2501.00332_MAIN-RAG: Multi-Agent Filtering Retrieval-Augmented Generation¶
引用: 36(2026-01-17)
组织:
Texas A&M University
Visa Research
总结¶
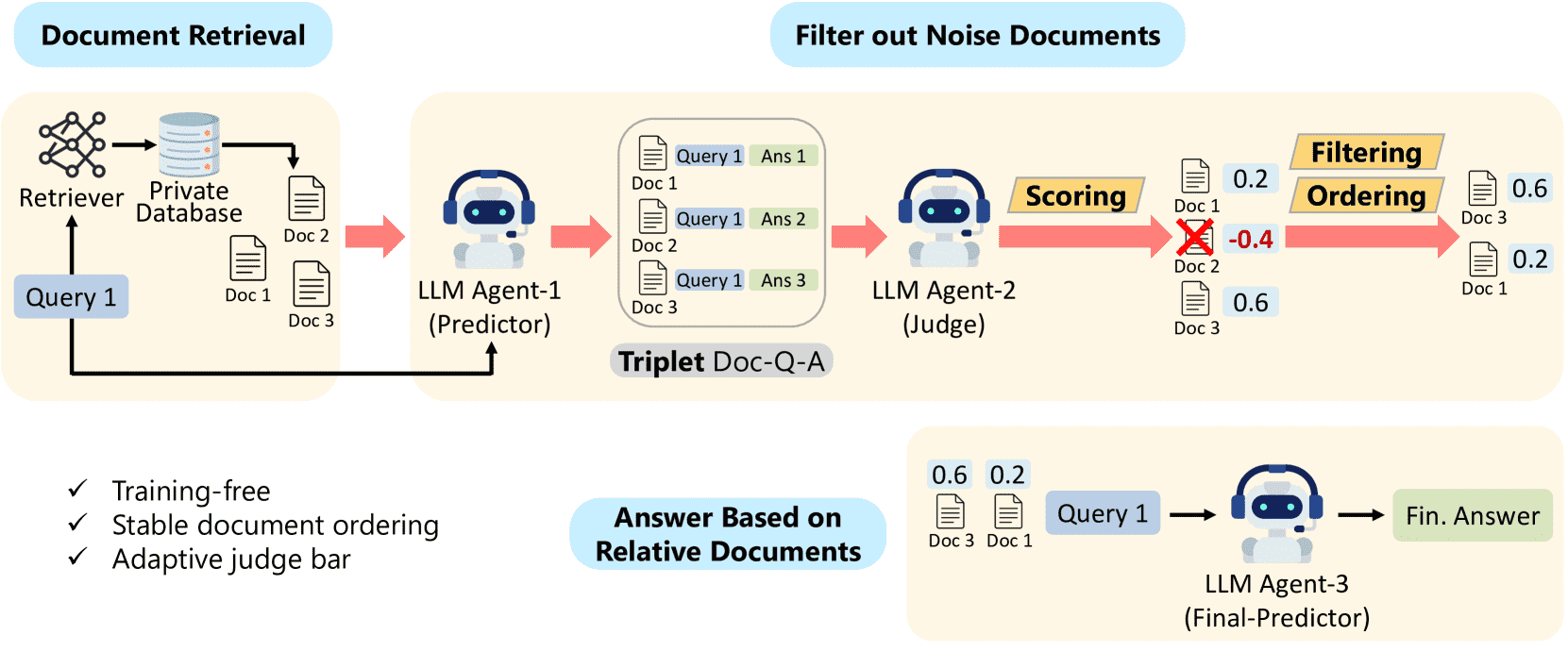
Figure 1:An overview of the proposed framework MAIN-RAG

Figure 11: System instructions of Agent-1 (Predictor), Agent-2 (Judge), and Agent-3 (Final-Predictor)
From Moonlight¶
三句摘要¶
✨ 这篇论文提出了一种名为 MAIN-RAG 的训练无关型 RAG 框架,旨在解决现有 RAG 系统中不相关或噪声文档影响性能的问题。
⚙️ MAIN-RAG 利用多个 LLM 代理(Predictor、Judge 和 Final-Predictor)协同过滤和评分检索到的文档,并引入了一个自适应过滤机制,根据文档得分分布动态调整相关性阈值。
📈 在四个 QA 基准测试中,MAIN-RAG 显著优于传统 RAG 方法,实现了 2-11% 的答案准确性提升,同时减少了不相关文档的数量,并表现出卓越的响应一致性。
关键词¶
Large Language Models (LLMs): 大型语言模型(LLMs)是处理各种自然语言处理任务的基础工具,但它们常因生成过时或不正确的信息(即“幻觉”)而受到限制。这些模型在问答、摘要和文本生成等方面表现出色,但依赖预训练的静态数据导致其在需要准确、最新和上下文相关回答的应用(如医疗、法律和客户支持)中存在严重问题。
Retrieval-Augmented Generation (RAG): 检索增强生成(RAG)是一种通过整合外部、实时信息检索来为大型语言模型(LLMs)的响应提供依据的解决方案,以减轻LLMs生成过时或不正确信息的问题。它结合了参数化知识(LLMs本身)和非参数化知识(检索到的外部文档),从而提升生成内容的准确性和时效性。
MAIN-RAG: MAIN-RAG(Multi-Agent Filtering Retrieval-Augmented Generation)是本文提出的一个新颖的、无需训练的RAG框架,旨在通过利用多个LLM代理协同过滤和评估检索到的文档,来增强RAG系统的性能和可靠性。它专注于在检索阶段之后,通过智能过滤机制来减少不相关或有噪声的文档,从而提高生成答案的准确性。
Multi-Agent Filtering: 多智能体过滤是一种应用于MAIN-RAG框架中的核心技术,它利用多个大型语言模型(LLM)代理协同工作,对检索到的文档进行过滤和评分。这种方法通过代理间的共识来确保文档的稳健选择,而无需额外的训练数据或模型微调,旨在识别并剔除可能误导LLM生成不准确答案的“噪声”文档。
Adaptive Judge Bar (τq): 自适应判断阈值(τq)是MAIN-RAG框架中的一个关键机制,用于动态调整过滤噪声文档的标准。它基于检索到的文档的分数分布,特别是相关文档和噪声文档的分数分布特性,来计算一个查询特有的阈值。该阈值能够根据查询的特点自适应地调整,以在最大限度地减少噪声的同时,保持对相关文档的高召回率,从而实现更有效的文档过滤。
Noisy Documents: 噪声文档是指在检索阶段被检索出来,但对回答查询没有帮助,甚至是误导性的文档。这些文档可能包含不相关的信息、事实错误,或者与查询的关联度非常低。在RAG系统中,存在噪声文档会降低LLM的响应准确性,增加计算开销,并损害系统的可靠性。MAIN-RAG框架的主要目标就是识别并过滤掉这些噪声文档。
LLM Agents: LLM代理是指在MAIN-RAG框架中扮演特定角色的独立的大型语言模型实例。该框架包含三个主要的LLM代理:Agent-1(预测器),负责根据每个文档生成潜在答案;Agent-2(判断器),负责评估文档与查询-答案三元组的相关性,并量化为相关性分数;Agent-3(最终预测器),负责使用过滤和排序后的文档来生成最终答案。
