2504.19413_❇️Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory¶
引用: 3(2025-08-09)
组织: mem0.ai
GitHub: https://github.com/mem0ai/mem0
总结¶
技术架构
混合数据库方法:结合向量数据库(存储语义信息)、键值数据库(快速检索)和图数据库(关系跟踪)
三级记忆体系:用户级/会话级/代理级记忆的分层管理,确保上下文连续性
遗忘曲线算法:自动衰减过时信息,强化高频使用数据,让记忆库智能更新
两种AI代理的记忆架构:
Mem0:一种基于文本的增量记忆提取与更新系统。
Mem0g:在Mem0基础上扩展的图结构记忆模型,支持更复杂的实体关系推理。
两大类评估指标
性能指标(Performance Metrics)
传统的F1 分数和 BLEU-1
LLM-as-a-Judge(J)作为补充评估指标
部署指标(Deployment Metrics)
Token 消耗(Token Consumption)
延迟(Latency)
延迟(Latency)
总延迟(total latency)
权衡点
更复杂的记忆架构可能提高准确性,但会增加 token 消耗和延迟
六类基线方法
已建立的 LOCOMO 基线
包括:LoCoMo、ReadAgent、MemoryBank、MemGPT、A-Mem
开源记忆系统(Open-Source Memory Solutions)
如 LangMem(Hot Path)等
检索增强生成(RAG)
全上下文处理(Full-Context Processing)
专有模型(Proprietary Models)
OpenAI 的 Memory 功能
记忆提供平台(Memory Providers)
Zep,一个专为 AI 代理设计的记忆管理平台
最佳场景
个性化学习助手:记忆用户学习偏好和进度
客服系统:保留用户历史交互,提供连续服务体验
游戏NPC:构建具有记忆能力的游戏角色
快速原型开发:需要快速集成记忆功能的AI应用
别人的总结¶
• 提出了 Mem0 和 Mem0⁸ 两种可扩展的记忆架构,旨在解决LLMs在长时间对话中上下文窗口受限的问题。 • Mem0 采用增量处理范式,通过动态提取、整合和检索对话中的显著信息来管理记忆。其核心在于一个两阶段的管道:提取阶段和更新阶段。在提取阶段,系统结合对话摘要、近期消息序列和新的消息对,通过LLM(如GPT-4o-mini)提取显著记忆。在更新阶段,系统评估每个候选记忆与现有记忆的一致性,并利用LLM的函数调用能力决定执行ADD、UPDATE、DELETE或NOOP操作,从而维护知识库的连贯性。 • Mem0⁸ 在Mem0的基础上,引入了基于图的记忆表示。记忆被表示为有向带标签图,其中节点代表实体(如人物、地点),边代表实体间的关系(如“居住在”)。这种图结构能够捕获复杂的、多跳的关联,对于处理复杂查询和时间推理至关重要。Mem0⁸的提取过程分为实体提取和关系生成两阶段,均由LLM驱动。存储和更新策略则涉及实体和关系的创建、更新和冲突检测,并利用Neo4j等图数据库作为底层存储。记忆检索采用实体中心和语义三元组相结合的双重方法,以实现最佳信息访问。实验结果表明,Mem0和Mem0⁸在记忆性能上显著优于现有系统,尤其在多跳和时间推理任务中表现出色,同时在计算效率上也有显著提升。
Abstract¶
本文探讨了大型语言模型(LLMs)在生成上下文连贯响应方面的能力,同时指出其固定上下文窗口在长期多会话对话中维护一致性方面的基本挑战。为此,作者提出了 Mem0,这是一种以记忆为中心的可扩展架构,能够动态地从正在进行的对话中提取、整合和检索重要信息。
在此基础上,作者进一步提出了一种改进版本,利用基于图的记忆表示(graph-based memory representations)来捕捉对话元素之间复杂的关系结构。
为了验证其有效性,作者在 LOCOMO 基准测试 上进行了全面评估,并将 Mem0 与六种基线方法进行了系统性比较:
已有的记忆增强系统
不同 chunk 大小和 k 值的检索增强生成(RAG)系统
处理完整对话历史的全上下文方法
开源记忆解决方案
专有模型系统
专用记忆管理平台
评估结果显示,Mem0 在四大类问题上表现优于所有现有记忆系统:
单跳(single-hop)
时序(temporal)
多跳(multi-hop)
开放领域(open-domain)
其中,Mem0 在 LLM-as-a-Judge 指标上比 OpenAI 的模型相对提升了 26%,而采用图记忆的 Mem0 整体得分比基础 Mem0 高出约 2%。
除了准确率的提升,Mem0 还显著降低了计算开销。相比全上下文方法,Mem0 的 p95 延迟降低了 91%,token 成本节省了 90%以上,在高级推理能力和实际部署限制之间实现了良好的平衡。
研究结果强调了在长期对话中保持一致性时,结构化、持久化的记忆机制的重要性,为构建更可靠、更高效的 LLM 驱动的 AI 代理系统铺平了道路。
1 Introduction¶
