2402.05136_LV-Eval: A Balanced Long-Context Benchmark with 5 Length Levels Up to 256K¶
引用: 32(2025-07-13)
组织:
1.Tsinghua University,
2.Infinigence-AI,
3.Shanghai Artificial Intelligence Laboratory
4.The Chinese University of Hong Kong,
5.Shanghai Jiao Tong University
Huggingface: https://huggingface.co/datasets/Infinigence/LVEval
总结¶
简介
评估长上下文处理能力的基准测试集
语言: 中英文
设计目标:提供一个在不同长度级别上平衡的评估框架
包含五个长度级别,最长可达 256k tokens
五个长度层级(16k、32k、64k、128k、256k)
数据集
任务类型
单跳问答(single-hop QA)
多跳问答(multi-hop QA)
测试样本组成
上下文(C)
问题(Q)
标准答案(A)
总数
11 个 QA 数据集
共包含 1,729 个 QA 对
生成 8,645 个合成上下文
构建步骤
上下文混合(Context Mixing Up)
混淆事实插入(Confusing Facts Insertion,CFI)
关键词替换(Keyword/Phrase Replacement,KPR)
11个数据集
Multi-hop QA
lic-mixup
originated from the Long-instruction-en2zh
下载地址: https://huggingface.co/datasets/Infinigence/LVEval/resolve/main/lic_mixup.zip
hotpotwikiqa-mixup
is originated from two Wikipedia-based multi-hop QA datasets: HotpotQA and 2WikiMultihopQA.
下载地址: https://huggingface.co/datasets/Infinigence/LVEval/resolve/main/hotpotwikiqa_mixup.zip
loogle-MR-mixup and loogle-CR-mixup
originate from LooGLE’s Long-dependency QA task
loogle-MR-mixup下载地址: https://huggingface.co/datasets/Infinigence/LVEval/resolve/main/loogle_MIR_mixup.zip
loogle-MR-mixup下载地址: https://huggingface.co/datasets/Infinigence/LVEval/resolve/main/loogle_CR_mixup.zip
dureader-mixup
is built from the DuReader dataset.
下载地址: https://huggingface.co/datasets/Infinigence/LVEval/resolve/main/dureader_mixup.zip
Single-hop QA
loogle-SD-mixup
contains 160 unique QA pairs and 800 documents originated from the short-dependency QA task in LooGLE.
下载地址: https://huggingface.co/datasets/Infinigence/LVEval/resolve/main/loogle_SD_mixup.zip
cmrc-mixup
is derived from the CMRC 2018 Public Datasets
