2306.10933_KAR: Towards Open-World Recommendation with Knowledge Augmentation from Large Language Models¶
引用: 260(2025-09-11)
组织:
Shanghai Jiao Tong University
Huawei Noah’s Ark Lab
Consumer Business Group, Huawei
GitHub: https://github.com/YunjiaXi/Open-World-Knowledge-Augmented-Recommendation
总结¶
总结
参考图: figure 2(overall framework), figure3(prompt)
推荐系统的分阶段处理
候选生成(Candidate Generation):生成一个较粗略的物品候选集。
排序(Ranking):对候选集中的物品进行排序,选择最相关的结果。
重排序(Reranking):对初步排序结果进行优化,考虑更多上下文信息。
KAR
核心思想是
从LLM中提取“开放世界知识”(即训练数据之外的海量通用知识),并将其转化为推荐系统能理解和使用的形式,最终提升推荐效果。
分为三个核心阶段
阶段一(知识推理与生成)
通过因子分解提示(Factorization Prompting),把问题拆解成多个关键因素(如电影推荐中的“类型”、“演员”、“导演”、“主题”等)。然后针对每个因素,让LLM提供两样东西:
推理知识:分析用户对这个因素的偏好(例如:用户A因为看了《Scream》和《What Lies Beneath》,所以可能喜欢“惊悚”类型)。
事实知识:描述候选物品在这个因素上的特性(例如:电影《Roman Holiday》具有“轻松诙谐的基调”)。
阶段二(知识适应)
把“顾问”(LLM)提供的文字报告(文本知识)翻译成推荐系统能听懂的“专业术语”(向量表示)
知识编码器:用一个像BERT这样的模型,把生成的文本知识转换成密集向量(Dense Vectors)。
混合专家适配器:这是一个核心创新模块。
它接收编码后的向量,并用一组“专家”网络(其实就是一堆小型的神经网络MLP)将其转换到低维的“推荐空间”。
共享专家:处理用户偏好和物品事实中的共性信息。
专属专家:分别处理用户偏好和物品事实中的独特信息。
门控网络:决定对于每个输入向量,应该更多地信任哪位“专家”的意见。
阶段三(知识利用)
做法:采用最简单直接的方式——把这两个新向量作为额外的特征字段,和用户、物品原有的特征(如用户ID、物品ID、历史行为等)一起,输入到现有的任何推荐模型(Backbone Model,如DeepFM、DIN等)中进行训练和预测。
目的:让推荐模型在做决策时,不仅能参考它自己学到的“域内知识”(如协同过滤信号),还能参考LLM提供的“开放世界知识”,从而做出更精准、更个性化的推荐。
优势:这种方式非常灵活,几乎可以 plug-and-play(即插即用)到任何现有的推荐模型上,而不需要改变模型本身的结构。
Ablation Study
推理知识比事实知识对模型性能提升更显著,因为推理知识可能捕获用户深层偏好。
同时使用两种知识可产生协同效果(1+1>2)。
推理知识提供了外部信息,结合事实知识能更好地匹配用户偏好与物品。
Abstract¶
推荐系统在各种在线服务中发挥着至关重要的作用。然而,由于训练与部署通常局限于特定领域,系统的“封闭性”限制了其获取开放世界知识的能力。
近年来,大语言模型(LLMs)的出现为解决这一问题带来了希望,因为它们能够编码大量世界知识并展现出推理能力。然而,先前尝试直接将LLM用于推荐系统并未取得令人满意的效果。
为了解决这一问题,本文提出了一个基于大语言模型的开放世界知识增强推荐框架,称为KAR。该框架旨在从LLM中获取两种外部知识:关于用户偏好的推理知识和关于物品的事实性知识。
