2505.07062_Seed1.5-VL Technical Report¶
组织: Seed Team, ByteDance
引用: 32(2025-07-14)
Seed1.5-VL Technical Report¶
该技术报告《Seed1.5-VL Technical Report》(编号 [2505.07062])介绍了 Seed1.5-VL 模型的相关技术细节。Seed1.5-VL 是一个视觉-语言模型,旨在提升在多模态任务中的表现,如图像理解、图像描述生成、视觉问答等任务。
报告主要内容包括:
模型架构:介绍了 Seed1.5-VL 的整体架构,结合了视觉编码器和语言编码器,以实现对图像和文本的联合建模。通常这类模型会使用预训练的视觉模型(如 Vision Transformer)和语言模型(如 BERT 或 GPT 系列)作为基础模块。
训练方法:详细描述了模型的训练策略,可能包括使用大规模图文对数据进行预训练,并采用对比学习、掩码语言建模等方法来增强模型的多模态理解能力。
数据集:报告中可能会提到所使用的训练和评估数据集,例如 COCO、Visual Genome、Conceptual Captions 等常见多模态数据集。
实验结果:展示了 Seed1.5-VL 在多个多模态任务上的性能表现,如图像-文本检索、视觉问答(VQA)、图像描述生成等。通过与其他先进模型的对比,说明了 Seed1.5-VL 的优势和有效性。
应用场景:讨论了 Seed1.5-VL 在现实场景中的应用潜力,如智能助手、图像搜索引擎、自动图像标注等。
总结来说,这篇技术报告主要围绕 Seed1.5-VL 的模型结构、训练方式、实验评估及其在多模态任务中的应用,展示了其在视觉-语言联合建模方面的最新进展与成果。
Abstract¶
文章内容总结:
本文介绍了Seed1.5-VL,这是一个用于多模态理解和推理的视觉语言基础模型。该模型由一个5.32亿参数的视觉编码器和一个包含200亿活跃参数的Mixture-of-Experts(MoE)语言模型组成。尽管其架构相对紧凑,Seed1.5-VL在多个公共基准测试中表现出色,共计在60个公共基准中的38个上达到了最先进的性能。在以代理为中心的任务,如GUI控制和游戏玩法中,该模型也超越了多个领先的多模态系统(如OpenAI CUA和Claude 3.7)。此外,Seed1.5-VL在视觉和视频理解之外还表现出强大的推理能力,尤其适合处理视觉谜题等多模态推理挑战。
本文详细介绍了模型设计、数据构建和训练过程,并对模型的评估方法和实际表现进行了全面分析。模型不仅在公共基准测试中表现优异,还在内部测试中展示了强大的代理能力。同时,作者也探讨了模型的局限性,并提出未来改进的方向。最后,作者展示了多个定性示例,包括成功案例与失败案例,以说明模型的实际表现和潜在问题。
文章旨在通过分享Seed1.5-VL的构建经验,推动多模态模型领域的进一步研究。该模型现已在火山引擎平台上开放使用。
1 Introduction¶
该论文的 引言部分 主要介绍了**视觉-语言模型(VLMs)**的发展现状、挑战以及研究团队在开发 Seed1.5-VL 模型中的主要方法和成果。以下是对该章节内容的总结:
1. 引言总结¶
1.1 背景与重要性¶
视觉-语言模型(VLMs) 作为多模态人工智能的核心范式,能够在开放的虚拟和物理环境中实现感知、推理和交互。
VLMs 在多个领域取得了显著进展,包括多模态推理、图像编辑、GUI代理、自动驾驶、机器人等。
它们也在教育、医疗、聊天机器人和可穿戴设备等现实应用中发挥重要作用。
1.2 现有挑战¶
尽管有显著进展,VLMs 仍无法达到人类水平的泛化能力,尤其在以下任务中表现不足:
3D空间理解
物体计数
创造性视觉推理
交互式游戏
主要挑战包括:
高质量视觉-语言标注数据稀缺,尤其是涉及底层感知现象的概念。
多模态数据的异构性 带来了训练和推理阶段的数据管道设计、并行训练策略和评估协议的复杂性。
1.3 Seed1.5-VL 模型介绍¶
目标:开发一个高效、通用的视觉-语言基础模型,以应对上述挑战。
主要方法:
构建多样化数据合成管道,针对OCR、视觉定位、计数、视频理解、尾部知识等关键能力进行预训练。
引入视觉谜题和游戏用于后训练,增强模型的推理能力。
预训练数据规模巨大,涵盖图像、视频、文本和人机交互数据,以获取广泛视觉知识和核心视觉能力。
研究并报告了预训练阶段的模型扩展行为。
在后训练阶段,结合人类反馈和可验证奖励信号,进一步提升模型的通用推理能力。
1.4 训练效率与技术优化¶
针对视觉编码器与语言模型之间的不对称结构,提出:
混合并行架构,优化不对称性。
视觉token重分配策略,平衡GPU负载。
定制数据加载器,减少I/O瓶颈。
结合其他系统级优化手段(如内核融合、选择性激活检查点、卸载技术),提升整体训练吞吐量。
1.5 模型评估与应用场景¶
在60个公开和内部基准中评估Seed1.5-VL,涵盖了视觉推理、定位、计数、视频理解和计算机使用等任务。
表现突出:在38个基准中达到SOTA(当前最优)水平,包括:
视觉语言基准:21/34
视频基准:14/19
GUI代理任务:3/7
部署于内部聊天机器人系统,用于监控其在动态交互环境中的真实表现和分布外(OOD)性能。
1.6 模型效率与开放性¶
Seed1.5-VL 采用紧凑高效的架构:
视觉编码器:5.32亿参数
语言模型:200亿活跃参数
该设计降低了推理成本和计算需求,适合用于交互式应用。
通过火山引擎API平台开放使用,提升模型的可访问性和用户体验。
1.7 后续章节结构¶
第2章:模型架构与图像/视频编码方法
第3章:数据合成与预训练过程,包括模态模型扩展规律与指标预测
第4章:后训练阶段的数据与技术
第5章:训练基础设施创新
第6章:综合评估结果、模型能力展示、局限性分析与未来研究方向
总结一句话¶
本文系统介绍了视觉-语言模型 Seed1.5-VL 的开发背景、关键技术、训练优化与评估结果,旨在推动多模态人工智能模型在真实世界交互场景中的广泛应用与性能提升。
2 Architecture¶
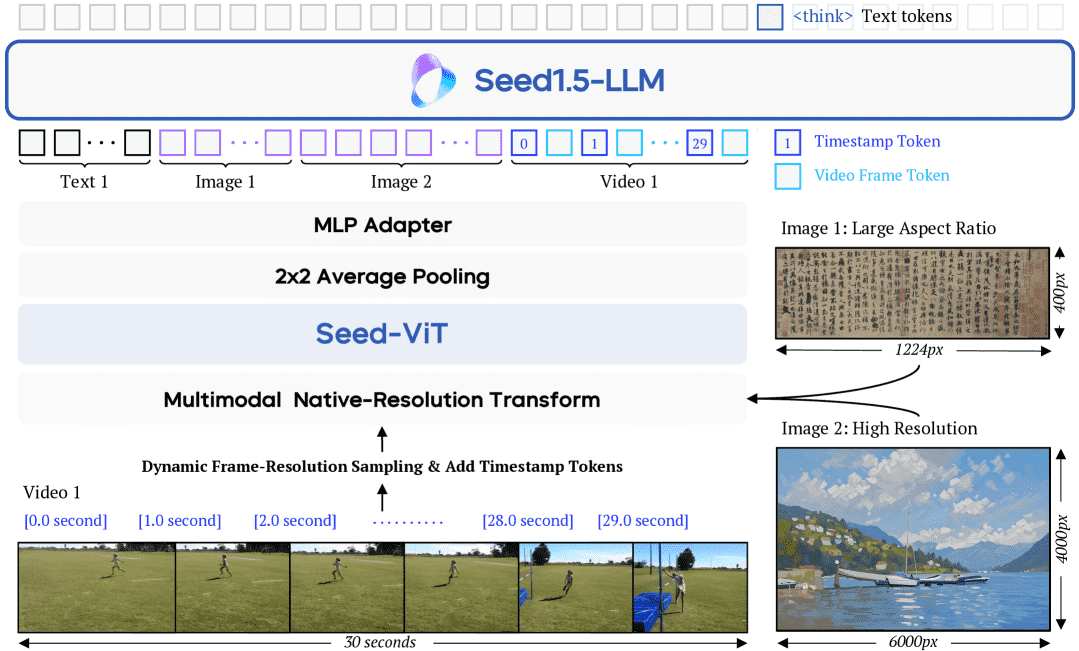
Figure 1:The architecture of Seed1.5-VL.
