和神经检索,结合注意力机制和思维链推理,但记忆仍是静态的(如StructRAG)。
最新: 走向推理感知记忆,使用检索-生成循环和智能体协作来动态演化记忆(如MATTER, GoG)。
核心挑战: 解决冲突仍然是巨大难题,信息合并缺乏一致性检查和来源标注,导致“幻觉”和事实漂移。初步的解决方案(如多步冲突解决)很有希望但尚难扩展。
多模态协调趋势:
在融合、检索和时间建模三个维度都有进展。
融合策略从联合嵌入发展到更精细的标识符记忆和跨模态图融合。
检索方法从静态相似度发展到包含时间上下文的方法(如时序图)。
关键发现: 60%的模型都编码了时间信息,说明时间在长期任务中极其重要。
操作控制变得更重要:早期的系统只关注检索,现在的新系统(如E-Agent, WorldMem)强调自我维护,能持续地更新、索引、压缩记忆内容,支持长期规划。
发表趋势 (Publication Trend)¶
跨文本推理的研究在数量上占主导。
融合研究(尤其是基于CLIP的)具有最高的引用量和影响力。
动态检索和冲突解决仍然是探索不足的领域。
未来方向 (隐含在文本中的总结)¶
开发冲突感知系统:需要能够明确标注信息来源并进行一致性验证的记忆系统。
发展自我维护架构:支持对记忆进行索引、更新和压缩,以实现长期、跨会话的记忆。
实现统一推理:将时间基础和多模态协调整合到一个统一的记忆推理框架中,以应对现实世界的长期任务。
4 Memory In Practice¶
4.1 Applications(应用场景)¶
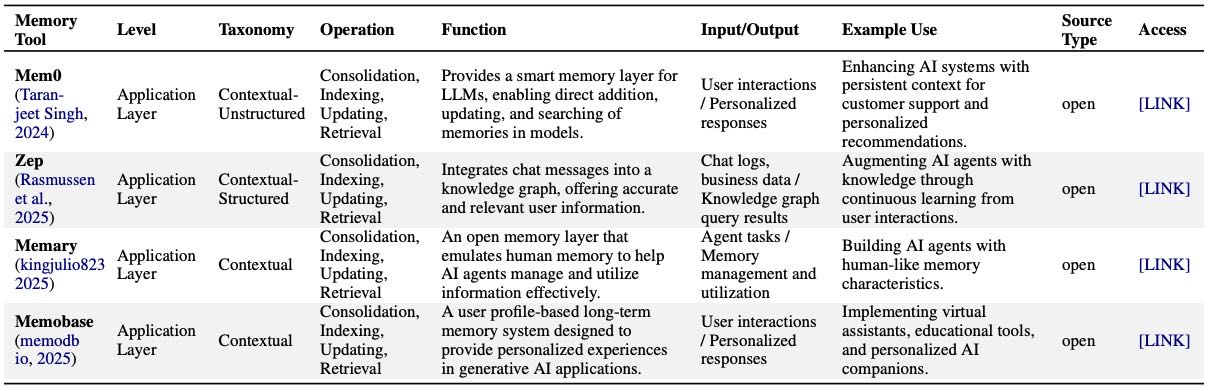
Table 19: Application Layer-Level Tools for Memory Management and Utilization.
