2601.06966_RealMem: Benchmarking LLMs in Real-World Memory-Driven Interaction¶
引用:
组织:
1Xidian University,
2Zhejiang University,
3Peking University,
4Shanghai Jiao Tong University,
5Renmin University of China,
6Sun Yat-sen University,
7University of the Chinese Academy of Sciences
链接:
总结¶
1. 文献背景、研究目的与问题概述¶
背景: 随着大语言模型(LLM)向通用人工智能(AGI)代理演进,AI正从简单的单轮对话转向长期的、具有上下文感知能力的协作伙伴。记忆系统成为维持长期一致性的核心组件。然而,现有的记忆基准测试(如LoCoMo、LongMemEval)多局限于闲聊或任务导向型对话,主要评估静态事实的检索,忽略了现实世界中常见的、跨越多个会话且目标不断演进的长期项目导向型交互。
研究目的: 作者旨在构建一个更贴近真实应用场景的基准测试——RealMem,用于评估LLM代理在处理复杂、长期、多项目并发时的记忆能力。
核心问题: 现有的记忆系统能否有效管理动态变化的项目状态?在面对跨会话的碎片化信息、时间推理需求以及用户隐含意图时,代理能否利用记忆维持项目的连贯性?
2. 研究方法、关键数据与主要发现¶
2.1 核心方法:三阶段数据合成管道¶
为了模拟真实世界的复杂性,RealMem设计了一套自动化的数据生成框架:
项目基础构建:
定义用户画像和长期项目目标(如“6个月减重15公斤”)。
引入项目属性作为动态状态变量,追踪进度变化。
采用“蓝图优先”策略,生成项目里程碑、事件列表和会话摘要,确保全局逻辑一致性。
多智能体对话生成:
利用用户代理和助手代理进行模拟交互。
交错分布: 模拟用户同时进行多个项目(如同时规划旅行和学习编程),将不同项目的会话混合,测试模型区分上下文的能力。
引入全局日程表以减少时间冲突幻觉。
记忆与日程管理:
专门的代理负责从对话中提取记忆点、更新日程表,并进行语义去重,形成闭环反馈。
2.2 关键数据¶
规模: 包含超过 2,000 个跨会话对话。
场景: 覆盖 11 个代表性场景(如健身、代码架构设计、心理咨询、旅行规划等)。
交互深度: 平均每个用户的上下文长度约 26.9万 tokens,平均会话数 205 轮。
问题类型: 包含 1,415 个自然用户查询,分为四大类(见下文)。
2.3 评估维度¶
RealMem定义了四种独特的查询类型来全面评估记忆能力:
静态检索: 基于已知信息推进下一步(如“接下来做什么?”)。
动态更新: 处理冲突并修改计划(如“行程缩短为12天,但要增加西海岸游玩”)。
主动对齐: 响应模糊的情感反馈,主动利用记忆推进任务(如用户只说“太棒了”,代理需判断下一步是订票还是细化攻略)。
时间推理: 处理日程冲突和时间约束。
2.4 主要发现¶
现有系统表现不佳: 即使是先进的记忆系统(如Mem0, A-mem, MemoryOS),在面对长期项目依赖时仍表现挣扎,与Oracle(理论最优)差距巨大。
检索质量决定生成质量: 实验表明,NDCG(排序质量) 比单纯的 Recall(召回率)更能决定最终回答的质量。高召回但低精度的检索会引入噪音,干扰模型判断。
场景敏感性: 模型在医疗咨询等实体明确的领域表现较好,但在代码架构设计等需要严格逻辑依赖的硬约束任务中表现最差。
