2404.12457_RAGCache: Efficient Knowledge Caching for Retrieval-Augmented Generation¶
引用: 197(2025-08-02)
组织:
1Peking University
2ByteDance Inc.
总结¶
说明
如下章节进行了详细整理
RAGCache Design
背景
使用 RAG 后,原始100token输入,可能需要注入1000token的检索知识,导致输入长度增长
分析了 RAG 系统的性能瓶颈,发现其主要受生成阶段的 prefill 延迟影响,尤其是文档长度较长时更为显著
实验表明,当输入序列长度超过 4000 个 token 时,LLM 的 prefill 时延可达到 1 秒
所以把常用的 prefill 阶段的检索知识缓存起来,减少长序列生成和重复检索的开销,从而提高性能。
实验结果:
使用缓存后,prefill 延迟可降低 11.5 倍。
即使考虑缓存传输开销,缓存命中时延也能比未缓存时降低 3.9 倍。
实验证明,文档引用存在明显的 幂律分布,即少数文档被频繁访问,因此缓存优化具有显著效果。
PGDSF
Prefix-aware Greedy Dual-Size Frequency (PGDSF) policy is employed to minimize the cache miss rate.
PGDSF calculates a priority based on the frequency, size of key-value tensors, last access time, and prefix-aware recomputation cost.
PGDSF示例场景
初始状态:GPU内存时钟 = 0,节点A优先级 = 10(
Clock=0,Frequency=2,Cost=5,Size=1)。节点A被访问:
更新
Clock= 当前时钟值(假设仍为0)。重新计算优先级(可能不变)。
GPU内存不足,驱逐节点A:
选择优先级最低的节点A驱逐。
更新GPU时钟 =
max{10}= 10。
后续新节点B加入:
新节点的
Clock继承当前时钟值(10),确保比旧节点更优先保留。
Abstract¶
本章节主要介绍了一种名为 RAGCache 的新型多级动态缓存系统,用于优化基于检索增强生成(Retrieval-Augmented Generation, RAG)的自然语言处理任务。RAG 结合了大规模语言模型(LLMs)和外部知识数据库的优势,提升了任务性能。然而,RAG 在生成过程中引入了长序列,导致计算和内存开销较大。
为了解决这一问题,RAGCache 通过分析当前 RAG 系统的瓶颈,提出将知识检索的中间状态进行缓存的优化策略。该系统将检索到的知识中间状态组织成“知识树”结构,并在GPU和主机内存中建立多级缓存。同时,RAGCache 设计了一种适用于语言模型推理特性和RAG检索模式的替换策略,并通过动态重叠检索与推理步骤来减少端到端延迟。
在实验中,RAGCache 集成到了当前先进的语言模型推理系统 vLLM 和向量数据库 Faiss 上。实验结果表明,RAGCache 将第一个 token 的生成时间(TTFT)最多减少 4 倍,吞吐量提高最多 2.1 倍。
1. Introduction¶
这段内容主要围绕检索增强生成(RAG)系统的性能瓶颈与优化方法展开,提出了一种新的缓存系统 RAGCache。以下是该章节的总结:
1. 引言概述¶
背景:近年来,大型语言模型(LLMs)如 GPT-4、LLaMA2 和 PalM 在问答、摘要和翻译等NLP任务中表现出色。RAG 通过从外部数据库(如 Wikipedia)检索上下文相关知识,进一步提升了生成质量。
RAG流程:系统首先检索相关文档,将其嵌入向量数据库,再将检索结果注入原始请求中,由LLM进行生成。
挑战:由于知识注入导致请求序列变长,计算和内存成本显著增加(通常提升10倍以上),对系统的扩展性和效率提出了挑战。
2. 现有工作与局限¶
系统优化:现有工作(如 vLLM 和 SGLang)通过共享中间状态来减少重新计算,但它们主要针对普通LLM推理,未考虑RAG的特性,因此在处理长序列请求时性能受限。