本节主要介绍基于记忆的人工智能系统在多个实际应用场景中的应用,包括知识推理、个性化服务、任务完成和多模态交互。这些系统通过参数化记忆、结构化记忆和非结构化记忆等多种形式,支撑复杂任务的完成。
知识中心型系统(Knowledge-centric systems)借助参数化记忆(parametric memory)将通用知识编码进模型权重中,广泛应用于编程、医学、金融和法律等领域。例如,通过指令微调,模型可以执行特定领域的推理任务。
用户中心型系统(User-centric systems)依赖情境记忆(contextual memory)建模用户偏好和行为历史,实现个性化对话和自适应教学。这类系统需要持续更新记忆以适应用户的动态需求。
任务导向型系统(Task-oriented agents)使用结构化记忆(如键值存储、工作流图)来维护对话连续性,并支持长期推理,如项目管理或虚拟助手场景。
多模态系统(Multi-modal systems)融合语言、视觉、音频等模态的参数化记忆和情境记忆,在自动驾驶和医疗决策等复杂环境中实现连贯交互。
重点总结:记忆系统不是被动的存储,而是主动的推理与适应机制,对于AI系统在复杂任务中的长期胜任力和泛化能力至关重要。
4.2 Products(产品应用)¶
本节探讨了记忆在实际产品中的体现。通过结合用户建模和结构化任务管理,记忆增强了产品在个性化、连贯性和任务执行方面的能力。
用户中心型产品(User-centric products)如 Replika(AI伴侣)、Amazon 推荐系统、Me.bot和 Tencent ima.copilot,利用持久化用户模型实现情感连续性和个性化推荐。
任务导向型产品(Task-oriented products)如 ChatGPT、Grok、GitHub Copilot、Coze 和 CodeBuddy,通过结构化记忆(如对话历史和任务表示)支持多轮对话和长期任务规划。
重点总结:这些产品展示了记忆架构如何在实际系统中被部署,以实现用户长期个性化、交互连贯性以及任务自适应执行,体现出记忆集成对用户体验和系统可靠性的直接影响。
4.3 Tools(工具与框架)¶
本节介绍了一个分层的记忆增强AI工具生态系统,涵盖基础组件、模块化框架和记忆层系统,分别支持长期上下文管理、用户建模、知识保留和自适应行为。
基础组件(Components):
包括向量数据库(如 FAISS)、图数据库(如 Neo4j)和大语言模型(如 Llama、GPT-4)。
检索机制(如 BM25、Contriever、OpenAI Embeddings)用于语义访问外部记忆。
重点:这些组件是构建记忆能力的基础,如语义相似性搜索、长期上下文理解等。
模块化框架(Frameworks):
提供可配置的记忆操作接口,如 LlamaIndex、LangChain、Graphiti、Letta 等。
重点:这些框架将复杂的记忆处理流程模块化,支持开发者构建多模态、持久化、可更新的记忆模块。
记忆层系统(Memory Layer Systems):
作为“记忆服务层”,提供调度、持久化和生命周期管理,例如 Mem0、Zep、Memary、Memobase。
重点:这类系统注重时间一致性、会话/话题索引和高效记忆检索,通常结合符号与亚符号记忆表示。
更多详细信息见表:表 17(组件)、表 18(框架)、表 19(内存层系统)和表 20(产品)。每个表都描述了该工具的适用内存类型、支持的作、输入/输出格式、核心功能、使用场景和源类型。
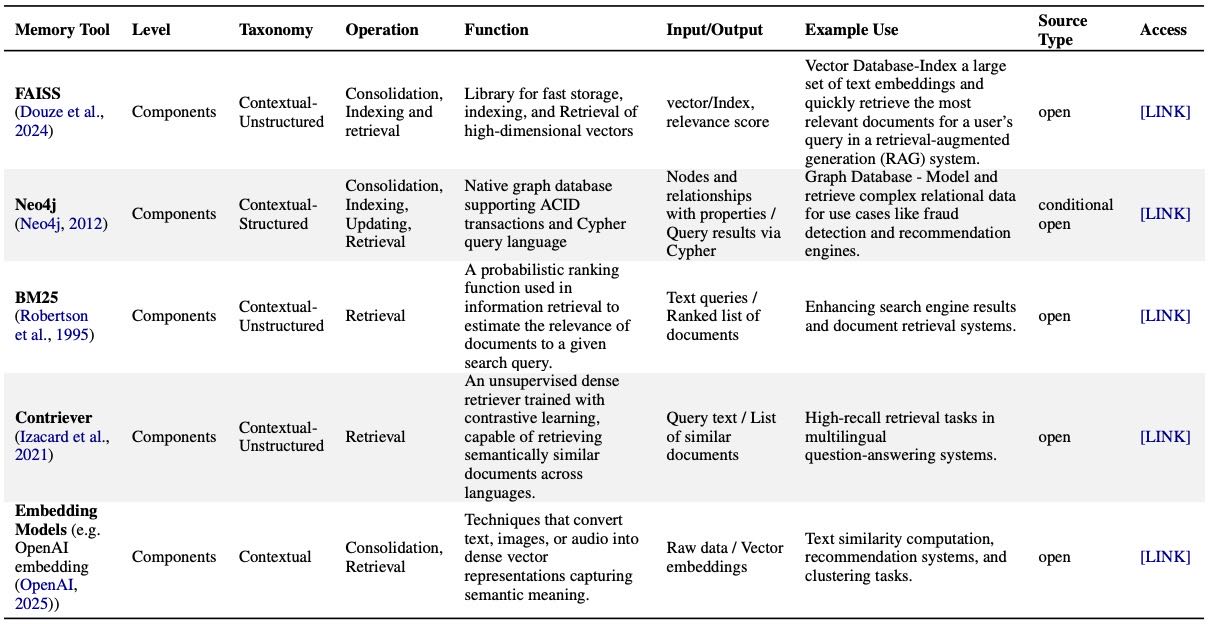
Table 17: Component-Level Tools for Memory Management and Utilization.