本节围绕“AI系统中记忆机制的必要性与局限性”展开,重点介绍了当前基于大语言模型(LLMs)的AI代理在长期记忆能力方面的不足,并提出了解决方案。
1. 人类记忆的作用与AI代理的挑战¶
核心观点:
人类记忆是智能的基础之一,它不仅塑造身份、指导决策,还支持学习、适应和建立关系。在交流中,记忆帮助我们记住过去对话、推断偏好,并构建他人心理模型。
重点内容:
人类能通过长期记忆保持对话的连贯性和上下文丰富性,跨越数日、数周甚至数月。
AI代理虽在语言生成方面取得进展,但由于依赖固定的上下文窗口(context window),无法在会话中断后持续记忆用户信息,导致重复提问、遗忘偏好、甚至矛盾的回答。
示例说明:
举例说明用户在初次对话中声明是“素食者并避免乳制品”,但在后续对话中,系统若无记忆机制,可能会推荐鸡肉,违背用户偏好。
有记忆机制的系统则能跨会话维护用户偏好,提供合适的建议。
2. 记忆机制对AI代理性能的提升¶
核心观点:
记忆能力不仅限于对话场景,还能显著提升AI代理在互动环境中的表现。
重点内容:
带有记忆的AI代理能更好地预测用户需求、从错误中学习,并跨任务泛化。
记忆增强系统通过动作与结果之间的因果关系优化决策,适应动态环境。
已有研究提出分层记忆架构(Hierarchical Memory Architectures)和自进化记忆系统(Autonomous Evolutionary Memory Systems)等机制,提升多轮对话的连贯性与长期推理能力。
3. LLMs的记忆局限性及其根本问题¶
核心观点:
尽管当前LLMs的上下文长度在提升,但其本质上仍是“短暂记忆”系统,无法真正模拟人类的记忆能力。
重点内容:
即使是GPT-4、 Claude 3.7 Sonnet、Gemini等具有数十万甚至百万token上下文长度的模型,也无法解决“跨会话信息丢失”的根本问题。
实际中,用户与AI的互动可能跨越数周或数月,远远超出上下文长度。
会话内容往往不具连续性,用户可能在编程任务后突然返回饮食问题,此时模型需从大量无关信息中提取关键点,但注意力机制对远距离token表现不佳,降低信息利用效率。
问题总结:
上下文扩展只是“延缓”了问题,并未“解决”长期记忆缺失的根本限制。
在医疗、教育等高风险领域,这种记忆缺陷会严重影响信任和连续性。
4. 提出的解决方案与Mem0系统¶
核心观点:
为解决上述问题,本文提出Mem0,一种新的记忆架构,旨在让AI代理能够动态捕捉、组织并检索重要信息,实现长期连贯对话。
重点内容:
Mem0:以图结构(graph-based)增强基础架构,更好地建模对话元素之间的复杂关系。
实验表现:
在LOCOMO基准上,Mem0在多种问题类型中优于现有记忆系统(包括记忆增强架构、RAG方法及开源和闭源方案)。
Mem0响应时间比全上下文方法低91%,在推理能力与部署效率之间取得平衡。
目标:
让AI从“短暂、健忘的回应者”转变为“可靠、长期的协作者”,重塑对话智能的未来。
总体结构回顾¶
内容模块 |
核心观点 |
强调重点 |
|---|---|---|
人类记忆与AI代理对比 |
人类记忆支持长期连贯对话,而AI受限于固定上下文 |
长期记忆的必要性 |
记忆机制对AI性能的提升 |
记忆增强系统提高预测、学习与泛化能力 |
分层与自进化系统 |
LLMs的记忆局限性 |
长上下文无法替代真正的长期记忆 |
上下文扩展的无效性 |
Mem0系统介绍 |
提出Mem0架构,实现长期、高效、图式化记忆 |
性能与效率的平衡 |
总结¶
本节为全文奠定了理论基础,指出AI代理缺乏长期记忆机制是当前系统无法实现真正“智能对话”的核心瓶颈。通过引入Mem0系统,作者提出了一种可行的解决方案,旨在让AI代理实现持续、连贯、人性化的交互体验,并在多个应用场景中具备实际部署价值。
2 Proposed Methods¶
本文介绍了两种AI代理的记忆架构:
Mem0:一种基于文本的增量记忆提取与更新系统。
Mem0g:在Mem0基础上扩展的图结构记忆模型,支持更复杂的实体关系推理。
2.1 Mem0¶
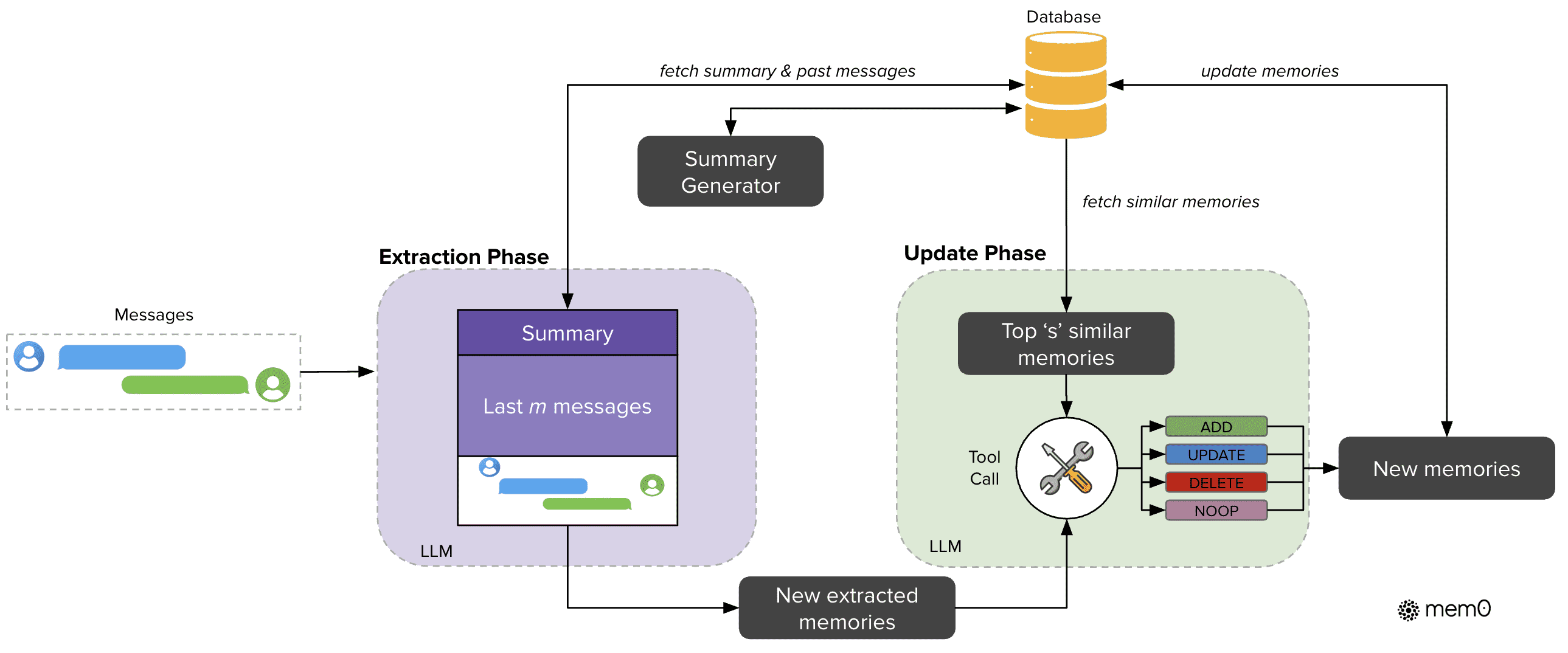
Figure 2:Architectural overview of the Mem0 system showing extraction and update phase. The extraction phase processes messages and historical context to create new memories. The update phase evaluates these extracted memories against similar existing ones, applying appropriate operations through a Tool Call mechanism. The database serves as the central repository, providing context for processing and storing updated memories.
