2506.05176_Qwen3_Embedding: Advancing Text Embedding and Reranking Through Foundation Models¶
引用: 23(2025-09-18)
组织:
Tongyi Lab Alibaba Group
总结¶
Abstract¶
Abstract 总结¶
本研究中,作者介绍了 Qwen3 Embedding 系列,这是对前一版本 GTE-Qwen 系列 的重要升级,特别是在 文本嵌入 和 重排序(reranking) 能力方面。该系列模型基于 Qwen3 基础模型 构建,充分利用了其在 多语言文本理解和生成 方面的强大能力。
核心内容:¶
训练方法:采用了一个创新的 多阶段训练流程,结合了 大规模无监督预训练 和 高质量数据集上的监督微调,从而提升了模型性能。
模型融合策略:通过有效的模型合并技术,确保了 Qwen3 Embedding 系列在 鲁棒性 和 适应性 上的优势。
数据合成:Qwen3 大语言模型不仅作为主干模型使用,还参与了 高质量、丰富且多样化的多领域、多语言训练数据的合成,从而优化训练流程。
模型配置与适用场景:¶
Qwen3 Embedding 系列提供了 三种模型尺寸 用于嵌入和重排序任务:0.6B、4B 和 8B,满足不同部署需求。
用户可以根据实际需要在 效率 和 效果 之间进行权衡。
实验评估与性能表现:¶
实验评估表明,Qwen3 Embedding 系列在多个基准测试中达到了 最先进的性能(SOTA)。
尤其在 多语言评估基准 MTEB 上表现突出,同时在 代码检索、跨语言检索和多语言检索任务 中也有显著优势。
开源与社区支持:¶
为促进研究的可复现性和社区发展,Qwen3 Embedding 模型已 开源,并采用 Apache 2.0 许可证 发布。
项目链接提供了访问源码和模型的渠道(如 Hugging Face、ModelScope、GitHub 等)。
其他说明:¶
本研究中,部分作者 贡献相同(Equal contribution)。
1 Introduction¶
本节主要介绍了文本嵌入(text embedding)和重排序(reranking)在自然语言处理和信息检索中的核心地位,并探讨了它们在大规模语言模型(LLMs)发展背景下的新挑战与进展。
1.1 背景与重要性¶