Seed1.5-VL 的架构包含三个主要组件:
SeedViT 视觉编码器:用于编码图像和视频,支持原生分辨率并采用二维 RoPE(2D RoPE)进行位置编码,增强对任意尺寸图像的适应能力。
MLP 适配器:将视觉特征映射到多模态 token,以便输入语言模型。
大型语言模型(LLM):处理融合后的多模态输入。
模型的核心创新点包括:
动态分辨率处理:支持任意尺寸图像,减少信息丢失。
视频处理策略:动态帧分辨率采样(Dynamic Frame-Resolution Sampling),在时间和空间维度上进行自适应采样。
时间戳标记:为每个视频帧添加时间戳 token,增强模型对时间信息的理解能力。
2.1 视觉编码器(SeedViT)¶
2.1.1 架构设计¶
SeedViT 是基于 ViT 的架构,包含 5320 万参数,具有强大的通用视觉感知能力。
采用 2D RoPE 替代传统 1D 位置嵌入,以适应任意图像尺寸。
输入图像首先通过双线性插值调整到 28×28 的倍数,然后分割为 14×14 的 patch,并通过线性嵌入层转换为 token。
使用注意力掩码防止不同图像间的错误注意力。
最后使用 2×2 平均池化降低特征维度,以提升计算效率并减少 token 数量。
2.1.2 预训练阶段¶
SeedViT 的预训练分为三个阶段:
Masked Image Modeling(MIM)+ 2D RoPE:使用 EVA02-CLIP-E 作为教师模型,学生模型在 MIM 任务中学习重构被遮蔽的图像块,提升视觉感知能力,尤其是在图表理解、OCR 等任务上。
原生分辨率对比学习(Native-Resolution Contrastive Learning):使用 MIM 预训练的模型和 SigLIP/SuperClass 损失函数,对齐图像和文本嵌入。
全模态预训练(Omni-modal Pre-training):基于 MiCo 框架,融合视频帧、音频、视觉文本和音频文本,构建统一的多模态表示。
预训练共使用了 70 亿 token 数据,涵盖无标签图像、图像-文本对以及视频-音频-文本三元组。
2.2 视频编码¶
Seed1.5-VL 在视频处理方面引入了 动态帧分辨率采样(Dynamic Frame-Resolution Sampling),该策略在时间和空间两个维度上进行自适应采样,以平衡语义丰富性和计算效率。
核心机制:¶
时间维度:根据任务需求动态调整帧率(默认 1 FPS,复杂任务可提升至 2 FPS 或 5 FPS)。
空间维度:每个视频最多使用 81,920 个 token,通过预设的分辨率层级(640, 512, 384, 256, 160, 128)进行自适应分配。
时间戳标记:每个帧前添加时间戳 token(如 [1.5 秒]),增强模型对时间信息的感知。
长视频处理机制:¶
若视频过长,超过预设 token 预算,模型会通过均匀采样减少帧数,以保证整体视频的信息完整性和处理效率。
总结¶
Seed1.5-VL 的架构设计强调动态分辨率支持和高效的视觉-语言融合能力。通过自定义的 SeedViT 编码器、MLP 适配器和动态视频采样策略,该模型能够灵活处理图像和视频输入,适应多种任务需求,同时保持计算效率和高精度。其预训练方法也充分考虑了多模态数据的利用,为模型提供了强大的多模态理解能力。
3 Pre-training¶
本章节主要介绍了 Seed1.5-VL 模型的 预训练阶段,重点包括 数据构建、训练方法 以及 模型扩展性分析。以下是各部分的总结:
3.1 预训练数据¶
预训练语料库包含 3万亿个高质量源token,覆盖多种视觉-文本对、OCR、视觉定位、3D理解、视频理解、STEM教育、GUI等任务,旨在提升模型多模态理解能力。
3.1.1 通用图像-文本对与知识数据¶
数据来源:互联网上的大规模图像-文本对,包括图像标题、Alt文本等,存在噪音和类别不平衡问题。
过滤策略:采用图像与文本相似度评分、去重、尺寸与文本长度限制、URL过滤等方法提升数据质量。
长尾分布实验:通过在生物分类任务上测试不同采样策略,证明限制常见类别的样本数可提升模型对罕见类别的识别能力。
重平衡策略:利用预训练模型自动标注语义域和命名实体,识别低频类别并进行数据增强,提升模型对视觉知识的覆盖广度。
3.1.2 光学字符识别(OCR)¶
构建了 10亿样本 的OCR训练集,涵盖文档、场景文本、表格、图表和流程图。
使用合成数据工具(如SynthDog、LaTeX)生成多样文本图像,涵盖艺术字体、手写体、非拉丁字符等。
图表数据:结合开源数据与LLM生成的图表(如ECharts、Matplotlib),构建超过1亿个图表样本。
表格数据:从HTML、LaTeX、Markdown等格式提取表格文本,生成5000万表格图像。
视觉问答(VQA):基于OCR、图表、表格生成QA对,提升模型对图像中文本的理解能力。
3.1.3 视觉定位与计数¶
定位数据:使用Objects365、OpenImages、RefCOCO等数据集,采用自动标注流程提升样本多样性。
点数据:通过PixMo-Points、Molmo、CountGD等工具生成1.7亿点标注样本。
计数数据:基于定位和点数据生成800万计数样本,涵盖密集场景。
3.1.4 3D空间理解¶
构建三种3D任务数据:相对深度排序、绝对深度估计、3D定位。
使用DepthAnything V2生成3.2亿token的深度排序数据;从公开数据集获取绝对深度估计数据(1800万样本,280亿token)。
3D定位数据通过公开数据集构建,生成77万QA对(13亿token)。
3.1.5 视频理解¶
数据分为三类:通用视频理解、时间定位、视频流理解。
使用视频描述、问答、动作识别等任务数据增强模型的时序理解能力。
视频流数据:包含交错式字幕/问答、主动推理、实时评论三类数据,用于模拟实时视频理解和动态响应。
3.1.6 STEM教育¶
构建包含 数学、物理、化学、生物 等领域的教育数据,涵盖图像理解与问题求解。
图像理解数据:包括320万教育定位样本、1000万表格、450万化学图、150万坐标图,以及K12标注数据。
问题求解数据:包括1亿K12级练习及数百万中文/英文图像相关问题,通过人工标注与自动化生成结合构建。
3.1.7 图形用户界面(GUI)¶
使用UI-TARS数据集,涵盖网页、App和桌面环境。
每个截图配有结构化元数据(元素类型、位置、深度),用于训练模型识别UI元素、理解布局、检测变化。
通过多步骤任务轨迹(观察、思考、操作)提升模型对GUI的推理能力,支持逐步规划和修正操作。