架构概述¶
Mem0采用增量式处理机制,支持在对话进行中实时提取和更新记忆。
系统包括两个核心阶段:提取(extraction)和更新(update)。
提取阶段:从对话消息对中提取关键信息,构建初步记忆。
更新阶段:通过语义匹配和工具调用机制,将新提取的记忆与已有记忆对比,决定是否添加、更新、删除或忽略。
提取阶段(Extraction)¶
输入为消息对 (mt-1, mt),通常是一个用户消息和一个助手回复。
系统结合两种上下文来源:
全局对话摘要 S(从数据库中获取)
最近 m 条消息(用于提供时间性上下文)
构建综合提示 P,用于调用 LLM 提取关键记忆集合 Ω。
提取的结果是候选记忆,用于更新知识库。
更新阶段(Update)¶
将每个候选记忆 ωi 与数据库中相似的 s 个现有记忆进行对比。
通过 LLM 的工具调用(tool call)决定执行以下四种操作之一:
ADD:新增记忆(无语义冲突)
UPDATE:更新已有记忆(补充信息)
DELETE:删除冲突记忆
NOOP:无需操作
系统通过这种方式保持知识库的一致性和时序性。
实验配置¶
m = 10(最近消息数)
s = 10(相似记忆数)
使用 GPT-4o-mini 作为推理引擎,使用向量数据库支持语义搜索。
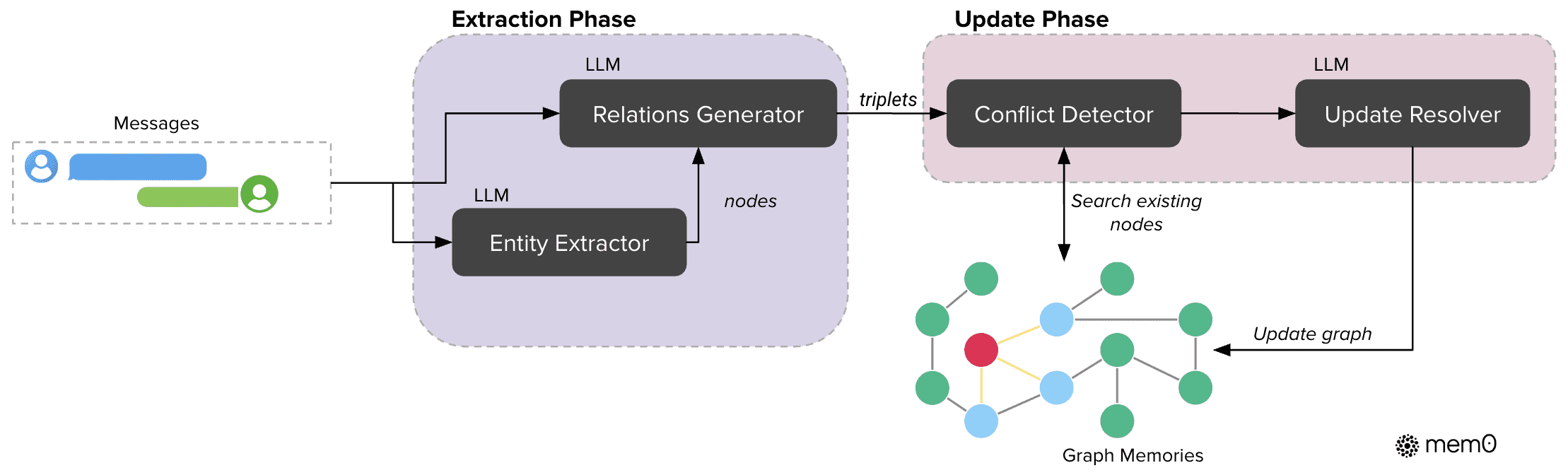
Figure 3:Graph-based memory architecture of Mem0g illustrating entity extraction and update phase. The extraction phase uses LLMs to convert conversation messages into entities and relation triplets. The update phase employs conflict detection and resolution mechanisms when integrating new information into the existing knowledge graph.
