2506.21605_MemBench: Towards More Comprehensive Evaluation on the Memory of LLM-based Agents¶
引用: 3(2025-10-29)
组织:
1Gaoling School of Artificial, Renmin University of China, Beijing, China,
2Huawei Noah’s Ark Lab
总结¶
MemBench
两种记忆层次:
事实性记忆(factual memory)
指具体的事实属性,如用户的亲戚年龄、事件时间等。
评估代理在单会话和多会话中进行知识更新和多实体属性整合推理的能力。
反思性记忆(reflective memory)
通过用户的低层次偏好(如对不同菜品的喜好)推断出高层次偏好(如口味类型)。
通过多个事实偏好的表达,增强记忆的可信度。
两种交互场景:
参与场景(participation)
不仅需要记住用户的发言,还需要记住自己生成的回复
观察场景(observation)
只需记住用户的发言
四种评估指标
记忆准确率(Memory Accuracy)
所有问题设计为多选题,评估代理选择的正确性。
记忆召回率(Memory Recall)
通过预设的“关键证据对话”来评估召回效果
记忆容量(Memory Capacity)
测试代理的记忆容量上限,即当记忆内容达到一定量时准确率是否显著下降。
记忆效率(Memory Efficiency)
处理时间成本
核心贡献
提供了一个多维度、多场景的记忆评估基准
通过引入不同记忆层次和交互方式,弥补了现有评估方法的不足
Abstract¶
近年来,研究强调了记忆机制在基于大语言模型(LLM)的智能体中的重要性。这种机制使智能体能够存储所观察到的信息,并适应动态环境。然而,评估这些智能体的记忆能力仍然面临挑战。
当前的评估方法普遍存在以下问题:
记忆层次的多样性不足(如区分事实性记忆与反思性记忆不够);
互动场景单一(缺乏如“参与”与“观察”等不同交互方式的覆盖);
缺乏全面的评估指标,无法从多个角度反映智能体的记忆能力。
为了解决这些问题,本文构建了一个更全面的数据集和基准测试系统,用于评估基于LLM的智能体的记忆能力。该数据集融合了两种记忆层次:
事实性记忆(factual memory)
反思性记忆(reflective memory)
并设计了两种交互场景:
参与(participation)
观察(observation)
基于该数据集,作者提出了一个名为MemBench的基准,用于从多个方面评估智能体的记忆能力,包括:
有效性(effectiveness)
效率(efficiency)
容量(capacity)
重点内容总结:¶
MemBench 是本文的核心贡献,它提供了一个多维度、多场景的记忆评估基准;
作者通过引入不同记忆层次和交互方式,弥补了现有评估方法的不足;
项目开源有利于推动后续研究和比较不同模型的记忆能力。
1 Introduction¶
近年来,大语言模型(LLMs)在自然语言处理和多领域复杂任务中表现出色。然而,传统的LLMs通常在静态环境中运行,不与外部环境交互,从而限制了其向通用人工智能(AGI)的发展。
为了解决这一问题,许多研究提出在基础模型基础上添加额外模块的LLM-based agents,使其能够自主学习和动态适应环境。其中,记忆模块是一个关键组成部分,它使LLM-based agents能够存储重要信息、积累经验,从而更好地应对动态任务并持续进化。
目前,已有研究从主观方式(如人类评估或LLM评分)或间接方式(如通过任务表现评估记忆机制)来评估记忆能力。最近,一些研究引入了长期对话数据集,用于客观评估长期记忆能力。
然而,现有研究仍存在以下局限性:
对记忆能力层次评估不足:主要集中于事实记忆(低层记忆,如用户喜欢的特定菜品),而忽略了反思性记忆(高层记忆,如用户口味偏好等隐含信息)。
局限于参与场景:大多仅在第一人称交互场景下评估记忆能力,忽略了观察场景(第三人称记录用户信息)。
缺乏对效率和容量的评估:主要集中于有效性,而忽略了在实际应用中同样重要的效率和容量。
为克服上述局限,本文提出一个更全面的数据集和基准(MemBench),用于评估LLM-based agents的记忆能力。其主要特点包括:
多场景数据集:涵盖参与场景和观察场景,用于评估不同使用场景下的记忆能力。
多层级记忆内容:同时评估事实记忆和反思性记忆,支持包括信息提取、跨会话推理、知识更新、时间推理和反思性总结等任务。
多指标评估基准:引入四个评估指标(准确率、召回率、容量和时间效率),对记忆性能的各个方面进行综合评估。
总结而言,本文提出了一个多场景、多层级的全新数据集和多指标评估基准,显著区别于先前工作。为了促进研究,作者已将数据集和项目开源在GitHub。
接下来,论文分章节介绍相关工作、数据集构建过程、基准测试与分析,并在最后总结全文。
3 Dataset Construction¶
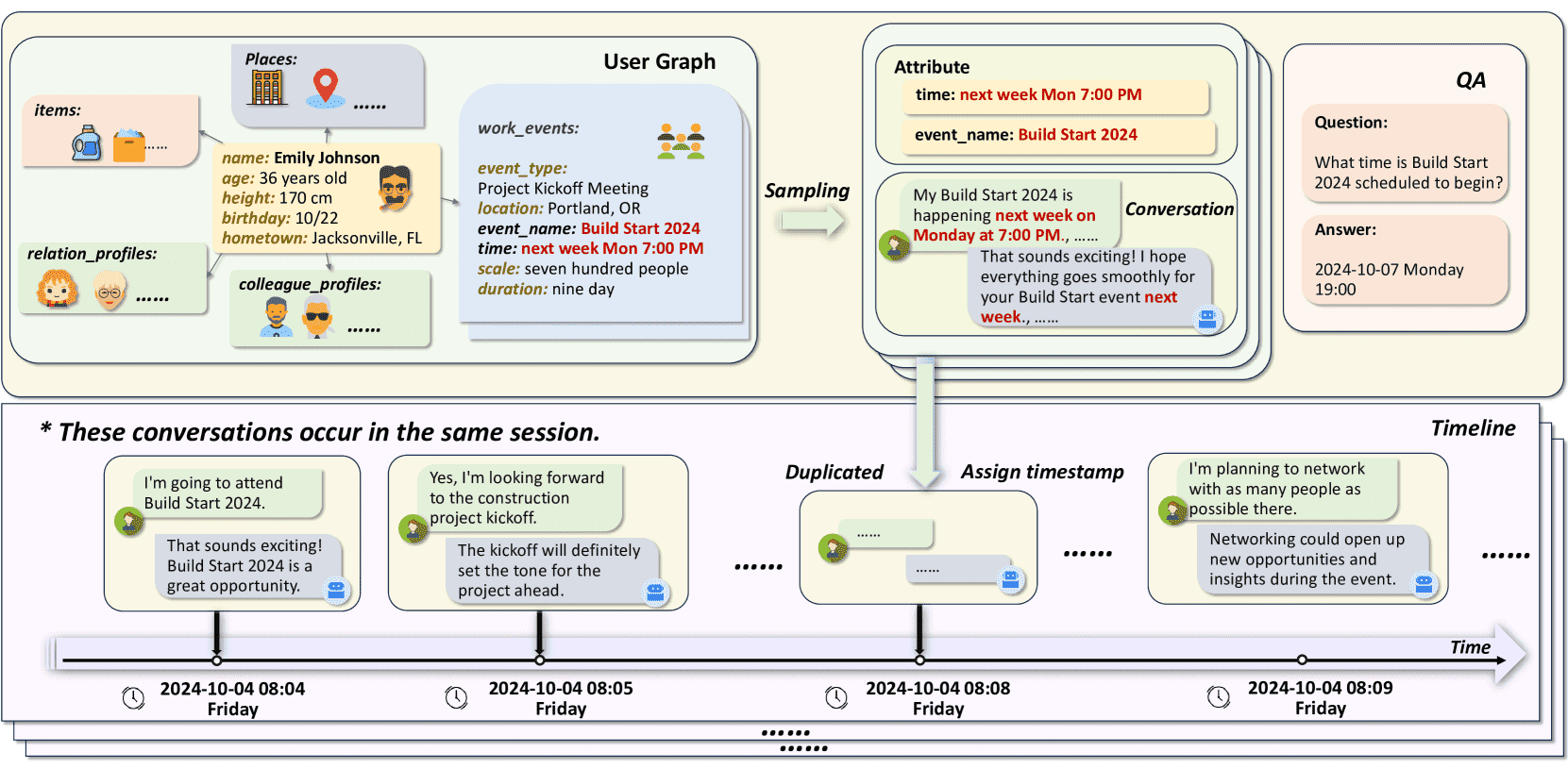
Figure 1:An example of generating dialogue data. First, the event “Build Start 2024” is extracted with the time “next week Mon 7:00 PM,” which is then used to generate evidence dialogues and questions. It’s merged with dialogues generated from other attributes to form a complete dialogue, and an answer is generated based on the provided time label “2024-10-07 Monday 19:00”.
展示了一个对话数据生成的示例:
从事件“Build Start 2024”和时间“下周周一晚上7点”生成证据对话和问题;
与其他属性生成的对话合并,形成完整对话;
根据提供的时间标签“2024-10-07 周一 19:00”生成答案。
此例展示了数据生成过程的结构和时间信息的重要性,用于评估智能体的记忆能力。
3.1 数据生成流程(Pipeline of Data Generation)¶
该部分介绍了数据集构建的基本流程,主要受到MemSim(Zhang et al., 2024)的启发。作者在原有框架的基础上,扩展了数据集,增加了对记忆更新能力和通过对话提取信息的评估,特别是在单会话和多会话场景下的能力评估。此外,还引入了反思性记忆(Reflective Memory)的生成方法,并将观察场景(Observation Scenario)扩展到参与场景(Participation Scenario)。
用户关系图采样(User’s Relation Graph Sampling)¶
基于MemSim的用户关系图方法,构建用户个人资料及其关联实体(包括人物、事件、地点和物品)的关系图。
利用推荐系统数据集(如MovieLens、Food、Goodreads)中的用户-物品关系和评分,提取用户的高层次偏好。
使用LLM(如GPT-4o-mini)来总结用户偏好,若没有类别信息,则通过LLM生成。
构建了高层次偏好与低层次事实属性之间的一对多映射,用于生成对话内容。
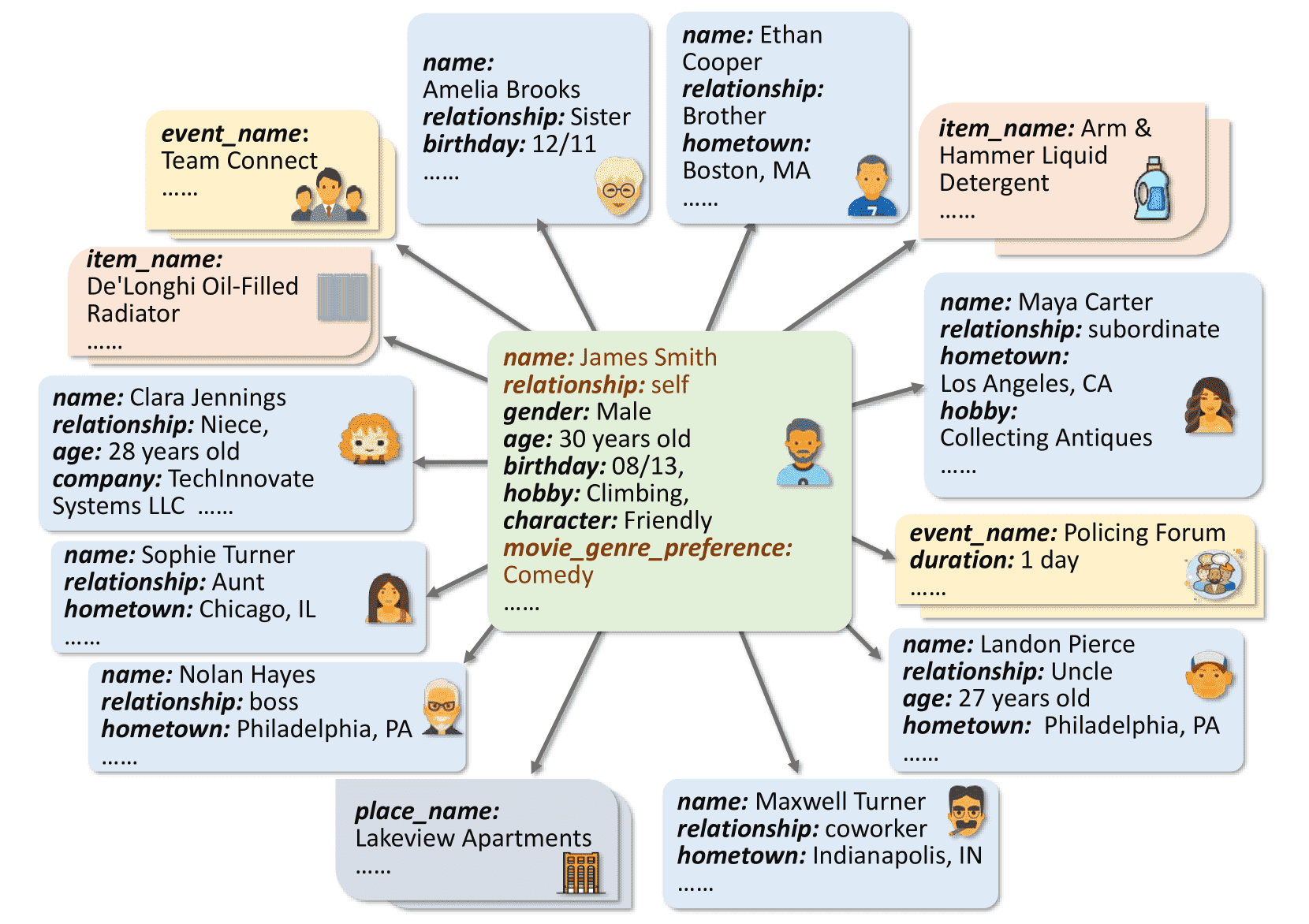
Figure 2:A user relation graph is composed of a user’s profile and his or her associated entities including individuals, events, items and places.
记忆数据集构建(Memory Dataset Construction)¶
Memsim提供的是观察场景下的数据生成方式,本文将其扩展为参与场景下,采用自对话方法生成数据。
在生成对话时,选择多个低层次偏好属性并生成相应的证据对话,插入在对话中,形成完整的会话。
采用基于时间的会话划分方法,在会话内部时间间隔短(如1分钟),跨会话时间间隔长(如1天)。
3.2 多场景记忆(Multi-scenario Memory)¶
根据记忆使用场景的不同,将数据集分为两类:
参与记忆场景(Participation Memory Scenario)¶
核心场景:用户与代理(Agent)之间的对话交互。