问题分析:作者通过系统特性分析发现,关键瓶颈在于文档注入引发的长序列处理。同时,作者识别出两个优化机会:
相同文档在多个请求中被重复使用,可共享中间状态。
部分文档被频繁检索,可缓存其状态以减少计算量。
3. RAGCache系统¶
目标:提出一种多级动态缓存系统 RAGCache,用于缓存检索文档的中间状态(如KV缓存),并跨请求共享。
核心设计:
知识树(Knowledge Tree):根据文档访问频率,将中间状态缓存在快的 GPU 内存或慢的主机内存中。
PGDSF替换策略:结合文档的顺序、大小、频率和最近性,设计前缀感知的贪婪双尺寸频率替换策略,以降低缓存缺失率。
请求调度策略:在高请求率下优化命中率。
动态推测流水线(Dynamic Speculative Pipelining):将 CPU 上的向量检索和 GPU 上的 LLM 推理重叠执行,以减少端到端延迟。
4. 实验结果¶
性能提升:
相比 vLLM + Faiss,RAGCache 在**首字生成时间(TTFT)**上快 4倍,吞吐量提升 2.1倍。
相比 SGLang,RAGCache 在 TTFT 上快 3.5倍,吞吐量提升 1.8倍。
结论:RAGCache 是首个针对 RAG 的中间状态缓存系统,通过多级缓存和流水线优化,显著提升了 RAG 系统的效率。
5. 主要贡献¶
对 RAG 系统进行了详细性能分析,识别了瓶颈与优化机会。
提出 RAGCache,首个缓存并共享外部知识中间状态的 RAG 系统。
设计了基于 RAG 特性的缓存替换策略(PGDSF)和动态流水线方法。
实现原型并验证效果,显著优于现有 RAG 系统。
该章节为后续详细介绍 RAGCache 的架构、算法和实验提供了坚实的背景与动机。
2. Background¶
该章节主要介绍了**Retrieval-Augmented Generation(RAG)**的背景及其工作原理。RAG 是一种结合大语言模型(LLMs)与外部知识库检索的混合方法,旨在提升生成模型的输出质量,使其更加准确、相关且富有上下文信息。RAG 通过在生成过程中动态检索外部知识库中的信息,结合 LLM 的上下文理解能力与数据库检索的精确性,从而实现更优的生成效果。
文章指出,近年来的研究表明,与纯生成模型相比,RAG 在多个基准任务中显著提升了生成质量,并已广泛应用于问答、内容生成和代码生成等领域,展示了其灵活性与潜力。
RAG 的工作流程分为两个步骤:检索(retrieval)和生成(generation)。在离线阶段,系统将外部知识源(如文档)转换为高维向量,并建立索引,以便快速检索。在在线阶段,系统根据用户请求在向量数据库中进行语义相似度检索,获取最相关的文档,将这些文档内容与用户请求结合,形成增强请求,再输入 LLM 生成最终响应。
从系统性能的角度来看,RAG 的性能受到检索和生成两个阶段的影响。其中,检索主要在 CPU 上运行,其耗时取决于数据库规模;生成主要在 GPU 上运行,其耗时由模型大小和序列长度决定。该章节最后指出,后续分析将聚焦于 RAG 的性能瓶颈,并寻找优化空间。
3. RAG System Characterization¶
本节对基于检索增强生成(RAG)系统的性能特征进行了全面分析,主要围绕三个核心方面展开:
一、性能瓶颈分析¶
LLM 推理阶段划分:
LLM 推理分为 prefill(预填充)和 decoding(解码)两个阶段。
Prefill 负责计算输入序列的 key-value 矩阵,是时间消耗的主要部分。
Decoding 则以自回归方式逐个生成输出 token。
RAG 中的瓶颈:
RAG 包含 检索 和 生成 两个步骤。尽管检索步骤速度很快(毫秒级别,尤其在大规模向量数据库中),但 生成步骤 受序列长度和模型规模影响显著。
实验表明,当输入序列长度超过 4000 个 token 时,LLM 的 prefill 时延可达到 1 秒。
文档长度(平均 3718 tokens)远大于用户请求的长度(如 MMLU 数据集),导致整体生成时延显著增加。