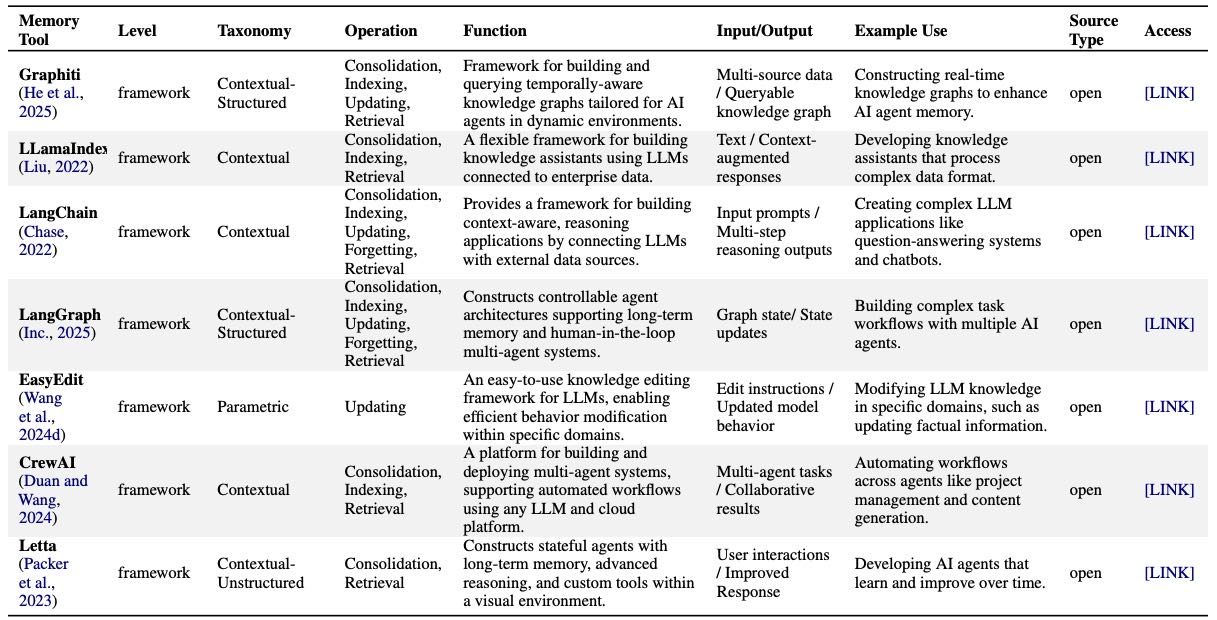
Table 18: Framework-Level Tools for Memory Management and Utilization.