本文重点介绍了 因子化提示(factorization prompting) 方法,用于引导出对用户偏好的精确推理。生成的推理知识和事实性知识通过一个混合专家适配器(hybrid-expert adaptor)被有效转换并压缩为增强向量,以便与推荐任务兼容。这些增强向量可以直接用于提升任何推荐模型的性能。
此外,为确保高效的推理,本文通过预处理和预存储LLM中的知识来优化效率。大量的实验表明,KAR在性能上显著优于最先进的基线方法,并且与各种推荐算法兼容。
最后,本文将KAR部署到华为的新闻和音乐推荐平台,并分别在在线A/B测试中取得了7%和1.7%的性能提升。
1. Introduction¶
推荐系统(Recommender Systems, RSs)在当今的在线服务中无处不在,广泛应用于电影推荐、在线购物和音乐流媒体等领域。然而,现有推荐系统大多运行在“封闭系统”中,仅依赖于特定领域内的数据,缺乏对“外部世界知识”的利用,限制了模型的学习能力与推荐效果。
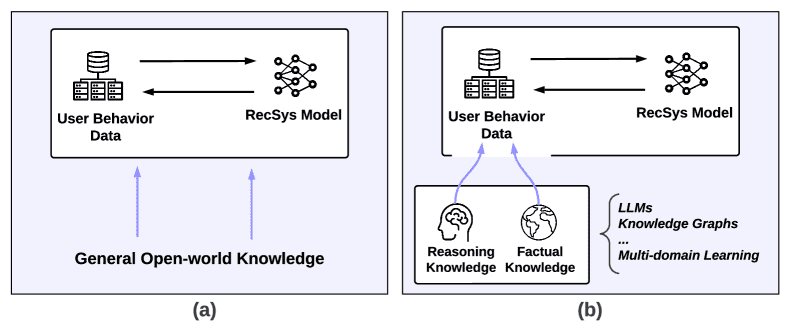
Figure 1.Comparison between (a) closed recommender systems and (b) open-world recommender systems.
通过图1的对比可以看出,传统推荐系统(图1a)仅限于封闭的数据环境,而开放世界推荐系统(图1b)则主张系统应主动从外部世界获取知识,以提升推荐质量与泛化能力。这种外部知识主要包括两类:
1.1 开放世界推荐的两类关键知识¶
推理知识(Reasoning Knowledge)
通过对用户行为与画像的分析,推断用户的深层偏好与动机。
包括用户的个性、职业、意图、兴趣和口味,甚至可根据季节或外部事件(如疫情期间对健康产品的兴趣)进行动态调整。
相比传统系统只识别基本行为模式,推理知识能够提供更“人性化”的推荐依据。
事实知识(Factual Knowledge)
从网络中直接获取的关于物品的常识性信息,例如电影的剧情、奖项、评论等。
这些信息可以扩展原始数据集,提高推荐系统的质量。
1.2 现有方法的局限¶
已有研究尝试通过知识图谱或多领域学习来补充封闭系统,但仍存在以下问题:
构建高质量的知识图谱或多领域数据集需要大量人力成本。
可用知识有限。
主要关注物品的事实知识,忽视用户推理知识的获取。
1.3 大语言模型(LLMs)的潜力¶
近年来,大语言模型(如 GPT-4、LLaMA)因其大规模参数和训练语料库而展现出强大的能力,包括逻辑推理、常识理解和生成文本。这些模型编码了丰富的世界知识,在连接推荐系统与外部世界知识方面具有巨大潜力。
1.4 LLMs 用作推荐器的挑战¶
尽管 LLMs 具有潜力,但直接将其应用于推荐任务仍面临以下挑战:
预测准确性不足
LLMs 未在推荐数据上进行训练,缺乏对用户偏好的建模能力。
推理延迟高
LLMs 模型庞大,难以在工业系统中实现实时推荐。
组合问题(Compositional Gap)
LLMs 虽能解答推荐任务的子问题,但难以生成完整的推荐结果。
1.5 本文的目标与贡献¶
为了解决上述问题,本文提出一个开放世界知识增强的推荐框架 KAR (Knowledge Augmented Recommendation)。该框架旨在结合传统推荐系统与 LLMs 的开放世界知识,提升推荐质量。
主要贡献如下:¶
提出首个结合 LLMs 推理知识的开放世界推荐系统
实现用户偏好逻辑推理,并将开放世界知识引入推荐系统,提升推荐质量。
知识向量化与兼容性设计
将外部知识转化为推荐系统可用的密集向量,兼容各种推荐算法。
作者已开源 KAR 代码及生成的知识数据,促进后续研究。
预处理与部署优势
知识可提前生成并存储,避免推理延迟。