在要求极高检索准确性的场景中,检索过程的延时也可能接近生成步骤,进一步加剧性能瓶颈。
二、优化机会分析 —— 缓存中间状态¶
为缓解性能瓶颈,提出了一种基于 缓存检索到的文档 key-value 状态 的优化方法。
缓存机制原理:
如果多个请求引用相同的文档,则可以复用该文档的 key-value 状态,避免重新计算。
缓存命中可显著减少 prefill 时延。
性能评估因素:
Full Prefill 延迟:未缓存时,需要完整计算整个序列的 key-value 状态。
缓存命中延迟:仅需计算请求部分的 key-value,且需考虑 GPU 与主机内存之间缓存传输的开销。
缓存未命中率:直接影响整体性能,需分析文档的引用模式。
实验结果:
使用缓存后,prefill 延迟可降低 11.5 倍。
即使考虑缓存传输开销,缓存命中时延也能比未缓存时降低 3.9 倍。
实验证明,文档引用存在明显的 幂律分布,即少数文档被频繁访问,因此缓存优化具有显著效果。
不同设置下的泛化性:
在不同嵌入模型(如 text-embedding-3-small)和近似最近邻(ANN)索引(如 FlatL2)下,文档引用模式保持相似。
说明缓存优化策略具有广泛适用性。
总结¶
本节系统地分析了 RAG 系统的性能瓶颈,发现其主要受生成阶段的 prefill 延迟影响,尤其是文档长度较长时更为显著。通过缓存检索到的文档 key-value 状态,可以大幅降低计算开销。实验表明,文档引用存在高度偏斜,使得缓存策略在实际中具有很大的优化空间。此外,该优化方法在不同设置下具有良好的泛化能力。
4. RAGCache Overview¶
本文介绍了 RAGCache,这是一个为 检索增强生成(RAG) 优化的多级动态缓存系统。其目标是通过缓存检索文档对应的 key-value 张量,减少重复计算,提高 LLM 推理效率。
主要内容总结如下:¶
1. RAGCache 的核心设计¶
知识树结构:使用基于文档 ID 的前缀树组织缓存的 key-value 张量,支持快速查找,且路径共享节点,提升不同请求间缓存利用率。
PGDSF 替换策略:一种结合频率、张量大小、最近访问时间以及前缀重计算成本的优先级策略,用于决定缓存淘汰,确保保留最有价值的张量。
RAG 控制器:负责协调外部知识库和 LLM 推理引擎之间的交互,并引入系统优化手段。
2. 系统架构流程¶
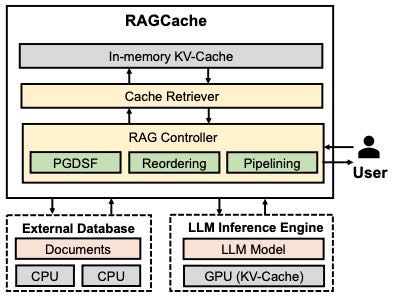
Figure 7. RAGCache overview
当请求到达时,RAG 控制器 从知识库检索相关文档。
缓存检索器(Cache Retriever) 查询缓存中是否存在对应 key-value 张量:
若命中,直接传入 LLM 进行推理,利用前缀缓存加速生成。
若未命中,由 LLM 推理生成新 token,生成后将新张量存入缓存并更新状态。
推理结果返回用户作为最终响应。
3. 关键优化技术¶
缓存感知重排序:重新安排请求顺序,提高缓存命中率,避免缓存抖动,同时保障请求公平性。
动态推测流水线:将知识检索与 LLM 推理重叠执行,降低延迟。利用中间检索结果提前启动生成过程,提升效率。
总结¶
RAGCache 通过多级缓存、智能替换策略和系统级优化,显著提升了基于 RAG 的 LLM 推理效率和响应速度,减少了对知识库的重复访问和计算开销,是当前 RAG 系统中的一项高效缓存解决方案。
5. RAGCache Design¶
本节介绍了RAGCache的设计,主要包含三个部分:
缓存结构与替换策略:提出了一种缓存结构,并引入了基于前缀感知的替换策略,用于有效管理缓存中的知识内容,提升缓存效率。
缓存感知的重排序策略:通过重排序策略优化查询顺序,以提高缓存命中率,减少不必要的知识检索开销。
动态推测流水线方法:设计了一种动态的推测流水线机制,用于在知识检索和大语言模型(LLM)推理之间进行重叠处理,从而提升整体系统性能。
5.1. Cache Structure and Replacement Policy¶
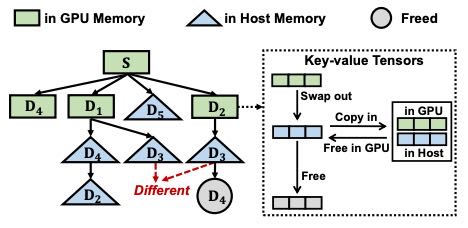
Figure 8. Knowledge tree.