下载地址: https://huggingface.co/datasets/Infinigence/LVEval/resolve/main/cmrc_mixup.zip
multifieldqa-en-mixup and multifieldqa-zh-mixup
are built from the MultiFieldQA datasets in LongBench
multifieldqa-en-mixup下载地址: https://huggingface.co/datasets/Infinigence/LVEval/resolve/main/multifieldqa_en_mixup.zip
multifieldqa-zh-mixup下载地址: https://huggingface.co/datasets/Infinigence/LVEval/resolve/main/multifieldqa_zh_mixup.zip
factrecall-en and factrecall-zh
are two synthetic datasets designed to assess the LLMs’ ability to identify a small piece of evidence (“fact”) located at various locations within a very lengthy context
factrecall-en下载地址: https://huggingface.co/datasets/Infinigence/LVEval/resolve/main/factrecall_en.zip
factrecall-zh下载地址: https://huggingface.co/datasets/Infinigence/LVEval/resolve/main/factrecall_zh.zip
Abstract¶
当前最先进的大模型(LLMs)声称能处理非常长的上下文(最多到256k tokens),但现有评测数据集的长度太短(通常在5k到21k之间),并且容易出现“知识泄漏”和评估不准的问题。
为了解决这些问题,本文提出了一个新的长上下文评测集 LV-Eval,它支持五种不同长度(16k 到 256k),包括两个任务(单跳问答、多跳问答),涵盖11个中英文数据集。
它设计了三种增强方法:插入干扰信息(CFI)、关键词替换(KPR)和基于关键词回忆的评分机制。
LV-Eval的优势是:可控评估长度、更具挑战性的问题、更少知识泄漏、更客观的评分。
1. Introduction¶
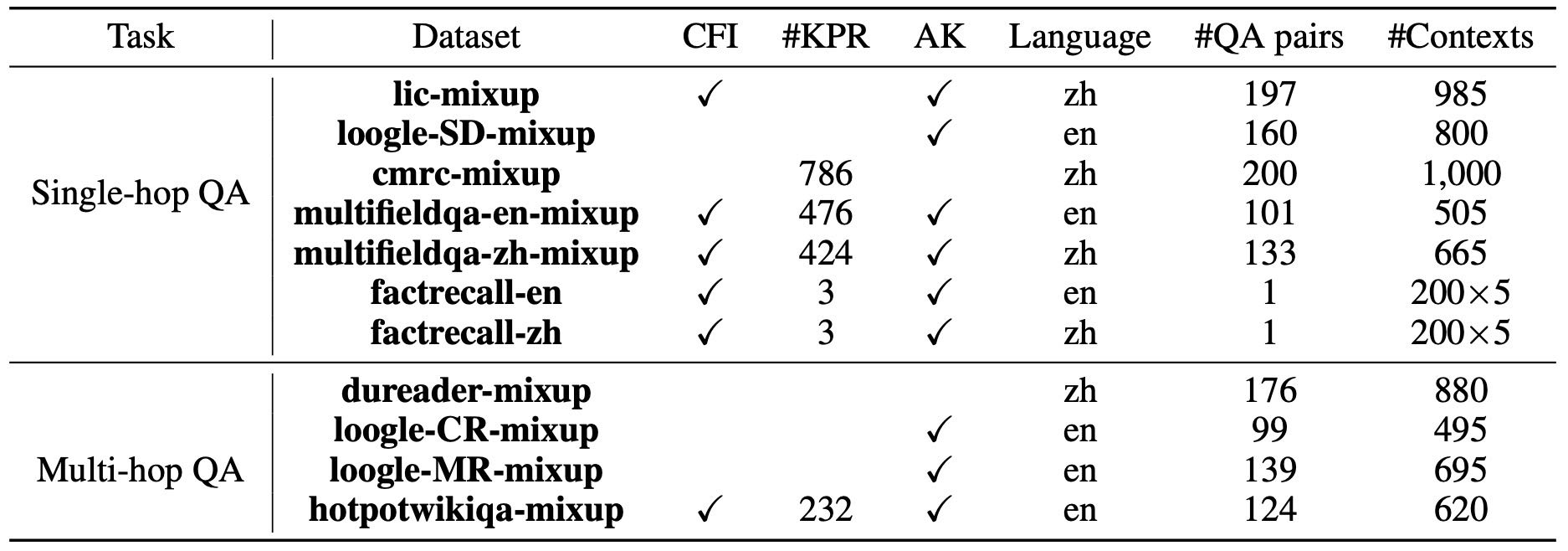
Table 2: Data statistics of LV-Eval
CFI: stand for “Confusing Fact Insertion
KPR: Keyword and Phrase Replacement
the number of KPR rules
AK: Answer Keywords
背景¶
大语言模型(LLMs)在处理长文本(如书籍、长对话)时,理解长上下文的能力非常关键。近年来,模型支持的上下文长度从最初的 2k tokens 提升到 32k、128k,甚至 200k tokens。
问题¶
目前的评测基准(benchmark)却跟不上模型能力的提升,存在以下几个问题:
上下文太短:现有基准平均长度只有 5k–32k 单词,不足以评估超长上下文理解能力。
内容可能出现在训练数据中:使用公开资料评测,容易造成“知识泄露”,模型靠记忆而非理解作答。
评分方法不准:多数用的是简单的自动评分,如 n-gram 匹配,容易被答题格式干扰,难以准确评估回答质量。
解决方案:LV-Eval 基准¶
作者提出了新的双语评测基准 LV-Eval,特点如下:
上下文更长:支持 16k 到 256k 五种长度,用相同的 QA 对于不同长度做测试,更好评估长文本理解能力。
设置干扰:引入干扰文本与错误信息,模拟真实复杂环境,检验模型是否能“去伪存真”。
替换关键词防止知识泄露:将原文中重要的关键词重新命名或改写,防止模型“猜答案”。