KAR 已部署于华为的新闻和音乐平台,实测提升了 7% 和 1.7% 的在线推荐效果,是首个成功应用于工业界的 LLM 推荐系统。
1.6 实验与广泛性验证¶
KAR 在多个公开数据集上显著优于现有最先进模型。
兼容性强,适用于多种推荐算法。
本文认为 KAR 为将 LLMs 知识注入推荐系统提供了可行路径,并为大规模开放世界推荐系统提供了实践框架。
总结¶
本章介绍了开放世界推荐系统的基本理念与挑战,指出现有方法的不足,并提出 KAR 框架作为解决方案。该框架通过引入 LLMs 的推理与事实知识,成功提升了推荐系统的性能与实用性,为未来推荐系统的演进提供了重要方向。
3. Preliminaries¶
推荐任务的建模与符号定义¶
本节主要对推荐任务进行建模,并引入相关符号定义。推荐任务通常被建模为一个多字段分类数据上的二分类问题。数据集定义为:
其中,\( x_i \) 表示第 \( i \) 个样本的特征向量,\( y_i \) 是对应的二元标签(0 表示未点击,1 表示点击)。值得注意的是,\( x_i \) 通常是稀疏的 one-hot 向量,涵盖多个字段信息,例如物品 ID、物品类型(genre)等。
更进一步地,可以将每个样本的特征表示为:
其中,\( F \) 表示字段数量,\( x_{i,k} \) 表示第 \( i \) 个样本在第 \( k \) 个字段上的特征,\( k=1,\ldots,F \)。
推荐模型的目标¶
推荐模型的目标是学习一个函数 \( f(\cdot) \),其参数为 \( \theta \),能够准确预测每个样本 \( x_i \) 对应的点击概率 \( P(y_i=1|x_i) \)。形式上,预测输出为:
这是推荐系统中最基本的建模方式。
工业推荐系统的分阶段处理¶
在实践中,工业界面对海量用户和物品,推荐系统通常被划分为多个阶段:
候选生成(Candidate Generation):生成一个较粗略的物品候选集。
排序(Ranking):对候选集中的物品进行排序,选择最相关的结果。
重排序(Reranking):对初步排序结果进行优化,考虑更多上下文信息。
通常,这些阶段会采用不同的模型来逐步缩小推荐范围。
传统模型的局限性¶
目前的推荐模型大多在封闭系统的特定数据集上训练,忽略了从开放世界知识(open-world knowledge)中获取潜在价值的可能性。这成为当前研究的一个重要挑战,也是后续改进模型性能的重要方向。
4. Methodology¶
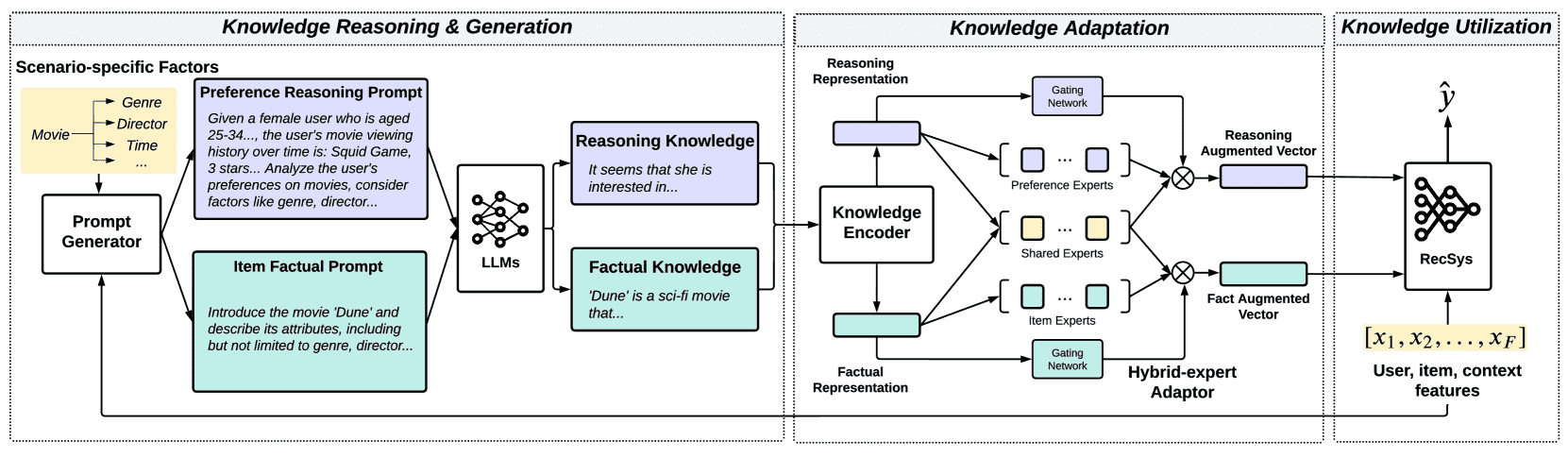
Figure 2.The overall framework of KAR, consisting of knowledge reasoning and generation stage, knowledge adaptation stage, and knowledge utilization stage. Knowledge reasoning and generation stage leverages our designed factorization prompting to extract the reasoning and factual knowledge from LLMs. Knowledge adaptation stage converts textual open-world knowledge into compact and the reasoning and fact augmented representations suitable for recommendation. Knowledge utilization stage integrates the reasoning and fact augmented vectors into an existing recommendation model.