架构差异: 层级化记忆架构(如MemoryOS)在动态更新和主动对齐上表现最优;图记忆在处理复杂实体关系和时间推理上具有优势。
3. 新颖概念通俗解读¶
3.1 长期项目导向型交互¶
概念: 这不是简单的“你问我答”,而是一个持续数月甚至数年的合作过程。
通俗解释: 想象你雇佣了一位真人私人助理。闲聊是“今天天气不错”;任务导向是“帮我订一张票”;而项目导向是“帮我策划一场为期半年的环球旅行”。在这个过程中,你的预算、时间表、喜好会变,助理必须记住三个月前你说过不喜欢早起,并且要把这些碎片信息串联起来,这就是RealMem要测试的能力。
3.2 主动对齐¶
概念: 代理不仅仅响应显性指令,还要根据历史记忆预判用户意图。
通俗解释: 当用户说“这个方案太完美了!”时,普通的AI可能只会回复“谢谢”。但具备主动对齐能力的AI会检索记忆,发现你的下一步计划是“预订机票”,于是它会主动问:“既然您满意方案,我们要现在帮您查看机票价格吗?”这就是从“被动听令”到“主动管家”的转变。
3.3 动态状态演化¶
概念: 记忆不是静态的数据库,而是随时间不断变化的流。
通俗解释: 就像玩游戏存档。如果你周一决定练剑术,周三又改主意要练魔法,AI的记忆系统必须覆盖旧档(练剑),更新为新档(练魔法),并且在周五你问“我该买什么装备”时,基于新档(魔法)给出建议,而不是基于旧档。RealMem特别强调这种“修改和覆盖”的能力。
4. 优缺点评价与后续研究方向¶
4.1 优点¶
场景真实性高: RealMem超越了简单的“大海捞针”式测试,引入了多项目并发、状态演变和模糊意图,极大地逼近了真实的人类-AI协作模式。
评估维度全面: 提出的四种查询类型(特别是动态更新和主动对齐)精准地击中了当前LLM代理的痛点。
方法论创新: 提出的三阶段合成管道保证了数据既有长程的逻辑连贯性,又有细粒度的状态变化。
4.2 局限性¶
数据合成依赖: 数据生成高度依赖Gemini 2.5等先进模型,虽然作者声称其比GPT系列更符合格式要求,但这可能引入模型自身的偏见或幻觉,且成本较高。
模态单一: 目前仅限于文本交互,未涉及工具使用或多媒体交互,而这对现实中的项目执行(如自动写代码运行、看图)至关重要。
4.3 后续研究方向¶
硬约束优化: 针对代码架构等逻辑严密领域的记忆管理进行专项优化,当前的语义匹配难以满足硬逻辑需求。
效率提升: 实验显示记忆写入延迟普遍高于读取延迟,未来需优化记忆摄入机制以支持实时交互。
多模态与工具集成: 将记忆基准扩展到包含工具调用和文件处理的场景,测试Agent在“实操”中的记忆表现。
总结: RealMem 为评估 LLM 的长期记忆能力设立了一个更高的标准。它揭示了当前 AI 代理在处理复杂、动态、长期项目时的“健忘”和“逻辑混乱”问题,证明了仅仅依靠高召回率的检索是不够的,未来的记忆系统必须具备更高精度的状态追踪和主动推理能力。
图解¶
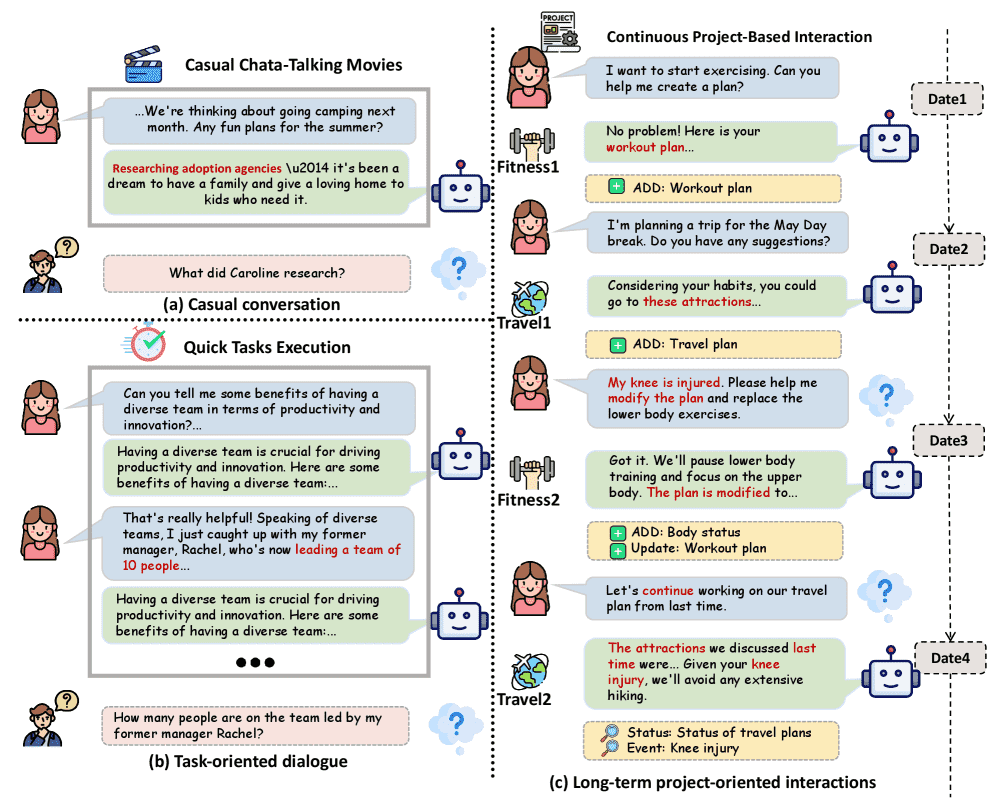
Figure 1:Comparison of three interaction paradigms in human–agent interactions: (a) casual conversation, (b) task-oriented dialogue, and (c) long-term project-oriented interactions spanning multiple sessions with interleaved projects and evolving context.