总结¶
本章详细介绍了 Seed1.5-VL 预训练阶段的 数据构建策略,涵盖视觉-文本对、OCR、视觉定位、3D理解、视频理解、STEM教育、GUI等多个维度。通过大规模、高质量、多样化的数据,配合自动标注、数据增强、重平衡等技术手段,构建了全面的多模态知识库,为模型在复杂任务中提供坚实的数据基础。
3.2 Training Recipe¶
3.2 训练策略总结¶
本节详细介绍了 Seed1.5-VL 模型在预训练阶段的三个阶段的训练策略和超参数设置。训练流程分为以下三个阶段,每个阶段的训练预算、序列长度、可训练组件、批量大小、学习率等参数均不同:
阶段 |
预算(token) |
序列长度 |
可训练组件 |
批量大小(token) |
学习率预热步数 |
最大学习率 |
最小学习率 |
|---|---|---|---|---|---|---|---|
阶段0 |
16B |
32,768 |
MLP适配器 |
8.4M |
100 |
2.52×10⁻⁴ |
4.50×10⁻⁵ |
阶段1 |
3T |
32,768 |
所有组件 |
71M |
500 |
5.22×10⁻⁵ |
5.22×10⁻⁶ |
阶段2 |
240B |
131,072 |
所有组件 |
71M |
0 |
5.22×10⁻⁶ |
5.22×10⁻⁶ |
各阶段训练目标:¶
阶段0:仅训练 MLP 适配器,视觉编码器和语言模型固定。此阶段用于对齐视觉和语言模块,提升模型的性能,实验表明省略该阶段会导致性能下降。
阶段1:所有参数可训练,主要目标是积累知识并增强模型的视觉定位和 OCR 能力。使用包含图像-文本对、OCR 数据等的多模态语料(3T tokens)。通过添加少量纯文本数据(约5%)来保持语言能力,添加少量指令数据以提升评估可靠性。
阶段2:增加训练数据的多样性,包括视频理解、编程、三维空间理解等新领域,并将序列长度提升至 131,072 以支持视频和复杂推理任务。所有参数继续训练,学习率从阶段1的结束值延续,不进行预热。
优化器和学习率设置:¶
使用 AdamW 优化器,参数为 β1=0.9,β2=0.95,权重衰减为 0.1。
阶段0和阶段1采用完整的余弦衰减学习率。
阶段2不使用学习率预热,并从阶段1加载优化器状态,学习率保持恒定。
作者也尝试了与现有方法类似的训练策略(阶段0同时训练 MLP 适配器和视觉编码器),但实验表明当前策略效果更好,认为原因可能是冻结的语言模型限制了视觉模块的学习能力。
3.3 缩放规律总结¶
这一节探讨了 Seed1.5-VL 在阶段1预训练过程中的规模效应(Scaling Laws),即训练损失与训练数据量之间的关系。模型由预训练组件(视觉编码器、MLP适配器、语言模型)构成,因此与传统的从随机初始化开始训练的 LLM 不同。
损失与训练数据量的幂律关系:¶
基于已有 LLM 缩放规律的研究,训练损失 \( \hat{L} \) 可建模为:
其中 \( N \) 为模型参数,\( D \) 为训练数据量。由于在阶段1中参数数量固定,模型简化为:
通过对数变换,可以得到:
实验结果:¶
OCR 和定位任务的损失:实验表明,OCR 和视觉定位类子数据集的训练损失与数据量呈幂律关系。例如:
OCR 损失:\( \log(\hat{L}_{\text{ocr}}) \approx -0.1817 \log(D) - 0.7011 \)
定位损失:\( \log(\hat{L}_{\text{grounding}}) \approx -0.0785 \log(D) - 0.0745 \)
损失与下游任务性能的关系:训练损失与下游任务的性能(如准确率)之间存在近似的对数线性关系。例如:
ChartQA 准确率:\( \text{Acc}_{\text{ChartQA}} \approx -0.0968 \log(\text{loss}_{\text{ocr}}) + 0.7139 \)
InfographicVQA 准确率:\( \text{Acc}_{\text{InfoVQA}} \approx -0.1488 \log(\text{loss}_{\text{ocr}}) + 0.5319 \)
这种关系在一定性能范围内成立,因为评估指标(如准确率)存在上下限(通常在 0 到 1 之间)。
意义与应用:¶
通过分析损失与训练数据量的关系,可以预测模型在特定下游任务上的性能。
这种缩放分析有助于优化训练策略、调整数据分布,并为模型训练的早期阶段提供性能预估。
综上,3.2 节提出了 Seed1.5-VL 的三阶段训练策略并详细描述了各阶段的设置和目标,3.3 节则通过实验证明模型损失与训练数据量之间存在可建模的幂律关系,并进一步分析了训练损失与下游任务性能之间的联系,为模型训练的优化和预测提供了理论支持。
4 Post-training¶
本节主要探讨了 Seed1.5-VL 模型的后训练(Post-training)过程,旨在通过监督微调(Supervised Fine-tuning, SFT)和强化学习(Reinforcement Learning, RL)相结合的方式,提升模型在视觉语言任务中的指令遵循能力和复杂推理能力。以下是各部分的总结:
4. Post-training 总览¶
目标:通过监督微调和强化学习,提升 Seed1.5-VL 模型在视觉语言任务中的表现,特别是在处理复杂、多步骤推理任务时的能力。
方法:采用迭代更新的方式,结合拒绝采样(rejection sampling)和在线强化学习(online RL),并在训练中使用高质量的“困难提示”(hard prompts)数据集。
关键点:
在强化学习中,仅对最终输出结果进行监督,而非对中间的推理过程进行监督。
通过数据流水线持续收集和筛选高难度和多样化的数据用于训练。
4.1 监督微调(SFT)¶
目的:为后续的强化学习打下基础,使模型具备基本的指令理解和推理能力。
数据组成:
通用指令数据:训练模型对复杂指令做出简洁准确的响应。
长链式推理(LongCoT)数据:通过提示工程和拒绝采样生成详细、逐步推理的响应。
数据构建过程:
初期通过众包采集约13,000个高质量指令-响应对。
后续从开放源数据中通过聚类、模型生成、人工筛选等方式,最终保留约30,000个高质量样本。
使用“自我指令生成”(self-instruct)方法合成复杂指令,并通过模型自生成+人工校验的方式提升数据质量。
训练设置:
使用约50,000个样本的SFT数据。
使用 AdamW 优化器,设置 β1=0.9、β2=0.95、权重衰减 0.1。