Training-free: 无需训练(Training-free)是MAIN-RAG框架的一个重要特性。这意味着该框架在部署和使用时,不需要对模型进行额外的训练或微调。它直接利用预训练好的LLMs作为其代理,通过精心设计的提示(prompting)和协作机制来完成文档过滤和增强生成任务,这使得它更加灵活、高效且易于应用。
摘要¶
MAIN-RAG (Multi-Agent Filtering Retrieval-Augmented Generation) 是一项针对 RAG (Retrieval-Augmented Generation) 系统中检索文档质量问题的训练无关 (training-free) 框架。当前 RAG 系统常因检索到不相关或噪声文档而导致性能下降、计算开销增加及响应可靠性降低。MAIN-RAG 通过引入多个人工智能代理 (LLM agents) 协作过滤和评分检索到的文档,以解决这些挑战,旨在提高答案准确性并减少不相关文档的数量。
核心方法 (Core Methodology): MAIN-RAG 的核心是一个三代理协作流程,用于在检索阶段之后、最终答案生成之前,对文档进行噪声过滤和排序。
Agent-1 (Predictor):
作用: 为每个检索到的文档针对给定查询生成一个初步答案。
流程: 对于一个查询 \(q\) 和从数据库中检索到的文档集合 \(D_q = \{d_1, d_2, \ldots, d_N\}\),Agent-1 会分别读取每个文档 \(d_i\) 并尝试回答 \(q\)。
输出: 生成一系列 (文档-查询-答案) 三元组 (Doc-Q-A Triplet),形式为 \((d_i, q, A_i)\),其中 \(A_i\) 是 Agent-1 基于文档 \(d_i\) 对查询 \(q\) 给出的答案。
Agent-2 (Judge):
作用: 评估每个 Doc-Q-A 三元组中文档对查询和答案的相关性,并量化其支持度。
流程: Agent-2 接收每个 \((d_i, q, A_i)\) 三元组。它被引导判断两个条件是否满足:(1) 文档 \(d_i\) 是否提供了回答查询 \(q\) 的具体信息;(2) Agent-1 生成的答案 \(A_i\) 是否直接基于文档 \(d_i\) 回答了查询。Agent-2 需以 “Yes” 或 “No” 作答,并提供判断依据。
量化相关性: 为了将 Agent-2 的自然语言判断量化为数值评分,该框架计算 “Yes” 和 “No” 这两个词的对数概率之差。具体来说,对于每个文档 \(d_i\),其相关性得分 \(r_i\) 计算公式为: $\(r_i = \log P(\text{"Yes"}\ |\ \text{Doc-Q-A}_i) - \log P(\text{"No"}\ |\ \text{Doc-Q-A}_i)\)\( 其中 \)P(\text{“Yes”}\ |\ \text{Doc-Q-A}_i)\( 和 \)P(\text{“No”}\ |\ \text{Doc-Q-A}_i)\( 分别是 Agent-2 在给定三元组 \)\text{Doc-Q-A}_i$ 的条件下,输出 “Yes” 和 “No” 标记的对数概率。正值表示文档更可能支持查询,负值则相反。
自适应判决阈值 \(\tau_q\) (Adaptive Judge Bar):
作用: 根据检索文档的相关性得分分布动态调整过滤阈值,以有效去除噪声同时保持相关文档的高召回率。
计算: 观察发现,相关文档的得分分布偏高且标准差较小,而噪声文档的得分分布更均匀且标准差较大。基于此偏向性,MAIN-RAG 提出使用当前查询 \(q\) 所有检索文档的相关性得分的平均值作为自适应判决阈值 \(\tau_q\)。即 \(\tau_q = \text{mean}(R)\),其中 \(R = [r_1, r_2, \ldots, r_N]\) 是所有文档的相关性得分。