图 2 展示了 KAR 框架的整体结构,分为三个阶段:
知识推理与生成阶段:利用 factorization prompting 从 LLM 提取推理与事实知识。
知识适配阶段:将开放世界知识转换为紧凑的增强表示,适应推荐任务。
知识利用阶段:将增强向量整合进推荐模型,提升性能。
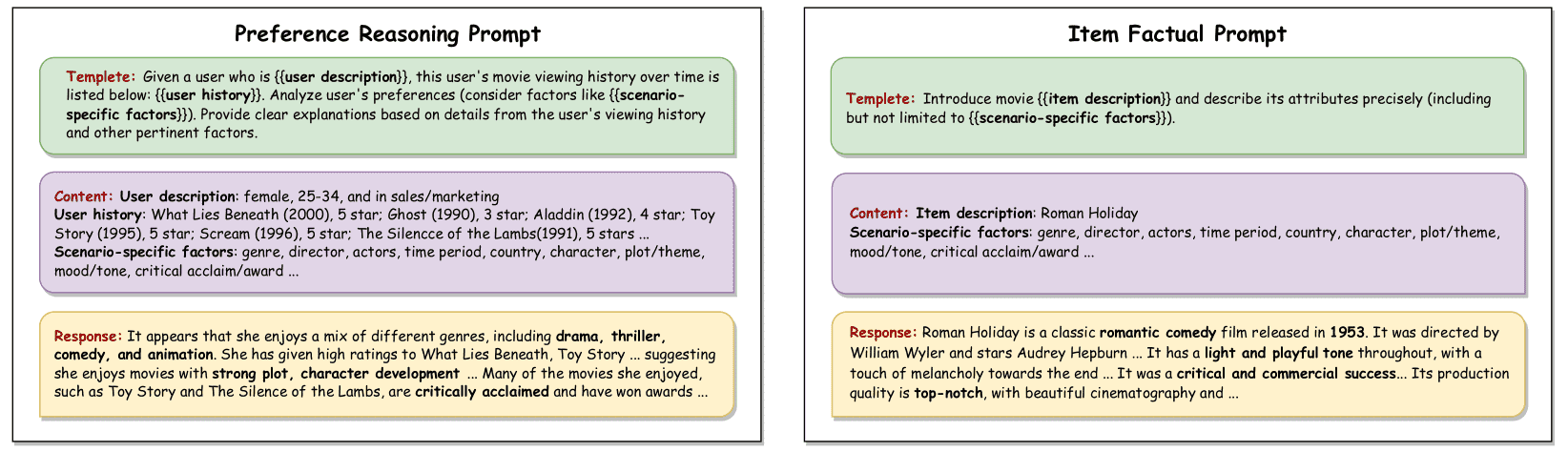
Figure 3.Example prompts for KAR.