1. 核心创新:基于知识树的键值张量缓存¶
与传统缓存的区别:传统系统缓存独立对象,而RAGCache缓存检索文档的键值张量(KV tensors),且这些张量对文档顺序敏感。
示例:文档序列
[D1,D3]和[D2,D3]中,即使都包含D3,其键值张量KV[1]和KV'[1]的值不同,因为张量生成依赖前序文档的顺序。
2. 知识树结构¶
设计目的:高效维护文档顺序并支持快速检索。
节点关系:每个文档对应一个节点,存储其键值张量的内存地址。根节点
S表示系统提示词,路径根→节点代表文档序列。内存管理:采用非连续内存块存储键值张量(参考vLLM),支持KV缓存复用。
优势:
并行服务:通过重叠路径同时处理多请求。
前缀匹配:检索时沿路径匹配,未命中则终止遍历,时间复杂度为
O(h)(h为树高)。
3. PGDSF替换策略¶
核心思想:基于经典GDSF策略,引入前缀感知优化,综合考虑访问频率、文档大小和计算成本。
优先级公式:
Priority = Clock + (Frequency × Cost) / Size
Clock:逻辑时钟,记录最近访问时间(GPU和主机内存分别维护)。Frequency:时间窗口内的访问频率。Cost:计算文档键值张量的时间(受GPU性能、文档大小和前序文档影响)。Size:文档的token数量。
动态调整:
优先级较低的节点首先被驱逐
时钟更新:时钟都从零开始,并在每次驱逐时更新
成本估算:通过双线性插值离线分析LLM预填充时间,动态调整未缓存token的计算成本(公式3)。
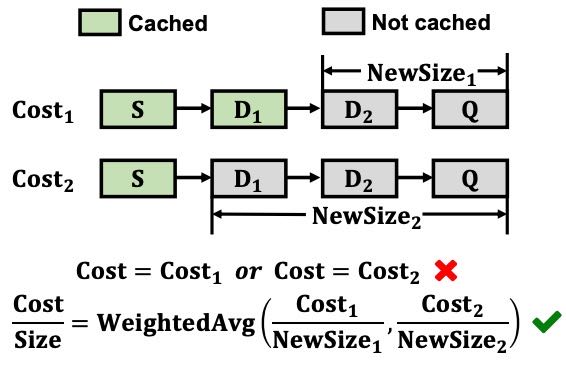
Figure 9. Cost estimation in PGDSF.
示例场景
初始状态:GPU内存时钟 = 0,节点A优先级 = 10(
Clock=0,Frequency=2,Cost=5,Size=1)。节点A被访问:
更新
Clock= 当前时钟值(假设仍为0)。重新计算优先级(可能不变)。
GPU内存不足,驱逐节点A:
选择优先级最低的节点A驱逐。
更新GPU时钟 =
max{10}= 10。
后续新节点B加入:
新节点的
Clock继承当前时钟值(10),确保比旧节点更优先保留。
4. 分层缓存管理¶
三级存储:GPU内存(高速)、主机内存(低速)、空闲区。
驱逐规则:
GPU内存满时,优先驱逐叶子节点中优先级最低的到主机内存。
主机内存满时类似处理,保持树结构的层级关系。
Swap-Out-Once策略:首次驱逐到主机内存后保留数据,后续GPU内存驱逐直接释放,减少PCIe带宽占用。
5. Algorithm 1 Knowledge Tree Operations:¶
更新 GPU 中的节点(UPDATE_NODE_IN_GPU)¶
核心逻辑:
更新访问频率
未缓存时用双线性插值估算计算成本
计算新优先级 Priority = Clock + AvgCost × Frequency
伪代码
function UPDATE_NODE_IN_GPU(node, is_cached, α, β):
# α: 当前请求中已缓存的 token 数量
# β: 当前请求中未缓存的 token 数量
# 更新访问频率
node.Frequency ← node.Frequency + 1
if is_cached is False:
# 如果节点未缓存,需估算计算成本(双线性插值)
# (1) 查找最近的插值点(α_l < α < α_h, β_l < β < β_h)
Find α_l < α < α_h and β_l < β < β_h from the profiler
# (2) 沿 α 轴插值(固定 β_l)
T_l ← T(α_l, β_l) + (α - α_l)/(α_h - α_l) * [T(α_h, β_l) - T(α_l, β_l)]
# (3) 沿 α 轴插值(固定 β_h)
T_h ← T(α_l, β_h) + (α - α_l)/(α_h - α_l) * [T(α_h, β_h) - T(α_l, β_h)]
# (4) 沿 β 轴插值,得到最终计算时间 T(α, β)
T(α, β) ← T_l + (β - β_l)/(β_h - β_l) * (T_h - T_l)
# (5) 更新节点的总计算成本和平均成本
node.TotalCost ← node.TotalCost + T(α, β)/β # 按 token 均摊成本
node.numComputed ← node.numComputed + 1
node.AvgCost ← node.TotalCost / node.numComputed