代理不仅需要记住用户的信息,还需记住自身的回应,例如在推荐请求中的回复。
数据由多个多轮对话会话组成。
观察记忆场景(Observation Memory Scenario)¶
被动接收:代理仅接收用户的消息,不主动回应。
数据由多个消息列表组成,无需交互操作。
3.3 多层次记忆(Multi-level Memory)¶
从记忆的内容层次划分,数据集包含两个主要类别:
事实性记忆(Factual Memory)¶
指具体的事实属性,如用户的亲戚年龄、事件时间等。
通过对话中的信息测试代理的记忆能力,例如对时间表达的转换(如“下一个星期一”转为具体日期)。
评估代理在单会话和多会话中进行知识更新和多实体属性整合推理的能力。
反思性记忆(Reflective Memory)¶
通过用户的低层次偏好(如对不同菜品的喜好)推断出高层次偏好(如口味类型)。
通过多个事实偏好的表达,增强记忆的可信度。
评估代理在不同层次上进行偏好提取与总结的能力。
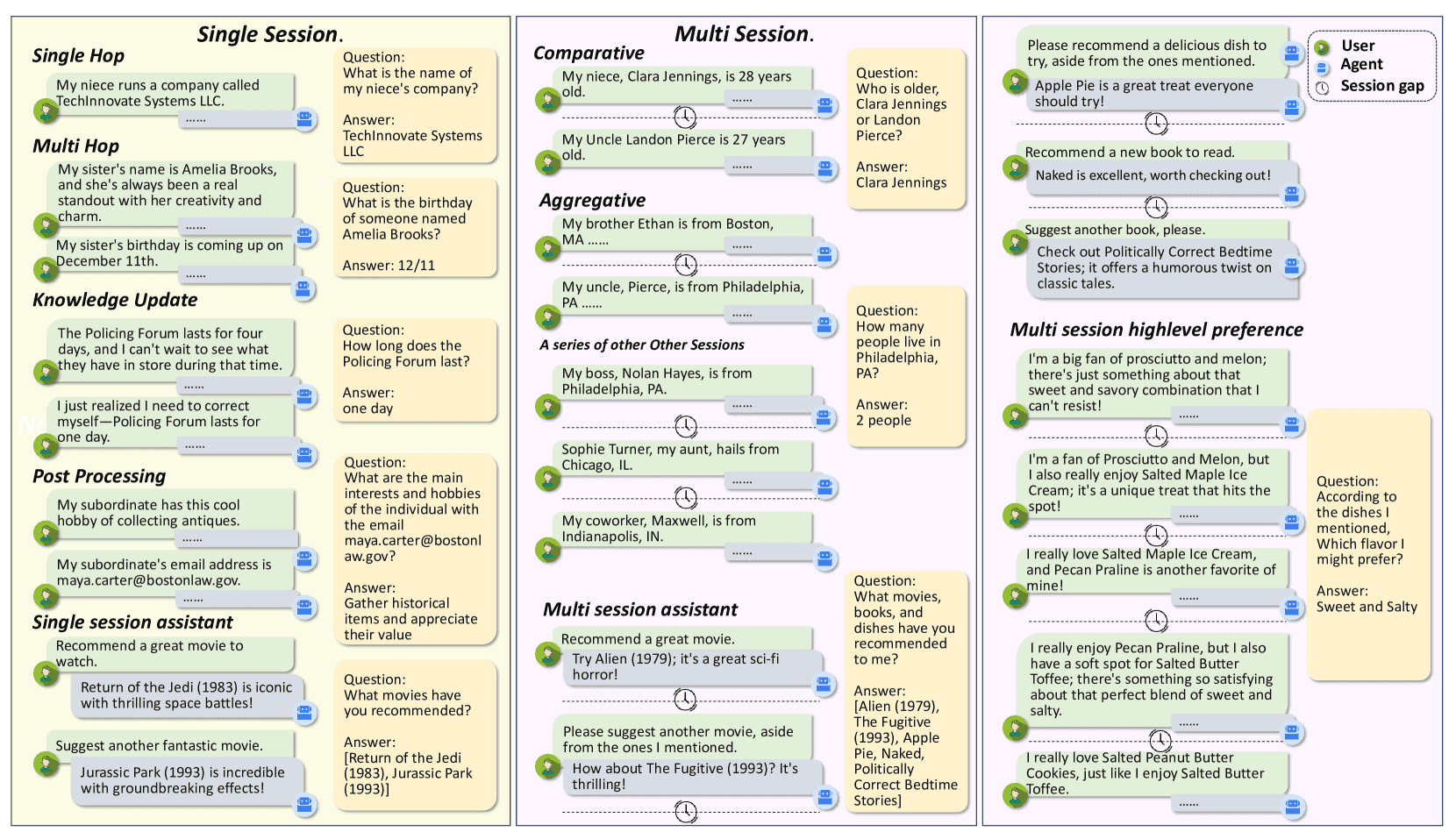
Figure 3:An overview of part categories of data used to test different abilities.
3.4 多指标评估(Multi-metric Evaluation)¶
为全面评估代理的记忆机制,提出了四种评估指标:
记忆准确率(Memory Accuracy)
所有问题设计为多选题,评估代理选择的正确性。
避免因表达多样性导致的误判。
记忆召回率(Memory Recall)
适用于检索型记忆机制,衡量代理检索信息的准确度。
通过预设的“关键证据对话”来评估召回效果。
记忆容量(Memory Capacity)
测试代理的记忆容量上限,即当记忆内容达到一定量时准确率是否显著下降。
检测代理存储和组织信息的能力。
记忆效率(Memory Efficiency)
不仅关注准确性和完整性,还关注处理时间成本。
评估记忆机制是否适用于实际应用。
3.5 数据集统计(Dataset Statistics)¶
数据集包含两大部分:
500个用户关系图(用户及其关联实体的图结构)。
用户与代理之间的多轮对话、用户消息列表以及对应的问题。
统计数据如表2所示,涵盖会话数、问题数、轨迹数及每轨迹平均token数(TPT)。
在真实对话中,关键证据对话在会话中分布较为均匀。
图4展示了各类别问题的分布情况以及关键证据对话在会话中的分布。
数据类型 |
会话数 |
问题数 |
轨迹数 |
平均token数(TPT) |
|---|---|---|---|---|
PS-RM |
3.5k |
3.5k |
3.5k |
2,195 |
PS-FM |
51k |
39k |
8k |
10,285 |
OS-RM |
2k |
2k |
2k |
745 |
OS-FM |
8.5k |
8.5k |
8.5k |
617 |
总结:
本章详细介绍了MemBench数据集的构建过程,包括用户关系图的构建、多场景与多层次记忆的划分、多指标的评估方式以及数据集的统计信息。数据集设计贴近现实场景,能够全面评估LLM代理在参与与观察场景下、事实性与反思性记忆方面的表现。
4 Benchmark¶
在这一节中,作者构建了一个基于其数据集的基准测试(benchmark),以评估基于大语言模型(LLM)的个人代理(agent)的记忆能力。为了更全面地评估代理记忆机制的上限,他们使用 News dataset(DataGuy 和 Amoako,2022)生成大量对话和消息作为“噪声记忆内容”,这些内容与测试问题无关。同时,确保这些噪声数据不会与真实记忆内容在事实层面产生冲突,从而可以灵活控制评估的难度。
4.1 Experimental Settings(实验设置)¶
为了更贴近现实场景中代理的记忆过程,特别是时间流动的影响,作者模拟了用户与代理之间的交互过程,按时间顺序输入需要记忆的内容。在每轮交互中,用户当前的发言被输入,而之前的对话内容只能通过记忆机制进行回溯。
在参与记忆场景中,代理不仅需要记住用户的发言,还需要记住自己生成的回复;而在观察记忆场景中,代理只需记住用户的发言。