2.2 Mem0g¶
架构概述¶
Mem0g 是对 Mem0 的扩展,采用图结构(Graph-based)存储记忆。
每个记忆被表示为带标签的有向图 G = (V, E, L):
V(节点):表示实体,如人名、地点。
E(边):表示实体之间的关系。
L(标签):为节点和边添加语义类型信息。
图结构支持更复杂的关系推理,例如跨多条记忆的路径查询。
提取阶段(Extraction)¶
分为两步:
实体提取模块:识别对话中的关键实体及其类型(如人、地点、事件)。
关系生成模块:提取实体之间的语义关系,形成三元组 (vs, r, vd),其中 r 是关系标签。
模块利用 LLM 的语义理解和提示工程,从对话中提取显式和隐式信息。
更新阶段(Update)¶
新关系三元组会被整合到现有知识图谱中。
通过语义相似度匹配查找现有实体节点。
冲突检测机制:识别并标记可能冲突的关系,但保留原始记录以支持时序推理。
使用 LLM 判断是否标记关系为过时(obsolete),而非直接删除。
记忆检索(Retrieval)¶
支持两种检索方式:
实体中心检索:基于查询中的实体,查找关联节点及其关系,形成子图。
语义三元组检索:将查询编码为向量,与图中所有关系三元组进行相似度匹配。
检索结果按相关性排序,返回符合阈值的结果。
实现细节¶
使用 Neo4j 作为图数据库。
LLM 模块采用 GPT-4o-mini,通过函数调用方式提取结构化信息。
结合图结构、语义嵌入和LLM 抽取,实现结构丰富性和语义灵活性的统一。
总结¶
Mem0 是一个基于文本的增量记忆系统,适合在对话中抽取和更新关键信息。
Mem0g 则在 Mem0 的基础上扩展为图结构记忆模型,支持更复杂的关系推理和多路径查询。
两者均使用 LLM 作为核心推理引擎,结合向量相似度匹配和记忆管理机制,实现知识库的动态维护与更新。
实验配置使用 GPT-4o-mini,结合向量数据库和图数据库,保证了系统的可扩展性和实用性。
3 Experimental Setup¶
3.1 数据集¶
重点内容:LOCOMO 数据集的结构和用途
LOCOMO 数据集是专为评估长期对话记忆设计的,包含 10 个长对话,每个对话平均包含约 600 条对话和 26000 个 token,分布在多个会话中。
每个对话记录了两个人讨论日常生活或过去事件的互动,并附带 约 200 个问题和相应的标准答案。
问题分为四种类型:单跳(single-hop)、多跳(multi-hop)、时间相关(temporal)和开放式(open-domain)。
原始数据集中还包括对抗性问题(adversarial),用于测试系统能否识别无法回答的问题。但该类别因缺乏标准答案被排除在当前实验之外。
总结: LOCOMO 是一个专门用于评估长期对话记忆系统性能的高质量数据集,包含丰富的问题类型,能够全面测试系统的记忆能力和回答能力。
3.2 评估指标¶
本节分为两大类评估指标:
(1) 性能指标(Performance Metrics)¶
传统指标的局限性: 研究通常使用 F1 分数和 BLEU-1 评估生成答案与标准答案的词法相似性,但这些指标在评估事实准确性时有严重缺陷。
例如:标准答案是 “Alice 是三月出生”,而系统生成 “Alice 是七月出生”,虽然词法重叠度高,但事实错误,传统指标可能给出高分。
提出 LLM-as-a-Judge(J)作为补充评估指标:
使用一个更强的 LLM 作为“法官”,从事实准确性、相关性、完整性、上下文恰当性等多个维度评估生成答案。
每个方法在完整数据集上进行 10 次独立运行,计算平均分和 ±1 个标准差。
J 的评估结果更贴近人类判断,解决了传统指标的语义评估不足问题。
总结: 性能指标使用传统指标(F1、BLEU-1)和 LLM-as-a-Judge 结合,以更全面地评估对话系统的回答质量。
(2) 部署指标(Deployment Metrics)¶
部署指标关注实际应用中的效率和成本问题:
Token 消耗(Token Consumption): 使用 ‘cl100k_base’ 编码,统计在检索过程中用于构建上下文的 token 数量。
对于基于记忆的系统,这些 token 是从知识库中检索的记忆;
对于 RAG 系统,是检索到的文本块总 token 数。
token 数量直接影响成本和效率。
延迟(Latency): 分为两部分:
搜索延迟(search latency):查找记忆或文本块所用时间;
总延迟(total latency):包括搜索时间和生成答案的时间。
系统设计的权衡点在于: 更复杂的记忆架构可能提高准确性,但会增加 token 消耗和延迟。因此,多维评估方法帮助研究者根据实际需求(如准确性 vs 高效性)做出决策。
总结: 部署指标关注 token 消耗和延迟,揭示系统设计中的效率与准确性之间的关键权衡,适用于实际部署场景。
3.3 基线方法(Baselines)¶
作者共比较了 六类基线方法,涵盖目前对话记忆系统的主流解决方案和开源工具,以全面评估所提出方法的性能。
(1) 已建立的 LOCOMO 基线¶
包括:LoCoMo、ReadAgent、MemoryBank、MemGPT、A-Mem。
这些方法在 LOCOMO 上已有基准结果,代表了当前对话记忆系统的发展趋势。
作者使用 gpt-4o-mini 作为评估模型,确保对比公平。
A-Mem 的实验由作者重新运行,以便生成 LLM-as-a-Judge 评估结果。
(2) 开源记忆系统(Open-Source Memory Solutions)¶
如 LangMem(Hot Path)等开源记忆系统,虽然未在 LOCOMO 上评估,但在相关对话任务中表现良好。
使用 gpt-4o-mini 和 text-embedding-small-3 嵌入模型进行初始化。
(3) 检索增强生成(RAG)¶
将整个对话历史分为不同长度的块(128 到 8192 token)。
每个块使用 text-embedding-small-3 嵌入,并在查询时检索最相关的 1 或 2 个块。
通过调整 块大小和检索数量 k,系统性评估 RAG 在长期对话记忆任务中的表现。
(4) 全上下文处理(Full-Context Processing)¶
将完整对话历史直接放入 LLM 的上下文窗口中处理。
简单但存在局限:随着对话长度增加,token 成本和延迟显著上升。
作为对比基准,用于衡量复杂记忆机制的必要性。
(5) 专有模型(Proprietary Models)¶
使用 OpenAI 的 Memory 功能(ChatGPT 接口),并基于 LOCOMO 数据集进行测试。
输入完整对话历史并生成带有时间戳的记忆,作为回答问题的上下文。
由于 OpenAI 不支持外部 API 调用,此方法使用全记忆上下文,模拟其最大潜力。
(6) 记忆提供平台(Memory Providers)¶
评估 Zep,这是一个专为 AI 代理设计的记忆管理平台。
保留对话的时间戳信息,确保时间敏感性问题能通过时间锚定记忆正确回答。
代表一种商业化记忆管理解决方案,特别适用于时间相关的对话任务。
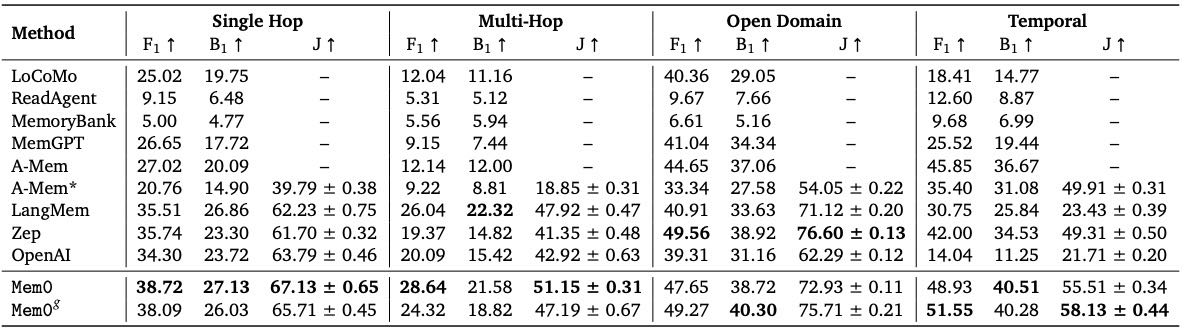
Table 1:Performance comparison of memory-enabled systems across different question types in the LOCOMO dataset. Evaluation metrics include F1 score (F1), BLEU-1 (B1), and LLM-as-a-Judge score (J), with higher values indicating better performance. (↑) represents higher score is better.
