10xx.xxxxx_PQ: Product Quantization for Nearest Neighbor Search¶
引用: 5025(2025-09-16)
组织: INRIA(法国国家信息与自动化研究所)
总结¶
总结方式
From Deepseek:
Prompt:
论文标题《xxxxx》地址:https://xxxx 给我讲解下这篇论文主要讲了哪些内容?
From Deepseek 全文总结
Prompt:
帮我理解下这篇论文(请按章节分段讲解):<全文内容>
From Deepseek¶
这篇由Hervé Jégou, Matthijs Douze 和 Cordelia Schmid撰写的论文《Product Quantization for Nearest Neighbor Search》是 高维向量近似最近邻搜索(Approximate Nearest Neighbor, ANN) 领域的一篇里程碑式的经典论文。它的核心贡献是提出了一种名为 乘积量化(Product Quantization, PQ) 的高效数据压缩和快速距离计算方法,极大地降低了大规模高维数据搜索的内存需求和计算成本。
1. 核心问题:高维数据的最近邻搜索之困¶
论文首先阐述了在高维空间中进行精确最近邻搜索的“维度灾难”问题:
计算成本高:精确算法(如线性扫描)的计算复杂度与数据规模(N)和维度(D)成正比(O(ND)),当N和D都很大时(例如百万级数据,上百维度),无法满足实时检索需求。
存储成本高:存储所有原始向量需要大量内存(例如,100万个128维的浮点数向量需要约500MB内存)。
因此,需要一种近似但高效的解决方案,在可接受的精度损失下,大幅提升速度和降低存储。
2. 核心思想:乘积量化(Product Quantization)¶
PQ的核心思想是“分而治之,组合量化”,它将高维空间分解为多个低维子空间的笛卡尔积,并分别对这些子空间进行量化。
a) 向量分解¶
将一个D维向量 x 切分成 m 个互不相交的子向量(subvectors),每个子向量的维度为 D* = D/m。
x = [x^1, x^2, ..., x^m]
类比:把一个长长的电话号码(国家码-区号-前缀-后缀)分成几段来记忆和处理。
b) 子空间量化¶
对每个子空间,使用 K-Means聚类算法 独立地构建一个 码本(codebook)。每个码本包含 k 个码字(codewords)(即聚类中心)。
对于第
j个子空间,我们得到一个码本C^j,其码字为{c_i^j}, i=1,2,...,k。这个子空间中的任何子向量都可以用离它最近的码字的索引
i来表示(即被量化为q^j(x^j) = c_i^j)。
c) 乘积量化¶
原始的高维向量 x 最终被其所有子向量的量化结果组合起来表示:
q(x) = (q^1(x^1), q^2(x^2), ..., q^m(x^m))
这个量化后的向量由 m 个码字索引 (i1, i2, ..., im) 组成。
“乘积”一词的由来:整个量化器的码本实际上是所有子码本的笛卡尔积(Cartesian Product)。整个量化器的总码字数量是
k^m个,这是一个极其巨大的数字(例如k=256, m=8,则有256^8 = 2^64个中心),但我们永远不需要显式地生成这个巨大的码本。我们只是通过组合m个小码本的方式,“隐式”地拥有了一个超大规模的码本。这是PQ方法巧妙且高效的关键。
3. 主要应用:用于最近邻搜索¶
PQ主要用于两种快速的ANN搜索方案:
方案一:PQ距离计算(SDC)¶
场景:已经有一个用PQ压缩的数据库。用户提交一个查询向量
q,我们需要在数据库中找出与q最近的向量。方法:不对称计算(Asymmetric Computation, ADC)
预处理(离线):用PQ压缩数据库中的所有向量