文本嵌入与重排序是众多自然语言处理任务(如网页搜索、问答系统、推荐系统等)的基础技术。高质量的嵌入模型能够捕捉文本之间的语义关系,而有效的重排序机制则能确保返回最相关的结果。近年来,随着生成式检索增强(Retrieval-Augmented Generation, RAG)和智能代理系统等新型应用的兴起,特别是在大型语言模型(如 Qwen3、GPT-4o)的推动下,对嵌入和重排序模型在可扩展性、上下文理解以及下游任务适配性方面提出了更高的要求和挑战。
1.2 大型语言模型带来的变革¶
在大型语言模型(LLMs)出现之前,主流方法是使用仅编码器的预训练模型(如 BERT)作为基础模型。但随着 LLMs 的兴起,其丰富的世界知识、理解能力和推理能力显著提升了嵌入和重排序模型的性能。此外,LLMs 还启发了新的训练范式,例如:
嵌入模型训练中,通过**多样化任务(如指令类型、领域、语言等)**的引入,提升了下游任务性能;
重排序模型训练中,结合零样本方法和监督微调等方式,也取得了显著进展。
1.3 本文贡献与方法¶
本文提出 Qwen3-Embedding 系列模型,基于 Qwen3 基础模型构建。该系列包括三类嵌入模型(0.6B、4B、8B)和三类重排序模型(0.6B、4B、8B),主要特点如下:
训练方法:采用多阶段训练流程,包括大规模无监督预训练 + 监督微调;
数据增强:利用 Qwen3 指令模型高效生成多语言、多任务的高质量文本相关数据;
模型优化:通过模型合并(model merging)提升鲁棒性和泛化能力;
功能支持:提供嵌入模型的灵活维度表示和可定制指令,便于在下游任务中灵活应用。
1.4 实验与性能¶
在多个任务和领域的基准测试中,Qwen3-Embedding 系列模型表现出最先进的性能,尤其在以下几个方面:
Qwen3-8B-Embedding 在 MTEB 多语言和代码基准中分别取得 70.58 和 80.68 分,优于此前的 SOTA 专有模型(如 Gemini-Embedding);
Qwen3-Reranker-0.6B 在多项检索任务中超越以往的顶尖模型;
Qwen3-Reranker-8B 表现更优,相比 0.6B 模型在多个任务中提升 3.0 分;
还进行了消融实验,分析了模型性能优异的关键因素。
1.5 后续结构安排¶
接下来的章节将详细介绍:
模型架构设计;
训练流程;
实验结果分析(嵌入与重排序模型);
总结与未来研究方向。
2 Model Architecture¶
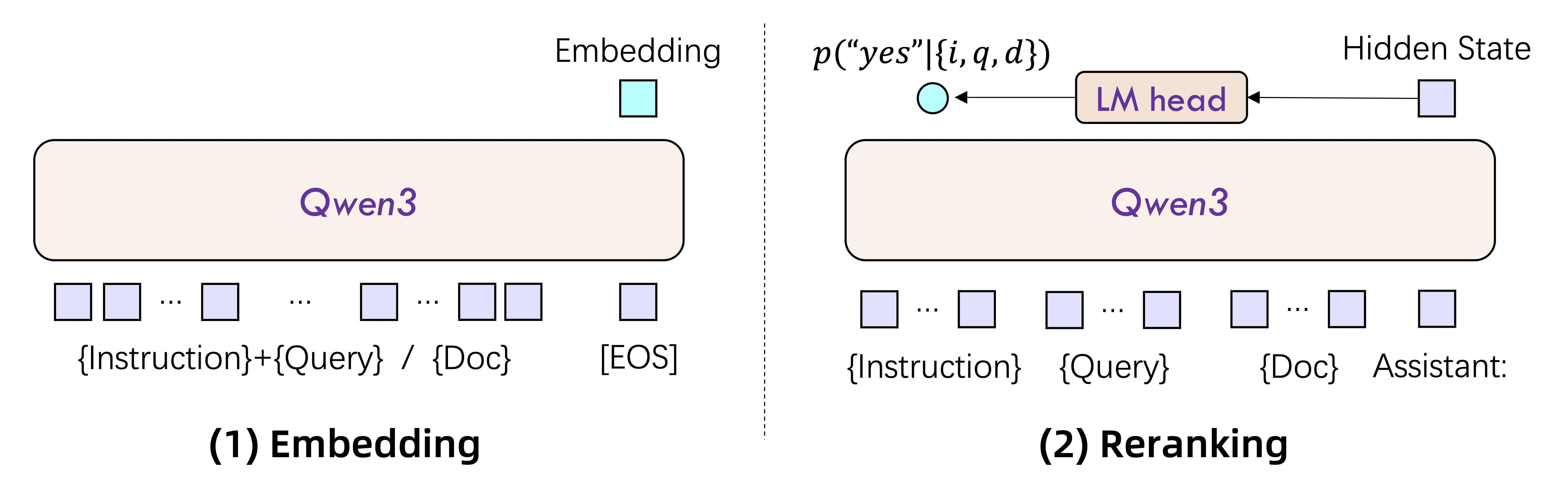
Figure 1:Model architecture of Qwen3-Embedding (left) and Qwen3-Reranker (right).