为创建不同难度层级的测试数据,作者在相邻对话中插入噪声会话,并控制其比例以生成平均长度超过100k token的测试数据。由于测试数据量大且代理记忆机制设计复杂,作者对两种不同大小的数据集进行了统一采样,分别记为 Sub-dataset 1(约10k token)和 Sub-dataset 2(约100k token)。
基于 MemEngine(Zhang et al., 2025),作者实现了七种不同的记忆机制,并使用 Qwen2.5-7B 作为代理的基础模型。这些机制包括:
FullMemory(全量记忆)
RecentMemory(最近记忆)
RetrievalMemory(检索记忆)
GenerativeAgent(生成式代理)
MemoryBank
MemGPT
Self-Controlled Memory (SCMemory)
所有涉及检索的机制均使用 multilingual-e5-small 进行检索。
4.2 Evaluations on Factual Memory(事实记忆评估)¶
表3 展示了在事实记忆任务上的评估结果,包括准确率(Participation/Observation-Accuracy)、效率(RT 和 WT)等指标。
在 Sub-dataset 1 中,FullMemory、RetrievalMemory 和 RecentMemory 表现优于其他方法。
但在 Sub-dataset 2 中(长对话),FullMemory 和 RecentMemory 的性能下降明显,尤其当目标信息超出记忆窗口时。
RetrievalMemory 在所有测试中表现较为稳定。
MemGPT 和 MemoryBank 在时间消耗上较高,尤其是 MemGPT 的读取时间较长,MemoryBank 的写入时间较长。
图5 展示了随着记忆 token 数量的增加,SCMemory、MemGPT、GenerativeAgent 和 RecentMemory 的准确率下降趋势,说明这些机制在 Qwen2.5-7B 模型中的记忆保留能力存在上限。
4.3 Evaluations on Reflective Memory(反思记忆评估)¶
表4 是针对反思记忆任务的评估结果。反思记忆评估了代理对自身行为或情绪的记录能力。
GenerativeAgent、MemGPT 和 MemoryBank 在 Sub-dataset 1 上表现良好,但在 Sub-dataset 2 上性能显著下降。
RetrievalMemory 在两个数据集上表现相对稳定。
性能下降可能与模型上下文窗口有限、记忆机制中存在“遗忘机制”有关。
该结果表明,设计良好的记忆机制能够有效捕捉反思记忆,但在长期交互中如何保持这一能力仍是研究难点。
4.4 Evaluations on Memory Capacity(记忆容量评估)¶
为了评估代理记忆机制的容量,作者测试了在 Sub-dataset 2(100k token)中,每个关键证据轮次后的回答准确率。
从图5可以看出,随着 token 数量的增加,MemGPT 和 SCMemory 的准确率急剧下降,说明在 Qwen2.5-7B 模型中,这些机制的记忆容量存在上限。
4.5 Comparison of Different Inference Models(不同推理模型的比较)¶
在实际应用中,代理可能使用不同模型作为基础。作者选择了四种常见模型进行对比测试:Qwen2.5-7B-Instruct、GPT-4o-mini、Meta-Llama-3.1-8B-Instruct 和 GLM-4b-chat。
表5 显示:
在大多数情况下,GPT-4o-mini 总体表现最好。
Meta-Llama-3.1-8B-Instruct 的事实记忆能力较弱,但反思记忆能力较好。
GenerativeAgent 使用 GPT-4o-mini 时时间消耗更大,但与其它模型的差异在多数情况下并不显著。
总结¶
本节通过构建包含噪声数据和不同长度的对话数据集,系统评估了几种常见代理记忆机制的性能。评估涵盖事实记忆和反思记忆两个维度,并测试了记忆容量与不同模型的影响。结果显示,RetrievalMemory 表现稳定且高效,而 GPT-4o-mini 在多数任务中表现最佳。研究还指出,长期交互中的记忆保留仍是值得深入探索的问题。
5 Conclusion¶