更客观的评分方式:人工标注答案关键词 + 黑名单词(如 the, a 等),按 recall + F1 双阶段计算,更准确反映模型真正理解能力。
实验发现¶
Moonshot-v1、Qwen-2.5-72B、Llama-3.1-70B 在 64k 以下表现最好。
一些模型(如 Yi-6B)虽然支持长上下文,但性能下降缓慢,绝对分数不一定更高。
引入“干扰信息”会明显降低模型表现,说明理解干扰是挑战。
LV-Eval 更好地解决了知识泄露与评分偏差问题。
3 LV-Eval Benchmark¶
LV-Eval 基准总结¶
1. 概述:
LV-Eval 是一个专注于评估模型长上下文能力的基准测试集,涵盖单跳问答(single-hop QA)和多跳问答(multi-hop QA)两种任务,共包含 11 个问答数据集(6 个英文,5 个中文),数据统计详见表 2。每个测试样本由三部分组成:上下文(C)、问题(Q)和标准答案(A),其中上下文是一个合成文档,包含回答该问题所需的信息。
2. 数据集构建:
数据来源: 9 个数据集基于现有公开数据集构建,2 个(factrecall-en 和 factrecall-zh)使用了 PG19 和《西游记》的文本。
长度划分: 每个数据集划分为 5 个长度等级:16k、32k、64k、128k、256k,每个 QA 对对应 5 个长度不同的上下文,便于评估模型在不同长度下的表现。
总数: 共包含 1,729 个 QA 对,生成 8,645 个合成上下文。
3. 上下文构建方法:
每个 QA 对按照以下三步构建上下文:
上下文混合(Context Mixing Up):
通过混合支持文档和干扰文档生成不同长度的上下文。对于 factrecall-en 和 factrecall-zh,干扰文档来自两本书。
对于其他数据集,干扰文档来自非相关 QA 对的上下文。
按目标长度逐步添加干扰文档并打乱顺序,形成最终上下文。
混淆事实插入(Confusing Fact Insertion, CFI):
使用 GPT-4 生成相似但事实不同的混淆事实,再由人工修订,插入上下文中。目的:增加模型区分关键信息与干扰信息的难度。
关键词和短语替换(Keyword and Phrase Replacement, KPR):
替换上下文和 QA 中的关键词,防止模型依赖训练记忆或常识。人工制定替换规则,并检查冲突,确保语义一致性。
4. 评估指标设计:
为避免传统 n-gram 指标(如 F1)的偏差,设计了两阶段评估机制:
关键词召回(Keyword Recall):若生成答案中关键词的召回率高于阈值(中文 0.2,英文 0.4),进入下一步。
F1 计算:排除非信息词(如 the、a、of)进行 F1 评估。
构建了词黑名单(word blacklist),筛选出高频但不重要的词语,提升评估的准确性。
5. 模型评估:
评估了 3 个商业模型和 12 个开源模型,涵盖不同上下文窗口大小(4k~1048k)。
对于上下文窗口小于测试数据的模型,采用中间截断并拼接头尾的方法,确保 QA 指令完整。
不同任务使用不同指标:大多数使用基于关键词的 F1,长答案任务使用 ROUGH-L。
总结:
LV-Eval 是一个结构清晰、设计严谨的长上下文评估基准,通过混合上下文、插入混淆事实、替换关键词等手段,有效提升了评估的难度与可靠性。其独特的长度控制和多模型评估机制,为大语言模型的长上下文理解能力研究提供了有力支持。
4 Evaluation¶
LV-Eval 是什么?¶
LV-Eval 是一个用于评估大模型长上下文能力的问答(QA)基准集合,包含了英文和中文的 11 个 QA 数据集,覆盖了单跳、多跳两种问答任务。
核心构成:¶
每个测试样本包含:
一段长文档(Context)
一个问题(Question)
一个标准答案(Answer)
每个 QA 对应 5 个不同长度的上下文(16K, 32K, 64K, 128K, 256K tokens),用来考察模型在不同上下文长度下的表现。
构建过程包含 3 个主要步骤:¶
上下文混合(Context Mixing Up):