核心思想(主段落)¶
该章节的核心思想是介绍嵌入(embedding)和重排序(reranking)模型如何在**任务感知(task-aware)**的方式下评估查询(query)和文档(document)之间的相关性。
给定一个查询
q和一个文档d,模型根据任务指令I定义的相似性标准评估它们的相关性。训练数据通常以如下的形式组织:
{I_i, q_i, d_i^+, d_{i,1}^−, ⋯, d_{i,n}^−},其中:d_i^+是与查询相关的正样本;d_{i,j}^−是不相关的负样本。
通过训练多样化的文本对,模型可以更好地适应下游任务,如检索(retrieval)、语义文本相似性(STS)、分类(classification)和聚类(clustering)。
Architecture(模型架构)¶
Qwen3 嵌入和重排序模型基于 Qwen3 基础模型的 稠密版本 构建。
提供三种模型规模:0.6B、4B 和 8B 参数。
模型初始化使用 Qwen3 基础模型,以利用其在文本建模和指令遵循方面的能力。
不同配置下的模型层(layers)、隐藏层大小(hidden size)和上下文长度(context length)详见 表1。
Embedding Models(嵌入模型)¶
使用带有 因果注意力机制(causal attention) 的大语言模型(LLM)生成文本嵌入。
在输入序列末尾添加
[EOS]标记,最终嵌入从该[EOS]对应的隐藏状态中提取。为了确保嵌入能遵循任务指令,模型将**指令(Instruction)和查询(Query)**拼接为一个输入上下文,文档保持不变。
输入格式为:
{Instruction} {Query}
Reranking Models(重排序模型)¶
重排序模型用于更精确地评估文本相似性,采用 点式重排序(point-wise reranking) 方法。
与嵌入模型类似,为实现指令跟随能力(instruction-following),模型在输入中包含指令。
使用 LLM 的聊天模板,将相似性评估任务转化为二分类问题(“yes” 或 “no”)。
输入模板如下:
<|im_start|>system Judge whether the Document meets the requirements based on the Query and the Instruct provided. Note that the answer can only be "yes" or "no". <|im_end|> <|im_start|>user <Instruct>: {Instruction} <Query>: {Query} <Document>: {Document} <|im_end|> <|im_start|>assistant相关性得分(relevance score)通过预测“yes”或“no”的概率计算得出,数学表达如下:
\[ \text{score}(q,d) = \frac{e^{P(\text{yes}|I,q,d)}}{e^{P(\text{yes}|I,q,d)} + e^{P(\text{no}|I,q,d)}} \]
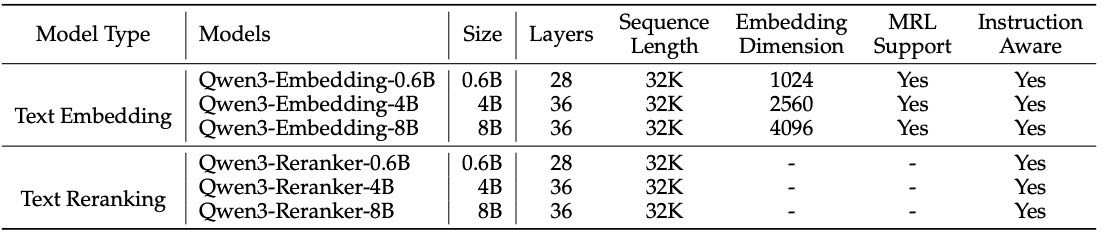
Table 1:Model architecture of Qwen3 Embedding models. “MRL Support” indicates whether the embedding model supports custom dimensions for the final embedding. “Instruction Aware” notes whether the embedding or reranker model supports customizing the input instruction according to different tasks.