训练时冻结视觉编码器参数,仅训练其他模块。
4.2 人类反馈的强化学习(RLHF)¶
目标:通过人类反馈提升模型在多模态任务中的表现,特别是在生成高质量、符合人类偏好的输出方面。
数据收集:
人工标注:采用5级评分系统对多个候选响应进行排序,注重多样性、正确性和格式一致性。
合成数据:通过模型生成多个响应,并利用视觉语言模型评估其正确性,构建明确的偏好排序。
奖励模型(Reward Model)构建:
使用经过指令调优的视觉语言模型,通过比较两个响应的优劣直接输出偏好标记。
为避免模型对响应顺序敏感,对响应的两个顺序进行概率计算。
采用迭代学习策略,确保奖励模型的稳定性与泛化性。
强化学习训练:
使用 PPO 算法进行在线强化学习。
使用奖励模型评分作为奖励信号,同时引入参考响应(如 SFT 模型的最佳答案)。
数据经过多阶段筛选,确保任务难度适中,奖励模型具有区分能力。
4.3 可验证奖励的强化学习(RLVR)¶
目标:在特定任务中(如数学、编程、图像识别等)使用规则或外部验证器直接评估模型输出的正确性,从而避免依赖主观的人类偏好。
应用场景:
视觉STEM任务:收集大量带有图像的数学题,通过拒绝采样筛选出中等难度问题,要求模型输出 LaTeX 格式答案,并使用 sympy 进行验证。
视觉感知与推理任务:
定位任务:通过输出边界框和中心点坐标,计算与真实框的IoU作为奖励。
视觉指令跟随:使用正则表达式验证模型是否正确执行指令。
视觉谜题与游戏:生成20,000个视觉谜题,要求模型输出答案并定位差异区域。通过字符串匹配验证答案。
“找不同”游戏:模型需识别图像差异并输出边界框,用于训练直接与图像交互的能力。
总结¶
Seed1.5-VL 的后训练过程通过监督微调和强化学习的结合,显著提升了模型在视觉语言任务中的表现。训练过程中,通过高质量数据构建、多阶段数据筛选、人类反馈与可验证奖励相结合的方式,确保模型能够生成准确、多样、符合人类偏好的输出。最终,模型不仅具备快速简洁的响应能力,还能处理复杂的长链式推理任务。
4.4 Hybrid Reinforcement Learning¶
总结:4.4 混合强化学习与 4.5 拒绝采样微调的迭代更新¶
本章节介绍了Seed1.5-VL模型在训练过程中采用的混合强化学习(Hybrid Reinforcement Learning)框架及其后续的迭代更新方法。
4.4 混合强化学习(Hybrid Reinforcement Learning)¶
混合框架:基于PPO算法的变体,结合了生成式奖励模型(RM)和验证器(verifiers),并引入了近期强化学习研究中的多项改进技术。
RLHF与RLVR结合:训练过程融合了基于人类反馈的强化学习(RLHF)和基于验证的强化学习(RLVR)。
格式奖励机制:要求模型输出遵循“thought”+“solution”的结构,若不符合则施加零奖励或惩罚,以规范输出格式。
混合奖励机制:根据任务类型将训练提示分为通用型和可验证型,分别由RM和验证器进行奖励。混合使用可提升模型的泛化与验证能力。
共享批评者(Critic):使用单一的Critic模型评估两种奖励来源(RM和验证器),因两者奖励范围一致([0,1]),便于统一建模。
KL系数设置:对通用提示使用较小的KL系数(1e-5),防止奖励黑客攻击;对可验证提示不使用KL系数,提高探索能力。
训练配置:上下文长度8192,最大输出长度16384,每轮采样4096个roll-outs,每轮训练8次梯度更新,使用512的小批量。RL阶段仅使用LongCoT响应,但普通响应也显著改善。
4.5 通过拒绝采样微调的迭代更新(Iterative Update by Rejection Sampling Fine-tuning)¶
冷启动策略:初始使用少量低质量的LongCoT样本进行SFT训练,随后通过强化学习提升模型表现。
拒绝采样微调:每次长链推理(LongCoT RL)模型迭代后,收集其在新挑战性提示上的正确响应,并将其加入下一轮SFT训练数据中,提升冷启动质量。
验证机制:使用与强化学习阶段相同的验证器来判定响应的正确性,并结合人工设计的正则表达式过滤器去除不良模式(如无限重复、过度思考等)。
迭代效果:当前版本Seed1.5-VL已进行四轮迭代训练,模型性能持续提升,未来有望进一步优化。
总体评价¶
该章节详细描述了Seed1.5-VL模型在强化学习训练与迭代优化方面的创新设计,融合了格式控制、奖励机制优化、共享价值模型、探索与约束管理等多个方面。此外,通过拒绝采样的迭代训练策略,持续提升模型质量,为模型在长链推理任务上的表现提供了坚实基础。
5 Training Infrastructure¶
本章主要介绍了Seed1.5-VL模型的训练基础设施,涵盖**大规模预训练(Pre-training)和后训练(Post-training)**两个阶段,重点在于提升训练效率、稳定性与可扩展性。
5.1 大规模预训练¶
在预训练阶段,作者提出了一系列优化技术,包括混合并行(Hybrid Parallelism)、负载均衡(Workload Balancing)、并行感知的数据加载(Parallelism-Aware Data Loading)和容错机制(Fault Tolerance),以应对视觉-语言模型(VLM)训练中遇到的挑战。
混合并行(Hybrid Parallelism):由于视觉编码器和语言模型的异构性,传统并行策略难以应用。为此,作者采用混合并行策略,视觉编码器和适配器使用ZeRO数据并行,而语言模型则采用包含专家并行、交织管道并行、ZeRO-1数据并行和上下文并行的四维并行方式。该方法简单高效,显著提升了训练速度。
负载均衡(Workload Balancing):为了解决图像数量不均衡带来的GPU负载不均问题,作者提出一种基于计算强度的贪心算法,将计算密集的图像分配给负载较低的GPU,并通过分组平衡策略减少数据重分布开销。
并行感知的数据加载(Parallelism-Aware Data Loading):为了减少多模态数据的I/O开销,作者设计了智能数据加载器。例如,只在一个GPU上加载数据并广播给其他GPU,减少重复读取。同时,通过移除无关图像和预取机制,降低PCIe通信和数据传输开销。
容错机制(Fault Tolerance):使用MegaScale框架实现训练过程中的容错,故障发生时从最近成功检查点恢复训练。同时结合ByteCheckpoint实现高效的检查点保存与恢复。
本阶段总共消耗了130万GPU小时的计算资源。
5.2 后训练框架¶