图片说明
A-Mem∗ represents results from our re-run of A-Mem to generate LLM-as-a-Judge scores by setting temperature as 0.
Mem0g indicates our proposed architecture enhanced with graph memory.
总结¶
本章构建了一个全面的实验框架,使用 LOCOMO 数据集,结合传统和 LLM 判断的性能指标与部署指标,系统性地评估了各类对话记忆系统的表现。基线方法覆盖了当前主流的解决方案,包括专有模型、开源系统、RAG、全上下文处理和商业化平台。通过多维度比较,作者为对话记忆系统的研究与应用提供了可比较、可复现且具实践意义的评估方法。
4 Evaluation Results, Analysis and Discussion.¶
本节对 Mem0 和 Mem0g 这两种基于记忆的系统进行评估与对比,涵盖多个任务类型(单跳、多跳、开放域、时序推理),并分析其性能、延迟和系统开销。
4.1 不同记忆系统间的性能比较¶
总体表现¶
本文提出的 Mem0 和 Mem0g 在所有三种评估指标(F1、B1、J)上,对大多数问题类型均设立了新的SOTA(最先进)。
Mem0 通过自然语言表示的记忆体取得了最佳结果,而 Mem0g 在加入图结构后,性能略有下降,说明在单跳问题中,图结构的增益有限。
单跳问题性能¶
Mem0 表现最好(F1=38.72,B1=27.13,J=67.13)
Mem0g 略有下降,说明图结构在单跳任务中对性能帮助有限。
Zep 和 LangMem 相比本文模型在 J 上分别低约 8%。
早期的 A-mem 表现较差,J 分数低超过 25,说明细粒度的结构化索引在简单任务中依然必要。
多跳问题性能¶
Mem0 在 F1 和 J 上均领先,显示其在整合多会话信息方面的优势。
Mem0g 表现不佳,说明在多跳任务中,图结构可能引入冗余或效率低下。
LangMem 表现有竞争力,但远不及 Mem0,再次验证本文的索引机制更优。
开放域性能¶
Zep 在 F1 和 J 上略胜 Mem0 和 Mem0g,说明其结合对话与外部知识的表现稍强。
Mem0g 的 J 得分 75.71,表现良好,仅次于 Zep。
表明:虽然结构化记忆在开放域中提升显著,但 Zep 仍略占优势。
时序推理性能¶
Mem0g 在所有指标中表现最佳(F1=51.55,J=58.13),说明图结构在时序任务中具有显著优势。
Mem0 在 J 上也表现不错(55.51),说明自然语言记忆在时序推理中也有一定帮助。
OpenAI 表现不佳,主因是缺乏时间戳,导致记忆缺失。
4.2 跨类别的性能分析¶
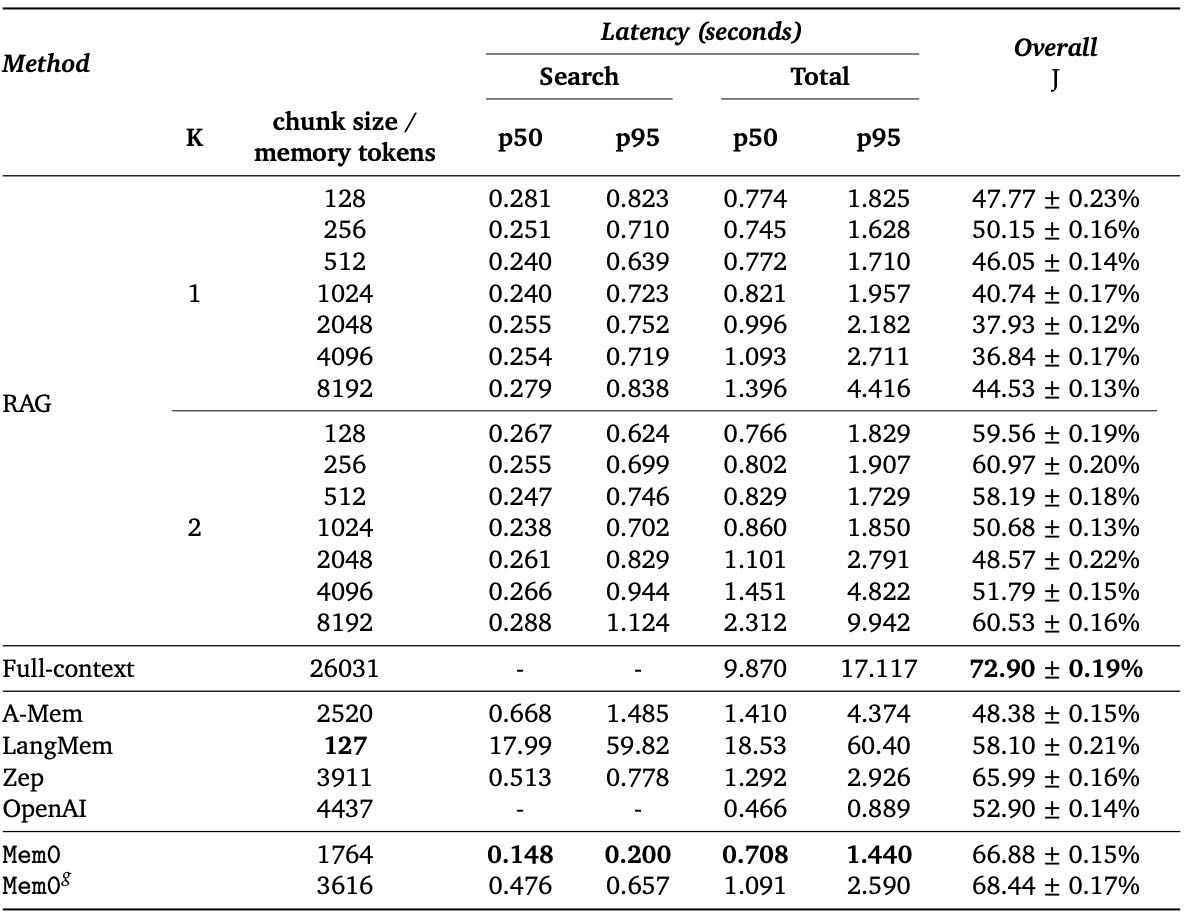
Table 2:Performance comparison of various baselines with proposed methods. Latency measurements show p50 (median) and p95 (95th percentile) values in seconds for both search time (time taken to fetch memories/chunks) and total time (time to generate the complete response). Overall LLM-as-a-Judge score (J) represents the quality metric of the generated responses on the entire LOCOMO dataset.