图解
MRL Support:表示嵌入模型是否支持自定义嵌入维度。
Instruction Aware:表示模型是否支持根据不同任务自定义输入指令。
小结¶
本节主要介绍了 Qwen3 嵌入和重排序模型的结构与实现方式。重点包括:
任务感知(Instruction-Aware) 是模型的核心设计原则;
嵌入模型 通过拼接指令与查询,生成任务相关的文本嵌入;
重排序模型 将相似性判断转化为二分类任务,提高了模型的评估精度;
提供了三种不同规模的模型选择,适用于不同场景;
通过表格和流程图进一步展示了模型架构和训练方式。
3 Models Training¶
本节介绍了 Qwen3 Embedding 模型的多阶段训练流程,并重点讲解了训练目标、合成数据的生成、高质量训练数据的筛选等内容。
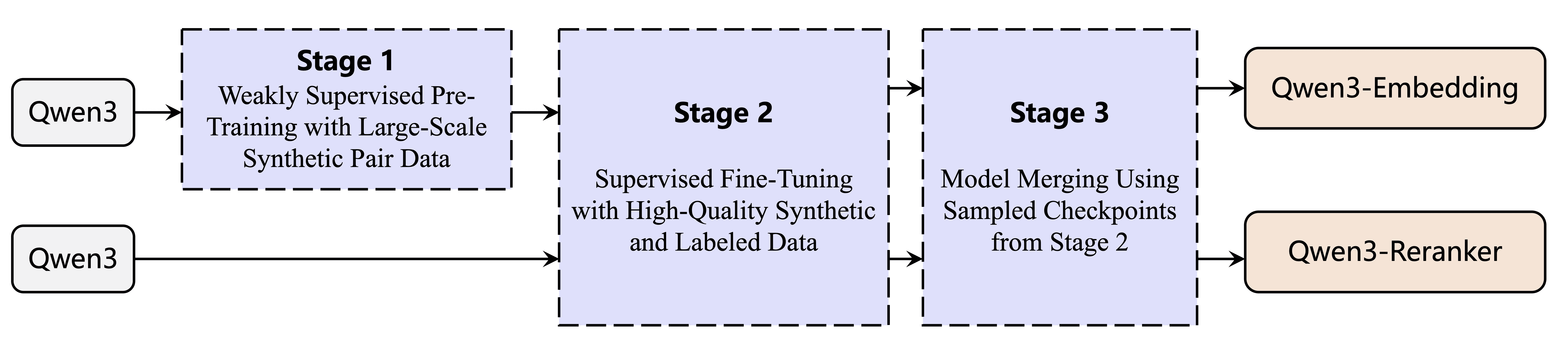
Figure 2:Training pipeline of Qwen3 Embedding and Reranking models.
图2:Qwen3 嵌入和重排序模型训练流程
图片展示了训练流程(见原文附图),包括数据准备、模型输入格式、训练目标以及相关性评估机制。
重点在于如何将指令、查询、文档输入模型,并通过损失函数来优化模型在任务感知的相关性判断能力。
3.1 Training Objective 训练目标¶
本部分介绍了嵌入模型和重排序模型在训练过程中使用的损失函数。
嵌入模型使用改进的对比损失(contrastive loss),基于 InfoNCE 框架。损失函数公式为:
\[ L_{\text{embedding}} = -\frac{1}{N} \sum_{i}^{N} \log \frac{e^{(s(q_i, d_i^+)/\tau)}}{Z_i} \]其中:
\( s(\cdot, \cdot) \) 是相似度函数(如余弦相似度);
\( \tau \) 是温度参数;
\( Z_i \) 是归一化因子,包含正样本与多个负样本的相似度分数。
\( Z_i \) 的计算中包含了以下几种负样本:
硬负样本(hard negatives);
同一批次中的其他查询;
同一批次中与正样本比较的文档;
同一批次中与查询比较的文档。
为了减少误负样本(false negatives)的影响,引入了掩码因子 \( m_{ij} \),当文档 \( d_j \) 的相似度高于正样本相似度 0.1 或者与 \( d_i^+ \) 相同时,设为 0,否则为 1。
重排序模型使用监督微调(SFT)损失:
\[ L_{\text{reranking}} = -\log p(l|\mathcal{P}(q,d)) \]其中 \( p(\cdot| \mathcal{P}(q,d)) \) 是 LLM 对于给定查询 \( q \) 和文档 \( d \) 的判断概率,\( l \) 为“yes”或“no”标签。该损失鼓励模型对正确标签分配更高的概率,从而提升排序性能。