# 更新节点优先级
node.Priority ← Clock + node.AvgCost × node.Frequency
GPU 内存驱逐(EVICT_IN_GPU)¶
核心逻辑:
从叶子节点中选择 Priority 最低的驱逐
更新 Clock
维护候选驱逐集(动态调整叶子节点)
伪代码
function EVICT_IN_GPU(required_size):
E ← ∅ # 待驱逐的节点集合
S ← {n ∈ GPU ∧ n.Children ∉ GPU} # GPU 中的叶子节点(候选驱逐集)
while Σ(n∈E) n.Size < required_size:
# 选择优先级最低的节点驱逐
n ← argmin(n∈S) n.Priority
E ← E ∪ {n}
# 更新逻辑时钟
Clock ← max{Clock, n.Priority}
# 如果父节点变为叶子(无子节点在 GPU),加入候选集
if n.Parent.Children ∉ GPU:
S ← S ∪ {n.Parent}
return E # 返回被驱逐的节点
示例讲解¶
假设我们有一个 知识树,其中包含以下节点(括号内为当前优先级):
Root (S)
D1 (Priority=15)
D3 (Priority=10)
D2 (Priority=20)
D4 (Priority=5)
访问节点 D3(触发更新)
请求参数
is_cached = False(D3 不在 GPU 缓存)α = 100(已缓存 token 数)β = 50(未缓存 token 数)
执行
UPDATE_NODE_IN_GPU(D3, False, 100, 50)更新频率
D3.Frequency从2→3。双线性插值估算计算时间
查表找到最近的插值点:
(α_l=80, α_h=120)(β_l=40, β_h=60)
计算
T(100, 50)(假设结果为T=200 ms)。
更新成本统计
D3.TotalCost += 200/50 = 14(假设原值为10→ 新值14)。D3.numComputed += 1(假设原值为3→ 新值4)。D3.AvgCost = 14 / 4 = 3.5。
计算新优先级
假设当前
Clock=10:
D3.Priority = 10 + 3.5 × 3 = 20.5(原为10,现更新为20.5)。
GPU 内存不足,触发驱逐
执行
EVICT_IN_GPU(required_size=2)初始化候选集
SGPU 中的叶子节点:
S = {D3, D4}(因为它们的子节点不在 GPU)。
选择优先级最低的节点
D3.Priority = 20.5D4.Priority = 5
→ 选择D4驱逐。
更新状态
E = {D4}(已驱逐节点集合)。更新
Clock = max{10, 5} = 10(无变化)。检查
D4.Parent(即D2):D2的子节点D4已被移除,但D2仍在 GPU,因此不加入S。
检查是否释放足够内存
假设
D4.Size = 3≥required_size=2,循环终止。
插入新节点 D5
将
D5加入 GPU 内存,其初始优先级为Clock + AvgCost × Frequency = 10 + 1 × 1 = 11。
最终 GPU 内存状态
Root (S)
D1 (Priority=15)
D3 (Priority=20.5)(更新)
D2 (Priority=20)
D4 (Priority=5)(已驱逐)
D5 (Priority=11)(新增)
总结¶
RAGCache通过知识树结构和PGDSF策略,解决了LLM中检索增强生成(RAG)的缓存难题,兼顾了顺序敏感性、访问效率与分层存储优化,显著提升了系统性能。
5.2. Cache-aware Reordering¶
核心问题¶
RAGCache 的缓存效率高度依赖缓存命中率,但用户请求的不可预测性会导致缓存颠簸(cache thrashing):
访问相同文档的请求可能分散到达,导致缓存频繁替换。
示例:假设请求
Q1, Q3, Q5...访问文档D1,Q2, Q4, Q6...访问D2,而缓存容量仅为 1 个文档。原始顺序
Q1, Q2, Q3, Q4...:每次请求都需替换缓存(命中率 0%)。优化顺序
Q1, Q3, Q5, Q2, Q4, Q6...:连续处理相同文档的请求,命中率提升至 66%。
关键场景分析¶
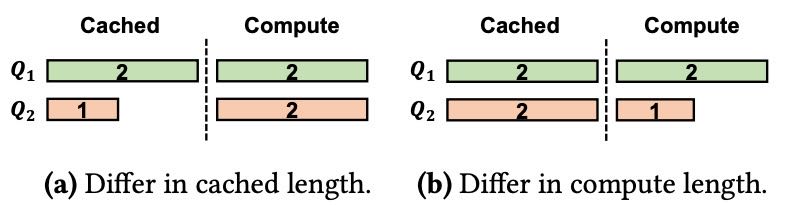
Figure 10. Cache-aware reordering.