灵活性: 为了增加灵活性,该框架还允许调整阈值,例如使用 \(\tau_q - n \cdot \sigma\),其中 \(\sigma\) 是得分的标准差,\(n\) 是一个超参数,允许在需要时放宽过滤条件,防止遗漏关键信息。
过滤与排序: 只有得分 \(r_i \ge \tau_q\) 的文档才会被保留,形成过滤后的集合 \(D_{filtered_q}\)。这些保留的文档会根据其相关性得分降序排列,因为研究表明 LLM 更倾向于处理输入开头的信息。
Agent-3 (Final-Predictor):
作用: 利用过滤并排序后的文档列表生成最终答案。
流程: Agent-3 接收经过 Agent-2 过滤和排序后的文档列表 \(D_{filtered_q}\),并基于这些精选文档回答原始查询 \(q\)。
主要贡献与优势 (Key Contributions and Advantages):
训练无关的多代理过滤: 引入一种无需额外训练的多代理框架,通过代理间的共识来过滤和排序检索文档,提升检索精度和 RAG 可靠性。
动态自适应过滤机制: 采用自适应阈值机制,根据查询特定的得分分布动态调整过滤标准,有效降噪同时保持高召回率。
实证验证: 在四个 QA 基准测试中,MAIN-RAG 持续优于传统 RAG 方法,实现了 2-11% 的答案准确率提升,并减少了不相关检索文档的数量。
实验结果 (Experimental Results): 实验在 ARC-Challenge (封闭式 QA)、TriviaQA (开放域 QA)、PopQA (开放域 QA) 和 ALCE-ASQA (长文本生成 QA) 等四个 QA 基准上进行。结果显示,与不带检索和训练无关的基线模型相比,MAIN-RAG (使用 Mistral-7B 或 Llama3-8B 作为代理) 在所有基准上均表现出显著优势。例如,在 PopQA 数据集上,MAIN-RAG 展现出特别大的优势,因为该数据集的问题高度依赖外部知识,而原始检索器可能检索到大量噪声文档。与部分训练型基线 (如 Self-RAG) 相比,训练无关的 MAIN-RAG 也能缩小性能差距,甚至在某些指标上表现更优。消融实验证实了自适应判决阈值 \(\tau_q\) 的有效性以及降序排列文档的重要性。
局限性 (Limitations):
当前研究主要集中于 RAG 工作流下的 LLM 推理,并未探讨 RAG 或提示语言模型的其他研究问题,例如上下文压缩、文档位置和排序、解码方法。
检索器和重排序器的选择与本文的主要研究方向正交。
LLM 推理的碳排放问题是潜在的环境风险,作者旨在通过减少重复实验和实施受控实验设置来缓解。
Abstract¶
本论文提出了一种无需训练的检索增强生成(RAG)框架——Multi-Agent Filtering Retrieval-Augmented Generation(MAIN-RAG),旨在解决现有RAG系统中因检索文档质量不高而导致的性能下降、计算开销大和回答不可靠的问题。
核心内容讲解:¶
问题背景:
大型语言模型(LLMs)在自然语言处理任务中广泛应用,但存在生成过时或错误信息的问题。
检索增强生成(RAG)通过引入外部实时信息来提升LLMs的回答质量。
然而,现有RAG系统在检索文档质量方面存在挑战,如检索到的文档包含无关或噪声信息,影响性能。
本文贡献(MAIN-RAG):
提出一种多智能体协同过滤机制,无需训练即可提升检索文档质量。
引入自适应过滤机制,根据评分分布动态调整相关性阈值,从而在保留高召回率的同时有效去除噪声。
利用多LLM代理之间的共识机制,确保文档选择的鲁棒性,无需额外数据或微调。
实验结果:
在四个问答基准数据集上进行测试,MAIN-RAG相比传统RAG方法,回答准确率提升了2%~11%。
显著减少了检索到的无关文档数量。
定量分析显示,MAIN-RAG在回答一致性和准确性方面优于基线方法,是一种具有竞争力的实用解决方案。
小结:¶