把与问题相关的支持文档与一些无关干扰文档混合。
用这些文档组合成不同长度的上下文。
混淆事实插入(Confusing Facts Insertion,CFI):
利用 GPT-4 生成与原始事实“相似但错误”的信息(不矛盾但会误导)。
人工校正后插入到上下文中,使问题更具挑战性。
关键词替换(Keyword/Phrase Replacement,KPR):
人工替换掉上下文和 QA 中容易被模型“记住”的词语或短语。
避免模型靠记忆答题,从而更加真实地评估理解能力。
评测指标优化:¶
引入 关键词优先的打分方式:
先检查模型回答是否包含关键答案词(Recall 达标)。
再用 F1 分数计算精度,忽略如 “a”“the” 等无效词。
这样可避免模型答得“看起来对”但实质“答非所问”的情况。
人工标注工作:¶
人工参与了混淆事实修订、关键词替换和答案关键词标注,确保高质量和公平性。
总结:¶
**LV-Eval 是一个专门为测试大模型“理解长文本”的能力而设计的中文/英文问答基准。**它通过控制文档长度、插入干扰信息和优化评分机制,提供了一个更真实、更有挑战性的测试环境。
5 Limitations¶
LV-Eval 仍存在一些局限性:
任务类型不全:LV-Eval 目前未涵盖摘要类任务。
模型覆盖不足:由于成本,部分最新模型(如 GPT-4-128k、GPT-4o)未被测试。
过拟合风险:由于测试数据公开,可能被针对性训练,影响评估可信度。
KPR 与 CFI 的人工成本:CFI 依赖人工修正,未来可考虑借助更强大模型替代。
总结¶
LV-Eval 是一个针对长上下文理解能力的综合评估基准,通过引入 CFI 和 KPR 等技术,提升了任务难度和评估的公平性。实验结果表明,尽管某些模型在特定条件下表现优异,但在长上下文和干扰环境下仍存在明显短板。未来研究方向包括提高模型对干扰信息的鲁棒性、降低人工标注成本,以及扩展到更多任务类型。
Appendix¶
本附录主要介绍了用于构建长上下文评估基准 LV-Eval 的数据集构建细节以及标注过程,内容可以分为以下几个部分总结:
一、附录A:QA对的详细构建方法¶
1. 多跳问答(Multi-hop QA)数据集¶
hotpotwikiqa-mixup:结合了 HotpotQA 和 2WikiMultihopQA 两个基于维基百科的多跳问答数据集,选择 124 个样本,分别包含 2 跳和 5 跳的问题。
loogle-MR-mixup 和 loogle-CR-mixup:来源于 LooGLE 的长依赖问答任务,分别对应多信息检索(MR)和理解与推理(CR)子任务,选择 139 和 99 个问题。
dureader-mixup:基于 DuReader 数据集,随机选取 200 个样本,手动去除 24 个答案过长的样本。
2. 单跳问答(Single-hop QA)数据集¶
lic-mixup:从 Hugging Face 的
Long-instruction-en2zh数据集中选取 197 个问答对,其余文档作为干扰信息。loogle-SD-mixup:来自 LooGLE 短依赖任务,包含 160 个 QA 对和 800 个文档。
cmrc-mixup:基于 CMRC 2018 中文机器阅读理解数据集,人工挑选 200 个 QA 对。
multifieldqa-en-mixup 和 multifieldqa-zh-mixup:来自 Long-Bench 的 MultiFieldQA 数据集,分别选取 101 和 133 个 QA 对。
factrecall-en 和 factrecall-zh:合成数据集,用于评估模型在长文本中识别关键事实的能力。每个上下文长度级别生成 200 个文档,中文干扰文档来自《西游记》。
二、附录B:标注细节¶
1. 标注人员¶
招募了 5 名标注人员,包括 3 名参与 LLM 研究的硕士生和 2 名语言学方向的硕士生。
所有标注员均为全职在场工作。
2. 标注时间¶
CFI(Confusing Fact Injection)任务:557 个混淆事实样本,由 2 名语言学硕士生在 3 天内完成验证。