场景一:相同计算需求,不同缓存上下文长度
条件:缓存容量为 4,请求
Q1和Q2的计算需求相同,但Q1的缓存上下文更长。如图 10.a 所示: Q1、Q2的缓存占用是2+1,还有1单位容量可用,Q1、Q2的计算都需要2
原始顺序
Q1, Q2:Q1的计算需要2单位,缓存不够,需清空
Q2的缓存以处理Q1Q1的缓存命中,成本 +0
Q1的计算成本 +2
之后重新计算
Q2的缓存,计算成本 +1处理
Q2计算成本 +2总计算成本为
2+1+2=5
优化顺序
Q2, Q1:优先处理缓存上下文更长的
Q1,总成本升至2+2+2=6(效率更低)。
结论:应优先处理缓存上下文更长的请求,以最大化缓存利用率。
场景二:相同缓存长度,不同计算需求
条件:缓存容量为 5,
Q1需计算 2 单位,Q2需计算 1 单位。如图 10.b 所示: Q1、Q2的缓存占用是2+2,还有1单位容量可用,Q1的计算需要2,Q2的计算需要1
原始顺序
Q1, Q2:需清空
Q2的缓存处理Q1Q1的缓存命中,成本 +0
Q1的计算成本 +2
之后完全重新计算
Q2的缓存,计算成本 +2处理
Q2计算成本 +1总成本
2+2+1=5。
优化顺序
Q2, Q1:优先处理计算量更小的
Q2Q2计算,缓存容量句,不用清空 Q1缓存
Q2缓存命中 +0
Q2的计算成本 +1
Q1的缓存命中,成本 +0
Q1的计算成本 +2
总成本
1+2=3。
结论:应优先处理计算量更小的请求,减少缓存替换的负面影响。
缓存感知重排序算法¶
基于上述分析,RAGCache 使用优先级队列对请求排序,优先级公式为:
$\(
\text{OrderPriority} = \frac{\text{Cached Length}}{\text{Computation Length}}
\)$
优先级逻辑:
分子(Cached Length):优先保留缓存中已存在的内容,减少替换。
分母(Computation Length):优先处理计算量小的请求,降低延迟。
效果:提升命中率、减少总计算时间。
防饥饿机制:为每个请求设置处理时间窗口,确保公平性。
总结¶
通过动态调整请求顺序,RAGCache 在有限缓存容量下:
减少频繁的缓存替换(颠簸)。
优先利用已有缓存或计算量小的请求。
平衡效率与公平性(通过时间窗口)。
5.3 动态推测流水线(Dynamic Speculative Pipelining)¶
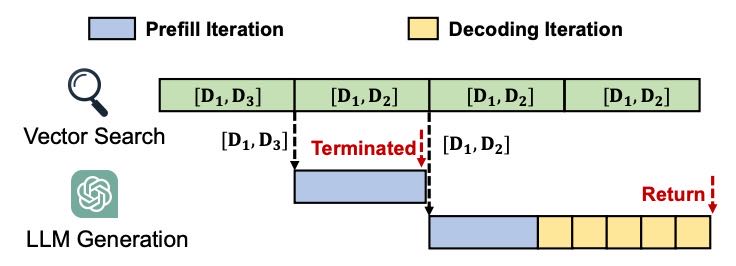
Figure 11. Speculative pipelining.
图解
阶段1:候选
[D1,D3]→ 启动生成。阶段2:候选变为
[D1,D2]→ 终止旧生成,启动新生成。阶段3:候选仍为
[D1,D2]→ 不干预LLM。阶段4:最终结果
[D1,D2]与最后一次生成匹配 → 直接返回结果。
背景与问题¶
RAG系统的性能瓶颈
LLM生成阶段是RAG的主要性能瓶颈(如3.1节所述)。
当向量数据库规模扩大或检索精度要求提高时,检索步骤可能引入显著延迟。
核心矛盾
检索延迟会拖慢整体流程,但若等待检索完成再启动LLM生成,会导致资源闲置。
解决方案:动态推测性流水线¶
核心思想:通过重叠(overlap)检索和生成步骤,利用检索过程的中间结果提前启动LLM生成,从而降低端到端延迟。
关键技术点¶
向量检索的动态性
向量检索会维护一个动态更新的Top-k候选文档队列(按相似度排序)。
关键发现:最终Top-k结果可能在检索中途就已确定(例如图11中,第2阶段已稳定为
[D1,D2],但检索持续到第4阶段)。
推测性生成机制
将检索过程分阶段(如4个阶段),每阶段结束后:
若候选文档变化 → 终止旧生成,启动新推测性生成。
若候选文档未变 → 继续当前生成。
最终匹配检查:
若最后一次推测生成与最终结果一致 → 直接返回结果。
否则 → LLM重新生成。
动态负载控制
问题:推测生成可能因错误结果浪费计算资源(高负载时性能下降)。
优化策略(定理5.1):
仅在LLM请求池未满且候选文档变化时启动推测生成。
若请求池非空且文档非最终结果 → 推迟推测以避免干扰。
实现逻辑(算法2):
检查请求池大小(
pool.size < max_prefill_bs)和文档变化(D_temp ≠ D)。满足条件时插入推测请求,否则继续检索。