y,存储的是它们的码字索引(i1, i2, ..., im)。查询(在线):
将查询向量
q同样分解为m个子向量。关键步骤:预先为每个子空间计算查询子向量
q^j到该子空间所有码字{c_i^j}的距离表(k个距离值)。这样会得到m张距离表。对于数据库中的每个压缩向量
y,其距离近似计算为:d(q, y) ≈ Σ_{j=1 to m} d(q^j, c_{i_j}^j)^2。这个计算只需要进行m次查表(从第j张距离表中取出第i_j个值)和m-1次加法,速度极快。
为什么“不对称”?因为查询向量
q是原始向量,而数据库向量y是压缩后的表示。这种不对称的距离计算比对称计算(双方都压缩)精度更高。
方案二:倒排索引与PQ结合(IVFADC)¶
这是论文提出的一个更强大、更实用的系统,结合了倒排索引(Inverted File Index) 和PQ。
粗糙量化(Coarse Quantizer):首先使用一个标准的K-Means(例如聚类中心数为
1024)对整个向量空间进行第一次粗略的划分。这个聚类中心称为** Voronoi Cell**。构建倒排索引:每个数据库向量
y都被分配到离它最近的那个粗糙聚类中心c_i。所有分配到同一个c_i的向量组成一个倒排列表(Inverted List)。残差向量与PQ压缩:对于一个向量
y和它所属的粗糙中心c_i,计算残差向量r = y - c_i。残差向量代表了该向量与粗糙中心的细微差异。然后,对这个残差向量(而不是原始向量)进行PQ压缩。搜索过程:
给定查询向量
q,先找到离它最近的w(通常w=1~100)个粗糙聚类中心。只搜索这些中心对应的倒排列表,大大减少了需要计算距离的候选集数量。在每个倒排列表内部,使用上面提到的ADC方法快速计算查询向量与残差压缩向量之间的距离:
d(q, y) ≈ d(q, c_i + r) ≈ d(q - c_i, r)。即用q - c_i作为查询,与压缩的残差向量r进行ADC计算。
IVFADC方法通过倒排索引(减少搜索范围) 和乘积量化(快速计算距离) 的两级机制,实现了速度和精度的绝佳平衡。
4. 主要贡献与优点总结¶
极高的压缩率:一个D维浮点数向量(需要4D字节)被压缩为m个字节(因为每个子索引用8bit,即k=256,就足够)。压缩比高达
32:1(当D=128,m=8时)。极快的距离计算:将复杂的欧氏距离计算转化为高效的查表-加法操作,比直接计算快几个数量级。
可扩展性:方法适用于海量数据集(数亿甚至数十亿级别)。
灵活性:PQ既可以独立使用(SDC),也可以与其他索引结构(如倒排索引IVF、图索引HNSW)完美结合,构成更强大的检索系统。至今,PQ及其变体(如OPQ)仍是大部分高性能ANN系统(如FAISS)的基石性技术。
总结¶
这篇论文的核心是提出了乘积量化(PQ) 这一创新思想,通过将高维向量分解并分段量化,巧妙地解决了海量高维数据检索中的存储和计算两大瓶颈。同时,论文提出的IVFADC系统架构(倒排索引+残差PQ)为后续的工业级向量数据库和检索系统提供了经典且高效的蓝图。
From Deepseek 全文总结¶
好的,我们来分段讲解这篇关于近似最近邻搜索的里程碑式论文——《Product Quantization for Nearest Neighbor Search》。
摘要 (Abstract)¶
核心思想:论文提出了一种基于乘积量化 (Product Quantization, PQ) 的近似最近邻搜索方法。
方法简述:将高维向量空间分解为多个低维子空间的笛卡尔积,并对每个子空间分别进行量化。一个向量可以用其各个子空间量化索引组成的短编码来表示。
距离计算:两个向量之间的欧氏距离可以高效地通过它们的编码来估算。论文还提出了一种非对称距离计算 (Asymmetric Distance Computation, ADC) 版本,它计算一个原始查询向量和一个编码后的数据库向量之间的距离,精度更高(因为用了原始查询向量,不是全部的量化版)。