本文提供了一个更为全面且可扩展的数据集,用于评估基于大语言模型(LLM)的智能体的记忆机制。该数据集涵盖了多种场景,包括参与式和观察式场景,记忆内容也分为反思性记忆和事实性记忆两个层次,是目前为止较为系统和多维度的数据集。
基于该数据集,作者构建了一个时序感知的评估框架,模拟用户与智能体之间的日常交互,并采用多种评估指标,包括准确性(accuracy)、回想性(recall)、容量(capacity)和时间效率(temporal efficiency),以全面衡量智能体的记忆表现。
文章重点评估了七种常见的智能体记忆机制在该基准上的表现,为后续研究提供了有价值的参考和比较基础。
Limitations¶
本文提出的数据集由用户及其相关实体的档案构成的图组成,有助于进一步探索智能体的记忆机制。这一部分的重点在于强调数据集和评估方法的局限性。
重点内容:
数据集的结构:数据集通过用户和相关实体的档案构建图结构,为研究智能体的记忆机制提供了基础。
评估方法的限制:当前的评估方法主要针对结构化数据的记忆能力进行评估。这说明现有的评估体系还不够完善,可能无法全面反映智能体的记忆表现。
结构化记忆能力的探索:尽管评估方法有限,但通过比较智能体在用户-智能体交互过程中构建相关实体档案或捕捉特定属性信息的能力,仍可以研究其结构化记忆的能力。
次要内容:
反思性记忆的探索空间:在反思性记忆方面,仍有许多未被探索的领域,例如用户的情感记忆。这表明未来的研究方向可以更加广泛和深入。
Ethics Statement¶
本研究中用于构建数据集的数据来自公开且已获授权的数据集。这些公开数据均按照其相应的许可协议用于研究目的,这是文章的重点内容,强调了数据来源的合法性和透明性。
文章还指出,由大型语言模型(LLM)生成的内容可能存在一定的风险,如无意中的偏见或有害输出。虽然研究人员已采取措施尽量减少这些风险,但这也是文章的重点内容之一,提醒用户在使用该数据集时需负责任地应用,以避免可能产生的伦理问题。
整体来看,本部分的内容较为简洁,重点在于数据使用的合规性以及对潜在伦理风险的提示,非重点内容已适当精简。
Acknowledgments¶
本研究部分受到国家自然科学基金(编号:62422215 和 62472427)的支持,同时得到了中国人民大学“双一流”重大创新与规划跨学科平台、中国人民大学公有云计算平台以及中国人民大学建设世界一流大学(学科)专项资金的资助。
此外,本研究还得到了华为创新研究计划的资助。作者衷心感谢 MindSpore(https://www.mindspore.cn)、CANN(神经网络计算架构)及昇腾 AI 处理器在本研究中提供的支持。
Appendix A Case Studies¶
以下是对附录 A(Appendix A)章节内容的总结,保持原文结构与重点,并对不重要内容进行精简:
A.1 用户关系图示例(User Relation Graph Example)¶
本节展示了数据集中各组件的示例,包括用户图谱(user graph)和测试用例。重点在于各类用户关系的详细属性信息,如用户自身、亲属、同事、事件、物品和地点等的描述。
UserProfile:描述了用户 James Smith 的基本信息、职业、爱好、联系方式、偏好等,涵盖多个维度,尤其是“highlevel preference”部分,包括电影类型、口味偏好和书籍类型,是重点内容。
RelativeProfile(亲属):以兄弟 Ethan Cooper 为例,展示了亲属的基本信息。
ColleagueProfile(同事):以上级 Nolan Hayes 为例,展示了工作关系中的同事信息。
EventProfile(事件):包括工作类活动和休息类活动,如团队建设与社区活动,包含时间、地点和规模等信息。
ItemProfile(物品):以洗衣液为例,展示了物品的所有权和用户评论。
PlaceProfile(地点):以 The Grove 为例,展示了用户对地点的评价。
表格总结:
表6总结了事实性记忆(Factual Memory)问题的类型,分为单跳、多跳、比较、聚合、后处理、知识更新、单会话助理、多会话助理等,是系统评估的重要依据。
表7总结了反思性记忆(Reflective Memory)问题类型,包括偏好和情感两类。
A.2 事实性记忆与反思性记忆映射示例(FM-RM Dictionary Example)¶