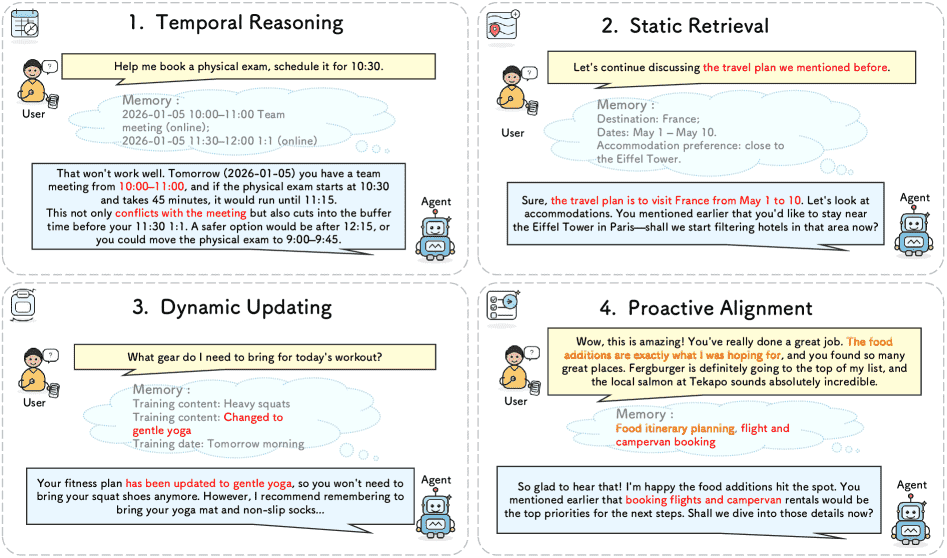
Figure 2:Examples of four query types in RealMem: (1) Temporal Reasoning resolves temporal constraints and schedule conflicts; (2) Static Retrieval ensures continuity by recalling accumulated context; (3) Dynamic Updating synchronizes memory with evolving project states; and (4) Proactive Alignment leverages user memory to anticipate implicit intents and goals.
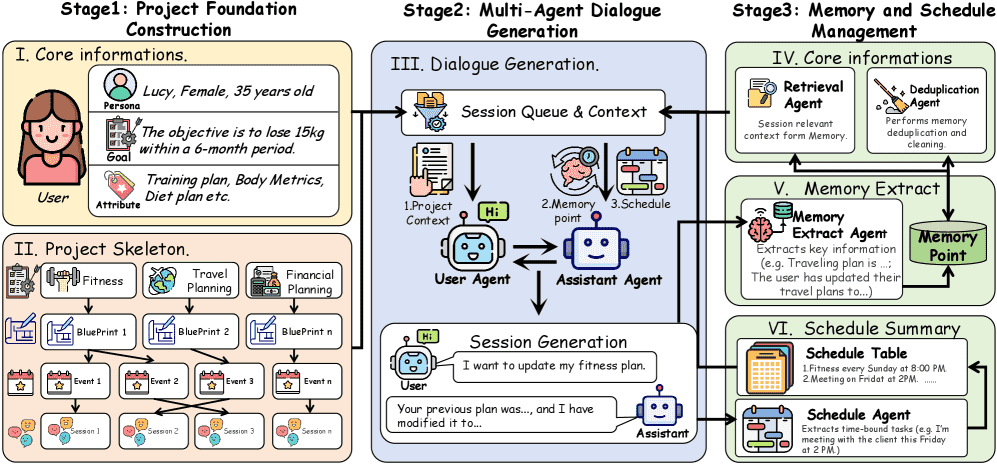
Figure 3:Overview of the data synthesis framework. The pipeline consists of three cascaded stages: (1) Project Foundation Construction, which initializes user personas and hierarchical project skeletons (i.e., blueprints, events, and sessions); (2) Multi-Agent Dialogue Generation, where the User Agent and Assistant Agent simulate interactions based on the session queue and dynamic context; and (3) Memory and Schedule Management, which iteratively retrieves, updates, and deduplicates memory points and schedule tables to ensure long-term consistency.