技术优势¶
降低延迟:通过重叠检索与生成,减少等待时间。
资源效率:动态策略避免高负载时的无效计算。
兼容性:适配批处理(batching)和并行检索等复杂场景。
总结¶
本章主要介绍了 RAGCache 的两个关键优化机制:缓存感知的请求重排序(Cache-aware Reordering) 和 动态推测流水线(Dynamic Speculative Pipelining),旨在提升缓存命中率与系统整体性能。
本章提出的两个机制—— 缓存感知重排序 和 动态推测流水线 ——分别从缓存利用效率和计算延迟两个方面对 RAGCache 进行了优化:
缓存感知重排序 通过优化请求顺序,提升了缓存命中率,减少重复计算。
动态推测流水线通过提前启动 LLM 生成,重叠检索与生成阶段,在保证性能的同时,有效降低了端到端延迟。
这些机制共同提升了 RAGCache 的系统效率和资源利用率,为大规模 RAG 系统的部署提供了有力支持。
6. Implementation¶
系统实现¶
RAGCache 的原型由约 5000 行 C++ 和 Python 代码实现;
基于 vLLM v0.3.0 构建,这是一个先进的大语言模型服务系统;
扩展了 vLLM 的预填充(prefill)内核,支持多种注意力机制(如多头注意力和组查询注意力)的 前缀缓存。
向量搜索优化(Pipelined Vector Search)¶
基于 Faiss,实现 动态推测流水线,支持 IVF 和 HNSW 两种索引方式;
IVF(倒排文件索引)将向量空间划分为多个簇,搜索时首先找到最近的簇;
HNSW(分层导航小世界图)通过多层图结构加速相似性搜索;
为流水线处理,修改了搜索流程:
IVF:将搜索拆分为多个阶段,每次返回当前 top-k 结果;
HNSW:将搜索时间切片,每段时间返回部分 top-k 结果;
这些修改旨在支持动态推测流水线,同时保留最终搜索语义。
容错机制(Fault Tolerance)¶
GPU 容错:GPU 内存作为一级缓存,存储知识树结构中的上层节点 KV 缓存;
GPU 故障会导致整个知识树失效,因此:
在主机内存中备份最常访问的上层节点(如系统提示);
使用 超时重试机制,请求失败后可重新计算或恢复计算。
7. Evaluation¶
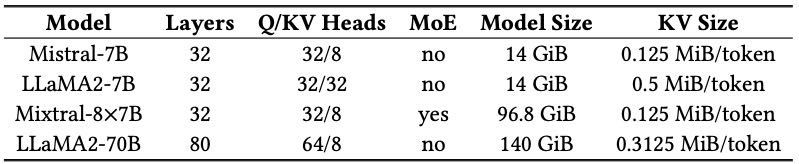
Table 1. Models used in the evaluation.
本章从四个方面对 RAGCache 进行了评估:(1)与最先进方法的总体性能对比;(2)在通用设置下的性能表现;(3)对 RAGCache 所用技术的消融研究;(4)RAGCache 的调度时间。
实验环境:
实验主要在 AWS EC2 g5.16xlarge 实例上运行,配备 64 个 vCPU、256 GiB 内存和 24 GiB 的 A10G GPU。
对于大模型部署,使用了两个 H800 GPU(各 80 GiB),通过 PCIe 5.0 连接,并使用 384 GiB 主机内存进行缓存。
检索与数据集:
使用 Wikipedia 作为知识库,采用 IVF 索引进行向量搜索。
评估工作负载包括 MMLU(多选知识问答)和 Natural Questions(自然语言问答),并模拟真实请求到达模式。
指标:
主要评估指标是平均时间到第一个 token(TTFT),同时测量系统吞吐量和缓存命中率。
基线:
与两个最先进系统 vLLM 和 SGLang 进行对比,两者分别采用 PagedAttention 和 LRU 缓存策略。
7.1 总体性能¶
在 MMLU 和 Natural Questions 数据集上,RAGCache 显著优于基线系统。平均 TTFT 比 vLLM 快 1.2–4 倍,比 SGLang 快 1.1–3.5 倍,吞吐量也提升 1.2–2.1 倍。RAGCache 通过 GPU 和主机内存的多级缓存机制,避免了频繁的 KV Cache 重新计算,从而提升性能。
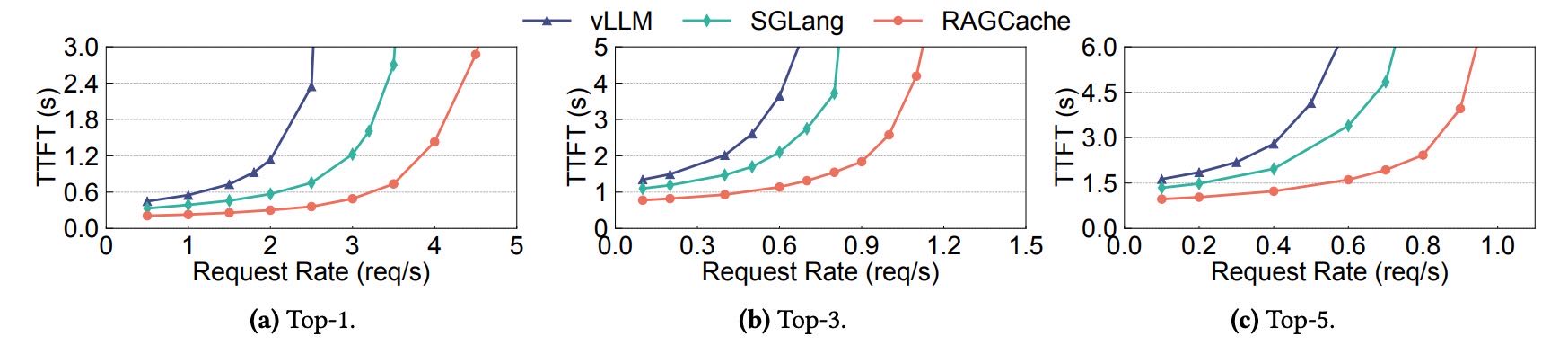
Figure 15. Performance with different top-𝑘 values.