本节展示了一个映射表,将事实性记忆属性与反思性记忆属性进行对应。例如:
电影类型(Action):列出多个动作类电影示例。
口味偏好(Sweet):列出甜食示例。
书籍类型(Health & Fitness):列出健康类书籍。
这些示例展示了系统如何将用户的显性信息(如评论)与潜在兴趣或情绪进行关联,是系统理解用户深层偏好的关键部分。
A.3 问题描述(Question Description)¶
本节是对表6和表7的简要说明,分别解释了事实性记忆和反思性记忆问题的类型定义。此处内容较为简略,主要起到引导作用。
A.4 参与示例(Participation Example)¶
本节提供了多种类型的问答示例,展示了系统如何根据对话内容进行信息提取和推理,分为以下几种类型:
单跳问题(Single-hop):直接从一个信息中提取答案。
多跳问题(Multi-hop):需要结合多个信息片段。
知识更新(Knowledge-updating):根据后续对话修正先前答案。
后处理问题(Post-processing):需要综合多个信息进行逻辑推理。
单会话助理(Single-session-assistant):在一个会话中提取多个推荐。
多会话助理(Multi-session-assistant):跨多个会话提取信息。
比较问题(Comparative):比较两个实体的属性。
聚合问题(Aggregative):统计多个实体的共同属性。
高级偏好(Highlevel Preference):识别用户对口味(如甜咸口味)的偏好。
这些示例详细展示了系统在不同任务下的表现和推理能力,是重点内容。
A.5 观察示例(Observation Example)¶
本节内容与参与示例类似,但未包含“助理(Assistant)”的回应,因此未提供具体例子,仅指出两者之间的区别。
总结(Summary)¶
附录 A 主要通过实际案例和问题类型定义,展示了系统的数据组成、推理方式和评估维度。其中:
用户关系图示例中详细描述了用户及其关系人的属性信息;
FM-RM 映射展示了系统对用户显性与隐性信息的处理;
参与示例通过问答形式展示了系统在多种推理任务中的表现;
问题类型表是评估模型记忆能力的核心依据。
整体而言,附录 A 为理解系统如何建模用户记忆提供了详实的数据基础和任务框架。
Appendix B Detail Data Statics¶
在该附录中,文章提供了两个数据集的详细统计信息:Participation 数据集和Observation 数据集,分别见 表8 和 表9。这些统计信息包括会话数量(# Session)、问题数量(# Question)和轨迹数量(# Trajectory)。这些数据用于评估基于大语言模型的智能体在记忆能力方面的表现。
表8:Participation 数据集的详细统计¶
表8展示了 Participation 数据集 中各类任务的数据规模。该数据集分为两类主要记忆类型:
RM(Reflective Memory):反思记忆
FM(Factual Memory):事实记忆
其中,每个类别下又细分为不同类型的任务,如:
sh(Single-hop):单跳任务
mh(Multi-hop):多跳任务
comp(Comparative):比较任务
agg(Aggregative):聚合任务
pp(Post-processing):后处理任务
ku(Knowledge Update):知识更新任务
ssa(Single Session Assistant):单会话助手
msa(Multi Session Assistant):多会话助手
重点内容如下:
RM 类型的任务 包括 RM-Pr(3.0k 会话)和 RM-Em(0.5k 会话),会话数与问题数相等,轨迹数与会话数一致。
FM 类型的任务 更加多样化:
FM-sh(8k 会话)与 FM-mh(8k 会话)的会话和问题数量较多,但轨迹数较少(1k),说明每个会话中的步骤较少。
FM-comp(8k 会话)的问题数只有 4k,说明每会话平均包含 0.5 个问题。
FM-agg(8k 会话)的问题数仅 1k,单个会话中平均包含 0.125 个问题,说明该类型任务较为复杂,每会话处理一个问题需要较多步骤。
FM-ssa(1.5k 会话)和 FM-msa(1.5k 会话)涉及会话助手任务,但后者问题数和轨迹数较少,说明多会话任务复杂度更高。