3.2 Multi-stage Training 多阶段训练¶
多阶段训练是训练文本嵌入模型的常用策略。通常包括两个阶段:
第一阶段:使用大规模、弱监督数据进行训练,这些数据可能包含噪声,但有助于模型泛化;
第二阶段:使用高质量的监督数据进行微调,进一步提升模型性能。
Qwen3 Embedding 在此基础上引入了以下创新:
大规模合成数据驱动的弱监督训练:利用基础模型(如 Qwen3-32B)生成多样化的配对数据,相比从开放领域收集数据,这种方法更具可控性,尤其适用于低资源语言和场景。
高质量合成数据用于监督微调:基于 Qwen3 强大的生成能力,合成数据质量高,因此在第二阶段选择性地纳入这些数据可以提升模型性能。
模型合并(Model Merging):在微调完成后,使用球面线性插值(slerp)技术合并多个模型检查点,提升模型的鲁棒性和泛化能力。
需要注意的是,重排序模型的训练过程不包括第一阶段的弱监督训练。
3.3 Synthetic Dataset 合成数据集¶
为了支持多任务的相似性训练,我们生成了多样化的文本对数据,涵盖检索、双语挖掘、分类和语义文本相似性(STS)等任务。合成数据的质量由 Qwen3-32B 模型保障。
数据生成过程中采用多语言预训练语料,并通过设计不同的提示策略(如查询类型、长度、难度和语言)确保数据的多样性和真实性。
为了提高查询多样性,模拟用户视角,根据文档内容生成角色化查询。
最终,我们生成了约 1.5 亿对弱监督训练数据。通过余弦相似度筛选(> 0.7),选出约 1200 万对高质量监督数据用于进一步训练。
实验表明,使用这些合成数据训练的嵌入模型在下游任务(尤其是 MTEB 多语言基准)中表现优异,超过了多个开源模型和商业 API。
总体总结¶
本节详细描述了 Qwen3 Embedding 模型的训练流程,重点在于:
使用改进的对比损失和监督微调损失进行模型训练;
采用多阶段训练策略,结合大规模合成数据与高质量监督数据;
引入模型合并技术提升泛化能力;
通过合成数据生成策略提升训练数据的多样性和质量;
最终在多种基准测试中表现优异,尤其是在多语言任务中。
4 Evaluation¶
本章节对 Qwen3 Embedding 模型的评估过程进行了全面介绍,重点在于通过多个基准数据集评估其在文本嵌入和重排序任务中的表现。以下是对原文各部分内容的结构化总结:
4.1 Settings 评估设置¶
评估任务与基准¶
使用 Massive Multilingual Text Embedding Benchmark (MMTEB) 作为主要评估基准。
MMTEB 是 MTEB 的扩展,覆盖 250 多种语言,包含 500 多个高质量任务。