本章描述的是一个如何利用大型语言模型(LLM)的强大能力来增强传统推荐系统(RS)的框架。其核心思想是:从LLM中提取“开放世界知识”(即训练数据之外的海量通用知识),并将其转化为推荐系统能理解和使用的形式,最终提升推荐效果。
三个阶段¶
整个框架(KAR)分为三个核心阶段,我们可以用一个简单的比喻来理解:
阶段一(知识推理与生成):像一位“资深顾问”
任务:向LLM提问,获取知识。
做法:不是笼统地问“用户喜欢什么?”,而是通过因子分解提示(Factorization Prompting),把问题拆解成多个关键因素(如电影推荐中的“类型”、“演员”、“导演”、“主题”等)。然后针对每个因素,让LLM提供两样东西:
推理知识:分析用户对这个因素的偏好(例如:用户A因为看了《Scream》和《What Lies Beneath》,所以可能喜欢“惊悚”类型)。
事实知识:描述候选物品在这个因素上的特性(例如:电影《Roman Holiday》具有“轻松诙谐的基调”)。
目的:这样拆解提问,既降低了LLM回答复杂问题的难度(解决了“组合鸿沟”问题),又保证了生成的用户偏好和物品特性是相互对齐的,避免了“答非所问”。
关键点:这些关键因素(Factors)是通过LLM初步建议加人类专家确认的方式为不同场景(电影、新闻等)定制的,一劳永逸。
阶段二(知识适应):像一位“翻译官”
任务:把“顾问”(LLM)提供的文字报告(文本知识)翻译成推荐系统能听懂的“专业术语”(向量表示)。
挑战:
LLM生成的是文本,传统推荐系统处理的是ID类特征和数值向量。
LLM的向量表示维度高(如4096维),且存在于“语义空间”,与推荐系统的“推荐空间”不匹配。
LLM的知识可能有噪声或不准确。
做法:
知识编码器:用一个像BERT这样的模型,把生成的文本知识转换成密集向量(Dense Vectors)。
混合专家适配器:这是一个核心创新模块。它接收编码后的向量,并用一组“专家”网络(其实就是一堆小型的神经网络MLP)将其转换到低维的“推荐空间”。
共享专家:处理用户偏好和物品事实中的共性信息。
专属专家:分别处理用户偏好和物品事实中的独特信息。
门控网络:决定对于每个输入向量,应该更多地信任哪位“专家”的意见。
目的:完成从“文本”到“向量”、从“高维语义空间”到“低维推荐空间”的转换和降维,同时通过多头专家机制增强鲁棒性,抑制噪声。
阶段三(知识利用):像一位“决策者”
任务:把“翻译官”处理好的新知识(两个增强向量:
r^ip用户推理增强向量 和r^iι物品事实增强向量)用起来。做法:采用最简单直接的方式——把这两个新向量作为额外的特征字段,和用户、物品原有的特征(如用户ID、物品ID、历史行为等)一起,输入到现有的任何推荐模型(Backbone Model,如DeepFM、DIN等)中进行训练和预测。
目的:让推荐模型在做决策时,不仅能参考它自己学到的“域内知识”(如协同过滤信号),还能参考LLM提供的“开放世界知识”,从而做出更精准、更个性化的推荐。
优势:这种方式非常灵活,几乎可以 plug-and-play(即插即用)到任何现有的推荐模型上,而不需要改变模型本身的结构。
关于加速策略的说明¶
由于LLM推理速度很慢,无法满足线上推荐实时性的要求,作者设计了一套高效的预处理和缓存策略:
预处理:在模型训练之前,就用LLM为所有用户和物品生成好知识,并通过编码器编码成向量,存入数据库。
训练与推理:训练和线上服务时,直接从数据库里读取这些预先生成的向量,完全绕开耗时的LLM调用。
极致优化:如果需要更快的速度和更小的存储,甚至可以提前把“适配器”转换好的最终增强向量(
r^ip和r^iι,维度很小,如32维)也存起来。这样线上推理时,推荐模型几乎没有任何额外开销。
为什么可行?