总体总结:¶
第四章《Memory In Practice》从应用、产品和工具三个层面,系统性地展示了记忆在AI系统中的实践落地。重点在于说明:
记忆不仅是存储,更是推理、规划与适应的关键使能者;
不同类型的系统(知识型、用户型、任务型、多模态)对记忆的需求各不相同;
实际产品中,记忆系统通过用户建模和结构化任务管理提升用户体验;
开发工具与框架的分层生态,支持了记忆功能的高效实现与扩展。
该章为后续研究和系统构建提供了实际参考和应用方向。
5 Memory in Humans and AI Systems¶
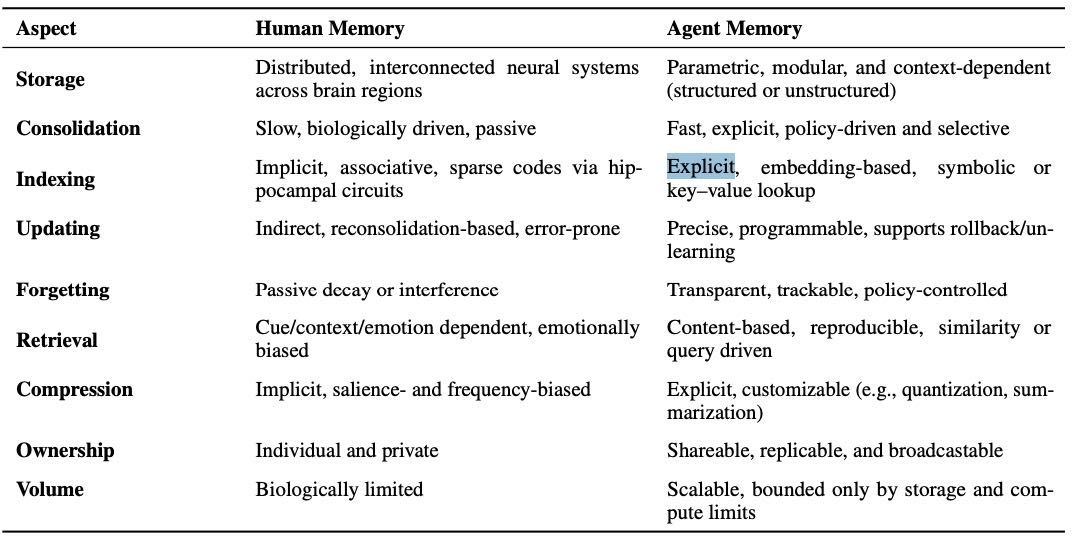
Table 2: Key differences between human and agent memory across operational dimensions.
Figure 18:Prompt for evaluating article relevance to specific task definitions.
System Instruction: Given the task and the abstract, evaluate the relevance of the abstract to the task.
Prompt Template:
"""
You are tasked with evaluating the relevance of a given article to a specific task definition.
Please read the following task definition, article title, and abstract carefully.
Based on the content, rate the relevance on a scale from 1 to 10,
where 1 means not relevant at all, and 10 means highly relevant.
Task Definition: {taskdef }
Article Title: {title}
Abstract: {abstract}
Please provide your rating in the format [[Rating]].
For example, if the relevance is high, you might respond with [[9]]. """
本节探讨人类与智能代理(AI系统)之间的记忆系统,分析其功能相似性与结构性差异。记忆系统的共同目标是支持学习、推理与决策,通过编码和检索过往信息实现这一目标。尽管人类与AI分别依赖生物体和工程架构,但它们在功能上存在显著的相似之处。
功能上的相似性¶
多时间尺度操作:两者都具备短期与长期记忆系统。人类的记忆分为工作记忆、情景记忆和语义记忆;AI系统则通过短期上下文窗口与持久的外部或参数化存储模块实现类似功能。
关联结构:两者都采用关联性结构以支持信息的检索与泛化。
多模态输入整合:人类和AI都能整合自然语言、视觉和听觉等多模态输入。
记忆系统的不完美性:两者都存在回忆错误或干扰现象。
结构与机制上的差异¶
尽管功能相似,人类与AI记忆在实现方式上存在显著差异,这些差异体现在存储、巩固、索引、检索、更新、遗忘、压缩等操作层面。为了系统呈现这些差异,文中通过表2从多个维度进行对比。
对比维度 |
人类记忆 |
代理(AI)记忆 |
|---|---|---|
存储 |
分布式、互连的神经系统 |
参数化、模块化、上下文依赖 |
巩固 |
缓慢、生物驱动、被动 |
快速、显式、策略驱动、选择性 |
索引 |
隐式、关联、稀疏编码 |