任务类型多样,包括检索、分类、语义相似性、代码检索、长文档检索、指令跟随等。
具体评估任务包括:
MMTEB:131 项任务
MTEB(英文 v2):41 项
CMTEB:32 项
MTEB-Code:12 项代码检索任务
文本重排序任务也进行了评估,分为三类:
基础相关性检索(英语、中文、多语言)
代码检索(MTEB-Code)
复杂指令检索(FollowIR)
对比方法¶
开源模型:NV-Embed-v2、GritLM-7B、GTE系列、E5、BGE 等。
商业API:OpenAI 的 text-embedding-3-large、Google 的 Gemini Embedding、Cohere 的 multilingual-v3.0。
重排序模型:Jina、mGTE、BGE-M3 等。
评估表格(重点内容)¶
表 3 展示了 Qwen3 Embedding 模型在不同规模下的性能表现:
Qwen3-Embedding-8B 在 MTEB(英文)、CMTEB、MTEB-Code 上表现最佳。
Qwen3-Embedding-0.6B 模型在参数量远少于基线模型的情况下,仍能与 Gemini Embedding 相媲美,表现出色。
重点强调了:
大模型(8B)优于中、小模型;
Qwen3 在多个任务上全面超越主流开源模型和部分商业模型。
4.2 Main Results 主要结果¶
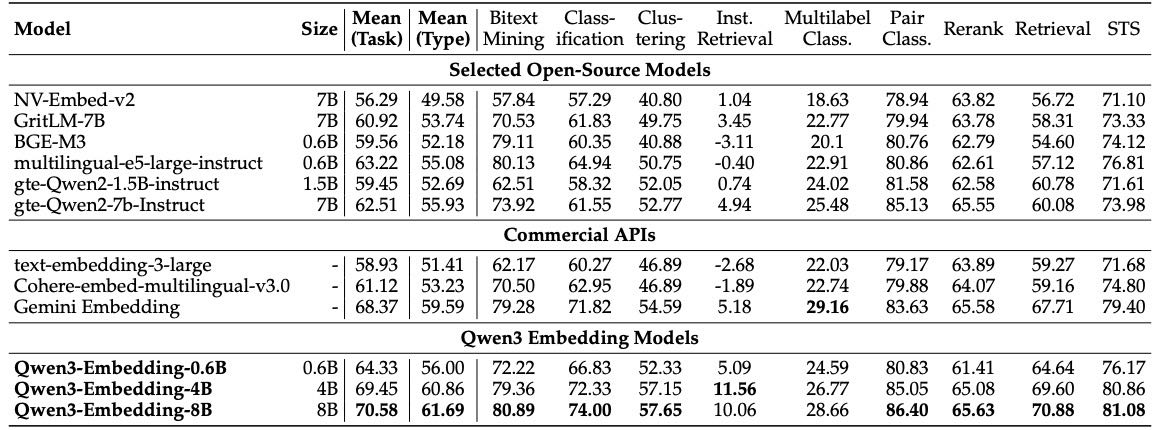
Table 2: Performance on MTEB Multilingual (Enevoldsen et al., 2025). For compared models, the scores are retrieved from MTEB online leaderboard on June 4th, 2025.
表2展示了 Qwen3 Embedding 模型与多个开源模型和商业 API 在 MTEB 多语言基准上的性能对比。Qwen3 Embedding 在多个子任务(如分类、聚类、检索、STS 等)上均取得领先成绩,尤其在 8B 版本上表现尤为突出。
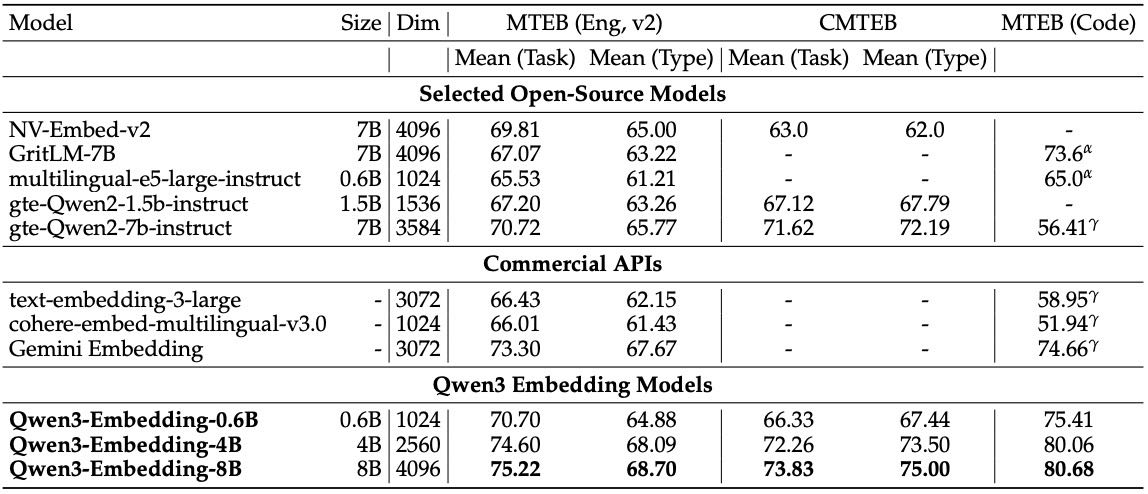
Table 3:Performance on MTEB Engilish, MTEB Chinese, MTEB Code. αTaken from (Enevoldsen et al., 2025). γTaken from (Lee et al., 2025b). For other compared models, the scores are retrieved from MTEB online leaderboard on June 4th, 2025.