物品特性相对稳定,生成一次可以复用很久。
用户长期偏好也相对稳定,可以用长期行为数据预生成。推荐模型自己会负责捕捉和更新用户的短期即时兴趣。
总结¶
这个KAR框架的精妙之处在于:
扬长避短:充分发挥LLM的知识库和推理优势,同时通过精巧的设计(因子分解提示、适配器)规避其缺点(速度慢、输出不直接可用、可能胡诌)。
模型无关:不破坏现有推荐系统的架构,可以轻松地与各种先进的推荐模型结合。
高效实用:通过预处理和缓存策略,解决了LLM在实时推荐系统中部署的核心瓶颈问题。
简单来说,它让LLM在幕后当好“智库”和“顾问”,让推荐系统在前台继续高效地当好“决策者”,强强联合,实现“1+1>2”的效果。
5. Experiment¶
5.1 实验设置(Setup)¶
本节从**七个研究问题(RQs)**出发,全面评估KAR框架的性能与泛化能力。涉及的问题包括KAR对基础模型的提升、与PLM方法的对比、知识来源(LLM vs. 知识图谱)的效果、在线部署效果、知识的类型(推理知识 vs. 事实知识)及其对性能的影响、不同的知识适配方法的效果,以及KAR的推理效率。
5.1.1 数据集(Dataset)¶
实验在两个公开数据集 MovieLens-1M 和 Amazon-Books 上进行:
MovieLens-1M:6000个用户,4000个电影,100万条评分数据。
Amazon-Books:11906个用户,17332本书,140万条交互数据。
数据预处理方式相似:将评分映射为二分类(4/5为正类,其余为负类),并划分训练集与测试集(9:1)。
特征包括用户特征(年龄、性别、职业等)、物品特征(ID、类别)及用户行为历史。
5.1.2 基础模型(Backbone Models)¶
KAR 是模型无关的框架,适用于多种推荐任务。实验选择了两类任务验证其有效性:
CTR预测:用于排序阶段,评估点击率。
重排序(Reranking):优化候选列表,提升用户满意度。
CTR模型包括:
用户行为模型(如 DIN、DIEN):关注用户行为序列建模。
特征交互模型(如 DeepFM、xDeepFM、DCNv2、FiBiNet、FiGNN、AutoInt):强调特征之间的交互关系。
重排序模型包括:DLCM、PRM、SetRank、MIR。
5.1.3 PLM基线(PLM-based Baselines)¶
实验将 KAR 与其他基于预训练语言模型的推荐方法进行对比,包括:
P5, UniSRec, VQ-Rec, TALLRec, LLM2DIN。
TALLRec 使用 LLaMa2-7B Chat 模型进行推荐任务的微调。
LLM2DIN 使用 chatGLM 生成物品嵌入。
5.1.4 评估指标(Evaluation Metrics)¶
CTR任务:AUC(越高越好)、LogLoss(越低越好)。
重排序任务:NDCG@K、MAP@K。
5.1.5 实现细节(Implementation Details)¶
使用 ChatGLM 生成知识并编码。
通过平均池化提取向量。
适配器(Hybrid-expert adaptor)使用 MLP。
参数优化通过网格搜索实现,确保所有模型公平比较。
5.2 有效性比较(Effectiveness Comparison)¶
5.2.1 KAR 对基础模型的提升(RQ1)¶
KAR 显著提升了多种基础模型的性能,如在 MovieLens-1M 上,FiBiNet 的 AUC 提升 1.49%,LogLoss 降低 2.27%。
KAR 对特征交互模型的提升更显著,可能是因为这些模型能更好地利用知识向量。
在重排序任务中,KAR 也显著提升了现有模型的性能,如 PRM 的 NDCG@7 提升 4.71%。
5.2.2 KAR 与 PLM 方法的对比(RQ2)¶
KAR 在性能上明显优于基于 PLM 的方法(如 TALLRec),例如在 Amazon-Books 上 AUC 提升 0.91%。
基于小 PLM 的方法(如 UniSRec、P5)提升有限,甚至不如基础模型。
KAR 与 LLM 结合(ChatGLM-6B)表现优越,但 LLM 作为初始化(如 LLM2DIN)提升有限。
5.2.3 KAR 与知识图谱的对比(RQ3)¶
LLM 提供的知识比知识图谱(KG)更具优势,可能因为 LLM 包含了用户偏好推理知识,而 KG 主要提供物品事实知识。
仅使用 LLM 知识即可达到最佳效果,表明 LLM 可能已包含 KG 的知识,无需额外结合。
5.3 在线部署与A/B测试(RQ4)¶
在华为新闻和音乐平台部署 KAR。
新闻平台中 KAR 提升了 7% 的召回率。