在后训练阶段,作者结合人类反馈(RLHF)和验证器反馈(RLVF),使用基于verl的强化学习框架对模型进行微调。
系统架构:采用单一控制器管理角色间的数据流,多个控制器管理角色内的数据和模型并行。验证器以进程形式部署,实现故障隔离,简化了实验部署和开发。
训练策略:沿用预训练阶段的训练系统与优化技术,使用3D并行进行Actor和Critic模型的更新,vLLM用于生成Rollout。奖励模型训练同样使用相同框架,共计消耗24,000 GPU小时。
并行方式:Actor和Critic采用3D并行(专家、管道、数据并行),Rollout生成和奖励模型推理采用张量并行。
后训练阶段总消耗60,000 GPU小时,并借助ByteCheckpoint实现高效检查点管理。
总结¶
本章全面介绍了Seed1.5-VL在训练阶段的技术实现,从预训练到后训练均采用了多种并行优化和工程策略,以提升训练效率和系统稳定性。通过混合并行、负载均衡、并行感知数据加载和容错机制,解决了VLM训练中的典型挑战。后训练阶段则结合强化学习和分布式系统设计,确保模型在真实场景中具备更好的性能与鲁棒性。
6 Evaluation¶
这篇论文的第六章“评估”部分主要展示了Seed1.5-VL模型在多个基准测试中的性能表现,并与当前最先进的模型进行了对比。以下是各部分的总结:
6.1 公开基准测试¶
6.1.1 视觉编码器的零样本分类能力¶
在多个ImageNet子集(如ImageNet-1K、ImageNet-A、ObjectNet等)上评估了Seed-ViT模型的零样本分类性能。结果显示,Seed-ViT(参数量为532M)在这些数据集上的平均准确率达到82.5%,与参数量为6B的InternVL-C-6B模型表现相当,甚至在部分数据集(如ObjectNet和ImageNet-A)上优于参数量更大的EVA-CLIP-18B模型(17.5B参数)。这表明Seed-ViT在真实世界图像变化下的鲁棒性较强。
6.1.2 视觉任务评估¶
Seed1.5-VL在多个视觉语言任务中与当前最先进的模型(如Gemini 2.5 Pro、OpenAI o1、Claude 3.7 Sonnet、Qwen 2.5-VL 72B等)进行比较,涵盖多模态推理、一般视觉问答、文档理解、定位与计数、三维空间理解等任务。总体而言,Seed1.5-VL在多个任务中表现优异,特别是在以下方面:
多模态推理:在MathVista、VLM are Blind、VisuLogic等任务中达到或接近SOTA水平。
一般视觉问答:在RealWorldQA、MMBench-en/cn、MMStar等任务中表现突出。
文档与图表理解:在TextVQA、InfographicVQA、DocVQA等任务中达到或超越当前最佳。
定位与计数:在BLINK、LVIS-MG、CountBench等任务中表现领先,尤其在LVIS-MG上优于传统目标检测器。
三维空间理解:在DA-2K、NYU-Depth V2等深度估计任务中表现优异,甚至显著优于其他VLM模型。
Seed1.5-VL提供了“思考”模式(使用长链推理)和“非思考”模式两种评估方式,其中“思考”模式在大多数任务中表现更优。
6.2 智能代理任务评估¶
该部分评估了模型在智能代理相关任务中的表现,但未提供详细数据,主要集中在后续部分(6.3)。
6.3 内部基准测试与行业领先模型对比¶
该部分详细介绍了团队设计的内部基准测试,并将Seed1.5-VL与当前行业领先的模型(如Gemini、Claude、Qwen等)进行了深入对比。测试涵盖游戏代理、GUI代理、GUI定位等多个应用场景。这部分内容未详细展开,但强调了Seed1.5-VL在复杂交互任务中的能力和优势。
6.4 模型限制¶
该部分讨论了模型的局限性,特别是在分布外泛化(Out-of-distribution Generalization)方面的表现。尽管在多数基准上表现优异,但在面对某些极端或未见过的场景时,模型的性能可能会下降。此外,模型在某些任务中(如3D目标检测)的“思考”模式反而导致性能下降,表明推理链的设计仍需优化。
总结¶
Seed1.5-VL在多个视觉语言任务上表现出色,尤其是在定位、计数、三维空间理解、文档与图表理解等任务上达到或接近SOTA水平。与参数量更大的模型相比,Seed1.5-VL在性能上具有显著优势,证明其在模型效率与泛化能力方面具备竞争力。不过,模型在某些复杂推理任务和分布外场景上的表现仍有提升空间。
6.1.3 Video Task Evaluation¶
本章节总结了 Seed1.5-VL 在多个任务上的评估表现,包括视频理解、多模态代理(GUI交互与游戏任务)和内部基准测试的设计与结果。
6.1.3 视频任务评估¶
Seed1.5-VL 在视频理解任务中表现突出,评估包括五个方面:短视频理解、长视频理解、流媒体视频处理、视频推理与视频定位任务。通过对比当前最先进的模型,Seed1.5-VL 在多个基准上达到 SOTA 性能。例如:
短视频理解:在 MotionBench、TVBench、Dream-1K 和 TempCompass 等任务中表现优异。
长视频理解:支持 128K token 的上下文长度(最多 640 帧),未来计划进一步扩展。
流媒体视频理解:在 OVBench、OVOBench、StreamBench 和 StreamingBench(主动任务)中达到 SOTA。
视频推理:在 Video-MMMU 和 MMVU 上分别得分为 81.4 和 70.1,略低于 Gemini 2.5 Pro。
视频定位任务:在 Charades-STA 和 TACoS 上表现最佳,显示出精准的时序定位能力。
6.2 多模态代理¶
在 GUI 交互和游戏任务中,Seed1.5-VL 展示了强大的视觉理解、推理与精准操作能力。
GUI 接地任务¶
Seed1.5-VL 在 ScreenSpot Pro 和 ScreenSpot v2 上分别达到 60.9 和 95.2 的高分,显著优于 OpenAI CUA 和 Claude 3.7 Sonnet。
GUI 代理任务¶
在多个 GUI 任务(如 OSWorld、Windows Agent Arena、WebVoyager、Online-Mind2Web 和 Android World)中,Seed1.5-VL 表现优于当前主流模型,展示了其在桌面、浏览器和移动端的广泛适应能力。
游戏代理任务¶