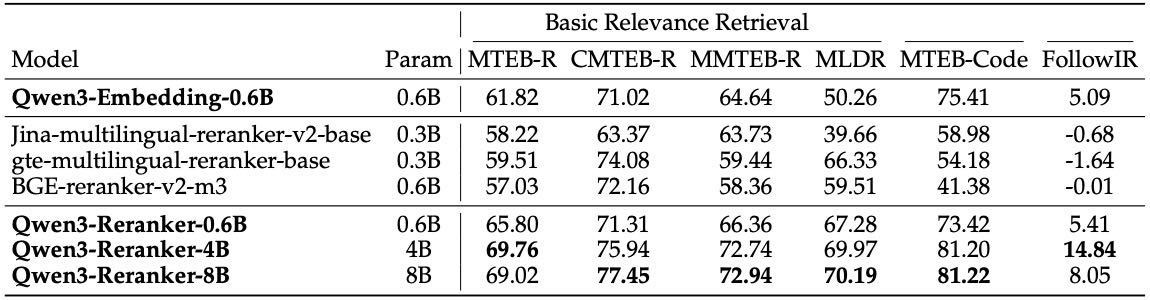
Table 4: Evaluation results for reranking models. We use the retrieval subsets of MTEB(eng, v2), MTEB(cmn, v1) and MMTEB, which are MTEB-R, CMTEB-R and MMTEM-R. The rest are all retrieval tasks. All scores are our runs based on the retrieval top-100 results from the first row.
Embedding 结果¶
MMTEB 评估(表 2):Qwen3-Embedding-4B/8B 表现最佳;Qwen3-Embedding-0.6B 表现接近 Gemini-Embedding。
MTEB(英文 v2)、CMTEB、MTEB-Code 评估(表 3):Qwen3 模型在所有任务中表现一致好,尤其是 4B 和 8B 版本显著优于其他模型。
Reranking 结果(重点内容)¶
表 4 展示了 Qwen3-Reranker 在多个重排序任务中的表现:
所有 Qwen3-Reranker 模型(0.6B、4B、8B)均优于原始 Qwen3-Embedding-0.6B。
Qwen3-Reranker-8B 在大多数任务中表现最优。
特别是在 FollowIR(复杂指令检索) 任务中,Qwen3-Reranker-4B 取得了 14.84 的显著提升,远超其他模型。
重排序模型的评估方法:使用 Qwen3-Embedding-0.6B 取 top-100 候选,再使用不同模型进行排序。
4.3 Analysis 分析¶
本节分析了 Qwen3 Embedding 模型训练框架中的两个关键要素:
1. 大规模弱监督预训练的有效性(重点内容)¶

Table 5: Performance (mean task) on MMTEB, MTEB(eng, v2), CMTEB and MTEB(code, v1) for Qwen3-Embedding-0.6B model with different training setting.