显式、基于嵌入、符号或键值查找 |
更新 |
间接、再巩固、易出错 |
精确、编程化、支持回滚/遗忘 |
遗忘 |
被动衰减或干扰 |
透明、可追踪、策略控制 |
检索 |
取决于线索/上下文/情感,具有情感偏向 |
基于内容、可重复、相似性或查询驱动 |
压缩 |
隐式、偏向显著性和频率 |
显式、可定制(如量化、摘要) |
所有 |
个体化、私有 |
可共享、可复制、可广播 |
容量 |
生物限制 |
可扩展,仅受限于存储与计算能力 |
深层次挑战与未来方向¶
随着AI系统变得愈发持久、代理导向和行为影响显著,记忆系统的设计面临更多挑战。例如:
记忆痕迹重复使用带来的行为偏移:代理的内部记忆频繁使用可能导致行为轨迹偏向某一方向,形成隐式的“身份”。
优化驱动的遗忘与压缩问题:在交互或安全关键场景中,低频但情感或社会显著的数据可能被错误删除。
冲突解决机制缺失:当前系统在处理新输入与已有记忆冲突时,依赖启发式方法,缺乏显式仲裁机制。
长期记忆管理:随着代理不断积累长期记忆,解决这些问题对于确保AI系统的对齐性、可解释性和鲁棒性变得至关重要。
总结:本章强调了人类与AI记忆系统在功能上的相似性,同时深入剖析其结构差异,并指出在AI系统发展过程中,设计更可靠、可控且符合人类价值观的记忆机制是未来研究的重点。
6 Open Challenges and Future Directions¶
本节概述了核心记忆相关主题中的开放性挑战,并提出了未来的研究方向。随后,我们探讨了更广泛的视角,包括受生物学启发的模型、终身学习、多智能体记忆和统一的记忆表示方式,这些进一步拓展了记忆系统的功能和理论基础。这些讨论共同为推进可靠、可解释且适应性强的记忆系统提供了路线图。
6.1 专题方向¶
设计以记忆为中心的AI系统需要解决核心限制和新兴需求。在RCI分析和趋势的指导下,我们概述了未来记忆研究中的关键挑战。
统一评估的必要性
当前缺乏对长期记忆中一致性、个性化和时间推理的统一评估。现有基准很少评估在动态、多会话设置中的记忆整合、更新、检索和遗忘等核心操作。这一缺口导致了“检索-生成不匹配”问题,即检索到的内容常常过时、无关或不一致。解决这些问题需要时间推理能力、结构感知生成以及稳健的检索系统,同时支持个性化复用和跨会话的自适应记忆管理。
长上下文处理:效率与表达性的平衡
扩展记忆长度加剧了计算成本与建模保真度之间的权衡。KV缓存压缩和重复利用等技术可以提高效率,但可能带来信息丢失或不稳定的风险。另一方面,复杂环境中的推理(尤其是在多源或多模态设置中)需要选择性上下文整合、源区分和注意力调控。未来需要机制来平衡上下文带宽与任务相关性及稳定性之间的关系。
参数化记忆修改的研究
尽管参数化记忆修改前景广阔,但仍需进一步研究提升其控制性、删除能力和可扩展性。当前的编辑方法缺乏特异性,而像TOFU这样的“遗忘”基准过于简单,难以揭示真实限制。大多数方法难以扩展到数千次以上的编辑,且不支持超过20B参数的模型。此外,终身学习研究仍不充分。未来的工作应开发更现实的基准,提高效率,并将编辑、遗忘和持续学习统一到一个框架中。
多源整合:一致性、压缩与协调
现代智能体依赖异构记忆(结构化知识、非结构化历史和多模态信号),但面临冗余、不一致和来源模糊的问题。这些问题源于时间范围不一致、语义冲突和归属缺失,尤其在跨模态时更为严重。解决这些问题需要冲突解决、时间定位和来源追踪。在多会话设置中,高效的索引和压缩对于可扩展性和可解释性也至关重要。
6.2 更广泛的视角¶
除了上述核心主题外,一些更广泛的视角正在兴起,进一步丰富了以记忆为中心的AI研究领域。
时空记忆
时空记忆不仅捕捉信息之间的结构关系,还捕捉其时间演化,使智能体能够适应性地更新知识,同时保留历史上下文。例如,一个AI系统可以记录用户曾不喜欢西兰花,但基于最近的购买行为调整记忆。通过维护对历史和当前状态的访问,时空记忆支持基于时间的推理和细致的个性化。然而,如何高效地管理并推理长期时空记忆仍然是关键挑战。