KPR(Keyword Phrase Replacement)任务:1,924 个关键词替换对,中文部分由 5 人 3 天完成,英文部分由 2 人 2 天完成。
答案关键词标注任务:955 个答案关键词样本,由 2 人在 1 天内完成。
3. 标注指导方针¶
CFI 指导方针:
生成的混淆事实需能产生干扰,且不能与原始事实冲突。
KPR 指导方针:
替换词/短语需与原词不同且非同义词;
尽可能多地替换词语以最大化与原句的差异;
优先替换无同义词的词;
替换后的句子即使与常识不符也是可以接受的,只要答案可从上下文中推导,且答案相关的信息在上下文中一致即可。
总结¶
本附录详细描述了 LV-Eval 基准中多个多跳和单跳问答数据集的构建过程,以及数据标注的具体细节,包括人员配置、时间安排和标注规则。通过这些数据构建和标注工作,构建了一个用于评估大语言模型在长上下文处理能力的平衡基准数据集。
Appendix C Detailed Evaluation Results¶
本章节详细分析了长上下文基准LV-Eval中**单跳问答(single-hop QA)和多跳问答(multi-hop QA)**任务的评估结果。以下是主要内容总结:
1. 多跳问答任务的挑战性分析¶
多跳问答任务更难:多跳任务(如
loogle-CR-mixup和loogle-MR-mixup)表现普遍较低,尤其在复杂上下文中提取多个事实时,模型易受干扰。长上下文影响性能:随着上下文长度增加(16k 到 256k token),部分模型表现下降明显,说明模型对长文本的处理能力仍有限。
部分模型表现相对较好:如
Meta-Llama-3.1-70B-Instruct和Qwen2.5-72B-Instruct-128k在多项任务中表现突出。
2. 单跳问答任务的评估结果¶
无混淆信息的单跳任务表现较好:在如
loogle-SD-mixup和cmrc-mixup等任务中,大型语言模型(LLM)能取得较高成绩。部分模型在英文任务中表现优异:如
ChatGLM3-6B-32k和Yi-6B-200k在英文factrecall-en任务中得分较高,说明 NIAH 任务可能不够具有挑战性。中英文任务表现差异明显:部分模型在英文任务表现优异,但在中文任务(如
factrecall-zh)中得分极低,尤其是上下文长度较大时。例如,Llama2-7B-Chat-hf在factrecall-zh上几乎得零分。
3. 上下文长度对模型性能的影响¶
上下文增加导致性能下降:模型在处理 256k token 的长文本时,整体表现显著下降,特别是在中文任务中。
小上下文模型在长文本任务中劣势明显:部分模型(如
Llama2-7B-Chat-hf)由于支持的上下文较短(如 4k token),在长文本任务中几乎无法完成。
4. 部分模型表现分析¶
表现较好的模型:
Meta-Llama-3.1-70B-Instruct、Qwen2.5-72B-Instruct-128k和GPT-4-8k在多个任务中表现稳定。ChatGLM3-6B-32k和Yi-6B-200k在英文任务中表现突出。
表现较差的模型:
Llama2-7B-Chat-hf、Qwen-7B-8k-Chat、Vicuna-7B-16k-v1.5在长上下文中文任务中得分接近零。部分模型在中英文任务间表现不均衡。
5. 评估数据与模型对比¶
详细评估表格:表 A6 和 A7 提供了所有模型在不同上下文长度和任务上的详细得分。
数据来源:包括
dureader-mixup、loogle-CR-MR-mixup、hotpotwikiqa-mixup、lic-mixup、cmrc-mixup、multifieldqa-en-zh-mixup以及factrecall-en-zh等多个数据集。模型范围:涵盖多个开源和闭源模型,如 Llama2、ChatGLM3、BlueLM、Yi、Qwen、GPT 等。
6. 结论与启示¶
多跳问答更具挑战性:模型在长上下文中整合多个事实的能力仍需提升。
单跳任务可作为“热身”任务:但不足以全面衡量模型的长上下文处理能力。