表 5 显示,仅使用合成数据训练的 Qwen3-Embedding-0.6B(第一行)已具有较强性能。
如果去掉合成数据训练(即无弱监督阶段),性能明显下降(第二行)。
结论:大规模弱监督预训练是提升模型性能的关键因素。
2. 模型合并的有效性(重点内容)¶
若不使用模型合并(即仅通过数据采样策略训练),模型性能(第三行)明显低于最终模型(第四行)。
结论:模型合并(Model Merging)技术对最终性能有显著提升作用。
总结¶
本章全面评估了 Qwen3 Embedding 模型在多种语言和任务下的表现,得出以下结论:
Qwen3 Embedding 模型在多个基准任务中表现优异,尤其在 8B 和 4B 版本上表现最强。
0.6B 小模型虽然参数较少,但性能接近甚至超越部分商业模型。
重排序任务中,Qwen3-Reranker 显著提升效果,8B 模型表现最佳。
训练框架中的关键要素(大规模弱监督预训练 + 模型合并)显著提升了模型性能,是 Qwen3 成功的重要因素。
5 Conclusion¶
本技术报告中,作者介绍了 Qwen3-Embedding 系列,这是一套基于 Qwen3 基础模型的文本嵌入和重排序模型。这些模型旨在在多种文本嵌入和重排序任务中表现出色,包括多语言检索、代码检索以及复杂指令跟随等。
重点内容:
模型构建方式:Qwen3-Embedding 系列模型是通过一个 强大的多阶段训练流程 构建的。该流程结合了在合成数据上进行的 大规模弱监督预训练,以及在高质量数据集上进行的 监督微调 和 模型合并。这确保了模型在多种任务和语言上的泛化能力。
Qwen3 LLMs 的作用:Qwen3 大语言模型在生成跨语言和跨任务的多样化训练数据方面起到了关键作用,从而提升了嵌入模型的能力和适应性。
评估结果:作者进行了全面的评估,结果表明 Qwen3-Embedding 模型在多个基准测试中达到了 最先进的性能,包括 MTEB、CMTEB、MMTEB 以及多个检索基准。
模型开放情况:
作者很高兴地宣布,Qwen3-Embedding 和 Qwen3-Reranker 模型(0.6B、4B 和 8B 参数规模)已开源,供社区使用和进一步开发。
总结:
Qwen3-Embedding 系列模型在结构设计、训练流程和性能表现上都具有显著优势,并且已开源,为研究和应用提供了强有力的工具。
Appendix A Appendix¶
A.1 合成数据¶
本节介绍用于预训练的四种类型合成数据:检索、双语挖掘、语义文本相似性、分类任务。目标是使模型能够适应多语言和跨语言多样性,并在预训练过程中更广泛地学习相似性任务的处理能力。数据通过 Qwen3 32B 模型生成。
合成检索数据使用“文档到查询”方法生成。具体流程包括两个阶段:
配置阶段:使用大语言模型(LLM)确定生成查询的“问题类型”、“难度”和“角色”。
查询生成阶段:根据配置信息生成具体查询。此外,还会指定生成查询的长度和语言。
角色选择时,从 Persona Hub 中选取与文档最相关的前五名候选人,以增强生成查询的多样性。生成过程采用特定模板,输入文档和角色信息,输出 JSON 格式的查询结果。
表格 6 提供了每个训练阶段使用的数据量统计:
弱监督预训练:使用 ∼150M 个合成数据对模型进行预训练。
监督微调:使用多个高质量数据集(如 MS MARCO、NQ、HotpotQA 等)和合成数据(约 7M 标注数据 + 12M 合成数据)对模型进行微调。
A.2 详细结果¶
本节展示了不同模型在多个基准测试上的性能表现,重点包括 MTEB 英文版(v2)、中文版(v1)以及代码相关任务(Code v1)。
表 7(MTEB(eng, v2))¶
比较了从在线排行榜上获取的多个模型在英文任务上的表现。Qwen3-Embedding-8B 性能最佳,平均分数为 75.22,表现为:
分类任务:68.70
聚类任务:90.43
双语分类任务:58.57
检索和语义相似性任务表现稳定。
表 8(MTEB(cmn, v1))¶
展示中文任务的性能,Qwen3-Embedding-8B 同样表现优异,平均得分为 73.84,具体如下:
分类任务:75.00
聚类任务:76.97
语义相似性任务:84.23
检索任务得分也较高。
表 9(MTEB(Code, v1))¶
专门评估代码相关任务的性能(如代码搜索、代码反馈、Stack Overflow 问答等),Qwen3-Reranker-8B 在多个子任务中表现最佳,nDCG@10 得分达到 81.22,尤其在代码翻译、检索和问答任务中表现突出。
总结:
本附录详细描述了合成数据的生成方法,并展示了 Qwen3 在多个语言和代码任务上的性能表现。特别是 Qwen3-Embedding 和 Qwen3-Reranker 系列模型在 MTEB 等多个基准测试中表现优异,尤其是在高参数模型(如 4B 和 8B)中性能提升显著。