参数知识的检索
尽管最近的研究声称可以定位并修改特定表示,但如何使模型从自身参数中选择性地检索知识仍是一个开放问题。如果能高效地检索和整合潜在知识,将显著提高记忆利用率,并减少对外部索引和记忆管理的依赖。
终身学习
智能体需要持续集成新信息,同时保留旧知识,因此需要具有稳定性和可塑性的记忆系统。参数记忆能使模型在权重中进行知识适应,但容易遗忘;结构化记忆(如知识图谱、表格)支持模块化和有针对性的更新。而非结构化记忆(如向量存储、原始对话历史)提供灵活检索,但需要动态压缩和相关性过滤。在持续学习框架下整合这些记忆类型,并采用巩固、选择性遗忘和交错训练等机制,是构建具备长期记忆管理能力的自适应、个性化终身智能体的关键。
受生物学启发的记忆设计
生物系统中的记忆机制为构建更具弹性和适应性的AI记忆架构提供了重要启示。大脑通过互补学习系统(海马体负责快速变化的事件记忆,皮层负责慢速整合的长期记忆)来应对稳定性和可塑性之间的矛盾。受此启发,AI模型越来越多地采用双记忆架构、突触巩固和经验回放机制来减少遗忘。认知概念如记忆再巩固、记忆容量限制和模块化知识也为更新感知的回忆、高效存储和上下文敏感泛化提供了策略参考。
K-Line理论与层级记忆
Minsky提出的K-Line理论指出,层级记忆结构是生物认知的基础,使人类能够高效地在不同抽象层次上组织记忆。例如,婴儿会将“苹果”和“香蕉”归类为“水果”或“食物”等更高层次的类别。在AI中,采用层级结构来组织记忆面临新的挑战,需要更高效和可扩展的记忆管理方法。
统一的记忆表示
参数化记忆提供紧凑隐式的知识存储,而外部记忆提供显式可解释的信息。统一它们的表示空间并建立联合索引机制,对于有效的记忆整合和检索至关重要。未来的研究可聚焦于开发统一的记忆表示框架,支持跨模态和知识形式的共享索引、混合存储和记忆操作。
多智能体系统中的记忆
在多智能体系统中,记忆不仅是个人的,也是分布式的。智能体需要管理自身记忆,同时与其他智能体互动学习。这带来了一些独特挑战,如记忆共享、对齐、冲突解决和一致性。有效的多智能体记忆系统应支持个性化经验的本地保留和通过共享记忆空间或通信协议的全局协调。未来的研究方向可能包括去中心化记忆架构、跨智能体记忆同步和集体记忆整合,以支持协作规划、推理和长期协调。
记忆威胁与安全性
尽管记忆显著增强了大语言模型的实用性和个性化能力,但其管理仍是一个关键的安全问题。记忆通常存储敏感和机密数据,使得添加或删除信息绝非易事。近期研究揭示了记忆处理中的严重漏洞,尤其是在旨在选择性删除数据的“机器遗忘”技术中。多项研究已证明这些方法容易受到恶意攻击,因此,更安全和可靠的记忆操作机制变得尤为重要。
Appendix A GPT-based Pipeline Selection¶
为了在大规模上进行与本研究分类法相一致的相关性过滤,作者设计了一条基于GPT的评分流水线。其目的是评估论文摘要与预定义任务定义之间的匹配程度(可参考表3)。每篇摘要都会与其对应的任务定义配对,并由模型在1到10的评分尺度上进行评分,评分≥8的论文被视为高度相关,从而被保留下来以进行进一步分析。
在选择评分模型时,作者采用了GPT-4o-mini。这是由于该模型在性能和效率之间取得了良好的平衡。尽管GPT-4o-mini的架构较为轻量,但它表现出色的零样本推理能力,使其在超过3万篇论文的摘要层面的主题相关性估计中既经济又准确。
最后,用于该评估过程的具体提示格式如图18所示。
Table 3: Definitions and features of the five memory-centric evaluation topics.