7.2 通用设置下的案例研究¶
不同 top-k 值的影响:在不同 top-k 检索数量(1、3、5)下,RAGCache 仍保持优势,平均 TTFT 比 vLLM 快 1.7–3.1 倍,比 SGLang 快 1.2–2.5 倍。
大模型性能:在部署 Mixtral-8×7B 和 LLaMA2-70B 时,RAGCache 在低请求率下表现出色,平均 TTFT 降低 1.4–2.1 倍,且在高请求率下仍能保持 TTFT 在设定的 SLA 之内。
7.3 消融研究¶
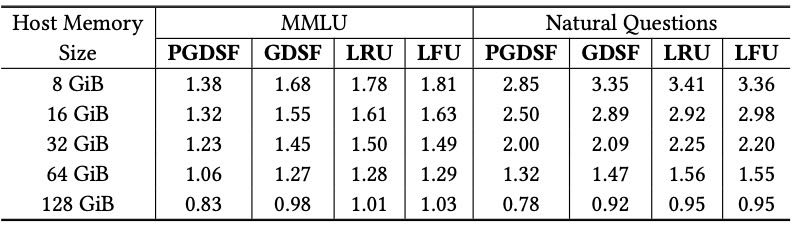
Table 2. Average TTFT (seconds) of different replacement policies with varying host memory size.
Prefix-aware GDSF 策略:RAGCache 采用的前缀感知 GDSF 策略在不同主机内存大小下,缓存命中率比 LRU 和 LFU 高 1.06–1.75 倍,平均 TTFT 降低 1.05–1.29 倍。
缓存感知重排序:在请求队列饱和情况下,RAGCache 通过缓存感知重排序,平均 TTFT 降低 1.2–2.1 倍。
动态推测流水线:动态推测流水线使 RAGCache 在不等待向量搜索完成时即可开始生成,平均 TTFT 降低 1.6 倍,非重叠检索时间减少 1.5–4.3 倍。
7.4 调度时间¶
RAGCache 的调度时间(包括知识树查找与更新、请求重排序和推测流水线决策)在所有请求率下都低于 1 毫秒,相较于秒级 TTFT,几乎可以忽略不计。
总结¶
RAGCache 通过多级缓存机制、高效替换策略和动态流水线,有效提升了 RAG 系统的性能。实验表明,其在不同模型规模、检索配置和负载下均优于当前最先进系统,展示了良好的通用性和扩展性。
8. Discussion¶
本章节讨论了在RAG(检索增强生成)系统中影响服务性能的关键因素及RAGCache的优化策略,主要包括以下两点内容:
输出令牌时间(TPOT)与首令牌时间(TTFT):在大语言模型(LLM)服务中,TPOT和TTFT是衡量性能的重要指标。RAG系统通过从外部知识库检索文档来增强输入,这显著增加了输入长度,进而延长了预填充阶段的TTFT。因此,TTFT成为RAG系统的首要关注点。RAGCache通过缓存最常检索文档的KV缓存,减少了TTFT,并通过加快预填充过程来降低TPOT,从而提升整体效率。
大top-k值的影响:当top-k值增大时,文档排列组合呈阶乘式增长,导致缓存命中率下降,重用性降低。为解决这一问题,RAGCache采用策略缓存较小top-k值的文档(如缓存top-3文档以应对top-5请求),在缓存命中率与缓存效率之间取得平衡。
10. Conclusion¶
本文总结了RAGCache的创新点和实验结果。RAGCache是一个为RAG系统设计的多级缓存系统,通过知识树结构和前缀感知的替换策略,减少了重复计算。同时,采用动态推测流水线机制,在RAG流程中重叠知识检索和大语言模型(LLM)推理,从而提升效率。实验结果显示,RAGCache在首字节响应时间(TTFT)和吞吐量方面分别比当前最先进的vLLM+Faiss方案提升了最高4倍和2.1倍。