本摘要清晰地阐述了MAIN-RAG的设计动机、核心机制和实验优势,强调其无需训练、高效过滤、提升准确率的特点,为当前RAG系统的改进提供了新思路。
1 Introduction¶
背景与问题¶
本节介绍了大型语言模型(LLMs)在自然语言处理(NLP)中的广泛应用,例如问答、摘要和文本生成。然而,LLMs依赖于静态的预训练数据,导致生成内容可能过时或不准确,这种现象被称为“幻觉”(hallucination)。这一问题在需要高准确性和时效性的领域(如医疗、法律和实时客服)尤为突出。
解决方案:检索增强生成(RAG)¶
为了解决上述问题,检索增强生成(RAG)被提出,通过引入实时文档检索机制,使LLMs的回答基于外部可靠知识。RAG方法分为两类:
训练型方法:如 Guu et al. (2020)、Karpukhin et al. (2020)、Wang et al. (2023),性能较强,但需要大量计算资源和训练时间。
无需训练的方法:如 Ram et al. (2023)、Li et al. (2023b)、Jiang et al. (2023b),更简单高效,但其效果依赖于检索文档的质量。
问题与挑战¶
现有RAG方法面临的主要挑战是检索文档中存在噪声或无关内容,这会:
降低回答准确性
增加计算开销
降低系统可靠性
因此,亟需一种有效机制来过滤和排序检索结果。
提出的方法:MAIN-RAG¶
本文提出了一种无需训练的多智能体过滤框架——MAIN-RAG,用于提升RAG系统的性能与可靠性。该框架不依赖模型训练,而是通过多个LLM代理(Agent)协作筛选文档,确保仅使用高质量内容生成回答。
框架结构(如图1所示)¶
MAIN-RAG由三个LLM代理组成:
Agent-1(Predictor):对每个查询生成初步答案。
Agent-2(Judge):评估“文档-问题-答案”三元组,判断文档是否有助于回答问题,并给出相关性评分。
Agent-3(Final-Predictor):基于过滤后的文档列表生成最终答案。
核心机制¶
动态自适应过滤机制:根据检索文档的评分分布动态调整相关性阈值,实现有效去噪,同时保持高召回率。
主要贡献¶
无需训练的多智能体过滤机制:通过多个LLM代理协作筛选和排序文档,提升检索精度和RAG系统的可靠性。
动态自适应过滤机制:根据查询特定的评分分布调整阈值,增强系统对不同任务的适应能力。
多基准验证:在四个问答数据集上进行实验,结果表明MAIN-RAG相比基线方法提升了2-11%的答案准确率,并有效减少了无关文档的引入。
总结¶
MAIN-RAG通过引入多智能体协作机制和动态过滤策略,解决了RAG系统中检索文档质量不高的问题,提供了一种高效、无需训练的解决方案,适用于需要高准确性和实时性的实际应用场景。
2 Preliminaries¶
2.1 符号与目标(Notations and Objectives)¶
本节介绍了RAG系统的基本结构和目标:通过过滤检索到的噪声文档,提升回答的准确性。
每个查询 \( q \in \mathcal{Q} \) 会通过检索器模型检索出一组文档 \( \mathcal{D}_q = \{d_1, d_2, \dots, d_N\} \)。
每个文档 \( d_i \) 都有一个相关性评分 \( r_i \),由第3.2节中提到的Agent-2(Judge)判断得出。
所有文档的相关性评分组成向量 \( \boldsymbol{R} = [r_1, r_2, \dots, r_N] \),用于对文档进行排序,形成排序后的文档列表 \( \mathcal{D}_q^{\text{rank}} \)。
系统为每个查询动态计算一个自适应判断阈值 \( \tau_q \)(见第3.3节),保留评分 \( r_i \geq \tau_q \) 的文档,形成过滤后的文档集合 \( \mathcal{D}_q^{\text{filtered}} \subseteq \mathcal{D}_q^{\text{rank}} \)。
重点示例:
查询 \( q \) 检索出文档集合 \( \mathcal{D}_q = \{d_1, d_2, d_3\} \),相关性评分为 \( \boldsymbol{R} = [3.8, 2.5, 4.2] \)。
排序后为 \( \mathcal{D}_q^{\text{rank}} = \{d_3, d_1, d_2\} \)。
若 \( \tau_q = 3.0 \),则过滤后的集合为 \( \mathcal{D}_q^{\text{filtered}} = \{d_3, d_1\} \)。
目标总结:本文旨在通过有效识别和过滤噪声文档,提升RAG系统在推理阶段的准确性和可靠性。
2.2 噪声检索文档的影响(Impact of Noisy Retrieval Documents)¶
本节强调了噪声文档对RAG系统性能的负面影响。
在RAG系统中,检索阶段若引入无关或噪声文档,会在推理阶段误导大语言模型(LLM),导致错误回答。
特别是在需要精确信息的任务(如问答)中,这种噪声会显著降低系统可靠性。
现有研究表明(Chen et al., 2024;Yu et al., 2024),LLM在面对噪声时鲁棒性较差,难以有效拒绝无关内容,从而影响整体性能。
因此,在检索后进行有效的噪声过滤是提升RAG系统鲁棒性和可靠性的关键。
3 Multi-Agent Filtering RAG (MAIN-RAG)¶
本节介绍了提出的 MAIN-RAG 框架,其核心目标是在传统 RAG 的检索阶段后,通过多智能体协作来识别并过滤噪声文档。该框架无需训练,包含三个角色明确的 LLM 智能体,分别负责预测、判断和最终生成。
3.1 MAIN-RAG 中 LLM 智能体的定义¶
MAIN-RAG 包含三个智能体:
Agent-1(Predictor):在文档检索后,为每个文档生成针对查询的预测答案,形成 文档-查询-答案三元组(Doc-Q-A),供 Agent-2 使用。
Agent-2(Judge):对每个 Doc-Q-A 三元组进行判断,输出“是”或“否”,表示文档是否相关。该判断将被量化为相关性得分,用于排序和过滤。
Agent-3(Final-Predictor):在过滤并排序文档后,使用剩余文档生成最终答案。
这三个智能体协同工作,实现从检索到过滤再到生成的完整流程。
3.2 相关性判断的量化¶
研究发现,LLM 在处理长上下文时更关注开头和结尾的内容,因此文档顺序会影响 RAG 的性能。通过在 RGB 基准上的实验(图3),验证了文档顺序对性能有显著影响。
为量化“是”或“否”的自然语言判断,提出使用 “是”与“否”标记的对数概率差值 作为文档相关性得分(图2)。该差值等价于两者的概率比值的对数,从而将判断转化为可排序的数值。
3.3 自适应判断阈值 τ_q¶
在获得文档相关性得分后,如何设定最优判断阈值以过滤噪声文档是一个关键问题。最优阈值应能保留所有相关文档并过滤所有噪声文档。
通过分析 RGB 基准上的得分分布(图4-6)发现:
相关文档得分偏高且标准差小,说明 LLM 对其判断较有信心;
噪声文档得分分布较均匀,标准差大,说明 LLM 判断不稳定。
因此,提出使用 每个查询文档的平均得分作为自适应判断阈值 τ_q,并引入超参数 n 调整阈值为:
其中 σ 是文档得分的标准差,n 是唯一超参数。该方法在不同噪声比例下均能有效过滤噪声并保留相关文档。
总结要点¶
MAIN-RAG 是一个无需训练的多智能体 RAG 框架,核心在于检索后过滤噪声文档。
三个智能体分别承担预测、判断和生成任务,形成闭环流程。
提出基于对数概率差值的相关性得分量化方法,使文档可排序。
引入自适应判断阈值 τ_q,结合平均得分与标准差,实现动态过滤,n 是唯一可调参数。
实验验证了文档顺序对性能的影响,以及 τ_q 在不同噪声比例下的有效性(图3-6)。
4 Experiments¶
本节通过实验评估 MAIN-RAG 的性能,旨在回答以下三个研究问题:
RQ1:MAIN-RAG 利用 LLM 代理作为噪声文档过滤器的表现如何?
RQ2:如何利用自适应判断阈值 τ_q 进行过滤和排序?
RQ3:τ_q 如何影响性能?