Topic Name |
Definition in Prompt |
|---|---|
Long-Term Memory |
Definition: Creating systems that ensure knowledge from past interactions remains accessible as new tasks emerge, maintaining continuity in multi-turn conversations. |
Long-Context |
Definition: Efficiently processing, interpreting, and utilizing very long input sequences without performance degradation. |
Parametric Memory Modification |
Definition: Managing and updating internal parameters to preserve accuracy, privacy, and adaptability without full retraining. |
Multi-Source |
Definition: Integrating and harmonizing diverse data types into a unified framework while resolving inconsistencies. |
Personalization* |
Definition: Building user-centric memory systems that adapt to individual preferences and history while preserving privacy. |
主题 |
定义与特征 |
|---|---|
长期记忆 |
确保过去交互的知识在新任务中仍可访问,支持连续对话。特征包括记忆存储、检索和归因。 |
长上下文 |
高效处理长输入序列,防止性能下降。特征包括优化注意力、上下文压缩和“中间丢失”问题缓解。 |
参数修改 |
通过更新模型内部参数来保留准确性、隐私和适应性,无需完全重训练。特征包括选择性遗忘、精确编辑、知识蒸馏等。 |
多源记忆 |
整合多种数据类型,解决不一致问题。特征包括多模态融合、语义一致性、冲突解决等。 |
个性化 |
构建以用户为中心的记忆系统,适应用户偏好和历史,同时保障隐私。特征包括隐私敏感的用户画像和长期一致性。 |
Appendix B Relative Citation Index¶
在本研究中,我们采用 **相对引用指数(Relative Citation Index, RCI)**来识别具有影响力的论文。该指标的灵感来源于RCR(Relative Citation Ratio),旨在通过考虑论文的发表年限来估计其预期引用次数,从而避免因发表时间不同而导致的原始引用次数偏差。
一、论文的“年龄”定义¶
论文的“年龄” \(A_i\) 定义为:
\(T\) 是引用数据收集的日期(本研究中为 2025 年 4 月 20 日);
\(\text{Year}_i\) 是论文 \(i\) 的首次发表年份。
二、构建引用–年龄关系模型¶
为了建模引用次数 \(C_i\) 与论文“年龄” \(A_i\) 之间的关系,研究尝试了三种模型:
线性模型(Linear): $\( C_i = \beta + \alpha A_i \quad \text{(公式 8)} \)$
指数模型(Exponential): $\( C_i = \exp(\beta + \alpha A_i) \quad \text{(公式 9)} \)$
对数–对数回归模型(Log-Log): $\( \log(C_i + 1) = \beta + \alpha \log A_i + \epsilon_i \quad \text{(公式 10)} \)$
其中,\(\beta\) 和 \(\alpha\) 为模型参数,\(\epsilon_i\) 为误差项。
三、数据收集与预处理¶
研究收集了 2022 至 2025 年间顶级 NLP 和 ML 会议(ACL、NAACL、EMNLP、NeurIPS、ICML、ICLR)的论文数据,共计 3,932 篇有效论文。为了减少不同研究领域的偏差,使用 GPT 评估论文与本研究中四个挑战的关联性,仅保留评分 8 分及以上 的论文。
论文的发表日期信息来自 Semantic Scholar API,若缺失则使用会议第一天作为发表日期。
四、模型选择与结果¶
通过拟合所有论文的引用次数与“年龄”关系,发现 对数–对数回归模型(Log-Log)表现最优:
拟合效果最佳,几乎完美地反映了引用中位数随时间的变化;
该模型保证论文刚发表时预期引用为 0,符合直觉。
最终估计的模型参数为:
\(\hat{\beta} = 1.878\)
\(\hat{\alpha} = 1.297\)
由此可计算任意论文 \(i\) 的预期引用次数(公式 11):
五、相对引用指数(RCI)的计算¶
相对引用指数(RCI)定义为实际引用次数与预期引用次数的比值(公式 12):
若 \(RCI_i \geq 1\),表示论文比预期引用次数更高,认为其影响力较大;
本研究重点关注 \(RCI \geq 1\) 的论文。
图 15 展示了不同“年龄”论文的引用分布,红色曲线表示模型预测的引用中位数。RCI 大于等于 1 的论文位于中位数以上,其影响力更高。
六、RCI 与研究趋势分析¶
结合 RCI 指数与论文发表数量的变化趋势,研究进一步分析了不同“记忆相关”研究主题的发展动态(见图 16 和 17)。