上下文长度是关键因素:模型性能随上下文长度增加而显著下降,中文任务尤其明显。
未来研究方向:
增强模型对复杂上下文的推理和整合能力。
探索更难的多跳任务设计。
提升小模型在长上下文中的表现。
总结¶
本章通过详细的数据分析展示了大型语言模型在长上下文问答任务中的表现,揭示了不同任务类型、不同上下文长度以及中英文任务之间的差异。结果表明,多跳任务和长上下文任务仍然极具挑战性,未来研究应重点关注如何提升模型在复杂上下文中的推理和信息整合能力。
Appendix D Detailed Ablation Results¶
Appendix D 详细消融实验结果总结¶
本节展示了CFI(Confusing Facts Insertion,混淆事实插入)和KPR(Keyword and Phrase Replacement,关键词和短语替换)两个技术在多个长上下文任务中的详细消融实验结果。实验覆盖了以下五个任务:
hotpotwikiqa-mixup(多跳问答)
multifieldqa-en-mixup(英文多领域问答)
multifieldqa-zh-mixup(中文多领域问答)
factrecall-en(英文事实回忆)
factrecall-zh(中文事实回忆)
每种任务的评估结果按上下文长度(16k、32k、64k、128k、256k)进行了划分,比较了在以下四种消融设置下的模型表现:
w. both:同时使用CFI和KPR
w. KPR:仅使用KPR
w. CFI:仅使用CFI
w.o. both:不使用CFI和KPR
主要结论包括:
不同模型表现差异显著:例如,ChatGLM3-6B-32k在多个任务中的表现优于Llama2-7B-Chat-hf和Vicuna-7B-16k-v1.5等模型,尤其是在256k长度任务中。
CFI与KPR对模型性能有显著影响:
在大多数模型中,添加CFI和KPR通常会降低模型性能。
**完全移除CFI和KPR(w.o. both)**时,模型表现通常最优,表明这些干扰手段对模型的准确性和鲁棒性构成了挑战。
上下文长度的影响:随着上下文长度增加(从16k到256k),大多数模型的表现逐渐下降,说明长上下文任务对模型的处理能力提出了更高要求。
英文任务 vs 中文任务:部分模型在英文任务中表现更优,而其他模型在中文任务中表现更好,例如ChatGLM3-6B-32k在中文任务中表现优于Llama-3-8b-Instruct。
模型抗干扰能力存在语言差异:例如,在factrecall-zh中,Llama-3-8b-Instruct的所有响应都被干扰事实误导,而在factrecall-en中,只有32%的响应被误导,说明模型在不同语言下的抗干扰能力存在显著差异。
Appendix E LV-Eval 数据示例¶
本节提供了factrecall-en和factrecall-zh任务中的数据样本示例,图中展示了上下文中的干扰事实和真实事实,以及模型需要根据这些信息进行事实回忆的结构。这些示例有助于理解任务设计和模型所面临的挑战。
Appendix F 模型失败案例¶
干扰事实导致的失败案例(见图A12):
Llama-3-8b-Instruct在factrecall-zh-16k中所有响应都被干扰事实误导。
在factrecall-en-16k中,32%的响应受到干扰,说明模型在不同语言中的抗干扰能力存在差异。
多跳推理失败案例(见图A13):
在hotpotwikiqa-mixup-16k中,模型未能正确完成多跳推理任务。例如,回答“电影《Nallavan Vazhvan》导演的死亡日期”需要从两个不同段落中提取信息并进行推理,但模型错误地选择了无关段落。
导演名字的缩写形式导致模型无法通过精确匹配找到正确答案,显示其对实体关系的理解存在局限。
总结¶
CFI和KPR显著影响模型性能,在多数情况下,移除这些干扰机制可以提升模型表现。
上下文长度越长,模型表现越差,说明长上下文任务对模型提出了更高要求。
英文与中文任务表现差异明显,部分模型在不同语言任务中的抗干扰能力存在显著差异。
多跳推理任务对模型是挑战,即使在强大模型如Llama 3中,也可能因事实混淆或实体匹配问题导致失败。