音乐平台中,KAR 提升了歌曲播放量、设备播放数和总播放时长。
使用 PCA 降维提高了存储效率。
说明 KAR 在工业环境中具备实用性和提升效果。
5.4 消融研究(Ablation Study)¶
5.4.1 推理知识与事实知识(RQ5)¶
推理知识比事实知识对模型性能提升更显著,因为推理知识可能捕获用户深层偏好。
同时使用两种知识可产生协同效果(1+1>2)。
推理知识提供了外部信息,结合事实知识能更好地匹配用户偏好与物品。
5.4.2 知识编码器与语义变换(RQ6)¶
使用 ChatGLM 编码的模型效果优于 BERT,可能因为 ChatGLM 更大、理解更优。
使用 MoE 或混合专家适配器可提升效果,表明从语义空间到推荐空间的映射需要复杂网络结构。
BERT 提供的信息有限,MoE 已足够。
5.5 效率研究(RQ7)¶
使用 LLM API 直接推理效率低(响应时间 4-6 秒),不适用于工业推荐系统。
TALLRec 等基于小 LLM 的模型也存在延迟问题(约 1 秒)。
**KAR 的两种优化策略(预处理 + 预存储)**将推理时间压缩至 100ms 以内,甚至与基础模型相当。
说明 KAR 可在低延迟要求下高效部署。
总结¶
本章通过 七个研究问题,从多个角度(模型提升、方法对比、知识来源、在线部署、知识类型、编码方式、推理效率)全面验证了 KAR 框架的有效性与工业可行性。实验表明:
KAR 显著提升了多种推荐模型在 CTR 和重排序任务中的表现;
与 PLM 和知识图谱方法相比,LLM 提供的知识更具优势;
KAR 的加速策略使其具备工业部署潜力;
KAR 的设计具有模型无关性和泛化性,适用于不同推荐场景。
6. Broader Impact¶
本章重点讨论了在将大语言模型(LLMs)集成到推荐系统(RSs)中时,需关注的隐私与安全问题,并说明了在设计 KAR 框架时如何应对这些问题。
1. 隐私保护(Privacy)¶
重点内容:KAR 框架设计时避免对用户数据的存储和记忆 KAR 利用 LLM 的推理能力和事实知识,无需对 LLM 进行微调,确保 LLM 不会保留或记住用户特定数据,从而降低了隐私泄露的风险。
关于外部 API 的使用 实验过程中可能使用外部 API 处理公开数据集,但在实际部署中通常使用内部模型(如华为的 Pangu LLM),以避免通过外部 API 泄露用户隐私信息。这一设计在在线 A/B 测试中也得到了验证(参考第 5.3 节)。
2. 内容安全(Security)¶
重点内容:避免直接展示 LLM 生成的内容 与一些直接展示 LLM 生成内容的方法不同(如 Gao et al., Liu et al., Dai et al. 的研究),KAR 采取了更积极的策略,以减轻 LLM 生成内容中可能存在的有害内容和**幻觉知识(hallucination)**问题。
KAR 的处理方式 KAR 首先将 LLM 生成的文本内容转化为鲁棒的表示形式,然后将这些表示整合进传统推荐系统中。这样做的优势在于:
不直接暴露 LLM 的原始输出,避免用户看到潜在的误导性内容;
能够利用传统 RS 中常用的过滤机制,进一步筛查出可能有害的推荐项。
3. 总体目标¶
KAR 的综合目标 KAR 在提升推荐性能的同时,努力实现用户隐私保护和推荐内容的安全性。通过上述设计措施,KAR 实现了在开放世界推荐场景下,兼顾效果与安全性的目标。
总结¶
本章强调了将 LLM 用于推荐系统时需关注的隐私和安全问题,并详细说明了 KAR 框架在这些方面所采取的措施。相比其他方法,KAR 通过避免模型微调、使用内部模型、转化内容表示等方式,有效降低了隐私风险和内容危害,展现了其在实际部署中的可行性和安全性优势。
7. Conclusion¶
本文提出了一种名为 KAR 的框架,旨在通过利用大型语言模型(LLM),将开放世界知识有效地整合到推荐系统中。
KAR 从 LLM 中识别出两类关键知识:用户偏好的推理知识和物品的事实知识。这些知识通过我们设计的因子分解提示方法(factorization prompting)可以被主动获取。这是文章的重点之一。
为了使这些知识适用于推荐任务,我们设计了一个混合专家适配器(hybrid-expert adaptor),将获取的知识进行转换。这一部分是实现知识与推荐系统兼容的关键,也是核心技术点之一。
通过这一过程得到的增强向量可以提升任意推荐模型的性能。此外,KAR 通过预处理和预存储 LLM 知识,实现了高效的推理过程,这也是框架的一个重要优势。
实验结果表明,KAR 相比于当前最先进的方法表现更优,并且与多种推荐算法具有良好的兼容性。这是本研究的最终结论和主要贡献。