在 14 个在线游戏中(如 2048、Hex-Frvr、Free-The-Key 等),Seed1.5-VL 在得分和通关等级上均优于其他模型,例如在 2048 得分 870.6,高于 OpenAI CUA 的 611.2 和 Claude 3.7 Sonnet 的 800.0。游戏任务作为多模态模型的严格测试,对模型的推理能力、长期策略规划和适应性提出了高要求,Seed1.5-VL 在这些方面表现出色。
6.3 内部基准测试¶
除了公开基准,研究者还构建了内部基准,以更全面评估模型能力。其设计原则包括:
核心能力优先:关注感知与推理等基础能力,而非表面对齐。
全面性:涵盖原子性任务(如图像细粒度识别)和集成性任务(如复杂多模态应用)。
评估方法先进:使用大型语言模型(LLM)作为评估者,提升了评估准确性。
防止过拟合:通过去重与数据刷新防止模型对基准数据的过拟合。
任务与输入多样性:图像来源多样,任务类型丰富,包含超过 100 个任务和 12,000 个样本,并特别设计了 OOD(分布外)任务,测试模型的泛化能力。
总结¶
Seed1.5-VL 在视频理解、GUI 交互与游戏任务等多个方面表现优异,达到或超越当前 SOTA 模型。通过内部基准测试的设计,进一步验证了其在核心能力与泛化能力上的优势,为未来多模态代理系统的开发提供了坚实基础。
6.3.2 Comparison with State-of-the-arts¶
本节内容主要围绕Seed1.5-VL模型与当前最先进的多模态大模型在多个维度上的比较、模型的泛化能力以及其存在的局限性进行分析总结,具体内容如下:
1. 与最先进模型的比较¶
在内部基准测试中,Seed1.5-VL模型在多个子任务上表现优异,整体得分为61.6,仅次于Gemini 2.5 Pro(61.6),排名第二。其主要优势体现在以下几个方面:
OOD(Out-of-Distribution)能力:与Gemini 2.5 Pro、OpenAI o1等模型表现相当,具备较强的泛化能力。
Agent能力:在任务执行和原子指令遵循方面表现突出。
STEM与文档理解能力:在STEM任务、文档和图表理解方面表现良好,尤其在图表理解上接近领先模型。
OCR与识别任务:在视觉识别和OCR任务中表现稳健,得分较高。
然而,模型在以下几个方面仍存在差距:
知识、推理、代码任务:相比Gemini 2.5 Pro等模型,存在一定的性能差距。
字幕生成与反事实推理:表现较弱,说明模型在语言生成和逻辑推理方面需要进一步优化。
模型当前约使用200亿参数,由于训练损失尚未饱和(在3万亿token后仍无饱和迹象),作者认为通过模型规模扩展和增加训练算力,可以预期性能进一步提升。
此外,模型在Llama 4 Maverick(170亿参数,采用MoE架构)的对比中表现更优,显示出更强的性能。
2. 泛化能力测试¶
Seed1.5-VL在非分布样本(OOD)任务中表现出色,与领先模型相当。通过内部Chatbot平台,展示了其在复杂现实场景中整合多种能力的能力,例如:
拼图解题(Rebus Puzzle):结合OCR、知识检索和推理能力,成功识别并解答视觉文字谜题。
代码修正:从图像中提取代码并进行纠错,体现了OCR和编程能力的结合。
生成新格式图表的代码:通过“逆向图形”生成Mermaid代码,满足特定空间约束,展示模型对图表结构的理解能力。
模型还通过引入搜索工具,展示了与用户偏好的对齐能力,其有用性得分为62.6%,略高于Gemini 2.5 Pro的57.4%。
3. 模型的局限性¶
尽管表现良好,Seed1.5-VL仍存在以下几点主要限制:
(1) 视觉感知的精细度不足¶
在复杂视觉任务中,如对象计数(尤其在不规则排列、颜色相似或部分遮挡情况下)和图像差异识别方面表现不佳。
难以准确理解空间关系,容易在不同视角下出现定位错误或内容识别错误。
(2) 高级推理能力有限¶
在组合搜索任务(如Klotski拼图、迷宫导航)中表现不佳,说明逻辑推理和策略生成能力不足。
对3D空间推理任务(如3D物体投影或操作)存在显著困难,这是大多数VLM的普遍问题。
时间推理和多图像推理能力较弱,难以在连续动作或多图逻辑任务中保持一致性。
(3) 模型幻觉问题¶
在视觉任务中,模型有时会优先依赖语言模型的知识先验,导致视觉信息被忽略或错误解释。
4. 未来方向¶
模型扩展:通过增加参数规模和训练数据量,提升模型整体性能。
工具集成:引入代码执行、搜索等外部工具,以增强模型在复杂推理任务中的表现。
图像生成能力:结合图像生成,辅助视觉Chain-of-Thought机制,提升推理能力。
3D与时间推理能力增强:探索新的架构或训练方法,以解决当前VLM在这些领域的能力瓶颈。
总结¶
Seed1.5-VL在多模态任务中表现出较强的综合能力,尤其在泛化和特定任务(如OCR、图表理解)方面接近或超越当前最先进的模型。然而,其在复杂推理、空间和时间感知、以及幻觉抑制方面仍面临挑战。未来的研究方向将聚焦于模型扩展、工具整合以及新推理机制的探索。
7 Conclusion and Next Steps¶
本文的第七章“结论与下一步工作”总结了研究的主要成果与未来研究方向。以下是对该章节内容的总结:
模型表现:研究团队提出了 Seed1.5-VL,这是一种多模态基础模型,在推理、OCR、图表理解、视觉定位、3D空间理解及视频理解等方面表现出色。尽管模型大小相对适中,但它在60个公共基准中的38个上达到了最先进的水平,尤其在 MMMU 基准上得分为77.9,这是衡量多模态推理能力的重要指标。
综合能力与泛化性:Seed1.5-VL 在训练数据之外的任务中也展现出强大的泛化能力,例如解决复杂的视觉推理任务(如Rebus谜题)、解释和纠正白板上的手写代码、以及作为计算机交互和游戏的智能体。这些能力表明其具备潜在的“涌现”能力,值得进一步研究。
未来方向:研究指出模型性能尚未出现饱和现象,因此增加模型参数和训练计算资源是值得尝试的短期方向。同时,识别出当前VLMs的局限性,包括稳健的3D空间推理、幻觉抑制以及复杂组合搜索等,这些将成为持续研究的重点。此外,团队正在探索将现有模型能力与图像生成结合(如视觉链式思维),并引入稳健的工具使用机制。
贡献与基础:文中强调了本研究建立在AI社区广泛的基础工作之上,包括Transformer和Vision Transformer等架构。为了促进后续研究,作者详细公开了模型架构、数据合成流程、训练方法、训练框架创新以及内部评估设计等关键信息。
8 Contributions and Acknowledgments¶
本章节主要总结了论文的贡献者和致谢部分的内容:
作者署名方式:论文作者按姓名字母顺序排列,部分名字为公司内部使用的别名。