Mem0 在单跳问题中表现特别好,受益于其高效的自然语言记忆结构。
Mem0g 在单跳任务中 B1 有所下降,但 J 保持竞争力,说明图结构更适用于语义复杂或关系密集型任务。
在多跳任务中,Mem0 明显优于 Mem0g,说明图结构在多步推理中可能引入冗余。
Mem0g 在时序和开放域任务中优势明显,强调了结构化记忆的重要性。
4.3 与 RAG 和全上下文模型的性能对比¶
方法 |
最佳 J 得分 |
备注 |
|---|---|---|
RAG (k=2, chunk=8192) |
~61% |
检索效果受限于冗余文本 |
Mem0 |
67% |
比 RAG 高约 10% |
Mem0g |
68% |
比 RAG 高约 12% |
全上下文模型 |
~73% |
精度最高,但延迟极高 |
Mem0 和 Mem0g 通过提取关键事实,减少噪声,提升了模型对关键信息的感知能力。
全上下文模型 虽精度高,但 延迟极高(约 17 秒),不适用于生产环境。
Mem0 和 Mem0g 在延迟上显著优化,p95 延迟分别为 1.44s 和 2.6s,比全上下文模型低 90% 左右。
4.4 延迟分析¶
Mem0 在搜索和总时延上均为最低(p50: 0.148s, p95: 0.200s),适合实时应用。
Mem0g 略慢(p50: 0.476s),但仍优于其他方法,且 J 得分最高(68.44%)。
Zep 和 LangMem 搜索延迟高,不适合交互式系统。
全上下文模型 虽无搜索延迟,但因处理大量文本(26k tokens),总延迟极高(>17s)。
4.5 记忆系统开销分析(Token 和构建时间)¶
方法 |
平均 Token 数 |
构建时间 |
|---|---|---|
Mem0 |
7,000 tokens |
快 |
Mem0g |
14,000 tokens |
较慢但可控 |
Zep |
600,000+ tokens |
构建时间长,延迟高 |
原始对话 |
26,000 tokens |
无压缩,效率低 |
Mem0 和 Mem0g 在 Token 使用上远优于 Zep。
Zep 由于存储冗余信息(节点摘要 + 边事实),导致 Token 数量极高,且构建过程延迟严重。
Mem0 构建速度快,用户可立即使用新记忆进行查询,适合生产部署。
总结观点¶
Mem0 适合单跳、多跳、开放域任务,高效、低延迟。
Mem0g 在时序推理与语义复杂任务中表现更优。
本文模型在精度和延迟方面找到了良好平衡,特别是相比 RAG 和全上下文模型。
Zep 虽精度高,但 Token 数量和延迟过高,不适用于实时系统。
附图说明(图 4)¶
图 4(a):搜索延迟与 J 分数比较,显示 Mem0 在搜索阶段最快。
图 4(b):总延迟与 J 分数比较,显示 Mem0 在总响应时间上最优,且 J 分数接近全上下文模型。
本节核心结论¶
Mem0 和 Mem0g 在不同任务中展现出互补性:前者适合效率优先的场景,后者适合结构化与语义密集的场景。
通过细粒度的记忆索引与结构化表示的合理使用,本文方法在性能、延迟与资源消耗之间达到了平衡,适合部署于生产级 AI 代理系统。
5 Conclusion and Future Work¶
本研究介绍了 Mem0 和 Mem0g,这两种互补的记忆架构旨在克服大型语言模型(LLMs)中固定上下文窗口的内在限制。通过动态提取、整合和检索紧凑的记忆表示,Mem0 在单跳和多跳推理任务中均达到了最先进的性能;而 Mem0g 通过图结构的扩展,在时间推理和开放领域任务中实现了显著提升。
在 LOCOMO 基准测试中,本研究方法在单跳、时间推理和多跳推理任务中分别比现有最佳方法提升了 5%、11% 和 7%。同时,与全上下文基线模型相比,Mem0 的 p95 延迟降低了 91% 以上,这表明其在精度与响应速度之间实现了出色的平衡。
Mem0 的密集记忆流水线擅长于快速检索简单查询,最小化了 token 使用和计算开销。
Mem0g 的结构化图表示则提供了更细致的关系清晰度,支持复杂事件序列和丰富上下文整合,同时不牺牲实际效率。
两者共同构成了一个多功能的记忆工具包,能够适应多样化的对话需求,并具备可扩展部署的能力。
未来工作¶
未来的研究方向包括:
优化图操作,以减少 Mem0g 中的延迟开销;
探索分层记忆架构,融合高效性与关系表示能力;
开发更复杂、受人类认知过程启发的记忆整合机制;
将记忆框架扩展至更广泛的应用领域,如过程推理和多模态交互,以验证其更广泛的应用潜力。
通过解决固定上下文窗口的根本限制,本研究为构建能够像人类一样进行长时间、上下文丰富的对话的AI系统提供了重要进展。
6 Acknowledgments¶
本文作者对几位专家表达了诚挚的感谢:Harsh Agarwal、Shyamal Anadkat、Prithvijit Chattopadhyay、Siddesh Choudhary、Rishabh Jain 和 Vaibhav Pandey。他们提供了宝贵的见解,并对初稿进行了详尽的审阅。重点在于,他们提出的建设性意见和详细的建议帮助作者改进了论文,提升了内容的清晰度和整体质量。作者对他们无私地奉献时间和专业知识表示由衷的感激。
Appendix A Prompts¶
Prompt Template for LLM as a Judge¶
(LLM作为裁判的提示模板)
目标:
让LLM对用户提出的问题及其生成答案进行判断,标记为“CORRECT”或“WRONG”。
输入内容包括:
一个问题(由一个用户向另一个用户提问)
一个“黄金答案”(即标准答案,ground truth)
一个生成答案(需要被评估的LLM生成的答案)
判断标准:
如果生成答案中提到了与黄金答案相同的话题,则应标记为“CORRECT”。
对于与时间相关的问题,只要生成答案与黄金答案表示的是同一日期或时间段,即使格式不同或使用相对时间表达(如“上个月”、“去年”),也应视为“CORRECT”。
要求LLM在做出判断后给出一句话的简要解释,然后返回JSON格式的“label”字段,值为“CORRECT”或“WRONG”,不能同时返回两者。
Your task is to label an answer to a question as "CORRECT" or "WRONG".