实验结果:该方法能高效搜索最近邻,尤其是与倒排文件系统 (inverted file system) 结合时。在SIFT和GIST图像描述符上的实验结果表明,其搜索准确率超越了当时三种最先进的方法。
规模验证:该方法在包含20亿向量的数据集上验证了其可扩展性。
1. 引言 (Introduction)¶
问题背景:在高维空间(如图像特征SIFT, GIST)中进行精确最近邻搜索非常耗时,存在“维度灾难”问题。即使使用KD-tree等索引方法,在高维下其效率也可能不如暴力线性搜索。
现有方法:近似最近邻搜索(ANN)通过牺牲少量准确率来换取速度提升。流行的方法包括E2LSH(有理论保证但内存消耗大)和FLANN(基于随机KD-tree和层次k-means的启发式方法)。但这些方法通常需要将原始向量存储在内存中以进行最终精确距离重排,严重限制了可处理的数据规模。
内存效率需求:大规模场景识别等问题需要处理百万至十亿级图像,内存效率成为关键指标。一些方法(如Torralba等人的工作、谱哈希SH)尝试将向量映射为短二进制码,在汉明空间中进行搜索。虽然节省内存,但汉明空间只能产生少量不同的距离值,限制了精度。
本文方法动机:
量化:本文通过量化来构造短编码。为了避免量化误差过大,需要非常多的聚类中心(如64位编码需要2^64个中心),直接使用k-means学习如此大的码书是不可能的。
乘积量化:PQ通过将向量切分为子向量并分别量化,解决了这个问题。它用多个小码书的笛卡尔积来生成一个巨大的隐式码书,使得学习、存储和计算都变得可行。
本文优势:
距离精度:相比汉明嵌入方法,PQ能产生更多样化的距离值,精度更高。
距离估计:PQ可以估计平方距离的期望值,这对于基于距离阈值的搜索或Lowe比率检验非常有用。
效率:PQ通过查表计算距离,其速度与计算汉明距离相当。
非穷举搜索:为了应对超大规模数据,论文结合了倒排文件和ADC(该方法被称为IVFADC),通过一个粗量化器快速定位最相关的向量子集,极大加速了搜索过程。
实验结果:在SIFT和GIST描述符上,该方法优于谱哈希(SH)、汉明嵌入(HE)和FLANN等state-of-the-art方法。
2. 背景:量化与乘积量化 (Background: Quantization, Product Quantizer)¶
向量量化:回顾了量化基本概念。量化器
q将向量x映射到码书C中的一个 centroidc_i。量化质量用均方误差(MSE)衡量。k-means算法能学习一个近似最优的量化器。乘积量化:
核心思想:将一个D维向量
x切分为m个连续的D维子向量(D = m * (D))。每个子向量使用一个独立的子量化器q_j进行量化。每个子量化器有k*个centroid。巨大码书:总的centroid数量是
k = (k*)^m。例如,m=8,k*=256(8位)时,k = 256^8 = 2^64,但只需要存储m x (k*) x (D*) = (k*) x D个值(即825616=32768个浮点数),而不是2^64 * 128个。效率:学习、存储和分配的复杂度都与
k*线性相关,而与巨大的k无关。参数选择:图1表明,在总码长相同时,使用更少的子空间(
m小)和更多的子中心(k*大)比更多的子空间和更少的子中心量化误差更小。但k*过大会增加计算和缓存开销,m=8, k*=256(生成64位编码)是一个常用且高效的配置。
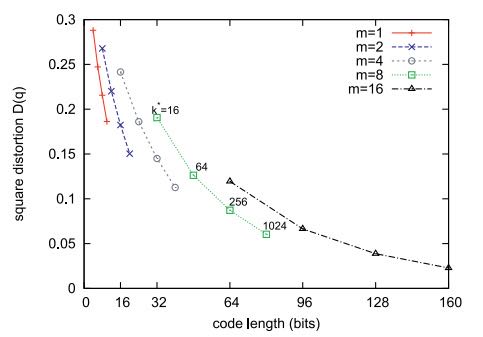
Fig. 1. SIFT: Quantization error associated with the parameters m and k*.