核心贡献者(Core Contributors):列出了对论文有核心贡献的47位研究人员,包括 Dong Gu、Faming Wu 等人,他们在 Seed1.5-VL 的开发、优化和评估中发挥了关键作用。
其他贡献者(Contributors):列举了136位对论文做出贡献的研究人员,尽管他们的参与程度可能不如核心贡献者,但也为项目的推进提供了支持。
致谢(Acknowledgments):作者对多位同事表示感谢,包括 Allie Guo、Bingyi Kang、Borui Wan 等人,感谢他们在论文撰写期间提供的宝贵意见、深入讨论以及在 Seed1.5-VL 的开发、评估、缺陷分析和未来研究方向探索方面的重要支持。
整体来看,本章节强调了论文背后的团队协作和众多研究人员的共同努力,体现了学术研究中合作与支持的重要性。
9 Qualitative examples¶
本章节展示了 Seed1.5-VL 模型在多种视觉推理任务中的表现,通过具体的定性示例,展示了模型在图像理解、逻辑推理、语言生成和多模态处理等方面的强大能力。主要内容总结如下:
视觉推理能力:
模型能够识别图像中从点 C 到点 A 的单色路径数量,展示了其在连续路径判断和颜色识别上的能力。
在地理定位任务中,模型通过分析建筑、植被、交通标志等细节,判断图片可能的地理位置,包括大陆、国家、城市和经纬度。
解谜类任务:
模型能够解决 Rebus 谜题(文字图谜),通过图像中的文字和图形线索,生成合理的语义推理,如“break + fast = breakfast”或“pot + 8 O’s = potato”。
在表情符号猜电影任务中,模型能够将表情符号与电影情节关联,正确识别出如《荒岛余生》、《洛奇》、《独立日》等电影名称。
文字游戏与语言推理:
在第一个文字游戏中,模型通过字母重组,识别出八个隐藏的国家首都名字,如“LONDON”和“BEIJING”。
在第二个文字游戏中,模型通过逻辑推理,利用排除法判断出五字母词“CHEWY”,满足所有猜词条件。
模型能力的多样性:
除了静态图像,模型还能处理视频时间定位任务,如根据用户查询在视频中定位特定事件。
展示了模型在 OCR(光学字符识别)与文档理解中的能力,包括多语言 OCR 解析。
模型还具备从单张图像中进行 3D 空间理解的能力,如根据深度排序图像中的物体。
模型的局限与失败案例:
模型在一些复杂任务中仍存在局限,例如空间想象、幻觉(hallucination)以及组合搜索的不稳定性。这些失败案例也帮助揭示了当前视觉语言模型(VLM)的不足之处。
总体而言,这一章节通过丰富的视觉与语言结合任务,展示了 Seed1.5-VL 在多模态推理方面的强大能力,同时也指出了其在处理复杂逻辑和空间想象时的局限性。
9.7 Visual Reasoning_ Visual Pattern Recognition¶
以下是文档章节内容总结:
9.7 Visual Reasoning: Visual Pattern Recognition¶
本节展示了模型在视觉推理方面的表现,通过识别图像中的模式规律来预测缺失的图案或元素。模型通过观察每行中前两个图形的组合规律,推导出第三个图形的形状。
例1:第三列是前两列的“并集”,即元素数量相加。
例2:通过结合两种图形(如箭头和方格)的结构特征,推断出第三种图形。
模型能够准确识别这些视觉规律,并选择正确的候选图案作为答案。
9.8 Visual Puzzles: Find the Differences¶
本节展示了模型在“找不同”类视觉任务中的能力。给定一对图像,模型能识别并标记出它们之间的差异区域,并以<bbox>格式输出每个差异的坐标范围。
示例包括:人物发型、帽子、画板和调色板颜色等不同之处。
模型展现了良好的视觉细节对比能力。
9.9 Geometry¶
本节展示了模型在几何问题求解中的能力,特别是对无限级数、相似三角形和面积计算的处理。
示例1:通过几何级数求和得出蓝色区域占比为 \( \frac{2}{3} \)。
示例2:利用相似三角形和已知面积,推导出矩形的面积为6。
模型能够进行多步逻辑推理,准确解决复杂的几何问题。
9.10 Counting in a complex scene¶
本节展示了模型在复杂场景中检测和计数物体的能力。给定一张包含大量樱桃番茄的图像,模型通过识别每个番茄的位置并计数,得出图像中共有27个樱桃番茄。
使用
<point>格式标记每个番茄的坐标位置。
模型能够识别密集排列的相似物体,并进行精确计数。
9.11 Spatial Understanding: Depth Sorting¶
模型展示了其空间理解能力,能够从单个图像中估计不同物体的深度顺序。
示例中,模型根据图像中物体的位置关系,判断出从近到远的顺序为:键盘、鼠标、耳机、杯子。
模型展现了对深度感知和空间关系的理解能力。
9.12 Video Temporal Grounding¶
本节展示了模型在视频时间定位任务中的能力,包括视频事件的分段和关键事件的定位。
示例中,模型能够识别并标注出视频中女子跑步、跳跃、起身等关键事件的时间段,并回答特定事件(如“跳跃”)的时间点。
模型能够准确地将视觉内容与时间信息对应。
9.13 OCR Parsing and Document Understanding¶
本节展示了模型在文档理解和OCR解析方面的表现。
模型能够从图像中提取文本,并根据用户的问题检索答案,如比较训练阶段的耗时、重复文档章节内容等。
模型展示了良好的信息提取和指令执行能力。
9.14 Multilingual OCR Parsing¶
模型展示了其在多语言OCR方面的表现,能够从多语言的收据图像中提取菜品名称、数量和价格,并生成表格。
示例中,模型将中文和英文菜品信息准确提取并组织成表格格式。
模型具备处理多种语言和结构复杂文档的能力。
9.15 Generate Code for a Diagram of Novel Format¶
模型展示了其图像到代码的生成能力,能够根据给定的图表图像生成相应的Mermaid代码。
示例中,模型成功生成了用于绘制“南方赛区”比赛流程图的Mermaid代码。
模型结合了OCR、逻辑推理和代码生成能力。
9.16 Image-conditioned Creative Writing¶
本节展示了模型在图像条件下的创意写作能力。
示例中,模型根据一张牵手图像生成了一首浪漫英文诗,捕捉了图像中的情感和视觉元素。
模型能够将视觉内容转化为富有诗意的文本。
9.17 Failure Cases: 3D Spatial Imagination¶