图 16:各主题的中位 RCI 分布¶
2023 年是关键转折点,随着大语言模型(LLMs)的兴起,长上下文(long-context) 和 参数化记忆(parametric memory) 的论文数量和质量同时提升,表明 LLM 推动了这两个领域的迅速发展。
相比之下,长期记忆(long-term memory) 和 多源记忆(multi-source memory) 的影响力较为稳定,未出现突破性进展。
图 17:各主题的论文数量与 RCI 趋势¶
所有主题的论文数量均显著增长,其中“长上下文”从 2022 年前的最少主题之一,成长为 2024 年的最热门主题。
长期记忆 的 RCI 逐步上升,反映其研究价值不断提升;
其他主题在 2023 年后的 RCI 中位数有所下降,但整体影响力仍维持在较高水平。
这些趋势表明,大模型的出现显著推动了记忆相关研究的进展,尤其是在长上下文和参数化记忆领域。
总结¶
本附录详细介绍了如何通过构建 相对引用指数(RCI)来衡量论文的影响力,重点模型选择为对数–对数回归模型,并结合论文发表趋势分析了不同“记忆”研究主题的发展轨迹。研究发现,大语言模型的兴起对长上下文和参数化记忆领域的影响最为显著,而其他领域则保持了相对稳定的影响力。
Appendix C Chord Analysis of Interactions Among Memory Types, Operations, Topics, and Venues¶
本文通过**弦状图(Chord diagram)**的方式,从两个角度对记忆研究进行了分析:
记忆类型、操作与研究主题之间的交互关系;
这些交互在主要机器学习(ML)和自然语言处理(NLP)会议中的分布情况。
C.1 记忆类型、操作与主题之间的交互分析¶
作者从 132 篇 RCI ≥ 1 的方法类论文 中提取数据,生成了最终的弦状图(图19),直观展示了不同类型、操作与研究主题之间的联系。
1. 记忆类型视角(Memory Types)¶
研究重点:当前研究主要集中于 参数记忆(parametric memory) 和 上下文非结构化记忆(contextual unstructured memory),特别是这几个操作:压缩(compression)、检索(retrieval)、遗忘(forgetting)和更新(updating)。
相对冷门领域:上下文结构化记忆(contextual structured memory) 研究较少,可能是因为大语言模型(LLMs)更擅长处理序列文本,对结构化输入的处理效果较差。
2. 操作视角(Operations)¶
研究热点:压缩与检索是最常研究的操作,它们是大多数研究中使用记忆的基础操作。
较冷门操作:索引(indexing) 关注较少,这可能是因为目前研究大多聚焦在如何使用记忆,而非如何高效组织记忆。
整合(consolidation):多指通过训练将知识存储到模型参数中,或者将知识转化为固定格式的外部记忆。
更新与遗忘:主要与参数调整和知识删除相关,尤其是参数记忆中。这些方向的目标是基于外部输入增量地修改模型参数,但由于模型内部的“黑箱”性质,相关研究仍处于早期探索阶段。
3. 主题视角(Topics)¶
参数修改:主要集中在参数记忆,有些研究尝试通过持续学习(continual learning) 来调整参数。
长上下文:主要涉及非结构化记忆中的压缩与检索,部分研究使用了键值缓存(key-value caches) 等参数化形式。
长期记忆:也集中在非结构化记忆,尤其是整合、压缩与检索。
多源记忆:研究较少,且通常涉及结构化与非结构化信息的整合。然而,多源记忆面临异构信息冲突的挑战,目前仍缺乏有效的整合策略。
总结与研究方向¶
结构化记忆与非结构化记忆的结合:当前对上下文结构化记忆的研究较少,未来可以探索如何将其与非结构化记忆结合,实现更完整的记忆操作。
多源记忆的整合:尽管挑战较大(如异构来源引发的记忆冲突),但设计鲁棒且一致的多源记忆整合策略是一个有前景的研究方向。
索引机制的探索:虽然索引在传统数据库系统中研究广泛,但在基于大语言模型的智能体中,相关研究仍然很少。由于记忆类型的复杂性与对向量化或稀疏检索方法的需求,需要为LLM推理和交互设计新的索引方法。
此附录章节通过弦状图展示了当前记忆研究的核心方向与潜在的研究空白,为进一步探索记忆机制提供了清晰的路线图。
C.2 Memory Interactions Across Conference Venues¶
本节内容主要探讨了不同会议领域中记忆操作与主题的交互情况,并结合会议论文、数据集和方法对记忆系统的运行、发展趋势以及潜在的研究方向进行了分析。
1. 不同会议中的操作分布¶
ML会议(如 ICLR、ICML、NeurIPS)更关注压缩(Compression)、遗忘(Forgetting)、更新(Updating)等操作,这些操作更多处于理论探索阶段,尚未广泛应用于实际系统。
NLP会议(如 ACL、EMNLP、NAACL)更侧重于检索(Retrieval)和巩固(Consolidation),这些操作更偏向实际应用。
索引(Indexing)在ML和NLP会议中都较为少见,可能是因为其与检索高度相关,且当前多采用向量索引方法,缺乏创新性。
2. 不同会议中的主题分布¶
长期记忆(Long-Term Memory)更常出现在NLP会议上,这可能与NLP更注重用户对话的延续性有关。
长上下文(Long-Context)更常见于ML会议,强调处理长输入序列及中间语义丢失的问题。
参数修改(Parametric Memory Modification)在ML会议中出现频率较高。
多源记忆(Multi-Source Memory)在NLP会议中更常见,反映了实际系统中多数据源整合的挑战。