4.1 任务与数据集¶
实验在多个下游任务上进行,包括:
封闭式任务:使用 ARC-Challenge 数据集(科学考试多选题),以准确率(accuracy)为评估指标。
开放域问答任务:使用 TriviaQA-unfiltered 和 PopQA 数据集,评估模型是否能生成包含正确答案的输出。
TriviaQA-unfiltered 使用 11,313 个测试查询。
PopQA 使用 1,399 个低频实体查询。
长文本生成任务:使用 ALCE-ASQA 数据集,评估指标包括正确性(str-em、rouge)和流畅性(MAUVE)。
所有实验均在零样本设置下进行,不提供示例。
4.2 基线模型¶
无检索的基线¶
包括 Llama2-7B/13B、Llama3-8B、Mistral-7B 等预训练模型。
指令调优模型如 Alpaca-7B/13B。
私有数据训练模型如 Llama2-chat-13B。
有检索的基线¶
训练型模型:
Self-RAG:Llama2-7B 的变体,加入检索和反思机制。
Llama2-FT-7B:在相同数据上微调但无反思机制。
Ret-Llama2-chat-13B:使用私有数据训练并结合检索。
非训练型 RAG 基线:
将检索到的文档直接拼接到查询前,输入预训练 LLM。
MAIN-RAG 的变体:
Naïve Multi-agent RAG:用“是/否”判断替代 Agent-2。
MAIN-RAG (Random):过滤后随机排序文档。
4.3 实验设置¶
MAIN-RAG 是一个无需训练的 RAG 框架,三个代理可由不同 LLM 实现。
默认使用 Mistral-7B 或 Llama3-8B 作为代理。
使用 Contriever-MS MARCO 作为检索器,每个查询检索最多 20 个文档。
所有实验使用 贪婪生成。
4.4 定量分析(RQ1)¶
MAIN-RAG 在四个 QA 基准任务上均优于所有无训练和无检索基线,提升幅度最高达:
6.1%(Mistral-7B)
12.0%(Llama3-8B)
特别是在 PopQA 上表现突出,因为其依赖外部知识,而 MAIN-RAG 能有效过滤噪声文档。
与训练型基线相比,MAIN-RAG 在 TriviaQA 和 PopQA 上表现接近甚至超越,如在 Rouge 指标上优于 Self-RAG 和 Llama2-FT。
4.5 自适应判断阈值 τ_q 的消融实验(RQ2)¶
τ_q 用于动态调整文档过滤阈值,实验比较了不同标准差调整的 τ_q(τ_q - n·σ)。
主要发现:¶
默认 τ_q 表现最佳或接近最佳,在多个任务和模型中稳定排名第二。
文档排序方式:默认使用降序排列(得分高在前)优于升序排列,符合 LLM 更关注输入开头信息的特性。
表格 2(部分结果):¶
模型 |
TriviaQA |
PopQA |
ARC-C |
|---|---|---|---|
Mistral-7B |
71.0 |
58.9 |
58.9 |
Llama3-8B |
74.1 |
64.0 |
61.9 |
4.6 τ_q 的案例研究(RQ3)¶
τ_q 通过计算查询相关文档的平均得分来动态设定,实验观察到:
相关文档得分分布偏高,而噪声文档得分分布更均匀且更低。
这种差异使得即使 τ_q 设置较高或较低,也能有效过滤噪声,提升 Agent-3 的预测准确性。
案例 1(正确):¶
问题:Montxu Miranda 出生在哪座城市?
τ_q = 9.575
正确答案:Santurce
案例 2(正确):¶
问题:Gmina Czorsztyn 的首府是?
τ_q = -8.425
正确答案:Maniowy
案例 3(错误):¶
问题:Arcangelo Ghisleri 的职业?
τ_q = 0.4875
错误回答:误判为“地理学家、作家、政治家”,实际应为“记者”。
总结¶
MAIN-RAG 在多个 QA 任务上显著优于无训练和无检索基线,甚至接近或超越部分训练型模型。
τ_q 的自适应机制能有效过滤噪声文档,并通过降序排列提升 LLM 的信息利用效率。
实验验证了 MAIN-RAG 的鲁棒性和泛化能力,尤其在依赖外部知识的任务(如 PopQA)中表现突出。
5 Conclusion and Future Work¶
本节总结了 MAIN-RAG 框架的研究成果,并提出了未来的研究方向。
主要结论¶
作者提出了一种无需训练的多智能体框架 MAIN-RAG,用于解决 RAG(Retrieval-Augmented Generation)中文档检索存在噪声的问题。该框架通过多个 LLM(大语言模型)代理协同过滤和排序检索结果,从而在提高相关信息召回率的同时,有效减少无关内容的干扰。
其中,MAIN-RAG 的核心创新是引入了一个自适应判断阈值(adaptive judge bar),该阈值根据每个查询中相关文档与噪声文档的评分分布动态调整,从而实现更精准的文档筛选。
实验结果表明,MAIN-RAG 在多个问答(QA)基准任务中始终优于现有的无需训练的 RAG 基线方法,验证了其有效性。
未来工作¶
作者提出了几个值得进一步研究的方向:
更细粒度的自适应判断机制:当前的 judge bar 是基于整体评分分布调整的,未来可探索更精细的判断策略,例如结合文档内容语义或上下文信息。
扩展到其他任务:MAIN-RAG 目前主要应用于问答任务,未来可尝试将其应用于如摘要生成、对话系统等其他 NLP 任务。
引入人工反馈或微调机制:虽然 MAIN-RAG 是训练-free 的,但未来可结合人工反馈或参数微调方法,进一步提升文档过滤的效果。
总结¶
本节强调了 MAIN-RAG 在解决 RAG 中噪声文档问题上的创新性和有效性,并指出其具有良好的扩展潜力。未来的研究将聚焦于提升判断机制的精度、任务泛化能力以及结合人工或训练方法优化性能。
6 Limitations¶
本节总结了论文研究中存在的局限性,主要包括以下几个方面:
实验范围的限制¶
作者在四个数据集上使用了两种不同的预训练语言模型(LLM)架构进行实验,主要关注的是在检索外部文档支持下的LLM推理过程(即RAG流程中的推理部分)。然而,论文未涉及RAG及相关提示工程中的其他重要研究问题,包括:
上下文压缩(context compression):如 Xu et al. (2024a) 和 Li et al. (2024) 的研究;
文档位置与排序(documents position and ordering):如 Liu et al. (2024) 和 Xu et al. (2024b) 的研究;
解码方法(decoding methods):如 Li et al. (2023a)、Shi et al. (2024) 和 Xu (2023) 的研究。
此外,论文中所使用的检索器(retrievers)和重排序器(rerankers)的选择也被视为与本研究核心目标无关的正交问题(orthogonal research agenda),相关研究包括 Lin et al. (2022a)、Asai et al. (2024a)、Xu (2024) 和 Xu et al. (2024c) 等。
环境影响的考量¶
作者指出,在RAG工作流下的LLM推理过程会产生一定的碳排放,这构成了研究的潜在环境风险。为缓解这一问题,作者采取了以下措施:
减少重复实验:通过提高实验结果的可预测性;
控制实验设置:以降低资源消耗和环境影响。
总结¶
本节强调了研究在实验设计和应用场景上的局限性,包括未覆盖的RAG相关技术方向,以及对环境影响的反思。作者通过优化实验效率来应对这些挑战。
Appendix A Computation Infrastructure¶
附录A 计算基础设施¶
为确保实验评估的公平性,所有实验均基于以下物理计算基础设施进行。
重点内容:
使用了 NVIDIA A100 型 GPU,共 4 张,总显存为 80 GB。
表格数据说明:
文中提供了表3,详细列出了实验所用的计算设备规格,包括:
设备属性 |
规格 |
|---|---|
计算基础设施类型 |
GPU |
GPU 型号 |
NVIDIA A100 |
GPU 数量 |
4 张 |
GPU 总显存 |
80 GB |
该表格简洁明了地展示了实验环境的硬件配置,为结果的可复现性和对比提供了保障。
Appendix B Performance Comparison among MAIN-RAG and Its Variant Baselines¶
本节主要比较了MAIN-RAG与其多个训练无关、无检索机制以及变体基线模型在多个基准测试中的性能表现。
核心结论:¶
MAIN-RAG在四个QA基准测试中均显著优于所有基线模型。
在使用Mistral-7B作为基础LLM时,MAIN-RAG的性能提升最高达到6.1%。
使用Llama3-8B时,性能提升更是高达12.0%。
关键分析:¶
PopQA数据集对外部知识依赖性强,因此对于预训练LLM来说,检索能力尤为关键。
MAIN-RAG在此类问题上表现突出,因为其多智能体过滤机制能有效应对检索器未在目标问题集上微调所导致的噪声文档问题。
图表支持:¶
图9:展示了在三个QA基准上,使用Mistral-7B时MAIN-RAG与各变体基线的性能对比。
图10:展示了在相同基准上,使用Llama3-8B时的对比结果。
这两张图清晰地显示MAIN-RAG在多个任务中均优于其变体和基线方法。
总结:¶
本节通过定量对比验证了MAIN-RAG在无需微调的检索增强生成(RAG)任务中的优越性,尤其是在依赖外部知识的问题上,其多智能体过滤机制显著提升了答案的准确率。
Appendix C System Instructions of Agent-1 (Predictor), Agent-2 (Judge), and Agent-3 (Final-Predictor)¶
本节介绍了 MAIN-RAG 框架中三个智能体(Agent-1、Agent-2 和 Agent-3)的系统指令设计,分别用于预测、文档噪声判断和最终答案生成。
Agent-1(预测器)的系统指令¶
功能:作为准确可靠的 AI 助手,基于外部文档回答问题。
要求:仅输出正确答案,不重复问题和指令。
重点:强调准确性和简洁性,不提供额外解释。