3. 基于量化的搜索 (Searching with Quantization)¶
距离计算:
对称距离计算 (SDC):查询向量
x和数据库向量y都被量化。用d(q(x), q(y))来近似d(x,y)。通过查表(预计算所有子量化器centroid两两之间的距离)和求和实现。非对称距离计算 (ADC):仅数据库向量
y被量化,查询向量x保持原始形式。用d(x, q(y))来近似d(x,y)。需要预计算查询子向量u_j(x)到子量化器所有centroid的距离,然后查表求和。ADC的误差更小,因为查询端没有引入量化误差。
误差分析:从数学上证明了距离估计的误差统计上以量化MSE为界。ADC的误差界限是MSE(q),而SDC的误差界限是2*MSE(q)。
距离估计修正:指出
d(x, q(y))会系统性地低估真实距离d(x,y)。论文推导了一个无偏的平方距离估计器~e(x,y) = ~d(x,y)^2 + ζ(q, q(y)),其中ζ是量化器在q(y)这个cell上的平均失真(量化误差)。这个修正项可以预先计算并存储在表里。但实验发现,虽然修正减少了偏差,却增加了方差,并且对最近邻搜索的准确性提升不大,因此在实际搜索中更推荐使用未修正的ADC。
4. 非穷举搜索 (Non-exhaustive Search)¶
IVFADC结构:结合倒排文件 (Inverted File) 和 ADC。
粗量化器 (Coarse Quantizer):一个标准的k-means量化器
q_c(k’通常为1k-1M),将向量分配到不同的倒排列表(Voronoi cell)中。残差编码:数据库向量
y被表示为(q_c(y), q_p(r(y))),其中残差r(y) = y - q_c(y)使用一个乘积量化器q_p进行编码。这类似于“粗量化器提供高位,乘积量化器提供低位”。搜索过程:
查询
x被分配到粗量化器的w个最近邻cell(多重分配)。只在这
w个对应的倒排列表中进行搜索。计算的是查询与粗中心之间的残差
x - q_c(y)和数据库残差编码q_p(r(y))之间的距离。
优势:避免了全局搜索,速度极大提升。同时,对残差进行量化比直接量化原始向量更精确。
5. 实验评估 (Evaluation of NN Search)¶
数据集:使用SIFT(局部特征)和GIST(全局特征)描述符进行评估。
评估指标:
recall@R,即真实最近邻在前R个返回结果中的查询所占的比例。关键实验结果:
SDC vs ADC:ADC显著优于SDC。
参数影响:对于固定码长,
m小k*大的配置优于m大k*小的配置。IVFADC的性能严重依赖于搜索的cell数量w。维度分组:子向量的划分方式(组件顺序)对性能有重要影响。按描述符的自然结构(如SIFT的空间块,GIST的朝向)分组比随机分组效果好得多。
与State-of-the-art对比:
vs 谱哈希(SH) & 汉明嵌入(HE):在相同码长(64位)下,PQ方法(ADC, IVFADC)的
recall@R曲线远优于SH和HE(图8,9)。IVFADC在低R值上表现最好。vs FLANN:在相同搜索精度下,IVFADC的搜索速度比FLANN更快,且内存占用低一个数量级(IVFADC索引<25MB vs FLANN>250MB)。
速度:IVFADC通过避免穷举搜索,比ADC/SDC快几个数量级(表5)。
大规模实验:在20亿SIFT向量数据集上,IVFADC比HE更快(图11)。
图像搜索应用:在一个完整的图像检索系统(基于SIFT词袋模型)中,IVFADC在平均精度(mAP)上 consistently 优于HE方法(图12)。
6. 结论 (Conclusion)¶
总结了提出的乘积量化(PQ) 方法,它能够高效准确地近似欧氏距离。
其与倒排文件结合的IVFADC方案,避免了穷举搜索,实现了高效率和高精度。
该方法在搜索准确率和内存使用的权衡上显著超越了当时的先进技术。
实验证明了其在SIFT和GIST上的优异表现,以及在20亿向量规模上的可扩展性。