You will be given the following data:
(1) a question (posed by one user to another user),
(2) a ‘gold’ (ground truth) answer,
(3) a generated answer
which you will score as CORRECT/WRONG.
The point of the question is to ask about something one user should know about the other user based on their prior conversations.
The gold answer will usually be a concise and short answer that includes the referenced topic, for example:
Question: Do you remember what I got the last time I went to Hawaii?
Gold answer: A shell necklace
The generated answer might be much longer, but you should be generous with your grading - as long as it touches on the same topic as the gold answer, it should be counted as CORRECT.
For time related questions, the gold answer will be a specific date, month, year, etc. The generated answer might be much longer or use relative time references (like ‘last Tuesday’ or ‘next month’), but you should be generous with your grading - as long as it refers to the same date or time period as the gold answer, it should be counted as CORRECT. Even if the format differs (e.g., ‘May 7th’ vs ‘7 May’), consider it CORRECT if it’s the same date.
Now it’s time for the real question:
Question: {question}
Gold answer: {gold_answer}
Generated answer: {generated_answer}
First, provide a short (one sentence) explanation of your reasoning, then finish with CORRECT or WRONG.
Do NOT include both CORRECT and WRONG in your response, or it will break the evaluation script.
Just return the label CORRECT or WRONG in a json format with the key as "label".
Prompt Template for Results Generation (Mem0)¶
(结果生成提示模板 - Mem0)
该提示用于从对话记忆中提取准确信息,用于回答问题。适用于一个记忆系统(Mem0)。
背景(Context):
提供两个对话参与者的记忆内容,包含时间戳。
需要基于这些记忆生成答案。
操作步骤(Instructions):
分析所有来自两个用户的记忆内容。
注意时间戳以确定答案的时间上下文。
如果问题涉及具体事件或事实,要查找记忆中的直接证据。
若存在矛盾信息,优先采用最新的记忆。
对时间相对表达(如“去年”、“两个月前”)进行计算,转换为具体日期。
转换后的时间信息用于回答问题,但回答中应忽略原始的时间表达。
答案应简短(5-6个词以内),并且仅基于记忆内容。
不要混淆记忆中提到的角色名称与实际用户的对应关系。
分步方法(Approach):
查找所有包含与问题相关的信息的记忆。
仔细分析内容与时间戳。
寻找明确的日期、时间、地点或事件。
如需计算时间(如“上个月”),需展示计算过程。
仅基于记忆内容生成精确、简洁的答案。
确保答案直接回答问题。
答案应明确,避免模糊的时间表达。
You are an intelligent memory assistant tasked with retrieving accurate information from conversation memories.
# CONTEXT:
You have access to memories from two speakers in a conversation. These memories contain timestamped information that may be relevant to answering the question.
# INSTRUCTIONS:
1. Carefully analyze all provided memories from both speakers
2. Pay special attention to the timestamps to determine the answer
3. If the question asks about a specific event or fact, look for direct evidence in the memories
4. If the memories contain contradictory information, prioritize the most recent memory
5. If there is a question about time references (like "last year", "two months ago", etc.),
calculate the actual date based on the memory timestamp. For example, if a memory from
4 May 2022 mentions "went to India last year," then the trip occurred in 2021.
6. Always convert relative time references to specific dates, months, or years. For example,
convert "last year" to "2022" or "two months ago" to "March 2023" based on the memory
timestamp. Ignore the reference while answering the question.
7. Focus only on the content of the memories from both speakers. Do not confuse character
names mentioned in memories with the actual users who created those memories.
8. The answer should be less than 5-6 words.
# APPROACH (Think step by step):
1. First, examine all memories that contain information related to the question
2. Examine the timestamps and content of these memories carefully
3. Look for explicit mentions of dates, times, locations, or events that answer the question
4. If the answer requires calculation (e.g., converting relative time references), show your work
5. Formulate a precise, concise answer based solely on the evidence in the memories
6. Double-check that your answer directly addresses the question asked
7. Ensure your final answer is specific and avoids vague time references
Memories for user {speaker_1_user_id}:
{speaker_1_memories}
Memories for user {speaker_2_user_id}:
{speaker_2_memories}
Question: {question}
Answer:
Prompt Template for Results Generation (Mem0g)¶
(结果生成提示模板 - Mem0^g)
此版本与上一版本相似,但增加了**知识图谱关系(relations)**的分析步骤,用于更好地理解用户之间的知识上下文。
区别(关键点):
在分析记忆的同时,也需考虑用户之间的知识图谱关系(relations)。
通过分析这些关系,可以更准确地理解用户的知识背景,从而生成更精准的答案。
分步方法(Approach):
与“Mem0”版本类似,但增加以下步骤:
5. 分析知识图谱关系,以理解用户的知识上下文。
8. 同样要求答案精确、简洁且基于记忆内容。
(same as previous)
# APPROACH (Think step by step):
1. First, examine all memories that contain information related to the question
2. Examine the timestamps and content of these memories carefully
3. Look for explicit mentions of dates, times, locations, or events that answer the
question
4. If the answer requires calculation (e.g., converting relative time references),
show your work
5. Analyze the knowledge graph relations to understand the user’s knowledge context
6. Formulate a precise, concise answer based solely on the evidence in the memories
7. Double-check that your answer directly addresses the question asked
8. Ensure your final answer is specific and avoids vague time references
Memories for user {speaker_1_user_id}:
{speaker_1_memories}
Relations for user {speaker_1_user_id}:
{speaker_1_graph_memories}
Memories for user {speaker_2_user_id}:
{speaker_2_memories}
Relations for user {speaker_2_user_id}:
{speaker_2_graph_memories}
Question: {question}
Answer:
Prompt Template for OpenAI ChatGPT¶
(OpenAI ChatGPT 提示模板)
目标:
从对话中提取相关信息,并为每个用户创建记忆条目,存储至知识库中。
示例对话:
2023年5月8日 下午1:56,Caroline 和 Melanie 的简短对话。
示例内容展示了如何从对话中提取信息并创建记忆条目,用于未来参考与个性化交互。
重点说明:
本提示主要用于记忆提取和存储,为后续的个性化对话提供支持。
无需复杂判断,重点在于信息提取和条目生成。
Can you please extract relevant information from this conversation and create memory entries for each user mentioned? Please store these memories in your knowledge base in addition to the timestamp provided for future reference and personalized interactions.