表9:Observation 数据集的详细统计¶
表9展示了 Observation 数据集 的统计信息。与 Participation 相比,该数据集的任务类型较少,未包含 ssa 和 msa 类型。
重点内容如下:
RM-Pr(1.5k 会话)和 RM-Em(0.5k 会话)与表8类似,但数据量更小。
FM 类型的任务 包括:
FM-sh(1.5k 会话)、FM-mh(1.5k 会话)等,这些类型的会话、问题和轨迹数量一致,说明任务结构较简单。
所有 FM 类型的任务在该数据集中都保持了 1:1:1 的比例,即每会话一个问题,一条轨迹。
FM-ku(1k 会话)的问题和轨迹数量一致,说明其任务结构较为统一。
总结¶
Participation 数据集 包含了更丰富的任务类型,尤其是涉及多种记忆类型和会话形式,具有更高的复杂性。
Observation 数据集 则更简洁,任务结构较为一致,适合用于基础行为观察。
两个数据集都通过 RM 和 FM 分类评估智能体在不同记忆任务上的表现,重点考察其在复杂情境下的记忆处理能力。
Appendix C Data Creation Prompt¶
C.1 人物口味识别提示(Profile Prompt)¶
功能:根据用户喜欢的菜品,从预设口味列表中识别出用户偏好。
操作方式:给出用户喜欢的菜品 [Dishes],从预设的 [Tastes] 中选择最匹配的一种或多种口味。
口味选项:包含甜、酸、辣、咸、鲜、苦等多种组合口味(共21种),如“甜咸”、“酸辣”、“甜咸辣”等。
输出格式:返回 JSON 格式,包含用户口味信息,如 {'taste': 'sweet'}。
重点:该部分是为后续对话生成提供用户口味背景信息,是构建个性化对话的起点。
C.2 对话生成提示(Self-dialogue Prompt)¶
该部分分为两个子类,分别为角色对话生成和事件对话生成,用于生成用户与个人助理之间的交互对话。
1. 角色对话生成提示(Role Dialogue Generation Prompt)¶
功能:根据用户提供的实体信息(如家庭成员、朋友等),生成一段互动对话。
要求:
生成指定轮次(
round_length)和句子数量(sentence_length)的对话。助理只能被动回应用户,不能提问或提供未知信息。
输出格式为 JSON 列表,每条记录包含用户与助理的发言。
重点强调:每条 JSON 必须包含用户和助理的发言,且结构统一。
示例说明:用户与助理围绕用户表弟 Ethan 的年龄、身高、性格等展开对话,助理只能回应,不能提问或补充信息。
2. 事件对话生成提示(Event Dialogue Generation Prompt)¶
功能:基于指定事件信息,生成用户与助理之间的对话。
要求:
用户开场需说明将参加某事件(如“我要去参加Climb Fest”)。
助理依然只能被动回应,不能提问或提供额外信息。
输出格式与角色对话相同,为 JSON 列表。
重点强调:对话内容必须严格基于给定事件信息,不得扩展。
示例说明:用户说明将参加某活动,助理回应活动可能的影响、准备情况等,但不提供新信息或提问。
C.3 观察提示(Observation Prompt)¶
该部分用于将用户输入的信息转换为更自然的表达方式,适用于对话生成的预处理。
1. 角色信息转换提示(Role Message Prompt)¶
功能:将用户输入的信息(如“我的老板 Lucas Grant 有硕士学位”)转换为自然的陈述句。
要求:
输出应为流畅的、语法正确的陈述句。
不改变原信息内容。
仅输出转换后的句子,不保留原句或额外描述。
重点强调:输出应符合口语化表达习惯,不使用复杂句式。
示例输出:Lucas Grant, who is my boss, has a Master’s degree.
2. 事件信息转换提示(Event Message Prompt)¶
功能:将用户输入的关于事件的信息转换为自然的陈述句。
要求:
与角色信息转换类似,但需注意:
避免使用“you”,改用第一人称(如 I, me, my)。
保持原意不变。
仅输出转换后的句子,不要添加任何说明。
示例输出:
Climb Fest draws a crowd of around nine hundred people.