总结:这篇论文的核心贡献是提出了乘积量化(PQ) 这一巧妙的构思,它将无法直接处理的大规模量化问题,分解为多个可处理的小规模子问题,从而实现了极高效的内存使用和快速的距离计算。非对称距离计算(ADC) 和倒排索引+残差量化(IVFADC) 的引入,进一步提升了精度和速度。这项工作为大规模高维向量检索领域奠定了坚实的基础,至今仍是相关应用和研究的基石。
周边概念¶
简单来说,SIFT 和 GIST 都是将一张图片转换成一个固定长度的数值向量。这个向量试图捕捉图像的核心视觉内容(如纹理、形状、边缘分布等),从而可以用于图像比对、检索、分类等任务。
1. SIFT (Scale-Invariant Feature Transform - 尺度不变特征变换)¶
核心思想:SIFT 是一种局部特征描述符。它不试图描述整张图片,而是在图片中寻找一些突出的、稳定的关键点(例如物体的角点、边缘交点、亮区的暗点等),然后为每一个关键点计算一个描述向量。
主要特点:
尺度不变性:无论是在放大还是缩小的图片上,都能检测到同一个关键点。
旋转不变性:无论图片如何旋转,描述符的方向信息会被校正,保证一致性。
对光照、视角变化部分鲁棒:对光线变化和小的视角变化不敏感。
工作原理(简化):
尺度空间极值检测:使用高斯差分函数在不同尺度下搜索图像,找到潜在的关键点。
关键点定位:精确定位关键点位置,并过滤掉不稳定或低对比度的点。
方向分配:根据关键点局部区域的梯度方向,为每个关键点分配一个主方向。
关键点描述:在关键点周围的 16x16 像素区域内,计算 8 个方向的梯度直方图,最终形成一个 128 维的向量(16个小区,每个小区8个方向:16*8=128)。这个128维的向量就是SIFT描述符。
为什么会导致“维度灾难”: 一张图像通常会提取出几百到几千个 SIFT 关键点(特征点)。虽然每个点的描述符是128维,但我们在进行图像搜索或匹配时,通常是在一个巨大的“特征点库”中进行最近邻搜索(例如,找出与当前特征点最匹配的另一个点)。这个库可能包含来自数百万张图片的数十亿个128维的点。在这个超高维空间(128维已经算高维)里进行海量点的最近邻搜索,就遇到了你问题中提到的效率瓶颈。
2. GIST (Global Image Descriptor - 全局图像描述符)¶
核心思想:与SIFT的“局部”思想相反,GIST是一种全局特征描述符。它试图用一个向量来概括整个场景的宏观信息,比如:这张图是海岸线、森林、街道还是室内场景?它侧重于空间的包络信息(Spatial Envelope)。
主要特点:
全局性:一个图像只有一个GIST描述向量。
场景语义:更擅长捕捉场景的类别和整体布局,而不是局部的精细细节。
计算高效:通常比计算数百个SIFT特征要快。
工作原理(简化):
将图像分割成 4x4 或 3x3 等数量的网格。
对每个网格区域,使用一系列不同方向和尺度的Gabor滤波器进行滤波。
对每个滤波器在每个网格内的响应进行池化(通常是取平均值)。
将所有网格、所有滤波器的响应值连接起来,形成一个长的特征向量。一个常见的配置(4x4网格,4尺度8方向)会产生一个 4x4x(4x8) = 512 维的向量。
为什么会导致“维度灾难”: 虽然一张图只有一个GIST向量(比如512维),但当我们需要在一个大规模图像数据库(例如100万张图片)中寻找与查询图片最相似的图片时,问题就变成了在100万个512维的向量中做最近邻搜索。这个搜索空间的维度(512维)和规模(100万点)同样非常高,导致精确搜索极其耗时。
总结与对比
特性 |
SIFT |
GIST |
|---|---|---|
类型 |
局部特征 |
全局特征 |
输出 |
每张图像有数百到数千个特征点,每个点是一个128维向量 |
每张图像只有一个描述向量(通常是512维或960维) |
描述内容 |
图像局部区域的细节、纹理、角点 |
整个场景的宏观布局和空间结构(如自然度、开放度、粗糙度等) |
主要用途 |
图像细节匹配、物体识别、图像拼接、手势识别 |
场景分类与识别( place recognition)、图像快速检索 |
导致“维度灾难”的原因 |
需要在数十亿个128维点的集合中搜索最近邻 |
需要在数百万个512维点的集合中搜索最近邻 |