Agent-2(评判器)的系统指令¶
功能:评估检索到的文档是否包含与问题无关或误导性的“噪声”信息。
判断标准:
文档是否提供了回答问题的具体信息;
LLM 生成的答案是否基于该文档直接回答了问题。
输出要求:
若两个条件都满足,输出 “Yes”;
若任一条件不满足(即文档为噪声),输出 “No” 并附上判断依据。
重点:强调对文档内容的验证能力,防止误导性信息影响最终答案。
Agent-3(最终预测器)的系统指令¶
功能:在过滤噪声文档后,生成最终答案。
设定:同样是准确可靠的 AI 助手,基于外部文档回答问题。
要求:仅输出正确答案,不重复问题和指令。
区别:与 Agent-1 类似,但作用于经过 Agent-2 过滤后的高质量文档。
图 11:三个 Agent 的系统指令图示¶
展示了 Agent-1、Agent-2 和 Agent-3 的系统指令流程图,说明三者在 MAIN-RAG 框架中的协作关系。
总结¶
本节详细定义了 MAIN-RAG 中三个智能体的职责与行为规范:
Agent-1 负责初步答案生成;
Agent-2 负责文档质量评估,识别噪声;
Agent-3 基于过滤后的文档生成最终答案。
三者协同工作,提升了基于检索增强生成(RAG)系统的准确性和鲁棒性。
Appendix D Case Studies of Different Adaptive Judge Bar τqsubscript𝜏𝑞\tau_{q}italic_τ start_POSTSUBSCRIPT italic_q end_POSTSUBSCRIPT in MAIN-RAG¶
本节通过多个案例研究,分析 MAIN-RAG 在不同自适应判断阈值(τq)下对文档的过滤与排序效果。重点在于展示 Agent-2(Judge)在高 τq 和低 τq 情况下的表现差异。
案例研究 1(高 τq)¶
问题:Montxu Miranda 出生在哪个城市?
τq 值:9.575(高置信度)
过滤与排序文档:文档明确指出 Montxu Miranda 于 1976 年 12 月 27 日出生于 Santurce。
Ground Truth:Santurtzi / Santurce
LLM 回答:正确,指出出生地为 Santurce。
分析:在高 τq 情况下,Agent-2 能有效识别出关键信息,LLM 能准确回答问题。
案例研究 2(低 τq)¶
问题:Gmina Czorsztyn 的首府是哪里?
τq 值:-8.425(低置信度)
过滤与排序文档:文档中提到 Sromowce Wyżne 是 Gmina Czorsztyn 下的一个村庄,但未直接指出首府。
Ground Truth:Maniowy
LLM 回答:正确,指出首府为 Maniowy。
分析:尽管 τq 很低,LLM 仍能从文档中推断出正确答案,说明在某些低置信度情况下仍可能获得正确结果。
案例研究 3(中等 τq)¶
问题:Arcangelo Ghisleri 的职业是什么?
τq 值:0.4875(中等置信度)
过滤与排序文档:文档列出多个名为 Arcangelo 的人物及其职业,但未明确提及 Ghisleri。
Ground Truth:记者(journalist)
LLM 回答:错误,误将 Arcangelo Ghisleri 认为是地理学家和政治家。
分析:在中等 τq 情况下,文档信息不够明确,导致 LLM 无法准确识别目标人物,出现错误回答。
图 12 - 15:不同数据集与 LLM 的案例对比¶
数据集:PopQA 和 TriviaQA
LLM 模型:Mistral-7B 和 Llama3-8B
图 12 & 13(PopQA 数据集)¶
案例 1(高 τq):Fernando García 出生地为 Santiago, Chile,LLM 正确回答。
案例 2(低 τq):Ittamalliyagoda 位于 Sri Lanka,LLM 正确推断。
案例 3(中等 τq):Andreas Rüdiger 的职业应为哲学家,LLM 错误识别为足球运动员。
图 14 & 15(TriviaQA 数据集)¶
案例 1(高 τq):Hoplite 是古希腊的公民士兵,LLM 正确回答。
案例 2(低 τq):Arthur Wynne 发明了填字游戏(crossword puzzle),LLM 正确识别。
案例 3(中等 τq):America’s Cup 被 Australia II 夺得,LLM 回答不准确,未明确指出 Australia II。
总结¶
高 τq 情况:Agent-2 能有效筛选出相关文档,LLM 能准确回答问题。
低 τq 情况:虽然置信度低,LLM 仍可能通过推理得出正确答案。
中等 τq 情况:文档信息模糊,LLM 容易产生错误判断。
重点结论:
Agent-2 在高 τq 下表现良好,但在低 τq 时判断力下降。
LLM 的回答质量依赖于文档的准确性和相关性。
τq 值作为过滤与排序的依据,对最终答案的准确性有显著影响。
本附录通过具体案例验证了 MAIN-RAG 框架在不同 τq 设置下的有效性与局限性。