总结¶
附录 C 提供了数据生成的核心提示模板,包括:
用户口味识别(C.1)用于提取个性化偏好;
角色和事件对话生成(C.2)用于构建自然对话;
角色和事件信息转换(C.3)用于预处理用户输入。
这些提示支持构建结构化、自然化的人机对话数据,为训练对话模型提供高质量输入。
Appendix D Result Details¶
D.1 Reflective Result(D.1 反思结果)¶
在表 10 中,展示了 10k-Reflective(反思)记忆数据集 上不同记忆机制的表现结果。该表主要评估了参与性(Participation)和观察性(Observation)任务在情感(emotion)和偏好(preference)两个维度上的准确率。
方法(Method) |
Participation-Accuracy(参与性准确率) |
Observation-Accuracy(观察性准确率) |
||
|---|---|---|---|---|
preference(偏好) |
emotion(情感) |
preference(偏好) |
emotion(情感) |
|
FullMemory |
0.733 |
0.593 |
0.883 |
0.630 |
RecentMemory |
0.700 |
0.481 |
0.867 |
0.556 |
RetrievalMemory |
0.692 |
0.556 |
0.883 |
0.593 |
GenerativeAgent |
0.742 |
0.412 |
0.883 |
0.676 |
MemoryBank |
0.692 |
0.296 |
0.900 |
0.481 |
MemGPT |
0.733 |
0.471 |
0.883 |
0.556 |
SCMemory |
0.542 |
0.294 |
0.783 |
0.333 |
重点分析:
FullMemory 表现较为均衡,是参与性与观察性任务中表现最好的方法之一。
GenerativeAgent 在 Observation-Emotion 上表现最佳(0.676),但参与性任务中情感维度较弱(0.412)。
SCMemory 整体表现最差,尤其是在参与性和观察性的情感维度上准确率最低。
D.2 Factual Result(D.2 事实结果)¶
本节展示了 10k-Factual(事实)记忆数据集 的详细结果,包括参与性任务(Participation)和观察性任务(Observation)的多个子类别的准确率。
表 11:10k-Factual-Participation 数据集结果¶
该表包括以下任务类型:
sh(单跳)
mh(多跳)
comp(比较性)
agg(聚合性)
pp(后处理)
ku(知识更新)
ssa(单会话助手)
msa(多会话助手)
Method |
sh |
mh |
comp |
agg |
pp |
ku |
ssa |
msa |
|---|---|---|---|---|---|---|---|---|
FullMemory |
0.825 |
0.8 |
0.55 |
0.275 |
0.625 |
0.75 |
0.7 |
0.55 |
RecentMemory |
0.85 |
0.75 |
0.425 |
0.45 |
0.65 |
0.725 |
0.717 |
0.5 |
RetrievalMemory |
0.875 |
0.775 |
0.55 |
0.275 |
0.475 |
0.675 |
0.4 |
0.3 |
GenerativeAgent |
0.75 |
0.675 |
0.3 |
0.35 |
0.525 |
0.525 |
0.267 |
0.55 |
MemoryBank |
0.575 |
0.7 |
0.25 |
0.25 |
0.475 |
0.55 |
0.417 |
0.4 |
MemGPT |
0.625 |
0.625 |
0.275 |
0.225 |
0.45 |
0.625 |
0.367 |
0.45 |
SCMemory |
0.575 |
0.475 |
0.05 |
0.275 |
0.525 |
0.475 |
0.217 |
0.1 |
重点分析:
RetrievalMemory 在 sh(单跳) 任务上表现最佳(0.875),但 agg(聚合性) 和 msa(多会话助手) 的表现较差。
FullMemory 在多个任务类型中表现稳定,特别是在 ku(知识更新) 和 ssa(单会话助手) 上表现较好。
SCMemory 在 comp(比较性) 任务中几乎最差(0.05),显示出其在较复杂推理任务中的不足。
表 12:10k-Factual-Observation 数据集结果¶
该表评估了观察性任务在以下类别中的表现:
sh(单跳)
mh(多跳)
comp(比较性)
agg(聚合性)
pp(后处理)
ku(知识更新)
Method |
sh |
mh |
comp |
agg |
pp |
ku |
|---|---|---|---|---|---|---|
FullMemory |
0.92 |
0.92 |
0.667 |
0.233 |
0.82 |
0.6 |
RecentMemory |
0.92 |
0.92 |
0.667 |
0.367 |
0.82 |
0.65 |
RetrievalMemory |
0.92 |
0.92 |
0.633 |
0.367 |
0.78 |
0.45 |
GenerativeAgent |
0.88 |
0.94 |
0.7 |
0.3 |
0.82 |
0.4 |
MemoryBank |
0.8 |
0.78 |
0.633 |
0.233 |
0.800 |
0.6 |
MemGPT |
0.94 |
0.92 |
0.667 |
0.233 |
0.82 |
0.600 |
SCMemory |
0.46 |
0.68 |
0.133 |
0.133 |
0.78 |
0.65 |
重点分析:
MemGPT 在 sh(单跳) 任务中表现最优(0.94),但 comp(比较性) 和 agg(聚合性) 的表现一般。
GenerativeAgent 在 mh(多跳) 任务中表现最佳(0.94),但 comp(比较性) 和 agg(聚合性) 相对较弱。
SCMemory 在 comp(比较性) 和 agg(聚合性) 上准确率最低(分别为 0.133),显示出其在复杂推理任务中的严重不足。
总结¶
本附录详细展示了不同记忆机制在 10k-Reflective(反思) 和 10k-Factual(事实) 记忆数据集上的表现情况。重点包括:
FullMemory 和 MemGPT 在多个任务中表现稳定。
GenerativeAgent 在某些任务上表现突出,但在情感和比较性任务中较弱。
SCMemory 整体表现较差,尤其是在复杂推理任务中。
这些结果对评估不同记忆机制的有效性提供了有力支持,并为未来研究提供了对比基准。