汉明空间¶
核心定义¶
汉明空间是一个由所有固定长度的二进制字符串(即由0和1组成的序列)构成的数学空间。在这个空间中,两个点(两个二进制字符串)之间的距离,由它们对应位置上值不同的个数来衡量。这个距离就叫做汉明距离。
因此,汉明空间就是一个定义了“汉明距离”作为度量标准的数学空间。
1. 汉明距离 - 空间的“尺子”¶
在深入空间之前,必须先理解它的“尺子”——汉明距离。
定义:两个等长的字符串(通常是二进制串)之间,对应位不同的数量。
计算公式:对于两个长度为
n的字符串a和b,其汉明距离D(a, b)可以表示为:D(a, b) = number of positions i where a[i] != b[i]举例:
a = 010101b = 110001比较每一位:
0vs1(不同),1vs1(相同),0vs0(相同),1vs0(不同),0vs0(相同),1vs1(相同)`不同的位置有:第1位和第4位。
所以,汉明距离
D(a, b) = 2。
2. 汉明空间的形象化理解¶
你可以把汉明空间想象成一个巨大的、多维的立方体,这个立方体叫做超立方体。
二维空间(正方形):所有2位的二进制串
{00, 01, 10, 11}构成一个正方形。点的距离是它们之间最短的边数。00和11的距离是2(需要先走到01或10,再走到11)。三维空间(立方体):所有3位的二进制串
{000, 001, 010, 011, 100, 101, 110, 111}构成一个立方体的8个顶点。点的距离同样是连接两点的最短边数。高维空间(超立方体):对于长度为
n的二进制串,它们就位于一个n维超立方体的顶点上。我们无法直观想象,但数学性质是相同的。
3. 为什么汉明空间如此重要?¶
汉明空间之所以在计算机科学中至关重要,是因为它具有一些非常独特且有用的性质:
计算极其高效: 计算两个二进制向量之间的汉明距离,只需要进行异或操作(XOR) 然后统计popcount(即计算结果中1的个数)。现代CPU的指令集(如x86的
POPCNT指令)可以在一个时钟周期内完成64位字的popcount计算,这使得汉明距离的计算速度极快,远超计算浮点数向量之间的欧氏距离或余弦相似度。紧凑的数据表示: 一个由浮点数(通常占32位)组成的高维特征向量,可以通过量化或哈希技术(如局部敏感哈希 - LSH)被压缩成一个很短(比如64位、128位、256位)的二进制编码。这极大地减少了存储开销和内存带宽需求。
非常适合近似最近邻搜索: 这是汉明空间最关键的应用。在大规模相似性搜索中,我们经常需要在高维空间(如图像特征SIFT, GIST)中寻找最近邻。正如你所知,精确搜索非常耗时。
解决方案:将这些高维向量通过哈希函数映射到汉明空间,变成二进制哈希码。
搜索过程就变成了:给定一个查询点的二进制码,在巨大的数据库中寻找与之汉明距离最小的点。
由于计算汉明距离和进行比特位比较非常快,并且可以用位运算和索引技术大幅加速,使得在海量数据中进行快速搜索成为可能。
应用实例¶
图像检索:将图片的深度学习特征或传统特征(SIFT等)转换为二进制哈希码。要搜索相似图片,只需比较查询图片哈希码与数据库中海量图片哈希码之间的汉明距离。
音频/视频指纹识别:系统为一段音频或视频生成一个唯一的二进制“指纹”。要识别一段未知媒体,只需计算其指纹与指纹库中所有指纹的汉明距离,找到距离最小的那个。
纠错码:在数据传输和存储中,通过引入冗余位,使得有效的码字之间具有较大的汉明距离。如果因错误导致接收到的码字与有效码字距离很小,就可以被自动检测并纠正到最近的有效码字上。
密码学:某些密码学协议会利用汉明距离的性质。
总结¶
方面 |
描述 |
|---|---|
是什么 |
一个由所有固定长度二进制串构成的空间,其距离由汉明距离定义。 |
核心操作 |
异或(XOR) 和 popcount(统计1的个数)。 |
关键优势 |
计算速度极快、存储效率极高。 |
主要应用 |
大规模近似最近邻搜索、指纹识别、数据压缩、纠错码。 |
简单来说,汉明空间为我们提供了一种将复杂相似性问题转化为极其高效的比特位比较问题的方法,从而解决了“维度灾难”带来的性能瓶颈。