本节讨论了模型在3D空间想象任务中的失败案例。
模型在骰子滚动预测和3D结构视图识别任务中,虽然最终答案正确,但推理过程存在错误。
这表明当前视觉语言模型在三维空间推理任务中仍有不足。
9.18 Failure Cases: Hallucination (Knowledge Prior)¶
本节展示了模型在生成非标准图结构(如Transformer网络中的非典型残差连接)时的幻觉问题。
模型倾向于生成符合常识的代码,但无法准确还原非标准结构。
这表明模型在依赖先验知识时可能产生偏差,无法处理非常规任务。
总结:¶
本章节全面展示了模型在视觉推理、模式识别、几何问题、文档理解、视频分析、图像生成、创意写作等方面的强大能力,同时也指出了其在3D空间推理和非标准结构识别中的局限性。这些例子不仅体现了模型的多功能性,也揭示了当前视觉语言模型的挑战和改进空间。
9.19 Failure Cases_ Combinatorial Search I¶
总结¶
9.19 组合搜索失败案例 I¶
本节讨论了一个需要组合搜索的数独类题目,要求找出一个三位数和一个两位数,使得它们的乘积以及参与乘法的每一位数字均为质数(2、3、5 或 7)。通过分析,模型尝试了多个组合,并最终得出 325×77=25025 的结论。虽然中间步骤中出现了 0(非质数),但该组合是唯一能满足大多数条件的解。然而,由于搜索空间较大(4^5=1024 种组合),当前的视觉语言模型(VLMs)如 Seed1.5-VL、Gemini 2.5 Pro 和 OpenAI o4-mini 在这类需要完整组合搜索的问题上表现不佳,无法可靠地完成推理过程。
9.20 组合搜索失败案例 II¶
本节展示了另一个组合搜索问题,要求模型从图像中统计所有正方形的数量(包括由小正方形组成的复合正方形)。正确答案是 17 个正方形,具体包括 1×1(10 个)、2×2(4 个)、3×3(2 个)和 4×4(1 个)。然而,现有的 VLMs 无法正确识别和计数所有正方形,暴露出它们在处理复杂视觉枚举和结构识别任务上的局限性。
总体总结:¶
这两节通过不同形式的组合搜索问题,展示了当前视觉语言模型在面对需要细致推理、组合分析和视觉枚举的任务时存在的不足。这些问题对模型的逻辑推理能力、系统性搜索能力和视觉理解能力提出了较高要求,而现有模型在这些方面仍存在明显缺陷。
10 Evaluation Details¶
本章节主要介绍了 Seed1.5-VL 模型的评估细节,包括内部基准的结构、与其他模型的对比、评估任务和使用的评估提示。以下是内容总结:
10.1 内部基准结构¶
层次结构:内部基准采用树状层级结构,分为四个层次。最上层为“视觉能力”和“综合能力”,往下依次细分出 11 个二级类别、43 个三级类别和 29 个四级类别,层次越细,能力划分越具体。
作用:这种细粒度的分类对模型开发至关重要,帮助开发者定位当前模型的不足、评估迭代改进效果,并指导未来开发方向。
准确率:表格中展示了各个能力类别的准确率,由 LLM-as-a-judge 与人工评估的一致性计算得出,最高可达 100%。
10.2 内部基准上的综合比较¶
模型对比:Seed1.5-VL 在内部基准上与 Gemini、GPT、Claude、Qwen、Llama、InternVL、StepFun 和 GLM 等八类主流模型进行比较,整体排名第二。
模型规模:Seed1.5-VL 的参数规模与 Llama 4 Maverick 相当(170 亿参数,采用 MoE 架构),并且在该基准上表现优于 Llama 4 Maverick。
思考模型占优:排名前五的模型中,思考型模型(Thinking Models)占主导地位,这与内部基准侧重综合能力的测试有关。
更新趋势:同一厂商的最新模型普遍优于旧版本,例如 GPT-4o-Latest 优于 GPT-4o-0513,Gemini 2.5 优于 Gemini 2.0。
10.3 能力与基准任务¶
测试能力:共评估了 10 大类能力,包括多模态推理、通用视觉问答、文档和图表理解、视觉定位与计数、空间理解、短视频与长视频理解、流式视频理解、视频定位、GUI 代理。
使用的公共基准:共使用 60 个公共基准,涵盖各类视觉与语言任务,例如 MMMU、MMStar、TextVQA、CountBench 等,具体任务包括数学视觉问题、图表理解、视觉定位、空间深度估计等。
10.4 评估提示(Evaluation Prompts)¶
评估模式:全部基准使用 0-shot 模式,依赖经过指令调优的模型。
思考模式激活:通过在提示前加入特定的引导语句(如用
<tool_call>和</tool_response>包裹推理过程),激活 Seed1.5-VL 的“思考模式”。模板设计:每个基准使用定制化的提示模板,包含占位符如
{question}、{options}、<image>、<video>等,具体模板因任务而异。多样性:提示模板包括开放式问题、多选题、定位任务、视频理解任务等,确保评估的多样性与精确性。
标准统一:多数基准采用 OpenCompass 或官方推荐的评估方式,保证评估结果的客观性和可比性。
总结¶
本章节系统性地展示了 Seed1.5-VL 在视觉语言能力评估中的全面表现,包括评估结构、模型对比、任务覆盖和提示设计。其内部基准的多级分类体系和丰富的公共基准任务,为模型性能的细致评估提供了坚实基础,同时通过与主流模型的对比,突显了其在综合能力上的竞争力。
DREAM-1K¶
本文节选部分展示了多个与视频理解相关的任务和数据集,主要涉及以下内容:
DREAM-1K:该部分要求对一个视频内容进行描述,重点在于动态事件,而不是情感或氛围。需要从视频中提取关键的动作和事件发展过程,并在一段话中进行概括。
TempCompass:该任务分为四个子任务:
多选问答(Multiple-choice QA):要求根据视频内容选择最佳答案。
是非问答(Yes/No QA):要求判断视频中是否发生了某个特定事件。
字幕匹配(Caption matching):判断给定的字幕是否与视频内容相符。
字幕生成(Caption generation):根据视频内容生成描述性字幕。
Charades-STA 和 TACoS:这两个数据集的任务是时间定位(Temporal Action Localization),即根据给定的动作标签(label),从视频中找出该动作的起始和结束时间点(以秒为单位)。
总体来看,这些任务涵盖了视频理解中的多个方面,包括事件描述、问答、字幕处理以及时间动作定位,体现了当前视频理解研究的多样性和复杂性。