(1:56 pm on 8 May, 2023) Caroline: Hey Mel! Good to see you! How have you been?
(1:56 pm on 8 May, 2023) Melanie: Hey Caroline! Good to see you! I’m swamped with the kids & work. What’s up with you? Anything new?
(1:56 pm on 8 May, 2023) Caroline: I went to a LGBTQ support group yesterday and it was so powerful.
...
总结¶
附录A详细列出了多个用于实验和评估的提示模板,重点如下:
LLM作为裁判:用于评估生成答案是否正确,强调语义一致性和时间表达的灵活性。
Mem0 系统:用于从对话记忆中提取信息生成答案,强调时间戳处理、最新信息优先、简洁回答。
Mem0^g:在Mem0基础上增加了对知识图谱关系的分析,以提高答案的上下文准确性。
ChatGPT提示:用于从对话中提取记忆,作为后续交互的数据基础。
这些提示模板是实验设计的重要组成部分,直接影响LLM在记忆系统中的表现与评估结果。
Appendix B Algorithm¶

Appendix C Selected Baselines¶
本节介绍了几种用于增强大语言模型(LLM)记忆能力的代表性基线方法,主要解决LLM在长对话、长文档处理和记忆保持方面的局限性。每种方法都提供了独特的记忆架构或处理流程,以提升模型的持久化记忆能力。
LoCoMo¶
LoCoMo 是一个用于增强LLM代理在长对话中保持一致性和连贯性的框架。其核心在于采用了双记忆系统:
短期记忆:通过会话结束后生成摘要(summary),用于快速获取对话的关键信息。
长期记忆:将对话中的每一句转化为观察(observation),存储为事实陈述,并记录其来源对话轮次。
此外,系统还引入了时间事件图(temporal event graph),用于追踪会话之间因果相关的事件,从而帮助模型在生成回复时综合考虑记忆内容、当前上下文、人物属性以及中间事件,实现数百轮、数十次会话间的记忆一致性和角色一致性。
重点内容:双记忆系统 + 时间事件图,是LoCoMo的核心创新点,特别适合用于多轮长对话任务。
ReadAgent¶
ReadAgent 针对LLM在处理长文本时的上下文窗口限制,提出了一个模仿人类阅读机制的三阶段流程:
Episode Pagination(片段分页):将文本按认知边界(而非机械切割)进行分割,增强自然性和认知连贯性。
Memory Gisting(摘要生成):对每个片段提取精炼的摘要,保留关键意义,但大幅减少token数量。
Interactive Lookup(交互式检索):在回答问题时,系统仅检索与当前问题最相关的原始文本,提高计算效率。
重点内容:ReadAgent的三阶段处理机制模拟了人类的阅读与记忆过程,使得LLM能够处理比其上下文窗口长得多的文档,同时保持理解和效率的平衡。
MemoryBank¶
MemoryBank 是一个用于为LLM提供长期记忆能力的系统,其核心结构由三个部分组成:
Memory Storage:存储详细的对话记录、事件摘要和用户画像等信息。
Memory Retrieval:通过双塔稠密检索模型提取与当前上下文相关的记忆。
Memory Updating:引入人类记忆的遗忘机制,即记忆在被使用时强化,未被使用时逐渐减弱,实现记忆的动态更新。
重点内容:MemoryBank通过“存储-检索-更新”的闭环机制,使得AI能够在多轮交互中保持上下文感知和用户画像的逐步完善,从而提升个性化对话能力。
MemGPT¶
MemGPT 采用类操作系统架构来克服LLM的上下文窗口限制,其核心机制包括:
分层内存系统:
Main Context(主上下文):类似RAM,用于存储当前会话的指令、对话历史和工作记忆。
External Context(外部上下文):类似硬盘,用于存储超出上下文窗口的数据,如完整对话历史和归档信息。
自控的内存操作机制:模型可根据需要,在不同层级之间“调页”调入/调出数据。
基于事件的控制流:支持复杂的多跳检索与任务执行。
重点内容:MemGPT的类操作系统架构是其最大亮点,使得固定上下文窗口的LLM能够处理超出上下文的长文档、长期对话及复杂任务,显著扩展了LLM的能力边界。
A-Mem¶
A-Mem 是专为LLM代理设计的一种智能记忆系统,其核心是动态构建和更新记忆图谱:
每个记忆以**note(笔记)**形式存储,包含关键词、描述、标签等结构化信息。
当新记忆创建时,系统通过语义嵌入检索已有相关笔记,并由LLM建立语义连接。
通过记忆演化机制,系统能够动态更新已有记忆的描述和属性,实现记忆结构的持续演化。
重点内容:A-Mem通过语义链接和结构化记忆管理,使得代理能够构建复杂的记忆网络,从而在交互中提供更丰富、更连贯的历史上下文支持。
总结¶
本节介绍了五种不同的LLM记忆增强方法,它们各自从不同的角度解决了LLM在长对话、长文档和记忆保持方面的挑战:
基线 |
核心机制 |
适用场景 |
|---|---|---|
LoCoMo |
双记忆系统 + 时间事件图 |
多轮对话、角色一致性 |
ReadAgent |
三阶段阅读机制 |
长文档处理 |
MemoryBank |
存储-检索-更新闭环 |
长期用户画像、上下文感知 |
MemGPT |
类操作系统架构 |
超长文档、复杂任务 |
A-Mem |
结构化记忆 + 语义链接 |
智能代理的记忆演化 |
这些基线共同展示了如何通过合理设计记忆系统,提升LLM在实际应用中的持久性和适应性。